mirror of
https://github.com/clearml/clearml-server
synced 2025-06-26 23:15:47 +00:00
Compare commits
182 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
d9bdebefc7 | ||
|
|
f29884f05a | ||
|
|
0f72d662f8 | ||
|
|
6202219034 | ||
|
|
bb3218f65d | ||
|
|
cbcaa7c789 | ||
|
|
427322a424 | ||
|
|
0e7d7d36a9 | ||
|
|
06032a6d66 | ||
|
|
b48f4eb2eb | ||
|
|
383b2666c4 | ||
|
|
50c373cf0d | ||
|
|
394a9de5fa | ||
|
|
fb5c06e9c3 | ||
|
|
1a9bbc9420 | ||
|
|
294da32401 | ||
|
|
7f00672010 | ||
|
|
99bf89a360 | ||
|
|
6c8508eb7f | ||
|
|
69714d5b5c | ||
|
|
f9516ec7d3 | ||
|
|
6fdde93dee | ||
|
|
7afc71ec91 | ||
|
|
4595117d91 | ||
|
|
8630cc1021 | ||
|
|
135885b609 | ||
|
|
eb0865662c | ||
|
|
b7b94e7ae5 | ||
|
|
72be8bee19 | ||
|
|
0722b20c1c | ||
|
|
a392a0e6ff | ||
|
|
e22fa2f478 | ||
|
|
8b49c1ac06 | ||
|
|
da1182a405 | ||
|
|
53e995ee8c | ||
|
|
4732dc1a88 | ||
|
|
e325bcaf67 | ||
|
|
a7c30453db | ||
|
|
dedac3b2fe | ||
|
|
7d10bbdf8e | ||
|
|
72213dffa4 | ||
|
|
f778837d4b | ||
|
|
153ed6a7b7 | ||
|
|
5d279c8c5a | ||
|
|
ed910d5f6a | ||
|
|
87d2b6fa15 | ||
|
|
94cfb17291 | ||
|
|
3f641d37b7 | ||
|
|
551be12f01 | ||
|
|
b536020058 | ||
|
|
fb6fbc0a06 | ||
|
|
5ae64fd791 | ||
|
|
f9776e4319 | ||
|
|
75e736e7d5 | ||
|
|
1e4756aa1d | ||
|
|
52529d3c55 | ||
|
|
53296e8891 | ||
|
|
1c87ebc900 | ||
|
|
14d9924ea0 | ||
|
|
69f9b424c7 | ||
|
|
1a6da301a8 | ||
|
|
2728b3ed14 | ||
|
|
38284eef1f | ||
|
|
9debe1adcd | ||
|
|
cc93c15f8a | ||
|
|
2c3f0e4ba3 | ||
|
|
c48eb34d8d | ||
|
|
49515e06e1 | ||
|
|
4a1d97c02f | ||
|
|
6c6c1c3f41 | ||
|
|
0ad687008c | ||
|
|
fe3dbc92dc | ||
|
|
dc53970ff0 | ||
|
|
73592b991b | ||
|
|
47b981a993 | ||
|
|
b500bcab0b | ||
|
|
59e910db1a | ||
|
|
2ecb430f02 | ||
|
|
a08722e394 | ||
|
|
67c210d9d7 | ||
|
|
101ba540f4 | ||
|
|
82fc28d477 | ||
|
|
7b73f699d2 | ||
|
|
a7e5380f67 | ||
|
|
bcade31786 | ||
|
|
6b902f85f4 | ||
|
|
6d4c974045 | ||
|
|
2346c6f3f5 | ||
|
|
82e51b4d36 | ||
|
|
e63599254e | ||
|
|
8e7e234161 | ||
|
|
17d94b26c3 | ||
|
|
1e701becd3 | ||
|
|
18c8dd449d | ||
|
|
50031c4d6d | ||
|
|
6101dc4f11 | ||
|
|
5d17059cbe | ||
|
|
b93e843143 | ||
|
|
1a732ccd8e | ||
|
|
2ea25e498f | ||
|
|
1b1cdb34ad | ||
|
|
e171a8b523 | ||
|
|
539b76d362 | ||
|
|
64b5e1f1f0 | ||
|
|
6a1eb9cea0 | ||
|
|
24907b4eaa | ||
|
|
efc540b837 | ||
|
|
96ffc89c64 | ||
|
|
4f2564d33a | ||
|
|
70ae090cc0 | ||
|
|
4f01778961 | ||
|
|
596bdd06ec | ||
|
|
6c56d0fc33 | ||
|
|
5f0213d2de | ||
|
|
15eb00a931 | ||
|
|
becc4fb6a2 | ||
|
|
32476a216a | ||
|
|
a9ba1580dc | ||
|
|
cfcd0b22a0 | ||
|
|
780355250c | ||
|
|
fd65ad38bc | ||
|
|
e29973a0b2 | ||
|
|
c259d0883e | ||
|
|
9eab017a31 | ||
|
|
68c7f307a2 | ||
|
|
0aa5694b58 | ||
|
|
639d72c5d6 | ||
|
|
70708ecdcc | ||
|
|
dacdd5e965 | ||
|
|
c199976f70 | ||
|
|
c3e2bc5ad7 | ||
|
|
f0c900c174 | ||
|
|
1bdbc44720 | ||
|
|
c6e765bd07 | ||
|
|
c037ddd044 | ||
|
|
ffe4764f20 | ||
|
|
1681fd6bf4 | ||
|
|
e55ce5536a | ||
|
|
b714952ab1 | ||
|
|
07fd8b9f2f | ||
|
|
d24f633a8e | ||
|
|
bed714890d | ||
|
|
02671910b2 | ||
|
|
1a00f29415 | ||
|
|
b7614622fc | ||
|
|
bc2cbe9a91 | ||
|
|
4daf607ff7 | ||
|
|
fd789ef20c | ||
|
|
76962667a3 | ||
|
|
a33c94e24f | ||
|
|
566b28dc4c | ||
|
|
54e3a156c1 | ||
|
|
8605186a97 | ||
|
|
61fb6553e6 | ||
|
|
76418eec1b | ||
|
|
b5cc858494 | ||
|
|
5c8519be1e | ||
|
|
18392ad2fd | ||
|
|
30c8be79b5 | ||
|
|
7c47946645 | ||
|
|
5684a7877c | ||
|
|
1568549fcc | ||
|
|
62533792b5 | ||
|
|
e9d4141460 | ||
|
|
8986f75356 | ||
|
|
1e40fc7922 | ||
|
|
eeab15e78c | ||
|
|
57714203b4 | ||
|
|
c14d201300 | ||
|
|
c70cbe04c1 | ||
|
|
c8f2b2b319 | ||
|
|
4af3c65e5d | ||
|
|
022fa7ba19 | ||
|
|
4f8cb35f9a | ||
|
|
d84b3688ca | ||
|
|
b4a20ef414 | ||
|
|
c461471942 | ||
|
|
351ddb73e7 | ||
|
|
02257fa18f | ||
|
|
8ef26e49f7 | ||
|
|
0c930f75a1 | ||
|
|
1c419ebf50 |
2
.gitignore
vendored
2
.gitignore
vendored
@@ -1,3 +1,4 @@
|
||||
syntax: glob
|
||||
.idea
|
||||
apierrors/errors
|
||||
static/build.json
|
||||
@@ -18,3 +19,4 @@ build
|
||||
dist
|
||||
code.tar.gz
|
||||
server/schema/services/_cache.json
|
||||
server/apierrors/errors/*
|
||||
|
||||
2
LICENSE
2
LICENSE
@@ -1,7 +1,7 @@
|
||||
Server Side Public License
|
||||
VERSION 1, OCTOBER 16, 2018
|
||||
|
||||
Copyright © 2018 MongoDB, Inc.
|
||||
Copyright © 2019 allegro.ai, Inc.
|
||||
|
||||
Everyone is permitted to copy and distribute verbatim copies of this
|
||||
license document, but changing it is not allowed.
|
||||
|
||||
313
README.md
313
README.md
@@ -1,246 +1,183 @@
|
||||
# TRAINS Server
|
||||
# Trains Server
|
||||
|
||||
## Magic Version Control & Experiment Manager for AI
|
||||
## Auto-Magical Experiment Manager & Version Control for AI
|
||||
|
||||
[](https://img.shields.io/badge/license-SSPL-green.svg)
|
||||
[](https://img.shields.io/badge/python-3.6%20%7C%203.7-blue.svg)
|
||||
[](https://img.shields.io/github/release-pre/allegroai/trains-server.svg)
|
||||
[](https://img.shields.io/badge/status-beta-yellow.svg)
|
||||
|
||||
### Help improve Trains by filling our 2-min [user survey](https://allegro.ai/lp/trains-user-survey/)
|
||||
|
||||
## Introduction
|
||||
|
||||
The **trains-server** is the infrastructure for [trains](https://github.com/allegroai/trains).
|
||||
It allows multiple users to collaborate and manage their experiments.
|
||||
|
||||
The **trains-server** contains the following components:
|
||||
The **trains-server** is the backend service infrastructure for [Trains](https://github.com/allegroai/trains).
|
||||
It allows multiple users to collaborate and manage their experiments.
|
||||
By default, **Trains** is set up to work with the **Trains** demo server, which is open to anyone and resets periodically.
|
||||
In order to host your own server, you will need to launch **trains-server** and point **Trains** to it.
|
||||
|
||||
* the Web-App which is a single-page UI for experiment management and browsing
|
||||
* a REST interface for:
|
||||
* documenting and logging experiment information, statistics and results
|
||||
* querying experiments history, logs and results
|
||||
* a locally-hosted file server for storing images and models making them easily accessible using the Web-App
|
||||
**trains-server** contains the following components:
|
||||
|
||||
You can quickly setup your **trains-server** using a pre-built Docker image (see [Installation](#installation)).
|
||||
* The **Trains** Web-App, a single-page UI for experiment management and browsing
|
||||
* RESTful API for:
|
||||
* Documenting and logging experiment information, statistics and results
|
||||
* Querying experiments history, logs and results
|
||||
* Locally-hosted file server for storing images and models making them easily accessible using the Web-App
|
||||
|
||||
When new releases are available, you can upgrade your pre-built Docker image (see [Upgrade](#upgrade)).
|
||||
You can quickly [deploy](#launching-trains-server) your **trains-server** using Docker, AWS EC2 AMI, or Kubernetes.
|
||||
|
||||
The **trains-server's** code is freely available [here](https://github.com/allegroai/trains-server).
|
||||
## System design
|
||||
|
||||
## System diagram
|
||||
|
||||
<pre>
|
||||
TRAINS-server
|
||||
+--------------------------------------------------------------------+
|
||||
| |
|
||||
| Server Docker Elastic Docker Mongo Docker |
|
||||
| +-------------------------+ +---------------+ +------------+ |
|
||||
| | Pythonic Server | | | | | |
|
||||
| | +-----------------+ | | ElasticSearch | | MongoDB | |
|
||||
| | | WEB server | | | | | | |
|
||||
| | | Port 8080 | | | | | | |
|
||||
| | +--------+--------+ | | | | | |
|
||||
| | | | | | | | |
|
||||
| | +--------+--------+ | | | | | |
|
||||
| | | API server +----------------------------+ | |
|
||||
| | | Port 8008 +---------+ | | | |
|
||||
| | +-----------------+ | +-------+-------+ +-----+------+ |
|
||||
| | | | | |
|
||||
| | +-----------------+ | +---+----------------+------+ |
|
||||
| | | File Server +-------+ | Host Storage | |
|
||||
| | | Port 8081 | | +-----+ | |
|
||||
| | +-----------------+ | +---------------------------+ |
|
||||
| +------------+------------+ |
|
||||
+---------------|----------------------------------------------------+
|
||||
|HTTP
|
||||
+--------+
|
||||
GPU Machine |
|
||||
+------------------------|-------------------------------------------+
|
||||
| +------------------|--------------+ |
|
||||
| | Training | | +---------------------+ |
|
||||
| | Code +---+------------+ | | trains configuration| |
|
||||
| | | TRAINS | | | ~/trains.conf | |
|
||||
| | | +------+ | |
|
||||
| | +----------------+ | +---------------------+ |
|
||||
| +---------------------------------+ |
|
||||
+--------------------------------------------------------------------+
|
||||
</pre>
|
||||
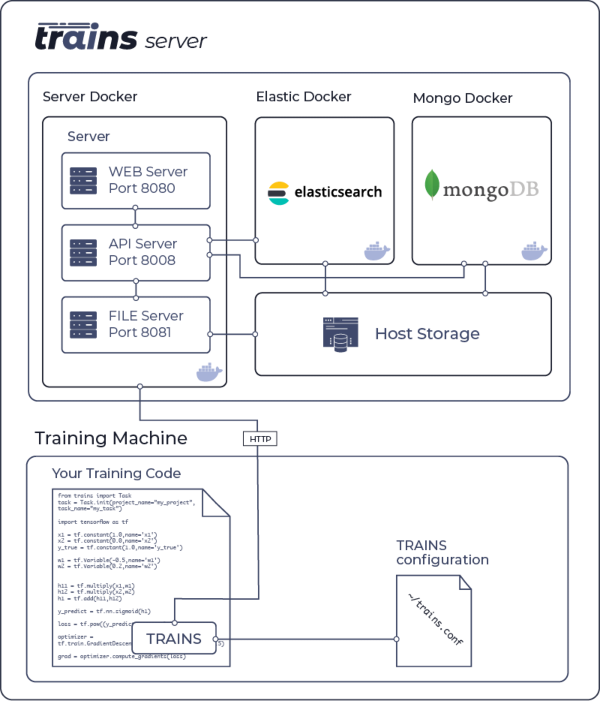
|
||||
|
||||
## Installation
|
||||
**trains-server** has two supported configurations:
|
||||
- Single IP (domain) with the following open ports
|
||||
- Web application on port 8080
|
||||
- API service on port 8008
|
||||
- File storage service on port 8081
|
||||
|
||||
This section contains the instructions to setup and launch a pre-built Docker image for the **trains-server**.
|
||||
|
||||
**Note**: This Docker image was tested with Linux, only. For Windows users, we recommend running the server
|
||||
on a Linux virtual machine.
|
||||
- Sub-Domain configuration with default http/s ports (80 or 443)
|
||||
- Web application on sub-domain: app.\*.\*
|
||||
- API service on sub-domain: api.\*.\*
|
||||
- File storage service on sub-domain: files.\*.\*
|
||||
|
||||
## Launching trains-server
|
||||
|
||||
### Prerequisites
|
||||
|
||||
You must be logged in as a user with sudo privileges.
|
||||
|
||||
### Setup
|
||||
The ports 8080/8081/8008 must be available for the **trains-server** services.
|
||||
|
||||
For example, to see if port `8080` is in use:
|
||||
|
||||
#### Step 1. Install Docker CE
|
||||
* Linux or macOS:
|
||||
|
||||
sudo lsof -Pn -i4 | grep :8080 | grep LISTEN
|
||||
|
||||
You must install Docker to run the pre-packaged **trains-server**.
|
||||
* Windows:
|
||||
|
||||
* For [Ubuntu](https://docs.docker.com/install/linux/docker-ce/ubuntu/) / Mint (x86_64/amd64):
|
||||
netstat -an |find /i "8080"
|
||||
|
||||
### Launching
|
||||
|
||||
Launch **trains-server** in any of the following formats:
|
||||
|
||||
```bash
|
||||
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
|
||||
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
|
||||
. /etc/os-release
|
||||
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $UBUNTU_CODENAME stable"
|
||||
sudo apt-get update
|
||||
sudo apt-get install -y docker-ce
|
||||
```
|
||||
- Pre-built [AWS EC2 AMI](https://github.com/allegroai/trains-server/blob/master/docs/install_aws.md)
|
||||
- Pre-built [GCP Custom Image](https://github.com/allegroai/trains-server/blob/master/docs/install_gcp.md)
|
||||
- Pre-built Docker Image
|
||||
- [Linux](https://github.com/allegroai/trains-server/blob/master/docs/install_linux_mac.md)
|
||||
- [macOS](https://github.com/allegroai/trains-server/blob/master/docs/install_linux_mac.md)
|
||||
- [Windows 10](https://github.com/allegroai/trains-server/blob/master/docs/install_win.md)
|
||||
- Kubernetes
|
||||
- [Kubernetes Helm](https://github.com/allegroai/trains-server-helm#prerequisites)
|
||||
- Manual [Kubernetes installation](https://github.com/allegroai/trains-server-k8s#prerequisites)
|
||||
|
||||
* For other operating systems, see [Supported platforms](https://docs.docker.com/install//#support) in the Docker documentation for instructions.
|
||||
## Connecting Trains to your trains-server
|
||||
|
||||
#### Step 2. Setup the Docker daemon
|
||||
By default, the **Trains** client is set up to work with the [**Trains** demo server](https://demoapp.trains.allegro.ai/).
|
||||
To have the **Trains** client use your **trains-server** instead:
|
||||
- Run the `trains-init` command for an interactive setup.
|
||||
- Or manually edit `~/trains.conf` file, making sure the server settings (`api_server`, `web_server`, `file_server`) are configured correctly, for example:
|
||||
|
||||
To run the ElasticSearch Docker container, you must setup the Docker daemon by modifing the default
|
||||
values required by Elastic in your Docker configuration file
|
||||
that are used by the **trains-server**. We provide instructions for the most common Docker configuration files.
|
||||
api {
|
||||
# API server on port 8008
|
||||
api_server: "http://localhost:8008"
|
||||
|
||||
You must edit or create a Docker configuration file:
|
||||
# web_server on port 8080
|
||||
web_server: "http://localhost:8080"
|
||||
|
||||
* If your Docker configuration file is `/etc/sysconfig/docker`, edit it.
|
||||
|
||||
Add the options in quotes to the available arguments in the `OPTIONS` section:
|
||||
|
||||
```bash
|
||||
OPTIONS="--default-ulimit nofile=1024:65536 --default-ulimit memlock=-1:-1"
|
||||
```
|
||||
|
||||
* Otherwise, edit `/etc/docker/daemon.json` (if it exists) or create it (if it does not exist).
|
||||
|
||||
Add or modify the `defaults-ulimits` section as shown below. Be sure your configuration file contains the `nofile` and `memlock` sub-sections and values shown.
|
||||
|
||||
**Note**: Your configuration file may contain other sections. If so, confirm that the sections are separated by commas. For more information about Docker configuration files, see an [Daemon configuration file](https://docs.docker.com/engine/reference/commandline/dockerd/#daemon-configuration-file) in the Docker documentation.
|
||||
|
||||
The **trains-server** required defaults values are:
|
||||
|
||||
```json
|
||||
{
|
||||
"default-ulimits": {
|
||||
"nofile": {
|
||||
"name": "nofile",
|
||||
"hard": 65536,
|
||||
"soft": 1024
|
||||
},
|
||||
"memlock":
|
||||
{
|
||||
"name": "memlock",
|
||||
"soft": -1,
|
||||
"hard": -1
|
||||
# file server on port 8081
|
||||
files_server: "http://localhost:8081"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Step 3. Restart the Docker daemon
|
||||
**Note**: If you have set up **trains-server** in a sub-domain configuration, then there is no need to specify a port number,
|
||||
it will be inferred from the http/s scheme.
|
||||
|
||||
You must restart the Docker daemon after modifying the configuration file:
|
||||
After launching the **trains-server** and configuring the **Trains** client to use the **trains-server**,
|
||||
you can [use](https://github.com/allegroai/trains#using-trains) **Trains** in your experiments and view them in your **trains-server** web server,
|
||||
for example http://localhost:8080.
|
||||
For more information about the Trains client, see [**Trains**](https://github.com/allegroai/trains).
|
||||
|
||||
```bash
|
||||
sudo service docker stop
|
||||
sudo service docker start
|
||||
```
|
||||
## Advanced Functionality
|
||||
|
||||
#### Step 4. Set the Maximum Number of Memory Map Areas
|
||||
**trains-server** provides a few additional useful features, which can be manually enabled:
|
||||
|
||||
* [Web login authentication](https://github.com/allegroai/trains-server/blob/master/docs/faq.md#web-auth)
|
||||
* [Non-responsive experiments watchdog](https://github.com/allegroai/trains-server/blob/master/docs/faq.md#watchdog-the-non-responsive-task-watchdog-settings)
|
||||
|
||||
The maximum number of memory map areas a process can use is defined
|
||||
using the `vm.max_map_count` kernel setting.
|
||||
## Restarting trains-server
|
||||
|
||||
Elastic requires that `vm.max_map_count` to be at least 262144.
|
||||
To restart the **trains-server**, you must first stop the containers, and then restart them.
|
||||
|
||||
* For CentOS 7, Ubuntu 16.04, Mint 18.3, Ubuntu 18.04 and Mint 19 users, we tested the following commands to set
|
||||
`vm.max_map_count`:
|
||||
```bash
|
||||
docker-compose down
|
||||
docker-compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
```bash
|
||||
sudo echo "vm.max_map_count=262144" > /tmp/99-trains.conf
|
||||
sudo mv /tmp/99-trains.conf /etc/sysctl.d/99-trains.conf
|
||||
sudo sysctl -w vm.max_map_count=262144
|
||||
```
|
||||
## Upgrading <a name="upgrade"></a>
|
||||
|
||||
* For information about setting this parameter on other systems, see the [elastic](https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod-mode) documentation.
|
||||
**trains-server** releases are also reflected in the [docker compose configuration file](https://github.com/allegroai/trains-server/blob/master/docker-compose.yml).
|
||||
We strongly encourage you to keep your **trains-server** up to date, by keeping up with the current release.
|
||||
|
||||
#### Step 5. Choose a Data Directory
|
||||
**Note**: The following upgrade instructions use the Linux OS as an example.
|
||||
|
||||
You must choose a directory on your system in which all data maintained by the **trains-server** is stored,
|
||||
create that directory, and set its permissions. The data stored in that directory includes the database, uploaded files and logs.
|
||||
To upgrade your existing **trains-server** deployment:
|
||||
|
||||
For example, if your data directory is `/opt/trains`, then use the following command:
|
||||
1. Shut down the docker containers
|
||||
```bash
|
||||
docker-compose down
|
||||
```
|
||||
|
||||
```bash
|
||||
sudo mkdir -p /opt/trains/data/elastic && sudo chown -R 1000:1000 /opt/trains
|
||||
```
|
||||
1. We highly recommend backing up your data directory before upgrading.
|
||||
|
||||
### Launching Docker Containers
|
||||
Assuming your data directory is `/opt/trains`, to archive all data into `~/trains_backup.tgz` execute:
|
||||
|
||||
Launch the Docker containers. For example, if your data directory is `\opt\trains`,
|
||||
then use the following commands:
|
||||
```bash
|
||||
sudo tar czvf ~/trains_backup.tgz /opt/trains/data
|
||||
```
|
||||
|
||||
```bash
|
||||
sudo docker run -d --restart="always" --name="trains-elastic" -e "ES_JAVA_OPTS=-Xms2g -Xmx2g" -e "bootstrap.memory_lock=true" -e "cluster.name=trains" -e "discovery.zen.minimum_master_nodes=1" -e "node.name=trains" -e "script.inline=true" -e "script.update=true" -e "thread_pool.bulk.queue_size=2000" -e "thread_pool.search.queue_size=10000" -e "xpack.security.enabled=false" -e "xpack.monitoring.enabled=false" -e "cluster.routing.allocation.node_initial_primaries_recoveries=500" -e "node.ingest=true" -e "http.compression_level=7" -e "reindex.remote.whitelist=*.*" -e "script.painless.regex.enabled=true" --network="host" -v /opt/trains/data/elastic:/usr/share/elasticsearch/data docker.elastic.co/elasticsearch/elasticsearch:5.6.16
|
||||
```
|
||||
<details>
|
||||
<summary>Restore instructions:</summary>
|
||||
|
||||
```bash
|
||||
sudo docker run -d --restart="always" --name="trains-mongo" -v /opt/trains/data/mongo/db:/data/db -v /opt/trains/data/mongo/configdb:/data/configdb --network="host" mongo:3.6.5
|
||||
```
|
||||
To restore this example backup, execute:
|
||||
```bash
|
||||
sudo rm -R /opt/trains/data
|
||||
sudo tar -xzf ~/trains_backup.tgz -C /opt/trains/data
|
||||
```
|
||||
</details>
|
||||
|
||||
```bash
|
||||
sudo docker run -d --restart="always" --name="trains-fileserver" --network="host" -v /opt/trains/logs:/var/log/trains -v /opt/trains/data/fileserver:/mnt/fileserver allegroai/trains:latest fileserver
|
||||
```
|
||||
1. Download the latest `docker-compose.yml` file.
|
||||
|
||||
```bash
|
||||
sudo docker run -d --restart="always" --name="trains-apiserver" --network="host" -v /opt/trains/logs:/var/log/trains allegroai/trains:latest apiserver
|
||||
```
|
||||
```bash
|
||||
curl https://raw.githubusercontent.com/allegroai/trains-server/master/docker-compose.yml -o docker-compose.yml
|
||||
```
|
||||
|
||||
```bash
|
||||
sudo docker run -d --restart="always" --name="trains-webserver" --network="host" -v /opt/trains/logs:/var/log/trains allegroai/trains:latest webserver
|
||||
```
|
||||
1. Spin up the docker containers, it will automatically pull the latest **trains-server** build
|
||||
```bash
|
||||
docker-compose -f docker-compose.yml pull
|
||||
docker-compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
After the **trains-server** Dockers are up, the following are available:
|
||||
**\* If something went wrong along the way, check our FAQ: [Common Docker Upgrade Errors](https://github.com/allegroai/trains-server/blob/master/docs/faq.md#common-docker-upgrade-errors).**
|
||||
|
||||
* API server on port `8008`
|
||||
* Web server on port `8080`
|
||||
* File server on port `8081`
|
||||
|
||||
## Upgrade
|
||||
## Community & Support
|
||||
|
||||
We are constantly updating, improving and adding to the **trains-server**.
|
||||
New releases will include new pre-built Docker images.
|
||||
When we release a new version and include a new pre-built Docker image for it, upgrade as follows:
|
||||
If you have any questions, look to the Trains server [FAQ](https://github.com/allegroai/trains-server/blob/master/docs/faq.md), or
|
||||
tag your questions on [stackoverflow](https://stackoverflow.com/questions/tagged/trains) with '**trains**' tag.
|
||||
|
||||
1. Shut down and remove each of your Docker instances using the following commands:
|
||||
For feature requests or bug reports, please use [GitHub issues](https://github.com/allegroai/trains-server/issues).
|
||||
|
||||
sudo docker stop <docker-name>
|
||||
sudo docker rm -v <docker-name>
|
||||
|
||||
The Docker names are (see [Launching Docker images](##launching-docker-images)):
|
||||
|
||||
* `trains-elastic`
|
||||
* `trains-mongo`
|
||||
* `trains-fileserver`
|
||||
* `trains-apiserver`
|
||||
* `trains-webserver`
|
||||
|
||||
2. We highly recommend backing up your data directory!. A simple way to do that is using `tar`:
|
||||
|
||||
For example, if your data directory is `/opt/trains`, use the following command:
|
||||
|
||||
sudo tar czvf ~/trains_backup.tgz /opt/trains/data
|
||||
|
||||
This back ups all data to an archive in your home directory.
|
||||
|
||||
To restore this example backup, use the following command:
|
||||
|
||||
sudo rm -R /opt/trains/data
|
||||
sudo tar -xzf ~/trains_backup.tgz -C /opt/trains/data
|
||||
|
||||
3. Launch the newly released Docker image (see [Launching Docker images](#Launching-docker-images)).
|
||||
Additionally, you can always find us at *trains@allegro.ai*
|
||||
|
||||
## License
|
||||
|
||||
[Server Side Public License v1.0](https://github.com/mongodb/mongo/blob/master/LICENSE-Community.txt)
|
||||
|
||||
**trains-server** relies *heavily* on both [MongoDB](https://github.com/mongodb/mongo) and [ElasticSearch](https://github.com/elastic/elasticsearch).
|
||||
With the recent changes in both MongoDB's and ElasticSearch's OSS license, we feel it is our job as a community to support the projects we love and cherish.
|
||||
We feel the cause for the license change in both cases is more than just, and chose [SSPL](https://www.mongodb.com/licensing/server-side-public-license) because it is the more general and flexible of the two.
|
||||
**trains-server** relies on both [MongoDB](https://github.com/mongodb/mongo) and [ElasticSearch](https://github.com/elastic/elasticsearch).
|
||||
With the recent changes in both MongoDB's and ElasticSearch's OSS license, we feel it is our responsibility as a
|
||||
member of the community to support the projects we love and cherish.
|
||||
We believe the cause for the license change in both cases is more than just,
|
||||
and chose [SSPL](https://www.mongodb.com/licensing/server-side-public-license) because it is the more general and flexible of the two licenses.
|
||||
|
||||
This is our way to say - we support you guys!
|
||||
|
||||
90
docker-compose-unified.yml
Normal file
90
docker-compose-unified.yml
Normal file
@@ -0,0 +1,90 @@
|
||||
version: "3.6"
|
||||
services:
|
||||
trainsserver:
|
||||
command:
|
||||
- -c
|
||||
- "echo \"#!/bin/bash\" > /opt/trains/all.sh && echo \"/opt/trains/wrapper.sh webserver&\" >> /opt/trains/all.sh && echo \"/opt/trains/wrapper.sh fileserver&\" >> /opt/trains/all.sh && echo \"/opt/trains/wrapper.sh apiserver\" >> /opt/trains/all.sh && cat /opt/trains/all.sh && chmod +x /opt/trains/all.sh && /opt/trains/all.sh"
|
||||
entrypoint: /bin/bash
|
||||
container_name: trains-server
|
||||
image: allegroai/trains:latest
|
||||
ports:
|
||||
- 8008:8008
|
||||
- 8080:80
|
||||
- 8081:8081
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/logs:/var/log/trains
|
||||
- /opt/trains/data/fileserver:/mnt/fileserver
|
||||
depends_on:
|
||||
- redis
|
||||
- mongo
|
||||
- elasticsearch
|
||||
environment:
|
||||
TRAINS_ELASTIC_SERVICE_HOST: elasticsearch
|
||||
TRAINS_ELASTIC_SERVICE_PORT: 9200
|
||||
TRAINS_MONGODB_SERVICE_HOST: mongo
|
||||
TRAINS_MONGODB_SERVICE_PORT: 27017
|
||||
TRAINS_REDIS_SERVICE_HOST: redis
|
||||
TRAINS_REDIS_SERVICE_PORT: 6379
|
||||
networks:
|
||||
- backend
|
||||
elasticsearch:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-elastic
|
||||
environment:
|
||||
ES_JAVA_OPTS: -Xms2g -Xmx2g
|
||||
bootstrap.memory_lock: "true"
|
||||
cluster.name: trains
|
||||
cluster.routing.allocation.node_initial_primaries_recoveries: "500"
|
||||
discovery.zen.minimum_master_nodes: "1"
|
||||
http.compression_level: "7"
|
||||
node.ingest: "true"
|
||||
node.name: trains
|
||||
reindex.remote.whitelist: '*.*'
|
||||
script.inline: "true"
|
||||
script.painless.regex.enabled: "true"
|
||||
script.update: "true"
|
||||
thread_pool.bulk.queue_size: "2000"
|
||||
thread_pool.search.queue_size: "10000"
|
||||
xpack.monitoring.enabled: "false"
|
||||
xpack.security.enabled: "false"
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
nofile:
|
||||
soft: 65536
|
||||
hard: 65536
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.16
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/data/elastic:/usr/share/elasticsearch/data
|
||||
ports:
|
||||
- "9200:9200"
|
||||
mongo:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-mongo
|
||||
image: mongo:3.6.5
|
||||
restart: unless-stopped
|
||||
command: --setParameter internalQueryExecMaxBlockingSortBytes=196100200
|
||||
volumes:
|
||||
- /opt/trains/data/mongo/db:/data/db
|
||||
- /opt/trains/data/mongo/configdb:/data/configdb
|
||||
ports:
|
||||
- "27017:27017"
|
||||
redis:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-redis
|
||||
image: redis:5.0
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/data/redis:/data
|
||||
ports:
|
||||
- "6379:6379"
|
||||
|
||||
networks:
|
||||
backend:
|
||||
driver: bridge
|
||||
120
docker-compose-win10.yml
Normal file
120
docker-compose-win10.yml
Normal file
@@ -0,0 +1,120 @@
|
||||
version: "3.6"
|
||||
services:
|
||||
|
||||
apiserver:
|
||||
command:
|
||||
- apiserver
|
||||
container_name: trains-apiserver
|
||||
image: allegroai/trains:latest
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- c:/opt/trains/logs:/var/log/trains
|
||||
- c:/opt/trains/config:/opt/trains/config
|
||||
depends_on:
|
||||
- redis
|
||||
- mongo
|
||||
- elasticsearch
|
||||
- fileserver
|
||||
environment:
|
||||
TRAINS_ELASTIC_SERVICE_HOST: elasticsearch
|
||||
TRAINS_ELASTIC_SERVICE_PORT: 9200
|
||||
TRAINS_MONGODB_SERVICE_HOST: mongo
|
||||
TRAINS_MONGODB_SERVICE_PORT: 27017
|
||||
TRAINS_REDIS_SERVICE_HOST: redis
|
||||
TRAINS_REDIS_SERVICE_PORT: 6379
|
||||
ports:
|
||||
- "8008:8008"
|
||||
networks:
|
||||
- backend
|
||||
|
||||
elasticsearch:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-elastic
|
||||
environment:
|
||||
ES_JAVA_OPTS: -Xms2g -Xmx2g
|
||||
bootstrap.memory_lock: "true"
|
||||
cluster.name: trains
|
||||
cluster.routing.allocation.node_initial_primaries_recoveries: "500"
|
||||
discovery.zen.minimum_master_nodes: "1"
|
||||
http.compression_level: "7"
|
||||
node.ingest: "true"
|
||||
node.name: trains
|
||||
reindex.remote.whitelist: '*.*'
|
||||
script.inline: "true"
|
||||
script.painless.regex.enabled: "true"
|
||||
script.update: "true"
|
||||
thread_pool.bulk.queue_size: "2000"
|
||||
thread_pool.search.queue_size: "10000"
|
||||
xpack.monitoring.enabled: "false"
|
||||
xpack.security.enabled: "false"
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
nofile:
|
||||
soft: 65536
|
||||
hard: 65536
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.16
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- c:/opt/trains/data/elastic:/usr/share/elasticsearch/data
|
||||
ports:
|
||||
- "9200:9200"
|
||||
|
||||
fileserver:
|
||||
networks:
|
||||
- backend
|
||||
command:
|
||||
- fileserver
|
||||
container_name: trains-fileserver
|
||||
image: allegroai/trains:latest
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- c:/opt/trains/logs:/var/log/trains
|
||||
- c:/opt/trains/data/fileserver:/mnt/fileserver
|
||||
ports:
|
||||
- "8081:8081"
|
||||
|
||||
mongo:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-mongo
|
||||
image: mongo:3.6.5
|
||||
restart: unless-stopped
|
||||
command: --setParameter internalQueryExecMaxBlockingSortBytes=196100200
|
||||
volumes:
|
||||
- mongodata:/data
|
||||
ports:
|
||||
- "27017:27017"
|
||||
|
||||
redis:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-redis
|
||||
image: redis:5.0
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- c:/opt/trains/data/redis:/data
|
||||
ports:
|
||||
- "6379:6379"
|
||||
|
||||
webserver:
|
||||
command:
|
||||
- webserver
|
||||
container_name: trains-webserver
|
||||
image: allegroai/trains:latest
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- c:/trains/logs:/var/log/trains
|
||||
depends_on:
|
||||
- apiserver
|
||||
ports:
|
||||
- "8080:80"
|
||||
|
||||
networks:
|
||||
backend:
|
||||
driver: bridge
|
||||
|
||||
volumes:
|
||||
mongodata:
|
||||
120
docker-compose.yml
Normal file
120
docker-compose.yml
Normal file
@@ -0,0 +1,120 @@
|
||||
version: "3.6"
|
||||
services:
|
||||
|
||||
apiserver:
|
||||
command:
|
||||
- apiserver
|
||||
container_name: trains-apiserver
|
||||
image: allegroai/trains:latest
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/logs:/var/log/trains
|
||||
- /opt/trains/config:/opt/trains/config
|
||||
depends_on:
|
||||
- redis
|
||||
- mongo
|
||||
- elasticsearch
|
||||
- fileserver
|
||||
environment:
|
||||
TRAINS_ELASTIC_SERVICE_HOST: elasticsearch
|
||||
TRAINS_ELASTIC_SERVICE_PORT: 9200
|
||||
TRAINS_MONGODB_SERVICE_HOST: mongo
|
||||
TRAINS_MONGODB_SERVICE_PORT: 27017
|
||||
TRAINS_REDIS_SERVICE_HOST: redis
|
||||
TRAINS_REDIS_SERVICE_PORT: 6379
|
||||
TRAINS__apiserver__mongo__pre_populate__enabled: "true"
|
||||
TRAINS__apiserver__mongo__pre_populate__zip_file: "/opt/trains/db-pre-populate/export.zip"
|
||||
ports:
|
||||
- "8008:8008"
|
||||
networks:
|
||||
- backend
|
||||
|
||||
elasticsearch:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-elastic
|
||||
environment:
|
||||
ES_JAVA_OPTS: -Xms2g -Xmx2g
|
||||
bootstrap.memory_lock: "true"
|
||||
cluster.name: trains
|
||||
cluster.routing.allocation.node_initial_primaries_recoveries: "500"
|
||||
discovery.zen.minimum_master_nodes: "1"
|
||||
http.compression_level: "7"
|
||||
node.ingest: "true"
|
||||
node.name: trains
|
||||
reindex.remote.whitelist: '*.*'
|
||||
script.inline: "true"
|
||||
script.painless.regex.enabled: "true"
|
||||
script.update: "true"
|
||||
thread_pool.bulk.queue_size: "2000"
|
||||
thread_pool.search.queue_size: "10000"
|
||||
xpack.monitoring.enabled: "false"
|
||||
xpack.security.enabled: "false"
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
nofile:
|
||||
soft: 65536
|
||||
hard: 65536
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.16
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/data/elastic:/usr/share/elasticsearch/data
|
||||
ports:
|
||||
- "9200:9200"
|
||||
|
||||
fileserver:
|
||||
networks:
|
||||
- backend
|
||||
command:
|
||||
- fileserver
|
||||
container_name: trains-fileserver
|
||||
image: allegroai/trains:latest
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/logs:/var/log/trains
|
||||
- /opt/trains/data/fileserver:/mnt/fileserver
|
||||
ports:
|
||||
- "8081:8081"
|
||||
|
||||
mongo:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-mongo
|
||||
image: mongo:3.6.5
|
||||
restart: unless-stopped
|
||||
command: --setParameter internalQueryExecMaxBlockingSortBytes=196100200
|
||||
volumes:
|
||||
- /opt/trains/data/mongo/db:/data/db
|
||||
- /opt/trains/data/mongo/configdb:/data/configdb
|
||||
ports:
|
||||
- "27017:27017"
|
||||
|
||||
redis:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-redis
|
||||
image: redis:5.0
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/data/redis:/data
|
||||
ports:
|
||||
- "6379:6379"
|
||||
|
||||
webserver:
|
||||
command:
|
||||
- webserver
|
||||
container_name: trains-webserver
|
||||
image: allegroai/trains:latest
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/logs:/var/log/trains
|
||||
depends_on:
|
||||
- apiserver
|
||||
ports:
|
||||
- "8080:80"
|
||||
|
||||
networks:
|
||||
backend:
|
||||
driver: bridge
|
||||
19
docs/apiserver.conf
Normal file
19
docs/apiserver.conf
Normal file
@@ -0,0 +1,19 @@
|
||||
auth {
|
||||
# Fixed users login credentials
|
||||
# No other user will be able to login
|
||||
fixed_users {
|
||||
enabled: true
|
||||
users: [
|
||||
{
|
||||
username: "jane"
|
||||
password: "12345678"
|
||||
name: "Jane Doe"
|
||||
},
|
||||
{
|
||||
username: "john"
|
||||
password: "12345678"
|
||||
name: "John Doe"
|
||||
},
|
||||
]
|
||||
}
|
||||
}
|
||||
328
docs/faq.md
Normal file
328
docs/faq.md
Normal file
@@ -0,0 +1,328 @@
|
||||
# trains-server FAQ
|
||||
|
||||
Launching **trains-server**
|
||||
|
||||
* How do I launch **trains-server** on:
|
||||
|
||||
* [Stand alone Linux Ubuntu systems?](#ubuntu)
|
||||
|
||||
* [macOS?](#mac-osx)
|
||||
|
||||
* [Windows 10?](#docker_compose_win10)
|
||||
|
||||
* [How do I restart trains-server?](#restart)
|
||||
|
||||
Kubernetes
|
||||
|
||||
* [Can I deploy trains-server on Kubernetes clusters?](#kubernetes)
|
||||
|
||||
* [Can I create a Helm Chart for trains-server Kubernetes deployment?](#helm)
|
||||
|
||||
Configuration
|
||||
|
||||
* [How do I configure trains-server for sub-domains and load balancers?](#sub-domains)
|
||||
|
||||
* [Can I add web login authentication to trains-server?](#web-auth)
|
||||
|
||||
* [Can I modify the non-responsive experiment watchdog settings?](#watchdog)
|
||||
|
||||
Troubleshooting
|
||||
|
||||
* [How do I fix Docker upgrade errors?](#common-docker-upgrade-errors)
|
||||
|
||||
* [Why is web login authentication not working?](#port-conflict)
|
||||
|
||||
## Launching **trains-server**
|
||||
|
||||
### How do I launch trains-server on stand alone Linux Ubuntu systems? <a name="ubuntu"></a>
|
||||
|
||||
To launch **trains-server** on a stand alone Linux Ubuntu:
|
||||
|
||||
1. Install [docker for Ubuntu](https://docs.docker.com/install/linux/docker-ce/ubuntu/).
|
||||
|
||||
1. Install `docker-compose` using the following commands (for more detailed information, see the [Install Docker Compose](https://docs.docker.com/compose/install/) in the Docker documentation):
|
||||
|
||||
sudo curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
|
||||
sudo chmod +x /usr/local/bin/docker-compose
|
||||
|
||||
1. Remove the previous installation of **trains-server**.
|
||||
|
||||
**WARNING**: This clears all existing **Trains** databases.
|
||||
|
||||
sudo rm -R /opt/trains/
|
||||
|
||||
1. Create local directories for the databases and storage.
|
||||
|
||||
sudo mkdir -p /opt/trains/data/elastic
|
||||
sudo mkdir -p /opt/trains/data/mongo/db
|
||||
sudo mkdir -p /opt/trains/data/mongo/configdb
|
||||
sudo mkdir -p /opt/trains/logs
|
||||
sudo mkdir -p /opt/trains/config
|
||||
sudo mkdir -p /opt/trains/data/fileserver
|
||||
sudo chown -R 1000:1000 /opt/trains
|
||||
|
||||
1. Clone the [trains-server](https://github.com/allegroai/trains-server) repository and change directories to the new **trains-server** directory.
|
||||
|
||||
git clone https://github.com/allegroai/trains-server.git
|
||||
cd trains-server
|
||||
|
||||
1. Run `docker-compose`
|
||||
|
||||
/usr/local/bin/docker-compose -f docker-compose.yml up
|
||||
|
||||
Your server is now running on [http://localhost:8080](http://localhost:8080)
|
||||
|
||||
### How do I launch trains-server on macOS? <a name="mac-osx"></a>
|
||||
|
||||
To launch **trains-server** on macOS:
|
||||
|
||||
1. Install [docker for macOS](https://docs.docker.com/docker-for-mac/install/).
|
||||
|
||||
1. Configure [Docker](https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod-mode).
|
||||
|
||||
screen ~/Library/Containers/com.docker.docker/Data/vms/0/tty
|
||||
sysctl -w vm.max_map_count=262144
|
||||
|
||||
1. Create local directories for the databases and storage.
|
||||
|
||||
sudo mkdir -p /opt/trains/data/elastic
|
||||
sudo mkdir -p /opt/trains/data/mongo/db
|
||||
sudo mkdir -p /opt/trains/data/mongo/configdb
|
||||
sudo mkdir -p /opt/trains/data/redis
|
||||
sudo mkdir -p /opt/trains/logs
|
||||
sudo mkdir -p /opt/trains/config
|
||||
sudo mkdir -p /opt/trains/data/fileserver
|
||||
sudo chown -R $(whoami):staff /opt/trains
|
||||
|
||||
1. Open the Docker app, select **Preferences**, and then on the **File Sharing** tab, add `/opt/trains`.
|
||||
|
||||
1. Clone the [trains-server](https://github.com/allegroai/trains-server) repository and change directories to the new **trains-server** directory.
|
||||
|
||||
git clone https://github.com/allegroai/trains-server.git
|
||||
cd trains-server
|
||||
|
||||
1. Run `docker-compose` with the docker compose file.
|
||||
|
||||
docker-compose -f docker-compose.yml up
|
||||
|
||||
Your server is now running on [http://localhost:8080](http://localhost:8080)
|
||||
|
||||
### How do I launch trains-server on Windows 10? <a name="docker_compose_win10"></a>
|
||||
|
||||
You can run **trains-server** on Windows 10 using Docker Desktop for Windows (see the Docker [System Requirements](https://docs.docker.com/docker-for-windows/install/#system-requirements)).
|
||||
|
||||
To launch **trains-server** on Windows 10:
|
||||
|
||||
1. Install the Docker Desktop for Windows application by either:
|
||||
|
||||
* following the [Install Docker Desktop on Windows](https://docs.docker.com/docker-for-windows/install/) instructions.
|
||||
* running the Docker installation [wizard](https://hub.docker.com/?overlay=onboarding).
|
||||
|
||||
1. Increase the memory allocation in Docker Desktop to `4GB`.
|
||||
|
||||
1. In your Windows notification area (system tray), right click the Docker icon.
|
||||
|
||||
1. Click *Settings*, *Advanced*, and then set the memory to at least `4096`.
|
||||
|
||||
1. Click *Apply*.
|
||||
|
||||
1. Create local directories for data and logs. Open PowerShell and execute the following commands:
|
||||
|
||||
cd c:
|
||||
mkdir c:\opt\trains\data
|
||||
mkdir c:\opt\trains\logs
|
||||
|
||||
1. Download the **trains-server** docker-compose YAML file [docker-compose-win10.yml](https://raw.githubusercontent.com/allegroai/trains-server/master/docker-compose-win10.yml) as `c:\opt\trains\docker-compose.yml`.
|
||||
|
||||
1. Run `docker-compose`. In PowerShell, execute the following commands:
|
||||
|
||||
docker-compose -f up docker-compose-win10.yml
|
||||
|
||||
Your server is now running on [http://localhost:8080](http://localhost:8080)
|
||||
|
||||
### How do I restart trains-server? <a name="restart"></a>
|
||||
|
||||
Restart *trains-server* by first stopping the Docker containers and then restarting them.
|
||||
|
||||
```bash
|
||||
docker-compose down
|
||||
docker-compose up -f docker-compose.yml
|
||||
```
|
||||
|
||||
**Note**: If you are using a different docker-compose YAML file, specify that file.
|
||||
|
||||
## Kubernetes
|
||||
|
||||
### Can I deploy trains-server on Kubernetes clusters? <a name="kubernetes"></a>
|
||||
|
||||
**trains-server** supports Kubernetes. See [trains-server-k8s](https://github.com/allegroai/trains-server-k8s)
|
||||
which contains the YAML files describing the required services and detailed instructions for deploying
|
||||
**trains-server** to a Kubernetes clusters.
|
||||
|
||||
### Can I create a Helm Chart for trains-server Kubernetes deployment? <a name="helm"></a>
|
||||
|
||||
**trains-server** supports creating a Helm chart for Kubernetes deployment. See [trains-server-helm](https://github.com/allegroai/trains-server-helm)
|
||||
which you can use to create a Helm chart for **trains-server** and contains detailed instructions for deploying
|
||||
**trains-server** to a Kubernetes clusters using Helm.
|
||||
|
||||
## Configuration
|
||||
|
||||
### How do I configure trains-server for sub-domains and load balancers? <a name="sub-domains"></a>
|
||||
|
||||
You can configure **trains-server** for sub-domains and a load balancer.
|
||||
|
||||
For example, if your domain is `trains.mydomain.com` and your sub-domains are `app` and `api`, then do the following:
|
||||
|
||||
1. If you are not using the current **trains-server** version, [upgrade](https://github.com/allegroai/trains-server#upgrade) **trains-server**.
|
||||
|
||||
1. Add the following to `/opt/trains/config/apiserver.conf`:
|
||||
|
||||
auth {
|
||||
cookies {
|
||||
httponly: true
|
||||
secure: true
|
||||
domain: ".trains.mydomain.com"
|
||||
max_age: 99999999999
|
||||
}
|
||||
}
|
||||
|
||||
1. Use the following load balancer configuration:
|
||||
|
||||
* Listeners:
|
||||
* Optional: HTTP listener, that redirects all traffic to HTTPS.
|
||||
* HTTPS listener for `app.` forwarded to `AppTargetGroup`
|
||||
* HTTPS listener for `api.` forwarded to `ApiTargetGroup`
|
||||
* HTTPS listener for `files.` forwarded to `FilesTargetGroup`
|
||||
* Target groups:
|
||||
* `AppTargetGroup`: HTTP based target group, port `8080`
|
||||
* `ApiTargetGroup`: HTTP based target group, port `8008`
|
||||
* `FilesTargetGroup`: HTTP based target group, port `8081`
|
||||
* Security and routing:
|
||||
* Load balancer: make sure the load balancers are able to receive traffic from the relevant IP addresses (Security groups and Subnets definitions).
|
||||
* Instances: make sure the load balancers are able to access the instances, using the relevant ports (Security groups definitions).
|
||||
|
||||
1. Run the Docker containers with our updated `docker run` commands (see [Launching Docker Containers](#https://github.com/allegroai/trains-server#launching-docker-containers)).
|
||||
|
||||
### Can I add web login authentication to trains-server? <a name="web-auth"></a>
|
||||
|
||||
By default, anyone can login to the **trains-server** Web-App.
|
||||
You can configure the **trains-server** to allow only a specific set of users to access the system.
|
||||
|
||||
To add web login authentication to **trains-server**:
|
||||
|
||||
1. If you are not using the current **trains-server** version, then [upgrade](https://github.com/allegroai/trains-server#upgrade).
|
||||
|
||||
1. In `/opt/trains/config/apiserver.conf`, add the `auth` section and in it specify the users, for example:
|
||||
|
||||
**Note**: A sample `apiserver.conf` configuration file is also available [here](https://github.com/allegroai/trains-server/blob/master/docs/apiserver.conf).
|
||||
|
||||
auth {
|
||||
# Fixed users login credentials
|
||||
# No other user will be able to login
|
||||
fixed_users {
|
||||
enabled: true
|
||||
users: [
|
||||
{
|
||||
username: "jane"
|
||||
password: "12345678"
|
||||
name: "Jane Doe"
|
||||
},
|
||||
{
|
||||
username: "john"
|
||||
password: "12345678"
|
||||
name: "John Doe"
|
||||
},
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
1. Restart **trains-server** (see the [Restarting trains-server](#restart) FAQ).
|
||||
|
||||
### Can I modify the experiment watchdog settings? <a name="watchdog"></a>
|
||||
|
||||
The non-responsive experiment watchdog monitors experiments that were not updated for a specified period of time
|
||||
and marks them as `aborted`. The watchdog is always active.
|
||||
|
||||
You can modify the following settings for the watchdog:
|
||||
|
||||
* the time threshold (in seconds) of experiment inactivity (default value is 7200 seconds (2 hours))
|
||||
* the time interval (in seconds) between watchdog cycles
|
||||
|
||||
To change the watchdog's settings:
|
||||
|
||||
1. In `/opt/trains/config`, add the `services.conf` file and in it specify the watchdog settings, for example:
|
||||
|
||||
**Note**: A sample watchdog `services.conf` configuration file is also available [here](https://github.com/allegroai/trains-server/blob/master/docs/services.conf).
|
||||
|
||||
tasks {
|
||||
non_responsive_tasks_watchdog {
|
||||
# In-progress tasks that haven't been updated for at least 'value' seconds will be stopped by the watchdog
|
||||
threshold_sec: 7200
|
||||
|
||||
# Watchdog will sleep for this number of seconds after each cycle
|
||||
watch_interval_sec: 900
|
||||
}
|
||||
}
|
||||
|
||||
1. Restart **trains-server** (see the [Restarting trains-server](#restart) FAQ).
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### How do I fix Docker upgrade errors? <a name="common-docker-upgrade-errors"></a>
|
||||
|
||||
To resolve the Docker error "... The container name "/trains-???" is already in use by ...", try removing deprecated images:
|
||||
|
||||
docker rm -f $(docker ps -a -q)
|
||||
|
||||
### Why is web login authentication not working?
|
||||
|
||||
A port conflict between the **trains-server** MongoDB and / or Elastic instances, and other
|
||||
instances running on your system may prevent web login authentication
|
||||
from working correctly.
|
||||
|
||||
**trains-server** uses the following default ports which may be in conflict with other instances:
|
||||
|
||||
* MongoDB port `27017`
|
||||
* Elastic port `9200`
|
||||
|
||||
You can check for port conflicts in the logs in `/opt/trains/log`.
|
||||
|
||||
If a port conflict occurs, change the MongoDB and / or Elastic ports in the `docker-compose.yml`,
|
||||
and then run the Docker compose commands to restart the **trains-server** instance.
|
||||
|
||||
To change the MongoDB and / or Elastic ports for **trains-server**:
|
||||
|
||||
1. Edit the `docker-compose.yml` file.
|
||||
|
||||
1. In the `services/trainsserver/environment` section, add the following environment variable(s):
|
||||
|
||||
* For MongoDB:
|
||||
|
||||
MONGODB_SERVICE_PORT: <new-mongodb-port>
|
||||
|
||||
* For Elastic:
|
||||
|
||||
ELASTIC_SERVICE_PORT: <new-elasticsearch-port>
|
||||
|
||||
For example:
|
||||
|
||||
MONGODB_SERVICE_PORT: 27018
|
||||
ELASTIC_SERVICE_PORT: 9201
|
||||
|
||||
1. For MongoDB, in the `services/mongo/ports` section, expose the new MongoDB port:
|
||||
|
||||
<new-mongodb-port>:27017
|
||||
|
||||
For example:
|
||||
|
||||
20718:27017
|
||||
|
||||
1. For Elastic, in the `services/elasticsearch/ports` section, expose the new Elastic port:
|
||||
|
||||
<new-elsticsearch-port>:9200
|
||||
|
||||
For example:
|
||||
|
||||
9201:9200
|
||||
|
||||
2. Restart **trains-server** (see the [Restarting trains-server](#restart) FAQ).
|
||||
261
docs/install_aws.md
Normal file
261
docs/install_aws.md
Normal file
@@ -0,0 +1,261 @@
|
||||
# Deploying **trains-server** on AWS
|
||||
|
||||
To easily deploy **trains-server** on AWS, use one of our pre-built Amazon Machine Images (AMIs).
|
||||
We provide AMIs per region for each released version of **trains-server**, see [Released versions](#released-versions) below.
|
||||
|
||||
Once the AMI is up and running, [configure the Trains client](https://github.com/allegroai/trains/blob/master/README.md#configuration) to use your **trains-server**.
|
||||
The service port numbers on our **trains-server** AMIs:
|
||||
|
||||
- Web application: `8080`
|
||||
- API Server: `8008`
|
||||
- File Server: `8081`
|
||||
|
||||
The persistent storage configuration:
|
||||
|
||||
- MongoDB: `/opt/trains/data/mongo/`
|
||||
- ElasticSearch: `/opt/trains/data/elastic/`
|
||||
- File Server: `/mnt/fileserver/`
|
||||
|
||||
For examples and use cases, check the [Trains usage examples](https://github.com/allegroai/trains/blob/master/docs/trains_examples.md).
|
||||
|
||||
For instructions on launching a custom AMI from the EC2 console, see the [AWS Knowledge Center](https://aws.amazon.com/premiumsupport/knowledge-center/launch-instance-custom-ami/) or detailed instructions in the [AWS Documentation](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/launching-instance.html).
|
||||
|
||||
The minimum recommended amount of RAM is 8GB. For example, **t3.large** or **t3a.large** would have the minimum recommended amount of resources.
|
||||
|
||||
## Upgrading
|
||||
|
||||
To upgrade **trains-server** on an existing EC2 instance based on one of these AMIs, SSH into the instance and follow the [upgrade instructions](../README.md#upgrade) for **trains-server**.
|
||||
|
||||
### Note on upgrading AMIs to v0.12
|
||||
|
||||
This upgrade includes the automatically updated AMI in Version 0.12. It also includes an additional REDIS docker to the **trains-server** setup.
|
||||
|
||||
To upgrade the AMI:
|
||||
|
||||
1. SSH to the EC2 machine running one of the `Latest Version AMI's`
|
||||
2. Execute the following bash commands
|
||||
```bash
|
||||
sudo bash
|
||||
echo "" >> /usr/bin/start_or_update_server.sh
|
||||
echo "sudo mkdir -p \${datadir}/redis" >> /usr/bin/start_or_update_server.sh
|
||||
echo "sudo docker stop trains-redis || true && sudo docker rm -v trains-redis || true" >> /usr/bin/start_or_update_server.sh
|
||||
echo "echo never | sudo tee -a /sys/kernel/mm/transparent_hugepage/enabled" >> /usr/bin/start_or_update_server.sh
|
||||
echo "sudo sysctl vm.overcommit_memory=1" >> /usr/bin/start_or_update_server.sh
|
||||
echo "sudo docker run -d --restart=always --name=trains-redis -v \${datadir}/redis:/data --network=host redis:5 redis-server" >> /usr/bin/start_or_update_server.sh
|
||||
```
|
||||
3. Reboot the EC2 machine
|
||||
|
||||
|
||||
## Released versions
|
||||
|
||||
The following sections contain lists of AMI Image IDs, per region, for each released **trains-server** version.
|
||||
|
||||
### Latest version AMI - v0.14.2 (auto update)<a name="autoupdate"></a>
|
||||
|
||||
For easier upgrades, the following AMIs automatically update to the latest release every reboot:
|
||||
|
||||
* **eu-north-1** : ami-095cc888970c06e09
|
||||
* **ap-south-1** : ami-07019e7b3febea37e
|
||||
* **eu-west-3** : ami-0433d76badf430c16
|
||||
* **eu-west-2** : ami-05794c2b23ff79990
|
||||
* **eu-west-1** : ami-03e3bcabd1863d666
|
||||
* **ap-northeast-2** : ami-00f14188b66a5803e
|
||||
* **ap-northeast-1** : ami-005c93e30c99dab0c
|
||||
* **sa-east-1** : ami-0d819231779e7d264
|
||||
* **ca-central-1** : ami-0eff2fd400939d960
|
||||
* **ap-southeast-1** : ami-049b21bfa0d35c21c
|
||||
* **ap-southeast-2** : ami-0318b96a72d5da068
|
||||
* **eu-central-1** : ami-0cdb9d794340b9704
|
||||
* **us-east-2** : ami-0d846a080fc5a9345
|
||||
* **us-west-1** : ami-0ef970342625159bf
|
||||
* **us-west-2** : ami-04f3d13b75c642506
|
||||
* **us-east-1** : ami-01bef4da91280a322
|
||||
|
||||
### v0.14.2 (static update)
|
||||
|
||||
* **eu-north-1** : ami-006d491e9e8869248
|
||||
* **ap-south-1** : ami-0e55ec221687f98e7
|
||||
* **eu-west-3** : ami-06ad9cf3c05c83e91
|
||||
* **eu-west-2** : ami-0d05839268e748cff
|
||||
* **eu-west-1** : ami-0d14c297789ce0d7a
|
||||
* **ap-northeast-2** : ami-0d7fd775f0e76cc6f
|
||||
* **ap-northeast-1** : ami-0c0a6e1daeb3f7a9c
|
||||
* **sa-east-1** : ami-01e0c5e30e94ec887
|
||||
* **ca-central-1** : ami-07a31896832734897
|
||||
* **ap-southeast-1** : ami-0886d5b2d4b7fccd5
|
||||
* **ap-southeast-2** : ami-0397d5a2db3c356fe
|
||||
* **eu-central-1** : ami-0629f26eea22f5c17
|
||||
* **us-east-2** : ami-0499c3d7bb45a1a6e
|
||||
* **us-west-1** : ami-02fa8a961a4daf9f0
|
||||
* **us-west-2** : ami-05c711cfab4342468
|
||||
* **us-east-1** : ami-0b97d99a08012c726
|
||||
|
||||
### v0.14.1 (static update)
|
||||
|
||||
* **eu-north-1** : ami-036defe1885dced2e
|
||||
* **ap-south-1** : ami-0b403aa1da6a5dc17
|
||||
* **eu-west-3** : ami-0d30c2d330d1255c4
|
||||
* **eu-west-2** : ami-06f0e8d075e50a029
|
||||
* **eu-west-1** : ami-0da721d874f282b6d
|
||||
* **ap-northeast-2** : ami-03bffe94675dd5f8c
|
||||
* **ap-northeast-1** : ami-0f96520d646423673
|
||||
* **sa-east-1** : ami-0c2f706a3b7d97282
|
||||
* **ca-central-1** : ami-0da74525dcfd74e32
|
||||
* **ap-southeast-1** : ami-066368a21cf6d232b
|
||||
* **ap-southeast-2** : ami-0bfd09170067f7318
|
||||
* **eu-central-1** : ami-06aa99b1c41492986
|
||||
* **us-east-2** : ami-065c1880f59d03272
|
||||
* **us-west-1** : ami-0b7f6b896f5058eba
|
||||
* **us-west-2** : ami-0041e10ca68eef29a
|
||||
* **us-east-1** : ami-0b7125e4305bbd7eb
|
||||
|
||||
### v0.14.0 (static update)
|
||||
* **eu-north-1** : ami-02de71586ec496e38
|
||||
* **ap-south-1** : ami-074b03849b51852e5
|
||||
* **eu-west-3** : ami-022c388835e0eeb03
|
||||
* **eu-west-2** : ami-0a151c236c6b27707
|
||||
* **eu-west-1** : ami-06de69b06b4e73312
|
||||
* **ap-northeast-2** : ami-0ee821b72d9f669b1
|
||||
* **ap-northeast-1** : ami-03687ae215e64e100
|
||||
* **sa-east-1** : ami-01eb83364b7f667af
|
||||
* **ca-central-1** : ami-02e9b35f9c90377e6
|
||||
* **ap-southeast-1** : ami-0d3ab5ab0048fea51
|
||||
* **ap-southeast-2** : ami-0bd39d908fe3a9e06
|
||||
* **eu-central-1** : ami-0b8638701311b35c4
|
||||
* **us-east-2** : ami-02ff039693fc3a614
|
||||
* **us-west-1** : ami-08634f7dfb608a9a7
|
||||
* **us-west-2** : ami-034d693ef742b9333
|
||||
* **us-east-1** : ami-0b828b05c323dde7f
|
||||
|
||||
### v0.13.0 (static update)
|
||||
* **eu-north-1** : ami-0d9c74a015e7510d8
|
||||
* **ap-south-1** : ami-02acd6dd0659bb5c1
|
||||
* **eu-west-3** : ami-0f0cc5cb6d9afd194
|
||||
* **eu-west-2** : ami-0298fdc0860206ed9
|
||||
* **eu-west-1** : ami-0cdc072e528401d5e
|
||||
* **ap-northeast-2** : ami-0055579cc95b0e53e
|
||||
* **ap-northeast-1** : ami-0ced7becb9b83b5d0
|
||||
* **sa-east-1** : ami-033345d0f16a1b5e4
|
||||
* **ca-central-1** : ami-06c63b05aed47ae67
|
||||
* **ap-southeast-1** : ami-09f0355f367f30602
|
||||
* **ap-southeast-2** : ami-0bd2314163ce0fba0
|
||||
* **eu-central-1** : ami-05fbae957df63e366
|
||||
* **us-east-2** : ami-050c51b5b4074d3fc
|
||||
* **us-west-1** : ami-06ad513073d4e5a19
|
||||
* **us-west-2** : ami-0c96e1361d1d4ca94
|
||||
* **us-east-1** : ami-07b669040d1eea213
|
||||
|
||||
### v0.12.1 (static update)
|
||||
* **eu-north-1** : ami-003118a8103286d84
|
||||
* **ap-south-1** : ami-02dfe86baa48e096f
|
||||
* **eu-west-3** : ami-0cc1f01267d2a780d
|
||||
* **eu-west-2** : ami-0e4c8332e5ce09585
|
||||
* **eu-west-1** : ami-03459a2f0b0a3b1ab
|
||||
* **ap-northeast-2** : ami-08f6c2aed3a53f24c
|
||||
* **ap-northeast-1** : ami-0b798eab95a7c5435
|
||||
* **sa-east-1** : ami-0d3ee166c09f0d1b2
|
||||
* **ca-central-1** : ami-00a758c56bd63acd5
|
||||
* **ap-southeast-1** : ami-0be64d4988cd03fbb
|
||||
* **ap-southeast-2** : ami-02087310d43a63f31
|
||||
* **eu-central-1** : ami-097bbefeac0c74225
|
||||
* **us-east-2** : ami-07eda256712b90f4d
|
||||
* **us-west-1** : ami-02ef2b55cbd01c7df
|
||||
* **us-west-2** : ami-037c6176ef4735360
|
||||
* **us-east-1** : ami-08715c20c0e3f1c15
|
||||
|
||||
### v0.12.0 (static update)
|
||||
|
||||
* **eu-north-1** : ami-03ff8ab48cd43e77e
|
||||
* **ap-south-1** : ami-079c1a41ff836487c
|
||||
* **eu-west-3** : ami-0121ef0398ae87ab0
|
||||
* **eu-west-2** : ami-09f0f97654d8c79de
|
||||
* **eu-west-1** : ami-0b7ba303f757bfcd9
|
||||
* **ap-northeast-2** : ami-053f416517b5f40a6
|
||||
* **ap-northeast-1** : ami-056dff06c698c2d9d
|
||||
* **sa-east-1** : ami-017ab655119258639
|
||||
* **ca-central-1** : ami-03bf5fa1d86ac97f6
|
||||
* **ap-southeast-1** : ami-0e667958002b0360c
|
||||
* **ap-southeast-2** : ami-091f1b69cb43b1933
|
||||
* **eu-central-1** : ami-068ec2f0e98c26541
|
||||
* **us-east-2** : ami-0524bbdc1b64ff83f
|
||||
* **us-west-1** : ami-0b4facd7534e393c9
|
||||
* **us-west-2** : ami-0018d5a7e58966848
|
||||
* **us-east-1** : ami-08f24178fc14a84d2
|
||||
|
||||
### v0.11.0 (static update)
|
||||
|
||||
* **eu-north-1** : ami-0cbe338f058018c97
|
||||
* **ap-south-1** : ami-06d72ff894f7a5e5d
|
||||
* **eu-west-3** : ami-00f2a45d67df2d2f3
|
||||
* **eu-west-2** : ami-0627ae688f4533237
|
||||
* **eu-west-1** : ami-00bf924ccb0354418
|
||||
* **ap-northeast-2** : ami-0800edf1d1dec1da8
|
||||
* **ap-northeast-1** : ami-07b2ed9709cdc4b15
|
||||
* **sa-east-1** : ami-0012c1648618b812c
|
||||
* **ca-central-1** : ami-02870b965d002fc8a
|
||||
* **ap-southeast-1** : ami-068ec23abf2473192
|
||||
* **ap-southeast-2** : ami-06664624728b5e01a
|
||||
* **eu-central-1** : ami-05f2a9304f237a6f0
|
||||
* **us-east-2** : ami-0ec242e6dca2b72b9
|
||||
* **us-west-1** : ami-050b6577acf246ceb
|
||||
* **us-west-2** : ami-0e384b6f78bf96ebe
|
||||
* **us-east-1** : ami-0a7b46f907d5d9c4a
|
||||
|
||||
### v0.10.1 (static update)
|
||||
|
||||
* **eu-north-1** : ami-09937ec4d18350c32
|
||||
* **ap-south-1** : ami-089d6ba7541ec4c7f
|
||||
* **eu-west-3** : ami-0accb1a94bdd5c5c1
|
||||
* **eu-west-2** : ami-0dd2c97bc678b8570
|
||||
* **eu-west-1** : ami-07a38865cbe7ca3cb
|
||||
* **ap-northeast-2** : ami-09aa0b7fe1cf3dd55
|
||||
* **ap-northeast-1** : ami-0905e7d1543e5ed36
|
||||
* **sa-east-1** : ami-08c0627daa67d7372
|
||||
* **ca-central-1** : ami-034add081712ff648
|
||||
* **ap-southeast-1** : ami-0c6caee3689b6e066
|
||||
* **ap-southeast-2** : ami-04994afd8dae5b417
|
||||
* **eu-central-1** : ami-06b10f8c30e1434f1
|
||||
* **us-east-2** : ami-0d3abe7a1fec535cc
|
||||
* **us-west-1** : ami-02bb610b70c55018b
|
||||
* **us-west-2** : ami-0d1cb8ba7de246ff0
|
||||
* **us-east-1** : ami-049ccba6abdb40cba
|
||||
|
||||
### v0.10.0 (static update)
|
||||
|
||||
* **eu-north-1** : ami-05ba33c763877e54e
|
||||
* **ap-south-1** : ami-0529eec569161cae5
|
||||
* **eu-west-3** : ami-03cb9396f63e26ff6
|
||||
* **eu-west-2** : ami-0dd28cc97283cc201
|
||||
* **eu-west-1** : ami-059cf379ae14b0a24
|
||||
* **ap-northeast-2** : ami-031409d71f1280616
|
||||
* **ap-northeast-1** : ami-0171437c68b3660aa
|
||||
* **sa-east-1** : ami-0eb440a3b6e591c7a
|
||||
* **ca-central-1** : ami-097da9ec155ee654a
|
||||
* **ap-southeast-1** : ami-0ab7ff3ea09826e39
|
||||
* **ap-southeast-2** : ami-00969c550ef2d1f60
|
||||
* **eu-central-1** : ami-02246400c51990acb
|
||||
* **us-east-2** : ami-0cafc1d730381d6fa
|
||||
* **eu-central-1** : ami-02246400c51990acb
|
||||
* **us-west-1** : ami-0e82a98ddbe995a65
|
||||
* **us-west-2** : ami-04a522ecb2250fb44
|
||||
* **us-east-1** : ami-0a66ddbd50959f91e
|
||||
|
||||
### v0.9.0 (static update)
|
||||
|
||||
* **us-east-1** : ami-0991ad536ecbacdac
|
||||
* **eu-north-1** : ami-07cbcdff501b14afe
|
||||
* **ap-south-1** : ami-014cf398b00d4db83
|
||||
* **eu-west-3** : ami-0396ba51e9b733581
|
||||
* **eu-west-2** : ami-09134f4c7a20bad09
|
||||
* **eu-west-1** : ami-00427ed0a1bbfa7b0
|
||||
* **ap-northeast-2** : ami-041756675ca1be954
|
||||
* **ap-northeast-1** : ami-0c09ebad05c9128ff
|
||||
* **sa-east-1** : ami-017a8de4e8d1e8c8e
|
||||
* **ca-central-1** : ami-049ec444470f852be
|
||||
* **ap-southeast-1** : ami-0c919b8f821a6c635
|
||||
* **ap-southeast-2** : ami-04844a0594712d27b
|
||||
* **eu-central-1** : ami-0b4e756e0f7c0617d
|
||||
* **us-east-2** : ami-03b01914b07428488
|
||||
* **us-west-1** : ami-0cf4768e9d47ed076
|
||||
* **us-west-2** : ami-0b145f37da31eb9fb
|
||||
|
||||
58
docs/install_gcp.md
Normal file
58
docs/install_gcp.md
Normal file
@@ -0,0 +1,58 @@
|
||||
# Deploying Trains Server on Google Cloud Platform
|
||||
|
||||
To easily deploy Trains Server on GCP, use one of our pre-built GCP Custom Images.
|
||||
We provide Custom Images for each released version of Trains Server, see [Released versions](#released-versions) below.
|
||||
|
||||
Once your GCP instance is up and running using our Custom Image, [configure the Trains client](https://github.com/allegroai/trains/blob/master/README.md#configuration) to use your **trains-server**.
|
||||
The service port numbers on our Trains Server GCP Custom Image are:
|
||||
|
||||
- Web application: `8080`
|
||||
- API Server: `8008`
|
||||
- File Server: `8081`
|
||||
|
||||
The persistent storage configuration:
|
||||
|
||||
- MongoDB: `/opt/trains/data/mongo/`
|
||||
- ElasticSearch: `/opt/trains/data/elastic/`
|
||||
- File Server: `/mnt/fileserver/`
|
||||
|
||||
For examples and use cases, check the [Trains usage examples](https://github.com/allegroai/trains/blob/master/docs/trains_examples.md).
|
||||
|
||||
## Importing the Custom Image to your GCP account
|
||||
|
||||
In order to launch an instance using the Trains Server GCP Custom Image, you'll need to import the image to your custom images list.
|
||||
|
||||
**Note:** there's **no need** to upload the image file to Google Cloud Storage - we already provide links to image files stored in Google Storage
|
||||
|
||||
To import the image to your custom images list:
|
||||
1. In the Cloud Console, go to the [Images](https://console.cloud.google.com/compute/images) page.
|
||||
1. At the top of the page, click **Create image**.
|
||||
1. In the **Name** field, specify a unique name for the image.
|
||||
1. Optionally, specify an image family for your new image, or configure specific encryption settings for the image.
|
||||
1. Click the **Source** menu and select **Cloud Storage file**.
|
||||
1. Enter the Trains Server image bucket path (see [Trains Server GCP Custom Image](#released-versions)), for example:
|
||||
`allegro-files/trains-server/trains-server.tar.gz`
|
||||
1. Click the **Create** button to import the image. The process can take several minutes depending on the size of the boot disk image.
|
||||
|
||||
For more information see [Import the image to your custom images list](https://cloud.google.com/compute/docs/import/import-existing-image#import_image) in the [Compute Engine Documentation](https://cloud.google.com/compute/docs).
|
||||
|
||||
## Launching an instance with a Custom Image
|
||||
|
||||
For instructions on launching an instance using a GCP Custom Image, see the [Manually importing virtual disks](https://cloud.google.com/compute/docs/import/import-existing-image#overview) in the [Compute Engine Documentation](https://cloud.google.com/compute/docs).
|
||||
For more information on Custom Images, see [Custom Images](https://cloud.google.com/compute/docs/images#custom_images) in the Compute Engine Documentation.
|
||||
|
||||
The minimum recommended requirements for Trains Server are:
|
||||
- 2 vCPUs
|
||||
- 7.5GB RAM
|
||||
|
||||
## Upgrading
|
||||
|
||||
To upgrade **trains-server** on an existing GCP instance based on one of these Custom Images, SSH into the instance and follow the [upgrade instructions](../README.md#upgrade) for **trains-server**.
|
||||
|
||||
## Released versions
|
||||
|
||||
The following sections contain lists of Custom Image URLs (exported in different formats) for each released **trains-server** version.
|
||||
|
||||
### Latest version image (v0.14.1)
|
||||
|
||||
- https://storage.googleapis.com/allegro-files/trains-server/trains-server.tar.gz
|
||||
97
docs/install_linux_mac.md
Normal file
97
docs/install_linux_mac.md
Normal file
@@ -0,0 +1,97 @@
|
||||
# Launching the **trains-server** Docker in Linux or macOS
|
||||
|
||||
For Linux or macOS, use our pre-built Docker image for easy deployment. The latest Docker images can be found [here](https://hub.docker.com/r/allegroai/trains).
|
||||
|
||||
For Linux users:
|
||||
|
||||
* You must be logged in as a user with sudo privileges.
|
||||
* Use `bash` for all command-line instructions in this installation.
|
||||
|
||||
To launch **trains-server** on Linux or macOS:
|
||||
|
||||
1. Install Docker.
|
||||
|
||||
* Linux - see [Docker for Ubuntu](https://docs.docker.com/install/linux/docker-ce/ubuntu/).
|
||||
* macOS - see [Docker for macOS](https://docs.docker.com/docker-for-mac/install/).
|
||||
|
||||
1. Verify the Docker CE installation. Execute the command:
|
||||
|
||||
sudo docker run hello-world
|
||||
|
||||
The expected is output is:
|
||||
|
||||
Hello from Docker!
|
||||
This message shows that your installation appears to be working correctly.
|
||||
To generate this message, Docker took the following steps:
|
||||
|
||||
1. The Docker client contacted the Docker daemon.
|
||||
2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64)
|
||||
3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading.
|
||||
4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal.
|
||||
|
||||
1. For Linux only, install `docker-compose`. Execute the following commands (for more information, see [Install Docker Compose](https://docs.docker.com/compose/install/) in the Docker documentation):
|
||||
|
||||
sudo curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
|
||||
sudo chmod +x /usr/local/bin/docker-compose
|
||||
|
||||
1. Increase `vm.max_map_count` for ElasticSearch docker.
|
||||
|
||||
Linux:
|
||||
|
||||
echo "vm.max_map_count=262144" > /tmp/99-trains.conf
|
||||
sudo mv /tmp/99-trains.conf /etc/sysctl.d/99-trains.conf
|
||||
sudo sysctl -w vm.max_map_count=262144
|
||||
sudo service docker restart
|
||||
|
||||
macOS:
|
||||
|
||||
screen ~/Library/Containers/com.docker.docker/Data/vms/0/tty
|
||||
sysctl -w vm.max_map_count=262144
|
||||
|
||||
|
||||
1. Remove any previous installation of **trains-server**.
|
||||
|
||||
**WARNING**: This clears all existing **Trains** databases.
|
||||
|
||||
sudo rm -R /opt/trains/
|
||||
|
||||
1. Create local directories for the databases and storage.
|
||||
|
||||
sudo mkdir -p /opt/trains/data/elastic
|
||||
sudo mkdir -p /opt/trains/data/mongo/db
|
||||
sudo mkdir -p /opt/trains/data/mongo/configdb
|
||||
sudo mkdir -p /opt/trains/data/redis
|
||||
sudo mkdir -p /opt/trains/logs
|
||||
sudo mkdir -p /opt/trains/config
|
||||
sudo mkdir -p /opt/trains/data/fileserver
|
||||
|
||||
1. For macOS only, open the Docker app, select **Preferences**, and then on the **File Sharing** tab, add `/opt/trains`.
|
||||
|
||||
1. Grant access to the Dockers.
|
||||
|
||||
Linux:
|
||||
|
||||
sudo chown -R 1000:1000 /opt/trains
|
||||
|
||||
macOS:
|
||||
|
||||
sudo chown -R $(whoami):staff /opt/trains
|
||||
|
||||
1. Download the **trains-server** docker-compose YAML file.
|
||||
|
||||
cd /opt/trains
|
||||
curl https://raw.githubusercontent.com/allegroai/trains-server/master/docker-compose.yml -o docker-compose.yml
|
||||
|
||||
1. Run `docker-compose` with the downloaded configuration file.
|
||||
|
||||
sudo docker-compose -f docker-compose.yml up
|
||||
|
||||
Your server is now running on [http://localhost:8080](http://localhost:8080) and the following ports are available:
|
||||
|
||||
* Web server on port `8080`
|
||||
* API server on port `8008`
|
||||
* File server on port `8081`
|
||||
|
||||
## Next Step
|
||||
|
||||
Configure the [Trains client for trains-server](https://github.com/allegroai/trains/blob/master/README.md#configuration).
|
||||
50
docs/install_win.md
Normal file
50
docs/install_win.md
Normal file
@@ -0,0 +1,50 @@
|
||||
# Launching the **trains-server** Docker in Windows 10
|
||||
|
||||
For Windows, we recommend launching our pre-built Docker image on a Linux virtual machine.
|
||||
However, you can launch **trains-server** on Windows 10 using Docker Desktop for Windows (see the Docker [System Requirements](https://docs.docker.com/docker-for-windows/install/#system-requirements)).
|
||||
|
||||
To launch **trains-server** on Windows 10:
|
||||
|
||||
1. Install the Docker Desktop for Windows application by either:
|
||||
|
||||
* Following the [Install Docker Desktop on Windows](https://docs.docker.com/docker-for-windows/install/) instructions.
|
||||
* Running the Docker installation [wizard](https://hub.docker.com/?overlay=onboarding).
|
||||
|
||||
1. Increase the memory allocation in Docker Desktop to `4GB`.
|
||||
|
||||
1. In your Windows notification area (system tray), right click the Docker icon.
|
||||
|
||||
1. Click *Settings*, *Advanced*, and then set the memory to at least `4096`.
|
||||
|
||||
1. Click *Apply*.
|
||||
|
||||
1. Remove any previous installation of **trains-server**.
|
||||
|
||||
**WARNING**: This clears all existing **Trains** databases.
|
||||
|
||||
rmdir c:\opt\trains /s
|
||||
|
||||
1. Create local directories for data and logs. Open PowerShell and execute the following commands:
|
||||
|
||||
cd c:
|
||||
mkdir c:\opt\trains\data
|
||||
mkdir c:\opt\trains\logs
|
||||
|
||||
1. Save the **trains-server** docker-compose YAML file.
|
||||
|
||||
cd c:\opt\trains
|
||||
curl https://raw.githubusercontent.com/allegroai/trains-server/master/docker-compose-win10.yml -o docker-compose-win10.yml
|
||||
|
||||
1. Run `docker-compose`. In PowerShell, execute the following commands:
|
||||
|
||||
docker-compose -f docker-compose-win10.yml up
|
||||
|
||||
Your server is now running on [http://localhost:8080](http://localhost:8080) and the following ports are available:
|
||||
|
||||
* Web server on port `8080`
|
||||
* API server on port `8008`
|
||||
* File server on port `8081`
|
||||
|
||||
## Next Step
|
||||
|
||||
Configure the [Trains client for trains-server](https://github.com/allegroai/trains/blob/master/README.md#configuration).
|
||||
9
docs/services.conf
Normal file
9
docs/services.conf
Normal file
@@ -0,0 +1,9 @@
|
||||
tasks {
|
||||
non_responsive_tasks_watchdog {
|
||||
# In-progress tasks that haven't been updated for at least 'value' seconds will be stopped by the watchdog
|
||||
threshold_sec: 7200
|
||||
|
||||
# Watchdog will sleep for this number of seconds after each cycle
|
||||
watch_interval_sec: 900
|
||||
}
|
||||
}
|
||||
557
fileserver/LICENSE
Normal file
557
fileserver/LICENSE
Normal file
@@ -0,0 +1,557 @@
|
||||
Server Side Public License
|
||||
VERSION 1, OCTOBER 16, 2018
|
||||
|
||||
Copyright © 2019 allegro.ai, Inc.
|
||||
|
||||
Everyone is permitted to copy and distribute verbatim copies of this
|
||||
license document, but changing it is not allowed.
|
||||
|
||||
TERMS AND CONDITIONS
|
||||
|
||||
0. Definitions.
|
||||
|
||||
“This License” refers to Server Side Public License.
|
||||
|
||||
“Copyright” also means copyright-like laws that apply to other kinds of
|
||||
works, such as semiconductor masks.
|
||||
|
||||
“The Program” refers to any copyrightable work licensed under this
|
||||
License. Each licensee is addressed as “you”. “Licensees” and
|
||||
“recipients” may be individuals or organizations.
|
||||
|
||||
To “modify” a work means to copy from or adapt all or part of the work in
|
||||
a fashion requiring copyright permission, other than the making of an
|
||||
exact copy. The resulting work is called a “modified version” of the
|
||||
earlier work or a work “based on” the earlier work.
|
||||
|
||||
A “covered work” means either the unmodified Program or a work based on
|
||||
the Program.
|
||||
|
||||
To “propagate” a work means to do anything with it that, without
|
||||
permission, would make you directly or secondarily liable for
|
||||
infringement under applicable copyright law, except executing it on a
|
||||
computer or modifying a private copy. Propagation includes copying,
|
||||
distribution (with or without modification), making available to the
|
||||
public, and in some countries other activities as well.
|
||||
|
||||
To “convey” a work means any kind of propagation that enables other
|
||||
parties to make or receive copies. Mere interaction with a user through a
|
||||
computer network, with no transfer of a copy, is not conveying.
|
||||
|
||||
An interactive user interface displays “Appropriate Legal Notices” to the
|
||||
extent that it includes a convenient and prominently visible feature that
|
||||
(1) displays an appropriate copyright notice, and (2) tells the user that
|
||||
there is no warranty for the work (except to the extent that warranties
|
||||
are provided), that licensees may convey the work under this License, and
|
||||
how to view a copy of this License. If the interface presents a list of
|
||||
user commands or options, such as a menu, a prominent item in the list
|
||||
meets this criterion.
|
||||
|
||||
1. Source Code.
|
||||
|
||||
The “source code” for a work means the preferred form of the work for
|
||||
making modifications to it. “Object code” means any non-source form of a
|
||||
work.
|
||||
|
||||
A “Standard Interface” means an interface that either is an official
|
||||
standard defined by a recognized standards body, or, in the case of
|
||||
interfaces specified for a particular programming language, one that is
|
||||
widely used among developers working in that language. The “System
|
||||
Libraries” of an executable work include anything, other than the work as
|
||||
a whole, that (a) is included in the normal form of packaging a Major
|
||||
Component, but which is not part of that Major Component, and (b) serves
|
||||
only to enable use of the work with that Major Component, or to implement
|
||||
a Standard Interface for which an implementation is available to the
|
||||
public in source code form. A “Major Component”, in this context, means a
|
||||
major essential component (kernel, window system, and so on) of the
|
||||
specific operating system (if any) on which the executable work runs, or
|
||||
a compiler used to produce the work, or an object code interpreter used
|
||||
to run it.
|
||||
|
||||
The “Corresponding Source” for a work in object code form means all the
|
||||
source code needed to generate, install, and (for an executable work) run
|
||||
the object code and to modify the work, including scripts to control
|
||||
those activities. However, it does not include the work's System
|
||||
Libraries, or general-purpose tools or generally available free programs
|
||||
which are used unmodified in performing those activities but which are
|
||||
not part of the work. For example, Corresponding Source includes
|
||||
interface definition files associated with source files for the work, and
|
||||
the source code for shared libraries and dynamically linked subprograms
|
||||
that the work is specifically designed to require, such as by intimate
|
||||
data communication or control flow between those subprograms and other
|
||||
parts of the work.
|
||||
|
||||
The Corresponding Source need not include anything that users can
|
||||
regenerate automatically from other parts of the Corresponding Source.
|
||||
|
||||
The Corresponding Source for a work in source code form is that same work.
|
||||
|
||||
2. Basic Permissions.
|
||||
|
||||
All rights granted under this License are granted for the term of
|
||||
copyright on the Program, and are irrevocable provided the stated
|
||||
conditions are met. This License explicitly affirms your unlimited
|
||||
permission to run the unmodified Program, subject to section 13. The
|
||||
output from running a covered work is covered by this License only if the
|
||||
output, given its content, constitutes a covered work. This License
|
||||
acknowledges your rights of fair use or other equivalent, as provided by
|
||||
copyright law. Subject to section 13, you may make, run and propagate
|
||||
covered works that you do not convey, without conditions so long as your
|
||||
license otherwise remains in force. You may convey covered works to
|
||||
others for the sole purpose of having them make modifications exclusively
|
||||
for you, or provide you with facilities for running those works, provided
|
||||
that you comply with the terms of this License in conveying all
|
||||
material for which you do not control copyright. Those thus making or
|
||||
running the covered works for you must do so exclusively on your
|
||||
behalf, under your direction and control, on terms that prohibit them
|
||||
from making any copies of your copyrighted material outside their
|
||||
relationship with you.
|
||||
|
||||
Conveying under any other circumstances is permitted solely under the
|
||||
conditions stated below. Sublicensing is not allowed; section 10 makes it
|
||||
unnecessary.
|
||||
|
||||
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
||||
|
||||
No covered work shall be deemed part of an effective technological
|
||||
measure under any applicable law fulfilling obligations under article 11
|
||||
of the WIPO copyright treaty adopted on 20 December 1996, or similar laws
|
||||
prohibiting or restricting circumvention of such measures.
|
||||
|
||||
When you convey a covered work, you waive any legal power to forbid
|
||||
circumvention of technological measures to the extent such circumvention is
|
||||
effected by exercising rights under this License with respect to the
|
||||
covered work, and you disclaim any intention to limit operation or
|
||||
modification of the work as a means of enforcing, against the work's users,
|
||||
your or third parties' legal rights to forbid circumvention of
|
||||
technological measures.
|
||||
|
||||
4. Conveying Verbatim Copies.
|
||||
|
||||
You may convey verbatim copies of the Program's source code as you
|
||||
receive it, in any medium, provided that you conspicuously and
|
||||
appropriately publish on each copy an appropriate copyright notice; keep
|
||||
intact all notices stating that this License and any non-permissive terms
|
||||
added in accord with section 7 apply to the code; keep intact all notices
|
||||
of the absence of any warranty; and give all recipients a copy of this
|
||||
License along with the Program. You may charge any price or no price for
|
||||
each copy that you convey, and you may offer support or warranty
|
||||
protection for a fee.
|
||||
|
||||
5. Conveying Modified Source Versions.
|
||||
|
||||
You may convey a work based on the Program, or the modifications to
|
||||
produce it from the Program, in the form of source code under the terms
|
||||
of section 4, provided that you also meet all of these conditions:
|
||||
|
||||
a) The work must carry prominent notices stating that you modified it,
|
||||
and giving a relevant date.
|
||||
|
||||
b) The work must carry prominent notices stating that it is released
|
||||
under this License and any conditions added under section 7. This
|
||||
requirement modifies the requirement in section 4 to “keep intact all
|
||||
notices”.
|
||||
|
||||
c) You must license the entire work, as a whole, under this License to
|
||||
anyone who comes into possession of a copy. This License will therefore
|
||||
apply, along with any applicable section 7 additional terms, to the
|
||||
whole of the work, and all its parts, regardless of how they are
|
||||
packaged. This License gives no permission to license the work in any
|
||||
other way, but it does not invalidate such permission if you have
|
||||
separately received it.
|
||||
|
||||
d) If the work has interactive user interfaces, each must display
|
||||
Appropriate Legal Notices; however, if the Program has interactive
|
||||
interfaces that do not display Appropriate Legal Notices, your work
|
||||
need not make them do so.
|
||||
|
||||
A compilation of a covered work with other separate and independent
|
||||
works, which are not by their nature extensions of the covered work, and
|
||||
which are not combined with it such as to form a larger program, in or on
|
||||
a volume of a storage or distribution medium, is called an “aggregate” if
|
||||
the compilation and its resulting copyright are not used to limit the
|
||||
access or legal rights of the compilation's users beyond what the
|
||||
individual works permit. Inclusion of a covered work in an aggregate does
|
||||
not cause this License to apply to the other parts of the aggregate.
|
||||
|
||||
6. Conveying Non-Source Forms.
|
||||
|
||||
You may convey a covered work in object code form under the terms of
|
||||
sections 4 and 5, provided that you also convey the machine-readable
|
||||
Corresponding Source under the terms of this License, in one of these
|
||||
ways:
|
||||
|
||||
a) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by the
|
||||
Corresponding Source fixed on a durable physical medium customarily
|
||||
used for software interchange.
|
||||
|
||||
b) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by a written
|
||||
offer, valid for at least three years and valid for as long as you
|
||||
offer spare parts or customer support for that product model, to give
|
||||
anyone who possesses the object code either (1) a copy of the
|
||||
Corresponding Source for all the software in the product that is
|
||||
covered by this License, on a durable physical medium customarily used
|
||||
for software interchange, for a price no more than your reasonable cost
|
||||
of physically performing this conveying of source, or (2) access to
|
||||
copy the Corresponding Source from a network server at no charge.
|
||||
|
||||
c) Convey individual copies of the object code with a copy of the
|
||||
written offer to provide the Corresponding Source. This alternative is
|
||||
allowed only occasionally and noncommercially, and only if you received
|
||||
the object code with such an offer, in accord with subsection 6b.
|
||||
|
||||
d) Convey the object code by offering access from a designated place
|
||||
(gratis or for a charge), and offer equivalent access to the
|
||||
Corresponding Source in the same way through the same place at no
|
||||
further charge. You need not require recipients to copy the
|
||||
Corresponding Source along with the object code. If the place to copy
|
||||
the object code is a network server, the Corresponding Source may be on
|
||||
a different server (operated by you or a third party) that supports
|
||||
equivalent copying facilities, provided you maintain clear directions
|
||||
next to the object code saying where to find the Corresponding Source.
|
||||
Regardless of what server hosts the Corresponding Source, you remain
|
||||
obligated to ensure that it is available for as long as needed to
|
||||
satisfy these requirements.
|
||||
|
||||
e) Convey the object code using peer-to-peer transmission, provided you
|
||||
inform other peers where the object code and Corresponding Source of
|
||||
the work are being offered to the general public at no charge under
|
||||
subsection 6d.
|
||||
|
||||
A separable portion of the object code, whose source code is excluded
|
||||
from the Corresponding Source as a System Library, need not be included
|
||||
in conveying the object code work.
|
||||
|
||||
A “User Product” is either (1) a “consumer product”, which means any
|
||||
tangible personal property which is normally used for personal, family,
|
||||
or household purposes, or (2) anything designed or sold for incorporation
|
||||
into a dwelling. In determining whether a product is a consumer product,
|
||||
doubtful cases shall be resolved in favor of coverage. For a particular
|
||||
product received by a particular user, “normally used” refers to a
|
||||
typical or common use of that class of product, regardless of the status
|
||||
of the particular user or of the way in which the particular user
|
||||
actually uses, or expects or is expected to use, the product. A product
|
||||
is a consumer product regardless of whether the product has substantial
|
||||
commercial, industrial or non-consumer uses, unless such uses represent
|
||||
the only significant mode of use of the product.
|
||||
|
||||
“Installation Information” for a User Product means any methods,
|
||||
procedures, authorization keys, or other information required to install
|
||||
and execute modified versions of a covered work in that User Product from
|
||||
a modified version of its Corresponding Source. The information must
|
||||
suffice to ensure that the continued functioning of the modified object
|
||||
code is in no case prevented or interfered with solely because
|
||||
modification has been made.
|
||||
|
||||
If you convey an object code work under this section in, or with, or
|
||||
specifically for use in, a User Product, and the conveying occurs as part
|
||||
of a transaction in which the right of possession and use of the User
|
||||
Product is transferred to the recipient in perpetuity or for a fixed term
|
||||
(regardless of how the transaction is characterized), the Corresponding
|
||||
Source conveyed under this section must be accompanied by the
|
||||
Installation Information. But this requirement does not apply if neither
|
||||
you nor any third party retains the ability to install modified object
|
||||
code on the User Product (for example, the work has been installed in
|
||||
ROM).
|
||||
|
||||
The requirement to provide Installation Information does not include a
|
||||
requirement to continue to provide support service, warranty, or updates
|
||||
for a work that has been modified or installed by the recipient, or for
|
||||
the User Product in which it has been modified or installed. Access
|
||||
to a network may be denied when the modification itself materially
|
||||
and adversely affects the operation of the network or violates the
|
||||
rules and protocols for communication across the network.
|
||||
|
||||
Corresponding Source conveyed, and Installation Information provided, in
|
||||
accord with this section must be in a format that is publicly documented
|
||||
(and with an implementation available to the public in source code form),
|
||||
and must require no special password or key for unpacking, reading or
|
||||
copying.
|
||||
|
||||
7. Additional Terms.
|
||||
|
||||
“Additional permissions” are terms that supplement the terms of this
|
||||
License by making exceptions from one or more of its conditions.
|
||||
Additional permissions that are applicable to the entire Program shall be
|
||||
treated as though they were included in this License, to the extent that
|
||||
they are valid under applicable law. If additional permissions apply only
|
||||
to part of the Program, that part may be used separately under those
|
||||
permissions, but the entire Program remains governed by this License
|
||||
without regard to the additional permissions. When you convey a copy of
|
||||
a covered work, you may at your option remove any additional permissions
|
||||
from that copy, or from any part of it. (Additional permissions may be
|
||||
written to require their own removal in certain cases when you modify the
|
||||
work.) You may place additional permissions on material, added by you to
|
||||
a covered work, for which you have or can give appropriate copyright
|
||||
permission.
|
||||
|
||||
Notwithstanding any other provision of this License, for material you add
|
||||
to a covered work, you may (if authorized by the copyright holders of
|
||||
that material) supplement the terms of this License with terms:
|
||||
|
||||
a) Disclaiming warranty or limiting liability differently from the
|
||||
terms of sections 15 and 16 of this License; or
|
||||
|
||||
b) Requiring preservation of specified reasonable legal notices or
|
||||
author attributions in that material or in the Appropriate Legal
|
||||
Notices displayed by works containing it; or
|
||||
|
||||
c) Prohibiting misrepresentation of the origin of that material, or
|
||||
requiring that modified versions of such material be marked in
|
||||
reasonable ways as different from the original version; or
|
||||
|
||||
d) Limiting the use for publicity purposes of names of licensors or
|
||||
authors of the material; or
|
||||
|
||||
e) Declining to grant rights under trademark law for use of some trade
|
||||
names, trademarks, or service marks; or
|
||||
|
||||
f) Requiring indemnification of licensors and authors of that material
|
||||
by anyone who conveys the material (or modified versions of it) with
|
||||
contractual assumptions of liability to the recipient, for any
|
||||
liability that these contractual assumptions directly impose on those
|
||||
licensors and authors.
|
||||
|
||||
All other non-permissive additional terms are considered “further
|
||||
restrictions” within the meaning of section 10. If the Program as you
|
||||
received it, or any part of it, contains a notice stating that it is
|
||||
governed by this License along with a term that is a further restriction,
|
||||
you may remove that term. If a license document contains a further
|
||||
restriction but permits relicensing or conveying under this License, you
|
||||
may add to a covered work material governed by the terms of that license
|
||||
document, provided that the further restriction does not survive such
|
||||
relicensing or conveying.
|
||||
|
||||
If you add terms to a covered work in accord with this section, you must
|
||||
place, in the relevant source files, a statement of the additional terms
|
||||
that apply to those files, or a notice indicating where to find the
|
||||
applicable terms. Additional terms, permissive or non-permissive, may be
|
||||
stated in the form of a separately written license, or stated as
|
||||
exceptions; the above requirements apply either way.
|
||||
|
||||
8. Termination.
|
||||
|
||||
You may not propagate or modify a covered work except as expressly
|
||||
provided under this License. Any attempt otherwise to propagate or modify
|
||||
it is void, and will automatically terminate your rights under this
|
||||
License (including any patent licenses granted under the third paragraph
|
||||
of section 11).
|
||||
|
||||
However, if you cease all violation of this License, then your license
|
||||
from a particular copyright holder is reinstated (a) provisionally,
|
||||
unless and until the copyright holder explicitly and finally terminates
|
||||
your license, and (b) permanently, if the copyright holder fails to
|
||||
notify you of the violation by some reasonable means prior to 60 days
|
||||
after the cessation.
|
||||
|
||||
Moreover, your license from a particular copyright holder is reinstated
|
||||
permanently if the copyright holder notifies you of the violation by some
|
||||
reasonable means, this is the first time you have received notice of
|
||||
violation of this License (for any work) from that copyright holder, and
|
||||
you cure the violation prior to 30 days after your receipt of the notice.
|
||||
|
||||
Termination of your rights under this section does not terminate the
|
||||
licenses of parties who have received copies or rights from you under
|
||||
this License. If your rights have been terminated and not permanently
|
||||
reinstated, you do not qualify to receive new licenses for the same
|
||||
material under section 10.
|
||||
|
||||
9. Acceptance Not Required for Having Copies.
|
||||
|
||||
You are not required to accept this License in order to receive or run a
|
||||
copy of the Program. Ancillary propagation of a covered work occurring
|
||||
solely as a consequence of using peer-to-peer transmission to receive a
|
||||
copy likewise does not require acceptance. However, nothing other than
|
||||
this License grants you permission to propagate or modify any covered
|
||||
work. These actions infringe copyright if you do not accept this License.
|
||||
Therefore, by modifying or propagating a covered work, you indicate your
|
||||
acceptance of this License to do so.
|
||||
|
||||
10. Automatic Licensing of Downstream Recipients.
|
||||
|
||||
Each time you convey a covered work, the recipient automatically receives
|
||||
a license from the original licensors, to run, modify and propagate that
|
||||
work, subject to this License. You are not responsible for enforcing
|
||||
compliance by third parties with this License.
|
||||
|
||||
An “entity transaction” is a transaction transferring control of an
|
||||
organization, or substantially all assets of one, or subdividing an
|
||||
organization, or merging organizations. If propagation of a covered work
|
||||
results from an entity transaction, each party to that transaction who
|
||||
receives a copy of the work also receives whatever licenses to the work
|
||||
the party's predecessor in interest had or could give under the previous
|
||||
paragraph, plus a right to possession of the Corresponding Source of the
|
||||
work from the predecessor in interest, if the predecessor has it or can
|
||||
get it with reasonable efforts.
|
||||
|
||||
You may not impose any further restrictions on the exercise of the rights
|
||||
granted or affirmed under this License. For example, you may not impose a
|
||||
license fee, royalty, or other charge for exercise of rights granted
|
||||
under this License, and you may not initiate litigation (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that any patent claim
|
||||
is infringed by making, using, selling, offering for sale, or importing
|
||||
the Program or any portion of it.
|
||||
|
||||
11. Patents.
|
||||
|
||||
A “contributor” is a copyright holder who authorizes use under this
|
||||
License of the Program or a work on which the Program is based. The work
|
||||
thus licensed is called the contributor's “contributor version”.
|
||||
|
||||
A contributor's “essential patent claims” are all patent claims owned or
|
||||
controlled by the contributor, whether already acquired or hereafter
|
||||
acquired, that would be infringed by some manner, permitted by this
|
||||
License, of making, using, or selling its contributor version, but do not
|
||||
include claims that would be infringed only as a consequence of further
|
||||
modification of the contributor version. For purposes of this definition,
|
||||
“control” includes the right to grant patent sublicenses in a manner
|
||||
consistent with the requirements of this License.
|
||||
|
||||
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
||||
patent license under the contributor's essential patent claims, to make,
|
||||
use, sell, offer for sale, import and otherwise run, modify and propagate
|
||||
the contents of its contributor version.
|
||||
|
||||
In the following three paragraphs, a “patent license” is any express
|
||||
agreement or commitment, however denominated, not to enforce a patent
|
||||
(such as an express permission to practice a patent or covenant not to
|
||||
sue for patent infringement). To “grant” such a patent license to a party
|
||||
means to make such an agreement or commitment not to enforce a patent
|
||||
against the party.
|
||||
|
||||
If you convey a covered work, knowingly relying on a patent license, and
|
||||
the Corresponding Source of the work is not available for anyone to copy,
|
||||
free of charge and under the terms of this License, through a publicly
|
||||
available network server or other readily accessible means, then you must
|
||||
either (1) cause the Corresponding Source to be so available, or (2)
|
||||
arrange to deprive yourself of the benefit of the patent license for this
|
||||
particular work, or (3) arrange, in a manner consistent with the
|
||||
requirements of this License, to extend the patent license to downstream
|
||||
recipients. “Knowingly relying” means you have actual knowledge that, but
|
||||
for the patent license, your conveying the covered work in a country, or
|
||||
your recipient's use of the covered work in a country, would infringe
|
||||
one or more identifiable patents in that country that you have reason
|
||||
to believe are valid.
|
||||
|
||||
If, pursuant to or in connection with a single transaction or
|
||||
arrangement, you convey, or propagate by procuring conveyance of, a
|
||||
covered work, and grant a patent license to some of the parties receiving
|
||||
the covered work authorizing them to use, propagate, modify or convey a
|
||||
specific copy of the covered work, then the patent license you grant is
|
||||
automatically extended to all recipients of the covered work and works
|
||||
based on it.
|
||||
|
||||
A patent license is “discriminatory” if it does not include within the
|
||||
scope of its coverage, prohibits the exercise of, or is conditioned on
|
||||
the non-exercise of one or more of the rights that are specifically
|
||||
granted under this License. You may not convey a covered work if you are
|
||||
a party to an arrangement with a third party that is in the business of
|
||||
distributing software, under which you make payment to the third party
|
||||
based on the extent of your activity of conveying the work, and under
|
||||
which the third party grants, to any of the parties who would receive the
|
||||
covered work from you, a discriminatory patent license (a) in connection
|
||||
with copies of the covered work conveyed by you (or copies made from
|
||||
those copies), or (b) primarily for and in connection with specific
|
||||
products or compilations that contain the covered work, unless you
|
||||
entered into that arrangement, or that patent license was granted, prior
|
||||
to 28 March 2007.
|
||||
|
||||
Nothing in this License shall be construed as excluding or limiting any
|
||||
implied license or other defenses to infringement that may otherwise be
|
||||
available to you under applicable patent law.
|
||||
|
||||
12. No Surrender of Others' Freedom.
|
||||
|
||||
If conditions are imposed on you (whether by court order, agreement or
|
||||
otherwise) that contradict the conditions of this License, they do not
|
||||
excuse you from the conditions of this License. If you cannot use,
|
||||
propagate or convey a covered work so as to satisfy simultaneously your
|
||||
obligations under this License and any other pertinent obligations, then
|
||||
as a consequence you may not use, propagate or convey it at all. For
|
||||
example, if you agree to terms that obligate you to collect a royalty for
|
||||
further conveying from those to whom you convey the Program, the only way
|
||||
you could satisfy both those terms and this License would be to refrain
|
||||
entirely from conveying the Program.
|
||||
|
||||
13. Offering the Program as a Service.
|
||||
|
||||
If you make the functionality of the Program or a modified version
|
||||
available to third parties as a service, you must make the Service Source
|
||||
Code available via network download to everyone at no charge, under the
|
||||
terms of this License. Making the functionality of the Program or
|
||||
modified version available to third parties as a service includes,
|
||||
without limitation, enabling third parties to interact with the
|
||||
functionality of the Program or modified version remotely through a
|
||||
computer network, offering a service the value of which entirely or
|
||||
primarily derives from the value of the Program or modified version, or
|
||||
offering a service that accomplishes for users the primary purpose of the
|
||||
Program or modified version.
|
||||
|
||||
“Service Source Code” means the Corresponding Source for the Program or
|
||||
the modified version, and the Corresponding Source for all programs that
|
||||
you use to make the Program or modified version available as a service,
|
||||
including, without limitation, management software, user interfaces,
|
||||
application program interfaces, automation software, monitoring software,
|
||||
backup software, storage software and hosting software, all such that a
|
||||
user could run an instance of the service using the Service Source Code
|
||||
you make available.
|
||||
|
||||
14. Revised Versions of this License.
|
||||
|
||||
MongoDB, Inc. may publish revised and/or new versions of the Server Side
|
||||
Public License from time to time. Such new versions will be similar in
|
||||
spirit to the present version, but may differ in detail to address new
|
||||
problems or concerns.
|
||||
|
||||
Each version is given a distinguishing version number. If the Program
|
||||
specifies that a certain numbered version of the Server Side Public
|
||||
License “or any later version” applies to it, you have the option of
|
||||
following the terms and conditions either of that numbered version or of
|
||||
any later version published by MongoDB, Inc. If the Program does not
|
||||
specify a version number of the Server Side Public License, you may
|
||||
choose any version ever published by MongoDB, Inc.
|
||||
|
||||
If the Program specifies that a proxy can decide which future versions of
|
||||
the Server Side Public License can be used, that proxy's public statement
|
||||
of acceptance of a version permanently authorizes you to choose that
|
||||
version for the Program.
|
||||
|
||||
Later license versions may give you additional or different permissions.
|
||||
However, no additional obligations are imposed on any author or copyright
|
||||
holder as a result of your choosing to follow a later version.
|
||||
|
||||
15. Disclaimer of Warranty.
|
||||
|
||||
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
||||
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
||||
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM “AS IS” WITHOUT WARRANTY
|
||||
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
||||
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
||||
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
||||
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
||||
|
||||
16. Limitation of Liability.
|
||||
|
||||
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
||||
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
||||
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING
|
||||
ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF
|
||||
THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO
|
||||
LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU
|
||||
OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER
|
||||
PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE
|
||||
POSSIBILITY OF SUCH DAMAGES.
|
||||
|
||||
17. Interpretation of Sections 15 and 16.
|
||||
|
||||
If the disclaimer of warranty and limitation of liability provided above
|
||||
cannot be given local legal effect according to their terms, reviewing
|
||||
courts shall apply local law that most closely approximates an absolute
|
||||
waiver of all civil liability in connection with the Program, unless a
|
||||
warranty or assumption of liability accompanies a copy of the Program in
|
||||
return for a fee.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
@@ -1,4 +1,7 @@
|
||||
import logging
|
||||
from functools import reduce
|
||||
from os import getenv
|
||||
from os.path import expandvars
|
||||
from pathlib import Path
|
||||
|
||||
from pyhocon import ConfigTree, ConfigFactory
|
||||
@@ -9,6 +12,10 @@ from pyparsing import (
|
||||
ParseSyntaxException,
|
||||
)
|
||||
|
||||
DEFAULT_EXTRA_CONFIG_PATH = "/opt/trains/config"
|
||||
EXTRA_CONFIG_PATH_ENV_KEY = "TRAINS_CONFIG_DIR"
|
||||
EXTRA_CONFIG_PATH_SEP = ":"
|
||||
|
||||
|
||||
class BasicConfig:
|
||||
NotSet = object()
|
||||
@@ -39,8 +46,32 @@ class BasicConfig:
|
||||
path = ".".join((self.prefix, Path(name).stem))
|
||||
return logging.getLogger(path)
|
||||
|
||||
def _read_env_paths(self, key):
|
||||
value = getenv(EXTRA_CONFIG_PATH_ENV_KEY, DEFAULT_EXTRA_CONFIG_PATH)
|
||||
if value is None:
|
||||
return
|
||||
paths = [
|
||||
Path(expandvars(v)).expanduser() for v in value.split(EXTRA_CONFIG_PATH_SEP)
|
||||
]
|
||||
invalid = [
|
||||
path
|
||||
for path in paths
|
||||
if not path.is_dir() and str(path) != DEFAULT_EXTRA_CONFIG_PATH
|
||||
]
|
||||
if invalid:
|
||||
print(f"WARNING: Invalid paths in {key} env var: {' '.join(invalid)}")
|
||||
return [path for path in paths if path.is_dir()]
|
||||
|
||||
def _load(self, verbose=True):
|
||||
self._config = self._read_recursive(self.folder, verbose=verbose)
|
||||
extra_config_paths = self._read_env_paths(EXTRA_CONFIG_PATH_ENV_KEY) or []
|
||||
|
||||
self._config = reduce(
|
||||
lambda config, path: ConfigTree.merge_configs(
|
||||
config, self._read_recursive(path, verbose=verbose), copy_trees=True
|
||||
),
|
||||
[self.folder] + extra_config_paths,
|
||||
ConfigTree(),
|
||||
)
|
||||
|
||||
def _read_recursive(self, conf_root, verbose=True):
|
||||
conf = ConfigTree()
|
||||
8
fileserver/config/default/fileserver.conf
Normal file
8
fileserver/config/default/fileserver.conf
Normal file
@@ -0,0 +1,8 @@
|
||||
download {
|
||||
# Add response headers requesting no caching for served files
|
||||
disable_browser_caching: false
|
||||
}
|
||||
|
||||
cors {
|
||||
origins: "*"
|
||||
}
|
||||
@@ -1,16 +1,21 @@
|
||||
""" A Simple file server for uploading and downloading files """
|
||||
import json
|
||||
import logging.config
|
||||
import os
|
||||
from argparse import ArgumentParser
|
||||
from pathlib import Path
|
||||
|
||||
from flask import Flask, request, send_from_directory, safe_join
|
||||
from pyhocon import ConfigFactory
|
||||
from flask_compress import Compress
|
||||
from flask_cors import CORS
|
||||
|
||||
logging.config.dictConfig(ConfigFactory.parse_file("logging.conf"))
|
||||
from config import config
|
||||
|
||||
app = Flask(__name__)
|
||||
CORS(app, **config.get("fileserver.cors"))
|
||||
Compress(app)
|
||||
|
||||
if os.environ.get("TRAINS_UPLOAD_FOLDER"):
|
||||
app.config["UPLOAD_FOLDER"] = os.environ.get("TRAINS_UPLOAD_FOLDER")
|
||||
|
||||
|
||||
@app.route("/", methods=["POST"])
|
||||
@@ -29,7 +34,15 @@ def upload():
|
||||
|
||||
@app.route("/<path:path>", methods=["GET"])
|
||||
def download(path):
|
||||
return send_from_directory(app.config["UPLOAD_FOLDER"], path)
|
||||
response = send_from_directory(app.config["UPLOAD_FOLDER"], path)
|
||||
if config.get("fileserver.download.disable_browser_caching", False):
|
||||
headers = response.headers
|
||||
headers["Pragma-directive"] = "no-cache"
|
||||
headers["Cache-directive"] = "no-cache"
|
||||
headers["Cache-control"] = "no-cache"
|
||||
headers["Pragma"] = "no-cache"
|
||||
headers["Expires"] = "0"
|
||||
return response
|
||||
|
||||
|
||||
def main():
|
||||
|
||||
@@ -1 +1,4 @@
|
||||
Flask
|
||||
Flask
|
||||
Flask-Cors>=3.0.5
|
||||
Flask-Compress>=1.4.0
|
||||
pyhocon>=0.3.35
|
||||
557
server/LICENSE
Normal file
557
server/LICENSE
Normal file
@@ -0,0 +1,557 @@
|
||||
Server Side Public License
|
||||
VERSION 1, OCTOBER 16, 2018
|
||||
|
||||
Copyright © 2019 allegro.ai, Inc.
|
||||
|
||||
Everyone is permitted to copy and distribute verbatim copies of this
|
||||
license document, but changing it is not allowed.
|
||||
|
||||
TERMS AND CONDITIONS
|
||||
|
||||
0. Definitions.
|
||||
|
||||
“This License” refers to Server Side Public License.
|
||||
|
||||
“Copyright” also means copyright-like laws that apply to other kinds of
|
||||
works, such as semiconductor masks.
|
||||
|
||||
“The Program” refers to any copyrightable work licensed under this
|
||||
License. Each licensee is addressed as “you”. “Licensees” and
|
||||
“recipients” may be individuals or organizations.
|
||||
|
||||
To “modify” a work means to copy from or adapt all or part of the work in
|
||||
a fashion requiring copyright permission, other than the making of an
|
||||
exact copy. The resulting work is called a “modified version” of the
|
||||
earlier work or a work “based on” the earlier work.
|
||||
|
||||
A “covered work” means either the unmodified Program or a work based on
|
||||
the Program.
|
||||
|
||||
To “propagate” a work means to do anything with it that, without
|
||||
permission, would make you directly or secondarily liable for
|
||||
infringement under applicable copyright law, except executing it on a
|
||||
computer or modifying a private copy. Propagation includes copying,
|
||||
distribution (with or without modification), making available to the
|
||||
public, and in some countries other activities as well.
|
||||
|
||||
To “convey” a work means any kind of propagation that enables other
|
||||
parties to make or receive copies. Mere interaction with a user through a
|
||||
computer network, with no transfer of a copy, is not conveying.
|
||||
|
||||
An interactive user interface displays “Appropriate Legal Notices” to the
|
||||
extent that it includes a convenient and prominently visible feature that
|
||||
(1) displays an appropriate copyright notice, and (2) tells the user that
|
||||
there is no warranty for the work (except to the extent that warranties
|
||||
are provided), that licensees may convey the work under this License, and
|
||||
how to view a copy of this License. If the interface presents a list of
|
||||
user commands or options, such as a menu, a prominent item in the list
|
||||
meets this criterion.
|
||||
|
||||
1. Source Code.
|
||||
|
||||
The “source code” for a work means the preferred form of the work for
|
||||
making modifications to it. “Object code” means any non-source form of a
|
||||
work.
|
||||
|
||||
A “Standard Interface” means an interface that either is an official
|
||||
standard defined by a recognized standards body, or, in the case of
|
||||
interfaces specified for a particular programming language, one that is
|
||||
widely used among developers working in that language. The “System
|
||||
Libraries” of an executable work include anything, other than the work as
|
||||
a whole, that (a) is included in the normal form of packaging a Major
|
||||
Component, but which is not part of that Major Component, and (b) serves
|
||||
only to enable use of the work with that Major Component, or to implement
|
||||
a Standard Interface for which an implementation is available to the
|
||||
public in source code form. A “Major Component”, in this context, means a
|
||||
major essential component (kernel, window system, and so on) of the
|
||||
specific operating system (if any) on which the executable work runs, or
|
||||
a compiler used to produce the work, or an object code interpreter used
|
||||
to run it.
|
||||
|
||||
The “Corresponding Source” for a work in object code form means all the
|
||||
source code needed to generate, install, and (for an executable work) run
|
||||
the object code and to modify the work, including scripts to control
|
||||
those activities. However, it does not include the work's System
|
||||
Libraries, or general-purpose tools or generally available free programs
|
||||
which are used unmodified in performing those activities but which are
|
||||
not part of the work. For example, Corresponding Source includes
|
||||
interface definition files associated with source files for the work, and
|
||||
the source code for shared libraries and dynamically linked subprograms
|
||||
that the work is specifically designed to require, such as by intimate
|
||||
data communication or control flow between those subprograms and other
|
||||
parts of the work.
|
||||
|
||||
The Corresponding Source need not include anything that users can
|
||||
regenerate automatically from other parts of the Corresponding Source.
|
||||
|
||||
The Corresponding Source for a work in source code form is that same work.
|
||||
|
||||
2. Basic Permissions.
|
||||
|
||||
All rights granted under this License are granted for the term of
|
||||
copyright on the Program, and are irrevocable provided the stated
|
||||
conditions are met. This License explicitly affirms your unlimited
|
||||
permission to run the unmodified Program, subject to section 13. The
|
||||
output from running a covered work is covered by this License only if the
|
||||
output, given its content, constitutes a covered work. This License
|
||||
acknowledges your rights of fair use or other equivalent, as provided by
|
||||
copyright law. Subject to section 13, you may make, run and propagate
|
||||
covered works that you do not convey, without conditions so long as your
|
||||
license otherwise remains in force. You may convey covered works to
|
||||
others for the sole purpose of having them make modifications exclusively
|
||||
for you, or provide you with facilities for running those works, provided
|
||||
that you comply with the terms of this License in conveying all
|
||||
material for which you do not control copyright. Those thus making or
|
||||
running the covered works for you must do so exclusively on your
|
||||
behalf, under your direction and control, on terms that prohibit them
|
||||
from making any copies of your copyrighted material outside their
|
||||
relationship with you.
|
||||
|
||||
Conveying under any other circumstances is permitted solely under the
|
||||
conditions stated below. Sublicensing is not allowed; section 10 makes it
|
||||
unnecessary.
|
||||
|
||||
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
||||
|
||||
No covered work shall be deemed part of an effective technological
|
||||
measure under any applicable law fulfilling obligations under article 11
|
||||
of the WIPO copyright treaty adopted on 20 December 1996, or similar laws
|
||||
prohibiting or restricting circumvention of such measures.
|
||||
|
||||
When you convey a covered work, you waive any legal power to forbid
|
||||
circumvention of technological measures to the extent such circumvention is
|
||||
effected by exercising rights under this License with respect to the
|
||||
covered work, and you disclaim any intention to limit operation or
|
||||
modification of the work as a means of enforcing, against the work's users,
|
||||
your or third parties' legal rights to forbid circumvention of
|
||||
technological measures.
|
||||
|
||||
4. Conveying Verbatim Copies.
|
||||
|
||||
You may convey verbatim copies of the Program's source code as you
|
||||
receive it, in any medium, provided that you conspicuously and
|
||||
appropriately publish on each copy an appropriate copyright notice; keep
|
||||
intact all notices stating that this License and any non-permissive terms
|
||||
added in accord with section 7 apply to the code; keep intact all notices
|
||||
of the absence of any warranty; and give all recipients a copy of this
|
||||
License along with the Program. You may charge any price or no price for
|
||||
each copy that you convey, and you may offer support or warranty
|
||||
protection for a fee.
|
||||
|
||||
5. Conveying Modified Source Versions.
|
||||
|
||||
You may convey a work based on the Program, or the modifications to
|
||||
produce it from the Program, in the form of source code under the terms
|
||||
of section 4, provided that you also meet all of these conditions:
|
||||
|
||||
a) The work must carry prominent notices stating that you modified it,
|
||||
and giving a relevant date.
|
||||
|
||||
b) The work must carry prominent notices stating that it is released
|
||||
under this License and any conditions added under section 7. This
|
||||
requirement modifies the requirement in section 4 to “keep intact all
|
||||
notices”.
|
||||
|
||||
c) You must license the entire work, as a whole, under this License to
|
||||
anyone who comes into possession of a copy. This License will therefore
|
||||
apply, along with any applicable section 7 additional terms, to the
|
||||
whole of the work, and all its parts, regardless of how they are
|
||||
packaged. This License gives no permission to license the work in any
|
||||
other way, but it does not invalidate such permission if you have
|
||||
separately received it.
|
||||
|
||||
d) If the work has interactive user interfaces, each must display
|
||||
Appropriate Legal Notices; however, if the Program has interactive
|
||||
interfaces that do not display Appropriate Legal Notices, your work
|
||||
need not make them do so.
|
||||
|
||||
A compilation of a covered work with other separate and independent
|
||||
works, which are not by their nature extensions of the covered work, and
|
||||
which are not combined with it such as to form a larger program, in or on
|
||||
a volume of a storage or distribution medium, is called an “aggregate” if
|
||||
the compilation and its resulting copyright are not used to limit the
|
||||
access or legal rights of the compilation's users beyond what the
|
||||
individual works permit. Inclusion of a covered work in an aggregate does
|
||||
not cause this License to apply to the other parts of the aggregate.
|
||||
|
||||
6. Conveying Non-Source Forms.
|
||||
|
||||
You may convey a covered work in object code form under the terms of
|
||||
sections 4 and 5, provided that you also convey the machine-readable
|
||||
Corresponding Source under the terms of this License, in one of these
|
||||
ways:
|
||||
|
||||
a) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by the
|
||||
Corresponding Source fixed on a durable physical medium customarily
|
||||
used for software interchange.
|
||||
|
||||
b) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by a written
|
||||
offer, valid for at least three years and valid for as long as you
|
||||
offer spare parts or customer support for that product model, to give
|
||||
anyone who possesses the object code either (1) a copy of the
|
||||
Corresponding Source for all the software in the product that is
|
||||
covered by this License, on a durable physical medium customarily used
|
||||
for software interchange, for a price no more than your reasonable cost
|
||||
of physically performing this conveying of source, or (2) access to
|
||||
copy the Corresponding Source from a network server at no charge.
|
||||
|
||||
c) Convey individual copies of the object code with a copy of the
|
||||
written offer to provide the Corresponding Source. This alternative is
|
||||
allowed only occasionally and noncommercially, and only if you received
|
||||
the object code with such an offer, in accord with subsection 6b.
|
||||
|
||||
d) Convey the object code by offering access from a designated place
|
||||
(gratis or for a charge), and offer equivalent access to the
|
||||
Corresponding Source in the same way through the same place at no
|
||||
further charge. You need not require recipients to copy the
|
||||
Corresponding Source along with the object code. If the place to copy
|
||||
the object code is a network server, the Corresponding Source may be on
|
||||
a different server (operated by you or a third party) that supports
|
||||
equivalent copying facilities, provided you maintain clear directions
|
||||
next to the object code saying where to find the Corresponding Source.
|
||||
Regardless of what server hosts the Corresponding Source, you remain
|
||||
obligated to ensure that it is available for as long as needed to
|
||||
satisfy these requirements.
|
||||
|
||||
e) Convey the object code using peer-to-peer transmission, provided you
|
||||
inform other peers where the object code and Corresponding Source of
|
||||
the work are being offered to the general public at no charge under
|
||||
subsection 6d.
|
||||
|
||||
A separable portion of the object code, whose source code is excluded
|
||||
from the Corresponding Source as a System Library, need not be included
|
||||
in conveying the object code work.
|
||||
|
||||
A “User Product” is either (1) a “consumer product”, which means any
|
||||
tangible personal property which is normally used for personal, family,
|
||||
or household purposes, or (2) anything designed or sold for incorporation
|
||||
into a dwelling. In determining whether a product is a consumer product,
|
||||
doubtful cases shall be resolved in favor of coverage. For a particular
|
||||
product received by a particular user, “normally used” refers to a
|
||||
typical or common use of that class of product, regardless of the status
|
||||
of the particular user or of the way in which the particular user
|
||||
actually uses, or expects or is expected to use, the product. A product
|
||||
is a consumer product regardless of whether the product has substantial
|
||||
commercial, industrial or non-consumer uses, unless such uses represent
|
||||
the only significant mode of use of the product.
|
||||
|
||||
“Installation Information” for a User Product means any methods,
|
||||
procedures, authorization keys, or other information required to install
|
||||
and execute modified versions of a covered work in that User Product from
|
||||
a modified version of its Corresponding Source. The information must
|
||||
suffice to ensure that the continued functioning of the modified object
|
||||
code is in no case prevented or interfered with solely because
|
||||
modification has been made.
|
||||
|
||||
If you convey an object code work under this section in, or with, or
|
||||
specifically for use in, a User Product, and the conveying occurs as part
|
||||
of a transaction in which the right of possession and use of the User
|
||||
Product is transferred to the recipient in perpetuity or for a fixed term
|
||||
(regardless of how the transaction is characterized), the Corresponding
|
||||
Source conveyed under this section must be accompanied by the
|
||||
Installation Information. But this requirement does not apply if neither
|
||||
you nor any third party retains the ability to install modified object
|
||||
code on the User Product (for example, the work has been installed in
|
||||
ROM).
|
||||
|
||||
The requirement to provide Installation Information does not include a
|
||||
requirement to continue to provide support service, warranty, or updates
|
||||
for a work that has been modified or installed by the recipient, or for
|
||||
the User Product in which it has been modified or installed. Access
|
||||
to a network may be denied when the modification itself materially
|
||||
and adversely affects the operation of the network or violates the
|
||||
rules and protocols for communication across the network.
|
||||
|
||||
Corresponding Source conveyed, and Installation Information provided, in
|
||||
accord with this section must be in a format that is publicly documented
|
||||
(and with an implementation available to the public in source code form),
|
||||
and must require no special password or key for unpacking, reading or
|
||||
copying.
|
||||
|
||||
7. Additional Terms.
|
||||
|
||||
“Additional permissions” are terms that supplement the terms of this
|
||||
License by making exceptions from one or more of its conditions.
|
||||
Additional permissions that are applicable to the entire Program shall be
|
||||
treated as though they were included in this License, to the extent that
|
||||
they are valid under applicable law. If additional permissions apply only
|
||||
to part of the Program, that part may be used separately under those
|
||||
permissions, but the entire Program remains governed by this License
|
||||
without regard to the additional permissions. When you convey a copy of
|
||||
a covered work, you may at your option remove any additional permissions
|
||||
from that copy, or from any part of it. (Additional permissions may be
|
||||
written to require their own removal in certain cases when you modify the
|
||||
work.) You may place additional permissions on material, added by you to
|
||||
a covered work, for which you have or can give appropriate copyright
|
||||
permission.
|
||||
|
||||
Notwithstanding any other provision of this License, for material you add
|
||||
to a covered work, you may (if authorized by the copyright holders of
|
||||
that material) supplement the terms of this License with terms:
|
||||
|
||||
a) Disclaiming warranty or limiting liability differently from the
|
||||
terms of sections 15 and 16 of this License; or
|
||||
|
||||
b) Requiring preservation of specified reasonable legal notices or
|
||||
author attributions in that material or in the Appropriate Legal
|
||||
Notices displayed by works containing it; or
|
||||
|
||||
c) Prohibiting misrepresentation of the origin of that material, or
|
||||
requiring that modified versions of such material be marked in
|
||||
reasonable ways as different from the original version; or
|
||||
|
||||
d) Limiting the use for publicity purposes of names of licensors or
|
||||
authors of the material; or
|
||||
|
||||
e) Declining to grant rights under trademark law for use of some trade
|
||||
names, trademarks, or service marks; or
|
||||
|
||||
f) Requiring indemnification of licensors and authors of that material
|
||||
by anyone who conveys the material (or modified versions of it) with
|
||||
contractual assumptions of liability to the recipient, for any
|
||||
liability that these contractual assumptions directly impose on those
|
||||
licensors and authors.
|
||||
|
||||
All other non-permissive additional terms are considered “further
|
||||
restrictions” within the meaning of section 10. If the Program as you
|
||||
received it, or any part of it, contains a notice stating that it is
|
||||
governed by this License along with a term that is a further restriction,
|
||||
you may remove that term. If a license document contains a further
|
||||
restriction but permits relicensing or conveying under this License, you
|
||||
may add to a covered work material governed by the terms of that license
|
||||
document, provided that the further restriction does not survive such
|
||||
relicensing or conveying.
|
||||
|
||||
If you add terms to a covered work in accord with this section, you must
|
||||
place, in the relevant source files, a statement of the additional terms
|
||||
that apply to those files, or a notice indicating where to find the
|
||||
applicable terms. Additional terms, permissive or non-permissive, may be
|
||||
stated in the form of a separately written license, or stated as
|
||||
exceptions; the above requirements apply either way.
|
||||
|
||||
8. Termination.
|
||||
|
||||
You may not propagate or modify a covered work except as expressly
|
||||
provided under this License. Any attempt otherwise to propagate or modify
|
||||
it is void, and will automatically terminate your rights under this
|
||||
License (including any patent licenses granted under the third paragraph
|
||||
of section 11).
|
||||
|
||||
However, if you cease all violation of this License, then your license
|
||||
from a particular copyright holder is reinstated (a) provisionally,
|
||||
unless and until the copyright holder explicitly and finally terminates
|
||||
your license, and (b) permanently, if the copyright holder fails to
|
||||
notify you of the violation by some reasonable means prior to 60 days
|
||||
after the cessation.
|
||||
|
||||
Moreover, your license from a particular copyright holder is reinstated
|
||||
permanently if the copyright holder notifies you of the violation by some
|
||||
reasonable means, this is the first time you have received notice of
|
||||
violation of this License (for any work) from that copyright holder, and
|
||||
you cure the violation prior to 30 days after your receipt of the notice.
|
||||
|
||||
Termination of your rights under this section does not terminate the
|
||||
licenses of parties who have received copies or rights from you under
|
||||
this License. If your rights have been terminated and not permanently
|
||||
reinstated, you do not qualify to receive new licenses for the same
|
||||
material under section 10.
|
||||
|
||||
9. Acceptance Not Required for Having Copies.
|
||||
|
||||
You are not required to accept this License in order to receive or run a
|
||||
copy of the Program. Ancillary propagation of a covered work occurring
|
||||
solely as a consequence of using peer-to-peer transmission to receive a
|
||||
copy likewise does not require acceptance. However, nothing other than
|
||||
this License grants you permission to propagate or modify any covered
|
||||
work. These actions infringe copyright if you do not accept this License.
|
||||
Therefore, by modifying or propagating a covered work, you indicate your
|
||||
acceptance of this License to do so.
|
||||
|
||||
10. Automatic Licensing of Downstream Recipients.
|
||||
|
||||
Each time you convey a covered work, the recipient automatically receives
|
||||
a license from the original licensors, to run, modify and propagate that
|
||||
work, subject to this License. You are not responsible for enforcing
|
||||
compliance by third parties with this License.
|
||||
|
||||
An “entity transaction” is a transaction transferring control of an
|
||||
organization, or substantially all assets of one, or subdividing an
|
||||
organization, or merging organizations. If propagation of a covered work
|
||||
results from an entity transaction, each party to that transaction who
|
||||
receives a copy of the work also receives whatever licenses to the work
|
||||
the party's predecessor in interest had or could give under the previous
|
||||
paragraph, plus a right to possession of the Corresponding Source of the
|
||||
work from the predecessor in interest, if the predecessor has it or can
|
||||
get it with reasonable efforts.
|
||||
|
||||
You may not impose any further restrictions on the exercise of the rights
|
||||
granted or affirmed under this License. For example, you may not impose a
|
||||
license fee, royalty, or other charge for exercise of rights granted
|
||||
under this License, and you may not initiate litigation (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that any patent claim
|
||||
is infringed by making, using, selling, offering for sale, or importing
|
||||
the Program or any portion of it.
|
||||
|
||||
11. Patents.
|
||||
|
||||
A “contributor” is a copyright holder who authorizes use under this
|
||||
License of the Program or a work on which the Program is based. The work
|
||||
thus licensed is called the contributor's “contributor version”.
|
||||
|
||||
A contributor's “essential patent claims” are all patent claims owned or
|
||||
controlled by the contributor, whether already acquired or hereafter
|
||||
acquired, that would be infringed by some manner, permitted by this
|
||||
License, of making, using, or selling its contributor version, but do not
|
||||
include claims that would be infringed only as a consequence of further
|
||||
modification of the contributor version. For purposes of this definition,
|
||||
“control” includes the right to grant patent sublicenses in a manner
|
||||
consistent with the requirements of this License.
|
||||
|
||||
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
||||
patent license under the contributor's essential patent claims, to make,
|
||||
use, sell, offer for sale, import and otherwise run, modify and propagate
|
||||
the contents of its contributor version.
|
||||
|
||||
In the following three paragraphs, a “patent license” is any express
|
||||
agreement or commitment, however denominated, not to enforce a patent
|
||||
(such as an express permission to practice a patent or covenant not to
|
||||
sue for patent infringement). To “grant” such a patent license to a party
|
||||
means to make such an agreement or commitment not to enforce a patent
|
||||
against the party.
|
||||
|
||||
If you convey a covered work, knowingly relying on a patent license, and
|
||||
the Corresponding Source of the work is not available for anyone to copy,
|
||||
free of charge and under the terms of this License, through a publicly
|
||||
available network server or other readily accessible means, then you must
|
||||
either (1) cause the Corresponding Source to be so available, or (2)
|
||||
arrange to deprive yourself of the benefit of the patent license for this
|
||||
particular work, or (3) arrange, in a manner consistent with the
|
||||
requirements of this License, to extend the patent license to downstream
|
||||
recipients. “Knowingly relying” means you have actual knowledge that, but
|
||||
for the patent license, your conveying the covered work in a country, or
|
||||
your recipient's use of the covered work in a country, would infringe
|
||||
one or more identifiable patents in that country that you have reason
|
||||
to believe are valid.
|
||||
|
||||
If, pursuant to or in connection with a single transaction or
|
||||
arrangement, you convey, or propagate by procuring conveyance of, a
|
||||
covered work, and grant a patent license to some of the parties receiving
|
||||
the covered work authorizing them to use, propagate, modify or convey a
|
||||
specific copy of the covered work, then the patent license you grant is
|
||||
automatically extended to all recipients of the covered work and works
|
||||
based on it.
|
||||
|
||||
A patent license is “discriminatory” if it does not include within the
|
||||
scope of its coverage, prohibits the exercise of, or is conditioned on
|
||||
the non-exercise of one or more of the rights that are specifically
|
||||
granted under this License. You may not convey a covered work if you are
|
||||
a party to an arrangement with a third party that is in the business of
|
||||
distributing software, under which you make payment to the third party
|
||||
based on the extent of your activity of conveying the work, and under
|
||||
which the third party grants, to any of the parties who would receive the
|
||||
covered work from you, a discriminatory patent license (a) in connection
|
||||
with copies of the covered work conveyed by you (or copies made from
|
||||
those copies), or (b) primarily for and in connection with specific
|
||||
products or compilations that contain the covered work, unless you
|
||||
entered into that arrangement, or that patent license was granted, prior
|
||||
to 28 March 2007.
|
||||
|
||||
Nothing in this License shall be construed as excluding or limiting any
|
||||
implied license or other defenses to infringement that may otherwise be
|
||||
available to you under applicable patent law.
|
||||
|
||||
12. No Surrender of Others' Freedom.
|
||||
|
||||
If conditions are imposed on you (whether by court order, agreement or
|
||||
otherwise) that contradict the conditions of this License, they do not
|
||||
excuse you from the conditions of this License. If you cannot use,
|
||||
propagate or convey a covered work so as to satisfy simultaneously your
|
||||
obligations under this License and any other pertinent obligations, then
|
||||
as a consequence you may not use, propagate or convey it at all. For
|
||||
example, if you agree to terms that obligate you to collect a royalty for
|
||||
further conveying from those to whom you convey the Program, the only way
|
||||
you could satisfy both those terms and this License would be to refrain
|
||||
entirely from conveying the Program.
|
||||
|
||||
13. Offering the Program as a Service.
|
||||
|
||||
If you make the functionality of the Program or a modified version
|
||||
available to third parties as a service, you must make the Service Source
|
||||
Code available via network download to everyone at no charge, under the
|
||||
terms of this License. Making the functionality of the Program or
|
||||
modified version available to third parties as a service includes,
|
||||
without limitation, enabling third parties to interact with the
|
||||
functionality of the Program or modified version remotely through a
|
||||
computer network, offering a service the value of which entirely or
|
||||
primarily derives from the value of the Program or modified version, or
|
||||
offering a service that accomplishes for users the primary purpose of the
|
||||
Program or modified version.
|
||||
|
||||
“Service Source Code” means the Corresponding Source for the Program or
|
||||
the modified version, and the Corresponding Source for all programs that
|
||||
you use to make the Program or modified version available as a service,
|
||||
including, without limitation, management software, user interfaces,
|
||||
application program interfaces, automation software, monitoring software,
|
||||
backup software, storage software and hosting software, all such that a
|
||||
user could run an instance of the service using the Service Source Code
|
||||
you make available.
|
||||
|
||||
14. Revised Versions of this License.
|
||||
|
||||
MongoDB, Inc. may publish revised and/or new versions of the Server Side
|
||||
Public License from time to time. Such new versions will be similar in
|
||||
spirit to the present version, but may differ in detail to address new
|
||||
problems or concerns.
|
||||
|
||||
Each version is given a distinguishing version number. If the Program
|
||||
specifies that a certain numbered version of the Server Side Public
|
||||
License “or any later version” applies to it, you have the option of
|
||||
following the terms and conditions either of that numbered version or of
|
||||
any later version published by MongoDB, Inc. If the Program does not
|
||||
specify a version number of the Server Side Public License, you may
|
||||
choose any version ever published by MongoDB, Inc.
|
||||
|
||||
If the Program specifies that a proxy can decide which future versions of
|
||||
the Server Side Public License can be used, that proxy's public statement
|
||||
of acceptance of a version permanently authorizes you to choose that
|
||||
version for the Program.
|
||||
|
||||
Later license versions may give you additional or different permissions.
|
||||
However, no additional obligations are imposed on any author or copyright
|
||||
holder as a result of your choosing to follow a later version.
|
||||
|
||||
15. Disclaimer of Warranty.
|
||||
|
||||
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
||||
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
||||
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM “AS IS” WITHOUT WARRANTY
|
||||
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
||||
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
||||
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
||||
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
||||
|
||||
16. Limitation of Liability.
|
||||
|
||||
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
||||
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
||||
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING
|
||||
ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF
|
||||
THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO
|
||||
LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU
|
||||
OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER
|
||||
PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE
|
||||
POSSIBILITY OF SUCH DAMAGES.
|
||||
|
||||
17. Interpretation of Sections 15 and 16.
|
||||
|
||||
If the disclaimer of warranty and limitation of liability provided above
|
||||
cannot be given local legal effect according to their terms, reviewing
|
||||
courts shall apply local law that most closely approximates an absolute
|
||||
waiver of all civil liability in connection with the Program, unless a
|
||||
warranty or assumption of liability accompanies a copy of the Program in
|
||||
return for a fee.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
1
server/api_version.py
Normal file
1
server/api_version.py
Normal file
@@ -0,0 +1 @@
|
||||
__version__ = "2.7.0"
|
||||
@@ -48,7 +48,6 @@ _error_codes = {
|
||||
129: ('task_publish_in_progress', 'Task publish in progress'),
|
||||
130: ('task_not_found', 'task not found'),
|
||||
|
||||
|
||||
# Models
|
||||
200: ('model_error', 'general task error'),
|
||||
201: ('invalid_model_id', 'invalid model id'),
|
||||
@@ -70,9 +69,28 @@ _error_codes = {
|
||||
403: ('project_not_found', 'project not found'),
|
||||
405: ('project_has_models', 'project has associated models'),
|
||||
|
||||
# Queues
|
||||
701: ('invalid_queue_id', 'invalid queue id'),
|
||||
702: ('queue_not_empty', 'queue is not empty'),
|
||||
703: ('invalid_queue_or_task_not_queued', 'invalid queue id or task not in queue'),
|
||||
704: ('removed_during_reposition', 'task was removed by another party during reposition'),
|
||||
705: ('failed_adding_during_reposition', 'failed adding task back to queue during reposition'),
|
||||
706: ('task_already_queued', 'failed adding task to queue since task is already queued'),
|
||||
707: ('no_default_queue', 'no queue is tagged as the default queue for this company'),
|
||||
708: ('multiple_default_queues', 'more than one queue is tagged as the default queue for this company'),
|
||||
|
||||
# Database
|
||||
800: ('data_validation_error', 'data validation error'),
|
||||
801: ('expected_unique_data', 'value combination already exists'),
|
||||
|
||||
# Workers
|
||||
1001: ('invalid_worker_id', 'invalid worker id'),
|
||||
1002: ('worker_registration_failed', 'worker registration failed'),
|
||||
1003: ('worker_registered', 'worker is already registered'),
|
||||
1004: ('worker_not_registered', 'worker is not registered'),
|
||||
1005: ('worker_stats_not_found', 'worker stats not found'),
|
||||
|
||||
1104: ('invalid_scroll_id', 'Invalid scroll id'),
|
||||
},
|
||||
|
||||
(401, 'unauthorized'): {
|
||||
@@ -83,12 +101,12 @@ _error_codes = {
|
||||
21: ('bad_credentials', 'unauthorized (malformed credentials)'),
|
||||
22: ('invalid_credentials', 'unauthorized (invalid credentials)'),
|
||||
30: ('invalid_token', 'invalid token'),
|
||||
31: ('blocked_token', 'token is blocked')
|
||||
31: ('blocked_token', 'token is blocked'),
|
||||
40: ('invalid_fixed_user', 'fixed user ID was not found')
|
||||
},
|
||||
|
||||
(403, 'forbidden'): {
|
||||
10: ('routing_error', 'forbidden (routing error)'),
|
||||
11: ('missing_routing_header', 'forbidden (missing routing header)'),
|
||||
12: ('blocked_internal_endpoint', 'forbidden (blocked internal endpoint)'),
|
||||
20: ('role_not_allowed', 'forbidden (not allowed for role)'),
|
||||
21: ('no_write_permission', 'forbidden (modification not allowed)'),
|
||||
@@ -104,6 +122,7 @@ _error_codes = {
|
||||
100: ('data_error', 'general data error'),
|
||||
101: ('inconsistent_data', 'inconsistent data encountered in document'),
|
||||
102: ('database_unavailable', 'database is temporarily unavailable'),
|
||||
110: ('update_failed', 'update failed'),
|
||||
|
||||
# Index-related issues
|
||||
201: ('missing_index', 'missing internal index'),
|
||||
|
||||
@@ -4,14 +4,13 @@ from enum import Enum
|
||||
from typing import Union, Type, Iterable
|
||||
|
||||
import jsonmodels.errors
|
||||
import jsonmodels.validators
|
||||
import six
|
||||
import validators
|
||||
from jsonmodels import fields
|
||||
from jsonmodels.fields import _LazyType
|
||||
from jsonmodels.fields import _LazyType, NotSet
|
||||
from jsonmodels.models import Base as ModelBase
|
||||
from jsonmodels.validators import Enum as EnumValidator
|
||||
from luqum.parser import parser, ParseError
|
||||
from validators import email as email_validator, domain as domain_validator
|
||||
|
||||
from apierrors import errors
|
||||
|
||||
@@ -25,6 +24,12 @@ def make_default(field_cls, default_value):
|
||||
|
||||
|
||||
class ListField(fields.ListField):
|
||||
def __init__(self, items_types=None, *args, default=NotSet, **kwargs):
|
||||
if default is not NotSet and callable(default):
|
||||
default = default()
|
||||
|
||||
super(ListField, self).__init__(items_types, *args, default=default, **kwargs)
|
||||
|
||||
def _cast_value(self, value):
|
||||
try:
|
||||
return super(ListField, self)._cast_value(value)
|
||||
@@ -61,9 +66,7 @@ class DictField(fields.BaseField):
|
||||
value_types = tuple()
|
||||
|
||||
return tuple(
|
||||
_LazyType(type_)
|
||||
if isinstance(type_, six.string_types)
|
||||
else type_
|
||||
_LazyType(type_) if isinstance(type_, six.string_types) else type_
|
||||
for type_ in value_types
|
||||
)
|
||||
|
||||
@@ -73,6 +76,9 @@ class DictField(fields.BaseField):
|
||||
if not self.value_types:
|
||||
return
|
||||
|
||||
if not value:
|
||||
return
|
||||
|
||||
for item in value.values():
|
||||
self.validate_single_value(item)
|
||||
|
||||
@@ -99,7 +105,7 @@ class IntField(fields.IntField):
|
||||
|
||||
|
||||
def validate_lucene_query(value):
|
||||
if value == '':
|
||||
if value == "":
|
||||
return
|
||||
try:
|
||||
parser.parse(value)
|
||||
@@ -117,6 +123,7 @@ class LuceneQueryField(fields.StringField):
|
||||
|
||||
class NullableEnumValidator(EnumValidator):
|
||||
"""Validator for enums that allows a None value."""
|
||||
|
||||
def validate(self, value):
|
||||
if value is not None:
|
||||
super(NullableEnumValidator, self).validate(value)
|
||||
@@ -144,12 +151,49 @@ class EnumField(fields.StringField):
|
||||
return super().parse_value(value)
|
||||
|
||||
|
||||
class ActualEnumField(fields.StringField):
|
||||
def __init__(
|
||||
self,
|
||||
enum_class: Type[Enum],
|
||||
*args,
|
||||
validators=None,
|
||||
required=False,
|
||||
default=None,
|
||||
**kwargs
|
||||
):
|
||||
self.__enum = enum_class
|
||||
self.types = (enum_class,)
|
||||
# noinspection PyTypeChecker
|
||||
choices = list(enum_class)
|
||||
validator_cls = EnumValidator if required else NullableEnumValidator
|
||||
validators = [*(validators or []), validator_cls(*choices)]
|
||||
super().__init__(
|
||||
default=self.parse_value(default) if default else NotSet,
|
||||
*args,
|
||||
required=required,
|
||||
validators=validators,
|
||||
**kwargs
|
||||
)
|
||||
|
||||
def parse_value(self, value):
|
||||
if value is None and not self.required:
|
||||
return self.get_default_value()
|
||||
try:
|
||||
# noinspection PyArgumentList
|
||||
return self.__enum(value)
|
||||
except ValueError:
|
||||
return value
|
||||
|
||||
def to_struct(self, value):
|
||||
return super().to_struct(value.value)
|
||||
|
||||
|
||||
class EmailField(fields.StringField):
|
||||
def validate(self, value):
|
||||
super().validate(value)
|
||||
if value is None:
|
||||
return
|
||||
if validators.email(value) is not True:
|
||||
if email_validator(value) is not True:
|
||||
raise errors.bad_request.InvalidEmailAddress()
|
||||
|
||||
|
||||
@@ -158,5 +202,14 @@ class DomainField(fields.StringField):
|
||||
super().validate(value)
|
||||
if value is None:
|
||||
return
|
||||
if validators.domain(value) is not True:
|
||||
if domain_validator(value) is not True:
|
||||
raise errors.bad_request.InvalidDomainName()
|
||||
|
||||
|
||||
class StringEnum(Enum):
|
||||
def __str__(self):
|
||||
return self.value
|
||||
|
||||
# noinspection PyMethodParameters
|
||||
def _generate_next_value_(name, start, count, last_values):
|
||||
return name
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
from jsonmodels.fields import IntField, StringField, BoolField, EmbeddedField
|
||||
from jsonmodels.fields import IntField, StringField, BoolField, EmbeddedField, DateTimeField
|
||||
from jsonmodels.models import Base
|
||||
from jsonmodels.validators import Max, Enum
|
||||
|
||||
@@ -79,6 +79,7 @@ class Credentials(Base):
|
||||
|
||||
class CredentialsResponse(Credentials):
|
||||
secret_key = StringField()
|
||||
last_used = DateTimeField(default=None)
|
||||
|
||||
|
||||
class CreateCredentialsResponse(Base):
|
||||
|
||||
@@ -58,3 +58,7 @@ class UpdateResponse(models.Base):
|
||||
class PagedRequest(models.Base):
|
||||
page = fields.IntField()
|
||||
page_size = fields.IntField()
|
||||
|
||||
|
||||
class IdResponse(models.Base):
|
||||
id = fields.StringField(required=True)
|
||||
|
||||
63
server/apimodels/events.py
Normal file
63
server/apimodels/events.py
Normal file
@@ -0,0 +1,63 @@
|
||||
from typing import Sequence
|
||||
|
||||
from jsonmodels import validators
|
||||
from jsonmodels.fields import StringField, BoolField
|
||||
from jsonmodels.models import Base
|
||||
from jsonmodels.validators import Length
|
||||
|
||||
from apimodels import ListField, IntField, ActualEnumField
|
||||
from bll.event.event_metrics import EventType
|
||||
from bll.event.scalar_key import ScalarKeyEnum
|
||||
|
||||
|
||||
class HistogramRequestBase(Base):
|
||||
samples: int = IntField(default=10000)
|
||||
key: ScalarKeyEnum = ActualEnumField(ScalarKeyEnum, default=ScalarKeyEnum.iter)
|
||||
|
||||
|
||||
class ScalarMetricsIterHistogramRequest(HistogramRequestBase):
|
||||
task: str = StringField(required=True)
|
||||
|
||||
|
||||
class MultiTaskScalarMetricsIterHistogramRequest(HistogramRequestBase):
|
||||
tasks: Sequence[str] = ListField(
|
||||
items_types=str, validators=[Length(minimum_value=1)]
|
||||
)
|
||||
|
||||
|
||||
class TaskMetric(Base):
|
||||
task: str = StringField(required=True)
|
||||
metric: str = StringField(required=True)
|
||||
|
||||
|
||||
class DebugImagesRequest(Base):
|
||||
metrics: Sequence[TaskMetric] = ListField(
|
||||
items_types=TaskMetric, validators=[Length(minimum_value=1)]
|
||||
)
|
||||
iters: int = IntField(default=1, validators=validators.Min(1))
|
||||
navigate_earlier: bool = BoolField(default=True)
|
||||
refresh: bool = BoolField(default=False)
|
||||
scroll_id: str = StringField()
|
||||
|
||||
|
||||
class IterationEvents(Base):
|
||||
iter: int = IntField()
|
||||
events: Sequence[dict] = ListField(items_types=dict)
|
||||
|
||||
|
||||
class MetricEvents(Base):
|
||||
task: str = StringField()
|
||||
metric: str = StringField()
|
||||
iterations: Sequence[IterationEvents] = ListField(items_types=IterationEvents)
|
||||
|
||||
|
||||
class DebugImageResponse(Base):
|
||||
metrics: Sequence[MetricEvents] = ListField(items_types=MetricEvents)
|
||||
scroll_id: str = StringField()
|
||||
|
||||
|
||||
class TaskMetricsRequest(Base):
|
||||
tasks: Sequence[str] = ListField(
|
||||
items_types=str, validators=[Length(minimum_value=1)]
|
||||
)
|
||||
event_type: EventType = ActualEnumField(EventType, required=True)
|
||||
@@ -9,8 +9,9 @@ from apimodels.tasks import PublishResponse as TaskPublishResponse
|
||||
class CreateModelRequest(models.Base):
|
||||
name = fields.StringField(required=True)
|
||||
uri = fields.StringField(required=True)
|
||||
labels = DictField(value_types=string_types+(int,), required=True)
|
||||
labels = DictField(value_types=string_types+(int,))
|
||||
tags = ListField(items_types=string_types)
|
||||
system_tags = ListField(items_types=string_types)
|
||||
comment = fields.StringField()
|
||||
public = fields.BoolField(default=False)
|
||||
project = fields.StringField()
|
||||
|
||||
16
server/apimodels/projects.py
Normal file
16
server/apimodels/projects.py
Normal file
@@ -0,0 +1,16 @@
|
||||
from jsonmodels import models, fields
|
||||
|
||||
|
||||
class ProjectReq(models.Base):
|
||||
project = fields.StringField()
|
||||
|
||||
|
||||
class GetHyperParamReq(ProjectReq):
|
||||
page = fields.IntField(default=0)
|
||||
page_size = fields.IntField(default=500)
|
||||
|
||||
|
||||
class GetHyperParamResp(models.Base):
|
||||
parameters = fields.ListField(str)
|
||||
remaining = fields.IntField()
|
||||
total = fields.IntField()
|
||||
60
server/apimodels/queues.py
Normal file
60
server/apimodels/queues.py
Normal file
@@ -0,0 +1,60 @@
|
||||
from jsonmodels import validators
|
||||
from jsonmodels.fields import StringField, IntField, BoolField, FloatField
|
||||
from jsonmodels.models import Base
|
||||
|
||||
from apimodels import ListField
|
||||
|
||||
|
||||
class GetDefaultResp(Base):
|
||||
id = StringField(required=True)
|
||||
name = StringField(required=True)
|
||||
|
||||
|
||||
class CreateRequest(Base):
|
||||
name = StringField(required=True)
|
||||
tags = ListField(items_types=[str])
|
||||
system_tags = ListField(items_types=[str])
|
||||
|
||||
|
||||
class QueueRequest(Base):
|
||||
queue = StringField(required=True)
|
||||
|
||||
|
||||
class DeleteRequest(QueueRequest):
|
||||
force = BoolField(default=False)
|
||||
|
||||
|
||||
class UpdateRequest(QueueRequest):
|
||||
name = StringField()
|
||||
tags = ListField(items_types=[str])
|
||||
system_tags = ListField(items_types=[str])
|
||||
|
||||
|
||||
class TaskRequest(QueueRequest):
|
||||
task = StringField(required=True)
|
||||
|
||||
|
||||
class MoveTaskRequest(TaskRequest):
|
||||
count = IntField(default=1)
|
||||
|
||||
|
||||
class MoveTaskResponse(Base):
|
||||
position = IntField()
|
||||
|
||||
|
||||
class GetMetricsRequest(Base):
|
||||
queue_ids = ListField([str])
|
||||
from_date = FloatField(required=True, validators=validators.Min(0))
|
||||
to_date = FloatField(required=True, validators=validators.Min(0))
|
||||
interval = IntField(required=True, validators=validators.Min(1))
|
||||
|
||||
|
||||
class QueueMetrics(Base):
|
||||
queue = StringField()
|
||||
dates = ListField(int)
|
||||
avg_waiting_times = ListField([float, int])
|
||||
queue_lengths = ListField(int)
|
||||
|
||||
|
||||
class GetMetricsResponse(Base):
|
||||
queues = ListField(QueueMetrics)
|
||||
15
server/apimodels/server.py
Normal file
15
server/apimodels/server.py
Normal file
@@ -0,0 +1,15 @@
|
||||
from jsonmodels.fields import BoolField, DateTimeField, StringField
|
||||
from jsonmodels.models import Base
|
||||
|
||||
|
||||
class ReportStatsOptionRequest(Base):
|
||||
enabled = BoolField(default=None, nullable=True)
|
||||
|
||||
|
||||
class ReportStatsOptionResponse(Base):
|
||||
supported = BoolField(default=True)
|
||||
enabled = BoolField()
|
||||
enabled_time = DateTimeField(nullable=True)
|
||||
enabled_version = StringField(nullable=True)
|
||||
enabled_user = StringField(nullable=True)
|
||||
current_version = StringField()
|
||||
@@ -1,6 +1,6 @@
|
||||
import six
|
||||
from jsonmodels import models
|
||||
from jsonmodels.fields import StringField, BoolField, IntField
|
||||
from jsonmodels.fields import StringField, BoolField, IntField, EmbeddedField
|
||||
from jsonmodels.validators import Enum
|
||||
|
||||
from apimodels import DictField, ListField
|
||||
@@ -9,12 +9,39 @@ from database.model.task.task import TaskType
|
||||
from database.utils import get_options
|
||||
|
||||
|
||||
class ArtifactTypeData(models.Base):
|
||||
preview = StringField()
|
||||
content_type = StringField()
|
||||
data_hash = StringField()
|
||||
|
||||
|
||||
class Artifact(models.Base):
|
||||
key = StringField(required=True)
|
||||
type = StringField(required=True)
|
||||
mode = StringField(validators=Enum("input", "output"), default="output")
|
||||
uri = StringField()
|
||||
hash = StringField()
|
||||
content_size = IntField()
|
||||
timestamp = IntField()
|
||||
type_data = EmbeddedField(ArtifactTypeData)
|
||||
display_data = ListField([list])
|
||||
|
||||
|
||||
class StartedResponse(UpdateResponse):
|
||||
started = IntField()
|
||||
|
||||
|
||||
class EnqueueResponse(UpdateResponse):
|
||||
queued = IntField()
|
||||
|
||||
|
||||
class DequeueResponse(UpdateResponse):
|
||||
dequeued = IntField()
|
||||
|
||||
|
||||
class ResetResponse(UpdateResponse):
|
||||
deleted_indices = ListField(items_types=six.string_types)
|
||||
dequeued = DictField()
|
||||
frames = DictField()
|
||||
events = DictField()
|
||||
model_deleted = IntField()
|
||||
@@ -30,6 +57,10 @@ class UpdateRequest(TaskRequest):
|
||||
force = BoolField(default=False)
|
||||
|
||||
|
||||
class EnqueueRequest(UpdateRequest):
|
||||
queue = StringField()
|
||||
|
||||
|
||||
class DeleteRequest(UpdateRequest):
|
||||
move_to_trash = BoolField(default=True)
|
||||
|
||||
@@ -55,3 +86,26 @@ class TaskData(models.Base):
|
||||
class CreateRequest(TaskData):
|
||||
name = StringField(required=True)
|
||||
type = StringField(required=True, validators=Enum(*get_options(TaskType)))
|
||||
|
||||
|
||||
class PingRequest(TaskRequest):
|
||||
pass
|
||||
|
||||
|
||||
class CloneRequest(TaskRequest):
|
||||
new_task_name = StringField()
|
||||
new_task_comment = StringField()
|
||||
new_task_tags = ListField([str])
|
||||
new_task_system_tags = ListField([str])
|
||||
new_task_parent = StringField()
|
||||
new_task_project = StringField()
|
||||
execution_overrides = DictField()
|
||||
|
||||
|
||||
class AddOrUpdateArtifactsRequest(TaskRequest):
|
||||
artifacts = ListField([Artifact], required=True)
|
||||
|
||||
|
||||
class AddOrUpdateArtifactsResponse(models.Base):
|
||||
added = ListField([str])
|
||||
updated = ListField([str])
|
||||
|
||||
183
server/apimodels/workers.py
Normal file
183
server/apimodels/workers.py
Normal file
@@ -0,0 +1,183 @@
|
||||
import json
|
||||
from enum import Enum
|
||||
|
||||
import six
|
||||
from jsonmodels import validators
|
||||
from jsonmodels.fields import (
|
||||
StringField,
|
||||
EmbeddedField,
|
||||
DateTimeField,
|
||||
IntField,
|
||||
FloatField,
|
||||
BoolField,
|
||||
)
|
||||
from jsonmodels.models import Base
|
||||
|
||||
from apimodels import make_default, ListField, EnumField
|
||||
|
||||
DEFAULT_TIMEOUT = 10 * 60
|
||||
|
||||
|
||||
class WorkerRequest(Base):
|
||||
worker = StringField(required=True)
|
||||
|
||||
|
||||
class RegisterRequest(WorkerRequest):
|
||||
timeout = make_default(
|
||||
IntField, DEFAULT_TIMEOUT
|
||||
)() # registration timeout in seconds (default is 10min)
|
||||
queues = ListField(six.string_types) # list of queues this worker listens to
|
||||
|
||||
|
||||
class MachineStats(Base):
|
||||
cpu_usage = ListField(six.integer_types + (float,))
|
||||
cpu_temperature = ListField(six.integer_types + (float,))
|
||||
gpu_usage = ListField(six.integer_types + (float,))
|
||||
gpu_temperature = ListField(six.integer_types + (float,))
|
||||
gpu_memory_free = ListField(six.integer_types + (float,))
|
||||
gpu_memory_used = ListField(six.integer_types + (float,))
|
||||
memory_used = FloatField()
|
||||
memory_free = FloatField()
|
||||
network_tx = FloatField()
|
||||
network_rx = FloatField()
|
||||
disk_free_home = FloatField()
|
||||
disk_free_temp = FloatField()
|
||||
disk_read = FloatField()
|
||||
disk_write = FloatField()
|
||||
|
||||
|
||||
class StatusReportRequest(WorkerRequest):
|
||||
task = StringField() # task the worker is running on
|
||||
queue = StringField() # queue from which task was taken
|
||||
queues = ListField(
|
||||
str
|
||||
) # list of queues this worker listens to. if None, this will not update the worker's queues list.
|
||||
timestamp = IntField(required=True)
|
||||
machine_stats = EmbeddedField(MachineStats)
|
||||
|
||||
|
||||
class IdNameEntry(Base):
|
||||
id = StringField(required=True)
|
||||
name = StringField()
|
||||
|
||||
|
||||
class WorkerEntry(Base):
|
||||
key = StringField() # not required due to migration issues
|
||||
id = StringField(required=True)
|
||||
user = EmbeddedField(IdNameEntry)
|
||||
company = EmbeddedField(IdNameEntry)
|
||||
ip = StringField()
|
||||
task = EmbeddedField(IdNameEntry)
|
||||
queue = StringField() # queue from which current task was taken
|
||||
queues = ListField(str) # list of queues this worker listens to
|
||||
register_time = DateTimeField(required=True)
|
||||
register_timeout = IntField(required=True)
|
||||
last_activity_time = DateTimeField(required=True)
|
||||
last_report_time = DateTimeField()
|
||||
|
||||
def to_json(self):
|
||||
return json.dumps(self.to_struct())
|
||||
|
||||
@classmethod
|
||||
def from_json(cls, s):
|
||||
return cls(**json.loads(s))
|
||||
|
||||
|
||||
class CurrentTaskEntry(IdNameEntry):
|
||||
running_time = IntField()
|
||||
last_iteration = IntField()
|
||||
|
||||
|
||||
class QueueEntry(IdNameEntry):
|
||||
next_task = EmbeddedField(IdNameEntry)
|
||||
num_tasks = IntField()
|
||||
|
||||
|
||||
class WorkerResponseEntry(WorkerEntry):
|
||||
task = EmbeddedField(CurrentTaskEntry)
|
||||
queue = EmbeddedField(QueueEntry)
|
||||
queues = ListField(QueueEntry)
|
||||
|
||||
|
||||
class GetAllRequest(Base):
|
||||
last_seen = IntField(default=3600)
|
||||
|
||||
|
||||
class GetAllResponse(Base):
|
||||
workers = ListField(WorkerResponseEntry)
|
||||
|
||||
|
||||
class StatsBase(Base):
|
||||
worker_ids = ListField(str)
|
||||
|
||||
|
||||
class StatsReportBase(StatsBase):
|
||||
from_date = FloatField(required=True, validators=validators.Min(0))
|
||||
to_date = FloatField(required=True, validators=validators.Min(0))
|
||||
interval = IntField(required=True, validators=validators.Min(1))
|
||||
|
||||
|
||||
class AggregationType(Enum):
|
||||
avg = "avg"
|
||||
min = "min"
|
||||
max = "max"
|
||||
|
||||
|
||||
class StatItem(Base):
|
||||
key = StringField(required=True)
|
||||
aggregation = EnumField(AggregationType, default=AggregationType.avg)
|
||||
|
||||
|
||||
class GetStatsRequest(StatsReportBase):
|
||||
items = ListField(
|
||||
StatItem, required=True, validators=validators.Length(minimum_value=1)
|
||||
)
|
||||
split_by_variant = BoolField(default=False)
|
||||
|
||||
|
||||
class AggregationStats(Base):
|
||||
aggregation = EnumField(AggregationType)
|
||||
values = ListField(float)
|
||||
|
||||
|
||||
class MetricStats(Base):
|
||||
metric = StringField()
|
||||
variant = StringField()
|
||||
dates = ListField(int)
|
||||
stats = ListField(AggregationStats)
|
||||
|
||||
|
||||
class WorkerStatistics(Base):
|
||||
worker = StringField()
|
||||
metrics = ListField(MetricStats)
|
||||
|
||||
|
||||
class GetStatsResponse(Base):
|
||||
workers = ListField(WorkerStatistics)
|
||||
|
||||
|
||||
class GetMetricKeysRequest(StatsBase):
|
||||
pass
|
||||
|
||||
|
||||
class MetricCategory(Base):
|
||||
name = StringField()
|
||||
metric_keys = ListField(str)
|
||||
|
||||
|
||||
class GetMetricKeysResponse(Base):
|
||||
categories = ListField(MetricCategory)
|
||||
|
||||
|
||||
class GetActivityReportRequest(StatsReportBase):
|
||||
pass
|
||||
|
||||
|
||||
class ActivityReportSeries(Base):
|
||||
dates = ListField(int)
|
||||
counts = ListField(int)
|
||||
|
||||
|
||||
class GetActivityReportResponse(Base):
|
||||
total = EmbeddedField(ActivityReportSeries)
|
||||
active = EmbeddedField(ActivityReportSeries)
|
||||
@@ -2,24 +2,16 @@ from datetime import datetime
|
||||
|
||||
import database
|
||||
from apierrors import errors
|
||||
from apimodels.auth import (
|
||||
GetTokenResponse,
|
||||
CreateUserRequest,
|
||||
Credentials as CredModel,
|
||||
)
|
||||
from apimodels.auth import GetTokenResponse, CreateUserRequest, Credentials as CredModel
|
||||
from apimodels.users import CreateRequest as Users_CreateRequest
|
||||
from bll.user import UserBLL
|
||||
from config import config
|
||||
from config.info import get_version, get_build_number
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.auth import User, Role, Credentials
|
||||
from database.model.company import Company
|
||||
from service_repo import APICall
|
||||
from service_repo.auth import (
|
||||
Identity,
|
||||
Token,
|
||||
get_client_id,
|
||||
get_secret_key,
|
||||
)
|
||||
from service_repo import APICall, ServiceRepo
|
||||
from service_repo.auth import Identity, Token, get_client_id, get_secret_key
|
||||
|
||||
log = config.logger("AuthBLL")
|
||||
|
||||
@@ -62,6 +54,9 @@ class AuthBLL:
|
||||
identity=identity,
|
||||
entities=entities,
|
||||
expiration_sec=expiration_sec,
|
||||
api_version=str(ServiceRepo.max_endpoint_version()),
|
||||
server_version=str(get_version()),
|
||||
server_build=str(get_build_number()),
|
||||
)
|
||||
|
||||
return GetTokenResponse(token=token.decode("ascii"))
|
||||
|
||||
464
server/bll/event/debug_images_iterator.py
Normal file
464
server/bll/event/debug_images_iterator.py
Normal file
@@ -0,0 +1,464 @@
|
||||
from collections import defaultdict
|
||||
from concurrent.futures.thread import ThreadPoolExecutor
|
||||
from functools import partial
|
||||
from itertools import chain
|
||||
from operator import attrgetter, itemgetter
|
||||
|
||||
import attr
|
||||
import dpath
|
||||
from boltons.iterutils import bucketize
|
||||
from elasticsearch import Elasticsearch
|
||||
from redis import StrictRedis
|
||||
from typing import Sequence, Tuple, Optional, Mapping
|
||||
|
||||
import database
|
||||
from apierrors import errors
|
||||
from bll.redis_cache_manager import RedisCacheManager
|
||||
from bll.event.event_metrics import EventMetrics
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from jsonmodels.models import Base
|
||||
from jsonmodels.fields import StringField, ListField, IntField
|
||||
|
||||
from database.model.task.metrics import MetricEventStats
|
||||
from database.model.task.task import Task
|
||||
from timing_context import TimingContext
|
||||
from utilities.json import loads, dumps
|
||||
|
||||
|
||||
class VariantScrollState(Base):
|
||||
name: str = StringField(required=True)
|
||||
recycle_url_marker: str = StringField()
|
||||
last_invalid_iteration: int = IntField()
|
||||
|
||||
|
||||
class MetricScrollState(Base):
|
||||
task: str = StringField(required=True)
|
||||
name: str = StringField(required=True)
|
||||
last_min_iter: Optional[int] = IntField()
|
||||
last_max_iter: Optional[int] = IntField()
|
||||
timestamp: int = IntField(default=0)
|
||||
variants: Sequence[VariantScrollState] = ListField([VariantScrollState])
|
||||
|
||||
def reset(self):
|
||||
"""Reset the scrolling state for the metric"""
|
||||
self.last_min_iter = self.last_max_iter = None
|
||||
|
||||
|
||||
class DebugImageEventsScrollState(Base):
|
||||
id: str = StringField(required=True)
|
||||
metrics: Sequence[MetricScrollState] = ListField([MetricScrollState])
|
||||
|
||||
def to_json(self):
|
||||
return dumps(self.to_struct())
|
||||
|
||||
@classmethod
|
||||
def from_json(cls, s):
|
||||
return cls(**loads(s))
|
||||
|
||||
|
||||
@attr.s(auto_attribs=True)
|
||||
class DebugImagesResult(object):
|
||||
metric_events: Sequence[tuple] = []
|
||||
next_scroll_id: str = None
|
||||
|
||||
|
||||
class DebugImagesIterator:
|
||||
EVENT_TYPE = "training_debug_image"
|
||||
STATE_EXPIRATION_SECONDS = 3600
|
||||
|
||||
@property
|
||||
def _max_workers(self):
|
||||
return config.get("services.events.max_metrics_concurrency", 4)
|
||||
|
||||
def __init__(self, redis: StrictRedis, es: Elasticsearch):
|
||||
self.es = es
|
||||
self.cache_manager = RedisCacheManager(
|
||||
state_class=DebugImageEventsScrollState,
|
||||
redis=redis,
|
||||
expiration_interval=self.STATE_EXPIRATION_SECONDS,
|
||||
)
|
||||
|
||||
def get_task_events(
|
||||
self,
|
||||
company_id: str,
|
||||
metrics: Sequence[Tuple[str, str]],
|
||||
iter_count: int,
|
||||
navigate_earlier: bool = True,
|
||||
refresh: bool = False,
|
||||
state_id: str = None,
|
||||
) -> DebugImagesResult:
|
||||
es_index = EventMetrics.get_index_name(company_id, self.EVENT_TYPE)
|
||||
if not self.es.indices.exists(es_index):
|
||||
return DebugImagesResult()
|
||||
|
||||
unique_metrics = set(metrics)
|
||||
state = self.cache_manager.get_state(state_id) if state_id else None
|
||||
if not state:
|
||||
state = DebugImageEventsScrollState(
|
||||
id=database.utils.id(),
|
||||
metrics=self._init_metric_states(es_index, list(unique_metrics)),
|
||||
)
|
||||
else:
|
||||
state_metrics = set((m.task, m.name) for m in state.metrics)
|
||||
if state_metrics != unique_metrics:
|
||||
raise errors.bad_request.InvalidScrollId(
|
||||
"while getting debug images events", scroll_id=state_id
|
||||
)
|
||||
|
||||
if refresh:
|
||||
self._reinit_outdated_metric_states(company_id, es_index, state)
|
||||
for metric_state in state.metrics:
|
||||
metric_state.reset()
|
||||
|
||||
res = DebugImagesResult(next_scroll_id=state.id)
|
||||
try:
|
||||
with ThreadPoolExecutor(self._max_workers) as pool:
|
||||
res.metric_events = list(
|
||||
pool.map(
|
||||
partial(
|
||||
self._get_task_metric_events,
|
||||
es_index=es_index,
|
||||
iter_count=iter_count,
|
||||
navigate_earlier=navigate_earlier,
|
||||
),
|
||||
state.metrics,
|
||||
)
|
||||
)
|
||||
finally:
|
||||
self.cache_manager.set_state(state)
|
||||
|
||||
return res
|
||||
|
||||
def _reinit_outdated_metric_states(
|
||||
self, company_id, es_index, state: DebugImageEventsScrollState
|
||||
):
|
||||
"""
|
||||
Determines the metrics for which new debug image events were added
|
||||
since their states were initialized and reinits these states
|
||||
"""
|
||||
task_ids = set(metric.task for metric in state.metrics)
|
||||
tasks = Task.objects(id__in=list(task_ids), company=company_id).only(
|
||||
"id", "metric_stats"
|
||||
)
|
||||
|
||||
def get_last_update_times_for_task_metrics(task: Task) -> Sequence[Tuple]:
|
||||
"""For metrics that reported debug image events get tuples of task_id/metric_name and last update times"""
|
||||
metric_stats: Mapping[str, MetricEventStats] = task.metric_stats
|
||||
if not metric_stats:
|
||||
return []
|
||||
|
||||
return [
|
||||
(
|
||||
(task.id, stats.metric),
|
||||
stats.event_stats_by_type[self.EVENT_TYPE].last_update,
|
||||
)
|
||||
for stats in metric_stats.values()
|
||||
if self.EVENT_TYPE in stats.event_stats_by_type
|
||||
]
|
||||
|
||||
update_times = dict(
|
||||
chain.from_iterable(
|
||||
get_last_update_times_for_task_metrics(task) for task in tasks
|
||||
)
|
||||
)
|
||||
outdated_metrics = [
|
||||
metric
|
||||
for metric in state.metrics
|
||||
if (metric.task, metric.name) in update_times
|
||||
and update_times[metric.task, metric.name] > metric.timestamp
|
||||
]
|
||||
state.metrics = [
|
||||
*(metric for metric in state.metrics if metric not in outdated_metrics),
|
||||
*(
|
||||
self._init_metric_states(
|
||||
es_index,
|
||||
[(metric.task, metric.name) for metric in outdated_metrics],
|
||||
)
|
||||
),
|
||||
]
|
||||
|
||||
def _init_metric_states(
|
||||
self, es_index, metrics: Sequence[Tuple[str, str]]
|
||||
) -> Sequence[MetricScrollState]:
|
||||
"""
|
||||
Returned initialized metric scroll stated for the requested task metrics
|
||||
"""
|
||||
tasks = defaultdict(list)
|
||||
for (task, metric) in metrics:
|
||||
tasks[task].append(metric)
|
||||
|
||||
with ThreadPoolExecutor(self._max_workers) as pool:
|
||||
return list(
|
||||
chain.from_iterable(
|
||||
pool.map(
|
||||
partial(self._init_metric_states_for_task, es_index=es_index),
|
||||
tasks.items(),
|
||||
)
|
||||
)
|
||||
)
|
||||
|
||||
def _init_metric_states_for_task(
|
||||
self, task_metrics: Tuple[str, Sequence[str]], es_index
|
||||
) -> Sequence[MetricScrollState]:
|
||||
"""
|
||||
Return metric scroll states for the task filled with the variant states
|
||||
for the variants that reported any debug images
|
||||
"""
|
||||
task, metrics = task_metrics
|
||||
es_req: dict = {
|
||||
"size": 0,
|
||||
"query": {
|
||||
"bool": {
|
||||
"must": [{"term": {"task": task}}, {"terms": {"metric": metrics}}]
|
||||
}
|
||||
},
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": EventMetrics.MAX_METRICS_COUNT,
|
||||
},
|
||||
"aggs": {
|
||||
"last_event_timestamp": {"max": {"field": "timestamp"}},
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": EventMetrics.MAX_VARIANTS_COUNT,
|
||||
},
|
||||
"aggs": {
|
||||
"urls": {
|
||||
"terms": {
|
||||
"field": "url",
|
||||
"order": {"max_iter": "desc"},
|
||||
"size": 1, # we need only one url from the most recent iteration
|
||||
},
|
||||
"aggs": {
|
||||
"max_iter": {"max": {"field": "iter"}},
|
||||
"iters": {
|
||||
"top_hits": {
|
||||
"sort": {"iter": {"order": "desc"}},
|
||||
"size": 2, # need two last iterations so that we can take
|
||||
# the second one as invalid
|
||||
"_source": "iter",
|
||||
}
|
||||
},
|
||||
},
|
||||
}
|
||||
},
|
||||
},
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "_init_metric_states"):
|
||||
es_res = self.es.search(index=es_index, body=es_req, routing=task)
|
||||
if "aggregations" not in es_res:
|
||||
return []
|
||||
|
||||
def init_variant_scroll_state(variant: dict):
|
||||
"""
|
||||
Return new variant scroll state for the passed variant bucket
|
||||
If the image urls get recycled then fill the last_invalid_iteration field
|
||||
"""
|
||||
state = VariantScrollState(name=variant["key"])
|
||||
top_iter_url = dpath.get(variant, "urls/buckets")[0]
|
||||
iters = dpath.get(top_iter_url, "iters/hits/hits")
|
||||
if len(iters) > 1:
|
||||
state.last_invalid_iteration = dpath.get(iters[1], "_source/iter")
|
||||
return state
|
||||
|
||||
return [
|
||||
MetricScrollState(
|
||||
task=task,
|
||||
name=metric["key"],
|
||||
variants=[
|
||||
init_variant_scroll_state(variant)
|
||||
for variant in dpath.get(metric, "variants/buckets")
|
||||
],
|
||||
timestamp=dpath.get(metric, "last_event_timestamp/value"),
|
||||
)
|
||||
for metric in dpath.get(es_res, "aggregations/metrics/buckets")
|
||||
]
|
||||
|
||||
def _get_task_metric_events(
|
||||
self,
|
||||
metric: MetricScrollState,
|
||||
es_index: str,
|
||||
iter_count: int,
|
||||
navigate_earlier: bool,
|
||||
) -> Tuple:
|
||||
"""
|
||||
Return task metric events grouped by iterations
|
||||
Update metric scroll state
|
||||
"""
|
||||
if metric.last_max_iter is None:
|
||||
# the first fetch is always from the latest iteration to the earlier ones
|
||||
navigate_earlier = True
|
||||
|
||||
must_conditions = [
|
||||
{"term": {"task": metric.task}},
|
||||
{"term": {"metric": metric.name}},
|
||||
]
|
||||
must_not_conditions = []
|
||||
|
||||
range_condition = None
|
||||
if navigate_earlier and metric.last_min_iter is not None:
|
||||
range_condition = {"lt": metric.last_min_iter}
|
||||
elif not navigate_earlier and metric.last_max_iter is not None:
|
||||
range_condition = {"gt": metric.last_max_iter}
|
||||
if range_condition:
|
||||
must_conditions.append({"range": {"iter": range_condition}})
|
||||
|
||||
if navigate_earlier:
|
||||
"""
|
||||
When navigating to earlier iterations consider only
|
||||
variants whose invalid iterations border is lower than
|
||||
our starting iteration. For these variants make sure
|
||||
that only events from the valid iterations are returned
|
||||
"""
|
||||
if not metric.last_min_iter:
|
||||
variants = metric.variants
|
||||
else:
|
||||
variants = list(
|
||||
v
|
||||
for v in metric.variants
|
||||
if v.last_invalid_iteration is None
|
||||
or v.last_invalid_iteration < metric.last_min_iter
|
||||
)
|
||||
if not variants:
|
||||
return metric.task, metric.name, []
|
||||
must_conditions.append(
|
||||
{"terms": {"variant": list(v.name for v in variants)}}
|
||||
)
|
||||
else:
|
||||
"""
|
||||
When navigating to later iterations all variants may be relevant.
|
||||
For the variants whose invalid border is higher than our starting
|
||||
iteration make sure that only events from valid iterations are returned
|
||||
"""
|
||||
variants = list(
|
||||
v
|
||||
for v in metric.variants
|
||||
if v.last_invalid_iteration is not None
|
||||
and v.last_invalid_iteration > metric.last_max_iter
|
||||
)
|
||||
|
||||
variants_conditions = [
|
||||
{
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"variant": v.name}},
|
||||
{"range": {"iter": {"lte": v.last_invalid_iteration}}},
|
||||
]
|
||||
}
|
||||
}
|
||||
for v in variants
|
||||
if v.last_invalid_iteration is not None
|
||||
]
|
||||
if variants_conditions:
|
||||
must_not_conditions.append({"bool": {"should": variants_conditions}})
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": {
|
||||
"bool": {"must": must_conditions, "must_not": must_not_conditions}
|
||||
},
|
||||
"aggs": {
|
||||
"iters": {
|
||||
"terms": {
|
||||
"field": "iter",
|
||||
"size": iter_count,
|
||||
"order": {"_term": "desc" if navigate_earlier else "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": EventMetrics.MAX_VARIANTS_COUNT,
|
||||
},
|
||||
"aggs": {
|
||||
"events": {
|
||||
"top_hits": {"sort": {"url": {"order": "desc"}}}
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
with translate_errors_context(), TimingContext("es", "get_debug_image_events"):
|
||||
es_res = self.es.search(index=es_index, body=es_req, routing=metric.task)
|
||||
if "aggregations" not in es_res:
|
||||
return metric.task, metric.name, []
|
||||
|
||||
def get_iteration_events(variant_buckets: Sequence[dict]) -> Sequence:
|
||||
return [
|
||||
ev["_source"]
|
||||
for v in variant_buckets
|
||||
for ev in dpath.get(v, "events/hits/hits")
|
||||
]
|
||||
|
||||
iterations = [
|
||||
{
|
||||
"iter": it["key"],
|
||||
"events": get_iteration_events(dpath.get(it, "variants/buckets")),
|
||||
}
|
||||
for it in dpath.get(es_res, "aggregations/iters/buckets")
|
||||
]
|
||||
if not navigate_earlier:
|
||||
iterations.sort(key=itemgetter("iter"), reverse=True)
|
||||
if iterations:
|
||||
metric.last_max_iter = iterations[0]["iter"]
|
||||
metric.last_min_iter = iterations[-1]["iter"]
|
||||
|
||||
# Commented for now since the last invalid iteration is calculated in the beginning
|
||||
# if navigate_earlier and any(
|
||||
# variant.last_invalid_iteration is None for variant in variants
|
||||
# ):
|
||||
# """
|
||||
# Variants validation flags due to recycling can
|
||||
# be set only on navigation to earlier frames
|
||||
# """
|
||||
# iterations = self._update_variants_invalid_iterations(variants, iterations)
|
||||
|
||||
return metric.task, metric.name, iterations
|
||||
|
||||
@staticmethod
|
||||
def _update_variants_invalid_iterations(
|
||||
variants: Sequence[VariantScrollState], iterations: Sequence[dict]
|
||||
) -> Sequence[dict]:
|
||||
"""
|
||||
This code is currently not in used since the invalid iterations
|
||||
are calculated during MetricState initialization
|
||||
For variants that do not have recycle url marker set it from the
|
||||
first event
|
||||
For variants that do not have last_invalid_iteration set check if the
|
||||
recycle marker was reached on a certain iteration and set it to the
|
||||
corresponding iteration
|
||||
For variants that have a newly set last_invalid_iteration remove
|
||||
events from the invalid iterations
|
||||
Return the updated iterations list
|
||||
"""
|
||||
variants_lookup = bucketize(variants, attrgetter("name"))
|
||||
for it in iterations:
|
||||
iteration = it["iter"]
|
||||
events_to_remove = []
|
||||
for event in it["events"]:
|
||||
variant = variants_lookup[event["variant"]][0]
|
||||
if (
|
||||
variant.last_invalid_iteration
|
||||
and variant.last_invalid_iteration >= iteration
|
||||
):
|
||||
events_to_remove.append(event)
|
||||
continue
|
||||
event_url = event.get("url")
|
||||
if not variant.recycle_url_marker:
|
||||
variant.recycle_url_marker = event_url
|
||||
elif variant.recycle_url_marker == event_url:
|
||||
variant.last_invalid_iteration = iteration
|
||||
events_to_remove.append(event)
|
||||
if events_to_remove:
|
||||
it["events"] = [ev for ev in it["events"] if ev not in events_to_remove]
|
||||
return [it for it in iterations if it["events"]]
|
||||
@@ -1,58 +1,67 @@
|
||||
import hashlib
|
||||
from collections import defaultdict
|
||||
from contextlib import closing
|
||||
from datetime import datetime
|
||||
from operator import attrgetter
|
||||
from typing import Sequence
|
||||
|
||||
import attr
|
||||
import six
|
||||
from elasticsearch import helpers
|
||||
from enum import Enum
|
||||
|
||||
from mongoengine import Q
|
||||
from nested_dict import nested_dict
|
||||
|
||||
import database.utils as dbutils
|
||||
import es_factory
|
||||
from apierrors import errors
|
||||
from bll.event.debug_images_iterator import DebugImagesIterator
|
||||
from bll.event.event_metrics import EventMetrics, EventType
|
||||
from bll.task import TaskBLL
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.task.task import Task
|
||||
from database.model.task.metrics import MetricEvent
|
||||
from database.model.task.task import Task, TaskStatus
|
||||
from redis_manager import redman
|
||||
from timing_context import TimingContext
|
||||
|
||||
|
||||
class EventType(Enum):
|
||||
metrics_scalar = "training_stats_scalar"
|
||||
metrics_vector = "training_stats_vector"
|
||||
metrics_image = "training_debug_image"
|
||||
metrics_plot = "plot"
|
||||
task_log = "log"
|
||||
|
||||
from utilities.dicts import flatten_nested_items
|
||||
|
||||
# noinspection PyTypeChecker
|
||||
EVENT_TYPES = set(map(attrgetter("value"), EventType))
|
||||
LOCKED_TASK_STATUSES = (TaskStatus.publishing, TaskStatus.published)
|
||||
|
||||
|
||||
@attr.s
|
||||
@attr.s(auto_attribs=True)
|
||||
class TaskEventsResult(object):
|
||||
events = attr.ib(type=list, default=attr.Factory(list))
|
||||
total_events = attr.ib(type=int, default=0)
|
||||
next_scroll_id = attr.ib(type=str, default=None)
|
||||
total_events: int = 0
|
||||
next_scroll_id: str = None
|
||||
events: list = attr.ib(factory=list)
|
||||
|
||||
|
||||
class EventBLL(object):
|
||||
id_fields = ["task", "iter", "metric", "variant", "key"]
|
||||
id_fields = ("task", "iter", "metric", "variant", "key")
|
||||
|
||||
def __init__(self, events_es=None):
|
||||
self.es = events_es if events_es is not None else es_factory.connect("events")
|
||||
def __init__(self, events_es=None, redis=None):
|
||||
self.es = events_es or es_factory.connect("events")
|
||||
self._metrics = EventMetrics(self.es)
|
||||
self._skip_iteration_for_metric = set(
|
||||
config.get("services.events.ignore_iteration.metrics", [])
|
||||
)
|
||||
self.redis = redis or redman.connection("apiserver")
|
||||
self.debug_images_iterator = DebugImagesIterator(es=self.es, redis=self.redis)
|
||||
|
||||
def add_events(self, company_id, events, worker):
|
||||
@property
|
||||
def metrics(self) -> EventMetrics:
|
||||
return self._metrics
|
||||
|
||||
def add_events(self, company_id, events, worker, allow_locked_tasks=False):
|
||||
actions = []
|
||||
task_ids = set()
|
||||
task_iteration = defaultdict(lambda: 0)
|
||||
task_last_events = nested_dict(
|
||||
task_last_scalar_events = nested_dict(
|
||||
3, dict
|
||||
) # task_id -> metric_hash -> variant_hash -> MetricEvent
|
||||
task_last_events = nested_dict(
|
||||
3, dict
|
||||
) # task_id -> metric_hash -> event_type -> MetricEvent
|
||||
|
||||
for event in events:
|
||||
# remove spaces from event type
|
||||
@@ -94,7 +103,10 @@ class EventBLL(object):
|
||||
event["value"] = event["values"]
|
||||
del event["values"]
|
||||
|
||||
index_name = EventBLL.get_index_name(company_id, event_type)
|
||||
event["metric"] = event.get("metric") or ""
|
||||
event["variant"] = event.get("variant") or ""
|
||||
|
||||
index_name = EventMetrics.get_index_name(company_id, event_type)
|
||||
es_action = {
|
||||
"_op_type": "index", # overwrite if exists with same ID
|
||||
"_index": index_name,
|
||||
@@ -112,12 +124,18 @@ class EventBLL(object):
|
||||
if task_id is not None:
|
||||
es_action["_routing"] = task_id
|
||||
task_ids.add(task_id)
|
||||
if iter is not None:
|
||||
if (
|
||||
iter is not None
|
||||
and event.get("metric") not in self._skip_iteration_for_metric
|
||||
):
|
||||
task_iteration[task_id] = max(iter, task_iteration[task_id])
|
||||
|
||||
self._update_last_metric_events_for_task(
|
||||
last_events=task_last_events[task_id], event=event,
|
||||
)
|
||||
if event_type == EventType.metrics_scalar.value:
|
||||
self._update_last_metric_event_for_task(
|
||||
task_last_events=task_last_events, task_id=task_id, event=event
|
||||
self._update_last_scalar_events_for_task(
|
||||
last_events=task_last_scalar_events[task_id], event=event
|
||||
)
|
||||
else:
|
||||
es_action["_routing"] = task_id
|
||||
@@ -127,11 +145,16 @@ class EventBLL(object):
|
||||
if task_ids:
|
||||
# verify task_ids
|
||||
with translate_errors_context(), TimingContext("mongo", "task_by_ids"):
|
||||
res = Task.objects(id__in=task_ids, company=company_id).only("id")
|
||||
extra_msg = None
|
||||
query = Q(id__in=task_ids, company=company_id)
|
||||
if not allow_locked_tasks:
|
||||
query &= Q(status__nin=LOCKED_TASK_STATUSES)
|
||||
extra_msg = "or task published"
|
||||
res = Task.objects(query).only("id")
|
||||
if len(res) < len(task_ids):
|
||||
invalid_task_ids = tuple(set(task_ids) - set(r.id for r in res))
|
||||
raise errors.bad_request.InvalidTaskId(
|
||||
company=company_id, ids=invalid_task_ids
|
||||
extra_msg, company=company_id, ids=invalid_task_ids
|
||||
)
|
||||
|
||||
errors_in_bulk = []
|
||||
@@ -154,13 +177,6 @@ class EventBLL(object):
|
||||
else:
|
||||
errors_in_bulk.append(info)
|
||||
|
||||
last_metrics = {
|
||||
t.id: t.to_proper_dict().get("last_metrics", {})
|
||||
for t in Task.objects(id__in=task_ids, company=company_id).only(
|
||||
"last_metrics"
|
||||
)
|
||||
}
|
||||
|
||||
remaining_tasks = set()
|
||||
now = datetime.utcnow()
|
||||
for task_id in task_ids:
|
||||
@@ -171,9 +187,9 @@ class EventBLL(object):
|
||||
company_id=company_id,
|
||||
task_id=task_id,
|
||||
now=now,
|
||||
iter=task_iteration.get(task_id),
|
||||
iter_max=task_iteration.get(task_id),
|
||||
last_scalar_events=task_last_scalar_events.get(task_id),
|
||||
last_events=task_last_events.get(task_id),
|
||||
last_metrics=last_metrics.get(task_id),
|
||||
)
|
||||
|
||||
if not updated:
|
||||
@@ -188,12 +204,12 @@ class EventBLL(object):
|
||||
|
||||
return added, errors_in_bulk
|
||||
|
||||
def _update_last_metric_event_for_task(self, task_last_events, task_id, event):
|
||||
def _update_last_scalar_events_for_task(self, last_events, event):
|
||||
"""
|
||||
Update task_last_events structure for the provided task_id with the provided event details if this event is more
|
||||
Update last_events structure with the provided event details if this event is more
|
||||
recent than the currently stored event for its metric/variant combination.
|
||||
|
||||
task_last_events contains [hashed_metric_name -> hashed_variant_name -> event]. Keys are hashed to avoid mongodb
|
||||
last_events contains [hashed_metric_name -> hashed_variant_name -> event]. Keys are hashed to avoid mongodb
|
||||
key conflicts due to invalid characters and/or long field names.
|
||||
"""
|
||||
metric = event.get("metric")
|
||||
@@ -204,14 +220,33 @@ class EventBLL(object):
|
||||
metric_hash = dbutils.hash_field_name(metric)
|
||||
variant_hash = dbutils.hash_field_name(variant)
|
||||
|
||||
last_events = task_last_events[task_id]
|
||||
|
||||
timestamp = last_events[metric_hash][variant_hash].get("timestamp", None)
|
||||
if timestamp is None or timestamp < event["timestamp"]:
|
||||
last_events[metric_hash][variant_hash] = event
|
||||
|
||||
def _update_last_metric_events_for_task(self, last_events, event):
|
||||
"""
|
||||
Update last_events structure with the provided event details if this event is more
|
||||
recent than the currently stored event for its metric/event_type combination.
|
||||
last_events contains [metric_name -> event_type -> event]
|
||||
"""
|
||||
metric = event.get("metric")
|
||||
event_type = event.get("type")
|
||||
if not (metric and event_type):
|
||||
return
|
||||
|
||||
timestamp = last_events[metric][event_type].get("timestamp", None)
|
||||
if timestamp is None or timestamp < event["timestamp"]:
|
||||
last_events[metric][event_type] = event
|
||||
|
||||
def _update_task(
|
||||
self, company_id, task_id, now, iter=None, last_events=None, last_metrics=None
|
||||
self,
|
||||
company_id,
|
||||
task_id,
|
||||
now,
|
||||
iter_max=None,
|
||||
last_scalar_events=None,
|
||||
last_events=None,
|
||||
):
|
||||
"""
|
||||
Update task information in DB with aggregated results after handling event(s) related to this task.
|
||||
@@ -222,27 +257,20 @@ class EventBLL(object):
|
||||
"""
|
||||
fields = {}
|
||||
|
||||
if iter is not None:
|
||||
fields["last_iteration"] = iter
|
||||
if iter_max is not None:
|
||||
fields["last_iteration_max"] = iter_max
|
||||
|
||||
if last_scalar_events:
|
||||
fields["last_scalar_values"] = list(
|
||||
flatten_nested_items(
|
||||
last_scalar_events,
|
||||
nesting=2,
|
||||
include_leaves=["value", "metric", "variant"],
|
||||
)
|
||||
)
|
||||
|
||||
if last_events:
|
||||
|
||||
def get_metric_event(ev):
|
||||
me = MetricEvent.from_dict(**ev)
|
||||
if "timestamp" in ev:
|
||||
me.timestamp = datetime.utcfromtimestamp(ev["timestamp"] / 1000)
|
||||
return me
|
||||
|
||||
new_last_metrics = nested_dict(2, MetricEvent)
|
||||
new_last_metrics.update(last_metrics)
|
||||
|
||||
for metric_hash, variants in last_events.items():
|
||||
for variant_hash, event in variants.items():
|
||||
new_last_metrics[metric_hash][variant_hash] = get_metric_event(
|
||||
event
|
||||
)
|
||||
|
||||
fields["last_metrics"] = new_last_metrics.to_dict()
|
||||
fields["last_events"] = last_events
|
||||
|
||||
if not fields:
|
||||
return False
|
||||
@@ -251,7 +279,7 @@ class EventBLL(object):
|
||||
|
||||
def _get_event_id(self, event):
|
||||
id_values = (str(event[field]) for field in self.id_fields if field in event)
|
||||
return "-".join(id_values)
|
||||
return hashlib.md5("-".join(id_values).encode()).hexdigest()
|
||||
|
||||
def scroll_task_events(
|
||||
self,
|
||||
@@ -270,7 +298,7 @@ class EventBLL(object):
|
||||
if event_type is None:
|
||||
event_type = "*"
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, event_type)
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
|
||||
if not self.es.indices.exists(es_index):
|
||||
return [], None, 0
|
||||
@@ -282,7 +310,9 @@ class EventBLL(object):
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "scroll_task_events"):
|
||||
es_res = self.es.search(index=es_index, body=es_req, scroll="1h")
|
||||
es_res = self.es.search(
|
||||
index=es_index, body=es_req, scroll="1h", routing=task_id
|
||||
)
|
||||
|
||||
events = [hit["_source"] for hit in es_res["hits"]["hits"]]
|
||||
next_scroll_id = es_res["_scroll_id"]
|
||||
@@ -290,6 +320,131 @@ class EventBLL(object):
|
||||
|
||||
return events, next_scroll_id, total_events
|
||||
|
||||
def get_last_iterations_per_event_metric_variant(
|
||||
self, es_index: str, task_id: str, num_last_iterations: int, event_type: str
|
||||
):
|
||||
if not self.es.indices.exists(es_index):
|
||||
return []
|
||||
|
||||
es_req: dict = {
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": EventMetrics.MAX_METRICS_COUNT,
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": EventMetrics.MAX_VARIANTS_COUNT,
|
||||
},
|
||||
"aggs": {
|
||||
"iters": {
|
||||
"terms": {
|
||||
"field": "iter",
|
||||
"size": num_last_iterations,
|
||||
"order": {"_term": "desc"},
|
||||
}
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
"query": {"bool": {"must": [{"term": {"task": task_id}}]}},
|
||||
}
|
||||
if event_type:
|
||||
es_req["query"]["bool"]["must"].append({"term": {"type": event_type}})
|
||||
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "task_last_iter_metric_variant"
|
||||
):
|
||||
es_res = self.es.search(index=es_index, body=es_req, routing=task_id)
|
||||
if "aggregations" not in es_res:
|
||||
return []
|
||||
|
||||
return [
|
||||
(metric["key"], variant["key"], iter["key"])
|
||||
for metric in es_res["aggregations"]["metrics"]["buckets"]
|
||||
for variant in metric["variants"]["buckets"]
|
||||
for iter in variant["iters"]["buckets"]
|
||||
]
|
||||
|
||||
def get_task_plots(
|
||||
self,
|
||||
company_id: str,
|
||||
tasks: Sequence[str],
|
||||
last_iterations_per_plot: int = None,
|
||||
sort=None,
|
||||
size: int = 500,
|
||||
scroll_id: str = None,
|
||||
):
|
||||
if scroll_id:
|
||||
with translate_errors_context(), TimingContext("es", "get_task_events"):
|
||||
es_res = self.es.scroll(scroll_id=scroll_id, scroll="1h")
|
||||
else:
|
||||
event_type = "plot"
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
if not self.es.indices.exists(es_index):
|
||||
return TaskEventsResult()
|
||||
|
||||
query = {"bool": defaultdict(list)}
|
||||
|
||||
if last_iterations_per_plot is None:
|
||||
must = query["bool"]["must"]
|
||||
must.append({"terms": {"task": tasks}})
|
||||
else:
|
||||
should = query["bool"]["should"]
|
||||
for i, task_id in enumerate(tasks):
|
||||
last_iters = self.get_last_iterations_per_event_metric_variant(
|
||||
es_index, task_id, last_iterations_per_plot, event_type
|
||||
)
|
||||
if not last_iters:
|
||||
continue
|
||||
|
||||
for metric, variant, iter in last_iters:
|
||||
should.append(
|
||||
{
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"task": task_id}},
|
||||
{"term": {"metric": metric}},
|
||||
{"term": {"variant": variant}},
|
||||
{"term": {"iter": iter}},
|
||||
]
|
||||
}
|
||||
}
|
||||
)
|
||||
if not should:
|
||||
return TaskEventsResult()
|
||||
|
||||
if sort is None:
|
||||
sort = [{"timestamp": {"order": "asc"}}]
|
||||
|
||||
es_req = {"sort": sort, "size": min(size, 10000), "query": query}
|
||||
|
||||
routing = ",".join(tasks)
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "get_task_plots"):
|
||||
es_res = self.es.search(
|
||||
index=es_index,
|
||||
body=es_req,
|
||||
ignore=404,
|
||||
routing=routing,
|
||||
scroll="1h",
|
||||
)
|
||||
|
||||
events = [doc["_source"] for doc in es_res.get("hits", {}).get("hits", [])]
|
||||
# scroll id may be missing when queering a totally empty DB
|
||||
next_scroll_id = es_res.get("_scroll_id")
|
||||
total_events = es_res["hits"]["total"]
|
||||
|
||||
return TaskEventsResult(
|
||||
events=events, next_scroll_id=next_scroll_id, total_events=total_events
|
||||
)
|
||||
|
||||
def get_task_events(
|
||||
self,
|
||||
company_id,
|
||||
@@ -311,7 +466,7 @@ class EventBLL(object):
|
||||
if event_type is None:
|
||||
event_type = "*"
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, event_type)
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
if not self.es.indices.exists(es_index):
|
||||
return TaskEventsResult()
|
||||
|
||||
@@ -374,7 +529,7 @@ class EventBLL(object):
|
||||
|
||||
def get_metrics_and_variants(self, company_id, task_id, event_type):
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, event_type)
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
|
||||
if not self.es.indices.exists(es_index):
|
||||
return {}
|
||||
@@ -383,8 +538,18 @@ class EventBLL(object):
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {"field": "metric", "size": 200},
|
||||
"aggs": {"variants": {"terms": {"field": "variant", "size": 200}}},
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": EventMetrics.MAX_METRICS_COUNT,
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": EventMetrics.MAX_VARIANTS_COUNT,
|
||||
}
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
"query": {"bool": {"must": [{"term": {"task": task_id}}]}},
|
||||
@@ -405,7 +570,7 @@ class EventBLL(object):
|
||||
return metrics
|
||||
|
||||
def get_task_latest_scalar_values(self, company_id, task_id):
|
||||
es_index = EventBLL.get_index_name(company_id, "training_stats_scalar")
|
||||
es_index = EventMetrics.get_index_name(company_id, "training_stats_scalar")
|
||||
|
||||
if not self.es.indices.exists(es_index):
|
||||
return {}
|
||||
@@ -424,14 +589,14 @@ class EventBLL(object):
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": 1000,
|
||||
"size": EventMetrics.MAX_METRICS_COUNT,
|
||||
"order": {"_term": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": 1000,
|
||||
"size": EventMetrics.MAX_VARIANTS_COUNT,
|
||||
"order": {"_term": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
@@ -488,147 +653,9 @@ class EventBLL(object):
|
||||
metrics.append(metric_summary)
|
||||
return metrics, max_timestamp
|
||||
|
||||
def compare_scalar_metrics_average_per_iter(
|
||||
self, company_id, task_ids, allow_public=True
|
||||
):
|
||||
assert isinstance(task_ids, list)
|
||||
|
||||
task_name_by_id = {}
|
||||
with translate_errors_context():
|
||||
task_objs = Task.get_many(
|
||||
company=company_id,
|
||||
query=Q(id__in=task_ids),
|
||||
allow_public=allow_public,
|
||||
override_projection=("id", "name"),
|
||||
return_dicts=False,
|
||||
)
|
||||
if len(task_objs) < len(task_ids):
|
||||
invalid = tuple(set(task_ids) - set(r.id for r in task_objs))
|
||||
raise errors.bad_request.InvalidTaskId(company=company_id, ids=invalid)
|
||||
|
||||
task_name_by_id = {t.id: t.name for t in task_objs}
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, "training_stats_scalar")
|
||||
if not self.es.indices.exists(es_index):
|
||||
return {}
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"_source": {"excludes": []},
|
||||
"query": {"terms": {"task": task_ids}},
|
||||
"aggs": {
|
||||
"iters": {
|
||||
"histogram": {"field": "iter", "interval": 1, "min_doc_count": 1},
|
||||
"aggs": {
|
||||
"metric_and_variant": {
|
||||
"terms": {
|
||||
"script": "doc['metric'].value +'/'+ doc['variant'].value",
|
||||
"size": 10000,
|
||||
},
|
||||
"aggs": {
|
||||
"tasks": {
|
||||
"terms": {"field": "task"},
|
||||
"aggs": {"avg_val": {"avg": {"field": "value"}}},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
with translate_errors_context(), TimingContext("es", "task_stats_comparison"):
|
||||
es_res = self.es.search(index=es_index, body=es_req)
|
||||
|
||||
if "aggregations" not in es_res:
|
||||
return
|
||||
|
||||
metrics = {}
|
||||
for iter_bucket in es_res["aggregations"]["iters"]["buckets"]:
|
||||
iteration = int(iter_bucket["key"])
|
||||
for metric_bucket in iter_bucket["metric_and_variant"]["buckets"]:
|
||||
metric_name = metric_bucket["key"]
|
||||
if metrics.get(metric_name) is None:
|
||||
metrics[metric_name] = {}
|
||||
|
||||
metric_data = metrics[metric_name]
|
||||
for task_bucket in metric_bucket["tasks"]["buckets"]:
|
||||
task_id = task_bucket["key"]
|
||||
value = task_bucket["avg_val"]["value"]
|
||||
if metric_data.get(task_id) is None:
|
||||
metric_data[task_id] = {
|
||||
"x": [],
|
||||
"y": [],
|
||||
"name": task_name_by_id[
|
||||
task_id
|
||||
], # todo: lookup task name from id
|
||||
}
|
||||
metric_data[task_id]["x"].append(iteration)
|
||||
metric_data[task_id]["y"].append(value)
|
||||
|
||||
return metrics
|
||||
|
||||
def get_scalar_metrics_average_per_iter(self, company_id, task_id):
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, "training_stats_scalar")
|
||||
if not self.es.indices.exists(es_index):
|
||||
return {}
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"_source": {"excludes": []},
|
||||
"query": {"term": {"task": task_id}},
|
||||
"aggs": {
|
||||
"iters": {
|
||||
"histogram": {"field": "iter", "interval": 1, "min_doc_count": 1},
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": 200,
|
||||
"order": {"_term": "desc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": 500,
|
||||
"order": {"_term": "desc"},
|
||||
},
|
||||
"aggs": {"avg_val": {"avg": {"field": "value"}}},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
"version": True,
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "task_stats_scalar"):
|
||||
es_res = self.es.search(index=es_index, body=es_req, routing=task_id)
|
||||
|
||||
metrics = {}
|
||||
if "aggregations" in es_res:
|
||||
for iter_bucket in es_res["aggregations"]["iters"]["buckets"]:
|
||||
iteration = int(iter_bucket["key"])
|
||||
for metric_bucket in iter_bucket["metrics"]["buckets"]:
|
||||
metric_name = metric_bucket["key"]
|
||||
if metrics.get(metric_name) is None:
|
||||
metrics[metric_name] = {}
|
||||
|
||||
metric_data = metrics[metric_name]
|
||||
for variant_bucket in metric_bucket["variants"]["buckets"]:
|
||||
variant = variant_bucket["key"]
|
||||
value = variant_bucket["avg_val"]["value"]
|
||||
if metric_data.get(variant) is None:
|
||||
metric_data[variant] = {"x": [], "y": [], "name": variant}
|
||||
metric_data[variant]["x"].append(iteration)
|
||||
metric_data[variant]["y"].append(value)
|
||||
return metrics
|
||||
|
||||
def get_vector_metrics_per_iter(self, company_id, task_id, metric, variant):
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, "training_stats_vector")
|
||||
es_index = EventMetrics.get_index_name(company_id, "training_stats_vector")
|
||||
if not self.es.indices.exists(es_index):
|
||||
return [], []
|
||||
|
||||
@@ -684,8 +711,20 @@ class EventBLL(object):
|
||||
|
||||
return [b["key"] for b in es_res["aggregations"]["iters"]["buckets"]]
|
||||
|
||||
def delete_task_events(self, company_id, task_id):
|
||||
es_index = EventBLL.get_index_name(company_id, "*")
|
||||
def delete_task_events(self, company_id, task_id, allow_locked=False):
|
||||
with translate_errors_context():
|
||||
extra_msg = None
|
||||
query = Q(id=task_id, company=company_id)
|
||||
if not allow_locked:
|
||||
query &= Q(status__nin=LOCKED_TASK_STATUSES)
|
||||
extra_msg = "or task published"
|
||||
res = Task.objects(query).only("id").first()
|
||||
if not res:
|
||||
raise errors.bad_request.InvalidTaskId(
|
||||
extra_msg, company=company_id, id=task_id
|
||||
)
|
||||
|
||||
es_index = EventMetrics.get_index_name(company_id, "*")
|
||||
es_req = {"query": {"term": {"task": task_id}}}
|
||||
with translate_errors_context(), TimingContext("es", "delete_task_events"):
|
||||
es_res = self.es.delete_by_query(
|
||||
@@ -693,8 +732,3 @@ class EventBLL(object):
|
||||
)
|
||||
|
||||
return es_res.get("deleted", 0)
|
||||
|
||||
@staticmethod
|
||||
def get_index_name(company_id, event_type):
|
||||
event_type = event_type.lower().replace(" ", "_")
|
||||
return "events-%s-%s" % (event_type, company_id)
|
||||
|
||||
496
server/bll/event/event_metrics.py
Normal file
496
server/bll/event/event_metrics.py
Normal file
@@ -0,0 +1,496 @@
|
||||
import itertools
|
||||
from collections import defaultdict
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
from enum import Enum
|
||||
from functools import partial
|
||||
from operator import itemgetter
|
||||
from typing import Sequence, Tuple, Callable, Iterable
|
||||
|
||||
from boltons.iterutils import bucketize
|
||||
from elasticsearch import Elasticsearch
|
||||
from mongoengine import Q
|
||||
|
||||
from apierrors import errors
|
||||
from bll.event.scalar_key import ScalarKey, ScalarKeyEnum
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.task.task import Task
|
||||
from timing_context import TimingContext
|
||||
from utilities import safe_get
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class EventType(Enum):
|
||||
metrics_scalar = "training_stats_scalar"
|
||||
metrics_vector = "training_stats_vector"
|
||||
metrics_image = "training_debug_image"
|
||||
metrics_plot = "plot"
|
||||
task_log = "log"
|
||||
|
||||
|
||||
class EventMetrics:
|
||||
MAX_TASKS_COUNT = 50
|
||||
MAX_METRICS_COUNT = 200
|
||||
MAX_VARIANTS_COUNT = 500
|
||||
MAX_AGGS_ELEMENTS_COUNT = 50
|
||||
|
||||
def __init__(self, es: Elasticsearch):
|
||||
self.es = es
|
||||
|
||||
@staticmethod
|
||||
def get_index_name(company_id, event_type):
|
||||
event_type = event_type.lower().replace(" ", "_")
|
||||
return f"events-{event_type}-{company_id}"
|
||||
|
||||
def get_scalar_metrics_average_per_iter(
|
||||
self, company_id: str, task_id: str, samples: int, key: ScalarKeyEnum
|
||||
) -> dict:
|
||||
"""
|
||||
Get scalar metric histogram per metric and variant
|
||||
The amount of points in each histogram should not exceed
|
||||
the requested samples
|
||||
"""
|
||||
|
||||
return self._run_get_scalar_metrics_as_parallel(
|
||||
company_id,
|
||||
task_ids=[task_id],
|
||||
samples=samples,
|
||||
key=ScalarKey.resolve(key),
|
||||
get_func=self._get_scalar_average,
|
||||
)
|
||||
|
||||
def compare_scalar_metrics_average_per_iter(
|
||||
self,
|
||||
company_id,
|
||||
task_ids: Sequence[str],
|
||||
samples,
|
||||
key: ScalarKeyEnum,
|
||||
allow_public=True,
|
||||
):
|
||||
"""
|
||||
Compare scalar metrics for different tasks per metric and variant
|
||||
The amount of points in each histogram should not exceed the requested samples
|
||||
"""
|
||||
if len(task_ids) > self.MAX_TASKS_COUNT:
|
||||
raise errors.BadRequest(
|
||||
f"Up to {self.MAX_TASKS_COUNT} tasks supported for comparison",
|
||||
len(task_ids),
|
||||
)
|
||||
|
||||
task_name_by_id = {}
|
||||
with translate_errors_context():
|
||||
task_objs = Task.get_many(
|
||||
company=company_id,
|
||||
query=Q(id__in=task_ids),
|
||||
allow_public=allow_public,
|
||||
override_projection=("id", "name"),
|
||||
return_dicts=False,
|
||||
)
|
||||
if len(task_objs) < len(task_ids):
|
||||
invalid = tuple(set(task_ids) - set(r.id for r in task_objs))
|
||||
raise errors.bad_request.InvalidTaskId(company=company_id, ids=invalid)
|
||||
|
||||
task_name_by_id = {t.id: t.name for t in task_objs}
|
||||
|
||||
ret = self._run_get_scalar_metrics_as_parallel(
|
||||
company_id,
|
||||
task_ids=task_ids,
|
||||
samples=samples,
|
||||
key=ScalarKey.resolve(key),
|
||||
get_func=self._get_scalar_average_per_task,
|
||||
)
|
||||
|
||||
for metric_data in ret.values():
|
||||
for variant_data in metric_data.values():
|
||||
for task_id, task_data in variant_data.items():
|
||||
task_data["name"] = task_name_by_id[task_id]
|
||||
|
||||
return ret
|
||||
|
||||
TaskMetric = Tuple[str, str, str]
|
||||
|
||||
MetricInterval = Tuple[int, Sequence[TaskMetric]]
|
||||
MetricData = Tuple[str, dict]
|
||||
|
||||
def _split_metrics_by_max_aggs_count(
|
||||
self, task_metrics: Sequence[TaskMetric]
|
||||
) -> Iterable[Sequence[TaskMetric]]:
|
||||
"""
|
||||
Return task metrics in groups where amount of task metrics in each group
|
||||
is roughly limited by MAX_AGGS_ELEMENTS_COUNT. The split is done on metrics and
|
||||
variants while always preserving all their tasks in the same group
|
||||
"""
|
||||
if len(task_metrics) < self.MAX_AGGS_ELEMENTS_COUNT:
|
||||
yield task_metrics
|
||||
return
|
||||
|
||||
tm_grouped = bucketize(task_metrics, key=itemgetter(1, 2))
|
||||
groups = []
|
||||
for group in tm_grouped.values():
|
||||
groups.append(group)
|
||||
if sum(map(len, groups)) >= self.MAX_AGGS_ELEMENTS_COUNT:
|
||||
yield list(itertools.chain(*groups))
|
||||
groups = []
|
||||
|
||||
if groups:
|
||||
yield list(itertools.chain(*groups))
|
||||
|
||||
return
|
||||
|
||||
def _run_get_scalar_metrics_as_parallel(
|
||||
self,
|
||||
company_id: str,
|
||||
task_ids: Sequence[str],
|
||||
samples: int,
|
||||
key: ScalarKey,
|
||||
get_func: Callable[
|
||||
[MetricInterval, Sequence[str], str, ScalarKey], Sequence[MetricData]
|
||||
],
|
||||
) -> dict:
|
||||
"""
|
||||
Group metrics per interval length and execute get_func for each group in parallel
|
||||
:param company_id: id of the company
|
||||
:params task_ids: ids of the tasks to collect data for
|
||||
:param samples: maximum number of samples per metric
|
||||
:param get_func: callable that given metric names for the same interval
|
||||
performs histogram aggregation for the metrics and return the aggregated data
|
||||
"""
|
||||
es_index = self.get_index_name(company_id, "training_stats_scalar")
|
||||
if not self.es.indices.exists(es_index):
|
||||
return {}
|
||||
|
||||
intervals = self._get_metric_intervals(
|
||||
es_index=es_index, task_ids=task_ids, samples=samples, field=key.field
|
||||
)
|
||||
|
||||
if not intervals:
|
||||
return {}
|
||||
|
||||
intervals = list(
|
||||
itertools.chain.from_iterable(
|
||||
zip(itertools.repeat(i), self._split_metrics_by_max_aggs_count(tms))
|
||||
for i, tms in intervals
|
||||
)
|
||||
)
|
||||
max_concurrency = config.get("services.events.max_metrics_concurrency", 4)
|
||||
with ThreadPoolExecutor(max_workers=max_concurrency) as pool:
|
||||
metrics = itertools.chain.from_iterable(
|
||||
pool.map(
|
||||
partial(get_func, task_ids=task_ids, es_index=es_index, key=key),
|
||||
intervals,
|
||||
)
|
||||
)
|
||||
|
||||
ret = defaultdict(dict)
|
||||
for metric_key, metric_values in metrics:
|
||||
ret[metric_key].update(metric_values)
|
||||
|
||||
return ret
|
||||
|
||||
def _get_metric_intervals(
|
||||
self, es_index, task_ids: Sequence[str], samples: int, field: str = "iter"
|
||||
) -> Sequence[MetricInterval]:
|
||||
"""
|
||||
Calculate interval per task metric variant so that the resulting
|
||||
amount of points does not exceed sample.
|
||||
Return metric variants grouped by interval value with 10% rounding
|
||||
For samples==0 return empty list
|
||||
"""
|
||||
default_intervals = [(1, [])]
|
||||
if not samples:
|
||||
return default_intervals
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": {"terms": {"task": task_ids}},
|
||||
"aggs": {
|
||||
"tasks": {
|
||||
"terms": {"field": "task", "size": self.MAX_TASKS_COUNT},
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": self.MAX_METRICS_COUNT,
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": self.MAX_VARIANTS_COUNT,
|
||||
},
|
||||
"aggs": {
|
||||
"count": {"value_count": {"field": field}},
|
||||
"min_index": {"min": {"field": field}},
|
||||
"max_index": {"max": {"field": field}},
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "task_stats_get_interval"):
|
||||
es_res = self.es.search(
|
||||
index=es_index, body=es_req, routing=",".join(task_ids)
|
||||
)
|
||||
|
||||
aggs_result = es_res.get("aggregations")
|
||||
if not aggs_result:
|
||||
return default_intervals
|
||||
|
||||
intervals = [
|
||||
(
|
||||
task["key"],
|
||||
metric["key"],
|
||||
variant["key"],
|
||||
self._calculate_metric_interval(variant, samples),
|
||||
)
|
||||
for task in aggs_result["tasks"]["buckets"]
|
||||
for metric in task["metrics"]["buckets"]
|
||||
for variant in metric["variants"]["buckets"]
|
||||
]
|
||||
|
||||
metric_intervals = []
|
||||
upper_border = 0
|
||||
interval_metrics = None
|
||||
for task, metric, variant, interval in sorted(intervals, key=itemgetter(3)):
|
||||
if not interval_metrics or interval > upper_border:
|
||||
interval_metrics = []
|
||||
metric_intervals.append((interval, interval_metrics))
|
||||
upper_border = interval + int(interval * 0.1)
|
||||
interval_metrics.append((task, metric, variant))
|
||||
|
||||
return metric_intervals
|
||||
|
||||
@staticmethod
|
||||
def _calculate_metric_interval(metric_variant: dict, samples: int) -> int:
|
||||
"""
|
||||
Calculate index interval per metric_variant variant so that the
|
||||
total amount of intervals does not exceeds the samples
|
||||
"""
|
||||
count = safe_get(metric_variant, "count/value")
|
||||
if not count or count < samples:
|
||||
return 1
|
||||
|
||||
min_index = safe_get(metric_variant, "min_index/value", default=0)
|
||||
max_index = safe_get(metric_variant, "max_index/value", default=min_index)
|
||||
return max(1, int(max_index - min_index + 1) // samples)
|
||||
|
||||
def _get_scalar_average(
|
||||
self,
|
||||
metrics_interval: MetricInterval,
|
||||
task_ids: Sequence[str],
|
||||
es_index: str,
|
||||
key: ScalarKey,
|
||||
) -> Sequence[MetricData]:
|
||||
"""
|
||||
Retrieve scalar histograms per several metric variants that share the same interval
|
||||
Note: the function works with a single task only
|
||||
"""
|
||||
|
||||
assert len(task_ids) == 1
|
||||
interval, task_metrics = metrics_interval
|
||||
aggregation = self._add_aggregation_average(key.get_aggregation(interval))
|
||||
aggs = {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": self.MAX_METRICS_COUNT,
|
||||
"order": {"_term": "desc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": self.MAX_VARIANTS_COUNT,
|
||||
"order": {"_term": "desc"},
|
||||
},
|
||||
"aggs": aggregation,
|
||||
}
|
||||
},
|
||||
}
|
||||
}
|
||||
aggs_result = self._query_aggregation_for_metrics_and_tasks(
|
||||
es_index, aggs=aggs, task_ids=task_ids, task_metrics=task_metrics
|
||||
)
|
||||
|
||||
if not aggs_result:
|
||||
return {}
|
||||
|
||||
metrics = [
|
||||
(
|
||||
metric["key"],
|
||||
{
|
||||
variant["key"]: {
|
||||
"name": variant["key"],
|
||||
**key.get_iterations_data(variant),
|
||||
}
|
||||
for variant in metric["variants"]["buckets"]
|
||||
},
|
||||
)
|
||||
for metric in aggs_result["metrics"]["buckets"]
|
||||
]
|
||||
return metrics
|
||||
|
||||
def _get_scalar_average_per_task(
|
||||
self,
|
||||
metrics_interval: MetricInterval,
|
||||
task_ids: Sequence[str],
|
||||
es_index: str,
|
||||
key: ScalarKey,
|
||||
) -> Sequence[MetricData]:
|
||||
"""
|
||||
Retrieve scalar histograms per several metric variants that share the same interval
|
||||
"""
|
||||
interval, task_metrics = metrics_interval
|
||||
|
||||
aggregation = self._add_aggregation_average(key.get_aggregation(interval))
|
||||
aggs = {
|
||||
"metrics": {
|
||||
"terms": {"field": "metric", "size": self.MAX_METRICS_COUNT},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {"field": "variant", "size": self.MAX_VARIANTS_COUNT},
|
||||
"aggs": {
|
||||
"tasks": {
|
||||
"terms": {
|
||||
"field": "task",
|
||||
"size": self.MAX_TASKS_COUNT,
|
||||
},
|
||||
"aggs": aggregation,
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
aggs_result = self._query_aggregation_for_metrics_and_tasks(
|
||||
es_index, aggs=aggs, task_ids=task_ids, task_metrics=task_metrics
|
||||
)
|
||||
|
||||
if not aggs_result:
|
||||
return {}
|
||||
|
||||
metrics = [
|
||||
(
|
||||
metric["key"],
|
||||
{
|
||||
variant["key"]: {
|
||||
task["key"]: key.get_iterations_data(task)
|
||||
for task in variant["tasks"]["buckets"]
|
||||
}
|
||||
for variant in metric["variants"]["buckets"]
|
||||
},
|
||||
)
|
||||
for metric in aggs_result["metrics"]["buckets"]
|
||||
]
|
||||
return metrics
|
||||
|
||||
@staticmethod
|
||||
def _add_aggregation_average(aggregation):
|
||||
average_agg = {"avg_val": {"avg": {"field": "value"}}}
|
||||
return {
|
||||
key: {**value, "aggs": {**value.get("aggs", {}), **average_agg}}
|
||||
for key, value in aggregation.items()
|
||||
}
|
||||
|
||||
def _query_aggregation_for_metrics_and_tasks(
|
||||
self,
|
||||
es_index: str,
|
||||
aggs: dict,
|
||||
task_ids: Sequence[str],
|
||||
task_metrics: Sequence[TaskMetric],
|
||||
) -> dict:
|
||||
"""
|
||||
Return the result of elastic search query for the given aggregation filtered
|
||||
by the given task_ids and metrics
|
||||
"""
|
||||
if task_metrics:
|
||||
condition = {
|
||||
"should": [
|
||||
self._build_metric_terms(task, metric, variant)
|
||||
for task, metric, variant in task_metrics
|
||||
]
|
||||
}
|
||||
else:
|
||||
condition = {"must": [{"terms": {"task": task_ids}}]}
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"_source": {"excludes": []},
|
||||
"query": {"bool": condition},
|
||||
"aggs": aggs,
|
||||
"version": True,
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "task_stats_scalar"):
|
||||
es_res = self.es.search(
|
||||
index=es_index, body=es_req, routing=",".join(task_ids)
|
||||
)
|
||||
|
||||
return es_res.get("aggregations")
|
||||
|
||||
@staticmethod
|
||||
def _build_metric_terms(task: str, metric: str, variant: str) -> dict:
|
||||
"""
|
||||
Build query term for a metric + variant
|
||||
"""
|
||||
return {
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"task": task}},
|
||||
{"term": {"metric": metric}},
|
||||
{"term": {"variant": variant}},
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
def get_tasks_metrics(
|
||||
self, company_id, task_ids: Sequence, event_type: EventType
|
||||
) -> Sequence[Tuple]:
|
||||
"""
|
||||
For the requested tasks return all the metrics that
|
||||
reported events of the requested types
|
||||
"""
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type.value)
|
||||
if not self.es.indices.exists(es_index):
|
||||
return [(tid, []) for tid in task_ids]
|
||||
|
||||
max_concurrency = config.get("services.events.max_metrics_concurrency", 4)
|
||||
with ThreadPoolExecutor(max_concurrency) as pool:
|
||||
res = pool.map(
|
||||
partial(
|
||||
self._get_task_metrics, es_index=es_index, event_type=event_type,
|
||||
),
|
||||
task_ids,
|
||||
)
|
||||
return list(zip(task_ids, res))
|
||||
|
||||
def _get_task_metrics(self, task_id, es_index, event_type: EventType) -> Sequence:
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": {
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"task": task_id}},
|
||||
{"term": {"type": event_type.value}},
|
||||
]
|
||||
}
|
||||
},
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {"field": "metric", "size": self.MAX_METRICS_COUNT}
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "_get_task_metrics"):
|
||||
es_res = self.es.search(index=es_index, body=es_req, routing=task_id)
|
||||
|
||||
return [
|
||||
metric["key"]
|
||||
for metric in safe_get(es_res, "aggregations/metrics/buckets", default=[])
|
||||
]
|
||||
161
server/bll/event/scalar_key.py
Normal file
161
server/bll/event/scalar_key.py
Normal file
@@ -0,0 +1,161 @@
|
||||
"""
|
||||
Module for polymorphism over different types of X axes in scalar aggregations
|
||||
"""
|
||||
from abc import ABC, abstractmethod
|
||||
from enum import auto
|
||||
|
||||
from apimodels import StringEnum
|
||||
from bll.util import extract_properties_to_lists
|
||||
from config import config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class ScalarKeyEnum(StringEnum):
|
||||
"""
|
||||
String enum representing X axes key
|
||||
"""
|
||||
|
||||
iter = auto()
|
||||
timestamp = auto()
|
||||
iso_time = auto()
|
||||
|
||||
|
||||
class ScalarKey(ABC):
|
||||
"""
|
||||
Abstract scalar key
|
||||
"""
|
||||
|
||||
_enum_to_key = {}
|
||||
bucket_key_key = "key"
|
||||
|
||||
@property
|
||||
@abstractmethod
|
||||
def enum_value(self) -> ScalarKeyEnum:
|
||||
"""
|
||||
Enum value accepted in API requests
|
||||
"""
|
||||
pass
|
||||
|
||||
@property
|
||||
@abstractmethod
|
||||
def name(self) -> str:
|
||||
"""
|
||||
Key name. Used as arbitrary internal key in elasticsearch queries
|
||||
"""
|
||||
pass
|
||||
|
||||
@property
|
||||
@abstractmethod
|
||||
def field(self) -> str:
|
||||
"""
|
||||
Event key to aggregate by
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_aggregation(self, interval: int) -> dict:
|
||||
"""
|
||||
Get aggregation for this type of key
|
||||
:param interval: elasticsearch aggregation interval
|
||||
"""
|
||||
pass
|
||||
|
||||
def __init_subclass__(cls, **kwargs):
|
||||
"""
|
||||
Save a mapping from enum values to key class
|
||||
"""
|
||||
if cls.enum_value not in ScalarKeyEnum:
|
||||
raise ValueError(f"{cls.enum_value!r} not in {ScalarKeyEnum.__name__}")
|
||||
if cls.enum_value in cls._enum_to_key:
|
||||
log.warning(
|
||||
f"'{cls.enum_value.value}' is already registered to {ScalarKey.__name__}"
|
||||
)
|
||||
cls._enum_to_key[cls.enum_value] = cls
|
||||
|
||||
@classmethod
|
||||
def resolve(cls, key: ScalarKeyEnum):
|
||||
"""
|
||||
Create a key instance from enum instance
|
||||
"""
|
||||
return cls._enum_to_key[key]()
|
||||
|
||||
def get_iterations_data(self, iter_buckets: dict) -> dict:
|
||||
"""
|
||||
Convert a list of bucket entries to `x`s array and `y`s array
|
||||
"""
|
||||
return extract_properties_to_lists(
|
||||
("x", "y"),
|
||||
iter_buckets[self.name]["buckets"],
|
||||
self._get_iterations_data_single,
|
||||
)
|
||||
|
||||
def _get_iterations_data_single(self, iter_data):
|
||||
"""
|
||||
Extract x value and y value from a single bucket item
|
||||
"""
|
||||
return int(iter_data[self.bucket_key_key]), iter_data["avg_val"]["value"]
|
||||
|
||||
|
||||
class TimestampKey(ScalarKey):
|
||||
"""
|
||||
Aggregate by timestamp in milliseconds since epoch
|
||||
"""
|
||||
|
||||
name = "timestamp"
|
||||
field = "timestamp"
|
||||
enum_value = ScalarKeyEnum.timestamp
|
||||
|
||||
def get_aggregation(self, interval: int) -> dict:
|
||||
return {
|
||||
self.name: {
|
||||
"date_histogram": {
|
||||
"field": "timestamp",
|
||||
"interval": f"{interval}ms",
|
||||
"min_doc_count": 1,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
class IterKey(ScalarKey):
|
||||
"""
|
||||
Aggregate by iteration number
|
||||
"""
|
||||
|
||||
name = "iters"
|
||||
field = "iter"
|
||||
enum_value = ScalarKeyEnum.iter
|
||||
|
||||
def get_aggregation(self, interval: int) -> dict:
|
||||
return {
|
||||
self.name: {
|
||||
"histogram": {"field": "iter", "interval": interval, "min_doc_count": 1}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
class ISOTimeKey(ScalarKey):
|
||||
"""
|
||||
Aggregate by time formatted as ISO strings
|
||||
"""
|
||||
|
||||
name = "iso_time"
|
||||
field = "timestamp"
|
||||
enum_value = ScalarKeyEnum.iso_time
|
||||
bucket_key_key = "key_as_string"
|
||||
|
||||
def get_aggregation(self, interval: int) -> dict:
|
||||
return {
|
||||
self.name: {
|
||||
"date_histogram": {
|
||||
"field": "timestamp",
|
||||
"interval": f"{interval}ms",
|
||||
"min_doc_count": 1,
|
||||
"format": "strict_date_time",
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
def _get_iterations_data_single(self, iter_data):
|
||||
return iter_data[self.bucket_key_key], iter_data["avg_val"]["value"]
|
||||
1
server/bll/query/__init__.py
Normal file
1
server/bll/query/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
from .builder import Builder
|
||||
36
server/bll/query/builder.py
Normal file
36
server/bll/query/builder.py
Normal file
@@ -0,0 +1,36 @@
|
||||
from typing import Optional, Sequence, Iterable, Union
|
||||
|
||||
from config import config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
RANGE_IGNORE_VALUE = -1
|
||||
|
||||
|
||||
class Builder:
|
||||
@staticmethod
|
||||
def dates_range(from_date: Union[int, float], to_date: Union[int, float]) -> dict:
|
||||
return {
|
||||
"range": {
|
||||
"timestamp": {
|
||||
"gte": int(from_date),
|
||||
"lte": int(to_date),
|
||||
"format": "epoch_second",
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@staticmethod
|
||||
def terms(field: str, values: Iterable[str]) -> dict:
|
||||
return {"terms": {field: list(values)}}
|
||||
|
||||
@staticmethod
|
||||
def normalize_range(
|
||||
range_: Sequence[Union[int, float]],
|
||||
ignore_value: Union[int, float] = RANGE_IGNORE_VALUE,
|
||||
) -> Optional[Sequence[Union[int, float]]]:
|
||||
if not range_ or set(range_) == {ignore_value}:
|
||||
return None
|
||||
if len(range_) < 2:
|
||||
return [range_[0]] * 2
|
||||
return range_
|
||||
1
server/bll/queue/__init__.py
Normal file
1
server/bll/queue/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
from .queue_bll import QueueBLL
|
||||
270
server/bll/queue/queue_bll.py
Normal file
270
server/bll/queue/queue_bll.py
Normal file
@@ -0,0 +1,270 @@
|
||||
from collections import defaultdict
|
||||
from datetime import datetime
|
||||
from typing import Callable, Sequence, Optional, Tuple
|
||||
|
||||
from elasticsearch import Elasticsearch
|
||||
|
||||
import database
|
||||
import es_factory
|
||||
from apierrors import errors
|
||||
from bll.queue.queue_metrics import QueueMetrics
|
||||
from bll.workers import WorkerBLL
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.queue import Queue, Entry
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class QueueBLL(object):
|
||||
def __init__(self, worker_bll: WorkerBLL = None, es: Elasticsearch = None):
|
||||
self.worker_bll = worker_bll or WorkerBLL()
|
||||
self.es = es or es_factory.connect("workers")
|
||||
self._metrics = QueueMetrics(self.es)
|
||||
|
||||
@property
|
||||
def metrics(self) -> QueueMetrics:
|
||||
return self._metrics
|
||||
|
||||
@staticmethod
|
||||
def create(
|
||||
company_id: str,
|
||||
name: str,
|
||||
tags: Optional[Sequence[str]] = None,
|
||||
system_tags: Optional[Sequence[str]] = None,
|
||||
) -> Queue:
|
||||
"""Creates a queue"""
|
||||
with translate_errors_context():
|
||||
now = datetime.utcnow()
|
||||
queue = Queue(
|
||||
id=database.utils.id(),
|
||||
company=company_id,
|
||||
created=now,
|
||||
name=name,
|
||||
tags=tags or [],
|
||||
system_tags=system_tags or [],
|
||||
last_update=now,
|
||||
)
|
||||
queue.save()
|
||||
return queue
|
||||
|
||||
def get_by_id(
|
||||
self, company_id: str, queue_id: str, only: Optional[Sequence[str]] = None
|
||||
) -> Queue:
|
||||
"""
|
||||
Get queue by id
|
||||
:raise errors.bad_request.InvalidQueueId: if the queue is not found
|
||||
"""
|
||||
with translate_errors_context():
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
qs = Queue.objects(**query)
|
||||
if only:
|
||||
qs = qs.only(*only)
|
||||
queue = qs.first()
|
||||
if not queue:
|
||||
raise errors.bad_request.InvalidQueueId(**query)
|
||||
|
||||
return queue
|
||||
|
||||
@classmethod
|
||||
def get_queue_with_task(cls, company_id: str, queue_id: str, task_id: str) -> Queue:
|
||||
with translate_errors_context():
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
queue = Queue.objects(entries__task=task_id, **query).first()
|
||||
if not queue:
|
||||
raise errors.bad_request.InvalidQueueOrTaskNotQueued(
|
||||
task=task_id, **query
|
||||
)
|
||||
|
||||
return queue
|
||||
|
||||
def get_default(self, company_id: str) -> Queue:
|
||||
"""
|
||||
Get the default queue
|
||||
:raise errors.bad_request.NoDefaultQueue: if the default queue not found
|
||||
:raise errors.bad_request.MultipleDefaultQueues: if more than one default queue is found
|
||||
"""
|
||||
with translate_errors_context():
|
||||
res = Queue.objects(company=company_id, system_tags="default").only(
|
||||
"id", "name"
|
||||
)
|
||||
if not res:
|
||||
raise errors.bad_request.NoDefaultQueue()
|
||||
if len(res) > 1:
|
||||
raise errors.bad_request.MultipleDefaultQueues(
|
||||
queues=tuple(r.id for r in res)
|
||||
)
|
||||
|
||||
return res.first()
|
||||
|
||||
def update(
|
||||
self, company_id: str, queue_id: str, **update_fields
|
||||
) -> Tuple[int, dict]:
|
||||
"""
|
||||
Partial update of the queue from update_fields
|
||||
:raise errors.bad_request.InvalidQueueId: if the queue is not found
|
||||
:return: number of updated objects and updated fields dictionary
|
||||
"""
|
||||
with translate_errors_context():
|
||||
# validate the queue exists
|
||||
self.get_by_id(company_id=company_id, queue_id=queue_id, only=("id",))
|
||||
return Queue.safe_update(company_id, queue_id, update_fields)
|
||||
|
||||
def delete(self, company_id: str, queue_id: str, force: bool) -> None:
|
||||
"""
|
||||
Delete the queue
|
||||
:raise errors.bad_request.InvalidQueueId: if the queue is not found
|
||||
:raise errors.bad_request.QueueNotEmpty: if the queue is not empty and 'force' not set
|
||||
"""
|
||||
with translate_errors_context():
|
||||
queue = self.get_by_id(company_id=company_id, queue_id=queue_id)
|
||||
if queue.entries and not force:
|
||||
raise errors.bad_request.QueueNotEmpty(
|
||||
"use force=true to delete", id=queue_id
|
||||
)
|
||||
queue.delete()
|
||||
|
||||
def get_all(self, company_id: str, query_dict: dict) -> Sequence[dict]:
|
||||
"""Get all the queues according to the query"""
|
||||
with translate_errors_context():
|
||||
return Queue.get_many(
|
||||
company=company_id, parameters=query_dict, query_dict=query_dict
|
||||
)
|
||||
|
||||
def get_queue_infos(self, company_id: str, query_dict: dict) -> Sequence[dict]:
|
||||
"""
|
||||
Get infos on all the company queues, including queue tasks and workers
|
||||
"""
|
||||
projection = Queue.get_extra_projection("entries.task.name")
|
||||
with translate_errors_context():
|
||||
res = Queue.get_many_with_join(
|
||||
company=company_id,
|
||||
query_dict=query_dict,
|
||||
override_projection=projection,
|
||||
)
|
||||
|
||||
queue_workers = defaultdict(list)
|
||||
for worker in self.worker_bll.get_all(company_id):
|
||||
for queue in worker.queues:
|
||||
queue_workers[queue].append(worker)
|
||||
|
||||
for item in res:
|
||||
item["workers"] = [
|
||||
{
|
||||
"name": w.id,
|
||||
"ip": w.ip,
|
||||
"task": w.task.to_struct() if w.task else None,
|
||||
}
|
||||
for w in queue_workers.get(item["id"], [])
|
||||
]
|
||||
|
||||
return res
|
||||
|
||||
def add_task(self, company_id: str, queue_id: str, task_id: str) -> dict:
|
||||
"""
|
||||
Add the task to the queue and return the queue update results
|
||||
:raise errors.bad_request.TaskAlreadyQueued: if the task is already in the queue
|
||||
:raise errors.bad_request.InvalidQueueOrTaskNotQueued: if the queue update operation failed
|
||||
"""
|
||||
with translate_errors_context():
|
||||
queue = self.get_by_id(company_id=company_id, queue_id=queue_id)
|
||||
if any(e.task == task_id for e in queue.entries):
|
||||
raise errors.bad_request.TaskAlreadyQueued(task=task_id)
|
||||
|
||||
self.metrics.log_queue_metrics_to_es(company_id=company_id, queues=[queue])
|
||||
|
||||
entry = Entry(added=datetime.utcnow(), task=task_id)
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
res = Queue.objects(entries__task__ne=task_id, **query).update_one(
|
||||
push__entries=entry, last_update=datetime.utcnow(), upsert=False
|
||||
)
|
||||
if not res:
|
||||
raise errors.bad_request.InvalidQueueOrTaskNotQueued(
|
||||
task=task_id, **query
|
||||
)
|
||||
|
||||
return res
|
||||
|
||||
def get_next_task(self, company_id: str, queue_id: str) -> Optional[Entry]:
|
||||
"""
|
||||
Atomically pop and return the first task from the queue (or None)
|
||||
:raise errors.bad_request.InvalidQueueId: if the queue does not exist
|
||||
"""
|
||||
with translate_errors_context():
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
queue = Queue.objects(**query).modify(pop__entries=-1, upsert=False)
|
||||
if not queue:
|
||||
raise errors.bad_request.InvalidQueueId(**query)
|
||||
|
||||
self.metrics.log_queue_metrics_to_es(company_id, queues=[queue])
|
||||
|
||||
if not queue.entries:
|
||||
return
|
||||
|
||||
try:
|
||||
Queue.objects(**query).update(last_update=datetime.utcnow())
|
||||
except Exception:
|
||||
log.exception("Error while updating Queue.last_update")
|
||||
|
||||
return queue.entries[0]
|
||||
|
||||
def remove_task(self, company_id: str, queue_id: str, task_id: str) -> int:
|
||||
"""
|
||||
Removes the task from the queue and returns the number of removed items
|
||||
:raise errors.bad_request.InvalidQueueOrTaskNotQueued: if the task is not found in the queue
|
||||
"""
|
||||
with translate_errors_context():
|
||||
queue = self.get_queue_with_task(
|
||||
company_id=company_id, queue_id=queue_id, task_id=task_id
|
||||
)
|
||||
self.metrics.log_queue_metrics_to_es(company_id, queues=[queue])
|
||||
|
||||
entries_to_remove = [e for e in queue.entries if e.task == task_id]
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
res = Queue.objects(entries__task=task_id, **query).update_one(
|
||||
pull_all__entries=entries_to_remove, last_update=datetime.utcnow()
|
||||
)
|
||||
|
||||
return len(entries_to_remove) if res else 0
|
||||
|
||||
def reposition_task(
|
||||
self,
|
||||
company_id: str,
|
||||
queue_id: str,
|
||||
task_id: str,
|
||||
pos_func: Callable[[int], int],
|
||||
) -> int:
|
||||
"""
|
||||
Moves the task in the queue to the position calculated by pos_func
|
||||
Returns the updated task position in the queue
|
||||
"""
|
||||
with translate_errors_context():
|
||||
queue = self.get_queue_with_task(
|
||||
company_id=company_id, queue_id=queue_id, task_id=task_id
|
||||
)
|
||||
|
||||
position = next(i for i, e in enumerate(queue.entries) if e.task == task_id)
|
||||
new_position = pos_func(position)
|
||||
|
||||
if new_position != position:
|
||||
entry = queue.entries[position]
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
updated = Queue.objects(entries__task=task_id, **query).update_one(
|
||||
pull__entries=entry, last_update=datetime.utcnow()
|
||||
)
|
||||
if not updated:
|
||||
raise errors.bad_request.RemovedDuringReposition(
|
||||
task=task_id, **query
|
||||
)
|
||||
inst = {"$push": {"entries": {"$each": [entry.to_proper_dict()]}}}
|
||||
if new_position >= 0:
|
||||
inst["$push"]["entries"]["$position"] = new_position
|
||||
res = Queue.objects(entries__task__ne=task_id, **query).update_one(
|
||||
__raw__=inst
|
||||
)
|
||||
if not res:
|
||||
raise errors.bad_request.FailedAddingDuringReposition(
|
||||
task=task_id, **query
|
||||
)
|
||||
|
||||
return new_position
|
||||
265
server/bll/queue/queue_metrics.py
Normal file
265
server/bll/queue/queue_metrics.py
Normal file
@@ -0,0 +1,265 @@
|
||||
from collections import defaultdict
|
||||
from datetime import datetime
|
||||
from typing import Sequence
|
||||
|
||||
import elasticsearch.helpers
|
||||
from elasticsearch import Elasticsearch
|
||||
|
||||
import es_factory
|
||||
from apierrors.errors import bad_request
|
||||
from bll.query import Builder as QueryBuilder
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.queue import Queue, Entry
|
||||
from timing_context import TimingContext
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class QueueMetrics:
|
||||
class EsKeys:
|
||||
DOC_TYPE = "metrics"
|
||||
WAITING_TIME_FIELD = "average_waiting_time"
|
||||
QUEUE_LENGTH_FIELD = "queue_length"
|
||||
TIMESTAMP_FIELD = "timestamp"
|
||||
QUEUE_FIELD = "queue"
|
||||
|
||||
def __init__(self, es: Elasticsearch):
|
||||
self.es = es
|
||||
|
||||
@staticmethod
|
||||
def _queue_metrics_prefix_for_company(company_id: str) -> str:
|
||||
"""Returns the es index prefix for the company"""
|
||||
return f"queue_metrics_{company_id}_"
|
||||
|
||||
@staticmethod
|
||||
def _get_es_index_suffix():
|
||||
"""Get the index name suffix for storing current month data"""
|
||||
return datetime.utcnow().strftime("%Y-%m")
|
||||
|
||||
@staticmethod
|
||||
def _calc_avg_waiting_time(entries: Sequence[Entry]) -> float:
|
||||
"""
|
||||
Calculate avg waiting time for the given tasks.
|
||||
Return 0 if the list is empty
|
||||
"""
|
||||
if not entries:
|
||||
return 0
|
||||
|
||||
now = datetime.utcnow()
|
||||
total_waiting_in_secs = sum((now - e.added).total_seconds() for e in entries)
|
||||
return total_waiting_in_secs / len(entries)
|
||||
|
||||
def log_queue_metrics_to_es(self, company_id: str, queues: Sequence[Queue]) -> bool:
|
||||
"""
|
||||
Calculate and write queue statistics (avg waiting time and queue length) to Elastic
|
||||
:return: True if the write to es was successful, false otherwise
|
||||
"""
|
||||
es_index = (
|
||||
self._queue_metrics_prefix_for_company(company_id)
|
||||
+ self._get_es_index_suffix()
|
||||
)
|
||||
|
||||
timestamp = es_factory.get_timestamp_millis()
|
||||
|
||||
def make_doc(queue: Queue) -> dict:
|
||||
entries = [e for e in queue.entries if e.added]
|
||||
return dict(
|
||||
_index=es_index,
|
||||
_type=self.EsKeys.DOC_TYPE,
|
||||
_source={
|
||||
self.EsKeys.TIMESTAMP_FIELD: timestamp,
|
||||
self.EsKeys.QUEUE_FIELD: queue.id,
|
||||
self.EsKeys.WAITING_TIME_FIELD: self._calc_avg_waiting_time(
|
||||
entries
|
||||
),
|
||||
self.EsKeys.QUEUE_LENGTH_FIELD: len(entries),
|
||||
},
|
||||
)
|
||||
|
||||
actions = list(map(make_doc, queues))
|
||||
|
||||
es_res = elasticsearch.helpers.bulk(self.es, actions)
|
||||
added, errors = es_res[:2]
|
||||
return (added == len(actions)) and not errors
|
||||
|
||||
def _log_current_metrics(self, company_id: str, queue_ids=Sequence[str]):
|
||||
query = dict(company=company_id)
|
||||
if queue_ids:
|
||||
query["id__in"] = list(queue_ids)
|
||||
queues = Queue.objects(**query)
|
||||
self.log_queue_metrics_to_es(company_id, queues=list(queues))
|
||||
|
||||
def _search_company_metrics(self, company_id: str, es_req: dict) -> dict:
|
||||
return self.es.search(
|
||||
index=f"{self._queue_metrics_prefix_for_company(company_id)}*",
|
||||
doc_type=self.EsKeys.DOC_TYPE,
|
||||
body=es_req,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def _get_dates_agg(cls, interval) -> dict:
|
||||
"""
|
||||
Aggregation for building date histogram with internal grouping per queue.
|
||||
We are grouping by queue inside date histogram and not vice versa so that
|
||||
it will be easy to average between queue metrics inside each date bucket.
|
||||
Ignore empty buckets.
|
||||
"""
|
||||
return {
|
||||
"dates": {
|
||||
"date_histogram": {
|
||||
"field": cls.EsKeys.TIMESTAMP_FIELD,
|
||||
"interval": f"{interval}s",
|
||||
"min_doc_count": 1,
|
||||
},
|
||||
"aggs": {
|
||||
"queues": {
|
||||
"terms": {"field": cls.EsKeys.QUEUE_FIELD},
|
||||
"aggs": cls._get_top_waiting_agg(),
|
||||
}
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _get_top_waiting_agg(cls) -> dict:
|
||||
"""
|
||||
Aggregation for getting max waiting time and the corresponding queue length
|
||||
inside each date->queue bucket
|
||||
"""
|
||||
return {
|
||||
"top_avg_waiting": {
|
||||
"top_hits": {
|
||||
"sort": [
|
||||
{cls.EsKeys.WAITING_TIME_FIELD: {"order": "desc"}},
|
||||
{cls.EsKeys.QUEUE_LENGTH_FIELD: {"order": "desc"}},
|
||||
],
|
||||
"_source": {
|
||||
"includes": [
|
||||
cls.EsKeys.WAITING_TIME_FIELD,
|
||||
cls.EsKeys.QUEUE_LENGTH_FIELD,
|
||||
]
|
||||
},
|
||||
"size": 1,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
def get_queue_metrics(
|
||||
self,
|
||||
company_id: str,
|
||||
from_date: float,
|
||||
to_date: float,
|
||||
interval: int,
|
||||
queue_ids: Sequence[str],
|
||||
) -> dict:
|
||||
"""
|
||||
Get the company queue metrics in the specified time range.
|
||||
Returned as date histograms of average values per queue and metric type.
|
||||
The from_date is extended by 'metrics_before_from_date' seconds from
|
||||
queues.conf due to possibly small amount of points. The default extension is 3600s
|
||||
In case no queue ids are specified the avg across all the
|
||||
company queues is calculated for each metric
|
||||
"""
|
||||
# self._log_current_metrics(company, queue_ids=queue_ids)
|
||||
|
||||
if from_date >= to_date:
|
||||
raise bad_request.FieldsValueError("from_date must be less than to_date")
|
||||
|
||||
seconds_before = config.get("services.queues.metrics_before_from_date", 3600)
|
||||
must_terms = [QueryBuilder.dates_range(from_date - seconds_before, to_date)]
|
||||
if queue_ids:
|
||||
must_terms.append(QueryBuilder.terms("queue", queue_ids))
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": {"bool": {"must": must_terms}},
|
||||
"aggs": self._get_dates_agg(interval),
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "get_queue_metrics"):
|
||||
res = self._search_company_metrics(company_id, es_req)
|
||||
|
||||
if "aggregations" not in res:
|
||||
return {}
|
||||
|
||||
date_metrics = [
|
||||
dict(
|
||||
timestamp=d["key"],
|
||||
queue_metrics=self._extract_queue_metrics(d["queues"]["buckets"]),
|
||||
)
|
||||
for d in res["aggregations"]["dates"]["buckets"]
|
||||
if d["doc_count"] > 0
|
||||
]
|
||||
if queue_ids:
|
||||
return self._datetime_histogram_per_queue(date_metrics)
|
||||
|
||||
return self._average_datetime_histogram(date_metrics)
|
||||
|
||||
@classmethod
|
||||
def _datetime_histogram_per_queue(cls, date_metrics: Sequence[dict]) -> dict:
|
||||
"""
|
||||
Build datetime histogram per queue from datetime histogram where every
|
||||
bucket contains all the queues metrics
|
||||
"""
|
||||
queues_data = defaultdict(list)
|
||||
for date_data in date_metrics:
|
||||
timestamp = date_data["timestamp"]
|
||||
for queue, metrics in date_data["queue_metrics"].items():
|
||||
queues_data[queue].append({"date": timestamp, **metrics})
|
||||
|
||||
return queues_data
|
||||
|
||||
@classmethod
|
||||
def _average_datetime_histogram(cls, date_metrics: Sequence[dict]) -> dict:
|
||||
"""
|
||||
Calculate weighted averages and total count for each bucket of date_metrics histogram.
|
||||
If for any queue the data is missing then take it from the previous bucket
|
||||
The result is returned as a dictionary with one key 'total'
|
||||
"""
|
||||
queues_total = []
|
||||
last_values = {}
|
||||
for date_data in date_metrics:
|
||||
date_metrics = date_data["queue_metrics"]
|
||||
queue_metrics = {
|
||||
**date_metrics,
|
||||
**{k: v for k, v in last_values.items() if k not in date_metrics},
|
||||
}
|
||||
|
||||
total_length = sum(m["queue_length"] for m in queue_metrics.values())
|
||||
if total_length:
|
||||
total_average = sum(
|
||||
m["avg_waiting_time"] * m["queue_length"] / total_length
|
||||
for m in queue_metrics.values()
|
||||
)
|
||||
else:
|
||||
total_average = 0
|
||||
|
||||
queues_total.append(
|
||||
dict(
|
||||
date=date_data["timestamp"],
|
||||
avg_waiting_time=total_average,
|
||||
queue_length=total_length,
|
||||
)
|
||||
)
|
||||
|
||||
for k, v in date_metrics.items():
|
||||
last_values[k] = v
|
||||
|
||||
return dict(total=queues_total)
|
||||
|
||||
@classmethod
|
||||
def _extract_queue_metrics(cls, queue_buckets: Sequence[dict]) -> dict:
|
||||
"""
|
||||
Extract ES data for single date and queue bucket
|
||||
"""
|
||||
queue_metrics = dict()
|
||||
for queue_data in queue_buckets:
|
||||
if not queue_data["doc_count"]:
|
||||
continue
|
||||
res = queue_data["top_avg_waiting"]["hits"]["hits"][0]["_source"]
|
||||
queue_metrics[queue_data["key"]] = {
|
||||
"queue_length": res[cls.EsKeys.QUEUE_LENGTH_FIELD],
|
||||
"avg_waiting_time": res[cls.EsKeys.WAITING_TIME_FIELD],
|
||||
}
|
||||
return queue_metrics
|
||||
44
server/bll/redis_cache_manager.py
Normal file
44
server/bll/redis_cache_manager.py
Normal file
@@ -0,0 +1,44 @@
|
||||
from typing import Optional, TypeVar, Generic, Type
|
||||
|
||||
from redis import StrictRedis
|
||||
|
||||
from timing_context import TimingContext
|
||||
|
||||
T = TypeVar("T")
|
||||
|
||||
|
||||
class RedisCacheManager(Generic[T]):
|
||||
"""
|
||||
Class for store/retreive of state objects from redis
|
||||
|
||||
self.state_class - class of the state
|
||||
self.redis - instance of redis
|
||||
self.expiration_interval - expiration interval in seconds
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self, state_class: Type[T], redis: StrictRedis, expiration_interval: int
|
||||
):
|
||||
self.state_class = state_class
|
||||
self.redis = redis
|
||||
self.expiration_interval = expiration_interval
|
||||
|
||||
def set_state(self, state: T) -> None:
|
||||
redis_key = self._get_redis_key(state.id)
|
||||
with TimingContext("redis", "cache_set_state"):
|
||||
self.redis.set(redis_key, state.to_json())
|
||||
self.redis.expire(redis_key, self.expiration_interval)
|
||||
|
||||
def get_state(self, state_id) -> Optional[T]:
|
||||
redis_key = self._get_redis_key(state_id)
|
||||
with TimingContext("redis", "cache_get_state"):
|
||||
response = self.redis.get(redis_key)
|
||||
if response:
|
||||
return self.state_class.from_json(response)
|
||||
|
||||
def delete_state(self, state_id) -> None:
|
||||
with TimingContext("redis", "cache_delete_state"):
|
||||
self.redis.delete(self._get_redis_key(state_id))
|
||||
|
||||
def _get_redis_key(self, state_id):
|
||||
return f"{self.state_class}/{state_id}"
|
||||
90
server/bll/statistics/resource_monitor.py
Normal file
90
server/bll/statistics/resource_monitor.py
Normal file
@@ -0,0 +1,90 @@
|
||||
from datetime import datetime
|
||||
import operator
|
||||
from threading import Thread, Lock
|
||||
from time import sleep
|
||||
|
||||
import attr
|
||||
import psutil
|
||||
|
||||
from utilities.threads_manager import ThreadsManager
|
||||
|
||||
|
||||
class ResourceMonitor(Thread):
|
||||
@attr.s(auto_attribs=True)
|
||||
class Sample:
|
||||
cpu_usage: float = 0.0
|
||||
mem_used_gb: float = 0
|
||||
mem_free_gb: float = 0
|
||||
|
||||
@classmethod
|
||||
def _apply(cls, op, *samples):
|
||||
return cls(
|
||||
**{
|
||||
field: op(*(getattr(sample, field) for sample in samples))
|
||||
for field in attr.fields_dict(cls)
|
||||
}
|
||||
)
|
||||
|
||||
def min(self, sample):
|
||||
return self._apply(min, self, sample)
|
||||
|
||||
def max(self, sample):
|
||||
return self._apply(max, self, sample)
|
||||
|
||||
def avg(self, sample, count):
|
||||
res = self._apply(lambda x: x * count, self)
|
||||
res = self._apply(operator.add, res, sample)
|
||||
res = self._apply(lambda x: x / (count + 1), res)
|
||||
return res
|
||||
|
||||
def __init__(self, sample_interval_sec=5):
|
||||
super(ResourceMonitor, self).__init__(daemon=True)
|
||||
self.sample_interval_sec = sample_interval_sec
|
||||
self._lock = Lock()
|
||||
self._clear()
|
||||
|
||||
def _clear(self):
|
||||
sample = self._get_sample()
|
||||
self._avg = sample
|
||||
self._min = sample
|
||||
self._max = sample
|
||||
self._clear_time = datetime.utcnow()
|
||||
self._count = 1
|
||||
|
||||
@classmethod
|
||||
def _get_sample(cls) -> Sample:
|
||||
return cls.Sample(
|
||||
cpu_usage=psutil.cpu_percent(),
|
||||
mem_used_gb=psutil.virtual_memory().used / (1024 ** 3),
|
||||
mem_free_gb=psutil.virtual_memory().free / (1024 ** 3),
|
||||
)
|
||||
|
||||
def run(self):
|
||||
while not ThreadsManager.terminating:
|
||||
sleep(self.sample_interval_sec)
|
||||
|
||||
sample = self._get_sample()
|
||||
|
||||
with self._lock:
|
||||
self._min = self._min.min(sample)
|
||||
self._max = self._max.max(sample)
|
||||
self._avg = self._avg.avg(sample, self._count)
|
||||
self._count += 1
|
||||
|
||||
def get_stats(self) -> dict:
|
||||
""" Returns current resource statistics and clears internal resource statistics """
|
||||
with self._lock:
|
||||
min_ = attr.asdict(self._min)
|
||||
max_ = attr.asdict(self._max)
|
||||
avg = attr.asdict(self._avg)
|
||||
interval = datetime.utcnow() - self._clear_time
|
||||
self._clear()
|
||||
|
||||
return {
|
||||
"interval_sec": interval.total_seconds(),
|
||||
"num_cores": psutil.cpu_count(),
|
||||
**{
|
||||
k: {"min": v, "max": max_[k], "avg": avg[k]}
|
||||
for k, v in min_.items()
|
||||
}
|
||||
}
|
||||
305
server/bll/statistics/stats_reporter.py
Normal file
305
server/bll/statistics/stats_reporter.py
Normal file
@@ -0,0 +1,305 @@
|
||||
import logging
|
||||
import queue
|
||||
import random
|
||||
import time
|
||||
from datetime import timedelta, datetime
|
||||
from time import sleep
|
||||
from typing import Sequence, Optional
|
||||
|
||||
import dpath
|
||||
import requests
|
||||
from requests.adapters import HTTPAdapter
|
||||
from requests.packages.urllib3.util.retry import Retry
|
||||
|
||||
from bll.query import Builder as QueryBuilder
|
||||
from bll.util import get_server_uuid
|
||||
from bll.workers import WorkerStats, WorkerBLL
|
||||
from config import config
|
||||
from config.info import get_deployment_type
|
||||
from database.model import Company, User
|
||||
from database.model.queue import Queue
|
||||
from database.model.task.task import Task
|
||||
from utilities import safe_get
|
||||
from utilities.json import dumps
|
||||
from utilities.threads_manager import ThreadsManager
|
||||
from version import __version__ as current_version
|
||||
from .resource_monitor import ResourceMonitor
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
worker_bll = WorkerBLL()
|
||||
|
||||
|
||||
class StatisticsReporter:
|
||||
threads = ThreadsManager("Statistics", resource_monitor=ResourceMonitor)
|
||||
send_queue = queue.Queue()
|
||||
supported = config.get("apiserver.statistics.supported", True)
|
||||
|
||||
@classmethod
|
||||
def start(cls):
|
||||
cls.start_sender()
|
||||
cls.start_reporter()
|
||||
|
||||
@classmethod
|
||||
@threads.register("reporter", daemon=True)
|
||||
def start_reporter(cls):
|
||||
"""
|
||||
Periodically send statistics reports for companies who have opted in.
|
||||
Note: in trains we usually have only a single company
|
||||
"""
|
||||
if not cls.supported:
|
||||
return
|
||||
|
||||
report_interval = timedelta(
|
||||
hours=config.get("apiserver.statistics.report_interval_hours", 24)
|
||||
)
|
||||
sleep(report_interval.total_seconds())
|
||||
while not ThreadsManager.terminating:
|
||||
try:
|
||||
for company in Company.objects(
|
||||
defaults__stats_option__enabled=True
|
||||
).only("id"):
|
||||
stats = cls.get_statistics(company.id)
|
||||
cls.send_queue.put(stats)
|
||||
|
||||
except Exception as ex:
|
||||
log.exception(f"Failed collecting stats: {str(ex)}")
|
||||
|
||||
sleep(report_interval.total_seconds())
|
||||
|
||||
@classmethod
|
||||
@threads.register("sender", daemon=True)
|
||||
def start_sender(cls):
|
||||
if not cls.supported:
|
||||
return
|
||||
|
||||
url = config.get("apiserver.statistics.url")
|
||||
|
||||
retries = config.get("apiserver.statistics.max_retries", 5)
|
||||
max_backoff = config.get("apiserver.statistics.max_backoff_sec", 5)
|
||||
session = requests.Session()
|
||||
adapter = HTTPAdapter(max_retries=Retry(retries))
|
||||
session.mount("http://", adapter)
|
||||
session.mount("https://", adapter)
|
||||
session.headers["Content-type"] = "application/json"
|
||||
|
||||
WarningFilter.attach()
|
||||
|
||||
while not ThreadsManager.terminating:
|
||||
try:
|
||||
report = cls.send_queue.get()
|
||||
|
||||
# Set a random backoff factor each time we send a report
|
||||
adapter.max_retries.backoff_factor = random.random() * max_backoff
|
||||
|
||||
session.post(url, data=dumps(report))
|
||||
|
||||
except Exception as ex:
|
||||
pass
|
||||
|
||||
@classmethod
|
||||
def get_statistics(cls, company_id: str) -> dict:
|
||||
"""
|
||||
Returns a statistics report per company
|
||||
"""
|
||||
return {
|
||||
"time": datetime.utcnow(),
|
||||
"company_id": company_id,
|
||||
"server": {
|
||||
"version": current_version,
|
||||
"deployment": get_deployment_type(),
|
||||
"uuid": get_server_uuid(),
|
||||
"queues": {"count": Queue.objects(company=company_id).count()},
|
||||
"users": {"count": User.objects(company=company_id).count()},
|
||||
"resources": cls.threads.resource_monitor.get_stats(),
|
||||
"experiments": next(
|
||||
iter(cls._get_experiments_stats(company_id).values()), {}
|
||||
),
|
||||
},
|
||||
"agents": cls._get_agents_statistics(company_id),
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _get_agents_statistics(cls, company_id: str) -> Sequence[dict]:
|
||||
result = cls._get_resource_stats_per_agent(company_id, key="resources")
|
||||
dpath.merge(
|
||||
result, cls._get_experiments_stats_per_agent(company_id, key="experiments")
|
||||
)
|
||||
return [{"uuid": agent_id, **data} for agent_id, data in result.items()]
|
||||
|
||||
@classmethod
|
||||
def _get_resource_stats_per_agent(cls, company_id: str, key: str) -> dict:
|
||||
agent_resource_threshold_sec = timedelta(
|
||||
hours=config.get("apiserver.statistics.report_interval_hours", 24)
|
||||
).total_seconds()
|
||||
to_timestamp = int(time.time())
|
||||
from_timestamp = to_timestamp - int(agent_resource_threshold_sec)
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": QueryBuilder.dates_range(from_timestamp, to_timestamp),
|
||||
"aggs": {
|
||||
"workers": {
|
||||
"terms": {"field": "worker"},
|
||||
"aggs": {
|
||||
"categories": {
|
||||
"terms": {"field": "category"},
|
||||
"aggs": {"count": {"cardinality": {"field": "variant"}}},
|
||||
},
|
||||
"metrics": {
|
||||
"terms": {"field": "metric"},
|
||||
"aggs": {
|
||||
"min": {"min": {"field": "value"}},
|
||||
"max": {"max": {"field": "value"}},
|
||||
"avg": {"avg": {"field": "value"}},
|
||||
},
|
||||
},
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
res = cls._run_worker_stats_query(company_id, es_req)
|
||||
|
||||
def _get_cardinality_fields(categories: Sequence[dict]) -> dict:
|
||||
names = {"cpu": "num_cores"}
|
||||
return {
|
||||
names[c["key"]]: safe_get(c, "count/value")
|
||||
for c in categories
|
||||
if c["key"] in names
|
||||
}
|
||||
|
||||
def _get_metric_fields(metrics: Sequence[dict]) -> dict:
|
||||
names = {
|
||||
"cpu_usage": "cpu_usage",
|
||||
"memory_used": "mem_used_gb",
|
||||
"memory_free": "mem_free_gb",
|
||||
}
|
||||
return {
|
||||
names[m["key"]]: {
|
||||
"min": safe_get(m, "min/value"),
|
||||
"max": safe_get(m, "max/value"),
|
||||
"avg": safe_get(m, "avg/value"),
|
||||
}
|
||||
for m in metrics
|
||||
if m["key"] in names
|
||||
}
|
||||
|
||||
buckets = safe_get(res, "aggregations/workers/buckets", default=[])
|
||||
return {
|
||||
b["key"]: {
|
||||
key: {
|
||||
"interval_sec": agent_resource_threshold_sec,
|
||||
**_get_cardinality_fields(safe_get(b, "categories/buckets", [])),
|
||||
**_get_metric_fields(safe_get(b, "metrics/buckets", [])),
|
||||
}
|
||||
}
|
||||
for b in buckets
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _get_experiments_stats_per_agent(cls, company_id: str, key: str) -> dict:
|
||||
agent_relevant_threshold = timedelta(
|
||||
days=config.get("apiserver.statistics.agent_relevant_threshold_days", 30)
|
||||
)
|
||||
to_timestamp = int(time.time())
|
||||
from_timestamp = to_timestamp - int(agent_relevant_threshold.total_seconds())
|
||||
workers = cls._get_active_workers(company_id, from_timestamp, to_timestamp)
|
||||
if not workers:
|
||||
return {}
|
||||
|
||||
stats = cls._get_experiments_stats(company_id, list(workers.keys()))
|
||||
return {
|
||||
worker_id: {key: {**workers[worker_id], **stat}}
|
||||
for worker_id, stat in stats.items()
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _get_active_workers(
|
||||
cls, company_id, from_timestamp: int, to_timestamp: int
|
||||
) -> dict:
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": QueryBuilder.dates_range(from_timestamp, to_timestamp),
|
||||
"aggs": {
|
||||
"workers": {
|
||||
"terms": {"field": "worker"},
|
||||
"aggs": {"last_activity_time": {"max": {"field": "timestamp"}}},
|
||||
}
|
||||
},
|
||||
}
|
||||
res = cls._run_worker_stats_query(company_id, es_req)
|
||||
buckets = safe_get(res, "aggregations/workers/buckets", default=[])
|
||||
return {
|
||||
b["key"]: {"last_activity_time": b["last_activity_time"]["value"]}
|
||||
for b in buckets
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _run_worker_stats_query(cls, company_id, es_req) -> dict:
|
||||
return worker_bll.es_client.search(
|
||||
index=f"{WorkerStats.worker_stats_prefix_for_company(company_id)}*",
|
||||
doc_type="stat",
|
||||
body=es_req,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def _get_experiments_stats(
|
||||
cls, company_id, workers: Optional[Sequence] = None
|
||||
) -> dict:
|
||||
pipeline = [
|
||||
{
|
||||
"$match": {
|
||||
"company": company_id,
|
||||
"started": {"$exists": True, "$ne": None},
|
||||
"last_update": {"$exists": True, "$ne": None},
|
||||
"status": {"$nin": ["created", "queued"]},
|
||||
**({"last_worker": {"$in": workers}} if workers else {}),
|
||||
}
|
||||
},
|
||||
{
|
||||
"$group": {
|
||||
"_id": "$last_worker" if workers else None,
|
||||
"count": {"$sum": 1},
|
||||
"avg_run_time_sec": {
|
||||
"$avg": {
|
||||
"$divide": [
|
||||
{"$subtract": ["$last_update", "$started"]},
|
||||
1000,
|
||||
]
|
||||
}
|
||||
},
|
||||
"avg_iterations": {"$avg": "$last_iteration"},
|
||||
}
|
||||
},
|
||||
{
|
||||
"$project": {
|
||||
"count": 1,
|
||||
"avg_run_time_sec": {"$trunc": "$avg_run_time_sec"},
|
||||
"avg_iterations": {"$trunc": "$avg_iterations"},
|
||||
}
|
||||
},
|
||||
]
|
||||
return {
|
||||
group["_id"]: {k: v for k, v in group.items() if k != "_id"}
|
||||
for group in Task.aggregate(*pipeline)
|
||||
}
|
||||
|
||||
|
||||
class WarningFilter(logging.Filter):
|
||||
@classmethod
|
||||
def attach(cls):
|
||||
from urllib3.connectionpool import (
|
||||
ConnectionPool,
|
||||
) # required to make sure the logger is created
|
||||
|
||||
assert ConnectionPool # make sure import is not optimized out
|
||||
|
||||
logging.getLogger("urllib3.connectionpool").addFilter(cls())
|
||||
|
||||
def filter(self, record):
|
||||
if (
|
||||
record.levelno == logging.WARNING
|
||||
and len(record.args) > 2
|
||||
and record.args[2] == "/stats"
|
||||
):
|
||||
return False
|
||||
return True
|
||||
@@ -4,4 +4,5 @@ from .utils import (
|
||||
update_project_time,
|
||||
validate_status_change,
|
||||
split_by,
|
||||
ParameterKeyEscaper,
|
||||
)
|
||||
|
||||
@@ -1,29 +1,46 @@
|
||||
import re
|
||||
from collections import OrderedDict
|
||||
from datetime import datetime
|
||||
from typing import Mapping, Collection
|
||||
from urllib.parse import urlparse
|
||||
from datetime import datetime, timedelta
|
||||
from operator import attrgetter
|
||||
from random import random
|
||||
from time import sleep
|
||||
from typing import Collection, Sequence, Tuple, Any, Optional, List, Dict
|
||||
|
||||
import pymongo.results
|
||||
import six
|
||||
from mongoengine import Q
|
||||
from six import string_types
|
||||
|
||||
import database.utils as dbutils
|
||||
import es_factory
|
||||
from apierrors import errors
|
||||
from apimodels.tasks import Artifact as ApiArtifact
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.fields import OutputDestinationField
|
||||
from database.model.model import Model
|
||||
from database.model.project import Project
|
||||
from database.model.task.metrics import MetricEvent
|
||||
from database.model.task.metrics import EventStats, MetricEventStats
|
||||
from database.model.task.output import Output
|
||||
from database.model.task.task import Task, TaskStatus, TaskStatusMessage, TaskTags
|
||||
from database.model.task.task import (
|
||||
Task,
|
||||
TaskStatus,
|
||||
TaskStatusMessage,
|
||||
TaskSystemTags,
|
||||
ArtifactModes,
|
||||
Artifact,
|
||||
)
|
||||
from database.utils import get_company_or_none_constraint, id as create_id
|
||||
from service_repo import APICall
|
||||
from timing_context import TimingContext
|
||||
from .utils import ChangeStatusRequest, validate_status_change
|
||||
from utilities.dicts import deep_merge
|
||||
from utilities.threads_manager import ThreadsManager
|
||||
from .utils import ChangeStatusRequest, validate_status_change, ParameterKeyEscaper
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class TaskBLL(object):
|
||||
threads = ThreadsManager("TaskBLL")
|
||||
|
||||
def __init__(self, events_es=None):
|
||||
self.events_es = (
|
||||
events_es if events_es is not None else es_factory.connect("events")
|
||||
@@ -138,7 +155,62 @@ class TaskBLL(object):
|
||||
return model
|
||||
|
||||
@classmethod
|
||||
def validate(cls, task: Task, force=False):
|
||||
def clone_task(
|
||||
cls,
|
||||
company_id,
|
||||
user_id,
|
||||
task_id,
|
||||
name: Optional[str] = None,
|
||||
comment: Optional[str] = None,
|
||||
parent: Optional[str] = None,
|
||||
project: Optional[str] = None,
|
||||
tags: Optional[Sequence[str]] = None,
|
||||
system_tags: Optional[Sequence[str]] = None,
|
||||
execution_overrides: Optional[dict] = None,
|
||||
) -> Task:
|
||||
task = cls.get_by_id(company_id=company_id, task_id=task_id)
|
||||
execution_dict = task.execution.to_proper_dict() if task.execution else {}
|
||||
if execution_overrides:
|
||||
parameters = execution_overrides.get("parameters")
|
||||
if parameters is not None:
|
||||
execution_overrides["parameters"] = {
|
||||
ParameterKeyEscaper.escape(k): v for k, v in parameters.items()
|
||||
}
|
||||
execution_dict = deep_merge(execution_dict, execution_overrides)
|
||||
artifacts = execution_dict.get("artifacts")
|
||||
if artifacts:
|
||||
execution_dict["artifacts"] = [
|
||||
a for a in artifacts if a.get("mode") != ArtifactModes.output
|
||||
]
|
||||
now = datetime.utcnow()
|
||||
|
||||
with translate_errors_context():
|
||||
new_task = Task(
|
||||
id=create_id(),
|
||||
user=user_id,
|
||||
company=company_id,
|
||||
created=now,
|
||||
last_update=now,
|
||||
name=name or task.name,
|
||||
comment=comment or task.comment,
|
||||
parent=parent or task.parent,
|
||||
project=project or task.project,
|
||||
tags=tags or task.tags,
|
||||
system_tags=system_tags or [],
|
||||
type=task.type,
|
||||
script=task.script,
|
||||
output=Output(destination=task.output.destination)
|
||||
if task.output
|
||||
else None,
|
||||
execution=execution_dict,
|
||||
)
|
||||
cls.validate(new_task)
|
||||
new_task.save()
|
||||
|
||||
return new_task
|
||||
|
||||
@classmethod
|
||||
def validate(cls, task: Task):
|
||||
assert isinstance(task, Task)
|
||||
|
||||
if task.parent and not Task.get(
|
||||
@@ -146,34 +218,12 @@ class TaskBLL(object):
|
||||
):
|
||||
raise errors.bad_request.InvalidTaskId("invalid parent", parent=task.parent)
|
||||
|
||||
if task.project:
|
||||
Project.get_for_writing(company=task.company, id=task.project)
|
||||
if task.project and not Project.get_for_writing(
|
||||
company=task.company, id=task.project
|
||||
):
|
||||
raise errors.bad_request.InvalidProjectId(id=task.project)
|
||||
|
||||
model = cls.validate_execution_model(task)
|
||||
if model and not force and not model.ready:
|
||||
raise errors.bad_request.ModelNotReady(
|
||||
"can't be used in a task", model=model.id
|
||||
)
|
||||
|
||||
if task.execution:
|
||||
if task.execution.parameters:
|
||||
cls._validate_execution_parameters(task.execution.parameters)
|
||||
|
||||
if task.output and task.output.destination:
|
||||
parsed_url = urlparse(task.output.destination)
|
||||
if parsed_url.scheme not in OutputDestinationField.schemes:
|
||||
raise errors.bad_request.FieldsValueError(
|
||||
"unsupported scheme for output destination",
|
||||
dest=task.output.destination,
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def _validate_execution_parameters(parameters):
|
||||
invalid_keys = [k for k in parameters if re.search(r"\s", k)]
|
||||
if invalid_keys:
|
||||
raise errors.bad_request.ValidationError(
|
||||
"execution.parameters keys contain whitespace", keys=invalid_keys
|
||||
)
|
||||
cls.validate_execution_model(task)
|
||||
|
||||
@staticmethod
|
||||
def get_unique_metric_variants(company_id, project_ids=None):
|
||||
@@ -213,7 +263,7 @@ class TaskBLL(object):
|
||||
]
|
||||
|
||||
with translate_errors_context():
|
||||
result = Task.objects.aggregate(*pipeline)
|
||||
result = Task.aggregate(*pipeline)
|
||||
return [r["metrics"][0] for r in result]
|
||||
|
||||
@staticmethod
|
||||
@@ -231,7 +281,8 @@ class TaskBLL(object):
|
||||
last_update: datetime = None,
|
||||
last_iteration: int = None,
|
||||
last_iteration_max: int = None,
|
||||
last_metrics: Mapping[str, Mapping[str, MetricEvent]] = None,
|
||||
last_scalar_values: Sequence[Tuple[Tuple[str, ...], Any]] = None,
|
||||
last_events: Dict[str, Dict[str, dict]] = None,
|
||||
**extra_updates,
|
||||
):
|
||||
"""
|
||||
@@ -243,7 +294,8 @@ class TaskBLL(object):
|
||||
task's last iteration value.
|
||||
:param last_iteration_max: Last reported iteration. Use this to conditionally set a value only
|
||||
if the current task's last iteration value is smaller than the provided value.
|
||||
:param last_metrics: Last reported metrics summary.
|
||||
:param last_scalar_values: Last reported metrics summary for scalar events (value, metric, variant).
|
||||
:param last_events: Last reported metrics summary (value, metric, event type).
|
||||
:param extra_updates: Extra task updates to include in this update call.
|
||||
:return:
|
||||
"""
|
||||
@@ -254,10 +306,34 @@ class TaskBLL(object):
|
||||
elif last_iteration_max is not None:
|
||||
extra_updates.update(max__last_iteration=last_iteration_max)
|
||||
|
||||
if last_metrics is not None:
|
||||
extra_updates.update(last_metrics=last_metrics)
|
||||
if last_scalar_values is not None:
|
||||
|
||||
return Task.objects(id=task_id, company=company_id).update(
|
||||
def op_path(op, *path):
|
||||
return "__".join((op, "last_metrics") + path)
|
||||
|
||||
for path, value in last_scalar_values:
|
||||
extra_updates[op_path("set", *path)] = value
|
||||
if path[-1] == "value":
|
||||
extra_updates[op_path("min", *path[:-1], "min_value")] = value
|
||||
extra_updates[op_path("max", *path[:-1], "max_value")] = value
|
||||
|
||||
if last_events is not None:
|
||||
|
||||
def events_per_type(metric_data: Dict[str, dict]) -> Dict[str, EventStats]:
|
||||
return {
|
||||
event_type: EventStats(last_update=event["timestamp"])
|
||||
for event_type, event in metric_data.items()
|
||||
}
|
||||
|
||||
metric_stats = {
|
||||
dbutils.hash_field_name(metric_key): MetricEventStats(
|
||||
metric=metric_key, event_stats_by_type=events_per_type(metric_data),
|
||||
)
|
||||
for metric_key, metric_data in last_events.items()
|
||||
}
|
||||
extra_updates["metric_stats"] = metric_stats
|
||||
|
||||
Task.objects(id=task_id, company=company_id).update(
|
||||
upsert=False, last_update=last_update, **extra_updates
|
||||
)
|
||||
|
||||
@@ -370,14 +446,30 @@ class TaskBLL(object):
|
||||
:return: updated task fields
|
||||
"""
|
||||
|
||||
task = TaskBLL.get_task_with_access(
|
||||
task = cls.get_task_with_access(
|
||||
task_id,
|
||||
company_id=company_id,
|
||||
only=("status", "project", "tags", "last_update"),
|
||||
only=(
|
||||
"status",
|
||||
"project",
|
||||
"tags",
|
||||
"system_tags",
|
||||
"last_worker",
|
||||
"last_update",
|
||||
),
|
||||
requires_write_access=True,
|
||||
)
|
||||
|
||||
if TaskTags.development in task.tags:
|
||||
def is_run_by_worker(t: Task) -> bool:
|
||||
"""Checks if there is an active worker running the task"""
|
||||
update_timeout = config.get("apiserver.workers.task_update_timeout", 600)
|
||||
return (
|
||||
t.last_worker
|
||||
and t.last_update
|
||||
and (datetime.utcnow() - t.last_update).total_seconds() < update_timeout
|
||||
)
|
||||
|
||||
if TaskSystemTags.development in task.system_tags or not is_run_by_worker(task):
|
||||
new_status = TaskStatus.stopped
|
||||
status_message = f"Stopped by {user_name}"
|
||||
else:
|
||||
@@ -391,3 +483,201 @@ class TaskBLL(object):
|
||||
status_message=status_message,
|
||||
force=force,
|
||||
).execute()
|
||||
|
||||
@classmethod
|
||||
def add_or_update_artifacts(
|
||||
cls, task_id: str, company_id: str, artifacts: List[ApiArtifact]
|
||||
) -> Tuple[List[str], List[str]]:
|
||||
key = attrgetter("key", "mode")
|
||||
|
||||
if not artifacts:
|
||||
return [], []
|
||||
|
||||
with translate_errors_context(), TimingContext("mongo", "update_artifacts"):
|
||||
artifacts: List[Artifact] = [
|
||||
Artifact(**artifact.to_struct()) for artifact in artifacts
|
||||
]
|
||||
|
||||
attempts = int(config.get("services.tasks.artifacts.update_attempts", 10))
|
||||
|
||||
for retry in range(attempts):
|
||||
task = cls.get_task_with_access(
|
||||
task_id, company_id=company_id, requires_write_access=True
|
||||
)
|
||||
|
||||
current = list(map(key, task.execution.artifacts))
|
||||
updated = [a for a in artifacts if key(a) in current]
|
||||
added = [a for a in artifacts if a not in updated]
|
||||
|
||||
filter = {"_id": task_id, "company": company_id}
|
||||
update = {}
|
||||
array_filters = None
|
||||
if current:
|
||||
filter["execution.artifacts"] = {
|
||||
"$size": len(current),
|
||||
"$all": [
|
||||
*(
|
||||
{"$elemMatch": {"key": key, "mode": mode}}
|
||||
for key, mode in current
|
||||
)
|
||||
],
|
||||
}
|
||||
else:
|
||||
filter["$or"] = [
|
||||
{"execution.artifacts": {"$exists": False}},
|
||||
{"execution.artifacts": {"$size": 0}},
|
||||
]
|
||||
|
||||
if added:
|
||||
update["$push"] = {
|
||||
"execution.artifacts": {"$each": [a.to_mongo() for a in added]}
|
||||
}
|
||||
if updated:
|
||||
update["$set"] = {
|
||||
f"execution.artifacts.$[artifact{index}]": artifact.to_mongo()
|
||||
for index, artifact in enumerate(updated)
|
||||
}
|
||||
array_filters = [
|
||||
{
|
||||
f"artifact{index}.key": artifact.key,
|
||||
f"artifact{index}.mode": artifact.mode,
|
||||
}
|
||||
for index, artifact in enumerate(updated)
|
||||
]
|
||||
|
||||
if not update:
|
||||
return [], []
|
||||
|
||||
result: pymongo.results.UpdateResult = Task._get_collection().update_one(
|
||||
filter=filter,
|
||||
update=update,
|
||||
array_filters=array_filters,
|
||||
upsert=False,
|
||||
)
|
||||
|
||||
if result.matched_count >= 1:
|
||||
break
|
||||
|
||||
wait_msec = random() * int(
|
||||
config.get("services.tasks.artifacts.update_retry_msec", 500)
|
||||
)
|
||||
|
||||
log.warning(
|
||||
f"Failed to update artifacts for task {task_id} (updated by another party),"
|
||||
f" retrying {retry+1}/{attempts} in {wait_msec}ms"
|
||||
)
|
||||
|
||||
sleep(wait_msec / 1000)
|
||||
else:
|
||||
raise errors.server_error.UpdateFailed(
|
||||
"task artifacts updated by another party"
|
||||
)
|
||||
|
||||
return [a.key for a in added], [a.key for a in updated]
|
||||
|
||||
@classmethod
|
||||
@threads.register("non_responsive_tasks_watchdog", daemon=True)
|
||||
def start_non_responsive_tasks_watchdog(cls):
|
||||
log = config.logger("non_responsive_tasks_watchdog")
|
||||
relevant_status = (TaskStatus.in_progress,)
|
||||
threshold = timedelta(
|
||||
seconds=config.get(
|
||||
"services.tasks.non_responsive_tasks_watchdog.threshold_sec", 7200
|
||||
)
|
||||
)
|
||||
watch_interval = config.get(
|
||||
"services.tasks.non_responsive_tasks_watchdog.watch_interval_sec", 900
|
||||
)
|
||||
sleep(watch_interval)
|
||||
while not ThreadsManager.terminating:
|
||||
try:
|
||||
|
||||
ref_time = datetime.utcnow() - threshold
|
||||
|
||||
log.info(
|
||||
f"Starting cleanup cycle for running tasks last updated before {ref_time}"
|
||||
)
|
||||
|
||||
tasks = list(
|
||||
Task.objects(
|
||||
status__in=relevant_status, last_update__lt=ref_time
|
||||
).only("id", "name", "status", "project", "last_update")
|
||||
)
|
||||
|
||||
if tasks:
|
||||
|
||||
log.info(f"Stopping {len(tasks)} non-responsive tasks")
|
||||
|
||||
for task in tasks:
|
||||
log.info(
|
||||
f"Stopping {task.id} ({task.name}), last updated at {task.last_update}"
|
||||
)
|
||||
ChangeStatusRequest(
|
||||
task=task,
|
||||
new_status=TaskStatus.stopped,
|
||||
status_reason="Forced stop (non-responsive)",
|
||||
status_message="Forced stop (non-responsive)",
|
||||
force=True,
|
||||
).execute()
|
||||
|
||||
log.info(f"Done")
|
||||
|
||||
except Exception as ex:
|
||||
log.exception(f"Failed stopping tasks: {str(ex)}")
|
||||
|
||||
sleep(watch_interval)
|
||||
|
||||
@staticmethod
|
||||
def get_aggregated_project_execution_parameters(
|
||||
company_id,
|
||||
project_ids: Sequence[str] = None,
|
||||
page: int = 0,
|
||||
page_size: int = 500,
|
||||
) -> Tuple[int, int, Sequence[str]]:
|
||||
|
||||
page = max(0, page)
|
||||
page_size = max(1, page_size)
|
||||
|
||||
pipeline = [
|
||||
{
|
||||
"$match": {
|
||||
"company": company_id,
|
||||
"execution.parameters": {"$exists": True, "$gt": {}},
|
||||
**({"project": {"$in": project_ids}} if project_ids else {}),
|
||||
}
|
||||
},
|
||||
{"$project": {"parameters": {"$objectToArray": "$execution.parameters"}}},
|
||||
{"$unwind": "$parameters"},
|
||||
{"$group": {"_id": "$parameters.k"}},
|
||||
{"$sort": {"_id": 1}},
|
||||
{
|
||||
"$group": {
|
||||
"_id": 1,
|
||||
"total": {"$sum": 1},
|
||||
"results": {"$push": "$$ROOT"},
|
||||
}
|
||||
},
|
||||
{
|
||||
"$project": {
|
||||
"total": 1,
|
||||
"results": {"$slice": ["$results", page * page_size, page_size]},
|
||||
}
|
||||
},
|
||||
]
|
||||
|
||||
with translate_errors_context():
|
||||
result = next(Task.aggregate(*pipeline), None)
|
||||
|
||||
total = 0
|
||||
remaining = 0
|
||||
results = []
|
||||
|
||||
if result:
|
||||
total = int(result.get("total", -1))
|
||||
results = [
|
||||
ParameterKeyEscaper.unescape(r["_id"])
|
||||
for r in result.get("results", [])
|
||||
]
|
||||
remaining = max(0, total - (len(results) + page * page_size))
|
||||
|
||||
return total, remaining, results
|
||||
|
||||
@@ -3,11 +3,12 @@ from typing import TypeVar, Callable, Tuple, Sequence
|
||||
|
||||
import attr
|
||||
import six
|
||||
from boltons.dictutils import OneToOne
|
||||
|
||||
from apierrors import errors
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.project import Project
|
||||
from database.model.task.task import Task, TaskStatus
|
||||
from database.model.task.task import Task, TaskStatus, TaskSystemTags
|
||||
from database.utils import get_options
|
||||
from timing_context import TimingContext
|
||||
from utilities.attrs import typed_attrs
|
||||
@@ -25,9 +26,10 @@ class ChangeStatusRequest(object):
|
||||
status_message = attr.ib(type=six.string_types, default="")
|
||||
force = attr.ib(type=bool, default=False)
|
||||
allow_same_state_transition = attr.ib(type=bool, default=True)
|
||||
current_status_override = attr.ib(default=None)
|
||||
|
||||
def execute(self, **kwargs):
|
||||
current_status = self.task.status
|
||||
current_status = self.current_status_override or self.task.status
|
||||
project_id = self.task.project
|
||||
|
||||
# Verify new status is allowed from current status (will throw exception if not valid)
|
||||
@@ -44,6 +46,9 @@ class ChangeStatusRequest(object):
|
||||
last_update=now,
|
||||
)
|
||||
|
||||
if self.new_status == TaskStatus.queued:
|
||||
fields["pull__system_tags"] = TaskSystemTags.development
|
||||
|
||||
def safe_mongoengine_key(key):
|
||||
return f"__{key}" if key in control else key
|
||||
|
||||
@@ -66,6 +71,10 @@ class ChangeStatusRequest(object):
|
||||
)
|
||||
|
||||
update_project_time(project_id)
|
||||
|
||||
# make sure that _raw_ queries are not returned back to the client
|
||||
fields.pop("__raw__", None)
|
||||
|
||||
return dict(updated=updated, fields=fields)
|
||||
|
||||
def validate_transition(self, current_status):
|
||||
@@ -95,8 +104,14 @@ def validate_status_change(current_status, new_status):
|
||||
|
||||
|
||||
state_machine = {
|
||||
TaskStatus.created: {TaskStatus.in_progress},
|
||||
TaskStatus.in_progress: {TaskStatus.stopped, TaskStatus.failed, TaskStatus.created},
|
||||
TaskStatus.created: {TaskStatus.queued, TaskStatus.in_progress},
|
||||
TaskStatus.queued: {TaskStatus.created, TaskStatus.in_progress},
|
||||
TaskStatus.in_progress: {
|
||||
TaskStatus.stopped,
|
||||
TaskStatus.failed,
|
||||
TaskStatus.created,
|
||||
TaskStatus.completed,
|
||||
},
|
||||
TaskStatus.stopped: {
|
||||
TaskStatus.closed,
|
||||
TaskStatus.created,
|
||||
@@ -104,6 +119,7 @@ state_machine = {
|
||||
TaskStatus.in_progress,
|
||||
TaskStatus.published,
|
||||
TaskStatus.publishing,
|
||||
TaskStatus.completed,
|
||||
},
|
||||
TaskStatus.closed: {
|
||||
TaskStatus.created,
|
||||
@@ -115,6 +131,11 @@ state_machine = {
|
||||
TaskStatus.failed: {TaskStatus.created, TaskStatus.stopped, TaskStatus.published},
|
||||
TaskStatus.publishing: {TaskStatus.published},
|
||||
TaskStatus.published: set(),
|
||||
TaskStatus.completed: {
|
||||
TaskStatus.published,
|
||||
TaskStatus.in_progress,
|
||||
TaskStatus.created,
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
@@ -124,9 +145,11 @@ def get_possible_status_changes(current_status):
|
||||
:return possible states from current state
|
||||
"""
|
||||
possible = state_machine.get(current_status)
|
||||
assert (
|
||||
possible is not None
|
||||
), f"Current status {current_status} not supported by state machine"
|
||||
if possible is None:
|
||||
raise errors.server_error.InternalError(
|
||||
f"Current status {current_status} not supported by state machine"
|
||||
)
|
||||
|
||||
return possible
|
||||
|
||||
|
||||
@@ -149,3 +172,26 @@ def split_by(
|
||||
[item for cond, item in applied if cond],
|
||||
[item for cond, item in applied if not cond],
|
||||
)
|
||||
|
||||
|
||||
class ParameterKeyEscaper:
|
||||
_mapping = OneToOne({".": "%2E", "$": "%24"})
|
||||
|
||||
@classmethod
|
||||
def escape(cls, value):
|
||||
""" Quote a parameter key """
|
||||
value = value.strip().replace("%", "%%")
|
||||
for c, r in cls._mapping.items():
|
||||
value = value.replace(c, r)
|
||||
return value
|
||||
|
||||
@classmethod
|
||||
def _unescape(cls, value):
|
||||
for c, r in cls._mapping.inv.items():
|
||||
value = value.replace(c, r)
|
||||
return value
|
||||
|
||||
@classmethod
|
||||
def unescape(cls, value):
|
||||
""" Unquote a quoted parameter key """
|
||||
return "%".join(map(cls._unescape, value.split("%%")))
|
||||
|
||||
73
server/bll/util.py
Normal file
73
server/bll/util.py
Normal file
@@ -0,0 +1,73 @@
|
||||
import functools
|
||||
from operator import itemgetter
|
||||
from typing import Sequence, Optional, Callable, Tuple, Dict, Any, Set
|
||||
|
||||
from database.model import AttributedDocument
|
||||
from database.model.settings import Settings
|
||||
|
||||
|
||||
def extract_properties_to_lists(
|
||||
key_names: Sequence[str],
|
||||
data: Sequence[dict],
|
||||
extract_func: Optional[Callable[[dict], Tuple]] = None,
|
||||
) -> dict:
|
||||
"""
|
||||
Given a list of dictionaries and names of dictionary keys
|
||||
builds a dictionary with the requested keys and values lists
|
||||
:param key_names: names of the keys in the resulting dictionary
|
||||
:param data: sequence of dictionaries to extract values from
|
||||
:param extract_func: the optional callable that extracts properties
|
||||
from a dictionary and put them in a tuple in the order corresponding to
|
||||
key_names. If not specified then properties are extracted according to key_names
|
||||
"""
|
||||
value_sequences = zip(*map(extract_func or itemgetter(*key_names), data))
|
||||
return dict(zip(key_names, map(list, value_sequences)))
|
||||
|
||||
|
||||
class SetFieldsResolver:
|
||||
"""
|
||||
The class receives set fields dictionary
|
||||
and for the set fields that require 'min' or 'max'
|
||||
operation replace them with a simple set in case the
|
||||
DB document does not have these fields set
|
||||
"""
|
||||
|
||||
SET_MODIFIERS = ("min", "max")
|
||||
|
||||
def __init__(self, set_fields: Dict[str, Any]):
|
||||
self.orig_fields = set_fields
|
||||
self.fields = {
|
||||
f: fname
|
||||
for f, modifier, dunder, fname in (
|
||||
(f,) + f.partition("__") for f in set_fields.keys()
|
||||
)
|
||||
if dunder and modifier in self.SET_MODIFIERS
|
||||
}
|
||||
|
||||
def _get_updated_name(self, doc: AttributedDocument, name: str) -> str:
|
||||
if name in self.fields and doc.get_field_value(self.fields[name]) is None:
|
||||
return self.fields[name]
|
||||
return name
|
||||
|
||||
def get_fields(self, doc: AttributedDocument):
|
||||
"""
|
||||
For the given document return the set fields instructions
|
||||
with min/max operations replaced with a single set in case
|
||||
the document does not have the field set
|
||||
"""
|
||||
return {
|
||||
self._get_updated_name(doc, name): value
|
||||
for name, value in self.orig_fields.items()
|
||||
}
|
||||
|
||||
def get_names(self) -> Set[str]:
|
||||
"""
|
||||
Returns the names of the fields that had min/max modifiers
|
||||
in the format suitable for projection (dot separated)
|
||||
"""
|
||||
return set(name.replace("__", ".") for name in self.fields.values())
|
||||
|
||||
|
||||
@functools.lru_cache()
|
||||
def get_server_uuid() -> Optional[str]:
|
||||
return Settings.get_by_key("server.uuid")
|
||||
422
server/bll/workers/__init__.py
Normal file
422
server/bll/workers/__init__.py
Normal file
@@ -0,0 +1,422 @@
|
||||
import itertools
|
||||
from datetime import datetime, timedelta
|
||||
from typing import Sequence, Set, Optional
|
||||
|
||||
import attr
|
||||
import elasticsearch.helpers
|
||||
|
||||
import es_factory
|
||||
from apierrors import APIError
|
||||
from apierrors.errors import bad_request, server_error
|
||||
from apimodels.workers import (
|
||||
DEFAULT_TIMEOUT,
|
||||
IdNameEntry,
|
||||
WorkerEntry,
|
||||
StatusReportRequest,
|
||||
WorkerResponseEntry,
|
||||
QueueEntry,
|
||||
MachineStats,
|
||||
)
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.auth import User
|
||||
from database.model.company import Company
|
||||
from database.model.queue import Queue
|
||||
from database.model.task.task import Task
|
||||
from redis_manager import redman
|
||||
from timing_context import TimingContext
|
||||
from tools import safe_get
|
||||
from .stats import WorkerStats
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class WorkerBLL:
|
||||
def __init__(self, es=None, redis=None):
|
||||
self.es_client = es if es is not None else es_factory.connect("workers")
|
||||
self.redis = redis if redis is not None else redman.connection("workers")
|
||||
self._stats = WorkerStats(self.es_client)
|
||||
|
||||
@property
|
||||
def stats(self) -> WorkerStats:
|
||||
return self._stats
|
||||
|
||||
def register_worker(
|
||||
self,
|
||||
company_id: str,
|
||||
user_id: str,
|
||||
worker: str,
|
||||
ip: str = "",
|
||||
queues: Sequence[str] = None,
|
||||
timeout: int = 0,
|
||||
) -> WorkerEntry:
|
||||
"""
|
||||
Register a worker
|
||||
:param company_id: worker's company ID
|
||||
:param user_id: user ID under which this worker is running
|
||||
:param worker: worker ID
|
||||
:param ip: the real ip of the worker
|
||||
:param queues: queues reported as being monitored by the worker
|
||||
:param timeout: registration expiration timeout in seconds
|
||||
:raise bad_request.InvalidUserId: in case the calling user or company does not exist
|
||||
:return: worker entry instance
|
||||
"""
|
||||
key = WorkerBLL._get_worker_key(company_id, user_id, worker)
|
||||
|
||||
timeout = timeout or DEFAULT_TIMEOUT
|
||||
queues = queues or []
|
||||
|
||||
with translate_errors_context():
|
||||
query = dict(id=user_id, company=company_id)
|
||||
user = User.objects(**query).only("id", "name").first()
|
||||
if not user:
|
||||
raise bad_request.InvalidUserId(**query)
|
||||
company = Company.objects(id=company_id).only("id", "name").first()
|
||||
if not company:
|
||||
raise server_error.InternalError("invalid company", company=company_id)
|
||||
|
||||
queue_objs = Queue.objects(company=company_id, id__in=queues).only("id")
|
||||
if len(queue_objs) < len(queues):
|
||||
invalid = set(queues).difference(q.id for q in queue_objs)
|
||||
raise bad_request.InvalidQueueId(ids=invalid)
|
||||
|
||||
now = datetime.utcnow()
|
||||
entry = WorkerEntry(
|
||||
key=key,
|
||||
id=worker,
|
||||
user=user.to_proper_dict(),
|
||||
company=company.to_proper_dict(),
|
||||
ip=ip,
|
||||
queues=queues,
|
||||
register_time=now,
|
||||
register_timeout=timeout,
|
||||
last_activity_time=now,
|
||||
)
|
||||
|
||||
self.redis.setex(key, timedelta(seconds=timeout), entry.to_json())
|
||||
|
||||
return entry
|
||||
|
||||
def unregister_worker(self, company_id: str, user_id: str, worker: str) -> None:
|
||||
"""
|
||||
Unregister a worker
|
||||
:param company_id: worker's company ID
|
||||
:param user_id: user ID under which this worker is running
|
||||
:param worker: worker ID
|
||||
:raise bad_request.WorkerNotRegistered: the worker was not previously registered
|
||||
"""
|
||||
with TimingContext("redis", "workers_unregister"):
|
||||
res = self.redis.delete(
|
||||
company_id, self._get_worker_key(company_id, user_id, worker)
|
||||
)
|
||||
if not res:
|
||||
raise bad_request.WorkerNotRegistered(worker=worker)
|
||||
|
||||
def status_report(
|
||||
self, company_id: str, user_id: str, ip: str, report: StatusReportRequest
|
||||
) -> None:
|
||||
"""
|
||||
Write worker status report
|
||||
:param company_id: worker's company ID
|
||||
:param user_id: user_id ID under which this worker is running
|
||||
:raise bad_request.InvalidTaskId: the reported task was not found
|
||||
:return: worker entry instance
|
||||
"""
|
||||
entry = self._get_worker(company_id, user_id, report.worker)
|
||||
|
||||
try:
|
||||
entry.ip = ip
|
||||
now = datetime.utcnow()
|
||||
entry.last_activity_time = now
|
||||
|
||||
if report.machine_stats:
|
||||
self._log_stats_to_es(
|
||||
company_id=company_id,
|
||||
company_name=entry.company.name,
|
||||
worker=report.worker,
|
||||
timestamp=report.timestamp,
|
||||
task=report.task,
|
||||
machine_stats=report.machine_stats,
|
||||
)
|
||||
|
||||
entry.queue = report.queue
|
||||
|
||||
if report.queues:
|
||||
entry.queues = report.queues
|
||||
|
||||
if not report.task:
|
||||
entry.task = None
|
||||
else:
|
||||
with translate_errors_context():
|
||||
query = dict(id=report.task, company=company_id)
|
||||
update = dict(
|
||||
last_worker=report.worker,
|
||||
last_worker_report=now,
|
||||
last_update=now,
|
||||
)
|
||||
# modify(new=True, ...) returns the modified object
|
||||
task = Task.objects(**query).modify(new=True, **update)
|
||||
if not task:
|
||||
raise bad_request.InvalidTaskId(**query)
|
||||
entry.task = IdNameEntry(id=task.id, name=task.name)
|
||||
|
||||
entry.last_report_time = now
|
||||
except APIError:
|
||||
raise
|
||||
except Exception as e:
|
||||
msg = "Failed processing worker status report"
|
||||
log.exception(msg)
|
||||
raise server_error.DataError(msg, err=e.args[0])
|
||||
finally:
|
||||
self._save_worker(entry)
|
||||
|
||||
def get_all(
|
||||
self, company_id: str, last_seen: Optional[int] = None
|
||||
) -> Sequence[WorkerEntry]:
|
||||
"""
|
||||
Get all the company workers that were active during the last_seen period
|
||||
:param company_id: worker's company id
|
||||
:param last_seen: period in seconds to check. Min value is 1 second
|
||||
:return:
|
||||
"""
|
||||
try:
|
||||
workers = self._get(company_id)
|
||||
except Exception as e:
|
||||
raise server_error.DataError("failed loading worker entries", err=e.args[0])
|
||||
|
||||
if last_seen:
|
||||
ref_time = datetime.utcnow() - timedelta(seconds=max(1, last_seen))
|
||||
workers = [
|
||||
w
|
||||
for w in workers
|
||||
if w.last_activity_time.replace(tzinfo=None) >= ref_time
|
||||
]
|
||||
|
||||
return workers
|
||||
|
||||
def get_all_with_projection(
|
||||
self, company_id: str, last_seen: int
|
||||
) -> Sequence[WorkerResponseEntry]:
|
||||
|
||||
helpers = list(
|
||||
map(
|
||||
WorkerConversionHelper.from_worker_entry,
|
||||
self.get_all(company_id=company_id, last_seen=last_seen),
|
||||
)
|
||||
)
|
||||
|
||||
task_ids = set(filter(None, (helper.task_id for helper in helpers)))
|
||||
all_queues = set(
|
||||
itertools.chain.from_iterable(helper.queue_ids for helper in helpers)
|
||||
)
|
||||
|
||||
queues_info = {}
|
||||
if all_queues:
|
||||
projection = [
|
||||
{"$match": {"_id": {"$in": list(all_queues)}}},
|
||||
{
|
||||
"$project": {
|
||||
"name": 1,
|
||||
"next_entry": {"$arrayElemAt": ["$entries", 0]},
|
||||
"num_entries": {"$size": "$entries"},
|
||||
}
|
||||
},
|
||||
]
|
||||
queues_info = {
|
||||
res["_id"]: res for res in Queue.objects.aggregate(*projection)
|
||||
}
|
||||
task_ids = task_ids.union(
|
||||
filter(
|
||||
None,
|
||||
(
|
||||
safe_get(info, "next_entry/task")
|
||||
for info in queues_info.values()
|
||||
),
|
||||
)
|
||||
)
|
||||
|
||||
tasks_info = {}
|
||||
if task_ids:
|
||||
tasks_info = {
|
||||
task.id: task
|
||||
for task in Task.objects(id__in=task_ids).only(
|
||||
"name", "started", "last_iteration"
|
||||
)
|
||||
}
|
||||
|
||||
def update_queue_entries(*entries):
|
||||
for entry in entries:
|
||||
if not entry:
|
||||
continue
|
||||
info = queues_info.get(entry.id, None)
|
||||
if not info:
|
||||
continue
|
||||
entry.name = info.get("name", None)
|
||||
entry.num_tasks = info.get("num_entries", 0)
|
||||
task_id = safe_get(info, "next_entry/task")
|
||||
if task_id:
|
||||
task = tasks_info.get(task_id, None)
|
||||
entry.next_task = IdNameEntry(
|
||||
id=task_id, name=task.name if task else None
|
||||
)
|
||||
|
||||
for helper in helpers:
|
||||
worker = helper.worker
|
||||
if helper.task_id:
|
||||
task = tasks_info.get(helper.task_id, None)
|
||||
if task:
|
||||
worker.task.running_time = (
|
||||
int((datetime.utcnow() - task.started).total_seconds() * 1000)
|
||||
if task.started
|
||||
else 0
|
||||
)
|
||||
worker.task.last_iteration = task.last_iteration
|
||||
|
||||
update_queue_entries(worker.queue)
|
||||
if worker.queues:
|
||||
update_queue_entries(*worker.queues)
|
||||
|
||||
return [helper.worker for helper in helpers]
|
||||
|
||||
@staticmethod
|
||||
def _get_worker_key(company: str, user: str, worker_id: str) -> str:
|
||||
"""Build redis key from company, user and worker_id"""
|
||||
return f"worker_{company}_{user}_{worker_id}"
|
||||
|
||||
def _get_worker(self, company_id: str, user_id: str, worker: str) -> WorkerEntry:
|
||||
"""
|
||||
Get a worker entry for the provided worker ID. The entry is loaded from Redis
|
||||
if it exists (i.e. worker has already been registered), otherwise the worker
|
||||
is registered and its entry stored into Redis).
|
||||
:param company_id: worker's company ID
|
||||
:param user_id: user ID under which this worker is running
|
||||
:param worker: worker ID
|
||||
:raise bad_request.InvalidWorkerId: in case the worker id was not found
|
||||
:return: worker entry instance
|
||||
"""
|
||||
key = self._get_worker_key(company_id, user_id, worker)
|
||||
|
||||
with TimingContext("redis", "get_worker"):
|
||||
data = self.redis.get(key)
|
||||
|
||||
if data:
|
||||
try:
|
||||
entry = WorkerEntry.from_json(data)
|
||||
if not entry.key:
|
||||
entry.key = key
|
||||
self._save_worker(entry)
|
||||
return entry
|
||||
except Exception as e:
|
||||
msg = "Failed parsing worker entry"
|
||||
log.exception(msg)
|
||||
raise server_error.DataError(msg, err=e.args[0])
|
||||
|
||||
# Failed loading worker from Redis
|
||||
if config.get("apiserver.workers.auto_register", False):
|
||||
try:
|
||||
return self.register_worker(company_id, user_id, worker)
|
||||
except Exception:
|
||||
log.error(
|
||||
"Failed auto registration of {} for company {}".format(
|
||||
worker, company_id
|
||||
)
|
||||
)
|
||||
|
||||
raise bad_request.InvalidWorkerId(worker=worker)
|
||||
|
||||
def _save_worker(self, entry: WorkerEntry) -> None:
|
||||
"""Save worker entry in Redis"""
|
||||
try:
|
||||
self.redis.setex(
|
||||
entry.key, timedelta(seconds=entry.register_timeout), entry.to_json()
|
||||
)
|
||||
except Exception:
|
||||
msg = "Failed saving worker entry"
|
||||
log.exception(msg)
|
||||
|
||||
def _get(
|
||||
self, company: str, user: str = "*", worker_id: str = "*"
|
||||
) -> Sequence[WorkerEntry]:
|
||||
"""Get worker entries matching the company and user, worker patterns"""
|
||||
match = self._get_worker_key(company, user, worker_id)
|
||||
with TimingContext("redis", "workers_get_all"):
|
||||
res = self.redis.scan_iter(match)
|
||||
return [WorkerEntry.from_json(self.redis.get(r)) for r in res]
|
||||
|
||||
@staticmethod
|
||||
def _get_es_index_suffix():
|
||||
"""Get the index name suffix for storing current month data"""
|
||||
return datetime.utcnow().strftime("%Y-%m")
|
||||
|
||||
def _log_stats_to_es(
|
||||
self,
|
||||
company_id: str,
|
||||
company_name: str,
|
||||
worker: str,
|
||||
timestamp: int,
|
||||
task: str,
|
||||
machine_stats: MachineStats,
|
||||
) -> bool:
|
||||
"""
|
||||
Actually writing the worker statistics to Elastic
|
||||
:return: True if successful, False otherwise
|
||||
"""
|
||||
es_index = (
|
||||
f"{self._stats.worker_stats_prefix_for_company(company_id)}"
|
||||
f"{self._get_es_index_suffix()}"
|
||||
)
|
||||
|
||||
def make_doc(category, metric, variant, value) -> dict:
|
||||
return dict(
|
||||
_index=es_index,
|
||||
_type="stat",
|
||||
_source=dict(
|
||||
timestamp=timestamp,
|
||||
worker=worker,
|
||||
company=company_name,
|
||||
task=task,
|
||||
category=category,
|
||||
metric=metric,
|
||||
variant=variant,
|
||||
value=float(value),
|
||||
),
|
||||
)
|
||||
|
||||
actions = []
|
||||
for field, value in machine_stats.to_struct().items():
|
||||
if not value:
|
||||
continue
|
||||
category = field.partition("_")[0]
|
||||
metric = field
|
||||
if not isinstance(value, (list, tuple)):
|
||||
actions.append(make_doc(category, metric, "total", value))
|
||||
else:
|
||||
actions.extend(
|
||||
make_doc(category, metric, str(i), val)
|
||||
for i, val in enumerate(value)
|
||||
)
|
||||
|
||||
es_res = elasticsearch.helpers.bulk(self.es_client, actions)
|
||||
added, errors = es_res[:2]
|
||||
return (added == len(actions)) and not errors
|
||||
|
||||
|
||||
@attr.s(auto_attribs=True)
|
||||
class WorkerConversionHelper:
|
||||
worker: WorkerResponseEntry
|
||||
task_id: str
|
||||
queue_ids: Set[str]
|
||||
|
||||
@classmethod
|
||||
def from_worker_entry(cls, worker: WorkerEntry):
|
||||
data = worker.to_struct()
|
||||
queue = data.pop("queue", None) or None
|
||||
queue_ids = set(data.pop("queues", []))
|
||||
queues = [QueueEntry(id=id) for id in queue_ids]
|
||||
if queue:
|
||||
queue = next((q for q in queues if q.id == queue), None)
|
||||
return cls(
|
||||
worker=WorkerResponseEntry(queues=queues, queue=queue, **data),
|
||||
task_id=worker.task.id if worker.task else None,
|
||||
queue_ids=queue_ids,
|
||||
)
|
||||
244
server/bll/workers/stats.py
Normal file
244
server/bll/workers/stats.py
Normal file
@@ -0,0 +1,244 @@
|
||||
from operator import attrgetter
|
||||
from typing import Optional, Sequence
|
||||
|
||||
from boltons.iterutils import bucketize
|
||||
|
||||
from apierrors.errors import bad_request
|
||||
from apimodels.workers import AggregationType, GetStatsRequest, StatItem
|
||||
from bll.query import Builder as QueryBuilder
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from timing_context import TimingContext
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class WorkerStats:
|
||||
def __init__(self, es):
|
||||
self.es = es
|
||||
|
||||
@staticmethod
|
||||
def worker_stats_prefix_for_company(company_id: str) -> str:
|
||||
"""Returns the es index prefix for the company"""
|
||||
return f"worker_stats_{company_id}_"
|
||||
|
||||
def _search_company_stats(self, company_id: str, es_req: dict) -> dict:
|
||||
return self.es.search(
|
||||
index=f"{self.worker_stats_prefix_for_company(company_id)}*",
|
||||
doc_type="stat",
|
||||
body=es_req,
|
||||
)
|
||||
|
||||
def get_worker_stats_keys(
|
||||
self, company_id: str, worker_ids: Optional[Sequence[str]]
|
||||
) -> dict:
|
||||
"""
|
||||
Get dictionary of metric types grouped by categories
|
||||
:param company_id: company id
|
||||
:param worker_ids: optional list of workers to get metric types from.
|
||||
If not specified them metrics for all the company workers returned
|
||||
:return:
|
||||
"""
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"categories": {
|
||||
"terms": {"field": "category"},
|
||||
"aggs": {"metrics": {"terms": {"field": "metric"}}},
|
||||
}
|
||||
},
|
||||
}
|
||||
if worker_ids:
|
||||
es_req["query"] = QueryBuilder.terms("worker", worker_ids)
|
||||
|
||||
res = self._search_company_stats(company_id, es_req)
|
||||
|
||||
if not res["hits"]["total"]:
|
||||
raise bad_request.WorkerStatsNotFound(
|
||||
f"No statistic metrics found for the company {company_id} and workers {worker_ids}"
|
||||
)
|
||||
|
||||
return {
|
||||
category["key"]: [
|
||||
metric["key"] for metric in category["metrics"]["buckets"]
|
||||
]
|
||||
for category in res["aggregations"]["categories"]["buckets"]
|
||||
}
|
||||
|
||||
def get_worker_stats(self, company_id: str, request: GetStatsRequest) -> dict:
|
||||
"""
|
||||
Get statistics for company workers metrics in the specified time range
|
||||
Returned as date histograms for different aggregation types
|
||||
grouped by worker, metric type (and optionally metric variant)
|
||||
Buckets with no metrics are not returned
|
||||
Note: all the statistics are retrieved as one ES query
|
||||
"""
|
||||
if request.from_date >= request.to_date:
|
||||
raise bad_request.FieldsValueError("from_date must be less than to_date")
|
||||
|
||||
def get_dates_agg() -> dict:
|
||||
es_to_agg_types = (
|
||||
("avg", AggregationType.avg.value),
|
||||
("min", AggregationType.min.value),
|
||||
("max", AggregationType.max.value),
|
||||
)
|
||||
|
||||
return {
|
||||
"dates": {
|
||||
"date_histogram": {
|
||||
"field": "timestamp",
|
||||
"interval": f"{request.interval}s",
|
||||
"min_doc_count": 1,
|
||||
},
|
||||
"aggs": {
|
||||
agg_type: {es_agg: {"field": "value"}}
|
||||
for es_agg, agg_type in es_to_agg_types
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
def get_variants_agg() -> dict:
|
||||
return {
|
||||
"variants": {"terms": {"field": "variant"}, "aggs": get_dates_agg()}
|
||||
}
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"workers": {
|
||||
"terms": {"field": "worker"},
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {"field": "metric"},
|
||||
"aggs": get_variants_agg()
|
||||
if request.split_by_variant
|
||||
else get_dates_agg(),
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
query_terms = [
|
||||
QueryBuilder.dates_range(request.from_date, request.to_date),
|
||||
QueryBuilder.terms("metric", {item.key for item in request.items}),
|
||||
]
|
||||
if request.worker_ids:
|
||||
query_terms.append(QueryBuilder.terms("worker", request.worker_ids))
|
||||
es_req["query"] = {"bool": {"must": query_terms}}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "get_worker_stats"):
|
||||
data = self._search_company_stats(company_id, es_req)
|
||||
|
||||
return self._extract_results(data, request.items, request.split_by_variant)
|
||||
|
||||
@staticmethod
|
||||
def _extract_results(
|
||||
data: dict, request_items: Sequence[StatItem], split_by_variant: bool
|
||||
) -> dict:
|
||||
"""
|
||||
Clean results returned from elastic search (remove "aggregations", "buckets" etc.),
|
||||
leave only aggregation types requested by the user and return a clean dictionary
|
||||
and return a "clean" dictionary of
|
||||
:param data: aggregation data retrieved from ES
|
||||
:param request_items: aggs types requested by the user
|
||||
:param split_by_variant: if False then aggregate by metric type, otherwise metric type + variant
|
||||
"""
|
||||
if "aggregations" not in data:
|
||||
return {}
|
||||
|
||||
items_by_key = bucketize(request_items, key=attrgetter("key"))
|
||||
aggs_per_metric = {
|
||||
key: [item.aggregation for item in items]
|
||||
for key, items in items_by_key.items()
|
||||
}
|
||||
|
||||
def extract_date_stats(date: dict, metric_key) -> dict:
|
||||
return {
|
||||
"date": date["key"],
|
||||
"count": date["doc_count"],
|
||||
**{agg: date[agg]["value"] for agg in aggs_per_metric[metric_key]},
|
||||
}
|
||||
|
||||
def extract_metric_results(
|
||||
metric_or_variant: dict, metric_key: str
|
||||
) -> Sequence[dict]:
|
||||
return [
|
||||
extract_date_stats(date, metric_key)
|
||||
for date in metric_or_variant["dates"]["buckets"]
|
||||
if date["doc_count"]
|
||||
]
|
||||
|
||||
def extract_variant_results(metric: dict) -> dict:
|
||||
metric_key = metric["key"]
|
||||
return {
|
||||
variant["key"]: extract_metric_results(variant, metric_key)
|
||||
for variant in metric["variants"]["buckets"]
|
||||
}
|
||||
|
||||
def extract_worker_results(worker: dict) -> dict:
|
||||
return {
|
||||
metric["key"]: extract_variant_results(metric)
|
||||
if split_by_variant
|
||||
else extract_metric_results(metric, metric["key"])
|
||||
for metric in worker["metrics"]["buckets"]
|
||||
}
|
||||
|
||||
return {
|
||||
worker["key"]: extract_worker_results(worker)
|
||||
for worker in data["aggregations"]["workers"]["buckets"]
|
||||
}
|
||||
|
||||
def get_activity_report(
|
||||
self,
|
||||
company_id: str,
|
||||
from_date: float,
|
||||
to_date: float,
|
||||
interval: int,
|
||||
active_only: bool,
|
||||
) -> Sequence[dict]:
|
||||
"""
|
||||
Get statistics for company workers metrics in the specified time range
|
||||
Returned as date histograms for different aggregation types
|
||||
grouped by worker, metric type (and optionally metric variant)
|
||||
Note: all the statistics are retrieved using one ES query
|
||||
"""
|
||||
if from_date >= to_date:
|
||||
raise bad_request.FieldsValueError("from_date must be less than to_date")
|
||||
|
||||
must = [QueryBuilder.dates_range(from_date, to_date)]
|
||||
if active_only:
|
||||
must.append({"exists": {"field": "task"}})
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"dates": {
|
||||
"date_histogram": {
|
||||
"field": "timestamp",
|
||||
"interval": f"{interval}s",
|
||||
},
|
||||
"aggs": {"workers_count": {"cardinality": {"field": "worker"}}},
|
||||
}
|
||||
},
|
||||
"query": {"bool": {"must": must}},
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "get_worker_activity_report"
|
||||
):
|
||||
data = self._search_company_stats(company_id, es_req)
|
||||
|
||||
if "aggregations" not in data:
|
||||
return {}
|
||||
|
||||
ret = [
|
||||
dict(date=date["key"], count=date["workers_count"]["value"])
|
||||
for date in data["aggregations"]["dates"]["buckets"]
|
||||
]
|
||||
|
||||
if ret and ret[-1]["date"] > (to_date - 0.9 * interval):
|
||||
# remove last interval if it's incomplete. Allow 10% tolerance
|
||||
ret.pop()
|
||||
|
||||
return ret
|
||||
@@ -1,4 +1,8 @@
|
||||
import logging
|
||||
import os
|
||||
from functools import reduce
|
||||
from os import getenv
|
||||
from os.path import expandvars
|
||||
from pathlib import Path
|
||||
|
||||
from pyhocon import ConfigTree, ConfigFactory
|
||||
@@ -9,6 +13,13 @@ from pyparsing import (
|
||||
ParseSyntaxException,
|
||||
)
|
||||
|
||||
DEFAULT_EXTRA_CONFIG_PATH = "/opt/trains/config"
|
||||
EXTRA_CONFIG_PATH_ENV_KEY = "TRAINS_CONFIG_DIR"
|
||||
EXTRA_CONFIG_PATH_SEP = ":"
|
||||
|
||||
EXTRA_CONFIG_VALUES_ENV_KEY_SEP = "__"
|
||||
EXTRA_CONFIG_VALUES_ENV_KEY_PREFIX = f"TRAINS{EXTRA_CONFIG_VALUES_ENV_KEY_SEP}"
|
||||
|
||||
|
||||
class BasicConfig:
|
||||
NotSet = object()
|
||||
@@ -36,11 +47,54 @@ class BasicConfig:
|
||||
def logger(self, name):
|
||||
if Path(name).is_file():
|
||||
name = Path(name).stem
|
||||
path = ".".join((self.prefix, Path(name).stem))
|
||||
path = ".".join((self.prefix, name))
|
||||
return logging.getLogger(path)
|
||||
|
||||
def _read_extra_env_config_values(self):
|
||||
""" Loads extra configuration from environment-injected values """
|
||||
result = ConfigTree()
|
||||
prefix = EXTRA_CONFIG_VALUES_ENV_KEY_PREFIX
|
||||
|
||||
keys = sorted(k for k in os.environ if k.startswith(prefix))
|
||||
for key in keys:
|
||||
path = key[len(prefix) :].replace(EXTRA_CONFIG_VALUES_ENV_KEY_SEP, ".")
|
||||
result = ConfigTree.merge_configs(
|
||||
result, ConfigFactory.parse_string(f"{path}: {os.environ[key]}")
|
||||
)
|
||||
|
||||
return result
|
||||
|
||||
def _read_env_paths(self, key):
|
||||
value = getenv(EXTRA_CONFIG_PATH_ENV_KEY, DEFAULT_EXTRA_CONFIG_PATH)
|
||||
if value is None:
|
||||
return
|
||||
paths = [
|
||||
Path(expandvars(v)).expanduser() for v in value.split(EXTRA_CONFIG_PATH_SEP)
|
||||
]
|
||||
invalid = [
|
||||
path
|
||||
for path in paths
|
||||
if not path.is_dir() and str(path) != DEFAULT_EXTRA_CONFIG_PATH
|
||||
]
|
||||
if invalid:
|
||||
print(f"WARNING: Invalid paths in {key} env var: {' '.join(invalid)}")
|
||||
return [path for path in paths if path.is_dir()]
|
||||
|
||||
def _load(self, verbose=True):
|
||||
self._config = self._read_recursive(self.folder, verbose=verbose)
|
||||
extra_config_paths = self._read_env_paths(EXTRA_CONFIG_PATH_ENV_KEY) or []
|
||||
extra_config_values = self._read_extra_env_config_values()
|
||||
configs = [
|
||||
self._read_recursive(path, verbose=verbose)
|
||||
for path in [self.folder] + extra_config_paths
|
||||
]
|
||||
|
||||
self._config = reduce(
|
||||
lambda last, config: ConfigTree.merge_configs(
|
||||
last, config, copy_trees=True
|
||||
),
|
||||
configs + [extra_config_values],
|
||||
ConfigTree(),
|
||||
)
|
||||
|
||||
def _read_recursive(self, conf_root, verbose=True):
|
||||
conf = ConfigTree()
|
||||
|
||||
@@ -21,12 +21,25 @@
|
||||
version {
|
||||
required: false
|
||||
default: 1.0
|
||||
# if set then calls to endpoints with the version
|
||||
# greater that the current max version will be rejected
|
||||
check_max_version: false
|
||||
}
|
||||
|
||||
mongo {
|
||||
# controls whether FieldDoesNotExist exception will be raised for any extra attribute existing in stored data
|
||||
# but not declared in a data model
|
||||
strict: false
|
||||
|
||||
aggregate {
|
||||
allow_disk_use: true
|
||||
}
|
||||
|
||||
pre_populate {
|
||||
enabled: false
|
||||
zip_file: "/path/to/export.zip"
|
||||
fail_on_error: false
|
||||
}
|
||||
}
|
||||
|
||||
auth {
|
||||
@@ -41,11 +54,71 @@
|
||||
|
||||
# cookie containing auth token, for requests arriving from a web-browser
|
||||
session_auth_cookie_name: "trains_token_basic"
|
||||
|
||||
# cookie configuration for authorization cookies generated by auth.login
|
||||
cookies {
|
||||
httponly: true # allow only http to access the cookies (no JS etc)
|
||||
secure: false # not using HTTPS
|
||||
domain: null # Limit to localhost is not supported
|
||||
max_age: 99999999999
|
||||
}
|
||||
|
||||
# # A list of fixed users
|
||||
# fixed_users {
|
||||
# enabled: true
|
||||
# users: [
|
||||
# {
|
||||
# username: "john"
|
||||
# password: "123456"
|
||||
# name: "john doe"
|
||||
# }
|
||||
#
|
||||
# ]
|
||||
# }
|
||||
}
|
||||
|
||||
cors {
|
||||
origins: "*"
|
||||
|
||||
# Not supported when origins is "*"
|
||||
supports_credentials: true
|
||||
}
|
||||
|
||||
default_company: "d1bd92a3b039400cbafc60a7a5b1e52b"
|
||||
|
||||
workers {
|
||||
# Auto-register unknown workers on status reports and other calls
|
||||
auto_register: true
|
||||
# Timeout in seconds on task status update. If exceeded
|
||||
# then task can be stopped without communicating to the worker
|
||||
task_update_timeout: 600
|
||||
}
|
||||
|
||||
check_for_updates {
|
||||
enabled: true
|
||||
|
||||
# Check for updates every 24 hours
|
||||
check_interval_sec: 86400
|
||||
|
||||
url: "https://updates.trains.allegro.ai/updates"
|
||||
|
||||
component_name: "trains-server"
|
||||
|
||||
# GET request timeout
|
||||
request_timeout_sec: 3.0
|
||||
}
|
||||
|
||||
statistics {
|
||||
# Note: statistics are sent ONLY if the user has actively opted-in
|
||||
supported: true
|
||||
|
||||
url: "https://updates.trains.allegro.ai/stats"
|
||||
|
||||
report_interval_hours: 24
|
||||
agent_relevant_threshold_days: 30
|
||||
|
||||
max_retries: 5
|
||||
max_backoff_sec: 5
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@@ -9,6 +9,17 @@ elastic {
|
||||
}
|
||||
index_version: "1"
|
||||
}
|
||||
|
||||
workers {
|
||||
hosts: [{host:"127.0.0.1", port:9200}]
|
||||
args {
|
||||
timeout: 60
|
||||
dead_timeout: 10
|
||||
max_retries: 5
|
||||
retry_on_timeout: true
|
||||
}
|
||||
index_version: "1"
|
||||
}
|
||||
}
|
||||
|
||||
mongo {
|
||||
@@ -19,3 +30,16 @@ mongo {
|
||||
host: "mongodb://127.0.0.1:27017/auth"
|
||||
}
|
||||
}
|
||||
|
||||
redis {
|
||||
apiserver {
|
||||
host: "127.0.0.1"
|
||||
port: 6379
|
||||
db: 0
|
||||
}
|
||||
workers {
|
||||
host: "127.0.0.1"
|
||||
port: 6379
|
||||
db: 4
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,3 +1,9 @@
|
||||
{
|
||||
es_index_prefix:"events"
|
||||
}
|
||||
es_index_prefix: "events"
|
||||
|
||||
ignore_iteration {
|
||||
metrics: [":monitor:machine", ":monitor:gpu"]
|
||||
}
|
||||
|
||||
# max number of concurrent queries to ES when calculating events metrics
|
||||
# should not exceed the amount of concurrent connections set in the ES driver
|
||||
max_metrics_concurrency: 4
|
||||
12
server/config/default/services/tasks.conf
Normal file
12
server/config/default/services/tasks.conf
Normal file
@@ -0,0 +1,12 @@
|
||||
non_responsive_tasks_watchdog {
|
||||
# In-progress tasks older than this value in seconds will be stopped by the watchdog
|
||||
threshold_sec: 7200
|
||||
|
||||
# Watchdog will sleep for this number of seconds after each cycle
|
||||
watch_interval_sec: 900
|
||||
}
|
||||
|
||||
artifacts {
|
||||
update_attempts: 10
|
||||
update_retry_msec: 500
|
||||
}
|
||||
43
server/config/info.py
Normal file
43
server/config/info.py
Normal file
@@ -0,0 +1,43 @@
|
||||
from functools import lru_cache
|
||||
from os import getenv
|
||||
from pathlib import Path
|
||||
from version import __version__
|
||||
|
||||
from config import config
|
||||
|
||||
root = Path(__file__).parent.parent
|
||||
|
||||
|
||||
def _get(prop_name, env_suffix=None, default=""):
|
||||
value = getenv(f"TRAINS_SERVER_{env_suffix or prop_name}")
|
||||
if value:
|
||||
return value
|
||||
|
||||
try:
|
||||
return (root / prop_name).read_text().strip()
|
||||
except FileNotFoundError:
|
||||
return default
|
||||
|
||||
|
||||
@lru_cache()
|
||||
def get_build_number():
|
||||
return _get("BUILD")
|
||||
|
||||
|
||||
@lru_cache()
|
||||
def get_version():
|
||||
return _get("VERSION", default=__version__)
|
||||
|
||||
|
||||
@lru_cache()
|
||||
def get_commit_number():
|
||||
return _get("COMMIT")
|
||||
|
||||
|
||||
@lru_cache()
|
||||
def get_deployment_type() -> str:
|
||||
return _get("DEPLOY", env_suffix="DEPLOYMENT_TYPE", default="manual")
|
||||
|
||||
|
||||
def get_default_company():
|
||||
return config.get("apiserver.default_company")
|
||||
@@ -1,3 +1,7 @@
|
||||
from os import getenv
|
||||
|
||||
from boltons.iterutils import first
|
||||
from furl import furl
|
||||
from jsonmodels import models
|
||||
from jsonmodels.errors import ValidationError
|
||||
from jsonmodels.fields import StringField
|
||||
@@ -8,9 +12,16 @@ from config import config
|
||||
from .defs import Database
|
||||
from .utils import get_items
|
||||
|
||||
log = config.logger(__file__)
|
||||
log = config.logger("database")
|
||||
|
||||
strict = config.get('apiserver.mongo.strict', True)
|
||||
strict = config.get("apiserver.mongo.strict", True)
|
||||
|
||||
OVERRIDE_HOST_ENV_KEY = (
|
||||
"TRAINS_MONGODB_SERVICE_HOST",
|
||||
"MONGODB_SERVICE_HOST",
|
||||
"MONGODB_SERVICE_SERVICE_HOST",
|
||||
)
|
||||
OVERRIDE_PORT_ENV_KEY = ("TRAINS_MONGODB_SERVICE_PORT", "MONGODB_SERVICE_PORT")
|
||||
|
||||
_entries = []
|
||||
|
||||
@@ -21,28 +32,47 @@ class DatabaseEntry(models.Base):
|
||||
|
||||
@property
|
||||
def health_alias(self):
|
||||
return '__health__' + self.alias
|
||||
return "__health__" + self.alias
|
||||
|
||||
|
||||
def initialize():
|
||||
db_entries = config.get('hosts.mongo', {})
|
||||
db_entries = config.get("hosts.mongo", {})
|
||||
missing = []
|
||||
log.info('Initializing database connections')
|
||||
log.info("Initializing database connections")
|
||||
|
||||
override_hostname = first(map(getenv, OVERRIDE_HOST_ENV_KEY), None)
|
||||
if override_hostname:
|
||||
log.info(f"Using override mongodb host {override_hostname}")
|
||||
|
||||
override_port = first(map(getenv, OVERRIDE_PORT_ENV_KEY), None)
|
||||
if override_port:
|
||||
log.info(f"Using override mongodb port {override_port}")
|
||||
|
||||
for key, alias in get_items(Database).items():
|
||||
if key not in db_entries:
|
||||
missing.append(key)
|
||||
continue
|
||||
|
||||
entry = DatabaseEntry(alias=alias, **db_entries.get(key))
|
||||
|
||||
if override_hostname:
|
||||
entry.host = furl(entry.host).set(host=override_hostname).url
|
||||
|
||||
if override_port:
|
||||
entry.host = furl(entry.host).set(port=override_port).url
|
||||
|
||||
try:
|
||||
entry.validate()
|
||||
log.info('Registering connection to %(alias)s (%(host)s)' % entry.to_struct())
|
||||
log.info(
|
||||
"Registering connection to %(alias)s (%(host)s)" % entry.to_struct()
|
||||
)
|
||||
register_connection(alias=alias, host=entry.host)
|
||||
|
||||
_entries.append(entry)
|
||||
except ValidationError as ex:
|
||||
raise Exception('Invalid database entry `%s`: %s' % (key, ex.args[0]))
|
||||
raise Exception("Invalid database entry `%s`: %s" % (key, ex.args[0]))
|
||||
if missing:
|
||||
raise ValueError('Missing database configuration for %s' % ', '.join(missing))
|
||||
raise ValueError("Missing database configuration for %s" % ", ".join(missing))
|
||||
|
||||
|
||||
def get_entries():
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
import re
|
||||
from operator import itemgetter
|
||||
from sys import maxsize
|
||||
from typing import Type, Tuple
|
||||
|
||||
import six
|
||||
from mongoengine import (
|
||||
@@ -11,6 +12,7 @@ from mongoengine import (
|
||||
SortedListField,
|
||||
MapField,
|
||||
DictField,
|
||||
DynamicField,
|
||||
)
|
||||
|
||||
|
||||
@@ -88,104 +90,6 @@ class CustomFloatField(FloatField):
|
||||
self.error("Float value must be greater than %s" % str(self.greater_than))
|
||||
|
||||
|
||||
# TODO: bucket name should be at most 63 characters....
|
||||
aws_s3_bucket_only_regex = (
|
||||
r"^s3://"
|
||||
r"(?:(?:\w[A-Z0-9\-]+\w)\.)*(?:\w[A-Z0-9\-]+\w)" # bucket name
|
||||
)
|
||||
|
||||
aws_s3_url_with_bucket_regex = (
|
||||
r"^s3://"
|
||||
r"(?:(?:\w[A-Z0-9\-]+\w)\.)*(?:\w[A-Z0-9\-]+\w)" # bucket name
|
||||
r"(?:(?:[A-Z0-9](?:[A-Z0-9-]{0,61}[A-Z0-9])?\.)+(?:[A-Z]{2,6}\.?|[A-Z0-9-]{2,}(?<!-)\.?))" # domain...
|
||||
)
|
||||
|
||||
non_aws_s3_regex = (
|
||||
r"^s3://"
|
||||
r"(?:(?:[A-Z0-9](?:[A-Z0-9-]{0,61}[A-Z0-9])?\.)+(?:[A-Z]{2,6}\.?|[A-Z0-9-]{2,}(?<!-)\.?)|" # domain...
|
||||
r"localhost|" # localhost...
|
||||
r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}|" # ...or ipv4
|
||||
r"\[?[A-F0-9]*:[A-F0-9:]+\]?)" # ...or ipv6
|
||||
r"(?::\d+)?" # optional port
|
||||
r"(?:/(?:(?:\w[A-Z0-9\-]+\w)\.)*(?:\w[A-Z0-9\-]+\w))" # bucket name
|
||||
)
|
||||
|
||||
google_gs_bucket_only_regex = (
|
||||
r"^gs://"
|
||||
r"(?:(?:\w[A-Z0-9\-_]+\w)\.)*(?:\w[A-Z0-9\-_]+\w)" # bucket name
|
||||
)
|
||||
|
||||
file_regex = r"^file://"
|
||||
|
||||
generic_url_regex = (
|
||||
r"^%s://" # scheme placeholder
|
||||
r"(?:(?:[A-Z0-9](?:[A-Z0-9-]{0,61}[A-Z0-9])?\.)+(?:[A-Z]{2,6}\.?|[A-Z0-9-]{2,}(?<!-)\.?)|" # domain...
|
||||
r"localhost|" # localhost...
|
||||
r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}|" # ...or ipv4
|
||||
r"\[?[A-F0-9]*:[A-F0-9:]+\]?)" # ...or ipv6
|
||||
r"(?::\d+)?" # optional port
|
||||
)
|
||||
|
||||
path_suffix = r"(?:/?|[/?]\S+)$"
|
||||
file_path_suffix = r"(?:/\S*[^/]+)$"
|
||||
|
||||
|
||||
class _RegexURLField(StringField):
|
||||
_regex = []
|
||||
|
||||
def __init__(self, regex, **kwargs):
|
||||
super(_RegexURLField, self).__init__(**kwargs)
|
||||
regex = regex if isinstance(regex, (tuple, list)) else [regex]
|
||||
self._regex = [
|
||||
re.compile(e, re.IGNORECASE) if isinstance(e, six.string_types) else e
|
||||
for e in regex
|
||||
]
|
||||
|
||||
def validate(self, value):
|
||||
# Check first if the scheme is valid
|
||||
if not any(regex for regex in self._regex if regex.match(value)):
|
||||
self.error("Invalid URL: {}".format(value))
|
||||
return
|
||||
|
||||
|
||||
class OutputDestinationField(_RegexURLField):
|
||||
""" A field representing task output URL """
|
||||
|
||||
schemes = ["s3", "gs", "file"]
|
||||
_expressions = (
|
||||
aws_s3_bucket_only_regex + path_suffix,
|
||||
aws_s3_url_with_bucket_regex + path_suffix,
|
||||
non_aws_s3_regex + path_suffix,
|
||||
google_gs_bucket_only_regex + path_suffix,
|
||||
file_regex + path_suffix,
|
||||
)
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
super(OutputDestinationField, self).__init__(self._expressions, **kwargs)
|
||||
|
||||
|
||||
class SupportedURLField(_RegexURLField):
|
||||
""" A field representing a model URL """
|
||||
|
||||
schemes = ["s3", "gs", "file", "http", "https"]
|
||||
|
||||
_expressions = tuple(
|
||||
pattern + file_path_suffix
|
||||
for pattern in (
|
||||
aws_s3_bucket_only_regex,
|
||||
aws_s3_url_with_bucket_regex,
|
||||
non_aws_s3_regex,
|
||||
google_gs_bucket_only_regex,
|
||||
file_regex,
|
||||
(generic_url_regex % "http"),
|
||||
(generic_url_regex % "https"),
|
||||
)
|
||||
)
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
super(SupportedURLField, self).__init__(self._expressions, **kwargs)
|
||||
|
||||
|
||||
class StrippedStringField(StringField):
|
||||
def __init__(
|
||||
self, regex=None, max_length=None, min_length=None, strip_chars=None, **kwargs
|
||||
@@ -235,3 +139,42 @@ class SafeDictField(DictField):
|
||||
|
||||
if contains_empty_key(value):
|
||||
self.error("Empty keys are not allowed in a DictField")
|
||||
|
||||
|
||||
class SafeSortedListField(SortedListField):
|
||||
"""
|
||||
SortedListField that does not raise an error in case items are not comparable
|
||||
(in which case they will be sorted by their string representation)
|
||||
"""
|
||||
def to_mongo(self, *args, **kwargs):
|
||||
try:
|
||||
return super(SafeSortedListField, self).to_mongo(*args, **kwargs)
|
||||
except TypeError:
|
||||
return self._safe_to_mongo(*args, **kwargs)
|
||||
|
||||
def _safe_to_mongo(self, value, use_db_field=True, fields=None):
|
||||
value = super(SortedListField, self).to_mongo(value, use_db_field, fields)
|
||||
if self._ordering is not None:
|
||||
def key(v): return str(itemgetter(self._ordering)(v))
|
||||
else:
|
||||
key = str
|
||||
return sorted(value, key=key, reverse=self._order_reverse)
|
||||
|
||||
|
||||
class UnionField(DynamicField):
|
||||
def __init__(self, types, *args, **kwargs):
|
||||
super(UnionField, self).__init__(*args, **kwargs)
|
||||
self.types: Tuple[Type] = tuple(types)
|
||||
|
||||
def validate(self, value, clean=True):
|
||||
if not isinstance(value, self.types):
|
||||
type_names = [t.__name__ for t in self.types]
|
||||
expected = " or ".join(
|
||||
filter(
|
||||
None,
|
||||
(", ".join(type_names[:-1]), type_names[-1]))
|
||||
)
|
||||
self.error(
|
||||
f"Expected {expected}, got {type(value).__name__}: {value}"
|
||||
)
|
||||
super(UnionField, self).validate(value, clean)
|
||||
|
||||
@@ -1,3 +1,5 @@
|
||||
from enum import Enum
|
||||
|
||||
from mongoengine import Document, StringField
|
||||
|
||||
from apierrors import errors
|
||||
@@ -54,3 +56,7 @@ def validate_id(cls, company, **kwargs):
|
||||
**{name: obj_id for obj_id in missing for name in id_to_name[obj_id]}
|
||||
)
|
||||
|
||||
|
||||
class EntityVisibility(Enum):
|
||||
active = "active"
|
||||
archived = "archived"
|
||||
|
||||
@@ -45,13 +45,14 @@ class Role(object):
|
||||
class Credentials(EmbeddedDocument):
|
||||
key = StringField(required=True)
|
||||
secret = StringField(required=True)
|
||||
last_used = DateTimeField()
|
||||
|
||||
|
||||
class User(DbModelMixin, AuthDocument):
|
||||
meta = {"db_alias": Database.auth, "strict": strict}
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
name = StringField(unique_with="company")
|
||||
name = StringField()
|
||||
|
||||
created = DateTimeField()
|
||||
""" User auth entry creation time """
|
||||
|
||||
@@ -1,11 +1,12 @@
|
||||
import re
|
||||
from collections import namedtuple
|
||||
from functools import reduce
|
||||
from typing import Collection
|
||||
from typing import Collection, Sequence, Union, Optional
|
||||
|
||||
from boltons.iterutils import first
|
||||
from dateutil.parser import parse as parse_datetime
|
||||
from mongoengine import Q, Document
|
||||
from six import string_types
|
||||
from mongoengine import Q, Document, ListField, StringField
|
||||
from pymongo.command_cursor import CommandCursor
|
||||
|
||||
from apierrors import errors
|
||||
from config import config
|
||||
@@ -13,7 +14,12 @@ from database.errors import MakeGetAllQueryError
|
||||
from database.projection import project_dict, ProjectionHelper
|
||||
from database.props import PropsMixin
|
||||
from database.query import RegexQ, RegexWrapper
|
||||
from database.utils import get_company_or_none_constraint, get_fields_with_attr
|
||||
from database.utils import (
|
||||
get_company_or_none_constraint,
|
||||
get_fields_choices,
|
||||
field_does_not_exist,
|
||||
field_exists,
|
||||
)
|
||||
|
||||
log = config.logger("dbmodel")
|
||||
|
||||
@@ -54,8 +60,9 @@ class ProperDictMixin(object):
|
||||
|
||||
class GetMixin(PropsMixin):
|
||||
_text_score = "$text_score"
|
||||
|
||||
_projection_key = "projection"
|
||||
_ordering_key = "order_by"
|
||||
_search_text_key = "search_text"
|
||||
|
||||
_multi_field_param_sep = "__"
|
||||
_multi_field_param_prefix = {
|
||||
@@ -68,7 +75,7 @@ class GetMixin(PropsMixin):
|
||||
def __init__(
|
||||
self,
|
||||
pattern_fields=("name",),
|
||||
list_fields=("tags", "id"),
|
||||
list_fields=("tags", "system_tags", "id"),
|
||||
datetime_fields=None,
|
||||
fields=None,
|
||||
):
|
||||
@@ -215,6 +222,24 @@ class GetMixin(PropsMixin):
|
||||
return get_company_or_none_constraint(company)
|
||||
return Q(company=company)
|
||||
|
||||
@classmethod
|
||||
def validate_order_by(cls, parameters, search_text) -> Sequence:
|
||||
"""
|
||||
Validate and extract order_by params as a list
|
||||
"""
|
||||
order_by = parameters.get(cls._ordering_key)
|
||||
if not order_by:
|
||||
return []
|
||||
|
||||
order_by = order_by if isinstance(order_by, list) else [order_by]
|
||||
order_by = [cls._text_score if x == "@text_score" else x for x in order_by]
|
||||
if not search_text and cls._text_score in order_by:
|
||||
raise errors.bad_request.FieldsValueError(
|
||||
"text score cannot be used in order_by when search text is not used"
|
||||
)
|
||||
|
||||
return order_by
|
||||
|
||||
@classmethod
|
||||
def validate_paging(
|
||||
cls, parameters=None, default_page=None, default_page_size=None
|
||||
@@ -245,11 +270,26 @@ class GetMixin(PropsMixin):
|
||||
return override_projection
|
||||
if not parameters:
|
||||
return []
|
||||
return parameters.get("projection") or parameters.get("only_fields", [])
|
||||
return parameters.get(cls._projection_key) or parameters.get("only_fields", [])
|
||||
|
||||
@classmethod
|
||||
def set_default_ordering(cls, parameters, value):
|
||||
parameters[cls._ordering_key] = parameters.get(cls._ordering_key) or value
|
||||
def set_projection(cls, parameters: dict, value: Sequence[str]) -> Sequence[str]:
|
||||
parameters.pop("only_fields", None)
|
||||
parameters[cls._projection_key] = value
|
||||
return value
|
||||
|
||||
@classmethod
|
||||
def get_ordering(cls, parameters: dict) -> Optional[Sequence[str]]:
|
||||
return parameters.get(cls._ordering_key)
|
||||
|
||||
@classmethod
|
||||
def set_ordering(cls, parameters: dict, value: Sequence[str]) -> Sequence[str]:
|
||||
parameters[cls._ordering_key] = value
|
||||
return value
|
||||
|
||||
@classmethod
|
||||
def set_default_ordering(cls, parameters: dict, value: Sequence[str]) -> None:
|
||||
cls.set_ordering(parameters, cls.get_ordering(parameters) or value)
|
||||
|
||||
@classmethod
|
||||
def get_many_with_join(
|
||||
@@ -332,8 +372,9 @@ class GetMixin(PropsMixin):
|
||||
`@text_score` keyword. A text index must be defined on the document type, otherwise an error will
|
||||
be raised.
|
||||
:param return_dicts: Return a list of dictionaries. If True, a list of dicts is returned (if projection was
|
||||
requested, each contains only the requested projection).
|
||||
If False, a QuerySet object is returned (lazy evaluated)
|
||||
requested, each contains only the requested projection). If False, a QuerySet object is returned
|
||||
(lazy evaluated). If return_dicts is requested then the entities with the None value in order_by field
|
||||
are returned last in the ordering.
|
||||
:param company: Company ID (required)
|
||||
:param parameters: Parameters dict from which paging ordering and searching parameters are extracted.
|
||||
:param query_dict: If provided, passed to prepare_query() along with all of the relevant arguments to produce
|
||||
@@ -356,17 +397,19 @@ class GetMixin(PropsMixin):
|
||||
q = cls._prepare_perm_query(company, allow_public=allow_public)
|
||||
_query = (q & query) if query else q
|
||||
|
||||
if return_dicts:
|
||||
return cls._get_many_override_none_ordering(
|
||||
query=_query,
|
||||
parameters=parameters,
|
||||
override_projection=override_projection,
|
||||
)
|
||||
|
||||
return cls._get_many_no_company(
|
||||
query=_query,
|
||||
parameters=parameters,
|
||||
override_projection=override_projection,
|
||||
return_dicts=return_dicts,
|
||||
query=_query, parameters=parameters, override_projection=override_projection
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def _get_many_no_company(
|
||||
cls, query, parameters=None, override_projection=None, return_dicts=True
|
||||
):
|
||||
def _get_many_no_company(cls, query, parameters=None, override_projection=None):
|
||||
"""
|
||||
Fetch all documents matching a provided query.
|
||||
This is a company-less version for internal uses. We assume the caller has either added any necessary
|
||||
@@ -375,44 +418,25 @@ class GetMixin(PropsMixin):
|
||||
NOTE: BE VERY CAREFUL WITH THIS CALL, as it allows returning data across companies.
|
||||
|
||||
:param query: Query object (mongoengine.Q)
|
||||
:param return_dicts: Return a list of dictionaries. If True, a list of dicts is returned (if projection was
|
||||
requested, each contains only the requested projection).
|
||||
If False, a QuerySet object is returned (lazy evaluated)
|
||||
:param parameters: Parameters dict from which paging ordering and searching parameters are extracted.
|
||||
:param override_projection: A list of projection fields overriding any projection specified in the `param_dict`
|
||||
argument
|
||||
"""
|
||||
parameters = parameters or {}
|
||||
|
||||
if not query:
|
||||
raise ValueError("query or call_data must be provided")
|
||||
|
||||
parameters = parameters or {}
|
||||
search_text = parameters.get(cls._search_text_key)
|
||||
order_by = cls.validate_order_by(parameters=parameters, search_text=search_text)
|
||||
page, page_size = cls.validate_paging(parameters=parameters)
|
||||
|
||||
order_by = parameters.get(cls._ordering_key)
|
||||
if order_by:
|
||||
order_by = order_by if isinstance(order_by, list) else [order_by]
|
||||
order_by = [cls._text_score if x == "@text_score" else x for x in order_by]
|
||||
|
||||
search_text = parameters.get("search_text")
|
||||
|
||||
only = cls.get_projection(parameters, override_projection)
|
||||
|
||||
if not search_text and order_by and cls._text_score in order_by:
|
||||
raise errors.bad_request.FieldsValueError(
|
||||
"text score cannot be used in order_by when search text is not used"
|
||||
)
|
||||
|
||||
qs = cls.objects(query)
|
||||
if search_text:
|
||||
qs = qs.search_text(search_text)
|
||||
if order_by:
|
||||
# add ordering
|
||||
qs = (
|
||||
qs.order_by(order_by)
|
||||
if isinstance(order_by, string_types)
|
||||
else qs.order_by(*order_by)
|
||||
)
|
||||
qs = qs.order_by(*order_by)
|
||||
if only:
|
||||
# add projection
|
||||
qs = qs.only(*only)
|
||||
@@ -424,10 +448,91 @@ class GetMixin(PropsMixin):
|
||||
# add paging
|
||||
qs = qs.skip(page * page_size).limit(page_size)
|
||||
|
||||
if return_dicts:
|
||||
return [obj.to_proper_dict(only=only) for obj in qs]
|
||||
return qs
|
||||
|
||||
@classmethod
|
||||
def _get_many_override_none_ordering(
|
||||
cls: Union[Document, "GetMixin"],
|
||||
query: Q = None,
|
||||
parameters: dict = None,
|
||||
override_projection: Collection[str] = None,
|
||||
) -> Sequence[dict]:
|
||||
"""
|
||||
Fetch all documents matching a provided query. For the first order by field
|
||||
the None values are sorted in the end regardless of the sorting order.
|
||||
This is a company-less version for internal uses. We assume the caller has either added any necessary
|
||||
constraints to the query or that no constraints are required.
|
||||
|
||||
NOTE: BE VERY CAREFUL WITH THIS CALL, as it allows returning data across companies.
|
||||
|
||||
:param query: Query object (mongoengine.Q)
|
||||
:param parameters: Parameters dict from which paging ordering and searching parameters are extracted.
|
||||
:param override_projection: A list of projection fields overriding any projection specified in the `param_dict`
|
||||
argument
|
||||
"""
|
||||
if not query:
|
||||
raise ValueError("query or call_data must be provided")
|
||||
|
||||
parameters = parameters or {}
|
||||
search_text = parameters.get(cls._search_text_key)
|
||||
order_by = cls.validate_order_by(parameters=parameters, search_text=search_text)
|
||||
page, page_size = cls.validate_paging(parameters=parameters)
|
||||
only = cls.get_projection(parameters, override_projection)
|
||||
|
||||
query_sets = [cls.objects(query)]
|
||||
if order_by:
|
||||
order_field = first(
|
||||
field for field in order_by if not field.startswith("$")
|
||||
)
|
||||
if (
|
||||
order_field
|
||||
and not order_field.startswith("-")
|
||||
and "[" not in order_field
|
||||
):
|
||||
params = {}
|
||||
mongo_field = order_field.replace(".", "__")
|
||||
if mongo_field in cls.get_field_names_for_type(of_type=ListField):
|
||||
params["is_list"] = True
|
||||
elif mongo_field in cls.get_field_names_for_type(of_type=StringField):
|
||||
params["empty_value"] = ""
|
||||
non_empty = query & field_exists(mongo_field, **params)
|
||||
empty = query & field_does_not_exist(mongo_field, **params)
|
||||
query_sets = [cls.objects(non_empty), cls.objects(empty)]
|
||||
|
||||
query_sets = [qs.order_by(*order_by) for qs in query_sets]
|
||||
|
||||
if search_text:
|
||||
query_sets = [qs.search_text(search_text) for qs in query_sets]
|
||||
|
||||
if only:
|
||||
# add projection
|
||||
query_sets = [qs.only(*only) for qs in query_sets]
|
||||
else:
|
||||
exclude = set(cls.get_exclude_fields())
|
||||
if exclude:
|
||||
query_sets = [qs.exclude(*exclude) for qs in query_sets]
|
||||
|
||||
if page is None or not page_size:
|
||||
return [obj.to_proper_dict(only=only) for qs in query_sets for obj in qs]
|
||||
|
||||
# add paging
|
||||
ret = []
|
||||
start = page * page_size
|
||||
for qs in query_sets:
|
||||
qs_size = qs.count()
|
||||
if qs_size < start:
|
||||
start -= qs_size
|
||||
continue
|
||||
ret.extend(
|
||||
obj.to_proper_dict(only=only) for obj in qs.skip(start).limit(page_size)
|
||||
)
|
||||
if len(ret) >= page_size:
|
||||
break
|
||||
start = 0
|
||||
page_size -= len(ret)
|
||||
|
||||
return ret
|
||||
|
||||
@classmethod
|
||||
def get_for_writing(
|
||||
cls, *args, _only: Collection[str] = None, **kwargs
|
||||
@@ -464,8 +569,8 @@ class UpdateMixin(object):
|
||||
def user_set_allowed(cls):
|
||||
res = getattr(cls, "__user_set_allowed_fields", None)
|
||||
if res is None:
|
||||
res = cls.__user_set_allowed_fields = dict(
|
||||
get_fields_with_attr(cls, "user_set_allowed")
|
||||
res = cls.__user_set_allowed_fields = get_fields_choices(
|
||||
cls, "user_set_allowed"
|
||||
)
|
||||
return res
|
||||
|
||||
@@ -503,7 +608,24 @@ class UpdateMixin(object):
|
||||
class DbModelMixin(GetMixin, ProperDictMixin, UpdateMixin):
|
||||
""" Provide convenience methods for a subclass of mongoengine.Document """
|
||||
|
||||
pass
|
||||
@classmethod
|
||||
def aggregate(
|
||||
cls: Document, *pipeline: dict, allow_disk_use=None, **kwargs
|
||||
) -> CommandCursor:
|
||||
"""
|
||||
Aggregate objects of this document class according to the provided pipeline.
|
||||
:param pipeline: a list of dictionaries describing the pipeline stages
|
||||
:param allow_disk_use: if True, allow the server to use disk space if aggregation query cannot fit in memory.
|
||||
If None, default behavior will be used (see apiserver.conf/mongo/aggregate/allow_disk_use)
|
||||
:param kwargs: additional keyword arguments passed to mongoengine
|
||||
:return:
|
||||
"""
|
||||
kwargs.update(
|
||||
allowDiskUse=allow_disk_use
|
||||
if allow_disk_use is not None
|
||||
else config.get("apiserver.mongo.aggregate.allow_disk_use", True)
|
||||
)
|
||||
return cls.objects.aggregate(*pipeline, **kwargs)
|
||||
|
||||
|
||||
def validate_id(cls, company, **kwargs):
|
||||
|
||||
@@ -1,23 +1,36 @@
|
||||
from mongoengine import Document, EmbeddedDocument, EmbeddedDocumentField, StringField, Q
|
||||
from mongoengine import (
|
||||
Document,
|
||||
EmbeddedDocument,
|
||||
EmbeddedDocumentField,
|
||||
StringField,
|
||||
Q,
|
||||
BooleanField,
|
||||
DateTimeField,
|
||||
)
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import StrippedStringField
|
||||
from database.model import DbModelMixin
|
||||
|
||||
|
||||
class ReportStatsOption(EmbeddedDocument):
|
||||
enabled = BooleanField(default=False) # opt-in for statistics reporting
|
||||
enabled_version = StringField() # server version when enabled
|
||||
enabled_time = DateTimeField() # time when enabled
|
||||
enabled_user = StringField() # ID of user who enabled
|
||||
|
||||
|
||||
class CompanyDefaults(EmbeddedDocument):
|
||||
cluster = StringField()
|
||||
stats_option = EmbeddedDocumentField(ReportStatsOption, default=ReportStatsOption)
|
||||
|
||||
|
||||
class Company(DbModelMixin, Document):
|
||||
meta = {
|
||||
'db_alias': Database.backend,
|
||||
'strict': strict,
|
||||
}
|
||||
meta = {"db_alias": Database.backend, "strict": strict}
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
name = StrippedStringField(unique=True, min_length=3)
|
||||
defaults = EmbeddedDocumentField(CompanyDefaults)
|
||||
defaults = EmbeddedDocumentField(CompanyDefaults, default=CompanyDefaults)
|
||||
|
||||
@classmethod
|
||||
def _prepare_perm_query(cls, company, allow_public=False):
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
from mongoengine import Document, StringField, DateTimeField, ListField, BooleanField
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import SupportedURLField, StrippedStringField, SafeDictField
|
||||
from database.fields import StrippedStringField, SafeDictField
|
||||
from database.model import DbModelMixin
|
||||
from database.model.model_labels import ModelLabels
|
||||
from database.model.company import Company
|
||||
@@ -12,35 +12,32 @@ from database.model.user import User
|
||||
|
||||
class Model(DbModelMixin, Document):
|
||||
meta = {
|
||||
'db_alias': Database.backend,
|
||||
'strict': strict,
|
||||
'indexes': [
|
||||
"db_alias": Database.backend,
|
||||
"strict": strict,
|
||||
"indexes": [
|
||||
"parent",
|
||||
"project",
|
||||
"task",
|
||||
("company", "name"),
|
||||
{
|
||||
'name': '%s.model.main_text_index' % Database.backend,
|
||||
'fields': [
|
||||
'$name',
|
||||
'$id',
|
||||
'$comment',
|
||||
'$parent',
|
||||
'$task',
|
||||
'$project',
|
||||
],
|
||||
'default_language': 'english',
|
||||
'weights': {
|
||||
'name': 10,
|
||||
'id': 10,
|
||||
'comment': 10,
|
||||
'parent': 5,
|
||||
'task': 3,
|
||||
'project': 3,
|
||||
}
|
||||
}
|
||||
"name": "%s.model.main_text_index" % Database.backend,
|
||||
"fields": ["$name", "$id", "$comment", "$parent", "$task", "$project"],
|
||||
"default_language": "english",
|
||||
"weights": {
|
||||
"name": 10,
|
||||
"id": 10,
|
||||
"comment": 10,
|
||||
"parent": 5,
|
||||
"task": 3,
|
||||
"project": 3,
|
||||
},
|
||||
},
|
||||
],
|
||||
}
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
name = StrippedStringField(user_set_allowed=True, min_length=3)
|
||||
parent = StringField(reference_field='Model', required=False)
|
||||
parent = StringField(reference_field="Model", required=False)
|
||||
user = StringField(required=True, reference_field=User)
|
||||
company = StringField(required=True, reference_field=Company)
|
||||
project = StringField(reference_field=Project, user_set_allowed=True)
|
||||
@@ -48,9 +45,12 @@ class Model(DbModelMixin, Document):
|
||||
task = StringField(reference_field=Task)
|
||||
comment = StringField(user_set_allowed=True)
|
||||
tags = ListField(StringField(required=True), user_set_allowed=True)
|
||||
uri = SupportedURLField(default='', user_set_allowed=True)
|
||||
system_tags = ListField(StringField(required=True), user_set_allowed=True)
|
||||
uri = StrippedStringField(default="", user_set_allowed=True)
|
||||
framework = StringField()
|
||||
design = SafeDictField()
|
||||
labels = ModelLabels()
|
||||
ready = BooleanField(required=True)
|
||||
ui_cache = SafeDictField(default=dict, user_set_allowed=True, exclude_by_default=True)
|
||||
ui_cache = SafeDictField(
|
||||
default=dict, user_set_allowed=True, exclude_by_default=True
|
||||
)
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
from mongoengine import StringField, DateTimeField, ListField
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import OutputDestinationField, StrippedStringField
|
||||
from database.fields import StrippedStringField
|
||||
from database.model import AttributedDocument
|
||||
from database.model.base import GetMixin
|
||||
|
||||
@@ -9,19 +9,21 @@ from database.model.base import GetMixin
|
||||
class Project(AttributedDocument):
|
||||
|
||||
get_all_query_options = GetMixin.QueryParameterOptions(
|
||||
pattern_fields=("name", "description"), list_fields=("tags", "id")
|
||||
pattern_fields=("name", "description"),
|
||||
list_fields=("tags", "system_tags", "id"),
|
||||
)
|
||||
|
||||
meta = {
|
||||
"db_alias": Database.backend,
|
||||
"strict": strict,
|
||||
"indexes": [
|
||||
("company", "name"),
|
||||
{
|
||||
"name": "%s.project.main_text_index" % Database.backend,
|
||||
"fields": ["$name", "$id", "$description"],
|
||||
"default_language": "english",
|
||||
"weights": {"name": 10, "id": 10, "description": 10},
|
||||
}
|
||||
},
|
||||
],
|
||||
}
|
||||
|
||||
@@ -34,6 +36,7 @@ class Project(AttributedDocument):
|
||||
)
|
||||
description = StringField(required=True)
|
||||
created = DateTimeField(required=True)
|
||||
tags = ListField(StringField(required=True), default=list)
|
||||
default_output_destination = OutputDestinationField()
|
||||
tags = ListField(StringField(required=True))
|
||||
system_tags = ListField(StringField(required=True))
|
||||
default_output_destination = StrippedStringField()
|
||||
last_update = DateTimeField()
|
||||
|
||||
47
server/database/model/queue.py
Normal file
47
server/database/model/queue.py
Normal file
@@ -0,0 +1,47 @@
|
||||
from mongoengine import (
|
||||
Document,
|
||||
EmbeddedDocument,
|
||||
StringField,
|
||||
DateTimeField,
|
||||
EmbeddedDocumentListField,
|
||||
ListField,
|
||||
)
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import StrippedStringField
|
||||
from database.model import DbModelMixin
|
||||
from database.model.base import ProperDictMixin, GetMixin
|
||||
from database.model.company import Company
|
||||
from database.model.task.task import Task
|
||||
|
||||
|
||||
class Entry(EmbeddedDocument, ProperDictMixin):
|
||||
""" Entry representing a task waiting in the queue """
|
||||
task = StringField(required=True, reference_field=Task)
|
||||
''' Task ID '''
|
||||
added = DateTimeField(required=True)
|
||||
''' Added to the queue '''
|
||||
|
||||
|
||||
class Queue(DbModelMixin, Document):
|
||||
|
||||
get_all_query_options = GetMixin.QueryParameterOptions(
|
||||
pattern_fields=("name",),
|
||||
list_fields=("tags", "system_tags", "id"),
|
||||
)
|
||||
|
||||
meta = {
|
||||
'db_alias': Database.backend,
|
||||
'strict': strict,
|
||||
}
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
name = StrippedStringField(
|
||||
required=True, unique_with="company", min_length=3, user_set_allowed=True
|
||||
)
|
||||
company = StringField(required=True, reference_field=Company)
|
||||
created = DateTimeField(required=True)
|
||||
tags = ListField(StringField(required=True), default=list, user_set_allowed=True)
|
||||
system_tags = ListField(StringField(required=True), user_set_allowed=True)
|
||||
entries = EmbeddedDocumentListField(Entry, default=list)
|
||||
last_update = DateTimeField()
|
||||
53
server/database/model/settings.py
Normal file
53
server/database/model/settings.py
Normal file
@@ -0,0 +1,53 @@
|
||||
from typing import Any, Optional, Sequence, Tuple
|
||||
|
||||
from mongoengine import Document, StringField, DynamicField, Q
|
||||
from mongoengine.errors import NotUniqueError
|
||||
|
||||
from database import Database, strict
|
||||
from database.model import DbModelMixin
|
||||
|
||||
|
||||
class Settings(DbModelMixin, Document):
|
||||
meta = {
|
||||
"db_alias": Database.backend,
|
||||
"strict": strict,
|
||||
}
|
||||
|
||||
key = StringField(primary_key=True)
|
||||
value = DynamicField()
|
||||
|
||||
@classmethod
|
||||
def get_by_key(cls, key: str, default: Optional[Any] = None, sep: str = ".") -> Any:
|
||||
key = key.strip(sep)
|
||||
res = Settings.objects(key=key).first()
|
||||
if not res:
|
||||
return default
|
||||
return res.value
|
||||
|
||||
@classmethod
|
||||
def get_by_prefix(
|
||||
cls, key_prefix: str, default: Optional[Any] = None, sep: str = "."
|
||||
) -> Sequence[Tuple[str, Any]]:
|
||||
key_prefix = key_prefix.strip(sep)
|
||||
query = Q(key=key_prefix) | Q(key__startswith=key_prefix + sep)
|
||||
res = Settings.objects(query)
|
||||
if not res:
|
||||
return default
|
||||
return [(x.key, x.value) for x in res]
|
||||
|
||||
@classmethod
|
||||
def set_or_add_value(cls, key: str, value: Any, sep: str = ".") -> bool:
|
||||
""" Sets a new value or adds a new key/value setting (if key does not exist) """
|
||||
key = key.strip(sep)
|
||||
res = Settings.objects(key=key).update(key=key, value=value, upsert=True)
|
||||
return bool(res)
|
||||
|
||||
@classmethod
|
||||
def add_value(cls, key: str, value: Any, sep: str = ".") -> bool:
|
||||
""" Adds a new key/value settings. Fails if key already exists. """
|
||||
key = key.strip(sep)
|
||||
try:
|
||||
res = Settings(key=key, value=value).save(force_insert=True)
|
||||
return bool(res)
|
||||
except NotUniqueError:
|
||||
return False
|
||||
@@ -1,14 +1,39 @@
|
||||
from mongoengine import EmbeddedDocument, StringField, DateTimeField, LongField, DynamicField
|
||||
from mongoengine import (
|
||||
EmbeddedDocument,
|
||||
StringField,
|
||||
DynamicField,
|
||||
LongField,
|
||||
EmbeddedDocumentField,
|
||||
)
|
||||
|
||||
from database.fields import SafeMapField
|
||||
|
||||
|
||||
class MetricEvent(EmbeddedDocument):
|
||||
metric = StringField(required=True, )
|
||||
variant = StringField(required=True)
|
||||
type = StringField(required=True)
|
||||
timestamp = DateTimeField(default=0, required=True)
|
||||
iter = LongField()
|
||||
value = DynamicField(required=True)
|
||||
meta = {
|
||||
# For backwards compatibility reasons
|
||||
"strict": False,
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, **kwargs):
|
||||
return cls(**{k: v for k, v in kwargs.items() if k in cls._fields})
|
||||
metric = StringField(required=True)
|
||||
variant = StringField(required=True)
|
||||
value = DynamicField(required=True)
|
||||
min_value = DynamicField() # for backwards compatibility reasons
|
||||
max_value = DynamicField() # for backwards compatibility reasons
|
||||
|
||||
|
||||
class EventStats(EmbeddedDocument):
|
||||
meta = {
|
||||
# For backwards compatibility reasons
|
||||
"strict": False,
|
||||
}
|
||||
last_update = LongField()
|
||||
|
||||
|
||||
class MetricEventStats(EmbeddedDocument):
|
||||
meta = {
|
||||
# For backwards compatibility reasons
|
||||
"strict": False,
|
||||
}
|
||||
metric = StringField(required=True)
|
||||
event_stats_by_type = SafeMapField(field=EmbeddedDocumentField(EventStats))
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
from mongoengine import EmbeddedDocument, StringField
|
||||
from database.utils import get_options
|
||||
|
||||
from database.fields import OutputDestinationField
|
||||
from database.fields import StrippedStringField
|
||||
from database.utils import get_options
|
||||
|
||||
|
||||
class Result(object):
|
||||
@@ -10,7 +10,7 @@ class Result(object):
|
||||
|
||||
|
||||
class Output(EmbeddedDocument):
|
||||
destination = OutputDestinationField()
|
||||
destination = StrippedStringField()
|
||||
model = StringField(reference_field='Model')
|
||||
error = StringField(user_set_allowed=True)
|
||||
result = StringField(choices=get_options(Result))
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
from enum import Enum
|
||||
|
||||
from mongoengine import (
|
||||
StringField,
|
||||
EmbeddedDocumentField,
|
||||
@@ -7,41 +5,52 @@ from mongoengine import (
|
||||
DateTimeField,
|
||||
IntField,
|
||||
ListField,
|
||||
LongField,
|
||||
)
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import StrippedStringField, SafeMapField, SafeDictField
|
||||
from database.fields import (
|
||||
StrippedStringField,
|
||||
SafeMapField,
|
||||
SafeDictField,
|
||||
UnionField,
|
||||
EmbeddedDocumentSortedListField,
|
||||
SafeSortedListField,
|
||||
)
|
||||
from database.model import AttributedDocument
|
||||
from database.model.base import ProperDictMixin
|
||||
from database.model.model_labels import ModelLabels
|
||||
from database.model.project import Project
|
||||
from database.utils import get_options
|
||||
from .metrics import MetricEvent
|
||||
from .metrics import MetricEvent, MetricEventStats
|
||||
from .output import Output
|
||||
|
||||
DEFAULT_LAST_ITERATION = 0
|
||||
|
||||
|
||||
class TaskStatus(object):
|
||||
created = 'created'
|
||||
in_progress = 'in_progress'
|
||||
stopped = 'stopped'
|
||||
publishing = 'publishing'
|
||||
published = 'published'
|
||||
closed = 'closed'
|
||||
failed = 'failed'
|
||||
unknown = 'unknown'
|
||||
created = "created"
|
||||
queued = "queued"
|
||||
in_progress = "in_progress"
|
||||
stopped = "stopped"
|
||||
publishing = "publishing"
|
||||
published = "published"
|
||||
closed = "closed"
|
||||
failed = "failed"
|
||||
completed = "completed"
|
||||
unknown = "unknown"
|
||||
|
||||
|
||||
class TaskStatusMessage(object):
|
||||
stopping = 'stopping'
|
||||
stopping = "stopping"
|
||||
|
||||
|
||||
class TaskTags(object):
|
||||
development = 'development'
|
||||
class TaskSystemTags(object):
|
||||
development = "development"
|
||||
|
||||
|
||||
class Script(EmbeddedDocument):
|
||||
binary = StringField(default='python')
|
||||
binary = StringField(default="python")
|
||||
repository = StringField(required=True)
|
||||
tag = StringField()
|
||||
branch = StringField()
|
||||
@@ -49,53 +58,84 @@ class Script(EmbeddedDocument):
|
||||
entry_point = StringField(required=True)
|
||||
working_dir = StringField()
|
||||
requirements = SafeDictField()
|
||||
diff = StringField()
|
||||
|
||||
|
||||
class Execution(EmbeddedDocument):
|
||||
class ArtifactTypeData(EmbeddedDocument):
|
||||
preview = StringField()
|
||||
content_type = StringField()
|
||||
data_hash = StringField()
|
||||
|
||||
|
||||
class ArtifactModes:
|
||||
input = "input"
|
||||
output = "output"
|
||||
|
||||
|
||||
class Artifact(EmbeddedDocument):
|
||||
key = StringField(required=True)
|
||||
type = StringField(required=True)
|
||||
mode = StringField(choices=get_options(ArtifactModes), default=ArtifactModes.output)
|
||||
uri = StringField()
|
||||
hash = StringField()
|
||||
content_size = LongField()
|
||||
timestamp = LongField()
|
||||
type_data = EmbeddedDocumentField(ArtifactTypeData)
|
||||
display_data = SafeSortedListField(ListField(UnionField((int, float, str))))
|
||||
|
||||
|
||||
class Execution(EmbeddedDocument, ProperDictMixin):
|
||||
test_split = IntField(default=0)
|
||||
parameters = SafeDictField(default=dict)
|
||||
model = StringField(reference_field='Model')
|
||||
model_desc = SafeMapField(StringField(default=''))
|
||||
model = StringField(reference_field="Model")
|
||||
model_desc = SafeMapField(StringField(default=""))
|
||||
model_labels = ModelLabels()
|
||||
framework = StringField()
|
||||
|
||||
artifacts = EmbeddedDocumentSortedListField(Artifact)
|
||||
docker_cmd = StringField()
|
||||
queue = StringField()
|
||||
''' Queue ID where task was queued '''
|
||||
""" Queue ID where task was queued """
|
||||
|
||||
|
||||
class TaskType(object):
|
||||
training = 'training'
|
||||
testing = 'testing'
|
||||
training = "training"
|
||||
testing = "testing"
|
||||
|
||||
|
||||
class Task(AttributedDocument):
|
||||
meta = {
|
||||
'db_alias': Database.backend,
|
||||
'strict': strict,
|
||||
'indexes': [
|
||||
'created',
|
||||
'started',
|
||||
'completed',
|
||||
"db_alias": Database.backend,
|
||||
"strict": strict,
|
||||
"indexes": [
|
||||
"created",
|
||||
"started",
|
||||
"completed",
|
||||
"parent",
|
||||
"project",
|
||||
("company", "name"),
|
||||
("company", "type", "system_tags", "status"),
|
||||
("company", "project", "type", "system_tags", "status"),
|
||||
("status", "last_update"), # for maintenance tasks
|
||||
{
|
||||
'name': '%s.task.main_text_index' % Database.backend,
|
||||
'fields': [
|
||||
'$name',
|
||||
'$id',
|
||||
'$comment',
|
||||
'$execution.model',
|
||||
'$output.model',
|
||||
'$script.repository',
|
||||
'$script.entry_point',
|
||||
"name": "%s.task.main_text_index" % Database.backend,
|
||||
"fields": [
|
||||
"$name",
|
||||
"$id",
|
||||
"$comment",
|
||||
"$execution.model",
|
||||
"$output.model",
|
||||
"$script.repository",
|
||||
"$script.entry_point",
|
||||
],
|
||||
'default_language': 'english',
|
||||
'weights': {
|
||||
'name': 10,
|
||||
'id': 10,
|
||||
'comment': 10,
|
||||
'execution.model': 2,
|
||||
'output.model': 2,
|
||||
'script.repository': 1,
|
||||
'script.entry_point': 1,
|
||||
"default_language": "english",
|
||||
"weights": {
|
||||
"name": 10,
|
||||
"id": 10,
|
||||
"comment": 10,
|
||||
"execution.model": 2,
|
||||
"output.model": 2,
|
||||
"script.repository": 1,
|
||||
"script.entry_point": 1,
|
||||
},
|
||||
},
|
||||
],
|
||||
@@ -121,12 +161,11 @@ class Task(AttributedDocument):
|
||||
output = EmbeddedDocumentField(Output, default=Output)
|
||||
execution: Execution = EmbeddedDocumentField(Execution, default=Execution)
|
||||
tags = ListField(StringField(required=True), user_set_allowed=True)
|
||||
system_tags = ListField(StringField(required=True), user_set_allowed=True)
|
||||
script = EmbeddedDocumentField(Script)
|
||||
last_worker = StringField()
|
||||
last_worker_report = DateTimeField()
|
||||
last_update = DateTimeField()
|
||||
last_iteration = IntField(default=DEFAULT_LAST_ITERATION)
|
||||
last_metrics = SafeMapField(field=SafeMapField(EmbeddedDocumentField(MetricEvent)))
|
||||
|
||||
|
||||
class TaskVisibility(Enum):
|
||||
active = 'active'
|
||||
archived = 'archived'
|
||||
metric_stats = SafeMapField(field=EmbeddedDocumentField(MetricEventStats))
|
||||
|
||||
@@ -1,7 +1,6 @@
|
||||
from mongoengine import Document, StringField
|
||||
from mongoengine import Document, StringField, DynamicField
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import SafeDictField
|
||||
from database.model import DbModelMixin
|
||||
from database.model.company import Company
|
||||
|
||||
@@ -18,4 +17,4 @@ class User(DbModelMixin, Document):
|
||||
family_name = StringField(user_set_allowed=True)
|
||||
given_name = StringField(user_set_allowed=True)
|
||||
avatar = StringField()
|
||||
preferences = SafeDictField(default=dict, exclude_by_default=True)
|
||||
preferences = DynamicField(default="", exclude_by_default=True)
|
||||
|
||||
18
server/database/model/version.py
Normal file
18
server/database/model/version.py
Normal file
@@ -0,0 +1,18 @@
|
||||
from mongoengine import Document, DateTimeField, StringField
|
||||
|
||||
from database import Database, strict
|
||||
from database.model import DbModelMixin
|
||||
|
||||
|
||||
class Version(DbModelMixin, Document):
|
||||
meta = {
|
||||
"collection": "versions", # custom collection name ('version' is not a proper collection name...)
|
||||
"db_alias": Database.backend, # although we'll use this model for all databases, a default must be defined
|
||||
"strict": strict,
|
||||
"indexes": [("-created", "-num")],
|
||||
}
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
num = StringField(required=True)
|
||||
created = DateTimeField(required=True)
|
||||
desc = StringField()
|
||||
@@ -1,13 +1,17 @@
|
||||
import threading
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
from itertools import groupby, chain
|
||||
from typing import Sequence, Dict, Callable, Tuple, Any, Type
|
||||
|
||||
import dpath
|
||||
import dpath.path
|
||||
|
||||
from apierrors import errors
|
||||
from database.props import PropsMixin
|
||||
|
||||
SEP = "."
|
||||
|
||||
def project_dict(data, projection, separator='.'):
|
||||
|
||||
def project_dict(data, projection, separator=SEP):
|
||||
"""
|
||||
Project partial data from a dictionary into a new dictionary
|
||||
:param data: Input dictionary
|
||||
@@ -30,19 +34,27 @@ def project_dict(data, projection, separator='.'):
|
||||
if path_part not in dst:
|
||||
dst[path_part] = [{} for _ in range(len(src_part))]
|
||||
elif not isinstance(dst[path_part], (list, tuple)):
|
||||
raise TypeError('Incompatible destination type %s for %s (list expected)'
|
||||
% (type(dst), separator.join(path_parts[:depth + 1])))
|
||||
raise TypeError(
|
||||
"Incompatible destination type %s for %s (list expected)"
|
||||
% (type(dst), separator.join(path_parts[: depth + 1]))
|
||||
)
|
||||
elif not len(dst[path_part]) == len(src_part):
|
||||
raise ValueError('Destination list length differs from source length for %s'
|
||||
% separator.join(path_parts[:depth + 1]))
|
||||
raise ValueError(
|
||||
"Destination list length differs from source length for %s"
|
||||
% separator.join(path_parts[: depth + 1])
|
||||
)
|
||||
|
||||
dst[path_part] = [copy_path(path_parts[depth + 1:], s, d)
|
||||
for s, d in zip(src_part, dst[path_part])]
|
||||
dst[path_part] = [
|
||||
copy_path(path_parts[depth + 1:], s, d)
|
||||
for s, d in zip(src_part, dst[path_part])
|
||||
]
|
||||
|
||||
return destination
|
||||
else:
|
||||
raise TypeError('Unsupported projection type %s for %s'
|
||||
% (type(src), separator.join(path_parts[:depth + 1])))
|
||||
raise TypeError(
|
||||
"Unsupported projection type %s for %s"
|
||||
% (type(src), separator.join(path_parts[: depth + 1]))
|
||||
)
|
||||
|
||||
last_part = path_parts[-1]
|
||||
dst[last_part] = src[last_part]
|
||||
@@ -53,12 +65,35 @@ def project_dict(data, projection, separator='.'):
|
||||
|
||||
for projection_path in sorted(projection):
|
||||
copy_path(
|
||||
path_parts=projection_path.split(separator),
|
||||
source=data,
|
||||
destination=result)
|
||||
path_parts=projection_path.split(separator), source=data, destination=result
|
||||
)
|
||||
return result
|
||||
|
||||
|
||||
class _ReferenceProxy(dict):
|
||||
def __init__(self, id):
|
||||
super(_ReferenceProxy, self).__init__(**({"id": id} if id else {}))
|
||||
|
||||
|
||||
class _ProxyManager:
|
||||
lock = threading.Lock()
|
||||
|
||||
def __init__(self):
|
||||
self._proxies: Dict[str, _ReferenceProxy] = {}
|
||||
|
||||
def add(self, id):
|
||||
with self.lock:
|
||||
proxy = self._proxies.get(id)
|
||||
if proxy is None:
|
||||
proxy = self._proxies[id] = _ReferenceProxy(id)
|
||||
return proxy
|
||||
|
||||
def update(self, result):
|
||||
proxy = self._proxies.get(result.get("id"))
|
||||
if proxy is not None:
|
||||
proxy.update(result)
|
||||
|
||||
|
||||
class ProjectionHelper(object):
|
||||
pool = ThreadPoolExecutor()
|
||||
|
||||
@@ -72,6 +107,11 @@ class ProjectionHelper(object):
|
||||
self._doc_cls = doc_cls
|
||||
self._doc_projection = None
|
||||
self._ref_projection = None
|
||||
self._proxy_manager = _ProxyManager()
|
||||
|
||||
# Cached dpath paths for each of the result documents
|
||||
self._cached_results_paths: Dict[int, Sequence[Tuple[Any, Type]]] = {}
|
||||
|
||||
self._parse_projection(projection)
|
||||
|
||||
def _collect_projection_fields(self, doc_cls, projection):
|
||||
@@ -81,8 +121,12 @@ class ProjectionHelper(object):
|
||||
:param projection: List of projection fields
|
||||
:return: A tuple of document projection and reference fields information
|
||||
"""
|
||||
doc_projection = set() # Projection fields for this class (used in the main query)
|
||||
ref_projection_info = [] # Projection information for reference fields (used in join queries)
|
||||
doc_projection = (
|
||||
set()
|
||||
) # Projection fields for this class (used in the main query)
|
||||
ref_projection_info = (
|
||||
[]
|
||||
) # Projection information for reference fields (used in join queries)
|
||||
for field in projection:
|
||||
for ref_field, ref_field_cls in doc_cls.get_reference_fields().items():
|
||||
if not field.startswith(ref_field):
|
||||
@@ -93,7 +137,7 @@ class ProjectionHelper(object):
|
||||
# use '<reference field name>.*')
|
||||
continue
|
||||
subfield = field[len(ref_field):]
|
||||
if not subfield.startswith('.'):
|
||||
if not subfield.startswith(SEP):
|
||||
# Starts with something that looks like a reference field, but isn't
|
||||
continue
|
||||
|
||||
@@ -103,10 +147,12 @@ class ProjectionHelper(object):
|
||||
# Not a reference field, just add to the top-level projection
|
||||
# We strip any trailing '*' since it means nothing for simple fields and for embedded documents
|
||||
orig_field = field
|
||||
if field.endswith('.*'):
|
||||
if field.endswith(".*"):
|
||||
field = field[:-2]
|
||||
if not field:
|
||||
raise errors.bad_request.InvalidFields(field=orig_field, object=doc_cls.__name__)
|
||||
raise errors.bad_request.InvalidFields(
|
||||
field=orig_field, object=doc_cls.__name__
|
||||
)
|
||||
doc_projection.add(field)
|
||||
return doc_projection, ref_projection_info
|
||||
|
||||
@@ -124,12 +170,14 @@ class ProjectionHelper(object):
|
||||
if not projection:
|
||||
return [], {}
|
||||
|
||||
doc_projection, ref_projection_info = self._collect_projection_fields(doc_cls, projection)
|
||||
doc_projection, ref_projection_info = self._collect_projection_fields(
|
||||
doc_cls, projection
|
||||
)
|
||||
|
||||
def normalize_cls_projection(cls_, fields):
|
||||
""" Normalize projection for this class and group (expand *, for once) """
|
||||
if '*' in fields:
|
||||
return list(fields.difference('*').union(cls_.get_fields()))
|
||||
if "*" in fields:
|
||||
return list(fields.difference("*").union(cls_.get_fields()))
|
||||
return list(fields)
|
||||
|
||||
def compute_ref_cls_projection(cls_, group):
|
||||
@@ -143,12 +191,16 @@ class ProjectionHelper(object):
|
||||
# Aggregate by reference field. We'll leave out '*' from the projected items since
|
||||
ref_projection = {
|
||||
ref_field: dict(cls=ref_cls, only=compute_ref_cls_projection(ref_cls, g))
|
||||
for (ref_field, ref_cls), g in groupby(sorted(ref_projection_info, key=sort_key), sort_key)
|
||||
for (ref_field, ref_cls), g in groupby(
|
||||
sorted(ref_projection_info, key=sort_key), sort_key
|
||||
)
|
||||
}
|
||||
|
||||
# Make sure this doesn't contain any reference field we'll join anyway
|
||||
# (i.e. in case only_fields=[project, project.name])
|
||||
doc_projection = normalize_cls_projection(doc_cls, doc_projection.difference(ref_projection).union({'id'}))
|
||||
doc_projection = normalize_cls_projection(
|
||||
doc_cls, doc_projection.difference(ref_projection).union({"id"})
|
||||
)
|
||||
|
||||
# Make sure that in case one or more field is a subfield of another field, we only use the the top-level field.
|
||||
# This is done since in such a case, MongoDB will only use the most restrictive field (most nested field) and
|
||||
@@ -158,13 +210,20 @@ class ProjectionHelper(object):
|
||||
doc_projection = [
|
||||
field
|
||||
for field in doc_projection
|
||||
if not any(field.startswith(f"{other_field}.") for other_field in projection_set - {field})
|
||||
if not any(
|
||||
field.startswith(f"{other_field}.")
|
||||
for other_field in projection_set - {field}
|
||||
)
|
||||
]
|
||||
|
||||
# Make sure we didn't get any invalid projection fields for this class
|
||||
invalid_fields = [f for f in doc_projection if f.split('.')[0] not in doc_cls.get_fields()]
|
||||
invalid_fields = [
|
||||
f for f in doc_projection if f.split(SEP)[0] not in doc_cls.get_fields()
|
||||
]
|
||||
if invalid_fields:
|
||||
raise errors.bad_request.InvalidFields(fields=invalid_fields, object=doc_cls.__name__)
|
||||
raise errors.bad_request.InvalidFields(
|
||||
fields=invalid_fields, object=doc_cls.__name__
|
||||
)
|
||||
|
||||
if ref_projection:
|
||||
# Join mode - use both normal projection fields and top-level reference fields
|
||||
@@ -178,11 +237,44 @@ class ProjectionHelper(object):
|
||||
self._doc_projection = doc_projection
|
||||
self._ref_projection = ref_projection
|
||||
|
||||
@staticmethod
|
||||
def _search(doc_cls, obj, path, only_values=True):
|
||||
""" Call dpath.search with yielded=True, collect result values """
|
||||
def _search(
|
||||
self,
|
||||
doc_cls: PropsMixin,
|
||||
obj: dict,
|
||||
path: str,
|
||||
factory: Callable[[str], dict] = None,
|
||||
) -> Sequence[str]:
|
||||
"""
|
||||
Search for a path in the given object, return the list of values found for the
|
||||
given path (multiple values may exist if the path is a glob expression)
|
||||
:param doc_cls: The document class represented by the object
|
||||
:param obj: Data object
|
||||
:param path: Path to a leaf in the data object ("." separated, may contain "*")
|
||||
(in case the path contains "*", there may be multiple values)
|
||||
:param factory: If provided, replace each value found with an instance provided by the factory.
|
||||
"""
|
||||
norm_path = doc_cls.get_dpath_translated_path(path)
|
||||
return [v if only_values else (k, v) for k, v in dpath.search(obj, norm_path, separator='.', yielded=True)]
|
||||
globlist = norm_path.strip(SEP).split(SEP)
|
||||
|
||||
obj_paths = self._cached_results_paths.get(id(obj))
|
||||
if obj_paths is None:
|
||||
obj_paths = self._cached_results_paths[id(obj)] = list(
|
||||
dpath.path.paths(obj, dirs=True, skip=True)
|
||||
)
|
||||
|
||||
paths = [p for p in obj_paths if dpath.path.match(p, globlist)]
|
||||
|
||||
def search_and_replace(p: Sequence[Tuple[str, Type]]) -> Any:
|
||||
parent = None
|
||||
target = obj
|
||||
for part in p:
|
||||
parent = target
|
||||
target = target[part[0]]
|
||||
if parent and factory:
|
||||
parent[p[-1][0]] = factory(target)
|
||||
return target
|
||||
|
||||
return [search_and_replace(p) for p in paths]
|
||||
|
||||
def project(self, results, projection_func):
|
||||
"""
|
||||
@@ -197,28 +289,50 @@ class ProjectionHelper(object):
|
||||
|
||||
if ref_projection:
|
||||
# Join mode - get results for each reference fields projection required (this is the join step)
|
||||
# Note: this is a recursive step, so we support nested reference fields
|
||||
# Note: this is a recursive step, so nested reference fields are supported
|
||||
|
||||
def do_projection(item):
|
||||
ref_field_name, data = item
|
||||
res = {}
|
||||
ids = list(filter(None, set(chain.from_iterable(self._search(cls, res, ref_field_name)
|
||||
for res in results))))
|
||||
if ids:
|
||||
doc_type = data['cls']
|
||||
doc_only = list(filter(None, data['only']))
|
||||
doc_only = list({'id'} | set(doc_only)) if doc_only else None
|
||||
res = {r['id']: r for r in projection_func(doc_type=doc_type, projection=doc_only, ids=ids)}
|
||||
data['res'] = res
|
||||
def collect_ids(ref_field_name):
|
||||
"""
|
||||
Collect unique IDs for the given reference path from all result documents.
|
||||
All collected IDs are replaced in the result dictionaries with a reference proxy generated by the
|
||||
proxies manager to allow rapid update later on when projection results are obtained.
|
||||
"""
|
||||
all_ids = (
|
||||
self._search(
|
||||
cls, res, ref_field_name, factory=self._proxy_manager.add
|
||||
)
|
||||
for res in results
|
||||
)
|
||||
return list(filter(None, set(chain.from_iterable(all_ids))))
|
||||
|
||||
items = list(ref_projection.items())
|
||||
if len(ref_projection) == 1:
|
||||
do_projection(items[0])
|
||||
else:
|
||||
for _ in self.pool.map(do_projection, items):
|
||||
# From ThreadPoolExecutor.map() documentation: If a call raises an exception then that exception
|
||||
# will be raised when its value is retrieved from the map() iterator
|
||||
pass
|
||||
items = [
|
||||
tup
|
||||
for tup in (
|
||||
(*item, collect_ids(item[0])) for item in ref_projection.items()
|
||||
)
|
||||
if tup[2]
|
||||
]
|
||||
|
||||
if items:
|
||||
def do_projection(item):
|
||||
ref_field_name, data, ids = item
|
||||
|
||||
doc_type = data["cls"]
|
||||
doc_only = list(filter(None, data["only"]))
|
||||
doc_only = list({"id"} | set(doc_only)) if doc_only else None
|
||||
|
||||
for res in projection_func(
|
||||
doc_type=doc_type, projection=doc_only, ids=ids
|
||||
):
|
||||
self._proxy_manager.update(res)
|
||||
|
||||
if len(ref_projection) == 1:
|
||||
do_projection(items[0])
|
||||
else:
|
||||
for _ in self.pool.map(do_projection, items):
|
||||
# From ThreadPoolExecutor.map() documentation: If a call raises an exception then that exception
|
||||
# will be raised when its value is retrieved from the map() iterator
|
||||
pass
|
||||
|
||||
def do_expand_reference_ids(result, skip_fields=None):
|
||||
ref_fields = cls.get_reference_fields()
|
||||
@@ -226,44 +340,18 @@ class ProjectionHelper(object):
|
||||
ref_fields = set(ref_fields) - set(skip_fields)
|
||||
self._expand_reference_fields(cls, result, ref_fields)
|
||||
|
||||
def merge_projection_result(result):
|
||||
for ref_field_name, data in ref_projection.items():
|
||||
res = data.get('res')
|
||||
if not res:
|
||||
self._expand_reference_fields(cls, result, [ref_field_name])
|
||||
continue
|
||||
ref_ids = self._search(cls, result, ref_field_name, only_values=False)
|
||||
if not ref_ids:
|
||||
continue
|
||||
for path, value in ref_ids:
|
||||
obj = res.get(value) or {'id': value}
|
||||
dpath.new(result, path, obj, separator='.')
|
||||
|
||||
# any reference field not projected should be expanded
|
||||
do_expand_reference_ids(result, skip_fields=list(ref_projection))
|
||||
|
||||
update_func = merge_projection_result if ref_projection else \
|
||||
do_expand_reference_ids if self._should_expand_reference_ids else None
|
||||
|
||||
if update_func:
|
||||
# any reference field not projected should be expanded
|
||||
if self._should_expand_reference_ids:
|
||||
for result in results:
|
||||
update_func(result)
|
||||
do_expand_reference_ids(
|
||||
result, skip_fields=list(ref_projection) if ref_projection else None
|
||||
)
|
||||
|
||||
return results
|
||||
|
||||
@classmethod
|
||||
def _expand_reference_fields(cls, doc_cls, result, fields):
|
||||
def _expand_reference_fields(self, doc_cls, result, fields):
|
||||
for ref_field_name in fields:
|
||||
ref_ids = cls._search(doc_cls, result, ref_field_name, only_values=False)
|
||||
if not ref_ids:
|
||||
continue
|
||||
for path, value in ref_ids:
|
||||
dpath.set(
|
||||
result,
|
||||
path,
|
||||
{'id': value} if value else {},
|
||||
separator='.')
|
||||
self._search(doc_cls, result, ref_field_name, factory=_ReferenceProxy)
|
||||
|
||||
@classmethod
|
||||
def expand_reference_ids(cls, doc_cls, result):
|
||||
cls._expand_reference_fields(doc_cls, result, doc_cls.get_reference_fields())
|
||||
def expand_reference_ids(self, doc_cls, result):
|
||||
self._expand_reference_fields(doc_cls, result, doc_cls.get_reference_fields())
|
||||
|
||||
@@ -1,17 +1,19 @@
|
||||
from collections import OrderedDict
|
||||
from collections import OrderedDict, defaultdict
|
||||
from itertools import chain
|
||||
from operator import attrgetter
|
||||
from threading import Lock
|
||||
from typing import Sequence
|
||||
|
||||
import six
|
||||
from mongoengine import EmbeddedDocumentField, EmbeddedDocumentListField
|
||||
from mongoengine.base import get_document
|
||||
from mongoengine.base import get_document, BaseField
|
||||
|
||||
from database.fields import (
|
||||
LengthRangeEmbeddedDocumentListField,
|
||||
UniqueEmbeddedDocumentListField,
|
||||
EmbeddedDocumentSortedListField,
|
||||
)
|
||||
from database.utils import get_fields, get_fields_and_attr
|
||||
from database.utils import get_fields, get_fields_attr
|
||||
|
||||
|
||||
class PropsMixin(object):
|
||||
@@ -19,6 +21,7 @@ class PropsMixin(object):
|
||||
__cached_reference_fields = None
|
||||
__cached_exclude_fields = None
|
||||
__cached_fields_with_instance = None
|
||||
__cached_field_names_per_type = None
|
||||
|
||||
__cached_dpath_computed_fields_lock = Lock()
|
||||
__cached_dpath_computed_fields = None
|
||||
@@ -29,6 +32,39 @@ class PropsMixin(object):
|
||||
cls.__cached_fields = get_fields(cls)
|
||||
return cls.__cached_fields
|
||||
|
||||
@classmethod
|
||||
def get_field_names_for_type(cls, of_type=BaseField):
|
||||
"""
|
||||
Return field names per type including subfields
|
||||
The fields of derived types are also returned
|
||||
"""
|
||||
assert issubclass(of_type, BaseField)
|
||||
if cls.__cached_field_names_per_type is None:
|
||||
fields = defaultdict(list)
|
||||
for name, field in get_fields(cls, return_instance=True, subfields=True):
|
||||
fields[type(field)].append(name)
|
||||
for type_ in fields:
|
||||
fields[type_].extend(
|
||||
chain.from_iterable(
|
||||
fields[other_type]
|
||||
for other_type in fields
|
||||
if other_type != type_ and issubclass(other_type, type_)
|
||||
)
|
||||
)
|
||||
cls.__cached_field_names_per_type = fields
|
||||
|
||||
if of_type not in cls.__cached_field_names_per_type:
|
||||
names = list(
|
||||
chain.from_iterable(
|
||||
field_names
|
||||
for type_, field_names in cls.__cached_field_names_per_type.items()
|
||||
if issubclass(type_, of_type)
|
||||
)
|
||||
)
|
||||
cls.__cached_field_names_per_type[of_type] = names
|
||||
|
||||
return cls.__cached_field_names_per_type[of_type]
|
||||
|
||||
@classmethod
|
||||
def get_fields_with_instance(cls, doc_cls):
|
||||
if cls.__cached_fields_with_instance is None:
|
||||
@@ -42,7 +78,7 @@ class PropsMixin(object):
|
||||
@staticmethod
|
||||
def _get_fields_with_attr(cls_, attr):
|
||||
""" Get all fields with the specified attribute (supports nested fields) """
|
||||
res = get_fields_and_attr(cls_, attr=attr)
|
||||
res = get_fields_attr(cls_, attr=attr)
|
||||
|
||||
def resolve_doc(v):
|
||||
if not isinstance(v, six.string_types):
|
||||
@@ -122,6 +158,14 @@ class PropsMixin(object):
|
||||
cls.__cached_reference_fields = OrderedDict(sorted(fields.items()))
|
||||
return cls.__cached_reference_fields
|
||||
|
||||
@classmethod
|
||||
def get_extra_projection(cls, fields: Sequence) -> tuple:
|
||||
if isinstance(fields, str):
|
||||
fields = [fields]
|
||||
return tuple(
|
||||
set(fields).union(cls.get_fields()).difference(cls.get_exclude_fields())
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def get_exclude_fields(cls):
|
||||
if cls.__cached_exclude_fields is None:
|
||||
@@ -140,3 +184,18 @@ class PropsMixin(object):
|
||||
result = separator.join(translated)
|
||||
cls.__cached_dpath_computed_fields[path] = result
|
||||
return cls.__cached_dpath_computed_fields[path]
|
||||
|
||||
def get_field_value(self, field_path: str, default=None):
|
||||
"""
|
||||
Return the document field_path value by the field_path name.
|
||||
The path may contain '.'. If on any level the path is
|
||||
not found then the default value is returned
|
||||
"""
|
||||
path_elements = field_path.split(".")
|
||||
current = self
|
||||
for name in path_elements:
|
||||
current = getattr(current, name, default)
|
||||
if current == default:
|
||||
break
|
||||
|
||||
return current
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
import hashlib
|
||||
from inspect import ismethod, getmembers
|
||||
from typing import Sequence, Tuple, Set, Optional, Callable, Any
|
||||
from uuid import uuid4
|
||||
|
||||
from mongoengine import EmbeddedDocumentField, ListField, Document, Q
|
||||
@@ -8,61 +9,65 @@ from mongoengine.base import BaseField
|
||||
from .errors import translate_errors_context, ParseCallError
|
||||
|
||||
|
||||
def get_fields(cls, of_type=BaseField, return_instance=False):
|
||||
def get_fields(cls, of_type=BaseField, return_instance=False, subfields=False):
|
||||
return _get_fields(
|
||||
cls,
|
||||
of_type=of_type,
|
||||
subfields=subfields,
|
||||
selector=lambda k, v: (k, v) if return_instance else k,
|
||||
)
|
||||
|
||||
|
||||
def get_fields_attr(cls, attr):
|
||||
""" get field names from a class containing mongoengine fields """
|
||||
res = []
|
||||
for cls_ in reversed(cls.mro()):
|
||||
res.extend([k if not return_instance else (k, v)
|
||||
for k, v in vars(cls_).items()
|
||||
if isinstance(v, of_type)])
|
||||
return res
|
||||
return dict(
|
||||
_get_fields(cls, with_attr=attr, selector=lambda k, v: (k, getattr(v, attr)))
|
||||
)
|
||||
|
||||
|
||||
def get_fields_and_attr(cls, attr):
|
||||
""" get field names from a class containing mongoengine fields """
|
||||
res = {}
|
||||
for cls_ in reversed(cls.mro()):
|
||||
res.update({k: getattr(v, attr)
|
||||
for k, v in vars(cls_).items()
|
||||
if isinstance(v, BaseField) and hasattr(v, attr)})
|
||||
return res
|
||||
def get_fields_choices(cls, attr):
|
||||
def get_choices(field_name: str, field: BaseField) -> Tuple:
|
||||
if isinstance(field, ListField):
|
||||
return field_name, field.field.choices
|
||||
return field_name, field.choices
|
||||
|
||||
return dict(_get_fields(cls, with_attr=attr, subfields=True, selector=get_choices))
|
||||
|
||||
|
||||
def _get_field_choices(name, field):
|
||||
field_t = type(field)
|
||||
if issubclass(field_t, EmbeddedDocumentField):
|
||||
obj = field.document_type_obj
|
||||
n, choices = _get_field_choices(field.name, obj.field)
|
||||
return '%s__%s' % (name, n), choices
|
||||
elif issubclass(type(field), ListField):
|
||||
return name, field.field.choices
|
||||
return name, field.choices
|
||||
|
||||
|
||||
def get_fields_with_attr(cls, attr, default=False):
|
||||
def _get_fields(
|
||||
cls,
|
||||
with_attr=None,
|
||||
of_type=BaseField,
|
||||
subfields=False,
|
||||
selector: Optional[Callable[[str, BaseField], Any]] = None,
|
||||
path: Tuple[str, ...] = (),
|
||||
):
|
||||
fields = []
|
||||
for field_name, field in cls._fields.items():
|
||||
if not getattr(field, attr, default):
|
||||
continue
|
||||
field_t = type(field)
|
||||
if issubclass(field_t, EmbeddedDocumentField):
|
||||
fields.extend((('%s__%s' % (field_name, name), choices)
|
||||
for name, choices in get_fields_with_attr(field.document_type, attr, default)))
|
||||
elif issubclass(type(field), ListField):
|
||||
fields.append((field_name, field.field.choices))
|
||||
else:
|
||||
fields.append((field_name, field.choices))
|
||||
field_path = path + (field_name,)
|
||||
if isinstance(field, of_type) and (not with_attr or hasattr(field, with_attr)):
|
||||
full_name = "__".join(field_path)
|
||||
fields.append(selector(full_name, field) if selector else full_name)
|
||||
|
||||
if subfields and isinstance(field, EmbeddedDocumentField):
|
||||
fields.extend(
|
||||
_get_fields(
|
||||
field.document_type,
|
||||
with_attr=with_attr,
|
||||
of_type=of_type,
|
||||
subfields=subfields,
|
||||
selector=selector,
|
||||
path=field_path,
|
||||
)
|
||||
)
|
||||
|
||||
return fields
|
||||
|
||||
|
||||
def get_items(cls):
|
||||
""" get key/value items from an enum-like class (members represent enumeration key/value) """
|
||||
|
||||
res = {
|
||||
k: v
|
||||
for k, v in getmembers(cls)
|
||||
if not (k.startswith("_") or ismethod(v))
|
||||
}
|
||||
res = {k: v for k, v in getmembers(cls) if not (k.startswith("_") or ismethod(v))}
|
||||
return res
|
||||
|
||||
|
||||
@@ -81,7 +86,7 @@ def parse_from_call(call_data, fields, cls_fields, discard_none_values=True):
|
||||
fields = {k: None for k in fields}
|
||||
fields = {k: v for k, v in fields.items() if k in cls_fields}
|
||||
res = {}
|
||||
with translate_errors_context('parsing call data'):
|
||||
with translate_errors_context("parsing call data"):
|
||||
for field, desc in fields.items():
|
||||
value = call_data.get(field)
|
||||
if value is None:
|
||||
@@ -91,22 +96,41 @@ def parse_from_call(call_data, fields, cls_fields, discard_none_values=True):
|
||||
continue
|
||||
if desc:
|
||||
if callable(desc):
|
||||
desc(value)
|
||||
try:
|
||||
desc(value)
|
||||
except TypeError:
|
||||
raise ParseCallError(f"expecting {desc.__name__}", field=field)
|
||||
except Exception as ex:
|
||||
raise ParseCallError(str(ex), field=field)
|
||||
else:
|
||||
if issubclass(desc, (list, tuple, dict)) and not isinstance(value, desc):
|
||||
raise ParseCallError('expecting %s' % desc.__name__, field=field)
|
||||
if issubclass(desc, Document) and not desc.objects(id=value).only('id'):
|
||||
raise ParseCallError('expecting %s id' % desc.__name__, id=value, field=field)
|
||||
if issubclass(desc, (list, tuple, dict)) and not isinstance(
|
||||
value, desc
|
||||
):
|
||||
raise ParseCallError(
|
||||
"expecting %s" % desc.__name__, field=field
|
||||
)
|
||||
if issubclass(desc, Document) and not desc.objects(id=value).only(
|
||||
"id"
|
||||
):
|
||||
raise ParseCallError(
|
||||
"expecting %s id" % desc.__name__, id=value, field=field
|
||||
)
|
||||
res[field] = value
|
||||
return res
|
||||
|
||||
|
||||
def init_cls_from_base(cls, instance):
|
||||
return cls(**{k: v for k, v in instance.to_mongo(use_db_field=False).to_dict().items() if k[0] != '_'})
|
||||
return cls(
|
||||
**{
|
||||
k: v
|
||||
for k, v in instance.to_mongo(use_db_field=False).to_dict().items()
|
||||
if k[0] != "_"
|
||||
}
|
||||
)
|
||||
|
||||
|
||||
def get_company_or_none_constraint(company=None):
|
||||
return Q(company__in=(company, None, '')) | Q(company__exists=False)
|
||||
return Q(company__in=(company, None, "")) | Q(company__exists=False)
|
||||
|
||||
|
||||
def field_does_not_exist(field: str, empty_value=None, is_list=False) -> Q:
|
||||
@@ -118,23 +142,43 @@ def field_does_not_exist(field: str, empty_value=None, is_list=False) -> Q:
|
||||
the length of the array will be used (len==0 means empty)
|
||||
:return:
|
||||
"""
|
||||
query = (Q(**{f"{field}__exists": False}) |
|
||||
Q(**{f"{field}__in": {empty_value, None}}))
|
||||
query = Q(**{f"{field}__exists": False}) | Q(
|
||||
**{f"{field}__in": {empty_value, None}}
|
||||
)
|
||||
if is_list:
|
||||
query |= Q(**{f"{field}__size": 0})
|
||||
return query
|
||||
|
||||
|
||||
def field_exists(field: str, empty_value=None, is_list=False) -> Q:
|
||||
"""
|
||||
Creates a query object used for finding a field that exists and is not None or empty.
|
||||
:param field: Field name
|
||||
:param empty_value: The empty value to test for (None means no specific empty value will be used)
|
||||
:param is_list: Is this a list (array) field. In this case, instead of testing for an empty value,
|
||||
the length of the array will be used (len==0 means empty)
|
||||
:return:
|
||||
"""
|
||||
query = Q(**{f"{field}__exists": True}) & Q(
|
||||
**{f"{field}__nin": {empty_value, None}}
|
||||
)
|
||||
if is_list:
|
||||
query &= Q(**{f"{field}__not__size": 0})
|
||||
return query
|
||||
|
||||
|
||||
def get_subkey(d, key_path, default=None):
|
||||
""" Get a key from a nested dictionary. kay_path is a '.' separated string of keys used to traverse
|
||||
the nested dictionary.
|
||||
"""
|
||||
keys = key_path.split('.')
|
||||
keys = key_path.split(".")
|
||||
for i, key in enumerate(keys):
|
||||
if not isinstance(d, dict):
|
||||
raise KeyError('Expecting a dict (%s)' % ('.'.join(keys[:i]) if i else 'bad input'))
|
||||
raise KeyError(
|
||||
"Expecting a dict (%s)" % (".".join(keys[:i]) if i else "bad input")
|
||||
)
|
||||
d = d.get(key)
|
||||
if key is None:
|
||||
if d is None:
|
||||
return default
|
||||
return d
|
||||
|
||||
@@ -158,3 +202,42 @@ def merge_dicts(*dicts):
|
||||
def filter_fields(cls, fields):
|
||||
"""From the fields dictionary return only the fields that match cls fields"""
|
||||
return {key: fields[key] for key in fields if key in get_fields(cls)}
|
||||
|
||||
|
||||
def _names_set(*names: str) -> Set[str]:
|
||||
"""
|
||||
Given a list of names return set with names and '-names'
|
||||
"""
|
||||
return set(names) | set(f"-{name}" for name in names)
|
||||
|
||||
|
||||
system_tag_names = {
|
||||
"model": _names_set("active", "archived"),
|
||||
"project": _names_set("archived", "public", "default"),
|
||||
"task": _names_set("active", "archived", "development"),
|
||||
"queue": _names_set("default"),
|
||||
}
|
||||
|
||||
system_tag_prefixes = {"task": _names_set("annotat")}
|
||||
|
||||
|
||||
def partition_tags(
|
||||
entity: str, tags: Sequence[str], system_tags: Optional[Sequence[str]] = ()
|
||||
) -> Tuple[Sequence[str], Sequence[str]]:
|
||||
"""
|
||||
Partition the given tags sequence into system and user-defined tags
|
||||
:param entity: The name of the entity that defines the list of the system tags
|
||||
:param tags: The tags to partition
|
||||
:param system_tags: Optional. If passed then these tags are considered system together
|
||||
with those defined for the entity.
|
||||
:return: a tuple where the first element is the sequence of user-defined tags and
|
||||
the second element is the sequence of system tags
|
||||
"""
|
||||
tags = set(tags)
|
||||
system_tags = set(system_tags)
|
||||
system_tags |= tags & system_tag_names[entity]
|
||||
|
||||
prefixes = system_tag_prefixes.get(entity, [])
|
||||
system_tags |= {t for t in tags for p in prefixes if t.lower().startswith(p)}
|
||||
|
||||
return list(tags - system_tags), list(system_tags)
|
||||
|
||||
@@ -10,7 +10,11 @@ from pathlib import Path
|
||||
from requests.adapters import HTTPAdapter
|
||||
from requests.packages.urllib3.util.retry import Retry
|
||||
|
||||
HERE = Path(__file__).parent
|
||||
HERE = Path(__file__).resolve().parent
|
||||
|
||||
session = requests.Session()
|
||||
adapter = HTTPAdapter(max_retries=Retry(5, backoff_factor=0.5))
|
||||
session.mount('http://', adapter)
|
||||
|
||||
|
||||
def apply_mappings_to_host(host: str):
|
||||
@@ -20,10 +24,6 @@ def apply_mappings_to_host(host: str):
|
||||
es_server = host
|
||||
url = f"{es_server}/_template/{f.stem}"
|
||||
|
||||
session = requests.Session()
|
||||
adapter = HTTPAdapter(max_retries=Retry(5, backoff_factor=0.5))
|
||||
session.mount('http://', adapter)
|
||||
|
||||
session.delete(url)
|
||||
r = session.post(
|
||||
url,
|
||||
|
||||
27
server/elastic/initialize.py
Normal file
27
server/elastic/initialize.py
Normal file
@@ -0,0 +1,27 @@
|
||||
from furl import furl
|
||||
|
||||
from config import config
|
||||
from elastic.apply_mappings import apply_mappings_to_host
|
||||
from es_factory import get_cluster_config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class MissingElasticConfiguration(Exception):
|
||||
"""
|
||||
Exception when cluster configuration is not found in config files
|
||||
"""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
def init_es_data():
|
||||
hosts_config = get_cluster_config("events").get("hosts")
|
||||
if not hosts_config:
|
||||
raise MissingElasticConfiguration("for cluster 'events'")
|
||||
|
||||
for conf in hosts_config:
|
||||
host = furl(scheme="http", host=conf["host"], port=conf["port"]).url
|
||||
log.info(f"Applying mappings to host: {host}")
|
||||
res = apply_mappings_to_host(host)
|
||||
log.info(res)
|
||||
@@ -1,7 +1,7 @@
|
||||
{
|
||||
"template": "events-*",
|
||||
"settings": {
|
||||
"number_of_shards": 5
|
||||
"number_of_shards": 1
|
||||
},
|
||||
"mappings": {
|
||||
"_default_": {
|
||||
|
||||
27
server/elastic/mappings/queue_metrics.json
Normal file
27
server/elastic/mappings/queue_metrics.json
Normal file
@@ -0,0 +1,27 @@
|
||||
{
|
||||
"template": "queue_metrics_*",
|
||||
"settings": {
|
||||
"number_of_shards": 1
|
||||
},
|
||||
"mappings": {
|
||||
"metrics": {
|
||||
"_source": {
|
||||
"enabled": true
|
||||
},
|
||||
"properties": {
|
||||
"timestamp": {
|
||||
"type": "date"
|
||||
},
|
||||
"queue": {
|
||||
"type": "keyword"
|
||||
},
|
||||
"average_waiting_time": {
|
||||
"type": "float"
|
||||
},
|
||||
"queue_length": {
|
||||
"type": "integer"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
23
server/elastic/mappings/worker_stats.json
Normal file
23
server/elastic/mappings/worker_stats.json
Normal file
@@ -0,0 +1,23 @@
|
||||
{
|
||||
"template": "worker_stats_*",
|
||||
"settings": {
|
||||
"number_of_shards": 1
|
||||
},
|
||||
"mappings": {
|
||||
"stat": {
|
||||
"_source": {
|
||||
"enabled": true
|
||||
},
|
||||
"properties": {
|
||||
"timestamp": { "type": "date" },
|
||||
"worker": { "type": "keyword" },
|
||||
"category": { "type": "keyword" },
|
||||
"metric": { "type": "keyword" },
|
||||
"variant": { "type": "keyword" },
|
||||
"value": { "type": "float" },
|
||||
"unit": { "type": "keyword" },
|
||||
"task": { "type": "keyword" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -1,11 +1,28 @@
|
||||
from datetime import datetime
|
||||
from os import getenv
|
||||
|
||||
from boltons.iterutils import first
|
||||
from elasticsearch import Elasticsearch, Transport
|
||||
|
||||
from config import config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
OVERRIDE_HOST_ENV_KEY = (
|
||||
"TRAINS_ELASTIC_SERVICE_HOST",
|
||||
"ELASTIC_SERVICE_HOST",
|
||||
"ELASTIC_SERVICE_SERVICE_HOST",
|
||||
)
|
||||
OVERRIDE_PORT_ENV_KEY = ("TRAINS_ELASTIC_SERVICE_PORT", "ELASTIC_SERVICE_PORT")
|
||||
|
||||
OVERRIDE_HOST = first(filter(None, map(getenv, OVERRIDE_HOST_ENV_KEY)))
|
||||
if OVERRIDE_HOST:
|
||||
log.info(f"Using override elastic host {OVERRIDE_HOST}")
|
||||
|
||||
OVERRIDE_PORT = first(filter(None, map(getenv, OVERRIDE_PORT_ENV_KEY)))
|
||||
if OVERRIDE_PORT:
|
||||
log.info(f"Using override elastic port {OVERRIDE_PORT}")
|
||||
|
||||
_instances = {}
|
||||
|
||||
|
||||
@@ -13,6 +30,7 @@ class MissingClusterConfiguration(Exception):
|
||||
"""
|
||||
Exception when cluster configuration is not found in config files
|
||||
"""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
@@ -20,6 +38,7 @@ class InvalidClusterConfiguration(Exception):
|
||||
"""
|
||||
Exception when cluster configuration does not contain required properties
|
||||
"""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
@@ -33,28 +52,41 @@ def connect(cluster_name):
|
||||
:raises InvalidClusterConfiguration: in case cluster config section misses needed properties
|
||||
"""
|
||||
if cluster_name not in _instances:
|
||||
cluster_config = _get_cluster_config(cluster_name)
|
||||
hosts = cluster_config.get('hosts', None)
|
||||
cluster_config = get_cluster_config(cluster_name)
|
||||
hosts = cluster_config.get("hosts", None)
|
||||
if not hosts:
|
||||
raise InvalidClusterConfiguration(cluster_name)
|
||||
args = cluster_config.get('args', {})
|
||||
_instances[cluster_name] = Elasticsearch(hosts=hosts, transport_class=Transport, **args)
|
||||
|
||||
args = cluster_config.get("args", {})
|
||||
_instances[cluster_name] = Elasticsearch(
|
||||
hosts=hosts, transport_class=Transport, **args
|
||||
)
|
||||
|
||||
return _instances[cluster_name]
|
||||
|
||||
|
||||
def _get_cluster_config(cluster_name):
|
||||
def get_cluster_config(cluster_name):
|
||||
"""
|
||||
Returns cluster config for the specified cluster path
|
||||
:param cluster_name: Dot separated cluster path in the configuration file
|
||||
:return: config section for the cluster
|
||||
:raises MissingClusterConfiguration: in case no config section is found for the cluster
|
||||
"""
|
||||
cluster_key = '.'.join(('hosts.elastic', cluster_name))
|
||||
cluster_key = ".".join(("hosts.elastic", cluster_name))
|
||||
cluster_config = config.get(cluster_key, None)
|
||||
if not cluster_config:
|
||||
raise MissingClusterConfiguration(cluster_name)
|
||||
|
||||
def set_host_prop(key, value):
|
||||
for host in cluster_config.get("hosts", []):
|
||||
host[key] = value
|
||||
|
||||
if OVERRIDE_HOST:
|
||||
set_host_prop("host", OVERRIDE_HOST)
|
||||
|
||||
if OVERRIDE_PORT:
|
||||
set_host_prop("port", OVERRIDE_PORT)
|
||||
|
||||
return cluster_config
|
||||
|
||||
|
||||
|
||||
@@ -1,82 +0,0 @@
|
||||
from datetime import datetime
|
||||
from furl import furl
|
||||
|
||||
from database.model.auth import User, Credentials
|
||||
from config import config
|
||||
from database.model.auth import Role
|
||||
from database.model.company import Company
|
||||
from elastic.apply_mappings import apply_mappings_to_host
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class MissingElasticConfiguration(Exception):
|
||||
"""
|
||||
Exception when cluster configuration is not found in config files
|
||||
"""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
def init_es_data():
|
||||
hosts_key = "hosts.elastic.events.hosts"
|
||||
hosts_config = config.get(hosts_key, None)
|
||||
if not hosts_config:
|
||||
raise MissingElasticConfiguration(hosts_key)
|
||||
|
||||
for conf in hosts_config:
|
||||
host = furl(scheme="http", host=conf["host"], port=conf["port"]).url
|
||||
log.info(f"Applying mappings to host: {host}")
|
||||
res = apply_mappings_to_host(host)
|
||||
log.info(res)
|
||||
|
||||
|
||||
def _ensure_company():
|
||||
company_id = config.get("apiserver.default_company")
|
||||
company = Company.objects(id=company_id).only("id").first()
|
||||
if company:
|
||||
return company_id
|
||||
|
||||
company_name = "trains"
|
||||
log.info(f"Creating company: {company_name}")
|
||||
company = Company(id=company_id, name=company_name)
|
||||
company.save()
|
||||
return company_id
|
||||
|
||||
|
||||
def _ensure_user(user_data, company_id):
|
||||
user = User.objects(
|
||||
credentials__match=Credentials(key=user_data["key"], secret=user_data["secret"])
|
||||
).first()
|
||||
if user:
|
||||
return user.id
|
||||
|
||||
log.info(f"Creating user: {user_data['name']}")
|
||||
user = User(
|
||||
id=f"__{user_data['name']}__",
|
||||
name=user_data["name"],
|
||||
company=company_id,
|
||||
role=user_data["role"],
|
||||
email=user_data["email"],
|
||||
created=datetime.utcnow(),
|
||||
credentials=[Credentials(key=user_data["key"], secret=user_data["secret"])],
|
||||
)
|
||||
|
||||
user.save()
|
||||
|
||||
return user.id
|
||||
|
||||
|
||||
def init_mongo_data():
|
||||
company_id = _ensure_company()
|
||||
users = [
|
||||
{"name": "apiserver", "role": Role.system, "email": "apiserver@example.com"},
|
||||
{"name": "webserver", "role": Role.system, "email": "webserver@example.com"},
|
||||
{"name": "tests", "role": Role.user, "email": "tests@example.com"},
|
||||
]
|
||||
|
||||
for user in users:
|
||||
credentials = config.get(f"secure.credentials.{user['name']}")
|
||||
user["key"] = credentials.user_key
|
||||
user["secret"] = credentials.user_secret
|
||||
_ensure_user(user, company_id)
|
||||
70
server/mongo/initialize/__init__.py
Normal file
70
server/mongo/initialize/__init__.py
Normal file
@@ -0,0 +1,70 @@
|
||||
from pathlib import Path
|
||||
|
||||
from config import config
|
||||
from database.model.auth import Role
|
||||
from service_repo.auth.fixed_user import FixedUser
|
||||
from .migration import _apply_migrations
|
||||
from .pre_populate import PrePopulate
|
||||
from .user import ensure_fixed_user, _ensure_auth_user, _ensure_backend_user
|
||||
from .util import _ensure_company, _ensure_default_queue, _ensure_uuid
|
||||
|
||||
log = config.logger(__package__)
|
||||
|
||||
|
||||
def init_mongo_data():
|
||||
try:
|
||||
empty_dbs = _apply_migrations(log)
|
||||
|
||||
_ensure_uuid()
|
||||
|
||||
company_id = _ensure_company(log)
|
||||
|
||||
_ensure_default_queue(company_id)
|
||||
|
||||
if empty_dbs and config.get("apiserver.mongo.pre_populate.enabled", False):
|
||||
zip_file = config.get("apiserver.mongo.pre_populate.zip_file")
|
||||
if not zip_file or not Path(zip_file).is_file():
|
||||
msg = f"Failed pre-populating database: invalid zip file {zip_file}"
|
||||
if config.get("apiserver.mongo.pre_populate.fail_on_error", False):
|
||||
log.error(msg)
|
||||
raise ValueError(msg)
|
||||
else:
|
||||
log.warning(msg)
|
||||
else:
|
||||
|
||||
user_id = _ensure_backend_user(
|
||||
"__allegroai__", company_id, "Allegro.ai"
|
||||
)
|
||||
|
||||
PrePopulate.import_from_zip(zip_file, user_id=user_id)
|
||||
|
||||
users = [
|
||||
{
|
||||
"name": "apiserver",
|
||||
"role": Role.system,
|
||||
"email": "apiserver@example.com",
|
||||
},
|
||||
{
|
||||
"name": "webserver",
|
||||
"role": Role.system,
|
||||
"email": "webserver@example.com",
|
||||
},
|
||||
{"name": "tests", "role": Role.user, "email": "tests@example.com"},
|
||||
]
|
||||
|
||||
for user in users:
|
||||
credentials = config.get(f"secure.credentials.{user['name']}")
|
||||
user["key"] = credentials.user_key
|
||||
user["secret"] = credentials.user_secret
|
||||
_ensure_auth_user(user, company_id, log=log)
|
||||
|
||||
if FixedUser.enabled():
|
||||
log.info("Fixed users mode is enabled")
|
||||
FixedUser.validate()
|
||||
for user in FixedUser.from_config():
|
||||
try:
|
||||
ensure_fixed_user(user, company_id, log=log)
|
||||
except Exception as ex:
|
||||
log.error(f"Failed creating fixed user {user.name}: {ex}")
|
||||
except Exception as ex:
|
||||
log.exception("Failed initializing mongodb")
|
||||
86
server/mongo/initialize/migration.py
Normal file
86
server/mongo/initialize/migration.py
Normal file
@@ -0,0 +1,86 @@
|
||||
import importlib.util
|
||||
from datetime import datetime
|
||||
from logging import Logger
|
||||
from pathlib import Path
|
||||
|
||||
from mongoengine.connection import get_db
|
||||
from semantic_version import Version
|
||||
|
||||
import database.utils
|
||||
from database import Database
|
||||
from database.model.version import Version as DatabaseVersion
|
||||
|
||||
migration_dir = Path(__file__).resolve().parent.with_name("migrations")
|
||||
|
||||
|
||||
def _apply_migrations(log: Logger) -> bool:
|
||||
"""
|
||||
Apply migrations as found in the migration dir.
|
||||
Returns a boolean indicating whether the database was empty prior to migration.
|
||||
"""
|
||||
log = log.getChild(Path(__file__).stem)
|
||||
|
||||
log.info(f"Started mongodb migrations")
|
||||
|
||||
if not migration_dir.is_dir():
|
||||
raise ValueError(f"Invalid migration dir {migration_dir}")
|
||||
|
||||
empty_dbs = not any(
|
||||
get_db(alias).collection_names()
|
||||
for alias in database.utils.get_options(Database)
|
||||
)
|
||||
|
||||
try:
|
||||
previous_versions = sorted(
|
||||
(Version(ver.num) for ver in DatabaseVersion.objects().only("num")),
|
||||
reverse=True,
|
||||
)
|
||||
except ValueError as ex:
|
||||
raise ValueError(f"Invalid database version number encountered: {ex}")
|
||||
|
||||
last_version = previous_versions[0] if previous_versions else Version("0.0.0")
|
||||
|
||||
try:
|
||||
new_scripts = {
|
||||
ver: path
|
||||
for ver, path in ((Version(f.stem), f) for f in migration_dir.glob("*.py"))
|
||||
if ver > last_version
|
||||
}
|
||||
except ValueError as ex:
|
||||
raise ValueError(f"Failed parsing migration version from file: {ex}")
|
||||
|
||||
dbs = {Database.auth: "migrate_auth", Database.backend: "migrate_backend"}
|
||||
|
||||
for script_version in sorted(new_scripts):
|
||||
script = new_scripts[script_version]
|
||||
|
||||
if empty_dbs:
|
||||
log.info(f"Skipping migration {script.name} (empty databases)")
|
||||
else:
|
||||
spec = importlib.util.spec_from_file_location(script.stem, str(script))
|
||||
module = importlib.util.module_from_spec(spec)
|
||||
spec.loader.exec_module(module)
|
||||
|
||||
for alias, func_name in dbs.items():
|
||||
func = getattr(module, func_name, None)
|
||||
if not func:
|
||||
continue
|
||||
try:
|
||||
log.info(f"Applying {script.stem}/{func_name}()")
|
||||
func(get_db(alias))
|
||||
except Exception:
|
||||
log.exception(f"Failed applying {script}:{func_name}()")
|
||||
raise ValueError(
|
||||
"Migration failed, aborting. Please restore backup."
|
||||
)
|
||||
|
||||
DatabaseVersion(
|
||||
id=database.utils.id(),
|
||||
num=script.stem,
|
||||
created=datetime.utcnow(),
|
||||
desc="Applied on server startup",
|
||||
).save()
|
||||
|
||||
log.info("Finished mongodb migrations")
|
||||
|
||||
return empty_dbs
|
||||
153
server/mongo/initialize/pre_populate.py
Normal file
153
server/mongo/initialize/pre_populate.py
Normal file
@@ -0,0 +1,153 @@
|
||||
import importlib
|
||||
from collections import defaultdict
|
||||
from datetime import datetime
|
||||
from os.path import splitext
|
||||
from typing import List, Optional, Any, Type, Set, Dict
|
||||
from zipfile import ZipFile, ZIP_BZIP2
|
||||
|
||||
import mongoengine
|
||||
from tqdm import tqdm
|
||||
|
||||
|
||||
class PrePopulate:
|
||||
@classmethod
|
||||
def export_to_zip(
|
||||
cls, filename: str, experiments: List[str] = None, projects: List[str] = None
|
||||
):
|
||||
with ZipFile(filename, mode="w", compression=ZIP_BZIP2) as zfile:
|
||||
cls._export(zfile, experiments, projects)
|
||||
|
||||
@classmethod
|
||||
def import_from_zip(cls, filename: str, user_id: str = None):
|
||||
with ZipFile(filename) as zfile:
|
||||
cls._import(zfile, user_id)
|
||||
|
||||
@staticmethod
|
||||
def _resolve_type(
|
||||
cls: Type[mongoengine.Document], ids: Optional[List[str]]
|
||||
) -> List[Any]:
|
||||
ids = set(ids)
|
||||
items = list(cls.objects(id__in=list(ids)))
|
||||
resolved = {i.id for i in items}
|
||||
missing = ids - resolved
|
||||
for name_candidate in missing:
|
||||
results = list(cls.objects(name=name_candidate))
|
||||
if not results:
|
||||
print(f"ERROR: no match for `{name_candidate}`")
|
||||
exit(1)
|
||||
elif len(results) > 1:
|
||||
print(f"ERROR: more than one match for `{name_candidate}`")
|
||||
exit(1)
|
||||
items.append(results[0])
|
||||
return items
|
||||
|
||||
@classmethod
|
||||
def _resolve_entities(
|
||||
cls, experiments: List[str] = None, projects: List[str] = None
|
||||
) -> Dict[Type[mongoengine.Document], Set[mongoengine.Document]]:
|
||||
from database.model.project import Project
|
||||
from database.model.task.task import Task
|
||||
|
||||
entities = defaultdict(set)
|
||||
|
||||
if projects:
|
||||
print("Reading projects...")
|
||||
entities[Project].update(cls._resolve_type(Project, projects))
|
||||
print("--> Reading project experiments...")
|
||||
objs = Task.objects(
|
||||
project__in=list(set(filter(None, (p.id for p in entities[Project]))))
|
||||
)
|
||||
entities[Task].update(o for o in objs if o.id not in (experiments or []))
|
||||
|
||||
if experiments:
|
||||
print("Reading experiments...")
|
||||
entities[Task].update(cls._resolve_type(Task, experiments))
|
||||
print("--> Reading experiments projects...")
|
||||
objs = Project.objects(
|
||||
id__in=list(set(filter(None, (p.project for p in entities[Task]))))
|
||||
)
|
||||
project_ids = {p.id for p in entities[Project]}
|
||||
entities[Project].update(o for o in objs if o.id not in project_ids)
|
||||
|
||||
return entities
|
||||
|
||||
@classmethod
|
||||
def _cleanup_task(cls, task):
|
||||
from database.model.task.task import TaskStatus
|
||||
|
||||
task.completed = None
|
||||
task.started = None
|
||||
if task.execution:
|
||||
task.execution.model = None
|
||||
task.execution.model_desc = None
|
||||
task.execution.model_labels = None
|
||||
if task.output:
|
||||
task.output.model = None
|
||||
|
||||
task.status = TaskStatus.created
|
||||
task.comment = "Auto generated by Allegro.ai"
|
||||
task.created = datetime.utcnow()
|
||||
task.last_iteration = 0
|
||||
task.last_update = task.created
|
||||
task.status_changed = task.created
|
||||
task.status_message = ""
|
||||
task.status_reason = ""
|
||||
task.user = ""
|
||||
|
||||
@classmethod
|
||||
def _cleanup_entity(cls, entity_cls, entity):
|
||||
from database.model.task.task import Task
|
||||
if entity_cls == Task:
|
||||
cls._cleanup_task(entity)
|
||||
|
||||
@classmethod
|
||||
def _export(
|
||||
cls, writer: ZipFile, experiments: List[str] = None, projects: List[str] = None
|
||||
):
|
||||
entities = cls._resolve_entities(experiments, projects)
|
||||
|
||||
for cls_, items in entities.items():
|
||||
if not items:
|
||||
continue
|
||||
filename = f"{cls_.__module__}.{cls_.__name__}.json"
|
||||
print(f"Writing {len(items)} items into {writer.filename}:{filename}")
|
||||
with writer.open(filename, "w") as f:
|
||||
f.write("[\n".encode("utf-8"))
|
||||
last = len(items) - 1
|
||||
for i, item in enumerate(items):
|
||||
cls._cleanup_entity(cls_, item)
|
||||
f.write(item.to_json().encode("utf-8"))
|
||||
if i != last:
|
||||
f.write(",".encode("utf-8"))
|
||||
f.write("\n".encode("utf-8"))
|
||||
f.write("]\n".encode("utf-8"))
|
||||
|
||||
@staticmethod
|
||||
def _import(reader: ZipFile, user_id: str = None):
|
||||
for file_info in reader.filelist:
|
||||
full_name = splitext(file_info.orig_filename)[0]
|
||||
print(f"Reading {reader.filename}:{full_name}...")
|
||||
module_name, _, class_name = full_name.rpartition(".")
|
||||
module = importlib.import_module(module_name)
|
||||
cls_: Type[mongoengine.Document] = getattr(module, class_name)
|
||||
|
||||
with reader.open(file_info) as f:
|
||||
for item in tqdm(
|
||||
f.readlines(),
|
||||
desc=f"Writing {cls_.__name__.lower()}s into database",
|
||||
unit="doc",
|
||||
):
|
||||
item = (
|
||||
item.decode("utf-8")
|
||||
.strip()
|
||||
.lstrip("[")
|
||||
.rstrip("]")
|
||||
.rstrip(",")
|
||||
.strip()
|
||||
)
|
||||
if not item:
|
||||
continue
|
||||
doc = cls_.from_json(item)
|
||||
if user_id is not None and hasattr(doc, "user"):
|
||||
doc.user = user_id
|
||||
doc.save(force_insert=True)
|
||||
74
server/mongo/initialize/user.py
Normal file
74
server/mongo/initialize/user.py
Normal file
@@ -0,0 +1,74 @@
|
||||
from datetime import datetime
|
||||
from logging import Logger
|
||||
|
||||
import attr
|
||||
|
||||
from database.model.auth import Role
|
||||
from database.model.auth import User as AuthUser, Credentials
|
||||
from database.model.user import User
|
||||
from service_repo.auth.fixed_user import FixedUser
|
||||
|
||||
|
||||
def _ensure_auth_user(user_data: dict, company_id: str, log: Logger):
|
||||
ensure_credentials = {"key", "secret"}.issubset(user_data)
|
||||
if ensure_credentials:
|
||||
user = AuthUser.objects(
|
||||
credentials__match=Credentials(
|
||||
key=user_data["key"], secret=user_data["secret"]
|
||||
)
|
||||
).first()
|
||||
if user:
|
||||
return user.id
|
||||
|
||||
log.info(f"Creating user: {user_data['name']}")
|
||||
user = AuthUser(
|
||||
id=user_data.get("id", f"__{user_data['name']}__"),
|
||||
name=user_data["name"],
|
||||
company=company_id,
|
||||
role=user_data["role"],
|
||||
email=user_data["email"],
|
||||
created=datetime.utcnow(),
|
||||
credentials=[Credentials(key=user_data["key"], secret=user_data["secret"])]
|
||||
if ensure_credentials
|
||||
else None,
|
||||
)
|
||||
|
||||
user.save()
|
||||
|
||||
return user.id
|
||||
|
||||
|
||||
def _ensure_backend_user(user_id: str, company_id: str, user_name: str):
|
||||
given_name, _, family_name = user_name.partition(" ")
|
||||
|
||||
User(
|
||||
id=user_id,
|
||||
company=company_id,
|
||||
name=user_name,
|
||||
given_name=given_name,
|
||||
family_name=family_name,
|
||||
).save()
|
||||
|
||||
return user_id
|
||||
|
||||
|
||||
def ensure_fixed_user(user: FixedUser, company_id: str, log: Logger):
|
||||
if User.objects(id=user.user_id).first():
|
||||
return
|
||||
|
||||
data = attr.asdict(user)
|
||||
data["id"] = user.user_id
|
||||
data["email"] = f"{user.user_id}@example.com"
|
||||
data["role"] = Role.user
|
||||
|
||||
_ensure_auth_user(user_data=data, company_id=company_id, log=log)
|
||||
|
||||
given_name, _, family_name = user.name.partition(" ")
|
||||
|
||||
User(
|
||||
id=user.user_id,
|
||||
company=company_id,
|
||||
name=user.name,
|
||||
given_name=given_name,
|
||||
family_name=family_name,
|
||||
).save()
|
||||
40
server/mongo/initialize/util.py
Normal file
40
server/mongo/initialize/util.py
Normal file
@@ -0,0 +1,40 @@
|
||||
from logging import Logger
|
||||
from uuid import uuid4
|
||||
|
||||
from bll.queue import QueueBLL
|
||||
from config import config
|
||||
from config.info import get_default_company
|
||||
from database.model.company import Company
|
||||
from database.model.queue import Queue
|
||||
from database.model.settings import Settings
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
def _ensure_company(log: Logger):
|
||||
company_id = get_default_company()
|
||||
company = Company.objects(id=company_id).only("id").first()
|
||||
if company:
|
||||
return company_id
|
||||
|
||||
company_name = "trains"
|
||||
log.info(f"Creating company: {company_name}")
|
||||
company = Company(id=company_id, name=company_name)
|
||||
company.save()
|
||||
return company_id
|
||||
|
||||
|
||||
def _ensure_default_queue(company):
|
||||
"""
|
||||
If no queue is present for the company then
|
||||
create a new one and mark it as a default
|
||||
"""
|
||||
queue = Queue.objects(company=company).only("id").first()
|
||||
if queue:
|
||||
return
|
||||
|
||||
QueueBLL.create(company, name="default", system_tags=["default"])
|
||||
|
||||
|
||||
def _ensure_uuid():
|
||||
Settings.add_value("server.uuid", str(uuid4()))
|
||||
18
server/mongo/migrations/0.12.1.py
Normal file
18
server/mongo/migrations/0.12.1.py
Normal file
@@ -0,0 +1,18 @@
|
||||
from pymongo.database import Database, Collection
|
||||
|
||||
from database.utils import partition_tags
|
||||
|
||||
|
||||
def migrate_backend(db: Database):
|
||||
for name in ("project", "task", "model"):
|
||||
collection: Collection = db[name]
|
||||
for doc in collection.find(projection=["tags", "system_tags"]):
|
||||
tags = doc.get("tags")
|
||||
if tags is not None:
|
||||
user_tags, system_tags = partition_tags(
|
||||
name, tags, doc.get("system_tags", [])
|
||||
)
|
||||
collection.update_one(
|
||||
{"_id": doc["_id"]},
|
||||
{"$set": {"system_tags": system_tags, "tags": user_tags}}
|
||||
)
|
||||
20
server/mongo/migrations/0.13.0.py
Normal file
20
server/mongo/migrations/0.13.0.py
Normal file
@@ -0,0 +1,20 @@
|
||||
import json
|
||||
|
||||
from pymongo.database import Database, Collection
|
||||
|
||||
|
||||
def migrate_auth(db: Database):
|
||||
collection: Collection = db["user"]
|
||||
if "name_1_company_1" in [doc["name"] for doc in collection.list_indexes()]:
|
||||
collection.drop_index("name_1_company_1")
|
||||
|
||||
|
||||
def migrate_backend(db: Database):
|
||||
collection: Collection = db["user"]
|
||||
users = collection.find(
|
||||
{"preferences": {"$exists": True, "$ne": None, "$type": "object"}}
|
||||
)
|
||||
for doc in users:
|
||||
collection.update_one(
|
||||
{"_id": doc["_id"]}, {"$set": {"preferences": json.dumps(doc["preferences"])}}
|
||||
)
|
||||
46
server/mongo/migrations/0.14.0.py
Normal file
46
server/mongo/migrations/0.14.0.py
Normal file
@@ -0,0 +1,46 @@
|
||||
import hashlib
|
||||
|
||||
from pymongo.database import Database, Collection
|
||||
|
||||
from service_repo.auth.fixed_user import FixedUser
|
||||
|
||||
|
||||
def _get_ids():
|
||||
if not FixedUser.enabled():
|
||||
return
|
||||
|
||||
return {
|
||||
hashlib.md5(f"{user.username}:{user.password}".encode()).hexdigest(): user.user_id
|
||||
for user in FixedUser.from_config()
|
||||
}
|
||||
|
||||
|
||||
def _switch_uuid(collection: Collection, uuid_field: str, uuids: dict):
|
||||
docs = list(collection.find({uuid_field: {"$in": [uuids]}}))
|
||||
if not docs:
|
||||
return
|
||||
replaced_uuids = [doc[uuid_field] for doc in docs]
|
||||
for doc in docs:
|
||||
doc[uuid_field] = uuids[doc[uuid_field]]
|
||||
collection.insert_many(docs)
|
||||
collection.delete_many({uuid_field: {"$in": replaced_uuids}})
|
||||
|
||||
|
||||
def migrate_auth(db: Database):
|
||||
uuids = _get_ids()
|
||||
if not uuids:
|
||||
return
|
||||
|
||||
collection = db["user"]
|
||||
collection.drop_index("name_1_company_1")
|
||||
|
||||
_switch_uuid(collection=collection, uuid_field="_id", uuids=uuids)
|
||||
|
||||
|
||||
def migrate_backend(db: Database):
|
||||
uuids = _get_ids()
|
||||
if not uuids:
|
||||
return
|
||||
|
||||
for name in ("project", "task", "model"):
|
||||
_switch_uuid(collection=db[name], uuid_field="user", uuids=uuids)
|
||||
195
server/redis_manager.py
Normal file
195
server/redis_manager.py
Normal file
@@ -0,0 +1,195 @@
|
||||
import threading
|
||||
from os import getenv
|
||||
from time import sleep
|
||||
|
||||
from boltons.iterutils import first
|
||||
from redis import StrictRedis
|
||||
from redis.sentinel import Sentinel, SentinelConnectionPool
|
||||
|
||||
from apierrors.errors.server_error import ConfigError, GeneralError
|
||||
from config import config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
OVERRIDE_HOST_ENV_KEY = ("TRAINS_REDIS_SERVICE_HOST", "REDIS_SERVICE_HOST")
|
||||
OVERRIDE_PORT_ENV_KEY = ("TRAINS_REDIS_SERVICE_PORT", "REDIS_SERVICE_PORT")
|
||||
|
||||
OVERRIDE_HOST = first(filter(None, map(getenv, OVERRIDE_HOST_ENV_KEY)))
|
||||
if OVERRIDE_HOST:
|
||||
log.info(f"Using override redis host {OVERRIDE_HOST}")
|
||||
|
||||
OVERRIDE_PORT = first(filter(None, map(getenv, OVERRIDE_PORT_ENV_KEY)))
|
||||
if OVERRIDE_PORT:
|
||||
log.info(f"Using override redis port {OVERRIDE_PORT}")
|
||||
|
||||
|
||||
class MyPubSubWorkerThread(threading.Thread):
|
||||
def __init__(self, sentinel, on_new_master, msg_sleep_time, daemon=True):
|
||||
super(MyPubSubWorkerThread, self).__init__()
|
||||
self.daemon = daemon
|
||||
self.sentinel = sentinel
|
||||
self.on_new_master = on_new_master
|
||||
self.sentinel_host = sentinel.connection_pool.connection_kwargs["host"]
|
||||
self.msg_sleep_time = msg_sleep_time
|
||||
self._running = False
|
||||
self.pubsub = None
|
||||
|
||||
def subscribe(self):
|
||||
if self.pubsub:
|
||||
try:
|
||||
self.pubsub.unsubscribe()
|
||||
self.pubsub.punsubscribe()
|
||||
except Exception:
|
||||
pass
|
||||
finally:
|
||||
self.pubsub = None
|
||||
|
||||
subscriptions = {"+switch-master": self.on_new_master}
|
||||
|
||||
while not self.pubsub or not self.pubsub.subscribed:
|
||||
try:
|
||||
self.pubsub = self.sentinel.pubsub()
|
||||
self.pubsub.subscribe(**subscriptions)
|
||||
except Exception as ex:
|
||||
log.warn(
|
||||
f"Error while subscribing to sentinel at {self.sentinel_host} ({ex.args[0]}) Sleeping and retrying"
|
||||
)
|
||||
sleep(3)
|
||||
log.info(f"Subscribed to sentinel {self.sentinel_host}")
|
||||
|
||||
def run(self):
|
||||
if self._running:
|
||||
return
|
||||
self._running = True
|
||||
|
||||
self.subscribe()
|
||||
|
||||
while self.pubsub.subscribed:
|
||||
try:
|
||||
self.pubsub.get_message(
|
||||
ignore_subscribe_messages=True, timeout=self.msg_sleep_time
|
||||
)
|
||||
except Exception as ex:
|
||||
log.warn(
|
||||
f"Error while getting message from sentinel {self.sentinel_host} ({ex.args[0]}) Resubscribing"
|
||||
)
|
||||
self.subscribe()
|
||||
|
||||
self.pubsub.close()
|
||||
self._running = False
|
||||
|
||||
def stop(self):
|
||||
# stopping simply unsubscribes from all channels and patterns.
|
||||
# the unsubscribe responses that are generated will short circuit
|
||||
# the loop in run(), calling pubsub.close() to clean up the connection
|
||||
self.pubsub.unsubscribe()
|
||||
self.pubsub.punsubscribe()
|
||||
|
||||
|
||||
# todo,future - multi master clusters?
|
||||
class RedisCluster(object):
|
||||
def __init__(self, sentinel_hosts, service_name, **connection_kwargs):
|
||||
self.service_name = service_name
|
||||
self.sentinel = Sentinel(sentinel_hosts, **connection_kwargs)
|
||||
self.master = None
|
||||
self.master_host_port = None
|
||||
self.reconfigure()
|
||||
self.sentinel_threads = {}
|
||||
self.listen()
|
||||
|
||||
def reconfigure(self):
|
||||
try:
|
||||
self.master_host_port = self.sentinel.discover_master(self.service_name)
|
||||
self.master = self.sentinel.master_for(self.service_name)
|
||||
log.info(f"Reconfigured master to {self.master_host_port}")
|
||||
except Exception as ex:
|
||||
log.error(f"Error while reconfiguring. {ex.args[0]}")
|
||||
|
||||
def listen(self):
|
||||
def on_new_master(workerThread):
|
||||
self.reconfigure()
|
||||
|
||||
for sentinel in self.sentinel.sentinels:
|
||||
sentinel_host = sentinel.connection_pool.connection_kwargs["host"]
|
||||
self.sentinel_threads[sentinel_host] = MyPubSubWorkerThread(
|
||||
sentinel, on_new_master, msg_sleep_time=0.001, daemon=True
|
||||
)
|
||||
self.sentinel_threads[sentinel_host].start()
|
||||
|
||||
|
||||
class RedisManager(object):
|
||||
def __init__(self, redis_config_dict):
|
||||
self.aliases = {}
|
||||
for alias, alias_config in redis_config_dict.items():
|
||||
|
||||
alias_config = alias_config.as_plain_ordered_dict()
|
||||
|
||||
is_cluster = alias_config.get("cluster", False)
|
||||
|
||||
host = OVERRIDE_HOST or alias_config.get("host", None)
|
||||
if host:
|
||||
alias_config["host"] = host
|
||||
|
||||
port = OVERRIDE_PORT or alias_config.get("port", None)
|
||||
if port:
|
||||
alias_config["port"] = port
|
||||
|
||||
db = alias_config.get("db", 0)
|
||||
|
||||
sentinels = alias_config.get("sentinels", None)
|
||||
service_name = alias_config.get("service_name", None)
|
||||
|
||||
if not is_cluster and sentinels:
|
||||
raise ConfigError(
|
||||
"Redis configuration is invalid. mixed regular and cluster mode",
|
||||
alias=alias,
|
||||
)
|
||||
if is_cluster and (not sentinels or not service_name):
|
||||
raise ConfigError(
|
||||
"Redis configuration is invalid. missing sentinels or service_name",
|
||||
alias=alias,
|
||||
)
|
||||
if not is_cluster and (not port or not host):
|
||||
raise ConfigError(
|
||||
"Redis configuration is invalid. missing port or host", alias=alias
|
||||
)
|
||||
|
||||
if is_cluster:
|
||||
# todo support all redis connection args via sentinel's connection_kwargs
|
||||
del alias_config["sentinels"]
|
||||
del alias_config["cluster"]
|
||||
del alias_config["service_name"]
|
||||
self.aliases[alias] = RedisCluster(
|
||||
sentinels, service_name, **alias_config
|
||||
)
|
||||
else:
|
||||
self.aliases[alias] = StrictRedis(**alias_config)
|
||||
|
||||
def connection(self, alias):
|
||||
obj = self.aliases.get(alias)
|
||||
if not obj:
|
||||
raise GeneralError(f"Invalid Redis alias {alias}")
|
||||
if isinstance(obj, RedisCluster):
|
||||
obj.master.get("health")
|
||||
return obj.master
|
||||
else:
|
||||
obj.get("health")
|
||||
return obj
|
||||
|
||||
def host(self, alias):
|
||||
r = self.connection(alias)
|
||||
pool = r.connection_pool
|
||||
if isinstance(pool, SentinelConnectionPool):
|
||||
connections = pool.connection_kwargs[
|
||||
"connection_pool"
|
||||
]._available_connections
|
||||
else:
|
||||
connections = pool._available_connections
|
||||
|
||||
if len(connections) > 0:
|
||||
return connections[0].host
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
redman = RedisManager(config.get("hosts.redis"))
|
||||
@@ -1,27 +1,30 @@
|
||||
six
|
||||
Flask>=0.12.2
|
||||
elasticsearch>=5.0.0,<6.0.0
|
||||
pyhocon>=0.3.35
|
||||
requests>=2.13.0
|
||||
arrow>=0.10.0
|
||||
pymongo==3.6.1 # 3.7 has a bug multiple users logged in
|
||||
Flask-Cors>=3.0.5
|
||||
Flask-Compress>=1.4.0
|
||||
mongoengine==0.16.2
|
||||
jsonmodels>=2.3
|
||||
pyjwt>=1.3.0
|
||||
gunicorn>=19.7.1
|
||||
Jinja2==2.10
|
||||
python-rapidjson>=0.6.3
|
||||
jsonschema>=2.6.0
|
||||
dpath>=1.4.2
|
||||
funcsigs==1.0.2
|
||||
luqum>=0.7.2
|
||||
typing>=3.6.4
|
||||
attrs>=19.1.0
|
||||
nested_dict>=1.61
|
||||
related>=0.7.2
|
||||
validators>=0.12.4
|
||||
fastjsonschema>=2.8
|
||||
boltons>=19.1.0
|
||||
semantic_version>=2.6.0,<3
|
||||
dpath>=1.4.2,<2.0
|
||||
elasticsearch>=5.0.0,<6.0.0
|
||||
fastjsonschema>=2.8
|
||||
Flask-Compress>=1.4.0
|
||||
Flask-Cors>=3.0.5
|
||||
Flask>=0.12.2
|
||||
funcsigs==1.0.2
|
||||
furl>=2.0.0
|
||||
gunicorn>=19.7.1
|
||||
humanfriendly==4.18
|
||||
Jinja2==2.10
|
||||
jsonmodels>=2.3
|
||||
jsonschema>=2.6.0
|
||||
luqum>=0.7.2
|
||||
mongoengine==0.16.2
|
||||
nested_dict>=1.61
|
||||
psutil>=5.6.5
|
||||
pyhocon>=0.3.35
|
||||
pyjwt>=1.3.0
|
||||
pymongo==3.6.1 # 3.7 has a bug multiple users logged in
|
||||
python-rapidjson>=0.6.3
|
||||
redis>=2.10.5
|
||||
related>=0.7.2
|
||||
requests>=2.13.0
|
||||
semantic_version>=2.8.0,<3
|
||||
six
|
||||
tqdm
|
||||
validators>=0.12.4
|
||||
@@ -15,6 +15,11 @@ _definitions {
|
||||
type: string
|
||||
description: ""
|
||||
}
|
||||
last_used {
|
||||
type: string
|
||||
description: ""
|
||||
format: "date-time"
|
||||
}
|
||||
}
|
||||
}
|
||||
role {
|
||||
@@ -52,6 +57,22 @@ login {
|
||||
}
|
||||
}
|
||||
|
||||
logout {
|
||||
internal: false
|
||||
allow_roles = [ "*" ]
|
||||
"2.2" {
|
||||
description: """Removes the authentication cookie from the current session"""
|
||||
request {
|
||||
type: object
|
||||
additionalProperties: false
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
additionalProperties: false
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
get_token_for_user {
|
||||
"2.1" {
|
||||
description: """Get a token for the specified user. Intended for internal use."""
|
||||
@@ -255,33 +276,6 @@ revoke_credentials {
|
||||
}
|
||||
}
|
||||
|
||||
delete_user {
|
||||
allow_roles = [ "system", "root", "admin" ]
|
||||
internal: false
|
||||
"2.1" {
|
||||
description: """Delete a new user manually. Only supported in on-premises deployments. This only removes the user's auth entry so that any references to the deleted user's ID will still have valid user information"""
|
||||
request {
|
||||
type: object
|
||||
required: [ user ]
|
||||
properties {
|
||||
user {
|
||||
type: string
|
||||
description: User ID
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
deleted {
|
||||
description: "True if user was successfully deleted, False otherwise"
|
||||
type: boolean
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
edit_user {
|
||||
internal: false
|
||||
allow_roles: ["system", "root", "admin"]
|
||||
@@ -317,4 +311,24 @@ edit_user {
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fixed_users_mode {
|
||||
authorize: false
|
||||
"2.1" {
|
||||
description: """ Return fixed users mode status"""
|
||||
request {
|
||||
type: object
|
||||
additionalProperties: false
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
enabled {
|
||||
description: "Fixed users mode enabled"
|
||||
type: boolean
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -149,6 +149,14 @@
|
||||
}
|
||||
}
|
||||
}
|
||||
scalar_key_enum {
|
||||
type: string
|
||||
enum: [
|
||||
iter
|
||||
timestamp
|
||||
iso_time
|
||||
]
|
||||
}
|
||||
log_level_enum {
|
||||
type: string
|
||||
enum: [
|
||||
@@ -163,6 +171,30 @@
|
||||
critical
|
||||
]
|
||||
}
|
||||
event_type_enum {
|
||||
type: string
|
||||
enum: [
|
||||
training_stats_scalar
|
||||
training_stats_vector
|
||||
training_debug_image
|
||||
plot
|
||||
log
|
||||
]
|
||||
}
|
||||
task_metric {
|
||||
type: object
|
||||
required: [task, metric]
|
||||
properties {
|
||||
task {
|
||||
description: "Task ID"
|
||||
type: string
|
||||
}
|
||||
metric {
|
||||
description: "Metric name"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
task_log_event {
|
||||
description: """A log event associated with a task."""
|
||||
type: object
|
||||
@@ -216,7 +248,7 @@
|
||||
}
|
||||
add_batch {
|
||||
"2.1" {
|
||||
description: "Adds a batch of events in a single call."
|
||||
description: "Adds a batch of events in a single call (json-lines format, stream-friendly)"
|
||||
batch_request: {
|
||||
action: add
|
||||
version: 1.5
|
||||
@@ -226,6 +258,7 @@
|
||||
properties {
|
||||
added { type: integer }
|
||||
errors { type: integer }
|
||||
errors_info { type: object }
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -243,6 +276,11 @@
|
||||
type: string
|
||||
description: "Task ID"
|
||||
}
|
||||
allow_locked {
|
||||
type: boolean
|
||||
description: "Allow deleting events even if the task is locked"
|
||||
default: false
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
@@ -306,6 +344,84 @@
|
||||
}
|
||||
}
|
||||
}
|
||||
"2.7" {
|
||||
description: "Get the debug image events for the requested amount of iterations per each task's metric"
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
metrics
|
||||
]
|
||||
properties {
|
||||
metrics {
|
||||
type: array
|
||||
items { "$ref": "#/definitions/task_metric" }
|
||||
description: "List metrics for which the envents will be retreived"
|
||||
}
|
||||
iters {
|
||||
type: integer
|
||||
description: "Max number of latest iterations for which to return debug images"
|
||||
}
|
||||
navigate_earlier {
|
||||
type: boolean
|
||||
description: "If set then events are retreived from latest iterations to earliest ones. Otherwise from earliest iterations to the latest. The default is True"
|
||||
}
|
||||
refresh {
|
||||
type: boolean
|
||||
description: "If set then scroll will be moved to the latest iterations. The default is False"
|
||||
}
|
||||
scroll_id {
|
||||
type: string
|
||||
description: "Scroll ID of previous call (used for getting more results)"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
metrics {
|
||||
type: array
|
||||
items: { type: object }
|
||||
description: "Debug image events grouped by task metrics and iterations"
|
||||
}
|
||||
scroll_id {
|
||||
type: string
|
||||
description: "Scroll ID for getting more results"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_task_metrics{
|
||||
"2.7": {
|
||||
description: "For each task, get a list of metrics for which the requested event type was reported"
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
tasks
|
||||
]
|
||||
properties {
|
||||
tasks {
|
||||
type: array
|
||||
items { type: string }
|
||||
description: "Task IDs"
|
||||
}
|
||||
event_type {
|
||||
"description": "Event type"
|
||||
"$ref": "#/definitions/event_type_enum"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
metrics {
|
||||
type: array
|
||||
items { type: object }
|
||||
description: "List of task with their metrics"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_task_log {
|
||||
"1.5" {
|
||||
@@ -414,6 +530,59 @@
|
||||
}
|
||||
}
|
||||
}
|
||||
"2.7" {
|
||||
description: "Get 'log' events for this task"
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
task
|
||||
]
|
||||
properties {
|
||||
task {
|
||||
type: string
|
||||
description: "Task ID"
|
||||
}
|
||||
batch_size {
|
||||
type: integer
|
||||
description: "The amount of log events to return"
|
||||
}
|
||||
navigate_earlier {
|
||||
type: boolean
|
||||
description: "If set then log events are retreived from the latest to the earliest ones (in timestamp descending order). Otherwise from the earliest to the latest ones (in timestamp ascending order). The default is True"
|
||||
}
|
||||
refresh {
|
||||
type: boolean
|
||||
description: "If set then scroll will be moved to the latest logs (if 'navigate_earlier' is set to True) or to the earliest (otherwise)"
|
||||
}
|
||||
scroll_id {
|
||||
type: string
|
||||
description: "Scroll ID of previous call (used for getting more results)"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
events {
|
||||
type: array
|
||||
items { type: object }
|
||||
description: "Log items list"
|
||||
}
|
||||
returned {
|
||||
type: integer
|
||||
description: "Number of log events returned"
|
||||
}
|
||||
total {
|
||||
type: number
|
||||
description: "Total number of log events available for this query"
|
||||
}
|
||||
scroll_id {
|
||||
type: string
|
||||
description: "Scroll ID for getting more results"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_task_events {
|
||||
"2.1" {
|
||||
@@ -442,7 +611,11 @@
|
||||
}
|
||||
batch_size {
|
||||
type: integer
|
||||
description: "Number of events to return each time"
|
||||
description: "Number of events to return each time (default 500)"
|
||||
}
|
||||
event_type {
|
||||
type: string
|
||||
description: "Return only events of this type"
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -682,6 +855,19 @@
|
||||
type: string
|
||||
description: "Task ID"
|
||||
}
|
||||
samples {
|
||||
description: "The amount of histogram points to return (0 to return all the points). Optional, the default value is 10000."
|
||||
type: integer
|
||||
}
|
||||
key {
|
||||
description: """
|
||||
Histogram x axis to use:
|
||||
iter - iteration number
|
||||
iso_time - event time as ISO formatted string
|
||||
timestamp - event timestamp as milliseconds since epoch
|
||||
"""
|
||||
"$ref": "#/definitions/scalar_key_enum"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
@@ -715,7 +901,19 @@
|
||||
description: "List of task Task IDs"
|
||||
}
|
||||
}
|
||||
|
||||
samples {
|
||||
description: "The amount of histogram points to return (0 to return all the points). Optional, the default value is 10000."
|
||||
type: integer
|
||||
}
|
||||
key {
|
||||
description: """
|
||||
Histogram x axis to use:
|
||||
iter - iteration number
|
||||
iso_time - event time as ISO formatted string
|
||||
timestamp - event timestamp as milliseconds since epoch
|
||||
"""
|
||||
"$ref": "#/definitions/scalar_key_enum"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
|
||||
@@ -57,9 +57,14 @@
|
||||
}
|
||||
tags {
|
||||
type: array
|
||||
description: "Tags"
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
framework {
|
||||
description: "Framework on which the model is based. Should be identical to the framework of the task which created the model"
|
||||
type: string
|
||||
@@ -159,7 +164,12 @@
|
||||
type: boolean
|
||||
}
|
||||
tags {
|
||||
description: "Tags list used to filter results. Prepend '-' to tag name to indicate exclusion"
|
||||
description: "User-defined tags list used to filter results. Prepend '-' to tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list used to filter results. Prepend '-' to system tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -251,7 +261,7 @@
|
||||
type: string
|
||||
}
|
||||
uri {
|
||||
description: "URI for the model"
|
||||
description: "URI for the model. Exactly one of uri or override_model_id is a required."
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
@@ -263,12 +273,17 @@
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
override_model_id {
|
||||
description: "Override model ID. If provided, this model is updated in the task."
|
||||
description: "Override model ID. If provided, this model is updated in the task. Exactly one of override_model_id or uri is required."
|
||||
type: string
|
||||
}
|
||||
iteration {
|
||||
@@ -309,7 +324,6 @@
|
||||
required: [
|
||||
uri
|
||||
name
|
||||
labels
|
||||
]
|
||||
properties {
|
||||
uri {
|
||||
@@ -325,10 +339,15 @@
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
framework {
|
||||
description: "Framework on which the model is based. Case insensitive. Should be identical to the framework of the task which created the model."
|
||||
type: string
|
||||
@@ -344,7 +363,7 @@
|
||||
additionalProperties { type: integer }
|
||||
}
|
||||
ready {
|
||||
description: "Indication if the model is final and can be used by other tasks Default is false."
|
||||
description: "Indication if the model is final and can be used by other tasks. Default is false."
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
@@ -408,10 +427,15 @@
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
framework {
|
||||
description: "Framework on which the model is based. Case insensitive. Should be identical to the framework of the task which created the model."
|
||||
type: string
|
||||
@@ -485,10 +509,15 @@
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
ready {
|
||||
description: "Indication if the model is final and can be used by other tasks Default is false."
|
||||
type: boolean
|
||||
|
||||
@@ -1,462 +1,523 @@
|
||||
{
|
||||
_description: "Provides support for defining Projects containing Tasks, Models and Dataset Versions."
|
||||
_definitions {
|
||||
multi_field_pattern_data {
|
||||
_description: "Provides support for defining Projects containing Tasks, Models and Dataset Versions."
|
||||
_definitions {
|
||||
multi_field_pattern_data {
|
||||
type: object
|
||||
properties {
|
||||
pattern {
|
||||
description: "Pattern string (regex)"
|
||||
type: string
|
||||
}
|
||||
fields {
|
||||
description: "List of field names"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
project {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
user {
|
||||
description: "Associated user id"
|
||||
type: string
|
||||
}
|
||||
company {
|
||||
description: "Company id"
|
||||
type: string
|
||||
}
|
||||
created {
|
||||
description: "Creation time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
tags {
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
last_update {
|
||||
description: """Last project update time. Reflects the last time the project metadata was changed or a task in this project has changed status"""
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
}
|
||||
}
|
||||
stats_status_count {
|
||||
type: object
|
||||
properties {
|
||||
total_runtime {
|
||||
description: "Total run time of all tasks in project (in seconds)"
|
||||
type: integer
|
||||
}
|
||||
status_count {
|
||||
description: "Status counts"
|
||||
type: object
|
||||
properties {
|
||||
created {
|
||||
description: "Number of 'created' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
queued {
|
||||
description: "Number of 'queued' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
in_progress {
|
||||
description: "Number of 'in_progress' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
stopped {
|
||||
description: "Number of 'stopped' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
published {
|
||||
description: "Number of 'published' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
closed {
|
||||
description: "Number of 'closed' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
failed {
|
||||
description: "Number of 'failed' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
unknown {
|
||||
description: "Number of 'unknown' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
stats {
|
||||
type: object
|
||||
properties {
|
||||
active {
|
||||
description: "Stats for active tasks"
|
||||
"$ref": "#/definitions/stats_status_count"
|
||||
}
|
||||
archived {
|
||||
description: "Stats for archived tasks"
|
||||
"$ref": "#/definitions/stats_status_count"
|
||||
}
|
||||
}
|
||||
}
|
||||
projects_get_all_response_single {
|
||||
// copy-paste from project definition
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
user {
|
||||
description: "Associated user id"
|
||||
type: string
|
||||
}
|
||||
company {
|
||||
description: "Company id"
|
||||
type: string
|
||||
}
|
||||
created {
|
||||
description: "Creation time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
tags {
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
// extra properties
|
||||
stats: {
|
||||
description: "Additional project stats"
|
||||
"$ref": "#/definitions/stats"
|
||||
}
|
||||
}
|
||||
}
|
||||
metric_variant_result {
|
||||
type: object
|
||||
properties {
|
||||
metric {
|
||||
description: "Metric name"
|
||||
type: string
|
||||
}
|
||||
metric_hash {
|
||||
description: """Metric name hash. Used instead of the metric name when categorizing
|
||||
last metrics events in task objects."""
|
||||
type: string
|
||||
}
|
||||
variant {
|
||||
description: "Variant name"
|
||||
type: string
|
||||
}
|
||||
variant_hash {
|
||||
description: """Variant name hash. Used instead of the variant name when categorizing
|
||||
last metrics events in task objects."""
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
create {
|
||||
"2.1" {
|
||||
description: "Create a new project"
|
||||
request {
|
||||
type: object
|
||||
required :[
|
||||
name
|
||||
description
|
||||
]
|
||||
properties {
|
||||
pattern {
|
||||
description: "Pattern string (regex)"
|
||||
name {
|
||||
description: "Project name Unique within the company."
|
||||
type: string
|
||||
}
|
||||
fields {
|
||||
description: "List of field names"
|
||||
description {
|
||||
description: "Project description. "
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
project_tags_enum {
|
||||
type: string
|
||||
enum: [ archived, public, default ]
|
||||
}
|
||||
project {
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
user {
|
||||
description: "Associated user id"
|
||||
type: string
|
||||
}
|
||||
company {
|
||||
description: "Company id"
|
||||
type: string
|
||||
}
|
||||
created {
|
||||
description: "Creation time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
tags {
|
||||
description: "Tags"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/project_tags_enum" }
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
last_update {
|
||||
description: """Last project update time. Reflects the last time the project metadata was changed or a task in this project has changed status"""
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
}
|
||||
}
|
||||
stats_status_count {
|
||||
type: object
|
||||
properties {
|
||||
total_runtime {
|
||||
description: "Total run time of all tasks in project (in seconds)"
|
||||
type: integer
|
||||
}
|
||||
status_count {
|
||||
description: "Status counts"
|
||||
type: object
|
||||
properties {
|
||||
created {
|
||||
description: "Number of 'created' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
queued {
|
||||
description: "Number of 'queued' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
in_progress {
|
||||
description: "Number of 'in_progress' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
stopped {
|
||||
description: "Number of 'stopped' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
published {
|
||||
description: "Number of 'published' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
closed {
|
||||
description: "Number of 'closed' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
failed {
|
||||
description: "Number of 'failed' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
unknown {
|
||||
description: "Number of 'unknown' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
stats {
|
||||
type: object
|
||||
properties {
|
||||
active {
|
||||
description: "Stats for active tasks"
|
||||
"$ref": "#/definitions/stats_status_count"
|
||||
}
|
||||
archived {
|
||||
description: "Stats for archived tasks"
|
||||
"$ref": "#/definitions/stats_status_count"
|
||||
}
|
||||
}
|
||||
}
|
||||
projects_get_all_response_single {
|
||||
// copy-paste from project definition
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
user {
|
||||
description: "Associated user id"
|
||||
type: string
|
||||
}
|
||||
company {
|
||||
description: "Company id"
|
||||
type: string
|
||||
}
|
||||
created {
|
||||
description: "Creation time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
tags {
|
||||
description: "Tags"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/project_tags_enum" }
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
// extra properties
|
||||
stats: {
|
||||
description: "Additional project stats"
|
||||
"$ref": "#/definitions/stats"
|
||||
}
|
||||
}
|
||||
}
|
||||
metric_variant_result {
|
||||
type: object
|
||||
properties {
|
||||
metric {
|
||||
description: "Metric name"
|
||||
type: string
|
||||
}
|
||||
metric_hash {
|
||||
description: """Metric name hash. Used instead of the metric name when categorizing
|
||||
last metrics events in task objects."""
|
||||
type: string
|
||||
}
|
||||
variant {
|
||||
description: "Variant name"
|
||||
type: string
|
||||
}
|
||||
variant_hash {
|
||||
description: """Variant name hash. Used instead of the variant name when categorizing
|
||||
last metrics events in task objects."""
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
create {
|
||||
"2.1" {
|
||||
description: "Create a new project"
|
||||
request {
|
||||
type: object
|
||||
required :[
|
||||
name
|
||||
description
|
||||
]
|
||||
properties {
|
||||
name {
|
||||
description: "Project name Unique within the company."
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description. "
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/project_tags_enum" }
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_by_id {
|
||||
"2.1" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
project {
|
||||
description: "Project info"
|
||||
"$ref": "#/definitions/project"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_all {
|
||||
"2.1" {
|
||||
description: "Get all the company's projects and all public projects"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "List of IDs to filter by"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
name {
|
||||
description: "Get only projects whose name matches this pattern (python regular expression syntax)"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Get only projects whose description matches this pattern (python regular expression syntax)"
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list used to filter results. Prepend '-' to tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
order_by {
|
||||
description: "List of field names to order by. When search_text is used, '@text_score' can be used as a field representing the text score of returned documents. Use '-' prefix to specify descending order. Optional, recommended when using page"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
page {
|
||||
description: "Page number, returns a specific page out of the resulting list of dataviews"
|
||||
type: integer
|
||||
minimum: 0
|
||||
}
|
||||
page_size {
|
||||
description: "Page size, specifies the number of results returned in each page (last page may contain fewer results)"
|
||||
type: integer
|
||||
minimum: 1
|
||||
}
|
||||
search_text {
|
||||
description: "Free text search query"
|
||||
type: string
|
||||
}
|
||||
only_fields {
|
||||
description: "List of document's field names (nesting is supported using '.', e.g. execution.model_labels). If provided, this list defines the query's projection (only these fields will be returned for each result entry)"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
_all_ {
|
||||
description: "Multi-field pattern condition (all fields match pattern)"
|
||||
"$ref": "#/definitions/multi_field_pattern_data"
|
||||
}
|
||||
_any_ {
|
||||
description: "Multi-field pattern condition (any field matches pattern)"
|
||||
"$ref": "#/definitions/multi_field_pattern_data"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
projects {
|
||||
description: "Projects list"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/projects_get_all_response_single" }
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_all_ex {
|
||||
internal: true
|
||||
"2.1": ${get_all."2.1"} {
|
||||
request {
|
||||
properties {
|
||||
include_stats {
|
||||
description: "If true, include project statistic in response."
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
stats_for_state {
|
||||
description: "Report stats include only statistics for tasks in the specified state. If Null is provided, stats for all task states will be returned."
|
||||
type: string
|
||||
enum: [ active, archived ]
|
||||
default: active
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
update {
|
||||
"2.1" {
|
||||
description: "Update project information"
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name. Unique within the company."
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description. "
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
updated {
|
||||
description: "Number of projects updated (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
fields {
|
||||
description: "Updated fields names and values"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
delete {
|
||||
"2.1" {
|
||||
description: "Deletes a project"
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
force {
|
||||
description: """If not true, fails if project has tasks.
|
||||
If true, and project has tasks, they will be unassigned"""
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
deleted {
|
||||
description: "Number of projects deleted (0 or 1)"
|
||||
type: integer
|
||||
}
|
||||
disassociated_tasks {
|
||||
description: "Number of tasks disassociated from the deleted project"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_unique_metric_variants {
|
||||
"2.1" {
|
||||
description: """Get all metric/variant pairs reported for tasks in a specific project.
|
||||
If no project is specified, metrics/variant paris reported for all tasks will be returned.
|
||||
If the project does not exist, an empty list will be returned."""
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
project {
|
||||
description: "Project ID"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
metrics {
|
||||
description: "A list of metric variants reported for tasks in this project"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/metric_variant_result" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_by_id {
|
||||
"2.1" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
project {
|
||||
description: "Project info"
|
||||
"$ref": "#/definitions/project"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_all {
|
||||
"2.1" {
|
||||
description: "Get all the company's projects and all public projects"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "List of IDs to filter by"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
name {
|
||||
description: "Get only projects whose name matches this pattern (python regular expression syntax)"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Get only projects whose description matches this pattern (python regular expression syntax)"
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "User-defined tags list used to filter results. Prepend '-' to tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list used to filter results. Prepend '-' to system tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
order_by {
|
||||
description: "List of field names to order by. When search_text is used, '@text_score' can be used as a field representing the text score of returned documents. Use '-' prefix to specify descending order. Optional, recommended when using page"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
page {
|
||||
description: "Page number, returns a specific page out of the resulting list of dataviews"
|
||||
type: integer
|
||||
minimum: 0
|
||||
}
|
||||
page_size {
|
||||
description: "Page size, specifies the number of results returned in each page (last page may contain fewer results)"
|
||||
type: integer
|
||||
minimum: 1
|
||||
}
|
||||
search_text {
|
||||
description: "Free text search query"
|
||||
type: string
|
||||
}
|
||||
only_fields {
|
||||
description: "List of document's field names (nesting is supported using '.', e.g. execution.model_labels). If provided, this list defines the query's projection (only these fields will be returned for each result entry)"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
_all_ {
|
||||
description: "Multi-field pattern condition (all fields match pattern)"
|
||||
"$ref": "#/definitions/multi_field_pattern_data"
|
||||
}
|
||||
_any_ {
|
||||
description: "Multi-field pattern condition (any field matches pattern)"
|
||||
"$ref": "#/definitions/multi_field_pattern_data"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
projects {
|
||||
description: "Projects list"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/projects_get_all_response_single" }
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_all_ex {
|
||||
internal: true
|
||||
"2.1": ${get_all."2.1"} {
|
||||
request {
|
||||
properties {
|
||||
include_stats {
|
||||
description: "If true, include project statistic in response."
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
stats_for_state {
|
||||
description: "Report stats include only statistics for tasks in the specified state. If Null is provided, stats for all task states will be returned."
|
||||
type: string
|
||||
enum: [ active, archived ]
|
||||
default: active
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
update {
|
||||
"2.1" {
|
||||
description: "Update project information"
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name. Unique within the company."
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description. "
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
updated {
|
||||
description: "Number of projects updated (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
fields {
|
||||
description: "Updated fields names and values"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
delete {
|
||||
"2.1" {
|
||||
description: "Deletes a project"
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
force {
|
||||
description: """If not true, fails if project has tasks.
|
||||
If true, and project has tasks, they will be unassigned"""
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
deleted {
|
||||
description: "Number of projects deleted (0 or 1)"
|
||||
type: integer
|
||||
}
|
||||
disassociated_tasks {
|
||||
description: "Number of tasks disassociated from the deleted project"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_unique_metric_variants {
|
||||
"2.1" {
|
||||
description: """Get all metric/variant pairs reported for tasks in a specific project.
|
||||
If no project is specified, metrics/variant paris reported for all tasks will be returned.
|
||||
If the project does not exist, an empty list will be returned."""
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
project {
|
||||
description: "Project ID"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
metrics {
|
||||
description: "A list of metric variants reported for tasks in this project"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/metric_variant_result" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_hyper_parameters {
|
||||
"2.2" {
|
||||
description: """Get a list of all hyper parameter names used in tasks within the given project."""
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
project {
|
||||
description: "Project ID"
|
||||
type: string
|
||||
}
|
||||
page {
|
||||
description: "Page number"
|
||||
default: 0
|
||||
type: integer
|
||||
}
|
||||
page_size {
|
||||
description: "Page size"
|
||||
default: 500
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
parameters {
|
||||
description: "A list of hyper parameter names"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
remaining {
|
||||
description: "Remaining results"
|
||||
type: integer
|
||||
}
|
||||
total {
|
||||
description: "Total number of results"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
568
server/schema/services/queues.conf
Normal file
568
server/schema/services/queues.conf
Normal file
@@ -0,0 +1,568 @@
|
||||
{
|
||||
_description: "Provides a management API for queues of tasks waiting to be executed by workers deployed anywhere (see Workers Service)."
|
||||
_definitions {
|
||||
queue_metrics {
|
||||
type: object
|
||||
properties: {
|
||||
queue: {
|
||||
type: string
|
||||
description: "ID of the queue"
|
||||
}
|
||||
dates {
|
||||
type: array
|
||||
description: "List of timestamps (in seconds from epoch) in the acceding order. The timestamps are separated by the requested interval. Timestamps where no queue status change was recorded are omitted."
|
||||
items { type: integer }
|
||||
}
|
||||
avg_waiting_times {
|
||||
type: array
|
||||
description: "List of average waiting times for tasks in the queue. The points correspond to the timestamps in the dates list. If more than one value exists for the given interval then the maximum value is taken."
|
||||
items { type: number }
|
||||
}
|
||||
queue_lengths {
|
||||
type: array
|
||||
description: "List of tasks counts in the queue. The points correspond to the timestamps in the dates list. If more than one value exists for the given interval then the count that corresponds to the maximum average value is taken."
|
||||
items { type: integer }
|
||||
}
|
||||
}
|
||||
}
|
||||
entry {
|
||||
type: object
|
||||
properties: {
|
||||
task {
|
||||
description: "Queued task ID"
|
||||
type: string
|
||||
}
|
||||
added {
|
||||
description: "Time this entry was added to the queue"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
}
|
||||
}
|
||||
queue {
|
||||
type: object
|
||||
properties: {
|
||||
id {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Queue name"
|
||||
type: string
|
||||
}
|
||||
user {
|
||||
description: "Associated user id"
|
||||
type: string
|
||||
}
|
||||
company {
|
||||
description: "Company id"
|
||||
type: string
|
||||
}
|
||||
created {
|
||||
description: "Queue creation time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
tags {
|
||||
description: "User-defined tags"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
entries {
|
||||
description: "List of ordered queue entries"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/entry" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
get_by_id {
|
||||
"2.4" {
|
||||
description: "Gets queue information"
|
||||
request {
|
||||
type: object
|
||||
required: [ queue ]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue ID"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue info"
|
||||
"$ref": "#/definitions/queue"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
// typescript generation hack
|
||||
get_all_ex {
|
||||
internal: true
|
||||
"2.4": ${get_all."2.4"}
|
||||
}
|
||||
get_all {
|
||||
"2.4" {
|
||||
description: "Get all queues"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
name {
|
||||
description: "Get only queues whose name matches this pattern (python regular expression syntax)"
|
||||
type: string
|
||||
}
|
||||
id {
|
||||
description: "List of Queue IDs used to filter results"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
tags {
|
||||
description: "User-defined tags list used to filter results. Prepend '-' to tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list used to filter results. Prepend '-' to system tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
page {
|
||||
description: "Page number, returns a specific page out of the result list of results."
|
||||
type: integer
|
||||
minimum: 0
|
||||
}
|
||||
page_size {
|
||||
description: "Page size, specifies the number of results returned in each page (last page may contain fewer results)"
|
||||
type: integer
|
||||
minimum: 1
|
||||
}
|
||||
order_by {
|
||||
description: "List of field names to order by. When search_text is used, '@text_score' can be used as a field representing the text score of returned documents. Use '-' prefix to specify descending order. Optional, recommended when using page"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
search_text {
|
||||
description: "Free text search query"
|
||||
type: string
|
||||
}
|
||||
only_fields {
|
||||
description: "List of document field names (nesting is supported using '.', e.g. execution.model_labels). If provided, this list defines the query's projection (only these fields will be returned for each result entry)"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
queues {
|
||||
description: "Queues list"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/queue"}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_default {
|
||||
"2.4" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
properties {}
|
||||
additionalProperties: false
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Queue name"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
create {
|
||||
"2.4" {
|
||||
description: "Create a new queue"
|
||||
request {
|
||||
type: object
|
||||
required: [ name ]
|
||||
properties {
|
||||
name {
|
||||
description: "Queue name Unique within the company."
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "New queue ID"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
update {
|
||||
"2.4" {
|
||||
description: "Update queue information"
|
||||
request {
|
||||
type: object
|
||||
required: [ queue ]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Queue name Unique within the company."
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
updated {
|
||||
description: "Number of queues updated (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
fields {
|
||||
description: "Updated fields names and values"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
delete {
|
||||
"2.4" {
|
||||
description: "Deletes a queue. If the queue is not empty and force is not set to true, queue will not be deleted."
|
||||
request {
|
||||
type: object
|
||||
required: [ queue ]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
force {
|
||||
description: "Force delete of non-empty queue. Defaults to false"
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
deleted {
|
||||
description: "Number of queues deleted (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
add_task {
|
||||
"2.4" {
|
||||
description: "Adds a task entry to the queue."
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
added {
|
||||
description: "Number of tasks added (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_next_task {
|
||||
"2.4" {
|
||||
description: "Gets the next task from the top of the queue (FIFO). The task entry is removed from the queue."
|
||||
request {
|
||||
type: object
|
||||
required: [ queue ]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
entry {
|
||||
description: "Entry information"
|
||||
"$ref": "#/definitions/entry"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
remove_task {
|
||||
"2.4" {
|
||||
description: "Removes a task entry from the queue."
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
removed {
|
||||
description: "Number of tasks removed (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
move_task_forward: {
|
||||
"2.4" {
|
||||
description: "Moves a task entry one step forward towards the top of the queue."
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
count {
|
||||
description: "Number of positions in the queue to move the task forward relative to the current position. Optional, the default value is 1."
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
position {
|
||||
description: "The new position of the task entry in the queue (index, -1 represents bottom of queue)"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
move_task_backward: {
|
||||
"2.4" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
count {
|
||||
description: "Number of positions in the queue to move the task forward relative to the current position. Optional, the default value is 1."
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
position {
|
||||
description: "The new position of the task entry in the queue (index, -1 represents bottom of queue)"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
move_task_to_front: {
|
||||
"2.4" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
position {
|
||||
description: "The new position of the task entry in the queue (index, -1 represents bottom of queue)"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
move_task_to_back: {
|
||||
"2.4" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
position {
|
||||
description: "The new position of the task entry in the queue (index, -1 represents bottom of queue)"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_queue_metrics : {
|
||||
"2.4" {
|
||||
description: "Returns metrics of the company queues. The metrics are avaraged in the specified interval."
|
||||
request {
|
||||
type: object
|
||||
required: [from_date, to_date, interval]
|
||||
properties: {
|
||||
from_date {
|
||||
description: "Starting time (in seconds from epoch) for collecting metrics"
|
||||
type: number
|
||||
}
|
||||
to_date {
|
||||
description: "Ending time (in seconds from epoch) for collecting metrics"
|
||||
type: number
|
||||
}
|
||||
interval {
|
||||
description: "Time interval in seconds for a single metrics point. The minimal value is 1"
|
||||
type: integer
|
||||
}
|
||||
queue_ids {
|
||||
description: "List of queue ids to collect metrics for. If not provided or empty then all then average metrics across all the company queues will be returned."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties: {
|
||||
queues {
|
||||
type: array
|
||||
description: "List of the requested queues with their metrics. If no queue ids were requested then 'all' queue is returned with the metrics averaged accross all the company queues."
|
||||
items { "$ref": "#/definitions/queue_metrics" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
128
server/schema/services/server.conf
Normal file
128
server/schema/services/server.conf
Normal file
@@ -0,0 +1,128 @@
|
||||
_description: "server utilities"
|
||||
_default {
|
||||
internal: true
|
||||
allow_roles: ["root", "system"]
|
||||
}
|
||||
get_stats {
|
||||
"2.1" {
|
||||
description: "Get the server collected statistics."
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
interval {
|
||||
description: "The period for statistics collection in seconds."
|
||||
type: long
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties: {
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
config {
|
||||
"2.1" {
|
||||
description: "Get server configuration. Secure section is not returned."
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
path {
|
||||
description: "Path of config value. Defaults to root"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
info {
|
||||
authorize = false
|
||||
allow_roles = [ "*" ]
|
||||
"2.1" {
|
||||
description: "Get server information, including version and build number"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
version {
|
||||
description: "Version string"
|
||||
type: string
|
||||
}
|
||||
build {
|
||||
description: "Build number"
|
||||
type: string
|
||||
}
|
||||
commit {
|
||||
description: "VCS commit number"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
endpoints {
|
||||
"2.1" {
|
||||
description: "Show available endpoints"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
report_stats_option {
|
||||
allow_roles = [ "*" ]
|
||||
"2.4" {
|
||||
description: "Get or set the report statistics option per-company"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
enabled {
|
||||
description: "If provided, sets the report statistics option (true/false)"
|
||||
type: boolean
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
enabled {
|
||||
description: "Returns the current report stats option value"
|
||||
type: boolean
|
||||
}
|
||||
enabled_time {
|
||||
description: "If enabled, returns the time at which option was enabled"
|
||||
type: string
|
||||
format: date-time
|
||||
}
|
||||
enabled_version {
|
||||
description: "If enabled, returns the server version at the time option was enabled"
|
||||
type: string
|
||||
}
|
||||
enabled_user {
|
||||
description: "If enabled, returns Id of the user who enabled the option"
|
||||
type: string
|
||||
}
|
||||
current_version {
|
||||
description: "Returns the current server version"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -69,13 +69,17 @@ _definitions {
|
||||
type: string
|
||||
}
|
||||
working_dir {
|
||||
description: "Path to the folder from which to run the script Default - root folder of repository[f]"
|
||||
description: "Path to the folder from which to run the script Default - root folder of repository"
|
||||
type: string
|
||||
}
|
||||
requirements {
|
||||
description: "A JSON object containing requirements strings by key"
|
||||
type: object
|
||||
}
|
||||
diff {
|
||||
description: "Uncommitted changes found in the repository when task was run"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
output {
|
||||
@@ -116,9 +120,83 @@ _definitions {
|
||||
frame_per_roi
|
||||
]
|
||||
}
|
||||
artifact_type_data {
|
||||
type: object
|
||||
properties {
|
||||
preview {
|
||||
description: "Description or textual data"
|
||||
type: string
|
||||
}
|
||||
content_type {
|
||||
description: "System defined raw data content type"
|
||||
type: string
|
||||
}
|
||||
data_hash {
|
||||
description: "Hash of raw data, without any headers or descriptive parts"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
artifact {
|
||||
type: object
|
||||
required: [key, type]
|
||||
properties {
|
||||
key {
|
||||
description: "Entry key"
|
||||
type: string
|
||||
}
|
||||
type {
|
||||
description: "System defined type"
|
||||
type: string
|
||||
}
|
||||
mode {
|
||||
description: "System defined input/output indication"
|
||||
type: string
|
||||
enum: [
|
||||
input
|
||||
output
|
||||
]
|
||||
default: output
|
||||
}
|
||||
uri {
|
||||
description: "Raw data location"
|
||||
type: string
|
||||
}
|
||||
content_size {
|
||||
description: "Raw data length in bytes"
|
||||
type: integer
|
||||
}
|
||||
hash {
|
||||
description: "Hash of entire raw data"
|
||||
type: string
|
||||
}
|
||||
timestamp {
|
||||
description: "Epoch time when artifact was created"
|
||||
type: integer
|
||||
}
|
||||
type_data {
|
||||
description: "Additional fields defined by the system"
|
||||
"$ref": "#/definitions/artifact_type_data"
|
||||
}
|
||||
display_data {
|
||||
description: "User-defined list of key/value pairs, sorted"
|
||||
type: array
|
||||
items {
|
||||
type: array
|
||||
items {
|
||||
type: string # can also be a number... TODO: upgrade the generator
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
execution {
|
||||
type: object
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue ID where task was queued."
|
||||
type: string
|
||||
}
|
||||
parameters {
|
||||
description: "Json object containing the Task parameters"
|
||||
type: object
|
||||
@@ -137,7 +215,7 @@ _definitions {
|
||||
description: """Json object representing the ids of the labels in the model.
|
||||
The keys are the layers' names and the values are the IDs.
|
||||
Not applicable for Register (Import) tasks.
|
||||
Mandatory for Training tasks[z]"""
|
||||
Mandatory for Training tasks"""
|
||||
type: object
|
||||
additionalProperties: { type: integer }
|
||||
}
|
||||
@@ -145,18 +223,29 @@ _definitions {
|
||||
description: """Framework related to the task. Case insensitive. Mandatory for Training tasks. """
|
||||
type: string
|
||||
}
|
||||
docker_cmd {
|
||||
description: "Command for running docker script for the execution of the task"
|
||||
type: string
|
||||
}
|
||||
artifacts {
|
||||
description: "Task artifacts"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/artifact" }
|
||||
}
|
||||
}
|
||||
}
|
||||
task_status_enum {
|
||||
type: string
|
||||
enum: [
|
||||
created
|
||||
queued
|
||||
in_progress
|
||||
stopped
|
||||
published
|
||||
publishing
|
||||
closed
|
||||
failed
|
||||
completed
|
||||
unknown
|
||||
]
|
||||
}
|
||||
@@ -178,21 +267,16 @@ _definitions {
|
||||
description: "Variant name"
|
||||
type: string
|
||||
}
|
||||
type {
|
||||
description: "Event type"
|
||||
type: string
|
||||
}
|
||||
timestamp {
|
||||
description: "Event report time (UTC)"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
iter {
|
||||
description: "Iteration number"
|
||||
type: integer
|
||||
}
|
||||
value {
|
||||
description: "Value"
|
||||
description: "Last value reported"
|
||||
type: number
|
||||
}
|
||||
min_value {
|
||||
description: "Minimum value reported"
|
||||
type: number
|
||||
}
|
||||
max_value {
|
||||
description: "Maximum value reported"
|
||||
type: number
|
||||
}
|
||||
}
|
||||
@@ -273,7 +357,12 @@ _definitions {
|
||||
"$ref": "#/definitions/script"
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -295,6 +384,15 @@ _definitions {
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
last_worker {
|
||||
description: "ID of last worker that handled the task"
|
||||
type: string
|
||||
}
|
||||
last_worker_report {
|
||||
description: "Last time a worker reported while working on this task"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
last_update {
|
||||
description: "Last time this task was created, updated, changed or events for this task were reported"
|
||||
type: string
|
||||
@@ -387,7 +485,12 @@ get_all {
|
||||
items { type: string }
|
||||
}
|
||||
tags {
|
||||
description: "List of task tags. Use '-' prefix to exclude tags"
|
||||
description: "List of task user-defined tags. Use '-' prefix to exclude tags"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "List of task system tags. Use '-' prefix to exclude system tags"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -447,6 +550,60 @@ get_all {
|
||||
}
|
||||
}
|
||||
}
|
||||
clone {
|
||||
"2.5" {
|
||||
description: "Clone an existing task"
|
||||
request {
|
||||
type: object
|
||||
required: [ task ]
|
||||
properties {
|
||||
task {
|
||||
description: "ID of the task"
|
||||
type: string
|
||||
}
|
||||
new_task_name {
|
||||
description: "The name of the cloned task. If not provided then taken from the original task"
|
||||
type: string
|
||||
}
|
||||
new_task_comment {
|
||||
description: "The comment of the cloned task. If not provided then taken from the original task"
|
||||
type: string
|
||||
}
|
||||
new_task_tags {
|
||||
description: "The user-defined tags of the cloned task. If not provided then taken from the original task"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
new_task_system_tags {
|
||||
description: "The system tags of the cloned task. If not provided then empty"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
new_task_parent {
|
||||
description: "The parent of the cloned task. If not provided then taken from the original task"
|
||||
type: string
|
||||
}
|
||||
new_task_project {
|
||||
description: "The project of the cloned task. If not provided then taken from the original task"
|
||||
type: string
|
||||
}
|
||||
execution_overrides {
|
||||
description: "The execution params for the cloned task. The params not specified are taken from the original task"
|
||||
"$ref": "#/definitions/execution"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "ID of the new task"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
create {
|
||||
"2.1" {
|
||||
description: "Create a new task"
|
||||
@@ -462,7 +619,12 @@ create {
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -522,7 +684,12 @@ validate {
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -580,7 +747,12 @@ update {
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -662,7 +834,12 @@ edit {
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -733,6 +910,11 @@ reset {
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
dequeued {
|
||||
description: "Response from queues.remove_task"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
frames {
|
||||
description: "Response from frames.rollback"
|
||||
type: object
|
||||
@@ -1009,6 +1191,85 @@ publish {
|
||||
}
|
||||
}
|
||||
}
|
||||
enqueue {
|
||||
"1.5" {
|
||||
description: """Adds a task into a queue.
|
||||
|
||||
Fails if task state is not 'created'.
|
||||
|
||||
Fails if the following parameters in the task were not filled:
|
||||
|
||||
* execution.script.repository
|
||||
|
||||
* execution.script.entrypoint
|
||||
"""
|
||||
request = {
|
||||
type: object
|
||||
required: [
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id. If not provided, task is added to the default queue."
|
||||
type: string
|
||||
}
|
||||
}
|
||||
|
||||
} ${_references.status_change_request}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
queued {
|
||||
description: "Number of tasks queued (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
updated {
|
||||
description: "Number of tasks updated (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
fields {
|
||||
description: "Updated fields names and values"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
dequeue {
|
||||
"1.5" {
|
||||
description: """Remove a task from its queue.
|
||||
Fails if task status is not queued."""
|
||||
request = {
|
||||
type: object
|
||||
required: [
|
||||
task
|
||||
]
|
||||
} ${_references.status_change_request}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
dequeued {
|
||||
description: "Number of tasks dequeued (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
updated {
|
||||
description: "Number of tasks updated (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
fields {
|
||||
description: "Updated fields names and values"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
set_requirements {
|
||||
"2.1" {
|
||||
description: """Set the script requirements for a task"""
|
||||
@@ -1046,3 +1307,91 @@ set_requirements {
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
completed {
|
||||
"2.2" {
|
||||
description: "Signal a task has completed"
|
||||
request = {
|
||||
type: object
|
||||
required: [
|
||||
task
|
||||
]
|
||||
properties.force = ${_references.force_arg} {
|
||||
description: "If not true, call fails if the task status is not in_progress/stopped"
|
||||
}
|
||||
} ${_references.status_change_request}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
updated {
|
||||
description: "Number of tasks updated (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
fields {
|
||||
description: "Updated fields names and values"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
ping {
|
||||
"2.1" {
|
||||
description: """ Refresh the task's last update time"""
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
task
|
||||
]
|
||||
properties {
|
||||
task {
|
||||
description: "Task ID"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
additionalProperties: false
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
add_or_update_artifacts {
|
||||
"2.6" {
|
||||
description: """ Update an existing artifact (search by key/mode) or add a new one """
|
||||
request {
|
||||
type: object
|
||||
required: [ task, artifacts ]
|
||||
properties {
|
||||
task {
|
||||
description: "Task ID"
|
||||
type: string
|
||||
}
|
||||
artifacts {
|
||||
description: "Artifacts to add or update"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/artifact" }
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
added {
|
||||
description: "Keys of artifacts added"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
updated {
|
||||
description: "Keys of artifacts updated"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user