4.2 KiB
Mini-Omni
Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
🤗 Hugging Face | 📖 Github | 📑 Technical report | 🤗 Datasets
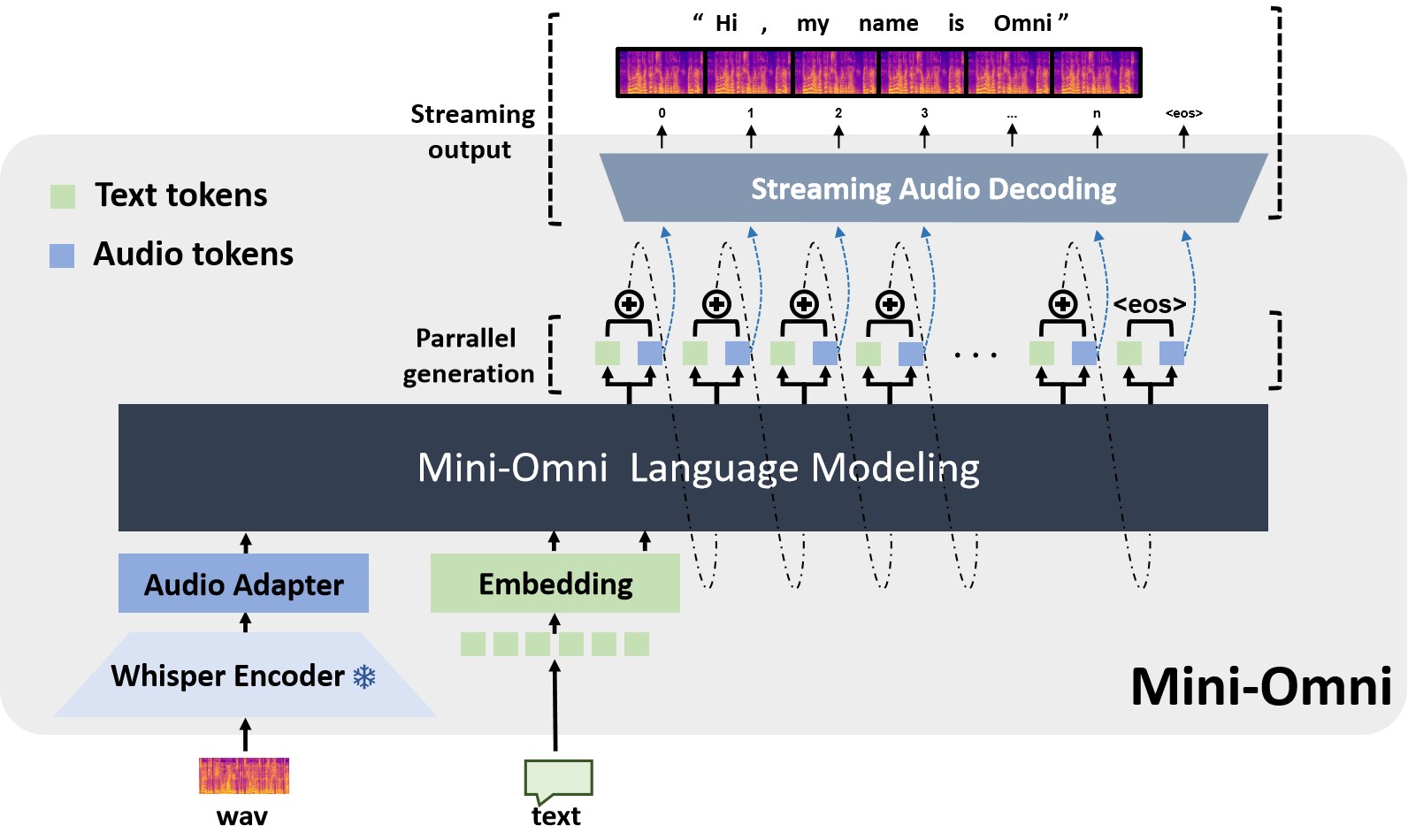
Mini-Omni is an open-source multimodal large language model that can hear, talk while thinking. Featuring real-time end-to-end speech input and streaming audio output conversational capabilities.
Updates
- 2024.09: VoiceAssistant-400K is uploaded to Hugging Face.
Features
✅ Real-time speech-to-speech conversational capabilities. No extra ASR or TTS models required.
✅ Talking while thinking, with the ability to generate text and audio at the same time.
✅ Streaming audio output capabilities.
✅ With "Audio-to-Text" and "Audio-to-Audio" batch inference to further boost the performance.
Demo
NOTE: need to unmute first.
https://github.com/user-attachments/assets/03bdde05-9514-4748-b527-003bea57f118
Install
Create a new conda environment and install the required packages:
conda create -n omni python=3.10
conda activate omni
git clone https://github.com/gpt-omni/mini-omni.git
cd mini-omni
pip install -r requirements.txt
Quick start
Interactive demo
- start server
NOTE: you need to start the server before running the streamlit or gradio demo with API_URL set to the server address.
sudo apt-get install ffmpeg
conda activate omni
cd mini-omni
python3 server.py --ip '0.0.0.0' --port 60808
- run streamlit demo
NOTE: you need to run streamlit locally with PyAudio installed. For error: ModuleNotFoundError: No module named 'utils.vad', please run export PYTHONPATH=./ first.
pip install PyAudio==0.2.14
API_URL=http://0.0.0.0:60808/chat streamlit run webui/omni_streamlit.py
- run gradio demo
API_URL=http://0.0.0.0:60808/chat python3 webui/omni_gradio.py
example:
NOTE: need to unmute first. Gradio seems can not play audio stream instantly, so the latency feels a bit longer.
https://github.com/user-attachments/assets/29187680-4c42-47ff-b352-f0ea333496d9
Local test
conda activate omni
cd mini-omni
# test run the preset audio samples and questions
python inference.py
FAQ
1. Does the model support other languages?
No, the model is only trained on English. However, as we use whisper as the audio encoder, the model can understand other languages which is supported by whisper (like chinese), but the output is only in English.
2. What is post_adapter in the code? does the open-source version support tts-adapter?
The post_adapter is tts-adapter in the model.py, but the open-source version does not support tts-adapter.
3. Error: ModuleNotFoundError: No module named 'utils.xxxx'
Run export PYTHONPATH=./ first. No need to run pip install utils, or just try: pip uninstall utils
4. Error: can not run streamlit in local browser, with remote streamlit server, issue: https://github.com/gpt-omni/mini-omni/issues/37
You need start streamlit locally with PyAudio installed.
Acknowledgements
- Qwen2 as the LLM backbone.
- litGPT for training and inference.
- whisper for audio encoding.
- snac for audio decoding.
- CosyVoice for generating synthetic speech.
- OpenOrca and MOSS for alignment.