mirror of
https://github.com/clearml/clearml
synced 2025-06-26 18:16:07 +00:00
Remove obsolete docs
This commit is contained in:
@@ -1,67 +0,0 @@
|
||||
# What is TRAINS?
|
||||
Behind every great scientist are great repeatable methods. Sadly, this is easier said than done.
|
||||
|
||||
When talented scientists, engineers, or developers work on their own, a mess may be unavoidable.
|
||||
Yet, it may still be manageable. However, with time and more people joining your project, managing the clutter takes
|
||||
its toll on productivity. As your project moves toward production, visibility and provenance for scaling your
|
||||
deep-learning efforts are a must.
|
||||
|
||||
For teams or entire companies, TRAINS logs everything in one central server and takes on the responsibilities for
|
||||
visibility and provenance so productivity does not suffer. TRAINS records and manages various deep learning
|
||||
research workloads and does so with practically zero integration costs.
|
||||
|
||||
We designed TRAINS specifically to require effortless integration so that teams can preserve their existing methods
|
||||
and practices. Use it on a daily basis to boost collaboration and visibility, or use it to automatically collect
|
||||
your experimentation logs, outputs, and data to one centralized server.
|
||||
|
||||
## Main Features
|
||||
|
||||
* Integrate with your current work flow with minimal effort
|
||||
* Seamless integration with leading frameworks, including: *PyTorch*, *TensorFlow*, *Keras*, *XGBoost*, *SciKit-Learn* and others coming soon
|
||||
* Support for *Jupyter Notebook* (see [trains-jupyter-plugin](https://github.com/allegroai/trains-jupyter-plugin))
|
||||
and *PyCharm* remote debugging (see [trains-pycharm-plugin](https://github.com/allegroai/trains-pycharm-plugin))
|
||||
* Log everything. Experiments become truly repeatable
|
||||
* Model logging with **automatic association** of **model + code + parameters + initial weights**
|
||||
* Automatically create a copy of models on centralized storage
|
||||
([supports shared folders, S3, GS,](https://github.com/allegroai/trains/blob/master/docs/faq.md#i-read-there-is-a-feature-for-centralized-model-storage-how-do-i-use-it-) and Azure is coming soon!)
|
||||
* Share and collaborate
|
||||
* Multi-user process tracking and collaboration
|
||||
* Centralized server for aggregating logs, records, and general bookkeeping
|
||||
* Increase productivity
|
||||
* Comprehensive **experiment comparison**: code commits, initial weights, hyper-parameters and metric results
|
||||
* Order & Organization
|
||||
* Manage and organize your experiments in projects
|
||||
* Query capabilities; sort and filter experiments by results metrics
|
||||
* And more
|
||||
* Stop an experiment on a remote machine using the web-app
|
||||
* A field-tested, feature-rich SDK for your on-the-fly customization needs
|
||||
|
||||
## TRAINS Automatically Logs
|
||||
|
||||
* Git repository, branch, commit id, entry point and local git diff
|
||||
* Python packages (including specific version)
|
||||
* Hyper-parameters
|
||||
* ArgParser for command line parameters with currently used values
|
||||
* Explicit parameters dictionary
|
||||
* Tensorflow Defines (absl-py)
|
||||
* Initial model weights file
|
||||
* Model snapshots
|
||||
* StdOut and StdErr
|
||||
* Tensorboard/TensorboardX scalars, metrics, histograms, images (with audio coming soon)
|
||||
* Matplotlib & Seaborn
|
||||
|
||||
## How TRAINS Works
|
||||
|
||||
TRAINS is a two part solution:
|
||||
|
||||
1. TRAINS [python package](https://pypi.org/project/trains/) (auto-magically connects your code, see [Using TRAINS](https://github.com/allegroai/trains#using-trains))
|
||||
2. [TRAINS-server](https://github.com/allegroai/trains-server) for logging, querying, control and UI ([Web-App](https://github.com/allegroai/trains-web))
|
||||
|
||||
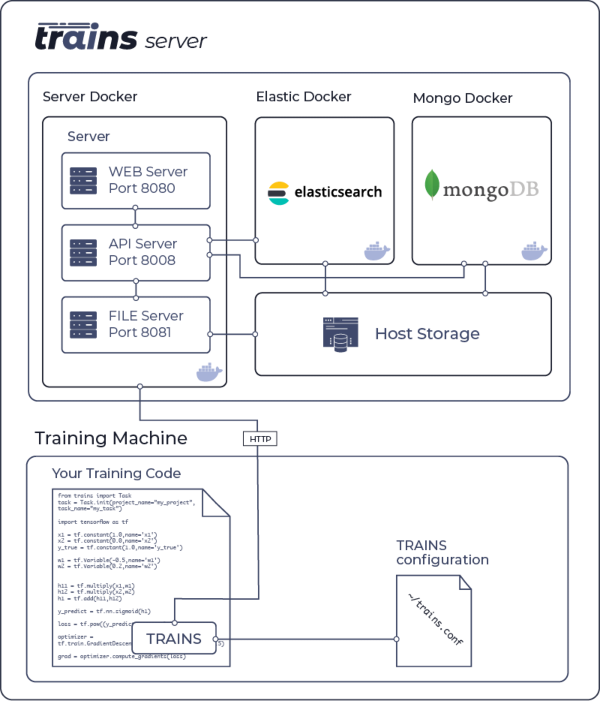
The following diagram illustrates the interaction of the [TRAINS-server](https://github.com/allegroai/trains-server)
|
||||
and a GPU training machine using the TRAINS python package
|
||||
|
||||
<!---
|
||||
|
||||
-->
|
||||
<img src="https://github.com/allegroai/trains/blob/master/docs/system_diagram.png?raw=true" width="50%">
|
||||
|
||||
427
docs/faq.md
427
docs/faq.md
@@ -1,427 +0,0 @@
|
||||
# TRAINS FAQ
|
||||
|
||||
General Information
|
||||
|
||||
* [How do I know a new version came out?](#new-version-auto-update)
|
||||
|
||||
Configuration
|
||||
|
||||
* [How can I change the location of TRAINS configuration file?](#change-config-path)
|
||||
* [How can I override TRAINS credentials from the OS environment?](#credentials-os-env)
|
||||
* [How can I track OS environment variables with experiments?](#track-env-vars)
|
||||
|
||||
Models
|
||||
|
||||
* [How can I sort models by a certain metric?](#custom-columns)
|
||||
* [Can I store more information on the models?](#store-more-model-info)
|
||||
* [Can I store the model configuration file as well?](#store-model-configuration)
|
||||
* [I am training multiple models at the same time, but I only see one of them. What happened?](#only-last-model-appears)
|
||||
* [Can I log input and output models manually?](#manually-log-models)
|
||||
|
||||
Experiments
|
||||
|
||||
* [I noticed I keep getting the message `warning: uncommitted code`. What does it mean?](#uncommitted-code-warning)
|
||||
* [I do not use Argparser for hyper-parameters. Do you have a solution?](#dont-want-argparser)
|
||||
* [I noticed that all of my experiments appear as `Training`. Are there other options?](#other-experiment-types)
|
||||
* [Sometimes I see experiments as running when in fact they are not. What's going on?](#experiment-running-but-stopped)
|
||||
* [My code throws an exception, but my experiment status is not "Failed". What happened?](#exception-not-failed)
|
||||
* [When I run my experiment, I get an SSL Connection error [CERTIFICATE_VERIFY_FAILED]. Do you have a solution?](#ssl-connection-error)
|
||||
* [How do I modify experiment names once they have been created?](#name-changing)
|
||||
|
||||
Graphs and Logs
|
||||
|
||||
* [The first log lines are missing from the experiment log tab. Where did they go?](#first-log-lines-missing)
|
||||
* [Can I create a graph comparing hyper-parameters vs model accuracy?](#compare-graph-parameters)
|
||||
* [I want to add more graphs, not just with Tensorboard. Is this supported?](#more-graph-types)
|
||||
|
||||
GIT and Storage
|
||||
|
||||
* [Is there something TRAINS can do about uncommitted code running?](#help-uncommitted-code)
|
||||
* [I read there is a feature for centralized model storage. How do I use it?](#centralized-model-storage)
|
||||
* [When using PyCharm to remotely debug a machine, the git repo is not detected. Do you have a solution?](#pycharm-remote-debug-detect-git)
|
||||
* Also see, [Git and Jupyter](#commit-git-in-jupyter)
|
||||
|
||||
Jupyter
|
||||
|
||||
* [I am using Jupyter Notebook. Is this supported?](#jupyter-notebook)
|
||||
* [Git is not well supported in Jupyter, so we just gave up on committing our code. Do you have a solution?](#commit-git-in-jupyter)
|
||||
|
||||
scikit-learn
|
||||
|
||||
* [Can I use TRAINS with scikit-learn?](#use-scikit-learn)
|
||||
|
||||
TRAINS API
|
||||
|
||||
* [How can I use the TRAINS API to fetch data?](#api)
|
||||
|
||||
## General Information
|
||||
|
||||
### How do I know a new version came out? <a name="new-version-auto-update"></a>
|
||||
|
||||
Starting v0.9.3 TRAINS notifies on a new version release.
|
||||
|
||||
For example, when a new client version available the notification is:
|
||||
```bash
|
||||
TRAINS new package available: UPGRADE to vX.Y.Z is recommended!
|
||||
```
|
||||
For example, when new server version available the notification is:
|
||||
```bash
|
||||
TRAINS-SERVER new version available: upgrade to vX.Y is recommended!
|
||||
```
|
||||
|
||||
|
||||
## Configuration
|
||||
|
||||
### How can I change the location of TRAINS configuration file? <a name="change-config-path"></a>
|
||||
|
||||
Set `TRAINS_CONFIG_FILE` OS environment variable to override the default configuration file location.
|
||||
|
||||
```bash
|
||||
export TRAINS_CONFIG_FILE="/home/user/mytrains.conf"
|
||||
```
|
||||
|
||||
### How can I override TRAINS credentials from the OS environment? <a name="credentials-os-env"></a>
|
||||
|
||||
Set the OS environment variables below, in order to override the configuration file / defaults.
|
||||
|
||||
```bash
|
||||
export TRAINS_API_ACCESS_KEY="key_here"
|
||||
export TRAINS_API_SECRET_KEY="secret_here"
|
||||
export TRAINS_API_HOST="http://localhost:8008"
|
||||
```
|
||||
|
||||
### How can I track OS environment variables with experiments? <a name="track-env-vars"></a>
|
||||
|
||||
Set the OS environment variable `TRAINS_LOG_ENVIRONMENT` with the variables you need track. See [Specifying Environment Variables to Track](https://github.com/allegroai/trains/blob/master/docs/logger.md#specifying-environment-variables-to-track).
|
||||
|
||||
## Models
|
||||
|
||||
### How can I sort models by a certain metric? <a name="custom-columns"></a>
|
||||
|
||||
Models are associated with the experiments that created them.
|
||||
In order to sort experiments by a specific metric, add a custom column in the experiments table,
|
||||
|
||||
<img src="https://github.com/allegroai/trains/blob/master/docs/screenshots/set_custom_column.png?raw=true" width=25%>
|
||||
<img src="https://github.com/allegroai/trains/blob/master/docs/screenshots/custom_column.png?raw=true" width=25%>
|
||||
|
||||
### Can I store more information on the models? <a name="store-more-model-info"></a>
|
||||
|
||||
#### For example, can I store enumeration of classes?
|
||||
|
||||
Yes! Use the `Task.set_model_label_enumeration()` method:
|
||||
|
||||
```python
|
||||
Task.current_task().set_model_label_enumeration( {"label": int(0), } )
|
||||
```
|
||||
|
||||
### Can I store the model configuration file as well? <a name="store-model-configuration"></a>
|
||||
|
||||
Yes! Use the `Task.connect_configuration()` method:
|
||||
|
||||
```python
|
||||
Task.current_task().connect_configuration("/path/to/file")
|
||||
```
|
||||
|
||||
### I am training multiple models at the same time, but I only see one of them. What happened? <a name="only-last-model-appears"></a>
|
||||
|
||||
All models can be found under the project's **Models** tab,
|
||||
that said, currently in the Experiment's information panel TRAINS shows only the last associated model.
|
||||
|
||||
This will be fixed in a future version.
|
||||
|
||||
### Can I log input and output models manually? <a name="manually-log-models"></a>
|
||||
|
||||
Yes! For example:
|
||||
|
||||
```python
|
||||
input_model = InputModel.import_model(link_to_initial_model_file)
|
||||
Task.current_task().connect(input_model)
|
||||
|
||||
OutputModel(Task.current_task()).update_weights(link_to_new_model_file_here)
|
||||
```
|
||||
|
||||
See [InputModel](https://github.com/allegroai/trains/blob/master/trains/model.py#L319) and [OutputModel](https://github.com/allegroai/trains/blob/master/trains/model.py#L539) for more information.
|
||||
|
||||
## Experiments
|
||||
|
||||
### I noticed I keep getting the message `warning: uncommitted code`. What does it mean? <a name="uncommitted-code-warning"></a>
|
||||
|
||||
TRAINS not only detects your current repository and git commit,
|
||||
but also warns you if you are using uncommitted code. TRAINS does this
|
||||
because uncommitted code means this experiment will be difficult to reproduce.
|
||||
|
||||
If you still don't care, just ignore this message - it is merely a warning.
|
||||
|
||||
### I do not use Argparser for hyper-parameters. Do you have a solution? <a name="dont-want-argparser"></a>
|
||||
|
||||
Yes! TRAINS supports [logging an experiment parameter dictionary](https://github.com/allegroai/trains/blob/master/docs/logger.md#logging-an-experiment-parameter-dictionary).
|
||||
|
||||
|
||||
### I noticed that all of my experiments appear as `Training`. Are there other options? <a name="other-experiment-types"></a>
|
||||
|
||||
Yes! When creating experiments and calling `Task.init`, you can provide an experiment type.
|
||||
The currently supported types are `Task.TaskTypes.training` and `Task.TaskTypes.testing`. For example:
|
||||
|
||||
```python
|
||||
task = Task.init(project_name, task_name, Task.TaskTypes.testing)
|
||||
```
|
||||
|
||||
If you feel we should add a few more, let us know in the [issues](https://github.com/allegroai/trains/issues) section.
|
||||
|
||||
### Sometimes I see experiments as running when in fact they are not. What's going on? <a name="experiment-running-but-stopped"></a>
|
||||
|
||||
TRAINS monitors your Python process. When the process exits in an orderly fashion, TRAINS closes the experiment.
|
||||
|
||||
When the process crashes and terminates abnormally, the stop signal is sometimes missed. In such a case, you can safely right click the experiment in the Web-App and stop it.
|
||||
|
||||
### My code throws an exception, but my experiment status is not "Failed". What happened? <a name="exception-not-failed"></a>
|
||||
|
||||
This issue was resolved in v0.9.2. Upgrade TRAINS:
|
||||
|
||||
```pip install -U trains```
|
||||
|
||||
### When I run my experiment, I get an SSL Connection error [CERTIFICATE_VERIFY_FAILED]. Do you have a solution? <a name="ssl-connection-error"></a>
|
||||
|
||||
Your firewall may be preventing the connection. Try one of the following solutions:
|
||||
|
||||
* Direct python "requests" to use the enterprise certificate file by setting the OS environment variables CURL_CA_BUNDLE or REQUESTS_CA_BUNDLE.
|
||||
|
||||
You can see a detailed discussion at [https://stackoverflow.com/questions/48391750/disable-python-requests-ssl-validation-for-an-imported-module](https://stackoverflow.com/questions/48391750/disable-python-requests-ssl-validation-for-an-imported-module).
|
||||
|
||||
2. Disable certificate verification (for security reasons, this is not recommended):
|
||||
|
||||
1. Upgrade TRAINS to the current version:
|
||||
|
||||
```pip install -U trains```
|
||||
|
||||
1. Create a new **trains.conf** configuration file (sample file [here](https://github.com/allegroai/trains/blob/master/docs/trains.conf)), containing:
|
||||
|
||||
```api { verify_certificate = False }```
|
||||
|
||||
1. Copy the new **trains.conf** file to ~/trains.conf (on Windows: C:\Users\your_username\trains.conf)
|
||||
|
||||
### How do I modify experiment names once they have been created? <a name="name-changing"></a>
|
||||
|
||||
An experiments' name is a user controlled property which can be accessed via the `Task.name` variable.
|
||||
This allows you to use meaningful naming schemes for to easily filter and compare different experiments.
|
||||
|
||||
For example, to distinguish between different experiments you can append the task Id to the task name:
|
||||
|
||||
```python
|
||||
task = Task.init('examples', 'train')
|
||||
task.name += ' {}'.format(task.id)
|
||||
```
|
||||
|
||||
Or, even for post-execution:
|
||||
|
||||
```python
|
||||
tasks = Task.get_tasks(project_name='examples', task_name='train')
|
||||
for t in tasks:
|
||||
t.name += ' {}'.format(task.id)
|
||||
```
|
||||
|
||||
Another example - To append a specific hyperparameter and its value to each task's name:
|
||||
|
||||
```python
|
||||
tasks = Task.get_tasks(project_name='examples', task_name='my_automl_experiment')
|
||||
for t in tasks:
|
||||
params = t.get_parameters()
|
||||
if 'my_secret_parameter' in params:
|
||||
t.name += ' my_secret_parameter={}'.format(params['my_secret_parameter'])
|
||||
```
|
||||
|
||||
Use it also when creating automation pipelines with a naming convention, see our [random search automation example](https://github.com/allegroai/trains/blob/master/examples/automl/automl_random_search_example.py).
|
||||
|
||||
## Graphs and Logs
|
||||
|
||||
### The first log lines are missing from the experiment log tab. Where did they go? <a name="first-log-lines-missing"></a>
|
||||
|
||||
Due to speed/optimization issues, we opted to display only the last several hundred log lines.
|
||||
|
||||
You can always downloaded the full log as a file using the Web-App.
|
||||
|
||||
### Can I create a graph comparing hyper-parameters vs model accuracy? <a name="compare-graph-parameters"></a>
|
||||
|
||||
Yes, you can manually create a plot with a single point X-axis for the hyper-parameter value,
|
||||
and Y-Axis for the accuracy. For example:
|
||||
|
||||
```python
|
||||
number_layers = 10
|
||||
accuracy = 0.95
|
||||
Task.current_task().get_logger().report_scatter2d(
|
||||
"performance", "accuracy", iteration=0,
|
||||
mode='markers', scatter=[(number_layers, accuracy)])
|
||||
```
|
||||
Assuming the hyper-parameter is "number_layers" with current value 10, and the accuracy for the trained model is 0.95.
|
||||
Then, the experiment comparison graph shows:
|
||||
|
||||
<img src="https://github.com/allegroai/trains/blob/master/docs/screenshots/compare_plots.png?raw=true" width="50%">
|
||||
|
||||
Another option is a histogram chart:
|
||||
```python
|
||||
number_layers = 10
|
||||
accuracy = 0.95
|
||||
Task.current_task().get_logger().report_vector(
|
||||
"performance", "accuracy", iteration=0, labels=['accuracy'],
|
||||
values=[accuracy], xlabels=['number_layers %d' % number_layers])
|
||||
```
|
||||
|
||||
<img src="https://github.com/allegroai/trains/blob/master/docs/screenshots/compare_plots_hist.png?raw=true" width="50%">
|
||||
|
||||
### I want to add more graphs, not just with Tensorboard. Is this supported? <a name="more-graph-types"></a>
|
||||
|
||||
Yes! Use the [Logger](https://github.com/allegroai/trains/blob/master/trains/logger.py) module. For more information, see [TRAINS Explicit Logging](https://github.com/allegroai/trains/blob/master/docs/logger.md).
|
||||
|
||||
## Git and Storage
|
||||
|
||||
### Is there something TRAINS can do about uncommitted code running? <a name="help-uncommitted-code"></a>
|
||||
|
||||
Yes! TRAINS currently stores the git diff as part of the experiment's information.
|
||||
The Web-App will soon present the git diff as well. This is coming very soon!
|
||||
|
||||
|
||||
### I read there is a feature for centralized model storage. How do I use it? <a name="centralized-model-storage"></a>
|
||||
|
||||
When calling `Task.init()`, providing the `output_uri` parameter allows you to specify the location in which model snapshots will be stored.
|
||||
|
||||
For example, calling:
|
||||
|
||||
```python
|
||||
task = Task.init(project_name, task_name, output_uri="/mnt/shared/folder")
|
||||
```
|
||||
|
||||
Will tell TRAINS to copy all stored snapshots into a sub-folder under `/mnt/shared/folder`.
|
||||
The sub-folder's name will contain the experiment's ID.
|
||||
Assuming the experiment's ID in this example is `6ea4f0b56d994320a713aeaf13a86d9d`, the following folder will be used:
|
||||
|
||||
`/mnt/shared/folder/task_6ea4f0b56d994320a713aeaf13a86d9d/models/`
|
||||
|
||||
TRAINS supports more storage types for `output_uri`:
|
||||
|
||||
```python
|
||||
# AWS S3 bucket
|
||||
task = Task.init(project_name, task_name, output_uri="s3://bucket-name/folder")
|
||||
```
|
||||
|
||||
```python
|
||||
# Google Cloud Storage bucket
|
||||
taks = Task.init(project_name, task_name, output_uri="gs://bucket-name/folder")
|
||||
```
|
||||
|
||||
**NOTE:** These require configuring the storage credentials in `~/trains.conf`.
|
||||
For a more detailed example, see [here](https://github.com/allegroai/trains/blob/master/docs/trains.conf#L55).
|
||||
|
||||
|
||||
|
||||
### When using PyCharm to remotely debug a machine, the git repo is not detected. Do you have a solution? <a name="pycharm-remote-debug-detect-git"></a>
|
||||
|
||||
Yes! Since this is such a common occurrence, we created a PyCharm plugin that allows a remote debugger to grab your local repository / commit ID. See our [TRAINS PyCharm Plugin](https://github.com/allegroai/trains-pycharm-plugin) repository for instructions and [latest release](https://github.com/allegroai/trains-pycharm-plugin/releases).
|
||||
|
||||
## Jupyter Notebooks
|
||||
|
||||
### I am using Jupyter Notebook. Is this supported? <a name="jupyter-notebook"></a>
|
||||
|
||||
Yes! You can run **TRAINS** in Jupyter Notebooks.
|
||||
|
||||
* Option 1: Install **trains** on your Jupyter Notebook host machine
|
||||
* Option 2: Install **trains** *in* your Jupyter Notebook and connect using **trains** credentials
|
||||
|
||||
**Option 1: Install trains on your Jupyter host machine**
|
||||
|
||||
1. Connect to your Juypter host machine.
|
||||
|
||||
1. Install the **trains** Python package.
|
||||
|
||||
pip install trains
|
||||
|
||||
1. Run the **trains** initialize wizard.
|
||||
|
||||
trains-init
|
||||
|
||||
1. In your Jupyter Notebook, you can now use **trains**.
|
||||
|
||||
**Option 2: Install trains in your Jupyter Notebook**
|
||||
|
||||
1. In the **trains** Web-App, Profile page, create credentials and copy your access key and secret key. These are required in the Step 3.
|
||||
|
||||
1. Install the **trains** Python package.
|
||||
|
||||
# install trains
|
||||
!pip install trains
|
||||
|
||||
1. Use the `Task.set_credentials()` method to specify the host, port, access key and secret key (see step 1).
|
||||
Notice: *host* is NOT the web server (default port 8080) but the API server (default port 8008)
|
||||
|
||||
# Set your credentials using the **trains** apiserver URI and port, access_key, and secret_key.
|
||||
Task.set_credentials(host='http://localhost:8008',key='<access_key>', secret='<secret_key>')
|
||||
|
||||
1. You can now use **trains**.
|
||||
|
||||
# create a task and start training
|
||||
task = Task.init('jupyer project', 'my notebook')
|
||||
|
||||
### Git is not well supported in Jupyter, so we just gave up on committing our code. Do you have a solution? <a name="commit-git-in-jupyter"></a>
|
||||
|
||||
Yes! Check our [TRAINS Jupyter Plugin](https://github.com/allegroai/trains-jupyter-plugin). This plugin allows you to commit your notebook directly from Jupyter. It also saves the Python version of your code and creates an updated `requirements.txt` so you know which packages you were using.
|
||||
|
||||
## scikit-learn
|
||||
|
||||
### Can I use TRAINS with scikit-learn? <a name="use-scikit-learn"></a>
|
||||
|
||||
Yes! `scikit-learn` is supported. Everything you do is logged.
|
||||
|
||||
Models are automatically logged when stored using *joblib*.
|
||||
|
||||
# from sklearn.externals import joblib
|
||||
import joblib
|
||||
joblib.dump(model, 'model.pkl')
|
||||
loaded_model = joblib.load('model.pkl')
|
||||
|
||||
|
||||
## TRAINS API
|
||||
|
||||
### How can I use the TRAINS API to fetch data? <a name="api"></a>
|
||||
|
||||
To fetch data using the **TRAINS** API, create an authenticated session and send requests for data using **TRAINS API** services and methods.
|
||||
The responses to the requests contain your data.
|
||||
|
||||
For example, to get the metrics for an experiment and print metrics as a histogram:
|
||||
|
||||
1. start an authenticated session
|
||||
1. send a request for all projects named `examples` using the `projects` service `GetAllRequest` method
|
||||
1. from the response, get the Ids of all those projects named `examples`
|
||||
1. send a request for all experiments (tasks) with those project Ids using the `tasks` service `GetAllRequest` method
|
||||
1. from the response, get the data for the experiment (task) Id `11` and print the experiment name
|
||||
1. send a request for a metrics histogram for experiment (task) Id `11` using the `events` service `ScalarMetricsIterHistogramRequest` method and print the histogram
|
||||
|
||||
```python
|
||||
# Import Session from the trains backend_api
|
||||
from trains.backend_api import Session
|
||||
# Import the services for tasks, events, and projects
|
||||
from trains.backend_api.services import tasks, events, projects
|
||||
|
||||
# Create an authenticated session
|
||||
session = Session()
|
||||
|
||||
# Get projects matching the project name 'examples'
|
||||
res = session.send(projects.GetAllRequest(name='examples'))
|
||||
# Get all the project Ids matching the project name 'examples"
|
||||
projects_id = [p.id for p in res.response.projects]
|
||||
print('project ids: {}'.format(projects_id))
|
||||
|
||||
# Get all the experiments/tasks
|
||||
res = session.send(tasks.GetAllRequest(project=projects_id))
|
||||
|
||||
# Do your work
|
||||
# For example, get the experiment whose Id is '11'
|
||||
task = res.response.tasks[11]
|
||||
print('task name: {}'.format(task.name))
|
||||
|
||||
# For example, for experiment Id '11', get the experiment metric values
|
||||
res = session.send(events.ScalarMetricsIterHistogramRequest(
|
||||
task=task.id,
|
||||
))
|
||||
scalars = res.response_data
|
||||
print('scalars {}'.format(scalars))
|
||||
```
|
||||
|
||||
Reference in New Issue
Block a user