mirror of
https://github.com/clearml/clearml-server
synced 2025-06-26 23:15:47 +00:00
Compare commits
563 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
c8e4d9eeac | ||
|
|
b51aa5c29b | ||
|
|
e7c9daa42b | ||
|
|
7357654249 | ||
|
|
a6f671b46a | ||
|
|
17a8b440bd | ||
|
|
eb2b9cbd9a | ||
|
|
797e503e67 | ||
|
|
30cfdac8f2 | ||
|
|
24bb87aaee | ||
|
|
dd49ba180a | ||
|
|
bda903d0d8 | ||
|
|
9739eb2d5a | ||
|
|
cfbb37238f | ||
|
|
6664c6237e | ||
|
|
74200a24bd | ||
|
|
2fb9288a6c | ||
|
|
5d014d81af | ||
|
|
3a2675abe1 | ||
|
|
f0d68b1ce9 | ||
|
|
15db9cdaef | ||
|
|
a45d47f5d7 | ||
|
|
b1a50c1370 | ||
|
|
22a2a02760 | ||
|
|
ab798e4170 | ||
|
|
f09ac672d2 | ||
|
|
2149b76f63 | ||
|
|
d96420aa67 | ||
|
|
ed6c7b7bcb | ||
|
|
a392bc0bd7 | ||
|
|
7e97ec5555 | ||
|
|
9c41124b81 | ||
|
|
14ff639bb0 | ||
|
|
e66257761a | ||
|
|
0ffde24dc2 | ||
|
|
d4fdcd9b32 | ||
|
|
18570bfccb | ||
|
|
54ce6c34c6 | ||
|
|
ae4c33fa0e | ||
|
|
c7cd949fd0 | ||
|
|
1ce4058157 | ||
|
|
7b6f24b24d | ||
|
|
d03a931d84 | ||
|
|
5cc7199661 | ||
|
|
6537e9ef69 | ||
|
|
930aaff791 | ||
|
|
1999fb2479 | ||
|
|
9db14cc31d | ||
|
|
e3cc689528 | ||
|
|
9e0adc77dd | ||
|
|
58d9a64537 | ||
|
|
d397d2ae20 | ||
|
|
2d711e1500 | ||
|
|
97992b0d9e | ||
|
|
bc23f1b0cf | ||
|
|
6b3eff1426 | ||
|
|
caaf801cd0 | ||
|
|
c23e8a90d0 | ||
|
|
fa5b28ca0e | ||
|
|
bfb55a9463 | ||
|
|
37e485e1f2 | ||
|
|
3451ff441f | ||
|
|
53c9b5525e | ||
|
|
e5230edac3 | ||
|
|
a54dd8030c | ||
|
|
482a5c34bc | ||
|
|
ee2a72c70f | ||
|
|
a0d8aaf3b9 | ||
|
|
de1f823213 | ||
|
|
0c9e2f92ee | ||
|
|
6c49e96ff0 | ||
|
|
81e3fc6577 | ||
|
|
e6dc4b7557 | ||
|
|
238a47a197 | ||
|
|
04e7076628 | ||
|
|
0531612bf4 | ||
|
|
3ae410a1e9 | ||
|
|
98ed3075dd | ||
|
|
b871bf4224 | ||
|
|
8d4c02fc3c | ||
|
|
b986980c75 | ||
|
|
a4fa567be2 | ||
|
|
ddb91f226a | ||
|
|
7772f47773 | ||
|
|
9c118d14e0 | ||
|
|
efd56e085e | ||
|
|
4dff163af4 | ||
|
|
242a78a0fe | ||
|
|
78989fea91 | ||
|
|
5de7c12062 | ||
|
|
3f79c19079 | ||
|
|
fe29743c54 | ||
|
|
d760cf5835 | ||
|
|
3695f25a5f | ||
|
|
c6f1beafdd | ||
|
|
68a54c34f3 | ||
|
|
ab495ae586 | ||
|
|
b058770af1 | ||
|
|
f7e833bf6f | ||
|
|
36b9ab0453 | ||
|
|
ec0436d0da | ||
|
|
0f6c4e75b7 | ||
|
|
a41ae112a1 | ||
|
|
c28f478ea8 | ||
|
|
c18eb99d06 | ||
|
|
3a60f00d93 | ||
|
|
ee87778548 | ||
|
|
52c0c4d438 | ||
|
|
d117a4f022 | ||
|
|
6683d2d7a9 | ||
|
|
05357fe25e | ||
|
|
adc1825843 | ||
|
|
0c15169668 | ||
|
|
123dc1dcfb | ||
|
|
b2feafac09 | ||
|
|
b41ab8c550 | ||
|
|
62d5779bd5 | ||
|
|
f8b9d9802e | ||
|
|
dd8a1503b0 | ||
|
|
cff98ae900 | ||
|
|
9b108740da | ||
|
|
08a7bc7c9f | ||
|
|
fb256d7e5b | ||
|
|
710443b078 | ||
|
|
e0cde2f7c9 | ||
|
|
60b9c8de14 | ||
|
|
ecffe26be4 | ||
|
|
2570bd9e26 | ||
|
|
174f84514a | ||
|
|
65cb8d7b43 | ||
|
|
5f8ef808a3 | ||
|
|
4941ac70e0 | ||
|
|
67cd461145 | ||
|
|
92b5fc6f9a | ||
|
|
b90165b4e4 | ||
|
|
6c2dcb5c8a | ||
|
|
3efed32934 | ||
|
|
69737308fe | ||
|
|
a6dbea808a | ||
|
|
5131b17901 | ||
|
|
5f21c3a56d | ||
|
|
2350ac64ed | ||
|
|
d146127c18 | ||
|
|
abd65e103e | ||
|
|
bf65ea7bd0 | ||
|
|
73e278a8ed | ||
|
|
d92dfbbdb7 | ||
|
|
5c1e419eb5 | ||
|
|
124684f53f | ||
|
|
455b5d6758 | ||
|
|
c04e2e498b | ||
|
|
da8a45072f | ||
|
|
e1992e2054 | ||
|
|
c17cedd93a | ||
|
|
b6ad8f8790 | ||
|
|
5acc7eebc3 | ||
|
|
941927dfcd | ||
|
|
02933a9c93 | ||
|
|
e537651f29 | ||
|
|
af09fba755 | ||
|
|
04ea9018a3 | ||
|
|
ff7e1be24f | ||
|
|
fc4fd9e61c | ||
|
|
8908c7dcf9 | ||
|
|
b9996e2c1a | ||
|
|
afdc56f37c | ||
|
|
a25cd5dae8 | ||
|
|
447adb9090 | ||
|
|
92fd98d5ad | ||
|
|
c4001b4037 | ||
|
|
970a32287a | ||
|
|
17cd48dada | ||
|
|
ea3b6e955f | ||
|
|
843450bb9b | ||
|
|
e149af58b1 | ||
|
|
604a38035b | ||
|
|
cae38a365b | ||
|
|
e334246b46 | ||
|
|
36e013b40c | ||
|
|
f20cd6536e | ||
|
|
446bd35006 | ||
|
|
a377a7e315 | ||
|
|
3d046ac282 | ||
|
|
a08fa9a0e1 | ||
|
|
5856ed2836 | ||
|
|
d295355d99 | ||
|
|
77350f6119 | ||
|
|
bc2c2ebbfd | ||
|
|
1502e02a1a | ||
|
|
d0e2313a24 | ||
|
|
d8ba1a8ea7 | ||
|
|
ca7937fc4e | ||
|
|
df89bcceef | ||
|
|
cfccbe05c1 | ||
|
|
e352a6a1e7 | ||
|
|
8a3d992aaf | ||
|
|
c37f3d8d5b | ||
|
|
a96870e092 | ||
|
|
6bf1032237 | ||
|
|
3d816c747d | ||
|
|
3f2b96266b | ||
|
|
22b16d12eb | ||
|
|
c55b6f30df | ||
|
|
b7045d3d28 | ||
|
|
e31a404885 | ||
|
|
643588b71a | ||
|
|
a64c4d264d | ||
|
|
567780e188 | ||
|
|
1bc8529d83 | ||
|
|
6b480d7e87 | ||
|
|
083fd315e9 | ||
|
|
ef20e76174 | ||
|
|
8c8910808e | ||
|
|
f6ad379310 | ||
|
|
c5d6ce3e65 | ||
|
|
694dbc31c4 | ||
|
|
6488dc54e6 | ||
|
|
158da9b480 | ||
|
|
ec2e071ab7 | ||
|
|
465e270342 | ||
|
|
6705aff56f | ||
|
|
9069cfe1da | ||
|
|
677bb3ba6d | ||
|
|
cb253cff9e | ||
|
|
39ceb5ac5c | ||
|
|
d4edeaaf1b | ||
|
|
56aea1ffb8 | ||
|
|
09ab2af34c | ||
|
|
8bb26a6b0b | ||
|
|
3f2304549d | ||
|
|
ad72a435f1 | ||
|
|
f34332344e | ||
|
|
d324b57dd7 | ||
|
|
2216bfe875 | ||
|
|
9beefa7473 | ||
|
|
8ebc334889 | ||
|
|
e662c850af | ||
|
|
1e5163e530 | ||
|
|
1567774765 | ||
|
|
babfcbb707 | ||
|
|
027edd86bb | ||
|
|
cc83aadae6 | ||
|
|
8c18660a82 | ||
|
|
4fe61ee25c | ||
|
|
e18b21639c | ||
|
|
1cef03b8c2 | ||
|
|
d60d6dfe99 | ||
|
|
27d086bca2 | ||
|
|
add3f011a0 | ||
|
|
ee90b0b024 | ||
|
|
9bf107866f | ||
|
|
4d2f282950 | ||
|
|
b55fad1b59 | ||
|
|
ba77ff11e9 | ||
|
|
b67aa05d6f | ||
|
|
6b0c45a861 | ||
|
|
dc9623e964 | ||
|
|
3d73d60826 | ||
|
|
9f0c9c3690 | ||
|
|
1a3d3494ce | ||
|
|
b99f620073 | ||
|
|
e2f265b4bc | ||
|
|
251ee57ffd | ||
|
|
7e03104f1c | ||
|
|
f1a258208e | ||
|
|
66cc49313b | ||
|
|
9ae2943f7d | ||
|
|
54326f707b | ||
|
|
3a3b57c15f | ||
|
|
8ea8ad34e6 | ||
|
|
179661a0d4 | ||
|
|
3d22ca1888 | ||
|
|
fdf6798d0c | ||
|
|
9d9a44b927 | ||
|
|
dad935e81d | ||
|
|
a75534ec34 | ||
|
|
eab33de97e | ||
|
|
29de110abb | ||
|
|
2e7f418ee2 | ||
|
|
dadb996d22 | ||
|
|
174f692edf | ||
|
|
f4d5168a20 | ||
|
|
5a438e8435 | ||
|
|
ce4814dc47 | ||
|
|
ef42d0265d | ||
|
|
3c5195028e | ||
|
|
0d5174c453 | ||
|
|
c034c1a986 | ||
|
|
1b49da8748 | ||
|
|
26bda01a28 | ||
|
|
f5008d80ad | ||
|
|
8b464e7ae6 | ||
|
|
78e4a58c91 | ||
|
|
7a4a5eb03e | ||
|
|
d029d56508 | ||
|
|
6411954002 | ||
|
|
7f4ad0d1ca | ||
|
|
4cd4b2914d | ||
|
|
1d55710a0b | ||
|
|
8f646043bb | ||
|
|
4b11a6efcd | ||
|
|
cb3a7c90a8 | ||
|
|
074842a122 | ||
|
|
749ff4a44f | ||
|
|
7d6918ecb0 | ||
|
|
47184c2833 | ||
|
|
6434f1028e | ||
|
|
daade08940 | ||
|
|
a1d289822f | ||
|
|
1ce34f2c74 | ||
|
|
c2dc73a71f | ||
|
|
07bb3b5df8 | ||
|
|
067ef82576 | ||
|
|
59fc98e0c4 | ||
|
|
a936a210e8 | ||
|
|
be0cf0caa8 | ||
|
|
a8d90887e2 | ||
|
|
6f3257fed3 | ||
|
|
4bb8834551 | ||
|
|
286b8c3df5 | ||
|
|
16430a6636 | ||
|
|
d7ddfde26e | ||
|
|
e6c0f1b6d8 | ||
|
|
641ed1b510 | ||
|
|
e29ad4c9b2 | ||
|
|
3473d2bb02 | ||
|
|
ba03924cb4 | ||
|
|
6870d8aba9 | ||
|
|
64c63d2560 | ||
|
|
88836fae66 | ||
|
|
436883148b | ||
|
|
f9f2f0ccf0 | ||
|
|
f879f6924f | ||
|
|
b9cb587580 | ||
|
|
370e92c3dd | ||
|
|
03094076c8 | ||
|
|
bdf6c353bd | ||
|
|
23736efbc3 | ||
|
|
3c8e27dc94 | ||
|
|
ca890c7ae8 | ||
|
|
30909df73f | ||
|
|
b97a6084ce | ||
|
|
50438bd931 | ||
|
|
28daf49c91 | ||
|
|
4707647c92 | ||
|
|
6974aa3a99 | ||
|
|
e2deff4eef | ||
|
|
59994ccf9c | ||
|
|
29c792d459 | ||
|
|
df334d083e | ||
|
|
b548958c80 | ||
|
|
7bdf8fe30d | ||
|
|
c71c65be87 | ||
|
|
1cc6a8f787 | ||
|
|
e5b92f4a80 | ||
|
|
3272d0f31f | ||
|
|
618a0b9473 | ||
|
|
bca3a6e556 | ||
|
|
8b0afd47a6 | ||
|
|
0303c3525f | ||
|
|
563c451ac9 | ||
|
|
91b1b34a6b | ||
|
|
0ad0495733 | ||
|
|
03ae90c4a6 | ||
|
|
be788965e0 | ||
|
|
d198138c5b | ||
|
|
cf441987af | ||
|
|
b89de43373 | ||
|
|
0ef018c931 | ||
|
|
323b5db07c | ||
|
|
f084f6b9e7 | ||
|
|
eb4c9f0b13 | ||
|
|
018582ff8a | ||
|
|
7dcc0f6df2 | ||
|
|
5e0893dd80 | ||
|
|
ca81922651 | ||
|
|
07cc2fb08b | ||
|
|
842654d3fe | ||
|
|
00e5e2a0b1 | ||
|
|
37e5d8a7e0 | ||
|
|
5b1f468957 | ||
|
|
9103bf7984 | ||
|
|
e848d05677 | ||
|
|
1c7de3a86e | ||
|
|
e12fd8f3df | ||
|
|
29ef134b79 | ||
|
|
e24389fda9 | ||
|
|
f4ead86449 | ||
|
|
171969c5ea | ||
|
|
89f81bfe5a | ||
|
|
b8e62f27e2 | ||
|
|
c7bbac73d0 | ||
|
|
f832ea565a | ||
|
|
22e9c2b7eb | ||
|
|
c67a56eb8d | ||
|
|
df65e1c7ad | ||
|
|
01115c1223 | ||
|
|
6de88c3b93 | ||
|
|
9d77827252 | ||
|
|
76fb97624d | ||
|
|
20d6582f51 | ||
|
|
7ebda33793 | ||
|
|
953124aa37 | ||
|
|
ba3451ce5a | ||
|
|
b93591ec32 | ||
|
|
0abfd8da0d | ||
|
|
a9cc4e36c6 | ||
|
|
fe1c963eec | ||
|
|
111d80e88d | ||
|
|
6718862dbe | ||
|
|
0fe1bf8a61 | ||
|
|
10f326eda9 | ||
|
|
cd0d6c1a3d | ||
|
|
3205f2df97 | ||
|
|
5bdbcfcd8d | ||
|
|
a2e2052b30 | ||
|
|
0146ded4f4 | ||
|
|
dccf9dd8f8 | ||
|
|
7816b402bb | ||
|
|
cd4ce30f7c | ||
|
|
8c7e230898 | ||
|
|
42ba696518 | ||
|
|
3f84e60a1f | ||
|
|
baba8b5b73 | ||
|
|
77397c4f21 | ||
|
|
8678091d8f | ||
|
|
aa22170ab4 | ||
|
|
901ec37290 | ||
|
|
21f2ea8b17 | ||
|
|
8219e3d4e2 | ||
|
|
3ed71a61d5 | ||
|
|
18a88a8e8f | ||
|
|
318a72987c | ||
|
|
5ce202cc99 | ||
|
|
d09528bc26 | ||
|
|
42d2a41dbe | ||
|
|
82be1840b0 | ||
|
|
27352c5cb6 | ||
|
|
1ea6408d41 | ||
|
|
5e095af3aa | ||
|
|
ab3dceed92 | ||
|
|
3bf5126d84 | ||
|
|
ab2ab7b23a | ||
|
|
c9184d125b | ||
|
|
0c0fdb72b9 | ||
|
|
86378053d4 | ||
|
|
b1cbba0cf1 | ||
|
|
f31526042d | ||
|
|
3f8d5bc346 | ||
|
|
11d76e7d8c | ||
|
|
e76c0fbc63 | ||
|
|
fdc9956da3 | ||
|
|
f4addaa653 | ||
|
|
667964cc82 | ||
|
|
e1309e30b7 | ||
|
|
9403942ef7 | ||
|
|
84a75d9e70 | ||
|
|
c85ab66ae6 | ||
|
|
bf7f0f646b | ||
|
|
dcdf2a3d58 | ||
|
|
f8d8fc40a6 | ||
|
|
45d434a123 | ||
|
|
1834abe5bc | ||
|
|
d6321588f3 | ||
|
|
c17b10ff1d | ||
|
|
b125a56f86 | ||
|
|
c43ce3a17b | ||
|
|
b0b09616a8 | ||
|
|
ede5586ccc | ||
|
|
a1dcdffa53 | ||
|
|
35a11db58e | ||
|
|
d9bdebefc7 | ||
|
|
f29884f05a | ||
|
|
0f72d662f8 | ||
|
|
6202219034 | ||
|
|
bb3218f65d | ||
|
|
cbcaa7c789 | ||
|
|
427322a424 | ||
|
|
0e7d7d36a9 | ||
|
|
06032a6d66 | ||
|
|
b48f4eb2eb | ||
|
|
383b2666c4 | ||
|
|
50c373cf0d | ||
|
|
394a9de5fa | ||
|
|
fb5c06e9c3 | ||
|
|
1a9bbc9420 | ||
|
|
294da32401 | ||
|
|
7f00672010 | ||
|
|
99bf89a360 | ||
|
|
6c8508eb7f | ||
|
|
69714d5b5c | ||
|
|
f9516ec7d3 | ||
|
|
6fdde93dee | ||
|
|
7afc71ec91 | ||
|
|
4595117d91 | ||
|
|
8630cc1021 | ||
|
|
135885b609 | ||
|
|
eb0865662c | ||
|
|
b7b94e7ae5 | ||
|
|
72be8bee19 | ||
|
|
0722b20c1c | ||
|
|
a392a0e6ff | ||
|
|
e22fa2f478 | ||
|
|
8b49c1ac06 | ||
|
|
da1182a405 | ||
|
|
53e995ee8c | ||
|
|
4732dc1a88 | ||
|
|
e325bcaf67 | ||
|
|
a7c30453db | ||
|
|
dedac3b2fe | ||
|
|
7d10bbdf8e | ||
|
|
72213dffa4 | ||
|
|
f778837d4b | ||
|
|
153ed6a7b7 | ||
|
|
5d279c8c5a | ||
|
|
ed910d5f6a | ||
|
|
87d2b6fa15 | ||
|
|
94cfb17291 | ||
|
|
3f641d37b7 | ||
|
|
551be12f01 | ||
|
|
b536020058 | ||
|
|
fb6fbc0a06 | ||
|
|
5ae64fd791 | ||
|
|
f9776e4319 | ||
|
|
75e736e7d5 | ||
|
|
1e4756aa1d | ||
|
|
52529d3c55 | ||
|
|
53296e8891 | ||
|
|
1c87ebc900 | ||
|
|
14d9924ea0 | ||
|
|
69f9b424c7 | ||
|
|
1a6da301a8 | ||
|
|
2728b3ed14 | ||
|
|
38284eef1f | ||
|
|
9debe1adcd | ||
|
|
cc93c15f8a | ||
|
|
2c3f0e4ba3 | ||
|
|
c48eb34d8d | ||
|
|
49515e06e1 | ||
|
|
4a1d97c02f | ||
|
|
6c6c1c3f41 | ||
|
|
0ad687008c | ||
|
|
fe3dbc92dc | ||
|
|
dc53970ff0 | ||
|
|
73592b991b | ||
|
|
47b981a993 | ||
|
|
b500bcab0b | ||
|
|
59e910db1a | ||
|
|
2ecb430f02 | ||
|
|
a08722e394 | ||
|
|
67c210d9d7 | ||
|
|
101ba540f4 | ||
|
|
82fc28d477 | ||
|
|
7b73f699d2 | ||
|
|
a7e5380f67 | ||
|
|
bcade31786 | ||
|
|
6b902f85f4 | ||
|
|
6d4c974045 | ||
|
|
2346c6f3f5 | ||
|
|
82e51b4d36 | ||
|
|
e63599254e | ||
|
|
8e7e234161 | ||
|
|
17d94b26c3 |
5
.gitignore
vendored
5
.gitignore
vendored
@@ -1,11 +1,10 @@
|
|||||||
|
syntax: glob
|
||||||
.idea
|
.idea
|
||||||
apierrors/errors
|
apierrors/errors
|
||||||
static/build.json
|
static/build.json
|
||||||
static/dashboard/node_modules
|
static/dashboard/node_modules
|
||||||
static/webapp/node_modules
|
static/webapp/node_modules
|
||||||
static/webapp/.git
|
static/webapp/.git
|
||||||
scripts/
|
|
||||||
generators/
|
|
||||||
*.pyc
|
*.pyc
|
||||||
__pycache__
|
__pycache__
|
||||||
.ropeproject
|
.ropeproject
|
||||||
@@ -13,10 +12,10 @@ test-reports
|
|||||||
.pytest_cache
|
.pytest_cache
|
||||||
venv
|
venv
|
||||||
*.noseids
|
*.noseids
|
||||||
build
|
|
||||||
*.egg-info
|
*.egg-info
|
||||||
.cache
|
.cache
|
||||||
.mypy_cache
|
.mypy_cache
|
||||||
dist
|
dist
|
||||||
code.tar.gz
|
code.tar.gz
|
||||||
server/schema/services/_cache.json
|
server/schema/services/_cache.json
|
||||||
|
server/apierrors/errors/*
|
||||||
|
|||||||
399
README.md
399
README.md
@@ -1,40 +1,68 @@
|
|||||||
# TRAINS Server
|
<div align="center">
|
||||||
|
|
||||||
## Auto-Magical Experiment Manager & Version Control for AI
|
<img src="docs/clearml_server_logo.png" width="250px">
|
||||||
|
|
||||||
|
**ClearML - Auto-Magical Suite of tools to streamline your ML workflow
|
||||||
|
</br>Experiment Manager, ML-Ops and Data-Management**
|
||||||
|
|
||||||
[](https://img.shields.io/badge/license-SSPL-green.svg)
|
[](https://img.shields.io/badge/license-SSPL-green.svg)
|
||||||
[](https://img.shields.io/badge/python-3.6%20%7C%203.7-blue.svg)
|
[](https://img.shields.io/badge/python-3.6%20%7C%203.7-blue.svg)
|
||||||
[](https://img.shields.io/github/release-pre/allegroai/trains-server.svg)
|
[](https://img.shields.io/github/release-pre/allegroai/trains-server.svg)
|
||||||
[](https://img.shields.io/badge/status-beta-yellow.svg)
|
[](https://artifacthub.io/packages/search?repo=allegroai)
|
||||||
|
|
||||||
## Introduction
|
</div>
|
||||||
|
|
||||||
The **trains-server** is the backend service infrastructure for [TRAINS](https://github.com/allegroai/trains).
|
---
|
||||||
|
<div align="center">
|
||||||
|
|
||||||
|
**Note regarding Apache Log4j2 Remote Code Execution (RCE) Vulnerability - CVE-2021-44228 - ESA-2021-31**
|
||||||
|
|
||||||
|
</div>
|
||||||
|
|
||||||
|
According to [ElasticSearch's latest report](https://discuss.elastic.co/t/apache-log4j2-remote-code-execution-rce-vulnerability-cve-2021-44228-esa-2021-31/291476),
|
||||||
|
supported versions of Elasticsearch (6.8.9+, 7.8+) used with recent versions of the JDK (JDK9+) **are not susceptible to either remote code execution or information leakage**
|
||||||
|
due to Elasticsearch’s usage of the Java Security Manager.
|
||||||
|
|
||||||
|
**As the latest version of ClearML Server uses Elasticsearch 7.10+ with JDK15, it is not affected by these vulnerabilities.**
|
||||||
|
|
||||||
|
As a precaution, we've upgraded the ES version to 7.16.2 and added the mitigation recommended by ElasticSearch to our latest [docker-compose.yml](https://github.com/allegroai/clearml-server/blob/cfccbe05c158b75e520581f86e9668291da5c70a/docker/docker-compose.yml#L42) file.
|
||||||
|
|
||||||
|
While previous Elasticsearch versions (5.6.11+, 6.4.0+ and 7.0.0+) used by older ClearML Server versions are only susceptible to the information leakage vulnerability
|
||||||
|
(which in any case **does not permit access to data within the Elasticsearch cluster**),
|
||||||
|
we still recommend upgrading to the latest version of ClearML Server. Alternatively, you can apply the mitigation as implemented in our latest
|
||||||
|
[docker-compose.yml](https://github.com/allegroai/clearml-server/blob/cfccbe05c158b75e520581f86e9668291da5c70a/docker/docker-compose.yml#L42) file.
|
||||||
|
|
||||||
|
**Update 15 December**: A further vulnerability (CVE-2021-45046) was disclosed on December 14th.
|
||||||
|
ElasticSearch's guidance for Elasticsearch remains unchanged by this new vulnerability, thus **not affecting ClearML Server**.
|
||||||
|
|
||||||
|
**Update 22 December**: To keep with ElasticSearch's recommendations, we've upgraded the ES version to the newly released 7.16.2
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## ClearML Server
|
||||||
|
#### *Formerly known as Trains Server*
|
||||||
|
|
||||||
|
The **ClearML Server** is the backend service infrastructure for [ClearML](https://github.com/allegroai/clearml).
|
||||||
It allows multiple users to collaborate and manage their experiments.
|
It allows multiple users to collaborate and manage their experiments.
|
||||||
By default, TRAINS is set up to work with the TRAINS demo server, which is open to anyone and resets periodically.
|
**ClearML** offers a [free hosted service](https://app.clear.ml/), which is maintained by **ClearML** and open to anyone.
|
||||||
In order to host your own server, you will need to install **trains-server** and point TRAINS to it.
|
In order to host your own server, you will need to launch the **ClearML Server** and point **ClearML** to it.
|
||||||
|
|
||||||
**trains-server** contains the following components:
|
The **ClearML Server** contains the following components:
|
||||||
|
|
||||||
* The TRAINS Web-App, a single-page UI for experiment management and browsing
|
* The **ClearML** Web-App, a single-page UI for experiment management and browsing
|
||||||
* RESTful API for:
|
* RESTful API for:
|
||||||
* Documenting and logging experiment information, statistics and results
|
* Documenting and logging experiment information, statistics and results
|
||||||
* Querying experiments history, logs and results
|
* Querying experiments history, logs and results
|
||||||
* Locally-hosted file server for storing images and models making them easily accessible using the Web-App
|
* Locally-hosted file server for storing images and models making them easily accessible using the Web-App
|
||||||
|
|
||||||
You can quickly setup your **trains-server** using:
|
You can quickly [deploy](#launching-the-clearml-server) your **ClearML Server** using Docker, AWS EC2 AMI, or Kubernetes.
|
||||||
- [Docker Installation](#installation)
|
|
||||||
- Pre-built Amazon [AWS image](#aws)
|
|
||||||
- [Kubernetes Helm](https://github.com/allegroai/trains-server-helm#trains-server-for-kubernetes-clusters-using-helm)
|
|
||||||
or manual [Kubernetes installation](https://github.com/allegroai/trains-server-k8s#trains-server-for-kubernetes-clusters)
|
|
||||||
|
|
||||||
|
|
||||||
## System design
|
## System design
|
||||||
|
|
||||||
|
|
||||||
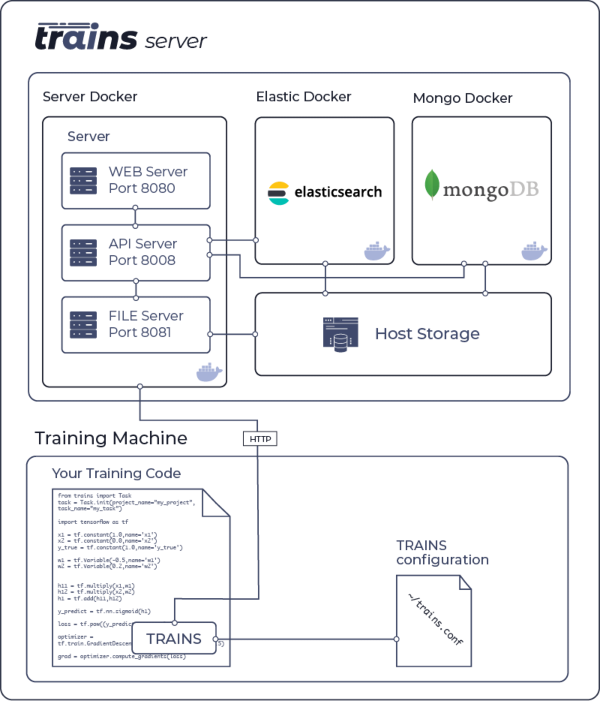
|

|
||||||
|
|
||||||
**trains-server** has two supported configurations:
|
The **ClearML Server** has two supported configurations:
|
||||||
- Single IP (domain) with the following open ports
|
- Single IP (domain) with the following open ports
|
||||||
- Web application on port 8080
|
- Web application on port 8080
|
||||||
- API service on port 8008
|
- API service on port 8008
|
||||||
@@ -44,155 +72,42 @@ You can quickly setup your **trains-server** using:
|
|||||||
- Web application on sub-domain: app.\*.\*
|
- Web application on sub-domain: app.\*.\*
|
||||||
- API service on sub-domain: api.\*.\*
|
- API service on sub-domain: api.\*.\*
|
||||||
- File storage service on sub-domain: files.\*.\*
|
- File storage service on sub-domain: files.\*.\*
|
||||||
|
|
||||||
|
## Launching The ClearML Server
|
||||||
|
|
||||||
## Install / Upgrade - AWS <a name="aws"></a>
|
### Prerequisites
|
||||||
|
|
||||||
Use one of our pre-installed Amazon Machine Images for easy deployment in AWS.
|
The ports 8080/8081/8008 must be available for the **ClearML Server** services.
|
||||||
|
|
||||||
|
For example, to see if port `8080` is in use:
|
||||||
|
|
||||||
For details and instructions, see [TRAINS-server: AWS pre-installed images](docs/install_aws.md).
|
* Linux or macOS:
|
||||||
|
|
||||||
|
sudo lsof -Pn -i4 | grep :8080 | grep LISTEN
|
||||||
|
|
||||||
## Docker Installation - Linux, Mac OS X <a name="installation"></a>
|
* Windows:
|
||||||
|
|
||||||
Use our pre-built Docker image for easy deployment in Linux and Mac OS X.
|
netstat -an |find /i "8080"
|
||||||
For Windows, we recommend installing our pre-built Docker image on a Linux virtual machine.
|
|
||||||
Latest docker images can be found [here](https://hub.docker.com/r/allegroai/trains).
|
### Launching
|
||||||
|
|
||||||
|
Launch The **ClearML Server** in any of the following formats:
|
||||||
|
|
||||||
1. Setup Docker ([docker-compose Ubuntu](docs/faq.md#ubuntu), [docker-compose OS X](docs/faq.md#mac-osx), [Setup Docker Service Manually](docs/docker_setup.md#setup-docker))
|
- Pre-built [AWS EC2 AMI](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_aws_ec2_ami)
|
||||||
|
- Pre-built [GCP Custom Image](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_gcp)
|
||||||
|
- Pre-built Docker Image
|
||||||
|
- [Linux](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_linux_mac)
|
||||||
|
- [macOS](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_linux_mac)
|
||||||
|
- [Windows 10](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_win)
|
||||||
|
- Kubernetes
|
||||||
|
- [Kubernetes Helm](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_kubernetes_helm)
|
||||||
|
- Manual [Kubernetes installation](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_kubernetes)
|
||||||
|
|
||||||
Make sure port 8080/8081/8008 are available for the `trains-server` services
|
## Connecting ClearML to your ClearML Server
|
||||||
|
|
||||||
Increase vm.max_map_count for `ElasticSearch` docker
|
In order to set up the **ClearML** client to work with your **ClearML Server**:
|
||||||
|
- Run the `clearml-init` command for an interactive setup.
|
||||||
```bash
|
- Or manually edit `~/clearml.conf` file, making sure the server settings (`api_server`, `web_server`, `file_server`) are configured correctly, for example:
|
||||||
echo "vm.max_map_count=262144" > /tmp/99-trains.conf
|
|
||||||
sudo mv /tmp/99-trains.conf /etc/sysctl.d/99-trains.conf
|
|
||||||
sudo sysctl -w vm.max_map_count=262144
|
|
||||||
|
|
||||||
sudo service docker restart
|
|
||||||
```
|
|
||||||
|
|
||||||
1. Create local directories for the databases and storage.
|
|
||||||
|
|
||||||
```bash
|
|
||||||
sudo mkdir -p /opt/trains/data/elastic
|
|
||||||
sudo mkdir -p /opt/trains/data/mongo/db
|
|
||||||
sudo mkdir -p /opt/trains/data/mongo/configdb
|
|
||||||
sudo mkdir -p /opt/trains/data/redis
|
|
||||||
sudo mkdir -p /opt/trains/logs
|
|
||||||
sudo mkdir -p /opt/trains/data/fileserver
|
|
||||||
sudo mkdir -p /opt/trains/config
|
|
||||||
```
|
|
||||||
|
|
||||||
Linux
|
|
||||||
```bash
|
|
||||||
$ sudo chown -R 1000:1000 /opt/trains
|
|
||||||
```
|
|
||||||
Mac OS X
|
|
||||||
```bash
|
|
||||||
$ sudo chown -R $(whoami):staff /opt/trains
|
|
||||||
```
|
|
||||||
|
|
||||||
1. Clone the [trains-server](https://github.com/allegroai/trains-server) repository and change directories to the new **trains-server** directory.
|
|
||||||
|
|
||||||
```bash
|
|
||||||
$ git clone https://github.com/allegroai/trains-server.git
|
|
||||||
$ cd trains-server
|
|
||||||
```
|
|
||||||
|
|
||||||
1. Launch the Docker containers <a name="launch-docker"></a>
|
|
||||||
|
|
||||||
* Automatically with docker-compose (details: [Linux/Ubuntu](docs/faq.md#ubuntu), [OS X](docs/faq.md#mac-osx))
|
|
||||||
|
|
||||||
```bash
|
|
||||||
$ docker-compose up
|
|
||||||
```
|
|
||||||
|
|
||||||
* Manually, see [Launching Docker Containers Manually](docs/docker_setup.md#launch) for instructions.
|
|
||||||
|
|
||||||
1. Your server is now running on [http://localhost:8080](http://localhost:8080) and the following ports are available:
|
|
||||||
|
|
||||||
* Web server on port `8080`
|
|
||||||
* API server on port `8008`
|
|
||||||
* File server on port `8081`
|
|
||||||
|
|
||||||
## Optional Configuration
|
|
||||||
|
|
||||||
The **trains-server** default configuration can be easily overridden using external configuration files. By default, the server will look for these files in `/opt/trains/config`.
|
|
||||||
|
|
||||||
In order to apply the new configuration, you must restart the server (see [Restarting trains-server](#restart-server)).
|
|
||||||
|
|
||||||
### Adding Web Login Authentication
|
|
||||||
|
|
||||||
By default anyone can login to the **trains-server** Web-App.
|
|
||||||
You can configure the **trains-server** to allow only a specific set of users to access the system.
|
|
||||||
|
|
||||||
Enable this feature by placing `apiserver.conf` file under `/opt/trains/config`.
|
|
||||||
|
|
||||||
|
|
||||||
Sample fixed user configuration file `/opt/trains/config/apiserver.conf`:
|
|
||||||
|
|
||||||
auth {
|
|
||||||
# Fixed users login credetials
|
|
||||||
# No other user will be able to login
|
|
||||||
fixed_users {
|
|
||||||
enabled: true
|
|
||||||
users: [
|
|
||||||
{
|
|
||||||
username: "jane"
|
|
||||||
password: "12345678"
|
|
||||||
name: "Jane Doe"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
username: "john"
|
|
||||||
password: "12345678"
|
|
||||||
name: "John Doe"
|
|
||||||
},
|
|
||||||
]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
To apply the `apiserver.conf` changes, you must restart the *trains-apiserver* (docker) (see [Restarting trains-server](#restart-server)).
|
|
||||||
|
|
||||||
### Configuring the Non-Responsive Experiments Watchdog
|
|
||||||
|
|
||||||
The non-responsive experiment watchdog, monitors experiments that were not updated for a given period of time,
|
|
||||||
and marks them as `aborted`. The watchdog is always active with a default of 7200 seconds (2 hours) of inactivity threshold.
|
|
||||||
|
|
||||||
To change the watchdog's timeouts, place a `services.conf` file under `/opt/trains/config`.
|
|
||||||
|
|
||||||
Sample watchdog configuration file `/opt/trains/config/services.conf`:
|
|
||||||
|
|
||||||
tasks {
|
|
||||||
non_responsive_tasks_watchdog {
|
|
||||||
# In-progress tasks that haven't been updated for at least 'value' seconds will be stopped by the watchdog
|
|
||||||
threshold_sec: 7200
|
|
||||||
|
|
||||||
# Watchdog will sleep for this number of seconds after each cycle
|
|
||||||
watch_interval_sec: 900
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
To apply the `services.conf` changes, you must restart the *trains-apiserver* (docker) (see [Restarting trains-server](#restart-server)).
|
|
||||||
|
|
||||||
### Restarting trains-server <a name="restart-server"></a>
|
|
||||||
|
|
||||||
To restart the **trains-server**, you must first stop and remove the containers, and then restart.
|
|
||||||
|
|
||||||
1. Restarting docker-compose containers.
|
|
||||||
|
|
||||||
$ docker-compose down
|
|
||||||
$ docker-compose up
|
|
||||||
|
|
||||||
1. Manually restarting dockers [instructions](docs/docker_setup.md#launch).
|
|
||||||
|
|
||||||
## Configuring **TRAINS** client
|
|
||||||
|
|
||||||
Once you have installed the **trains-server**, make sure to configure **TRAINS** [client](https://github.com/allegroai/trains)
|
|
||||||
to use your locally installed server (and not the demo server).
|
|
||||||
|
|
||||||
- Run the `trains-init` command for an interactive setup
|
|
||||||
|
|
||||||
- Or manually edit `~/trains.conf` file, making sure the `api_server` value is configured correctly, for example:
|
|
||||||
|
|
||||||
api {
|
api {
|
||||||
# API server on port 8008
|
# API server on port 8008
|
||||||
@@ -205,104 +120,122 @@ to use your locally installed server (and not the demo server).
|
|||||||
files_server: "http://localhost:8081"
|
files_server: "http://localhost:8081"
|
||||||
}
|
}
|
||||||
|
|
||||||
* Notice that if you setup **trains-server** in a sub-domain configuration, there is no need to specify a port number,
|
**Note**: If you have set up your **ClearML Server** in a sub-domain configuration, then there is no need to specify a port number,
|
||||||
it will be inferred from the http/s scheme.
|
it will be inferred from the http/s scheme.
|
||||||
|
|
||||||
See [Installing and Configuring TRAINS](https://github.com/allegroai/trains#configuration) for more details.
|
After launching the **ClearML Server** and configuring the **ClearML** client to use the **ClearML Server**,
|
||||||
|
you can [use](https://github.com/allegroai/clearml) **ClearML** in your experiments and view them in your **ClearML Server** web server,
|
||||||
|
for example http://localhost:8080.
|
||||||
|
For more information about the ClearML client, see [**ClearML**](https://github.com/allegroai/clearml).
|
||||||
|
|
||||||
## What next?
|
## ClearML-Agent Services <a name="services"></a>
|
||||||
|
|
||||||
Now that the **trains-server** is installed, and TRAINS is configured to use it,
|
As of version 0.15 of **ClearML Server**, dockerized deployment includes a **ClearML-Agent Services** container running as
|
||||||
you can [use](https://github.com/allegroai/trains#using-trains) TRAINS in your experiments and view them in the web server,
|
part of the docker container collection.
|
||||||
for example http://localhost:8080
|
|
||||||
|
ClearML-Agent Services is an extension of ClearML-Agent that provides the ability to launch long-lasting jobs
|
||||||
|
that previously had to be executed on local / dedicated machines. It allows a single agent to
|
||||||
|
launch multiple dockers (Tasks) for different use cases. To name a few use cases, auto-scaler service (spinning instances
|
||||||
|
when the need arises and the budget allows), Controllers (Implementing pipelines and more sophisticated DevOps logic),
|
||||||
|
Optimizer (such as Hyper-parameter Optimization or sweeping), and Application (such as interactive Bokeh apps for
|
||||||
|
increased data transparency)
|
||||||
|
|
||||||
|
ClearML-Agent Services container will spin **any** task enqueued into the dedicated `services` queue.
|
||||||
|
Every task launched by ClearML-Agent Services will be registered as a new node in the system,
|
||||||
|
providing tracking and transparency capabilities.
|
||||||
|
You can also run the ClearML-Agent Services manually, see details in [ClearML-agent services mode](https://github.com/allegroai/clearml-agent#clearml-agent-services-mode-)
|
||||||
|
|
||||||
|
**Note**: It is the user's responsibility to make sure the proper tasks are pushed into the `services` queue.
|
||||||
|
Do not enqueue training / inference tasks into the `services` queue, as it will put unnecessary load on the server.
|
||||||
|
|
||||||
|
## Advanced Functionality
|
||||||
|
|
||||||
|
The **ClearML Server** provides a few additional useful features, which can be manually enabled:
|
||||||
|
|
||||||
|
* [Web login authentication](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_config#web-login-authentication)
|
||||||
|
* [Non-responsive experiments watchdog](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_config#non-responsive-task-watchdog)
|
||||||
|
|
||||||
|
## Restarting ClearML Server
|
||||||
|
|
||||||
|
To restart the **ClearML Server**, you must first stop the containers, and then restart them.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker-compose down
|
||||||
|
docker-compose -f docker-compose.yml up
|
||||||
|
```
|
||||||
|
|
||||||
## Upgrading <a name="upgrade"></a>
|
## Upgrading <a name="upgrade"></a>
|
||||||
|
|
||||||
We are constantly updating, improving and adding to the **trains-server**.
|
**ClearML Server** releases are also reflected in the [docker compose configuration file](https://github.com/allegroai/trains-server/blob/master/docker/docker-compose.yml).
|
||||||
New releases will include new pre-built Docker images.
|
We strongly encourage you to keep your **ClearML Server** up to date, by keeping up with the current release.
|
||||||
When we release a new version and include a new pre-built Docker image for it, upgrade as follows:
|
|
||||||
|
|
||||||
* Upgrading your docker-compose installation
|
**Note**: The following upgrade instructions use the Linux OS as an example.
|
||||||
|
|
||||||
* Shut down the docker containers
|
To upgrade your existing **ClearML Server** deployment:
|
||||||
```bash
|
|
||||||
$ docker-compose down
|
|
||||||
```
|
|
||||||
|
|
||||||
* We highly recommend backing up your data directory before upgrading
|
|
||||||
(see **Step ii** in the Manual Docker upgrade)
|
|
||||||
|
|
||||||
* Spin up the docker containers, it will automatically pull the latest trains-server build
|
1. Shut down the docker containers
|
||||||
```bash
|
```bash
|
||||||
$ docker-compose up
|
docker-compose down
|
||||||
```
|
```
|
||||||
|
|
||||||
* In case of a docker error: "... The container name "/trains-???" is already in use by ..."
|
1. We highly recommend backing up your data directory before upgrading.
|
||||||
Try removing deprecated images with:
|
|
||||||
```bash
|
|
||||||
$ docker rm -f $(docker ps -a -q)
|
|
||||||
```
|
|
||||||
|
|
||||||
* Manual Docker upgrade
|
Assuming your data directory is `/opt/clearml`, to archive all data into `~/clearml_backup.tgz` execute:
|
||||||
1. Shut down and remove each of your Docker instances using the following commands:
|
|
||||||
|
```bash
|
||||||
```bash
|
sudo tar czvf ~/clearml_backup.tgz /opt/clearml/data
|
||||||
$ sudo docker stop <docker-name>
|
```
|
||||||
$ sudo docker rm -v <docker-name>
|
|
||||||
```
|
<details>
|
||||||
|
<summary>Restore instructions:</summary>
|
||||||
The Docker names are (see [Launching Docker Containers](#launch-docker)):
|
|
||||||
|
To restore this example backup, execute:
|
||||||
* `trains-elastic`
|
```bash
|
||||||
* `trains-mongo`
|
sudo rm -R /opt/clearml/data
|
||||||
* `trains-redis`
|
sudo tar -xzf ~/clearml_backup.tgz -C /opt/clearml/data
|
||||||
* `trains-fileserver`
|
```
|
||||||
* `trains-apiserver`
|
</details>
|
||||||
* `trains-webserver`
|
|
||||||
|
1. Download the latest `docker-compose.yml` file.
|
||||||
2. We highly recommend backing up your data directory!. A simple way to do that is using `tar`:
|
|
||||||
|
```bash
|
||||||
For example, if your data directory is `/opt/trains`, use the following command:
|
curl https://raw.githubusercontent.com/allegroai/trains-server/master/docker/docker-compose.yml -o docker-compose.yml
|
||||||
|
```
|
||||||
```bash
|
|
||||||
$ sudo tar czvf ~/trains_backup.tgz /opt/trains/data
|
1. Configure the ClearML-Agent Services (not supported on Windows installation).
|
||||||
```
|
If `CLEARML_HOST_IP` is not provided, ClearML-Agent Services will use the external
|
||||||
This backups all data to an archive in your home directory.
|
public address of the **ClearML Server**. If `CLEARML_AGENT_GIT_USER` / `CLEARML_AGENT_GIT_PASS` are not provided,
|
||||||
|
the ClearML-Agent Services will not be able to access any private repositories for running service tasks.
|
||||||
To restore this example backup, use the following command:
|
|
||||||
```bash
|
```bash
|
||||||
$ sudo rm -R /opt/trains/data
|
export CLEARML_HOST_IP=server_host_ip_here
|
||||||
$ sudo tar -xzf ~/trains_backup.tgz -C /opt/trains/data
|
export CLEARML_AGENT_GIT_USER=git_username_here
|
||||||
```
|
export CLEARML_AGENT_GIT_PASS=git_password_here
|
||||||
|
```
|
||||||
3. Pull the new **trains-server** docker image using the following command:
|
|
||||||
|
1. Spin up the docker containers, it will automatically pull the latest **ClearML Server** build
|
||||||
```bash
|
```bash
|
||||||
$ sudo docker pull allegroai/trains:latest
|
docker-compose -f docker-compose.yml pull
|
||||||
```
|
docker-compose -f docker-compose.yml up
|
||||||
|
```
|
||||||
If you wish to pull a different version, replace `latest` with the required version number, for example:
|
|
||||||
```bash
|
**\* If something went wrong along the way, check our FAQ: [Common Docker Upgrade Errors](https://clear.ml/docs/latest/docs/faq/).**
|
||||||
$ sudo docker pull allegroai/trains:0.11.0
|
|
||||||
```
|
|
||||||
|
|
||||||
4. Launch the newly released Docker image (see [Launching Docker Containers](#launch-docker)).
|
|
||||||
|
|
||||||
|
|
||||||
## Community & Support
|
## Community & Support
|
||||||
|
|
||||||
If you have any questions, look to the TRAINS-server [FAQ](https://github.com/allegroai/trains-server/blob/master/docs/faq.md), or
|
If you have any questions, look to the ClearML [FAQ](https://clear.ml/docs/latest/docs/faq), or
|
||||||
tag your questions on [stackoverflow](https://stackoverflow.com/questions/tagged/trains) with '**trains**' tag.
|
tag your questions on [stackoverflow](https://stackoverflow.com/questions/tagged/clearml) with '**clearml**' tag.
|
||||||
|
|
||||||
For feature requests or bug reports, please use [GitHub issues](https://github.com/allegroai/trains-server/issues).
|
For feature requests or bug reports, please use [GitHub issues](https://github.com/allegroai/clearml-server/issues).
|
||||||
|
|
||||||
Additionally, you can always find us at *trains@allegro.ai*
|
Additionally, you can always find us at *clearml@allegro.ai*
|
||||||
|
|
||||||
## License
|
## License
|
||||||
|
|
||||||
[Server Side Public License v1.0](https://github.com/mongodb/mongo/blob/master/LICENSE-Community.txt)
|
[Server Side Public License v1.0](https://github.com/mongodb/mongo/blob/master/LICENSE-Community.txt)
|
||||||
|
|
||||||
**trains-server** relies on both [MongoDB](https://github.com/mongodb/mongo) and [ElasticSearch](https://github.com/elastic/elasticsearch).
|
The **ClearML Server** relies on both [MongoDB](https://github.com/mongodb/mongo) and [ElasticSearch](https://github.com/elastic/elasticsearch).
|
||||||
With the recent changes in both MongoDB's and ElasticSearch's OSS license, we feel it is our responsibility as a
|
With the recent changes in both MongoDB's and ElasticSearch's OSS license, we feel it is our responsibility as a
|
||||||
member of the community to support the projects we love and cherish.
|
member of the community to support the projects we love and cherish.
|
||||||
We believe the cause for the license change in both cases is more than just,
|
We believe the cause for the license change in both cases is more than just,
|
||||||
|
|||||||
6
apiserver/apierrors/__init__.py
Normal file
6
apiserver/apierrors/__init__.py
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
from .apierror import APIError
|
||||||
|
from .base import BaseError
|
||||||
|
|
||||||
|
from apiserver.apierrors_generator import ErrorsGenerator
|
||||||
|
|
||||||
|
ErrorsGenerator.generate_python_files()
|
||||||
@@ -1,9 +1,10 @@
|
|||||||
class APIError(Exception):
|
class APIError(Exception):
|
||||||
def __init__(self, msg, code=500, subcode=0, **_):
|
def __init__(self, msg, code=500, subcode=0, error_data=None, **_):
|
||||||
super(APIError, self).__init__()
|
super(APIError, self).__init__()
|
||||||
self._msg = msg
|
self._msg = msg
|
||||||
self._code = code
|
self._code = code
|
||||||
self._subcode = subcode
|
self._subcode = subcode
|
||||||
|
self._error_data = error_data or {}
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def msg(self):
|
def msg(self):
|
||||||
@@ -17,5 +18,9 @@ class APIError(Exception):
|
|||||||
def subcode(self):
|
def subcode(self):
|
||||||
return self._subcode
|
return self._subcode
|
||||||
|
|
||||||
|
@property
|
||||||
|
def error_data(self):
|
||||||
|
return self._error_data
|
||||||
|
|
||||||
def __str__(self):
|
def __str__(self):
|
||||||
return self.msg
|
return self.msg
|
||||||
@@ -1,9 +1,13 @@
|
|||||||
import six
|
|
||||||
from boltons.typeutils import classproperty
|
|
||||||
from typing import Tuple
|
from typing import Tuple
|
||||||
|
|
||||||
|
import six
|
||||||
|
from boltons.iterutils import is_collection, remap
|
||||||
|
from boltons.typeutils import classproperty
|
||||||
|
|
||||||
from .apierror import APIError
|
from .apierror import APIError
|
||||||
|
|
||||||
|
jsonable_types = (dict, list, tuple, str, int, float, bool, type(None))
|
||||||
|
|
||||||
|
|
||||||
class BaseError(APIError):
|
class BaseError(APIError):
|
||||||
_default_code = 500
|
_default_code = 500
|
||||||
@@ -19,15 +23,26 @@ class BaseError(APIError):
|
|||||||
f"{k}={self._format_kwarg(v)}" for k, v in kwargs.items()
|
f"{k}={self._format_kwarg(v)}" for k, v in kwargs.items()
|
||||||
)
|
)
|
||||||
message += f": {kwargs_msg}"
|
message += f": {kwargs_msg}"
|
||||||
params = kwargs.copy()
|
|
||||||
params.update(
|
super(BaseError, self).__init__(
|
||||||
code=self._default_code, subcode=self._default_subcode, msg=message
|
code=self._default_code,
|
||||||
|
subcode=self._default_subcode,
|
||||||
|
msg=message,
|
||||||
|
error_data=self._to_safe_json_types(kwargs),
|
||||||
)
|
)
|
||||||
super(BaseError, self).__init__(**params)
|
|
||||||
|
@staticmethod
|
||||||
|
def _to_safe_json_types(data):
|
||||||
|
def visit(_, k, v):
|
||||||
|
if not isinstance(v, jsonable_types):
|
||||||
|
v = str(v)
|
||||||
|
return k, v
|
||||||
|
|
||||||
|
return remap(data, visit=visit)
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def _format_kwarg(value):
|
def _format_kwarg(value):
|
||||||
if isinstance(value, (tuple, list)):
|
if is_collection(value):
|
||||||
return f'({", ".join(str(v) for v in value)})'
|
return f'({", ".join(str(v) for v in value)})'
|
||||||
elif isinstance(value, six.string_types):
|
elif isinstance(value, six.string_types):
|
||||||
return value
|
return value
|
||||||
151
apiserver/apierrors/errors.conf
Normal file
151
apiserver/apierrors/errors.conf
Normal file
@@ -0,0 +1,151 @@
|
|||||||
|
301 {
|
||||||
|
_: "moved_permanently"
|
||||||
|
1: ["not_supported", "this endpoint is no longer supported for the requested API version"]
|
||||||
|
}
|
||||||
|
|
||||||
|
400 {
|
||||||
|
_: "bad_request"
|
||||||
|
1: ["not_supported", "endpoint is not supported"]
|
||||||
|
2: ["request_path_has_invalid_version", "request path has invalid version"]
|
||||||
|
5: ["invalid_headers", "invalid headers"]
|
||||||
|
6: ["impersonation_error", "impersonation error"]
|
||||||
|
|
||||||
|
10: ["invalid_id", "invalid object id"]
|
||||||
|
11: ["missing_required_fields", "missing required fields"]
|
||||||
|
12: ["validation_error", "validation error"]
|
||||||
|
13: ["fields_not_allowed_for_role", "fields not allowed for role"]
|
||||||
|
14: ["invalid fields", "fields not defined for object"]
|
||||||
|
15: ["fields_conflict", "conflicting fields"]
|
||||||
|
16: ["fields_value_error", "invalid value for fields"]
|
||||||
|
17: ["batch_contains_no_items", "batch request contains no items"]
|
||||||
|
18: ["batch_validation_error", "batch request validation error"]
|
||||||
|
19: ["invalid_lucene_syntax", "malformed lucene query"]
|
||||||
|
20: ["fields_type_error", "invalid type for fields"]
|
||||||
|
21: ["invalid_regex_error", "malformed regular expression"]
|
||||||
|
22: ["invalid_email_address", "malformed email address"]
|
||||||
|
23: ["invalid_domain_name", "malformed domain name"]
|
||||||
|
24: ["not_public_object", "object is not public"]
|
||||||
|
|
||||||
|
# Auth / Login
|
||||||
|
75: ["invalid_access_key", "access key not found for user"]
|
||||||
|
|
||||||
|
# Tasks
|
||||||
|
100: ["task_error", "general task error"]
|
||||||
|
101: ["invalid_task_id", "invalid task id"]
|
||||||
|
102: ["task_validation_error", "task validation error"]
|
||||||
|
110: ["invalid_task_status", "invalid task status"]
|
||||||
|
111: ["task_not_started", "task not started (invalid task status)"]
|
||||||
|
112: ["task_in_progress", "task in progress (invalid task status)"]
|
||||||
|
113: ["task_published", "task published (invalid task status)"]
|
||||||
|
114: ["task_status_unknown", "task unknown (invalid task status)"]
|
||||||
|
120: ["invalid_task_execution_progress", "invalid task execution progress"]
|
||||||
|
121: ["failed_changing_task_status", "failed changing task status. probably someone changed it before you"]
|
||||||
|
122: ["missing_task_fields", "task is missing expected fields"]
|
||||||
|
123: ["task_cannot_be_deleted", "task cannot be deleted"]
|
||||||
|
125: ["task_has_jobs_running", "task has jobs that haven't completed yet"]
|
||||||
|
126: ["invalid_task_type", "invalid task type for this operations"]
|
||||||
|
127: ["invalid_task_input", "invalid task output"]
|
||||||
|
128: ["invalid_task_output", "invalid task output"]
|
||||||
|
129: ["task_publish_in_progress", "Task publish in progress"]
|
||||||
|
130: ["task_not_found", "task not found"]
|
||||||
|
131: ["events_not_added", "events not added"]
|
||||||
|
|
||||||
|
# Reports
|
||||||
|
150: ["operation_supported_on_reports_only", "passed task is not report"]
|
||||||
|
|
||||||
|
# Models
|
||||||
|
200: ["model_error", "general task error"]
|
||||||
|
201: ["invalid_model_id", "invalid model id"]
|
||||||
|
202: ["model_not_ready", "model is not ready"]
|
||||||
|
203: ["model_is_ready", "model is ready"]
|
||||||
|
204: ["invalid_model_uri", "invalid model URI"]
|
||||||
|
205: ["model_in_use", "model is used by tasks"]
|
||||||
|
206: ["model_creating_task_exists", "task that created this model exists"]
|
||||||
|
|
||||||
|
# Users
|
||||||
|
300: ["invalid_user", "invalid user"]
|
||||||
|
301: ["invalid_user_id", "invalid user id"]
|
||||||
|
302: ["user_id_exists", "user id already exists"]
|
||||||
|
305: ["invalid_preferences_update", "Malformed key and/or value"]
|
||||||
|
|
||||||
|
# Projects
|
||||||
|
401: ["invalid_project_id", "invalid project id"]
|
||||||
|
402: ["project_has_tasks", "project has associated tasks"]
|
||||||
|
403: ["project_not_found", "project not found"]
|
||||||
|
405: ["project_has_models", "project has associated models"]
|
||||||
|
407: ["invalid_project_name", "invalid project name"]
|
||||||
|
408: ["cannot_update_project_location", "Cannot update project location. Use projects.move instead"]
|
||||||
|
409: ["project_path_exceeds_max", "Project path exceed the maximum allowed depth"]
|
||||||
|
410: ["project_source_and_destination_are_the_same", "Project has the same source and destination paths"]
|
||||||
|
411: ["project_cannot_be_moved_under_itself", "Project can not be moved under itself in the projects hierarchy"]
|
||||||
|
412: ["project_cannot_be_merged_into_its_child", "Project can not be merged into its own child"]
|
||||||
|
|
||||||
|
# Queues
|
||||||
|
701: ["invalid_queue_id", "invalid queue id"]
|
||||||
|
702: ["queue_not_empty", "queue is not empty"]
|
||||||
|
703: ["invalid_queue_or_task_not_queued", "invalid queue id or task not in queue"]
|
||||||
|
704: ["removed_during_reposition", "task was removed by another party during reposition"]
|
||||||
|
705: ["failed_adding_during_reposition", "failed adding task back to queue during reposition"]
|
||||||
|
706: ["task_already_queued", "failed adding task to queue since task is already queued"]
|
||||||
|
707: ["no_default_queue", "no queue is tagged as the default queue for this company"]
|
||||||
|
708: ["multiple_default_queues", "more than one queue is tagged as the default queue for this company"]
|
||||||
|
|
||||||
|
# Database
|
||||||
|
800: ["data_validation_error", "data validation error"]
|
||||||
|
801: ["expected_unique_data", "value combination already exists (unique field already contains this value)"]
|
||||||
|
|
||||||
|
# Workers
|
||||||
|
1001: ["invalid_worker_id", "invalid worker id"]
|
||||||
|
1002: ["worker_registration_failed", "worker registration failed"]
|
||||||
|
1003: ["worker_registered", "worker is already registered"]
|
||||||
|
1004: ["worker_not_registered", "worker is not registered"]
|
||||||
|
1005: ["worker_stats_not_found", "worker stats not found"]
|
||||||
|
|
||||||
|
1104: ["invalid_scroll_id", "Invalid scroll id"]
|
||||||
|
}
|
||||||
|
|
||||||
|
401 {
|
||||||
|
_: "unauthorized"
|
||||||
|
1: ["not_authorized", "unauthorized (not authorized for endpoint)"]
|
||||||
|
2: ["entity_not_allowed", "unauthorized (entity not allowed)"]
|
||||||
|
10: ["bad_auth_type", "unauthorized (bad authentication header type)"]
|
||||||
|
20: ["no_credentials", "unauthorized (missing credentials)"]
|
||||||
|
21: ["bad_credentials", "unauthorized (malformed credentials)"]
|
||||||
|
22: ["invalid_credentials", "unauthorized (invalid credentials)"]
|
||||||
|
30: ["invalid_token", "invalid token"]
|
||||||
|
31: ["blocked_token", "token is blocked"]
|
||||||
|
40: ["invalid_fixed_user", "fixed user ID was not found"]
|
||||||
|
}
|
||||||
|
|
||||||
|
403: {
|
||||||
|
_: "forbidden"
|
||||||
|
10: ["routing_error", "forbidden (routing error)"]
|
||||||
|
12: ["blocked_internal_endpoint", "forbidden (blocked internal endpoint)"]
|
||||||
|
20: ["role_not_allowed", "forbidden (not allowed for role)"]
|
||||||
|
21: ["no_write_permission", "forbidden (modification not allowed)"]
|
||||||
|
}
|
||||||
|
|
||||||
|
410: {
|
||||||
|
_: "gone"
|
||||||
|
1: ["not_supported", "thus endpoint is not supported any more"]
|
||||||
|
}
|
||||||
|
|
||||||
|
500 {
|
||||||
|
_: "server_error"
|
||||||
|
0: ["general_error", "general server error"]
|
||||||
|
1: ["internal_error", "internal server error"]
|
||||||
|
2: ["config_error", "configuration error"]
|
||||||
|
3: ["build_info_error", "build info unavailable or corrupted"]
|
||||||
|
4: ["low_disk_space", "Critical server error! Server reports low or insufficient disk space. Please resolve immediately by allocating additional disk space or freeing up storage space."]
|
||||||
|
10: ["transaction_error", "a transaction call has returned with an error"]
|
||||||
|
# Database-related issues
|
||||||
|
100: ["data_error", "general data error"]
|
||||||
|
101: ["inconsistent_data", "inconsistent data encountered in document"]
|
||||||
|
102: ["database_unavailable", "database is temporarily unavailable"]
|
||||||
|
110: ["update_failed", "update failed"]
|
||||||
|
|
||||||
|
# Index-related issues
|
||||||
|
201: ["missing_index", "missing internal index"]
|
||||||
|
|
||||||
|
9999: ["not_implemented", "action is not yet implemented"]
|
||||||
|
}
|
||||||
1
apiserver/apierrors_generator/__init__.py
Normal file
1
apiserver/apierrors_generator/__init__.py
Normal file
@@ -0,0 +1 @@
|
|||||||
|
from .errors_generator import ErrorsGenerator
|
||||||
4
apiserver/apierrors_generator/__main__.py
Normal file
4
apiserver/apierrors_generator/__main__.py
Normal file
@@ -0,0 +1,4 @@
|
|||||||
|
from .errors_generator import ErrorsGenerator
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
ErrorsGenerator.generate_python_files()
|
||||||
31
apiserver/apierrors_generator/errors_generator.py
Normal file
31
apiserver/apierrors_generator/errors_generator.py
Normal file
@@ -0,0 +1,31 @@
|
|||||||
|
from functools import reduce
|
||||||
|
from pathlib import Path
|
||||||
|
from typing import Union
|
||||||
|
|
||||||
|
from pyhocon import ConfigFactory, ConfigTree
|
||||||
|
|
||||||
|
from .generator import Generator
|
||||||
|
|
||||||
|
|
||||||
|
class ErrorsGenerator:
|
||||||
|
_apierrors_path = Path(__file__).parents[1] / "apierrors"
|
||||||
|
_files = [_apierrors_path / "errors.conf"]
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _get_codes(cls):
|
||||||
|
return {
|
||||||
|
(k, v.pop("_")): v
|
||||||
|
for k, v in reduce(
|
||||||
|
ConfigTree.merge_configs, map(ConfigFactory.parse_file, cls._files),
|
||||||
|
).items()
|
||||||
|
}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def add_errors_file(cls, path: Union[Path, str]):
|
||||||
|
cls._files.append(path)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def generate_python_files(cls):
|
||||||
|
Generator(cls._apierrors_path / "errors", format_pep8=False).make_errors(
|
||||||
|
cls._get_codes()
|
||||||
|
)
|
||||||
@@ -8,9 +8,12 @@ from pathlib import Path
|
|||||||
|
|
||||||
env = jinja2.Environment(
|
env = jinja2.Environment(
|
||||||
loader=jinja2.FileSystemLoader(str(Path(__file__).parent)),
|
loader=jinja2.FileSystemLoader(str(Path(__file__).parent)),
|
||||||
autoescape=jinja2.select_autoescape(disabled_extensions=('py',), default_for_string=False),
|
autoescape=jinja2.select_autoescape(
|
||||||
|
disabled_extensions=("py",), default_for_string=False
|
||||||
|
),
|
||||||
trim_blocks=True,
|
trim_blocks=True,
|
||||||
lstrip_blocks=True)
|
lstrip_blocks=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
def env_filter(name=None):
|
def env_filter(name=None):
|
||||||
@@ -19,14 +22,14 @@ def env_filter(name=None):
|
|||||||
|
|
||||||
@env_filter()
|
@env_filter()
|
||||||
def cls_name(name):
|
def cls_name(name):
|
||||||
delims = list(map(re.escape, (' ', '_')))
|
delims = list(map(re.escape, (" ", "_")))
|
||||||
parts = re.split('|'.join(delims), name)
|
parts = re.split("|".join(delims), name)
|
||||||
return ''.join(x.capitalize() for x in parts)
|
return "".join(x.capitalize() for x in parts)
|
||||||
|
|
||||||
|
|
||||||
class Generator(object):
|
class Generator(object):
|
||||||
_base_class_name = 'BaseError'
|
_base_class_name = "BaseError"
|
||||||
_base_class_module = 'apierrors.base'
|
_base_class_module = "apiserver.apierrors.base"
|
||||||
|
|
||||||
def __init__(self, path, format_pep8=True, use_md5=True):
|
def __init__(self, path, format_pep8=True, use_md5=True):
|
||||||
self._use_md5 = use_md5
|
self._use_md5 = use_md5
|
||||||
@@ -35,29 +38,37 @@ class Generator(object):
|
|||||||
self._path.mkdir(parents=True, exist_ok=True)
|
self._path.mkdir(parents=True, exist_ok=True)
|
||||||
|
|
||||||
def _make_init_file(self, path):
|
def _make_init_file(self, path):
|
||||||
(self._path / path / '__init__.py').write_bytes('')
|
(self._path / path / "__init__.py").write_bytes(b"")
|
||||||
|
|
||||||
def _do_render(self, file, template, context):
|
def _do_render(self, file, template, context):
|
||||||
with file.open('w') as f:
|
with file.open("w") as f:
|
||||||
result = template.render(
|
result = template.render(
|
||||||
base_class_name=self._base_class_name,
|
base_class_name=self._base_class_name,
|
||||||
base_class_module=self._base_class_module,
|
base_class_module=self._base_class_module,
|
||||||
**context)
|
**context
|
||||||
|
)
|
||||||
if self._format_pep8:
|
if self._format_pep8:
|
||||||
result = autopep8.fix_code(result, options={'aggressive': 1, 'verbose': 0, 'max_line_length': 120})
|
import autopep8
|
||||||
|
|
||||||
|
result = autopep8.fix_code(
|
||||||
|
result,
|
||||||
|
options={"aggressive": 1, "verbose": 0, "max_line_length": 120},
|
||||||
|
)
|
||||||
f.write(result)
|
f.write(result)
|
||||||
|
|
||||||
def _make_section(self, name, code, subcodes):
|
def _make_section(self, name, code, subcodes):
|
||||||
self._do_render(
|
self._do_render(
|
||||||
file=(self._path / name).with_suffix('.py'),
|
file=(self._path / name).with_suffix(".py"),
|
||||||
template=env.get_template('templates/section.jinja2'),
|
template=env.get_template("templates/section.jinja2"),
|
||||||
context=dict(code=code, subcodes=list(subcodes.items()),))
|
context=dict(code=code, subcodes=list(subcodes.items()),),
|
||||||
|
)
|
||||||
|
|
||||||
def _make_init(self, sections):
|
def _make_init(self, sections):
|
||||||
self._do_render(
|
self._do_render(
|
||||||
file=(self._path / '__init__.py'),
|
file=(self._path / "__init__.py"),
|
||||||
template=env.get_template('templates/init.jinja2'),
|
template=env.get_template("templates/init.jinja2"),
|
||||||
context=dict(sections=sections,))
|
context=dict(sections=sections,),
|
||||||
|
)
|
||||||
|
|
||||||
def _key_to_str(self, data):
|
def _key_to_str(self, data):
|
||||||
if isinstance(data, dict):
|
if isinstance(data, dict):
|
||||||
@@ -66,11 +77,11 @@ class Generator(object):
|
|||||||
|
|
||||||
def _calc_digest(self, data):
|
def _calc_digest(self, data):
|
||||||
data = json.dumps(self._key_to_str(data), sort_keys=True)
|
data = json.dumps(self._key_to_str(data), sort_keys=True)
|
||||||
return hashlib.md5(data.encode('utf8')).hexdigest()
|
return hashlib.md5(data.encode("utf8")).hexdigest()
|
||||||
|
|
||||||
def make_errors(self, errors):
|
def make_errors(self, errors):
|
||||||
digest = None
|
digest = None
|
||||||
digest_file = self._path / 'digest.md5'
|
digest_file = self._path / "digest.md5"
|
||||||
if self._use_md5:
|
if self._use_md5:
|
||||||
digest = self._calc_digest(errors)
|
digest = self._calc_digest(errors)
|
||||||
if digest_file.is_file():
|
if digest_file.is_file():
|
||||||
@@ -79,7 +90,7 @@ class Generator(object):
|
|||||||
|
|
||||||
self._make_init(errors)
|
self._make_init(errors)
|
||||||
for (code, section_name), subcodes in errors.items():
|
for (code, section_name), subcodes in errors.items():
|
||||||
self._make_section(section_name, code, subcodes)
|
self._make_section(section_name, int(code), subcodes)
|
||||||
|
|
||||||
if self._use_md5:
|
if self._use_md5:
|
||||||
digest_file.write_text(digest)
|
digest_file.write_text(digest)
|
||||||
@@ -5,5 +5,5 @@ from {{ base_class_module }} import {{ base_class_name }}
|
|||||||
{% for subcode, (name, msg) in subcodes %}
|
{% for subcode, (name, msg) in subcodes %}
|
||||||
|
|
||||||
|
|
||||||
{{ error_class(name|cls_name, msg, code, subcode) -}}
|
{{ error_class(name|cls_name, msg, code, subcode|int) -}}
|
||||||
{% endfor %}
|
{% endfor %}
|
||||||
@@ -1,18 +1,35 @@
|
|||||||
from __future__ import absolute_import
|
|
||||||
|
|
||||||
from enum import Enum
|
from enum import Enum
|
||||||
from typing import Union, Type, Iterable
|
from typing import Union, Type, Iterable
|
||||||
|
|
||||||
import jsonmodels.errors
|
import jsonmodels.errors
|
||||||
import six
|
import six
|
||||||
import validators
|
|
||||||
from jsonmodels import fields
|
from jsonmodels import fields
|
||||||
from jsonmodels.fields import _LazyType, NotSet
|
from jsonmodels.fields import _LazyType, NotSet
|
||||||
from jsonmodels.models import Base as ModelBase
|
from jsonmodels.models import Base as ModelBase
|
||||||
from jsonmodels.validators import Enum as EnumValidator
|
from jsonmodels.validators import Enum as EnumValidator
|
||||||
from luqum.parser import parser, ParseError
|
from mongoengine.base import BaseDocument
|
||||||
|
from validators import email as email_validator, domain as domain_validator
|
||||||
|
|
||||||
from apierrors import errors
|
from apiserver.apierrors import errors
|
||||||
|
from apiserver.utilities.json import loads, dumps
|
||||||
|
|
||||||
|
|
||||||
|
class EmailField(fields.StringField):
|
||||||
|
def validate(self, value):
|
||||||
|
super().validate(value)
|
||||||
|
if value is None:
|
||||||
|
return
|
||||||
|
if email_validator(value) is not True:
|
||||||
|
raise errors.bad_request.InvalidEmailAddress()
|
||||||
|
|
||||||
|
|
||||||
|
class DomainField(fields.StringField):
|
||||||
|
def validate(self, value):
|
||||||
|
super().validate(value)
|
||||||
|
if value is None:
|
||||||
|
return
|
||||||
|
if domain_validator(value) is not True:
|
||||||
|
raise errors.bad_request.InvalidDomainName()
|
||||||
|
|
||||||
|
|
||||||
def make_default(field_cls, default_value):
|
def make_default(field_cls, default_value):
|
||||||
@@ -34,6 +51,8 @@ class ListField(fields.ListField):
|
|||||||
try:
|
try:
|
||||||
return super(ListField, self)._cast_value(value)
|
return super(ListField, self)._cast_value(value)
|
||||||
except TypeError:
|
except TypeError:
|
||||||
|
if len(self.items_types) == 1 and issubclass(self.items_types[0], Enum):
|
||||||
|
return self.items_types[0](value)
|
||||||
return value
|
return value
|
||||||
|
|
||||||
def validate_single_value(self, item):
|
def validate_single_value(self, item):
|
||||||
@@ -66,18 +85,44 @@ class DictField(fields.BaseField):
|
|||||||
value_types = tuple()
|
value_types = tuple()
|
||||||
|
|
||||||
return tuple(
|
return tuple(
|
||||||
_LazyType(type_)
|
_LazyType(type_) if isinstance(type_, six.string_types) else type_
|
||||||
if isinstance(type_, six.string_types)
|
|
||||||
else type_
|
|
||||||
for type_ in value_types
|
for type_ in value_types
|
||||||
)
|
)
|
||||||
|
|
||||||
|
def parse_value(self, values):
|
||||||
|
"""Cast value to proper collection."""
|
||||||
|
result = self.get_default_value()
|
||||||
|
|
||||||
|
if values is None:
|
||||||
|
return result
|
||||||
|
|
||||||
|
if not self.value_types or not isinstance(values, dict):
|
||||||
|
return values
|
||||||
|
|
||||||
|
return {key: self._cast_value(value) for key, value in values.items()}
|
||||||
|
|
||||||
|
def _cast_value(self, value):
|
||||||
|
if isinstance(value, self.value_types):
|
||||||
|
return value
|
||||||
|
else:
|
||||||
|
if len(self.value_types) != 1:
|
||||||
|
tpl = 'Cannot decide which type to choose from "{types}".'
|
||||||
|
raise jsonmodels.errors.ValidationError(
|
||||||
|
tpl.format(
|
||||||
|
types=', '.join([t.__name__ for t in self.value_types])
|
||||||
|
)
|
||||||
|
)
|
||||||
|
return self.value_types[0](**value)
|
||||||
|
|
||||||
def validate(self, value):
|
def validate(self, value):
|
||||||
super(DictField, self).validate(value)
|
super(DictField, self).validate(value)
|
||||||
|
|
||||||
if not self.value_types:
|
if not self.value_types:
|
||||||
return
|
return
|
||||||
|
|
||||||
|
if not value:
|
||||||
|
return
|
||||||
|
|
||||||
for item in value.values():
|
for item in value.values():
|
||||||
self.validate_single_value(item)
|
self.validate_single_value(item)
|
||||||
|
|
||||||
@@ -94,6 +139,15 @@ class DictField(fields.BaseField):
|
|||||||
)
|
)
|
||||||
)
|
)
|
||||||
|
|
||||||
|
def _elem_to_struct(self, value):
|
||||||
|
try:
|
||||||
|
return value.to_struct()
|
||||||
|
except AttributeError:
|
||||||
|
return value
|
||||||
|
|
||||||
|
def to_struct(self, values):
|
||||||
|
return {k: self._elem_to_struct(v) for k, v in values.items()}
|
||||||
|
|
||||||
|
|
||||||
class IntField(fields.IntField):
|
class IntField(fields.IntField):
|
||||||
def parse_value(self, value):
|
def parse_value(self, value):
|
||||||
@@ -103,25 +157,9 @@ class IntField(fields.IntField):
|
|||||||
return value
|
return value
|
||||||
|
|
||||||
|
|
||||||
def validate_lucene_query(value):
|
|
||||||
if value == '':
|
|
||||||
return
|
|
||||||
try:
|
|
||||||
parser.parse(value)
|
|
||||||
except ParseError as e:
|
|
||||||
raise errors.bad_request.InvalidLuceneSyntax(error=e)
|
|
||||||
|
|
||||||
|
|
||||||
class LuceneQueryField(fields.StringField):
|
|
||||||
def validate(self, value):
|
|
||||||
super(LuceneQueryField, self).validate(value)
|
|
||||||
if value is None:
|
|
||||||
return
|
|
||||||
validate_lucene_query(value)
|
|
||||||
|
|
||||||
|
|
||||||
class NullableEnumValidator(EnumValidator):
|
class NullableEnumValidator(EnumValidator):
|
||||||
"""Validator for enums that allows a None value."""
|
"""Validator for enums that allows a None value."""
|
||||||
|
|
||||||
def validate(self, value):
|
def validate(self, value):
|
||||||
if value is not None:
|
if value is not None:
|
||||||
super(NullableEnumValidator, self).validate(value)
|
super(NullableEnumValidator, self).validate(value)
|
||||||
@@ -150,10 +188,6 @@ class EnumField(fields.StringField):
|
|||||||
|
|
||||||
|
|
||||||
class ActualEnumField(fields.StringField):
|
class ActualEnumField(fields.StringField):
|
||||||
@property
|
|
||||||
def types(self):
|
|
||||||
return (self.__enum,)
|
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
self,
|
self,
|
||||||
enum_class: Type[Enum],
|
enum_class: Type[Enum],
|
||||||
@@ -164,12 +198,13 @@ class ActualEnumField(fields.StringField):
|
|||||||
**kwargs
|
**kwargs
|
||||||
):
|
):
|
||||||
self.__enum = enum_class
|
self.__enum = enum_class
|
||||||
|
self.types = (enum_class,)
|
||||||
# noinspection PyTypeChecker
|
# noinspection PyTypeChecker
|
||||||
choices = list(enum_class)
|
choices = list(enum_class)
|
||||||
validator_cls = EnumValidator if required else NullableEnumValidator
|
validator_cls = EnumValidator if required else NullableEnumValidator
|
||||||
validators = [*(validators or []), validator_cls(*choices)]
|
validators = [*(validators or []), validator_cls(*choices)]
|
||||||
super().__init__(
|
super().__init__(
|
||||||
default=default and self.parse_value(default),
|
default=self.parse_value(default) if default else NotSet,
|
||||||
*args,
|
*args,
|
||||||
required=required,
|
required=required,
|
||||||
validators=validators,
|
validators=validators,
|
||||||
@@ -177,7 +212,7 @@ class ActualEnumField(fields.StringField):
|
|||||||
)
|
)
|
||||||
|
|
||||||
def parse_value(self, value):
|
def parse_value(self, value):
|
||||||
if value is None and not self.required:
|
if value is NotSet and not self.required:
|
||||||
return self.get_default_value()
|
return self.get_default_value()
|
||||||
try:
|
try:
|
||||||
# noinspection PyArgumentList
|
# noinspection PyArgumentList
|
||||||
@@ -189,28 +224,74 @@ class ActualEnumField(fields.StringField):
|
|||||||
return super().to_struct(value.value)
|
return super().to_struct(value.value)
|
||||||
|
|
||||||
|
|
||||||
class EmailField(fields.StringField):
|
class JsonSerializableMixin:
|
||||||
def validate(self, value):
|
def to_json(self: ModelBase):
|
||||||
super().validate(value)
|
return dumps(self.to_struct())
|
||||||
if value is None:
|
|
||||||
return
|
@classmethod
|
||||||
if validators.email(value) is not True:
|
def from_json(cls: Type[ModelBase], s):
|
||||||
raise errors.bad_request.InvalidEmailAddress()
|
return cls(**loads(s))
|
||||||
|
|
||||||
|
|
||||||
class DomainField(fields.StringField):
|
def callable_default(cls: Type[fields.BaseField]) -> Type[fields.BaseField]:
|
||||||
def validate(self, value):
|
class _Wrapped(cls):
|
||||||
super().validate(value)
|
_callable_default = None
|
||||||
if value is None:
|
|
||||||
return
|
def get_default_value(self):
|
||||||
if validators.domain(value) is not True:
|
if self._callable_default:
|
||||||
raise errors.bad_request.InvalidDomainName()
|
return self._callable_default()
|
||||||
|
return super(_Wrapped, self).get_default_value()
|
||||||
|
|
||||||
|
def __init__(self, *args, default=None, **kwargs):
|
||||||
|
if default and callable(default):
|
||||||
|
self._callable_default = default
|
||||||
|
default = default()
|
||||||
|
super(_Wrapped, self).__init__(*args, default=default, **kwargs)
|
||||||
|
|
||||||
|
return _Wrapped
|
||||||
|
|
||||||
|
|
||||||
class StringEnum(Enum):
|
class MongoengineFieldsDict(DictField):
|
||||||
def __str__(self):
|
"""
|
||||||
return self.value
|
DictField representing mongoengine field names/value mapping.
|
||||||
|
Used to convert mongoengine-style field/subfield notation to user-presentable syntax, including handling update
|
||||||
|
operators.
|
||||||
|
"""
|
||||||
|
|
||||||
# noinspection PyMethodParameters
|
mongoengine_update_operators = (
|
||||||
def _generate_next_value_(name, start, count, last_values):
|
"inc",
|
||||||
return name
|
"dec",
|
||||||
|
"push",
|
||||||
|
"push_all",
|
||||||
|
"pop",
|
||||||
|
"pull",
|
||||||
|
"pull_all",
|
||||||
|
"add_to_set",
|
||||||
|
)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _normalize_mongo_value(value):
|
||||||
|
if isinstance(value, BaseDocument):
|
||||||
|
return value.to_mongo()
|
||||||
|
return value
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _normalize_mongo_field_path(cls, path, value):
|
||||||
|
parts = path.split("__")
|
||||||
|
if len(parts) > 1:
|
||||||
|
if parts[0] == "set":
|
||||||
|
parts = parts[1:]
|
||||||
|
elif parts[0] == "unset":
|
||||||
|
parts = parts[1:]
|
||||||
|
value = None
|
||||||
|
elif parts[0] in cls.mongoengine_update_operators:
|
||||||
|
return None, None
|
||||||
|
return ".".join(parts), cls._normalize_mongo_value(value)
|
||||||
|
|
||||||
|
def parse_value(self, value):
|
||||||
|
value = super(MongoengineFieldsDict, self).parse_value(value)
|
||||||
|
return {
|
||||||
|
k: v
|
||||||
|
for k, v in (self._normalize_mongo_field_path(*p) for p in value.items())
|
||||||
|
if k is not None
|
||||||
|
}
|
||||||
@@ -2,10 +2,10 @@ from jsonmodels.fields import IntField, StringField, BoolField, EmbeddedField, D
|
|||||||
from jsonmodels.models import Base
|
from jsonmodels.models import Base
|
||||||
from jsonmodels.validators import Max, Enum
|
from jsonmodels.validators import Max, Enum
|
||||||
|
|
||||||
from apimodels import ListField, EnumField
|
from apiserver.apimodels import ListField, EnumField
|
||||||
from config import config
|
from apiserver.config_repo import config
|
||||||
from database.model.auth import Role
|
from apiserver.database.model.auth import Role
|
||||||
from database.utils import get_options
|
from apiserver.database.utils import get_options
|
||||||
|
|
||||||
|
|
||||||
class GetTokenRequest(Base):
|
class GetTokenRequest(Base):
|
||||||
@@ -75,11 +75,17 @@ class CreateUserResponse(Base):
|
|||||||
class Credentials(Base):
|
class Credentials(Base):
|
||||||
access_key = StringField(required=True)
|
access_key = StringField(required=True)
|
||||||
secret_key = StringField(required=True)
|
secret_key = StringField(required=True)
|
||||||
|
label = StringField()
|
||||||
|
|
||||||
|
|
||||||
class CredentialsResponse(Credentials):
|
class CredentialsResponse(Credentials):
|
||||||
secret_key = StringField()
|
secret_key = StringField()
|
||||||
last_used = DateTimeField(default=None)
|
last_used = DateTimeField(default=None)
|
||||||
|
last_used_from = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class CreateCredentialsRequest(Base):
|
||||||
|
label = StringField()
|
||||||
|
|
||||||
|
|
||||||
class CreateCredentialsResponse(Base):
|
class CreateCredentialsResponse(Base):
|
||||||
@@ -90,6 +96,11 @@ class GetCredentialsResponse(Base):
|
|||||||
credentials = ListField(CredentialsResponse)
|
credentials = ListField(CredentialsResponse)
|
||||||
|
|
||||||
|
|
||||||
|
class EditCredentialsRequest(Base):
|
||||||
|
access_key = StringField(required=True)
|
||||||
|
label = StringField()
|
||||||
|
|
||||||
|
|
||||||
class RevokeCredentialsRequest(Base):
|
class RevokeCredentialsRequest(Base):
|
||||||
access_key = StringField(required=True)
|
access_key = StringField(required=True)
|
||||||
|
|
||||||
28
apiserver/apimodels/base.py
Normal file
28
apiserver/apimodels/base.py
Normal file
@@ -0,0 +1,28 @@
|
|||||||
|
from jsonmodels import models, fields
|
||||||
|
from jsonmodels.validators import Length
|
||||||
|
|
||||||
|
from apiserver.apimodels import MongoengineFieldsDict, ListField
|
||||||
|
|
||||||
|
|
||||||
|
class UpdateResponse(models.Base):
|
||||||
|
updated = fields.IntField(required=True)
|
||||||
|
fields = MongoengineFieldsDict()
|
||||||
|
|
||||||
|
|
||||||
|
class PagedRequest(models.Base):
|
||||||
|
page = fields.IntField()
|
||||||
|
page_size = fields.IntField()
|
||||||
|
|
||||||
|
|
||||||
|
class IdResponse(models.Base):
|
||||||
|
id = fields.StringField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class MakePublicRequest(models.Base):
|
||||||
|
ids = ListField(items_types=str, validators=[Length(minimum_value=1)])
|
||||||
|
|
||||||
|
|
||||||
|
class MoveRequest(models.Base):
|
||||||
|
ids = ListField([str], validators=Length(minimum_value=1))
|
||||||
|
project = fields.StringField()
|
||||||
|
project_name = fields.StringField()
|
||||||
25
apiserver/apimodels/batch.py
Normal file
25
apiserver/apimodels/batch.py
Normal file
@@ -0,0 +1,25 @@
|
|||||||
|
from typing import Sequence
|
||||||
|
|
||||||
|
from jsonmodels.fields import StringField
|
||||||
|
from jsonmodels.models import Base
|
||||||
|
from jsonmodels.validators import Length
|
||||||
|
|
||||||
|
from apiserver.apimodels import ListField
|
||||||
|
from apiserver.apimodels.base import UpdateResponse
|
||||||
|
|
||||||
|
|
||||||
|
class BatchRequest(Base):
|
||||||
|
ids: Sequence[str] = ListField([str], validators=Length(minimum_value=1))
|
||||||
|
|
||||||
|
|
||||||
|
class BatchResponse(Base):
|
||||||
|
succeeded: Sequence[dict] = ListField([dict])
|
||||||
|
failed: Sequence[dict] = ListField([dict])
|
||||||
|
|
||||||
|
|
||||||
|
class UpdateBatchItem(UpdateResponse):
|
||||||
|
id: str = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class UpdateBatchResponse(BatchResponse):
|
||||||
|
succeeded: Sequence[UpdateBatchItem] = ListField(UpdateBatchItem)
|
||||||
34
apiserver/apimodels/custom_validators/__init__.py
Normal file
34
apiserver/apimodels/custom_validators/__init__.py
Normal file
@@ -0,0 +1,34 @@
|
|||||||
|
import validators
|
||||||
|
from jsonmodels.errors import ValidationError
|
||||||
|
|
||||||
|
|
||||||
|
class ForEach(object):
|
||||||
|
def __init__(self, validator):
|
||||||
|
self.validator = validator
|
||||||
|
|
||||||
|
def validate(self, values):
|
||||||
|
for value in values:
|
||||||
|
self.validator.validate(value)
|
||||||
|
|
||||||
|
def modify_schema(self, field_schema):
|
||||||
|
return self.validator.modify_schema(field_schema)
|
||||||
|
|
||||||
|
|
||||||
|
class Hostname(object):
|
||||||
|
|
||||||
|
def validate(self, value):
|
||||||
|
if validators.domain(value) is not True:
|
||||||
|
raise ValidationError(f"Value '{value}' is not a valid hostname")
|
||||||
|
|
||||||
|
def modify_schema(self, field_schema):
|
||||||
|
field_schema["format"] = "hostname"
|
||||||
|
|
||||||
|
|
||||||
|
class Email(object):
|
||||||
|
|
||||||
|
def validate(self, value):
|
||||||
|
if validators.email(value) is not True:
|
||||||
|
raise ValidationError(f"Value '{value}' is not a valid email address")
|
||||||
|
|
||||||
|
def modify_schema(self, field_schema):
|
||||||
|
field_schema["format"] = "email"
|
||||||
174
apiserver/apimodels/events.py
Normal file
174
apiserver/apimodels/events.py
Normal file
@@ -0,0 +1,174 @@
|
|||||||
|
from enum import auto
|
||||||
|
from typing import Sequence, Optional
|
||||||
|
|
||||||
|
from jsonmodels import validators
|
||||||
|
from jsonmodels.fields import StringField, BoolField, EmbeddedField
|
||||||
|
from jsonmodels.models import Base
|
||||||
|
from jsonmodels.validators import Length, Min, Max
|
||||||
|
|
||||||
|
from apiserver.apimodels import ListField, IntField, ActualEnumField
|
||||||
|
from apiserver.bll.event.event_common import EventType
|
||||||
|
from apiserver.bll.event.scalar_key import ScalarKeyEnum
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.utilities.stringenum import StringEnum
|
||||||
|
|
||||||
|
|
||||||
|
class HistogramRequestBase(Base):
|
||||||
|
samples: int = IntField(default=2000, validators=[Min(1), Max(6000)])
|
||||||
|
key: ScalarKeyEnum = ActualEnumField(ScalarKeyEnum, default=ScalarKeyEnum.iter)
|
||||||
|
|
||||||
|
|
||||||
|
class MetricVariants(Base):
|
||||||
|
metric: str = StringField(required=True)
|
||||||
|
variants: Sequence[str] = ListField(items_types=str)
|
||||||
|
|
||||||
|
|
||||||
|
class ScalarMetricsIterHistogramRequest(HistogramRequestBase):
|
||||||
|
task: str = StringField(required=True)
|
||||||
|
metrics: Sequence[MetricVariants] = ListField(items_types=MetricVariants)
|
||||||
|
model_events: bool = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class MultiTaskScalarMetricsIterHistogramRequest(HistogramRequestBase):
|
||||||
|
tasks: Sequence[str] = ListField(
|
||||||
|
items_types=str,
|
||||||
|
validators=[
|
||||||
|
Length(
|
||||||
|
minimum_value=1,
|
||||||
|
maximum_value=config.get(
|
||||||
|
"services.tasks.multi_task_histogram_limit", 100
|
||||||
|
),
|
||||||
|
)
|
||||||
|
],
|
||||||
|
)
|
||||||
|
model_events: bool = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class TaskMetric(Base):
|
||||||
|
task: str = StringField(required=True)
|
||||||
|
metric: str = StringField(default=None)
|
||||||
|
variants: Sequence[str] = ListField(items_types=str)
|
||||||
|
|
||||||
|
|
||||||
|
class MetricEventsRequest(Base):
|
||||||
|
metrics: Sequence[TaskMetric] = ListField(
|
||||||
|
items_types=TaskMetric, validators=[Length(minimum_value=1)]
|
||||||
|
)
|
||||||
|
iters: int = IntField(default=1, validators=validators.Min(1))
|
||||||
|
navigate_earlier: bool = BoolField(default=True)
|
||||||
|
refresh: bool = BoolField(default=False)
|
||||||
|
scroll_id: str = StringField()
|
||||||
|
model_events: bool = BoolField()
|
||||||
|
|
||||||
|
|
||||||
|
class GetVariantSampleRequest(Base):
|
||||||
|
task: str = StringField(required=True)
|
||||||
|
metric: str = StringField(required=True)
|
||||||
|
variant: str = StringField(required=True)
|
||||||
|
iteration: Optional[int] = IntField()
|
||||||
|
refresh: bool = BoolField(default=False)
|
||||||
|
scroll_id: Optional[str] = StringField()
|
||||||
|
navigate_current_metric: bool = BoolField(default=True)
|
||||||
|
model_events: bool = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class GetMetricSamplesRequest(Base):
|
||||||
|
task: str = StringField(required=True)
|
||||||
|
metric: str = StringField(required=True)
|
||||||
|
iteration: Optional[int] = IntField()
|
||||||
|
refresh: bool = BoolField(default=False)
|
||||||
|
scroll_id: Optional[str] = StringField()
|
||||||
|
navigate_current_metric: bool = BoolField(default=True)
|
||||||
|
model_events: bool = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class NextHistorySampleRequest(Base):
|
||||||
|
task: str = StringField(required=True)
|
||||||
|
scroll_id: Optional[str] = StringField()
|
||||||
|
navigate_earlier: bool = BoolField(default=True)
|
||||||
|
next_iteration: bool = BoolField(default=False)
|
||||||
|
model_events: bool = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class LogOrderEnum(StringEnum):
|
||||||
|
asc = auto()
|
||||||
|
desc = auto()
|
||||||
|
|
||||||
|
|
||||||
|
class TaskEventsRequestBase(Base):
|
||||||
|
task: str = StringField(required=True)
|
||||||
|
batch_size: int = IntField(default=500)
|
||||||
|
|
||||||
|
|
||||||
|
class TaskEventsRequest(TaskEventsRequestBase):
|
||||||
|
metrics: Sequence[MetricVariants] = ListField(items_types=MetricVariants)
|
||||||
|
event_type: EventType = ActualEnumField(EventType, default=EventType.all)
|
||||||
|
order: Optional[str] = ActualEnumField(LogOrderEnum, default=LogOrderEnum.asc)
|
||||||
|
scroll_id: str = StringField()
|
||||||
|
count_total: bool = BoolField(default=True)
|
||||||
|
model_events: bool = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class LogEventsRequest(TaskEventsRequestBase):
|
||||||
|
batch_size: int = IntField(default=5000)
|
||||||
|
navigate_earlier: bool = BoolField(default=True)
|
||||||
|
from_timestamp: Optional[int] = IntField()
|
||||||
|
order: Optional[str] = ActualEnumField(LogOrderEnum)
|
||||||
|
|
||||||
|
|
||||||
|
class ScalarMetricsIterRawRequest(TaskEventsRequestBase):
|
||||||
|
batch_size: int = IntField()
|
||||||
|
key: ScalarKeyEnum = ActualEnumField(ScalarKeyEnum, default=ScalarKeyEnum.iter)
|
||||||
|
metric: MetricVariants = EmbeddedField(MetricVariants, required=True)
|
||||||
|
count_total: bool = BoolField(default=False)
|
||||||
|
scroll_id: str = StringField()
|
||||||
|
model_events: bool = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class IterationEvents(Base):
|
||||||
|
iter: int = IntField()
|
||||||
|
events: Sequence[dict] = ListField(items_types=dict)
|
||||||
|
|
||||||
|
|
||||||
|
class MetricEvents(Base):
|
||||||
|
task: str = StringField()
|
||||||
|
iterations: Sequence[IterationEvents] = ListField(items_types=IterationEvents)
|
||||||
|
|
||||||
|
|
||||||
|
class MetricEventsResponse(Base):
|
||||||
|
metrics: Sequence[MetricEvents] = ListField(items_types=MetricEvents)
|
||||||
|
scroll_id: str = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class MultiTasksRequestBase(Base):
|
||||||
|
tasks: Sequence[str] = ListField(
|
||||||
|
items_types=str, validators=[Length(minimum_value=1)]
|
||||||
|
)
|
||||||
|
model_events: bool = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class SingleValueMetricsRequest(MultiTasksRequestBase):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class TaskMetricsRequest(MultiTasksRequestBase):
|
||||||
|
event_type: EventType = ActualEnumField(EventType, required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class TaskPlotsRequest(Base):
|
||||||
|
task: str = StringField(required=True)
|
||||||
|
iters: int = IntField(default=1)
|
||||||
|
scroll_id: str = StringField()
|
||||||
|
no_scroll: bool = BoolField(default=False)
|
||||||
|
metrics: Sequence[MetricVariants] = ListField(items_types=MetricVariants)
|
||||||
|
model_events: bool = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class ClearScrollRequest(Base):
|
||||||
|
scroll_id: str = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class ClearTaskLogRequest(Base):
|
||||||
|
task: str = StringField(required=True)
|
||||||
|
threshold_sec = IntField()
|
||||||
|
allow_locked = BoolField(default=False)
|
||||||
34
apiserver/apimodels/login.py
Normal file
34
apiserver/apimodels/login.py
Normal file
@@ -0,0 +1,34 @@
|
|||||||
|
from jsonmodels.fields import StringField, BoolField, EmbeddedField, ListField
|
||||||
|
from jsonmodels.models import Base
|
||||||
|
|
||||||
|
from apiserver.apimodels import DictField, callable_default
|
||||||
|
|
||||||
|
|
||||||
|
class GetSupportedModesRequest(Base):
|
||||||
|
state = StringField(help_text="ASCII base64 encoded application state")
|
||||||
|
callback_url_prefix = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class BasicGuestMode(Base):
|
||||||
|
enabled = BoolField(default=False)
|
||||||
|
name = StringField()
|
||||||
|
username = StringField()
|
||||||
|
password = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class BasicMode(Base):
|
||||||
|
enabled = BoolField(default=False)
|
||||||
|
guest = callable_default(EmbeddedField)(BasicGuestMode, default=BasicGuestMode)
|
||||||
|
|
||||||
|
|
||||||
|
class ServerErrors(Base):
|
||||||
|
missed_es_upgrade = BoolField(default=False)
|
||||||
|
es_connection_error = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class GetSupportedModesResponse(Base):
|
||||||
|
basic = EmbeddedField(BasicMode)
|
||||||
|
server_errors = EmbeddedField(ServerErrors)
|
||||||
|
sso = DictField([str, type(None)])
|
||||||
|
sso_providers = ListField([dict])
|
||||||
|
authenticated = BoolField(default=False)
|
||||||
24
apiserver/apimodels/metadata.py
Normal file
24
apiserver/apimodels/metadata.py
Normal file
@@ -0,0 +1,24 @@
|
|||||||
|
from typing import Sequence
|
||||||
|
|
||||||
|
from jsonmodels import validators
|
||||||
|
from jsonmodels.fields import StringField, BoolField
|
||||||
|
from jsonmodels.models import Base
|
||||||
|
|
||||||
|
from apiserver.apimodels import ListField
|
||||||
|
|
||||||
|
|
||||||
|
class MetadataItem(Base):
|
||||||
|
key = StringField(required=True)
|
||||||
|
type = StringField(required=True)
|
||||||
|
value = StringField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteMetadata(Base):
|
||||||
|
keys: Sequence[str] = ListField(str, validators=validators.Length(minimum_value=1))
|
||||||
|
|
||||||
|
|
||||||
|
class AddOrUpdateMetadata(Base):
|
||||||
|
metadata: Sequence[MetadataItem] = ListField(
|
||||||
|
[MetadataItem], validators=validators.Length(minimum_value=1)
|
||||||
|
)
|
||||||
|
replace_metadata = BoolField(default=False)
|
||||||
82
apiserver/apimodels/models.py
Normal file
82
apiserver/apimodels/models.py
Normal file
@@ -0,0 +1,82 @@
|
|||||||
|
from jsonmodels import models, fields
|
||||||
|
from six import string_types
|
||||||
|
|
||||||
|
from apiserver.apimodels import ListField, DictField
|
||||||
|
from apiserver.apimodels.base import UpdateResponse
|
||||||
|
from apiserver.apimodels.batch import BatchRequest
|
||||||
|
from apiserver.apimodels.metadata import (
|
||||||
|
MetadataItem,
|
||||||
|
DeleteMetadata,
|
||||||
|
AddOrUpdateMetadata,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class GetFrameworksRequest(models.Base):
|
||||||
|
projects = fields.ListField(items_types=[str])
|
||||||
|
|
||||||
|
|
||||||
|
class CreateModelRequest(models.Base):
|
||||||
|
name = fields.StringField(required=True)
|
||||||
|
uri = fields.StringField(required=True)
|
||||||
|
labels = DictField(value_types=string_types + (int,))
|
||||||
|
tags = ListField(items_types=string_types)
|
||||||
|
system_tags = ListField(items_types=string_types)
|
||||||
|
comment = fields.StringField()
|
||||||
|
public = fields.BoolField(default=False)
|
||||||
|
project = fields.StringField()
|
||||||
|
parent = fields.StringField()
|
||||||
|
framework = fields.StringField()
|
||||||
|
design = DictField()
|
||||||
|
ready = fields.BoolField(default=True)
|
||||||
|
ui_cache = DictField()
|
||||||
|
task = fields.StringField()
|
||||||
|
metadata = DictField(value_types=[MetadataItem])
|
||||||
|
|
||||||
|
|
||||||
|
class CreateModelResponse(models.Base):
|
||||||
|
id = fields.StringField(required=True)
|
||||||
|
created = fields.BoolField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class ModelRequest(models.Base):
|
||||||
|
model = fields.StringField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteModelRequest(ModelRequest):
|
||||||
|
force = fields.BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class ModelsDeleteManyRequest(BatchRequest):
|
||||||
|
force = fields.BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class PublishModelRequest(ModelRequest):
|
||||||
|
force_publish_task = fields.BoolField(default=False)
|
||||||
|
publish_task = fields.BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class ModelTaskPublishResponse(models.Base):
|
||||||
|
id = fields.StringField(required=True)
|
||||||
|
data = fields.EmbeddedField(UpdateResponse)
|
||||||
|
|
||||||
|
|
||||||
|
class PublishModelResponse(UpdateResponse):
|
||||||
|
published_task = fields.EmbeddedField(ModelTaskPublishResponse)
|
||||||
|
|
||||||
|
|
||||||
|
class ModelsPublishManyRequest(BatchRequest):
|
||||||
|
force_publish_task = fields.BoolField(default=False)
|
||||||
|
publish_task = fields.BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteMetadataRequest(DeleteMetadata):
|
||||||
|
model = fields.StringField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class AddOrUpdateMetadataRequest(AddOrUpdateMetadata):
|
||||||
|
model = fields.StringField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class ModelsGetRequest(models.Base):
|
||||||
|
include_stats = fields.BoolField(default=False)
|
||||||
|
allow_public = fields.BoolField(default=True)
|
||||||
25
apiserver/apimodels/organization.py
Normal file
25
apiserver/apimodels/organization.py
Normal file
@@ -0,0 +1,25 @@
|
|||||||
|
from jsonmodels import fields, models
|
||||||
|
|
||||||
|
from apiserver.apimodels import DictField
|
||||||
|
|
||||||
|
|
||||||
|
class Filter(models.Base):
|
||||||
|
tags = fields.ListField([str])
|
||||||
|
system_tags = fields.ListField([str])
|
||||||
|
|
||||||
|
|
||||||
|
class TagsRequest(models.Base):
|
||||||
|
include_system = fields.BoolField(default=False)
|
||||||
|
filter = fields.EmbeddedField(Filter)
|
||||||
|
|
||||||
|
|
||||||
|
class EntitiesCountRequest(models.Base):
|
||||||
|
projects = DictField()
|
||||||
|
tasks = DictField()
|
||||||
|
models = DictField()
|
||||||
|
pipelines = DictField()
|
||||||
|
datasets = DictField()
|
||||||
|
reports = DictField()
|
||||||
|
active_users = fields.ListField(str)
|
||||||
|
search_hidden = fields.BoolField(default=False)
|
||||||
|
allow_public = fields.BoolField(default=True)
|
||||||
19
apiserver/apimodels/pipelines.py
Normal file
19
apiserver/apimodels/pipelines.py
Normal file
@@ -0,0 +1,19 @@
|
|||||||
|
from jsonmodels import models, fields
|
||||||
|
|
||||||
|
from apiserver.apimodels import ListField
|
||||||
|
|
||||||
|
|
||||||
|
class Arg(models.Base):
|
||||||
|
name = fields.StringField(required=True)
|
||||||
|
value = fields.StringField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class StartPipelineRequest(models.Base):
|
||||||
|
task = fields.StringField(required=True)
|
||||||
|
queue = fields.StringField(required=True)
|
||||||
|
args = ListField(Arg)
|
||||||
|
|
||||||
|
|
||||||
|
class StartPipelineResponse(models.Base):
|
||||||
|
pipeline = fields.StringField(required=True)
|
||||||
|
enqueued = fields.BoolField(required=True)
|
||||||
79
apiserver/apimodels/projects.py
Normal file
79
apiserver/apimodels/projects.py
Normal file
@@ -0,0 +1,79 @@
|
|||||||
|
from enum import Enum
|
||||||
|
|
||||||
|
from jsonmodels import models, fields
|
||||||
|
|
||||||
|
from apiserver.apimodels import ListField, ActualEnumField, DictField
|
||||||
|
from apiserver.apimodels.organization import TagsRequest
|
||||||
|
from apiserver.database.model import EntityVisibility
|
||||||
|
|
||||||
|
|
||||||
|
class ProjectRequest(models.Base):
|
||||||
|
project = fields.StringField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class MergeRequest(ProjectRequest):
|
||||||
|
destination_project = fields.StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class MoveRequest(ProjectRequest):
|
||||||
|
new_location = fields.StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteRequest(ProjectRequest):
|
||||||
|
force = fields.BoolField(default=False)
|
||||||
|
delete_contents = fields.BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class ProjectOrNoneRequest(models.Base):
|
||||||
|
project = fields.StringField()
|
||||||
|
include_subprojects = fields.BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class GetParamsRequest(ProjectOrNoneRequest):
|
||||||
|
page = fields.IntField(default=0)
|
||||||
|
page_size = fields.IntField(default=500)
|
||||||
|
|
||||||
|
|
||||||
|
class ProjectTagsRequest(TagsRequest):
|
||||||
|
projects = ListField(str)
|
||||||
|
|
||||||
|
|
||||||
|
class MultiProjectRequest(models.Base):
|
||||||
|
projects = fields.ListField(str)
|
||||||
|
include_subprojects = fields.BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class ProjectTaskParentsRequest(MultiProjectRequest):
|
||||||
|
tasks_state = ActualEnumField(EntityVisibility)
|
||||||
|
|
||||||
|
|
||||||
|
class ProjectHyperparamValuesRequest(MultiProjectRequest):
|
||||||
|
section = fields.StringField(required=True)
|
||||||
|
name = fields.StringField(required=True)
|
||||||
|
allow_public = fields.BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class ProjectModelMetadataValuesRequest(MultiProjectRequest):
|
||||||
|
key = fields.StringField(required=True)
|
||||||
|
allow_public = fields.BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class ProjectChildrenType(Enum):
|
||||||
|
pipeline = "pipeline"
|
||||||
|
report = "report"
|
||||||
|
dataset = "dataset"
|
||||||
|
|
||||||
|
|
||||||
|
class ProjectsGetRequest(models.Base):
|
||||||
|
include_dataset_stats = fields.BoolField(default=False)
|
||||||
|
include_stats = fields.BoolField(default=False)
|
||||||
|
include_stats_filter = DictField()
|
||||||
|
stats_with_children = fields.BoolField(default=True)
|
||||||
|
stats_for_state = ActualEnumField(EntityVisibility, default=EntityVisibility.active)
|
||||||
|
non_public = fields.BoolField(default=False) # legacy, use allow_public instead
|
||||||
|
active_users = fields.ListField(str)
|
||||||
|
check_own_contents = fields.BoolField(default=False)
|
||||||
|
shallow_search = fields.BoolField(default=False)
|
||||||
|
search_hidden = fields.BoolField(default=False)
|
||||||
|
allow_public = fields.BoolField(default=True)
|
||||||
|
children_type = ActualEnumField(ProjectChildrenType)
|
||||||
@@ -2,7 +2,12 @@ from jsonmodels import validators
|
|||||||
from jsonmodels.fields import StringField, IntField, BoolField, FloatField
|
from jsonmodels.fields import StringField, IntField, BoolField, FloatField
|
||||||
from jsonmodels.models import Base
|
from jsonmodels.models import Base
|
||||||
|
|
||||||
from apimodels import ListField
|
from apiserver.apimodels import ListField, DictField
|
||||||
|
from apiserver.apimodels.metadata import (
|
||||||
|
MetadataItem,
|
||||||
|
DeleteMetadata,
|
||||||
|
AddOrUpdateMetadata,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
class GetDefaultResp(Base):
|
class GetDefaultResp(Base):
|
||||||
@@ -14,12 +19,28 @@ class CreateRequest(Base):
|
|||||||
name = StringField(required=True)
|
name = StringField(required=True)
|
||||||
tags = ListField(items_types=[str])
|
tags = ListField(items_types=[str])
|
||||||
system_tags = ListField(items_types=[str])
|
system_tags = ListField(items_types=[str])
|
||||||
|
metadata = DictField(value_types=[MetadataItem])
|
||||||
|
|
||||||
|
|
||||||
class QueueRequest(Base):
|
class QueueRequest(Base):
|
||||||
queue = StringField(required=True)
|
queue = StringField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class GetByIdRequest(QueueRequest):
|
||||||
|
max_task_entries = IntField()
|
||||||
|
|
||||||
|
|
||||||
|
class GetAllRequest(Base):
|
||||||
|
max_task_entries = IntField()
|
||||||
|
search_hidden = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class GetNextTaskRequest(QueueRequest):
|
||||||
|
queue = StringField(required=True)
|
||||||
|
get_task_info = BoolField(default=False)
|
||||||
|
task = StringField()
|
||||||
|
|
||||||
|
|
||||||
class DeleteRequest(QueueRequest):
|
class DeleteRequest(QueueRequest):
|
||||||
force = BoolField(default=False)
|
force = BoolField(default=False)
|
||||||
|
|
||||||
@@ -28,6 +49,7 @@ class UpdateRequest(QueueRequest):
|
|||||||
name = StringField()
|
name = StringField()
|
||||||
tags = ListField(items_types=[str])
|
tags = ListField(items_types=[str])
|
||||||
system_tags = ListField(items_types=[str])
|
system_tags = ListField(items_types=[str])
|
||||||
|
metadata = DictField(value_types=[MetadataItem])
|
||||||
|
|
||||||
|
|
||||||
class TaskRequest(QueueRequest):
|
class TaskRequest(QueueRequest):
|
||||||
@@ -47,6 +69,7 @@ class GetMetricsRequest(Base):
|
|||||||
from_date = FloatField(required=True, validators=validators.Min(0))
|
from_date = FloatField(required=True, validators=validators.Min(0))
|
||||||
to_date = FloatField(required=True, validators=validators.Min(0))
|
to_date = FloatField(required=True, validators=validators.Min(0))
|
||||||
interval = IntField(required=True, validators=validators.Min(1))
|
interval = IntField(required=True, validators=validators.Min(1))
|
||||||
|
refresh = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
class QueueMetrics(Base):
|
class QueueMetrics(Base):
|
||||||
@@ -58,3 +81,11 @@ class QueueMetrics(Base):
|
|||||||
|
|
||||||
class GetMetricsResponse(Base):
|
class GetMetricsResponse(Base):
|
||||||
queues = ListField(QueueMetrics)
|
queues = ListField(QueueMetrics)
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteMetadataRequest(DeleteMetadata):
|
||||||
|
queue = StringField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class AddOrUpdateMetadataRequest(AddOrUpdateMetadata):
|
||||||
|
queue = StringField(required=True)
|
||||||
72
apiserver/apimodels/reports.py
Normal file
72
apiserver/apimodels/reports.py
Normal file
@@ -0,0 +1,72 @@
|
|||||||
|
from typing import Sequence
|
||||||
|
|
||||||
|
from jsonmodels import validators
|
||||||
|
from jsonmodels.fields import StringField, ListField, BoolField, EmbeddedField, IntField
|
||||||
|
from jsonmodels.models import Base
|
||||||
|
from jsonmodels.validators import Length
|
||||||
|
|
||||||
|
from apiserver.apimodels.events import MetricVariants, HistogramRequestBase
|
||||||
|
|
||||||
|
|
||||||
|
class UpdateReportRequest(Base):
|
||||||
|
task = StringField(required=True)
|
||||||
|
name = StringField(nullable=True, validators=Length(minimum_value=3))
|
||||||
|
tags = ListField(items_types=[str])
|
||||||
|
comment = StringField()
|
||||||
|
report = StringField()
|
||||||
|
report_assets = ListField(items_types=[str])
|
||||||
|
|
||||||
|
|
||||||
|
class CreateReportRequest(Base):
|
||||||
|
name = StringField(required=True, validators=Length(minimum_value=3))
|
||||||
|
tags = ListField(items_types=[str])
|
||||||
|
comment = StringField()
|
||||||
|
report = StringField()
|
||||||
|
project = StringField()
|
||||||
|
report_assets = ListField(items_types=[str])
|
||||||
|
|
||||||
|
|
||||||
|
class PublishReportRequest(Base):
|
||||||
|
task = StringField(required=True)
|
||||||
|
message = StringField(default="")
|
||||||
|
|
||||||
|
|
||||||
|
class ArchiveReportRequest(Base):
|
||||||
|
task = StringField(required=True)
|
||||||
|
message = StringField(default="")
|
||||||
|
|
||||||
|
|
||||||
|
class ShareReportRequest(Base):
|
||||||
|
task = StringField(required=True)
|
||||||
|
share = BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteReportRequest(Base):
|
||||||
|
task = StringField(required=True)
|
||||||
|
force = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class MoveReportRequest(Base):
|
||||||
|
task = StringField(required=True)
|
||||||
|
project = StringField()
|
||||||
|
project_name = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class EventsRequest(Base):
|
||||||
|
iters = IntField(default=1, validators=validators.Min(1))
|
||||||
|
metrics: Sequence[MetricVariants] = ListField(items_types=MetricVariants)
|
||||||
|
|
||||||
|
|
||||||
|
class ScalarMetricsIterHistogram(HistogramRequestBase):
|
||||||
|
metrics: Sequence[MetricVariants] = ListField(items_types=MetricVariants)
|
||||||
|
|
||||||
|
|
||||||
|
class GetTasksDataRequest(Base):
|
||||||
|
debug_images: EventsRequest = EmbeddedField(EventsRequest)
|
||||||
|
plots: EventsRequest = EmbeddedField(EventsRequest)
|
||||||
|
scalar_metrics_iter_histogram: ScalarMetricsIterHistogram = EmbeddedField(ScalarMetricsIterHistogram)
|
||||||
|
allow_public = BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class GetAllRequest(Base):
|
||||||
|
allow_public = BoolField(default=True)
|
||||||
15
apiserver/apimodels/server.py
Normal file
15
apiserver/apimodels/server.py
Normal file
@@ -0,0 +1,15 @@
|
|||||||
|
from jsonmodels.fields import BoolField, DateTimeField, StringField
|
||||||
|
from jsonmodels.models import Base
|
||||||
|
|
||||||
|
|
||||||
|
class ReportStatsOptionRequest(Base):
|
||||||
|
enabled = BoolField(default=None, nullable=True)
|
||||||
|
|
||||||
|
|
||||||
|
class ReportStatsOptionResponse(Base):
|
||||||
|
supported = BoolField(default=True)
|
||||||
|
enabled = BoolField()
|
||||||
|
enabled_time = DateTimeField(nullable=True)
|
||||||
|
enabled_version = StringField(nullable=True)
|
||||||
|
enabled_user = StringField(nullable=True)
|
||||||
|
current_version = StringField()
|
||||||
325
apiserver/apimodels/tasks.py
Normal file
325
apiserver/apimodels/tasks.py
Normal file
@@ -0,0 +1,325 @@
|
|||||||
|
from typing import Sequence
|
||||||
|
|
||||||
|
from jsonmodels import models
|
||||||
|
from jsonmodels.fields import StringField, BoolField, IntField, EmbeddedField
|
||||||
|
from jsonmodels.validators import Enum, Length
|
||||||
|
|
||||||
|
from apiserver.apimodels import DictField, ListField
|
||||||
|
from apiserver.apimodels.base import UpdateResponse
|
||||||
|
from apiserver.apimodels.batch import BatchRequest, UpdateBatchItem, BatchResponse
|
||||||
|
from apiserver.database.model.task.task import (
|
||||||
|
TaskType,
|
||||||
|
ArtifactModes,
|
||||||
|
DEFAULT_ARTIFACT_MODE,
|
||||||
|
TaskModelTypes,
|
||||||
|
)
|
||||||
|
from apiserver.database.utils import get_options
|
||||||
|
|
||||||
|
|
||||||
|
class ArtifactTypeData(models.Base):
|
||||||
|
preview = StringField()
|
||||||
|
content_type = StringField()
|
||||||
|
data_hash = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class Artifact(models.Base):
|
||||||
|
key = StringField(required=True)
|
||||||
|
type = StringField(required=True)
|
||||||
|
mode = StringField(
|
||||||
|
validators=Enum(*get_options(ArtifactModes)), default=DEFAULT_ARTIFACT_MODE
|
||||||
|
)
|
||||||
|
uri = StringField()
|
||||||
|
hash = StringField()
|
||||||
|
content_size = IntField()
|
||||||
|
timestamp = IntField()
|
||||||
|
type_data = EmbeddedField(ArtifactTypeData)
|
||||||
|
display_data = ListField([list])
|
||||||
|
|
||||||
|
|
||||||
|
class StartedResponse(UpdateResponse):
|
||||||
|
started = IntField()
|
||||||
|
|
||||||
|
|
||||||
|
class EnqueueResponse(UpdateResponse):
|
||||||
|
queued = IntField()
|
||||||
|
queue_watched = BoolField()
|
||||||
|
|
||||||
|
|
||||||
|
class EnqueueBatchItem(UpdateBatchItem):
|
||||||
|
queued: bool = BoolField()
|
||||||
|
|
||||||
|
|
||||||
|
class EnqueueManyResponse(BatchResponse):
|
||||||
|
succeeded: Sequence[EnqueueBatchItem] = ListField(EnqueueBatchItem)
|
||||||
|
queue_watched = BoolField()
|
||||||
|
|
||||||
|
|
||||||
|
class DequeueResponse(UpdateResponse):
|
||||||
|
dequeued = IntField()
|
||||||
|
|
||||||
|
|
||||||
|
class DequeueBatchItem(UpdateBatchItem):
|
||||||
|
dequeued: bool = BoolField()
|
||||||
|
|
||||||
|
|
||||||
|
class DequeueManyResponse(BatchResponse):
|
||||||
|
succeeded: Sequence[DequeueBatchItem] = ListField(DequeueBatchItem)
|
||||||
|
|
||||||
|
|
||||||
|
class ResetResponse(UpdateResponse):
|
||||||
|
dequeued = DictField()
|
||||||
|
events = DictField()
|
||||||
|
deleted_models = IntField()
|
||||||
|
urls = DictField()
|
||||||
|
|
||||||
|
|
||||||
|
class ResetBatchItem(UpdateBatchItem):
|
||||||
|
dequeued: bool = BoolField()
|
||||||
|
deleted_models = IntField()
|
||||||
|
urls = DictField()
|
||||||
|
|
||||||
|
|
||||||
|
class ResetManyResponse(BatchResponse):
|
||||||
|
succeeded: Sequence[ResetBatchItem] = ListField(ResetBatchItem)
|
||||||
|
|
||||||
|
|
||||||
|
class TaskRequest(models.Base):
|
||||||
|
task = StringField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class TaskUpdateRequest(TaskRequest):
|
||||||
|
force = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class UpdateRequest(TaskUpdateRequest):
|
||||||
|
status_reason = StringField(default="")
|
||||||
|
status_message = StringField(default="")
|
||||||
|
|
||||||
|
|
||||||
|
class EnqueueRequest(UpdateRequest):
|
||||||
|
queue = StringField()
|
||||||
|
queue_name = StringField()
|
||||||
|
verify_watched_queue = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteRequest(UpdateRequest):
|
||||||
|
move_to_trash = BoolField(default=True)
|
||||||
|
return_file_urls = BoolField(default=False)
|
||||||
|
delete_output_models = BoolField(default=True)
|
||||||
|
delete_external_artifacts = BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class SetRequirementsRequest(TaskRequest):
|
||||||
|
requirements = DictField(required=True)
|
||||||
|
|
||||||
|
|
||||||
|
class CompletedRequest(UpdateRequest):
|
||||||
|
publish = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class CompletedResponse(UpdateResponse):
|
||||||
|
published = IntField(default=0)
|
||||||
|
|
||||||
|
|
||||||
|
class PublishRequest(UpdateRequest):
|
||||||
|
publish_model = BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class TaskData(models.Base):
|
||||||
|
"""
|
||||||
|
This is a partial description of task can be updated incrementally
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class CreateRequest(TaskData):
|
||||||
|
name = StringField(required=True)
|
||||||
|
type = StringField(required=True, validators=Enum(*get_options(TaskType)))
|
||||||
|
|
||||||
|
|
||||||
|
class PingRequest(TaskRequest):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class GetTypesRequest(models.Base):
|
||||||
|
projects = ListField(items_types=[str])
|
||||||
|
|
||||||
|
|
||||||
|
class TaskInputModel(models.Base):
|
||||||
|
name = StringField()
|
||||||
|
model = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class CloneRequest(TaskRequest):
|
||||||
|
new_task_name = StringField()
|
||||||
|
new_task_comment = StringField()
|
||||||
|
new_task_tags = ListField([str])
|
||||||
|
new_task_system_tags = ListField([str])
|
||||||
|
new_task_parent = StringField()
|
||||||
|
new_task_project = StringField()
|
||||||
|
new_task_hyperparams = DictField()
|
||||||
|
new_task_configuration = DictField()
|
||||||
|
new_task_container = DictField()
|
||||||
|
new_task_input_models = ListField([TaskInputModel])
|
||||||
|
execution_overrides = DictField()
|
||||||
|
validate_references = BoolField(default=False)
|
||||||
|
new_project_name = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class AddOrUpdateArtifactsRequest(TaskUpdateRequest):
|
||||||
|
artifacts = ListField([Artifact], validators=Length(minimum_value=1))
|
||||||
|
|
||||||
|
|
||||||
|
class ArtifactId(models.Base):
|
||||||
|
key = StringField(required=True)
|
||||||
|
mode = StringField(
|
||||||
|
validators=Enum(*get_options(ArtifactModes)), default=DEFAULT_ARTIFACT_MODE
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteArtifactsRequest(TaskUpdateRequest):
|
||||||
|
artifacts = ListField([ArtifactId], validators=Length(minimum_value=1))
|
||||||
|
|
||||||
|
|
||||||
|
class ResetRequest(UpdateRequest):
|
||||||
|
clear_all = BoolField(default=False)
|
||||||
|
return_file_urls = BoolField(default=False)
|
||||||
|
delete_output_models = BoolField(default=True)
|
||||||
|
delete_external_artifacts = BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class MultiTaskRequest(models.Base):
|
||||||
|
tasks = ListField([str], validators=Length(minimum_value=1))
|
||||||
|
|
||||||
|
|
||||||
|
class GetHyperParamsRequest(MultiTaskRequest):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class HyperParamItem(models.Base):
|
||||||
|
section = StringField(required=True, validators=Length(minimum_value=1))
|
||||||
|
name = StringField(required=True, validators=Length(minimum_value=1))
|
||||||
|
value = StringField(required=True)
|
||||||
|
type = StringField()
|
||||||
|
description = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class ReplaceHyperparams(object):
|
||||||
|
none = "none"
|
||||||
|
section = "section"
|
||||||
|
all = "all"
|
||||||
|
|
||||||
|
|
||||||
|
class EditHyperParamsRequest(TaskUpdateRequest):
|
||||||
|
hyperparams: Sequence[HyperParamItem] = ListField(
|
||||||
|
[HyperParamItem], validators=Length(minimum_value=1)
|
||||||
|
)
|
||||||
|
replace_hyperparams = StringField(
|
||||||
|
validators=Enum(*get_options(ReplaceHyperparams)),
|
||||||
|
default=ReplaceHyperparams.none,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class HyperParamKey(models.Base):
|
||||||
|
section = StringField(required=True, validators=Length(minimum_value=1))
|
||||||
|
name = StringField(nullable=True)
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteHyperParamsRequest(TaskUpdateRequest):
|
||||||
|
hyperparams: Sequence[HyperParamKey] = ListField(
|
||||||
|
[HyperParamKey], validators=Length(minimum_value=1)
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class GetConfigurationsRequest(MultiTaskRequest):
|
||||||
|
names = ListField([str])
|
||||||
|
|
||||||
|
|
||||||
|
class GetConfigurationNamesRequest(MultiTaskRequest):
|
||||||
|
skip_empty = BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class Configuration(models.Base):
|
||||||
|
name = StringField(required=True, validators=Length(minimum_value=1))
|
||||||
|
value = StringField(required=True)
|
||||||
|
type = StringField()
|
||||||
|
description = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class EditConfigurationRequest(TaskUpdateRequest):
|
||||||
|
configuration: Sequence[Configuration] = ListField(
|
||||||
|
[Configuration], validators=Length(minimum_value=1)
|
||||||
|
)
|
||||||
|
replace_configuration = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteConfigurationRequest(TaskUpdateRequest):
|
||||||
|
configuration: Sequence[str] = ListField([str], validators=Length(minimum_value=1))
|
||||||
|
|
||||||
|
|
||||||
|
class ArchiveRequest(MultiTaskRequest):
|
||||||
|
status_reason = StringField(default="")
|
||||||
|
status_message = StringField(default="")
|
||||||
|
|
||||||
|
|
||||||
|
class ArchiveResponse(models.Base):
|
||||||
|
archived = IntField()
|
||||||
|
|
||||||
|
|
||||||
|
class TaskBatchRequest(BatchRequest):
|
||||||
|
status_reason = StringField(default="")
|
||||||
|
status_message = StringField(default="")
|
||||||
|
|
||||||
|
|
||||||
|
class StopManyRequest(TaskBatchRequest):
|
||||||
|
force = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class EnqueueManyRequest(TaskBatchRequest):
|
||||||
|
queue = StringField()
|
||||||
|
queue_name = StringField()
|
||||||
|
validate_tasks = BoolField(default=False)
|
||||||
|
verify_watched_queue = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteManyRequest(TaskBatchRequest):
|
||||||
|
move_to_trash = BoolField(default=True)
|
||||||
|
return_file_urls = BoolField(default=False)
|
||||||
|
delete_output_models = BoolField(default=True)
|
||||||
|
force = BoolField(default=False)
|
||||||
|
delete_external_artifacts = BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class ResetManyRequest(TaskBatchRequest):
|
||||||
|
clear_all = BoolField(default=False)
|
||||||
|
return_file_urls = BoolField(default=False)
|
||||||
|
delete_output_models = BoolField(default=True)
|
||||||
|
force = BoolField(default=False)
|
||||||
|
delete_external_artifacts = BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
class PublishManyRequest(TaskBatchRequest):
|
||||||
|
publish_model = BoolField(default=True)
|
||||||
|
force = BoolField(default=False)
|
||||||
|
|
||||||
|
|
||||||
|
class AddUpdateModelRequest(TaskRequest):
|
||||||
|
name = StringField(required=True)
|
||||||
|
model = StringField(required=True)
|
||||||
|
type = StringField(required=True, validators=Enum(*get_options(TaskModelTypes)))
|
||||||
|
iteration = IntField()
|
||||||
|
|
||||||
|
|
||||||
|
class ModelItemKey(models.Base):
|
||||||
|
name = StringField(required=True)
|
||||||
|
type = StringField(required=True, validators=Enum(*get_options(TaskModelTypes)))
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteModelsRequest(TaskRequest):
|
||||||
|
models: Sequence[ModelItemKey] = ListField(
|
||||||
|
[ModelItemKey], validators=Length(minimum_value=1)
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class GetAllReq(models.Base):
|
||||||
|
allow_public = BoolField(default=True)
|
||||||
|
search_hidden = BoolField(default=False)
|
||||||
@@ -1,7 +1,7 @@
|
|||||||
from jsonmodels.fields import StringField
|
from jsonmodels.fields import StringField
|
||||||
from jsonmodels.models import Base
|
from jsonmodels.models import Base
|
||||||
|
|
||||||
from apimodels import DictField
|
from apiserver.apimodels import DictField
|
||||||
|
|
||||||
|
|
||||||
class CreateRequest(Base):
|
class CreateRequest(Base):
|
||||||
@@ -1,4 +1,3 @@
|
|||||||
import json
|
|
||||||
from enum import Enum
|
from enum import Enum
|
||||||
|
|
||||||
import six
|
import six
|
||||||
@@ -13,19 +12,19 @@ from jsonmodels.fields import (
|
|||||||
)
|
)
|
||||||
from jsonmodels.models import Base
|
from jsonmodels.models import Base
|
||||||
|
|
||||||
from apimodels import make_default, ListField, EnumField
|
from apiserver.apimodels import make_default, ListField, EnumField, JsonSerializableMixin
|
||||||
|
|
||||||
DEFAULT_TIMEOUT = 10 * 60
|
DEFAULT_TIMEOUT = 10 * 60
|
||||||
|
|
||||||
|
|
||||||
class WorkerRequest(Base):
|
class WorkerRequest(Base):
|
||||||
worker = StringField(required=True)
|
worker = StringField(required=True)
|
||||||
|
tags = ListField(str)
|
||||||
|
system_tags = ListField(str)
|
||||||
|
|
||||||
|
|
||||||
class RegisterRequest(WorkerRequest):
|
class RegisterRequest(WorkerRequest):
|
||||||
timeout = make_default(
|
timeout = IntField(default=0) # registration timeout in seconds (if not specified, default is 10min)
|
||||||
IntField, DEFAULT_TIMEOUT
|
|
||||||
)() # registration timeout in seconds (default is 10min)
|
|
||||||
queues = ListField(six.string_types) # list of queues this worker listens to
|
queues = ListField(six.string_types) # list of queues this worker listens to
|
||||||
|
|
||||||
|
|
||||||
@@ -61,26 +60,22 @@ class IdNameEntry(Base):
|
|||||||
name = StringField()
|
name = StringField()
|
||||||
|
|
||||||
|
|
||||||
class WorkerEntry(Base):
|
class WorkerEntry(Base, JsonSerializableMixin):
|
||||||
key = StringField() # not required due to migration issues
|
key = StringField() # not required due to migration issues
|
||||||
id = StringField(required=True)
|
id = StringField(required=True)
|
||||||
user = EmbeddedField(IdNameEntry)
|
user = EmbeddedField(IdNameEntry)
|
||||||
company = EmbeddedField(IdNameEntry)
|
company = EmbeddedField(IdNameEntry)
|
||||||
ip = StringField()
|
ip = StringField()
|
||||||
task = EmbeddedField(IdNameEntry)
|
task = EmbeddedField(IdNameEntry)
|
||||||
|
project = EmbeddedField(IdNameEntry)
|
||||||
queue = StringField() # queue from which current task was taken
|
queue = StringField() # queue from which current task was taken
|
||||||
queues = ListField(str) # list of queues this worker listens to
|
queues = ListField(str) # list of queues this worker listens to
|
||||||
register_time = DateTimeField(required=True)
|
register_time = DateTimeField(required=True)
|
||||||
register_timeout = IntField(required=True)
|
register_timeout = IntField(required=True)
|
||||||
last_activity_time = DateTimeField(required=True)
|
last_activity_time = DateTimeField(required=True)
|
||||||
last_report_time = DateTimeField()
|
last_report_time = DateTimeField()
|
||||||
|
tags = ListField(str)
|
||||||
def to_json(self):
|
system_tags = ListField(str)
|
||||||
return json.dumps(self.to_struct())
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def from_json(cls, s):
|
|
||||||
return cls(**json.loads(s))
|
|
||||||
|
|
||||||
|
|
||||||
class CurrentTaskEntry(IdNameEntry):
|
class CurrentTaskEntry(IdNameEntry):
|
||||||
@@ -101,6 +96,8 @@ class WorkerResponseEntry(WorkerEntry):
|
|||||||
|
|
||||||
class GetAllRequest(Base):
|
class GetAllRequest(Base):
|
||||||
last_seen = IntField(default=3600)
|
last_seen = IntField(default=3600)
|
||||||
|
tags = ListField(str)
|
||||||
|
system_tags = ListField(str)
|
||||||
|
|
||||||
|
|
||||||
class GetAllResponse(Base):
|
class GetAllResponse(Base):
|
||||||
@@ -1,17 +1,21 @@
|
|||||||
from datetime import datetime
|
from datetime import datetime
|
||||||
|
|
||||||
import database
|
from apiserver import database
|
||||||
from apierrors import errors
|
from apiserver.apierrors import errors
|
||||||
from apimodels.auth import GetTokenResponse, CreateUserRequest, Credentials as CredModel
|
from apiserver.apimodels.auth import (
|
||||||
from apimodels.users import CreateRequest as Users_CreateRequest
|
GetTokenResponse,
|
||||||
from bll.user import UserBLL
|
CreateUserRequest,
|
||||||
from config import config
|
Credentials as CredModel,
|
||||||
from config.info import get_version, get_build_number
|
)
|
||||||
from database.errors import translate_errors_context
|
from apiserver.apimodels.users import CreateRequest as Users_CreateRequest
|
||||||
from database.model.auth import User, Role, Credentials
|
from apiserver.bll.user import UserBLL
|
||||||
from database.model.company import Company
|
from apiserver.config_repo import config
|
||||||
from service_repo import APICall, ServiceRepo
|
from apiserver.config.info import get_version, get_build_number
|
||||||
from service_repo.auth import Identity, Token, get_client_id, get_secret_key
|
from apiserver.database.errors import translate_errors_context
|
||||||
|
from apiserver.database.model.auth import User, Role, Credentials
|
||||||
|
from apiserver.database.model.company import Company
|
||||||
|
from apiserver.service_repo import APICall, ServiceRepo
|
||||||
|
from apiserver.service_repo.auth import Identity, Token, get_client_id, get_secret_key
|
||||||
|
|
||||||
log = config.logger("AuthBLL")
|
log = config.logger("AuthBLL")
|
||||||
|
|
||||||
@@ -57,9 +61,10 @@ class AuthBLL:
|
|||||||
api_version=str(ServiceRepo.max_endpoint_version()),
|
api_version=str(ServiceRepo.max_endpoint_version()),
|
||||||
server_version=str(get_version()),
|
server_version=str(get_version()),
|
||||||
server_build=str(get_build_number()),
|
server_build=str(get_build_number()),
|
||||||
|
feature_set="basic",
|
||||||
)
|
)
|
||||||
|
|
||||||
return GetTokenResponse(token=token.decode("ascii"))
|
return GetTokenResponse(token=token)
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def create_user(request: CreateUserRequest, call: APICall = None) -> str:
|
def create_user(request: CreateUserRequest, call: APICall = None) -> str:
|
||||||
@@ -144,7 +149,7 @@ class AuthBLL:
|
|||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def create_credentials(
|
def create_credentials(
|
||||||
cls, user_id: str, company_id: str, role: str = None
|
cls, user_id: str, company_id: str, role: str = None, label: str = None,
|
||||||
) -> CredModel:
|
) -> CredModel:
|
||||||
|
|
||||||
with translate_errors_context():
|
with translate_errors_context():
|
||||||
@@ -153,9 +158,11 @@ class AuthBLL:
|
|||||||
if not user:
|
if not user:
|
||||||
raise errors.bad_request.InvalidUserId(**query)
|
raise errors.bad_request.InvalidUserId(**query)
|
||||||
|
|
||||||
cred = CredModel(access_key=get_client_id(), secret_key=get_secret_key())
|
cred = CredModel(
|
||||||
|
access_key=get_client_id(), secret_key=get_secret_key(), label=label
|
||||||
|
)
|
||||||
user.credentials.append(
|
user.credentials.append(
|
||||||
Credentials(key=cred.access_key, secret=cred.secret_key)
|
Credentials(key=cred.access_key, secret=cred.secret_key, label=label)
|
||||||
)
|
)
|
||||||
user.save()
|
user.save()
|
||||||
|
|
||||||
1161
apiserver/bll/event/event_bll.py
Normal file
1161
apiserver/bll/event/event_bll.py
Normal file
File diff suppressed because it is too large
Load Diff
166
apiserver/bll/event/event_common.py
Normal file
166
apiserver/bll/event/event_common.py
Normal file
@@ -0,0 +1,166 @@
|
|||||||
|
import base64
|
||||||
|
import zlib
|
||||||
|
from enum import Enum
|
||||||
|
from typing import Union, Sequence, Mapping, Tuple
|
||||||
|
|
||||||
|
from boltons.typeutils import classproperty
|
||||||
|
from elasticsearch import Elasticsearch
|
||||||
|
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.errors import translate_errors_context
|
||||||
|
from apiserver.database.model.task.task import Task
|
||||||
|
from apiserver.tools import safe_get
|
||||||
|
|
||||||
|
|
||||||
|
class EventType(Enum):
|
||||||
|
metrics_scalar = "training_stats_scalar"
|
||||||
|
metrics_vector = "training_stats_vector"
|
||||||
|
metrics_image = "training_debug_image"
|
||||||
|
metrics_plot = "plot"
|
||||||
|
task_log = "log"
|
||||||
|
all = "*"
|
||||||
|
|
||||||
|
|
||||||
|
SINGLE_SCALAR_ITERATION = -(2 ** 31)
|
||||||
|
MetricVariants = Mapping[str, Sequence[str]]
|
||||||
|
TaskCompanies = Mapping[str, Sequence[Task]]
|
||||||
|
|
||||||
|
|
||||||
|
class EventSettings:
|
||||||
|
_max_es_allowed_aggregation_buckets = 10000
|
||||||
|
|
||||||
|
@classproperty
|
||||||
|
def max_workers(self):
|
||||||
|
return config.get("services.events.events_retrieval.max_metrics_concurrency", 4)
|
||||||
|
|
||||||
|
@classproperty
|
||||||
|
def state_expiration_sec(self):
|
||||||
|
return config.get(
|
||||||
|
f"services.events.events_retrieval.state_expiration_sec", 3600
|
||||||
|
)
|
||||||
|
|
||||||
|
@classproperty
|
||||||
|
def max_es_buckets(self):
|
||||||
|
percentage = (
|
||||||
|
min(
|
||||||
|
100,
|
||||||
|
config.get(
|
||||||
|
"services.events.events_retrieval.dynamic_metrics_count_threshold",
|
||||||
|
80,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
/ 100
|
||||||
|
)
|
||||||
|
return int(self._max_es_allowed_aggregation_buckets * percentage)
|
||||||
|
|
||||||
|
|
||||||
|
def get_index_name(company_id: Union[str, Sequence[str]], event_type: str):
|
||||||
|
event_type = event_type.lower().replace(" ", "_")
|
||||||
|
if isinstance(company_id, str):
|
||||||
|
company_id = [company_id]
|
||||||
|
|
||||||
|
return ",".join(f"events-{event_type}-{(c_id or '').lower()}" for c_id in company_id)
|
||||||
|
|
||||||
|
|
||||||
|
def check_empty_data(es: Elasticsearch, company_id: str, event_type: EventType) -> bool:
|
||||||
|
es_index = get_index_name(company_id, event_type.value)
|
||||||
|
if not es.indices.exists(es_index):
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def search_company_events(
|
||||||
|
es: Elasticsearch,
|
||||||
|
company_id: Union[str, Sequence[str]],
|
||||||
|
event_type: EventType,
|
||||||
|
body: dict,
|
||||||
|
**kwargs,
|
||||||
|
) -> dict:
|
||||||
|
es_index = get_index_name(company_id, event_type.value)
|
||||||
|
return es.search(index=es_index, body=body, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def delete_company_events(
|
||||||
|
es: Elasticsearch, company_id: str, event_type: EventType, body: dict, **kwargs
|
||||||
|
) -> dict:
|
||||||
|
es_index = get_index_name(company_id, event_type.value)
|
||||||
|
return es.delete_by_query(index=es_index, body=body, conflicts="proceed", **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def count_company_events(
|
||||||
|
es: Elasticsearch, company_id: str, event_type: EventType, body: dict, **kwargs
|
||||||
|
) -> dict:
|
||||||
|
es_index = get_index_name(company_id, event_type.value)
|
||||||
|
return es.count(index=es_index, body=body, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def get_max_metric_and_variant_counts(
|
||||||
|
es: Elasticsearch,
|
||||||
|
company_id: Union[str, Sequence[str]],
|
||||||
|
event_type: EventType,
|
||||||
|
query: dict,
|
||||||
|
**kwargs,
|
||||||
|
) -> Tuple[int, int]:
|
||||||
|
dynamic = config.get(
|
||||||
|
"services.events.events_retrieval.dynamic_metrics_count", False
|
||||||
|
)
|
||||||
|
max_metrics_count = config.get(
|
||||||
|
"services.events.events_retrieval.max_metrics_count", 100
|
||||||
|
)
|
||||||
|
max_variants_count = config.get(
|
||||||
|
"services.events.events_retrieval.max_variants_count", 100
|
||||||
|
)
|
||||||
|
if not dynamic:
|
||||||
|
return max_metrics_count, max_variants_count
|
||||||
|
|
||||||
|
es_req: dict = {
|
||||||
|
"size": 0,
|
||||||
|
"query": query,
|
||||||
|
"aggs": {"metrics_count": {"cardinality": {"field": "metric"}}},
|
||||||
|
}
|
||||||
|
with translate_errors_context():
|
||||||
|
es_res = search_company_events(
|
||||||
|
es, company_id=company_id, event_type=event_type, body=es_req, **kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
metrics_count = safe_get(
|
||||||
|
es_res, "aggregations/metrics_count/value", max_metrics_count
|
||||||
|
)
|
||||||
|
if not metrics_count:
|
||||||
|
return max_metrics_count, max_variants_count
|
||||||
|
|
||||||
|
return metrics_count, int(EventSettings.max_es_buckets / metrics_count)
|
||||||
|
|
||||||
|
|
||||||
|
def get_metric_variants_condition(metric_variants: MetricVariants,) -> Sequence:
|
||||||
|
conditions = [
|
||||||
|
{
|
||||||
|
"bool": {
|
||||||
|
"must": [
|
||||||
|
{"term": {"metric": metric}},
|
||||||
|
{"terms": {"variant": variants}},
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
if variants
|
||||||
|
else {"term": {"metric": metric}}
|
||||||
|
for metric, variants in metric_variants.items()
|
||||||
|
]
|
||||||
|
|
||||||
|
return {"bool": {"should": conditions}}
|
||||||
|
|
||||||
|
|
||||||
|
class PlotFields:
|
||||||
|
valid_plot = "valid_plot"
|
||||||
|
plot_len = "plot_len"
|
||||||
|
plot_str = "plot_str"
|
||||||
|
plot_data = "plot_data"
|
||||||
|
source_urls = "source_urls"
|
||||||
|
|
||||||
|
|
||||||
|
def uncompress_plot(event: dict):
|
||||||
|
plot_data = event.pop(PlotFields.plot_data, None)
|
||||||
|
if plot_data and event.get(PlotFields.plot_str) is None:
|
||||||
|
event[PlotFields.plot_str] = zlib.decompress(
|
||||||
|
base64.b64decode(plot_data)
|
||||||
|
).decode()
|
||||||
499
apiserver/bll/event/event_metrics.py
Normal file
499
apiserver/bll/event/event_metrics.py
Normal file
@@ -0,0 +1,499 @@
|
|||||||
|
import itertools
|
||||||
|
import math
|
||||||
|
from collections import defaultdict
|
||||||
|
from concurrent.futures.thread import ThreadPoolExecutor
|
||||||
|
from functools import partial
|
||||||
|
from operator import itemgetter
|
||||||
|
from typing import Sequence, Tuple, Mapping
|
||||||
|
|
||||||
|
from boltons.iterutils import bucketize
|
||||||
|
from elasticsearch import Elasticsearch
|
||||||
|
|
||||||
|
from apiserver.bll.event.event_common import (
|
||||||
|
EventType,
|
||||||
|
EventSettings,
|
||||||
|
search_company_events,
|
||||||
|
check_empty_data,
|
||||||
|
MetricVariants,
|
||||||
|
get_metric_variants_condition,
|
||||||
|
get_max_metric_and_variant_counts,
|
||||||
|
SINGLE_SCALAR_ITERATION,
|
||||||
|
TaskCompanies,
|
||||||
|
)
|
||||||
|
from apiserver.bll.event.scalar_key import ScalarKey, ScalarKeyEnum
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.errors import translate_errors_context
|
||||||
|
from apiserver.tools import safe_get
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
|
||||||
|
|
||||||
|
class EventMetrics:
|
||||||
|
MAX_AGGS_ELEMENTS_COUNT = 50
|
||||||
|
MAX_SAMPLE_BUCKETS = 6000
|
||||||
|
|
||||||
|
def __init__(self, es: Elasticsearch):
|
||||||
|
self.es = es
|
||||||
|
|
||||||
|
def get_scalar_metrics_average_per_iter(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
task_id: str,
|
||||||
|
samples: int,
|
||||||
|
key: ScalarKeyEnum,
|
||||||
|
metric_variants: MetricVariants = None,
|
||||||
|
) -> dict:
|
||||||
|
"""
|
||||||
|
Get scalar metric histogram per metric and variant
|
||||||
|
The amount of points in each histogram should not exceed
|
||||||
|
the requested samples
|
||||||
|
"""
|
||||||
|
event_type = EventType.metrics_scalar
|
||||||
|
if check_empty_data(self.es, company_id=company_id, event_type=event_type):
|
||||||
|
return {}
|
||||||
|
|
||||||
|
return self._get_scalar_average_per_iter_core(
|
||||||
|
task_id=task_id,
|
||||||
|
company_id=company_id,
|
||||||
|
event_type=event_type,
|
||||||
|
samples=samples,
|
||||||
|
key=ScalarKey.resolve(key),
|
||||||
|
metric_variants=metric_variants,
|
||||||
|
)
|
||||||
|
|
||||||
|
def _get_scalar_average_per_iter_core(
|
||||||
|
self,
|
||||||
|
task_id: str,
|
||||||
|
company_id: str,
|
||||||
|
event_type: EventType,
|
||||||
|
samples: int,
|
||||||
|
key: ScalarKey,
|
||||||
|
run_parallel: bool = True,
|
||||||
|
metric_variants: MetricVariants = None,
|
||||||
|
) -> dict:
|
||||||
|
intervals = self._get_task_metric_intervals(
|
||||||
|
company_id=company_id,
|
||||||
|
event_type=event_type,
|
||||||
|
task_id=task_id,
|
||||||
|
samples=samples,
|
||||||
|
field=key.field,
|
||||||
|
metric_variants=metric_variants,
|
||||||
|
)
|
||||||
|
if not intervals:
|
||||||
|
return {}
|
||||||
|
interval_groups = self._group_task_metric_intervals(intervals)
|
||||||
|
|
||||||
|
get_scalar_average = partial(
|
||||||
|
self._get_scalar_average,
|
||||||
|
task_id=task_id,
|
||||||
|
company_id=company_id,
|
||||||
|
event_type=event_type,
|
||||||
|
key=key,
|
||||||
|
)
|
||||||
|
if run_parallel:
|
||||||
|
with ThreadPoolExecutor(max_workers=EventSettings.max_workers) as pool:
|
||||||
|
metrics = itertools.chain.from_iterable(
|
||||||
|
pool.map(get_scalar_average, interval_groups)
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
metrics = itertools.chain.from_iterable(
|
||||||
|
get_scalar_average(group) for group in interval_groups
|
||||||
|
)
|
||||||
|
|
||||||
|
ret = defaultdict(dict)
|
||||||
|
for metric_key, metric_values in metrics:
|
||||||
|
ret[metric_key].update(metric_values)
|
||||||
|
|
||||||
|
return ret
|
||||||
|
|
||||||
|
def compare_scalar_metrics_average_per_iter(
|
||||||
|
self,
|
||||||
|
companies: TaskCompanies,
|
||||||
|
samples,
|
||||||
|
key: ScalarKeyEnum,
|
||||||
|
metric_variants: MetricVariants = None,
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
Compare scalar metrics for different tasks per metric and variant
|
||||||
|
The amount of points in each histogram should not exceed the requested samples
|
||||||
|
"""
|
||||||
|
event_type = EventType.metrics_scalar
|
||||||
|
companies = {
|
||||||
|
company_id: tasks
|
||||||
|
for company_id, tasks in companies.items()
|
||||||
|
if not check_empty_data(
|
||||||
|
self.es, company_id=company_id, event_type=event_type
|
||||||
|
)
|
||||||
|
}
|
||||||
|
if not companies:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
get_scalar_average_per_iter = partial(
|
||||||
|
self._get_scalar_average_per_iter_core,
|
||||||
|
event_type=event_type,
|
||||||
|
samples=samples,
|
||||||
|
key=ScalarKey.resolve(key),
|
||||||
|
metric_variants=metric_variants,
|
||||||
|
run_parallel=False,
|
||||||
|
)
|
||||||
|
task_ids, company_ids = zip(
|
||||||
|
*(
|
||||||
|
(t.id, t.company)
|
||||||
|
for t in itertools.chain.from_iterable(companies.values())
|
||||||
|
)
|
||||||
|
)
|
||||||
|
with ThreadPoolExecutor(max_workers=EventSettings.max_workers) as pool:
|
||||||
|
task_metrics = zip(
|
||||||
|
task_ids, pool.map(get_scalar_average_per_iter, task_ids, company_ids)
|
||||||
|
)
|
||||||
|
|
||||||
|
task_names = {
|
||||||
|
t.id: t.name for t in itertools.chain.from_iterable(companies.values())
|
||||||
|
}
|
||||||
|
res = defaultdict(lambda: defaultdict(dict))
|
||||||
|
for task_id, task_data in task_metrics:
|
||||||
|
task_name = task_names[task_id]
|
||||||
|
for metric_key, metric_data in task_data.items():
|
||||||
|
for variant_key, variant_data in metric_data.items():
|
||||||
|
variant_data["name"] = task_name
|
||||||
|
res[metric_key][variant_key][task_id] = variant_data
|
||||||
|
|
||||||
|
return res
|
||||||
|
|
||||||
|
def get_task_single_value_metrics(
|
||||||
|
self, companies: TaskCompanies
|
||||||
|
) -> Mapping[str, dict]:
|
||||||
|
"""
|
||||||
|
For the requested tasks return all the events delivered for the single iteration (-2**31)
|
||||||
|
"""
|
||||||
|
companies = {
|
||||||
|
company_id: [t.id for t in tasks]
|
||||||
|
for company_id, tasks in companies.items()
|
||||||
|
if not check_empty_data(
|
||||||
|
self.es, company_id=company_id, event_type=EventType.metrics_scalar
|
||||||
|
)
|
||||||
|
}
|
||||||
|
if not companies:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
with ThreadPoolExecutor(max_workers=EventSettings.max_workers) as pool:
|
||||||
|
task_events = list(
|
||||||
|
itertools.chain.from_iterable(
|
||||||
|
pool.map(self._get_task_single_value_metrics, companies.items())
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
def _get_value(event: dict):
|
||||||
|
return {
|
||||||
|
field: event.get(field)
|
||||||
|
for field in ("metric", "variant", "value", "timestamp")
|
||||||
|
}
|
||||||
|
|
||||||
|
return {
|
||||||
|
task: [_get_value(e) for e in events]
|
||||||
|
for task, events in bucketize(task_events, itemgetter("task")).items()
|
||||||
|
}
|
||||||
|
|
||||||
|
def _get_task_single_value_metrics(
|
||||||
|
self, tasks: Tuple[str, Sequence[str]]
|
||||||
|
) -> Sequence[dict]:
|
||||||
|
company_id, task_ids = tasks
|
||||||
|
es_req = {
|
||||||
|
"size": 10000,
|
||||||
|
"query": {
|
||||||
|
"bool": {
|
||||||
|
"must": [
|
||||||
|
{"terms": {"task": task_ids}},
|
||||||
|
{"term": {"iter": SINGLE_SCALAR_ITERATION}},
|
||||||
|
]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
with translate_errors_context():
|
||||||
|
es_res = search_company_events(
|
||||||
|
body=es_req,
|
||||||
|
es=self.es,
|
||||||
|
company_id=company_id,
|
||||||
|
event_type=EventType.metrics_scalar,
|
||||||
|
)
|
||||||
|
if not es_res["hits"]["total"]["value"]:
|
||||||
|
return []
|
||||||
|
|
||||||
|
return [hit["_source"] for hit in es_res["hits"]["hits"]]
|
||||||
|
|
||||||
|
MetricInterval = Tuple[str, str, int, int]
|
||||||
|
MetricIntervalGroup = Tuple[int, Sequence[Tuple[str, str]]]
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _group_task_metric_intervals(
|
||||||
|
cls, intervals: Sequence[MetricInterval]
|
||||||
|
) -> Sequence[MetricIntervalGroup]:
|
||||||
|
"""
|
||||||
|
Group task metric intervals so that the following conditions are meat:
|
||||||
|
- All the metrics in the same group have the same interval (with 10% rounding)
|
||||||
|
- The amount of metrics in the group does not exceed MAX_AGGS_ELEMENTS_COUNT
|
||||||
|
- The total count of samples in the group does not exceed MAX_SAMPLE_BUCKETS
|
||||||
|
"""
|
||||||
|
metric_interval_groups = []
|
||||||
|
interval_group = []
|
||||||
|
group_interval_upper_bound = 0
|
||||||
|
group_max_interval = 0
|
||||||
|
group_samples = 0
|
||||||
|
for metric, variant, interval, size in sorted(intervals, key=itemgetter(2)):
|
||||||
|
if (
|
||||||
|
interval > group_interval_upper_bound
|
||||||
|
or (group_samples + size) > cls.MAX_SAMPLE_BUCKETS
|
||||||
|
or len(interval_group) >= cls.MAX_AGGS_ELEMENTS_COUNT
|
||||||
|
):
|
||||||
|
if interval_group:
|
||||||
|
metric_interval_groups.append((group_max_interval, interval_group))
|
||||||
|
interval_group = []
|
||||||
|
group_max_interval = interval
|
||||||
|
group_interval_upper_bound = interval + int(interval * 0.1)
|
||||||
|
group_samples = 0
|
||||||
|
interval_group.append((metric, variant))
|
||||||
|
group_samples += size
|
||||||
|
group_max_interval = max(group_max_interval, interval)
|
||||||
|
if interval_group:
|
||||||
|
metric_interval_groups.append((group_max_interval, interval_group))
|
||||||
|
|
||||||
|
return metric_interval_groups
|
||||||
|
|
||||||
|
def _get_task_metric_intervals(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
event_type: EventType,
|
||||||
|
task_id: str,
|
||||||
|
samples: int,
|
||||||
|
field: str = "iter",
|
||||||
|
metric_variants: MetricVariants = None,
|
||||||
|
) -> Sequence[MetricInterval]:
|
||||||
|
"""
|
||||||
|
Calculate interval per task metric variant so that the resulting
|
||||||
|
amount of points does not exceed sample.
|
||||||
|
Return the list og metric variant intervals as the following tuple:
|
||||||
|
(metric, variant, interval, samples)
|
||||||
|
"""
|
||||||
|
must = self._task_conditions(task_id)
|
||||||
|
if metric_variants:
|
||||||
|
must.append(get_metric_variants_condition(metric_variants))
|
||||||
|
query = {"bool": {"must": must}}
|
||||||
|
search_args = dict(es=self.es, company_id=company_id, event_type=event_type)
|
||||||
|
max_metrics, max_variants = get_max_metric_and_variant_counts(
|
||||||
|
query=query, **search_args,
|
||||||
|
)
|
||||||
|
max_variants = int(max_variants // 2)
|
||||||
|
es_req = {
|
||||||
|
"size": 0,
|
||||||
|
"query": query,
|
||||||
|
"aggs": {
|
||||||
|
"metrics": {
|
||||||
|
"terms": {
|
||||||
|
"field": "metric",
|
||||||
|
"size": max_metrics,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"variants": {
|
||||||
|
"terms": {
|
||||||
|
"field": "variant",
|
||||||
|
"size": max_variants,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"count": {"value_count": {"field": field}},
|
||||||
|
"min_index": {"min": {"field": field}},
|
||||||
|
"max_index": {"max": {"field": field}},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
es_res = search_company_events(body=es_req, **search_args)
|
||||||
|
|
||||||
|
aggs_result = es_res.get("aggregations")
|
||||||
|
if not aggs_result:
|
||||||
|
return []
|
||||||
|
|
||||||
|
return [
|
||||||
|
self._build_metric_interval(metric["key"], variant["key"], variant, samples)
|
||||||
|
for metric in aggs_result["metrics"]["buckets"]
|
||||||
|
for variant in metric["variants"]["buckets"]
|
||||||
|
]
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _build_metric_interval(
|
||||||
|
metric: str, variant: str, data: dict, samples: int
|
||||||
|
) -> Tuple[str, str, int, int]:
|
||||||
|
"""
|
||||||
|
Calculate index interval per metric_variant variant so that the
|
||||||
|
total amount of intervals does not exceeds the samples
|
||||||
|
Return the interval and resulting amount of intervals
|
||||||
|
"""
|
||||||
|
count = safe_get(data, "count/value", default=0)
|
||||||
|
if count < samples:
|
||||||
|
return metric, variant, 1, count
|
||||||
|
|
||||||
|
min_index = safe_get(data, "min_index/value", default=0)
|
||||||
|
max_index = safe_get(data, "max_index/value", default=min_index)
|
||||||
|
index_range = max_index - min_index + 1
|
||||||
|
interval = max(1, math.ceil(float(index_range) / samples))
|
||||||
|
max_samples = math.ceil(float(index_range) / interval)
|
||||||
|
return (
|
||||||
|
metric,
|
||||||
|
variant,
|
||||||
|
interval,
|
||||||
|
max_samples,
|
||||||
|
)
|
||||||
|
|
||||||
|
MetricData = Tuple[str, dict]
|
||||||
|
|
||||||
|
def _get_scalar_average(
|
||||||
|
self,
|
||||||
|
metrics_interval: MetricIntervalGroup,
|
||||||
|
task_id: str,
|
||||||
|
company_id: str,
|
||||||
|
event_type: EventType,
|
||||||
|
key: ScalarKey,
|
||||||
|
) -> Sequence[MetricData]:
|
||||||
|
"""
|
||||||
|
Retrieve scalar histograms per several metric variants that share the same interval
|
||||||
|
"""
|
||||||
|
interval, metrics = metrics_interval
|
||||||
|
aggregation = self._add_aggregation_average(key.get_aggregation(interval))
|
||||||
|
query = self._get_task_metrics_query(task_id=task_id, metrics=metrics)
|
||||||
|
search_args = dict(es=self.es, company_id=company_id, event_type=event_type)
|
||||||
|
max_metrics, max_variants = get_max_metric_and_variant_counts(
|
||||||
|
query=query, **search_args,
|
||||||
|
)
|
||||||
|
max_variants = int(max_variants // 2)
|
||||||
|
es_req = {
|
||||||
|
"size": 0,
|
||||||
|
"query": query,
|
||||||
|
"aggs": {
|
||||||
|
"metrics": {
|
||||||
|
"terms": {
|
||||||
|
"field": "metric",
|
||||||
|
"size": max_metrics,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"variants": {
|
||||||
|
"terms": {
|
||||||
|
"field": "variant",
|
||||||
|
"size": max_variants,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
},
|
||||||
|
"aggs": aggregation,
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
with translate_errors_context():
|
||||||
|
es_res = search_company_events(body=es_req, **search_args)
|
||||||
|
|
||||||
|
aggs_result = es_res.get("aggregations")
|
||||||
|
if not aggs_result:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
metrics = [
|
||||||
|
(
|
||||||
|
metric["key"],
|
||||||
|
{
|
||||||
|
variant["key"]: {
|
||||||
|
"name": variant["key"],
|
||||||
|
**key.get_iterations_data(variant),
|
||||||
|
}
|
||||||
|
for variant in metric["variants"]["buckets"]
|
||||||
|
},
|
||||||
|
)
|
||||||
|
for metric in aggs_result["metrics"]["buckets"]
|
||||||
|
]
|
||||||
|
return metrics
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _add_aggregation_average(aggregation):
|
||||||
|
average_agg = {"avg_val": {"avg": {"field": "value"}}}
|
||||||
|
return {
|
||||||
|
key: {**value, "aggs": {**value.get("aggs", {}), **average_agg}}
|
||||||
|
for key, value in aggregation.items()
|
||||||
|
}
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _task_conditions(task_id: str) -> list:
|
||||||
|
return [
|
||||||
|
{"term": {"task": task_id}},
|
||||||
|
{"range": {"iter": {"gt": SINGLE_SCALAR_ITERATION}}},
|
||||||
|
]
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _get_task_metrics_query(
|
||||||
|
cls, task_id: str, metrics: Sequence[Tuple[str, str]],
|
||||||
|
):
|
||||||
|
must = cls._task_conditions(task_id)
|
||||||
|
if metrics:
|
||||||
|
should = [
|
||||||
|
{
|
||||||
|
"bool": {
|
||||||
|
"must": [
|
||||||
|
{"term": {"metric": metric}},
|
||||||
|
{"term": {"variant": variant}},
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
for metric, variant in metrics
|
||||||
|
]
|
||||||
|
must.append({"bool": {"should": should}})
|
||||||
|
|
||||||
|
return {"bool": {"must": must}}
|
||||||
|
|
||||||
|
def get_task_metrics(
|
||||||
|
self, company_id, task_ids: Sequence, event_type: EventType
|
||||||
|
) -> Sequence:
|
||||||
|
"""
|
||||||
|
For the requested tasks return all the metrics that
|
||||||
|
reported events of the requested types
|
||||||
|
"""
|
||||||
|
if check_empty_data(self.es, company_id, event_type):
|
||||||
|
return {}
|
||||||
|
|
||||||
|
with ThreadPoolExecutor(EventSettings.max_workers) as pool:
|
||||||
|
res = pool.map(
|
||||||
|
partial(
|
||||||
|
self._get_task_metrics,
|
||||||
|
company_id=company_id,
|
||||||
|
event_type=event_type,
|
||||||
|
),
|
||||||
|
task_ids,
|
||||||
|
)
|
||||||
|
return list(zip(task_ids, res))
|
||||||
|
|
||||||
|
def _get_task_metrics(
|
||||||
|
self, task_id: str, company_id: str, event_type: EventType
|
||||||
|
) -> Sequence:
|
||||||
|
es_req = {
|
||||||
|
"size": 0,
|
||||||
|
"query": {"bool": {"must": self._task_conditions(task_id)}},
|
||||||
|
"aggs": {
|
||||||
|
"metrics": {
|
||||||
|
"terms": {
|
||||||
|
"field": "metric",
|
||||||
|
"size": EventSettings.max_es_buckets,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
es_res = search_company_events(
|
||||||
|
self.es, company_id=company_id, event_type=event_type, body=es_req
|
||||||
|
)
|
||||||
|
|
||||||
|
return [
|
||||||
|
metric["key"]
|
||||||
|
for metric in safe_get(es_res, "aggregations/metrics/buckets", default=[])
|
||||||
|
]
|
||||||
197
apiserver/bll/event/events_iterator.py
Normal file
197
apiserver/bll/event/events_iterator.py
Normal file
@@ -0,0 +1,197 @@
|
|||||||
|
from typing import Optional, Tuple, Sequence, Any
|
||||||
|
|
||||||
|
import attr
|
||||||
|
import jsonmodels.models
|
||||||
|
import jwt
|
||||||
|
from elasticsearch import Elasticsearch
|
||||||
|
from jwt.algorithms import get_default_algorithms
|
||||||
|
|
||||||
|
from apiserver.bll.event.event_common import (
|
||||||
|
check_empty_data,
|
||||||
|
search_company_events,
|
||||||
|
EventType,
|
||||||
|
MetricVariants,
|
||||||
|
get_metric_variants_condition,
|
||||||
|
count_company_events,
|
||||||
|
)
|
||||||
|
from apiserver.bll.event.scalar_key import ScalarKeyEnum, ScalarKey
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.errors import translate_errors_context
|
||||||
|
|
||||||
|
|
||||||
|
@attr.s(auto_attribs=True)
|
||||||
|
class TaskEventsResult:
|
||||||
|
total_events: int = 0
|
||||||
|
next_scroll_id: str = None
|
||||||
|
events: list = attr.Factory(list)
|
||||||
|
|
||||||
|
|
||||||
|
class EventsIterator:
|
||||||
|
def __init__(self, es: Elasticsearch):
|
||||||
|
self.es = es
|
||||||
|
|
||||||
|
def get_task_events(
|
||||||
|
self,
|
||||||
|
event_type: EventType,
|
||||||
|
company_id: str,
|
||||||
|
task_id: str,
|
||||||
|
batch_size: int,
|
||||||
|
navigate_earlier: bool = True,
|
||||||
|
from_key_value: Optional[Any] = None,
|
||||||
|
metric_variants: MetricVariants = None,
|
||||||
|
key: ScalarKeyEnum = ScalarKeyEnum.timestamp,
|
||||||
|
**kwargs,
|
||||||
|
) -> TaskEventsResult:
|
||||||
|
if check_empty_data(self.es, company_id, event_type):
|
||||||
|
return TaskEventsResult()
|
||||||
|
|
||||||
|
from_key_value = kwargs.pop("from_timestamp", from_key_value)
|
||||||
|
|
||||||
|
res = TaskEventsResult()
|
||||||
|
res.events, res.total_events = self._get_events(
|
||||||
|
event_type=event_type,
|
||||||
|
company_id=company_id,
|
||||||
|
task_id=task_id,
|
||||||
|
batch_size=batch_size,
|
||||||
|
navigate_earlier=navigate_earlier,
|
||||||
|
from_key_value=from_key_value,
|
||||||
|
metric_variants=metric_variants,
|
||||||
|
key=ScalarKey.resolve(key),
|
||||||
|
)
|
||||||
|
return res
|
||||||
|
|
||||||
|
def count_task_events(
|
||||||
|
self,
|
||||||
|
event_type: EventType,
|
||||||
|
company_id: str,
|
||||||
|
task_id: str,
|
||||||
|
metric_variants: MetricVariants = None,
|
||||||
|
) -> int:
|
||||||
|
if check_empty_data(self.es, company_id, event_type):
|
||||||
|
return 0
|
||||||
|
|
||||||
|
query, _ = self._get_initial_query_and_must(task_id, metric_variants)
|
||||||
|
es_req = {
|
||||||
|
"query": query,
|
||||||
|
}
|
||||||
|
|
||||||
|
with translate_errors_context():
|
||||||
|
es_result = count_company_events(
|
||||||
|
self.es, company_id=company_id, event_type=event_type, body=es_req,
|
||||||
|
)
|
||||||
|
|
||||||
|
return es_result["count"]
|
||||||
|
|
||||||
|
def _get_events(
|
||||||
|
self,
|
||||||
|
event_type: EventType,
|
||||||
|
company_id: str,
|
||||||
|
task_id: str,
|
||||||
|
batch_size: int,
|
||||||
|
navigate_earlier: bool,
|
||||||
|
key: ScalarKey,
|
||||||
|
from_key_value: Optional[Any],
|
||||||
|
metric_variants: MetricVariants = None,
|
||||||
|
) -> Tuple[Sequence[dict], int]:
|
||||||
|
"""
|
||||||
|
Return up to 'batch size' events starting from the previous key-field value (timestamp or iter) either in the
|
||||||
|
direction of earlier events (navigate_earlier=True) or in the direction of later events.
|
||||||
|
If from_key_field is not set then start either from latest or earliest.
|
||||||
|
For the last key-field value all the events are brought (even if the resulting size exceeds batch_size)
|
||||||
|
so that events with this value will not be lost between the calls.
|
||||||
|
"""
|
||||||
|
query, must = self._get_initial_query_and_must(task_id, metric_variants)
|
||||||
|
|
||||||
|
# retrieve the next batch of events
|
||||||
|
es_req = {
|
||||||
|
"size": batch_size,
|
||||||
|
"query": query,
|
||||||
|
"sort": {key.field: "desc" if navigate_earlier else "asc"},
|
||||||
|
}
|
||||||
|
|
||||||
|
if from_key_value:
|
||||||
|
es_req["search_after"] = [from_key_value]
|
||||||
|
|
||||||
|
with translate_errors_context():
|
||||||
|
es_result = search_company_events(
|
||||||
|
self.es, company_id=company_id, event_type=event_type, body=es_req,
|
||||||
|
)
|
||||||
|
hits = es_result["hits"]["hits"]
|
||||||
|
hits_total = es_result["hits"]["total"]["value"]
|
||||||
|
if not hits:
|
||||||
|
return [], hits_total
|
||||||
|
|
||||||
|
events = [hit["_source"] for hit in hits]
|
||||||
|
|
||||||
|
# retrieve the events that match the last event timestamp
|
||||||
|
# but did not make it into the previous call due to batch_size limitation
|
||||||
|
es_req = {
|
||||||
|
"size": 10000,
|
||||||
|
"query": {
|
||||||
|
"bool": {
|
||||||
|
"must": must + [{"term": {key.field: events[-1][key.field]}}]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
es_result = search_company_events(
|
||||||
|
self.es, company_id=company_id, event_type=event_type, body=es_req,
|
||||||
|
)
|
||||||
|
last_second_hits = es_result["hits"]["hits"]
|
||||||
|
if not last_second_hits or len(last_second_hits) < 2:
|
||||||
|
# if only one element is returned for the last timestamp
|
||||||
|
# then it is already present in the events
|
||||||
|
return events, hits_total
|
||||||
|
|
||||||
|
already_present_ids = set(hit["_id"] for hit in hits)
|
||||||
|
last_second_events = [
|
||||||
|
hit["_source"]
|
||||||
|
for hit in last_second_hits
|
||||||
|
if hit["_id"] not in already_present_ids
|
||||||
|
]
|
||||||
|
|
||||||
|
# return the list merged from original query results +
|
||||||
|
# leftovers from the last timestamp
|
||||||
|
return (
|
||||||
|
[*events, *last_second_events],
|
||||||
|
hits_total,
|
||||||
|
)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _get_initial_query_and_must(
|
||||||
|
task_id: str, metric_variants: MetricVariants = None
|
||||||
|
) -> Tuple[dict, list]:
|
||||||
|
if not metric_variants:
|
||||||
|
must = [{"term": {"task": task_id}}]
|
||||||
|
query = {"term": {"task": task_id}}
|
||||||
|
else:
|
||||||
|
must = [
|
||||||
|
{"term": {"task": task_id}},
|
||||||
|
get_metric_variants_condition(metric_variants),
|
||||||
|
]
|
||||||
|
query = {"bool": {"must": must}}
|
||||||
|
return query, must
|
||||||
|
|
||||||
|
|
||||||
|
class Scroll(jsonmodels.models.Base):
|
||||||
|
def get_scroll_id(self) -> str:
|
||||||
|
return jwt.encode(
|
||||||
|
self.to_struct(),
|
||||||
|
key=config.get(
|
||||||
|
"services.events.events_retrieval.scroll_id_key", "1234567890"
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_scroll_id(cls, scroll_id: str):
|
||||||
|
try:
|
||||||
|
return cls(
|
||||||
|
**jwt.decode(
|
||||||
|
scroll_id,
|
||||||
|
key=config.get(
|
||||||
|
"services.events.events_retrieval.scroll_id_key", "1234567890"
|
||||||
|
),
|
||||||
|
algorithms=get_default_algorithms(),
|
||||||
|
)
|
||||||
|
)
|
||||||
|
except jwt.PyJWTError:
|
||||||
|
raise ValueError("Invalid Scroll ID")
|
||||||
455
apiserver/bll/event/history_debug_image_iterator.py
Normal file
455
apiserver/bll/event/history_debug_image_iterator.py
Normal file
@@ -0,0 +1,455 @@
|
|||||||
|
import operator
|
||||||
|
from operator import attrgetter
|
||||||
|
from typing import Sequence, Tuple, Optional, Mapping
|
||||||
|
|
||||||
|
import attr
|
||||||
|
from boltons.iterutils import first, bucketize
|
||||||
|
from elasticsearch import Elasticsearch
|
||||||
|
from jsonmodels.fields import StringField, IntField, BoolField, ListField
|
||||||
|
from jsonmodels.models import Base
|
||||||
|
from redis.client import StrictRedis
|
||||||
|
|
||||||
|
from apiserver.utilities.dicts import nested_get
|
||||||
|
from .event_common import (
|
||||||
|
EventType,
|
||||||
|
EventSettings,
|
||||||
|
check_empty_data,
|
||||||
|
search_company_events,
|
||||||
|
get_max_metric_and_variant_counts,
|
||||||
|
)
|
||||||
|
from apiserver.apimodels import JsonSerializableMixin
|
||||||
|
from apiserver.bll.redis_cache_manager import RedisCacheManager
|
||||||
|
from apiserver.apierrors import errors
|
||||||
|
|
||||||
|
|
||||||
|
class VariantState(Base):
|
||||||
|
name: str = StringField(required=True)
|
||||||
|
metric: str = StringField(default=None)
|
||||||
|
min_iteration: int = IntField()
|
||||||
|
max_iteration: int = IntField()
|
||||||
|
|
||||||
|
|
||||||
|
class DebugImageSampleState(Base, JsonSerializableMixin):
|
||||||
|
id: str = StringField(required=True)
|
||||||
|
iteration: int = IntField()
|
||||||
|
variant: str = StringField()
|
||||||
|
task: str = StringField()
|
||||||
|
metric: str = StringField()
|
||||||
|
variant_states: Sequence[VariantState] = ListField([VariantState])
|
||||||
|
warning: str = StringField()
|
||||||
|
navigate_current_metric = BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
@attr.s(auto_attribs=True)
|
||||||
|
class VariantSampleResult(object):
|
||||||
|
scroll_id: str = None
|
||||||
|
event: dict = None
|
||||||
|
min_iteration: int = None
|
||||||
|
max_iteration: int = None
|
||||||
|
|
||||||
|
|
||||||
|
class HistoryDebugImageIterator:
|
||||||
|
event_type = EventType.metrics_image
|
||||||
|
|
||||||
|
def __init__(self, redis: StrictRedis, es: Elasticsearch):
|
||||||
|
self.es = es
|
||||||
|
self.cache_manager = RedisCacheManager(
|
||||||
|
state_class=DebugImageSampleState,
|
||||||
|
redis=redis,
|
||||||
|
expiration_interval=EventSettings.state_expiration_sec,
|
||||||
|
)
|
||||||
|
|
||||||
|
def get_next_sample(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
task: str,
|
||||||
|
state_id: str,
|
||||||
|
navigate_earlier: bool,
|
||||||
|
next_iteration: bool,
|
||||||
|
) -> VariantSampleResult:
|
||||||
|
"""
|
||||||
|
Get the sample for next/prev variant on the current iteration
|
||||||
|
If does not exist then try getting sample for the first/last variant from next/prev iteration
|
||||||
|
"""
|
||||||
|
res = VariantSampleResult(scroll_id=state_id)
|
||||||
|
state = self.cache_manager.get_state(state_id)
|
||||||
|
if not state or state.task != task:
|
||||||
|
raise errors.bad_request.InvalidScrollId(scroll_id=state_id)
|
||||||
|
|
||||||
|
if check_empty_data(self.es, company_id=company_id, event_type=self.event_type):
|
||||||
|
return res
|
||||||
|
|
||||||
|
if next_iteration:
|
||||||
|
event = self._get_next_for_another_iteration(
|
||||||
|
company_id=company_id, navigate_earlier=navigate_earlier, state=state
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
# noinspection PyArgumentList
|
||||||
|
event = first(
|
||||||
|
f(company_id=company_id, navigate_earlier=navigate_earlier, state=state)
|
||||||
|
for f in (
|
||||||
|
self._get_next_for_current_iteration,
|
||||||
|
self._get_next_for_another_iteration,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
if not event:
|
||||||
|
return res
|
||||||
|
|
||||||
|
self._fill_res_and_update_state(event=event, res=res, state=state)
|
||||||
|
self.cache_manager.set_state(state=state)
|
||||||
|
return res
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _fill_res_and_update_state(
|
||||||
|
event: dict, res: VariantSampleResult, state: DebugImageSampleState
|
||||||
|
):
|
||||||
|
state.variant = event["variant"]
|
||||||
|
state.metric = event["metric"]
|
||||||
|
state.iteration = event["iter"]
|
||||||
|
res.event = event
|
||||||
|
var_state = first(
|
||||||
|
vs
|
||||||
|
for vs in state.variant_states
|
||||||
|
if vs.name == state.variant and vs.metric == state.metric
|
||||||
|
)
|
||||||
|
if var_state:
|
||||||
|
res.min_iteration = var_state.min_iteration
|
||||||
|
res.max_iteration = var_state.max_iteration
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _get_metric_conditions(variants: Sequence[VariantState]) -> dict:
|
||||||
|
metrics = bucketize(variants, key=attrgetter("metric"))
|
||||||
|
|
||||||
|
def _get_variants_conditions(metric_variants: Sequence[VariantState]) -> dict:
|
||||||
|
variants_conditions = [
|
||||||
|
{
|
||||||
|
"bool": {
|
||||||
|
"must": [
|
||||||
|
{"term": {"variant": v.name}},
|
||||||
|
{"range": {"iter": {"gte": v.min_iteration}}},
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
for v in metric_variants
|
||||||
|
]
|
||||||
|
return {"bool": {"should": variants_conditions}}
|
||||||
|
|
||||||
|
metrics_conditions = [
|
||||||
|
{
|
||||||
|
"bool": {
|
||||||
|
"must": [
|
||||||
|
{"term": {"metric": metric}},
|
||||||
|
_get_variants_conditions(metric_variants),
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
for metric, metric_variants in metrics.items()
|
||||||
|
]
|
||||||
|
return {"bool": {"should": metrics_conditions}}
|
||||||
|
|
||||||
|
def _get_next_for_current_iteration(
|
||||||
|
self, company_id: str, navigate_earlier: bool, state: DebugImageSampleState
|
||||||
|
) -> Optional[dict]:
|
||||||
|
"""
|
||||||
|
Get the sample for next (if navigate_earlier is False) or previous variant sorted by name for the same iteration
|
||||||
|
Only variants for which the iteration falls into their valid range are considered
|
||||||
|
Return None if no such variant or sample is found
|
||||||
|
"""
|
||||||
|
if state.navigate_current_metric:
|
||||||
|
variants = [
|
||||||
|
var_state
|
||||||
|
for var_state in state.variant_states
|
||||||
|
if var_state.metric == state.metric
|
||||||
|
]
|
||||||
|
else:
|
||||||
|
variants = state.variant_states
|
||||||
|
|
||||||
|
cmp = operator.lt if navigate_earlier else operator.gt
|
||||||
|
variants = [
|
||||||
|
var_state
|
||||||
|
for var_state in variants
|
||||||
|
if cmp((var_state.metric, var_state.name), (state.metric, state.variant))
|
||||||
|
and var_state.min_iteration <= state.iteration
|
||||||
|
]
|
||||||
|
if not variants:
|
||||||
|
return
|
||||||
|
|
||||||
|
must_conditions = [
|
||||||
|
{"term": {"task": state.task}},
|
||||||
|
{"term": {"iter": state.iteration}},
|
||||||
|
self._get_metric_conditions(variants),
|
||||||
|
{"exists": {"field": "url"}},
|
||||||
|
]
|
||||||
|
order = "desc" if navigate_earlier else "asc"
|
||||||
|
es_req = {
|
||||||
|
"size": 1,
|
||||||
|
"sort": [{"metric": order}, {"variant": order}],
|
||||||
|
"query": {"bool": {"must": must_conditions}},
|
||||||
|
}
|
||||||
|
|
||||||
|
es_res = search_company_events(
|
||||||
|
self.es,
|
||||||
|
company_id=company_id,
|
||||||
|
event_type=self.event_type,
|
||||||
|
body=es_req,
|
||||||
|
)
|
||||||
|
|
||||||
|
hits = nested_get(es_res, ("hits", "hits"))
|
||||||
|
if not hits:
|
||||||
|
return
|
||||||
|
|
||||||
|
return hits[0]["_source"]
|
||||||
|
|
||||||
|
def _get_next_for_another_iteration(
|
||||||
|
self, company_id: str, navigate_earlier: bool, state: DebugImageSampleState
|
||||||
|
) -> Optional[dict]:
|
||||||
|
"""
|
||||||
|
Get the sample for the first variant for the next iteration (if navigate_earlier is set to False)
|
||||||
|
or from the last variant for the previous iteration (otherwise)
|
||||||
|
The variants for which the sample falls in invalid range are discarded
|
||||||
|
If no suitable sample is found then None is returned
|
||||||
|
"""
|
||||||
|
if state.navigate_current_metric:
|
||||||
|
variants = [
|
||||||
|
var_state
|
||||||
|
for var_state in state.variant_states
|
||||||
|
if var_state.metric == state.metric
|
||||||
|
]
|
||||||
|
else:
|
||||||
|
variants = state.variant_states
|
||||||
|
|
||||||
|
if navigate_earlier:
|
||||||
|
range_operator = "lt"
|
||||||
|
order = "desc"
|
||||||
|
variants = [
|
||||||
|
var_state
|
||||||
|
for var_state in variants
|
||||||
|
if var_state.min_iteration < state.iteration
|
||||||
|
]
|
||||||
|
else:
|
||||||
|
range_operator = "gt"
|
||||||
|
order = "asc"
|
||||||
|
variants = variants
|
||||||
|
|
||||||
|
if not variants:
|
||||||
|
return
|
||||||
|
|
||||||
|
must_conditions = [
|
||||||
|
{"term": {"task": state.task}},
|
||||||
|
self._get_metric_conditions(variants),
|
||||||
|
{"range": {"iter": {range_operator: state.iteration}}},
|
||||||
|
{"exists": {"field": "url"}},
|
||||||
|
]
|
||||||
|
es_req = {
|
||||||
|
"size": 1,
|
||||||
|
"sort": [{"iter": order}, {"metric": order}, {"variant": order}],
|
||||||
|
"query": {"bool": {"must": must_conditions}},
|
||||||
|
}
|
||||||
|
es_res = search_company_events(
|
||||||
|
self.es,
|
||||||
|
company_id=company_id,
|
||||||
|
event_type=self.event_type,
|
||||||
|
body=es_req,
|
||||||
|
)
|
||||||
|
|
||||||
|
hits = nested_get(es_res, ("hits", "hits"))
|
||||||
|
if not hits:
|
||||||
|
return
|
||||||
|
|
||||||
|
return hits[0]["_source"]
|
||||||
|
|
||||||
|
def get_sample_for_variant(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
task: str,
|
||||||
|
metric: str,
|
||||||
|
variant: str,
|
||||||
|
iteration: Optional[int] = None,
|
||||||
|
refresh: bool = False,
|
||||||
|
state_id: str = None,
|
||||||
|
navigate_current_metric: bool = True,
|
||||||
|
) -> VariantSampleResult:
|
||||||
|
"""
|
||||||
|
Get the sample for the requested iteration or the latest before it
|
||||||
|
If the iteration is not passed then get the latest event
|
||||||
|
"""
|
||||||
|
res = VariantSampleResult()
|
||||||
|
if check_empty_data(self.es, company_id=company_id, event_type=self.event_type):
|
||||||
|
return res
|
||||||
|
|
||||||
|
def init_state(state_: DebugImageSampleState):
|
||||||
|
state_.task = task
|
||||||
|
state_.metric = metric
|
||||||
|
state_.navigate_current_metric = navigate_current_metric
|
||||||
|
self._reset_variant_states(company_id=company_id, state=state_)
|
||||||
|
|
||||||
|
def validate_state(state_: DebugImageSampleState):
|
||||||
|
if (
|
||||||
|
state_.task != task
|
||||||
|
or state_.navigate_current_metric != navigate_current_metric
|
||||||
|
or (state_.navigate_current_metric and state_.metric != metric)
|
||||||
|
):
|
||||||
|
raise errors.bad_request.InvalidScrollId(
|
||||||
|
"Task and metric stored in the state do not match the passed ones",
|
||||||
|
scroll_id=state_.id,
|
||||||
|
)
|
||||||
|
# fix old variant states:
|
||||||
|
for vs in state_.variant_states:
|
||||||
|
if vs.metric is None:
|
||||||
|
vs.metric = metric
|
||||||
|
if refresh:
|
||||||
|
self._reset_variant_states(company_id=company_id, state=state_)
|
||||||
|
|
||||||
|
state: DebugImageSampleState
|
||||||
|
with self.cache_manager.get_or_create_state(
|
||||||
|
state_id=state_id, init_state=init_state, validate_state=validate_state,
|
||||||
|
) as state:
|
||||||
|
res.scroll_id = state.id
|
||||||
|
|
||||||
|
var_state = first(
|
||||||
|
vs
|
||||||
|
for vs in state.variant_states
|
||||||
|
if vs.name == variant and vs.metric == metric
|
||||||
|
)
|
||||||
|
if not var_state:
|
||||||
|
return res
|
||||||
|
|
||||||
|
res.min_iteration = var_state.min_iteration
|
||||||
|
res.max_iteration = var_state.max_iteration
|
||||||
|
|
||||||
|
must_conditions = [
|
||||||
|
{"term": {"task": task}},
|
||||||
|
{"term": {"metric": metric}},
|
||||||
|
{"term": {"variant": variant}},
|
||||||
|
{"exists": {"field": "url"}},
|
||||||
|
]
|
||||||
|
if iteration is not None:
|
||||||
|
must_conditions.append(
|
||||||
|
{
|
||||||
|
"range": {
|
||||||
|
"iter": {"lte": iteration, "gte": var_state.min_iteration}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
must_conditions.append(
|
||||||
|
{"range": {"iter": {"gte": var_state.min_iteration}}}
|
||||||
|
)
|
||||||
|
|
||||||
|
es_req = {
|
||||||
|
"size": 1,
|
||||||
|
"sort": {"iter": "desc"},
|
||||||
|
"query": {"bool": {"must": must_conditions}},
|
||||||
|
}
|
||||||
|
|
||||||
|
es_res = search_company_events(
|
||||||
|
self.es,
|
||||||
|
company_id=company_id,
|
||||||
|
event_type=self.event_type,
|
||||||
|
body=es_req,
|
||||||
|
)
|
||||||
|
|
||||||
|
hits = nested_get(es_res, ("hits", "hits"))
|
||||||
|
if not hits:
|
||||||
|
return res
|
||||||
|
|
||||||
|
self._fill_res_and_update_state(
|
||||||
|
event=hits[0]["_source"], res=res, state=state
|
||||||
|
)
|
||||||
|
return res
|
||||||
|
|
||||||
|
def _reset_variant_states(self, company_id: str, state: DebugImageSampleState):
|
||||||
|
metrics = self._get_metric_variant_iterations(
|
||||||
|
company_id=company_id,
|
||||||
|
task=state.task,
|
||||||
|
metric=state.metric if state.navigate_current_metric else None,
|
||||||
|
)
|
||||||
|
state.variant_states = [
|
||||||
|
VariantState(
|
||||||
|
metric=metric,
|
||||||
|
name=var_name,
|
||||||
|
min_iteration=min_iter,
|
||||||
|
max_iteration=max_iter,
|
||||||
|
)
|
||||||
|
for metric, variants in metrics.items()
|
||||||
|
for var_name, min_iter, max_iter in variants
|
||||||
|
]
|
||||||
|
|
||||||
|
def _get_metric_variant_iterations(
|
||||||
|
self, company_id: str, task: str, metric: str,
|
||||||
|
) -> Mapping[str, Sequence[Tuple[str, int, int]]]:
|
||||||
|
"""
|
||||||
|
Return valid min and max iterations that the task reported events of the required type
|
||||||
|
"""
|
||||||
|
must = [
|
||||||
|
{"term": {"task": task}},
|
||||||
|
{"exists": {"field": "url"}},
|
||||||
|
]
|
||||||
|
if metric is not None:
|
||||||
|
must.append({"term": {"metric": metric}})
|
||||||
|
query = {"bool": {"must": must}}
|
||||||
|
|
||||||
|
search_args = dict(
|
||||||
|
es=self.es, company_id=company_id, event_type=self.event_type,
|
||||||
|
)
|
||||||
|
max_metrics, max_variants = get_max_metric_and_variant_counts(
|
||||||
|
query=query, **search_args
|
||||||
|
)
|
||||||
|
max_variants = int(max_variants // 2)
|
||||||
|
es_req: dict = {
|
||||||
|
"size": 0,
|
||||||
|
"query": query,
|
||||||
|
"aggs": {
|
||||||
|
"metrics": {
|
||||||
|
"terms": {
|
||||||
|
"field": "metric",
|
||||||
|
"size": max_metrics,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"variants": {
|
||||||
|
"terms": {
|
||||||
|
"field": "variant",
|
||||||
|
"size": max_variants,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"last_iter": {"max": {"field": "iter"}},
|
||||||
|
"urls": {
|
||||||
|
# group by urls and choose the minimal iteration
|
||||||
|
# from all the maximal iterations per url
|
||||||
|
"terms": {
|
||||||
|
"field": "url",
|
||||||
|
"order": {"max_iter": "asc"},
|
||||||
|
"size": 1,
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
# find max iteration for each url
|
||||||
|
"max_iter": {"max": {"field": "iter"}}
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
es_res = search_company_events(body=es_req, **search_args)
|
||||||
|
|
||||||
|
def get_variant_data(variant_bucket: dict) -> Tuple[str, int, int]:
|
||||||
|
variant = variant_bucket["key"]
|
||||||
|
urls = nested_get(variant_bucket, ("urls", "buckets"))
|
||||||
|
min_iter = int(urls[0]["max_iter"]["value"])
|
||||||
|
max_iter = int(variant_bucket["last_iter"]["value"])
|
||||||
|
return variant, min_iter, max_iter
|
||||||
|
|
||||||
|
return {
|
||||||
|
metric_bucket["key"]: [
|
||||||
|
get_variant_data(variant_bucket)
|
||||||
|
for variant_bucket in nested_get(metric_bucket, ("variants", "buckets"))
|
||||||
|
]
|
||||||
|
for metric_bucket in nested_get(
|
||||||
|
es_res, ("aggregations", "metrics", "buckets")
|
||||||
|
)
|
||||||
|
}
|
||||||
316
apiserver/bll/event/history_plots_iterator.py
Normal file
316
apiserver/bll/event/history_plots_iterator.py
Normal file
@@ -0,0 +1,316 @@
|
|||||||
|
from typing import Sequence, Tuple, Optional, Mapping
|
||||||
|
|
||||||
|
import attr
|
||||||
|
from boltons.iterutils import first
|
||||||
|
from elasticsearch import Elasticsearch
|
||||||
|
from jsonmodels.fields import StringField, IntField, ListField, BoolField
|
||||||
|
from jsonmodels.models import Base
|
||||||
|
from redis.client import StrictRedis
|
||||||
|
|
||||||
|
from .event_common import (
|
||||||
|
EventType,
|
||||||
|
uncompress_plot,
|
||||||
|
EventSettings,
|
||||||
|
check_empty_data,
|
||||||
|
search_company_events,
|
||||||
|
)
|
||||||
|
from apiserver.apimodels import JsonSerializableMixin
|
||||||
|
from apiserver.utilities.dicts import nested_get
|
||||||
|
from apiserver.bll.redis_cache_manager import RedisCacheManager
|
||||||
|
from apiserver.apierrors import errors
|
||||||
|
|
||||||
|
|
||||||
|
class MetricState(Base):
|
||||||
|
name: str = StringField(default=None)
|
||||||
|
min_iteration: int = IntField()
|
||||||
|
max_iteration: int = IntField()
|
||||||
|
|
||||||
|
|
||||||
|
class PlotsSampleState(Base, JsonSerializableMixin):
|
||||||
|
id: str = StringField(required=True)
|
||||||
|
iteration: int = IntField()
|
||||||
|
task: str = StringField()
|
||||||
|
metric: str = StringField()
|
||||||
|
metric_states: Sequence[MetricState] = ListField([MetricState])
|
||||||
|
warning: str = StringField()
|
||||||
|
navigate_current_metric = BoolField(default=True)
|
||||||
|
|
||||||
|
|
||||||
|
@attr.s(auto_attribs=True)
|
||||||
|
class MetricSamplesResult(object):
|
||||||
|
scroll_id: str = None
|
||||||
|
events: list = []
|
||||||
|
min_iteration: int = None
|
||||||
|
max_iteration: int = None
|
||||||
|
|
||||||
|
|
||||||
|
class HistoryPlotsIterator:
|
||||||
|
event_type = EventType.metrics_plot
|
||||||
|
|
||||||
|
def __init__(self, redis: StrictRedis, es: Elasticsearch):
|
||||||
|
self.es = es
|
||||||
|
self.cache_manager = RedisCacheManager(
|
||||||
|
state_class=PlotsSampleState,
|
||||||
|
redis=redis,
|
||||||
|
expiration_interval=EventSettings.state_expiration_sec,
|
||||||
|
)
|
||||||
|
|
||||||
|
def get_next_sample(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
task: str,
|
||||||
|
state_id: str,
|
||||||
|
navigate_earlier: bool,
|
||||||
|
next_iteration: bool,
|
||||||
|
) -> MetricSamplesResult:
|
||||||
|
"""
|
||||||
|
Get the samples for next/prev metric on the current iteration
|
||||||
|
If does not exist then try getting sample for the first/last metric from next/prev iteration
|
||||||
|
"""
|
||||||
|
res = MetricSamplesResult(scroll_id=state_id)
|
||||||
|
state = self.cache_manager.get_state(state_id)
|
||||||
|
if not state or state.task != task:
|
||||||
|
raise errors.bad_request.InvalidScrollId(scroll_id=state_id)
|
||||||
|
|
||||||
|
if check_empty_data(self.es, company_id=company_id, event_type=self.event_type):
|
||||||
|
return res
|
||||||
|
|
||||||
|
if navigate_earlier:
|
||||||
|
range_operator = "lt"
|
||||||
|
order = "desc"
|
||||||
|
else:
|
||||||
|
range_operator = "gt"
|
||||||
|
order = "asc"
|
||||||
|
|
||||||
|
must_conditions = [
|
||||||
|
{"term": {"task": state.task}},
|
||||||
|
]
|
||||||
|
if state.navigate_current_metric:
|
||||||
|
must_conditions.append({"term": {"metric": state.metric}})
|
||||||
|
|
||||||
|
next_iteration_condition = {
|
||||||
|
"range": {"iter": {range_operator: state.iteration}}
|
||||||
|
}
|
||||||
|
if next_iteration or state.navigate_current_metric:
|
||||||
|
must_conditions.append(next_iteration_condition)
|
||||||
|
else:
|
||||||
|
next_metric_condition = {
|
||||||
|
"bool": {
|
||||||
|
"must": [
|
||||||
|
{"term": {"iter": state.iteration}},
|
||||||
|
{"range": {"metric": {range_operator: state.metric}}},
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
must_conditions.append(
|
||||||
|
{"bool": {"should": [next_metric_condition, next_iteration_condition]}}
|
||||||
|
)
|
||||||
|
|
||||||
|
events = self._get_metric_events_for_condition(
|
||||||
|
company_id=company_id,
|
||||||
|
task=state.task,
|
||||||
|
order=order,
|
||||||
|
must_conditions=must_conditions,
|
||||||
|
)
|
||||||
|
|
||||||
|
if not events:
|
||||||
|
return res
|
||||||
|
|
||||||
|
self._fill_res_and_update_state(events=events, res=res, state=state)
|
||||||
|
self.cache_manager.set_state(state=state)
|
||||||
|
return res
|
||||||
|
|
||||||
|
def get_samples_for_metric(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
task: str,
|
||||||
|
metric: str,
|
||||||
|
iteration: Optional[int] = None,
|
||||||
|
refresh: bool = False,
|
||||||
|
state_id: str = None,
|
||||||
|
navigate_current_metric: bool = True,
|
||||||
|
) -> MetricSamplesResult:
|
||||||
|
"""
|
||||||
|
Get the sample for the requested iteration or the latest before it
|
||||||
|
If the iteration is not passed then get the latest event
|
||||||
|
"""
|
||||||
|
res = MetricSamplesResult()
|
||||||
|
if check_empty_data(self.es, company_id=company_id, event_type=self.event_type):
|
||||||
|
return res
|
||||||
|
|
||||||
|
def init_state(state_: PlotsSampleState):
|
||||||
|
state_.task = task
|
||||||
|
state_.metric = metric
|
||||||
|
state_.navigate_current_metric = navigate_current_metric
|
||||||
|
self._reset_metric_states(company_id=company_id, state=state_)
|
||||||
|
|
||||||
|
def validate_state(state_: PlotsSampleState):
|
||||||
|
if (
|
||||||
|
state_.task != task
|
||||||
|
or state_.navigate_current_metric != navigate_current_metric
|
||||||
|
or (state_.navigate_current_metric and state_.metric != metric)
|
||||||
|
):
|
||||||
|
raise errors.bad_request.InvalidScrollId(
|
||||||
|
"Task and metric stored in the state do not match the passed ones",
|
||||||
|
scroll_id=state_.id,
|
||||||
|
)
|
||||||
|
if refresh:
|
||||||
|
self._reset_metric_states(company_id=company_id, state=state_)
|
||||||
|
|
||||||
|
state: PlotsSampleState
|
||||||
|
with self.cache_manager.get_or_create_state(
|
||||||
|
state_id=state_id, init_state=init_state, validate_state=validate_state,
|
||||||
|
) as state:
|
||||||
|
res.scroll_id = state.id
|
||||||
|
|
||||||
|
metric_state = first(ms for ms in state.metric_states if ms.name == metric)
|
||||||
|
if not metric_state:
|
||||||
|
return res
|
||||||
|
|
||||||
|
res.min_iteration = metric_state.min_iteration
|
||||||
|
res.max_iteration = metric_state.max_iteration
|
||||||
|
|
||||||
|
must_conditions = [
|
||||||
|
{"term": {"task": task}},
|
||||||
|
{"term": {"metric": metric}},
|
||||||
|
]
|
||||||
|
if iteration is not None:
|
||||||
|
must_conditions.append({"range": {"iter": {"lte": iteration}}})
|
||||||
|
|
||||||
|
events = self._get_metric_events_for_condition(
|
||||||
|
company_id=company_id,
|
||||||
|
task=state.task,
|
||||||
|
order="desc",
|
||||||
|
must_conditions=must_conditions,
|
||||||
|
)
|
||||||
|
if not events:
|
||||||
|
return res
|
||||||
|
|
||||||
|
self._fill_res_and_update_state(events=events, res=res, state=state)
|
||||||
|
return res
|
||||||
|
|
||||||
|
def _reset_metric_states(self, company_id: str, state: PlotsSampleState):
|
||||||
|
metrics = self._get_metric_iterations(
|
||||||
|
company_id=company_id,
|
||||||
|
task=state.task,
|
||||||
|
metric=state.metric if state.navigate_current_metric else None,
|
||||||
|
)
|
||||||
|
state.metric_states = [
|
||||||
|
MetricState(name=metric, min_iteration=min_iter, max_iteration=max_iter)
|
||||||
|
for metric, (min_iter, max_iter) in metrics.items()
|
||||||
|
]
|
||||||
|
|
||||||
|
def _get_metric_iterations(
|
||||||
|
self, company_id: str, task: str, metric: str,
|
||||||
|
) -> Mapping[str, Tuple[int, int]]:
|
||||||
|
"""
|
||||||
|
Return valid min and max iterations that the task reported events of the required type
|
||||||
|
"""
|
||||||
|
must = [
|
||||||
|
{"term": {"task": task}},
|
||||||
|
]
|
||||||
|
if metric is not None:
|
||||||
|
must.append({"term": {"metric": metric}})
|
||||||
|
query = {"bool": {"must": must}}
|
||||||
|
|
||||||
|
es_req: dict = {
|
||||||
|
"size": 0,
|
||||||
|
"query": query,
|
||||||
|
"aggs": {
|
||||||
|
"metrics": {
|
||||||
|
"terms": {
|
||||||
|
"field": "metric",
|
||||||
|
"size": 5000,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"last_iter": {"max": {"field": "iter"}},
|
||||||
|
"first_iter": {"min": {"field": "iter"}},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
es_res = search_company_events(
|
||||||
|
body=es_req,
|
||||||
|
es=self.es,
|
||||||
|
company_id=company_id,
|
||||||
|
event_type=self.event_type,
|
||||||
|
)
|
||||||
|
|
||||||
|
return {
|
||||||
|
metric_bucket["key"]: (
|
||||||
|
int(metric_bucket["first_iter"]["value"]),
|
||||||
|
int(metric_bucket["last_iter"]["value"]),
|
||||||
|
)
|
||||||
|
for metric_bucket in nested_get(
|
||||||
|
es_res, ("aggregations", "metrics", "buckets")
|
||||||
|
)
|
||||||
|
}
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _fill_res_and_update_state(
|
||||||
|
events: Sequence[dict], res: MetricSamplesResult, state: PlotsSampleState
|
||||||
|
):
|
||||||
|
for event in events:
|
||||||
|
uncompress_plot(event)
|
||||||
|
state.metric = events[0]["metric"]
|
||||||
|
state.iteration = events[0]["iter"]
|
||||||
|
res.events = events
|
||||||
|
metric_state = first(
|
||||||
|
ms for ms in state.metric_states if ms.name == state.metric
|
||||||
|
)
|
||||||
|
if metric_state:
|
||||||
|
res.min_iteration = metric_state.min_iteration
|
||||||
|
res.max_iteration = metric_state.max_iteration
|
||||||
|
|
||||||
|
def _get_metric_events_for_condition(
|
||||||
|
self, company_id: str, task: str, order: str, must_conditions: Sequence
|
||||||
|
) -> Sequence:
|
||||||
|
es_req = {
|
||||||
|
"size": 0,
|
||||||
|
"query": {"bool": {"must": must_conditions}},
|
||||||
|
"aggs": {
|
||||||
|
"iters": {
|
||||||
|
"terms": {"field": "iter", "size": 1, "order": {"_key": order}},
|
||||||
|
"aggs": {
|
||||||
|
"metrics": {
|
||||||
|
"terms": {
|
||||||
|
"field": "metric",
|
||||||
|
"size": 1,
|
||||||
|
"order": {"_key": order},
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"events": {
|
||||||
|
"top_hits": {
|
||||||
|
"sort": {"variant": {"order": "asc"}},
|
||||||
|
"size": 100,
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
es_res = search_company_events(
|
||||||
|
self.es,
|
||||||
|
company_id=company_id,
|
||||||
|
event_type=self.event_type,
|
||||||
|
body=es_req,
|
||||||
|
)
|
||||||
|
|
||||||
|
aggs_result = es_res.get("aggregations")
|
||||||
|
if not aggs_result:
|
||||||
|
return []
|
||||||
|
|
||||||
|
for level in ("iters", "metrics"):
|
||||||
|
level_data = aggs_result[level]["buckets"]
|
||||||
|
if not level_data:
|
||||||
|
return []
|
||||||
|
aggs_result = level_data[0]
|
||||||
|
|
||||||
|
return [
|
||||||
|
hit["_source"]
|
||||||
|
for hit in nested_get(aggs_result, ("events", "hits", "hits"))
|
||||||
|
]
|
||||||
53
apiserver/bll/event/metric_debug_images_iterator.py
Normal file
53
apiserver/bll/event/metric_debug_images_iterator.py
Normal file
@@ -0,0 +1,53 @@
|
|||||||
|
from typing import Sequence, Tuple, Callable
|
||||||
|
|
||||||
|
from elasticsearch import Elasticsearch
|
||||||
|
from redis.client import StrictRedis
|
||||||
|
|
||||||
|
from apiserver.utilities.dicts import nested_get
|
||||||
|
from .event_common import EventType
|
||||||
|
from .metric_events_iterator import MetricEventsIterator, VariantState
|
||||||
|
|
||||||
|
|
||||||
|
class MetricDebugImagesIterator(MetricEventsIterator):
|
||||||
|
def __init__(self, redis: StrictRedis, es: Elasticsearch):
|
||||||
|
super().__init__(redis, es, EventType.metrics_image)
|
||||||
|
|
||||||
|
def _get_extra_conditions(self) -> Sequence[dict]:
|
||||||
|
return [{"exists": {"field": "url"}}]
|
||||||
|
|
||||||
|
def _get_variant_state_aggs(self) -> Tuple[dict, Callable[[dict, VariantState], None]]:
|
||||||
|
aggs = {
|
||||||
|
"urls": {
|
||||||
|
"terms": {
|
||||||
|
"field": "url",
|
||||||
|
"order": {"max_iter": "desc"},
|
||||||
|
"size": 1, # we need only one url from the most recent iteration
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"max_iter": {"max": {"field": "iter"}},
|
||||||
|
"iters": {
|
||||||
|
"top_hits": {
|
||||||
|
"sort": {"iter": {"order": "desc"}},
|
||||||
|
"size": 2, # need two last iterations so that we can take
|
||||||
|
# the second one as invalid
|
||||||
|
"_source": "iter",
|
||||||
|
}
|
||||||
|
},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
def fill_variant_state_data(variant_bucket: dict, state: VariantState):
|
||||||
|
"""If the image urls get recycled then fill the last_invalid_iteration field"""
|
||||||
|
top_iter_url = nested_get(variant_bucket, ("urls", "buckets"))[0]
|
||||||
|
iters = nested_get(top_iter_url, ("iters", "hits", "hits"))
|
||||||
|
if len(iters) > 1:
|
||||||
|
state.last_invalid_iteration = nested_get(iters[1], ("_source", "iter"))
|
||||||
|
|
||||||
|
return aggs, fill_variant_state_data
|
||||||
|
|
||||||
|
def _process_event(self, event: dict) -> dict:
|
||||||
|
return event
|
||||||
|
|
||||||
|
def _get_same_variant_events_order(self) -> dict:
|
||||||
|
return {"url": {"order": "desc"}}
|
||||||
451
apiserver/bll/event/metric_events_iterator.py
Normal file
451
apiserver/bll/event/metric_events_iterator.py
Normal file
@@ -0,0 +1,451 @@
|
|||||||
|
import abc
|
||||||
|
from concurrent.futures.thread import ThreadPoolExecutor
|
||||||
|
from datetime import datetime
|
||||||
|
from functools import partial
|
||||||
|
from operator import itemgetter
|
||||||
|
from typing import Sequence, Tuple, Optional, Mapping, Callable
|
||||||
|
|
||||||
|
import attr
|
||||||
|
import dpath
|
||||||
|
from boltons.iterutils import first
|
||||||
|
from elasticsearch import Elasticsearch
|
||||||
|
from jsonmodels.fields import StringField, ListField, IntField
|
||||||
|
from jsonmodels.models import Base
|
||||||
|
from redis import StrictRedis
|
||||||
|
|
||||||
|
from apiserver.apimodels import JsonSerializableMixin
|
||||||
|
from apiserver.bll.event.event_common import (
|
||||||
|
EventSettings,
|
||||||
|
check_empty_data,
|
||||||
|
search_company_events,
|
||||||
|
EventType,
|
||||||
|
get_metric_variants_condition,
|
||||||
|
get_max_metric_and_variant_counts,
|
||||||
|
)
|
||||||
|
from apiserver.bll.redis_cache_manager import RedisCacheManager
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.errors import translate_errors_context
|
||||||
|
from apiserver.database.model.task.metrics import MetricEventStats
|
||||||
|
from apiserver.database.model.task.task import Task
|
||||||
|
|
||||||
|
|
||||||
|
class VariantState(Base):
|
||||||
|
variant: str = StringField(required=True)
|
||||||
|
last_invalid_iteration: int = IntField()
|
||||||
|
|
||||||
|
|
||||||
|
class MetricState(Base):
|
||||||
|
metric: str = StringField(required=True)
|
||||||
|
variants: Sequence[VariantState] = ListField([VariantState], required=True)
|
||||||
|
timestamp: int = IntField(default=0)
|
||||||
|
|
||||||
|
|
||||||
|
class TaskScrollState(Base):
|
||||||
|
task: str = StringField(required=True)
|
||||||
|
metrics: Sequence[MetricState] = ListField([MetricState], required=True)
|
||||||
|
last_min_iter: Optional[int] = IntField()
|
||||||
|
last_max_iter: Optional[int] = IntField()
|
||||||
|
|
||||||
|
def reset(self):
|
||||||
|
"""Reset the scrolling state for the metric"""
|
||||||
|
self.last_min_iter = self.last_max_iter = None
|
||||||
|
|
||||||
|
|
||||||
|
class MetricEventsScrollState(Base, JsonSerializableMixin):
|
||||||
|
id: str = StringField(required=True)
|
||||||
|
tasks: Sequence[TaskScrollState] = ListField([TaskScrollState])
|
||||||
|
warning: str = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
@attr.s(auto_attribs=True)
|
||||||
|
class MetricEventsResult(object):
|
||||||
|
metric_events: Sequence[tuple] = []
|
||||||
|
next_scroll_id: str = None
|
||||||
|
|
||||||
|
|
||||||
|
class MetricEventsIterator:
|
||||||
|
def __init__(self, redis: StrictRedis, es: Elasticsearch, event_type: EventType):
|
||||||
|
self.es = es
|
||||||
|
self.event_type = event_type
|
||||||
|
self.cache_manager = RedisCacheManager(
|
||||||
|
state_class=MetricEventsScrollState,
|
||||||
|
redis=redis,
|
||||||
|
expiration_interval=EventSettings.state_expiration_sec,
|
||||||
|
)
|
||||||
|
|
||||||
|
def get_task_events(
|
||||||
|
self,
|
||||||
|
companies: Mapping[str, str],
|
||||||
|
task_metrics: Mapping[str, dict],
|
||||||
|
iter_count: int,
|
||||||
|
navigate_earlier: bool = True,
|
||||||
|
refresh: bool = False,
|
||||||
|
state_id: str = None,
|
||||||
|
) -> MetricEventsResult:
|
||||||
|
companies = {
|
||||||
|
task_id: company_id
|
||||||
|
for task_id, company_id in companies.items()
|
||||||
|
if not check_empty_data(
|
||||||
|
self.es, company_id=company_id, event_type=EventType.metrics_scalar
|
||||||
|
)
|
||||||
|
}
|
||||||
|
if not companies:
|
||||||
|
return MetricEventsResult()
|
||||||
|
|
||||||
|
def init_state(state_: MetricEventsScrollState):
|
||||||
|
state_.tasks = self._init_task_states(companies, task_metrics)
|
||||||
|
|
||||||
|
def validate_state(state_: MetricEventsScrollState):
|
||||||
|
"""
|
||||||
|
Validate that the metrics stored in the state are the same
|
||||||
|
as requested in the current call.
|
||||||
|
Refresh the state if requested
|
||||||
|
"""
|
||||||
|
if refresh:
|
||||||
|
self._reinit_outdated_task_states(companies, state_, task_metrics)
|
||||||
|
|
||||||
|
with self.cache_manager.get_or_create_state(
|
||||||
|
state_id=state_id, init_state=init_state, validate_state=validate_state
|
||||||
|
) as state:
|
||||||
|
res = MetricEventsResult(next_scroll_id=state.id)
|
||||||
|
specific_variants_requested = any(
|
||||||
|
variants
|
||||||
|
for t, metrics in task_metrics.items()
|
||||||
|
if metrics
|
||||||
|
for m, variants in metrics.items()
|
||||||
|
)
|
||||||
|
with ThreadPoolExecutor(EventSettings.max_workers) as pool:
|
||||||
|
res.metric_events = list(
|
||||||
|
pool.map(
|
||||||
|
partial(
|
||||||
|
self._get_task_metric_events,
|
||||||
|
companies=companies,
|
||||||
|
iter_count=iter_count,
|
||||||
|
navigate_earlier=navigate_earlier,
|
||||||
|
specific_variants_requested=specific_variants_requested,
|
||||||
|
),
|
||||||
|
state.tasks,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
return res
|
||||||
|
|
||||||
|
def _reinit_outdated_task_states(
|
||||||
|
self,
|
||||||
|
companies: Mapping[str, str],
|
||||||
|
state: MetricEventsScrollState,
|
||||||
|
task_metrics: Mapping[str, dict],
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
Determine the metrics for which new event_type events were added
|
||||||
|
since their states were initialized and re-init these states
|
||||||
|
"""
|
||||||
|
tasks = Task.objects(id__in=list(task_metrics)).only("id", "metric_stats")
|
||||||
|
|
||||||
|
def get_last_update_times_for_task_metrics(
|
||||||
|
task: Task,
|
||||||
|
) -> Mapping[str, datetime]:
|
||||||
|
"""For metrics that reported event_type events get mapping of the metric name to the last update times"""
|
||||||
|
metric_stats: Mapping[str, MetricEventStats] = task.metric_stats
|
||||||
|
if not metric_stats:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
requested_metrics = task_metrics[task.id]
|
||||||
|
return {
|
||||||
|
stats.metric: stats.event_stats_by_type[
|
||||||
|
self.event_type.value
|
||||||
|
].last_update
|
||||||
|
for stats in metric_stats.values()
|
||||||
|
if self.event_type.value in stats.event_stats_by_type
|
||||||
|
and (not requested_metrics or stats.metric in requested_metrics)
|
||||||
|
}
|
||||||
|
|
||||||
|
update_times = {
|
||||||
|
task.id: get_last_update_times_for_task_metrics(task) for task in tasks
|
||||||
|
}
|
||||||
|
task_metric_states = {
|
||||||
|
task_state.task: {
|
||||||
|
metric_state.metric: metric_state for metric_state in task_state.metrics
|
||||||
|
}
|
||||||
|
for task_state in state.tasks
|
||||||
|
}
|
||||||
|
task_metrics_to_recalc = {}
|
||||||
|
for task, metrics_times in update_times.items():
|
||||||
|
old_metric_states = task_metric_states[task]
|
||||||
|
metrics_to_recalc = {
|
||||||
|
m: task_metrics[task].get(m)
|
||||||
|
for m, t in metrics_times.items()
|
||||||
|
if m not in old_metric_states or old_metric_states[m].timestamp < t
|
||||||
|
}
|
||||||
|
if metrics_to_recalc:
|
||||||
|
task_metrics_to_recalc[task] = metrics_to_recalc
|
||||||
|
|
||||||
|
updated_task_states = self._init_task_states(companies, task_metrics_to_recalc)
|
||||||
|
|
||||||
|
def merge_with_updated_task_states(
|
||||||
|
old_state: TaskScrollState, updates: Sequence[TaskScrollState]
|
||||||
|
) -> TaskScrollState:
|
||||||
|
task = old_state.task
|
||||||
|
updated_state = first(uts for uts in updates if uts.task == task)
|
||||||
|
if not updated_state:
|
||||||
|
old_state.reset()
|
||||||
|
return old_state
|
||||||
|
|
||||||
|
updated_metrics = [m.metric for m in updated_state.metrics]
|
||||||
|
return TaskScrollState(
|
||||||
|
task=task,
|
||||||
|
metrics=[
|
||||||
|
*updated_state.metrics,
|
||||||
|
*(
|
||||||
|
old_metric
|
||||||
|
for old_metric in old_state.metrics
|
||||||
|
if old_metric.metric not in updated_metrics
|
||||||
|
),
|
||||||
|
],
|
||||||
|
)
|
||||||
|
|
||||||
|
state.tasks = [
|
||||||
|
merge_with_updated_task_states(task_state, updated_task_states)
|
||||||
|
for task_state in state.tasks
|
||||||
|
]
|
||||||
|
|
||||||
|
def _init_task_states(
|
||||||
|
self, companies: Mapping[str, str], task_metrics: Mapping[str, dict]
|
||||||
|
) -> Sequence[TaskScrollState]:
|
||||||
|
"""
|
||||||
|
Returned initialized metric scroll stated for the requested task metrics
|
||||||
|
"""
|
||||||
|
with ThreadPoolExecutor(EventSettings.max_workers) as pool:
|
||||||
|
task_metric_states = pool.map(
|
||||||
|
partial(self._init_metric_states_for_task, companies=companies),
|
||||||
|
task_metrics.items(),
|
||||||
|
)
|
||||||
|
|
||||||
|
return [
|
||||||
|
TaskScrollState(task=task, metrics=metric_states,)
|
||||||
|
for task, metric_states in zip(task_metrics, task_metric_states)
|
||||||
|
]
|
||||||
|
|
||||||
|
@abc.abstractmethod
|
||||||
|
def _get_extra_conditions(self) -> Sequence[dict]:
|
||||||
|
pass
|
||||||
|
|
||||||
|
@abc.abstractmethod
|
||||||
|
def _get_variant_state_aggs(
|
||||||
|
self,
|
||||||
|
) -> Tuple[dict, Callable[[dict, VariantState], None]]:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def _init_metric_states_for_task(
|
||||||
|
self, task_metrics: Tuple[str, dict], companies: Mapping[str, str]
|
||||||
|
) -> Sequence[MetricState]:
|
||||||
|
"""
|
||||||
|
Return metric scroll states for the task filled with the variant states
|
||||||
|
for the variants that reported any event_type events
|
||||||
|
"""
|
||||||
|
task, metrics = task_metrics
|
||||||
|
company_id = companies[task]
|
||||||
|
must = [{"term": {"task": task}}, *self._get_extra_conditions()]
|
||||||
|
if metrics:
|
||||||
|
must.append(get_metric_variants_condition(metrics))
|
||||||
|
query = {"bool": {"must": must}}
|
||||||
|
|
||||||
|
search_args = dict(
|
||||||
|
es=self.es, company_id=company_id, event_type=self.event_type
|
||||||
|
)
|
||||||
|
max_metrics, max_variants = get_max_metric_and_variant_counts(
|
||||||
|
query=query, **search_args
|
||||||
|
)
|
||||||
|
max_variants = int(max_variants // 2)
|
||||||
|
variant_state_aggs, fill_variant_state_data = self._get_variant_state_aggs()
|
||||||
|
es_req: dict = {
|
||||||
|
"size": 0,
|
||||||
|
"query": query,
|
||||||
|
"aggs": {
|
||||||
|
"metrics": {
|
||||||
|
"terms": {
|
||||||
|
"field": "metric",
|
||||||
|
"size": max_metrics,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"last_event_timestamp": {"max": {"field": "timestamp"}},
|
||||||
|
"variants": {
|
||||||
|
"terms": {
|
||||||
|
"field": "variant",
|
||||||
|
"size": max_variants,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
},
|
||||||
|
**(
|
||||||
|
{"aggs": variant_state_aggs}
|
||||||
|
if variant_state_aggs
|
||||||
|
else {}
|
||||||
|
),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
with translate_errors_context():
|
||||||
|
es_res = search_company_events(body=es_req, **search_args)
|
||||||
|
if "aggregations" not in es_res:
|
||||||
|
return []
|
||||||
|
|
||||||
|
def init_variant_state(variant: dict):
|
||||||
|
"""
|
||||||
|
Return new variant state for the passed variant bucket
|
||||||
|
"""
|
||||||
|
state = VariantState(variant=variant["key"])
|
||||||
|
if fill_variant_state_data:
|
||||||
|
fill_variant_state_data(variant, state)
|
||||||
|
|
||||||
|
return state
|
||||||
|
|
||||||
|
return [
|
||||||
|
MetricState(
|
||||||
|
metric=metric["key"],
|
||||||
|
timestamp=dpath.get(metric, "last_event_timestamp/value"),
|
||||||
|
variants=[
|
||||||
|
init_variant_state(variant)
|
||||||
|
for variant in dpath.get(metric, "variants/buckets")
|
||||||
|
],
|
||||||
|
)
|
||||||
|
for metric in dpath.get(es_res, "aggregations/metrics/buckets")
|
||||||
|
]
|
||||||
|
|
||||||
|
@abc.abstractmethod
|
||||||
|
def _process_event(self, event: dict) -> dict:
|
||||||
|
pass
|
||||||
|
|
||||||
|
@abc.abstractmethod
|
||||||
|
def _get_same_variant_events_order(self) -> dict:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def _get_task_metric_events(
|
||||||
|
self,
|
||||||
|
task_state: TaskScrollState,
|
||||||
|
companies: Mapping[str, str],
|
||||||
|
iter_count: int,
|
||||||
|
navigate_earlier: bool,
|
||||||
|
specific_variants_requested: bool,
|
||||||
|
) -> Tuple:
|
||||||
|
"""
|
||||||
|
Return task metric events grouped by iterations
|
||||||
|
Update task scroll state
|
||||||
|
"""
|
||||||
|
if not task_state.metrics:
|
||||||
|
return task_state.task, []
|
||||||
|
|
||||||
|
if task_state.last_max_iter is None:
|
||||||
|
# the first fetch is always from the latest iteration to the earlier ones
|
||||||
|
navigate_earlier = True
|
||||||
|
|
||||||
|
must_conditions = [
|
||||||
|
{"term": {"task": task_state.task}},
|
||||||
|
{"terms": {"metric": [m.metric for m in task_state.metrics]}},
|
||||||
|
*self._get_extra_conditions(),
|
||||||
|
]
|
||||||
|
|
||||||
|
range_condition = None
|
||||||
|
if navigate_earlier and task_state.last_min_iter is not None:
|
||||||
|
range_condition = {"lt": task_state.last_min_iter}
|
||||||
|
elif not navigate_earlier and task_state.last_max_iter is not None:
|
||||||
|
range_condition = {"gt": task_state.last_max_iter}
|
||||||
|
if range_condition:
|
||||||
|
must_conditions.append({"range": {"iter": range_condition}})
|
||||||
|
|
||||||
|
metrics_count = len(task_state.metrics)
|
||||||
|
max_variants = int(EventSettings.max_es_buckets / (metrics_count * iter_count))
|
||||||
|
es_req = {
|
||||||
|
"size": 0,
|
||||||
|
"query": {"bool": {"must": must_conditions}},
|
||||||
|
"aggs": {
|
||||||
|
"iters": {
|
||||||
|
"terms": {
|
||||||
|
"field": "iter",
|
||||||
|
"size": iter_count,
|
||||||
|
"order": {"_key": "desc" if navigate_earlier else "asc"},
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"metrics": {
|
||||||
|
"terms": {
|
||||||
|
"field": "metric",
|
||||||
|
"size": metrics_count,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"variants": {
|
||||||
|
"terms": {
|
||||||
|
"field": "variant",
|
||||||
|
"size": max_variants,
|
||||||
|
"order": {"_key": "asc"},
|
||||||
|
},
|
||||||
|
"aggs": {
|
||||||
|
"events": {
|
||||||
|
"top_hits": {
|
||||||
|
"sort": self._get_same_variant_events_order()
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
with translate_errors_context():
|
||||||
|
es_res = search_company_events(
|
||||||
|
self.es,
|
||||||
|
company_id=companies[task_state.task],
|
||||||
|
event_type=self.event_type,
|
||||||
|
body=es_req,
|
||||||
|
)
|
||||||
|
if "aggregations" not in es_res:
|
||||||
|
return task_state.task, []
|
||||||
|
|
||||||
|
invalid_iterations = {
|
||||||
|
(m.metric, v.variant): v.last_invalid_iteration
|
||||||
|
for m in task_state.metrics
|
||||||
|
for v in m.variants
|
||||||
|
}
|
||||||
|
allow_uninitialized = (
|
||||||
|
False
|
||||||
|
if specific_variants_requested
|
||||||
|
else config.get(
|
||||||
|
"services.events.events_retrieval.debug_images.allow_uninitialized_variants",
|
||||||
|
False,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
def is_valid_event(event: dict) -> bool:
|
||||||
|
key = event.get("metric"), event.get("variant")
|
||||||
|
if key not in invalid_iterations:
|
||||||
|
return allow_uninitialized
|
||||||
|
|
||||||
|
max_invalid = invalid_iterations[key]
|
||||||
|
return max_invalid is None or event.get("iter") > max_invalid
|
||||||
|
|
||||||
|
def get_iteration_events(it_: dict) -> Sequence:
|
||||||
|
return [
|
||||||
|
self._process_event(ev["_source"])
|
||||||
|
for m in dpath.get(it_, "metrics/buckets")
|
||||||
|
for v in dpath.get(m, "variants/buckets")
|
||||||
|
for ev in dpath.get(v, "events/hits/hits")
|
||||||
|
if is_valid_event(ev["_source"])
|
||||||
|
]
|
||||||
|
|
||||||
|
iterations = []
|
||||||
|
for it in dpath.get(es_res, "aggregations/iters/buckets"):
|
||||||
|
events = get_iteration_events(it)
|
||||||
|
if events:
|
||||||
|
iterations.append({"iter": it["key"], "events": events})
|
||||||
|
|
||||||
|
if not navigate_earlier:
|
||||||
|
iterations.sort(key=itemgetter("iter"), reverse=True)
|
||||||
|
if iterations:
|
||||||
|
task_state.last_max_iter = iterations[0]["iter"]
|
||||||
|
task_state.last_min_iter = iterations[-1]["iter"]
|
||||||
|
|
||||||
|
return task_state.task, iterations
|
||||||
25
apiserver/bll/event/metric_plots_iterator.py
Normal file
25
apiserver/bll/event/metric_plots_iterator.py
Normal file
@@ -0,0 +1,25 @@
|
|||||||
|
from typing import Sequence
|
||||||
|
|
||||||
|
from elasticsearch import Elasticsearch
|
||||||
|
from redis.client import StrictRedis
|
||||||
|
|
||||||
|
from .event_common import EventType, uncompress_plot
|
||||||
|
from .metric_events_iterator import MetricEventsIterator
|
||||||
|
|
||||||
|
|
||||||
|
class MetricPlotsIterator(MetricEventsIterator):
|
||||||
|
def __init__(self, redis: StrictRedis, es: Elasticsearch):
|
||||||
|
super().__init__(redis, es, EventType.metrics_plot)
|
||||||
|
|
||||||
|
def _get_extra_conditions(self) -> Sequence[dict]:
|
||||||
|
return []
|
||||||
|
|
||||||
|
def _get_variant_state_aggs(self):
|
||||||
|
return None, None
|
||||||
|
|
||||||
|
def _process_event(self, event: dict) -> dict:
|
||||||
|
uncompress_plot(event)
|
||||||
|
return event
|
||||||
|
|
||||||
|
def _get_same_variant_events_order(self) -> dict:
|
||||||
|
return {"timestamp": {"order": "desc"}}
|
||||||
@@ -4,9 +4,11 @@ Module for polymorphism over different types of X axes in scalar aggregations
|
|||||||
from abc import ABC, abstractmethod
|
from abc import ABC, abstractmethod
|
||||||
from enum import auto
|
from enum import auto
|
||||||
|
|
||||||
from apimodels import StringEnum
|
from typing import Any
|
||||||
from bll.util import extract_properties_to_lists
|
|
||||||
from config import config
|
from apiserver.utilities import extract_properties_to_lists
|
||||||
|
from apiserver.utilities.stringenum import StringEnum
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
|
||||||
log = config.logger(__file__)
|
log = config.logger(__file__)
|
||||||
|
|
||||||
@@ -96,6 +98,10 @@ class ScalarKey(ABC):
|
|||||||
"""
|
"""
|
||||||
return int(iter_data[self.bucket_key_key]), iter_data["avg_val"]["value"]
|
return int(iter_data[self.bucket_key_key]), iter_data["avg_val"]["value"]
|
||||||
|
|
||||||
|
def cast_value(self, value: Any) -> Any:
|
||||||
|
"""Cast value to appropriate type"""
|
||||||
|
return value
|
||||||
|
|
||||||
|
|
||||||
class TimestampKey(ScalarKey):
|
class TimestampKey(ScalarKey):
|
||||||
"""
|
"""
|
||||||
@@ -111,12 +117,15 @@ class TimestampKey(ScalarKey):
|
|||||||
self.name: {
|
self.name: {
|
||||||
"date_histogram": {
|
"date_histogram": {
|
||||||
"field": "timestamp",
|
"field": "timestamp",
|
||||||
"interval": interval,
|
"fixed_interval": f"{interval}ms",
|
||||||
"min_doc_count": 1,
|
"min_doc_count": 1,
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
def cast_value(self, value: Any) -> int:
|
||||||
|
return int(value)
|
||||||
|
|
||||||
|
|
||||||
class IterKey(ScalarKey):
|
class IterKey(ScalarKey):
|
||||||
"""
|
"""
|
||||||
@@ -134,6 +143,9 @@ class IterKey(ScalarKey):
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
def cast_value(self, value: Any) -> int:
|
||||||
|
return int(value)
|
||||||
|
|
||||||
|
|
||||||
class ISOTimeKey(ScalarKey):
|
class ISOTimeKey(ScalarKey):
|
||||||
"""
|
"""
|
||||||
@@ -150,7 +162,7 @@ class ISOTimeKey(ScalarKey):
|
|||||||
self.name: {
|
self.name: {
|
||||||
"date_histogram": {
|
"date_histogram": {
|
||||||
"field": "timestamp",
|
"field": "timestamp",
|
||||||
"interval": interval,
|
"fixed_interval": f"{interval}ms",
|
||||||
"min_doc_count": 1,
|
"min_doc_count": 1,
|
||||||
"format": "strict_date_time",
|
"format": "strict_date_time",
|
||||||
}
|
}
|
||||||
190
apiserver/bll/model/__init__.py
Normal file
190
apiserver/bll/model/__init__.py
Normal file
@@ -0,0 +1,190 @@
|
|||||||
|
from datetime import datetime
|
||||||
|
from typing import Callable, Tuple, Sequence, Dict, Optional
|
||||||
|
|
||||||
|
from mongoengine import Q
|
||||||
|
|
||||||
|
from apiserver.apierrors import errors
|
||||||
|
from apiserver.apimodels.models import ModelTaskPublishResponse
|
||||||
|
from apiserver.bll.task.utils import deleted_prefix
|
||||||
|
from apiserver.database.model import EntityVisibility
|
||||||
|
from apiserver.database.model.model import Model
|
||||||
|
from apiserver.database.model.task.task import Task, TaskStatus
|
||||||
|
from .metadata import Metadata
|
||||||
|
|
||||||
|
|
||||||
|
class ModelBLL:
|
||||||
|
@classmethod
|
||||||
|
def get_company_model_by_id(
|
||||||
|
cls, company_id: str, model_id: str, only_fields=None
|
||||||
|
) -> Model:
|
||||||
|
query = dict(company=company_id, id=model_id)
|
||||||
|
qs = Model.objects(**query)
|
||||||
|
if only_fields:
|
||||||
|
qs = qs.only(*only_fields)
|
||||||
|
model = qs.first()
|
||||||
|
if not model:
|
||||||
|
raise errors.bad_request.InvalidModelId(**query)
|
||||||
|
return model
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def assert_exists(
|
||||||
|
company_id,
|
||||||
|
model_ids,
|
||||||
|
only=None,
|
||||||
|
allow_public=False,
|
||||||
|
return_models=True,
|
||||||
|
) -> Optional[Sequence[Model]]:
|
||||||
|
model_ids = [model_ids] if isinstance(model_ids, str) else model_ids
|
||||||
|
ids = set(model_ids)
|
||||||
|
query = Q(id__in=ids)
|
||||||
|
|
||||||
|
q = Model.get_many(
|
||||||
|
company=company_id,
|
||||||
|
query=query,
|
||||||
|
allow_public=allow_public,
|
||||||
|
return_dicts=False,
|
||||||
|
)
|
||||||
|
if only:
|
||||||
|
q = q.only(*only)
|
||||||
|
|
||||||
|
if q.count() != len(ids):
|
||||||
|
raise errors.bad_request.InvalidModelId(ids=model_ids)
|
||||||
|
|
||||||
|
if return_models:
|
||||||
|
return list(q)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def publish_model(
|
||||||
|
cls,
|
||||||
|
model_id: str,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
force_publish_task: bool = False,
|
||||||
|
publish_task_func: Callable[[str, str, str, bool], dict] = None,
|
||||||
|
) -> Tuple[int, ModelTaskPublishResponse]:
|
||||||
|
model = cls.get_company_model_by_id(company_id=company_id, model_id=model_id)
|
||||||
|
if model.ready:
|
||||||
|
raise errors.bad_request.ModelIsReady(company=company_id, model=model_id)
|
||||||
|
|
||||||
|
published_task = None
|
||||||
|
if model.task and publish_task_func:
|
||||||
|
task = (
|
||||||
|
Task.objects(id=model.task, company=company_id)
|
||||||
|
.only("id", "status")
|
||||||
|
.first()
|
||||||
|
)
|
||||||
|
if task and task.status != TaskStatus.published:
|
||||||
|
task_publish_res = publish_task_func(
|
||||||
|
model.task, company_id, user_id, force_publish_task
|
||||||
|
)
|
||||||
|
published_task = ModelTaskPublishResponse(
|
||||||
|
id=model.task, data=task_publish_res
|
||||||
|
)
|
||||||
|
|
||||||
|
updated = model.update(upsert=False, ready=True, last_update=datetime.utcnow())
|
||||||
|
return updated, published_task
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def delete_model(
|
||||||
|
cls, model_id: str, company_id: str, force: bool
|
||||||
|
) -> Tuple[int, Model]:
|
||||||
|
model = cls.get_company_model_by_id(
|
||||||
|
company_id=company_id,
|
||||||
|
model_id=model_id,
|
||||||
|
only_fields=("id", "task", "project", "uri"),
|
||||||
|
)
|
||||||
|
deleted_model_id = f"{deleted_prefix}{model_id}"
|
||||||
|
|
||||||
|
using_tasks = Task.objects(models__input__model=model_id).only("id")
|
||||||
|
if using_tasks:
|
||||||
|
if not force:
|
||||||
|
raise errors.bad_request.ModelInUse(
|
||||||
|
"as execution model, use force=True to delete",
|
||||||
|
num_tasks=len(using_tasks),
|
||||||
|
)
|
||||||
|
# update deleted model id in using tasks
|
||||||
|
Task._get_collection().update_many(
|
||||||
|
filter={"_id": {"$in": [t.id for t in using_tasks]}},
|
||||||
|
update={"$set": {"models.input.$[elem].model": deleted_model_id}},
|
||||||
|
array_filters=[{"elem.model": model_id}],
|
||||||
|
upsert=False,
|
||||||
|
)
|
||||||
|
|
||||||
|
if model.task:
|
||||||
|
task = Task.objects(id=model.task).first()
|
||||||
|
if task and task.status == TaskStatus.published:
|
||||||
|
if not force:
|
||||||
|
raise errors.bad_request.ModelCreatingTaskExists(
|
||||||
|
"and published, use force=True to delete", task=model.task
|
||||||
|
)
|
||||||
|
if task.models.output and model_id in task.models.output:
|
||||||
|
now = datetime.utcnow()
|
||||||
|
Task._get_collection().update_one(
|
||||||
|
filter={"_id": model.task, "models.output.model": model_id},
|
||||||
|
update={
|
||||||
|
"$set": {
|
||||||
|
"models.output.$[elem].model": deleted_model_id,
|
||||||
|
"output.error": f"model deleted on {now.isoformat()}",
|
||||||
|
},
|
||||||
|
"last_change": now,
|
||||||
|
},
|
||||||
|
array_filters=[{"elem.model": model_id}],
|
||||||
|
upsert=False,
|
||||||
|
)
|
||||||
|
|
||||||
|
del_count = Model.objects(id=model_id, company=company_id).delete()
|
||||||
|
return del_count, model
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def archive_model(cls, model_id: str, company_id: str):
|
||||||
|
cls.get_company_model_by_id(
|
||||||
|
company_id=company_id, model_id=model_id, only_fields=("id",)
|
||||||
|
)
|
||||||
|
archived = Model.objects(company=company_id, id=model_id).update(
|
||||||
|
add_to_set__system_tags=EntityVisibility.archived.value,
|
||||||
|
last_update=datetime.utcnow(),
|
||||||
|
)
|
||||||
|
|
||||||
|
return archived
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def unarchive_model(cls, model_id: str, company_id: str):
|
||||||
|
cls.get_company_model_by_id(
|
||||||
|
company_id=company_id, model_id=model_id, only_fields=("id",)
|
||||||
|
)
|
||||||
|
unarchived = Model.objects(company=company_id, id=model_id).update(
|
||||||
|
pull__system_tags=EntityVisibility.archived.value,
|
||||||
|
last_update=datetime.utcnow(),
|
||||||
|
)
|
||||||
|
|
||||||
|
return unarchived
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_model_stats(
|
||||||
|
cls, company: str, model_ids: Sequence[str],
|
||||||
|
) -> Dict[str, dict]:
|
||||||
|
if not model_ids:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
result = Model.aggregate(
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"$match": {
|
||||||
|
"company": {"$in": [None, "", company]},
|
||||||
|
"_id": {"$in": model_ids},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"$addFields": {
|
||||||
|
"labels_count": {"$size": {"$objectToArray": "$labels"}}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"$project": {"labels_count": 1},
|
||||||
|
},
|
||||||
|
]
|
||||||
|
)
|
||||||
|
return {
|
||||||
|
r.pop("_id"): r
|
||||||
|
for r in result
|
||||||
|
}
|
||||||
108
apiserver/bll/model/metadata.py
Normal file
108
apiserver/bll/model/metadata.py
Normal file
@@ -0,0 +1,108 @@
|
|||||||
|
from typing import Sequence, Union, Mapping
|
||||||
|
|
||||||
|
from mongoengine import Document
|
||||||
|
|
||||||
|
from apiserver.apierrors import errors
|
||||||
|
from apiserver.apimodels.metadata import MetadataItem
|
||||||
|
from apiserver.database.model.base import GetMixin
|
||||||
|
from apiserver.service_repo import APICall
|
||||||
|
from apiserver.utilities.parameter_key_escaper import (
|
||||||
|
ParameterKeyEscaper,
|
||||||
|
mongoengine_safe,
|
||||||
|
)
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
|
||||||
|
|
||||||
|
class Metadata:
|
||||||
|
@staticmethod
|
||||||
|
def metadata_from_api(
|
||||||
|
api_data: Union[Mapping[str, MetadataItem], Sequence[MetadataItem]]
|
||||||
|
) -> dict:
|
||||||
|
if not api_data:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
if isinstance(api_data, dict):
|
||||||
|
return {
|
||||||
|
ParameterKeyEscaper.escape(k): v.to_struct()
|
||||||
|
for k, v in api_data.items()
|
||||||
|
}
|
||||||
|
|
||||||
|
return {
|
||||||
|
ParameterKeyEscaper.escape(item.key): item.to_struct() for item in api_data
|
||||||
|
}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def edit_metadata(
|
||||||
|
cls,
|
||||||
|
obj: Document,
|
||||||
|
items: Sequence[MetadataItem],
|
||||||
|
replace_metadata: bool,
|
||||||
|
**more_updates,
|
||||||
|
) -> int:
|
||||||
|
update_cmds = dict()
|
||||||
|
metadata = cls.metadata_from_api(items)
|
||||||
|
if replace_metadata:
|
||||||
|
update_cmds["set__metadata"] = metadata
|
||||||
|
else:
|
||||||
|
for key, value in metadata.items():
|
||||||
|
update_cmds[f"set__metadata__{mongoengine_safe(key)}"] = value
|
||||||
|
|
||||||
|
return obj.update(**update_cmds, **more_updates)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def delete_metadata(cls, obj: Document, keys: Sequence[str], **more_updates) -> int:
|
||||||
|
return obj.update(
|
||||||
|
**{
|
||||||
|
f"unset__metadata__{ParameterKeyEscaper.escape(key)}": 1
|
||||||
|
for key in set(keys)
|
||||||
|
},
|
||||||
|
**more_updates,
|
||||||
|
)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _process_path(path: str):
|
||||||
|
"""
|
||||||
|
Frontend does a partial escaping on the path so the all '.' in key names are escaped
|
||||||
|
Need to unescape and apply a full mongo escaping
|
||||||
|
"""
|
||||||
|
parts = path.split(".")
|
||||||
|
if len(parts) < 2 or len(parts) > 3:
|
||||||
|
raise errors.bad_request.ValidationError("invalid field", path=path)
|
||||||
|
return ".".join(
|
||||||
|
ParameterKeyEscaper.escape(ParameterKeyEscaper.unescape(p)) for p in parts
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def escape_paths(cls, paths: Sequence[str]) -> Sequence[str]:
|
||||||
|
for prefix in (
|
||||||
|
"metadata.",
|
||||||
|
"-metadata.",
|
||||||
|
):
|
||||||
|
paths = [
|
||||||
|
cls._process_path(path) if path.startswith(prefix) else path
|
||||||
|
for path in paths
|
||||||
|
]
|
||||||
|
return paths
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def escape_query_parameters(cls, call: APICall) -> dict:
|
||||||
|
if not call.data:
|
||||||
|
return call.data
|
||||||
|
|
||||||
|
keys = list(call.data)
|
||||||
|
call_data = {
|
||||||
|
safe_key: call.data[key]
|
||||||
|
for key, safe_key in zip(keys, Metadata.escape_paths(keys))
|
||||||
|
}
|
||||||
|
|
||||||
|
projection = GetMixin.get_projection(call_data)
|
||||||
|
if projection:
|
||||||
|
GetMixin.set_projection(call_data, Metadata.escape_paths(projection))
|
||||||
|
|
||||||
|
ordering = GetMixin.get_ordering(call_data)
|
||||||
|
if ordering:
|
||||||
|
GetMixin.set_ordering(call_data, Metadata.escape_paths(ordering))
|
||||||
|
|
||||||
|
return call_data
|
||||||
63
apiserver/bll/organization/__init__.py
Normal file
63
apiserver/bll/organization/__init__.py
Normal file
@@ -0,0 +1,63 @@
|
|||||||
|
from collections import defaultdict
|
||||||
|
from enum import Enum
|
||||||
|
from typing import Sequence, Dict
|
||||||
|
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.model.model import Model
|
||||||
|
from apiserver.database.model.task.task import Task
|
||||||
|
from apiserver.redis_manager import redman
|
||||||
|
from .tags_cache import _TagsCache
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
|
||||||
|
|
||||||
|
class Tags(Enum):
|
||||||
|
Task = "task"
|
||||||
|
Model = "model"
|
||||||
|
|
||||||
|
|
||||||
|
class OrgBLL:
|
||||||
|
def __init__(self, redis=None):
|
||||||
|
self.redis = redis or redman.connection("apiserver")
|
||||||
|
self._task_tags = _TagsCache(Task, self.redis)
|
||||||
|
self._model_tags = _TagsCache(Model, self.redis)
|
||||||
|
|
||||||
|
def get_tags(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
entity: Tags,
|
||||||
|
include_system: bool = False,
|
||||||
|
filter_: Dict[str, Sequence[str]] = None,
|
||||||
|
projects: Sequence[str] = None,
|
||||||
|
) -> dict:
|
||||||
|
tags_cache = self._get_tags_cache_for_entity(entity)
|
||||||
|
if not projects:
|
||||||
|
return tags_cache.get_tags(
|
||||||
|
company_id, include_system=include_system, filter_=filter_
|
||||||
|
)
|
||||||
|
|
||||||
|
ret = defaultdict(set)
|
||||||
|
for project in projects:
|
||||||
|
project_tags = tags_cache.get_tags(
|
||||||
|
company_id,
|
||||||
|
include_system=include_system,
|
||||||
|
filter_=filter_,
|
||||||
|
project=project,
|
||||||
|
)
|
||||||
|
for field, tags in project_tags.items():
|
||||||
|
ret[field] |= tags
|
||||||
|
|
||||||
|
return ret
|
||||||
|
|
||||||
|
def update_tags(
|
||||||
|
self, company_id: str, entity: Tags, project: str, tags=None, system_tags=None,
|
||||||
|
):
|
||||||
|
tags_cache = self._get_tags_cache_for_entity(entity)
|
||||||
|
tags_cache.update_tags(company_id, project, tags, system_tags)
|
||||||
|
|
||||||
|
def reset_tags(self, company_id: str, entity: Tags, projects: Sequence[str]):
|
||||||
|
tags_cache = self._get_tags_cache_for_entity(entity)
|
||||||
|
tags_cache.reset_tags(company_id, projects=projects)
|
||||||
|
|
||||||
|
def _get_tags_cache_for_entity(self, entity: Tags) -> _TagsCache:
|
||||||
|
return self._task_tags if entity == Tags.Task else self._model_tags
|
||||||
148
apiserver/bll/organization/tags_cache.py
Normal file
148
apiserver/bll/organization/tags_cache.py
Normal file
@@ -0,0 +1,148 @@
|
|||||||
|
from itertools import chain
|
||||||
|
from typing import Sequence, Union, Type, Dict
|
||||||
|
|
||||||
|
from mongoengine import Q
|
||||||
|
from redis import Redis
|
||||||
|
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.bll.project import project_ids_with_children
|
||||||
|
from apiserver.database.model import EntityVisibility
|
||||||
|
from apiserver.database.model.base import GetMixin
|
||||||
|
from apiserver.database.model.model import Model
|
||||||
|
from apiserver.database.model.task.task import Task
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
_settings_prefix = "services.organization"
|
||||||
|
|
||||||
|
|
||||||
|
class _TagsCache:
|
||||||
|
_tags_field = "tags"
|
||||||
|
_system_tags_field = "system_tags"
|
||||||
|
_dummy_tag = "__dummy__"
|
||||||
|
# prepend our list in redis with this tag since empty lists are auto deleted
|
||||||
|
|
||||||
|
def __init__(self, db_cls: Union[Type[Model], Type[Task]], redis: Redis):
|
||||||
|
self.db_cls = db_cls
|
||||||
|
self.redis = redis
|
||||||
|
|
||||||
|
@property
|
||||||
|
def _tags_cache_expiration_seconds(self):
|
||||||
|
return config.get(f"{_settings_prefix}.tags_cache.expiration_seconds", 3600)
|
||||||
|
|
||||||
|
def _get_tags_from_db(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
field: str,
|
||||||
|
project: str = None,
|
||||||
|
filter_: Dict[str, Sequence[str]] = None,
|
||||||
|
) -> set:
|
||||||
|
query = Q(company=company_id)
|
||||||
|
if filter_:
|
||||||
|
for name, vals in filter_.items():
|
||||||
|
if vals:
|
||||||
|
query &= GetMixin.get_list_field_query(name, vals)
|
||||||
|
if project:
|
||||||
|
query &= Q(project__in=project_ids_with_children([project]))
|
||||||
|
else:
|
||||||
|
query &= Q(system_tags__nin=[EntityVisibility.hidden.value])
|
||||||
|
|
||||||
|
return self.db_cls.objects(query).distinct(field)
|
||||||
|
|
||||||
|
def _get_tags_cache_key(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
field: str,
|
||||||
|
project: str = None,
|
||||||
|
filter_: Dict[str, Sequence[str]] = None,
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
Project None means 'from all company projects'
|
||||||
|
The key is built in the way that scanning company keys for 'all company projects'
|
||||||
|
will not return the keys related to the particular company projects and vice versa.
|
||||||
|
So that we can have a fine grain control on what redis keys to invalidate
|
||||||
|
"""
|
||||||
|
filter_str = None
|
||||||
|
if filter_:
|
||||||
|
filter_str = "_".join(
|
||||||
|
["filter", *chain.from_iterable([f, *v] for f, v in filter_.items())]
|
||||||
|
)
|
||||||
|
key_parts = [field, company_id, project, self.db_cls.__name__, filter_str]
|
||||||
|
return "_".join(filter(None, key_parts))
|
||||||
|
|
||||||
|
def get_tags(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
include_system: bool = False,
|
||||||
|
filter_: Dict[str, Sequence[str]] = None,
|
||||||
|
project: str = None,
|
||||||
|
) -> dict:
|
||||||
|
"""
|
||||||
|
Get tags and optionally system tags for the company
|
||||||
|
Return the dictionary of tags per tags field name
|
||||||
|
The function retrieves both cached values from Redis in one call
|
||||||
|
and re calculates any of them if missing in Redis
|
||||||
|
"""
|
||||||
|
fields = [self._tags_field]
|
||||||
|
if include_system:
|
||||||
|
fields.append(self._system_tags_field)
|
||||||
|
|
||||||
|
ret = {}
|
||||||
|
for field in fields:
|
||||||
|
redis_key = self._get_tags_cache_key(
|
||||||
|
company_id, field=field, project=project, filter_=filter_
|
||||||
|
)
|
||||||
|
cached_tags = self.redis.lrange(redis_key, 0, -1)
|
||||||
|
if cached_tags:
|
||||||
|
tags = [c.decode() for c in cached_tags[1:]]
|
||||||
|
else:
|
||||||
|
tags = list(
|
||||||
|
self._get_tags_from_db(
|
||||||
|
company_id, field=field, project=project, filter_=filter_
|
||||||
|
)
|
||||||
|
)
|
||||||
|
self.redis.rpush(redis_key, self._dummy_tag, *tags)
|
||||||
|
self.redis.expire(redis_key, self._tags_cache_expiration_seconds)
|
||||||
|
|
||||||
|
ret[field] = set(tags)
|
||||||
|
|
||||||
|
return ret
|
||||||
|
|
||||||
|
def update_tags(self, company_id: str, project: str, tags=None, system_tags=None):
|
||||||
|
"""
|
||||||
|
Updates tags. If reset is set then both tags and system_tags
|
||||||
|
are recalculated. Otherwise only those that are not 'None'
|
||||||
|
"""
|
||||||
|
fields = [
|
||||||
|
field
|
||||||
|
for field, update in (
|
||||||
|
(self._tags_field, tags),
|
||||||
|
(self._system_tags_field, system_tags),
|
||||||
|
)
|
||||||
|
if update is not None
|
||||||
|
]
|
||||||
|
if not fields:
|
||||||
|
return
|
||||||
|
|
||||||
|
self._delete_redis_keys(company_id, projects=[project], fields=fields)
|
||||||
|
|
||||||
|
def reset_tags(self, company_id: str, projects: Sequence[str]):
|
||||||
|
self._delete_redis_keys(
|
||||||
|
company_id,
|
||||||
|
projects=projects,
|
||||||
|
fields=(self._tags_field, self._system_tags_field),
|
||||||
|
)
|
||||||
|
|
||||||
|
def _delete_redis_keys(
|
||||||
|
self, company_id: str, projects: [Sequence[str]], fields: Sequence[str]
|
||||||
|
):
|
||||||
|
redis_keys = list(
|
||||||
|
chain.from_iterable(
|
||||||
|
self.redis.keys(
|
||||||
|
self._get_tags_cache_key(company_id, field=f, project=p) + "*"
|
||||||
|
)
|
||||||
|
for f in fields
|
||||||
|
for p in set(projects) | {None}
|
||||||
|
)
|
||||||
|
)
|
||||||
|
if redis_keys:
|
||||||
|
self.redis.delete(*redis_keys)
|
||||||
3
apiserver/bll/project/__init__.py
Normal file
3
apiserver/bll/project/__init__.py
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
from .project_bll import ProjectBLL
|
||||||
|
from .project_queries import ProjectQueries
|
||||||
|
from .sub_projects import _ids_with_children as project_ids_with_children
|
||||||
1173
apiserver/bll/project/project_bll.py
Normal file
1173
apiserver/bll/project/project_bll.py
Normal file
File diff suppressed because it is too large
Load Diff
223
apiserver/bll/project/project_cleanup.py
Normal file
223
apiserver/bll/project/project_cleanup.py
Normal file
@@ -0,0 +1,223 @@
|
|||||||
|
from collections import defaultdict
|
||||||
|
from typing import Tuple, Set, Sequence
|
||||||
|
|
||||||
|
import attr
|
||||||
|
|
||||||
|
from apiserver.apierrors import errors
|
||||||
|
from apiserver.bll.event import EventBLL
|
||||||
|
from apiserver.bll.task.task_cleanup import (
|
||||||
|
collect_debug_image_urls,
|
||||||
|
collect_plot_image_urls,
|
||||||
|
TaskUrls,
|
||||||
|
_schedule_for_delete,
|
||||||
|
)
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.model import EntityVisibility
|
||||||
|
from apiserver.database.model.model import Model
|
||||||
|
from apiserver.database.model.project import Project
|
||||||
|
from apiserver.database.model.task.task import Task, ArtifactModes, TaskType
|
||||||
|
from .project_bll import ProjectBLL
|
||||||
|
from .sub_projects import _ids_with_children
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
event_bll = EventBLL()
|
||||||
|
async_events_delete = config.get("services.tasks.async_events_delete", False)
|
||||||
|
|
||||||
|
|
||||||
|
@attr.s(auto_attribs=True)
|
||||||
|
class DeleteProjectResult:
|
||||||
|
deleted: int = 0
|
||||||
|
disassociated_tasks: int = 0
|
||||||
|
deleted_models: int = 0
|
||||||
|
deleted_tasks: int = 0
|
||||||
|
urls: TaskUrls = None
|
||||||
|
|
||||||
|
|
||||||
|
def validate_project_delete(company: str, project_id: str):
|
||||||
|
project = Project.get_for_writing(
|
||||||
|
company=company, id=project_id, _only=("id", "path", "system_tags")
|
||||||
|
)
|
||||||
|
if not project:
|
||||||
|
raise errors.bad_request.InvalidProjectId(id=project_id)
|
||||||
|
is_pipeline = "pipeline" in (project.system_tags or [])
|
||||||
|
project_ids = _ids_with_children([project_id])
|
||||||
|
ret = {}
|
||||||
|
for cls in ProjectBLL.child_classes:
|
||||||
|
ret[f"{cls.__name__.lower()}s"] = cls.objects(project__in=project_ids).count()
|
||||||
|
for cls in ProjectBLL.child_classes:
|
||||||
|
query = dict(
|
||||||
|
project__in=project_ids, system_tags__nin=[EntityVisibility.archived.value]
|
||||||
|
)
|
||||||
|
name = f"non_archived_{cls.__name__.lower()}s"
|
||||||
|
if not is_pipeline:
|
||||||
|
ret[name] = cls.objects(**query).count()
|
||||||
|
else:
|
||||||
|
ret[name] = (
|
||||||
|
cls.objects(**query, type=TaskType.controller).count()
|
||||||
|
if cls == Task
|
||||||
|
else 0
|
||||||
|
)
|
||||||
|
|
||||||
|
return ret
|
||||||
|
|
||||||
|
|
||||||
|
def delete_project(
|
||||||
|
company: str,
|
||||||
|
user: str,
|
||||||
|
project_id: str,
|
||||||
|
force: bool,
|
||||||
|
delete_contents: bool,
|
||||||
|
delete_external_artifacts=True,
|
||||||
|
) -> Tuple[DeleteProjectResult, Set[str]]:
|
||||||
|
project = Project.get_for_writing(
|
||||||
|
company=company, id=project_id, _only=("id", "path", "system_tags")
|
||||||
|
)
|
||||||
|
if not project:
|
||||||
|
raise errors.bad_request.InvalidProjectId(id=project_id)
|
||||||
|
|
||||||
|
delete_external_artifacts = delete_external_artifacts and config.get(
|
||||||
|
"services.async_urls_delete.enabled", False
|
||||||
|
)
|
||||||
|
is_pipeline = "pipeline" in (project.system_tags or [])
|
||||||
|
project_ids = _ids_with_children([project_id])
|
||||||
|
if not force:
|
||||||
|
query = dict(
|
||||||
|
project__in=project_ids, system_tags__nin=[EntityVisibility.archived.value]
|
||||||
|
)
|
||||||
|
if not is_pipeline:
|
||||||
|
for cls, error in (
|
||||||
|
(Task, errors.bad_request.ProjectHasTasks),
|
||||||
|
(Model, errors.bad_request.ProjectHasModels),
|
||||||
|
):
|
||||||
|
non_archived = cls.objects(**query).only("id")
|
||||||
|
if non_archived:
|
||||||
|
raise error("use force=true to delete", id=project_id)
|
||||||
|
else:
|
||||||
|
non_archived = Task.objects(**query, type=TaskType.controller).only("id")
|
||||||
|
if non_archived:
|
||||||
|
raise errors.bad_request.ProjectHasTasks(
|
||||||
|
"please archive all the runs inside the project", id=project_id
|
||||||
|
)
|
||||||
|
|
||||||
|
if not delete_contents:
|
||||||
|
disassociated = defaultdict(int)
|
||||||
|
for cls in ProjectBLL.child_classes:
|
||||||
|
disassociated[cls] = cls.objects(project__in=project_ids).update(project=None)
|
||||||
|
res = DeleteProjectResult(disassociated_tasks=disassociated[Task])
|
||||||
|
else:
|
||||||
|
deleted_models, model_event_urls, model_urls = _delete_models(
|
||||||
|
company=company, projects=project_ids
|
||||||
|
)
|
||||||
|
deleted_tasks, task_event_urls, artifact_urls = _delete_tasks(
|
||||||
|
company=company, projects=project_ids
|
||||||
|
)
|
||||||
|
event_urls = task_event_urls | model_event_urls
|
||||||
|
if delete_external_artifacts:
|
||||||
|
scheduled = _schedule_for_delete(
|
||||||
|
task_id=project_id,
|
||||||
|
company=company,
|
||||||
|
user=user,
|
||||||
|
urls=event_urls | model_urls | artifact_urls,
|
||||||
|
can_delete_folders=True,
|
||||||
|
)
|
||||||
|
for urls in (event_urls, model_urls, artifact_urls):
|
||||||
|
urls.difference_update(scheduled)
|
||||||
|
res = DeleteProjectResult(
|
||||||
|
deleted_tasks=deleted_tasks,
|
||||||
|
deleted_models=deleted_models,
|
||||||
|
urls=TaskUrls(
|
||||||
|
model_urls=list(model_urls),
|
||||||
|
event_urls=list(event_urls),
|
||||||
|
artifact_urls=list(artifact_urls),
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
affected = {*project_ids, *(project.path or [])}
|
||||||
|
res.deleted = Project.objects(id__in=project_ids).delete()
|
||||||
|
|
||||||
|
return res, affected
|
||||||
|
|
||||||
|
|
||||||
|
def _delete_tasks(company: str, projects: Sequence[str]) -> Tuple[int, Set, Set]:
|
||||||
|
"""
|
||||||
|
Delete only the task themselves and their non published version.
|
||||||
|
Child models under the same project are deleted separately.
|
||||||
|
Children tasks should be deleted in the same api call.
|
||||||
|
If any child entities are left in another projects then updated their parent task to None
|
||||||
|
"""
|
||||||
|
tasks = Task.objects(project__in=projects).only("id", "execution__artifacts")
|
||||||
|
if not tasks:
|
||||||
|
return 0, set(), set()
|
||||||
|
|
||||||
|
task_ids = {t.id for t in tasks}
|
||||||
|
Task.objects(parent__in=task_ids, project__nin=projects).update(parent=None)
|
||||||
|
Model.objects(task__in=task_ids, project__nin=projects).update(task=None)
|
||||||
|
|
||||||
|
event_urls, artifact_urls = set(), set()
|
||||||
|
for task in tasks:
|
||||||
|
event_urls.update(collect_debug_image_urls(company, task.id))
|
||||||
|
event_urls.update(collect_plot_image_urls(company, task.id))
|
||||||
|
if task.execution and task.execution.artifacts:
|
||||||
|
artifact_urls.update(
|
||||||
|
{
|
||||||
|
a.uri
|
||||||
|
for a in task.execution.artifacts.values()
|
||||||
|
if a.mode == ArtifactModes.output and a.uri
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
event_bll.delete_multi_task_events(
|
||||||
|
company, list(task_ids), async_delete=async_events_delete
|
||||||
|
)
|
||||||
|
deleted = tasks.delete()
|
||||||
|
return deleted, event_urls, artifact_urls
|
||||||
|
|
||||||
|
|
||||||
|
def _delete_models(
|
||||||
|
company: str, projects: Sequence[str]
|
||||||
|
) -> Tuple[int, Set[str], Set[str]]:
|
||||||
|
"""
|
||||||
|
Delete project models and update the tasks from other projects
|
||||||
|
that reference them to reference None.
|
||||||
|
"""
|
||||||
|
models = Model.objects(project__in=projects).only("task", "id", "uri")
|
||||||
|
if not models:
|
||||||
|
return 0, set(), set()
|
||||||
|
|
||||||
|
model_ids = list({m.id for m in models})
|
||||||
|
|
||||||
|
Task._get_collection().update_many(
|
||||||
|
filter={
|
||||||
|
"project": {"$nin": projects},
|
||||||
|
"models.input.model": {"$in": model_ids},
|
||||||
|
},
|
||||||
|
update={"$set": {"models.input.$[elem].model": None}},
|
||||||
|
array_filters=[{"elem.model": {"$in": model_ids}}],
|
||||||
|
upsert=False,
|
||||||
|
)
|
||||||
|
|
||||||
|
model_tasks = list({m.task for m in models if m.task})
|
||||||
|
if model_tasks:
|
||||||
|
Task._get_collection().update_many(
|
||||||
|
filter={
|
||||||
|
"_id": {"$in": model_tasks},
|
||||||
|
"project": {"$nin": projects},
|
||||||
|
"models.output.model": {"$in": model_ids},
|
||||||
|
},
|
||||||
|
update={"$set": {"models.output.$[elem].model": None}},
|
||||||
|
array_filters=[{"elem.model": {"$in": model_ids}}],
|
||||||
|
upsert=False,
|
||||||
|
)
|
||||||
|
|
||||||
|
event_urls, model_urls = set(), set()
|
||||||
|
for m in models:
|
||||||
|
event_urls.update(collect_debug_image_urls(company, m.id))
|
||||||
|
event_urls.update(collect_plot_image_urls(company, m.id))
|
||||||
|
if m.uri:
|
||||||
|
model_urls.add(m.uri)
|
||||||
|
|
||||||
|
event_bll.delete_multi_task_events(
|
||||||
|
company, model_ids, async_delete=async_events_delete
|
||||||
|
)
|
||||||
|
deleted = models.delete()
|
||||||
|
return deleted, event_urls, model_urls
|
||||||
370
apiserver/bll/project/project_queries.py
Normal file
370
apiserver/bll/project/project_queries.py
Normal file
@@ -0,0 +1,370 @@
|
|||||||
|
import json
|
||||||
|
from collections import OrderedDict
|
||||||
|
from datetime import datetime
|
||||||
|
from typing import (
|
||||||
|
Sequence,
|
||||||
|
Optional,
|
||||||
|
Tuple,
|
||||||
|
)
|
||||||
|
|
||||||
|
from redis import StrictRedis
|
||||||
|
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.model.model import Model
|
||||||
|
from apiserver.database.model.task.task import Task
|
||||||
|
from apiserver.redis_manager import redman
|
||||||
|
from apiserver.utilities.dicts import nested_get
|
||||||
|
from apiserver.utilities.parameter_key_escaper import ParameterKeyEscaper
|
||||||
|
from .sub_projects import _ids_with_children
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
|
||||||
|
|
||||||
|
class ProjectQueries:
|
||||||
|
def __init__(self, redis=None):
|
||||||
|
self.redis: StrictRedis = redis or redman.connection("apiserver")
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _get_project_constraint(
|
||||||
|
project_ids: Sequence[str], include_subprojects: bool
|
||||||
|
) -> dict:
|
||||||
|
"""
|
||||||
|
If passed projects is None means top level projects
|
||||||
|
If passed projects is empty means no project filtering
|
||||||
|
"""
|
||||||
|
if include_subprojects:
|
||||||
|
if not project_ids:
|
||||||
|
return {}
|
||||||
|
project_ids = _ids_with_children(project_ids)
|
||||||
|
|
||||||
|
if project_ids is None:
|
||||||
|
project_ids = [None]
|
||||||
|
if not project_ids:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
return {"project": {"$in": project_ids}}
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _get_company_constraint(company_id: str, allow_public: bool = True) -> dict:
|
||||||
|
if allow_public:
|
||||||
|
return {"company": {"$in": [None, "", company_id]}}
|
||||||
|
|
||||||
|
return {"company": company_id}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_aggregated_project_parameters(
|
||||||
|
cls,
|
||||||
|
company_id,
|
||||||
|
project_ids: Sequence[str],
|
||||||
|
include_subprojects: bool,
|
||||||
|
page: int = 0,
|
||||||
|
page_size: int = 500,
|
||||||
|
) -> Tuple[int, int, Sequence[dict]]:
|
||||||
|
page = max(0, page)
|
||||||
|
page_size = max(1, page_size)
|
||||||
|
pipeline = [
|
||||||
|
{
|
||||||
|
"$match": {
|
||||||
|
**cls._get_company_constraint(company_id),
|
||||||
|
**cls._get_project_constraint(project_ids, include_subprojects),
|
||||||
|
"hyperparams": {"$exists": True, "$gt": {}},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{"$project": {"sections": {"$objectToArray": "$hyperparams"}}},
|
||||||
|
{"$unwind": "$sections"},
|
||||||
|
{
|
||||||
|
"$project": {
|
||||||
|
"section": "$sections.k",
|
||||||
|
"names": {"$objectToArray": "$sections.v"},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{"$unwind": "$names"},
|
||||||
|
{"$group": {"_id": {"section": "$section", "name": "$names.k"}}},
|
||||||
|
{"$sort": OrderedDict({"_id.section": 1, "_id.name": 1})},
|
||||||
|
{"$skip": page * page_size},
|
||||||
|
{"$limit": page_size},
|
||||||
|
{
|
||||||
|
"$group": {
|
||||||
|
"_id": 1,
|
||||||
|
"total": {"$sum": 1},
|
||||||
|
"results": {"$push": "$$ROOT"},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
]
|
||||||
|
|
||||||
|
result = next(Task.aggregate(pipeline), None)
|
||||||
|
|
||||||
|
total = 0
|
||||||
|
remaining = 0
|
||||||
|
results = []
|
||||||
|
|
||||||
|
if result:
|
||||||
|
total = int(result.get("total", -1))
|
||||||
|
results = [
|
||||||
|
{
|
||||||
|
"section": ParameterKeyEscaper.unescape(
|
||||||
|
nested_get(r, ("_id", "section"))
|
||||||
|
),
|
||||||
|
"name": ParameterKeyEscaper.unescape(
|
||||||
|
nested_get(r, ("_id", "name"))
|
||||||
|
),
|
||||||
|
}
|
||||||
|
for r in result.get("results", [])
|
||||||
|
]
|
||||||
|
remaining = max(0, total - (len(results) + page * page_size))
|
||||||
|
|
||||||
|
return total, remaining, results
|
||||||
|
|
||||||
|
ParamValues = Tuple[int, Sequence[str]]
|
||||||
|
|
||||||
|
def _get_cached_param_values(
|
||||||
|
self, key: str, last_update: datetime, allowed_delta_sec=0
|
||||||
|
) -> Optional[ParamValues]:
|
||||||
|
try:
|
||||||
|
cached = self.redis.get(key)
|
||||||
|
if not cached:
|
||||||
|
return
|
||||||
|
|
||||||
|
data = json.loads(cached)
|
||||||
|
cached_last_update = datetime.fromtimestamp(data["last_update"])
|
||||||
|
if (last_update - cached_last_update).total_seconds() <= allowed_delta_sec:
|
||||||
|
return data["total"], data["values"]
|
||||||
|
except Exception as ex:
|
||||||
|
log.error(f"Error retrieving params cached values: {str(ex)}")
|
||||||
|
|
||||||
|
def get_task_hyperparam_distinct_values(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
project_ids: Sequence[str],
|
||||||
|
section: str,
|
||||||
|
name: str,
|
||||||
|
include_subprojects: bool,
|
||||||
|
allow_public: bool = True,
|
||||||
|
) -> ParamValues:
|
||||||
|
company_constraint = self._get_company_constraint(company_id, allow_public)
|
||||||
|
project_constraint = self._get_project_constraint(
|
||||||
|
project_ids, include_subprojects
|
||||||
|
)
|
||||||
|
key_path = f"hyperparams.{ParameterKeyEscaper.escape(section)}.{ParameterKeyEscaper.escape(name)}"
|
||||||
|
last_updated_task = (
|
||||||
|
Task.objects(
|
||||||
|
**company_constraint,
|
||||||
|
**project_constraint,
|
||||||
|
**{f"{key_path.replace('.', '__')}__exists": True},
|
||||||
|
)
|
||||||
|
.only("last_update")
|
||||||
|
.order_by("-last_update")
|
||||||
|
.limit(1)
|
||||||
|
.first()
|
||||||
|
)
|
||||||
|
if not last_updated_task:
|
||||||
|
return 0, []
|
||||||
|
|
||||||
|
redis_key = f"hyperparam_values_{company_id}_{'_'.join(project_ids)}_{section}_{name}_{allow_public}"
|
||||||
|
last_update = last_updated_task.last_update or datetime.utcnow()
|
||||||
|
cached_res = self._get_cached_param_values(
|
||||||
|
key=redis_key,
|
||||||
|
last_update=last_update,
|
||||||
|
allowed_delta_sec=config.get(
|
||||||
|
"services.tasks.hyperparam_values.cache_allowed_outdate_sec", 60
|
||||||
|
),
|
||||||
|
)
|
||||||
|
if cached_res:
|
||||||
|
return cached_res
|
||||||
|
|
||||||
|
max_values = config.get("services.tasks.hyperparam_values.max_count", 100)
|
||||||
|
pipeline = [
|
||||||
|
{
|
||||||
|
"$match": {
|
||||||
|
**company_constraint,
|
||||||
|
**project_constraint,
|
||||||
|
key_path: {"$exists": True},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{"$project": {"value": f"${key_path}.value"}},
|
||||||
|
{"$group": {"_id": "$value"}},
|
||||||
|
{"$sort": {"_id": 1}},
|
||||||
|
{"$limit": max_values},
|
||||||
|
{
|
||||||
|
"$group": {
|
||||||
|
"_id": 1,
|
||||||
|
"total": {"$sum": 1},
|
||||||
|
"results": {"$push": "$$ROOT._id"},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
]
|
||||||
|
|
||||||
|
result = next(Task.aggregate(pipeline, collation=Task._numeric_locale), None)
|
||||||
|
if not result:
|
||||||
|
return 0, []
|
||||||
|
|
||||||
|
total = int(result.get("total", 0))
|
||||||
|
values = result.get("results", [])
|
||||||
|
|
||||||
|
ttl = config.get("services.tasks.hyperparam_values.cache_ttl_sec", 86400)
|
||||||
|
cached = dict(last_update=last_update.timestamp(), total=total, values=values)
|
||||||
|
self.redis.setex(redis_key, ttl, json.dumps(cached))
|
||||||
|
|
||||||
|
return total, values
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_unique_metric_variants(
|
||||||
|
cls, company_id, project_ids: Sequence[str], include_subprojects: bool
|
||||||
|
):
|
||||||
|
pipeline = [
|
||||||
|
{
|
||||||
|
"$match": {
|
||||||
|
**cls._get_company_constraint(company_id),
|
||||||
|
**cls._get_project_constraint(project_ids, include_subprojects),
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{"$project": {"metrics": {"$objectToArray": "$last_metrics"}}},
|
||||||
|
{"$unwind": "$metrics"},
|
||||||
|
{
|
||||||
|
"$project": {
|
||||||
|
"metric": "$metrics.k",
|
||||||
|
"variants": {"$objectToArray": "$metrics.v"},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{"$unwind": "$variants"},
|
||||||
|
{
|
||||||
|
"$group": {
|
||||||
|
"_id": {
|
||||||
|
"metric": "$variants.v.metric",
|
||||||
|
"variant": "$variants.v.variant",
|
||||||
|
},
|
||||||
|
"metrics": {
|
||||||
|
"$addToSet": {
|
||||||
|
"metric": "$variants.v.metric",
|
||||||
|
"metric_hash": "$metric",
|
||||||
|
"variant": "$variants.v.variant",
|
||||||
|
"variant_hash": "$variants.k",
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{"$sort": OrderedDict({"_id.metric": 1, "_id.variant": 1})},
|
||||||
|
]
|
||||||
|
|
||||||
|
result = Task.aggregate(pipeline)
|
||||||
|
return [r["metrics"][0] for r in result]
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_model_metadata_keys(
|
||||||
|
cls,
|
||||||
|
company_id,
|
||||||
|
project_ids: Sequence[str],
|
||||||
|
include_subprojects: bool,
|
||||||
|
page: int = 0,
|
||||||
|
page_size: int = 500,
|
||||||
|
) -> Tuple[int, int, Sequence[dict]]:
|
||||||
|
page = max(0, page)
|
||||||
|
page_size = max(1, page_size)
|
||||||
|
pipeline = [
|
||||||
|
{
|
||||||
|
"$match": {
|
||||||
|
**cls._get_company_constraint(company_id),
|
||||||
|
**cls._get_project_constraint(project_ids, include_subprojects),
|
||||||
|
"metadata": {"$exists": True, "$gt": {}},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{"$project": {"metadata": {"$objectToArray": "$metadata"}}},
|
||||||
|
{"$unwind": "$metadata"},
|
||||||
|
{"$group": {"_id": "$metadata.k"}},
|
||||||
|
{"$sort": {"_id": 1}},
|
||||||
|
{"$skip": page * page_size},
|
||||||
|
{"$limit": page_size},
|
||||||
|
{
|
||||||
|
"$group": {
|
||||||
|
"_id": 1,
|
||||||
|
"total": {"$sum": 1},
|
||||||
|
"results": {"$push": "$$ROOT"},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
]
|
||||||
|
|
||||||
|
result = next(Model.aggregate(pipeline), None)
|
||||||
|
|
||||||
|
total = 0
|
||||||
|
remaining = 0
|
||||||
|
results = []
|
||||||
|
|
||||||
|
if result:
|
||||||
|
total = int(result.get("total", -1))
|
||||||
|
results = [
|
||||||
|
ParameterKeyEscaper.unescape(r.get("_id"))
|
||||||
|
for r in result.get("results", [])
|
||||||
|
]
|
||||||
|
remaining = max(0, total - (len(results) + page * page_size))
|
||||||
|
|
||||||
|
return total, remaining, results
|
||||||
|
|
||||||
|
def get_model_metadata_distinct_values(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
project_ids: Sequence[str],
|
||||||
|
key: str,
|
||||||
|
include_subprojects: bool,
|
||||||
|
allow_public: bool = True,
|
||||||
|
) -> ParamValues:
|
||||||
|
company_constraint = self._get_company_constraint(company_id, allow_public)
|
||||||
|
project_constraint = self._get_project_constraint(
|
||||||
|
project_ids, include_subprojects
|
||||||
|
)
|
||||||
|
key_path = f"metadata.{ParameterKeyEscaper.escape(key)}"
|
||||||
|
last_updated_model = (
|
||||||
|
Model.objects(
|
||||||
|
**company_constraint,
|
||||||
|
**project_constraint,
|
||||||
|
**{f"{key_path.replace('.', '__')}__exists": True},
|
||||||
|
)
|
||||||
|
.only("last_update")
|
||||||
|
.order_by("-last_update")
|
||||||
|
.limit(1)
|
||||||
|
.first()
|
||||||
|
)
|
||||||
|
if not last_updated_model:
|
||||||
|
return 0, []
|
||||||
|
|
||||||
|
redis_key = f"modelmetadata_values_{company_id}_{'_'.join(project_ids)}_{key}_{allow_public}"
|
||||||
|
last_update = last_updated_model.last_update or datetime.utcnow()
|
||||||
|
cached_res = self._get_cached_param_values(
|
||||||
|
key=redis_key, last_update=last_update
|
||||||
|
)
|
||||||
|
if cached_res:
|
||||||
|
return cached_res
|
||||||
|
|
||||||
|
max_values = config.get("services.models.metadata_values.max_count", 100)
|
||||||
|
pipeline = [
|
||||||
|
{
|
||||||
|
"$match": {
|
||||||
|
**company_constraint,
|
||||||
|
**project_constraint,
|
||||||
|
key_path: {"$exists": True},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{"$project": {"value": f"${key_path}.value"}},
|
||||||
|
{"$group": {"_id": "$value"}},
|
||||||
|
{"$sort": {"_id": 1}},
|
||||||
|
{"$limit": max_values},
|
||||||
|
{
|
||||||
|
"$group": {
|
||||||
|
"_id": 1,
|
||||||
|
"total": {"$sum": 1},
|
||||||
|
"results": {"$push": "$$ROOT._id"},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
]
|
||||||
|
|
||||||
|
result = next(Model.aggregate(pipeline, collation=Model._numeric_locale), None)
|
||||||
|
if not result:
|
||||||
|
return 0, []
|
||||||
|
|
||||||
|
total = int(result.get("total", 0))
|
||||||
|
values = result.get("results", [])
|
||||||
|
|
||||||
|
ttl = config.get("services.models.metadata_values.cache_ttl_sec", 86400)
|
||||||
|
cached = dict(last_update=last_update.timestamp(), total=total, values=values)
|
||||||
|
self.redis.setex(redis_key, ttl, json.dumps(cached))
|
||||||
|
|
||||||
|
return total, values
|
||||||
198
apiserver/bll/project/sub_projects.py
Normal file
198
apiserver/bll/project/sub_projects.py
Normal file
@@ -0,0 +1,198 @@
|
|||||||
|
import itertools
|
||||||
|
from datetime import datetime
|
||||||
|
from typing import Tuple, Optional, Sequence, Mapping
|
||||||
|
|
||||||
|
from apiserver import database
|
||||||
|
from apiserver.apierrors import errors
|
||||||
|
from apiserver.database.model import EntityVisibility
|
||||||
|
from apiserver.database.model.project import Project
|
||||||
|
|
||||||
|
name_separator = "/"
|
||||||
|
|
||||||
|
|
||||||
|
def _get_project_depth(project_name: str) -> int:
|
||||||
|
return len(list(filter(None, project_name.split(name_separator))))
|
||||||
|
|
||||||
|
|
||||||
|
def _validate_project_name(project_name: str, raise_if_empty=True) -> Tuple[str, str]:
|
||||||
|
"""
|
||||||
|
Remove redundant '/' characters. Ensure that the project name is not empty
|
||||||
|
Return the cleaned up project name and location
|
||||||
|
"""
|
||||||
|
name_parts = [p.strip() for p in project_name.split(name_separator) if p]
|
||||||
|
if not name_parts:
|
||||||
|
if raise_if_empty:
|
||||||
|
raise errors.bad_request.InvalidProjectName(name=project_name)
|
||||||
|
return "", ""
|
||||||
|
|
||||||
|
return name_separator.join(name_parts), name_separator.join(name_parts[:-1])
|
||||||
|
|
||||||
|
|
||||||
|
def _ensure_project(
|
||||||
|
company: str, user: str, name: str, creation_params: dict = None
|
||||||
|
) -> Optional[Project]:
|
||||||
|
"""
|
||||||
|
Makes sure that the project with the given name exists
|
||||||
|
If needed auto-create the project and all the missing projects in the path to it
|
||||||
|
Return the project
|
||||||
|
"""
|
||||||
|
name, location = _validate_project_name(name, raise_if_empty=False)
|
||||||
|
if not name:
|
||||||
|
return None
|
||||||
|
|
||||||
|
project = _get_writable_project_from_name(company, name)
|
||||||
|
if project:
|
||||||
|
return project
|
||||||
|
|
||||||
|
now = datetime.utcnow()
|
||||||
|
project = Project(
|
||||||
|
id=database.utils.id(),
|
||||||
|
user=user,
|
||||||
|
company=company,
|
||||||
|
created=now,
|
||||||
|
last_update=now,
|
||||||
|
name=name,
|
||||||
|
basename=name.split("/")[-1],
|
||||||
|
**(creation_params or dict(description="")),
|
||||||
|
)
|
||||||
|
parent = _ensure_project(company, user, location, creation_params=creation_params)
|
||||||
|
_save_under_parent(project=project, parent=parent)
|
||||||
|
if parent:
|
||||||
|
parent.update(last_update=now)
|
||||||
|
|
||||||
|
return project
|
||||||
|
|
||||||
|
|
||||||
|
def _save_under_parent(project: Project, parent: Optional[Project]):
|
||||||
|
"""
|
||||||
|
Save the project under the given parent project or top level (parent=None)
|
||||||
|
Check that the project location matches the parent name
|
||||||
|
"""
|
||||||
|
location, _, _ = project.name.rpartition(name_separator)
|
||||||
|
if not parent:
|
||||||
|
if location:
|
||||||
|
raise ValueError(
|
||||||
|
f"Project location {location} does not match empty parent name"
|
||||||
|
)
|
||||||
|
project.parent = None
|
||||||
|
project.path = []
|
||||||
|
project.save()
|
||||||
|
return
|
||||||
|
|
||||||
|
if location != parent.name:
|
||||||
|
raise ValueError(
|
||||||
|
f"Project location {location} does not match parent name {parent.name}"
|
||||||
|
)
|
||||||
|
project.parent = parent.id
|
||||||
|
project.path = [*(parent.path or []), parent.id]
|
||||||
|
project.save()
|
||||||
|
|
||||||
|
|
||||||
|
def _get_writable_project_from_name(
|
||||||
|
company,
|
||||||
|
name,
|
||||||
|
_only: Optional[Sequence[str]] = ("id", "name", "path", "company", "parent"),
|
||||||
|
) -> Optional[Project]:
|
||||||
|
"""
|
||||||
|
Return a project from name. If the project not found then return None
|
||||||
|
"""
|
||||||
|
qs = Project.objects(company=company, name=name)
|
||||||
|
if _only:
|
||||||
|
qs = qs.only(*_only)
|
||||||
|
return qs.first()
|
||||||
|
|
||||||
|
|
||||||
|
ProjectsChildren = Mapping[str, Sequence[Project]]
|
||||||
|
|
||||||
|
|
||||||
|
def _get_sub_projects(
|
||||||
|
project_ids: Sequence[str],
|
||||||
|
_only: Sequence[str] = ("id", "path"),
|
||||||
|
search_hidden=True,
|
||||||
|
allowed_ids: Sequence[str] = None,
|
||||||
|
) -> ProjectsChildren:
|
||||||
|
"""
|
||||||
|
Return the list of child projects of all the levels for the parent project ids
|
||||||
|
"""
|
||||||
|
query = dict(path__in=project_ids)
|
||||||
|
if not search_hidden:
|
||||||
|
query["system_tags__nin"] = [EntityVisibility.hidden.value]
|
||||||
|
if allowed_ids:
|
||||||
|
query["id__in"] = allowed_ids
|
||||||
|
|
||||||
|
qs = Project.objects(**query)
|
||||||
|
if _only:
|
||||||
|
_only = set(_only) | {"path"}
|
||||||
|
qs = qs.only(*_only)
|
||||||
|
subprojects = list(qs)
|
||||||
|
|
||||||
|
return {
|
||||||
|
pid: [s for s in subprojects if pid in (s.path or [])] for pid in project_ids
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def _ids_with_parents(project_ids: Sequence[str]) -> Sequence[str]:
|
||||||
|
"""
|
||||||
|
Return project ids with all the parent projects
|
||||||
|
"""
|
||||||
|
projects = Project.objects(id__in=project_ids).only("id", "path")
|
||||||
|
parent_ids = set(itertools.chain.from_iterable(p.path for p in projects if p.path))
|
||||||
|
return list({*(p.id for p in projects), *parent_ids})
|
||||||
|
|
||||||
|
|
||||||
|
def _ids_with_children(project_ids: Sequence[str]) -> Sequence[str]:
|
||||||
|
"""
|
||||||
|
Return project ids with the ids of all the subprojects
|
||||||
|
"""
|
||||||
|
subprojects = Project.objects(path__in=project_ids).only("id")
|
||||||
|
return list({*project_ids, *(child.id for child in subprojects)})
|
||||||
|
|
||||||
|
|
||||||
|
def _update_subproject_names(
|
||||||
|
project: Project,
|
||||||
|
children: Sequence[Project],
|
||||||
|
old_name: str,
|
||||||
|
update_path: bool = False,
|
||||||
|
old_path: Sequence[str] = None,
|
||||||
|
) -> int:
|
||||||
|
"""
|
||||||
|
Update sub project names when the base project name changes
|
||||||
|
Optionally update the paths
|
||||||
|
"""
|
||||||
|
updated = 0
|
||||||
|
now = datetime.utcnow()
|
||||||
|
for child in children:
|
||||||
|
child_suffix = name_separator.join(
|
||||||
|
child.name.split(name_separator)[len(old_name.split(name_separator)):]
|
||||||
|
)
|
||||||
|
updates = {
|
||||||
|
"name": name_separator.join((project.name, child_suffix)),
|
||||||
|
"last_update": now,
|
||||||
|
}
|
||||||
|
if update_path:
|
||||||
|
updates["path"] = project.path + child.path[len(old_path):]
|
||||||
|
updated += child.update(upsert=False, **updates)
|
||||||
|
|
||||||
|
return updated
|
||||||
|
|
||||||
|
|
||||||
|
def _reposition_project_with_children(
|
||||||
|
project: Project, children: Sequence[Project], parent: Project
|
||||||
|
) -> int:
|
||||||
|
new_location = parent.name if parent else None
|
||||||
|
old_name = project.name
|
||||||
|
old_path = project.path
|
||||||
|
project.name = name_separator.join(
|
||||||
|
filter(None, (new_location, project.name.split(name_separator)[-1]))
|
||||||
|
)
|
||||||
|
project.last_update = datetime.utcnow()
|
||||||
|
_save_under_parent(project, parent=parent)
|
||||||
|
|
||||||
|
moved = 1 + _update_subproject_names(
|
||||||
|
project=project,
|
||||||
|
children=children,
|
||||||
|
old_name=old_name,
|
||||||
|
update_path=True,
|
||||||
|
old_path=old_path,
|
||||||
|
)
|
||||||
|
return moved
|
||||||
@@ -1,6 +1,6 @@
|
|||||||
from typing import Optional, Sequence, Iterable, Union
|
from typing import Optional, Sequence, Iterable, Union
|
||||||
|
|
||||||
from config import config
|
from apiserver.config_repo import config
|
||||||
|
|
||||||
log = config.logger(__file__)
|
log = config.logger(__file__)
|
||||||
|
|
||||||
@@ -3,14 +3,19 @@ from datetime import datetime
|
|||||||
from typing import Callable, Sequence, Optional, Tuple
|
from typing import Callable, Sequence, Optional, Tuple
|
||||||
|
|
||||||
from elasticsearch import Elasticsearch
|
from elasticsearch import Elasticsearch
|
||||||
|
from mongoengine import Q
|
||||||
|
|
||||||
import database
|
from apiserver import database
|
||||||
import es_factory
|
from apiserver.database.model.task.task import Task, TaskStatus
|
||||||
from apierrors import errors
|
from apiserver.es_factory import es_factory
|
||||||
from bll.queue.queue_metrics import QueueMetrics
|
from apiserver.apierrors import errors
|
||||||
from bll.workers import WorkerBLL
|
from apiserver.bll.queue.queue_metrics import QueueMetrics
|
||||||
from database.errors import translate_errors_context
|
from apiserver.bll.workers import WorkerBLL
|
||||||
from database.model.queue import Queue, Entry
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.errors import translate_errors_context
|
||||||
|
from apiserver.database.model.queue import Queue, Entry
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
|
||||||
|
|
||||||
class QueueBLL(object):
|
class QueueBLL(object):
|
||||||
@@ -29,6 +34,7 @@ class QueueBLL(object):
|
|||||||
name: str,
|
name: str,
|
||||||
tags: Optional[Sequence[str]] = None,
|
tags: Optional[Sequence[str]] = None,
|
||||||
system_tags: Optional[Sequence[str]] = None,
|
system_tags: Optional[Sequence[str]] = None,
|
||||||
|
metadata: Optional[dict] = None,
|
||||||
) -> Queue:
|
) -> Queue:
|
||||||
"""Creates a queue"""
|
"""Creates a queue"""
|
||||||
with translate_errors_context():
|
with translate_errors_context():
|
||||||
@@ -40,13 +46,31 @@ class QueueBLL(object):
|
|||||||
name=name,
|
name=name,
|
||||||
tags=tags or [],
|
tags=tags or [],
|
||||||
system_tags=system_tags or [],
|
system_tags=system_tags or [],
|
||||||
|
metadata=metadata,
|
||||||
last_update=now,
|
last_update=now,
|
||||||
)
|
)
|
||||||
queue.save()
|
queue.save()
|
||||||
return queue
|
return queue
|
||||||
|
|
||||||
|
def get_by_name(
|
||||||
|
self, company_id: str, queue_name: str, only: Optional[Sequence[str]] = None,
|
||||||
|
) -> Queue:
|
||||||
|
qs = Queue.objects(name=queue_name, company=company_id)
|
||||||
|
if only:
|
||||||
|
qs = qs.only(*only)
|
||||||
|
|
||||||
|
return qs.first()
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _get_task_entries_projection(max_task_entries: int) -> dict:
|
||||||
|
return dict(slice__entries=max_task_entries)
|
||||||
|
|
||||||
def get_by_id(
|
def get_by_id(
|
||||||
self, company_id: str, queue_id: str, only: Optional[Sequence[str]] = None
|
self,
|
||||||
|
company_id: str,
|
||||||
|
queue_id: str,
|
||||||
|
only: Optional[Sequence[str]] = None,
|
||||||
|
max_task_entries: int = None,
|
||||||
) -> Queue:
|
) -> Queue:
|
||||||
"""
|
"""
|
||||||
Get queue by id
|
Get queue by id
|
||||||
@@ -57,6 +81,8 @@ class QueueBLL(object):
|
|||||||
qs = Queue.objects(**query)
|
qs = Queue.objects(**query)
|
||||||
if only:
|
if only:
|
||||||
qs = qs.only(*only)
|
qs = qs.only(*only)
|
||||||
|
if max_task_entries:
|
||||||
|
qs = qs.fields(**self._get_task_entries_projection(max_task_entries))
|
||||||
queue = qs.first()
|
queue = qs.first()
|
||||||
if not queue:
|
if not queue:
|
||||||
raise errors.bad_request.InvalidQueueId(**query)
|
raise errors.bad_request.InvalidQueueId(**query)
|
||||||
@@ -107,7 +133,7 @@ class QueueBLL(object):
|
|||||||
self.get_by_id(company_id=company_id, queue_id=queue_id, only=("id",))
|
self.get_by_id(company_id=company_id, queue_id=queue_id, only=("id",))
|
||||||
return Queue.safe_update(company_id, queue_id, update_fields)
|
return Queue.safe_update(company_id, queue_id, update_fields)
|
||||||
|
|
||||||
def delete(self, company_id: str, queue_id: str, force: bool) -> None:
|
def delete(self, company_id: str, user_id: str, queue_id: str, force: bool) -> None:
|
||||||
"""
|
"""
|
||||||
Delete the queue
|
Delete the queue
|
||||||
:raise errors.bad_request.InvalidQueueId: if the queue is not found
|
:raise errors.bad_request.InvalidQueueId: if the queue is not found
|
||||||
@@ -115,20 +141,73 @@ class QueueBLL(object):
|
|||||||
"""
|
"""
|
||||||
with translate_errors_context():
|
with translate_errors_context():
|
||||||
queue = self.get_by_id(company_id=company_id, queue_id=queue_id)
|
queue = self.get_by_id(company_id=company_id, queue_id=queue_id)
|
||||||
if queue.entries and not force:
|
if queue.entries:
|
||||||
raise errors.bad_request.QueueNotEmpty(
|
if not force:
|
||||||
"use force=true to delete", id=queue_id
|
raise errors.bad_request.QueueNotEmpty(
|
||||||
)
|
"use force=true to delete", id=queue_id
|
||||||
|
)
|
||||||
|
from apiserver.bll.task import ChangeStatusRequest
|
||||||
|
|
||||||
|
for item in queue.entries:
|
||||||
|
try:
|
||||||
|
task = Task.get_for_writing(
|
||||||
|
company=company_id,
|
||||||
|
id=item.task,
|
||||||
|
_only=["id", "status", "enqueue_status", "project"],
|
||||||
|
)
|
||||||
|
if not task:
|
||||||
|
continue
|
||||||
|
|
||||||
|
ChangeStatusRequest(
|
||||||
|
task=task,
|
||||||
|
new_status=task.enqueue_status or TaskStatus.created,
|
||||||
|
status_reason="Queue was deleted",
|
||||||
|
status_message="",
|
||||||
|
user_id=user_id,
|
||||||
|
).execute(enqueue_status=None)
|
||||||
|
except Exception as ex:
|
||||||
|
log.exception(
|
||||||
|
f"Failed dequeuing task {item.task} from queue: {queue_id}"
|
||||||
|
)
|
||||||
|
|
||||||
queue.delete()
|
queue.delete()
|
||||||
|
|
||||||
def get_all(self, company_id: str, query_dict: dict) -> Sequence[dict]:
|
def get_all(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
query_dict: dict,
|
||||||
|
query: Q = None,
|
||||||
|
max_task_entries: int = None,
|
||||||
|
ret_params: dict = None,
|
||||||
|
) -> Sequence[dict]:
|
||||||
"""Get all the queues according to the query"""
|
"""Get all the queues according to the query"""
|
||||||
with translate_errors_context():
|
with translate_errors_context():
|
||||||
return Queue.get_many(
|
return Queue.get_many(
|
||||||
company=company_id, parameters=query_dict, query_dict=query_dict
|
company=company_id,
|
||||||
|
parameters=query_dict,
|
||||||
|
query_dict=query_dict,
|
||||||
|
query=query,
|
||||||
|
projection_fields=self._get_task_entries_projection(max_task_entries)
|
||||||
|
if max_task_entries
|
||||||
|
else None,
|
||||||
|
ret_params=ret_params,
|
||||||
)
|
)
|
||||||
|
|
||||||
def get_queue_infos(self, company_id: str, query_dict: dict) -> Sequence[dict]:
|
def check_for_workers(self, company_id: str, queue_id: str) -> bool:
|
||||||
|
for worker in self.worker_bll.get_all(company_id):
|
||||||
|
if queue_id in worker.queues:
|
||||||
|
return True
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
def get_queue_infos(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
query_dict: dict,
|
||||||
|
query: Q = None,
|
||||||
|
max_task_entries: int = None,
|
||||||
|
ret_params: dict = None,
|
||||||
|
) -> Sequence[dict]:
|
||||||
"""
|
"""
|
||||||
Get infos on all the company queues, including queue tasks and workers
|
Get infos on all the company queues, including queue tasks and workers
|
||||||
"""
|
"""
|
||||||
@@ -137,7 +216,12 @@ class QueueBLL(object):
|
|||||||
res = Queue.get_many_with_join(
|
res = Queue.get_many_with_join(
|
||||||
company=company_id,
|
company=company_id,
|
||||||
query_dict=query_dict,
|
query_dict=query_dict,
|
||||||
|
query=query,
|
||||||
override_projection=projection,
|
override_projection=projection,
|
||||||
|
projection_fields=self._get_task_entries_projection(max_task_entries)
|
||||||
|
if max_task_entries
|
||||||
|
else None,
|
||||||
|
ret_params=ret_params,
|
||||||
)
|
)
|
||||||
|
|
||||||
queue_workers = defaultdict(list)
|
queue_workers = defaultdict(list)
|
||||||
@@ -168,13 +252,15 @@ class QueueBLL(object):
|
|||||||
if any(e.task == task_id for e in queue.entries):
|
if any(e.task == task_id for e in queue.entries):
|
||||||
raise errors.bad_request.TaskAlreadyQueued(task=task_id)
|
raise errors.bad_request.TaskAlreadyQueued(task=task_id)
|
||||||
|
|
||||||
self.metrics.log_queue_metrics_to_es(company_id=company_id, queues=[queue])
|
|
||||||
|
|
||||||
entry = Entry(added=datetime.utcnow(), task=task_id)
|
entry = Entry(added=datetime.utcnow(), task=task_id)
|
||||||
query = dict(id=queue_id, company=company_id)
|
query = dict(id=queue_id, company=company_id)
|
||||||
res = Queue.objects(entries__task__ne=task_id, **query).update_one(
|
res = Queue.objects(entries__task__ne=task_id, **query).update_one(
|
||||||
push__entries=entry, last_update=datetime.utcnow(), upsert=False
|
push__entries=entry, last_update=datetime.utcnow(), upsert=False
|
||||||
)
|
)
|
||||||
|
|
||||||
|
queue.reload()
|
||||||
|
self.metrics.log_queue_metrics_to_es(company_id=company_id, queues=[queue])
|
||||||
|
|
||||||
if not res:
|
if not res:
|
||||||
raise errors.bad_request.InvalidQueueOrTaskNotQueued(
|
raise errors.bad_request.InvalidQueueOrTaskNotQueued(
|
||||||
task=task_id, **query
|
task=task_id, **query
|
||||||
@@ -182,24 +268,33 @@ class QueueBLL(object):
|
|||||||
|
|
||||||
return res
|
return res
|
||||||
|
|
||||||
def get_next_task(self, company_id: str, queue_id: str) -> Optional[Entry]:
|
def get_next_task(
|
||||||
|
self, company_id: str, queue_id: str, task_id: str = None
|
||||||
|
) -> Optional[Entry]:
|
||||||
"""
|
"""
|
||||||
Atomically pop and return the first task from the queue (or None)
|
Atomically pop and return the first task from the queue (or None)
|
||||||
:raise errors.bad_request.InvalidQueueId: if the queue does not exist
|
:raise errors.bad_request.InvalidQueueId: if the queue does not exist
|
||||||
"""
|
"""
|
||||||
with translate_errors_context():
|
with translate_errors_context():
|
||||||
query = dict(id=queue_id, company=company_id)
|
query = dict(id=queue_id, company=company_id)
|
||||||
queue = Queue.objects(**query).modify(
|
queue = Queue.objects(
|
||||||
pop__entries=-1, last_update=datetime.utcnow(), upsert=False
|
**query, **({"entries__0__task": task_id} if task_id else {})
|
||||||
)
|
).modify(pop__entries=-1, upsert=False)
|
||||||
if not queue:
|
if not queue:
|
||||||
raise errors.bad_request.InvalidQueueId(**query)
|
if not task_id or not Queue.objects(**query).first():
|
||||||
|
raise errors.bad_request.InvalidQueueId(**query)
|
||||||
|
return
|
||||||
|
|
||||||
self.metrics.log_queue_metrics_to_es(company_id, queues=[queue])
|
self.metrics.log_queue_metrics_to_es(company_id, queues=[queue])
|
||||||
|
|
||||||
if not queue.entries:
|
if not queue.entries:
|
||||||
return
|
return
|
||||||
|
|
||||||
|
try:
|
||||||
|
Queue.objects(**query).update(last_update=datetime.utcnow())
|
||||||
|
except Exception:
|
||||||
|
log.exception("Error while updating Queue.last_update")
|
||||||
|
|
||||||
return queue.entries[0]
|
return queue.entries[0]
|
||||||
|
|
||||||
def remove_task(self, company_id: str, queue_id: str, task_id: str) -> int:
|
def remove_task(self, company_id: str, queue_id: str, task_id: str) -> int:
|
||||||
@@ -211,7 +306,6 @@ class QueueBLL(object):
|
|||||||
queue = self.get_queue_with_task(
|
queue = self.get_queue_with_task(
|
||||||
company_id=company_id, queue_id=queue_id, task_id=task_id
|
company_id=company_id, queue_id=queue_id, task_id=task_id
|
||||||
)
|
)
|
||||||
self.metrics.log_queue_metrics_to_es(company_id, queues=[queue])
|
|
||||||
|
|
||||||
entries_to_remove = [e for e in queue.entries if e.task == task_id]
|
entries_to_remove = [e for e in queue.entries if e.task == task_id]
|
||||||
query = dict(id=queue_id, company=company_id)
|
query = dict(id=queue_id, company=company_id)
|
||||||
@@ -219,6 +313,9 @@ class QueueBLL(object):
|
|||||||
pull_all__entries=entries_to_remove, last_update=datetime.utcnow()
|
pull_all__entries=entries_to_remove, last_update=datetime.utcnow()
|
||||||
)
|
)
|
||||||
|
|
||||||
|
queue.reload()
|
||||||
|
self.metrics.log_queue_metrics_to_es(company_id=company_id, queues=[queue])
|
||||||
|
|
||||||
return len(entries_to_remove) if res else 0
|
return len(entries_to_remove) if res else 0
|
||||||
|
|
||||||
def reposition_task(
|
def reposition_task(
|
||||||
@@ -262,3 +359,22 @@ class QueueBLL(object):
|
|||||||
)
|
)
|
||||||
|
|
||||||
return new_position
|
return new_position
|
||||||
|
|
||||||
|
def count_entries(self, company: str, queue_id: str) -> Optional[int]:
|
||||||
|
res = next(
|
||||||
|
Queue.aggregate(
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"$match": {
|
||||||
|
"company": {"$in": [None, "", company]},
|
||||||
|
"_id": queue_id,
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{"$project": {"count": {"$size": "$entries"}}},
|
||||||
|
]
|
||||||
|
),
|
||||||
|
None,
|
||||||
|
)
|
||||||
|
if res is None:
|
||||||
|
raise errors.bad_request.InvalidQueueId(queue_id=queue_id)
|
||||||
|
return int(res.get("count"))
|
||||||
@@ -1,36 +1,42 @@
|
|||||||
|
import json
|
||||||
from collections import defaultdict
|
from collections import defaultdict
|
||||||
from datetime import datetime
|
from datetime import datetime
|
||||||
|
from time import sleep
|
||||||
from typing import Sequence
|
from typing import Sequence
|
||||||
|
|
||||||
import elasticsearch.helpers
|
from boltons.typeutils import classproperty
|
||||||
from elasticsearch import Elasticsearch
|
from elasticsearch import Elasticsearch
|
||||||
|
|
||||||
import es_factory
|
from apiserver.es_factory import es_factory
|
||||||
from apierrors.errors import bad_request
|
from apiserver.apierrors.errors import bad_request
|
||||||
from bll.query import Builder as QueryBuilder
|
from apiserver.bll.query import Builder as QueryBuilder
|
||||||
from config import config
|
from apiserver.config_repo import config
|
||||||
from database.errors import translate_errors_context
|
from apiserver.database.errors import translate_errors_context
|
||||||
from database.model.queue import Queue, Entry
|
from apiserver.database.model.queue import Queue, Entry
|
||||||
from timing_context import TimingContext
|
from apiserver.redis_manager import redman
|
||||||
|
from apiserver.utilities.threads_manager import ThreadsManager
|
||||||
|
|
||||||
log = config.logger(__file__)
|
log = config.logger(__file__)
|
||||||
|
_conf = config.get("services.queues")
|
||||||
|
_queue_metrics_key_pattern = "queue_metrics_{queue}"
|
||||||
|
redis = redman.connection("apiserver")
|
||||||
|
|
||||||
|
|
||||||
|
class EsKeys:
|
||||||
|
WAITING_TIME_FIELD = "average_waiting_time"
|
||||||
|
QUEUE_LENGTH_FIELD = "queue_length"
|
||||||
|
TIMESTAMP_FIELD = "timestamp"
|
||||||
|
QUEUE_FIELD = "queue"
|
||||||
|
|
||||||
|
|
||||||
class QueueMetrics:
|
class QueueMetrics:
|
||||||
class EsKeys:
|
|
||||||
DOC_TYPE = "metrics"
|
|
||||||
WAITING_TIME_FIELD = "average_waiting_time"
|
|
||||||
QUEUE_LENGTH_FIELD = "queue_length"
|
|
||||||
TIMESTAMP_FIELD = "timestamp"
|
|
||||||
QUEUE_FIELD = "queue"
|
|
||||||
|
|
||||||
def __init__(self, es: Elasticsearch):
|
def __init__(self, es: Elasticsearch):
|
||||||
self.es = es
|
self.es = es
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def _queue_metrics_prefix_for_company(company_id: str) -> str:
|
def _queue_metrics_prefix_for_company(company_id: str) -> str:
|
||||||
"""Returns the es index prefix for the company"""
|
"""Returns the es index prefix for the company"""
|
||||||
return f"queue_metrics_{company_id}_"
|
return f"queue_metrics_{company_id.lower()}_"
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def _get_es_index_suffix():
|
def _get_es_index_suffix():
|
||||||
@@ -50,7 +56,7 @@ class QueueMetrics:
|
|||||||
total_waiting_in_secs = sum((now - e.added).total_seconds() for e in entries)
|
total_waiting_in_secs = sum((now - e.added).total_seconds() for e in entries)
|
||||||
return total_waiting_in_secs / len(entries)
|
return total_waiting_in_secs / len(entries)
|
||||||
|
|
||||||
def log_queue_metrics_to_es(self, company_id: str, queues: Sequence[Queue]) -> bool:
|
def log_queue_metrics_to_es(self, company_id: str, queues: Sequence[Queue]) -> int:
|
||||||
"""
|
"""
|
||||||
Calculate and write queue statistics (avg waiting time and queue length) to Elastic
|
Calculate and write queue statistics (avg waiting time and queue length) to Elastic
|
||||||
:return: True if the write to es was successful, false otherwise
|
:return: True if the write to es was successful, false otherwise
|
||||||
@@ -64,24 +70,22 @@ class QueueMetrics:
|
|||||||
|
|
||||||
def make_doc(queue: Queue) -> dict:
|
def make_doc(queue: Queue) -> dict:
|
||||||
entries = [e for e in queue.entries if e.added]
|
entries = [e for e in queue.entries if e.added]
|
||||||
return dict(
|
return {
|
||||||
_index=es_index,
|
EsKeys.TIMESTAMP_FIELD: timestamp,
|
||||||
_type=self.EsKeys.DOC_TYPE,
|
EsKeys.QUEUE_FIELD: queue.id,
|
||||||
_source={
|
EsKeys.WAITING_TIME_FIELD: self._calc_avg_waiting_time(entries),
|
||||||
self.EsKeys.TIMESTAMP_FIELD: timestamp,
|
EsKeys.QUEUE_LENGTH_FIELD: len(entries),
|
||||||
self.EsKeys.QUEUE_FIELD: queue.id,
|
}
|
||||||
self.EsKeys.WAITING_TIME_FIELD: self._calc_avg_waiting_time(
|
|
||||||
entries
|
|
||||||
),
|
|
||||||
self.EsKeys.QUEUE_LENGTH_FIELD: len(entries),
|
|
||||||
},
|
|
||||||
)
|
|
||||||
|
|
||||||
actions = list(map(make_doc, queues))
|
logged = 0
|
||||||
|
for q in queues:
|
||||||
|
queue_doc = make_doc(q)
|
||||||
|
self.es.index(index=es_index, body=queue_doc)
|
||||||
|
redis_key = _queue_metrics_key_pattern.format(queue=q.id)
|
||||||
|
redis.set(redis_key, json.dumps(queue_doc))
|
||||||
|
logged += 1
|
||||||
|
|
||||||
es_res = elasticsearch.helpers.bulk(self.es, actions)
|
return logged
|
||||||
added, errors = es_res[:2]
|
|
||||||
return (added == len(actions)) and not errors
|
|
||||||
|
|
||||||
def _log_current_metrics(self, company_id: str, queue_ids=Sequence[str]):
|
def _log_current_metrics(self, company_id: str, queue_ids=Sequence[str]):
|
||||||
query = dict(company=company_id)
|
query = dict(company=company_id)
|
||||||
@@ -92,9 +96,7 @@ class QueueMetrics:
|
|||||||
|
|
||||||
def _search_company_metrics(self, company_id: str, es_req: dict) -> dict:
|
def _search_company_metrics(self, company_id: str, es_req: dict) -> dict:
|
||||||
return self.es.search(
|
return self.es.search(
|
||||||
index=f"{self._queue_metrics_prefix_for_company(company_id)}*",
|
index=f"{self._queue_metrics_prefix_for_company(company_id)}*", body=es_req,
|
||||||
doc_type=self.EsKeys.DOC_TYPE,
|
|
||||||
body=es_req,
|
|
||||||
)
|
)
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
@@ -108,13 +110,13 @@ class QueueMetrics:
|
|||||||
return {
|
return {
|
||||||
"dates": {
|
"dates": {
|
||||||
"date_histogram": {
|
"date_histogram": {
|
||||||
"field": cls.EsKeys.TIMESTAMP_FIELD,
|
"field": EsKeys.TIMESTAMP_FIELD,
|
||||||
"interval": f"{interval}s",
|
"fixed_interval": f"{interval}s",
|
||||||
"min_doc_count": 1,
|
"min_doc_count": 1,
|
||||||
},
|
},
|
||||||
"aggs": {
|
"aggs": {
|
||||||
"queues": {
|
"queues": {
|
||||||
"terms": {"field": cls.EsKeys.QUEUE_FIELD},
|
"terms": {"field": EsKeys.QUEUE_FIELD},
|
||||||
"aggs": cls._get_top_waiting_agg(),
|
"aggs": cls._get_top_waiting_agg(),
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
@@ -131,13 +133,13 @@ class QueueMetrics:
|
|||||||
"top_avg_waiting": {
|
"top_avg_waiting": {
|
||||||
"top_hits": {
|
"top_hits": {
|
||||||
"sort": [
|
"sort": [
|
||||||
{cls.EsKeys.WAITING_TIME_FIELD: {"order": "desc"}},
|
{EsKeys.WAITING_TIME_FIELD: {"order": "desc"}},
|
||||||
{cls.EsKeys.QUEUE_LENGTH_FIELD: {"order": "desc"}},
|
{EsKeys.QUEUE_LENGTH_FIELD: {"order": "desc"}},
|
||||||
],
|
],
|
||||||
"_source": {
|
"_source": {
|
||||||
"includes": [
|
"includes": [
|
||||||
cls.EsKeys.WAITING_TIME_FIELD,
|
EsKeys.WAITING_TIME_FIELD,
|
||||||
cls.EsKeys.QUEUE_LENGTH_FIELD,
|
EsKeys.QUEUE_LENGTH_FIELD,
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
"size": 1,
|
"size": 1,
|
||||||
@@ -152,6 +154,7 @@ class QueueMetrics:
|
|||||||
to_date: float,
|
to_date: float,
|
||||||
interval: int,
|
interval: int,
|
||||||
queue_ids: Sequence[str],
|
queue_ids: Sequence[str],
|
||||||
|
refresh: bool = False,
|
||||||
) -> dict:
|
) -> dict:
|
||||||
"""
|
"""
|
||||||
Get the company queue metrics in the specified time range.
|
Get the company queue metrics in the specified time range.
|
||||||
@@ -161,7 +164,8 @@ class QueueMetrics:
|
|||||||
In case no queue ids are specified the avg across all the
|
In case no queue ids are specified the avg across all the
|
||||||
company queues is calculated for each metric
|
company queues is calculated for each metric
|
||||||
"""
|
"""
|
||||||
# self._log_current_metrics(company_id, queue_ids=queue_ids)
|
if refresh:
|
||||||
|
self._log_current_metrics(company_id, queue_ids=queue_ids)
|
||||||
|
|
||||||
if from_date >= to_date:
|
if from_date >= to_date:
|
||||||
raise bad_request.FieldsValueError("from_date must be less than to_date")
|
raise bad_request.FieldsValueError("from_date must be less than to_date")
|
||||||
@@ -177,7 +181,7 @@ class QueueMetrics:
|
|||||||
"aggs": self._get_dates_agg(interval),
|
"aggs": self._get_dates_agg(interval),
|
||||||
}
|
}
|
||||||
|
|
||||||
with translate_errors_context(), TimingContext("es", "get_queue_metrics"):
|
with translate_errors_context():
|
||||||
res = self._search_company_metrics(company_id, es_req)
|
res = self._search_company_metrics(company_id, es_req)
|
||||||
|
|
||||||
if "aggregations" not in res:
|
if "aggregations" not in res:
|
||||||
@@ -259,7 +263,52 @@ class QueueMetrics:
|
|||||||
continue
|
continue
|
||||||
res = queue_data["top_avg_waiting"]["hits"]["hits"][0]["_source"]
|
res = queue_data["top_avg_waiting"]["hits"]["hits"][0]["_source"]
|
||||||
queue_metrics[queue_data["key"]] = {
|
queue_metrics[queue_data["key"]] = {
|
||||||
"queue_length": res[cls.EsKeys.QUEUE_LENGTH_FIELD],
|
"queue_length": res[EsKeys.QUEUE_LENGTH_FIELD],
|
||||||
"avg_waiting_time": res[cls.EsKeys.WAITING_TIME_FIELD],
|
"avg_waiting_time": res[EsKeys.WAITING_TIME_FIELD],
|
||||||
}
|
}
|
||||||
return queue_metrics
|
return queue_metrics
|
||||||
|
|
||||||
|
|
||||||
|
class MetricsRefresher:
|
||||||
|
threads = ThreadsManager()
|
||||||
|
|
||||||
|
@classproperty
|
||||||
|
def watch_interval_sec(self):
|
||||||
|
return _conf.get("metrics_refresh_interval_sec", 300)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@threads.register("queue_metrics_refresh_watchdog", daemon=True)
|
||||||
|
def start(cls, queue_metrics: QueueMetrics = None):
|
||||||
|
if not cls.watch_interval_sec:
|
||||||
|
return
|
||||||
|
|
||||||
|
if not queue_metrics:
|
||||||
|
from .queue_bll import QueueBLL
|
||||||
|
|
||||||
|
queue_metrics = QueueBLL().metrics
|
||||||
|
|
||||||
|
sleep(10)
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
for queue in Queue.objects():
|
||||||
|
timestamp = es_factory.get_timestamp_millis()
|
||||||
|
doc_time = 0
|
||||||
|
try:
|
||||||
|
redis_key = _queue_metrics_key_pattern.format(queue=queue.id)
|
||||||
|
data = redis.get(redis_key)
|
||||||
|
if data:
|
||||||
|
queue_doc = json.loads(data)
|
||||||
|
doc_time = int(queue_doc.get(EsKeys.TIMESTAMP_FIELD))
|
||||||
|
except Exception as ex:
|
||||||
|
log.exception(
|
||||||
|
f"Error reading queue metrics data for queue {queue.id}: {str(ex)}"
|
||||||
|
)
|
||||||
|
|
||||||
|
if (
|
||||||
|
not doc_time
|
||||||
|
or (timestamp - doc_time) > cls.watch_interval_sec * 1000
|
||||||
|
):
|
||||||
|
queue_metrics.log_queue_metrics_to_es(queue.company, [queue])
|
||||||
|
except Exception as ex:
|
||||||
|
log.exception(f"Failed collecting queue metrics: {str(ex)}")
|
||||||
|
sleep(60)
|
||||||
87
apiserver/bll/redis_cache_manager.py
Normal file
87
apiserver/bll/redis_cache_manager.py
Normal file
@@ -0,0 +1,87 @@
|
|||||||
|
from contextlib import contextmanager
|
||||||
|
from typing import Optional, TypeVar, Generic, Type, Callable
|
||||||
|
|
||||||
|
from redis import StrictRedis
|
||||||
|
|
||||||
|
from apiserver import database
|
||||||
|
|
||||||
|
T = TypeVar("T")
|
||||||
|
|
||||||
|
|
||||||
|
def _do_nothing(_: T):
|
||||||
|
return
|
||||||
|
|
||||||
|
|
||||||
|
class RedisCacheManager(Generic[T]):
|
||||||
|
"""
|
||||||
|
Class for store/retrieve of state objects from redis
|
||||||
|
|
||||||
|
self.state_class - class of the state
|
||||||
|
self.redis - instance of redis
|
||||||
|
self.expiration_interval - expiration interval in seconds
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, state_class: Type[T], redis: StrictRedis, expiration_interval: int
|
||||||
|
):
|
||||||
|
self.state_class = state_class
|
||||||
|
self.redis = redis
|
||||||
|
self.expiration_interval = expiration_interval
|
||||||
|
|
||||||
|
def set_state(self, state: T) -> None:
|
||||||
|
redis_key = self._get_redis_key(state.id)
|
||||||
|
self.redis.set(redis_key, state.to_json())
|
||||||
|
self.redis.expire(redis_key, self.expiration_interval)
|
||||||
|
|
||||||
|
def get_state(self, state_id) -> Optional[T]:
|
||||||
|
redis_key = self._get_redis_key(state_id)
|
||||||
|
response = self.redis.get(redis_key)
|
||||||
|
if response:
|
||||||
|
return self.state_class.from_json(response)
|
||||||
|
|
||||||
|
def delete_state(self, state_id) -> None:
|
||||||
|
self.redis.delete(self._get_redis_key(state_id))
|
||||||
|
|
||||||
|
def _get_redis_key(self, state_id):
|
||||||
|
return f"{self.state_class}/{state_id}"
|
||||||
|
|
||||||
|
def get_or_create_state_core(
|
||||||
|
self,
|
||||||
|
state_id=None,
|
||||||
|
init_state: Callable[[T], None] = _do_nothing,
|
||||||
|
validate_state: Callable[[T], None] = _do_nothing,
|
||||||
|
) -> T:
|
||||||
|
state = self.get_state(state_id) if state_id else None
|
||||||
|
if state:
|
||||||
|
validate_state(state)
|
||||||
|
else:
|
||||||
|
state = self.state_class(id=database.utils.id())
|
||||||
|
init_state(state)
|
||||||
|
|
||||||
|
return state
|
||||||
|
|
||||||
|
@contextmanager
|
||||||
|
def get_or_create_state(
|
||||||
|
self,
|
||||||
|
state_id=None,
|
||||||
|
init_state: Callable[[T], None] = _do_nothing,
|
||||||
|
validate_state: Callable[[T], None] = _do_nothing,
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
Try to retrieve state with the given id from the Redis cache if yes then validates it
|
||||||
|
If no then create a new one with randomly generated id
|
||||||
|
Yield the state and write it back to redis once the user code block exits
|
||||||
|
:param state_id: id of the state to retrieve
|
||||||
|
:param init_state: user callback to init the newly created state
|
||||||
|
If not passed then no init except for the id generation is done
|
||||||
|
:param validate_state: user callback to validate the state if retrieved from cache
|
||||||
|
Should throw an exception if the state is not valid. If not passed then no validation is done
|
||||||
|
"""
|
||||||
|
state = self.get_or_create_state_core(
|
||||||
|
state_id=state_id, init_state=init_state, validate_state=validate_state
|
||||||
|
)
|
||||||
|
|
||||||
|
try:
|
||||||
|
yield state
|
||||||
|
finally:
|
||||||
|
self.set_state(state)
|
||||||
97
apiserver/bll/statistics/resource_monitor.py
Normal file
97
apiserver/bll/statistics/resource_monitor.py
Normal file
@@ -0,0 +1,97 @@
|
|||||||
|
from datetime import datetime
|
||||||
|
import operator
|
||||||
|
from threading import Lock
|
||||||
|
from time import sleep
|
||||||
|
|
||||||
|
import attr
|
||||||
|
import psutil
|
||||||
|
|
||||||
|
from apiserver.utilities.threads_manager import ThreadsManager
|
||||||
|
|
||||||
|
|
||||||
|
stat_threads = ThreadsManager("Statistics")
|
||||||
|
|
||||||
|
|
||||||
|
@attr.s(auto_attribs=True)
|
||||||
|
class Sample:
|
||||||
|
cpu_usage: float = 0.0
|
||||||
|
mem_used_gb: float = 0
|
||||||
|
mem_free_gb: float = 0
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _apply(cls, op, *samples):
|
||||||
|
return cls(
|
||||||
|
**{
|
||||||
|
field: op(*(getattr(sample, field) for sample in samples))
|
||||||
|
for field in attr.fields_dict(cls)
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
def min(self, sample):
|
||||||
|
return self._apply(min, self, sample)
|
||||||
|
|
||||||
|
def max(self, sample):
|
||||||
|
return self._apply(max, self, sample)
|
||||||
|
|
||||||
|
def avg(self, sample, count):
|
||||||
|
res = self._apply(lambda x: x * count, self)
|
||||||
|
res = self._apply(operator.add, res, sample)
|
||||||
|
res = self._apply(lambda x: x / (count + 1), res)
|
||||||
|
return res
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_current_sample(cls) -> "Sample":
|
||||||
|
return cls(
|
||||||
|
cpu_usage=psutil.cpu_percent(),
|
||||||
|
mem_used_gb=psutil.virtual_memory().used / (1024 ** 3),
|
||||||
|
mem_free_gb=psutil.virtual_memory().free / (1024 ** 3),
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class ResourceMonitor:
|
||||||
|
class Accumulator:
|
||||||
|
def __init__(self):
|
||||||
|
sample = Sample.get_current_sample()
|
||||||
|
self.avg = sample
|
||||||
|
self.min = sample
|
||||||
|
self.max = sample
|
||||||
|
self.time = datetime.utcnow()
|
||||||
|
self.count = 1
|
||||||
|
|
||||||
|
def add_sample(self, sample: Sample):
|
||||||
|
self.min = self.min.min(sample)
|
||||||
|
self.max = self.max.max(sample)
|
||||||
|
self.avg = self.avg.avg(sample, self.count)
|
||||||
|
self.count += 1
|
||||||
|
|
||||||
|
sample_interval_sec = 5
|
||||||
|
_lock = Lock()
|
||||||
|
accumulator = Accumulator()
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@stat_threads.register("resource_monitor", daemon=True)
|
||||||
|
def start(cls):
|
||||||
|
while True:
|
||||||
|
sleep(cls.sample_interval_sec)
|
||||||
|
sample = Sample.get_current_sample()
|
||||||
|
with cls._lock:
|
||||||
|
cls.accumulator.add_sample(sample)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_stats(cls) -> dict:
|
||||||
|
""" Returns current resource statistics and clears internal resource statistics """
|
||||||
|
with cls._lock:
|
||||||
|
min_ = attr.asdict(cls.accumulator.min)
|
||||||
|
max_ = attr.asdict(cls.accumulator.max)
|
||||||
|
avg = attr.asdict(cls.accumulator.avg)
|
||||||
|
interval = datetime.utcnow() - cls.accumulator.time
|
||||||
|
cls.accumulator = cls.Accumulator()
|
||||||
|
|
||||||
|
return {
|
||||||
|
"interval_sec": interval.total_seconds(),
|
||||||
|
"num_cores": psutil.cpu_count(),
|
||||||
|
**{
|
||||||
|
k: {"min": v, "max": max_[k], "avg": avg[k]}
|
||||||
|
for k, v in min_.items()
|
||||||
|
}
|
||||||
|
}
|
||||||
305
apiserver/bll/statistics/stats_reporter.py
Normal file
305
apiserver/bll/statistics/stats_reporter.py
Normal file
@@ -0,0 +1,305 @@
|
|||||||
|
import logging
|
||||||
|
import queue
|
||||||
|
import random
|
||||||
|
import time
|
||||||
|
from datetime import timedelta, datetime
|
||||||
|
from time import sleep
|
||||||
|
from typing import Sequence, Optional
|
||||||
|
|
||||||
|
import dpath
|
||||||
|
import requests
|
||||||
|
from requests.adapters import HTTPAdapter
|
||||||
|
from requests.packages.urllib3.util.retry import Retry
|
||||||
|
|
||||||
|
from apiserver.bll.query import Builder as QueryBuilder
|
||||||
|
from apiserver.bll.util import get_server_uuid
|
||||||
|
from apiserver.bll.workers import WorkerStats, WorkerBLL
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.config.info import get_deployment_type
|
||||||
|
from apiserver.database.model import Company, User
|
||||||
|
from apiserver.database.model.queue import Queue
|
||||||
|
from apiserver.database.model.task.task import Task
|
||||||
|
from apiserver.tools import safe_get
|
||||||
|
from apiserver.utilities.json import dumps
|
||||||
|
from apiserver.version import __version__ as current_version
|
||||||
|
from .resource_monitor import ResourceMonitor, stat_threads
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
|
||||||
|
worker_bll = WorkerBLL()
|
||||||
|
|
||||||
|
|
||||||
|
class StatisticsReporter:
|
||||||
|
send_queue = queue.Queue()
|
||||||
|
supported = config.get("apiserver.statistics.supported", True)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def start(cls):
|
||||||
|
if not cls.supported:
|
||||||
|
return
|
||||||
|
ResourceMonitor.start()
|
||||||
|
cls.start_sender()
|
||||||
|
cls.start_reporter()
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@stat_threads.register("reporter", daemon=True)
|
||||||
|
def start_reporter(cls):
|
||||||
|
"""
|
||||||
|
Periodically send statistics reports for companies who have opted in.
|
||||||
|
Note: in clearml we usually have only a single company
|
||||||
|
"""
|
||||||
|
if not cls.supported:
|
||||||
|
return
|
||||||
|
|
||||||
|
report_interval = timedelta(
|
||||||
|
hours=config.get("apiserver.statistics.report_interval_hours", 24)
|
||||||
|
)
|
||||||
|
sleep(report_interval.total_seconds())
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
for company in Company.objects(
|
||||||
|
defaults__stats_option__enabled=True
|
||||||
|
).only("id"):
|
||||||
|
stats = cls.get_statistics(company.id)
|
||||||
|
cls.send_queue.put(stats)
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
log.exception(f"Failed collecting stats: {str(ex)}")
|
||||||
|
|
||||||
|
sleep(report_interval.total_seconds())
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@stat_threads.register("sender", daemon=True)
|
||||||
|
def start_sender(cls):
|
||||||
|
if not cls.supported:
|
||||||
|
return
|
||||||
|
|
||||||
|
url = config.get("apiserver.statistics.url")
|
||||||
|
|
||||||
|
retries = config.get("apiserver.statistics.max_retries", 5)
|
||||||
|
max_backoff = config.get("apiserver.statistics.max_backoff_sec", 5)
|
||||||
|
session = requests.Session()
|
||||||
|
adapter = HTTPAdapter(max_retries=Retry(retries))
|
||||||
|
session.mount("http://", adapter)
|
||||||
|
session.mount("https://", adapter)
|
||||||
|
session.headers["Content-type"] = "application/json"
|
||||||
|
|
||||||
|
WarningFilter.attach()
|
||||||
|
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
report = cls.send_queue.get()
|
||||||
|
|
||||||
|
# Set a random backoff factor each time we send a report
|
||||||
|
adapter.max_retries.backoff_factor = random.random() * max_backoff
|
||||||
|
|
||||||
|
session.post(url, data=dumps(report))
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
pass
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_statistics(cls, company_id: str) -> dict:
|
||||||
|
"""
|
||||||
|
Returns a statistics report per company
|
||||||
|
"""
|
||||||
|
return {
|
||||||
|
"time": datetime.utcnow(),
|
||||||
|
"company_id": company_id,
|
||||||
|
"server": {
|
||||||
|
"version": current_version,
|
||||||
|
"deployment": get_deployment_type(),
|
||||||
|
"uuid": get_server_uuid(),
|
||||||
|
"queues": {"count": Queue.objects(company=company_id).count()},
|
||||||
|
"users": {"count": User.objects(company=company_id).count()},
|
||||||
|
"resources": ResourceMonitor.get_stats(),
|
||||||
|
"experiments": next(
|
||||||
|
iter(cls._get_experiments_stats(company_id).values()), {}
|
||||||
|
),
|
||||||
|
},
|
||||||
|
"agents": cls._get_agents_statistics(company_id),
|
||||||
|
}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _get_agents_statistics(cls, company_id: str) -> Sequence[dict]:
|
||||||
|
result = cls._get_resource_stats_per_agent(company_id, key="resources")
|
||||||
|
dpath.merge(
|
||||||
|
result, cls._get_experiments_stats_per_agent(company_id, key="experiments")
|
||||||
|
)
|
||||||
|
return [{"uuid": agent_id, **data} for agent_id, data in result.items()]
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _get_resource_stats_per_agent(cls, company_id: str, key: str) -> dict:
|
||||||
|
agent_resource_threshold_sec = timedelta(
|
||||||
|
hours=config.get("apiserver.statistics.report_interval_hours", 24)
|
||||||
|
).total_seconds()
|
||||||
|
to_timestamp = int(time.time())
|
||||||
|
from_timestamp = to_timestamp - int(agent_resource_threshold_sec)
|
||||||
|
es_req = {
|
||||||
|
"size": 0,
|
||||||
|
"query": QueryBuilder.dates_range(from_timestamp, to_timestamp),
|
||||||
|
"aggs": {
|
||||||
|
"workers": {
|
||||||
|
"terms": {"field": "worker"},
|
||||||
|
"aggs": {
|
||||||
|
"categories": {
|
||||||
|
"terms": {"field": "category"},
|
||||||
|
"aggs": {"count": {"cardinality": {"field": "variant"}}},
|
||||||
|
},
|
||||||
|
"metrics": {
|
||||||
|
"terms": {"field": "metric"},
|
||||||
|
"aggs": {
|
||||||
|
"min": {"min": {"field": "value"}},
|
||||||
|
"max": {"max": {"field": "value"}},
|
||||||
|
"avg": {"avg": {"field": "value"}},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
res = cls._run_worker_stats_query(company_id, es_req)
|
||||||
|
|
||||||
|
def _get_cardinality_fields(categories: Sequence[dict]) -> dict:
|
||||||
|
names = {"cpu": "num_cores"}
|
||||||
|
return {
|
||||||
|
names[c["key"]]: safe_get(c, "count/value")
|
||||||
|
for c in categories
|
||||||
|
if c["key"] in names
|
||||||
|
}
|
||||||
|
|
||||||
|
def _get_metric_fields(metrics: Sequence[dict]) -> dict:
|
||||||
|
names = {
|
||||||
|
"cpu_usage": "cpu_usage",
|
||||||
|
"memory_used": "mem_used_gb",
|
||||||
|
"memory_free": "mem_free_gb",
|
||||||
|
}
|
||||||
|
return {
|
||||||
|
names[m["key"]]: {
|
||||||
|
"min": safe_get(m, "min/value"),
|
||||||
|
"max": safe_get(m, "max/value"),
|
||||||
|
"avg": safe_get(m, "avg/value"),
|
||||||
|
}
|
||||||
|
for m in metrics
|
||||||
|
if m["key"] in names
|
||||||
|
}
|
||||||
|
|
||||||
|
buckets = safe_get(res, "aggregations/workers/buckets", default=[])
|
||||||
|
return {
|
||||||
|
b["key"]: {
|
||||||
|
key: {
|
||||||
|
"interval_sec": agent_resource_threshold_sec,
|
||||||
|
**_get_cardinality_fields(safe_get(b, "categories/buckets", [])),
|
||||||
|
**_get_metric_fields(safe_get(b, "metrics/buckets", [])),
|
||||||
|
}
|
||||||
|
}
|
||||||
|
for b in buckets
|
||||||
|
}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _get_experiments_stats_per_agent(cls, company_id: str, key: str) -> dict:
|
||||||
|
agent_relevant_threshold = timedelta(
|
||||||
|
days=config.get("apiserver.statistics.agent_relevant_threshold_days", 30)
|
||||||
|
)
|
||||||
|
to_timestamp = int(time.time())
|
||||||
|
from_timestamp = to_timestamp - int(agent_relevant_threshold.total_seconds())
|
||||||
|
workers = cls._get_active_workers(company_id, from_timestamp, to_timestamp)
|
||||||
|
if not workers:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
stats = cls._get_experiments_stats(company_id, list(workers.keys()))
|
||||||
|
return {
|
||||||
|
worker_id: {key: {**workers[worker_id], **stat}}
|
||||||
|
for worker_id, stat in stats.items()
|
||||||
|
}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _get_active_workers(
|
||||||
|
cls, company_id, from_timestamp: int, to_timestamp: int
|
||||||
|
) -> dict:
|
||||||
|
es_req = {
|
||||||
|
"size": 0,
|
||||||
|
"query": QueryBuilder.dates_range(from_timestamp, to_timestamp),
|
||||||
|
"aggs": {
|
||||||
|
"workers": {
|
||||||
|
"terms": {"field": "worker"},
|
||||||
|
"aggs": {"last_activity_time": {"max": {"field": "timestamp"}}},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
}
|
||||||
|
res = cls._run_worker_stats_query(company_id, es_req)
|
||||||
|
buckets = safe_get(res, "aggregations/workers/buckets", default=[])
|
||||||
|
return {
|
||||||
|
b["key"]: {"last_activity_time": b["last_activity_time"]["value"]}
|
||||||
|
for b in buckets
|
||||||
|
}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _run_worker_stats_query(cls, company_id, es_req) -> dict:
|
||||||
|
return worker_bll.es_client.search(
|
||||||
|
index=f"{WorkerStats.worker_stats_prefix_for_company(company_id)}*",
|
||||||
|
body=es_req,
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _get_experiments_stats(
|
||||||
|
cls, company_id, workers: Optional[Sequence] = None
|
||||||
|
) -> dict:
|
||||||
|
pipeline = [
|
||||||
|
{
|
||||||
|
"$match": {
|
||||||
|
"company": company_id,
|
||||||
|
"started": {"$exists": True, "$ne": None},
|
||||||
|
"last_update": {"$exists": True, "$ne": None},
|
||||||
|
"status": {"$nin": ["created", "queued"]},
|
||||||
|
**({"last_worker": {"$in": workers}} if workers else {}),
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"$group": {
|
||||||
|
"_id": "$last_worker" if workers else None,
|
||||||
|
"count": {"$sum": 1},
|
||||||
|
"avg_run_time_sec": {
|
||||||
|
"$avg": {
|
||||||
|
"$divide": [
|
||||||
|
{"$subtract": ["$last_update", "$started"]},
|
||||||
|
1000,
|
||||||
|
]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"avg_iterations": {"$avg": "$last_iteration"},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"$project": {
|
||||||
|
"count": 1,
|
||||||
|
"avg_run_time_sec": {"$trunc": "$avg_run_time_sec"},
|
||||||
|
"avg_iterations": {"$trunc": "$avg_iterations"},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
]
|
||||||
|
return {
|
||||||
|
group["_id"]: {k: v for k, v in group.items() if k != "_id"}
|
||||||
|
for group in Task.aggregate(pipeline)
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
class WarningFilter(logging.Filter):
|
||||||
|
@classmethod
|
||||||
|
def attach(cls):
|
||||||
|
from urllib3.connectionpool import (
|
||||||
|
ConnectionPool,
|
||||||
|
) # required to make sure the logger is created
|
||||||
|
|
||||||
|
assert ConnectionPool # make sure import is not optimized out
|
||||||
|
|
||||||
|
logging.getLogger("urllib3.connectionpool").addFilter(cls())
|
||||||
|
|
||||||
|
def filter(self, record):
|
||||||
|
if (
|
||||||
|
record.levelno == logging.WARNING
|
||||||
|
and len(record.args) > 2
|
||||||
|
and record.args[2] == "/stats"
|
||||||
|
):
|
||||||
|
return False
|
||||||
|
return True
|
||||||
48
apiserver/bll/storage/__init__.py
Normal file
48
apiserver/bll/storage/__init__.py
Normal file
@@ -0,0 +1,48 @@
|
|||||||
|
from copy import copy
|
||||||
|
|
||||||
|
from boltons.cacheutils import cachedproperty
|
||||||
|
from clearml.backend_config.bucket_config import (
|
||||||
|
S3BucketConfigurations,
|
||||||
|
AzureContainerConfigurations,
|
||||||
|
GSBucketConfigurations,
|
||||||
|
)
|
||||||
|
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
|
||||||
|
|
||||||
|
class StorageBLL:
|
||||||
|
default_aws_configs: S3BucketConfigurations = None
|
||||||
|
conf = config.get("services.storage_credentials")
|
||||||
|
|
||||||
|
@cachedproperty
|
||||||
|
def _default_aws_configs(self) -> S3BucketConfigurations:
|
||||||
|
return S3BucketConfigurations.from_config(self.conf.get("aws.s3"))
|
||||||
|
|
||||||
|
@cachedproperty
|
||||||
|
def _default_azure_configs(self) -> AzureContainerConfigurations:
|
||||||
|
return AzureContainerConfigurations.from_config(self.conf.get("azure.storage"))
|
||||||
|
|
||||||
|
@cachedproperty
|
||||||
|
def _default_gs_configs(self) -> GSBucketConfigurations:
|
||||||
|
return GSBucketConfigurations.from_config(self.conf.get("google.storage"))
|
||||||
|
|
||||||
|
def get_azure_settings_for_company(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
) -> AzureContainerConfigurations:
|
||||||
|
return copy(self._default_azure_configs)
|
||||||
|
|
||||||
|
def get_gs_settings_for_company(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
) -> GSBucketConfigurations:
|
||||||
|
return copy(self._default_gs_configs)
|
||||||
|
|
||||||
|
def get_aws_settings_for_company(
|
||||||
|
self,
|
||||||
|
company_id: str,
|
||||||
|
) -> S3BucketConfigurations:
|
||||||
|
return copy(self._default_aws_configs)
|
||||||
@@ -3,5 +3,4 @@ from .utils import (
|
|||||||
ChangeStatusRequest,
|
ChangeStatusRequest,
|
||||||
update_project_time,
|
update_project_time,
|
||||||
validate_status_change,
|
validate_status_change,
|
||||||
split_by,
|
|
||||||
)
|
)
|
||||||
88
apiserver/bll/task/artifacts.py
Normal file
88
apiserver/bll/task/artifacts.py
Normal file
@@ -0,0 +1,88 @@
|
|||||||
|
from operator import itemgetter
|
||||||
|
from typing import Sequence
|
||||||
|
|
||||||
|
from apiserver.apimodels.tasks import Artifact as ApiArtifact, ArtifactId
|
||||||
|
from apiserver.bll.task.utils import get_task_for_update, update_task
|
||||||
|
from apiserver.database.model.task.task import DEFAULT_ARTIFACT_MODE, Artifact
|
||||||
|
from apiserver.database.utils import hash_field_name
|
||||||
|
from apiserver.utilities.dicts import nested_get, nested_set
|
||||||
|
from apiserver.utilities.parameter_key_escaper import mongoengine_safe
|
||||||
|
|
||||||
|
|
||||||
|
def get_artifact_id(artifact: dict):
|
||||||
|
"""
|
||||||
|
Calculate id from 'key' and 'mode' fields
|
||||||
|
Return hash on on the id so that it will not contain mongo illegal characters
|
||||||
|
"""
|
||||||
|
key_hash: str = hash_field_name(artifact["key"])
|
||||||
|
mode: str = artifact.get("mode", DEFAULT_ARTIFACT_MODE)
|
||||||
|
return f"{key_hash}_{mode}"
|
||||||
|
|
||||||
|
|
||||||
|
def artifacts_prepare_for_save(fields: dict):
|
||||||
|
artifacts_field = ("execution", "artifacts")
|
||||||
|
artifacts = nested_get(fields, artifacts_field)
|
||||||
|
if artifacts is None:
|
||||||
|
return
|
||||||
|
|
||||||
|
nested_set(
|
||||||
|
fields, artifacts_field, value={get_artifact_id(a): a for a in artifacts}
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def artifacts_unprepare_from_saved(fields):
|
||||||
|
artifacts_field = ("execution", "artifacts")
|
||||||
|
artifacts = nested_get(fields, artifacts_field)
|
||||||
|
if artifacts is None:
|
||||||
|
return
|
||||||
|
|
||||||
|
nested_set(
|
||||||
|
fields,
|
||||||
|
artifacts_field,
|
||||||
|
value=sorted(artifacts.values(), key=itemgetter("key")),
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class Artifacts:
|
||||||
|
@classmethod
|
||||||
|
def add_or_update_artifacts(
|
||||||
|
cls,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
task_id: str,
|
||||||
|
artifacts: Sequence[ApiArtifact],
|
||||||
|
force: bool,
|
||||||
|
) -> int:
|
||||||
|
task = get_task_for_update(company_id=company_id, task_id=task_id, force=force,)
|
||||||
|
|
||||||
|
artifacts = {
|
||||||
|
get_artifact_id(a): Artifact(**a)
|
||||||
|
for a in (api_artifact.to_struct() for api_artifact in artifacts)
|
||||||
|
}
|
||||||
|
|
||||||
|
update_cmds = {
|
||||||
|
f"set__execution__artifacts__{mongoengine_safe(name)}": value
|
||||||
|
for name, value in artifacts.items()
|
||||||
|
}
|
||||||
|
return update_task(task, user_id=user_id, update_cmds=update_cmds)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def delete_artifacts(
|
||||||
|
cls,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
task_id: str,
|
||||||
|
artifact_ids: Sequence[ArtifactId],
|
||||||
|
force: bool,
|
||||||
|
) -> int:
|
||||||
|
task = get_task_for_update(company_id=company_id, task_id=task_id, force=force,)
|
||||||
|
|
||||||
|
artifact_ids = [
|
||||||
|
get_artifact_id(a)
|
||||||
|
for a in (artifact_id.to_struct() for artifact_id in artifact_ids)
|
||||||
|
]
|
||||||
|
delete_cmds = {
|
||||||
|
f"unset__execution__artifacts__{id_}": 1 for id_ in set(artifact_ids)
|
||||||
|
}
|
||||||
|
|
||||||
|
return update_task(task, user_id=user_id, update_cmds=delete_cmds)
|
||||||
249
apiserver/bll/task/hyperparams.py
Normal file
249
apiserver/bll/task/hyperparams.py
Normal file
@@ -0,0 +1,249 @@
|
|||||||
|
from itertools import chain
|
||||||
|
from operator import attrgetter
|
||||||
|
from typing import Sequence, Dict
|
||||||
|
|
||||||
|
from boltons import iterutils
|
||||||
|
|
||||||
|
from apiserver.apierrors import errors
|
||||||
|
from apiserver.apimodels.tasks import (
|
||||||
|
HyperParamKey,
|
||||||
|
HyperParamItem,
|
||||||
|
ReplaceHyperparams,
|
||||||
|
Configuration,
|
||||||
|
)
|
||||||
|
from apiserver.bll.task import TaskBLL
|
||||||
|
from apiserver.bll.task.utils import get_task_for_update, update_task
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.model.task.task import ParamsItem, Task, ConfigurationItem
|
||||||
|
from apiserver.utilities.parameter_key_escaper import (
|
||||||
|
ParameterKeyEscaper,
|
||||||
|
mongoengine_safe,
|
||||||
|
)
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
task_bll = TaskBLL()
|
||||||
|
|
||||||
|
|
||||||
|
class HyperParams:
|
||||||
|
_properties_section = "properties"
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_params(cls, company_id: str, task_ids: Sequence[str]) -> Dict[str, dict]:
|
||||||
|
only = ("id", "hyperparams")
|
||||||
|
tasks = task_bll.assert_exists(
|
||||||
|
company_id=company_id, task_ids=task_ids, only=only, allow_public=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
return {
|
||||||
|
task.id: {"hyperparams": cls._get_params_list(items=task.hyperparams)}
|
||||||
|
for task in tasks
|
||||||
|
}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _get_params_list(
|
||||||
|
cls, items: Dict[str, Dict[str, ParamsItem]]
|
||||||
|
) -> Sequence[dict]:
|
||||||
|
ret = list(chain.from_iterable(v.values() for v in items.values()))
|
||||||
|
return [
|
||||||
|
p.to_proper_dict() for p in sorted(ret, key=attrgetter("section", "name"))
|
||||||
|
]
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _normalize_params(cls, params: Sequence) -> bool:
|
||||||
|
"""
|
||||||
|
Lower case properties section and return True if it is the only section
|
||||||
|
"""
|
||||||
|
for p in params:
|
||||||
|
if p.section.lower() == cls._properties_section:
|
||||||
|
p.section = cls._properties_section
|
||||||
|
|
||||||
|
return all(p.section == cls._properties_section for p in params)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def delete_params(
|
||||||
|
cls,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
task_id: str,
|
||||||
|
hyperparams: Sequence[HyperParamKey],
|
||||||
|
force: bool,
|
||||||
|
) -> int:
|
||||||
|
properties_only = cls._normalize_params(hyperparams)
|
||||||
|
task = get_task_for_update(
|
||||||
|
company_id=company_id,
|
||||||
|
task_id=task_id,
|
||||||
|
allow_all_statuses=properties_only,
|
||||||
|
force=force,
|
||||||
|
)
|
||||||
|
|
||||||
|
with_param, without_param = iterutils.partition(
|
||||||
|
hyperparams, key=lambda p: bool(p.name)
|
||||||
|
)
|
||||||
|
sections_to_delete = {p.section for p in without_param}
|
||||||
|
delete_cmds = {
|
||||||
|
f"unset__hyperparams__{ParameterKeyEscaper.escape(section)}": 1
|
||||||
|
for section in sections_to_delete
|
||||||
|
}
|
||||||
|
|
||||||
|
for item in with_param:
|
||||||
|
section = ParameterKeyEscaper.escape(item.section)
|
||||||
|
if item.section in sections_to_delete:
|
||||||
|
raise errors.bad_request.FieldsConflict(
|
||||||
|
"Cannot delete section field if the whole section was scheduled for deletion"
|
||||||
|
)
|
||||||
|
name = ParameterKeyEscaper.escape(item.name)
|
||||||
|
delete_cmds[f"unset__hyperparams__{section}__{name}"] = 1
|
||||||
|
|
||||||
|
return update_task(
|
||||||
|
task,
|
||||||
|
user_id=user_id,
|
||||||
|
update_cmds=delete_cmds,
|
||||||
|
set_last_update=not properties_only,
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def edit_params(
|
||||||
|
cls,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
task_id: str,
|
||||||
|
hyperparams: Sequence[HyperParamItem],
|
||||||
|
replace_hyperparams: str,
|
||||||
|
force: bool,
|
||||||
|
) -> int:
|
||||||
|
properties_only = cls._normalize_params(hyperparams)
|
||||||
|
task = get_task_for_update(
|
||||||
|
company_id=company_id,
|
||||||
|
task_id=task_id,
|
||||||
|
allow_all_statuses=properties_only,
|
||||||
|
force=force,
|
||||||
|
)
|
||||||
|
|
||||||
|
update_cmds = dict()
|
||||||
|
hyperparams = cls._db_dicts_from_list(hyperparams)
|
||||||
|
if replace_hyperparams == ReplaceHyperparams.all:
|
||||||
|
update_cmds["set__hyperparams"] = hyperparams
|
||||||
|
elif replace_hyperparams == ReplaceHyperparams.section:
|
||||||
|
for section, value in hyperparams.items():
|
||||||
|
update_cmds[f"set__hyperparams__{mongoengine_safe(section)}"] = value
|
||||||
|
else:
|
||||||
|
for section, section_params in hyperparams.items():
|
||||||
|
for name, value in section_params.items():
|
||||||
|
update_cmds[
|
||||||
|
f"set__hyperparams__{section}__{mongoengine_safe(name)}"
|
||||||
|
] = value
|
||||||
|
|
||||||
|
return update_task(
|
||||||
|
task,
|
||||||
|
user_id=user_id,
|
||||||
|
update_cmds=update_cmds,
|
||||||
|
set_last_update=not properties_only,
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _db_dicts_from_list(cls, items: Sequence[HyperParamItem]) -> Dict[str, dict]:
|
||||||
|
sections = iterutils.bucketize(items, key=attrgetter("section"))
|
||||||
|
return {
|
||||||
|
ParameterKeyEscaper.escape(section): {
|
||||||
|
ParameterKeyEscaper.escape(param.name): ParamsItem(**param.to_struct())
|
||||||
|
for param in params
|
||||||
|
}
|
||||||
|
for section, params in sections.items()
|
||||||
|
}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_configurations(
|
||||||
|
cls, company_id: str, task_ids: Sequence[str], names: Sequence[str]
|
||||||
|
) -> Dict[str, dict]:
|
||||||
|
only = ["id"]
|
||||||
|
if names:
|
||||||
|
only.extend(
|
||||||
|
f"configuration.{ParameterKeyEscaper.escape(name)}" for name in names
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
only.append("configuration")
|
||||||
|
tasks = task_bll.assert_exists(
|
||||||
|
company_id=company_id, task_ids=task_ids, only=only, allow_public=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
return {
|
||||||
|
task.id: {
|
||||||
|
"configuration": [
|
||||||
|
c.to_proper_dict()
|
||||||
|
for c in sorted(task.configuration.values(), key=attrgetter("name"))
|
||||||
|
]
|
||||||
|
}
|
||||||
|
for task in tasks
|
||||||
|
}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_configuration_names(
|
||||||
|
cls, company_id: str, task_ids: Sequence[str], skip_empty: bool
|
||||||
|
) -> Dict[str, list]:
|
||||||
|
skip_empty_condition = {"$match": {"items.v.value": {"$nin": [None, ""]}}}
|
||||||
|
pipeline = [
|
||||||
|
{
|
||||||
|
"$match": {
|
||||||
|
"company": {"$in": [None, "", company_id]},
|
||||||
|
"_id": {"$in": task_ids},
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{"$project": {"items": {"$objectToArray": "$configuration"}}},
|
||||||
|
{"$unwind": "$items"},
|
||||||
|
*([skip_empty_condition] if skip_empty else []),
|
||||||
|
{"$group": {"_id": "$_id", "names": {"$addToSet": "$items.k"}}},
|
||||||
|
]
|
||||||
|
|
||||||
|
tasks = Task.aggregate(pipeline)
|
||||||
|
|
||||||
|
return {
|
||||||
|
task["_id"]: {
|
||||||
|
"names": sorted(
|
||||||
|
ParameterKeyEscaper.unescape(name) for name in task["names"]
|
||||||
|
)
|
||||||
|
}
|
||||||
|
for task in tasks
|
||||||
|
}
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def edit_configuration(
|
||||||
|
cls,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
task_id: str,
|
||||||
|
configuration: Sequence[Configuration],
|
||||||
|
replace_configuration: bool,
|
||||||
|
force: bool,
|
||||||
|
) -> int:
|
||||||
|
task = get_task_for_update(company_id=company_id, task_id=task_id, force=force)
|
||||||
|
|
||||||
|
update_cmds = dict()
|
||||||
|
configuration = {
|
||||||
|
ParameterKeyEscaper.escape(c.name): ConfigurationItem(**c.to_struct())
|
||||||
|
for c in configuration
|
||||||
|
}
|
||||||
|
if replace_configuration:
|
||||||
|
update_cmds["set__configuration"] = configuration
|
||||||
|
else:
|
||||||
|
for name, value in configuration.items():
|
||||||
|
update_cmds[f"set__configuration__{mongoengine_safe(name)}"] = value
|
||||||
|
|
||||||
|
return update_task(task, user_id=user_id, update_cmds=update_cmds)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def delete_configuration(
|
||||||
|
cls,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
task_id: str,
|
||||||
|
configuration: Sequence[str],
|
||||||
|
force: bool,
|
||||||
|
) -> int:
|
||||||
|
task = get_task_for_update(company_id=company_id, task_id=task_id, force=force)
|
||||||
|
|
||||||
|
delete_cmds = {
|
||||||
|
f"unset__configuration__{ParameterKeyEscaper.escape(name)}": 1
|
||||||
|
for name in set(configuration)
|
||||||
|
}
|
||||||
|
|
||||||
|
return update_task(task, user_id=user_id, update_cmds=delete_cmds)
|
||||||
98
apiserver/bll/task/non_responsive_tasks_watchdog.py
Normal file
98
apiserver/bll/task/non_responsive_tasks_watchdog.py
Normal file
@@ -0,0 +1,98 @@
|
|||||||
|
from datetime import timedelta, datetime
|
||||||
|
from time import sleep
|
||||||
|
|
||||||
|
from apiserver.bll.task import update_project_time
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.model.task.task import TaskStatus, Task
|
||||||
|
from apiserver.utilities.threads_manager import ThreadsManager
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
|
||||||
|
|
||||||
|
class NonResponsiveTasksWatchdog:
|
||||||
|
threads = ThreadsManager()
|
||||||
|
|
||||||
|
class _Settings:
|
||||||
|
"""
|
||||||
|
Retrieves watchdog settings from the config file
|
||||||
|
The properties are not cached so that the updates in
|
||||||
|
the config file are reflected
|
||||||
|
"""
|
||||||
|
|
||||||
|
_prefix = "services.tasks.non_responsive_tasks_watchdog"
|
||||||
|
|
||||||
|
@property
|
||||||
|
def enabled(self):
|
||||||
|
return config.get(f"{self._prefix}.enabled", True)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def watch_interval_sec(self):
|
||||||
|
return config.get(f"{self._prefix}.watch_interval_sec", 900)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def threshold_sec(self):
|
||||||
|
return config.get(f"{self._prefix}.threshold_sec", 7200)
|
||||||
|
|
||||||
|
settings = _Settings()
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@threads.register("non_responsive_tasks_watchdog", daemon=True)
|
||||||
|
def start(cls):
|
||||||
|
sleep(cls.settings.watch_interval_sec)
|
||||||
|
while True:
|
||||||
|
watch_interval = cls.settings.watch_interval_sec
|
||||||
|
if cls.settings.enabled:
|
||||||
|
try:
|
||||||
|
stopped = cls.cleanup_tasks(
|
||||||
|
threshold_sec=cls.settings.threshold_sec
|
||||||
|
)
|
||||||
|
log.info(f"{stopped} non-responsive tasks stopped")
|
||||||
|
except Exception as ex:
|
||||||
|
log.exception(f"Failed stopping tasks: {str(ex)}")
|
||||||
|
sleep(watch_interval)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def cleanup_tasks(cls, threshold_sec):
|
||||||
|
relevant_status = (TaskStatus.in_progress,)
|
||||||
|
threshold = timedelta(seconds=threshold_sec)
|
||||||
|
ref_time = datetime.utcnow() - threshold
|
||||||
|
log.info(
|
||||||
|
f"Starting cleanup cycle for running tasks last updated before {ref_time}"
|
||||||
|
)
|
||||||
|
|
||||||
|
tasks = list(
|
||||||
|
Task.objects(status__in=relevant_status, last_update__lt=ref_time).only(
|
||||||
|
"id", "name", "status", "project", "last_update"
|
||||||
|
)
|
||||||
|
)
|
||||||
|
log.info(f"{len(tasks)} non-responsive tasks found")
|
||||||
|
if not tasks:
|
||||||
|
return 0
|
||||||
|
|
||||||
|
err_count = 0
|
||||||
|
project_ids = set()
|
||||||
|
now = datetime.utcnow()
|
||||||
|
for task in tasks:
|
||||||
|
log.info(
|
||||||
|
f"Stopping {task.id} ({task.name}), last updated at {task.last_update}"
|
||||||
|
)
|
||||||
|
# noinspection PyBroadException
|
||||||
|
try:
|
||||||
|
updated = Task.objects(id=task.id, status=task.status).update(
|
||||||
|
status=TaskStatus.stopped,
|
||||||
|
status_reason="Forced stop (non-responsive)",
|
||||||
|
status_message="Forced stop (non-responsive)",
|
||||||
|
status_changed=now,
|
||||||
|
last_update=now,
|
||||||
|
last_change=now,
|
||||||
|
)
|
||||||
|
if updated:
|
||||||
|
project_ids.add(task.project)
|
||||||
|
else:
|
||||||
|
err_count += 1
|
||||||
|
except Exception as ex:
|
||||||
|
log.error("Failed setting status: %s", str(ex))
|
||||||
|
|
||||||
|
update_project_time(list(project_ids))
|
||||||
|
|
||||||
|
return len(tasks) - err_count
|
||||||
216
apiserver/bll/task/param_utils.py
Normal file
216
apiserver/bll/task/param_utils.py
Normal file
@@ -0,0 +1,216 @@
|
|||||||
|
import itertools
|
||||||
|
from typing import Sequence, Tuple, Optional
|
||||||
|
|
||||||
|
|
||||||
|
from apiserver.apierrors import errors
|
||||||
|
from apiserver.database.model.task.task import Task
|
||||||
|
from apiserver.utilities.dicts import nested_get, nested_delete, nested_set
|
||||||
|
from apiserver.utilities.parameter_key_escaper import ParameterKeyEscaper
|
||||||
|
|
||||||
|
|
||||||
|
hyperparams_default_section = "Args"
|
||||||
|
hyperparams_legacy_type = "legacy"
|
||||||
|
tf_define_section = "TF_DEFINE"
|
||||||
|
|
||||||
|
|
||||||
|
def split_param_name(full_name: str, default_section: str) -> Tuple[Optional[str], str]:
|
||||||
|
"""
|
||||||
|
Return parameter section and name. The section is either TF_DEFINE or the default one
|
||||||
|
"""
|
||||||
|
if default_section is None:
|
||||||
|
return None, full_name
|
||||||
|
|
||||||
|
section, _, name = full_name.partition("/")
|
||||||
|
if section != tf_define_section:
|
||||||
|
return default_section, full_name
|
||||||
|
|
||||||
|
if not name:
|
||||||
|
raise errors.bad_request.ValidationError("Parameter name cannot be empty")
|
||||||
|
return section, name
|
||||||
|
|
||||||
|
|
||||||
|
def _get_full_param_name(param: dict) -> str:
|
||||||
|
section = param.get("section")
|
||||||
|
if section != tf_define_section:
|
||||||
|
return param["name"]
|
||||||
|
|
||||||
|
return "/".join((section, param["name"]))
|
||||||
|
|
||||||
|
|
||||||
|
def _remove_legacy_params(data: dict, with_sections: bool = False) -> int:
|
||||||
|
"""
|
||||||
|
Remove the legacy params from the data dict and return the number of removed params
|
||||||
|
If the path not found then return 0
|
||||||
|
"""
|
||||||
|
removed = 0
|
||||||
|
if not data:
|
||||||
|
return removed
|
||||||
|
|
||||||
|
if with_sections:
|
||||||
|
for section, section_data in list(data.items()):
|
||||||
|
removed += _remove_legacy_params(section_data)
|
||||||
|
if not section_data:
|
||||||
|
"""If section is empty after removing legacy params then delete it"""
|
||||||
|
del data[section]
|
||||||
|
else:
|
||||||
|
for key, param in list(data.items()):
|
||||||
|
if param.get("type") == hyperparams_legacy_type:
|
||||||
|
removed += 1
|
||||||
|
del data[key]
|
||||||
|
|
||||||
|
return removed
|
||||||
|
|
||||||
|
|
||||||
|
def _get_legacy_params(data: dict, with_sections: bool = False) -> Sequence[dict]:
|
||||||
|
"""
|
||||||
|
Remove the legacy params from the data dict and return the number of removed params
|
||||||
|
If the path not found then return 0
|
||||||
|
"""
|
||||||
|
if not data:
|
||||||
|
return []
|
||||||
|
|
||||||
|
if with_sections:
|
||||||
|
return list(
|
||||||
|
itertools.chain.from_iterable(
|
||||||
|
_get_legacy_params(section_data) for section_data in data.values()
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
return [
|
||||||
|
param for param in data.values() if param.get("type") == hyperparams_legacy_type
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def params_prepare_for_save(fields: dict, previous_task: Task = None):
|
||||||
|
"""
|
||||||
|
If legacy hyper params or configuration is passed then replace the corresponding section in the new structure
|
||||||
|
Escape all the section and param names for hyper params and configuration to make it mongo sage
|
||||||
|
"""
|
||||||
|
for old_params_field, new_params_field, default_section in (
|
||||||
|
(("execution", "parameters"), "hyperparams", hyperparams_default_section),
|
||||||
|
(("execution", "model_desc"), "configuration", None),
|
||||||
|
):
|
||||||
|
legacy_params = nested_get(fields, old_params_field)
|
||||||
|
if legacy_params is None:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if (
|
||||||
|
not fields.get(new_params_field)
|
||||||
|
and previous_task
|
||||||
|
and previous_task[new_params_field]
|
||||||
|
):
|
||||||
|
previous_data = previous_task.to_proper_dict().get(new_params_field)
|
||||||
|
removed = _remove_legacy_params(
|
||||||
|
previous_data, with_sections=default_section is not None
|
||||||
|
)
|
||||||
|
if not legacy_params and not removed:
|
||||||
|
# if we only need to delete legacy fields from the db
|
||||||
|
# but they are not there then there is no point to proceed
|
||||||
|
continue
|
||||||
|
|
||||||
|
fields_update = {new_params_field: previous_data}
|
||||||
|
params_unprepare_from_saved(fields_update)
|
||||||
|
fields.update(fields_update)
|
||||||
|
|
||||||
|
for full_name, value in legacy_params.items():
|
||||||
|
section, name = split_param_name(full_name, default_section)
|
||||||
|
new_path = list(filter(None, (new_params_field, section, name)))
|
||||||
|
new_param = dict(name=name, type=hyperparams_legacy_type, value=str(value))
|
||||||
|
if section is not None:
|
||||||
|
new_param["section"] = section
|
||||||
|
nested_set(fields, new_path, new_param)
|
||||||
|
nested_delete(fields, old_params_field)
|
||||||
|
|
||||||
|
def ensure_non_empty(k: str, desc: str) -> str:
|
||||||
|
if not k:
|
||||||
|
raise errors.bad_request.ValidationError(
|
||||||
|
f"Empty {desc} name is not allowed"
|
||||||
|
)
|
||||||
|
return k
|
||||||
|
|
||||||
|
params = fields.get("hyperparams")
|
||||||
|
if params:
|
||||||
|
escaped_params = {
|
||||||
|
ParameterKeyEscaper.escape(ensure_non_empty(key, "section")): {
|
||||||
|
ParameterKeyEscaper.escape(ensure_non_empty(k, "parameter")): v
|
||||||
|
for k, v in value.items()
|
||||||
|
}
|
||||||
|
for key, value in params.items()
|
||||||
|
}
|
||||||
|
fields["hyperparams"] = escaped_params
|
||||||
|
|
||||||
|
params = fields.get("configuration")
|
||||||
|
if params:
|
||||||
|
escaped_params = {
|
||||||
|
ParameterKeyEscaper.escape(ensure_non_empty(key, "configuration")): value
|
||||||
|
for key, value in params.items()
|
||||||
|
}
|
||||||
|
fields["configuration"] = escaped_params
|
||||||
|
|
||||||
|
|
||||||
|
def params_unprepare_from_saved(fields, copy_to_legacy=False):
|
||||||
|
"""
|
||||||
|
Unescape all section and param names for hyper params and configuration
|
||||||
|
If copy_to_legacy is set then copy hyperparams and configuration data to the legacy location for the old clients
|
||||||
|
"""
|
||||||
|
for param_field in ("hyperparams", "configuration"):
|
||||||
|
params = fields.get(param_field)
|
||||||
|
if params:
|
||||||
|
unescaped_params = {
|
||||||
|
ParameterKeyEscaper.unescape(key): {
|
||||||
|
ParameterKeyEscaper.unescape(k): v for k, v in value.items()
|
||||||
|
}
|
||||||
|
if isinstance(value, dict)
|
||||||
|
else value
|
||||||
|
for key, value in params.items()
|
||||||
|
}
|
||||||
|
fields[param_field] = unescaped_params
|
||||||
|
|
||||||
|
if copy_to_legacy:
|
||||||
|
for new_params_field, old_params_field, use_sections in (
|
||||||
|
("hyperparams", ("execution", "parameters"), True),
|
||||||
|
("configuration", ("execution", "model_desc"), False),
|
||||||
|
):
|
||||||
|
legacy_params = _get_legacy_params(
|
||||||
|
fields.get(new_params_field), with_sections=use_sections
|
||||||
|
)
|
||||||
|
if legacy_params:
|
||||||
|
nested_set(
|
||||||
|
fields,
|
||||||
|
old_params_field,
|
||||||
|
{_get_full_param_name(p): p["value"] for p in legacy_params},
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def _process_path(path: str):
|
||||||
|
"""
|
||||||
|
Frontend does a partial escaping on the path so the all '.' in section and key names are escaped
|
||||||
|
Need to unescape and apply a full mongo escaping
|
||||||
|
"""
|
||||||
|
parts = path.split(".")
|
||||||
|
if len(parts) < 2 or len(parts) > 4:
|
||||||
|
raise errors.bad_request.ValidationError("invalid task field", path=path)
|
||||||
|
return ".".join(
|
||||||
|
ParameterKeyEscaper.escape(ParameterKeyEscaper.unescape(p)) for p in parts
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def escape_paths(paths: Sequence[str]) -> Sequence[str]:
|
||||||
|
for old_prefix, new_prefix in (
|
||||||
|
("execution.parameters", f"hyperparams.{hyperparams_default_section}"),
|
||||||
|
("execution.model_desc", "configuration"),
|
||||||
|
("execution.docker_cmd", "container"),
|
||||||
|
):
|
||||||
|
path: str
|
||||||
|
paths = [path.replace(old_prefix, new_prefix) for path in paths]
|
||||||
|
|
||||||
|
for prefix in (
|
||||||
|
"hyperparams.",
|
||||||
|
"-hyperparams.",
|
||||||
|
"configuration.",
|
||||||
|
"-configuration.",
|
||||||
|
):
|
||||||
|
paths = [
|
||||||
|
_process_path(path) if path.startswith(prefix) else path for path in paths
|
||||||
|
]
|
||||||
|
return paths
|
||||||
571
apiserver/bll/task/task_bll.py
Normal file
571
apiserver/bll/task/task_bll.py
Normal file
@@ -0,0 +1,571 @@
|
|||||||
|
from datetime import datetime
|
||||||
|
from typing import Collection, Sequence, Tuple, Optional, Dict
|
||||||
|
|
||||||
|
import six
|
||||||
|
from mongoengine import Q
|
||||||
|
from redis import StrictRedis
|
||||||
|
from six import string_types
|
||||||
|
|
||||||
|
import apiserver.database.utils as dbutils
|
||||||
|
from apiserver.apierrors import errors
|
||||||
|
from apiserver.apimodels.tasks import TaskInputModel
|
||||||
|
from apiserver.bll.queue import QueueBLL
|
||||||
|
from apiserver.bll.organization import OrgBLL, Tags
|
||||||
|
from apiserver.bll.project import ProjectBLL
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.errors import translate_errors_context
|
||||||
|
from apiserver.database.model.model import Model
|
||||||
|
from apiserver.database.model.project import Project
|
||||||
|
from apiserver.database.model.task.metrics import EventStats, MetricEventStats
|
||||||
|
from apiserver.database.model.task.output import Output
|
||||||
|
from apiserver.database.model.task.task import (
|
||||||
|
Task,
|
||||||
|
TaskStatus,
|
||||||
|
TaskSystemTags,
|
||||||
|
ArtifactModes,
|
||||||
|
ModelItem,
|
||||||
|
Models,
|
||||||
|
DEFAULT_ARTIFACT_MODE,
|
||||||
|
TaskModelNames,
|
||||||
|
TaskModelTypes,
|
||||||
|
)
|
||||||
|
from apiserver.database.model import EntityVisibility
|
||||||
|
from apiserver.database.utils import get_company_or_none_constraint, id as create_id
|
||||||
|
from apiserver.es_factory import es_factory
|
||||||
|
from apiserver.redis_manager import redman
|
||||||
|
from apiserver.services.utils import validate_tags, escape_dict_field, escape_dict
|
||||||
|
from .artifacts import artifacts_prepare_for_save
|
||||||
|
from .param_utils import params_prepare_for_save
|
||||||
|
from .utils import (
|
||||||
|
ChangeStatusRequest,
|
||||||
|
update_project_time,
|
||||||
|
deleted_prefix,
|
||||||
|
)
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
org_bll = OrgBLL()
|
||||||
|
queue_bll = QueueBLL()
|
||||||
|
project_bll = ProjectBLL()
|
||||||
|
|
||||||
|
|
||||||
|
class TaskBLL:
|
||||||
|
def __init__(self, events_es=None, redis=None):
|
||||||
|
self.events_es = events_es or es_factory.connect("events")
|
||||||
|
self.redis: StrictRedis = redis or redman.connection("apiserver")
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def get_task_with_access(
|
||||||
|
task_id, company_id, only=None, allow_public=False, requires_write_access=False
|
||||||
|
) -> Task:
|
||||||
|
"""
|
||||||
|
Gets a task that has a required write access
|
||||||
|
:except errors.bad_request.InvalidTaskId: if the task is not found
|
||||||
|
:except errors.forbidden.NoWritePermission: if write_access was required and the task cannot be modified
|
||||||
|
"""
|
||||||
|
with translate_errors_context():
|
||||||
|
query = dict(id=task_id, company=company_id)
|
||||||
|
if requires_write_access:
|
||||||
|
task = Task.get_for_writing(_only=only, **query)
|
||||||
|
else:
|
||||||
|
task = Task.get(_only=only, **query, include_public=allow_public)
|
||||||
|
|
||||||
|
if not task:
|
||||||
|
raise errors.bad_request.InvalidTaskId(**query)
|
||||||
|
|
||||||
|
return task
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def get_by_id(
|
||||||
|
company_id, task_id, required_status=None, only_fields=None, allow_public=False,
|
||||||
|
):
|
||||||
|
if only_fields:
|
||||||
|
if isinstance(only_fields, string_types):
|
||||||
|
only_fields = [only_fields]
|
||||||
|
else:
|
||||||
|
only_fields = list(only_fields)
|
||||||
|
only_fields = only_fields + ["status"]
|
||||||
|
|
||||||
|
tasks = Task.get_many(
|
||||||
|
company=company_id,
|
||||||
|
query=Q(id=task_id),
|
||||||
|
allow_public=allow_public,
|
||||||
|
override_projection=only_fields,
|
||||||
|
return_dicts=False,
|
||||||
|
)
|
||||||
|
task = None if not tasks else tasks[0]
|
||||||
|
|
||||||
|
if not task:
|
||||||
|
raise errors.bad_request.InvalidTaskId(id=task_id)
|
||||||
|
|
||||||
|
if required_status and not task.status == required_status:
|
||||||
|
raise errors.bad_request.InvalidTaskStatus(expected=required_status)
|
||||||
|
|
||||||
|
return task
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def assert_exists(
|
||||||
|
company_id, task_ids, only=None, allow_public=False, return_tasks=True
|
||||||
|
) -> Optional[Sequence[Task]]:
|
||||||
|
task_ids = [task_ids] if isinstance(task_ids, six.string_types) else task_ids
|
||||||
|
with translate_errors_context():
|
||||||
|
ids = set(task_ids)
|
||||||
|
q = Task.get_many(
|
||||||
|
company=company_id,
|
||||||
|
query=Q(id__in=ids),
|
||||||
|
allow_public=allow_public,
|
||||||
|
return_dicts=False,
|
||||||
|
)
|
||||||
|
if only:
|
||||||
|
# Make sure to reset fields filters (some fields are excluded by default) since this
|
||||||
|
# is an internal call and specific fields were requested.
|
||||||
|
q = q.all_fields().only(*only)
|
||||||
|
|
||||||
|
if q.count() != len(ids):
|
||||||
|
raise errors.bad_request.InvalidTaskId(ids=task_ids)
|
||||||
|
|
||||||
|
if return_tasks:
|
||||||
|
return list(q)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def create(company: str, user: str, fields: dict):
|
||||||
|
now = datetime.utcnow()
|
||||||
|
return Task(
|
||||||
|
id=create_id(),
|
||||||
|
user=user,
|
||||||
|
company=company,
|
||||||
|
created=now,
|
||||||
|
last_update=now,
|
||||||
|
last_change=now,
|
||||||
|
last_changed_by=user,
|
||||||
|
**fields,
|
||||||
|
)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def validate_input_models(task, allow_only_public=False):
|
||||||
|
if not task.models.input:
|
||||||
|
return
|
||||||
|
|
||||||
|
company = None if allow_only_public else task.company
|
||||||
|
model_ids = set(m.model for m in task.models.input)
|
||||||
|
models = Model.objects(
|
||||||
|
Q(id__in=model_ids) & get_company_or_none_constraint(company)
|
||||||
|
).only("id")
|
||||||
|
missing = model_ids - {m.id for m in models}
|
||||||
|
if missing:
|
||||||
|
raise errors.bad_request.InvalidModelId(models=missing)
|
||||||
|
|
||||||
|
return
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def clone_task(
|
||||||
|
cls,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
task_id: str,
|
||||||
|
name: Optional[str] = None,
|
||||||
|
comment: Optional[str] = None,
|
||||||
|
parent: Optional[str] = None,
|
||||||
|
project: Optional[str] = None,
|
||||||
|
tags: Optional[Sequence[str]] = None,
|
||||||
|
system_tags: Optional[Sequence[str]] = None,
|
||||||
|
hyperparams: Optional[dict] = None,
|
||||||
|
configuration: Optional[dict] = None,
|
||||||
|
container: Optional[dict] = None,
|
||||||
|
execution_overrides: Optional[dict] = None,
|
||||||
|
input_models: Optional[Sequence[TaskInputModel]] = None,
|
||||||
|
validate_references: bool = False,
|
||||||
|
new_project_name: str = None,
|
||||||
|
) -> Tuple[Task, dict]:
|
||||||
|
validate_tags(tags, system_tags)
|
||||||
|
params_dict = {
|
||||||
|
field: value
|
||||||
|
for field, value in (
|
||||||
|
("hyperparams", hyperparams),
|
||||||
|
("configuration", configuration),
|
||||||
|
)
|
||||||
|
if value is not None
|
||||||
|
}
|
||||||
|
|
||||||
|
task = cls.get_by_id(company_id=company_id, task_id=task_id, allow_public=True)
|
||||||
|
|
||||||
|
now = datetime.utcnow()
|
||||||
|
if input_models:
|
||||||
|
input_models = [
|
||||||
|
ModelItem(model=m.model, name=m.name, updated=now) for m in input_models
|
||||||
|
]
|
||||||
|
|
||||||
|
execution_dict = task.execution.to_proper_dict() if task.execution else {}
|
||||||
|
if execution_overrides:
|
||||||
|
execution_model = execution_overrides.pop("model", None)
|
||||||
|
if not input_models and execution_model:
|
||||||
|
input_models = [
|
||||||
|
ModelItem(
|
||||||
|
model=execution_model,
|
||||||
|
name=TaskModelNames[TaskModelTypes.input],
|
||||||
|
updated=now,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
docker_cmd = execution_overrides.pop("docker_cmd", None)
|
||||||
|
if not container and docker_cmd:
|
||||||
|
image, _, arguments = docker_cmd.partition(" ")
|
||||||
|
container = {"image": image, "arguments": arguments}
|
||||||
|
|
||||||
|
artifacts_prepare_for_save({"execution": execution_overrides})
|
||||||
|
|
||||||
|
params_dict["execution"] = {}
|
||||||
|
for legacy_param in ("parameters", "configuration"):
|
||||||
|
legacy_value = execution_overrides.pop(legacy_param, None)
|
||||||
|
if legacy_value is not None:
|
||||||
|
params_dict["execution"] = legacy_value
|
||||||
|
|
||||||
|
escape_dict_field(execution_overrides, "model_labels")
|
||||||
|
|
||||||
|
execution_dict.update(execution_overrides)
|
||||||
|
|
||||||
|
params_prepare_for_save(params_dict, previous_task=task)
|
||||||
|
|
||||||
|
artifacts = execution_dict.get("artifacts")
|
||||||
|
if artifacts:
|
||||||
|
execution_dict["artifacts"] = {
|
||||||
|
k: a
|
||||||
|
for k, a in artifacts.items()
|
||||||
|
if a.get("mode", DEFAULT_ARTIFACT_MODE) != ArtifactModes.output
|
||||||
|
}
|
||||||
|
execution_dict.pop("queue", None)
|
||||||
|
|
||||||
|
new_project_data = None
|
||||||
|
if not project and new_project_name:
|
||||||
|
# Use a project with the provided name, or create a new project
|
||||||
|
project = ProjectBLL.find_or_create(
|
||||||
|
project_name=new_project_name,
|
||||||
|
user=user_id,
|
||||||
|
company=company_id,
|
||||||
|
description="",
|
||||||
|
)
|
||||||
|
new_project_data = {"id": project, "name": new_project_name}
|
||||||
|
|
||||||
|
def clean_system_tags(input_tags: Sequence[str]) -> Sequence[str]:
|
||||||
|
if not input_tags:
|
||||||
|
return input_tags
|
||||||
|
|
||||||
|
return [
|
||||||
|
tag
|
||||||
|
for tag in input_tags
|
||||||
|
if tag
|
||||||
|
not in [TaskSystemTags.development, EntityVisibility.archived.value]
|
||||||
|
]
|
||||||
|
|
||||||
|
def ensure_int_labels(execution: dict) -> dict:
|
||||||
|
if not execution:
|
||||||
|
return execution
|
||||||
|
|
||||||
|
model_labels = execution.get("model_labels")
|
||||||
|
if model_labels:
|
||||||
|
execution["model_labels"] = {k: int(v) for k, v in model_labels.items()}
|
||||||
|
|
||||||
|
return execution
|
||||||
|
|
||||||
|
parent_task = (
|
||||||
|
task.parent
|
||||||
|
if task.parent and not task.parent.startswith(deleted_prefix)
|
||||||
|
else task.id
|
||||||
|
)
|
||||||
|
new_task = Task(
|
||||||
|
id=create_id(),
|
||||||
|
user=user_id,
|
||||||
|
company=company_id,
|
||||||
|
created=now,
|
||||||
|
last_update=now,
|
||||||
|
last_change=now,
|
||||||
|
last_changed_by=user_id,
|
||||||
|
name=name or task.name,
|
||||||
|
comment=comment or task.comment,
|
||||||
|
parent=parent or parent_task,
|
||||||
|
project=project or task.project,
|
||||||
|
tags=tags or task.tags,
|
||||||
|
system_tags=system_tags or clean_system_tags(task.system_tags),
|
||||||
|
type=task.type,
|
||||||
|
script=task.script,
|
||||||
|
output=Output(destination=task.output.destination) if task.output else None,
|
||||||
|
models=Models(input=input_models or task.models.input),
|
||||||
|
container=escape_dict(container) or task.container,
|
||||||
|
execution=ensure_int_labels(execution_dict),
|
||||||
|
configuration=params_dict.get("configuration") or task.configuration,
|
||||||
|
hyperparams=params_dict.get("hyperparams") or task.hyperparams,
|
||||||
|
)
|
||||||
|
cls.validate(
|
||||||
|
new_task,
|
||||||
|
validate_models=validate_references or input_models,
|
||||||
|
validate_parent=validate_references or parent,
|
||||||
|
validate_project=validate_references or project,
|
||||||
|
)
|
||||||
|
new_task.save()
|
||||||
|
|
||||||
|
if task.project == new_task.project:
|
||||||
|
updated_tags = tags
|
||||||
|
updated_system_tags = system_tags
|
||||||
|
else:
|
||||||
|
updated_tags = new_task.tags
|
||||||
|
updated_system_tags = new_task.system_tags
|
||||||
|
org_bll.update_tags(
|
||||||
|
company_id,
|
||||||
|
Tags.Task,
|
||||||
|
project=new_task.project,
|
||||||
|
tags=updated_tags,
|
||||||
|
system_tags=updated_system_tags,
|
||||||
|
)
|
||||||
|
update_project_time(new_task.project)
|
||||||
|
|
||||||
|
return new_task, new_project_data
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def validate(
|
||||||
|
cls,
|
||||||
|
task: Task,
|
||||||
|
validate_models=True,
|
||||||
|
validate_parent=True,
|
||||||
|
validate_project=True,
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
Validate task properties according to the flag
|
||||||
|
Task project is always checked for being writable
|
||||||
|
in order to disable the modification of public projects
|
||||||
|
"""
|
||||||
|
if (
|
||||||
|
validate_parent
|
||||||
|
and task.parent
|
||||||
|
and not task.parent.startswith(deleted_prefix)
|
||||||
|
and not Task.get(
|
||||||
|
company=task.company, id=task.parent, _only=("id",), include_public=True
|
||||||
|
)
|
||||||
|
):
|
||||||
|
raise errors.bad_request.InvalidTaskId("invalid parent", parent=task.parent)
|
||||||
|
|
||||||
|
if task.project:
|
||||||
|
project = Project.get_for_writing(company=task.company, id=task.project)
|
||||||
|
if validate_project and not project:
|
||||||
|
raise errors.bad_request.InvalidProjectId(id=task.project)
|
||||||
|
|
||||||
|
if validate_models:
|
||||||
|
cls.validate_input_models(task)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def set_last_update(
|
||||||
|
task_ids: Collection[str],
|
||||||
|
company_id: str,
|
||||||
|
last_update: datetime,
|
||||||
|
**extra_updates,
|
||||||
|
):
|
||||||
|
tasks = Task.objects(id__in=task_ids, company=company_id).only(
|
||||||
|
"status", "started"
|
||||||
|
)
|
||||||
|
count = 0
|
||||||
|
for task in tasks:
|
||||||
|
updates = extra_updates
|
||||||
|
if task.status == TaskStatus.in_progress and task.started:
|
||||||
|
updates = {
|
||||||
|
"active_duration": (
|
||||||
|
datetime.utcnow() - task.started
|
||||||
|
).total_seconds(),
|
||||||
|
**extra_updates,
|
||||||
|
}
|
||||||
|
count += Task.objects(id=task.id, company=company_id).update(
|
||||||
|
upsert=False,
|
||||||
|
last_update=last_update,
|
||||||
|
last_change=last_update,
|
||||||
|
**updates,
|
||||||
|
)
|
||||||
|
return count
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def update_statistics(
|
||||||
|
task_id: str,
|
||||||
|
company_id: str,
|
||||||
|
last_update: datetime = None,
|
||||||
|
last_iteration: int = None,
|
||||||
|
last_iteration_max: int = None,
|
||||||
|
last_scalar_events: Dict[str, Dict[str, dict]] = None,
|
||||||
|
last_events: Dict[str, Dict[str, dict]] = None,
|
||||||
|
**extra_updates,
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
Update task statistics
|
||||||
|
:param task_id: Task's ID.
|
||||||
|
:param company_id: Task's company ID.
|
||||||
|
:param last_update: Last update time. If not provided, defaults to datetime.utcnow().
|
||||||
|
:param last_iteration: Last reported iteration. Use this to set a value regardless of current
|
||||||
|
task's last iteration value.
|
||||||
|
:param last_iteration_max: Last reported iteration. Use this to conditionally set a value only
|
||||||
|
if the current task's last iteration value is smaller than the provided value.
|
||||||
|
:param last_scalar_values: Last reported metrics summary for scalar events (value, metric, variant).
|
||||||
|
:param last_events: Last reported metrics summary (value, metric, event type).
|
||||||
|
:param extra_updates: Extra task updates to include in this update call.
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
last_update = last_update or datetime.utcnow()
|
||||||
|
|
||||||
|
if last_iteration is not None:
|
||||||
|
extra_updates.update(last_iteration=last_iteration)
|
||||||
|
elif last_iteration_max is not None:
|
||||||
|
extra_updates.update(max__last_iteration=last_iteration_max)
|
||||||
|
|
||||||
|
raw_updates = {}
|
||||||
|
if last_scalar_events is not None:
|
||||||
|
max_values = config.get("services.tasks.max_last_metrics", 2000)
|
||||||
|
total_metrics = set()
|
||||||
|
if max_values:
|
||||||
|
query = dict(id=task_id)
|
||||||
|
to_add = sum(len(v) for m, v in last_scalar_events.items())
|
||||||
|
if to_add <= max_values:
|
||||||
|
query[f"unique_metrics__{max_values-to_add}__exists"] = True
|
||||||
|
task = Task.objects(**query).only("unique_metrics").first()
|
||||||
|
if task and task.unique_metrics:
|
||||||
|
total_metrics = set(task.unique_metrics)
|
||||||
|
|
||||||
|
new_metrics = []
|
||||||
|
|
||||||
|
def add_last_metric_conditional_update(
|
||||||
|
metric_path: str, metric_value, iter_value: int, is_min: bool
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
Build an aggregation for an atomic update of the min or max value and the corresponding iteration
|
||||||
|
"""
|
||||||
|
if is_min:
|
||||||
|
field_prefix = "min"
|
||||||
|
op = "$gt"
|
||||||
|
else:
|
||||||
|
field_prefix = "max"
|
||||||
|
op = "$lt"
|
||||||
|
|
||||||
|
value_field = f"{metric_path}__{field_prefix}_value".replace("__", ".")
|
||||||
|
condition = {
|
||||||
|
"$or": [
|
||||||
|
{"$lte": [f"${value_field}", None]},
|
||||||
|
{op: [f"${value_field}", metric_value]},
|
||||||
|
]
|
||||||
|
}
|
||||||
|
raw_updates[value_field] = {
|
||||||
|
"$cond": [condition, metric_value, f"${value_field}"]
|
||||||
|
}
|
||||||
|
|
||||||
|
value_iteration_field = f"{metric_path}__{field_prefix}_value_iteration".replace(
|
||||||
|
"__", "."
|
||||||
|
)
|
||||||
|
raw_updates[value_iteration_field] = {
|
||||||
|
"$cond": [
|
||||||
|
condition,
|
||||||
|
iter_value,
|
||||||
|
f"${value_iteration_field}",
|
||||||
|
]
|
||||||
|
}
|
||||||
|
|
||||||
|
for metric_key, metric_data in last_scalar_events.items():
|
||||||
|
for variant_key, variant_data in metric_data.items():
|
||||||
|
metric = (
|
||||||
|
f"{variant_data.get('metric')}/{variant_data.get('variant')}"
|
||||||
|
)
|
||||||
|
if max_values:
|
||||||
|
if (
|
||||||
|
len(total_metrics) >= max_values
|
||||||
|
and metric not in total_metrics
|
||||||
|
):
|
||||||
|
continue
|
||||||
|
total_metrics.add(metric)
|
||||||
|
|
||||||
|
new_metrics.append(metric)
|
||||||
|
path = f"last_metrics__{metric_key}__{variant_key}"
|
||||||
|
for key, value in variant_data.items():
|
||||||
|
if key in ("min_value", "max_value"):
|
||||||
|
add_last_metric_conditional_update(
|
||||||
|
metric_path=path,
|
||||||
|
metric_value=value,
|
||||||
|
iter_value=variant_data.get(f"{key}_iter", 0),
|
||||||
|
is_min=(key == "min_value"),
|
||||||
|
)
|
||||||
|
elif key in ("metric", "variant", "value"):
|
||||||
|
extra_updates[f"set__{path}__{key}"] = value
|
||||||
|
if new_metrics:
|
||||||
|
extra_updates["add_to_set__unique_metrics"] = new_metrics
|
||||||
|
|
||||||
|
if last_events is not None:
|
||||||
|
|
||||||
|
def events_per_type(metric_data_: Dict[str, dict]) -> Dict[str, EventStats]:
|
||||||
|
return {
|
||||||
|
event_type: EventStats(last_update=event["timestamp"])
|
||||||
|
for event_type, event in metric_data_.items()
|
||||||
|
}
|
||||||
|
|
||||||
|
metric_stats = {
|
||||||
|
dbutils.hash_field_name(metric_key): MetricEventStats(
|
||||||
|
metric=metric_key, event_stats_by_type=events_per_type(metric_data)
|
||||||
|
)
|
||||||
|
for metric_key, metric_data in last_events.items()
|
||||||
|
}
|
||||||
|
extra_updates["metric_stats"] = metric_stats
|
||||||
|
|
||||||
|
ret = TaskBLL.set_last_update(
|
||||||
|
task_ids=[task_id],
|
||||||
|
company_id=company_id,
|
||||||
|
last_update=last_update,
|
||||||
|
**extra_updates,
|
||||||
|
)
|
||||||
|
if ret and raw_updates:
|
||||||
|
Task.objects(id=task_id).update_one(__raw__=[{"$set": raw_updates}])
|
||||||
|
|
||||||
|
return ret
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def dequeue_and_change_status(
|
||||||
|
cls,
|
||||||
|
task: Task,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
status_message: str,
|
||||||
|
status_reason: str,
|
||||||
|
):
|
||||||
|
try:
|
||||||
|
cls.dequeue(task, company_id)
|
||||||
|
except errors.bad_request.InvalidQueueOrTaskNotQueued:
|
||||||
|
# dequeue may fail if the queue was deleted
|
||||||
|
pass
|
||||||
|
|
||||||
|
return ChangeStatusRequest(
|
||||||
|
task=task,
|
||||||
|
new_status=task.enqueue_status or TaskStatus.created,
|
||||||
|
status_reason=status_reason,
|
||||||
|
status_message=status_message,
|
||||||
|
user_id=user_id,
|
||||||
|
).execute(enqueue_status=None)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def dequeue(cls, task: Task, company_id: str, silent_fail=False):
|
||||||
|
"""
|
||||||
|
Dequeue the task from the queue
|
||||||
|
:param task: task to dequeue
|
||||||
|
:param company_id: task's company ID.
|
||||||
|
:param silent_fail: do not throw exceptions. APIError is still thrown
|
||||||
|
:raise errors.bad_request.InvalidTaskId: if the task's status is not queued
|
||||||
|
:raise errors.bad_request.MissingRequiredFields: if the task is not queued
|
||||||
|
:raise APIError or errors.server_error.TransactionError: if internal call to queues.remove_task fails
|
||||||
|
:return: the result of queues.remove_task call. None in case of silent failure
|
||||||
|
"""
|
||||||
|
if task.status not in (TaskStatus.queued,):
|
||||||
|
if silent_fail:
|
||||||
|
return
|
||||||
|
raise errors.bad_request.InvalidTaskId(
|
||||||
|
status=task.status, expected=TaskStatus.queued
|
||||||
|
)
|
||||||
|
|
||||||
|
if not task.execution or not task.execution.queue:
|
||||||
|
if silent_fail:
|
||||||
|
return
|
||||||
|
raise errors.bad_request.MissingRequiredFields(
|
||||||
|
"task has no queue value", field="execution.queue"
|
||||||
|
)
|
||||||
|
|
||||||
|
return {
|
||||||
|
"removed": queue_bll.remove_task(
|
||||||
|
company_id=company_id, queue_id=task.execution.queue, task_id=task.id
|
||||||
|
)
|
||||||
|
}
|
||||||
335
apiserver/bll/task/task_cleanup.py
Normal file
335
apiserver/bll/task/task_cleanup.py
Normal file
@@ -0,0 +1,335 @@
|
|||||||
|
from datetime import datetime
|
||||||
|
from itertools import chain
|
||||||
|
from operator import attrgetter
|
||||||
|
from typing import Sequence, Set, Tuple
|
||||||
|
|
||||||
|
import attr
|
||||||
|
from boltons.iterutils import partition, bucketize, first
|
||||||
|
from furl import furl
|
||||||
|
from mongoengine import NotUniqueError
|
||||||
|
from pymongo.errors import DuplicateKeyError
|
||||||
|
|
||||||
|
from apiserver.apierrors import errors
|
||||||
|
from apiserver.bll.event import EventBLL
|
||||||
|
from apiserver.bll.event.event_bll import PlotFields
|
||||||
|
from apiserver.bll.task.utils import deleted_prefix
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.model.model import Model
|
||||||
|
from apiserver.database.model.task.task import Task, TaskStatus, ArtifactModes
|
||||||
|
from apiserver.database.model.url_to_delete import (
|
||||||
|
StorageType,
|
||||||
|
UrlToDelete,
|
||||||
|
FileType,
|
||||||
|
DeletionStatus,
|
||||||
|
)
|
||||||
|
from apiserver.database.utils import id as db_id
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
event_bll = EventBLL()
|
||||||
|
async_events_delete = config.get("services.tasks.async_events_delete", False)
|
||||||
|
|
||||||
|
|
||||||
|
@attr.s(auto_attribs=True)
|
||||||
|
class TaskUrls:
|
||||||
|
model_urls: Sequence[str]
|
||||||
|
event_urls: Sequence[str]
|
||||||
|
artifact_urls: Sequence[str]
|
||||||
|
|
||||||
|
def __add__(self, other: "TaskUrls"):
|
||||||
|
if not other:
|
||||||
|
return self
|
||||||
|
|
||||||
|
return TaskUrls(
|
||||||
|
model_urls=list(set(self.model_urls) | set(other.model_urls)),
|
||||||
|
event_urls=list(set(self.event_urls) | set(other.event_urls)),
|
||||||
|
artifact_urls=list(set(self.artifact_urls) | set(other.artifact_urls)),
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
@attr.s(auto_attribs=True)
|
||||||
|
class CleanupResult:
|
||||||
|
"""
|
||||||
|
Counts of objects modified in task cleanup operation
|
||||||
|
"""
|
||||||
|
|
||||||
|
updated_children: int
|
||||||
|
updated_models: int
|
||||||
|
deleted_models: int
|
||||||
|
urls: TaskUrls = None
|
||||||
|
|
||||||
|
def __add__(self, other: "CleanupResult"):
|
||||||
|
if not other:
|
||||||
|
return self
|
||||||
|
|
||||||
|
return CleanupResult(
|
||||||
|
updated_children=self.updated_children + other.updated_children,
|
||||||
|
updated_models=self.updated_models + other.updated_models,
|
||||||
|
deleted_models=self.deleted_models + other.deleted_models,
|
||||||
|
urls=self.urls + other.urls if self.urls else other.urls,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def collect_plot_image_urls(company: str, task_or_model: str) -> Set[str]:
|
||||||
|
urls = set()
|
||||||
|
next_scroll_id = None
|
||||||
|
while True:
|
||||||
|
events, next_scroll_id = event_bll.get_plot_image_urls(
|
||||||
|
company_id=company, task_id=task_or_model, scroll_id=next_scroll_id
|
||||||
|
)
|
||||||
|
if not events:
|
||||||
|
break
|
||||||
|
for event in events:
|
||||||
|
event_urls = event.get(PlotFields.source_urls)
|
||||||
|
if event_urls:
|
||||||
|
urls.update(set(event_urls))
|
||||||
|
|
||||||
|
return urls
|
||||||
|
|
||||||
|
|
||||||
|
def collect_debug_image_urls(company: str, task_or_model: str) -> Set[str]:
|
||||||
|
"""
|
||||||
|
Return the set of unique image urls
|
||||||
|
Uses DebugImagesIterator to make sure that we do not retrieve recycled urls
|
||||||
|
"""
|
||||||
|
after_key = None
|
||||||
|
urls = set()
|
||||||
|
while True:
|
||||||
|
res, after_key = event_bll.get_debug_image_urls(
|
||||||
|
company_id=company, task_id=task_or_model, after_key=after_key,
|
||||||
|
)
|
||||||
|
urls.update(res)
|
||||||
|
if not after_key:
|
||||||
|
break
|
||||||
|
|
||||||
|
return urls
|
||||||
|
|
||||||
|
|
||||||
|
supported_storage_types = {
|
||||||
|
"https://": StorageType.fileserver,
|
||||||
|
"http://": StorageType.fileserver,
|
||||||
|
"s3://": StorageType.s3,
|
||||||
|
"azure://": StorageType.azure,
|
||||||
|
"gs://": StorageType.gs,
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def _schedule_for_delete(
|
||||||
|
company: str, user: str, task_id: str, urls: Set[str], can_delete_folders: bool,
|
||||||
|
) -> Set[str]:
|
||||||
|
urls_per_storage = bucketize(
|
||||||
|
urls,
|
||||||
|
key=lambda u: first(
|
||||||
|
type_
|
||||||
|
for prefix, type_ in supported_storage_types.items()
|
||||||
|
if u.startswith(prefix)
|
||||||
|
),
|
||||||
|
)
|
||||||
|
urls_per_storage.pop(None, None)
|
||||||
|
|
||||||
|
processed_urls = set()
|
||||||
|
for storage_type, storage_urls in urls_per_storage.items():
|
||||||
|
delete_folders = (storage_type == StorageType.fileserver) and can_delete_folders
|
||||||
|
scheduled_to_delete = set()
|
||||||
|
for url in storage_urls:
|
||||||
|
folder = None
|
||||||
|
if delete_folders:
|
||||||
|
try:
|
||||||
|
parsed = furl(url)
|
||||||
|
if parsed.path and len(parsed.path.segments) > 1:
|
||||||
|
folder = parsed.remove(
|
||||||
|
args=True, fragment=True, path=parsed.path.segments[-1]
|
||||||
|
).url.rstrip("/")
|
||||||
|
except Exception as ex:
|
||||||
|
pass
|
||||||
|
|
||||||
|
to_delete = folder or url
|
||||||
|
if to_delete in scheduled_to_delete:
|
||||||
|
processed_urls.add(url)
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
UrlToDelete(
|
||||||
|
id=db_id(),
|
||||||
|
company=company,
|
||||||
|
user=user,
|
||||||
|
url=to_delete,
|
||||||
|
task=task_id,
|
||||||
|
created=datetime.utcnow(),
|
||||||
|
storage_type=storage_type,
|
||||||
|
type=FileType.folder if folder else FileType.file,
|
||||||
|
).save()
|
||||||
|
except (DuplicateKeyError, NotUniqueError):
|
||||||
|
existing = UrlToDelete.objects(company=company, url=to_delete).first()
|
||||||
|
if existing:
|
||||||
|
existing.update(
|
||||||
|
user=user,
|
||||||
|
task=task_id,
|
||||||
|
created=datetime.utcnow(),
|
||||||
|
retry_count=0,
|
||||||
|
unset__last_failure_time=1,
|
||||||
|
unset__last_failure_reason=1,
|
||||||
|
status=DeletionStatus.created,
|
||||||
|
)
|
||||||
|
processed_urls.add(url)
|
||||||
|
scheduled_to_delete.add(to_delete)
|
||||||
|
|
||||||
|
return processed_urls
|
||||||
|
|
||||||
|
|
||||||
|
def cleanup_task(
|
||||||
|
company: str,
|
||||||
|
user: str,
|
||||||
|
task: Task,
|
||||||
|
force: bool = False,
|
||||||
|
update_children=True,
|
||||||
|
return_file_urls=False,
|
||||||
|
delete_output_models=True,
|
||||||
|
delete_external_artifacts=True,
|
||||||
|
) -> CleanupResult:
|
||||||
|
"""
|
||||||
|
Validate task deletion and delete/modify all its output.
|
||||||
|
:param task: task object
|
||||||
|
:param force: whether to delete task with published outputs
|
||||||
|
:return: count of delete and modified items
|
||||||
|
"""
|
||||||
|
published_models, draft_models, in_use_model_ids = verify_task_children_and_ouptuts(
|
||||||
|
task, force
|
||||||
|
)
|
||||||
|
delete_external_artifacts = delete_external_artifacts and config.get(
|
||||||
|
"services.async_urls_delete.enabled", False
|
||||||
|
)
|
||||||
|
event_urls, artifact_urls, model_urls = set(), set(), set()
|
||||||
|
if return_file_urls or delete_external_artifacts:
|
||||||
|
event_urls = collect_debug_image_urls(task.company, task.id)
|
||||||
|
event_urls.update(collect_plot_image_urls(task.company, task.id))
|
||||||
|
if task.execution and task.execution.artifacts:
|
||||||
|
artifact_urls = {
|
||||||
|
a.uri
|
||||||
|
for a in task.execution.artifacts.values()
|
||||||
|
if a.mode == ArtifactModes.output and a.uri
|
||||||
|
}
|
||||||
|
model_urls = {
|
||||||
|
m.uri for m in draft_models if m.uri and m.id not in in_use_model_ids
|
||||||
|
}
|
||||||
|
|
||||||
|
deleted_task_id = f"{deleted_prefix}{task.id}"
|
||||||
|
updated_children = 0
|
||||||
|
if update_children:
|
||||||
|
updated_children = Task.objects(parent=task.id).update(parent=deleted_task_id)
|
||||||
|
|
||||||
|
deleted_models = 0
|
||||||
|
updated_models = 0
|
||||||
|
for models, allow_delete in ((draft_models, True), (published_models, False)):
|
||||||
|
if not models:
|
||||||
|
continue
|
||||||
|
if delete_output_models and allow_delete:
|
||||||
|
model_ids = set(m.id for m in models if m.id not in in_use_model_ids)
|
||||||
|
for m_id in model_ids:
|
||||||
|
if return_file_urls or delete_external_artifacts:
|
||||||
|
event_urls.update(collect_debug_image_urls(task.company, m_id))
|
||||||
|
event_urls.update(collect_plot_image_urls(task.company, m_id))
|
||||||
|
try:
|
||||||
|
event_bll.delete_task_events(
|
||||||
|
task.company,
|
||||||
|
m_id,
|
||||||
|
allow_locked=True,
|
||||||
|
model=True,
|
||||||
|
async_delete=async_events_delete,
|
||||||
|
)
|
||||||
|
except errors.bad_request.InvalidModelId as ex:
|
||||||
|
log.info(f"Error deleting events for the model {m_id}: {str(ex)}")
|
||||||
|
|
||||||
|
deleted_models += Model.objects(id__in=list(model_ids)).delete()
|
||||||
|
if in_use_model_ids:
|
||||||
|
Model.objects(id__in=list(in_use_model_ids)).update(unset__task=1)
|
||||||
|
continue
|
||||||
|
|
||||||
|
if update_children:
|
||||||
|
updated_models += Model.objects(id__in=[m.id for m in models]).update(
|
||||||
|
task=deleted_task_id
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
Model.objects(id__in=[m.id for m in models]).update(unset__task=1)
|
||||||
|
|
||||||
|
event_bll.delete_task_events(
|
||||||
|
task.company, task.id, allow_locked=force, async_delete=async_events_delete
|
||||||
|
)
|
||||||
|
|
||||||
|
if delete_external_artifacts:
|
||||||
|
scheduled = _schedule_for_delete(
|
||||||
|
task_id=task.id,
|
||||||
|
company=company,
|
||||||
|
user=user,
|
||||||
|
urls=event_urls | model_urls | artifact_urls,
|
||||||
|
can_delete_folders=not in_use_model_ids and not published_models,
|
||||||
|
)
|
||||||
|
for urls in (event_urls, model_urls, artifact_urls):
|
||||||
|
urls.difference_update(scheduled)
|
||||||
|
|
||||||
|
return CleanupResult(
|
||||||
|
deleted_models=deleted_models,
|
||||||
|
updated_children=updated_children,
|
||||||
|
updated_models=updated_models,
|
||||||
|
urls=TaskUrls(
|
||||||
|
event_urls=list(event_urls),
|
||||||
|
artifact_urls=list(artifact_urls),
|
||||||
|
model_urls=list(model_urls),
|
||||||
|
)
|
||||||
|
if return_file_urls
|
||||||
|
else None,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def verify_task_children_and_ouptuts(
|
||||||
|
task, force: bool
|
||||||
|
) -> Tuple[Sequence[Model], Sequence[Model], Set[str]]:
|
||||||
|
if not force:
|
||||||
|
published_children_count = Task.objects(
|
||||||
|
parent=task.id, status=TaskStatus.published
|
||||||
|
).count()
|
||||||
|
if published_children_count:
|
||||||
|
raise errors.bad_request.TaskCannotBeDeleted(
|
||||||
|
"has children, use force=True",
|
||||||
|
task=task.id,
|
||||||
|
children=published_children_count,
|
||||||
|
)
|
||||||
|
|
||||||
|
model_fields = ["id", "ready", "uri"]
|
||||||
|
published_models, draft_models = partition(
|
||||||
|
Model.objects(task=task.id).only(*model_fields), key=attrgetter("ready"),
|
||||||
|
)
|
||||||
|
if not force and published_models:
|
||||||
|
raise errors.bad_request.TaskCannotBeDeleted(
|
||||||
|
"has output models, use force=True",
|
||||||
|
task=task.id,
|
||||||
|
models=len(published_models),
|
||||||
|
)
|
||||||
|
|
||||||
|
if task.models and task.models.output:
|
||||||
|
model_ids = [m.model for m in task.models.output]
|
||||||
|
for output_model in Model.objects(id__in=model_ids).only(*model_fields):
|
||||||
|
if output_model.ready:
|
||||||
|
if not force:
|
||||||
|
raise errors.bad_request.TaskCannotBeDeleted(
|
||||||
|
"has output model, use force=True",
|
||||||
|
task=task.id,
|
||||||
|
model=output_model.id,
|
||||||
|
)
|
||||||
|
published_models.append(output_model)
|
||||||
|
else:
|
||||||
|
draft_models.append(output_model)
|
||||||
|
|
||||||
|
in_use_model_ids = {}
|
||||||
|
if draft_models:
|
||||||
|
model_ids = {m.id for m in draft_models}
|
||||||
|
dependent_tasks = Task.objects(models__input__model__in=list(model_ids)).only(
|
||||||
|
"id", "models"
|
||||||
|
)
|
||||||
|
in_use_model_ids = model_ids & {
|
||||||
|
m.model
|
||||||
|
for m in chain.from_iterable(
|
||||||
|
t.models.input for t in dependent_tasks if t.models
|
||||||
|
)
|
||||||
|
}
|
||||||
|
|
||||||
|
return published_models, draft_models, in_use_model_ids
|
||||||
480
apiserver/bll/task/task_operations.py
Normal file
480
apiserver/bll/task/task_operations.py
Normal file
@@ -0,0 +1,480 @@
|
|||||||
|
from datetime import datetime
|
||||||
|
from typing import Callable, Any, Tuple, Union, Sequence
|
||||||
|
|
||||||
|
from apiserver.apierrors import errors, APIError
|
||||||
|
from apiserver.bll.queue import QueueBLL
|
||||||
|
from apiserver.bll.task import (
|
||||||
|
TaskBLL,
|
||||||
|
validate_status_change,
|
||||||
|
ChangeStatusRequest,
|
||||||
|
update_project_time,
|
||||||
|
)
|
||||||
|
from apiserver.bll.task.task_cleanup import cleanup_task, CleanupResult
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.database.model import EntityVisibility
|
||||||
|
from apiserver.database.model.model import Model
|
||||||
|
from apiserver.database.model.task.output import Output
|
||||||
|
from apiserver.database.model.task.task import (
|
||||||
|
TaskStatus,
|
||||||
|
Task,
|
||||||
|
TaskSystemTags,
|
||||||
|
TaskStatusMessage,
|
||||||
|
ArtifactModes,
|
||||||
|
Execution,
|
||||||
|
DEFAULT_LAST_ITERATION,
|
||||||
|
)
|
||||||
|
from apiserver.utilities.dicts import nested_set
|
||||||
|
|
||||||
|
log = config.logger(__file__)
|
||||||
|
queue_bll = QueueBLL()
|
||||||
|
|
||||||
|
|
||||||
|
def archive_task(
|
||||||
|
task: Union[str, Task],
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
status_message: str,
|
||||||
|
status_reason: str,
|
||||||
|
) -> int:
|
||||||
|
"""
|
||||||
|
Deque and archive task
|
||||||
|
Return 1 if successful
|
||||||
|
"""
|
||||||
|
if isinstance(task, str):
|
||||||
|
task = TaskBLL.get_task_with_access(
|
||||||
|
task,
|
||||||
|
company_id=company_id,
|
||||||
|
only=(
|
||||||
|
"id",
|
||||||
|
"execution",
|
||||||
|
"status",
|
||||||
|
"project",
|
||||||
|
"system_tags",
|
||||||
|
"enqueue_status",
|
||||||
|
),
|
||||||
|
requires_write_access=True,
|
||||||
|
)
|
||||||
|
try:
|
||||||
|
TaskBLL.dequeue_and_change_status(
|
||||||
|
task,
|
||||||
|
company_id=company_id,
|
||||||
|
user_id=user_id,
|
||||||
|
status_message=status_message,
|
||||||
|
status_reason=status_reason,
|
||||||
|
)
|
||||||
|
except APIError:
|
||||||
|
# dequeue may fail if the task was not enqueued
|
||||||
|
pass
|
||||||
|
|
||||||
|
return task.update(
|
||||||
|
status_message=status_message,
|
||||||
|
status_reason=status_reason,
|
||||||
|
add_to_set__system_tags=EntityVisibility.archived.value,
|
||||||
|
last_change=datetime.utcnow(),
|
||||||
|
last_changed_by=user_id,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def unarchive_task(
|
||||||
|
task: str, company_id: str, user_id: str, status_message: str, status_reason: str,
|
||||||
|
) -> int:
|
||||||
|
"""
|
||||||
|
Unarchive task. Return 1 if successful
|
||||||
|
"""
|
||||||
|
task = TaskBLL.get_task_with_access(
|
||||||
|
task, company_id=company_id, only=("id",), requires_write_access=True,
|
||||||
|
)
|
||||||
|
return task.update(
|
||||||
|
status_message=status_message,
|
||||||
|
status_reason=status_reason,
|
||||||
|
pull__system_tags=EntityVisibility.archived.value,
|
||||||
|
last_change=datetime.utcnow(),
|
||||||
|
last_changed_by=user_id,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def dequeue_task(
|
||||||
|
task_id: str,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
status_message: str,
|
||||||
|
status_reason: str,
|
||||||
|
) -> Tuple[int, dict]:
|
||||||
|
query = dict(id=task_id, company=company_id)
|
||||||
|
task = Task.get_for_writing(**query)
|
||||||
|
if not task:
|
||||||
|
raise errors.bad_request.InvalidTaskId(**query)
|
||||||
|
|
||||||
|
res = TaskBLL.dequeue_and_change_status(
|
||||||
|
task,
|
||||||
|
company_id=company_id,
|
||||||
|
user_id=user_id,
|
||||||
|
status_message=status_message,
|
||||||
|
status_reason=status_reason,
|
||||||
|
)
|
||||||
|
return 1, res
|
||||||
|
|
||||||
|
|
||||||
|
def enqueue_task(
|
||||||
|
task_id: str,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
queue_id: str,
|
||||||
|
status_message: str,
|
||||||
|
status_reason: str,
|
||||||
|
queue_name: str = None,
|
||||||
|
validate: bool = False,
|
||||||
|
force: bool = False,
|
||||||
|
) -> Tuple[int, dict]:
|
||||||
|
if queue_id and queue_name:
|
||||||
|
raise errors.bad_request.ValidationError(
|
||||||
|
"Either queue id or queue name should be provided"
|
||||||
|
)
|
||||||
|
|
||||||
|
if queue_name:
|
||||||
|
queue = queue_bll.get_by_name(
|
||||||
|
company_id=company_id, queue_name=queue_name, only=("id",)
|
||||||
|
)
|
||||||
|
if not queue:
|
||||||
|
queue = queue_bll.create(company_id=company_id, name=queue_name)
|
||||||
|
queue_id = queue.id
|
||||||
|
|
||||||
|
if not queue_id:
|
||||||
|
# try to get default queue
|
||||||
|
queue_id = queue_bll.get_default(company_id).id
|
||||||
|
|
||||||
|
query = dict(id=task_id, company=company_id)
|
||||||
|
task = Task.get_for_writing(**query)
|
||||||
|
if not task:
|
||||||
|
raise errors.bad_request.InvalidTaskId(**query)
|
||||||
|
|
||||||
|
if validate:
|
||||||
|
TaskBLL.validate(task)
|
||||||
|
|
||||||
|
res = ChangeStatusRequest(
|
||||||
|
task=task,
|
||||||
|
new_status=TaskStatus.queued,
|
||||||
|
status_reason=status_reason,
|
||||||
|
status_message=status_message,
|
||||||
|
allow_same_state_transition=False,
|
||||||
|
force=force,
|
||||||
|
user_id=user_id,
|
||||||
|
).execute(enqueue_status=task.status)
|
||||||
|
|
||||||
|
try:
|
||||||
|
queue_bll.add_task(company_id=company_id, queue_id=queue_id, task_id=task.id)
|
||||||
|
except Exception:
|
||||||
|
# failed enqueueing, revert to previous state
|
||||||
|
ChangeStatusRequest(
|
||||||
|
task=task,
|
||||||
|
current_status_override=TaskStatus.queued,
|
||||||
|
new_status=task.status,
|
||||||
|
force=True,
|
||||||
|
status_reason="failed enqueueing",
|
||||||
|
user_id=user_id,
|
||||||
|
).execute(enqueue_status=None)
|
||||||
|
raise
|
||||||
|
|
||||||
|
# set the current queue ID in the task
|
||||||
|
if task.execution:
|
||||||
|
Task.objects(**query).update(execution__queue=queue_id, multi=False)
|
||||||
|
else:
|
||||||
|
Task.objects(**query).update(execution=Execution(queue=queue_id), multi=False)
|
||||||
|
|
||||||
|
nested_set(res, ("fields", "execution.queue"), queue_id)
|
||||||
|
return 1, res
|
||||||
|
|
||||||
|
|
||||||
|
def move_tasks_to_trash(tasks: Sequence[str]) -> int:
|
||||||
|
try:
|
||||||
|
collection_name = Task._get_collection_name()
|
||||||
|
trash_collection_name = f"{collection_name}__trash"
|
||||||
|
Task.aggregate(
|
||||||
|
[
|
||||||
|
{"$match": {"_id": {"$in": tasks}}},
|
||||||
|
{
|
||||||
|
"$merge": {
|
||||||
|
"into": trash_collection_name,
|
||||||
|
"on": "_id",
|
||||||
|
"whenMatched": "replace",
|
||||||
|
"whenNotMatched": "insert",
|
||||||
|
}
|
||||||
|
},
|
||||||
|
],
|
||||||
|
allow_disk_use=True,
|
||||||
|
)
|
||||||
|
except Exception as ex:
|
||||||
|
log.error(f"Error copying tasks to trash {str(ex)}")
|
||||||
|
|
||||||
|
return Task.objects(id__in=tasks).delete()
|
||||||
|
|
||||||
|
|
||||||
|
def delete_task(
|
||||||
|
task_id: str,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
move_to_trash: bool,
|
||||||
|
force: bool,
|
||||||
|
return_file_urls: bool,
|
||||||
|
delete_output_models: bool,
|
||||||
|
status_message: str,
|
||||||
|
status_reason: str,
|
||||||
|
delete_external_artifacts: bool,
|
||||||
|
) -> Tuple[int, Task, CleanupResult]:
|
||||||
|
task = TaskBLL.get_task_with_access(
|
||||||
|
task_id, company_id=company_id, requires_write_access=True
|
||||||
|
)
|
||||||
|
|
||||||
|
if (
|
||||||
|
task.status != TaskStatus.created
|
||||||
|
and EntityVisibility.archived.value not in task.system_tags
|
||||||
|
and not force
|
||||||
|
):
|
||||||
|
raise errors.bad_request.TaskCannotBeDeleted(
|
||||||
|
"due to status, use force=True",
|
||||||
|
task=task.id,
|
||||||
|
expected=TaskStatus.created,
|
||||||
|
current=task.status,
|
||||||
|
)
|
||||||
|
|
||||||
|
try:
|
||||||
|
TaskBLL.dequeue_and_change_status(
|
||||||
|
task,
|
||||||
|
company_id=company_id,
|
||||||
|
user_id=user_id,
|
||||||
|
status_message=status_message,
|
||||||
|
status_reason=status_reason,
|
||||||
|
)
|
||||||
|
except APIError:
|
||||||
|
# dequeue may fail if the task was not enqueued
|
||||||
|
pass
|
||||||
|
|
||||||
|
cleanup_res = cleanup_task(
|
||||||
|
company=company_id,
|
||||||
|
user=user_id,
|
||||||
|
task=task,
|
||||||
|
force=force,
|
||||||
|
return_file_urls=return_file_urls,
|
||||||
|
delete_output_models=delete_output_models,
|
||||||
|
delete_external_artifacts=delete_external_artifacts,
|
||||||
|
)
|
||||||
|
|
||||||
|
if move_to_trash:
|
||||||
|
# make sure that whatever changes were done to the task are saved
|
||||||
|
# the task itself will be deleted later in the move_tasks_to_trash operation
|
||||||
|
task.save()
|
||||||
|
else:
|
||||||
|
task.delete()
|
||||||
|
|
||||||
|
update_project_time(task.project)
|
||||||
|
return 1, task, cleanup_res
|
||||||
|
|
||||||
|
|
||||||
|
def reset_task(
|
||||||
|
task_id: str,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
force: bool,
|
||||||
|
return_file_urls: bool,
|
||||||
|
delete_output_models: bool,
|
||||||
|
clear_all: bool,
|
||||||
|
delete_external_artifacts: bool,
|
||||||
|
) -> Tuple[dict, CleanupResult, dict]:
|
||||||
|
task = TaskBLL.get_task_with_access(
|
||||||
|
task_id, company_id=company_id, requires_write_access=True
|
||||||
|
)
|
||||||
|
|
||||||
|
if not force and task.status == TaskStatus.published:
|
||||||
|
raise errors.bad_request.InvalidTaskStatus(task_id=task.id, status=task.status)
|
||||||
|
|
||||||
|
dequeued = {}
|
||||||
|
updates = {}
|
||||||
|
|
||||||
|
try:
|
||||||
|
dequeued = TaskBLL.dequeue(task, company_id, silent_fail=True)
|
||||||
|
except APIError:
|
||||||
|
# dequeue may fail if the task was not enqueued
|
||||||
|
pass
|
||||||
|
|
||||||
|
cleaned_up = cleanup_task(
|
||||||
|
company=company_id,
|
||||||
|
user=user_id,
|
||||||
|
task=task,
|
||||||
|
force=force,
|
||||||
|
update_children=False,
|
||||||
|
return_file_urls=return_file_urls,
|
||||||
|
delete_output_models=delete_output_models,
|
||||||
|
delete_external_artifacts=delete_external_artifacts,
|
||||||
|
)
|
||||||
|
|
||||||
|
updates.update(
|
||||||
|
set__last_iteration=DEFAULT_LAST_ITERATION,
|
||||||
|
set__last_metrics={},
|
||||||
|
set__unique_metrics=[],
|
||||||
|
set__metric_stats={},
|
||||||
|
set__models__output=[],
|
||||||
|
set__runtime={},
|
||||||
|
unset__output__result=1,
|
||||||
|
unset__output__error=1,
|
||||||
|
unset__last_worker=1,
|
||||||
|
unset__last_worker_report=1,
|
||||||
|
)
|
||||||
|
|
||||||
|
if clear_all:
|
||||||
|
updates.update(
|
||||||
|
set__execution=Execution(), unset__script=1,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
updates.update(unset__execution__queue=1)
|
||||||
|
if task.execution and task.execution.artifacts:
|
||||||
|
updates.update(
|
||||||
|
set__execution__artifacts={
|
||||||
|
key: artifact
|
||||||
|
for key, artifact in task.execution.artifacts.items()
|
||||||
|
if artifact.mode == ArtifactModes.input
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
res = ChangeStatusRequest(
|
||||||
|
task=task,
|
||||||
|
new_status=TaskStatus.created,
|
||||||
|
force=force,
|
||||||
|
status_reason="reset",
|
||||||
|
status_message="reset",
|
||||||
|
user_id=user_id,
|
||||||
|
).execute(
|
||||||
|
started=None,
|
||||||
|
completed=None,
|
||||||
|
published=None,
|
||||||
|
active_duration=None,
|
||||||
|
enqueue_status=None,
|
||||||
|
**updates,
|
||||||
|
)
|
||||||
|
|
||||||
|
return dequeued, cleaned_up, res
|
||||||
|
|
||||||
|
|
||||||
|
def publish_task(
|
||||||
|
task_id: str,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
force: bool,
|
||||||
|
publish_model_func: Callable[[str, str, str], Any] = None,
|
||||||
|
status_message: str = "",
|
||||||
|
status_reason: str = "",
|
||||||
|
) -> dict:
|
||||||
|
task = TaskBLL.get_task_with_access(
|
||||||
|
task_id, company_id=company_id, requires_write_access=True
|
||||||
|
)
|
||||||
|
if not force:
|
||||||
|
validate_status_change(task.status, TaskStatus.published)
|
||||||
|
|
||||||
|
previous_task_status = task.status
|
||||||
|
output = task.output or Output()
|
||||||
|
publish_failed = False
|
||||||
|
|
||||||
|
try:
|
||||||
|
# set state to publishing
|
||||||
|
task.status = TaskStatus.publishing
|
||||||
|
task.save()
|
||||||
|
|
||||||
|
# publish task models
|
||||||
|
if task.models and task.models.output and publish_model_func:
|
||||||
|
model_id = task.models.output[-1].model
|
||||||
|
model = (
|
||||||
|
Model.objects(id=model_id, company=company_id)
|
||||||
|
.only("id", "ready")
|
||||||
|
.first()
|
||||||
|
)
|
||||||
|
if model and not model.ready:
|
||||||
|
publish_model_func(model.id, company_id, user_id)
|
||||||
|
|
||||||
|
# set task status to published, and update (or set) it's new output (view and models)
|
||||||
|
return ChangeStatusRequest(
|
||||||
|
task=task,
|
||||||
|
new_status=TaskStatus.published,
|
||||||
|
force=force,
|
||||||
|
status_reason=status_reason,
|
||||||
|
status_message=status_message,
|
||||||
|
user_id=user_id,
|
||||||
|
).execute(published=datetime.utcnow(), output=output)
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
publish_failed = True
|
||||||
|
raise ex
|
||||||
|
finally:
|
||||||
|
if publish_failed:
|
||||||
|
task.status = previous_task_status
|
||||||
|
task.save()
|
||||||
|
|
||||||
|
|
||||||
|
def stop_task(
|
||||||
|
task_id: str,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
user_name: str,
|
||||||
|
status_reason: str,
|
||||||
|
force: bool,
|
||||||
|
) -> dict:
|
||||||
|
"""
|
||||||
|
Stop a running task. Requires task status 'in_progress' and
|
||||||
|
execution_progress 'running', or force=True. Development task or
|
||||||
|
task that has no associated worker is stopped immediately.
|
||||||
|
For a non-development task with worker only the status message
|
||||||
|
is set to 'stopping' to allow the worker to stop the task and report by itself
|
||||||
|
:return: updated task fields
|
||||||
|
"""
|
||||||
|
|
||||||
|
task = TaskBLL.get_task_with_access(
|
||||||
|
task_id,
|
||||||
|
company_id=company_id,
|
||||||
|
only=(
|
||||||
|
"status",
|
||||||
|
"project",
|
||||||
|
"tags",
|
||||||
|
"system_tags",
|
||||||
|
"last_worker",
|
||||||
|
"last_update",
|
||||||
|
"execution.queue",
|
||||||
|
),
|
||||||
|
requires_write_access=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
def is_run_by_worker(t: Task) -> bool:
|
||||||
|
"""Checks if there is an active worker running the task"""
|
||||||
|
update_timeout = config.get("apiserver.workers.task_update_timeout", 600)
|
||||||
|
return (
|
||||||
|
t.last_worker
|
||||||
|
and t.last_update
|
||||||
|
and (datetime.utcnow() - t.last_update).total_seconds() < update_timeout
|
||||||
|
)
|
||||||
|
|
||||||
|
is_queued = task.status == TaskStatus.queued
|
||||||
|
set_stopped = (
|
||||||
|
is_queued
|
||||||
|
or TaskSystemTags.development in task.system_tags
|
||||||
|
or not is_run_by_worker(task)
|
||||||
|
)
|
||||||
|
|
||||||
|
if set_stopped:
|
||||||
|
if is_queued:
|
||||||
|
try:
|
||||||
|
TaskBLL.dequeue(task, company_id=company_id, silent_fail=True)
|
||||||
|
except APIError:
|
||||||
|
# dequeue may fail if the task was not enqueued
|
||||||
|
pass
|
||||||
|
|
||||||
|
new_status = TaskStatus.stopped
|
||||||
|
status_message = f"Stopped by {user_name}"
|
||||||
|
else:
|
||||||
|
new_status = task.status
|
||||||
|
status_message = TaskStatusMessage.stopping
|
||||||
|
|
||||||
|
return ChangeStatusRequest(
|
||||||
|
task=task,
|
||||||
|
new_status=new_status,
|
||||||
|
status_reason=status_reason,
|
||||||
|
status_message=status_message,
|
||||||
|
force=force,
|
||||||
|
user_id=user_id,
|
||||||
|
).execute()
|
||||||
@@ -1,18 +1,18 @@
|
|||||||
from datetime import datetime
|
from datetime import datetime
|
||||||
from typing import TypeVar, Callable, Tuple, Sequence
|
from typing import Sequence, Union
|
||||||
|
|
||||||
import attr
|
import attr
|
||||||
import six
|
import six
|
||||||
|
|
||||||
from apierrors import errors
|
from apiserver.apierrors import errors
|
||||||
from database.errors import translate_errors_context
|
from apiserver.database.errors import translate_errors_context
|
||||||
from database.model.project import Project
|
from apiserver.database.model.project import Project
|
||||||
from database.model.task.task import Task, TaskStatus, TaskSystemTags
|
from apiserver.database.model.task.task import Task, TaskStatus, TaskSystemTags
|
||||||
from database.utils import get_options
|
from apiserver.database.utils import get_options
|
||||||
from timing_context import TimingContext
|
from apiserver.utilities.attrs import typed_attrs
|
||||||
from utilities.attrs import typed_attrs
|
|
||||||
|
|
||||||
valid_statuses = get_options(TaskStatus)
|
valid_statuses = get_options(TaskStatus)
|
||||||
|
deleted_prefix = "__DELETED__"
|
||||||
|
|
||||||
|
|
||||||
@typed_attrs
|
@typed_attrs
|
||||||
@@ -26,6 +26,7 @@ class ChangeStatusRequest(object):
|
|||||||
force = attr.ib(type=bool, default=False)
|
force = attr.ib(type=bool, default=False)
|
||||||
allow_same_state_transition = attr.ib(type=bool, default=True)
|
allow_same_state_transition = attr.ib(type=bool, default=True)
|
||||||
current_status_override = attr.ib(default=None)
|
current_status_override = attr.ib(default=None)
|
||||||
|
user_id = attr.ib(type=str, default=None)
|
||||||
|
|
||||||
def execute(self, **kwargs):
|
def execute(self, **kwargs):
|
||||||
current_status = self.current_status_override or self.task.status
|
current_status = self.current_status_override or self.task.status
|
||||||
@@ -43,6 +44,8 @@ class ChangeStatusRequest(object):
|
|||||||
status_message=self.status_message,
|
status_message=self.status_message,
|
||||||
status_changed=now,
|
status_changed=now,
|
||||||
last_update=now,
|
last_update=now,
|
||||||
|
last_change=now,
|
||||||
|
last_changed_by=self.user_id,
|
||||||
)
|
)
|
||||||
|
|
||||||
if self.new_status == TaskStatus.queued:
|
if self.new_status == TaskStatus.queued:
|
||||||
@@ -53,7 +56,7 @@ class ChangeStatusRequest(object):
|
|||||||
|
|
||||||
fields.update({safe_mongoengine_key(k): v for k, v in kwargs.items()})
|
fields.update({safe_mongoengine_key(k): v for k, v in kwargs.items()})
|
||||||
|
|
||||||
with translate_errors_context(), TimingContext("mongo", "task_status"):
|
with translate_errors_context():
|
||||||
# atomic change of task status by querying the task with the EXPECTED status before modifying it
|
# atomic change of task status by querying the task with the EXPECTED status before modifying it
|
||||||
params = fields.copy()
|
params = fields.copy()
|
||||||
params.update(control)
|
params.update(control)
|
||||||
@@ -104,7 +107,7 @@ def validate_status_change(current_status, new_status):
|
|||||||
|
|
||||||
state_machine = {
|
state_machine = {
|
||||||
TaskStatus.created: {TaskStatus.queued, TaskStatus.in_progress},
|
TaskStatus.created: {TaskStatus.queued, TaskStatus.in_progress},
|
||||||
TaskStatus.queued: {TaskStatus.created, TaskStatus.in_progress},
|
TaskStatus.queued: {TaskStatus.created, TaskStatus.in_progress, TaskStatus.stopped},
|
||||||
TaskStatus.in_progress: {
|
TaskStatus.in_progress: {
|
||||||
TaskStatus.stopped,
|
TaskStatus.stopped,
|
||||||
TaskStatus.failed,
|
TaskStatus.failed,
|
||||||
@@ -115,6 +118,7 @@ state_machine = {
|
|||||||
TaskStatus.closed,
|
TaskStatus.closed,
|
||||||
TaskStatus.created,
|
TaskStatus.created,
|
||||||
TaskStatus.failed,
|
TaskStatus.failed,
|
||||||
|
TaskStatus.queued,
|
||||||
TaskStatus.in_progress,
|
TaskStatus.in_progress,
|
||||||
TaskStatus.published,
|
TaskStatus.published,
|
||||||
TaskStatus.publishing,
|
TaskStatus.publishing,
|
||||||
@@ -152,22 +156,42 @@ def get_possible_status_changes(current_status):
|
|||||||
return possible
|
return possible
|
||||||
|
|
||||||
|
|
||||||
def update_project_time(project_id):
|
def update_project_time(project_ids: Union[str, Sequence[str]]):
|
||||||
if project_id:
|
if not project_ids:
|
||||||
Project.objects(id=project_id).update(last_update=datetime.utcnow())
|
return
|
||||||
|
|
||||||
|
if isinstance(project_ids, str):
|
||||||
|
project_ids = [project_ids]
|
||||||
|
|
||||||
|
return Project.objects(id__in=project_ids).update(last_update=datetime.utcnow())
|
||||||
|
|
||||||
|
|
||||||
T = TypeVar("T")
|
def get_task_for_update(
|
||||||
|
company_id: str, task_id: str, allow_all_statuses: bool = False, force: bool = False
|
||||||
|
) -> Task:
|
||||||
def split_by(
|
|
||||||
condition: Callable[[T], bool], items: Sequence[T]
|
|
||||||
) -> Tuple[Sequence[T], Sequence[T]]:
|
|
||||||
"""
|
"""
|
||||||
split "items" to two lists by "condition"
|
Loads only task id and return the task only if it is updatable (status == 'created')
|
||||||
"""
|
"""
|
||||||
applied = zip(map(condition, items), items)
|
task = Task.get_for_writing(company=company_id, id=task_id, _only=("id", "status"))
|
||||||
return (
|
if not task:
|
||||||
[item for cond, item in applied if cond],
|
raise errors.bad_request.InvalidTaskId(id=task_id)
|
||||||
[item for cond, item in applied if not cond],
|
|
||||||
|
if allow_all_statuses:
|
||||||
|
return task
|
||||||
|
|
||||||
|
allowed_statuses = (
|
||||||
|
[TaskStatus.created, TaskStatus.in_progress] if force else [TaskStatus.created]
|
||||||
)
|
)
|
||||||
|
if task.status not in allowed_statuses:
|
||||||
|
raise errors.bad_request.InvalidTaskStatus(
|
||||||
|
expected=TaskStatus.created, status=task.status
|
||||||
|
)
|
||||||
|
return task
|
||||||
|
|
||||||
|
|
||||||
|
def update_task(task: Task, user_id: str, update_cmds: dict, set_last_update: bool = True):
|
||||||
|
now = datetime.utcnow()
|
||||||
|
last_updates = dict(last_change=now, last_changed_by=user_id)
|
||||||
|
if set_last_update:
|
||||||
|
last_updates.update(last_update=now)
|
||||||
|
return task.update(**update_cmds, **last_updates)
|
||||||
@@ -1,7 +1,9 @@
|
|||||||
from apierrors import errors
|
from datetime import datetime
|
||||||
from apimodels.users import CreateRequest
|
|
||||||
from database.errors import translate_errors_context
|
from apiserver.apierrors import errors
|
||||||
from database.model.user import User
|
from apiserver.apimodels.users import CreateRequest
|
||||||
|
from apiserver.database.errors import translate_errors_context
|
||||||
|
from apiserver.database.model.user import User
|
||||||
|
|
||||||
|
|
||||||
class UserBLL:
|
class UserBLL:
|
||||||
@@ -12,7 +14,7 @@ class UserBLL:
|
|||||||
if user_id and User.objects(id=user_id).only("id"):
|
if user_id and User.objects(id=user_id).only("id"):
|
||||||
raise errors.bad_request.UserIdExists(id=user_id)
|
raise errors.bad_request.UserIdExists(id=user_id)
|
||||||
|
|
||||||
user = User(**request.to_struct())
|
user = User(**request.to_struct(), created=datetime.utcnow())
|
||||||
user.save(force_insert=True)
|
user.save(force_insert=True)
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
134
apiserver/bll/util.py
Normal file
134
apiserver/bll/util.py
Normal file
@@ -0,0 +1,134 @@
|
|||||||
|
import functools
|
||||||
|
import itertools
|
||||||
|
from concurrent.futures.thread import ThreadPoolExecutor
|
||||||
|
from typing import (
|
||||||
|
Optional,
|
||||||
|
Callable,
|
||||||
|
Dict,
|
||||||
|
Any,
|
||||||
|
Set,
|
||||||
|
Iterable,
|
||||||
|
Tuple,
|
||||||
|
Sequence,
|
||||||
|
TypeVar,
|
||||||
|
)
|
||||||
|
|
||||||
|
from boltons import iterutils
|
||||||
|
|
||||||
|
from apiserver.apierrors import APIError
|
||||||
|
from apiserver.database.model import AttributedDocument
|
||||||
|
from apiserver.database.model.settings import Settings
|
||||||
|
|
||||||
|
|
||||||
|
class SetFieldsResolver:
|
||||||
|
"""
|
||||||
|
The class receives set fields dictionary
|
||||||
|
and for the set fields that require 'min' or 'max'
|
||||||
|
operation replace them with a simple set in case the
|
||||||
|
DB document does not have these fields set
|
||||||
|
"""
|
||||||
|
|
||||||
|
SET_MODIFIERS = ("min", "max")
|
||||||
|
|
||||||
|
def __init__(self, set_fields: Dict[str, Any]):
|
||||||
|
self.orig_fields = {}
|
||||||
|
self.fields = {}
|
||||||
|
self.add_fields(**set_fields)
|
||||||
|
|
||||||
|
def add_fields(self, **set_fields: Any):
|
||||||
|
self.orig_fields.update(set_fields)
|
||||||
|
self.fields.update(
|
||||||
|
{
|
||||||
|
f: fname
|
||||||
|
for f, modifier, dunder, fname in (
|
||||||
|
(f,) + f.partition("__") for f in set_fields.keys()
|
||||||
|
)
|
||||||
|
if dunder and modifier in self.SET_MODIFIERS
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
def _get_updated_name(self, doc: AttributedDocument, name: str) -> str:
|
||||||
|
if name in self.fields and doc.get_field_value(self.fields[name]) is None:
|
||||||
|
return self.fields[name]
|
||||||
|
return name
|
||||||
|
|
||||||
|
def get_fields(self, doc: AttributedDocument):
|
||||||
|
"""
|
||||||
|
For the given document return the set fields instructions
|
||||||
|
with min/max operations replaced with a single set in case
|
||||||
|
the document does not have the field set
|
||||||
|
"""
|
||||||
|
return {
|
||||||
|
self._get_updated_name(doc, name): value
|
||||||
|
for name, value in self.orig_fields.items()
|
||||||
|
}
|
||||||
|
|
||||||
|
def get_names(self) -> Set[str]:
|
||||||
|
"""
|
||||||
|
Returns the names of the fields that had min/max modifiers
|
||||||
|
in the format suitable for projection (dot separated)
|
||||||
|
"""
|
||||||
|
return set(name.replace("__", ".") for name in self.fields.values())
|
||||||
|
|
||||||
|
|
||||||
|
@functools.lru_cache()
|
||||||
|
def get_server_uuid() -> Optional[str]:
|
||||||
|
return Settings.get_by_key("server.uuid")
|
||||||
|
|
||||||
|
|
||||||
|
def parallel_chunked_decorator(func: Callable = None, chunk_size: int = 100):
|
||||||
|
"""
|
||||||
|
Decorates a method for parallel chunked execution. The method should have
|
||||||
|
one positional parameter (that is used for breaking into chunks)
|
||||||
|
and arbitrary number of keyword params. The return value should be iterable
|
||||||
|
The results are concatenated in the same order as the passed params
|
||||||
|
"""
|
||||||
|
if func is None:
|
||||||
|
return functools.partial(parallel_chunked_decorator, chunk_size=chunk_size)
|
||||||
|
|
||||||
|
@functools.wraps(func)
|
||||||
|
def wrapper(self, iterable: Iterable, **kwargs):
|
||||||
|
assert iterutils.is_collection(
|
||||||
|
iterable
|
||||||
|
), "The positional parameter should be an iterable for breaking into chunks"
|
||||||
|
|
||||||
|
func_with_params = functools.partial(func, self, **kwargs)
|
||||||
|
with ThreadPoolExecutor() as pool:
|
||||||
|
return list(
|
||||||
|
itertools.chain.from_iterable(
|
||||||
|
filter(
|
||||||
|
None,
|
||||||
|
pool.map(
|
||||||
|
func_with_params,
|
||||||
|
iterutils.chunked_iter(iterable, chunk_size),
|
||||||
|
),
|
||||||
|
)
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
return wrapper
|
||||||
|
|
||||||
|
|
||||||
|
T = TypeVar("T")
|
||||||
|
|
||||||
|
|
||||||
|
def run_batch_operation(
|
||||||
|
func: Callable[[str], T], ids: Sequence[str]
|
||||||
|
) -> Tuple[Sequence[Tuple[str, T]], Sequence[dict]]:
|
||||||
|
results = list()
|
||||||
|
failures = list()
|
||||||
|
for _id in ids:
|
||||||
|
try:
|
||||||
|
results.append((_id, func(_id)))
|
||||||
|
except APIError as err:
|
||||||
|
failures.append(
|
||||||
|
{
|
||||||
|
"id": _id,
|
||||||
|
"error": {
|
||||||
|
"codes": [err.code, err.subcode],
|
||||||
|
"msg": err.msg,
|
||||||
|
"data": err.error_data,
|
||||||
|
},
|
||||||
|
}
|
||||||
|
)
|
||||||
|
return results, failures
|
||||||
@@ -1,13 +1,16 @@
|
|||||||
import itertools
|
import itertools
|
||||||
from datetime import datetime, timedelta
|
from datetime import datetime, timedelta
|
||||||
|
from time import time
|
||||||
from typing import Sequence, Set, Optional
|
from typing import Sequence, Set, Optional
|
||||||
|
|
||||||
import attr
|
import attr
|
||||||
import elasticsearch.helpers
|
import elasticsearch.helpers
|
||||||
import es_factory
|
from boltons.iterutils import partition
|
||||||
from apierrors import APIError
|
|
||||||
from apierrors.errors import bad_request, server_error
|
from apiserver.es_factory import es_factory
|
||||||
from apimodels.workers import (
|
from apiserver.apierrors import APIError
|
||||||
|
from apiserver.apierrors.errors import bad_request, server_error
|
||||||
|
from apiserver.apimodels.workers import (
|
||||||
DEFAULT_TIMEOUT,
|
DEFAULT_TIMEOUT,
|
||||||
IdNameEntry,
|
IdNameEntry,
|
||||||
WorkerEntry,
|
WorkerEntry,
|
||||||
@@ -16,16 +19,15 @@ from apimodels.workers import (
|
|||||||
QueueEntry,
|
QueueEntry,
|
||||||
MachineStats,
|
MachineStats,
|
||||||
)
|
)
|
||||||
from config import config
|
from apiserver.config_repo import config
|
||||||
from database.errors import translate_errors_context
|
from apiserver.database.errors import translate_errors_context
|
||||||
from database.model.auth import User
|
from apiserver.database.model.auth import User
|
||||||
from database.model.company import Company
|
from apiserver.database.model.company import Company
|
||||||
from database.model.queue import Queue
|
from apiserver.database.model.project import Project
|
||||||
from database.model.task.task import Task
|
from apiserver.database.model.queue import Queue
|
||||||
from service_repo.redis_manager import redman
|
from apiserver.database.model.task.task import Task
|
||||||
from timing_context import TimingContext
|
from apiserver.redis_manager import redman
|
||||||
from tools import safe_get
|
from apiserver.tools import safe_get
|
||||||
|
|
||||||
from .stats import WorkerStats
|
from .stats import WorkerStats
|
||||||
|
|
||||||
log = config.logger(__file__)
|
log = config.logger(__file__)
|
||||||
@@ -33,9 +35,9 @@ log = config.logger(__file__)
|
|||||||
|
|
||||||
class WorkerBLL:
|
class WorkerBLL:
|
||||||
def __init__(self, es=None, redis=None):
|
def __init__(self, es=None, redis=None):
|
||||||
self.es = es if es is not None else es_factory.connect("workers")
|
self.es_client = es or es_factory.connect("workers")
|
||||||
self.redis = redis if redis is not None else redman.connection("workers")
|
self.redis = redis or redman.connection("workers")
|
||||||
self._stats = WorkerStats(self.es)
|
self._stats = WorkerStats(self.es_client)
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def stats(self) -> WorkerStats:
|
def stats(self) -> WorkerStats:
|
||||||
@@ -49,6 +51,8 @@ class WorkerBLL:
|
|||||||
ip: str = "",
|
ip: str = "",
|
||||||
queues: Sequence[str] = None,
|
queues: Sequence[str] = None,
|
||||||
timeout: int = 0,
|
timeout: int = 0,
|
||||||
|
tags: Sequence[str] = None,
|
||||||
|
system_tags: Sequence[str] = None,
|
||||||
) -> WorkerEntry:
|
) -> WorkerEntry:
|
||||||
"""
|
"""
|
||||||
Register a worker
|
Register a worker
|
||||||
@@ -58,6 +62,7 @@ class WorkerBLL:
|
|||||||
:param ip: the real ip of the worker
|
:param ip: the real ip of the worker
|
||||||
:param queues: queues reported as being monitored by the worker
|
:param queues: queues reported as being monitored by the worker
|
||||||
:param timeout: registration expiration timeout in seconds
|
:param timeout: registration expiration timeout in seconds
|
||||||
|
:param tags: a list of tags for this worker
|
||||||
:raise bad_request.InvalidUserId: in case the calling user or company does not exist
|
:raise bad_request.InvalidUserId: in case the calling user or company does not exist
|
||||||
:return: worker entry instance
|
:return: worker entry instance
|
||||||
"""
|
"""
|
||||||
@@ -73,7 +78,7 @@ class WorkerBLL:
|
|||||||
raise bad_request.InvalidUserId(**query)
|
raise bad_request.InvalidUserId(**query)
|
||||||
company = Company.objects(id=company_id).only("id", "name").first()
|
company = Company.objects(id=company_id).only("id", "name").first()
|
||||||
if not company:
|
if not company:
|
||||||
raise server_error.InternalError("invalid company", company=company_id)
|
raise bad_request.InvalidId("invalid company", company=company_id)
|
||||||
|
|
||||||
queue_objs = Queue.objects(company=company_id, id__in=queues).only("id")
|
queue_objs = Queue.objects(company=company_id, id__in=queues).only("id")
|
||||||
if len(queue_objs) < len(queues):
|
if len(queue_objs) < len(queues):
|
||||||
@@ -91,9 +96,11 @@ class WorkerBLL:
|
|||||||
register_time=now,
|
register_time=now,
|
||||||
register_timeout=timeout,
|
register_timeout=timeout,
|
||||||
last_activity_time=now,
|
last_activity_time=now,
|
||||||
|
tags=tags,
|
||||||
|
system_tags=system_tags,
|
||||||
)
|
)
|
||||||
|
|
||||||
self.redis.setex(key, timedelta(seconds=timeout), entry.to_json())
|
self._save_worker_data(entry)
|
||||||
|
|
||||||
return entry
|
return entry
|
||||||
|
|
||||||
@@ -105,20 +112,28 @@ class WorkerBLL:
|
|||||||
:param worker: worker ID
|
:param worker: worker ID
|
||||||
:raise bad_request.WorkerNotRegistered: the worker was not previously registered
|
:raise bad_request.WorkerNotRegistered: the worker was not previously registered
|
||||||
"""
|
"""
|
||||||
with TimingContext("redis", "workers_unregister"):
|
res = self.redis.delete(
|
||||||
res = self.redis.delete(
|
company_id, self._get_worker_key(company_id, user_id, worker)
|
||||||
company_id, self._get_worker_key(company_id, user_id, worker)
|
)
|
||||||
)
|
if not res and not config.get("apiserver.workers.auto_unregister", False):
|
||||||
if not res:
|
|
||||||
raise bad_request.WorkerNotRegistered(worker=worker)
|
raise bad_request.WorkerNotRegistered(worker=worker)
|
||||||
|
|
||||||
def status_report(
|
def status_report(
|
||||||
self, company_id: str, user_id: str, ip: str, report: StatusReportRequest
|
self,
|
||||||
|
company_id: str,
|
||||||
|
user_id: str,
|
||||||
|
ip: str,
|
||||||
|
report: StatusReportRequest,
|
||||||
|
tags: Sequence[str] = None,
|
||||||
|
system_tags: Sequence[str] = None,
|
||||||
) -> None:
|
) -> None:
|
||||||
"""
|
"""
|
||||||
Write worker status report
|
Write worker status report
|
||||||
:param company_id: worker's company ID
|
:param company_id: worker's company ID
|
||||||
:param user_id: user_id ID under which this worker is running
|
:param user_id: user_id ID under which this worker is running
|
||||||
|
:param ip: worker IP
|
||||||
|
:param report: the report itself
|
||||||
|
:param tags: tags for this worker
|
||||||
:raise bad_request.InvalidTaskId: the reported task was not found
|
:raise bad_request.InvalidTaskId: the reported task was not found
|
||||||
:return: worker entry instance
|
:return: worker entry instance
|
||||||
"""
|
"""
|
||||||
@@ -129,11 +144,16 @@ class WorkerBLL:
|
|||||||
now = datetime.utcnow()
|
now = datetime.utcnow()
|
||||||
entry.last_activity_time = now
|
entry.last_activity_time = now
|
||||||
|
|
||||||
|
if tags is not None:
|
||||||
|
entry.tags = tags
|
||||||
|
if system_tags is not None:
|
||||||
|
entry.system_tags = system_tags
|
||||||
|
|
||||||
if report.machine_stats:
|
if report.machine_stats:
|
||||||
self._log_stats_to_es(
|
self._log_stats_to_es(
|
||||||
company_id=company_id,
|
company_id=company_id,
|
||||||
company_name=entry.company.name,
|
company_name=entry.company.name,
|
||||||
worker=report.worker,
|
worker=entry.key,
|
||||||
timestamp=report.timestamp,
|
timestamp=report.timestamp,
|
||||||
task=report.task,
|
task=report.task,
|
||||||
machine_stats=report.machine_stats,
|
machine_stats=report.machine_stats,
|
||||||
@@ -146,6 +166,7 @@ class WorkerBLL:
|
|||||||
|
|
||||||
if not report.task:
|
if not report.task:
|
||||||
entry.task = None
|
entry.task = None
|
||||||
|
entry.project = None
|
||||||
else:
|
else:
|
||||||
with translate_errors_context():
|
with translate_errors_context():
|
||||||
query = dict(id=report.task, company=company_id)
|
query = dict(id=report.task, company=company_id)
|
||||||
@@ -153,6 +174,7 @@ class WorkerBLL:
|
|||||||
last_worker=report.worker,
|
last_worker=report.worker,
|
||||||
last_worker_report=now,
|
last_worker_report=now,
|
||||||
last_update=now,
|
last_update=now,
|
||||||
|
last_change=now,
|
||||||
)
|
)
|
||||||
# modify(new=True, ...) returns the modified object
|
# modify(new=True, ...) returns the modified object
|
||||||
task = Task.objects(**query).modify(new=True, **update)
|
task = Task.objects(**query).modify(new=True, **update)
|
||||||
@@ -160,6 +182,14 @@ class WorkerBLL:
|
|||||||
raise bad_request.InvalidTaskId(**query)
|
raise bad_request.InvalidTaskId(**query)
|
||||||
entry.task = IdNameEntry(id=task.id, name=task.name)
|
entry.task = IdNameEntry(id=task.id, name=task.name)
|
||||||
|
|
||||||
|
entry.project = None
|
||||||
|
if task.project:
|
||||||
|
project = Project.objects(id=task.project).only("name").first()
|
||||||
|
if project:
|
||||||
|
entry.project = IdNameEntry(
|
||||||
|
id=project.id, name=project.name
|
||||||
|
)
|
||||||
|
|
||||||
entry.last_report_time = now
|
entry.last_report_time = now
|
||||||
except APIError:
|
except APIError:
|
||||||
raise
|
raise
|
||||||
@@ -171,7 +201,11 @@ class WorkerBLL:
|
|||||||
self._save_worker(entry)
|
self._save_worker(entry)
|
||||||
|
|
||||||
def get_all(
|
def get_all(
|
||||||
self, company_id: str, last_seen: Optional[int] = None
|
self,
|
||||||
|
company_id: str,
|
||||||
|
last_seen: Optional[int] = None,
|
||||||
|
tags: Sequence[str] = None,
|
||||||
|
system_tags: Sequence[str] = None,
|
||||||
) -> Sequence[WorkerEntry]:
|
) -> Sequence[WorkerEntry]:
|
||||||
"""
|
"""
|
||||||
Get all the company workers that were active during the last_seen period
|
Get all the company workers that were active during the last_seen period
|
||||||
@@ -180,7 +214,7 @@ class WorkerBLL:
|
|||||||
:return:
|
:return:
|
||||||
"""
|
"""
|
||||||
try:
|
try:
|
||||||
workers = self._get(company_id)
|
workers = self._get(company_id, user_tags=tags, system_tags=system_tags)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
raise server_error.DataError("failed loading worker entries", err=e.args[0])
|
raise server_error.DataError("failed loading worker entries", err=e.args[0])
|
||||||
|
|
||||||
@@ -195,13 +229,22 @@ class WorkerBLL:
|
|||||||
return workers
|
return workers
|
||||||
|
|
||||||
def get_all_with_projection(
|
def get_all_with_projection(
|
||||||
self, company_id: str, last_seen: int
|
self,
|
||||||
|
company_id: str,
|
||||||
|
last_seen: int,
|
||||||
|
tags: Sequence[str] = None,
|
||||||
|
system_tags: Sequence[str] = None,
|
||||||
) -> Sequence[WorkerResponseEntry]:
|
) -> Sequence[WorkerResponseEntry]:
|
||||||
|
|
||||||
helpers = list(
|
helpers = list(
|
||||||
map(
|
map(
|
||||||
WorkerConversionHelper.from_worker_entry,
|
WorkerConversionHelper.from_worker_entry,
|
||||||
self.get_all(company_id=company_id, last_seen=last_seen),
|
self.get_all(
|
||||||
|
company_id=company_id,
|
||||||
|
last_seen=last_seen,
|
||||||
|
tags=tags,
|
||||||
|
system_tags=system_tags,
|
||||||
|
),
|
||||||
)
|
)
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -223,7 +266,7 @@ class WorkerBLL:
|
|||||||
},
|
},
|
||||||
]
|
]
|
||||||
queues_info = {
|
queues_info = {
|
||||||
res["_id"]: res for res in Queue.objects.aggregate(*projection)
|
res["_id"]: res for res in Queue.objects.aggregate(projection)
|
||||||
}
|
}
|
||||||
task_ids = task_ids.union(
|
task_ids = task_ids.union(
|
||||||
filter(
|
filter(
|
||||||
@@ -240,7 +283,7 @@ class WorkerBLL:
|
|||||||
tasks_info = {
|
tasks_info = {
|
||||||
task.id: task
|
task.id: task
|
||||||
for task in Task.objects(id__in=task_ids).only(
|
for task in Task.objects(id__in=task_ids).only(
|
||||||
"name", "started", "last_iteration"
|
"name", "started", "last_iteration", "active_duration"
|
||||||
)
|
)
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -265,11 +308,7 @@ class WorkerBLL:
|
|||||||
if helper.task_id:
|
if helper.task_id:
|
||||||
task = tasks_info.get(helper.task_id, None)
|
task = tasks_info.get(helper.task_id, None)
|
||||||
if task:
|
if task:
|
||||||
worker.task.running_time = (
|
worker.task.running_time = (task.active_duration or 0) * 1000
|
||||||
int((datetime.utcnow() - task.started).total_seconds() * 1000)
|
|
||||||
if task.started
|
|
||||||
else 0
|
|
||||||
)
|
|
||||||
worker.task.last_iteration = task.last_iteration
|
worker.task.last_iteration = task.last_iteration
|
||||||
|
|
||||||
update_queue_entries(worker.queue)
|
update_queue_entries(worker.queue)
|
||||||
@@ -296,8 +335,7 @@ class WorkerBLL:
|
|||||||
"""
|
"""
|
||||||
key = self._get_worker_key(company_id, user_id, worker)
|
key = self._get_worker_key(company_id, user_id, worker)
|
||||||
|
|
||||||
with TimingContext("redis", "get_worker"):
|
data = self.redis.get(key)
|
||||||
data = self.redis.get(key)
|
|
||||||
|
|
||||||
if data:
|
if data:
|
||||||
try:
|
try:
|
||||||
@@ -324,24 +362,119 @@ class WorkerBLL:
|
|||||||
|
|
||||||
raise bad_request.InvalidWorkerId(worker=worker)
|
raise bad_request.InvalidWorkerId(worker=worker)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _get_tagged_workers_key(company: str, tags_field: str, tag: str) -> str:
|
||||||
|
"""Build redis key from company, user and worker_id"""
|
||||||
|
return f"workers.{tags_field}_{company}_{tag}"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _get_all_workers_key(company: str) -> str:
|
||||||
|
"""Build redis key from company, user and worker_id"""
|
||||||
|
return f"workers_{company}"
|
||||||
|
|
||||||
|
def _save_worker_data(self, entry: WorkerEntry):
|
||||||
|
self.redis.setex(
|
||||||
|
entry.key, timedelta(seconds=entry.register_timeout), entry.to_json()
|
||||||
|
)
|
||||||
|
company_id = entry.company.id
|
||||||
|
expiration = int(time()) + entry.register_timeout
|
||||||
|
worker_item = {entry.key: expiration}
|
||||||
|
self.redis.zadd(self._get_all_workers_key(company_id), worker_item)
|
||||||
|
for tags, tags_field in (
|
||||||
|
(entry.tags, "tags"),
|
||||||
|
(entry.system_tags, "systemtags"),
|
||||||
|
):
|
||||||
|
for tag in tags:
|
||||||
|
name = self._get_tagged_workers_key(company_id, tags_field, tag)
|
||||||
|
self.redis.zadd(name, worker_item)
|
||||||
|
|
||||||
def _save_worker(self, entry: WorkerEntry) -> None:
|
def _save_worker(self, entry: WorkerEntry) -> None:
|
||||||
"""Save worker entry in Redis"""
|
"""Save worker entry in Redis"""
|
||||||
try:
|
try:
|
||||||
self.redis.setex(
|
self._save_worker_data(entry)
|
||||||
entry.key, timedelta(seconds=entry.register_timeout), entry.to_json()
|
|
||||||
)
|
|
||||||
except Exception:
|
except Exception:
|
||||||
msg = "Failed saving worker entry"
|
msg = "Failed saving worker entry"
|
||||||
log.exception(msg)
|
log.exception(msg)
|
||||||
|
|
||||||
def _get(
|
def _get(
|
||||||
self, company: str, user: str = "*", worker_id: str = "*"
|
self,
|
||||||
|
company: str,
|
||||||
|
user: str = "*",
|
||||||
|
worker_id: str = "*",
|
||||||
|
user_tags: Sequence[str] = None,
|
||||||
|
system_tags: Sequence[str] = None,
|
||||||
) -> Sequence[WorkerEntry]:
|
) -> Sequence[WorkerEntry]:
|
||||||
"""Get worker entries matching the company and user, worker patterns"""
|
"""Get worker entries matching the company and user, worker patterns"""
|
||||||
match = self._get_worker_key(company, user, worker_id)
|
|
||||||
with TimingContext("redis", "workers_get_all"):
|
def filter_by_user(in_keys: Set[bytes]) -> Set[bytes]:
|
||||||
res = self.redis.scan_iter(match)
|
if user == "*":
|
||||||
return [WorkerEntry.from_json(self.redis.get(r)) for r in res]
|
return in_keys
|
||||||
|
user_bytes = user.encode()
|
||||||
|
return {k for k in in_keys if user_bytes in k}
|
||||||
|
|
||||||
|
if user_tags or system_tags:
|
||||||
|
worker_keys = set()
|
||||||
|
for tags, tags_field in (
|
||||||
|
(user_tags, "tags"),
|
||||||
|
(system_tags, "systemtags"),
|
||||||
|
):
|
||||||
|
if not tags:
|
||||||
|
continue
|
||||||
|
timestamp = int(time())
|
||||||
|
include, exclude = partition(tags, key=lambda x: x[0] != "-")
|
||||||
|
if include:
|
||||||
|
tagged_workers = set()
|
||||||
|
for tag in include:
|
||||||
|
tagged_workers_key = self._get_tagged_workers_key(
|
||||||
|
company, tags_field, tag
|
||||||
|
)
|
||||||
|
self.redis.zremrangebyscore(
|
||||||
|
tagged_workers_key, min=0, max=timestamp
|
||||||
|
)
|
||||||
|
tagged_workers.update(
|
||||||
|
self.redis.zrange(tagged_workers_key, 0, -1)
|
||||||
|
)
|
||||||
|
tagged_workers = filter_by_user(tagged_workers)
|
||||||
|
worker_keys = (
|
||||||
|
worker_keys.intersection(tagged_workers)
|
||||||
|
if worker_keys
|
||||||
|
else tagged_workers
|
||||||
|
)
|
||||||
|
if not worker_keys:
|
||||||
|
return []
|
||||||
|
if exclude:
|
||||||
|
if not worker_keys:
|
||||||
|
all_workers_key = self._get_all_workers_key(company)
|
||||||
|
self.redis.zremrangebyscore(
|
||||||
|
all_workers_key, min=0, max=timestamp
|
||||||
|
)
|
||||||
|
worker_keys.update(self.redis.zrange(all_workers_key, 0, -1))
|
||||||
|
worker_keys = filter_by_user(worker_keys)
|
||||||
|
if not worker_keys:
|
||||||
|
return []
|
||||||
|
for tag in exclude:
|
||||||
|
tagged_workers_key = self._get_tagged_workers_key(
|
||||||
|
company, tags_field, tag[1:]
|
||||||
|
)
|
||||||
|
self.redis.zremrangebyscore(
|
||||||
|
tagged_workers_key, min=0, max=timestamp
|
||||||
|
)
|
||||||
|
worker_keys.difference_update(
|
||||||
|
self.redis.zrange(tagged_workers_key, 0, -1)
|
||||||
|
)
|
||||||
|
if not worker_keys:
|
||||||
|
return []
|
||||||
|
else:
|
||||||
|
match = self._get_worker_key(company, user, "*")
|
||||||
|
worker_keys = self.redis.scan_iter(match)
|
||||||
|
|
||||||
|
entries = []
|
||||||
|
for key in worker_keys:
|
||||||
|
data = self.redis.get(key)
|
||||||
|
if data:
|
||||||
|
entries.append(WorkerEntry.from_json(data))
|
||||||
|
|
||||||
|
return entries
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def _get_es_index_suffix():
|
def _get_es_index_suffix():
|
||||||
@@ -369,7 +502,6 @@ class WorkerBLL:
|
|||||||
def make_doc(category, metric, variant, value) -> dict:
|
def make_doc(category, metric, variant, value) -> dict:
|
||||||
return dict(
|
return dict(
|
||||||
_index=es_index,
|
_index=es_index,
|
||||||
_type="stat",
|
|
||||||
_source=dict(
|
_source=dict(
|
||||||
timestamp=timestamp,
|
timestamp=timestamp,
|
||||||
worker=worker,
|
worker=worker,
|
||||||
@@ -396,7 +528,7 @@ class WorkerBLL:
|
|||||||
for i, val in enumerate(value)
|
for i, val in enumerate(value)
|
||||||
)
|
)
|
||||||
|
|
||||||
es_res = elasticsearch.helpers.bulk(self.es, actions)
|
es_res = elasticsearch.helpers.bulk(self.es_client, actions)
|
||||||
added, errors = es_res[:2]
|
added, errors = es_res[:2]
|
||||||
return (added == len(actions)) and not errors
|
return (added == len(actions)) and not errors
|
||||||
|
|
||||||
@@ -3,12 +3,11 @@ from typing import Optional, Sequence
|
|||||||
|
|
||||||
from boltons.iterutils import bucketize
|
from boltons.iterutils import bucketize
|
||||||
|
|
||||||
from apierrors.errors import bad_request
|
from apiserver.apierrors.errors import bad_request
|
||||||
from apimodels.workers import AggregationType, GetStatsRequest, StatItem
|
from apiserver.apimodels.workers import AggregationType, GetStatsRequest, StatItem
|
||||||
from bll.query import Builder as QueryBuilder
|
from apiserver.bll.query import Builder as QueryBuilder
|
||||||
from config import config
|
from apiserver.config_repo import config
|
||||||
from database.errors import translate_errors_context
|
from apiserver.database.errors import translate_errors_context
|
||||||
from timing_context import TimingContext
|
|
||||||
|
|
||||||
log = config.logger(__file__)
|
log = config.logger(__file__)
|
||||||
|
|
||||||
@@ -20,12 +19,11 @@ class WorkerStats:
|
|||||||
@staticmethod
|
@staticmethod
|
||||||
def worker_stats_prefix_for_company(company_id: str) -> str:
|
def worker_stats_prefix_for_company(company_id: str) -> str:
|
||||||
"""Returns the es index prefix for the company"""
|
"""Returns the es index prefix for the company"""
|
||||||
return f"worker_stats_{company_id}_"
|
return f"worker_stats_{company_id.lower()}_"
|
||||||
|
|
||||||
def _search_company_stats(self, company_id: str, es_req: dict) -> dict:
|
def _search_company_stats(self, company_id: str, es_req: dict) -> dict:
|
||||||
return self.es.search(
|
return self.es.search(
|
||||||
index=f"{self.worker_stats_prefix_for_company(company_id)}*",
|
index=f"{self.worker_stats_prefix_for_company(company_id)}*",
|
||||||
doc_type="stat",
|
|
||||||
body=es_req,
|
body=es_req,
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -53,7 +51,7 @@ class WorkerStats:
|
|||||||
|
|
||||||
res = self._search_company_stats(company_id, es_req)
|
res = self._search_company_stats(company_id, es_req)
|
||||||
|
|
||||||
if not res["hits"]["total"]:
|
if not res["hits"]["total"]["value"]:
|
||||||
raise bad_request.WorkerStatsNotFound(
|
raise bad_request.WorkerStatsNotFound(
|
||||||
f"No statistic metrics found for the company {company_id} and workers {worker_ids}"
|
f"No statistic metrics found for the company {company_id} and workers {worker_ids}"
|
||||||
)
|
)
|
||||||
@@ -87,7 +85,7 @@ class WorkerStats:
|
|||||||
"dates": {
|
"dates": {
|
||||||
"date_histogram": {
|
"date_histogram": {
|
||||||
"field": "timestamp",
|
"field": "timestamp",
|
||||||
"interval": f"{request.interval}s",
|
"fixed_interval": f"{request.interval}s",
|
||||||
"min_doc_count": 1,
|
"min_doc_count": 1,
|
||||||
},
|
},
|
||||||
"aggs": {
|
"aggs": {
|
||||||
@@ -127,7 +125,7 @@ class WorkerStats:
|
|||||||
query_terms.append(QueryBuilder.terms("worker", request.worker_ids))
|
query_terms.append(QueryBuilder.terms("worker", request.worker_ids))
|
||||||
es_req["query"] = {"bool": {"must": query_terms}}
|
es_req["query"] = {"bool": {"must": query_terms}}
|
||||||
|
|
||||||
with translate_errors_context(), TimingContext("es", "get_worker_stats"):
|
with translate_errors_context():
|
||||||
data = self._search_company_stats(company_id, es_req)
|
data = self._search_company_stats(company_id, es_req)
|
||||||
|
|
||||||
return self._extract_results(data, request.items, request.split_by_variant)
|
return self._extract_results(data, request.items, request.split_by_variant)
|
||||||
@@ -216,7 +214,7 @@ class WorkerStats:
|
|||||||
"dates": {
|
"dates": {
|
||||||
"date_histogram": {
|
"date_histogram": {
|
||||||
"field": "timestamp",
|
"field": "timestamp",
|
||||||
"interval": f"{interval}s",
|
"fixed_interval": f"{interval}s",
|
||||||
},
|
},
|
||||||
"aggs": {"workers_count": {"cardinality": {"field": "worker"}}},
|
"aggs": {"workers_count": {"cardinality": {"field": "worker"}}},
|
||||||
}
|
}
|
||||||
@@ -224,9 +222,7 @@ class WorkerStats:
|
|||||||
"query": {"bool": {"must": must}},
|
"query": {"bool": {"must": must}},
|
||||||
}
|
}
|
||||||
|
|
||||||
with translate_errors_context(), TimingContext(
|
with translate_errors_context():
|
||||||
"es", "get_worker_activity_report"
|
|
||||||
):
|
|
||||||
data = self._search_company_stats(company_id, es_req)
|
data = self._search_company_stats(company_id, es_req)
|
||||||
|
|
||||||
if "aggregations" not in data:
|
if "aggregations" not in data:
|
||||||
1
apiserver/config/__init__.py
Normal file
1
apiserver/config/__init__.py
Normal file
@@ -0,0 +1 @@
|
|||||||
|
from .basic import BasicConfig, ConfigurationError
|
||||||
217
apiserver/config/basic.py
Normal file
217
apiserver/config/basic.py
Normal file
@@ -0,0 +1,217 @@
|
|||||||
|
import logging
|
||||||
|
import logging.config
|
||||||
|
import os
|
||||||
|
import platform
|
||||||
|
from functools import reduce
|
||||||
|
from os import getenv
|
||||||
|
from os.path import expandvars
|
||||||
|
from pathlib import Path
|
||||||
|
from typing import List, Any, TypeVar, Sequence
|
||||||
|
|
||||||
|
from boltons.iterutils import first
|
||||||
|
from pyhocon import ConfigTree, ConfigFactory, ConfigValues
|
||||||
|
from pyparsing import (
|
||||||
|
ParseFatalException,
|
||||||
|
ParseException,
|
||||||
|
RecursiveGrammarException,
|
||||||
|
ParseSyntaxException,
|
||||||
|
)
|
||||||
|
|
||||||
|
from apiserver.utilities import json
|
||||||
|
|
||||||
|
EXTRA_CONFIG_PATHS = ("/opt/trains/config", "/opt/clearml/config")
|
||||||
|
DEFAULT_PREFIXES = ("clearml", "trains")
|
||||||
|
EXTRA_CONFIG_PATH_SEP = ":" if platform.system() != "Windows" else ";"
|
||||||
|
|
||||||
|
|
||||||
|
class BasicConfig:
|
||||||
|
NotSet = object()
|
||||||
|
|
||||||
|
extra_config_values_env_key_sep = "__"
|
||||||
|
default_config_dir = "default"
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
folder: str = None,
|
||||||
|
verbose: bool = True,
|
||||||
|
prefix: Sequence[str] = DEFAULT_PREFIXES,
|
||||||
|
):
|
||||||
|
folder = (
|
||||||
|
Path(folder)
|
||||||
|
if folder
|
||||||
|
else Path(__file__).with_name(self.default_config_dir)
|
||||||
|
)
|
||||||
|
if not folder.is_dir():
|
||||||
|
raise ValueError("Invalid configuration folder")
|
||||||
|
|
||||||
|
self.verbose = verbose
|
||||||
|
|
||||||
|
self.extra_config_path_override_var = [
|
||||||
|
f"{p.upper()}_CONFIG_DIR" for p in prefix
|
||||||
|
]
|
||||||
|
|
||||||
|
self.prefix = prefix[0]
|
||||||
|
self.extra_config_values_env_key_prefix = [
|
||||||
|
f"{p.upper()}{self.extra_config_values_env_key_sep}"
|
||||||
|
for p in reversed(prefix)
|
||||||
|
]
|
||||||
|
|
||||||
|
self._paths = [folder, *self._get_paths()]
|
||||||
|
self._config = self._reload()
|
||||||
|
|
||||||
|
def __getitem__(self, key):
|
||||||
|
return self._config[key]
|
||||||
|
|
||||||
|
def get(self, key: str, default: Any = NotSet) -> Any:
|
||||||
|
value = self._config.get(key, default)
|
||||||
|
if value is self.NotSet:
|
||||||
|
raise KeyError(
|
||||||
|
f"Unable to find value for key '{key}' and default value was not provided."
|
||||||
|
)
|
||||||
|
return value
|
||||||
|
|
||||||
|
def to_dict(self) -> dict:
|
||||||
|
return self._config.as_plain_ordered_dict()
|
||||||
|
|
||||||
|
def as_json(self) -> str:
|
||||||
|
return json.dumps(self.to_dict(), indent=2)
|
||||||
|
|
||||||
|
def logger(self, name: str) -> logging.Logger:
|
||||||
|
if Path(name).is_file():
|
||||||
|
name = Path(name).stem
|
||||||
|
if name == "__init__" and Path(name).parent.stem:
|
||||||
|
name = Path(name).parent.stem
|
||||||
|
path = ".".join((self.prefix, name))
|
||||||
|
return logging.getLogger(path)
|
||||||
|
|
||||||
|
def _read_extra_env_config_values(self) -> ConfigTree:
|
||||||
|
""" Loads extra configuration from environment-injected values """
|
||||||
|
result = ConfigTree()
|
||||||
|
|
||||||
|
for prefix in self.extra_config_values_env_key_prefix:
|
||||||
|
keys = sorted(k for k in os.environ if k.startswith(prefix))
|
||||||
|
for key in keys:
|
||||||
|
path = (
|
||||||
|
key[len(prefix) :]
|
||||||
|
.replace(self.extra_config_values_env_key_sep, ".")
|
||||||
|
.lower()
|
||||||
|
)
|
||||||
|
result = self._merge_configs(
|
||||||
|
result, ConfigFactory.parse_string(f"{path}: {os.environ[key]}")
|
||||||
|
)
|
||||||
|
|
||||||
|
return result
|
||||||
|
|
||||||
|
def _get_paths(self) -> List[Path]:
|
||||||
|
default_paths = EXTRA_CONFIG_PATH_SEP.join(EXTRA_CONFIG_PATHS)
|
||||||
|
value = first(map(getenv, self.extra_config_path_override_var), default_paths)
|
||||||
|
|
||||||
|
paths = [
|
||||||
|
Path(expandvars(v)).expanduser() for v in value.split(EXTRA_CONFIG_PATH_SEP)
|
||||||
|
]
|
||||||
|
|
||||||
|
if value is not default_paths:
|
||||||
|
invalid = [path for path in paths if not path.is_dir()]
|
||||||
|
if invalid:
|
||||||
|
print(
|
||||||
|
f"WARNING: Invalid paths in {self.extra_config_path_override_var} env var: {' '.join(map(str, invalid))}"
|
||||||
|
)
|
||||||
|
|
||||||
|
return [path for path in paths if path.is_dir()]
|
||||||
|
|
||||||
|
def reload(self):
|
||||||
|
self._config = self._reload()
|
||||||
|
|
||||||
|
def _reload(self) -> ConfigTree:
|
||||||
|
extra_config_values = self._read_extra_env_config_values()
|
||||||
|
|
||||||
|
configs = [self._read_recursive(path) for path in self._paths]
|
||||||
|
|
||||||
|
return reduce(
|
||||||
|
lambda last, config: self._merge_configs(
|
||||||
|
last, config, copy_trees=True
|
||||||
|
),
|
||||||
|
configs + [extra_config_values],
|
||||||
|
ConfigTree(),
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _merge_configs(cls, a, b, copy_trees=False, override_prefix="-"):
|
||||||
|
"""Based on pyhocon.ConfigTree.merge_configs, with dict override support using a `-` key prefix"""
|
||||||
|
for key, value in b.items():
|
||||||
|
override = key.startswith(override_prefix)
|
||||||
|
if override:
|
||||||
|
key = key[len(override_prefix):]
|
||||||
|
# if key is in both a and b and both values are dictionary then merge it otherwise override it
|
||||||
|
if not override and key in a and isinstance(a[key], ConfigTree) and isinstance(b[key], ConfigTree):
|
||||||
|
if copy_trees:
|
||||||
|
a[key] = a[key].copy()
|
||||||
|
cls._merge_configs(a[key], b[key], copy_trees=copy_trees)
|
||||||
|
else:
|
||||||
|
if isinstance(value, ConfigValues):
|
||||||
|
value.parent = a
|
||||||
|
value.key = key
|
||||||
|
if key in a:
|
||||||
|
value.overriden_value = a[key]
|
||||||
|
a[key] = value
|
||||||
|
if a.root:
|
||||||
|
if b.root:
|
||||||
|
a.history[key] = a.history.get(key, []) + b.history.get(key, [value])
|
||||||
|
else:
|
||||||
|
a.history[key] = a.history.get(key, []) + [value]
|
||||||
|
|
||||||
|
return a
|
||||||
|
|
||||||
|
def _read_recursive(self, conf_root) -> ConfigTree:
|
||||||
|
conf = ConfigTree()
|
||||||
|
|
||||||
|
if not conf_root:
|
||||||
|
return conf
|
||||||
|
|
||||||
|
if not conf_root.is_dir():
|
||||||
|
if self.verbose:
|
||||||
|
if not conf_root.exists():
|
||||||
|
print(f"No config in {conf_root}")
|
||||||
|
else:
|
||||||
|
print(f"Not a directory: {conf_root}")
|
||||||
|
return conf
|
||||||
|
|
||||||
|
if self.verbose:
|
||||||
|
print(f"Loading config from {conf_root}")
|
||||||
|
|
||||||
|
for file in conf_root.rglob("*.conf"):
|
||||||
|
key = ".".join(file.relative_to(conf_root).with_suffix("").parts)
|
||||||
|
conf.put(key, self._read_single_file(file))
|
||||||
|
|
||||||
|
return conf
|
||||||
|
|
||||||
|
def _read_single_file(self, file_path):
|
||||||
|
if self.verbose:
|
||||||
|
print(f"Loading config from file {file_path}")
|
||||||
|
|
||||||
|
try:
|
||||||
|
return ConfigFactory.parse_file(file_path)
|
||||||
|
except ParseSyntaxException as ex:
|
||||||
|
msg = f"Failed parsing {file_path} ({ex.__class__.__name__}): (at char {ex.loc}, line:{ex.lineno}, col:{ex.column})"
|
||||||
|
raise ConfigurationError(msg, file_path=file_path) from ex
|
||||||
|
except (ParseException, ParseFatalException, RecursiveGrammarException) as ex:
|
||||||
|
msg = f"Failed parsing {file_path} ({ex.__class__.__name__}): {ex}"
|
||||||
|
raise ConfigurationError(msg) from ex
|
||||||
|
except Exception as ex:
|
||||||
|
print(f"Failed loading {file_path}: {ex}")
|
||||||
|
raise
|
||||||
|
|
||||||
|
def initialize_logging(self):
|
||||||
|
logging_config = self.get("logging", None)
|
||||||
|
if not logging_config:
|
||||||
|
return
|
||||||
|
logging.config.dictConfig(logging_config)
|
||||||
|
|
||||||
|
|
||||||
|
class ConfigurationError(Exception):
|
||||||
|
def __init__(self, msg, file_path=None, *args):
|
||||||
|
super().__init__(msg, *args)
|
||||||
|
self.file_path = file_path
|
||||||
|
|
||||||
|
|
||||||
|
ConfigType = TypeVar("ConfigType", bound=BasicConfig)
|
||||||
@@ -3,7 +3,7 @@
|
|||||||
debug: false # Debug mode
|
debug: false # Debug mode
|
||||||
pretty_json: false # prettify json response
|
pretty_json: false # prettify json response
|
||||||
return_stack: true # return stack trace on error
|
return_stack: true # return stack trace on error
|
||||||
log_calls: true # Log API Calls
|
return_stack_to_caller: true # top-level control on whether to return stack trace in an API response
|
||||||
|
|
||||||
# if 'return_stack' is true and error contains a status code, return stack trace only for these status codes
|
# if 'return_stack' is true and error contains a status code, return stack trace only for these status codes
|
||||||
# valid values are:
|
# valid values are:
|
||||||
@@ -26,13 +26,31 @@
|
|||||||
check_max_version: false
|
check_max_version: false
|
||||||
}
|
}
|
||||||
|
|
||||||
|
pre_populate {
|
||||||
|
enabled: false
|
||||||
|
zip_files: ["/path/to/export.zip"]
|
||||||
|
fail_on_error: false
|
||||||
|
# artifacts_path: "/mnt/fileserver"
|
||||||
|
}
|
||||||
|
|
||||||
|
# time in seconds to take an exclusive lock to init es and mongodb
|
||||||
|
# not including the pre_populate
|
||||||
|
db_init_timout: 120
|
||||||
|
|
||||||
mongo {
|
mongo {
|
||||||
# controls whether FieldDoesNotExist exception will be raised for any extra attribute existing in stored data
|
# controls whether FieldDoesNotExist exception will be raised for any extra attribute existing in stored data
|
||||||
# but not declared in a data model
|
# but not declared in a data model
|
||||||
strict: false
|
strict: false
|
||||||
|
}
|
||||||
|
|
||||||
aggregate {
|
elastic {
|
||||||
allow_disk_use: true
|
probing {
|
||||||
|
# settings for inital probing of elastic connection
|
||||||
|
max_retries: 4
|
||||||
|
timeout: 30
|
||||||
|
}
|
||||||
|
upgrade_monitoring {
|
||||||
|
v16_migration_verification: true
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -47,7 +65,7 @@
|
|||||||
default_expiration_sec: 2592000
|
default_expiration_sec: 2592000
|
||||||
|
|
||||||
# cookie containing auth token, for requests arriving from a web-browser
|
# cookie containing auth token, for requests arriving from a web-browser
|
||||||
session_auth_cookie_name: "trains_token_basic"
|
session_auth_cookie_name: "clearml_token_basic"
|
||||||
|
|
||||||
# cookie configuration for authorization cookies generated by auth.login
|
# cookie configuration for authorization cookies generated by auth.login
|
||||||
cookies {
|
cookies {
|
||||||
@@ -57,9 +75,16 @@
|
|||||||
max_age: 99999999999
|
max_age: 99999999999
|
||||||
}
|
}
|
||||||
|
|
||||||
|
# provide a cookie domain override per company
|
||||||
|
# cookies_domain_override {
|
||||||
|
# <company-id>: <domain>
|
||||||
|
# }
|
||||||
|
|
||||||
# # A list of fixed users
|
# # A list of fixed users
|
||||||
|
# # Note: password may be bcrypt-hashed (generate using `python -c 'import bcrypt; print(bcrypt.hashpw("password", bcrypt.gensalt()))'`)
|
||||||
# fixed_users {
|
# fixed_users {
|
||||||
# enabled: true
|
# enabled: true
|
||||||
|
# pass_hashed: false
|
||||||
# users: [
|
# users: [
|
||||||
# {
|
# {
|
||||||
# username: "john"
|
# username: "john"
|
||||||
@@ -83,9 +108,15 @@
|
|||||||
workers {
|
workers {
|
||||||
# Auto-register unknown workers on status reports and other calls
|
# Auto-register unknown workers on status reports and other calls
|
||||||
auto_register: true
|
auto_register: true
|
||||||
|
# Assume unknow workers have unregistered (i.e. do not raise unregistered error)
|
||||||
|
auto_unregister: true
|
||||||
# Timeout in seconds on task status update. If exceeded
|
# Timeout in seconds on task status update. If exceeded
|
||||||
# then task can be stopped without communicating to the worker
|
# then task can be stopped without communicating to the worker
|
||||||
task_update_timeout: 600
|
task_update_timeout: 600
|
||||||
|
|
||||||
|
# Timeout in seconds for worker registration (or status report). If a worker did not report for this long,
|
||||||
|
# it is discarded from the server's table
|
||||||
|
default_timeout: 600
|
||||||
}
|
}
|
||||||
|
|
||||||
check_for_updates {
|
check_for_updates {
|
||||||
@@ -94,11 +125,32 @@
|
|||||||
# Check for updates every 24 hours
|
# Check for updates every 24 hours
|
||||||
check_interval_sec: 86400
|
check_interval_sec: 86400
|
||||||
|
|
||||||
url: "https://updates.trains.allegro.ai/updates"
|
url: "https://updates.clear.ml/updates"
|
||||||
|
|
||||||
component_name: "trains-server"
|
component_name: "clearml-server"
|
||||||
|
|
||||||
# GET request timeout
|
# GET request timeout
|
||||||
request_timeout_sec: 3.0
|
request_timeout_sec: 3.0
|
||||||
}
|
}
|
||||||
|
|
||||||
|
statistics {
|
||||||
|
# Note: statistics are sent ONLY if the user has actively opted-in
|
||||||
|
supported: true
|
||||||
|
|
||||||
|
url: "https://updates.clear.ml/stats"
|
||||||
|
|
||||||
|
report_interval_hours: 24
|
||||||
|
agent_relevant_threshold_days: 30
|
||||||
|
|
||||||
|
max_retries: 5
|
||||||
|
max_backoff_sec: 5
|
||||||
|
}
|
||||||
|
|
||||||
|
getting_started_info {
|
||||||
|
"agentName": "clearml",
|
||||||
|
"configure": "clearml-init",
|
||||||
|
"install": "pip install clearml",
|
||||||
|
"packageName": "clearml"
|
||||||
|
}
|
||||||
|
|
||||||
}
|
}
|
||||||
@@ -1,10 +1,12 @@
|
|||||||
|
fileserver = "http://localhost:8081"
|
||||||
|
|
||||||
elastic {
|
elastic {
|
||||||
events {
|
events {
|
||||||
hosts: [{host: "127.0.0.1", port: 9200}]
|
hosts: [{host: "127.0.0.1", port: 9200}]
|
||||||
args {
|
args {
|
||||||
timeout: 60
|
timeout: 60
|
||||||
dead_timeout: 10
|
dead_timeout: 10
|
||||||
max_retries: 5
|
max_retries: 3
|
||||||
retry_on_timeout: true
|
retry_on_timeout: true
|
||||||
}
|
}
|
||||||
index_version: "1"
|
index_version: "1"
|
||||||
@@ -15,7 +17,7 @@ elastic {
|
|||||||
args {
|
args {
|
||||||
timeout: 60
|
timeout: 60
|
||||||
dead_timeout: 10
|
dead_timeout: 10
|
||||||
max_retries: 5
|
max_retries: 3
|
||||||
retry_on_timeout: true
|
retry_on_timeout: true
|
||||||
}
|
}
|
||||||
index_version: "1"
|
index_version: "1"
|
||||||
@@ -32,6 +34,11 @@ mongo {
|
|||||||
}
|
}
|
||||||
|
|
||||||
redis {
|
redis {
|
||||||
|
apiserver {
|
||||||
|
host: "127.0.0.1"
|
||||||
|
port: 6379
|
||||||
|
db: 0
|
||||||
|
}
|
||||||
workers {
|
workers {
|
||||||
host: "127.0.0.1"
|
host: "127.0.0.1"
|
||||||
port: 6379
|
port: 6379
|
||||||
@@ -16,7 +16,7 @@
|
|||||||
backupCount: 3
|
backupCount: 3
|
||||||
maxBytes: 10240000,
|
maxBytes: 10240000,
|
||||||
class: "logging.handlers.RotatingFileHandler",
|
class: "logging.handlers.RotatingFileHandler",
|
||||||
filename: "/var/log/trains/apiserver.log"
|
filename: "/var/log/clearml/apiserver.log"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
root {
|
root {
|
||||||
@@ -13,17 +13,22 @@
|
|||||||
credentials {
|
credentials {
|
||||||
# system credentials as they appear in the auth DB, used for intra-service communications
|
# system credentials as they appear in the auth DB, used for intra-service communications
|
||||||
apiserver {
|
apiserver {
|
||||||
|
role: "system"
|
||||||
user_key: "62T8CP7HGBC6647XF9314C2VY67RJO"
|
user_key: "62T8CP7HGBC6647XF9314C2VY67RJO"
|
||||||
user_secret: "FhS8VZv_I4%6Mo$8S1BWc$n$=o1dMYSivuiWU-Vguq7qGOKskG-d+b@tn_Iq"
|
user_secret: "FhS8VZv_I4%6Mo$8S1BWc$n$=o1dMYSivuiWU-Vguq7qGOKskG-d+b@tn_Iq"
|
||||||
}
|
}
|
||||||
webserver {
|
webserver {
|
||||||
|
role: "system"
|
||||||
user_key: "EYVQ385RW7Y2QQUH88CZ7DWIQ1WUHP"
|
user_key: "EYVQ385RW7Y2QQUH88CZ7DWIQ1WUHP"
|
||||||
user_secret: "yfc8KQo*GMXb*9p((qcYC7ByFIpF7I&4VH3BfUYXH%o9vX1ZUZQEEw1Inc)S"
|
user_secret: "yfc8KQo*GMXb*9p((qcYC7ByFIpF7I&4VH3BfUYXH%o9vX1ZUZQEEw1Inc)S"
|
||||||
|
revoke_in_fixed_mode: true
|
||||||
}
|
}
|
||||||
tests {
|
tests {
|
||||||
|
role: "user"
|
||||||
|
display_name: "Default User"
|
||||||
user_key: "EGRTCO8JMSIGI6S39GTP43NFWXDQOW"
|
user_key: "EGRTCO8JMSIGI6S39GTP43NFWXDQOW"
|
||||||
user_secret: "x!XTov_G-#vspE*Y(h$Anm&DIc5Ou-F)jsl$PdOyj5wG1&E!Z8"
|
user_secret: "x!XTov_G-#vspE*Y(h$Anm&DIc5Ou-F)jsl$PdOyj5wG1&E!Z8"
|
||||||
|
revoke_in_fixed_mode: true
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
9
apiserver/config/default/services/_mongo.conf
Normal file
9
apiserver/config/default/services/_mongo.conf
Normal file
@@ -0,0 +1,9 @@
|
|||||||
|
max_page_size: 500
|
||||||
|
|
||||||
|
# expiration time in seconds for the redis scroll states in get_many family of apis
|
||||||
|
scroll_state_expiration_seconds: 600
|
||||||
|
|
||||||
|
allow_disk_use {
|
||||||
|
sort: true
|
||||||
|
aggregate: true
|
||||||
|
}
|
||||||
12
apiserver/config/default/services/async_urls_delete.conf
Normal file
12
apiserver/config/default/services/async_urls_delete.conf
Normal file
@@ -0,0 +1,12 @@
|
|||||||
|
# if set to True then on task delete/reset external file urls for know storage types are scheduled for async delete
|
||||||
|
# otherwise they are returned to a client for the client side delete
|
||||||
|
enabled: true
|
||||||
|
max_retries: 3
|
||||||
|
retry_timeout_sec: 60
|
||||||
|
|
||||||
|
fileserver {
|
||||||
|
# fileserver url prefixes. Evaluated in the order of priority
|
||||||
|
# Can be in the form <schema>://host:port/path or /path
|
||||||
|
url_prefixes: ["https://files.community-master.hosted.allegro.ai/"]
|
||||||
|
timeout_sec: 300
|
||||||
|
}
|
||||||
16
apiserver/config/default/services/auth.conf
Normal file
16
apiserver/config/default/services/auth.conf
Normal file
@@ -0,0 +1,16 @@
|
|||||||
|
fixed_users {
|
||||||
|
guest {
|
||||||
|
enabled: false
|
||||||
|
|
||||||
|
default_company: "025315a9321f49f8be07f5ac48fbcf92"
|
||||||
|
|
||||||
|
name: "Guest"
|
||||||
|
username: "guest"
|
||||||
|
password: "guest"
|
||||||
|
|
||||||
|
# Allow access only to the following endpoints when using user/pass credentials
|
||||||
|
allow_endpoints: [
|
||||||
|
"auth.login"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
45
apiserver/config/default/services/events.conf
Normal file
45
apiserver/config/default/services/events.conf
Normal file
@@ -0,0 +1,45 @@
|
|||||||
|
es_index_prefix: "events"
|
||||||
|
|
||||||
|
ignore_iteration {
|
||||||
|
metrics: [":monitor:machine", ":monitor:gpu"]
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
events_retrieval {
|
||||||
|
state_expiration_sec: 3600
|
||||||
|
|
||||||
|
# max number of concurrent queries to ES when calculating events metrics
|
||||||
|
# should not exceed the amount of concurrent connections set in the ES driver
|
||||||
|
max_metrics_concurrency: 4
|
||||||
|
|
||||||
|
# If set then max_metrics_count and max_variants_count are calculated dynamically on user data
|
||||||
|
dynamic_metrics_count: true
|
||||||
|
|
||||||
|
# The percentage from the ES aggs limit (10000) to use for the max_metrics and max_variants calculation
|
||||||
|
dynamic_metrics_count_threshold: 80
|
||||||
|
|
||||||
|
# the max amount of metrics to aggregate on
|
||||||
|
max_metrics_count: 100
|
||||||
|
|
||||||
|
# the max amount of variants to aggregate on
|
||||||
|
max_variants_count: 100
|
||||||
|
|
||||||
|
debug_images {
|
||||||
|
# Allow to return the debug images for the variants with uninitialized valid iterations border
|
||||||
|
allow_uninitialized_variants: true
|
||||||
|
}
|
||||||
|
|
||||||
|
max_raw_scalars_size: 200000
|
||||||
|
|
||||||
|
scroll_id_key: "cTN5VEtWEC6QrHvUl0FTx9kNyO0CcCK1p57akxma"
|
||||||
|
}
|
||||||
|
|
||||||
|
# if set then plot str will be checked for the valid json on plot add
|
||||||
|
# and the result of the check is written to the db
|
||||||
|
validate_plot_str: false
|
||||||
|
|
||||||
|
# If not 0 then the plots equal or greater to the size will be stored compressed in the DB
|
||||||
|
plot_compression_threshold: 100000
|
||||||
|
|
||||||
|
# async events delete threshold
|
||||||
|
max_async_deleted_events_per_sec: 1000
|
||||||
7
apiserver/config/default/services/models.conf
Normal file
7
apiserver/config/default/services/models.conf
Normal file
@@ -0,0 +1,7 @@
|
|||||||
|
metadata_values {
|
||||||
|
# maximal amount of distinct model values to retrieve
|
||||||
|
max_count: 100
|
||||||
|
|
||||||
|
# cache ttl sec
|
||||||
|
cache_ttl_sec: 86400
|
||||||
|
}
|
||||||
3
apiserver/config/default/services/organization.conf
Normal file
3
apiserver/config/default/services/organization.conf
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
tags_cache {
|
||||||
|
expiration_seconds: 3600
|
||||||
|
}
|
||||||
18
apiserver/config/default/services/projects.conf
Normal file
18
apiserver/config/default/services/projects.conf
Normal file
@@ -0,0 +1,18 @@
|
|||||||
|
# Order of featured projects, by name or ID
|
||||||
|
featured {
|
||||||
|
order: [
|
||||||
|
# {id: "<project-id>"}
|
||||||
|
# OR
|
||||||
|
# {name: "<project-name>"}
|
||||||
|
# OR
|
||||||
|
# {name_regex: "<python-regex>"}
|
||||||
|
]
|
||||||
|
|
||||||
|
# default featured index for public projects not specified in the order
|
||||||
|
public_default: 9999
|
||||||
|
}
|
||||||
|
|
||||||
|
sub_projects {
|
||||||
|
# the max sub project depth
|
||||||
|
max_depth: 10
|
||||||
|
}
|
||||||
8
apiserver/config/default/services/queues.conf
Normal file
8
apiserver/config/default/services/queues.conf
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
{
|
||||||
|
metrics_before_from_date: 3600
|
||||||
|
# interval in seconds to update queue metrics. Put 0 to disable
|
||||||
|
metrics_refresh_interval_sec: 300
|
||||||
|
# the queues with these tags will not be returned from get_all/get_all_ex unless id or name specified
|
||||||
|
# or search_hidden is set
|
||||||
|
hidden_tags: [k8s-glue]
|
||||||
|
}
|
||||||
53
apiserver/config/default/services/storage_credentials.conf
Normal file
53
apiserver/config/default/services/storage_credentials.conf
Normal file
@@ -0,0 +1,53 @@
|
|||||||
|
aws {
|
||||||
|
s3 {
|
||||||
|
# S3 credentials, used for read/write access by various SDK elements
|
||||||
|
# default, used for any bucket not specified below
|
||||||
|
key: ""
|
||||||
|
secret: ""
|
||||||
|
region: ""
|
||||||
|
use_credentials_chain: false
|
||||||
|
# Additional ExtraArgs passed to boto3 when uploading files. Can also be set per-bucket under "credentials".
|
||||||
|
extra_args: {}
|
||||||
|
credentials: [
|
||||||
|
# specifies key/secret credentials to use when handling s3 urls (read or write)
|
||||||
|
# {
|
||||||
|
# bucket: "my-bucket-name"
|
||||||
|
# key: "my-access-key"
|
||||||
|
# secret: "my-secret-key"
|
||||||
|
# },
|
||||||
|
{
|
||||||
|
# This will apply to all buckets in this host (unless key/value is specifically provided for a given bucket)
|
||||||
|
host: "localhost:9000"
|
||||||
|
key: "evg_user"
|
||||||
|
secret: "evg_pass"
|
||||||
|
multipart: false
|
||||||
|
secure: false
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
google.storage {
|
||||||
|
# Default project and credentials file
|
||||||
|
# Will be used when no bucket configuration is found
|
||||||
|
// project: "clearml"
|
||||||
|
// credentials_json: "/path/to/credentials.json"
|
||||||
|
//
|
||||||
|
// # Specific credentials per bucket and sub directory
|
||||||
|
// credentials = [
|
||||||
|
// {
|
||||||
|
// bucket: "my-bucket"
|
||||||
|
// subdir: "path/in/bucket" # Not required
|
||||||
|
// project: "clearml"
|
||||||
|
// credentials_json: "/path/to/credentials.json"
|
||||||
|
// },
|
||||||
|
// ]
|
||||||
|
}
|
||||||
|
azure.storage {
|
||||||
|
# containers: [
|
||||||
|
# {
|
||||||
|
# account_name: "clearml"
|
||||||
|
# account_key: "secret"
|
||||||
|
# # container_name:
|
||||||
|
# }
|
||||||
|
# ]
|
||||||
|
}
|
||||||
29
apiserver/config/default/services/tasks.conf
Normal file
29
apiserver/config/default/services/tasks.conf
Normal file
@@ -0,0 +1,29 @@
|
|||||||
|
non_responsive_tasks_watchdog {
|
||||||
|
enabled: true
|
||||||
|
|
||||||
|
# In-progress tasks older than this value in seconds will be stopped by the watchdog
|
||||||
|
threshold_sec: 7200
|
||||||
|
|
||||||
|
# Watchdog will sleep for this number of seconds after each cycle
|
||||||
|
watch_interval_sec: 900
|
||||||
|
}
|
||||||
|
|
||||||
|
multi_task_histogram_limit: 100
|
||||||
|
|
||||||
|
hyperparam_values {
|
||||||
|
# maximal amount of distinct hyperparam values to retrieve
|
||||||
|
max_count: 100
|
||||||
|
|
||||||
|
# max allowed outdate time for the cashed result
|
||||||
|
cache_allowed_outdate_sec: 60
|
||||||
|
|
||||||
|
# cache ttl sec
|
||||||
|
cache_ttl_sec: 86400
|
||||||
|
}
|
||||||
|
|
||||||
|
# the maximum amount of unique last metrics/variants combinations
|
||||||
|
# for which the last values are stored in a task
|
||||||
|
max_last_metrics: 2000
|
||||||
|
|
||||||
|
# if set then call to tasks.delete/cleanup does not wait for ES events deletion
|
||||||
|
async_events_delete: false
|
||||||
51
apiserver/config/info.py
Normal file
51
apiserver/config/info.py
Normal file
@@ -0,0 +1,51 @@
|
|||||||
|
from functools import lru_cache
|
||||||
|
from os import getenv
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
from boltons.iterutils import first
|
||||||
|
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from apiserver.version import __version__
|
||||||
|
|
||||||
|
root = Path(__file__).parent.parent
|
||||||
|
|
||||||
|
|
||||||
|
def _get(prop_name, env_suffix=None, default=""):
|
||||||
|
suffix = env_suffix or prop_name
|
||||||
|
keys = [f"{p}_SERVER_{suffix}" for p in ("CLEARML", "TRAINS")]
|
||||||
|
value = first(map(getenv, keys))
|
||||||
|
if value:
|
||||||
|
return value
|
||||||
|
|
||||||
|
try:
|
||||||
|
return (root / prop_name).read_text().strip()
|
||||||
|
except FileNotFoundError:
|
||||||
|
return default
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache()
|
||||||
|
def get_build_number():
|
||||||
|
return _get("BUILD")
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache()
|
||||||
|
def get_version():
|
||||||
|
return _get("VERSION", default=__version__)
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache()
|
||||||
|
def get_commit_number():
|
||||||
|
return _get("COMMIT")
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache()
|
||||||
|
def get_deployment_type() -> str:
|
||||||
|
return _get("DEPLOY", env_suffix="DEPLOYMENT_TYPE", default="manual")
|
||||||
|
|
||||||
|
|
||||||
|
def get_default_company():
|
||||||
|
return config.get("apiserver.default_company")
|
||||||
|
|
||||||
|
|
||||||
|
missed_es_upgrade = False
|
||||||
|
es_connection_error = False
|
||||||
4
apiserver/config_repo.py
Normal file
4
apiserver/config_repo.py
Normal file
@@ -0,0 +1,4 @@
|
|||||||
|
from apiserver.config import BasicConfig
|
||||||
|
|
||||||
|
config = BasicConfig()
|
||||||
|
config.initialize_logging()
|
||||||
137
apiserver/database/__init__.py
Normal file
137
apiserver/database/__init__.py
Normal file
@@ -0,0 +1,137 @@
|
|||||||
|
from os import getenv
|
||||||
|
|
||||||
|
from boltons.iterutils import first
|
||||||
|
from furl import furl
|
||||||
|
from jsonmodels import models
|
||||||
|
from jsonmodels.errors import ValidationError
|
||||||
|
from jsonmodels.fields import StringField
|
||||||
|
from mongoengine import register_connection
|
||||||
|
from mongoengine.connection import get_connection, disconnect
|
||||||
|
|
||||||
|
from apiserver.config_repo import config
|
||||||
|
from .defs import Database
|
||||||
|
from .utils import get_items
|
||||||
|
|
||||||
|
log = config.logger("database")
|
||||||
|
|
||||||
|
strict = config.get("apiserver.mongo.strict", True)
|
||||||
|
|
||||||
|
OVERRIDE_HOST_ENV_KEY = (
|
||||||
|
"CLEARML_MONGODB_SERVICE_HOST",
|
||||||
|
"TRAINS_MONGODB_SERVICE_HOST",
|
||||||
|
"MONGODB_SERVICE_HOST",
|
||||||
|
"MONGODB_SERVICE_SERVICE_HOST",
|
||||||
|
)
|
||||||
|
OVERRIDE_PORT_ENV_KEY = (
|
||||||
|
"CLEARML_MONGODB_SERVICE_PORT",
|
||||||
|
"TRAINS_MONGODB_SERVICE_PORT",
|
||||||
|
"MONGODB_SERVICE_PORT",
|
||||||
|
)
|
||||||
|
|
||||||
|
OVERRIDE_CONNECTION_STRING_ENV_KEY = "CLEARML_MONGODB_SERVICE_CONNECTION_STRING"
|
||||||
|
OVERRIDE_USERNAME_ENV_KEY = "CLEARML_MONGODB_SERVICE_USERNAME"
|
||||||
|
OVERRIDE_PASSWORD_ENV_KEY = "CLEARML_MONGODB_SERVICE_PASSWORD"
|
||||||
|
OVERRIDE_QUERY_ENV_KEY = "CLEARML_MONGODB_SERVICE_QUERY"
|
||||||
|
|
||||||
|
|
||||||
|
class DatabaseEntry(models.Base):
|
||||||
|
host = StringField(required=True)
|
||||||
|
alias = StringField()
|
||||||
|
|
||||||
|
|
||||||
|
class DatabaseFactory:
|
||||||
|
_entries = []
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _create_db_entry(cls, alias: str, settings: dict) -> DatabaseEntry:
|
||||||
|
return DatabaseEntry(alias=alias, **settings)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def initialize(cls):
|
||||||
|
db_entries = config.get("hosts.mongo", {})
|
||||||
|
missing = []
|
||||||
|
log.info("Initializing database connections")
|
||||||
|
|
||||||
|
override_connection_string = getenv(OVERRIDE_CONNECTION_STRING_ENV_KEY)
|
||||||
|
override_hostname = first(map(getenv, OVERRIDE_HOST_ENV_KEY), None)
|
||||||
|
override_port = first(map(getenv, OVERRIDE_PORT_ENV_KEY), None)
|
||||||
|
override_username = getenv(OVERRIDE_USERNAME_ENV_KEY)
|
||||||
|
override_password = getenv(OVERRIDE_PASSWORD_ENV_KEY)
|
||||||
|
override_query = getenv(OVERRIDE_QUERY_ENV_KEY)
|
||||||
|
|
||||||
|
if override_connection_string:
|
||||||
|
log.info(f"Using override mongodb connection string template {override_connection_string}")
|
||||||
|
else:
|
||||||
|
if override_hostname:
|
||||||
|
log.info(f"Using override mongodb host {override_hostname}")
|
||||||
|
if override_port:
|
||||||
|
log.info(f"Using override mongodb port {override_port}")
|
||||||
|
if override_username:
|
||||||
|
log.info(f"Using override mongodb username {override_username}")
|
||||||
|
if override_password:
|
||||||
|
log.info(f"Using override mongodb password ******")
|
||||||
|
if override_query:
|
||||||
|
log.info(f"Using override mongodb query {override_query}")
|
||||||
|
|
||||||
|
for key, alias in get_items(Database).items():
|
||||||
|
if key not in db_entries:
|
||||||
|
missing.append(key)
|
||||||
|
continue
|
||||||
|
|
||||||
|
entry = cls._create_db_entry(alias=alias, settings=db_entries.get(key))
|
||||||
|
|
||||||
|
if override_connection_string:
|
||||||
|
con_str = f"{override_connection_string.rstrip('/')}/{key}"
|
||||||
|
log.info(f"Using override mongodb connection string for {alias}: {con_str}")
|
||||||
|
entry.host = con_str
|
||||||
|
else:
|
||||||
|
if override_hostname:
|
||||||
|
entry.host = furl(entry.host).set(host=override_hostname).url
|
||||||
|
if override_port:
|
||||||
|
entry.host = furl(entry.host).set(port=override_port).url
|
||||||
|
if override_username:
|
||||||
|
entry.host = furl(entry.host).set(username=override_username).url
|
||||||
|
if override_password:
|
||||||
|
entry.host = furl(entry.host).set(password=override_password).url
|
||||||
|
if override_query:
|
||||||
|
entry.host = furl(entry.host).set(query=override_query).url
|
||||||
|
|
||||||
|
try:
|
||||||
|
entry.validate()
|
||||||
|
log.info(
|
||||||
|
"Registering connection to %(alias)s (%(host)s)" % entry.to_struct()
|
||||||
|
)
|
||||||
|
register_connection(**entry.to_struct())
|
||||||
|
|
||||||
|
cls._entries.append(entry)
|
||||||
|
except ValidationError as ex:
|
||||||
|
raise Exception("Invalid database entry `%s`: %s" % (key, ex.args[0]))
|
||||||
|
if missing:
|
||||||
|
raise ValueError(
|
||||||
|
"Missing database configuration for %s" % ", ".join(missing)
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_entries(cls):
|
||||||
|
return cls._entries
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_hosts(cls):
|
||||||
|
return [entry.host for entry in cls.get_entries()]
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_aliases(cls):
|
||||||
|
return [entry.alias for entry in cls.get_entries()]
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def reconnect(cls):
|
||||||
|
for entry in cls.get_entries():
|
||||||
|
# there is bug in the current implementation that prevents
|
||||||
|
# reconnection from work so workaround this
|
||||||
|
# get_connection(entry.alias, reconnect=True)
|
||||||
|
disconnect(entry.alias)
|
||||||
|
register_connection(**entry.to_struct())
|
||||||
|
get_connection(entry.alias)
|
||||||
|
|
||||||
|
|
||||||
|
db = DatabaseFactory()
|
||||||
@@ -1,6 +1,7 @@
|
|||||||
import re
|
import re
|
||||||
from contextlib import contextmanager
|
from contextlib import contextmanager
|
||||||
from functools import wraps
|
from functools import wraps
|
||||||
|
from textwrap import shorten
|
||||||
|
|
||||||
import dpath
|
import dpath
|
||||||
from dpath.exceptions import InvalidKeyName
|
from dpath.exceptions import InvalidKeyName
|
||||||
@@ -17,7 +18,7 @@ from mongoengine.errors import (
|
|||||||
)
|
)
|
||||||
from pymongo.errors import PyMongoError, NotMasterError
|
from pymongo.errors import PyMongoError, NotMasterError
|
||||||
|
|
||||||
from apierrors import errors
|
from apiserver.apierrors import errors
|
||||||
|
|
||||||
|
|
||||||
class MakeGetAllQueryError(Exception):
|
class MakeGetAllQueryError(Exception):
|
||||||
@@ -33,7 +34,7 @@ class ParseCallError(Exception):
|
|||||||
self.params = kwargs
|
self.params = kwargs
|
||||||
|
|
||||||
|
|
||||||
def throws_default_error(err_cls):
|
def throws_default_error(err_cls, shorten_width: int = None):
|
||||||
"""
|
"""
|
||||||
Used to make functions (Exception, str) -> Optional[str] searching for specialized error messages raise those
|
Used to make functions (Exception, str) -> Optional[str] searching for specialized error messages raise those
|
||||||
messages in ``err_cls``. If the decorated function does not find a suitable error message,
|
messages in ``err_cls``. If the decorated function does not find a suitable error message,
|
||||||
@@ -45,25 +46,49 @@ def throws_default_error(err_cls):
|
|||||||
@wraps(func)
|
@wraps(func)
|
||||||
def wrapper(self, e, message, **kwargs):
|
def wrapper(self, e, message, **kwargs):
|
||||||
extra_info = func(self, e, message, **kwargs)
|
extra_info = func(self, e, message, **kwargs)
|
||||||
raise err_cls(message, err=e, extra_info=extra_info)
|
err = str(e)
|
||||||
|
if shorten_width:
|
||||||
|
err = shorten(err, shorten_width, placeholder="...")
|
||||||
|
raise err_cls(message, err=err, extra_info=extra_info)
|
||||||
|
|
||||||
return wrapper
|
return wrapper
|
||||||
|
|
||||||
return decorator
|
return decorator
|
||||||
|
|
||||||
|
|
||||||
|
# noinspection RegExpRedundantEscape
|
||||||
class ElasticErrorsHandler(object):
|
class ElasticErrorsHandler(object):
|
||||||
@classmethod
|
@classmethod
|
||||||
@throws_default_error(errors.server_error.DataError)
|
def _bulk_meta_error(cls, error):
|
||||||
|
try:
|
||||||
|
_, err_type = next(dpath.search(error, "*/error/type", yielded=True))
|
||||||
|
_, reason = next(dpath.search(error, "*/error/reason", yielded=True))
|
||||||
|
if err_type == "cluster_block_exception":
|
||||||
|
raise errors.server_error.LowDiskSpace(
|
||||||
|
"metrics, logs and all indexed data is in read-only mode!",
|
||||||
|
reason=re.sub(r"^index\s\[.*?\]\s", "", reason) if reason else ""
|
||||||
|
)
|
||||||
|
return
|
||||||
|
except StopIteration:
|
||||||
|
pass
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@throws_default_error(errors.server_error.DataError, shorten_width=200)
|
||||||
def bulk_error(cls, e, _, **__):
|
def bulk_error(cls, e, _, **__):
|
||||||
if not e.errors:
|
if not e.errors:
|
||||||
return
|
return
|
||||||
|
|
||||||
|
# Currently we only handle the first error
|
||||||
|
error = e.errors[0]
|
||||||
|
|
||||||
|
cls._bulk_meta_error(error)
|
||||||
|
|
||||||
# Else try returning a better error string
|
# Else try returning a better error string
|
||||||
for _, reason in dpath.search(e.errors[0], "*/error/reason", yielded=True):
|
for _, reason in dpath.search(e.errors[0], "*/error/reason", yielded=True):
|
||||||
return reason
|
return reason
|
||||||
|
|
||||||
|
|
||||||
|
# noinspection RegExpRedundantEscape
|
||||||
class MongoEngineErrorsHandler(object):
|
class MongoEngineErrorsHandler(object):
|
||||||
# NotUniqueError
|
# NotUniqueError
|
||||||
__not_unique_regex = re.compile(
|
__not_unique_regex = re.compile(
|
||||||
@@ -81,6 +106,7 @@ class MongoEngineErrorsHandler(object):
|
|||||||
def validation_error(cls, e: ValidationError, message, **_):
|
def validation_error(cls, e: ValidationError, message, **_):
|
||||||
# Thrown when a document is validated. Documents are validated by default on save and on update
|
# Thrown when a document is validated. Documents are validated by default on save and on update
|
||||||
err_dict = e.errors or {e.field_name: e.message}
|
err_dict = e.errors or {e.field_name: e.message}
|
||||||
|
err_dict = {key: str(value) for key, value in err_dict.items()}
|
||||||
raise errors.bad_request.DataValidationError(message, **err_dict)
|
raise errors.bad_request.DataValidationError(message, **err_dict)
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
@@ -140,7 +166,10 @@ class MongoEngineErrorsHandler(object):
|
|||||||
@classmethod
|
@classmethod
|
||||||
@throws_default_error(errors.server_error.InternalError)
|
@throws_default_error(errors.server_error.InternalError)
|
||||||
def invalid_query_error(cls, e, message, **_):
|
def invalid_query_error(cls, e, message, **_):
|
||||||
pass
|
if e.args:
|
||||||
|
inner = e.args[0]
|
||||||
|
if isinstance(inner, LookUpError):
|
||||||
|
cls.lookup_error(inner, message)
|
||||||
|
|
||||||
|
|
||||||
@contextmanager
|
@contextmanager
|
||||||
@@ -14,6 +14,9 @@ from mongoengine import (
|
|||||||
DictField,
|
DictField,
|
||||||
DynamicField,
|
DynamicField,
|
||||||
)
|
)
|
||||||
|
from mongoengine.fields import key_not_string, key_starts_with_dollar, EmailField
|
||||||
|
|
||||||
|
NoneType = type(None)
|
||||||
|
|
||||||
|
|
||||||
class LengthRangeListField(ListField):
|
class LengthRangeListField(ListField):
|
||||||
@@ -90,6 +93,24 @@ class CustomFloatField(FloatField):
|
|||||||
self.error("Float value must be greater than %s" % str(self.greater_than))
|
self.error("Float value must be greater than %s" % str(self.greater_than))
|
||||||
|
|
||||||
|
|
||||||
|
class CanonicEmailField(EmailField):
|
||||||
|
"""email field that is always lower cased"""
|
||||||
|
def __set__(self, instance, value: str):
|
||||||
|
if value is not None:
|
||||||
|
try:
|
||||||
|
value = value.lower()
|
||||||
|
except AttributeError:
|
||||||
|
pass
|
||||||
|
super().__set__(instance, value)
|
||||||
|
|
||||||
|
def prepare_query_value(self, op, value):
|
||||||
|
if not isinstance(op, six.string_types):
|
||||||
|
return value
|
||||||
|
if value is not None:
|
||||||
|
value = value.lower()
|
||||||
|
return super().prepare_query_value(op, value)
|
||||||
|
|
||||||
|
|
||||||
class StrippedStringField(StringField):
|
class StrippedStringField(StringField):
|
||||||
def __init__(
|
def __init__(
|
||||||
self, regex=None, max_length=None, min_length=None, strip_chars=None, **kwargs
|
self, regex=None, max_length=None, min_length=None, strip_chars=None, **kwargs
|
||||||
@@ -125,17 +146,46 @@ def contains_empty_key(d):
|
|||||||
return True
|
return True
|
||||||
|
|
||||||
|
|
||||||
class SafeMapField(MapField):
|
class DictValidationMixin:
|
||||||
|
"""
|
||||||
|
DictField validation in MongoEngine requires default alias and permissions to access DB version:
|
||||||
|
https://github.com/MongoEngine/mongoengine/issues/2239
|
||||||
|
This is a stripped down implementation that does not require any of the above and implies Mongo ver 3.6+
|
||||||
|
"""
|
||||||
|
|
||||||
|
def _safe_validate(self: DictField, value):
|
||||||
|
if not isinstance(value, dict):
|
||||||
|
self.error("Only dictionaries may be used in a DictField")
|
||||||
|
|
||||||
|
if key_not_string(value):
|
||||||
|
msg = "Invalid dictionary key - documents must have only string keys"
|
||||||
|
self.error(msg)
|
||||||
|
|
||||||
|
if key_starts_with_dollar(value):
|
||||||
|
self.error(
|
||||||
|
'Invalid dictionary key name - keys may not startswith "$" characters'
|
||||||
|
)
|
||||||
|
super(DictField, self).validate(value)
|
||||||
|
|
||||||
|
|
||||||
|
class SafeMapField(MapField, DictValidationMixin):
|
||||||
def validate(self, value):
|
def validate(self, value):
|
||||||
super(SafeMapField, self).validate(value)
|
self._safe_validate(value)
|
||||||
|
|
||||||
if contains_empty_key(value):
|
if contains_empty_key(value):
|
||||||
self.error("Empty keys are not allowed in a MapField")
|
self.error("Empty keys are not allowed in a MapField")
|
||||||
|
|
||||||
|
|
||||||
class SafeDictField(DictField):
|
class NullableStringField(StringField):
|
||||||
def validate(self, value):
|
def validate(self, value):
|
||||||
super(SafeDictField, self).validate(value)
|
if value is None:
|
||||||
|
return
|
||||||
|
super(NullableStringField, self).validate(value)
|
||||||
|
|
||||||
|
|
||||||
|
class SafeDictField(DictField, DictValidationMixin):
|
||||||
|
def validate(self, value):
|
||||||
|
self._safe_validate(value)
|
||||||
|
|
||||||
if contains_empty_key(value):
|
if contains_empty_key(value):
|
||||||
self.error("Empty keys are not allowed in a DictField")
|
self.error("Empty keys are not allowed in a DictField")
|
||||||
@@ -146,6 +196,7 @@ class SafeSortedListField(SortedListField):
|
|||||||
SortedListField that does not raise an error in case items are not comparable
|
SortedListField that does not raise an error in case items are not comparable
|
||||||
(in which case they will be sorted by their string representation)
|
(in which case they will be sorted by their string representation)
|
||||||
"""
|
"""
|
||||||
|
|
||||||
def to_mongo(self, *args, **kwargs):
|
def to_mongo(self, *args, **kwargs):
|
||||||
try:
|
try:
|
||||||
return super(SafeSortedListField, self).to_mongo(*args, **kwargs)
|
return super(SafeSortedListField, self).to_mongo(*args, **kwargs)
|
||||||
@@ -155,7 +206,10 @@ class SafeSortedListField(SortedListField):
|
|||||||
def _safe_to_mongo(self, value, use_db_field=True, fields=None):
|
def _safe_to_mongo(self, value, use_db_field=True, fields=None):
|
||||||
value = super(SortedListField, self).to_mongo(value, use_db_field, fields)
|
value = super(SortedListField, self).to_mongo(value, use_db_field, fields)
|
||||||
if self._ordering is not None:
|
if self._ordering is not None:
|
||||||
def key(v): return str(itemgetter(self._ordering)(v))
|
|
||||||
|
def key(v):
|
||||||
|
return str(itemgetter(self._ordering)(v))
|
||||||
|
|
||||||
else:
|
else:
|
||||||
key = str
|
key = str
|
||||||
return sorted(value, key=key, reverse=self._order_reverse)
|
return sorted(value, key=key, reverse=self._order_reverse)
|
||||||
@@ -2,10 +2,10 @@ from enum import Enum
|
|||||||
|
|
||||||
from mongoengine import Document, StringField
|
from mongoengine import Document, StringField
|
||||||
|
|
||||||
from apierrors import errors
|
from apiserver.apierrors import errors
|
||||||
from database.model.base import DbModelMixin, ABSTRACT_FLAG
|
from apiserver.database.model.base import DbModelMixin, ABSTRACT_FLAG
|
||||||
from database.model.company import Company
|
from apiserver.database.model.company import Company
|
||||||
from database.model.user import User
|
from apiserver.database.model.user import User
|
||||||
|
|
||||||
|
|
||||||
class AttributedDocument(DbModelMixin, Document):
|
class AttributedDocument(DbModelMixin, Document):
|
||||||
@@ -60,3 +60,4 @@ def validate_id(cls, company, **kwargs):
|
|||||||
class EntityVisibility(Enum):
|
class EntityVisibility(Enum):
|
||||||
active = "active"
|
active = "active"
|
||||||
archived = "archived"
|
archived = "archived"
|
||||||
|
hidden = "hidden"
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user