merge upstream
@@ -74,7 +74,7 @@ Unlike proprietary AI platforms that dictate your roadmap, **Open WebUI puts you
|
||||
Security is a business-critical requirement. Open WebUI is built to support **SOC 2, HIPAA, GDPR, FedRAMP, and ISO 27001 compliance**, ensuring enterprise security best practices with **on-premise and air-gapped deployments**.
|
||||
|
||||
### ⚡ **Reliable, Scalable, and Performance-Optimized**
|
||||
Built for large-scale enterprise deployments with **multi-node high availability**, Open WebUI ensures **99.99% uptime**, optimized workloads, and **scalability across regions and business units**.
|
||||
Built for large-scale enterprise deployments with **multi-node high availability**, Open WebUI can be configured to ensure **99.99% uptime**, optimized workloads, and **scalability across regions and business units**.
|
||||
|
||||
### 💡 **Fully Customizable & Modular**
|
||||
Customize every aspect of Open WebUI to fit your enterprise’s needs. **White-label, extend, and integrate** seamlessly with **your existing systems**, including **LDAP, Active Directory, and custom AI models**.
|
||||
|
||||
@@ -27,7 +27,12 @@ Integration Steps
|
||||
docker run -p 5001:5001 -e DOCLING_SERVE_ENABLE_UI=true quay.io/docling-project/docling-serve
|
||||
```
|
||||
|
||||
### Step 2: Configure OpenWebUI to use Docling
|
||||
*With GPU support:
|
||||
```bash
|
||||
docker run --gpus all -p 5001:5001 -e DOCLING_SERVE_ENABLE_UI=true quay.io/docling-project/docling-serve
|
||||
```
|
||||
|
||||
### Step 2: Configure Open WebUI to use Docling
|
||||
|
||||
* Log in to your Open WebUI instance.
|
||||
* Navigate to the `Admin Panel` settings menu.
|
||||
|
||||
@@ -31,7 +31,7 @@ Integration Steps
|
||||
* Go to `API Keys` or `https://console.mistral.ai/api-keys`
|
||||
* Create a new key and make sure to copy it
|
||||
|
||||
### Step 3: Configure OpenWebUI to use Mistral OCR
|
||||
### Step 3: Configure Open WebUI to use Mistral OCR
|
||||
|
||||
* Log in to your Open WebUI instance.
|
||||
* Navigate to the `Admin Panel` settings menu.
|
||||
|
||||
336
docs/features/plugin/tools/development.mdx
Normal file
@@ -0,0 +1,336 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
title: "🛠️ Development"
|
||||
---
|
||||
|
||||
|
||||
|
||||
## Writing A Custom Toolkit
|
||||
|
||||
Toolkits are defined in a single Python file, with a top level docstring with metadata and a `Tools` class.
|
||||
|
||||
### Example Top-Level Docstring
|
||||
|
||||
```python
|
||||
"""
|
||||
title: String Inverse
|
||||
author: Your Name
|
||||
author_url: https://website.com
|
||||
git_url: https://github.com/username/string-reverse.git
|
||||
description: This tool calculates the inverse of a string
|
||||
required_open_webui_version: 0.4.0
|
||||
requirements: langchain-openai, langgraph, ollama, langchain_ollama
|
||||
version: 0.4.0
|
||||
licence: MIT
|
||||
"""
|
||||
```
|
||||
|
||||
### Tools Class
|
||||
|
||||
Tools have to be defined as methods within a class called `Tools`, with optional subclasses called `Valves` and `UserValves`, for example:
|
||||
|
||||
```python
|
||||
class Tools:
|
||||
def __init__(self):
|
||||
"""Initialize the Tool."""
|
||||
self.valves = self.Valves()
|
||||
|
||||
class Valves(BaseModel):
|
||||
api_key: str = Field("", description="Your API key here")
|
||||
|
||||
def reverse_string(self, string: str) -> str:
|
||||
"""
|
||||
Reverses the input string.
|
||||
:param string: The string to reverse
|
||||
"""
|
||||
# example usage of valves
|
||||
if self.valves.api_key != "42":
|
||||
return "Wrong API key"
|
||||
return string[::-1]
|
||||
```
|
||||
|
||||
### Type Hints
|
||||
Each tool must have type hints for arguments. As of version Open WebUI version 0.4.3, the types may also be nested, such as `queries_and_docs: list[tuple[str, int]]`. Those type hints are used to generate the JSON schema that is sent to the model. Tools without type hints will work with a lot less consistency.
|
||||
|
||||
### Valves and UserValves - (optional, but HIGHLY encouraged)
|
||||
|
||||
Valves and UserValves are used to allow users to provide dynamic details such as an API key or a configuration option. These will create a fillable field or a bool switch in the GUI menu for the given function.
|
||||
|
||||
Valves are configurable by admins alone and UserValves are configurable by any users.
|
||||
|
||||
<details>
|
||||
<summary>Commented example</summary>
|
||||
|
||||
```
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
class Tools:
|
||||
# Notice the current indentation: Valves and UserValves must be declared as
|
||||
# attributes of a Tools, Filter or Pipe class. Here we take the
|
||||
# example of a Tool.
|
||||
class Valves(BaseModel):
|
||||
# Valves and UserValves inherit from pydantic's BaseModel. This
|
||||
# enables complex use cases like model validators etc.
|
||||
test_valve: int = Field( # Notice the type hint: it is used to
|
||||
# choose the kind of UI element to show the user (buttons,
|
||||
# texts, etc).
|
||||
default=4,
|
||||
description="A valve controlling a numberical value"
|
||||
# required=False, # you can enforce fields using True
|
||||
)
|
||||
pass
|
||||
# Note that this 'pass' helps for parsing and is recommended.
|
||||
|
||||
# UserValves are defined the same way.
|
||||
class UserValves(BaseModel):
|
||||
test_user_valve: bool = Field(
|
||||
default=False, description="A user valve controlling a True/False (on/off) switch"
|
||||
)
|
||||
pass
|
||||
|
||||
def __init__(self):
|
||||
self.valves = self.Valves()
|
||||
# Because they are set by the admin, they are accessible directly
|
||||
# upon code execution.
|
||||
pass
|
||||
|
||||
# The __user__ handling is the same for Filters, Tools and Functions.
|
||||
def test_the_tool(self, message: str, __user__: dict):
|
||||
"""
|
||||
This is a test tool. If the user asks you to test the tools, put any
|
||||
string you want in the message argument.
|
||||
|
||||
:param message: Any string you want.
|
||||
:return: The same string as input.
|
||||
"""
|
||||
# Because UserValves are defined per user they are only available
|
||||
# on use.
|
||||
# Note that although __user__ is a dict, __user__["valves"] is a
|
||||
# UserValves object. Hence you can access values like that:
|
||||
test_user_valve = __user__["valves"].test_user_valve
|
||||
# Or:
|
||||
test_user_valve = dict(__user__["valves"])["test_user_valve"]
|
||||
# But this will return the default value instead of the actual value:
|
||||
# test_user_valve = __user__["valves"]["test_user_valve"] # Do not do that!
|
||||
|
||||
return message + f"\nThe user valve set value is: {test_user_valve}"
|
||||
|
||||
```
|
||||
</details>
|
||||
|
||||
### Optional Arguments
|
||||
Below is a list of optional arguments your tools can depend on:
|
||||
- `__event_emitter__`: Emit events (see following section)
|
||||
- `__event_call__`: Same as event emitter but can be used for user interactions
|
||||
- `__user__`: A dictionary with user information. It also contains the `UserValves` object in `__user__["valves"]`.
|
||||
- `__metadata__`: Dictionary with chat metadata
|
||||
- `__messages__`: List of previous messages
|
||||
- `__files__`: Attached files
|
||||
- `__model__`: Model name
|
||||
|
||||
Just add them as argument to any method of your Tool class just like `__user__` in the example above.
|
||||
|
||||
### Event Emitters
|
||||
Event Emitters are used to add additional information to the chat interface. Similarly to Filter Outlets, Event Emitters are capable of appending content to the chat. Unlike Filter Outlets, they are not capable of stripping information. Additionally, emitters can be activated at any stage during the Tool.
|
||||
|
||||
There are two different types of Event Emitters:
|
||||
|
||||
If the model seems to be unable to call the tool, make sure it is enabled (either via the Model page or via the `+` sign next to the chat input field). You can also turn the `Function Calling` argument of the `Advanced Params` section of the Model page from `Default` to `Native`.
|
||||
|
||||
#### Status
|
||||
This is used to add statuses to a message while it is performing steps. These can be done at any stage during the Tool. These statuses appear right above the message content. These are very useful for Tools that delay the LLM response or process large amounts of information. This allows you to inform users what is being processed in real-time.
|
||||
|
||||
```
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status", # We set the type here
|
||||
"data": {"description": "Message that shows up in the chat", "done": False, "hidden": False},
|
||||
# Note done is False here indicating we are still emitting statuses
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>Example</summary>
|
||||
|
||||
```
|
||||
async def test_function(
|
||||
self, prompt: str, __user__: dict, __event_emitter__=None
|
||||
) -> str:
|
||||
"""
|
||||
This is a demo
|
||||
|
||||
:param test: this is a test parameter
|
||||
"""
|
||||
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status", # We set the type here
|
||||
"data": {"description": "Message that shows up in the chat", "done": False},
|
||||
# Note done is False here indicating we are still emitting statuses
|
||||
}
|
||||
)
|
||||
|
||||
# Do some other logic here
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {"description": "Completed a task message", "done": True, "hidden": False},
|
||||
# Note done is True here indicating we are done emitting statuses
|
||||
# You can also set "hidden": True if you want to remove the status once the message is returned
|
||||
}
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {"description": f"An error occured: {e}", "done": True},
|
||||
}
|
||||
)
|
||||
|
||||
return f"Tell the user: {e}"
|
||||
```
|
||||
</details>
|
||||
|
||||
#### Message
|
||||
This type is used to append a message to the LLM at any stage in the Tool. This means that you can append messages, embed images, and even render web pages before, or after, or during the LLM response.
|
||||
|
||||
```
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "message", # We set the type here
|
||||
"data": {"content": "This message will be appended to the chat."},
|
||||
# Note that with message types we do NOT have to set a done condition
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>Example</summary>
|
||||
|
||||
```
|
||||
async def test_function(
|
||||
self, prompt: str, __user__: dict, __event_emitter__=None
|
||||
) -> str:
|
||||
"""
|
||||
This is a demo
|
||||
|
||||
:param test: this is a test parameter
|
||||
"""
|
||||
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "message", # We set the type here
|
||||
"data": {"content": "This message will be appended to the chat."},
|
||||
# Note that with message types we do NOT have to set a done condition
|
||||
}
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {"description": f"An error occured: {e}", "done": True},
|
||||
}
|
||||
)
|
||||
|
||||
return f"Tell the user: {e}"
|
||||
```
|
||||
</details>
|
||||
|
||||
#### Citations
|
||||
This type is used to provide citations or references in the chat. You can utilize it to specify the content, the source, and any relevant metadata. Below is an example of how to emit a citation event:
|
||||
|
||||
```
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "citation",
|
||||
"data": {
|
||||
"document": [content],
|
||||
"metadata": [
|
||||
{
|
||||
"date_accessed": datetime.now().isoformat(),
|
||||
"source": title,
|
||||
}
|
||||
],
|
||||
"source": {"name": title, "url": url},
|
||||
},
|
||||
}
|
||||
)
|
||||
```
|
||||
If you are sending multiple citations, you can iterate over citations and call the emitter multiple times. When implementing custom citations, ensure that you set `self.citation = False` in your `Tools` class `__init__` method. Otherwise, the built-in citations will override the ones you have pushed in. For example:
|
||||
|
||||
```python
|
||||
def __init__(self):
|
||||
self.citation = False
|
||||
```
|
||||
|
||||
Warning: if you set `self.citation = True`, this will replace any custom citations you send with the automatically generated return citation. By disabling it, you can fully manage your own citation references.
|
||||
|
||||
<details>
|
||||
<summary>Example</summary>
|
||||
|
||||
```
|
||||
class Tools:
|
||||
class UserValves(BaseModel):
|
||||
test: bool = Field(
|
||||
default=True, description="test"
|
||||
)
|
||||
|
||||
def __init__(self):
|
||||
self.citation = False
|
||||
|
||||
async def test_function(
|
||||
self, prompt: str, __user__: dict, __event_emitter__=None
|
||||
) -> str:
|
||||
"""
|
||||
This is a demo that just creates a citation
|
||||
|
||||
:param test: this is a test parameter
|
||||
"""
|
||||
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "citation",
|
||||
"data": {
|
||||
"document": ["This message will be appended to the chat as a citation when clicked into"],
|
||||
"metadata": [
|
||||
{
|
||||
"date_accessed": datetime.now().isoformat(),
|
||||
"source": title,
|
||||
}
|
||||
],
|
||||
"source": {"name": "Title of the content", "url": "http://link-to-citation"},
|
||||
},
|
||||
}
|
||||
)
|
||||
```
|
||||
</details>
|
||||
|
||||
## External packages
|
||||
|
||||
In the Tools definition metadata you can specify custom packages. When you click `Save` the line will be parsed and `pip install` will be run on all requirements at once.
|
||||
|
||||
Keep in mind that as pip is used in the same process as Open WebUI, the UI will be completely unresponsive during the installation.
|
||||
|
||||
No measures are taken to handle package conflicts with Open WebUI's requirements. That means that specifying requirements can break Open WebUI if you're not careful. You might be able to work around this by specifying `open-webui` itself as a requirement.
|
||||
|
||||
|
||||
<details>
|
||||
<summary>Example</summary>
|
||||
|
||||
```
|
||||
"""
|
||||
title: myToolName
|
||||
author: myName
|
||||
funding_url: [any link here will be shown behind a `Heart` button for users to show their support to you]
|
||||
version: 1.0.0
|
||||
# the version is displayed in the UI to help users keep track of updates.
|
||||
license: GPLv3
|
||||
description: [recommended]
|
||||
requirements: package1>=2.7.0,package2,package3
|
||||
"""
|
||||
```
|
||||
|
||||
</details>
|
||||
@@ -1,377 +1,139 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
title: "⚙️ Tools"
|
||||
sidebar_position: 2
|
||||
title: "⚙️ Tools"
|
||||
---
|
||||
|
||||
## What are Tools?
|
||||
Tools are python scripts that are provided to an LLM at the time of the request. Tools allow LLMs to perform actions and receive additional context as a result. Generally speaking, your LLM of choice will need to support function calling for tools to be reliably utilized.
|
||||
# ⚙️ What are Tools?
|
||||
|
||||
Tools enable many use cases for chats, including web search, web scraping, and API interactions within the chat.
|
||||
Tools are small Python scripts that add superpowers to your LLM. When enabled, they allow your chatbot to do amazing things — like search the web, scrape data, generate images, talk back using AI voices, and more.
|
||||
|
||||
Many Tools are available to use on the [Community Website](https://openwebui.com/tools) and can easily be imported into your Open WebUI instance.
|
||||
Think of Tools as useful plugins that your AI can use when chatting with you.
|
||||
|
||||
## How can I use Tools?
|
||||
[Once installed](#how-to-install-tools), Tools can be used by assigning them to any LLM that supports function calling and then enabling that Tool. To assign a Tool to a model, you need to navigate to Workspace => Models. Here you can select the model for which you’d like to enable any Tools.
|
||||
---
|
||||
|
||||
Once you click the pencil icon to edit the model settings, scroll down to the Tools section and check any Tools you wish to enable. Once done you must click save.
|
||||
## 🚀 What Can Tools Help Me Do?
|
||||
|
||||
Now that Tools are enabled for the model, you can click the “+” icon when chatting with an LLM to use various Tools. Please keep in mind that enabling a Tool does not force it to be used. It means the LLM will be provided the option to call this Tool.
|
||||
Here are just a few examples of what Tools let your AI assistant do:
|
||||
|
||||
Lastly, we do provide a filter function on the community site that allows LLMs to autoselect Tools without you needing to enable them in the “+” icon menu: https://openwebui.com/f/hub/autotool_filter/
|
||||
|
||||
Please note: when using the AutoTool Filter, you will still need to take the steps above to enable the Tools per model.
|
||||
|
||||
## How to install Tools
|
||||
The Tools import process is quite simple. You will have two options:
|
||||
|
||||
### Download and import manually
|
||||
Navigate to the community site: https://openwebui.com/tools/
|
||||
1) Click on the Tool you wish to import
|
||||
2) Click the blue “Get” button in the top right-hand corner of the page
|
||||
3) Click “Download as JSON export”
|
||||
4) You can now upload the Tool into Open WebUI by navigating to Workspace => Tools and clicking “Import Tools”
|
||||
|
||||
### Import via your Open WebUI URL
|
||||
1) Navigate to the community site: https://openwebui.com/tools/
|
||||
2) Click on the Tool you wish to import
|
||||
3) Click the blue “Get” button in the top right-hand corner of the page
|
||||
4) Enter the IP address of your Open WebUI instance and click “Import to WebUI” which will automatically open your instance and allow you to import the Tool.
|
||||
|
||||
Note: You can install your own Tools and other Tools not tracked on the community site using the manual import method. Please do not import Tools you do not understand or are not from a trustworthy source. Running unknown code is ALWAYS a risk.
|
||||
|
||||
## What sorts of things can Tools do?
|
||||
Tools enable diverse use cases for interactive conversations by providing a wide range of functionality such as:
|
||||
|
||||
- [**Web Search**](https://openwebui.com/t/constliakos/web_search/): Perform live web searches to fetch real-time information.
|
||||
- [**Image Generation**](https://openwebui.com/t/justinrahb/image_gen/): Generate images based on the user prompt
|
||||
- [**External Voice Synthesis**](https://openwebui.com/t/justinrahb/elevenlabs_tts/): Make API requests within the chat to integrate external voice synthesis service ElevenLabs and generate audio based on the LLM output.
|
||||
|
||||
## Writing A Custom Toolkit
|
||||
|
||||
Toolkits are defined in a single Python file, with a top level docstring with metadata and a `Tools` class.
|
||||
|
||||
### Example Top-Level Docstring
|
||||
|
||||
```python
|
||||
"""
|
||||
title: String Inverse
|
||||
author: Your Name
|
||||
author_url: https://website.com
|
||||
git_url: https://github.com/username/string-reverse.git
|
||||
description: This tool calculates the inverse of a string
|
||||
required_open_webui_version: 0.4.0
|
||||
requirements: langchain-openai, langgraph, ollama, langchain_ollama
|
||||
version: 0.4.0
|
||||
licence: MIT
|
||||
"""
|
||||
```
|
||||
|
||||
### Tools Class
|
||||
|
||||
Tools have to be defined as methods within a class called `Tools`, with optional subclasses called `Valves` and `UserValves`, for example:
|
||||
|
||||
```python
|
||||
class Tools:
|
||||
def __init__(self):
|
||||
"""Initialize the Tool."""
|
||||
self.valves = self.Valves()
|
||||
|
||||
class Valves(BaseModel):
|
||||
api_key: str = Field("", description="Your API key here")
|
||||
|
||||
def reverse_string(self, string: str) -> str:
|
||||
"""
|
||||
Reverses the input string.
|
||||
:param string: The string to reverse
|
||||
"""
|
||||
# example usage of valves
|
||||
if self.valves.api_key != "42":
|
||||
return "Wrong API key"
|
||||
return string[::-1]
|
||||
```
|
||||
|
||||
### Type Hints
|
||||
Each tool must have type hints for arguments. As of version OpenWebUI version 0.4.3, the types may also be nested, such as `queries_and_docs: list[tuple[str, int]]`. Those type hints are used to generate the JSON schema that is sent to the model. Tools without type hints will work with a lot less consistency.
|
||||
|
||||
### Valves and UserValves - (optional, but HIGHLY encouraged)
|
||||
|
||||
Valves and UserValves are used to allow users to provide dynamic details such as an API key or a configuration option. These will create a fillable field or a bool switch in the GUI menu for the given function.
|
||||
|
||||
Valves are configurable by admins alone and UserValves are configurable by any users.
|
||||
|
||||
<details>
|
||||
<summary>Commented example</summary>
|
||||
|
||||
```
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
class Tools:
|
||||
# Notice the current indentation: Valves and UserValves must be declared as
|
||||
# attributes of a Tools, Filter or Pipe class. Here we take the
|
||||
# example of a Tool.
|
||||
class Valves(BaseModel):
|
||||
# Valves and UserValves inherit from pydantic's BaseModel. This
|
||||
# enables complex use cases like model validators etc.
|
||||
test_valve: int = Field( # Notice the type hint: it is used to
|
||||
# choose the kind of UI element to show the user (buttons,
|
||||
# texts, etc).
|
||||
default=4,
|
||||
description="A valve controlling a numberical value"
|
||||
# required=False, # you can enforce fields using True
|
||||
)
|
||||
pass
|
||||
# Note that this 'pass' helps for parsing and is recommended.
|
||||
|
||||
# UserValves are defined the same way.
|
||||
class UserValves(BaseModel):
|
||||
test_user_valve: bool = Field(
|
||||
default=False, description="A user valve controlling a True/False (on/off) switch"
|
||||
)
|
||||
pass
|
||||
|
||||
def __init__(self):
|
||||
self.valves = self.Valves()
|
||||
# Because they are set by the admin, they are accessible directly
|
||||
# upon code execution.
|
||||
pass
|
||||
|
||||
# The __user__ handling is the same for Filters, Tools and Functions.
|
||||
def test_the_tool(self, message: str, __user__: dict):
|
||||
"""
|
||||
This is a test tool. If the user asks you to test the tools, put any
|
||||
string you want in the message argument.
|
||||
|
||||
:param message: Any string you want.
|
||||
:return: The same string as input.
|
||||
"""
|
||||
# Because UserValves are defined per user they are only available
|
||||
# on use.
|
||||
# Note that although __user__ is a dict, __user__["valves"] is a
|
||||
# UserValves object. Hence you can access values like that:
|
||||
test_user_valve = __user__["valves"].test_user_valve
|
||||
# Or:
|
||||
test_user_valve = dict(__user__["valves"])["test_user_valve"]
|
||||
# But this will return the default value instead of the actual value:
|
||||
# test_user_valve = __user__["valves"]["test_user_valve"] # Do not do that!
|
||||
|
||||
return message + f"\nThe user valve set value is: {test_user_valve}"
|
||||
|
||||
```
|
||||
</details>
|
||||
|
||||
### Optional Arguments
|
||||
Below is a list of optional arguments your tools can depend on:
|
||||
- `__event_emitter__`: Emit events (see following section)
|
||||
- `__event_call__`: Same as event emitter but can be used for user interactions
|
||||
- `__user__`: A dictionary with user information. It also contains the `UserValves` object in `__user__["valves"]`.
|
||||
- `__metadata__`: Dictionary with chat metadata
|
||||
- `__messages__`: List of previous messages
|
||||
- `__files__`: Attached files
|
||||
- `__model__`: Model name
|
||||
|
||||
Just add them as argument to any method of your Tool class just like `__user__` in the example above.
|
||||
|
||||
### Event Emitters
|
||||
Event Emitters are used to add additional information to the chat interface. Similarly to Filter Outlets, Event Emitters are capable of appending content to the chat. Unlike Filter Outlets, they are not capable of stripping information. Additionally, emitters can be activated at any stage during the Tool.
|
||||
|
||||
There are two different types of Event Emitters:
|
||||
|
||||
If the model seems to be unable to call the tool, make sure it is enabled (either via the Model page or via the `+` sign next to the chat input field). You can also turn the `Function Calling` argument of the `Advanced Params` section of the Model page from `Default` to `Native`.
|
||||
|
||||
#### Status
|
||||
This is used to add statuses to a message while it is performing steps. These can be done at any stage during the Tool. These statuses appear right above the message content. These are very useful for Tools that delay the LLM response or process large amounts of information. This allows you to inform users what is being processed in real-time.
|
||||
|
||||
```
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status", # We set the type here
|
||||
"data": {"description": "Message that shows up in the chat", "done": False, "hidden": False},
|
||||
# Note done is False here indicating we are still emitting statuses
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>Example</summary>
|
||||
|
||||
```
|
||||
async def test_function(
|
||||
self, prompt: str, __user__: dict, __event_emitter__=None
|
||||
) -> str:
|
||||
"""
|
||||
This is a demo
|
||||
|
||||
:param test: this is a test parameter
|
||||
"""
|
||||
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status", # We set the type here
|
||||
"data": {"description": "Message that shows up in the chat", "done": False},
|
||||
# Note done is False here indicating we are still emitting statuses
|
||||
}
|
||||
)
|
||||
|
||||
# Do some other logic here
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {"description": "Completed a task message", "done": True, "hidden": False},
|
||||
# Note done is True here indicating we are done emitting statuses
|
||||
# You can also set "hidden": True if you want to remove the status once the message is returned
|
||||
}
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {"description": f"An error occured: {e}", "done": True},
|
||||
}
|
||||
)
|
||||
|
||||
return f"Tell the user: {e}"
|
||||
```
|
||||
</details>
|
||||
|
||||
#### Message
|
||||
This type is used to append a message to the LLM at any stage in the Tool. This means that you can append messages, embed images, and even render web pages before, or after, or during the LLM response.
|
||||
|
||||
```
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "message", # We set the type here
|
||||
"data": {"content": "This message will be appended to the chat."},
|
||||
# Note that with message types we do NOT have to set a done condition
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>Example</summary>
|
||||
|
||||
```
|
||||
async def test_function(
|
||||
self, prompt: str, __user__: dict, __event_emitter__=None
|
||||
) -> str:
|
||||
"""
|
||||
This is a demo
|
||||
|
||||
:param test: this is a test parameter
|
||||
"""
|
||||
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "message", # We set the type here
|
||||
"data": {"content": "This message will be appended to the chat."},
|
||||
# Note that with message types we do NOT have to set a done condition
|
||||
}
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "status",
|
||||
"data": {"description": f"An error occured: {e}", "done": True},
|
||||
}
|
||||
)
|
||||
|
||||
return f"Tell the user: {e}"
|
||||
```
|
||||
</details>
|
||||
|
||||
#### Citations
|
||||
This type is used to provide citations or references in the chat. You can utilize it to specify the content, the source, and any relevant metadata. Below is an example of how to emit a citation event:
|
||||
|
||||
```
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "citation",
|
||||
"data": {
|
||||
"document": [content],
|
||||
"metadata": [
|
||||
{
|
||||
"date_accessed": datetime.now().isoformat(),
|
||||
"source": title,
|
||||
}
|
||||
],
|
||||
"source": {"name": title, "url": url},
|
||||
},
|
||||
}
|
||||
)
|
||||
```
|
||||
If you are sending multiple citations, you can iterate over citations and call the emitter multiple times. When implementing custom citations, ensure that you set `self.citation = False` in your `Tools` class `__init__` method. Otherwise, the built-in citations will override the ones you have pushed in. For example:
|
||||
|
||||
```python
|
||||
def __init__(self):
|
||||
self.citation = False
|
||||
```
|
||||
|
||||
Warning: if you set `self.citation = True`, this will replace any custom citations you send with the automatically generated return citation. By disabling it, you can fully manage your own citation references.
|
||||
|
||||
<details>
|
||||
<summary>Example</summary>
|
||||
|
||||
```
|
||||
class Tools:
|
||||
class UserValves(BaseModel):
|
||||
test: bool = Field(
|
||||
default=True, description="test"
|
||||
)
|
||||
|
||||
def __init__(self):
|
||||
self.citation = False
|
||||
|
||||
async def test_function(
|
||||
self, prompt: str, __user__: dict, __event_emitter__=None
|
||||
) -> str:
|
||||
"""
|
||||
This is a demo that just creates a citation
|
||||
|
||||
:param test: this is a test parameter
|
||||
"""
|
||||
|
||||
await __event_emitter__(
|
||||
{
|
||||
"type": "citation",
|
||||
"data": {
|
||||
"document": ["This message will be appended to the chat as a citation when clicked into"],
|
||||
"metadata": [
|
||||
{
|
||||
"date_accessed": datetime.now().isoformat(),
|
||||
"source": title,
|
||||
}
|
||||
],
|
||||
"source": {"name": "Title of the content", "url": "http://link-to-citation"},
|
||||
},
|
||||
}
|
||||
)
|
||||
```
|
||||
</details>
|
||||
|
||||
## External packages
|
||||
|
||||
In the Tools definition metadata you can specify custom packages. When you click `Save` the line will be parsed and `pip install` will be run on all requirements at once.
|
||||
|
||||
Keep in mind that as pip is used in the same process as Open-WebUI, the UI will be completely unresponsive during the installation.
|
||||
|
||||
No measures are taken to handle package conflicts with Open-WebUI's requirements. That means that specifying requirements can break OpenWebUI if you're not careful. You might be able to work around this by specifying `open-webui` itself as a requirement.
|
||||
|
||||
|
||||
<details>
|
||||
<summary>Example</summary>
|
||||
|
||||
```
|
||||
"""
|
||||
title: myToolName
|
||||
author: myName
|
||||
funding_url: [any link here will be shown behind a `Heart` button for users to show their support to you]
|
||||
version: 1.0.0
|
||||
# the version is displayed in the UI to help users keep track of updates.
|
||||
license: GPLv3
|
||||
description: [recommended]
|
||||
requirements: package1>=2.7.0,package2,package3
|
||||
"""
|
||||
```
|
||||
|
||||
</details>
|
||||
- 🌍 Web Search: Get real-time answers by searching the internet.
|
||||
- 🖼️ Image Generation: Create images from your prompts.
|
||||
- 🔊 Voice Output: Generate AI voices using ElevenLabs.
|
||||
|
||||
Explore ready-to-use tools here:
|
||||
🧰 [Tools Showcase](https://openwebui.com/tools)
|
||||
|
||||
---
|
||||
|
||||
|
||||
## 📦 How to Install Tools
|
||||
|
||||
There are two easy ways to install Tools in Open WebUI:
|
||||
|
||||
1. Go to [Community Tool Library](https://openwebui.com/tools)
|
||||
2. Choose a Tool, then click the Get button.
|
||||
3. Enter your Open WebUI instance’s IP address or URL.
|
||||
4. Click “Import to WebUI” — done!
|
||||
|
||||
🛑 Safety Tip: Never import a Tool you don’t recognize or trust. These are Python scripts and might run unsafe code.
|
||||
|
||||
---
|
||||
|
||||
|
||||
## 🔧 How to Use Tools in Open WebUI
|
||||
|
||||
Once you've installed Tools (we’ll show you how below), here’s how to enable and use them:
|
||||
|
||||
You have two ways to enable a Tool for your model:
|
||||
|
||||
### ➕ Option 1: Enable from the Chat Window
|
||||
|
||||
While chatting, click the ➕ icon in the input area. You’ll see a list of available Tools — you can enable any of them on the fly for that session.
|
||||
|
||||
💡 Tip: Enabling a Tool gives the model permission to use it — but it may not use it unless it's useful for the task.
|
||||
|
||||
### ✏️ Option 2: Enable by Default (Recommended for Frequent Use)
|
||||
1. Go to: Workspace ➡️ Models
|
||||
2. Choose the model you’re using (like GPT-4 or LLaMa2) and click the ✏️ edit icon.
|
||||
3. Scroll down to the “Tools” section.
|
||||
4. ✅ Check the Tools you want your model to have access to by default.
|
||||
5. Click Save.
|
||||
|
||||
This ensures the model always has these Tools ready to use whenever you chat with it.
|
||||
|
||||
You can also let your LLM auto-select the right Tools using the AutoTool Filter:
|
||||
|
||||
🔗 [AutoTool Filter](https://openwebui.com/f/hub/autotool_filter/)
|
||||
|
||||
🎯 Note: Even when using AutoTool, you still need to enable your Tools using Option 2.
|
||||
|
||||
✅ And that’s it — your LLM is now Tool-powered! You're ready to supercharge your chats with web search, image generation, voice output, and more.
|
||||
|
||||
---
|
||||
|
||||
## 🧠 Choosing How Tools Are Used: Default vs Native
|
||||
|
||||
Once Tools are enabled for your model, Open WebUI gives you two different ways to let your LLM use them in conversations.
|
||||
|
||||
You can decide how the model should call Tools by choosing between:
|
||||
|
||||
- 🟡 Default Mode (Prompt-based)
|
||||
- 🟢 Native Mode (Built-in function calling)
|
||||
|
||||
Let’s break it down:
|
||||
|
||||
### 🟡 Default Mode (Prompt-based Tool Triggering)
|
||||
|
||||
This is the default setting in Open WebUI.
|
||||
|
||||
Here, your LLM doesn’t need to natively support function calling. Instead, we guide the model using smart tool selection prompt template to select and use a Tool.
|
||||
|
||||
✅ Works with almost any model
|
||||
✅ Great way to unlock Tools with basic or local models
|
||||
❗ Not as reliable or flexible as Native Mode when chaining tools
|
||||
|
||||
### 🟢 Native Mode (Function Calling Built-In)
|
||||
|
||||
If your model does support “native” function calling (like GPT-4o or GPT-3.5-turbo-1106), you can use this powerful mode to let the LLM decide — in real time — when and how to call multiple Tools during a single chat message.
|
||||
|
||||
✅ Fast, accurate, and can chain multiple Tools in one response
|
||||
✅ The most natural and advanced experience
|
||||
❗ Requires a model that actually supports native function calling
|
||||
|
||||
### ✳️ How to Switch Between Modes
|
||||
|
||||
Want to enable native function calling in your chats? Here's how:
|
||||
|
||||

|
||||
|
||||
1. Open the chat window with your model.
|
||||
2. Click ⚙️ Chat Controls > Advanced Params.
|
||||
3. Look for the Function Calling setting and switch it from Default → Native
|
||||
|
||||
That’s it! Your chat is now using true native Tool support (as long as the model supports it).
|
||||
|
||||
➡️ We recommend using GPT-4o or another OpenAI model for the best native function-calling experience.
|
||||
🔎 Some local models may claim support, but often struggle with accurate or complex Tool usage.
|
||||
|
||||
💡 Summary:
|
||||
|
||||
| Mode | Who it’s for | Pros | Cons |
|
||||
|----------|----------------------------------|-----------------------------------------|--------------------------------------|
|
||||
| Default | Any model | Broad compatibility, safer, flexible | May be less accurate or slower |
|
||||
| Native | GPT-4o, etc. | Fast, smart, excellent tool chaining | Needs proper function call support |
|
||||
|
||||
Choose the one that works best for your setup — and remember, you can always switch on the fly via Chat Controls.
|
||||
|
||||
👏 And that's it — your LLM now knows how and when to use Tools, intelligently.
|
||||
|
||||
---
|
||||
|
||||
## 🧠 Summary
|
||||
|
||||
Tools are add-ons that help your AI model do much more than just chat. From answering real-time questions to generating images or speaking out loud — Tools bring your AI to life.
|
||||
|
||||
- Visit: [https://openwebui.com/tools](https://openwebui.com/tools) to discover new Tools.
|
||||
- Install them manually or with one-click.
|
||||
- Enable them per model from Workspace ➡️ Models.
|
||||
- Use them in chat by clicking ➕
|
||||
|
||||
Now go make your AI waaaaay smarter 🤖✨
|
||||
|
||||
@@ -6,8 +6,8 @@ title: "🖥️ Workspace"
|
||||
The Workspace in Open WebUI provides a comprehensive environment for managing your AI interactions and configurations. It consists of several key components:
|
||||
|
||||
- [🤖 Models](./models.md) - Create and manage custom models tailored to specific purposes
|
||||
- [📚 Knowledge](./knowledge.md) - Manage your knowledge bases for retrieval augmented generation
|
||||
- [📝 Prompts](./prompts.md) - Create and organize reusable prompts
|
||||
- [🧠 Knowledge](./knowledge.md) - Manage your knowledge bases for retrieval augmented generation
|
||||
- [📚 Prompts](./prompts.md) - Create and organize reusable prompts
|
||||
- [🔒 Permissions](./permissions.md) - Configure access controls and feature availability
|
||||
|
||||
Each section of the Workspace is designed to give you fine-grained control over your Open WebUI experience, allowing for customization and optimization of your AI interactions.
|
||||
|
||||
@@ -29,7 +29,7 @@ Some examples of what you might store in Knowledge:
|
||||
|
||||
### How to Use Knowledge in Chats
|
||||
|
||||
Accessing stored Knowledge in your chats is easy! By simply referencing what’s saved(using '#' before the name), Open WebUI can pull in data or follow specific guidelines that you’ve set up in the Knowledge section.
|
||||
Accessing stored Knowledge in your chats is easy! By simply referencing what’s saved (using '#' before the name), Open WebUI can pull in data or follow specific guidelines that you’ve set up in the Knowledge section.
|
||||
|
||||
For example:
|
||||
|
||||
|
||||
@@ -3,4 +3,61 @@ sidebar_position: 2
|
||||
title: "📚 Prompts"
|
||||
---
|
||||
|
||||
COMING SOON!
|
||||
The `Prompts` section of the `Workspace` within Open WebUI enables users to create, manage, and share custom prompts. This feature streamlines interactions with AI models by allowing users to save frequently used prompts and easily access them through slash commands.
|
||||
|
||||
### Prompt Management
|
||||
|
||||
The Prompts interface provides several key features for managing your custom prompts:
|
||||
|
||||
* **Create**: Design new prompts with customizable titles, access levels, and content.
|
||||
* **Share**: Share prompts with other users based on configured access permissions.
|
||||
* **Access Control**: Set visibility and usage permissions for each prompt (refer to [Permissions](./permissions.md) for more details).
|
||||
* **Slash Commands**: Quickly access prompts using custom slash commands during chat sessions.
|
||||
|
||||
### Creating and Editing Prompts
|
||||
|
||||
When creating or editing a prompt, you can configure the following settings:
|
||||
|
||||
* **Title**: Give your prompt a descriptive name for easy identification.
|
||||
* **Access**: Set the access level to control who can view and use the prompt.
|
||||
* **Command**: Define a slash command that will trigger the prompt (e.g., `/summarize`).
|
||||
* **Prompt Content**: Write the actual prompt text that will be sent to the model.
|
||||
|
||||
### Prompt Variables
|
||||
|
||||
Open WebUI supports dynamic prompt variables that can be included in your prompts:
|
||||
|
||||
* **Clipboard Content**: Use `{{CLIPBOARD}}` to insert content from your clipboard.
|
||||
* **Date and Time**:
|
||||
* `{{CURRENT_DATE}}`: Current date
|
||||
* `{{CURRENT_DATETIME}}`: Current date and time
|
||||
* `{{CURRENT_TIME}}`: Current time
|
||||
* `{{CURRENT_TIMEZONE}}`: Current timezone
|
||||
* `{{CURRENT_WEEKDAY}}`: Current day of the week
|
||||
* **User Information**:
|
||||
* `{{USER_NAME}}`: Current user's name
|
||||
* `{{USER_LANGUAGE}}`: User's selected language
|
||||
* `{{USER_LOCATION}}`: User's location (requires HTTPS and Settings > Interface toggle)
|
||||
|
||||
### Variable Usage Guidelines
|
||||
|
||||
* Enclose variables with double curly braces: `{{variable}}`
|
||||
* The `{{USER_LOCATION}}` variable requires:
|
||||
* A secure HTTPS connection
|
||||
* Enabling the feature in Settings > Interface
|
||||
* The `{{CLIPBOARD}}` variable requires clipboard access permission from your device
|
||||
|
||||
### Access Control and Permissions
|
||||
|
||||
Prompt management is controlled by the following permission settings:
|
||||
|
||||
* **Prompts Access**: Users need the `USER_PERMISSIONS_WORKSPACE_PROMPTS_ACCESS` permission to create and manage prompts.
|
||||
* For detailed information about configuring permissions, refer to the [Permissions documentation](./permissions.md).
|
||||
|
||||
### Best Practices
|
||||
|
||||
* Use clear, descriptive titles for your prompts
|
||||
* Create intuitive slash commands that reflect the prompt's purpose
|
||||
* Document any specific requirements or expected inputs in the prompt description
|
||||
* Test prompts with different variable combinations to ensure they work as intended
|
||||
* Consider access levels carefully when sharing prompts with other users - public sharing means that it will appear automatically for all users when they hit `/` in a chat, so you want to avoid creating too many.
|
||||
|
||||
@@ -1,116 +1,278 @@
|
||||
---
|
||||
sidebar_position: 5
|
||||
title: "🛠️ Development Guide"
|
||||
title: "🛠️ Local Development Guide"
|
||||
---
|
||||
|
||||
Welcome to the **Open WebUI Development Setup Guide!** Whether you're a novice or an experienced developer, this guide will help you set up a **local development environment** for both the frontend and backend components. Let’s dive in! 🚀
|
||||
# Ready to Contribute to Open WebUI? Let's Get Started! 🚀
|
||||
|
||||
## System Requirements
|
||||
Excited to dive into Open WebUI development? This comprehensive guide will walk you through setting up your **local development environment** quickly and easily. Whether you're a seasoned developer or just starting out, we'll get you ready to tweak the frontend, enhance the backend, and contribute to the future of Open WebUI! Let's get your development environment up and running in simple, detailed steps!
|
||||
|
||||
- **Operating System**: Linux (or WSL on Windows) or macOS
|
||||
- **Python Version**: Python 3.11+
|
||||
- **Node.js Version**: 22.10+
|
||||
## Prerequisites
|
||||
|
||||
## Development Methods
|
||||
Before you begin, ensure your system meets these minimum requirements:
|
||||
|
||||
### 🐧 Local Development Setup
|
||||
- **Operating System:** Linux (or WSL on Windows), Windows 11, or macOS. *(Recommended for best compatibility)*
|
||||
- **Python:** Version **3.11 or higher**. *(Required for backend services)*
|
||||
- **Node.js:** Version **22.10 or higher**. *(Required for frontend development)*
|
||||
- **IDE (Recommended):** We recommend using an IDE like [VSCode](https://code.visualstudio.com/) for code editing, debugging, and integrated terminal access. Feel free to use your favorite IDE if you have one!
|
||||
- **[Optional] GitHub Desktop:** For easier management of the Git repository, especially if you are less familiar with command-line Git, consider installing [GitHub Desktop](https://desktop.github.com/).
|
||||
|
||||
1. **Clone the Repository**:
|
||||
## Setting Up Your Local Environment
|
||||
|
||||
```bash
|
||||
git clone https://github.com/open-webui/open-webui.git
|
||||
cd open-webui
|
||||
```
|
||||
We'll set up both the frontend (user interface) and backend (API and server logic) of Open WebUI.
|
||||
|
||||
2. **Frontend Setup**:
|
||||
- Create a `.env` file:
|
||||
### 1. Clone the Repository
|
||||
|
||||
First, use `git clone` to download the Open WebUI repository to your local machine. This will create a local copy of the project on your computer.
|
||||
|
||||
1. **Open your terminal** (or Git Bash if you're on Windows and using Git Bash).
|
||||
2. **Navigate to the directory** where you want to store the Open WebUI project.
|
||||
3. **Clone the repository:** Run the following command:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/open-webui/open-webui.git
|
||||
cd open-webui
|
||||
```
|
||||
|
||||
The `git clone` command downloads the project files from GitHub. The `cd open-webui` command then navigates you into the newly created project directory.
|
||||
|
||||
### 2. Frontend Setup (User Interface)
|
||||
|
||||
Let's get the user interface (what you see in your browser) up and running first:
|
||||
|
||||
1. **Configure Environment Variables:**
|
||||
- Copy the example environment file to `.env`:
|
||||
|
||||
```bash
|
||||
cp -RPp .env.example .env
|
||||
```
|
||||
|
||||
- Install dependencies:
|
||||
This command copies the `.env.example` file to a new file named `.env`. The `.env` file is where you'll configure environment variables for the frontend.
|
||||
|
||||
- **Customize `.env`**: Open the `.env` file in your code editor (like VSCode). This file contains configuration variables for the frontend, such as API endpoints and other settings. For local development, the default settings in `.env.example` are usually sufficient to start with. However, you can customize them if needed.
|
||||
|
||||
**Important:** Do not commit sensitive information to `.env` if you are contributing back to the repository.
|
||||
|
||||
1. **Install Frontend Dependencies:**
|
||||
- **Navigate to the frontend directory:** If you're not already in the project root (`open-webui` directory), ensure you are there.
|
||||
|
||||
```bash
|
||||
# If you are not in the project root, run:
|
||||
cd open-webui
|
||||
```
|
||||
|
||||
- Install the required JavaScript packages:
|
||||
|
||||
```bash
|
||||
npm install
|
||||
```
|
||||
|
||||
- Start the frontend server:
|
||||
This command uses `npm` (Node Package Manager) to read the `package.json` file in the project root directory and download all the necessary JavaScript libraries and tools required for the frontend to run. This might take a few minutes depending on your internet connection.
|
||||
|
||||
2. **Start the Frontend Development Server:**
|
||||
|
||||
```bash
|
||||
npm run dev
|
||||
```
|
||||
|
||||
🌐 Available at: [http://localhost:5173](http://localhost:5173).
|
||||
This command launches the frontend development server. If the steps were followed successfully, it will usually indicate the server is running and provide a local URL.
|
||||
|
||||
3. **Backend Setup**:
|
||||
- Navigate to the backend:
|
||||
🎉 **Access the Frontend:** Open your web browser and go to [http://localhost:5173](http://localhost:5173). You should see a message indicating that Open WebUI's frontend is running and is waiting for the backend to be available. Don't worry about that message yet! Let's set up the backend next. **Keep this terminal running** – it's serving your frontend!
|
||||
|
||||
```bash
|
||||
cd backend
|
||||
```
|
||||
### 3. Backend Setup (API and Server)
|
||||
|
||||
- Use **Conda** for environment setup:
|
||||
For a smoother development experience, we **strongly recommend** using separate terminal instances for your frontend and backend processes. This keeps your workflows organized and makes it easier to manage each part of the application independently.
|
||||
|
||||
**Why Separate Terminals?**
|
||||
|
||||
- **Process Isolation:** The frontend and backend development servers are distinct programs. Running them in separate terminals ensures they don't interfere with each other and allows for independent restarts or stops.
|
||||
- **Clearer Logs and Output:** Each terminal will display the logs and output specific to either the frontend or backend. This makes debugging and monitoring much easier, as you're not sifting through interleaved logs.
|
||||
- **Reduced Terminal Clutter:** Mixing frontend and backend commands in a single terminal can become confusing. Separate terminals keep your command history and active processes organized.
|
||||
- **Improved Workflow Efficiency:** You can work on frontend tasks (like running `npm run dev`) in one terminal and simultaneously manage backend tasks (like starting the server or checking logs) in another, without having to switch contexts constantly within a single terminal.
|
||||
|
||||
**Using VSCode Integrated Terminals (Recommended):**
|
||||
|
||||
VSCode's integrated terminal feature makes managing multiple terminals incredibly easy. Here's how to leverage it for frontend and backend separation:
|
||||
|
||||
1. **Frontend Terminal (You likely already have this):** If you followed the Frontend Setup steps, you probably already have a terminal open in VSCode at the project root (`open-webui` directory). This is where you'll run your frontend commands (`npm run dev`, etc.). Ensure you are in the `open-webui` directory for the next steps if you are not already.
|
||||
|
||||
2. **Backend Terminal (Open a New One):**
|
||||
- In VSCode, go to **Terminal > New Terminal** (or use the shortcut `Ctrl+Shift+` on Windows/Linux or `Cmd+Shift+` on macOS). This will open a new integrated terminal panel.
|
||||
- **Navigate to the `backend` directory:** In this *new* terminal, use the `cd backend` command to change the directory to the `backend` folder within your project. This ensures all backend-related commands are executed in the correct context.
|
||||
|
||||
Now you have **two separate terminal instances within VSCode**: one for the frontend (likely in the `open-webui` directory) and one specifically for the backend (inside the `backend` directory). You can easily switch between these terminals within VSCode to manage your frontend and backend processes independently. This setup is highly recommended for a cleaner and more efficient development workflow.
|
||||
|
||||
**Backend Setup Steps (in your *backend* terminal):**
|
||||
|
||||
1. **Navigate to the Backend Directory:** (You should already be in the `backend` directory in your *new* terminal from the previous step). If not, run:
|
||||
|
||||
```bash
|
||||
cd backend
|
||||
```
|
||||
|
||||
2. **Create and Activate a Conda Environment (Recommended):**
|
||||
- We highly recommend using Conda to manage Python dependencies and isolate your project environment. This prevents conflicts with other Python projects on your system and ensures you have the correct Python version and libraries.
|
||||
|
||||
```bash
|
||||
conda create --name open-webui python=3.11
|
||||
conda activate open-webui
|
||||
```
|
||||
|
||||
- Install dependencies:
|
||||
- `conda create --name open-webui python=3.11`: This command creates a new Conda environment named `open-webui` using Python version 3.11. If you chose a different Python 3.11.x version, that's fine.
|
||||
- `conda activate open-webui`: This command activates the newly created Conda environment. Once activated, your terminal prompt will usually change to indicate you are in the `open-webui` environment (e.g., it might show `(open-webui)` at the beginning of the line).
|
||||
|
||||
**Make sure you activate the environment in your backend terminal before proceeding.**
|
||||
|
||||
*(Using Conda is optional but strongly recommended for managing Python dependencies and avoiding conflicts.)* If you choose not to use Conda, ensure you are using Python 3.11 or higher and proceed to the next step, but be aware of potential dependency conflicts.
|
||||
|
||||
1. **Install Backend Dependencies:**
|
||||
- In your *backend* terminal (and with the Conda environment activated if you are using Conda), run:
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt -U
|
||||
```
|
||||
|
||||
- Start the backend:
|
||||
This command uses `pip` (Python Package Installer) to read the `requirements.txt` file in the `backend` directory. `requirements.txt` lists all the Python libraries that the backend needs to run. `pip install` downloads and installs these libraries into your active Python environment (your Conda environment if you are using it, or your system-wide Python environment otherwise). The `-U` flag ensures you get the latest compatible versions of the libraries.
|
||||
|
||||
2. **Start the Backend Development Server:**
|
||||
- In your *backend* terminal, run:
|
||||
|
||||
```bash
|
||||
sh dev.sh
|
||||
```
|
||||
|
||||
📄 API docs available at: [http://localhost:8080/docs](http://localhost:8080/docs).
|
||||
This command executes the `dev.sh` script. This script likely contains the command to start the backend development server. *(You can open and examine the `dev.sh` file in your code editor to see the exact command being run if you are curious.)* The backend server will usually start and print some output to the terminal.
|
||||
|
||||
📄 **Explore the API Documentation:** Once the backend is running, you can access the automatically generated API documentation in your web browser at [http://localhost:8080/docs](http://localhost:8080/docs). This documentation is incredibly valuable for understanding the backend API endpoints, how to interact with the backend, and what data it expects and returns. Keep this documentation handy as you develop!
|
||||
|
||||
## 🐛 Troubleshooting
|
||||
🎉 **Congratulations!** If you have followed all the steps, you should now have both the frontend and backend development servers running locally. Go back to your browser tab where you accessed the frontend (usually [http://localhost:5173](http://localhost:5173)). **Refresh the page.** You should now see the full Open WebUI application running in your browser, connected to your local backend!
|
||||
|
||||
### **FATAL ERROR: Reached Heap Limit**
|
||||
## Troubleshooting Common Issues
|
||||
|
||||
If you encounter memory-related errors during the build, increase the **Node.js heap size**:
|
||||
Here are solutions to some common problems you might encounter during setup or development:
|
||||
|
||||
1. **Modify Dockerfile**:
|
||||
### 💥 "FATAL ERROR: Reached Heap Limit" (Frontend)
|
||||
|
||||
```dockerfile
|
||||
ENV NODE_OPTIONS=--max-old-space-size=4096
|
||||
```
|
||||
This error, often seen during frontend development, indicates that Node.js is running out of memory during the build process, especially when working with large frontend applications.
|
||||
|
||||
2. **Allocate at least 4 GB of RAM** to Node.js.
|
||||
**Solution:** Increase the Node.js heap size. This gives Node.js more memory to work with. You have a couple of options:
|
||||
|
||||
---
|
||||
1. **Using `NODE_OPTIONS` Environment Variable (Recommended for Development):**
|
||||
- This is a temporary way to increase the memory limit for the current terminal session. Before running `npm run dev` or `npm run build` in your *frontend* terminal, set the `NODE_OPTIONS` environment variable:
|
||||
|
||||
### **Other Issues**
|
||||
```bash
|
||||
export NODE_OPTIONS="--max-old-space-size=4096" # For Linux/macOS (bash, zsh)
|
||||
# set NODE_OPTIONS=--max-old-space-size=4096 # For Windows (Command Prompt)
|
||||
# $env:NODE_OPTIONS="--max-old-space-size=4096" # For Windows (PowerShell)
|
||||
npm run dev
|
||||
```
|
||||
|
||||
- **Port Conflicts**:
|
||||
Ensure that no other processes are using **ports 8080 or 5173**.
|
||||
Choose the command appropriate for your operating system and terminal. `4096` represents 4GB of memory. You can try increasing this value further if needed (e.g., `8192` for 8GB). This setting will only apply to commands run in the current terminal session.
|
||||
|
||||
- **Hot Reload Not Working**:
|
||||
Verify that **watch mode** is enabled for both frontend and backend.
|
||||
2. **Modifying `Dockerfile` (For Dockerized Environments):**
|
||||
- If you are working with Docker, you can permanently set the `NODE_OPTIONS` environment variable within your `Dockerfile`. This is useful for consistent memory allocation in Dockerized environments, as shown in the original guide example:
|
||||
|
||||
```dockerfile
|
||||
ENV NODE_OPTIONS=--max-old-space-size=4096
|
||||
```
|
||||
|
||||
- **Allocate Sufficient RAM:** Regardless of the method, ensure your system or Docker container has enough RAM available for Node.js to use. **At least 4 GB of RAM is recommended**, and more might be needed for larger projects or complex builds. Close unnecessary applications to free up RAM.
|
||||
|
||||
### ⚠️ Port Conflicts (Frontend & Backend)
|
||||
|
||||
If you see errors related to ports, such as "Address already in use" or "Port already bound," it means another application on your system is already using port `5173` (default for frontend) or `8080` (default for backend). Only one application can use a specific port at a time.
|
||||
|
||||
**Solution:**
|
||||
|
||||
1. **Identify the Conflicting Process:** You need to find out which application is using the port you need.
|
||||
- **Linux/macOS:** Open a new terminal and use the `lsof` or `netstat` commands:
|
||||
- `lsof -i :5173` (or `:8080` for the backend port)
|
||||
- `netstat -tulnp | grep 5173` (or `8080`)
|
||||
These commands will list the process ID (PID) and the name of the process using the specified port.
|
||||
- **Windows:** Open Command Prompt or PowerShell as an administrator and use `netstat` or `Get-NetTCPConnection`:
|
||||
- `netstat -ano | findstr :5173` (or `:8080`) (Command Prompt)
|
||||
- `Get-Process -Id (Get-NetTCPConnection -LocalPort 5173).OwningProcess` (PowerShell)
|
||||
These commands will also show the PID of the process using the port.
|
||||
|
||||
2. **Terminate the Conflicting Process:** Once you identify the process ID (PID), you can stop the application using that port. **Be careful when terminating processes, especially if you are unsure what they are.**
|
||||
- **Linux/macOS:** Use the `kill` command: `kill <PID>` (replace `<PID>` with the actual process ID). If the process doesn't terminate with `kill`, you can use `kill -9 <PID>` (force kill), but use this with caution.
|
||||
- **Windows:** Use the `taskkill` command in Command Prompt or PowerShell as administrator: `taskkill /PID <PID> /F` (replace `<PID>` with the process ID). The `/F` flag forces termination.
|
||||
|
||||
3. **Alternatively, Change Ports (Advanced):**
|
||||
- If you cannot terminate the conflicting process (e.g., it's a system service you need), you can configure Open WebUI to use different ports for the frontend and/or backend. This usually involves modifying configuration files.
|
||||
- **Frontend Port:** Check the frontend documentation or configuration files (often in `vite.config.js` or similar) for how to change the development server port. You might need to adjust the `.env` file as well if the frontend uses environment variables for the port.
|
||||
- **Backend Port:** Examine the `dev.sh` script or backend configuration files to see how the backend port is set. You might need to modify the startup command or a configuration file to change the backend port. If you change the backend port, you'll likely need to update the frontend's `.env` file to point to the new backend URL.
|
||||
|
||||
### 🔄 Hot Reload Not Working
|
||||
|
||||
Hot reload (or hot module replacement - HMR) is a fantastic development feature that automatically refreshes your browser when you make changes to the code. If it's not working, it can significantly slow down your development workflow.
|
||||
|
||||
**Troubleshooting Steps:**
|
||||
|
||||
1. **Verify Development Servers are Running:** Double-check that both `npm run dev` (frontend) and `sh dev.sh` (backend) are running in their respective terminals and haven't encountered any errors. Look for messages in the terminal output indicating they are running and in "watch mode" or "development mode." If there are errors, address them first.
|
||||
2. **Check for Watch Mode/HMR Messages:** When the development servers start, they should usually print messages in the terminal indicating that hot reload or watch mode is enabled. Look for phrases like "HMR enabled," "watching for file changes," or similar. If you don't see these messages, there might be a configuration issue.
|
||||
3. **Browser Cache:** Sometimes, your browser's cache can prevent you from seeing the latest changes, even if hot reload is working. Try a **hard refresh** in your browser:
|
||||
- **Windows/Linux:** Ctrl+Shift+R
|
||||
- **macOS:** Cmd+Shift+R
|
||||
- Alternatively, you can try clearing your browser cache or opening the frontend in a private/incognito browser window.
|
||||
4. **Dependency Issues (Frontend):** Outdated or corrupted frontend dependencies can sometimes interfere with hot reloading. Try refreshing your frontend dependencies:
|
||||
- In your *frontend* terminal, run:
|
||||
|
||||
```bash
|
||||
rm -rf node_modules && npm install
|
||||
```
|
||||
|
||||
This command deletes the `node_modules` directory (where dependencies are stored) and then reinstalls them from scratch. This can resolve issues caused by corrupted or outdated packages.
|
||||
5. **Backend Restart Required (For Backend Changes):** Hot reload typically works best for frontend code changes (UI, styling, components). For significant backend code changes (especially changes to server logic, API endpoints, or dependencies), you might need to **manually restart the backend server** (by stopping `sh dev.sh` in your backend terminal and running it again). Hot reload for backend changes is often less reliable or not automatically configured in many backend development setups.
|
||||
6. **IDE/Editor Issues:** In rare cases, issues with your IDE or code editor might prevent file changes from being properly detected by the development servers. Try restarting your IDE or ensuring that files are being saved correctly.
|
||||
7. **Configuration Problems (Advanced):** If none of the above steps work, there might be a more complex configuration issue with the frontend or backend development server setup. Consult the project's documentation, configuration files (e.g., `vite.config.js` for frontend, backend server configuration files), or seek help from the Open WebUI community or maintainers.
|
||||
|
||||
## Contributing to Open WebUI
|
||||
|
||||
### Local Workflow
|
||||
We warmly welcome your contributions to Open WebUI! Your help is valuable in making this project even better. Here's a quick guide for a smooth and effective contribution workflow:
|
||||
|
||||
1. **Commit Changes Regularly** to track progress.
|
||||
2. **Sync with the Main Branch** to avoid conflicts:
|
||||
1. **Understand the Project Structure:** Take some time to familiarize yourself with the project's directory structure, especially the `frontend` and `backend` folders. Look at the code, configuration files, and documentation to get a sense of how things are organized.
|
||||
2. **Start with Small Contributions:** If you are new to the project, consider starting with smaller contributions like:
|
||||
- **Documentation improvements:** Fix typos, clarify explanations, add more details to the documentation.
|
||||
- **Bug fixes:** Address reported bugs or issues.
|
||||
- **Small UI enhancements:** Improve styling, fix minor layout issues.
|
||||
These smaller contributions are a great way to get familiar with the codebase and the contribution process.
|
||||
3. **Discuss Larger Changes First:** If you are planning to implement a significant new feature or make substantial changes, it's highly recommended to **discuss your ideas with the project maintainers or community first.** You can do this by:
|
||||
- **Opening an issue** on the GitHub repository to propose your feature or change.
|
||||
- **Joining the Open WebUI community channels** (if available, check the project's README or website for links) and discussing your ideas there.
|
||||
This helps ensure that your contribution aligns with the project's goals and avoids wasted effort on features that might not be merged.
|
||||
4. **Create a Separate Branch for Your Work:** **Never commit directly to the `dev` branch.** Always create a new branch for each feature or bug fix you are working on. This keeps your changes isolated and makes it easier to manage and submit pull requests.
|
||||
- To create a new branch (e.g., named `my-feature-branch`) based on the `dev` branch:
|
||||
|
||||
```bash
|
||||
git checkout dev
|
||||
git pull origin dev # Ensure your local dev branch is up-to-date
|
||||
git checkout -b my-feature-branch
|
||||
```
|
||||
|
||||
5. **Commit Changes Frequently and Write Clear Commit Messages:** Make small, logical commits as you develop features or fix bugs. **Write clear and concise commit messages** that explain what changes you made and why. Good commit messages make it easier to understand the history of changes and are essential for collaboration.
|
||||
- Example of a good commit message: `Fix: Corrected typo in documentation for backend setup`
|
||||
- Example of a good commit message: `Feat: Implemented user profile page with basic information display`
|
||||
6. **Stay Synced with the `dev` Branch Regularly:** While working on your branch, periodically sync your branch with the latest changes from the `dev` branch to minimize merge conflicts later:
|
||||
|
||||
```bash
|
||||
git pull origin main
|
||||
git checkout dev
|
||||
git pull origin dev
|
||||
git checkout my-feature-branch
|
||||
git merge dev
|
||||
```
|
||||
|
||||
3. **Run Tests Before Pushing**:
|
||||
Resolve any merge conflicts that arise during the `git merge` step.
|
||||
7. **Run Tests (If Available) Before Pushing:** While this guide doesn't detail specific testing procedures for Open WebUI, it's a good practice to run any available tests before pushing your code. Check the project's documentation or `package.json` (for frontend) and backend files for test-related commands (e.g., `npm run test`, `pytest`, etc.). Running tests helps ensure your changes haven't introduced regressions or broken existing functionality.
|
||||
8. **Submit a Pull Request (PR):** Once you have completed your work, tested it (if applicable), and are ready to contribute your changes, submit a pull request (PR) to the `dev` branch of the Open WebUI repository on GitHub.
|
||||
- **Go to the Open WebUI repository on GitHub.**
|
||||
- **Navigate to your branch.**
|
||||
- **Click the "Contribute" or "Pull Request" button** (usually green).
|
||||
- **Fill out the PR form:**
|
||||
- **Title:** Give your PR a clear and descriptive title that summarizes your changes (e.g., "Fix: Resolved issue with login form validation").
|
||||
- **Description:** Provide a more detailed description of your changes, the problem you are solving (if applicable), and any relevant context. Link to any related issues if there are any.
|
||||
- **Submit the PR.**
|
||||
|
||||
```bash
|
||||
npm run test
|
||||
```
|
||||
Project maintainers will review your pull request, provide feedback, and potentially merge your changes. Be responsive to feedback and be prepared to make revisions if requested.
|
||||
|
||||
Happy coding! 🎉
|
||||
**Thank you for reading this comprehensive guide and for your interest in contributing to Open WebUI! We're excited to see your contributions and help you become a part of the Open WebUI community!** 🎉 Happy coding!
|
||||
|
||||
@@ -1,27 +1,54 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
title: "🔒HTTPS Encryption"
|
||||
title: "🔒 Enabling HTTPS Encryption"
|
||||
---
|
||||
|
||||
## Overview
|
||||
# Secure Your Open WebUI with HTTPS 🔒
|
||||
|
||||
While HTTPS encryption is **not required** to operate Open WebUI in most cases, certain features—such as **Voice Calls**—will be blocked by modern web browsers unless HTTPS is enabled. If you do not plan to use these features, you can skip this section.
|
||||
This guide explains how to enable HTTPS encryption for your Open WebUI instance. While **HTTPS is not strictly required** for basic operation, it's highly recommended for security and is **necessary for certain features like Voice Calls** to function in modern web browsers.
|
||||
|
||||
## Importance of HTTPS
|
||||
## Why HTTPS Matters 🛡️
|
||||
|
||||
For deployments at high risk of traffic interception, such as those hosted on the internet, it is recommended to implement HTTPS encryption. This ensures that the username/password signup and authentication process remains secure, protecting sensitive user data from potential threats.
|
||||
HTTPS (Hypertext Transfer Protocol Secure) encrypts communication between your web browser and the Open WebUI server. This encryption provides several key benefits:
|
||||
|
||||
## Choosing Your HTTPS Solution
|
||||
* **Privacy and Security:** Protects sensitive data like usernames, passwords, and chat content from eavesdropping and interception, especially on public networks.
|
||||
* **Integrity:** Ensures that data transmitted between the browser and server is not tampered with during transit.
|
||||
* **Feature Compatibility:** **Crucially, modern browsers block access to certain "secure context" features, such as microphone access for Voice Calls, unless the website is served over HTTPS.**
|
||||
* **Trust and User Confidence:** HTTPS is indicated by a padlock icon in the browser address bar, building user trust and confidence in your Open WebUI deployment.
|
||||
|
||||
The choice of HTTPS encryption solution is up to the user and should align with the existing infrastructure. Here are some common scenarios:
|
||||
**When is HTTPS Especially Important?**
|
||||
|
||||
- **AWS Environments**: Utilizing an AWS Elastic Load Balancer is often a practical choice for managing HTTPS.
|
||||
- **Docker Container Environments**: Popular solutions include Nginx, Traefik, and Caddy.
|
||||
- **Cloudflare**: Offers easy HTTPS setup with minimal server-side configuration, suitable for a wide range of applications.
|
||||
- **Ngrok**: Provides a quick way to set up HTTPS for local development environments, particularly useful for testing and demos.
|
||||
* **Internet-Facing Deployments:** If your Open WebUI instance is accessible from the public internet, HTTPS is strongly recommended to protect against security risks.
|
||||
* **Voice Call Feature:** If you plan to use the Voice Call feature in Open WebUI, HTTPS is **mandatory**.
|
||||
* **Sensitive Data Handling:** If you are concerned about the privacy of user data, enabling HTTPS is a crucial security measure.
|
||||
|
||||
## Further Guidance
|
||||
## Choosing the Right HTTPS Solution for You 🛠️
|
||||
|
||||
For detailed instructions and community-submitted tutorials on actual HTTPS encryption deployments, please refer to the [Deployment Tutorials](../../tutorials/deployment/).
|
||||
The best HTTPS solution depends on your existing infrastructure and technical expertise. Here are some common and effective options:
|
||||
|
||||
This documentation provides a starting point for understanding the options available for enabling HTTPS encryption in your environment.
|
||||
* **Cloud Providers (e.g., AWS, Google Cloud, Azure):**
|
||||
* **Load Balancers:** Cloud providers typically offer managed load balancers (like AWS Elastic Load Balancer) that can handle HTTPS termination (encryption/decryption) for you. This is often the most straightforward and scalable approach in cloud environments.
|
||||
* **Docker Container Environments:**
|
||||
* **Reverse Proxies (Nginx, Traefik, Caddy):** Popular reverse proxies like Nginx, Traefik, and Caddy are excellent choices for managing HTTPS in Dockerized deployments. They can automatically obtain and renew SSL/TLS certificates (e.g., using Let's Encrypt) and handle HTTPS termination.
|
||||
* **Nginx:** Highly configurable and widely used.
|
||||
* **Traefik:** Designed for modern microservices and container environments, with automatic configuration and Let's Encrypt integration.
|
||||
* **Caddy:** Focuses on ease of use and automatic HTTPS configuration.
|
||||
* **Cloudflare:**
|
||||
* **Simplified HTTPS:** Cloudflare provides a CDN (Content Delivery Network) and security services, including very easy HTTPS setup. It often requires minimal server-side configuration changes and is suitable for a wide range of deployments.
|
||||
* **Ngrok:**
|
||||
* **Local Development HTTPS:** Ngrok is a convenient tool for quickly exposing your local development server over HTTPS. It's particularly useful for testing features that require HTTPS (like Voice Calls) during development and for demos. **Not recommended for production deployments.**
|
||||
|
||||
**Key Considerations When Choosing:**
|
||||
|
||||
* **Complexity:** Some solutions (like Cloudflare or Caddy) are simpler to set up than others (like manually configuring Nginx).
|
||||
* **Automation:** Solutions like Traefik and Caddy offer automatic certificate management, which simplifies ongoing maintenance.
|
||||
* **Scalability and Performance:** Consider the performance and scalability needs of your Open WebUI instance when choosing a solution, especially for high-traffic deployments.
|
||||
* **Cost:** Some solutions (like cloud load balancers or Cloudflare's paid plans) may have associated costs. Let's Encrypt and many reverse proxies are free and open-source.
|
||||
|
||||
## 📚 Explore Deployment Tutorials for Step-by-Step Guides
|
||||
|
||||
For detailed, practical instructions and community-contributed tutorials on setting up HTTPS encryption with various solutions, please visit the **[Deployment Tutorials](../../tutorials/deployment/)** section.
|
||||
|
||||
These tutorials often provide specific, step-by-step guides for different environments and HTTPS solutions, making the process easier to follow.
|
||||
|
||||
By implementing HTTPS, you significantly enhance the security and functionality of your Open WebUI instance, ensuring a safer and more feature-rich experience for yourself and your users.
|
||||
|
||||
@@ -1,70 +1,119 @@
|
||||
---
|
||||
sidebar_position: 5
|
||||
title: "📜 Open WebUI Logging"
|
||||
title: "📜 Logging in Open WebUI"
|
||||
---
|
||||
|
||||
## Browser Client Logging ##
|
||||
# Understanding Open WebUI Logging 🪵
|
||||
|
||||
Client logging generally occurs via [JavaScript](https://developer.mozilla.org/en-US/docs/Web/API/console/log_static) `console.log()` and can be accessed using the built-in browser-specific developer tools:
|
||||
Logging is essential for debugging, monitoring, and understanding how Open WebUI is behaving. This guide explains how logging works in both the **browser client** (frontend) and the **application server/backend**.
|
||||
|
||||
* Blink
|
||||
* [Chrome/Chromium](https://developer.chrome.com/docs/devtools/)
|
||||
* [Edge](https://learn.microsoft.com/en-us/microsoft-edge/devtools-guide-chromium/overview)
|
||||
* Gecko
|
||||
* [Firefox](https://firefox-source-docs.mozilla.org/devtools-user/)
|
||||
* WebKit
|
||||
* [Safari](https://developer.apple.com/safari/tools/)
|
||||
## 🖥️ Browser Client Logging (Frontend)
|
||||
|
||||
## Application Server/Backend Logging ##
|
||||
For frontend development and debugging, Open WebUI utilizes standard browser console logging. This means you can see logs directly within your web browser's built-in developer tools.
|
||||
|
||||
Logging is an ongoing work-in-progress but some level of control is available using environment variables. [Python Logging](https://docs.python.org/3/howto/logging.html) `log()` and `print()` statements send information to the console. The default level is `INFO`. Ideally, sensitive data will only be exposed with `DEBUG` level.
|
||||
**How to Access Browser Logs:**
|
||||
|
||||
### Logging Levels ###
|
||||
1. **Open Developer Tools:** In most browsers, you can open developer tools by:
|
||||
- **Right-clicking** anywhere on the Open WebUI page and selecting "Inspect" or "Inspect Element".
|
||||
- Pressing **F12** (or Cmd+Opt+I on macOS).
|
||||
|
||||
The following [logging levels](https://docs.python.org/3/howto/logging.html#logging-levels) values are supported:
|
||||
2. **Navigate to the "Console" Tab:** Within the developer tools panel, find and click on the "Console" tab.
|
||||
|
||||
| Level | Numeric value |
|
||||
| ---------- | ------------- |
|
||||
| `CRITICAL` | 50 |
|
||||
| `ERROR` | 40 |
|
||||
| `WARNING` | 30 |
|
||||
| `INFO` | 20 |
|
||||
| `DEBUG` | 10 |
|
||||
| `NOTSET` | 0 |
|
||||
**Types of Browser Logs:**
|
||||
|
||||
### Global ###
|
||||
Open WebUI primarily uses [JavaScript's](https://developer.mozilla.org/en-US/docs/Web/API/console/log_static) `console.log()` for client-side logging. You'll see various types of messages in the console, including:
|
||||
|
||||
The default global log level of `INFO` can be overridden with the `GLOBAL_LOG_LEVEL` environment variable. When set, this executes a [basicConfig](https://docs.python.org/3/library/logging.html#logging.basicConfig) statement with the `force` argument set to *True* within `config.py`. This results in reconfiguration of all attached loggers:
|
||||
> *If this keyword argument is specified as true, any existing handlers attached to the root logger are removed and closed, before carrying out the configuration as specified by the other arguments.*
|
||||
- **Informational messages:** General application flow and status.
|
||||
- **Warnings:** Potential issues or non-critical errors.
|
||||
- **Errors:** Problems that might be affecting functionality.
|
||||
|
||||
The stream uses standard output (`sys.stdout`). In addition to all Open-WebUI `log()` statements, this also affects any imported Python modules that use the Python Logging module `basicConfig` mechanism including [urllib](https://docs.python.org/3/library/urllib.html).
|
||||
**Browser-Specific Developer Tools:**
|
||||
|
||||
For example, to set `DEBUG` logging level as a Docker parameter use:
|
||||
Different browsers offer slightly different developer tools, but they all provide a console for viewing JavaScript logs. Here are links to documentation for popular browsers:
|
||||
|
||||
```
|
||||
--env GLOBAL_LOG_LEVEL="DEBUG"
|
||||
```
|
||||
- **[Blink] Chrome/Chromium (e.g., Chrome, Edge):** [Chrome DevTools Documentation](https://developer.chrome.com/docs/devtools/)
|
||||
- **[Gecko] Firefox:** [Firefox Developer Tools Documentation](https://firefox-source-docs.mozilla.org/devtools-user/)
|
||||
- **[WebKit] Safari:** [Safari Developer Tools Documentation](https://developer.apple.com/safari/tools/)
|
||||
|
||||
or for Docker Compose put this in the environment section of the docker-compose.yml file (notice the absence of quotation signs):
|
||||
```
|
||||
## ⚙️ Application Server/Backend Logging (Python)
|
||||
|
||||
The backend of Open WebUI uses Python's built-in `logging` module to record events and information on the server side. These logs are crucial for understanding server behavior, diagnosing errors, and monitoring performance.
|
||||
|
||||
**Key Concepts:**
|
||||
|
||||
- **Python `logging` Module:** Open WebUI leverages the standard Python `logging` library. If you're familiar with Python logging, you'll find this section straightforward. (For more in-depth information, see the [Python Logging Documentation](https://docs.python.org/3/howto/logging.html#logging-levels)).
|
||||
- **Console Output:** By default, backend logs are sent to the console (standard output), making them visible in your terminal or Docker container logs.
|
||||
- **Logging Levels:** Logging levels control the verbosity of the logs. You can configure Open WebUI to show more or less detailed information based on these levels.
|
||||
|
||||
### 🚦 Logging Levels Explained
|
||||
|
||||
Python logging uses a hierarchy of levels to categorize log messages by severity. Here's a breakdown of the levels, from most to least severe:
|
||||
|
||||
| Level | Numeric Value | Description | Use Case |
|
||||
| ----------- | ------------- | --------------------------------------------------------------------------- | --------------------------------------------------------------------------- |
|
||||
| `CRITICAL` | 50 | **Severe errors** that may lead to application termination. | Catastrophic failures, data corruption. |
|
||||
| `ERROR` | 40 | **Errors** that indicate problems but the application might still function. | Recoverable errors, failed operations. |
|
||||
| `WARNING` | 30 | **Potential issues** or unexpected situations that should be investigated. | Deprecation warnings, resource constraints. |
|
||||
| `INFO` | 20 | **General informational messages** about application operation. | Startup messages, key events, normal operation flow. |
|
||||
| `DEBUG` | 10 | **Detailed debugging information** for developers. | Function calls, variable values, detailed execution steps. |
|
||||
| `NOTSET` | 0 | **All messages are logged.** (Usually defaults to `WARNING` if not set). | Useful for capturing absolutely everything, typically for very specific debugging. |
|
||||
|
||||
**Default Level:** Open WebUI's default logging level is `INFO`.
|
||||
|
||||
### 🌍 Global Logging Level (`GLOBAL_LOG_LEVEL`)
|
||||
|
||||
You can change the **global** logging level for the entire Open WebUI backend using the `GLOBAL_LOG_LEVEL` environment variable. This is the most straightforward way to control overall logging verbosity.
|
||||
|
||||
**How it Works:**
|
||||
|
||||
Setting `GLOBAL_LOG_LEVEL` configures the root logger in Python, affecting all loggers in Open WebUI and potentially some third-party libraries that use [basicConfig](https://docs.python.org/3/library/logging.html#logging.basicConfig). It uses `logging.basicConfig(force=True)`, which means it will override any existing root logger configuration.
|
||||
|
||||
**Example: Setting to `DEBUG`**
|
||||
|
||||
- **Docker Parameter:**
|
||||
|
||||
```bash
|
||||
--env GLOBAL_LOG_LEVEL="DEBUG"
|
||||
```
|
||||
|
||||
- **Docker Compose (`docker-compose.yml`):**
|
||||
|
||||
```yaml
|
||||
environment:
|
||||
- GLOBAL_LOG_LEVEL=DEBUG
|
||||
```
|
||||
|
||||
**Impact:** Setting `GLOBAL_LOG_LEVEL` to `DEBUG` will produce the most verbose logs, including detailed information that is helpful for development and troubleshooting. For production environments, `INFO` or `WARNING` might be more appropriate to reduce log volume.
|
||||
|
||||
### ⚙️ App/Backend Specific Logging Levels
|
||||
|
||||
For more granular control, Open WebUI provides environment variables to set logging levels for specific backend components. Logging is an ongoing work-in-progress, but some level of control is made available using these environment variables. These variables allow you to fine-tune logging for different parts of the application.
|
||||
|
||||
**Available Environment Variables:**
|
||||
|
||||
| Environment Variable | Component/Module | Description |
|
||||
| -------------------- | ------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
| `AUDIO_LOG_LEVEL` | Audio processing | Logging related to audio transcription (faster-whisper), text-to-speech (TTS), and audio handling. |
|
||||
| `COMFYUI_LOG_LEVEL` | ComfyUI Integration | Logging for interactions with ComfyUI, if you are using this integration. |
|
||||
| `CONFIG_LOG_LEVEL` | Configuration Management | Logging related to loading and processing Open WebUI configuration files. |
|
||||
| `DB_LOG_LEVEL` | Database Operations (Peewee) | Logging for database interactions using the Peewee ORM (Object-Relational Mapper). |
|
||||
| `IMAGES_LOG_LEVEL` | Image Generation (AUTOMATIC1111/Stable Diffusion) | Logging for image generation tasks, especially when using AUTOMATIC1111 Stable Diffusion integration. |
|
||||
| `MAIN_LOG_LEVEL` | Main Application Execution (Root Logger) | Logging from the main application entry point and root logger. |
|
||||
| `MODELS_LOG_LEVEL` | Model Management | Logging related to loading, managing, and interacting with language models (LLMs), including authentication. |
|
||||
| `OLLAMA_LOG_LEVEL` | Ollama Backend Integration | Logging for communication and interaction with the Ollama backend. |
|
||||
| `OPENAI_LOG_LEVEL` | OpenAI API Integration | Logging for interactions with the OpenAI API (e.g., for models like GPT). |
|
||||
| `RAG_LOG_LEVEL` | Retrieval-Augmented Generation (RAG) | Logging for the RAG pipeline, including Chroma vector database and Sentence-Transformers. |
|
||||
| `WEBHOOK_LOG_LEVEL` | Authentication Webhook | Extended logging for authentication webhook functionality. |
|
||||
|
||||
**How to Use:**
|
||||
|
||||
You can set these environment variables in the same way as `GLOBAL_LOG_LEVEL` (Docker parameters, Docker Compose `environment` section). For example, to get more detailed logging for Ollama interactions, you could set:
|
||||
|
||||
```yaml
|
||||
environment:
|
||||
- GLOBAL_LOG_LEVEL=DEBUG
|
||||
- OLLAMA_LOG_LEVEL=DEBUG
|
||||
```
|
||||
|
||||
### App/Backend ###
|
||||
**Important Note:** Unlike `GLOBAL_LOG_LEVEL`, these app-specific variables might not affect logging from *all* third-party modules. They primarily control logging within Open WebUI's codebase.
|
||||
|
||||
Some level of granularity is possible using any of the following combination of variables. Note that `basicConfig` `force` isn't presently used so these statements may only affect Open-WebUI logging and not 3rd party modules.
|
||||
|
||||
| Environment Variable | App/Backend |
|
||||
| -------------------- | ----------------------------------------------------------------- |
|
||||
| `AUDIO_LOG_LEVEL` | Audio transcription using faster-whisper, TTS etc. |
|
||||
| `COMFYUI_LOG_LEVEL` | ComfyUI integration handling |
|
||||
| `CONFIG_LOG_LEVEL` | Configuration handling |
|
||||
| `DB_LOG_LEVEL` | Internal Peewee Database |
|
||||
| `IMAGES_LOG_LEVEL` | AUTOMATIC1111 stable diffusion image generation |
|
||||
| `MAIN_LOG_LEVEL` | Main (root) execution |
|
||||
| `MODELS_LOG_LEVEL` | LLM model interaction, authentication, etc. |
|
||||
| `OLLAMA_LOG_LEVEL` | Ollama backend interaction |
|
||||
| `OPENAI_LOG_LEVEL` | OpenAI interaction |
|
||||
| `RAG_LOG_LEVEL` | Retrieval-Augmented Generation using Chroma/Sentence-Transformers |
|
||||
| `WEBHOOK_LOG_LEVEL` | Authentication webhook extended logging |
|
||||
By understanding and utilizing these logging mechanisms, you can effectively monitor, debug, and gain insights into your Open WebUI instance.
|
||||
|
||||
@@ -1,115 +1,171 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
title: "📊 Monitoring"
|
||||
title: "📊 Monitoring Your Open WebUI"
|
||||
---
|
||||
|
||||
# Monitoring Open WebUI
|
||||
# Keep Your Open WebUI Healthy with Monitoring 🩺
|
||||
|
||||
Monitoring your Open WebUI instance is crucial for ensuring reliable service and quickly identifying issues. This guide covers three levels of monitoring:
|
||||
- Basic health checks for service availability
|
||||
- Model connectivity verification
|
||||
- Deep health checks with model response testing
|
||||
Monitoring your Open WebUI instance is crucial for ensuring it runs reliably, performs well, and allows you to quickly identify and resolve any issues. This guide outlines three levels of monitoring, from basic availability checks to in-depth model response testing.
|
||||
|
||||
## Basic Health Check Endpoint
|
||||
**Why Monitor?**
|
||||
|
||||
Open WebUI exposes a health check endpoint at `/health` that returns a 200 OK status when the service is running properly.
|
||||
* **Ensure Uptime:** Proactively detect outages and service disruptions.
|
||||
* **Performance Insights:** Track response times and identify potential bottlenecks.
|
||||
* **Early Issue Detection:** Catch problems before they impact users significantly.
|
||||
* **Peace of Mind:** Gain confidence that your Open WebUI instance is running smoothly.
|
||||
|
||||
## 🚦 Levels of Monitoring
|
||||
|
||||
We'll cover three levels of monitoring, progressing from basic to more comprehensive:
|
||||
|
||||
1. **Basic Health Check:** Verifies if the Open WebUI service is running and responding.
|
||||
2. **Model Connectivity Check:** Confirms that Open WebUI can connect to and list your configured models.
|
||||
3. **Model Response Testing (Deep Health Check):** Ensures that models can actually process requests and generate responses.
|
||||
|
||||
## Level 1: Basic Health Check Endpoint ✅
|
||||
|
||||
The simplest level of monitoring is checking the `/health` endpoint. This endpoint is publicly accessible (no authentication required) and returns a `200 OK` status code when the Open WebUI service is running correctly.
|
||||
|
||||
**How to Test:**
|
||||
|
||||
You can use `curl` or any HTTP client to check this endpoint:
|
||||
|
||||
```bash
|
||||
# No auth needed for this endpoint
|
||||
curl https://your-open-webuiinstance/health
|
||||
# Basic health check - no authentication needed
|
||||
curl https://your-open-webui-instance/health
|
||||
```
|
||||
|
||||
### Using Uptime Kuma
|
||||
[Uptime Kuma](https://github.com/louislam/uptime-kuma) is a great, easy to use, open source, self-hosted uptime monitoring tool.
|
||||
**Expected Output:** A successful health check will return a `200 OK` HTTP status code. The content of the response body is usually not important for a basic health check.
|
||||
|
||||
1. In your Uptime Kuma dashboard, click "Add New Monitor"
|
||||
2. Set the following configuration:
|
||||
- Monitor Type: HTTP(s)
|
||||
- Name: Open WebUI
|
||||
- URL: `http://your-open-webuiinstance:8080/health`
|
||||
- Monitoring Interval: 60 seconds (or your preferred interval)
|
||||
- Retry count: 3 (recommended)
|
||||
### Using Uptime Kuma for Basic Health Checks 🐻
|
||||
|
||||
The health check will verify:
|
||||
- The web server is responding
|
||||
- The application is running
|
||||
- Basic database connectivity
|
||||
[Uptime Kuma](https://github.com/louislam/uptime-kuma) is a fantastic, open-source, and easy-to-use self-hosted uptime monitoring tool. It's highly recommended for monitoring Open WebUI.
|
||||
|
||||
## Open WebUI Model Connectivity
|
||||
**Steps to Set Up in Uptime Kuma:**
|
||||
|
||||
To verify that Open WebUI can successfully connect to and list your configured models, you can monitor the models endpoint. This endpoint requires authentication and checks Open WebUI's ability to communicate with your model providers.
|
||||
1. **Add a New Monitor:** In your Uptime Kuma dashboard, click "Add New Monitor".
|
||||
2. **Configure Monitor Settings:**
|
||||
* **Monitor Type:** Select "HTTP(s)".
|
||||
* **Name:** Give your monitor a descriptive name, e.g., "Open WebUI Health Check".
|
||||
* **URL:** Enter the health check endpoint URL: `http://your-open-webui-instance:8080/health` (Replace `your-open-webui-instance:8080` with your actual Open WebUI address and port).
|
||||
* **Monitoring Interval:** Set the frequency of checks (e.g., `60 seconds` for every minute).
|
||||
* **Retry Count:** Set the number of retries before considering the service down (e.g., `3` retries).
|
||||
|
||||
See [API documentation](https://docs.openwebui.com/getting-started/api-endpoints/#-retrieve-all-models) for more details about the models endpoint.
|
||||
**What This Check Verifies:**
|
||||
|
||||
* **Web Server Availability:** Ensures the web server (e.g., Nginx, Uvicorn) is responding to requests.
|
||||
* **Application Running:** Confirms that the Open WebUI application itself is running and initialized.
|
||||
* **Basic Database Connectivity:** Typically includes a basic check to ensure the application can connect to the database.
|
||||
|
||||
## Level 2: Open WebUI Model Connectivity 🔗
|
||||
|
||||
To go beyond basic availability, you can monitor the `/api/models` endpoint. This endpoint **requires authentication** and verifies that Open WebUI can successfully communicate with your configured model providers (e.g., Ollama, OpenAI) and retrieve a list of available models.
|
||||
|
||||
**Why Monitor Model Connectivity?**
|
||||
|
||||
* **Model Provider Issues:** Detect problems with your model provider services (e.g., API outages, authentication failures).
|
||||
* **Configuration Errors:** Identify misconfigurations in your model provider settings within Open WebUI.
|
||||
* **Ensure Model Availability:** Confirm that the models you expect to be available are actually accessible to Open WebUI.
|
||||
|
||||
**API Endpoint Details:**
|
||||
|
||||
See the [Open WebUI API documentation](https://docs.openwebui.com/getting-started/api-endpoints/#-retrieve-all-models) for full details about the `/api/models` endpoint and its response structure.
|
||||
|
||||
**How to Test with `curl` (Authenticated):**
|
||||
|
||||
You'll need an API key to access this endpoint. See the "Authentication Setup" section below for instructions on generating an API key.
|
||||
|
||||
```bash
|
||||
# See steps below to get an API key
|
||||
curl -H "Authorization: Bearer sk-adfadsflkhasdflkasdflkh" https://your-open-webuiinstance/api/models
|
||||
# Authenticated model connectivity check
|
||||
curl -H "Authorization: Bearer YOUR_API_KEY" https://your-open-webui-instance/api/models
|
||||
```
|
||||
|
||||
### Authentication Setup
|
||||
*(Replace `YOUR_API_KEY` with your actual API key and `your-open-webui-instance` with your Open WebUI address.)*
|
||||
|
||||
1. Enable API Keys (Admin required):
|
||||
- Go to Admin Settings > General
|
||||
- Enable the "Enable API Key" setting
|
||||
- Save changes
|
||||
**Expected Output:** A successful request will return a `200 OK` status code and a JSON response containing a list of models.
|
||||
|
||||
2. Get your API key [docs](https://docs.openwebui.com/getting-started/api-endpoints):
|
||||
- (Optional), consider making a non-admin user for the monitoring API key
|
||||
- Go to Settings > Account in Open WebUI
|
||||
- Generate a new API key specifically for monitoring
|
||||
- Copy the API key for use in Uptime Kuma
|
||||
### Authentication Setup for API Key 🔑
|
||||
|
||||
Note: If you don't see the option to generate API keys in your Settings > Account, check with your administrator to ensure API keys are enabled.
|
||||
Before you can monitor the `/api/models` endpoint, you need to enable API keys in Open WebUI and generate one:
|
||||
|
||||
### Using Uptime Kuma for Model Connectivity
|
||||
1. **Enable API Keys (Admin Required):**
|
||||
* Log in to Open WebUI as an administrator.
|
||||
* Go to **Admin Settings** (usually in the top right menu) > **General**.
|
||||
* Find the "Enable API Key" setting and **turn it ON**.
|
||||
* Click **Save Changes**.
|
||||
|
||||
1. Create a new monitor in Uptime Kuma:
|
||||
- Monitor Type: HTTP(s) - JSON Query
|
||||
- Name: Open WebUI Model Connectivity
|
||||
- URL: `http://your-open-webuiinstance:8080/api/models`
|
||||
- Method: GET
|
||||
- Expected Status Code: 200
|
||||
- JSON Query: `$count(data[*])>0`
|
||||
- Expected Value: `true`
|
||||
- Monitoring Interval: 300 seconds (5 minutes recommended)
|
||||
2. **Generate an API Key (User Settings):**
|
||||
* Go to your **User Settings** (usually by clicking on your profile icon in the top right).
|
||||
* Navigate to the **Account** section.
|
||||
* Click **Generate New API Key**.
|
||||
* Give the API key a descriptive name (e.g., "Monitoring API Key").
|
||||
* **Copy the generated API key** and store it securely. You'll need this for your monitoring setup.
|
||||
|
||||
2. Configure Authentication:
|
||||
- In the Headers section, add:
|
||||
```
|
||||
{
|
||||
"Authorization": "Bearer sk-abc123adfsdfsdfsdfsfdsdf"
|
||||
}
|
||||
```
|
||||
- Replace `YOUR_API_KEY` with the API key you generated
|
||||
*(Optional but Recommended):* For security best practices, consider creating a **non-administrator user account** specifically for monitoring and generate an API key for that user. This limits the potential impact if the monitoring API key is compromised.
|
||||
|
||||
Alternative JSON Queries:
|
||||
```
|
||||
# At least 1 models by ollama provider
|
||||
$count(data[owned_by='ollama'])>1
|
||||
*If you don't see the API key generation option in your settings, contact your Open WebUI administrator to ensure API keys are enabled.*
|
||||
|
||||
# Check if specific model exists (returns true/false)
|
||||
$exists(data[id='gpt-4o'])
|
||||
### Using Uptime Kuma for Model Connectivity Monitoring 🐻
|
||||
|
||||
# Check multiple models (returns true if ALL exist)
|
||||
$count(data[id in ['gpt-4o', 'gpt-4o-mini']]) = 2
|
||||
```
|
||||
1. **Create a New Monitor in Uptime Kuma:**
|
||||
* Monitor Type: "HTTP(s) - JSON Query".
|
||||
* Name: "Open WebUI Model Connectivity Check".
|
||||
* URL: `http://your-open-webui-instance:8080/api/models` (Replace with your URL).
|
||||
* Method: "GET".
|
||||
* Expected Status Code: `200`.
|
||||
|
||||
You can test JSONata queries at [jsonata.org](https://try.jsonata.org/) to verify they work with your API response.
|
||||
2. **Configure JSON Query (Verify Model List):**
|
||||
* **JSON Query:** `$count(data[*])>0`
|
||||
* **Explanation:** This JSONata query checks if the `data` array in the API response (which contains the list of models) has a count greater than 0. In other words, it verifies that at least one model is returned.
|
||||
* **Expected Value:** `true` (The query should return `true` if models are listed).
|
||||
|
||||
## Model Response Testing
|
||||
3. **Add Authentication Headers:**
|
||||
* In the "Headers" section of the Uptime Kuma monitor configuration, click "Add Header".
|
||||
* **Header Name:** `Authorization`
|
||||
* **Header Value:** `Bearer YOUR_API_KEY` (Replace `YOUR_API_KEY` with the API key you generated).
|
||||
|
||||
To verify that models can actually process requests, you can monitor the chat completions endpoint. This provides a deeper health check by ensuring models can generate responses.
|
||||
4. **Set Monitoring Interval:** Recommended interval: `300 seconds` (5 minutes) or longer, as model lists don't typically change very frequently.
|
||||
|
||||
**Alternative JSON Queries (Advanced):**
|
||||
|
||||
You can use more specific JSONata queries to check for particular models or providers. Here are some examples:
|
||||
|
||||
* **Check for at least one Ollama model:** `$count(data[owned_by='ollama'])>0`
|
||||
* **Check if a specific model exists (e.g., 'gpt-4o'):** `$exists(data[id='gpt-4o'])`
|
||||
* **Check if multiple specific models exist (e.g., 'gpt-4o' and 'gpt-4o-mini'):** `$count(data[id in ['gpt-4o', 'gpt-4o-mini']]) = 2`
|
||||
|
||||
You can test and refine your JSONata queries at [jsonata.org](https://try.jsonata.org/) using a sample API response to ensure they work as expected.
|
||||
|
||||
## Level 3: Model Response Testing (Deep Health Check) 🤖
|
||||
|
||||
For the most comprehensive monitoring, you can test if models are actually capable of processing requests and generating responses. This involves sending a simple chat completion request to the `/api/chat/completions` endpoint.
|
||||
|
||||
**Why Test Model Responses?**
|
||||
|
||||
* **End-to-End Verification:** Confirms that the entire model pipeline is working, from API request to model response.
|
||||
* **Model Loading Issues:** Detects problems with specific models failing to load or respond.
|
||||
* **Backend Processing Errors:** Catches errors in the backend logic that might prevent models from generating completions.
|
||||
|
||||
**How to Test with `curl` (Authenticated POST Request):**
|
||||
|
||||
This test requires an API key and sends a POST request with a simple message to the chat completions endpoint.
|
||||
|
||||
```bash
|
||||
# Test model response
|
||||
curl -X POST https://your-open-webuiinstance/api/chat/completions \
|
||||
-H "Authorization: Bearer sk-adfadsflkhasdflkasdflkh" \
|
||||
# Test model response - authenticated POST request
|
||||
curl -X POST https://your-open-webui-instance/api/chat/completions \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"messages": [{"role": "user", "content": "Respond with the word HEALTHY"}],
|
||||
"model": "llama3.1",
|
||||
"temperature": 0
|
||||
"model": "llama3.1", # Replace with a model you expect to be available
|
||||
"temperature": 0 # Set temperature to 0 for consistent responses
|
||||
}'
|
||||
```
|
||||
|
||||
*(Replace `YOUR_API_KEY`, `your-open-webui-instance`, and `llama3.1` with your actual values.)*
|
||||
|
||||
**Expected Output:** A successful request will return a `200 OK` status code and a JSON response containing a chat completion. You can verify that the response includes the word "HEALTHY" (or a similar expected response based on your prompt).
|
||||
|
||||
**Setting up Level 3 Monitoring in Uptime Kuma would involve configuring an HTTP(s) monitor with a POST request, JSON body, authentication headers, and potentially JSON query to validate the response content. This is a more advanced setup and can be customized based on your specific needs.**
|
||||
|
||||
By implementing these monitoring levels, you can proactively ensure the health, reliability, and performance of your Open WebUI instance, providing a consistently positive experience for users.
|
||||
|
||||
@@ -66,6 +66,39 @@ To ensure secure access to the API, authentication is required 🛡️. You can
|
||||
return response.json()
|
||||
```
|
||||
|
||||
### 🦙 Ollama API Proxy Support
|
||||
|
||||
If you want to interact directly with Ollama models—including for embedding generation or raw prompt streaming—Open WebUI offers a transparent passthrough to the native Ollama API via a proxy route.
|
||||
|
||||
- **Base URL**: `/ollama/<api>`
|
||||
- **Reference**: [Ollama API Documentation](https://github.com/ollama/ollama/blob/main/docs/api.md)
|
||||
|
||||
#### 🔁 Generate Completion (Streaming)
|
||||
|
||||
```bash
|
||||
curl http://localhost:3000/ollama/api/generate -d '{
|
||||
"model": "llama3.2",
|
||||
"prompt": "Why is the sky blue?"
|
||||
}'
|
||||
```
|
||||
|
||||
#### 📦 List Available Models
|
||||
|
||||
```bash
|
||||
curl http://localhost:3000/ollama/api/tags
|
||||
```
|
||||
|
||||
#### 🧠 Generate Embeddings
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:3000/ollama/api/embed -d '{
|
||||
"model": "llama3.2",
|
||||
"input": ["Open WebUI is great!", "Let's generate embeddings."]
|
||||
}'
|
||||
```
|
||||
|
||||
This is ideal for building search indexes, retrieval systems, or custom pipelines using Ollama models behind the Open WebUI.
|
||||
|
||||
### 🧩 Retrieval Augmented Generation (RAG)
|
||||
|
||||
The Retrieval Augmented Generation (RAG) feature allows you to enhance responses by incorporating data from external sources. Below, you will find the methods for managing files and knowledge collections via the API, and how to use them in chat completions effectively.
|
||||
|
||||
128
docs/getting-started/quick-start/starting-with-llama-cpp.mdx
Normal file
@@ -0,0 +1,128 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
title: "🦙Starting with Llama.cpp"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Open WebUI makes it simple and flexible to connect and manage a local Llama.cpp server to run efficient, quantized language models. Whether you’ve compiled Llama.cpp yourself or you're using precompiled binaries, this guide will walk you through how to:
|
||||
|
||||
- Set up your Llama.cpp server
|
||||
- Load large models locally
|
||||
- Integrate with Open WebUI for a seamless interface
|
||||
|
||||
Let’s get you started!
|
||||
|
||||
---
|
||||
|
||||
## Step 1: Install Llama.cpp
|
||||
|
||||
To run models with Llama.cpp, you first need the Llama.cpp server installed locally.
|
||||
|
||||
You can either:
|
||||
|
||||
- 📦 [Download prebuilt binaries](https://github.com/ggerganov/llama.cpp/releases)
|
||||
- 🛠️ Or build it from source by following the [official build instructions](https://github.com/ggerganov/llama.cpp/blob/master/docs/build.md)
|
||||
|
||||
After installing, make sure `llama-server` is available in your local system path or take note of its location.
|
||||
|
||||
---
|
||||
|
||||
## Step 2: Download a Supported Model
|
||||
|
||||
You can load and run various GGUF-format quantized LLMs using Llama.cpp. One impressive example is the DeepSeek-R1 1.58-bit model optimized by UnslothAI. To download this version:
|
||||
|
||||
1. Visit the [Unsloth DeepSeek-R1 repository on Hugging Face](https://huggingface.co/unsloth/DeepSeek-R1-GGUF)
|
||||
2. Download the 1.58-bit quantized version – around 131GB.
|
||||
|
||||
Alternatively, use Python to download programmatically:
|
||||
|
||||
```python
|
||||
# pip install huggingface_hub hf_transfer
|
||||
|
||||
from huggingface_hub import snapshot_download
|
||||
|
||||
snapshot_download(
|
||||
repo_id = "unsloth/DeepSeek-R1-GGUF",
|
||||
local_dir = "DeepSeek-R1-GGUF",
|
||||
allow_patterns = ["*UD-IQ1_S*"], # Download only 1.58-bit variant
|
||||
)
|
||||
```
|
||||
|
||||
This will download the model files into a directory like:
|
||||
```
|
||||
DeepSeek-R1-GGUF/
|
||||
└── DeepSeek-R1-UD-IQ1_S/
|
||||
├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
|
||||
├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
|
||||
└── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
|
||||
```
|
||||
|
||||
📍 Keep track of the full path to the first GGUF file — you’ll need it in Step 3.
|
||||
|
||||
---
|
||||
|
||||
## Step 3: Serve the Model with Llama.cpp
|
||||
|
||||
Start the model server using the llama-server binary. Navigate to your llama.cpp folder (e.g., build/bin) and run:
|
||||
|
||||
```bash
|
||||
./llama-server \
|
||||
--model /your/full/path/to/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
|
||||
--port 10000 \
|
||||
--ctx-size 1024 \
|
||||
--n-gpu-layers 40
|
||||
```
|
||||
|
||||
🛠️ Tweak the parameters to suit your machine:
|
||||
|
||||
- --model: Path to your .gguf model file
|
||||
- --port: 10000 (or choose another open port)
|
||||
- --ctx-size: Token context length (can increase if RAM allows)
|
||||
- --n-gpu-layers: Layers offloaded to GPU for faster performance
|
||||
|
||||
Once the server runs, it will expose a local OpenAI-compatible API on:
|
||||
|
||||
```
|
||||
http://127.0.0.1:10000
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Step 4: Connect Llama.cpp to Open WebUI
|
||||
|
||||
To control and query your locally running model directly from Open WebUI:
|
||||
|
||||
1. Open Open WebUI in your browser
|
||||
2. Go to ⚙️ Admin Settings → Connections → OpenAI Connections
|
||||
3. Click ➕ Add Connection and enter:
|
||||
|
||||
- URL: `http://127.0.0.1:10000/v1`
|
||||
(Or use `http://host.docker.internal:10000/v1` if running WebUI inside Docker)
|
||||
- API Key: `none` (leave blank)
|
||||
|
||||
💡 Once saved, Open WebUI will begin using your local Llama.cpp server as a backend!
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## Quick Tip: Try Out the Model via Chat Interface
|
||||
|
||||
Once connected, select the model from the Open WebUI chat menu and start interacting!
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## You're Ready to Go!
|
||||
|
||||
Once configured, Open WebUI makes it easy to:
|
||||
|
||||
- Manage and switch between local models served by Llama.cpp
|
||||
- Use the OpenAI-compatible API with no key needed
|
||||
- Experiment with massive models like DeepSeek-R1 — right from your machine!
|
||||
|
||||
---
|
||||
|
||||
🚀 Have fun experimenting and building!
|
||||
@@ -1,6 +1,6 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
title: "🦙 Starting With Ollama"
|
||||
title: "👉 Starting With Ollama"
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
76
docs/getting-started/quick-start/starting-with-openai.mdx
Normal file
@@ -0,0 +1,76 @@
|
||||
---
|
||||
|
||||
sidebar_position: 2
|
||||
title: "🤖 Starting With OpenAI"
|
||||
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Open WebUI makes it easy to connect and use OpenAI and other OpenAI-compatible APIs. This guide will walk you through adding your API key, setting the correct endpoint, and selecting models — so you can start chatting right away.
|
||||
|
||||
---
|
||||
|
||||
## Step 1: Get Your OpenAI API Key
|
||||
|
||||
To use OpenAI models (such as GPT-4 or o3-mini), you need an API key from a supported provider.
|
||||
|
||||
You can use:
|
||||
|
||||
- OpenAI directly (https://platform.openai.com/account/api-keys)
|
||||
- Azure OpenAI
|
||||
- Any OpenAI-compatible service (e.g., LocalAI, FastChat, Helicone, LiteLLM, OpenRouter etc.)
|
||||
|
||||
👉 Once you have the key, copy it and keep it handy.
|
||||
|
||||
For most OpenAI usage, the default API base URL is:
|
||||
https://api.openai.com/v1
|
||||
|
||||
Other providers use different URLs — check your provider’s documentation.
|
||||
|
||||
---
|
||||
|
||||
## Step 2: Add the API Connection in Open WebUI
|
||||
|
||||
Once Open WebUI is running:
|
||||
|
||||
1. Go to the ⚙️ **Admin Settings**.
|
||||
2. Navigate to **Connections > OpenAI > Manage** (look for the wrench icon).
|
||||
3. Click ➕ **Add New Connection**.
|
||||
4. Fill in the following:
|
||||
- API URL: https://api.openai.com/v1 (or the URL of your specific provider)
|
||||
- API Key: Paste your key here
|
||||
|
||||
5. Click Save ✅.
|
||||
|
||||
This securely stores your credentials and sets up the connection.
|
||||
|
||||
Here’s what it looks like:
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## Step 3: Start Using Models
|
||||
|
||||
Once your connection is saved, you can start using models right inside Open WebUI.
|
||||
|
||||
🧠 You don’t need to download any models — just select one from the Model Selector and start chatting. If a model is supported by your provider, you’ll be able to use it instantly via their API.
|
||||
|
||||
Here’s what model selection looks like:
|
||||
|
||||

|
||||
|
||||
Simply choose GPT-4, o3-mini, or any compatible model offered by your provider.
|
||||
|
||||
---
|
||||
|
||||
## All Set!
|
||||
|
||||
That’s it! Your OpenAI-compatible API connection is ready to use.
|
||||
|
||||
With Open WebUI and OpenAI, you get powerful language models, an intuitive interface, and instant access to chat capabilities — no setup headaches.
|
||||
|
||||
If you run into issues or need additional support, visit our [help section](/troubleshooting).
|
||||
|
||||
Happy prompting! 🎉
|
||||
@@ -29,6 +29,13 @@ Helm helps you manage Kubernetes applications.
|
||||
kubectl get pods
|
||||
```
|
||||
|
||||
:::warning
|
||||
|
||||
If you intend to scale Open WebUI using multiple nodes/pods/workers in a clustered environment, you need to setup a NoSQL key-value database.
|
||||
There are some [environment variables](https://docs.openwebui.com/getting-started/env-configuration/) that need to be set to the same value for all service-instances, otherwise consistency problems, faulty sessions and other issues will occur!
|
||||
|
||||
:::
|
||||
|
||||
## Access the WebUI
|
||||
|
||||
Set up port forwarding or load balancing to access Open WebUI from outside the cluster.
|
||||
|
||||
@@ -29,6 +29,13 @@ Kustomize allows you to customize Kubernetes YAML configurations.
|
||||
kubectl get pods
|
||||
```
|
||||
|
||||
:::warning
|
||||
|
||||
If you intend to scale Open WebUI using multiple nodes/pods/workers in a clustered environment, you need to setup a NoSQL key-value database.
|
||||
There are some [environment variables](https://docs.openwebui.com/getting-started/env-configuration/) that need to be set to the same value for all service-instances, otherwise consistency problems, faulty sessions and other issues will occur!
|
||||
|
||||
:::
|
||||
|
||||
## Access the WebUI
|
||||
|
||||
Set up port forwarding or load balancing to access Open WebUI from outside the cluster.
|
||||
|
||||
@@ -42,40 +42,6 @@ uvicorn main:app --host 0.0.0.0 --reload
|
||||
|
||||
Now, simply point your OpenAPI-compatible clients or AI agents to your local or publicly deployed URL—no configuration headaches, no complicated transports.
|
||||
|
||||
## 📂 Server Examples
|
||||
|
||||
Reference implementations provided in this repository demonstrate common use-cases clearly and simply:
|
||||
|
||||
- **Filesystem Access** _(servers/filesystem)_ - Manage local file operations safely with configurable restrictions.
|
||||
- **Git Server** _(servers/git)_ - Expose Git repositories for searching, reading, and possibly writing via controlled API endpoints.
|
||||
- **WIP: Database Server** _(servers/database)_ - Query and inspect database schemas across common DB engines like PostgreSQL, MySQL, and SQLite.
|
||||
- **Memory & Knowledge Graph** _(servers/memory)_ - Persistent memory management and semantic knowledge querying using popular and reliable storage techniques.
|
||||
- **WIP: Web Search & Fetch** _(servers/web-search)_ - Retrieve and convert web-based content securely into structured API results usable by LLMs.
|
||||
|
||||
(More examples and reference implementations will be actively developed and continually updated.)
|
||||
|
||||
## 🔌 Bridge to MCP (Optional)
|
||||
|
||||
For the easiest way to expose your MCP tools as OpenAPI-compatible APIs, we recommend using [mcpo](https://github.com/open-webui/mcpo). This enables tool providers who initially implemented MCP servers to expose them effortlessly as standard OpenAPI-compatible APIs, ensuring existing MCP servers and resources remain accessible without additional hassle.
|
||||
|
||||
**Quick Usage:**
|
||||
```bash
|
||||
uvx mcpo --port 8000 -- uvx mcp-server-time --local-timezone=America/New_York
|
||||
```
|
||||
|
||||
Alternatively, we also provide a simple Python-based proxy server:
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
cd servers/mcp-proxy
|
||||
pip install -r requirements.txt
|
||||
python main.py --host 0.0.0.0 --port 8000 -- uvx mcp-server-time --local-timezone=America/New_York
|
||||
```
|
||||
|
||||
Both methods help bridge existing MCP servers with OpenAPI clients, removing transport and security complexities during integration or migration.
|
||||
|
||||
|
||||
|
||||
## 🌱 Open WebUI Community
|
||||
|
||||
- For general discussions, technical exchange, and announcements, visit our [Community Discussions](https://github.com/open-webui/openapi-servers/discussions) page.
|
||||
|
||||
@@ -102,6 +102,8 @@ That's it! You're now running the MCP-to-OpenAPI Proxy locally and exposing the
|
||||
|
||||
Feel free to replace `uvx mcp-server-time --local-timezone=America/New_York` with your preferred MCP Server command from other available MCP implementations found in the official repository.
|
||||
|
||||
🤝 **To integrate with Open WebUI after launching the server, check our [docs](https://docs.openwebui.com/openapi-servers/open-webui/).**
|
||||
|
||||
### 🚀 Accessing the Generated APIs
|
||||
|
||||
As soon as it starts, the MCP Proxy (`mcpo`) automatically:
|
||||
|
||||
@@ -49,6 +49,53 @@ Next, connect your running tool server to Open WebUI:
|
||||
|
||||

|
||||
|
||||
### 🧑💻 User Tool Servers vs. 🛠️ Global Tool Servers
|
||||
|
||||
There are two ways to register tool servers in Open WebUI:
|
||||
|
||||
#### 1. User Tool Servers (added via regular Settings)
|
||||
|
||||
- Only accessible to the user who registered the tool server.
|
||||
- The connection is made directly from the browser (client-side) by the user.
|
||||
- Perfect for personal workflows or when testing custom/local tools.
|
||||
|
||||
#### 2. Global Tool Servers (added via Admin Settings)
|
||||
|
||||
Admins can manage shared tool servers available to all or selected users across the entire deployment:
|
||||
|
||||
- Go to 🛠️ **Admin Settings > Tools**.
|
||||
- Add the tool server URL just as you would in user settings.
|
||||
- These tools are treated similarly to Open WebUI’s built-in tools.
|
||||
|
||||
### 👉 Optional: Using a Config File with mcpo
|
||||
|
||||
If you're running multiple tools through mcpo using a config file, take note:
|
||||
|
||||
🧩 Each tool is mounted under its own unique path!
|
||||
|
||||
For example, if you’re using memory and time tools simultaneously through mcpo, they’ll each be available at a distinct route:
|
||||
|
||||
- http://localhost:8000/time
|
||||
- http://localhost:8000/memory
|
||||
|
||||
This means:
|
||||
|
||||
- When connecting a tool in Open WebUI, you must enter the full route to that specific tool — do NOT enter just the root URL (http://localhost:8000).
|
||||
- Add each tool individually in Open WebUI Settings using their respective subpath URLs.
|
||||
|
||||

|
||||
|
||||
✅ Good:
|
||||
|
||||
http://localhost:8000/time
|
||||
http://localhost:8000/memory
|
||||
|
||||
🚫 Not valid:
|
||||
|
||||
http://localhost:8000
|
||||
|
||||
This ensures Open WebUI recognizes and communicates with each tool server correctly.
|
||||
|
||||
---
|
||||
|
||||
## Step 3: Confirm Your Tool Server Is Connected ✅
|
||||
@@ -69,6 +116,28 @@ Clicking this icon opens a popup where you can:
|
||||
|
||||

|
||||
|
||||
### 🛠️ Global Tool Servers Look Different — And Are Hidden by Default!
|
||||
|
||||
If you've connected a Global Tool Server (i.e., one that’s admin-configured), it will not appear automatically in the input area like user tool servers do.
|
||||
|
||||
Instead:
|
||||
|
||||
- Global tools are hidden by default and must be explicitly activated per user.
|
||||
- To enable them, you'll need to click on the ➕ button in the message input area (bottom left of the chat box), and manually toggle on the specific global tool(s) you want to use.
|
||||
|
||||
Here’s what that looks like:
|
||||
|
||||

|
||||
|
||||
⚠️ Important Notes for Global Tool Servers:
|
||||
|
||||
- They will not show up in the tool indicator popup until enabled from the ➕ menu.
|
||||
- Each global tool must be individually toggled on to become active inside your current chat.
|
||||
- Once toggled on, they function the same way as user tools.
|
||||
- Admins can control access to global tools via role-based permissions.
|
||||
|
||||
This is ideal for team setups or shared environments, where commonly-used tools (e.g. document search, memory, or web lookup) should be centrally accessible by multiple users.
|
||||
|
||||
---
|
||||
|
||||
## (Optional) Step 4: Use "Native" Function Calling (ReACT-style) Tool Use 🧠
|
||||
|
||||
121
docs/troubleshooting/rag.mdx
Normal file
@@ -0,0 +1,121 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
title: "🧠 Troubleshooting RAG (Retrieval-Augmented Generation)"
|
||||
---
|
||||
|
||||
Retrieval-Augmented Generation (RAG) enables language models to reason over external content—documents, knowledge bases, and more—by retrieving relevant info and feeding it into the model. But when things don’t work as expected (e.g., the model "hallucinates" or misses relevant info), it's often not the model's fault—it's a context issue.
|
||||
|
||||
Let’s break down the common causes and solutions so you can supercharge your RAG accuracy! 🚀
|
||||
|
||||
## Common RAG Issues and How to Fix Them 🛠️
|
||||
|
||||
### 1. The Model "Can’t See" Your Content 👁️❌
|
||||
|
||||
This is the most common problem—and it's typically caused by issues during your content ingestion process. The model doesn’t hallucinate because it’s wrong, it hallucinates because it was never given the right content in the first place.
|
||||
|
||||
✅ Solution: Check your content extraction settings
|
||||
|
||||
- Navigate to: **Admin Settings > Documents**.
|
||||
- Make sure you're using a robust content extraction engine such as:
|
||||
- Apache Tika
|
||||
- Docling
|
||||
- Custom extractors (depending on your document types)
|
||||
|
||||
📌 Tip: Try uploading a document and preview the extracted content. If it’s blank or missing key sections, you need to adjust your extractor settings or use a different engine.
|
||||
|
||||
---
|
||||
|
||||
### 2. Only a Small Part of the Document is Being Used 📄➡️✂️
|
||||
|
||||
Open WebUI is designed to work with models that have limited context windows by default. For instance, many local models (e.g. Ollama's default models) are limited to 2048 tokens. Because of this, Open WebUI aggressively trims down the retrieved content to fit within the assumed available space.
|
||||
|
||||
✅ Solutions:
|
||||
|
||||
- Go to **Admin Settings > Documents**
|
||||
- Either:
|
||||
- 💡 Enable “Bypass Embedding and Retrieval” — This sends full content directly without applying strict retrieval filters.
|
||||
- 🔍 Toggle on “Full Context Mode” — This injects more comprehensive content into the model prompt.
|
||||
|
||||
📌 Warning: Be mindful of context limits—if your model can’t handle more tokens, it will still get cut off.
|
||||
|
||||
---
|
||||
|
||||
### 3. Token Limit is Too Short ⏳
|
||||
|
||||
Even if retrieval works, your model might still not process all the content it receives—because it simply can’t.
|
||||
|
||||
By default, many models (especially Ollama-hosted LLMs) are limited to a 2048-token context window. That means only a fraction of your retrieved data will actually be used.
|
||||
|
||||
✅ Solutions:
|
||||
|
||||
- 🛠️ Extend the model’s context length:
|
||||
- Navigate to the **Model Editor or Chat Controls**
|
||||
- Modify the context length (e.g., increase to 8192+ tokens if supported)
|
||||
|
||||
ℹ️ Note: The 2048-token default is a big limiter. For better RAG results, we recommend using models that support longer contexts.
|
||||
|
||||
✅ Alternative: Use an external LLM with larger context capacity
|
||||
|
||||
- Try GPT-4, GPT-4o, Claude 3, Gemini 1.5, or Mixtral with 8k+ context
|
||||
- Compare performance to Ollama—notice the accuracy difference when more content can be injected!
|
||||
|
||||
📌 Tip: Stick with external models for better RAG performance in production use cases.
|
||||
|
||||
---
|
||||
|
||||
### 4. Embedding Model is Low-Quality or Mismatched 📉🧠
|
||||
|
||||
Bad embeddings = bad retrieval. If the vector representation of your content is poor, the retriever won't pull the right content—no matter how powerful your LLM is.
|
||||
|
||||
✅ Solution:
|
||||
|
||||
- Change to a high-quality embedding model (e.g., all-MiniLM-L6-v2, Instructor X, or OpenAI embeddings)
|
||||
- Go to: **Admin Settings > Documents**
|
||||
- After changing the model, be sure to:
|
||||
- ⏳ Reindex all existing documents so the new embeddings take effect.
|
||||
|
||||
📌 Remember: Embedding quality directly affects what content is retrieved.
|
||||
|
||||
---
|
||||
|
||||
### 5. ❌ 400: 'NoneType' object has no attribute 'encode'
|
||||
|
||||
This error indicates a misconfigured or missing embedding model. When Open WebUI tries to create embeddings but doesn’t have a valid model loaded, it can’t process the text—and the result is this cryptic error.
|
||||
|
||||
💥 Cause:
|
||||
- Your embedding model isn’t set up properly.
|
||||
- It might not have downloaded completely.
|
||||
- Or if you're using an external embedding model, it may not be accessible.
|
||||
|
||||
✅ Solution:
|
||||
|
||||
- Go to: **Admin Settings > Documents > Embedding Model**
|
||||
- Save the embedding model again—even if it's already selected. This forces a recheck/download.
|
||||
- If you're using a remote/external embedding tool, make sure it's running and accessible to Open WebUI.
|
||||
|
||||
📌 Tip: After fixing the configuration, try re-embedding a document and verify no error is shown in the logs.
|
||||
|
||||
---
|
||||
|
||||
## 🧪 Pro Tip: Test with GPT-4o or GPT-4
|
||||
|
||||
If you’re not sure whether the issue is with retrieval, token limits, or embedding—try using GPT-4o temporarily (e.g., via OpenAI API). If the results suddenly become more accurate, it's a strong signal that your local model’s context limit (2048 by default in Ollama) is the bottleneck.
|
||||
|
||||
- GPT-4o handles larger inputs (128k tokens!)
|
||||
- Provides a great benchmark to evaluate your system's RAG reliability
|
||||
|
||||
---
|
||||
|
||||
## Summary Checklist ✅
|
||||
|
||||
| Problem | Fix |
|
||||
|--------|------|
|
||||
| 🤔 Model can’t “see” content | Check document extractor settings |
|
||||
| 🧹 Only part of content used | Enable Full Context Mode or Bypass Embedding |
|
||||
| ⏱ Limited by 2048 token cap | Increase model context length or use large-context LLM |
|
||||
| 📉 Inaccurate retrieval | Switch to a better embedding model, then reindex |
|
||||
| Still confused? | Test with GPT-4o and compare outputs |
|
||||
|
||||
---
|
||||
|
||||
By optimizing these areas—extraction, embedding, retrieval, and model context—you can dramatically improve how accurately your LLM works with your documents. Don’t let a 2048-token window or weak retrieval pipeline hold back your AI’s power 🎯.
|
||||
@@ -3,9 +3,9 @@ sidebar_position: 20
|
||||
title: "💥 Monitoring and Debugging with Langfuse"
|
||||
---
|
||||
|
||||
# Langfuse Integration with OpenWebUI
|
||||
# Langfuse Integration with Open WebUI
|
||||
|
||||
[Langfuse](https://langfuse.com/) ([GitHub](https://github.com/langfuse/langfuse)) offers open source observability and evaluations for OpenWebUI. By enabling the Langfuse integration, you can trace your application data with Langfuse to develop, monitor, and improve the use of OpenWebUI, including:
|
||||
[Langfuse](https://langfuse.com/) ([GitHub](https://github.com/langfuse/langfuse)) offers open source observability and evaluations for Open WebUI. By enabling the Langfuse integration, you can trace your application data with Langfuse to develop, monitor, and improve the use of Open WebUI, including:
|
||||
|
||||
- Application [traces](https://langfuse.com/docs/tracing)
|
||||
- Usage patterns
|
||||
@@ -13,20 +13,20 @@ title: "💥 Monitoring and Debugging with Langfuse"
|
||||
- Replay sessions to debug issues
|
||||
- [Evaluations](https://langfuse.com/docs/scores/overview)
|
||||
|
||||
## How to integrate Langfuse with OpenWebUI
|
||||
## How to integrate Langfuse with Open WebUI
|
||||
|
||||
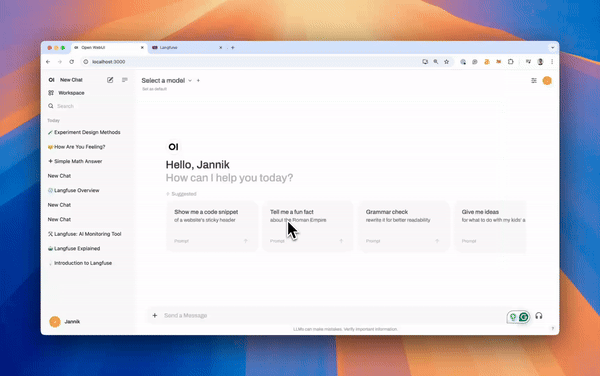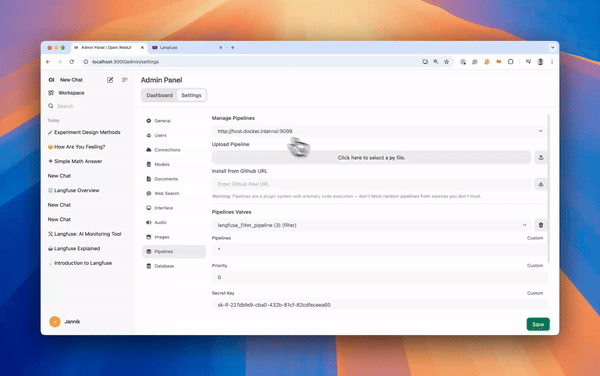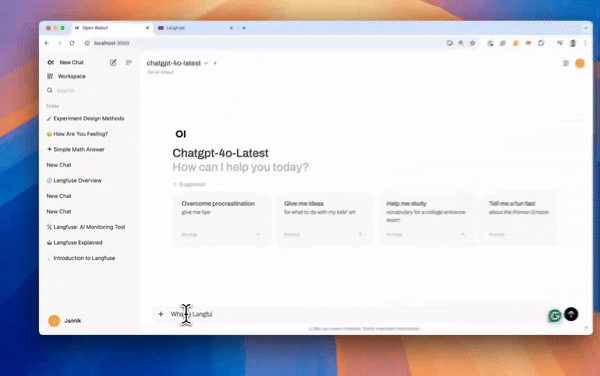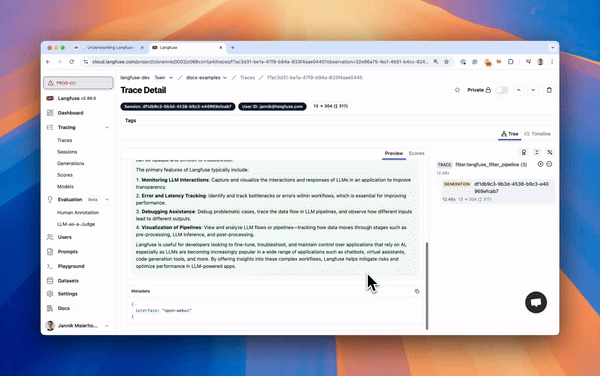
|
||||
_Langfuse integration steps_
|
||||
|
||||
[Pipelines](https://github.com/open-webui/pipelines/) in OpenWebUi is an UI-agnostic framework for OpenAI API plugins. It enables the injection of plugins that intercept, process, and forward user prompts to the final LLM, allowing for enhanced control and customization of prompt handling.
|
||||
[Pipelines](https://github.com/open-webui/pipelines/) in Open WebUI is an UI-agnostic framework for OpenAI API plugins. It enables the injection of plugins that intercept, process, and forward user prompts to the final LLM, allowing for enhanced control and customization of prompt handling.
|
||||
|
||||
To trace your application data with Langfuse, you can use the [Langfuse pipeline](https://github.com/open-webui/pipelines/blob/d4fca4c37c4b8603be7797245e749e9086f35130/examples/filters/langfuse_filter_pipeline.py), which enables real-time monitoring and analysis of message interactions.
|
||||
|
||||
## Quick Start Guide
|
||||
|
||||
### Step 1: Setup OpenWebUI
|
||||
### Step 1: Setup Open WebUI
|
||||
|
||||
Make sure to have OpenWebUI running. To do so, have a look at the [OpenWebUI documentation](https://docs.openwebui.com/).
|
||||
Make sure to have Open WebUI running. To do so, have a look at the [Open WebUI documentation](https://docs.openwebui.com/).
|
||||
|
||||
### Step 2: Set Up Pipelines
|
||||
|
||||
@@ -36,14 +36,14 @@ Launch [Pipelines](https://github.com/open-webui/pipelines/) by using Docker. Us
|
||||
docker run -p 9099:9099 --add-host=host.docker.internal:host-gateway -v pipelines:/app/pipelines --name pipelines --restart always ghcr.io/open-webui/pipelines:main
|
||||
```
|
||||
|
||||
### Step 3: Connecting OpenWebUI with Pipelines
|
||||
### Step 3: Connecting Open WebUI with Pipelines
|
||||
|
||||
In the _Admin Settings_, create and save a new connection of type OpenAI API with the following details:
|
||||
|
||||
- **URL:** http://host.docker.internal:9099 (this is where the previously launched Docker container is running).
|
||||
- **Password:** 0p3n-w3bu! (standard password)
|
||||
|
||||
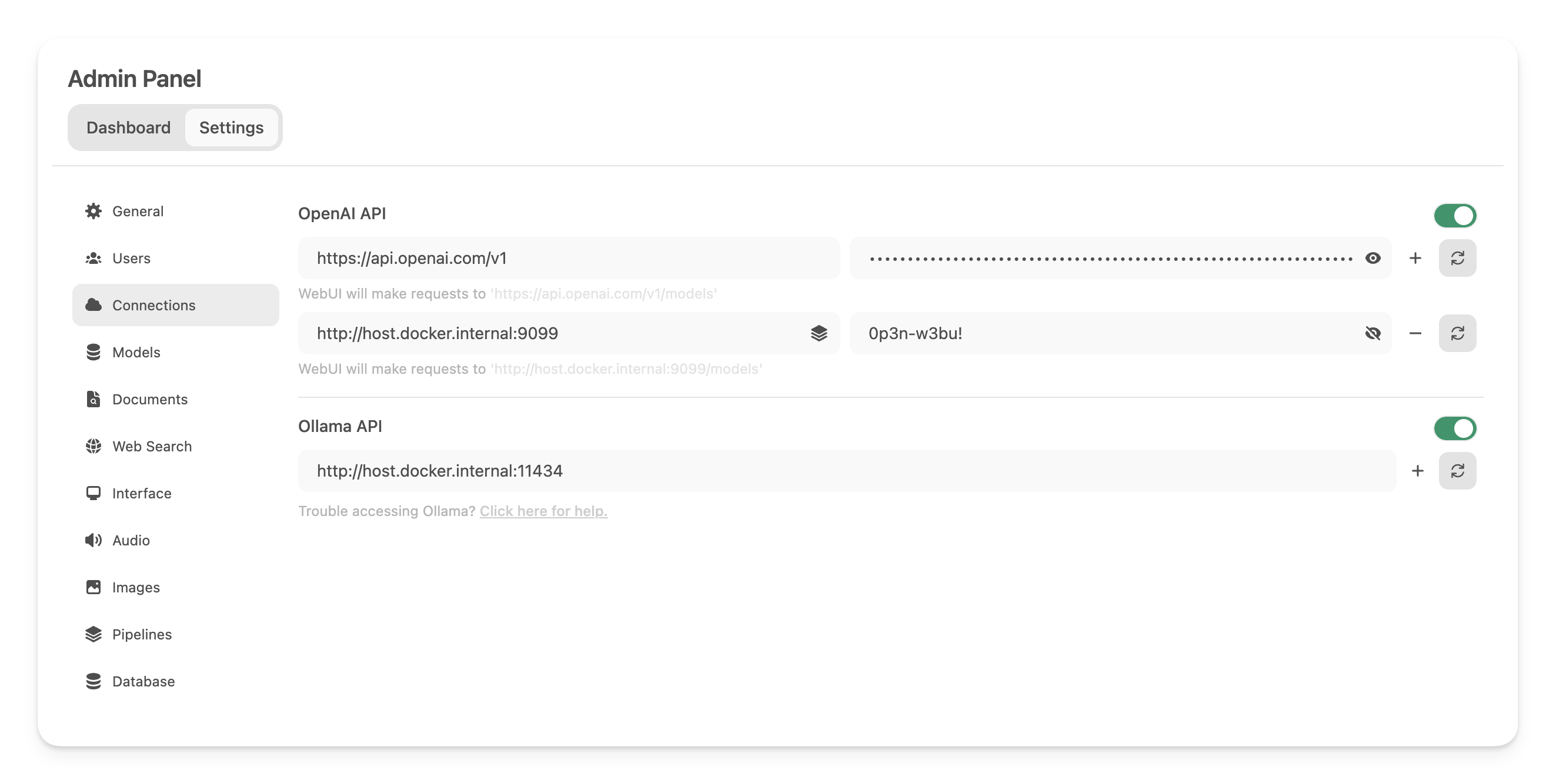
|
||||

|
||||
|
||||
### Step 4: Adding the Langfuse Filter Pipeline
|
||||
|
||||
@@ -55,18 +55,18 @@ https://github.com/open-webui/pipelines/blob/main/examples/filters/langfuse_filt
|
||||
|
||||
Now, add your Langfuse API keys below. If you haven't signed up to Langfuse yet, you can get your API keys by creating an account [here](https://cloud.langfuse.com).
|
||||
|
||||
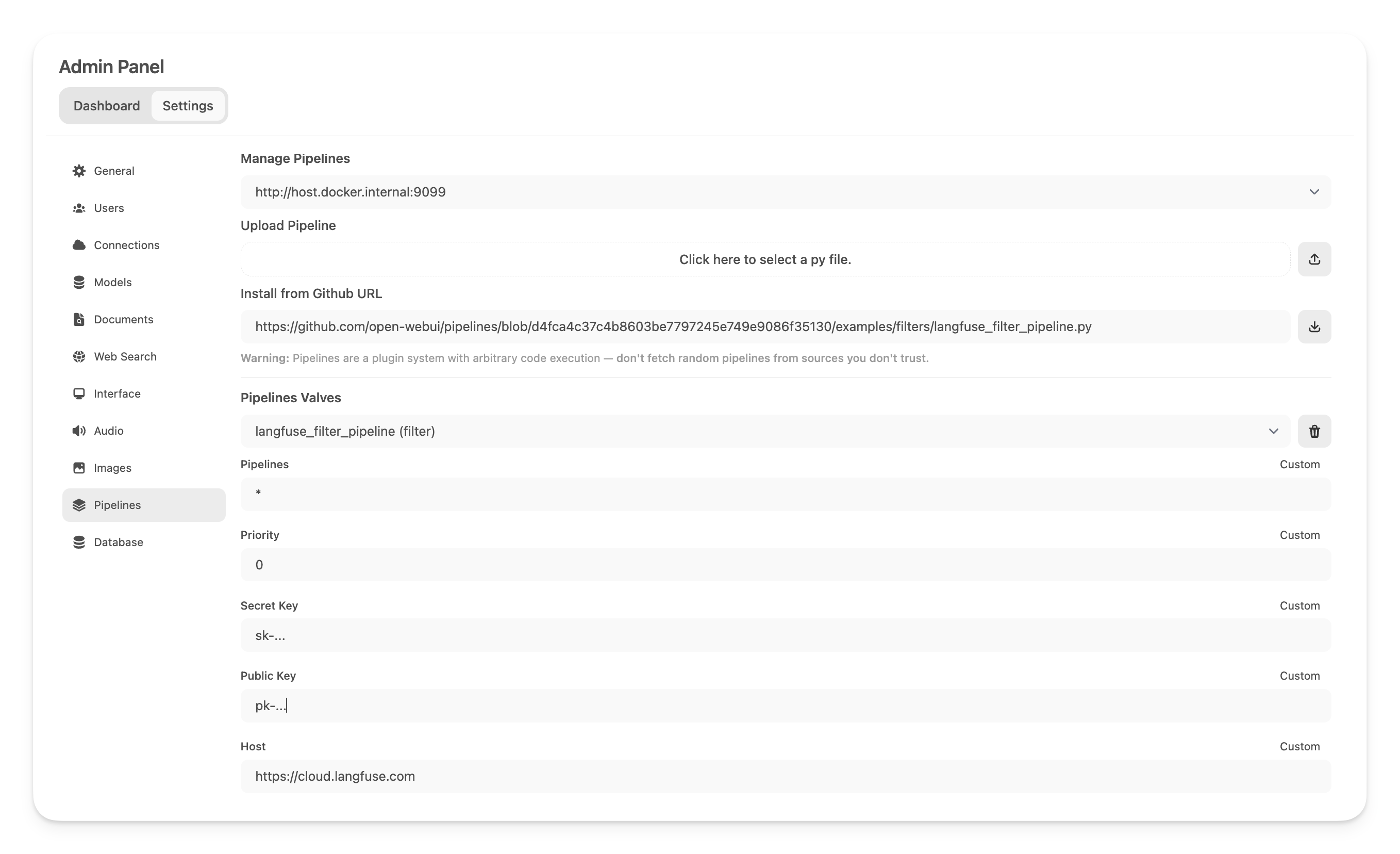
|
||||

|
||||
|
||||
_**Note:** Capture usage (token counts) for OpenAi models while streaming is enabled, you have to navigate to the model settings in OpenWebUI and check the "Usage" [box](https://github.com/open-webui/open-webui/discussions/5770#discussioncomment-10778586) below _Capabilities_._
|
||||
_**Note:** Capture usage (token counts) for OpenAi models while streaming is enabled, you have to navigate to the model settings in Open WebUI and check the "Usage" [box](https://github.com/open-webui/open-webui/discussions/5770#discussioncomment-10778586) below _Capabilities_._
|
||||
|
||||
### Step 5: See your traces in Langfuse
|
||||
|
||||
You can now interact with your OpenWebUI application and see the traces in Langfuse.
|
||||
You can now interact with your Open WebUI application and see the traces in Langfuse.
|
||||
|
||||
[Example trace](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/904a8c1f-4974-4f8f-8a2f-129ae78d99c5?observation=fe5b127b-e71c-45ab-8ee5-439d4c0edc28) in the Langfuse UI:
|
||||
|
||||
|
||||

|
||||
|
||||
## Learn more
|
||||
|
||||
For a comprehensive guide on OpenWebUI Pipelines, visit [this post](https://ikasten.io/2024/06/03/getting-started-with-openwebui-pipelines/).
|
||||
For a comprehensive guide on Open WebUI Pipelines, visit [this post](https://ikasten.io/2024/06/03/getting-started-with-openwebui-pipelines/).
|
||||
|
||||
@@ -4,7 +4,7 @@ title: "🔠 LibreTranslate Integration"
|
||||
---
|
||||
|
||||
:::warning
|
||||
This tutorial is a community contribution and is not supported by the OpenWebUI team. It serves only as a demonstration on how to customize OpenWebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
This tutorial is a community contribution and is not supported by the Open WebUI team. It serves only as a demonstration on how to customize Open WebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
:::
|
||||
|
||||
Overview
|
||||
|
||||
@@ -147,5 +147,5 @@ Restart your Open WebUI instance after setting these environment variables.
|
||||
* **400 Bad Request/Redirect URI Mismatch:** Double-check that the **Sign-in redirect URI** in your Okta application exactly matches `<your-open-webui-url>/oauth/oidc/callback`.
|
||||
* **Groups Not Syncing:** Verify that the `OAUTH_GROUP_CLAIM` environment variable matches the claim name configured in the Okta ID Token settings. Ensure the user has logged out and back in after group changes - a login flow is required to update OIDC. Remember admin groups are not synced.
|
||||
* **Configuration Errors:** Review the Open WebUI server logs for detailed error messages related to OIDC configuration.
|
||||
* Refer to the official [Open WebUI SSO Documentation](../features/sso.md).
|
||||
* Refer to the official [Open WebUI SSO Documentation](/features/sso.md).
|
||||
* Consult the [Okta Developer Documentation](https://developer.okta.com/docs/).
|
||||
@@ -11,11 +11,11 @@ This tutorial is a community contribution and is not supported by the Open WebUI
|
||||
|
||||
Nobody likes losing data!
|
||||
|
||||
If you're self-hosting OpenWebUI, then you may wish to institute some kind of formal backup plan in order to ensure that you retain a second and third copy of parts of your configuration.
|
||||
If you're self-hosting Open WebUI, then you may wish to institute some kind of formal backup plan in order to ensure that you retain a second and third copy of parts of your configuration.
|
||||
|
||||
This guide is intended to recommend some basic recommendations for how users might go about doing that.
|
||||
|
||||
This guide assumes that the user has installed OpenWebUI via Docker (or intends to do so)
|
||||
This guide assumes that the user has installed Open WebUI via Docker (or intends to do so)
|
||||
|
||||
## Ensuring data persistence
|
||||
|
||||
@@ -27,7 +27,7 @@ Docker containers are ephemeral and data must be persisted to ensure its surviva
|
||||
|
||||
If you're using the Docker Compose from the project repository, you will be deploying Open Web UI using Docker volumes.
|
||||
|
||||
For Ollama and OpenWebUI the mounts are:
|
||||
For Ollama and Open WebUI the mounts are:
|
||||
|
||||
```yaml
|
||||
ollama:
|
||||
@@ -349,7 +349,7 @@ In addition to scripting your own backup jobs, you can find commercial offerings
|
||||
|
||||
# Host Level Backups
|
||||
|
||||
Your OpenWebUI instance might be provisioned on a host (physical or virtualised) which you control.
|
||||
Your Open WebUI instance might be provisioned on a host (physical or virtualised) which you control.
|
||||
|
||||
Host level backups involve creating snapshots or backups but of the entire VM rather than running applications.
|
||||
|
||||
@@ -388,4 +388,4 @@ In the interest of keeping this guide reasonably thorough these additional subje
|
||||
| Encryption | Modify backup scripts to incorporate encryption at rest for enhanced security. |
|
||||
| Disaster Recovery and Testing | Develop a disaster recovery plan and regularly test the backup and restore process. |
|
||||
| Alternative Backup Tools | Explore other command-line backup tools like `borgbackup` or `restic` for advanced features. |
|
||||
| Email Notifications and Webhooks | Implement email notifications or webhooks to monitor backup success or failure. |
|
||||
| Email Notifications and Webhooks | Implement email notifications or webhooks to monitor backup success or failure. |
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
### Using a Self-Signed Certificate and Nginx on Windows without Docker
|
||||
|
||||
For basic internal/development installations, you can use nginx and a self-signed certificate to proxy openwebui to https, allowing use of features such as microphone input over LAN. (By default, most browsers will not allow microphone input on insecure non-localhost urls)
|
||||
For basic internal/development installations, you can use nginx and a self-signed certificate to proxy Open WebUI to https, allowing use of features such as microphone input over LAN. (By default, most browsers will not allow microphone input on insecure non-localhost urls)
|
||||
|
||||
This guide assumes you installed openwebui using pip and are running `open-webui serve`
|
||||
This guide assumes you installed Open WebUI using pip and are running `open-webui serve`
|
||||
|
||||
#### Step 1: Installing openssl for certificate generation
|
||||
|
||||
@@ -46,7 +46,7 @@ Move the generated nginx.key and nginx.crt files to a folder of your choice, or
|
||||
|
||||
Open C:\nginx\conf\nginx.conf in a text editor
|
||||
|
||||
If you want openwebui to be accessible over your local LAN, be sure to note your LAN ip address using `ipconfig` e.g. 192.168.1.15
|
||||
If you want Open WebUI to be accessible over your local LAN, be sure to note your LAN ip address using `ipconfig` e.g. 192.168.1.15
|
||||
|
||||
Set it up as follows:
|
||||
|
||||
@@ -145,4 +145,4 @@ Run nginx by running `nginx`. If an nginx service is already started, you can re
|
||||
|
||||
---
|
||||
|
||||
You should now be able to access openwebui on https://192.168.1.15 (or your own LAN ip as appropriate). Be sure to allow windows firewall access as needed.
|
||||
You should now be able to access Open WebUI on https://192.168.1.15 (or your own LAN ip as appropriate). Be sure to allow windows firewall access as needed.
|
||||
|
||||
@@ -52,7 +52,7 @@ This tutorial is a community contribution and is not supported by the Open WebUI
|
||||
|
||||
### You can choose between GPU or CPU versions
|
||||
|
||||
### GPU Version (Requires NVIDIA GPU with CUDA 12.1)
|
||||
### GPU Version (Requires NVIDIA GPU with CUDA 12.8)
|
||||
|
||||
Using docker run:
|
||||
|
||||
|
||||
@@ -98,7 +98,7 @@ Community-contributed tutorials must include the the following:
|
||||
|
||||
```
|
||||
:::warning
|
||||
This tutorial is a community contribution and is not supported by the Open WebUI team. It serves only as a demonstration on how to customize OpenWebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
This tutorial is a community contribution and is not supported by the Open WebUI team. It serves only as a demonstration on how to customize Open WebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
:::
|
||||
```
|
||||
|
||||
|
||||
@@ -40,6 +40,10 @@ const config: Config = {
|
||||
[
|
||||
"classic",
|
||||
{
|
||||
gtag: {
|
||||
trackingID: "G-522JSJVWTB",
|
||||
anonymizeIP: false,
|
||||
},
|
||||
docs: {
|
||||
sidebarPath: "./sidebars.ts",
|
||||
routeBasePath: "/",
|
||||
|
||||
4292
package-lock.json
generated
@@ -22,6 +22,7 @@
|
||||
},
|
||||
"dependencies": {
|
||||
"@docusaurus/core": "^3.5.2",
|
||||
"@docusaurus/plugin-google-gtag": "^3.7.0",
|
||||
"@docusaurus/preset-classic": "^3.5.2",
|
||||
"@docusaurus/theme-mermaid": "^3.5.2",
|
||||
"@mdx-js/react": "^3.0.1",
|
||||
|
||||
@@ -6,12 +6,13 @@ import urllib.request
|
||||
import os
|
||||
|
||||
|
||||
def find_env_vars(code):
|
||||
def find_env_vars(code, filename):
|
||||
tree = ast.parse(code)
|
||||
env_vars_found = {} # Dictionary to store env vars, filenames, defaults, and types
|
||||
|
||||
class EnvVarVisitor(ast.NodeVisitor):
|
||||
def __init__(self):
|
||||
self.env_vars = set()
|
||||
self.current_env_vars = {} # Store env vars with potential defaults and types
|
||||
|
||||
def visit_Subscript(self, node):
|
||||
if isinstance(node.value, ast.Attribute):
|
||||
@@ -21,32 +22,158 @@ def find_env_vars(code):
|
||||
and node.value.attr == "environ"
|
||||
):
|
||||
if isinstance(node.slice, ast.Constant):
|
||||
self.env_vars.add(node.slice.value)
|
||||
env_var_name = node.slice.value
|
||||
if env_var_name not in self.current_env_vars:
|
||||
self.current_env_vars[env_var_name] = {"default": None, "type": "str"} # Default type str for os.environ
|
||||
elif isinstance(node.slice, ast.BinOp):
|
||||
# Handle dynamically constructed env var names like os.environ["VAR_" + "NAME"]
|
||||
self.env_vars.add(ast.unparse(node.slice))
|
||||
env_var_name = ast.unparse(node.slice)
|
||||
if env_var_name not in self.current_env_vars:
|
||||
self.current_env_vars[env_var_name] = {"default": None, "type": "str"} # Default type str for os.environ
|
||||
self.generic_visit(node)
|
||||
|
||||
def visit_Call(self, node):
|
||||
if isinstance(node.func, ast.Attribute):
|
||||
# Check for os.getenv("VAR_NAME", "default_value")
|
||||
if (
|
||||
isinstance(node.func.value, ast.Name)
|
||||
and node.func.value.id == "os"
|
||||
and node.func.attr in ("getenv", "get")
|
||||
) or (
|
||||
and node.func.attr == "getenv"
|
||||
):
|
||||
if node.args and isinstance(node.args[0], ast.Constant):
|
||||
env_var_name = node.args[0].value
|
||||
default_value = None
|
||||
var_type = "str" # Default type str for os.getenv
|
||||
if len(node.args) > 1:
|
||||
default_node = node.args[1]
|
||||
if isinstance(default_node, ast.Constant):
|
||||
default_value = default_node.value
|
||||
var_type = "str" # Still str if default is constant string
|
||||
elif isinstance(default_node, ast.Name) and default_node.id == 'None': # Check for None literal
|
||||
default_value = None
|
||||
var_type = "str" # Still str even if default is None in getenv
|
||||
else: # Capture other default expressions as unparsed code
|
||||
default_value = ast.unparse(default_node)
|
||||
var_type = "str" # Assume str if complex default in getenv
|
||||
if env_var_name not in self.current_env_vars:
|
||||
self.current_env_vars[env_var_name] = {"default": default_value, "type": var_type}
|
||||
|
||||
# Check for os.environ.get("VAR_NAME", "default_value")
|
||||
elif (
|
||||
isinstance(node.func.value, ast.Attribute)
|
||||
and isinstance(node.func.value.value, ast.Name)
|
||||
and node.func.value.value.id == "os"
|
||||
and node.func.value.attr == "environ"
|
||||
and node.func.attr == "get"
|
||||
):
|
||||
if isinstance(node.args[0], ast.Constant):
|
||||
self.env_vars.add(node.args[0].value)
|
||||
if node.args and isinstance(node.args[0], ast.Constant):
|
||||
env_var_name = node.args[0].value
|
||||
default_value = None
|
||||
var_type = "str" # Default type str for os.environ.get
|
||||
if len(node.args) > 1:
|
||||
default_node = node.args[1]
|
||||
if isinstance(default_node, ast.Constant):
|
||||
default_value = default_node.value
|
||||
var_type = "str" # Still str if default is constant string
|
||||
elif isinstance(default_node, ast.Name) and default_node.id == 'None': # Check for None literal
|
||||
default_value = None
|
||||
var_type = "str" # Still str even if default is None in get
|
||||
else: # Capture other default expressions as unparsed code
|
||||
default_value = ast.unparse(default_node)
|
||||
var_type = "str" # Assume str if complex default in get
|
||||
if env_var_name not in self.current_env_vars:
|
||||
self.current_env_vars[env_var_name] = {"default": default_value, "type": var_type}
|
||||
|
||||
elif isinstance(node.func, ast.Name) and node.func.id == "PersistentConfig":
|
||||
if node.args and isinstance(node.args[0], ast.Constant):
|
||||
env_var_name = node.args[0].value
|
||||
default_value = None
|
||||
var_type = "str" # Assume str as base type for PersistentConfig, will refine
|
||||
if len(node.args) > 2: # Default value is the third argument
|
||||
default_node = node.args[2]
|
||||
if isinstance(default_node, ast.Constant):
|
||||
default_value = default_node.value
|
||||
if isinstance(default_value, bool):
|
||||
var_type = "bool"
|
||||
elif isinstance(default_value, int):
|
||||
var_type = "int"
|
||||
elif isinstance(default_value, float):
|
||||
var_type = "float"
|
||||
else:
|
||||
var_type = "str" # String constant
|
||||
elif isinstance(default_node, ast.List):
|
||||
default_value = ast.unparse(default_node)
|
||||
var_type = "list[dict]" # Assuming list of dicts for DEFAULT_PROMPT_SUGGESTIONS case, refine if needed
|
||||
elif isinstance(default_node, ast.Dict):
|
||||
default_value = ast.unparse(default_node)
|
||||
var_type = "dict"
|
||||
elif isinstance(default_node, ast.Tuple):
|
||||
default_value = ast.unparse(default_node)
|
||||
var_type = "tuple"
|
||||
elif isinstance(default_node, ast.Set):
|
||||
default_value = ast.unparse(default_node)
|
||||
var_type = "set"
|
||||
elif isinstance(default_node, ast.Name): # Capture variable name as default
|
||||
default_value = default_node.id
|
||||
var_type = "str" # Assume str if variable default
|
||||
elif isinstance(default_node, ast.Call): # Check if default_node is a Call (function call)
|
||||
if isinstance(default_node.func, ast.Name) and default_node.func.id == "int":
|
||||
var_type = "int"
|
||||
elif isinstance(default_node.func, ast.Name) and default_node.func.id == "float":
|
||||
var_type = "float"
|
||||
elif isinstance(default_node.func, ast.Name) and default_node.func.id == "bool":
|
||||
var_type = "bool"
|
||||
elif isinstance(default_node.func, ast.Name) and default_node.func.id == "str":
|
||||
var_type = "str"
|
||||
elif isinstance(default_node.func, ast.Attribute) and default_node.func.attr == 'getenv' and isinstance(default_node.func.value, ast.Name) and default_node.func.value.id == 'os':
|
||||
if len(default_node.args) > 1 and isinstance(default_node.args[1], ast.Constant):
|
||||
default_value = default_node.args[1].value # Extract default from os.getenv within PersistentConfig
|
||||
var_type = "str" # Still string from getenv
|
||||
elif len(default_node.args) == 1:
|
||||
default_value = None # No default in os.getenv
|
||||
var_type = "str" # Still string from getenv
|
||||
elif isinstance(default_node.func, ast.Attribute) and default_node.func.attr == 'get' and isinstance(default_node.func.value, ast.Attribute) and default_node.func.value.attr == 'environ' and isinstance(default_node.func.value.value, ast.Name) and default_node.func.value.value.id == 'os':
|
||||
if len(default_node.args) > 1 and isinstance(default_node.args[1], ast.Constant):
|
||||
default_value = default_node.args[1].value # Extract default from os.environ.get within PersistentConfig
|
||||
var_type = "str" # Still string from getenv
|
||||
elif len(default_node.args) == 1:
|
||||
default_value = None # No default in os.environ.get
|
||||
var_type = "str" # Still string from getenv
|
||||
else: # Capture other function calls as unparsed code
|
||||
default_value = ast.unparse(default_node)
|
||||
var_type = "str" # Assume str for complex call
|
||||
elif isinstance(default_node, ast.Compare): # Handle boolean expressions like 'os.getenv(...) == "true"'
|
||||
default_value = ast.unparse(default_node) # Capture the whole boolean expression as unparsed code
|
||||
var_type = "bool" # Likely boolean from comparison
|
||||
|
||||
elif isinstance(default_node, ast.Name) and default_node.id == 'None': # Check for None literal in PersistentConfig
|
||||
default_value = None
|
||||
var_type = "str" # Could be anything, but let's say str as base
|
||||
|
||||
elif default_node: # Capture any other default expressions as unparsed code
|
||||
default_value = ast.unparse(default_node)
|
||||
var_type = "str" # Assume str for other expressions
|
||||
|
||||
if env_var_name not in self.current_env_vars:
|
||||
self.current_env_vars[env_var_name] = {"default": default_value, "type": var_type}
|
||||
|
||||
self.generic_visit(node)
|
||||
|
||||
def finalize_env_vars(self, filename, env_vars_found):
|
||||
for env_var, context in self.current_env_vars.items(): # context is now a dict with default and type
|
||||
if env_var not in env_vars_found:
|
||||
env_vars_found[env_var] = {"files": set(), "default": None, "type": "str"} # Initialize type as str if not found before
|
||||
env_vars_found[env_var]["files"].add(filename)
|
||||
if env_vars_found[env_var]["default"] is None: # Only set default if not already set
|
||||
env_vars_found[env_var]["default"] = context["default"]
|
||||
if env_vars_found[env_var]["type"] == "str": # Only set type if still default str, otherwise keep more specific type
|
||||
env_vars_found[env_var]["type"] = context["type"]
|
||||
|
||||
|
||||
visitor = EnvVarVisitor()
|
||||
visitor.visit(tree)
|
||||
return visitor.env_vars
|
||||
visitor.finalize_env_vars(filename, env_vars_found) # Pass filename to finalize
|
||||
return env_vars_found
|
||||
|
||||
|
||||
def main():
|
||||
@@ -65,15 +192,24 @@ def main():
|
||||
]
|
||||
filenames = ["config.py", "env.py", "migrations/env.py"]
|
||||
|
||||
all_env_vars = set()
|
||||
all_env_vars_with_context = {} # Changed to dictionary to store context
|
||||
|
||||
try:
|
||||
for url, filename in zip(urls, filenames):
|
||||
with urllib.request.urlopen(url) as response:
|
||||
contents = response.read().decode("utf-8")
|
||||
|
||||
for env_var in find_env_vars(contents):
|
||||
all_env_vars.add(env_var)
|
||||
file_env_vars = find_env_vars(contents, filename) # Pass filename here
|
||||
for env_var, context in file_env_vars.items(): # context is now a dict
|
||||
if env_var not in all_env_vars_with_context:
|
||||
all_env_vars_with_context[env_var] = {"files": set(), "default": None, "type": "str"} # Initialize type as str
|
||||
all_env_vars_with_context[env_var]["files"].update(context["files"]) # Merge file sets
|
||||
if all_env_vars_with_context[env_var]["default"] is None: # Only set default if not already set
|
||||
all_env_vars_with_context[env_var]["default"] = context["default"]
|
||||
if all_env_vars_with_context[env_var]["type"] == "str": # Only update type if still default str, keep more specific type
|
||||
all_env_vars_with_context[env_var]["type"] = context["type"]
|
||||
|
||||
|
||||
except urllib.error.URLError as e:
|
||||
print(f"Failed to open URL: {e}")
|
||||
sys.exit(1)
|
||||
@@ -91,7 +227,7 @@ def main():
|
||||
documented_env_vars = set()
|
||||
script_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
docs_file = os.path.join(
|
||||
script_dir, *[part for part in ["..", "docs", "getting-started", "advanced-topics", "env-configuration.md"]]
|
||||
script_dir, *[part for part in ["..", "docs", "getting-started", "env-configuration.md"]]
|
||||
)
|
||||
|
||||
try:
|
||||
@@ -105,14 +241,48 @@ def main():
|
||||
sys.exit(1)
|
||||
|
||||
print("\nEnvironment variables accessed but not documented:")
|
||||
not_documented_env_vars = all_env_vars - documented_env_vars - ignored_env_vars
|
||||
for env_var in sorted(not_documented_env_vars):
|
||||
print(env_var)
|
||||
if not not_documented_env_vars:
|
||||
print("None")
|
||||
not_documented_env_vars_with_context = {
|
||||
env_var: context
|
||||
for env_var, context in all_env_vars_with_context.items()
|
||||
if env_var not in documented_env_vars and env_var not in ignored_env_vars
|
||||
}
|
||||
|
||||
persistent_config_vars = {}
|
||||
other_undocumented_vars = {}
|
||||
|
||||
for env_var, context in not_documented_env_vars_with_context.items():
|
||||
if "config.py" in context["files"]: # Check if 'config.py' is in the set of files
|
||||
persistent_config_vars[env_var] = context
|
||||
else:
|
||||
other_undocumented_vars[env_var] = context
|
||||
|
||||
def format_default_output(default, var_type):
|
||||
if default is None:
|
||||
return "(default: None)"
|
||||
elif var_type == "list[dict]" or var_type == "dict" or var_type == "tuple" or var_type == "set":
|
||||
return f"(default: {default}, type: {var_type})" # Show full default for complex types
|
||||
else:
|
||||
return f"(default: '{default}', type: {var_type})" # Quote string defaults
|
||||
|
||||
if persistent_config_vars:
|
||||
print("\n PersistentConfig environment variables (accessed in config.py):")
|
||||
for env_var in sorted(persistent_config_vars.keys()):
|
||||
default_str = format_default_output(persistent_config_vars[env_var]['default'], persistent_config_vars[env_var]['type'])
|
||||
print(f" - {env_var} {default_str}")
|
||||
|
||||
if other_undocumented_vars:
|
||||
print("\n Other undocumented environment variables:")
|
||||
for env_var in sorted(other_undocumented_vars.keys()):
|
||||
default_str = format_default_output(other_undocumented_vars[env_var]['default'], other_undocumented_vars[env_var]['type'])
|
||||
print(
|
||||
f" - {env_var} {default_str} (in files: {', '.join(sorted(other_undocumented_vars[env_var]['files']))})"
|
||||
) # Show files and defaults and types
|
||||
|
||||
if not persistent_config_vars and not other_undocumented_vars:
|
||||
print(" None")
|
||||
|
||||
print("\nEnvironment variables documented but not accessed:")
|
||||
diff = documented_env_vars - all_env_vars - ignored_env_vars
|
||||
diff = documented_env_vars - set(all_env_vars_with_context.keys()) - ignored_env_vars # Use keys of the dict
|
||||
for env_var in sorted(diff):
|
||||
print(env_var)
|
||||
if not diff:
|
||||
@@ -120,4 +290,4 @@ def main():
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
main()
|
||||
|
||||
@@ -13,7 +13,7 @@ export const TopBanners = () => {
|
||||
{
|
||||
imgSrc: "/sponsors/banners/placeholder.png",
|
||||
mobileImgSrc: "/sponsors/banners/placeholder-mobile.png",
|
||||
url: "mailto:sales@openwebui.com?subject=Sponsorship Inquiry: Open WebUI",
|
||||
url: "https://forms.gle/92mvG3ESYj47zzRL9",
|
||||
name: "Open WebUI",
|
||||
description:
|
||||
"The top banner spot is reserved for Emerald+ Enterprise sponsors on a first-come, first-served basis",
|
||||
|
||||
BIN
static/images/features/plugin/tools/chat-controls.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
BIN
static/images/getting-started/quick-start/manage-openai.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 76 KiB |
BIN
static/images/getting-started/quick-start/selector-openai.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 65 KiB |
{kind=link}
|
After Width: | Height: | Size: 33 KiB |
BIN
static/images/openapi-servers/open-webui/mcpo-config-tools.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 51 KiB |
{kind=link}
|
Before Width: | Height: | Size: 23 KiB After Width: | Height: | Size: 24 KiB |