2.2 KiB
sidebar_position, title
| sidebar_position | title |
|---|---|
| 10 | Local LLM Setup with IPEX-LLM on Intel GPU |
:::note This guide is verified with Open WebUI setup through Mannual Installation. :::
Local LLM Setup with IPEX-LLM on Intel GPU
:::info IPEX-LLM is a PyTorch library for running LLM on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc A-Series, Flex and Max) with very low latency. :::
This tutorial demonstrates how to setup Open WebUI with IPEX-LLM accelerated Ollama backend hosted on Intel GPU. By following this guide, you will be able to setup Open WebUI even on a low-cost PC (i.e. only with integrated GPU), and achieve a smooth experience.
Start Ollama Serve on Intel GPU
Refer to this guide from IPEX-LLM official documentation about how to install and run Ollama serve accelerated by IPEX-LLM on Intel GPU.
:::tip
If you would like to reach the Ollama serve from another machine, make sure you set or export the environment variable OLLAMA_HOST=0.0.0.0 before executing the command ollama serve.
:::
Configure Open WebUI
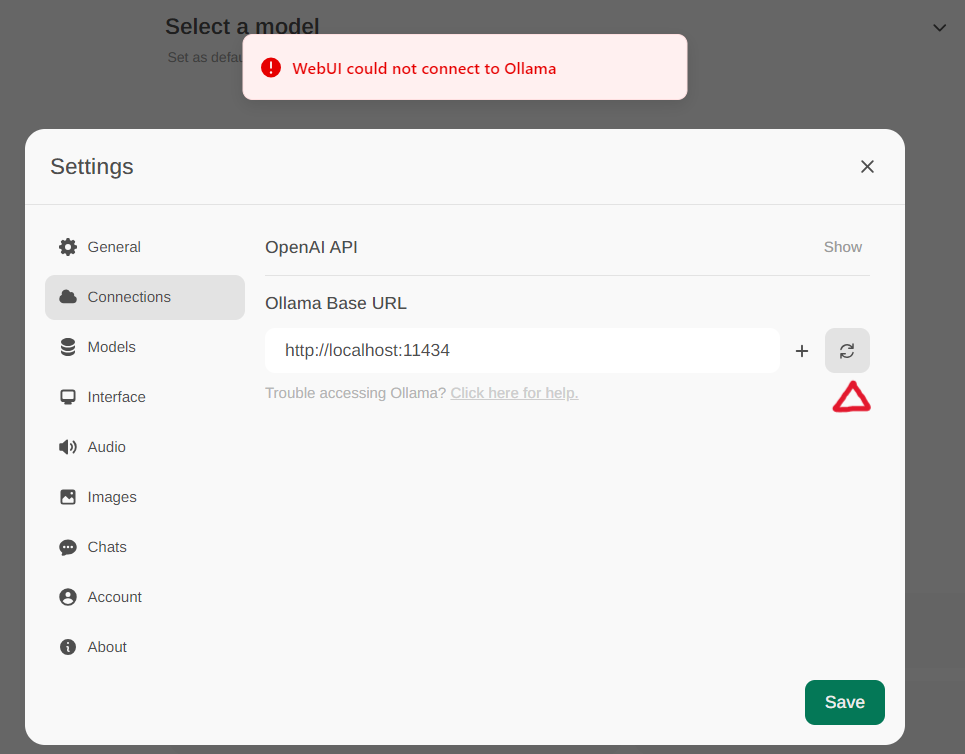
Access the Ollama settings through Settings -> Connections in the menu. By default, the Ollama Base URL is preset to https://localhost:11434, as illustrated in the snapshot below. To verify the status of the Ollama service connection, click the Refresh button located next to the textbox. If the WebUI is unable to establish a connection with the Ollama server, you will see an error message stating, WebUI could not connect to Ollama.
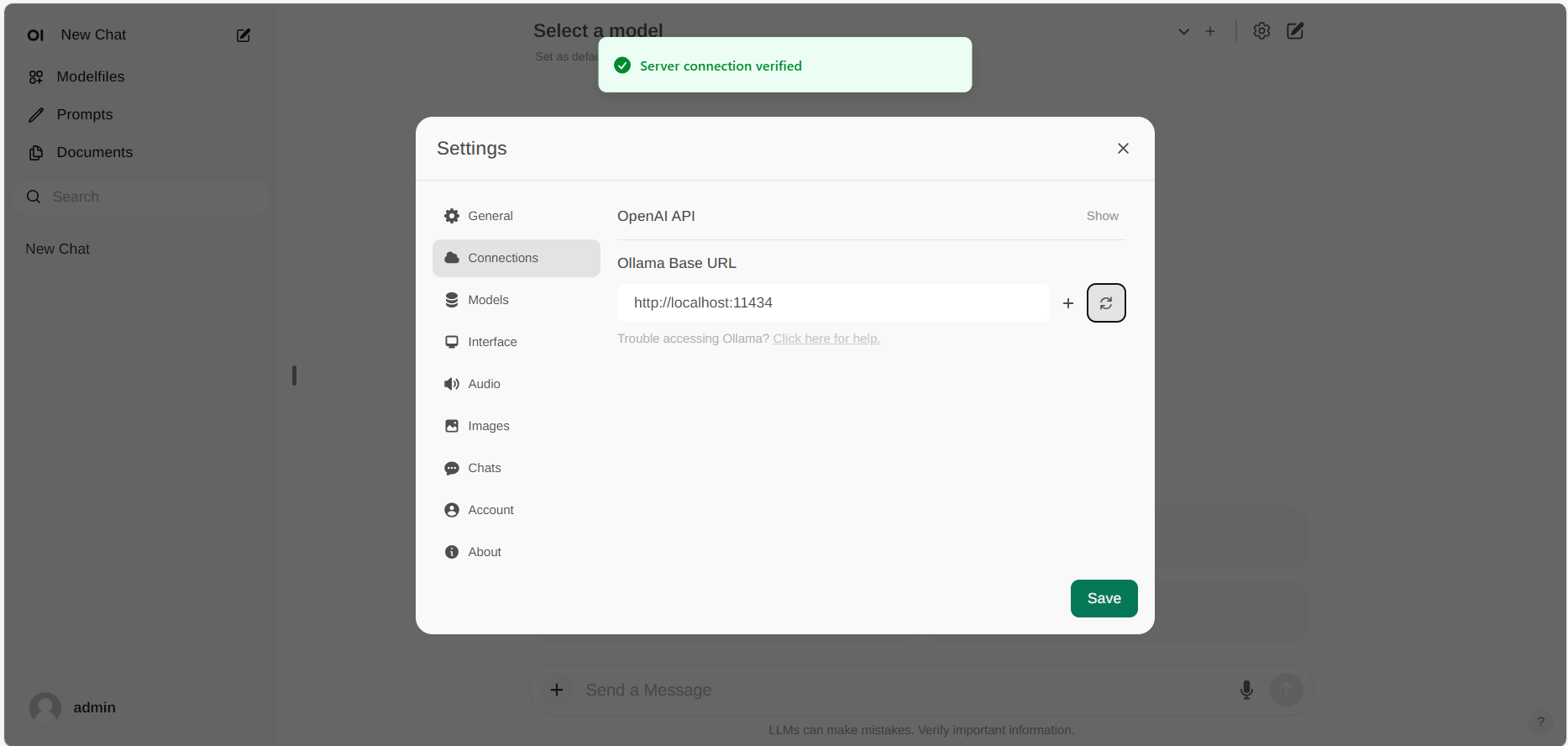
If the connection is successful, you will see a message stating Service Connection Verified, as illustrated below.
:::tip If you want to use an Ollama server hosted at a different URL, simply update the Ollama Base URL to the new URL and press the Refresh button to re-confirm the connection to Ollama. :::