mirror of
https://github.com/clearml/clearml
synced 2025-01-31 17:17:00 +00:00
68 lines
3.7 KiB
Markdown
68 lines
3.7 KiB
Markdown
# What is TRAINS?
|
|
Behind every great scientist are great repeatable methods. Sadly, this is easier said than done.
|
|
|
|
When talented scientists, engineers, or developers work on their own, a mess may be unavoidable.
|
|
Yet, it may still be manageable. However, with time and more people joining your project, managing the clutter takes
|
|
its toll on productivity. As your project moves toward production, visibility and provenance for scaling your
|
|
deep-learning efforts are a must.
|
|
|
|
For teams or entire companies, TRAINS logs everything in one central server and takes on the responsibilities for
|
|
visibility and provenance so productivity does not suffer. TRAINS records and manages various deep learning
|
|
research workloads and does so with practically zero integration costs.
|
|
|
|
We designed TRAINS specifically to require effortless integration so that teams can preserve their existing methods
|
|
and practices. Use it on a daily basis to boost collaboration and visibility, or use it to automatically collect
|
|
your experimentation logs, outputs, and data to one centralized server.
|
|
|
|
## Main Features
|
|
|
|
* Integrate with your current work flow with minimal effort
|
|
* Seamless integration with leading frameworks, including: *PyTorch*, *TensorFlow*, *Keras*, *XGBoost*, *SciKit-Learn* and others coming soon
|
|
* Support for *Jupyter Notebook* (see [trains-jupyter-plugin](https://github.com/allegroai/trains-jupyter-plugin))
|
|
and *PyCharm* remote debugging (see [trains-pycharm-plugin](https://github.com/allegroai/trains-pycharm-plugin))
|
|
* Log everything. Experiments become truly repeatable
|
|
* Model logging with **automatic association** of **model + code + parameters + initial weights**
|
|
* Automatically create a copy of models on centralized storage
|
|
([supports shared folders, S3, GS,](https://github.com/allegroai/trains/blob/master/docs/faq.md#i-read-there-is-a-feature-for-centralized-model-storage-how-do-i-use-it-) and Azure is coming soon!)
|
|
* Share and collaborate
|
|
* Multi-user process tracking and collaboration
|
|
* Centralized server for aggregating logs, records, and general bookkeeping
|
|
* Increase productivity
|
|
* Comprehensive **experiment comparison**: code commits, initial weights, hyper-parameters and metric results
|
|
* Order & Organization
|
|
* Manage and organize your experiments in projects
|
|
* Query capabilities; sort and filter experiments by results metrics
|
|
* And more
|
|
* Stop an experiment on a remote machine using the web-app
|
|
* A field-tested, feature-rich SDK for your on-the-fly customization needs
|
|
|
|
## TRAINS Automatically Logs
|
|
|
|
* Git repository, branch, commit id, entry point and local git diff
|
|
* Python packages (including specific version)
|
|
* Hyper-parameters
|
|
* ArgParser for command line parameters with currently used values
|
|
* Explicit parameters dictionary
|
|
* Tensorflow Defines (absl-py)
|
|
* Initial model weights file
|
|
* Model snapshots
|
|
* StdOut and StdErr
|
|
* Tensorboard/TensorboardX scalars, metrics, histograms, images (with audio coming soon)
|
|
* Matplotlib & Seaborn
|
|
|
|
## How TRAINS Works
|
|
|
|
TRAINS is a two part solution:
|
|
|
|
1. TRAINS [python package](https://pypi.org/project/trains/) (auto-magically connects your code, see [Using TRAINS](https://github.com/allegroai/trains#using-trains))
|
|
2. [TRAINS-server](https://github.com/allegroai/trains-server) for logging, querying, control and UI ([Web-App](https://github.com/allegroai/trains-web))
|
|
|
|
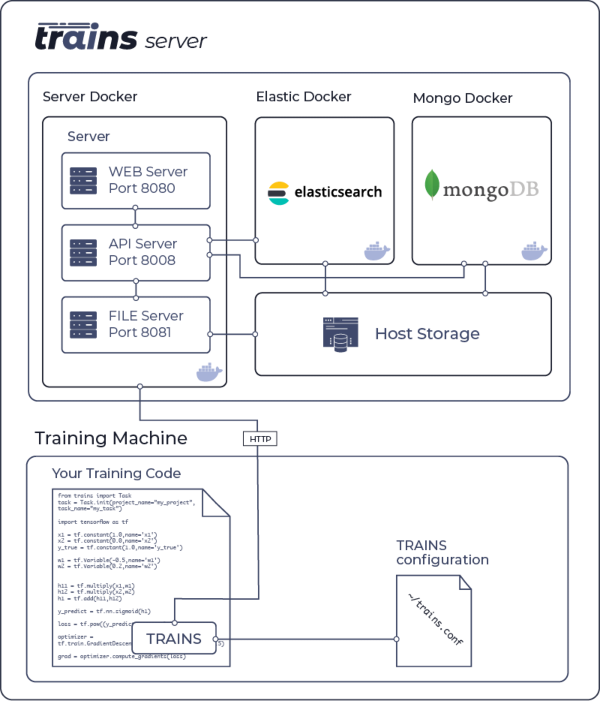
The following diagram illustrates the interaction of the [TRAINS-server](https://github.com/allegroai/trains-server)
|
|
and a GPU training machine using the TRAINS python package
|
|
|
|
<!---
|
|
|
|
-->
|
|
<img src="https://github.com/allegroai/trains/blob/master/docs/system_diagram.png?raw=true" width="50%">
|
|
|