mirror of
https://github.com/clearml/clearml-server
synced 2025-06-26 23:15:47 +00:00
Compare commits
206 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
1bc8529d83 | ||
|
|
6b480d7e87 | ||
|
|
083fd315e9 | ||
|
|
ef20e76174 | ||
|
|
8c8910808e | ||
|
|
f6ad379310 | ||
|
|
c5d6ce3e65 | ||
|
|
694dbc31c4 | ||
|
|
6488dc54e6 | ||
|
|
158da9b480 | ||
|
|
ec2e071ab7 | ||
|
|
465e270342 | ||
|
|
6705aff56f | ||
|
|
9069cfe1da | ||
|
|
677bb3ba6d | ||
|
|
cb253cff9e | ||
|
|
39ceb5ac5c | ||
|
|
d4edeaaf1b | ||
|
|
56aea1ffb8 | ||
|
|
09ab2af34c | ||
|
|
8bb26a6b0b | ||
|
|
3f2304549d | ||
|
|
ad72a435f1 | ||
|
|
f34332344e | ||
|
|
d324b57dd7 | ||
|
|
2216bfe875 | ||
|
|
9beefa7473 | ||
|
|
8ebc334889 | ||
|
|
e662c850af | ||
|
|
1e5163e530 | ||
|
|
1567774765 | ||
|
|
babfcbb707 | ||
|
|
027edd86bb | ||
|
|
cc83aadae6 | ||
|
|
8c18660a82 | ||
|
|
4fe61ee25c | ||
|
|
e18b21639c | ||
|
|
1cef03b8c2 | ||
|
|
d60d6dfe99 | ||
|
|
27d086bca2 | ||
|
|
add3f011a0 | ||
|
|
ee90b0b024 | ||
|
|
9bf107866f | ||
|
|
4d2f282950 | ||
|
|
b55fad1b59 | ||
|
|
ba77ff11e9 | ||
|
|
b67aa05d6f | ||
|
|
6b0c45a861 | ||
|
|
dc9623e964 | ||
|
|
3d73d60826 | ||
|
|
9f0c9c3690 | ||
|
|
1a3d3494ce | ||
|
|
b99f620073 | ||
|
|
e2f265b4bc | ||
|
|
251ee57ffd | ||
|
|
7e03104f1c | ||
|
|
f1a258208e | ||
|
|
66cc49313b | ||
|
|
9ae2943f7d | ||
|
|
54326f707b | ||
|
|
3a3b57c15f | ||
|
|
8ea8ad34e6 | ||
|
|
179661a0d4 | ||
|
|
3d22ca1888 | ||
|
|
fdf6798d0c | ||
|
|
9d9a44b927 | ||
|
|
dad935e81d | ||
|
|
a75534ec34 | ||
|
|
eab33de97e | ||
|
|
29de110abb | ||
|
|
2e7f418ee2 | ||
|
|
dadb996d22 | ||
|
|
174f692edf | ||
|
|
f4d5168a20 | ||
|
|
5a438e8435 | ||
|
|
ce4814dc47 | ||
|
|
ef42d0265d | ||
|
|
3c5195028e | ||
|
|
0d5174c453 | ||
|
|
c034c1a986 | ||
|
|
1b49da8748 | ||
|
|
26bda01a28 | ||
|
|
f5008d80ad | ||
|
|
8b464e7ae6 | ||
|
|
78e4a58c91 | ||
|
|
7a4a5eb03e | ||
|
|
d029d56508 | ||
|
|
6411954002 | ||
|
|
7f4ad0d1ca | ||
|
|
4cd4b2914d | ||
|
|
1d55710a0b | ||
|
|
8f646043bb | ||
|
|
4b11a6efcd | ||
|
|
cb3a7c90a8 | ||
|
|
074842a122 | ||
|
|
749ff4a44f | ||
|
|
7d6918ecb0 | ||
|
|
47184c2833 | ||
|
|
6434f1028e | ||
|
|
daade08940 | ||
|
|
a1d289822f | ||
|
|
1ce34f2c74 | ||
|
|
c2dc73a71f | ||
|
|
07bb3b5df8 | ||
|
|
067ef82576 | ||
|
|
59fc98e0c4 | ||
|
|
a936a210e8 | ||
|
|
be0cf0caa8 | ||
|
|
a8d90887e2 | ||
|
|
6f3257fed3 | ||
|
|
4bb8834551 | ||
|
|
286b8c3df5 | ||
|
|
16430a6636 | ||
|
|
d7ddfde26e | ||
|
|
e6c0f1b6d8 | ||
|
|
641ed1b510 | ||
|
|
e29ad4c9b2 | ||
|
|
3473d2bb02 | ||
|
|
ba03924cb4 | ||
|
|
6870d8aba9 | ||
|
|
64c63d2560 | ||
|
|
88836fae66 | ||
|
|
436883148b | ||
|
|
f9f2f0ccf0 | ||
|
|
f879f6924f | ||
|
|
b9cb587580 | ||
|
|
370e92c3dd | ||
|
|
03094076c8 | ||
|
|
bdf6c353bd | ||
|
|
23736efbc3 | ||
|
|
3c8e27dc94 | ||
|
|
ca890c7ae8 | ||
|
|
30909df73f | ||
|
|
b97a6084ce | ||
|
|
50438bd931 | ||
|
|
28daf49c91 | ||
|
|
4707647c92 | ||
|
|
6974aa3a99 | ||
|
|
e2deff4eef | ||
|
|
59994ccf9c | ||
|
|
29c792d459 | ||
|
|
df334d083e | ||
|
|
b548958c80 | ||
|
|
7bdf8fe30d | ||
|
|
c71c65be87 | ||
|
|
1cc6a8f787 | ||
|
|
e5b92f4a80 | ||
|
|
3272d0f31f | ||
|
|
618a0b9473 | ||
|
|
bca3a6e556 | ||
|
|
8b0afd47a6 | ||
|
|
0303c3525f | ||
|
|
563c451ac9 | ||
|
|
91b1b34a6b | ||
|
|
0ad0495733 | ||
|
|
03ae90c4a6 | ||
|
|
be788965e0 | ||
|
|
d198138c5b | ||
|
|
cf441987af | ||
|
|
b89de43373 | ||
|
|
0ef018c931 | ||
|
|
323b5db07c | ||
|
|
f084f6b9e7 | ||
|
|
eb4c9f0b13 | ||
|
|
018582ff8a | ||
|
|
7dcc0f6df2 | ||
|
|
5e0893dd80 | ||
|
|
ca81922651 | ||
|
|
07cc2fb08b | ||
|
|
842654d3fe | ||
|
|
00e5e2a0b1 | ||
|
|
37e5d8a7e0 | ||
|
|
5b1f468957 | ||
|
|
9103bf7984 | ||
|
|
e848d05677 | ||
|
|
1c7de3a86e | ||
|
|
e12fd8f3df | ||
|
|
29ef134b79 | ||
|
|
e24389fda9 | ||
|
|
f4ead86449 | ||
|
|
171969c5ea | ||
|
|
89f81bfe5a | ||
|
|
b8e62f27e2 | ||
|
|
c7bbac73d0 | ||
|
|
f832ea565a | ||
|
|
22e9c2b7eb | ||
|
|
c67a56eb8d | ||
|
|
df65e1c7ad | ||
|
|
01115c1223 | ||
|
|
6de88c3b93 | ||
|
|
9d77827252 | ||
|
|
76fb97624d | ||
|
|
20d6582f51 | ||
|
|
7ebda33793 | ||
|
|
953124aa37 | ||
|
|
ba3451ce5a | ||
|
|
b93591ec32 | ||
|
|
0abfd8da0d | ||
|
|
a9cc4e36c6 | ||
|
|
fe1c963eec | ||
|
|
111d80e88d | ||
|
|
6718862dbe | ||
|
|
0fe1bf8a61 | ||
|
|
10f326eda9 | ||
|
|
cd0d6c1a3d | ||
|
|
3205f2df97 |
141
README.md
141
README.md
@@ -1,39 +1,54 @@
|
||||
# Trains Server
|
||||
<div align="center">
|
||||
|
||||
## Auto-Magical Experiment Manager & Version Control for AI - ε Devops Included!
|
||||
<img src="docs/clearml_server_logo.png" width="250px">
|
||||
|
||||
**ClearML - Auto-Magical Suite of tools to streamline your ML workflow
|
||||
</br>Experiment Manager, ML-Ops and Data-Management**
|
||||
|
||||
[](https://img.shields.io/badge/license-SSPL-green.svg)
|
||||
[](https://img.shields.io/badge/python-3.6%20%7C%203.7-blue.svg)
|
||||
[](https://img.shields.io/github/release-pre/allegroai/trains-server.svg)
|
||||
[](https://img.shields.io/badge/status-beta-yellow.svg)
|
||||
[](https://artifacthub.io/packages/search?repo=allegroai)
|
||||
|
||||
### Help improve Trains by filling our 2-min [user survey](https://allegro.ai/lp/trains-user-survey/)
|
||||
</div>
|
||||
|
||||
## :rocket: Trains-Agent Services is now included, for more information see [services](https://github.com/allegroai/trains-server#services)
|
||||
---
|
||||
<div align="center">
|
||||
|
||||
## Introduction
|
||||
**v0.16 Upgrade Notice**
|
||||
|
||||
The **trains-server** is the backend service infrastructure for [Trains](https://github.com/allegroai/trains).
|
||||
</div>
|
||||
|
||||
In v0.16, the Elasticsearch subsystem of ClearML Server has been upgraded from version 5.6 to version 7.6. This change necessitates the migration of the database contents to accommodate the change in index structure across the different versions.
|
||||
|
||||
Follow [this procedure](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_es7_migration) to migrate existing data.
|
||||
|
||||
---
|
||||
|
||||
### ClearML Server
|
||||
#### *Formerly known as Trains Server*
|
||||
|
||||
The **ClearML Server** is the backend service infrastructure for [ClearML](https://github.com/allegroai/clearml).
|
||||
It allows multiple users to collaborate and manage their experiments.
|
||||
By default, **Trains** is set up to work with the **Trains** demo server, which is open to anyone and resets periodically.
|
||||
In order to host your own server, you will need to launch **trains-server** and point **Trains** to it.
|
||||
By default, **ClearML** is set up to work with the **ClearML** demo server, which is open to anyone and resets periodically.
|
||||
In order to host your own server, you will need to launch the **ClearML Server** and point **ClearML** to it.
|
||||
|
||||
**trains-server** contains the following components:
|
||||
The **ClearML Server** contains the following components:
|
||||
|
||||
* The **Trains** Web-App, a single-page UI for experiment management and browsing
|
||||
* The **ClearML** Web-App, a single-page UI for experiment management and browsing
|
||||
* RESTful API for:
|
||||
* Documenting and logging experiment information, statistics and results
|
||||
* Querying experiments history, logs and results
|
||||
* Locally-hosted file server for storing images and models making them easily accessible using the Web-App
|
||||
|
||||
You can quickly [deploy](#launching-trains-server) your **trains-server** using Docker, AWS EC2 AMI, or Kubernetes.
|
||||
You can quickly [deploy](#launching-the-clearml-server) your **ClearML Server** using Docker, AWS EC2 AMI, or Kubernetes.
|
||||
|
||||
## System design
|
||||
|
||||
|
||||
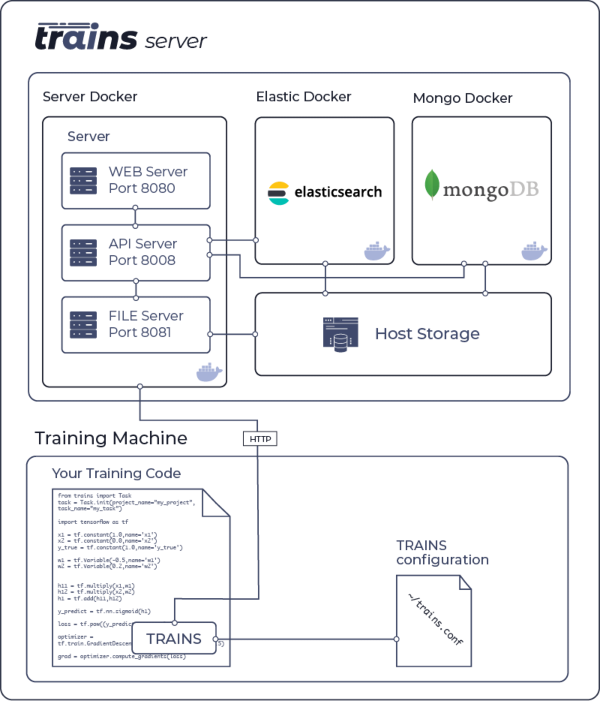
|
||||

|
||||
|
||||
**trains-server** has two supported configurations:
|
||||
The **ClearML Server** has two supported configurations:
|
||||
- Single IP (domain) with the following open ports
|
||||
- Web application on port 8080
|
||||
- API service on port 8008
|
||||
@@ -44,11 +59,11 @@ You can quickly [deploy](#launching-trains-server) your **trains-server** using
|
||||
- API service on sub-domain: api.\*.\*
|
||||
- File storage service on sub-domain: files.\*.\*
|
||||
|
||||
## Launching trains-server
|
||||
## Launching The ClearML Server
|
||||
|
||||
### Prerequisites
|
||||
|
||||
The ports 8080/8081/8008 must be available for the **trains-server** services.
|
||||
The ports 8080/8081/8008 must be available for the **ClearML Server** services.
|
||||
|
||||
For example, to see if port `8080` is in use:
|
||||
|
||||
@@ -62,24 +77,24 @@ For example, to see if port `8080` is in use:
|
||||
|
||||
### Launching
|
||||
|
||||
Launch **trains-server** in any of the following formats:
|
||||
Launch The **ClearML Server** in any of the following formats:
|
||||
|
||||
- Pre-built [AWS EC2 AMI](https://allegro.ai/docs/deploying_trains/trains_server_aws_ec2_ami/)
|
||||
- Pre-built [GCP Custom Image](https://allegro.ai/docs/deploying_trains/trains_server_gcp/)
|
||||
- Pre-built [AWS EC2 AMI](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_aws_ec2_ami)
|
||||
- Pre-built [GCP Custom Image](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_gcp)
|
||||
- Pre-built Docker Image
|
||||
- [Linux](https://allegro.ai/docs/deploying_trains/trains_server_linux_mac/)
|
||||
- [macOS](https://allegro.ai/docs/deploying_trains/trains_server_linux_mac/)
|
||||
- [Windows 10](https://allegro.ai/docs/deploying_trains/trains_server_win/)
|
||||
- [Linux](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_linux_mac)
|
||||
- [macOS](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_linux_mac)
|
||||
- [Windows 10](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_win)
|
||||
- Kubernetes
|
||||
- [Kubernetes Helm](https://allegro.ai/docs/deploying_trains/trains_server_kubernetes_helm/)
|
||||
- Manual [Kubernetes installation](https://allegro.ai/docs/deploying_trains/trains_server_kubernetes/)
|
||||
- [Kubernetes Helm](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_kubernetes_helm)
|
||||
- Manual [Kubernetes installation](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_kubernetes)
|
||||
|
||||
## Connecting Trains to your trains-server
|
||||
## Connecting ClearML to your ClearML Server
|
||||
|
||||
By default, the **Trains** client is set up to work with the [**Trains** demo server](https://demoapp.trains.allegro.ai/).
|
||||
To have the **Trains** client use your **trains-server** instead:
|
||||
- Run the `trains-init` command for an interactive setup.
|
||||
- Or manually edit `~/trains.conf` file, making sure the server settings (`api_server`, `web_server`, `file_server`) are configured correctly, for example:
|
||||
By default, the **ClearML** client is set up to work with the [**ClearML** demo server](https://demoapp.demo.clear.ml/).
|
||||
To have the **ClearML** client use your **ClearML Server** instead:
|
||||
- Run the `clearml-init` command for an interactive setup.
|
||||
- Or manually edit `~/clearml.conf` file, making sure the server settings (`api_server`, `web_server`, `file_server`) are configured correctly, for example:
|
||||
|
||||
api {
|
||||
# API server on port 8008
|
||||
@@ -92,44 +107,44 @@ To have the **Trains** client use your **trains-server** instead:
|
||||
files_server: "http://localhost:8081"
|
||||
}
|
||||
|
||||
**Note**: If you have set up **trains-server** in a sub-domain configuration, then there is no need to specify a port number,
|
||||
**Note**: If you have set up your **ClearML Server** in a sub-domain configuration, then there is no need to specify a port number,
|
||||
it will be inferred from the http/s scheme.
|
||||
|
||||
After launching the **trains-server** and configuring the **Trains** client to use the **trains-server**,
|
||||
you can [use](https://github.com/allegroai/trains#using-trains) **Trains** in your experiments and view them in your **trains-server** web server,
|
||||
After launching the **ClearML Server** and configuring the **ClearML** client to use the **ClearML Server**,
|
||||
you can [use](https://github.com/allegroai/clearml) **ClearML** in your experiments and view them in your **ClearML Server** web server,
|
||||
for example http://localhost:8080.
|
||||
For more information about the Trains client, see [**Trains**](https://github.com/allegroai/trains).
|
||||
For more information about the ClearML client, see [**ClearML**](https://github.com/allegroai/clearml).
|
||||
|
||||
## Trains-Agent Services <a name="services"></a>
|
||||
## ClearML-Agent Services <a name="services"></a>
|
||||
|
||||
As of version 0.15 of **trains-server**, dockerized deployment includes a **Trains-Agent Services** container running as
|
||||
As of version 0.15 of **ClearML Server**, dockerized deployment includes a **ClearML-Agent Services** container running as
|
||||
part of the docker container collection.
|
||||
|
||||
Trains-Agent Services is an extension of Trains-Agent that provides the ability to launch long-lasting jobs
|
||||
ClearML-Agent Services is an extension of ClearML-Agent that provides the ability to launch long-lasting jobs
|
||||
that previously had to be executed on local / dedicated machines. It allows a single agent to
|
||||
launch multiple dockers (Tasks) for different use cases. To name a few use cases, auto-scaler service (spinning instances
|
||||
when the need arises and the budget allows), Controllers (Implementing pipelines and more sophisticated DevOps logic),
|
||||
Optimizer (such as Hyper-parameter Optimization or sweeping), and Application (such as interactive Bokeh apps for
|
||||
increased data transparency)
|
||||
|
||||
Trains-Agent Services container will spin **any** task enqueued into the dedicated `services` queue.
|
||||
Every task launched by Trains-Agent Services will be registered as a new node in the system,
|
||||
ClearML-Agent Services container will spin **any** task enqueued into the dedicated `services` queue.
|
||||
Every task launched by ClearML-Agent Services will be registered as a new node in the system,
|
||||
providing tracking and transparency capabilities.
|
||||
You can also run the Trains-Agent Services manually, see details in [trains-agent services mode](https://github.com/allegroai/trains-agent#trains-agent-services-mode-)
|
||||
You can also run the ClearML-Agent Services manually, see details in [ClearML-agent services mode](https://github.com/allegroai/clearml-agent#clearml-agent-services-mode-)
|
||||
|
||||
**Note**: It is the user's responsibility to make sure the proper tasks are pushed into the `services` queue.
|
||||
Do not enqueue training / inference tasks into the `services` queue, as it will put unnecessary load on the server.
|
||||
|
||||
## Advanced Functionality
|
||||
|
||||
**trains-server** provides a few additional useful features, which can be manually enabled:
|
||||
The **ClearML Server** provides a few additional useful features, which can be manually enabled:
|
||||
|
||||
* [Web login authentication](https://allegro.ai/docs/faq/faq/#web-auth)
|
||||
* [Non-responsive experiments watchdog](https://allegro.ai/docs/faq/faq/#watchdog)
|
||||
* [Web login authentication](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_config#web-login-authentication)
|
||||
* [Non-responsive experiments watchdog](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server_config#non-responsive-task-watchdog)
|
||||
|
||||
## Restarting trains-server
|
||||
## Restarting ClearML Server
|
||||
|
||||
To restart the **trains-server**, you must first stop the containers, and then restart them.
|
||||
To restart the **ClearML Server**, you must first stop the containers, and then restart them.
|
||||
|
||||
```bash
|
||||
docker-compose down
|
||||
@@ -138,12 +153,12 @@ To restart the **trains-server**, you must first stop the containers, and then r
|
||||
|
||||
## Upgrading <a name="upgrade"></a>
|
||||
|
||||
**trains-server** releases are also reflected in the [docker compose configuration file](https://github.com/allegroai/trains-server/blob/master/docker-compose.yml).
|
||||
We strongly encourage you to keep your **trains-server** up to date, by keeping up with the current release.
|
||||
**ClearML Server** releases are also reflected in the [docker compose configuration file](https://github.com/allegroai/trains-server/blob/master/docker/docker-compose.yml).
|
||||
We strongly encourage you to keep your **ClearML Server** up to date, by keeping up with the current release.
|
||||
|
||||
**Note**: The following upgrade instructions use the Linux OS as an example.
|
||||
|
||||
To upgrade your existing **trains-server** deployment:
|
||||
To upgrade your existing **ClearML Server** deployment:
|
||||
|
||||
1. Shut down the docker containers
|
||||
```bash
|
||||
@@ -152,10 +167,10 @@ To upgrade your existing **trains-server** deployment:
|
||||
|
||||
1. We highly recommend backing up your data directory before upgrading.
|
||||
|
||||
Assuming your data directory is `/opt/trains`, to archive all data into `~/trains_backup.tgz` execute:
|
||||
Assuming your data directory is `/opt/clearml`, to archive all data into `~/clearml_backup.tgz` execute:
|
||||
|
||||
```bash
|
||||
sudo tar czvf ~/trains_backup.tgz /opt/trains/data
|
||||
sudo tar czvf ~/clearml_backup.tgz /opt/clearml/data
|
||||
```
|
||||
|
||||
<details>
|
||||
@@ -163,21 +178,21 @@ To upgrade your existing **trains-server** deployment:
|
||||
|
||||
To restore this example backup, execute:
|
||||
```bash
|
||||
sudo rm -R /opt/trains/data
|
||||
sudo tar -xzf ~/trains_backup.tgz -C /opt/trains/data
|
||||
sudo rm -R /opt/clearml/data
|
||||
sudo tar -xzf ~/clearml_backup.tgz -C /opt/clearml/data
|
||||
```
|
||||
</details>
|
||||
|
||||
1. Download the latest `docker-compose.yml` file.
|
||||
|
||||
```bash
|
||||
curl https://raw.githubusercontent.com/allegroai/trains-server/master/docker-compose.yml -o docker-compose.yml
|
||||
curl https://raw.githubusercontent.com/allegroai/trains-server/master/docker/docker-compose.yml -o docker-compose.yml
|
||||
```
|
||||
|
||||
1. Configure the Trains-Agent Services (not supported on Windows installation).
|
||||
If `TRAINS_HOST_IP` is not provided, Trains-Agent Services will use the external
|
||||
public address of the **trains-server**. If `TRAINS_AGENT_GIT_USER` / `TRAINS_AGENT_GIT_PASS` are not provided,
|
||||
the Trains-Agent Services will not be able to access any private repositories for running service tasks.
|
||||
1. Configure the ClearML-Agent Services (not supported on Windows installation).
|
||||
If `TRAINS_HOST_IP` is not provided, ClearML-Agent Services will use the external
|
||||
public address of the **ClearML Server**. If `TRAINS_AGENT_GIT_USER` / `TRAINS_AGENT_GIT_PASS` are not provided,
|
||||
the ClearML-Agent Services will not be able to access any private repositories for running service tasks.
|
||||
|
||||
```bash
|
||||
export TRAINS_HOST_IP=server_host_ip_here
|
||||
@@ -185,29 +200,29 @@ To upgrade your existing **trains-server** deployment:
|
||||
export TRAINS_AGENT_GIT_PASS=git_password_here
|
||||
```
|
||||
|
||||
1. Spin up the docker containers, it will automatically pull the latest **trains-server** build
|
||||
1. Spin up the docker containers, it will automatically pull the latest **ClearML Server** build
|
||||
```bash
|
||||
docker-compose -f docker-compose.yml pull
|
||||
docker-compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
**\* If something went wrong along the way, check our FAQ: [Common Docker Upgrade Errors](https://allegro.ai/docs/faq/faq/#common-docker-upgrade-errors).**
|
||||
**\* If something went wrong along the way, check our FAQ: [Common Docker Upgrade Errors](https://clear.ml/docs/latest/docs/faq/).**
|
||||
|
||||
|
||||
## Community & Support
|
||||
|
||||
If you have any questions, look to the Trains [FAQ](https://allegro.ai/docs/faq/faq/), or
|
||||
tag your questions on [stackoverflow](https://stackoverflow.com/questions/tagged/trains) with '**trains**' tag.
|
||||
If you have any questions, look to the ClearML [FAQ](https://clear.ml/docs/latest/docs/faq), or
|
||||
tag your questions on [stackoverflow](https://stackoverflow.com/questions/tagged/clearml) with '**clearml**' tag.
|
||||
|
||||
For feature requests or bug reports, please use [GitHub issues](https://github.com/allegroai/trains-server/issues).
|
||||
For feature requests or bug reports, please use [GitHub issues](https://github.com/allegroai/clearml-server/issues).
|
||||
|
||||
Additionally, you can always find us at *trains@allegro.ai*
|
||||
Additionally, you can always find us at *clearml@allegro.ai*
|
||||
|
||||
## License
|
||||
|
||||
[Server Side Public License v1.0](https://github.com/mongodb/mongo/blob/master/LICENSE-Community.txt)
|
||||
|
||||
**trains-server** relies on both [MongoDB](https://github.com/mongodb/mongo) and [ElasticSearch](https://github.com/elastic/elasticsearch).
|
||||
The **ClearML Server** relies on both [MongoDB](https://github.com/mongodb/mongo) and [ElasticSearch](https://github.com/elastic/elasticsearch).
|
||||
With the recent changes in both MongoDB's and ElasticSearch's OSS license, we feel it is our responsibility as a
|
||||
member of the community to support the projects we love and cherish.
|
||||
We believe the cause for the license change in both cases is more than just,
|
||||
|
||||
6
apiserver/apierrors/__init__.py
Normal file
6
apiserver/apierrors/__init__.py
Normal file
@@ -0,0 +1,6 @@
|
||||
from .apierror import APIError
|
||||
from .base import BaseError
|
||||
|
||||
from apiserver.apierrors_generator import ErrorsGenerator
|
||||
|
||||
ErrorsGenerator.generate_python_files()
|
||||
@@ -1,9 +1,10 @@
|
||||
class APIError(Exception):
|
||||
def __init__(self, msg, code=500, subcode=0, **_):
|
||||
def __init__(self, msg, code=500, subcode=0, error_data=None, **_):
|
||||
super(APIError, self).__init__()
|
||||
self._msg = msg
|
||||
self._code = code
|
||||
self._subcode = subcode
|
||||
self._error_data = error_data or {}
|
||||
|
||||
@property
|
||||
def msg(self):
|
||||
@@ -17,5 +18,9 @@ class APIError(Exception):
|
||||
def subcode(self):
|
||||
return self._subcode
|
||||
|
||||
@property
|
||||
def error_data(self):
|
||||
return self._error_data
|
||||
|
||||
def __str__(self):
|
||||
return self.msg
|
||||
@@ -1,9 +1,13 @@
|
||||
import six
|
||||
from boltons.typeutils import classproperty
|
||||
from typing import Tuple
|
||||
|
||||
import six
|
||||
from boltons.iterutils import is_collection, remap
|
||||
from boltons.typeutils import classproperty
|
||||
|
||||
from .apierror import APIError
|
||||
|
||||
jsonable_types = (dict, list, tuple, str, int, float, bool, type(None))
|
||||
|
||||
|
||||
class BaseError(APIError):
|
||||
_default_code = 500
|
||||
@@ -19,15 +23,26 @@ class BaseError(APIError):
|
||||
f"{k}={self._format_kwarg(v)}" for k, v in kwargs.items()
|
||||
)
|
||||
message += f": {kwargs_msg}"
|
||||
params = kwargs.copy()
|
||||
params.update(
|
||||
code=self._default_code, subcode=self._default_subcode, msg=message
|
||||
|
||||
super(BaseError, self).__init__(
|
||||
code=self._default_code,
|
||||
subcode=self._default_subcode,
|
||||
msg=message,
|
||||
error_data=self._to_safe_json_types(kwargs),
|
||||
)
|
||||
super(BaseError, self).__init__(**params)
|
||||
|
||||
@staticmethod
|
||||
def _to_safe_json_types(data):
|
||||
def visit(_, k, v):
|
||||
if not isinstance(v, jsonable_types):
|
||||
v = str(v)
|
||||
return k, v
|
||||
|
||||
return remap(data, visit=visit)
|
||||
|
||||
@staticmethod
|
||||
def _format_kwarg(value):
|
||||
if isinstance(value, (tuple, list)):
|
||||
if is_collection(value):
|
||||
return f'({", ".join(str(v) for v in value)})'
|
||||
elif isinstance(value, six.string_types):
|
||||
return value
|
||||
143
apiserver/apierrors/errors.conf
Normal file
143
apiserver/apierrors/errors.conf
Normal file
@@ -0,0 +1,143 @@
|
||||
301 {
|
||||
_: "moved_permanently"
|
||||
1: ["not_supported", "this endpoint is no longer supported for the requested API version"]
|
||||
}
|
||||
|
||||
400 {
|
||||
_: "bad_request"
|
||||
1: ["not_supported", "endpoint is not supported"]
|
||||
2: ["request_path_has_invalid_version", "request path has invalid version"]
|
||||
5: ["invalid_headers", "invalid headers"]
|
||||
6: ["impersonation_error", "impersonation error"]
|
||||
|
||||
10: ["invalid_id", "invalid object id"]
|
||||
11: ["missing_required_fields", "missing required fields"]
|
||||
12: ["validation_error", "validation error"]
|
||||
13: ["fields_not_allowed_for_role", "fields not allowed for role"]
|
||||
14: ["invalid fields", "fields not defined for object"]
|
||||
15: ["fields_conflict", "conflicting fields"]
|
||||
16: ["fields_value_error", "invalid value for fields"]
|
||||
17: ["batch_contains_no_items", "batch request contains no items"]
|
||||
18: ["batch_validation_error", "batch request validation error"]
|
||||
19: ["invalid_lucene_syntax", "malformed lucene query"]
|
||||
20: ["fields_type_error", "invalid type for fields"]
|
||||
21: ["invalid_regex_error", "malformed regular expression"]
|
||||
22: ["invalid_email_address", "malformed email address"]
|
||||
23: ["invalid_domain_name", "malformed domain name"]
|
||||
24: ["not_public_object", "object is not public"]
|
||||
|
||||
# Tasks
|
||||
100: ["task_error", "general task error"]
|
||||
101: ["invalid_task_id", "invalid task id"]
|
||||
102: ["task_validation_error", "task validation error"]
|
||||
110: ["invalid_task_status", "invalid task status"]
|
||||
111: ["task_not_started", "task not started (invalid task status)"]
|
||||
112: ["task_in_progress", "task in progress (invalid task status)"]
|
||||
113: ["task_published", "task published (invalid task status)"]
|
||||
114: ["task_status_unknown", "task unknown (invalid task status)"]
|
||||
120: ["invalid_task_execution_progress", "invalid task execution progress"]
|
||||
121: ["failed_changing_task_status", "failed changing task status. probably someone changed it before you"]
|
||||
122: ["missing_task_fields", "task is missing expected fields"]
|
||||
123: ["task_cannot_be_deleted", "task cannot be deleted"]
|
||||
125: ["task_has_jobs_running", "task has jobs that haven't completed yet"]
|
||||
126: ["invalid_task_type", "invalid task type for this operations"]
|
||||
127: ["invalid_task_input", "invalid task output"]
|
||||
128: ["invalid_task_output", "invalid task output"]
|
||||
129: ["task_publish_in_progress", "Task publish in progress"]
|
||||
130: ["task_not_found", "task not found"]
|
||||
131: ["events_not_added", "events not added"]
|
||||
|
||||
# Models
|
||||
200: ["model_error", "general task error"]
|
||||
201: ["invalid_model_id", "invalid model id"]
|
||||
202: ["model_not_ready", "model is not ready"]
|
||||
203: ["model_is_ready", "model is ready"]
|
||||
204: ["invalid_model_uri", "invalid model URI"]
|
||||
205: ["model_in_use", "model is used by tasks"]
|
||||
206: ["model_creating_task_exists", "task that created this model exists"]
|
||||
|
||||
# Users
|
||||
300: ["invalid_user", "invalid user"]
|
||||
301: ["invalid_user_id", "invalid user id"]
|
||||
302: ["user_id_exists", "user id already exists"]
|
||||
305: ["invalid_preferences_update", "Malformed key and/or value"]
|
||||
|
||||
# Projects
|
||||
401: ["invalid_project_id", "invalid project id"]
|
||||
402: ["project_has_tasks", "project has associated tasks"]
|
||||
403: ["project_not_found", "project not found"]
|
||||
405: ["project_has_models", "project has associated models"]
|
||||
407: ["invalid_project_name", "invalid project name"]
|
||||
408: ["cannot_update_project_location", "Cannot update project location. Use projects.move instead"]
|
||||
409: ["project_path_exceeds_max", "Project path exceed the maximum allowed depth"]
|
||||
410: ["project_source_and_destination_are_the_same", "Project has the same source and destination paths"]
|
||||
|
||||
# Queues
|
||||
701: ["invalid_queue_id", "invalid queue id"]
|
||||
702: ["queue_not_empty", "queue is not empty"]
|
||||
703: ["invalid_queue_or_task_not_queued", "invalid queue id or task not in queue"]
|
||||
704: ["removed_during_reposition", "task was removed by another party during reposition"]
|
||||
705: ["failed_adding_during_reposition", "failed adding task back to queue during reposition"]
|
||||
706: ["task_already_queued", "failed adding task to queue since task is already queued"]
|
||||
707: ["no_default_queue", "no queue is tagged as the default queue for this company"]
|
||||
708: ["multiple_default_queues", "more than one queue is tagged as the default queue for this company"]
|
||||
|
||||
# Database
|
||||
800: ["data_validation_error", "data validation error"]
|
||||
801: ["expected_unique_data", "value combination already exists"]
|
||||
|
||||
# Workers
|
||||
1001: ["invalid_worker_id", "invalid worker id"]
|
||||
1002: ["worker_registration_failed", "worker registration failed"]
|
||||
1003: ["worker_registered", "worker is already registered"]
|
||||
1004: ["worker_not_registered", "worker is not registered"]
|
||||
1005: ["worker_stats_not_found", "worker stats not found"]
|
||||
|
||||
1104: ["invalid_scroll_id", "Invalid scroll id"]
|
||||
}
|
||||
|
||||
401 {
|
||||
_: "unauthorized"
|
||||
1: ["not_authorized", "unauthorized (not authorized for endpoint)"]
|
||||
2: ["entity_not_allowed", "unauthorized (entity not allowed)"]
|
||||
10: ["bad_auth_type", "unauthorized (bad authentication header type)"]
|
||||
20: ["no_credentials", "unauthorized (missing credentials)"]
|
||||
21: ["bad_credentials", "unauthorized (malformed credentials)"]
|
||||
22: ["invalid_credentials", "unauthorized (invalid credentials)"]
|
||||
30: ["invalid_token", "invalid token"]
|
||||
31: ["blocked_token", "token is blocked"]
|
||||
40: ["invalid_fixed_user", "fixed user ID was not found"]
|
||||
}
|
||||
|
||||
403: {
|
||||
_: "forbidden"
|
||||
10: ["routing_error", "forbidden (routing error)"]
|
||||
12: ["blocked_internal_endpoint", "forbidden (blocked internal endpoint)"]
|
||||
20: ["role_not_allowed", "forbidden (not allowed for role)"]
|
||||
21: ["no_write_permission", "forbidden (modification not allowed)"]
|
||||
}
|
||||
|
||||
410: {
|
||||
_: "gone"
|
||||
1: ["not_supported", "thus endpoint is not supported any more"]
|
||||
}
|
||||
|
||||
500 {
|
||||
_: "server_error"
|
||||
0: ["general_error", "general server error"]
|
||||
1: ["internal_error", "internal server error"]
|
||||
2: ["config_error", "configuration error"]
|
||||
3: ["build_info_error", "build info unavailable or corrupted"]
|
||||
4: ["low_disk_space", "Critical server error! Server reports low or insufficient disk space. Please resolve immediately by allocating additional disk space or freeing up storage space."]
|
||||
10: ["transaction_error", "a transaction call has returned with an error"]
|
||||
# Database-related issues
|
||||
100: ["data_error", "general data error"]
|
||||
101: ["inconsistent_data", "inconsistent data encountered in document"]
|
||||
102: ["database_unavailable", "database is temporarily unavailable"]
|
||||
110: ["update_failed", "update failed"]
|
||||
|
||||
# Index-related issues
|
||||
201: ["missing_index", "missing internal index"]
|
||||
|
||||
9999: ["not_implemented", "action is not yet implemented"]
|
||||
}
|
||||
1
apiserver/apierrors_generator/__init__.py
Normal file
1
apiserver/apierrors_generator/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
from .errors_generator import ErrorsGenerator
|
||||
4
apiserver/apierrors_generator/__main__.py
Normal file
4
apiserver/apierrors_generator/__main__.py
Normal file
@@ -0,0 +1,4 @@
|
||||
from .errors_generator import ErrorsGenerator
|
||||
|
||||
if __name__ == '__main__':
|
||||
ErrorsGenerator.generate_python_files()
|
||||
31
apiserver/apierrors_generator/errors_generator.py
Normal file
31
apiserver/apierrors_generator/errors_generator.py
Normal file
@@ -0,0 +1,31 @@
|
||||
from functools import reduce
|
||||
from pathlib import Path
|
||||
from typing import Union
|
||||
|
||||
from pyhocon import ConfigFactory, ConfigTree
|
||||
|
||||
from .generator import Generator
|
||||
|
||||
|
||||
class ErrorsGenerator:
|
||||
_apierrors_path = Path(__file__).parents[1] / "apierrors"
|
||||
_files = [_apierrors_path / "errors.conf"]
|
||||
|
||||
@classmethod
|
||||
def _get_codes(cls):
|
||||
return {
|
||||
(k, v.pop("_")): v
|
||||
for k, v in reduce(
|
||||
ConfigTree.merge_configs, map(ConfigFactory.parse_file, cls._files),
|
||||
).items()
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def add_errors_file(cls, path: Union[Path, str]):
|
||||
cls._files.append(path)
|
||||
|
||||
@classmethod
|
||||
def generate_python_files(cls):
|
||||
Generator(cls._apierrors_path / "errors", format_pep8=False).make_errors(
|
||||
cls._get_codes()
|
||||
)
|
||||
@@ -8,9 +8,12 @@ from pathlib import Path
|
||||
|
||||
env = jinja2.Environment(
|
||||
loader=jinja2.FileSystemLoader(str(Path(__file__).parent)),
|
||||
autoescape=jinja2.select_autoescape(disabled_extensions=('py',), default_for_string=False),
|
||||
autoescape=jinja2.select_autoescape(
|
||||
disabled_extensions=("py",), default_for_string=False
|
||||
),
|
||||
trim_blocks=True,
|
||||
lstrip_blocks=True)
|
||||
lstrip_blocks=True,
|
||||
)
|
||||
|
||||
|
||||
def env_filter(name=None):
|
||||
@@ -19,14 +22,14 @@ def env_filter(name=None):
|
||||
|
||||
@env_filter()
|
||||
def cls_name(name):
|
||||
delims = list(map(re.escape, (' ', '_')))
|
||||
parts = re.split('|'.join(delims), name)
|
||||
return ''.join(x.capitalize() for x in parts)
|
||||
delims = list(map(re.escape, (" ", "_")))
|
||||
parts = re.split("|".join(delims), name)
|
||||
return "".join(x.capitalize() for x in parts)
|
||||
|
||||
|
||||
class Generator(object):
|
||||
_base_class_name = 'BaseError'
|
||||
_base_class_module = 'apierrors.base'
|
||||
_base_class_name = "BaseError"
|
||||
_base_class_module = "apiserver.apierrors.base"
|
||||
|
||||
def __init__(self, path, format_pep8=True, use_md5=True):
|
||||
self._use_md5 = use_md5
|
||||
@@ -35,29 +38,37 @@ class Generator(object):
|
||||
self._path.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
def _make_init_file(self, path):
|
||||
(self._path / path / '__init__.py').write_bytes('')
|
||||
(self._path / path / "__init__.py").write_bytes(b"")
|
||||
|
||||
def _do_render(self, file, template, context):
|
||||
with file.open('w') as f:
|
||||
with file.open("w") as f:
|
||||
result = template.render(
|
||||
base_class_name=self._base_class_name,
|
||||
base_class_module=self._base_class_module,
|
||||
**context)
|
||||
**context
|
||||
)
|
||||
if self._format_pep8:
|
||||
result = autopep8.fix_code(result, options={'aggressive': 1, 'verbose': 0, 'max_line_length': 120})
|
||||
import autopep8
|
||||
|
||||
result = autopep8.fix_code(
|
||||
result,
|
||||
options={"aggressive": 1, "verbose": 0, "max_line_length": 120},
|
||||
)
|
||||
f.write(result)
|
||||
|
||||
def _make_section(self, name, code, subcodes):
|
||||
self._do_render(
|
||||
file=(self._path / name).with_suffix('.py'),
|
||||
template=env.get_template('templates/section.jinja2'),
|
||||
context=dict(code=code, subcodes=list(subcodes.items()),))
|
||||
file=(self._path / name).with_suffix(".py"),
|
||||
template=env.get_template("templates/section.jinja2"),
|
||||
context=dict(code=code, subcodes=list(subcodes.items()),),
|
||||
)
|
||||
|
||||
def _make_init(self, sections):
|
||||
self._do_render(
|
||||
file=(self._path / '__init__.py'),
|
||||
template=env.get_template('templates/init.jinja2'),
|
||||
context=dict(sections=sections,))
|
||||
file=(self._path / "__init__.py"),
|
||||
template=env.get_template("templates/init.jinja2"),
|
||||
context=dict(sections=sections,),
|
||||
)
|
||||
|
||||
def _key_to_str(self, data):
|
||||
if isinstance(data, dict):
|
||||
@@ -66,11 +77,11 @@ class Generator(object):
|
||||
|
||||
def _calc_digest(self, data):
|
||||
data = json.dumps(self._key_to_str(data), sort_keys=True)
|
||||
return hashlib.md5(data.encode('utf8')).hexdigest()
|
||||
return hashlib.md5(data.encode("utf8")).hexdigest()
|
||||
|
||||
def make_errors(self, errors):
|
||||
digest = None
|
||||
digest_file = self._path / 'digest.md5'
|
||||
digest_file = self._path / "digest.md5"
|
||||
if self._use_md5:
|
||||
digest = self._calc_digest(errors)
|
||||
if digest_file.is_file():
|
||||
@@ -79,7 +90,7 @@ class Generator(object):
|
||||
|
||||
self._make_init(errors)
|
||||
for (code, section_name), subcodes in errors.items():
|
||||
self._make_section(section_name, code, subcodes)
|
||||
self._make_section(section_name, int(code), subcodes)
|
||||
|
||||
if self._use_md5:
|
||||
digest_file.write_text(digest)
|
||||
@@ -5,5 +5,5 @@ from {{ base_class_module }} import {{ base_class_name }}
|
||||
{% for subcode, (name, msg) in subcodes %}
|
||||
|
||||
|
||||
{{ error_class(name|cls_name, msg, code, subcode) -}}
|
||||
{{ error_class(name|cls_name, msg, code, subcode|int) -}}
|
||||
{% endfor %}
|
||||
@@ -1,5 +1,3 @@
|
||||
from __future__ import absolute_import
|
||||
|
||||
from enum import Enum
|
||||
from typing import Union, Type, Iterable
|
||||
|
||||
@@ -9,11 +7,29 @@ from jsonmodels import fields
|
||||
from jsonmodels.fields import _LazyType, NotSet
|
||||
from jsonmodels.models import Base as ModelBase
|
||||
from jsonmodels.validators import Enum as EnumValidator
|
||||
from luqum.parser import parser, ParseError
|
||||
from mongoengine.base import BaseDocument
|
||||
from validators import email as email_validator, domain as domain_validator
|
||||
|
||||
from apierrors import errors
|
||||
from utilities.json import loads, dumps
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.utilities.json import loads, dumps
|
||||
|
||||
|
||||
class EmailField(fields.StringField):
|
||||
def validate(self, value):
|
||||
super().validate(value)
|
||||
if value is None:
|
||||
return
|
||||
if email_validator(value) is not True:
|
||||
raise errors.bad_request.InvalidEmailAddress()
|
||||
|
||||
|
||||
class DomainField(fields.StringField):
|
||||
def validate(self, value):
|
||||
super().validate(value)
|
||||
if value is None:
|
||||
return
|
||||
if domain_validator(value) is not True:
|
||||
raise errors.bad_request.InvalidDomainName()
|
||||
|
||||
|
||||
def make_default(field_cls, default_value):
|
||||
@@ -35,6 +51,8 @@ class ListField(fields.ListField):
|
||||
try:
|
||||
return super(ListField, self)._cast_value(value)
|
||||
except TypeError:
|
||||
if len(self.items_types) == 1 and issubclass(self.items_types[0], Enum):
|
||||
return self.items_types[0](value)
|
||||
return value
|
||||
|
||||
def validate_single_value(self, item):
|
||||
@@ -43,6 +61,12 @@ class ListField(fields.ListField):
|
||||
item.validate()
|
||||
|
||||
|
||||
# since there is no distinction between None and empty DictField
|
||||
# this value can be used as sentinel in order to distinguish
|
||||
# between not set and empty DictField
|
||||
DictFieldNotSet = {}
|
||||
|
||||
|
||||
class DictField(fields.BaseField):
|
||||
types = (dict,)
|
||||
|
||||
@@ -71,6 +95,31 @@ class DictField(fields.BaseField):
|
||||
for type_ in value_types
|
||||
)
|
||||
|
||||
def parse_value(self, values):
|
||||
"""Cast value to proper collection."""
|
||||
result = self.get_default_value()
|
||||
|
||||
if values is None:
|
||||
return result
|
||||
|
||||
if not self.value_types or not isinstance(values, dict):
|
||||
return values
|
||||
|
||||
return {key: self._cast_value(value) for key, value in values.items()}
|
||||
|
||||
def _cast_value(self, value):
|
||||
if isinstance(value, self.value_types):
|
||||
return value
|
||||
else:
|
||||
if len(self.value_types) != 1:
|
||||
tpl = 'Cannot decide which type to choose from "{types}".'
|
||||
raise jsonmodels.errors.ValidationError(
|
||||
tpl.format(
|
||||
types=', '.join([t.__name__ for t in self.value_types])
|
||||
)
|
||||
)
|
||||
return self.value_types[0](**value)
|
||||
|
||||
def validate(self, value):
|
||||
super(DictField, self).validate(value)
|
||||
|
||||
@@ -96,6 +145,15 @@ class DictField(fields.BaseField):
|
||||
)
|
||||
)
|
||||
|
||||
def _elem_to_struct(self, value):
|
||||
try:
|
||||
return value.to_struct()
|
||||
except AttributeError:
|
||||
return value
|
||||
|
||||
def to_struct(self, values):
|
||||
return {k: self._elem_to_struct(v) for k, v in values.items()}
|
||||
|
||||
|
||||
class IntField(fields.IntField):
|
||||
def parse_value(self, value):
|
||||
@@ -105,23 +163,6 @@ class IntField(fields.IntField):
|
||||
return value
|
||||
|
||||
|
||||
def validate_lucene_query(value):
|
||||
if value == "":
|
||||
return
|
||||
try:
|
||||
parser.parse(value)
|
||||
except ParseError as e:
|
||||
raise errors.bad_request.InvalidLuceneSyntax(error=e)
|
||||
|
||||
|
||||
class LuceneQueryField(fields.StringField):
|
||||
def validate(self, value):
|
||||
super(LuceneQueryField, self).validate(value)
|
||||
if value is None:
|
||||
return
|
||||
validate_lucene_query(value)
|
||||
|
||||
|
||||
class NullableEnumValidator(EnumValidator):
|
||||
"""Validator for enums that allows a None value."""
|
||||
|
||||
@@ -177,7 +218,7 @@ class ActualEnumField(fields.StringField):
|
||||
)
|
||||
|
||||
def parse_value(self, value):
|
||||
if value is None and not self.required:
|
||||
if value is NotSet and not self.required:
|
||||
return self.get_default_value()
|
||||
try:
|
||||
# noinspection PyArgumentList
|
||||
@@ -189,24 +230,6 @@ class ActualEnumField(fields.StringField):
|
||||
return super().to_struct(value.value)
|
||||
|
||||
|
||||
class EmailField(fields.StringField):
|
||||
def validate(self, value):
|
||||
super().validate(value)
|
||||
if value is None:
|
||||
return
|
||||
if email_validator(value) is not True:
|
||||
raise errors.bad_request.InvalidEmailAddress()
|
||||
|
||||
|
||||
class DomainField(fields.StringField):
|
||||
def validate(self, value):
|
||||
super().validate(value)
|
||||
if value is None:
|
||||
return
|
||||
if domain_validator(value) is not True:
|
||||
raise errors.bad_request.InvalidDomainName()
|
||||
|
||||
|
||||
class JsonSerializableMixin:
|
||||
def to_json(self: ModelBase):
|
||||
return dumps(self.to_struct())
|
||||
@@ -214,3 +237,67 @@ class JsonSerializableMixin:
|
||||
@classmethod
|
||||
def from_json(cls: Type[ModelBase], s):
|
||||
return cls(**loads(s))
|
||||
|
||||
|
||||
def callable_default(cls: Type[fields.BaseField]) -> Type[fields.BaseField]:
|
||||
class _Wrapped(cls):
|
||||
_callable_default = None
|
||||
|
||||
def get_default_value(self):
|
||||
if self._callable_default:
|
||||
return self._callable_default()
|
||||
return super(_Wrapped, self).get_default_value()
|
||||
|
||||
def __init__(self, *args, default=None, **kwargs):
|
||||
if default and callable(default):
|
||||
self._callable_default = default
|
||||
default = default()
|
||||
super(_Wrapped, self).__init__(*args, default=default, **kwargs)
|
||||
|
||||
return _Wrapped
|
||||
|
||||
|
||||
class MongoengineFieldsDict(DictField):
|
||||
"""
|
||||
DictField representing mongoengine field names/value mapping.
|
||||
Used to convert mongoengine-style field/subfield notation to user-presentable syntax, including handling update
|
||||
operators.
|
||||
"""
|
||||
|
||||
mongoengine_update_operators = (
|
||||
"inc",
|
||||
"dec",
|
||||
"push",
|
||||
"push_all",
|
||||
"pop",
|
||||
"pull",
|
||||
"pull_all",
|
||||
"add_to_set",
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def _normalize_mongo_value(value):
|
||||
if isinstance(value, BaseDocument):
|
||||
return value.to_mongo()
|
||||
return value
|
||||
|
||||
@classmethod
|
||||
def _normalize_mongo_field_path(cls, path, value):
|
||||
parts = path.split("__")
|
||||
if len(parts) > 1:
|
||||
if parts[0] == "set":
|
||||
parts = parts[1:]
|
||||
elif parts[0] == "unset":
|
||||
parts = parts[1:]
|
||||
value = None
|
||||
elif parts[0] in cls.mongoengine_update_operators:
|
||||
return None, None
|
||||
return ".".join(parts), cls._normalize_mongo_value(value)
|
||||
|
||||
def parse_value(self, value):
|
||||
value = super(MongoengineFieldsDict, self).parse_value(value)
|
||||
return {
|
||||
k: v
|
||||
for k, v in (self._normalize_mongo_field_path(*p) for p in value.items())
|
||||
if k is not None
|
||||
}
|
||||
@@ -2,10 +2,10 @@ from jsonmodels.fields import IntField, StringField, BoolField, EmbeddedField, D
|
||||
from jsonmodels.models import Base
|
||||
from jsonmodels.validators import Max, Enum
|
||||
|
||||
from apimodels import ListField, EnumField
|
||||
from config import config
|
||||
from database.model.auth import Role
|
||||
from database.utils import get_options
|
||||
from apiserver.apimodels import ListField, EnumField
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.model.auth import Role
|
||||
from apiserver.database.utils import get_options
|
||||
|
||||
|
||||
class GetTokenRequest(Base):
|
||||
28
apiserver/apimodels/base.py
Normal file
28
apiserver/apimodels/base.py
Normal file
@@ -0,0 +1,28 @@
|
||||
from jsonmodels import models, fields
|
||||
from jsonmodels.validators import Length
|
||||
|
||||
from apiserver.apimodels import MongoengineFieldsDict, ListField
|
||||
|
||||
|
||||
class UpdateResponse(models.Base):
|
||||
updated = fields.IntField(required=True)
|
||||
fields = MongoengineFieldsDict()
|
||||
|
||||
|
||||
class PagedRequest(models.Base):
|
||||
page = fields.IntField()
|
||||
page_size = fields.IntField()
|
||||
|
||||
|
||||
class IdResponse(models.Base):
|
||||
id = fields.StringField(required=True)
|
||||
|
||||
|
||||
class MakePublicRequest(models.Base):
|
||||
ids = ListField(items_types=str, validators=[Length(minimum_value=1)])
|
||||
|
||||
|
||||
class MoveRequest(models.Base):
|
||||
ids = ListField([str], validators=Length(minimum_value=1))
|
||||
project = fields.StringField()
|
||||
project_name = fields.StringField()
|
||||
25
apiserver/apimodels/batch.py
Normal file
25
apiserver/apimodels/batch.py
Normal file
@@ -0,0 +1,25 @@
|
||||
from typing import Sequence
|
||||
|
||||
from jsonmodels.fields import StringField
|
||||
from jsonmodels.models import Base
|
||||
from jsonmodels.validators import Length
|
||||
|
||||
from apiserver.apimodels import ListField
|
||||
from apiserver.apimodels.base import UpdateResponse
|
||||
|
||||
|
||||
class BatchRequest(Base):
|
||||
ids: Sequence[str] = ListField([str], validators=Length(minimum_value=1))
|
||||
|
||||
|
||||
class BatchResponse(Base):
|
||||
succeeded: Sequence[dict] = ListField([dict])
|
||||
failed: Sequence[dict] = ListField([dict])
|
||||
|
||||
|
||||
class UpdateBatchItem(UpdateResponse):
|
||||
id: str = StringField()
|
||||
|
||||
|
||||
class UpdateBatchResponse(BatchResponse):
|
||||
succeeded: Sequence[UpdateBatchItem] = ListField(UpdateBatchItem)
|
||||
34
apiserver/apimodels/custom_validators/__init__.py
Normal file
34
apiserver/apimodels/custom_validators/__init__.py
Normal file
@@ -0,0 +1,34 @@
|
||||
import validators
|
||||
from jsonmodels.errors import ValidationError
|
||||
|
||||
|
||||
class ForEach(object):
|
||||
def __init__(self, validator):
|
||||
self.validator = validator
|
||||
|
||||
def validate(self, values):
|
||||
for value in values:
|
||||
self.validator.validate(value)
|
||||
|
||||
def modify_schema(self, field_schema):
|
||||
return self.validator.modify_schema(field_schema)
|
||||
|
||||
|
||||
class Hostname(object):
|
||||
|
||||
def validate(self, value):
|
||||
if validators.domain(value) is not True:
|
||||
raise ValidationError(f"Value '{value}' is not a valid hostname")
|
||||
|
||||
def modify_schema(self, field_schema):
|
||||
field_schema["format"] = "hostname"
|
||||
|
||||
|
||||
class Email(object):
|
||||
|
||||
def validate(self, value):
|
||||
if validators.email(value) is not True:
|
||||
raise ValidationError(f"Value '{value}' is not a valid email address")
|
||||
|
||||
def modify_schema(self, field_schema):
|
||||
field_schema["format"] = "email"
|
||||
@@ -6,30 +6,46 @@ from jsonmodels.fields import StringField, BoolField
|
||||
from jsonmodels.models import Base
|
||||
from jsonmodels.validators import Length, Min, Max
|
||||
|
||||
from apimodels import ListField, IntField, ActualEnumField
|
||||
from bll.event.event_metrics import EventType
|
||||
from bll.event.scalar_key import ScalarKeyEnum
|
||||
from utilities.stringenum import StringEnum
|
||||
from apiserver.apimodels import ListField, IntField, ActualEnumField
|
||||
from apiserver.bll.event.event_common import EventType
|
||||
from apiserver.bll.event.scalar_key import ScalarKeyEnum
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.utilities.stringenum import StringEnum
|
||||
|
||||
|
||||
class HistogramRequestBase(Base):
|
||||
samples: int = IntField(default=6000, validators=[Min(1), Max(6000)])
|
||||
samples: int = IntField(default=2000, validators=[Min(1), Max(6000)])
|
||||
key: ScalarKeyEnum = ActualEnumField(ScalarKeyEnum, default=ScalarKeyEnum.iter)
|
||||
|
||||
|
||||
class MetricVariants(Base):
|
||||
metric: str = StringField(required=True)
|
||||
variants: Sequence[str] = ListField(items_types=str)
|
||||
|
||||
|
||||
class ScalarMetricsIterHistogramRequest(HistogramRequestBase):
|
||||
task: str = StringField(required=True)
|
||||
metrics: Sequence[MetricVariants] = ListField(items_types=MetricVariants)
|
||||
|
||||
|
||||
class MultiTaskScalarMetricsIterHistogramRequest(HistogramRequestBase):
|
||||
tasks: Sequence[str] = ListField(
|
||||
items_types=str, validators=[Length(minimum_value=1, maximum_value=10)]
|
||||
items_types=str,
|
||||
validators=[
|
||||
Length(
|
||||
minimum_value=1,
|
||||
maximum_value=config.get(
|
||||
"services.tasks.multi_task_histogram_limit", 10
|
||||
),
|
||||
)
|
||||
],
|
||||
)
|
||||
|
||||
|
||||
class TaskMetric(Base):
|
||||
task: str = StringField(required=True)
|
||||
metric: str = StringField(required=True)
|
||||
metric: str = StringField(default=None)
|
||||
variants: Sequence[str] = ListField(items_types=str)
|
||||
|
||||
|
||||
class DebugImagesRequest(Base):
|
||||
@@ -42,6 +58,24 @@ class DebugImagesRequest(Base):
|
||||
scroll_id: str = StringField()
|
||||
|
||||
|
||||
class TaskMetricVariant(Base):
|
||||
task: str = StringField(required=True)
|
||||
metric: str = StringField(required=True)
|
||||
variant: str = StringField(required=True)
|
||||
|
||||
|
||||
class GetDebugImageSampleRequest(TaskMetricVariant):
|
||||
iteration: Optional[int] = IntField()
|
||||
refresh: bool = BoolField(default=False)
|
||||
scroll_id: Optional[str] = StringField()
|
||||
|
||||
|
||||
class NextDebugImageSampleRequest(Base):
|
||||
task: str = StringField(required=True)
|
||||
scroll_id: Optional[str] = StringField()
|
||||
navigate_earlier: bool = BoolField(default=True)
|
||||
|
||||
|
||||
class LogOrderEnum(StringEnum):
|
||||
asc = auto()
|
||||
desc = auto()
|
||||
@@ -62,7 +96,6 @@ class IterationEvents(Base):
|
||||
|
||||
class MetricEvents(Base):
|
||||
task: str = StringField()
|
||||
metric: str = StringField()
|
||||
iterations: Sequence[IterationEvents] = ListField(items_types=IterationEvents)
|
||||
|
||||
|
||||
@@ -76,3 +109,10 @@ class TaskMetricsRequest(Base):
|
||||
items_types=str, validators=[Length(minimum_value=1)]
|
||||
)
|
||||
event_type: EventType = ActualEnumField(EventType, required=True)
|
||||
|
||||
|
||||
class TaskPlotsRequest(Base):
|
||||
task: str = StringField(required=True)
|
||||
iters: int = IntField(default=1)
|
||||
scroll_id: str = StringField()
|
||||
metrics: Sequence[MetricVariants] = ListField(items_types=MetricVariants)
|
||||
34
apiserver/apimodels/login.py
Normal file
34
apiserver/apimodels/login.py
Normal file
@@ -0,0 +1,34 @@
|
||||
from jsonmodels.fields import StringField, BoolField, EmbeddedField, ListField
|
||||
from jsonmodels.models import Base
|
||||
|
||||
from apiserver.apimodels import DictField, callable_default
|
||||
|
||||
|
||||
class GetSupportedModesRequest(Base):
|
||||
state = StringField(help_text="ASCII base64 encoded application state")
|
||||
callback_url_prefix = StringField()
|
||||
|
||||
|
||||
class BasicGuestMode(Base):
|
||||
enabled = BoolField(default=False)
|
||||
name = StringField()
|
||||
username = StringField()
|
||||
password = StringField()
|
||||
|
||||
|
||||
class BasicMode(Base):
|
||||
enabled = BoolField(default=False)
|
||||
guest = callable_default(EmbeddedField)(BasicGuestMode, default=BasicGuestMode)
|
||||
|
||||
|
||||
class ServerErrors(Base):
|
||||
missed_es_upgrade = BoolField(default=False)
|
||||
es_connection_error = BoolField(default=False)
|
||||
|
||||
|
||||
class GetSupportedModesResponse(Base):
|
||||
basic = EmbeddedField(BasicMode)
|
||||
server_errors = EmbeddedField(ServerErrors)
|
||||
sso = DictField([str, type(None)])
|
||||
sso_providers = ListField([dict])
|
||||
authenticated = BoolField(default=False)
|
||||
23
apiserver/apimodels/metadata.py
Normal file
23
apiserver/apimodels/metadata.py
Normal file
@@ -0,0 +1,23 @@
|
||||
from typing import Sequence
|
||||
|
||||
from jsonmodels import validators
|
||||
from jsonmodels.fields import StringField
|
||||
from jsonmodels.models import Base
|
||||
|
||||
from apiserver.apimodels import ListField
|
||||
|
||||
|
||||
class MetadataItem(Base):
|
||||
key = StringField(required=True)
|
||||
type = StringField(required=True)
|
||||
value = StringField(required=True)
|
||||
|
||||
|
||||
class DeleteMetadata(Base):
|
||||
keys: Sequence[str] = ListField(str, validators=validators.Length(minimum_value=1))
|
||||
|
||||
|
||||
class AddOrUpdateMetadata(Base):
|
||||
metadata: Sequence[MetadataItem] = ListField(
|
||||
[MetadataItem], validators=validators.Length(minimum_value=1)
|
||||
)
|
||||
@@ -1,9 +1,14 @@
|
||||
from jsonmodels import models, fields
|
||||
from six import string_types
|
||||
|
||||
from apimodels import ListField, DictField
|
||||
from apimodels.base import UpdateResponse
|
||||
from apimodels.tasks import PublishResponse as TaskPublishResponse
|
||||
from apiserver.apimodels import ListField, DictField
|
||||
from apiserver.apimodels.base import UpdateResponse
|
||||
from apiserver.apimodels.batch import BatchRequest
|
||||
from apiserver.apimodels.metadata import (
|
||||
MetadataItem,
|
||||
DeleteMetadata,
|
||||
AddOrUpdateMetadata,
|
||||
)
|
||||
|
||||
|
||||
class GetFrameworksRequest(models.Base):
|
||||
@@ -13,7 +18,7 @@ class GetFrameworksRequest(models.Base):
|
||||
class CreateModelRequest(models.Base):
|
||||
name = fields.StringField(required=True)
|
||||
uri = fields.StringField(required=True)
|
||||
labels = DictField(value_types=string_types+(int,))
|
||||
labels = DictField(value_types=string_types + (int,))
|
||||
tags = ListField(items_types=string_types)
|
||||
system_tags = ListField(items_types=string_types)
|
||||
comment = fields.StringField()
|
||||
@@ -25,6 +30,7 @@ class CreateModelRequest(models.Base):
|
||||
ready = fields.BoolField(default=True)
|
||||
ui_cache = DictField()
|
||||
task = fields.StringField()
|
||||
metadata = ListField(items_types=[MetadataItem])
|
||||
|
||||
|
||||
class CreateModelResponse(models.Base):
|
||||
@@ -32,17 +38,40 @@ class CreateModelResponse(models.Base):
|
||||
created = fields.BoolField(required=True)
|
||||
|
||||
|
||||
class PublishModelRequest(models.Base):
|
||||
class ModelRequest(models.Base):
|
||||
model = fields.StringField(required=True)
|
||||
|
||||
|
||||
class DeleteModelRequest(ModelRequest):
|
||||
force = fields.BoolField(default=False)
|
||||
|
||||
|
||||
class ModelsDeleteManyRequest(BatchRequest):
|
||||
force = fields.BoolField(default=False)
|
||||
|
||||
|
||||
class PublishModelRequest(ModelRequest):
|
||||
force_publish_task = fields.BoolField(default=False)
|
||||
publish_task = fields.BoolField(default=True)
|
||||
|
||||
|
||||
class ModelTaskPublishResponse(models.Base):
|
||||
id = fields.StringField(required=True)
|
||||
data = fields.EmbeddedField(TaskPublishResponse)
|
||||
data = fields.EmbeddedField(UpdateResponse)
|
||||
|
||||
|
||||
class PublishModelResponse(UpdateResponse):
|
||||
published_task = fields.EmbeddedField(ModelTaskPublishResponse)
|
||||
updated = fields.IntField()
|
||||
|
||||
|
||||
class ModelsPublishManyRequest(BatchRequest):
|
||||
force_publish_task = fields.BoolField(default=False)
|
||||
publish_task = fields.BoolField(default=True)
|
||||
|
||||
|
||||
class DeleteMetadataRequest(DeleteMetadata):
|
||||
model = fields.StringField(required=True)
|
||||
|
||||
|
||||
class AddOrUpdateMetadataRequest(AddOrUpdateMetadata):
|
||||
model = fields.StringField(required=True)
|
||||
60
apiserver/apimodels/projects.py
Normal file
60
apiserver/apimodels/projects.py
Normal file
@@ -0,0 +1,60 @@
|
||||
from jsonmodels import models, fields
|
||||
|
||||
from apiserver.apimodels import ListField, ActualEnumField
|
||||
from apiserver.apimodels.organization import TagsRequest
|
||||
from apiserver.database.model import EntityVisibility
|
||||
|
||||
|
||||
class ProjectRequest(models.Base):
|
||||
project = fields.StringField(required=True)
|
||||
|
||||
|
||||
class MergeRequest(ProjectRequest):
|
||||
destination_project = fields.StringField()
|
||||
|
||||
|
||||
class MoveRequest(ProjectRequest):
|
||||
new_location = fields.StringField()
|
||||
|
||||
|
||||
class DeleteRequest(ProjectRequest):
|
||||
force = fields.BoolField(default=False)
|
||||
delete_contents = fields.BoolField(default=False)
|
||||
|
||||
|
||||
class ProjectOrNoneRequest(models.Base):
|
||||
project = fields.StringField()
|
||||
include_subprojects = fields.BoolField(default=True)
|
||||
|
||||
|
||||
class GetHyperParamRequest(ProjectOrNoneRequest):
|
||||
page = fields.IntField(default=0)
|
||||
page_size = fields.IntField(default=500)
|
||||
|
||||
|
||||
class ProjectTagsRequest(TagsRequest):
|
||||
projects = ListField(str)
|
||||
|
||||
|
||||
class MultiProjectRequest(models.Base):
|
||||
projects = fields.ListField(str)
|
||||
include_subprojects = fields.BoolField(default=True)
|
||||
|
||||
|
||||
class ProjectTaskParentsRequest(MultiProjectRequest):
|
||||
tasks_state = ActualEnumField(EntityVisibility)
|
||||
|
||||
|
||||
class ProjectHyperparamValuesRequest(MultiProjectRequest):
|
||||
section = fields.StringField(required=True)
|
||||
name = fields.StringField(required=True)
|
||||
allow_public = fields.BoolField(default=True)
|
||||
|
||||
|
||||
class ProjectsGetRequest(models.Base):
|
||||
include_stats = fields.BoolField(default=False)
|
||||
stats_for_state = ActualEnumField(EntityVisibility, default=EntityVisibility.active)
|
||||
non_public = fields.BoolField(default=False)
|
||||
active_users = fields.ListField(str)
|
||||
check_own_contents = fields.BoolField(default=False)
|
||||
shallow_search = fields.BoolField(default=False)
|
||||
@@ -2,7 +2,12 @@ from jsonmodels import validators
|
||||
from jsonmodels.fields import StringField, IntField, BoolField, FloatField
|
||||
from jsonmodels.models import Base
|
||||
|
||||
from apimodels import ListField
|
||||
from apiserver.apimodels import ListField
|
||||
from apiserver.apimodels.metadata import (
|
||||
MetadataItem,
|
||||
DeleteMetadata,
|
||||
AddOrUpdateMetadata,
|
||||
)
|
||||
|
||||
|
||||
class GetDefaultResp(Base):
|
||||
@@ -14,6 +19,7 @@ class CreateRequest(Base):
|
||||
name = StringField(required=True)
|
||||
tags = ListField(items_types=[str])
|
||||
system_tags = ListField(items_types=[str])
|
||||
metadata = ListField(items_types=[MetadataItem])
|
||||
|
||||
|
||||
class QueueRequest(Base):
|
||||
@@ -28,6 +34,7 @@ class UpdateRequest(QueueRequest):
|
||||
name = StringField()
|
||||
tags = ListField(items_types=[str])
|
||||
system_tags = ListField(items_types=[str])
|
||||
metadata = ListField(items_types=[MetadataItem])
|
||||
|
||||
|
||||
class TaskRequest(QueueRequest):
|
||||
@@ -58,3 +65,11 @@ class QueueMetrics(Base):
|
||||
|
||||
class GetMetricsResponse(Base):
|
||||
queues = ListField(QueueMetrics)
|
||||
|
||||
|
||||
class DeleteMetadataRequest(DeleteMetadata):
|
||||
queue = StringField(required=True)
|
||||
|
||||
|
||||
class AddOrUpdateMetadataRequest(AddOrUpdateMetadata):
|
||||
queue = StringField(required=True)
|
||||
302
apiserver/apimodels/tasks.py
Normal file
302
apiserver/apimodels/tasks.py
Normal file
@@ -0,0 +1,302 @@
|
||||
from typing import Sequence
|
||||
|
||||
from jsonmodels import models
|
||||
from jsonmodels.fields import StringField, BoolField, IntField, EmbeddedField
|
||||
from jsonmodels.validators import Enum, Length
|
||||
|
||||
from apiserver.apimodels import DictField, ListField
|
||||
from apiserver.apimodels.base import UpdateResponse
|
||||
from apiserver.apimodels.batch import BatchRequest, UpdateBatchItem, BatchResponse
|
||||
from apiserver.database.model.task.task import (
|
||||
TaskType,
|
||||
ArtifactModes,
|
||||
DEFAULT_ARTIFACT_MODE,
|
||||
TaskModelTypes,
|
||||
)
|
||||
from apiserver.database.utils import get_options
|
||||
|
||||
|
||||
class ArtifactTypeData(models.Base):
|
||||
preview = StringField()
|
||||
content_type = StringField()
|
||||
data_hash = StringField()
|
||||
|
||||
|
||||
class Artifact(models.Base):
|
||||
key = StringField(required=True)
|
||||
type = StringField(required=True)
|
||||
mode = StringField(
|
||||
validators=Enum(*get_options(ArtifactModes)), default=DEFAULT_ARTIFACT_MODE
|
||||
)
|
||||
uri = StringField()
|
||||
hash = StringField()
|
||||
content_size = IntField()
|
||||
timestamp = IntField()
|
||||
type_data = EmbeddedField(ArtifactTypeData)
|
||||
display_data = ListField([list])
|
||||
|
||||
|
||||
class StartedResponse(UpdateResponse):
|
||||
started = IntField()
|
||||
|
||||
|
||||
class EnqueueResponse(UpdateResponse):
|
||||
queued = IntField()
|
||||
|
||||
|
||||
class EnqueueBatchItem(UpdateBatchItem):
|
||||
queued: bool = BoolField()
|
||||
|
||||
|
||||
class EnqueueManyResponse(BatchResponse):
|
||||
succeeded: Sequence[EnqueueBatchItem] = ListField(EnqueueBatchItem)
|
||||
|
||||
|
||||
class DequeueResponse(UpdateResponse):
|
||||
dequeued = IntField()
|
||||
|
||||
|
||||
class DequeueBatchItem(UpdateBatchItem):
|
||||
dequeued: bool = BoolField()
|
||||
|
||||
|
||||
class DequeueManyResponse(BatchResponse):
|
||||
succeeded: Sequence[DequeueBatchItem] = ListField(DequeueBatchItem)
|
||||
|
||||
|
||||
class ResetResponse(UpdateResponse):
|
||||
dequeued = DictField()
|
||||
events = DictField()
|
||||
deleted_models = IntField()
|
||||
urls = DictField()
|
||||
|
||||
|
||||
class ResetBatchItem(UpdateBatchItem):
|
||||
dequeued: bool = BoolField()
|
||||
deleted_models = IntField()
|
||||
urls = DictField()
|
||||
|
||||
|
||||
class ResetManyResponse(BatchResponse):
|
||||
succeeded: Sequence[ResetBatchItem] = ListField(ResetBatchItem)
|
||||
|
||||
|
||||
class TaskRequest(models.Base):
|
||||
task = StringField(required=True)
|
||||
|
||||
|
||||
class TaskUpdateRequest(TaskRequest):
|
||||
force = BoolField(default=False)
|
||||
|
||||
|
||||
class UpdateRequest(TaskUpdateRequest):
|
||||
status_reason = StringField(default="")
|
||||
status_message = StringField(default="")
|
||||
|
||||
|
||||
class EnqueueRequest(UpdateRequest):
|
||||
queue = StringField()
|
||||
|
||||
|
||||
class DeleteRequest(UpdateRequest):
|
||||
move_to_trash = BoolField(default=True)
|
||||
return_file_urls = BoolField(default=False)
|
||||
delete_output_models = BoolField(default=True)
|
||||
|
||||
|
||||
class SetRequirementsRequest(TaskRequest):
|
||||
requirements = DictField(required=True)
|
||||
|
||||
|
||||
class PublishRequest(UpdateRequest):
|
||||
publish_model = BoolField(default=True)
|
||||
|
||||
|
||||
class TaskData(models.Base):
|
||||
"""
|
||||
This is a partial description of task can be updated incrementally
|
||||
"""
|
||||
|
||||
|
||||
class CreateRequest(TaskData):
|
||||
name = StringField(required=True)
|
||||
type = StringField(required=True, validators=Enum(*get_options(TaskType)))
|
||||
|
||||
|
||||
class PingRequest(TaskRequest):
|
||||
pass
|
||||
|
||||
|
||||
class GetTypesRequest(models.Base):
|
||||
projects = ListField(items_types=[str])
|
||||
|
||||
|
||||
class TaskInputModel(models.Base):
|
||||
name = StringField()
|
||||
model = StringField()
|
||||
|
||||
|
||||
class CloneRequest(TaskRequest):
|
||||
new_task_name = StringField()
|
||||
new_task_comment = StringField()
|
||||
new_task_tags = ListField([str])
|
||||
new_task_system_tags = ListField([str])
|
||||
new_task_parent = StringField()
|
||||
new_task_project = StringField()
|
||||
new_task_hyperparams = DictField()
|
||||
new_task_configuration = DictField()
|
||||
new_task_container = DictField()
|
||||
new_task_input_models = ListField([TaskInputModel])
|
||||
execution_overrides = DictField()
|
||||
validate_references = BoolField(default=False)
|
||||
new_project_name = StringField()
|
||||
|
||||
|
||||
class AddOrUpdateArtifactsRequest(TaskUpdateRequest):
|
||||
artifacts = ListField([Artifact], validators=Length(minimum_value=1))
|
||||
|
||||
|
||||
class ArtifactId(models.Base):
|
||||
key = StringField(required=True)
|
||||
mode = StringField(
|
||||
validators=Enum(*get_options(ArtifactModes)), default=DEFAULT_ARTIFACT_MODE
|
||||
)
|
||||
|
||||
|
||||
class DeleteArtifactsRequest(TaskUpdateRequest):
|
||||
artifacts = ListField([ArtifactId], validators=Length(minimum_value=1))
|
||||
|
||||
|
||||
class ResetRequest(UpdateRequest):
|
||||
clear_all = BoolField(default=False)
|
||||
return_file_urls = BoolField(default=False)
|
||||
delete_output_models = BoolField(default=True)
|
||||
|
||||
|
||||
class MultiTaskRequest(models.Base):
|
||||
tasks = ListField([str], validators=Length(minimum_value=1))
|
||||
|
||||
|
||||
class GetHyperParamsRequest(MultiTaskRequest):
|
||||
pass
|
||||
|
||||
|
||||
class HyperParamItem(models.Base):
|
||||
section = StringField(required=True, validators=Length(minimum_value=1))
|
||||
name = StringField(required=True, validators=Length(minimum_value=1))
|
||||
value = StringField(required=True)
|
||||
type = StringField()
|
||||
description = StringField()
|
||||
|
||||
|
||||
class ReplaceHyperparams(object):
|
||||
none = "none"
|
||||
section = "section"
|
||||
all = "all"
|
||||
|
||||
|
||||
class EditHyperParamsRequest(TaskUpdateRequest):
|
||||
hyperparams: Sequence[HyperParamItem] = ListField(
|
||||
[HyperParamItem], validators=Length(minimum_value=1)
|
||||
)
|
||||
replace_hyperparams = StringField(
|
||||
validators=Enum(*get_options(ReplaceHyperparams)),
|
||||
default=ReplaceHyperparams.none,
|
||||
)
|
||||
|
||||
|
||||
class HyperParamKey(models.Base):
|
||||
section = StringField(required=True, validators=Length(minimum_value=1))
|
||||
name = StringField(nullable=True)
|
||||
|
||||
|
||||
class DeleteHyperParamsRequest(TaskUpdateRequest):
|
||||
hyperparams: Sequence[HyperParamKey] = ListField(
|
||||
[HyperParamKey], validators=Length(minimum_value=1)
|
||||
)
|
||||
|
||||
|
||||
class GetConfigurationsRequest(MultiTaskRequest):
|
||||
names = ListField([str])
|
||||
|
||||
|
||||
class GetConfigurationNamesRequest(MultiTaskRequest):
|
||||
skip_empty = BoolField(default=True)
|
||||
|
||||
|
||||
class Configuration(models.Base):
|
||||
name = StringField(required=True, validators=Length(minimum_value=1))
|
||||
value = StringField(required=True)
|
||||
type = StringField()
|
||||
description = StringField()
|
||||
|
||||
|
||||
class EditConfigurationRequest(TaskUpdateRequest):
|
||||
configuration: Sequence[Configuration] = ListField(
|
||||
[Configuration], validators=Length(minimum_value=1)
|
||||
)
|
||||
replace_configuration = BoolField(default=False)
|
||||
|
||||
|
||||
class DeleteConfigurationRequest(TaskUpdateRequest):
|
||||
configuration: Sequence[str] = ListField([str], validators=Length(minimum_value=1))
|
||||
|
||||
|
||||
class ArchiveRequest(MultiTaskRequest):
|
||||
status_reason = StringField(default="")
|
||||
status_message = StringField(default="")
|
||||
|
||||
|
||||
class ArchiveResponse(models.Base):
|
||||
archived = IntField()
|
||||
|
||||
|
||||
class TaskBatchRequest(BatchRequest):
|
||||
status_reason = StringField(default="")
|
||||
status_message = StringField(default="")
|
||||
|
||||
|
||||
class StopManyRequest(TaskBatchRequest):
|
||||
force = BoolField(default=False)
|
||||
|
||||
|
||||
class EnqueueManyRequest(TaskBatchRequest):
|
||||
queue = StringField()
|
||||
validate_tasks = BoolField(default=False)
|
||||
|
||||
|
||||
class DeleteManyRequest(TaskBatchRequest):
|
||||
move_to_trash = BoolField(default=True)
|
||||
return_file_urls = BoolField(default=False)
|
||||
delete_output_models = BoolField(default=True)
|
||||
force = BoolField(default=False)
|
||||
|
||||
|
||||
class ResetManyRequest(TaskBatchRequest):
|
||||
clear_all = BoolField(default=False)
|
||||
return_file_urls = BoolField(default=False)
|
||||
delete_output_models = BoolField(default=True)
|
||||
force = BoolField(default=False)
|
||||
|
||||
|
||||
class PublishManyRequest(TaskBatchRequest):
|
||||
publish_model = BoolField(default=True)
|
||||
force = BoolField(default=False)
|
||||
|
||||
|
||||
class AddUpdateModelRequest(TaskRequest):
|
||||
name = StringField(required=True)
|
||||
model = StringField(required=True)
|
||||
type = StringField(required=True, validators=Enum(*get_options(TaskModelTypes)))
|
||||
iteration = IntField()
|
||||
|
||||
|
||||
class ModelItemKey(models.Base):
|
||||
name = StringField(required=True)
|
||||
type = StringField(required=True, validators=Enum(*get_options(TaskModelTypes)))
|
||||
|
||||
|
||||
class DeleteModelsRequest(TaskRequest):
|
||||
models: Sequence[ModelItemKey] = ListField(
|
||||
[ModelItemKey], validators=Length(minimum_value=1)
|
||||
)
|
||||
@@ -1,7 +1,7 @@
|
||||
from jsonmodels.fields import StringField
|
||||
from jsonmodels.models import Base
|
||||
|
||||
from apimodels import DictField
|
||||
from apiserver.apimodels import DictField
|
||||
|
||||
|
||||
class CreateRequest(Base):
|
||||
@@ -12,7 +12,7 @@ from jsonmodels.fields import (
|
||||
)
|
||||
from jsonmodels.models import Base
|
||||
|
||||
from apimodels import make_default, ListField, EnumField, JsonSerializableMixin
|
||||
from apiserver.apimodels import make_default, ListField, EnumField, JsonSerializableMixin
|
||||
|
||||
DEFAULT_TIMEOUT = 10 * 60
|
||||
|
||||
@@ -1,17 +1,17 @@
|
||||
from datetime import datetime
|
||||
|
||||
import database
|
||||
from apierrors import errors
|
||||
from apimodels.auth import GetTokenResponse, CreateUserRequest, Credentials as CredModel
|
||||
from apimodels.users import CreateRequest as Users_CreateRequest
|
||||
from bll.user import UserBLL
|
||||
from config import config
|
||||
from config.info import get_version, get_build_number
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.auth import User, Role, Credentials
|
||||
from database.model.company import Company
|
||||
from service_repo import APICall, ServiceRepo
|
||||
from service_repo.auth import Identity, Token, get_client_id, get_secret_key
|
||||
from apiserver import database
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.apimodels.auth import GetTokenResponse, CreateUserRequest, Credentials as CredModel
|
||||
from apiserver.apimodels.users import CreateRequest as Users_CreateRequest
|
||||
from apiserver.bll.user import UserBLL
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.config.info import get_version, get_build_number
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.database.model.auth import User, Role, Credentials
|
||||
from apiserver.database.model.company import Company
|
||||
from apiserver.service_repo import APICall, ServiceRepo
|
||||
from apiserver.service_repo.auth import Identity, Token, get_client_id, get_secret_key
|
||||
|
||||
log = config.logger("AuthBLL")
|
||||
|
||||
@@ -57,6 +57,7 @@ class AuthBLL:
|
||||
api_version=str(ServiceRepo.max_endpoint_version()),
|
||||
server_version=str(get_version()),
|
||||
server_build=str(get_build_number()),
|
||||
feature_set="basic",
|
||||
)
|
||||
|
||||
return GetTokenResponse(token=token.decode("ascii"))
|
||||
415
apiserver/bll/event/debug_images_iterator.py
Normal file
415
apiserver/bll/event/debug_images_iterator.py
Normal file
@@ -0,0 +1,415 @@
|
||||
from concurrent.futures.thread import ThreadPoolExecutor
|
||||
from datetime import datetime
|
||||
from functools import partial
|
||||
from operator import itemgetter
|
||||
from typing import Sequence, Tuple, Optional, Mapping
|
||||
|
||||
import attr
|
||||
import dpath
|
||||
from boltons.iterutils import first
|
||||
from elasticsearch import Elasticsearch
|
||||
from jsonmodels.fields import StringField, ListField, IntField
|
||||
from jsonmodels.models import Base
|
||||
from redis import StrictRedis
|
||||
|
||||
from apiserver.apimodels import JsonSerializableMixin
|
||||
from apiserver.bll.event.event_common import (
|
||||
EventSettings,
|
||||
check_empty_data,
|
||||
search_company_events,
|
||||
EventType,
|
||||
get_metric_variants_condition,
|
||||
)
|
||||
from apiserver.bll.redis_cache_manager import RedisCacheManager
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.database.model.task.metrics import MetricEventStats
|
||||
from apiserver.database.model.task.task import Task
|
||||
from apiserver.timing_context import TimingContext
|
||||
|
||||
|
||||
class VariantState(Base):
|
||||
variant: str = StringField(required=True)
|
||||
last_invalid_iteration: int = IntField()
|
||||
|
||||
|
||||
class MetricState(Base):
|
||||
metric: str = StringField(required=True)
|
||||
variants: Sequence[VariantState] = ListField([VariantState], required=True)
|
||||
timestamp: int = IntField(default=0)
|
||||
|
||||
|
||||
class TaskScrollState(Base):
|
||||
task: str = StringField(required=True)
|
||||
metrics: Sequence[MetricState] = ListField([MetricState], required=True)
|
||||
last_min_iter: Optional[int] = IntField()
|
||||
last_max_iter: Optional[int] = IntField()
|
||||
|
||||
def reset(self):
|
||||
"""Reset the scrolling state for the metric"""
|
||||
self.last_min_iter = self.last_max_iter = None
|
||||
|
||||
|
||||
class DebugImageEventsScrollState(Base, JsonSerializableMixin):
|
||||
id: str = StringField(required=True)
|
||||
tasks: Sequence[TaskScrollState] = ListField([TaskScrollState])
|
||||
warning: str = StringField()
|
||||
|
||||
|
||||
@attr.s(auto_attribs=True)
|
||||
class DebugImagesResult(object):
|
||||
metric_events: Sequence[tuple] = []
|
||||
next_scroll_id: str = None
|
||||
|
||||
|
||||
class DebugImagesIterator:
|
||||
EVENT_TYPE = EventType.metrics_image
|
||||
|
||||
def __init__(self, redis: StrictRedis, es: Elasticsearch):
|
||||
self.es = es
|
||||
self.cache_manager = RedisCacheManager(
|
||||
state_class=DebugImageEventsScrollState,
|
||||
redis=redis,
|
||||
expiration_interval=EventSettings.state_expiration_sec,
|
||||
)
|
||||
|
||||
def get_task_events(
|
||||
self,
|
||||
company_id: str,
|
||||
task_metrics: Mapping[str, dict],
|
||||
iter_count: int,
|
||||
navigate_earlier: bool = True,
|
||||
refresh: bool = False,
|
||||
state_id: str = None,
|
||||
) -> DebugImagesResult:
|
||||
if check_empty_data(self.es, company_id, self.EVENT_TYPE):
|
||||
return DebugImagesResult()
|
||||
|
||||
def init_state(state_: DebugImageEventsScrollState):
|
||||
state_.tasks = self._init_task_states(company_id, task_metrics)
|
||||
|
||||
def validate_state(state_: DebugImageEventsScrollState):
|
||||
"""
|
||||
Validate that the metrics stored in the state are the same
|
||||
as requested in the current call.
|
||||
Refresh the state if requested
|
||||
"""
|
||||
if refresh:
|
||||
self._reinit_outdated_task_states(company_id, state_, task_metrics)
|
||||
|
||||
with self.cache_manager.get_or_create_state(
|
||||
state_id=state_id, init_state=init_state, validate_state=validate_state
|
||||
) as state:
|
||||
res = DebugImagesResult(next_scroll_id=state.id)
|
||||
with ThreadPoolExecutor(EventSettings.max_workers) as pool:
|
||||
res.metric_events = list(
|
||||
pool.map(
|
||||
partial(
|
||||
self._get_task_metric_events,
|
||||
company_id=company_id,
|
||||
iter_count=iter_count,
|
||||
navigate_earlier=navigate_earlier,
|
||||
),
|
||||
state.tasks,
|
||||
)
|
||||
)
|
||||
|
||||
return res
|
||||
|
||||
def _reinit_outdated_task_states(
|
||||
self,
|
||||
company_id,
|
||||
state: DebugImageEventsScrollState,
|
||||
task_metrics: Mapping[str, dict],
|
||||
):
|
||||
"""
|
||||
Determine the metrics for which new debug image events were added
|
||||
since their states were initialized and re-init these states
|
||||
"""
|
||||
tasks = Task.objects(id__in=list(task_metrics), company=company_id).only(
|
||||
"id", "metric_stats"
|
||||
)
|
||||
|
||||
def get_last_update_times_for_task_metrics(
|
||||
task: Task,
|
||||
) -> Mapping[str, datetime]:
|
||||
"""For metrics that reported debug image events get mapping of the metric name to the last update times"""
|
||||
metric_stats: Mapping[str, MetricEventStats] = task.metric_stats
|
||||
if not metric_stats:
|
||||
return {}
|
||||
|
||||
requested_metrics = task_metrics[task.id]
|
||||
return {
|
||||
stats.metric: stats.event_stats_by_type[
|
||||
self.EVENT_TYPE.value
|
||||
].last_update
|
||||
for stats in metric_stats.values()
|
||||
if self.EVENT_TYPE.value in stats.event_stats_by_type
|
||||
and (not requested_metrics or stats.metric in requested_metrics)
|
||||
}
|
||||
|
||||
update_times = {
|
||||
task.id: get_last_update_times_for_task_metrics(task) for task in tasks
|
||||
}
|
||||
task_metric_states = {
|
||||
task_state.task: {
|
||||
metric_state.metric: metric_state for metric_state in task_state.metrics
|
||||
}
|
||||
for task_state in state.tasks
|
||||
}
|
||||
task_metrics_to_recalc = {}
|
||||
for task, metrics_times in update_times.items():
|
||||
old_metric_states = task_metric_states[task]
|
||||
metrics_to_recalc = {
|
||||
m: task_metrics[task].get(m)
|
||||
for m, t in metrics_times.items()
|
||||
if m not in old_metric_states or old_metric_states[m].timestamp < t
|
||||
}
|
||||
if metrics_to_recalc:
|
||||
task_metrics_to_recalc[task] = metrics_to_recalc
|
||||
|
||||
updated_task_states = self._init_task_states(company_id, task_metrics_to_recalc)
|
||||
|
||||
def merge_with_updated_task_states(
|
||||
old_state: TaskScrollState, updates: Sequence[TaskScrollState]
|
||||
) -> TaskScrollState:
|
||||
task = old_state.task
|
||||
updated_state = first(uts for uts in updates if uts.task == task)
|
||||
if not updated_state:
|
||||
old_state.reset()
|
||||
return old_state
|
||||
|
||||
updated_metrics = [m.metric for m in updated_state.metrics]
|
||||
return TaskScrollState(
|
||||
task=task,
|
||||
metrics=[
|
||||
*updated_state.metrics,
|
||||
*(
|
||||
old_metric
|
||||
for old_metric in old_state.metrics
|
||||
if old_metric.metric not in updated_metrics
|
||||
),
|
||||
],
|
||||
)
|
||||
|
||||
state.tasks = [
|
||||
merge_with_updated_task_states(task_state, updated_task_states)
|
||||
for task_state in state.tasks
|
||||
]
|
||||
|
||||
def _init_task_states(
|
||||
self, company_id: str, task_metrics: Mapping[str, dict]
|
||||
) -> Sequence[TaskScrollState]:
|
||||
"""
|
||||
Returned initialized metric scroll stated for the requested task metrics
|
||||
"""
|
||||
with ThreadPoolExecutor(EventSettings.max_workers) as pool:
|
||||
task_metric_states = pool.map(
|
||||
partial(self._init_metric_states_for_task, company_id=company_id),
|
||||
task_metrics.items(),
|
||||
)
|
||||
|
||||
return [
|
||||
TaskScrollState(task=task, metrics=metric_states,)
|
||||
for task, metric_states in zip(task_metrics, task_metric_states)
|
||||
]
|
||||
|
||||
def _init_metric_states_for_task(
|
||||
self, task_metrics: Tuple[str, dict], company_id: str
|
||||
) -> Sequence[MetricState]:
|
||||
"""
|
||||
Return metric scroll states for the task filled with the variant states
|
||||
for the variants that reported any debug images
|
||||
"""
|
||||
task, metrics = task_metrics
|
||||
must = [{"term": {"task": task}}, {"exists": {"field": "url"}}]
|
||||
if metrics:
|
||||
must.append(get_metric_variants_condition(metrics))
|
||||
query = {"bool": {"must": must}}
|
||||
es_req: dict = {
|
||||
"size": 0,
|
||||
"query": query,
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": EventSettings.max_metrics_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"last_event_timestamp": {"max": {"field": "timestamp"}},
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": EventSettings.max_variants_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"urls": {
|
||||
"terms": {
|
||||
"field": "url",
|
||||
"order": {"max_iter": "desc"},
|
||||
"size": 1, # we need only one url from the most recent iteration
|
||||
},
|
||||
"aggs": {
|
||||
"max_iter": {"max": {"field": "iter"}},
|
||||
"iters": {
|
||||
"top_hits": {
|
||||
"sort": {"iter": {"order": "desc"}},
|
||||
"size": 2, # need two last iterations so that we can take
|
||||
# the second one as invalid
|
||||
"_source": "iter",
|
||||
}
|
||||
},
|
||||
},
|
||||
}
|
||||
},
|
||||
},
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "_init_metric_states"):
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=self.EVENT_TYPE, body=es_req,
|
||||
)
|
||||
if "aggregations" not in es_res:
|
||||
return []
|
||||
|
||||
def init_variant_state(variant: dict):
|
||||
"""
|
||||
Return new variant state for the passed variant bucket
|
||||
If the image urls get recycled then fill the last_invalid_iteration field
|
||||
"""
|
||||
state = VariantState(variant=variant["key"])
|
||||
top_iter_url = dpath.get(variant, "urls/buckets")[0]
|
||||
iters = dpath.get(top_iter_url, "iters/hits/hits")
|
||||
if len(iters) > 1:
|
||||
state.last_invalid_iteration = dpath.get(iters[1], "_source/iter")
|
||||
return state
|
||||
|
||||
return [
|
||||
MetricState(
|
||||
metric=metric["key"],
|
||||
timestamp=dpath.get(metric, "last_event_timestamp/value"),
|
||||
variants=[
|
||||
init_variant_state(variant)
|
||||
for variant in dpath.get(metric, "variants/buckets")
|
||||
],
|
||||
)
|
||||
for metric in dpath.get(es_res, "aggregations/metrics/buckets")
|
||||
]
|
||||
|
||||
def _get_task_metric_events(
|
||||
self,
|
||||
task_state: TaskScrollState,
|
||||
company_id: str,
|
||||
iter_count: int,
|
||||
navigate_earlier: bool,
|
||||
) -> Tuple:
|
||||
"""
|
||||
Return task metric events grouped by iterations
|
||||
Update task scroll state
|
||||
"""
|
||||
if not task_state.metrics:
|
||||
return task_state.task, []
|
||||
|
||||
if task_state.last_max_iter is None:
|
||||
# the first fetch is always from the latest iteration to the earlier ones
|
||||
navigate_earlier = True
|
||||
|
||||
must_conditions = [
|
||||
{"term": {"task": task_state.task}},
|
||||
{"terms": {"metric": [m.metric for m in task_state.metrics]}},
|
||||
{"exists": {"field": "url"}},
|
||||
]
|
||||
|
||||
range_condition = None
|
||||
if navigate_earlier and task_state.last_min_iter is not None:
|
||||
range_condition = {"lt": task_state.last_min_iter}
|
||||
elif not navigate_earlier and task_state.last_max_iter is not None:
|
||||
range_condition = {"gt": task_state.last_max_iter}
|
||||
if range_condition:
|
||||
must_conditions.append({"range": {"iter": range_condition}})
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": {"bool": {"must": must_conditions}},
|
||||
"aggs": {
|
||||
"iters": {
|
||||
"terms": {
|
||||
"field": "iter",
|
||||
"size": iter_count,
|
||||
"order": {"_key": "desc" if navigate_earlier else "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": EventSettings.max_metrics_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": EventSettings.max_variants_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"events": {
|
||||
"top_hits": {
|
||||
"sort": {"url": {"order": "desc"}}
|
||||
}
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
with translate_errors_context(), TimingContext("es", "get_debug_image_events"):
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=self.EVENT_TYPE, body=es_req,
|
||||
)
|
||||
if "aggregations" not in es_res:
|
||||
return task_state.task, []
|
||||
|
||||
invalid_iterations = {
|
||||
(m.metric, v.variant): v.last_invalid_iteration
|
||||
for m in task_state.metrics
|
||||
for v in m.variants
|
||||
}
|
||||
|
||||
def is_valid_event(event: dict) -> bool:
|
||||
key = event.get("metric"), event.get("variant")
|
||||
if key not in invalid_iterations:
|
||||
return False
|
||||
|
||||
max_invalid = invalid_iterations[key]
|
||||
return max_invalid is None or event.get("iter") > max_invalid
|
||||
|
||||
def get_iteration_events(it_: dict) -> Sequence:
|
||||
return [
|
||||
ev["_source"]
|
||||
for m in dpath.get(it_, "metrics/buckets")
|
||||
for v in dpath.get(m, "variants/buckets")
|
||||
for ev in dpath.get(v, "events/hits/hits")
|
||||
if is_valid_event(ev["_source"])
|
||||
]
|
||||
|
||||
iterations = []
|
||||
for it in dpath.get(es_res, "aggregations/iters/buckets"):
|
||||
events = get_iteration_events(it)
|
||||
if events:
|
||||
iterations.append({"iter": it["key"], "events": events})
|
||||
|
||||
if not navigate_earlier:
|
||||
iterations.sort(key=itemgetter("iter"), reverse=True)
|
||||
if iterations:
|
||||
task_state.last_max_iter = iterations[0]["iter"]
|
||||
task_state.last_min_iter = iterations[-1]["iter"]
|
||||
|
||||
return task_state.task, iterations
|
||||
375
apiserver/bll/event/debug_sample_history.py
Normal file
375
apiserver/bll/event/debug_sample_history.py
Normal file
@@ -0,0 +1,375 @@
|
||||
import operator
|
||||
from typing import Sequence, Tuple, Optional
|
||||
|
||||
import attr
|
||||
from boltons.iterutils import first
|
||||
from elasticsearch import Elasticsearch
|
||||
from jsonmodels.fields import StringField, ListField, IntField, BoolField
|
||||
from jsonmodels.models import Base
|
||||
from redis import StrictRedis
|
||||
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.apimodels import JsonSerializableMixin
|
||||
from apiserver.bll.event.event_common import (
|
||||
EventSettings,
|
||||
EventType,
|
||||
check_empty_data,
|
||||
search_company_events,
|
||||
)
|
||||
from apiserver.bll.redis_cache_manager import RedisCacheManager
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.timing_context import TimingContext
|
||||
from apiserver.utilities.dicts import nested_get
|
||||
|
||||
|
||||
class VariantState(Base):
|
||||
name: str = StringField(required=True)
|
||||
min_iteration: int = IntField()
|
||||
max_iteration: int = IntField()
|
||||
|
||||
|
||||
class DebugSampleHistoryState(Base, JsonSerializableMixin):
|
||||
id: str = StringField(required=True)
|
||||
iteration: int = IntField()
|
||||
variant: str = StringField()
|
||||
task: str = StringField()
|
||||
metric: str = StringField()
|
||||
reached_first: bool = BoolField()
|
||||
reached_last: bool = BoolField()
|
||||
variant_states: Sequence[VariantState] = ListField([VariantState])
|
||||
warning: str = StringField()
|
||||
|
||||
|
||||
@attr.s(auto_attribs=True)
|
||||
class DebugSampleHistoryResult(object):
|
||||
scroll_id: str = None
|
||||
event: dict = None
|
||||
min_iteration: int = None
|
||||
max_iteration: int = None
|
||||
|
||||
|
||||
class DebugSampleHistory:
|
||||
EVENT_TYPE = EventType.metrics_image
|
||||
|
||||
def __init__(self, redis: StrictRedis, es: Elasticsearch):
|
||||
self.es = es
|
||||
self.cache_manager = RedisCacheManager(
|
||||
state_class=DebugSampleHistoryState,
|
||||
redis=redis,
|
||||
expiration_interval=EventSettings.state_expiration_sec,
|
||||
)
|
||||
|
||||
def get_next_debug_image(
|
||||
self, company_id: str, task: str, state_id: str, navigate_earlier: bool
|
||||
) -> DebugSampleHistoryResult:
|
||||
"""
|
||||
Get the debug image for next/prev variant on the current iteration
|
||||
If does not exist then try getting image for the first/last variant from next/prev iteration
|
||||
"""
|
||||
res = DebugSampleHistoryResult(scroll_id=state_id)
|
||||
state = self.cache_manager.get_state(state_id)
|
||||
if not state or state.task != task:
|
||||
raise errors.bad_request.InvalidScrollId(scroll_id=state_id)
|
||||
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=self.EVENT_TYPE):
|
||||
return res
|
||||
|
||||
image = self._get_next_for_current_iteration(
|
||||
company_id=company_id, navigate_earlier=navigate_earlier, state=state
|
||||
) or self._get_next_for_another_iteration(
|
||||
company_id=company_id, navigate_earlier=navigate_earlier, state=state
|
||||
)
|
||||
if not image:
|
||||
return res
|
||||
|
||||
self._fill_res_and_update_state(image=image, res=res, state=state)
|
||||
self.cache_manager.set_state(state=state)
|
||||
return res
|
||||
|
||||
def _fill_res_and_update_state(
|
||||
self, image: dict, res: DebugSampleHistoryResult, state: DebugSampleHistoryState
|
||||
):
|
||||
state.variant = image["variant"]
|
||||
state.iteration = image["iter"]
|
||||
res.event = image
|
||||
var_state = first(s for s in state.variant_states if s.name == state.variant)
|
||||
if var_state:
|
||||
res.min_iteration = var_state.min_iteration
|
||||
res.max_iteration = var_state.max_iteration
|
||||
|
||||
def _get_next_for_current_iteration(
|
||||
self, company_id: str, navigate_earlier: bool, state: DebugSampleHistoryState
|
||||
) -> Optional[dict]:
|
||||
"""
|
||||
Get the image for next (if navigated earlier is False) or previous variant sorted by name for the same iteration
|
||||
Only variants for which the iteration falls into their valid range are considered
|
||||
Return None if no such variant or image is found
|
||||
"""
|
||||
cmp = operator.lt if navigate_earlier else operator.gt
|
||||
variants = [
|
||||
var_state
|
||||
for var_state in state.variant_states
|
||||
if cmp(var_state.name, state.variant)
|
||||
and var_state.min_iteration <= state.iteration
|
||||
]
|
||||
if not variants:
|
||||
return
|
||||
|
||||
must_conditions = [
|
||||
{"term": {"task": state.task}},
|
||||
{"term": {"metric": state.metric}},
|
||||
{"terms": {"variant": [v.name for v in variants]}},
|
||||
{"term": {"iter": state.iteration}},
|
||||
{"exists": {"field": "url"}},
|
||||
]
|
||||
es_req = {
|
||||
"size": 1,
|
||||
"sort": {"variant": "desc" if navigate_earlier else "asc"},
|
||||
"query": {"bool": {"must": must_conditions}},
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "get_next_for_current_iteration"
|
||||
):
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=self.EVENT_TYPE, body=es_req
|
||||
)
|
||||
|
||||
hits = nested_get(es_res, ("hits", "hits"))
|
||||
if not hits:
|
||||
return
|
||||
|
||||
return hits[0]["_source"]
|
||||
|
||||
def _get_next_for_another_iteration(
|
||||
self, company_id: str, navigate_earlier: bool, state: DebugSampleHistoryState
|
||||
) -> Optional[dict]:
|
||||
"""
|
||||
Get the image for the first variant for the next iteration (if navigate_earlier is set to False)
|
||||
or from the last variant for the previous iteration (otherwise)
|
||||
The variants for which the image falls in invalid range are discarded
|
||||
If no suitable image is found then None is returned
|
||||
"""
|
||||
|
||||
must_conditions = [
|
||||
{"term": {"task": state.task}},
|
||||
{"term": {"metric": state.metric}},
|
||||
{"exists": {"field": "url"}},
|
||||
]
|
||||
|
||||
if navigate_earlier:
|
||||
range_operator = "lt"
|
||||
order = "desc"
|
||||
variants = [
|
||||
var_state
|
||||
for var_state in state.variant_states
|
||||
if var_state.min_iteration < state.iteration
|
||||
]
|
||||
else:
|
||||
range_operator = "gt"
|
||||
order = "asc"
|
||||
variants = state.variant_states
|
||||
|
||||
if not variants:
|
||||
return
|
||||
|
||||
variants_conditions = [
|
||||
{
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"variant": v.name}},
|
||||
{"range": {"iter": {"gte": v.min_iteration}}},
|
||||
]
|
||||
}
|
||||
}
|
||||
for v in variants
|
||||
]
|
||||
must_conditions.append({"bool": {"should": variants_conditions}})
|
||||
must_conditions.append({"range": {"iter": {range_operator: state.iteration}}},)
|
||||
|
||||
es_req = {
|
||||
"size": 1,
|
||||
"sort": [{"iter": order}, {"variant": order}],
|
||||
"query": {"bool": {"must": must_conditions}},
|
||||
}
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "get_next_for_another_iteration"
|
||||
):
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=self.EVENT_TYPE, body=es_req
|
||||
)
|
||||
|
||||
hits = nested_get(es_res, ("hits", "hits"))
|
||||
if not hits:
|
||||
return
|
||||
|
||||
return hits[0]["_source"]
|
||||
|
||||
def get_debug_image_for_variant(
|
||||
self,
|
||||
company_id: str,
|
||||
task: str,
|
||||
metric: str,
|
||||
variant: str,
|
||||
iteration: Optional[int] = None,
|
||||
refresh: bool = False,
|
||||
state_id: str = None,
|
||||
) -> DebugSampleHistoryResult:
|
||||
"""
|
||||
Get the debug image for the requested iteration or the latest before it
|
||||
If the iteration is not passed then get the latest event
|
||||
"""
|
||||
res = DebugSampleHistoryResult()
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=self.EVENT_TYPE):
|
||||
return res
|
||||
|
||||
def init_state(state_: DebugSampleHistoryState):
|
||||
state_.task = task
|
||||
state_.metric = metric
|
||||
self._reset_variant_states(company_id=company_id, state=state_)
|
||||
|
||||
def validate_state(state_: DebugSampleHistoryState):
|
||||
if state_.task != task or state_.metric != metric:
|
||||
raise errors.bad_request.InvalidScrollId(
|
||||
"Task and metric stored in the state do not match the passed ones",
|
||||
scroll_id=state_.id,
|
||||
)
|
||||
if refresh:
|
||||
self._reset_variant_states(company_id=company_id, state=state_)
|
||||
|
||||
state: DebugSampleHistoryState
|
||||
with self.cache_manager.get_or_create_state(
|
||||
state_id=state_id, init_state=init_state, validate_state=validate_state,
|
||||
) as state:
|
||||
res.scroll_id = state.id
|
||||
|
||||
var_state = first(s for s in state.variant_states if s.name == variant)
|
||||
if not var_state:
|
||||
return res
|
||||
|
||||
res.min_iteration = var_state.min_iteration
|
||||
res.max_iteration = var_state.max_iteration
|
||||
|
||||
must_conditions = [
|
||||
{"term": {"task": task}},
|
||||
{"term": {"metric": metric}},
|
||||
{"term": {"variant": variant}},
|
||||
{"exists": {"field": "url"}},
|
||||
]
|
||||
if iteration is not None:
|
||||
must_conditions.append(
|
||||
{
|
||||
"range": {
|
||||
"iter": {"lte": iteration, "gte": var_state.min_iteration}
|
||||
}
|
||||
}
|
||||
)
|
||||
else:
|
||||
must_conditions.append(
|
||||
{"range": {"iter": {"gte": var_state.min_iteration}}}
|
||||
)
|
||||
|
||||
es_req = {
|
||||
"size": 1,
|
||||
"sort": {"iter": "desc"},
|
||||
"query": {"bool": {"must": must_conditions}},
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "get_debug_image_for_variant"
|
||||
):
|
||||
es_res = search_company_events(
|
||||
self.es,
|
||||
company_id=company_id,
|
||||
event_type=self.EVENT_TYPE,
|
||||
body=es_req,
|
||||
)
|
||||
|
||||
hits = nested_get(es_res, ("hits", "hits"))
|
||||
if not hits:
|
||||
return res
|
||||
|
||||
self._fill_res_and_update_state(
|
||||
image=hits[0]["_source"], res=res, state=state
|
||||
)
|
||||
return res
|
||||
|
||||
def _reset_variant_states(self, company_id: str, state: DebugSampleHistoryState):
|
||||
variant_iterations = self._get_variant_iterations(
|
||||
company_id=company_id, task=state.task, metric=state.metric
|
||||
)
|
||||
state.variant_states = [
|
||||
VariantState(name=var_name, min_iteration=min_iter, max_iteration=max_iter)
|
||||
for var_name, min_iter, max_iter in variant_iterations
|
||||
]
|
||||
|
||||
def _get_variant_iterations(
|
||||
self,
|
||||
company_id: str,
|
||||
task: str,
|
||||
metric: str,
|
||||
variants: Optional[Sequence[str]] = None,
|
||||
) -> Sequence[Tuple[str, int, int]]:
|
||||
"""
|
||||
Return valid min and max iterations that the task reported images
|
||||
The min iteration is the lowest iteration that contains non-recycled image url
|
||||
"""
|
||||
must = [
|
||||
{"term": {"task": task}},
|
||||
{"term": {"metric": metric}},
|
||||
{"exists": {"field": "url"}},
|
||||
]
|
||||
if variants:
|
||||
must.append({"terms": {"variant": variants}})
|
||||
|
||||
es_req: dict = {
|
||||
"size": 0,
|
||||
"query": {"bool": {"must": must}},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
# all variants that sent debug images
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": EventSettings.max_variants_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"last_iter": {"max": {"field": "iter"}},
|
||||
"urls": {
|
||||
# group by urls and choose the minimal iteration
|
||||
# from all the maximal iterations per url
|
||||
"terms": {
|
||||
"field": "url",
|
||||
"order": {"max_iter": "asc"},
|
||||
"size": 1,
|
||||
},
|
||||
"aggs": {
|
||||
# find max iteration for each url
|
||||
"max_iter": {"max": {"field": "iter"}}
|
||||
},
|
||||
},
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "get_debug_image_iterations"
|
||||
):
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=self.EVENT_TYPE, body=es_req
|
||||
)
|
||||
|
||||
def get_variant_data(variant_bucket: dict) -> Tuple[str, int, int]:
|
||||
variant = variant_bucket["key"]
|
||||
urls = nested_get(variant_bucket, ("urls", "buckets"))
|
||||
min_iter = int(urls[0]["max_iter"]["value"])
|
||||
max_iter = int(variant_bucket["last_iter"]["value"])
|
||||
return variant, min_iter, max_iter
|
||||
|
||||
return [
|
||||
get_variant_data(variant_bucket)
|
||||
for variant_bucket in nested_get(
|
||||
es_res, ("aggregations", "variants", "buckets")
|
||||
)
|
||||
]
|
||||
@@ -1,38 +1,68 @@
|
||||
import base64
|
||||
import hashlib
|
||||
import re
|
||||
import zlib
|
||||
from collections import defaultdict
|
||||
from contextlib import closing
|
||||
from datetime import datetime
|
||||
from operator import attrgetter
|
||||
from typing import Sequence, Set, Tuple, Optional
|
||||
from typing import Sequence, Set, Tuple, Optional, List, Mapping, Union
|
||||
|
||||
import six
|
||||
from elasticsearch import helpers
|
||||
from elasticsearch.helpers import BulkIndexError
|
||||
from mongoengine import Q
|
||||
from nested_dict import nested_dict
|
||||
|
||||
import database.utils as dbutils
|
||||
import es_factory
|
||||
from apierrors import errors
|
||||
from bll.event.debug_images_iterator import DebugImagesIterator
|
||||
from bll.event.event_metrics import EventMetrics, EventType
|
||||
from bll.event.log_events_iterator import LogEventsIterator, TaskEventsResult
|
||||
from bll.task import TaskBLL
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.task.task import Task, TaskStatus
|
||||
from redis_manager import redman
|
||||
from timing_context import TimingContext
|
||||
from tools import safe_get
|
||||
from utilities.dicts import flatten_nested_items
|
||||
from apiserver.bll.event.debug_sample_history import DebugSampleHistory
|
||||
from apiserver.bll.event.event_common import (
|
||||
EventType,
|
||||
EventSettings,
|
||||
get_index_name,
|
||||
check_empty_data,
|
||||
search_company_events,
|
||||
delete_company_events,
|
||||
MetricVariants,
|
||||
get_metric_variants_condition,
|
||||
)
|
||||
from apiserver.bll.util import parallel_chunked_decorator
|
||||
from apiserver.database import utils as dbutils
|
||||
from apiserver.es_factory import es_factory
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.bll.event.debug_images_iterator import DebugImagesIterator
|
||||
from apiserver.bll.event.event_metrics import EventMetrics
|
||||
from apiserver.bll.event.log_events_iterator import LogEventsIterator, TaskEventsResult
|
||||
from apiserver.bll.task import TaskBLL
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.database.model.task.task import Task, TaskStatus
|
||||
from apiserver.redis_manager import redman
|
||||
from apiserver.timing_context import TimingContext
|
||||
from apiserver.tools import safe_get
|
||||
from apiserver.utilities.dicts import flatten_nested_items
|
||||
from apiserver.utilities.json import loads
|
||||
|
||||
# noinspection PyTypeChecker
|
||||
EVENT_TYPES = set(map(attrgetter("value"), EventType))
|
||||
EVENT_TYPES: Set[str] = set(map(attrgetter("value"), EventType))
|
||||
LOCKED_TASK_STATUSES = (TaskStatus.publishing, TaskStatus.published)
|
||||
MAX_LONG = 2 ** 63 - 1
|
||||
MIN_LONG = -(2 ** 63)
|
||||
|
||||
|
||||
class PlotFields:
|
||||
valid_plot = "valid_plot"
|
||||
plot_len = "plot_len"
|
||||
plot_str = "plot_str"
|
||||
plot_data = "plot_data"
|
||||
source_urls = "source_urls"
|
||||
|
||||
|
||||
class EventBLL(object):
|
||||
id_fields = ("task", "iter", "metric", "variant", "key")
|
||||
empty_scroll = "FFFF"
|
||||
img_source_regex = re.compile(
|
||||
r"['\"]source['\"]:\s?['\"]([a-z][a-z0-9+\-.]*://.*?)['\"]",
|
||||
flags=re.IGNORECASE,
|
||||
)
|
||||
|
||||
def __init__(self, events_es=None, redis=None):
|
||||
self.es = events_es or es_factory.connect("events")
|
||||
@@ -42,6 +72,7 @@ class EventBLL(object):
|
||||
)
|
||||
self.redis = redis or redman.connection("apiserver")
|
||||
self.debug_images_iterator = DebugImagesIterator(es=self.es, redis=self.redis)
|
||||
self.debug_sample_history = DebugSampleHistory(es=self.es, redis=self.redis)
|
||||
self.log_events_iterator = LogEventsIterator(es=self.es)
|
||||
|
||||
@property
|
||||
@@ -64,7 +95,7 @@ class EventBLL(object):
|
||||
def add_events(
|
||||
self, company_id, events, worker, allow_locked_tasks=False
|
||||
) -> Tuple[int, int, dict]:
|
||||
actions = []
|
||||
actions: List[dict] = []
|
||||
task_ids = set()
|
||||
task_iteration = defaultdict(lambda: 0)
|
||||
task_last_scalar_events = nested_dict(
|
||||
@@ -74,6 +105,7 @@ class EventBLL(object):
|
||||
3, dict
|
||||
) # task_id -> metric_hash -> event_type -> MetricEvent
|
||||
errors_per_type = defaultdict(int)
|
||||
invalid_iteration_error = f"Iteration number should not exceed {MAX_LONG}"
|
||||
valid_tasks = self._get_valid_tasks(
|
||||
company_id,
|
||||
task_ids={
|
||||
@@ -81,6 +113,7 @@ class EventBLL(object):
|
||||
},
|
||||
allow_locked_tasks=allow_locked_tasks,
|
||||
)
|
||||
|
||||
for event in events:
|
||||
# remove spaces from event type
|
||||
event_type = event.get("type")
|
||||
@@ -122,6 +155,9 @@ class EventBLL(object):
|
||||
iter = event.get("iter")
|
||||
if iter is not None:
|
||||
iter = int(iter)
|
||||
if iter > MAX_LONG or iter < MIN_LONG:
|
||||
errors_per_type[invalid_iteration_error] += 1
|
||||
continue
|
||||
event["iter"] = iter
|
||||
|
||||
# used to have "values" to indicate array. no need anymore
|
||||
@@ -132,7 +168,7 @@ class EventBLL(object):
|
||||
event["metric"] = event.get("metric") or ""
|
||||
event["variant"] = event.get("variant") or ""
|
||||
|
||||
index_name = EventMetrics.get_index_name(company_id, event_type)
|
||||
index_name = get_index_name(company_id, event_type)
|
||||
es_action = {
|
||||
"_op_type": "index", # overwrite if exists with same ID
|
||||
"_index": index_name,
|
||||
@@ -140,7 +176,7 @@ class EventBLL(object):
|
||||
}
|
||||
|
||||
# for "log" events, don't assing custom _id - whatever is sent, is written (not overwritten)
|
||||
if event_type != "log":
|
||||
if event_type != EventType.task_log.value:
|
||||
es_action["_id"] = self._get_event_id(event)
|
||||
else:
|
||||
es_action["_id"] = dbutils.id()
|
||||
@@ -162,51 +198,71 @@ class EventBLL(object):
|
||||
|
||||
actions.append(es_action)
|
||||
|
||||
plot_actions = [
|
||||
action["_source"]
|
||||
for action in actions
|
||||
if action["_source"]["type"] == EventType.metrics_plot.value
|
||||
]
|
||||
if plot_actions:
|
||||
self.validate_and_compress_plots(
|
||||
plot_actions,
|
||||
validate_json=config.get("services.events.validate_plot_str", False),
|
||||
compression_threshold=config.get(
|
||||
"services.events.plot_compression_threshold", 100_000
|
||||
),
|
||||
)
|
||||
|
||||
added = 0
|
||||
if actions:
|
||||
chunk_size = 500
|
||||
with translate_errors_context(), TimingContext("es", "events_add_batch"):
|
||||
# TODO: replace it with helpers.parallel_bulk in the future once the parallel pool leak is fixed
|
||||
with closing(
|
||||
helpers.streaming_bulk(
|
||||
self.es,
|
||||
actions,
|
||||
chunk_size=chunk_size,
|
||||
# thread_count=8,
|
||||
refresh=True,
|
||||
)
|
||||
) as it:
|
||||
for success, info in it:
|
||||
if success:
|
||||
added += chunk_size
|
||||
else:
|
||||
errors_per_type["Error when indexing events batch"] += 1
|
||||
with translate_errors_context():
|
||||
if actions:
|
||||
chunk_size = 500
|
||||
with TimingContext("es", "events_add_batch"):
|
||||
# TODO: replace it with helpers.parallel_bulk in the future once the parallel pool leak is fixed
|
||||
with closing(
|
||||
helpers.streaming_bulk(
|
||||
self.es,
|
||||
actions,
|
||||
chunk_size=chunk_size,
|
||||
# thread_count=8,
|
||||
refresh=True,
|
||||
)
|
||||
) as it:
|
||||
for success, info in it:
|
||||
if success:
|
||||
added += 1
|
||||
else:
|
||||
errors_per_type["Error when indexing events batch"] += 1
|
||||
|
||||
remaining_tasks = set()
|
||||
now = datetime.utcnow()
|
||||
for task_id in task_ids:
|
||||
# Update related tasks. For reasons of performance, we prefer to update
|
||||
# all of them and not only those who's events were successful
|
||||
updated = self._update_task(
|
||||
company_id=company_id,
|
||||
task_id=task_id,
|
||||
now=now,
|
||||
iter_max=task_iteration.get(task_id),
|
||||
last_scalar_events=task_last_scalar_events.get(task_id),
|
||||
last_events=task_last_events.get(task_id),
|
||||
)
|
||||
remaining_tasks = set()
|
||||
now = datetime.utcnow()
|
||||
for task_id in task_ids:
|
||||
# Update related tasks. For reasons of performance, we prefer to update
|
||||
# all of them and not only those who's events were successful
|
||||
updated = self._update_task(
|
||||
company_id=company_id,
|
||||
task_id=task_id,
|
||||
now=now,
|
||||
iter_max=task_iteration.get(task_id),
|
||||
last_scalar_events=task_last_scalar_events.get(task_id),
|
||||
last_events=task_last_events.get(task_id),
|
||||
)
|
||||
|
||||
if not updated:
|
||||
remaining_tasks.add(task_id)
|
||||
continue
|
||||
if not updated:
|
||||
remaining_tasks.add(task_id)
|
||||
continue
|
||||
|
||||
if remaining_tasks:
|
||||
TaskBLL.set_last_update(
|
||||
remaining_tasks, company_id, last_update=now
|
||||
)
|
||||
if remaining_tasks:
|
||||
TaskBLL.set_last_update(
|
||||
remaining_tasks, company_id, last_update=now
|
||||
)
|
||||
|
||||
# Compensate for always adding chunk_size on success (last chunk is probably smaller)
|
||||
added = min(added, len(actions))
|
||||
# this is for backwards compatibility with streaming bulk throwing exception on those
|
||||
invalid_iterations_count = errors_per_type.get(invalid_iteration_error)
|
||||
if invalid_iterations_count:
|
||||
raise BulkIndexError(
|
||||
f"{invalid_iterations_count} document(s) failed to index.",
|
||||
[invalid_iteration_error],
|
||||
)
|
||||
|
||||
if not added:
|
||||
raise errors.bad_request.EventsNotAdded(**errors_per_type)
|
||||
@@ -214,6 +270,57 @@ class EventBLL(object):
|
||||
errors_count = sum(errors_per_type.values())
|
||||
return added, errors_count, errors_per_type
|
||||
|
||||
@parallel_chunked_decorator(chunk_size=10)
|
||||
def validate_and_compress_plots(
|
||||
self,
|
||||
plot_events: Sequence[dict],
|
||||
validate_json: bool,
|
||||
compression_threshold: int,
|
||||
):
|
||||
for event in plot_events:
|
||||
validate = validate_json and not event.pop("skip_validation", False)
|
||||
plot_str = event.get(PlotFields.plot_str)
|
||||
if not plot_str:
|
||||
event[PlotFields.plot_len] = 0
|
||||
if validate:
|
||||
event[PlotFields.valid_plot] = False
|
||||
continue
|
||||
|
||||
plot_len = len(plot_str)
|
||||
event[PlotFields.plot_len] = plot_len
|
||||
if validate:
|
||||
event[PlotFields.valid_plot] = self._is_valid_json(plot_str)
|
||||
|
||||
urls = {match for match in self.img_source_regex.findall(plot_str)}
|
||||
if urls:
|
||||
event[PlotFields.source_urls] = list(urls)
|
||||
|
||||
if compression_threshold and plot_len >= compression_threshold:
|
||||
event[PlotFields.plot_data] = base64.encodebytes(
|
||||
zlib.compress(plot_str.encode(), level=1)
|
||||
).decode("ascii")
|
||||
event.pop(PlotFields.plot_str, None)
|
||||
|
||||
@parallel_chunked_decorator(chunk_size=10)
|
||||
def uncompress_plots(self, plot_events: Sequence[dict]):
|
||||
for event in plot_events:
|
||||
plot_data = event.pop(PlotFields.plot_data, None)
|
||||
if plot_data and event.get(PlotFields.plot_str) is None:
|
||||
event[PlotFields.plot_str] = zlib.decompress(
|
||||
base64.b64decode(plot_data)
|
||||
).decode()
|
||||
|
||||
@staticmethod
|
||||
def _is_valid_json(text: str) -> bool:
|
||||
"""Check str for valid json"""
|
||||
if not text:
|
||||
return False
|
||||
try:
|
||||
loads(text)
|
||||
except Exception:
|
||||
return False
|
||||
return True
|
||||
|
||||
def _update_last_scalar_events_for_task(self, last_events, event):
|
||||
"""
|
||||
Update last_events structure with the provided event details if this event is more
|
||||
@@ -315,10 +422,10 @@ class EventBLL(object):
|
||||
|
||||
def scroll_task_events(
|
||||
self,
|
||||
company_id,
|
||||
task_id,
|
||||
order,
|
||||
event_type=None,
|
||||
company_id: str,
|
||||
task_id: str,
|
||||
order: str,
|
||||
event_type: EventType,
|
||||
batch_size=10000,
|
||||
scroll_id=None,
|
||||
):
|
||||
@@ -330,12 +437,7 @@ class EventBLL(object):
|
||||
es_res = self.es.scroll(scroll_id=scroll_id, scroll="1h")
|
||||
else:
|
||||
size = min(batch_size, 10000)
|
||||
if event_type is None:
|
||||
event_type = "*"
|
||||
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
|
||||
if not self.es.indices.exists(es_index):
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=event_type):
|
||||
return [], None, 0
|
||||
|
||||
es_req = {
|
||||
@@ -345,30 +447,51 @@ class EventBLL(object):
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "scroll_task_events"):
|
||||
es_res = self.es.search(index=es_index, body=es_req, scroll="1h")
|
||||
es_res = search_company_events(
|
||||
self.es,
|
||||
company_id=company_id,
|
||||
event_type=event_type,
|
||||
body=es_req,
|
||||
scroll="1h",
|
||||
)
|
||||
|
||||
events, total_events, next_scroll_id = self._get_events_from_es_res(es_res)
|
||||
if event_type in (EventType.metrics_plot, EventType.all):
|
||||
self.uncompress_plots(events)
|
||||
|
||||
return events, next_scroll_id, total_events
|
||||
|
||||
def get_last_iterations_per_event_metric_variant(
|
||||
self, es_index: str, task_id: str, num_last_iterations: int, event_type: str
|
||||
self,
|
||||
company_id: str,
|
||||
task_id: str,
|
||||
num_last_iterations: int,
|
||||
event_type: EventType,
|
||||
metric_variants: MetricVariants = None,
|
||||
):
|
||||
if not self.es.indices.exists(es_index):
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=event_type):
|
||||
return []
|
||||
|
||||
must = [{"term": {"task": task_id}}]
|
||||
if metric_variants:
|
||||
must.append(get_metric_variants_condition(metric_variants))
|
||||
query = {"bool": {"must": must}}
|
||||
|
||||
es_req: dict = {
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": EventMetrics.MAX_METRICS_COUNT,
|
||||
"size": EventSettings.max_metrics_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": EventMetrics.MAX_VARIANTS_COUNT,
|
||||
"size": EventSettings.max_variants_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"iters": {
|
||||
@@ -383,15 +506,16 @@ class EventBLL(object):
|
||||
},
|
||||
}
|
||||
},
|
||||
"query": {"bool": {"must": [{"term": {"task": task_id}}]}},
|
||||
"query": query,
|
||||
}
|
||||
if event_type:
|
||||
es_req["query"]["bool"]["must"].append({"term": {"type": event_type}})
|
||||
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "task_last_iter_metric_variant"
|
||||
):
|
||||
es_res = self.es.search(index=es_index, body=es_req)
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=event_type, body=es_req
|
||||
)
|
||||
|
||||
if "aggregations" not in es_res:
|
||||
return []
|
||||
|
||||
@@ -410,27 +534,46 @@ class EventBLL(object):
|
||||
sort=None,
|
||||
size: int = 500,
|
||||
scroll_id: str = None,
|
||||
metric_variants: MetricVariants = None,
|
||||
):
|
||||
if scroll_id == self.empty_scroll:
|
||||
return [], scroll_id, 0
|
||||
return TaskEventsResult()
|
||||
|
||||
if scroll_id:
|
||||
with translate_errors_context(), TimingContext("es", "get_task_events"):
|
||||
es_res = self.es.scroll(scroll_id=scroll_id, scroll="1h")
|
||||
else:
|
||||
event_type = "plot"
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
if not self.es.indices.exists(es_index):
|
||||
event_type = EventType.metrics_plot
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=event_type):
|
||||
return TaskEventsResult()
|
||||
|
||||
must = []
|
||||
plot_valid_condition = {
|
||||
"bool": {
|
||||
"should": [
|
||||
{"term": {PlotFields.valid_plot: True}},
|
||||
{
|
||||
"bool": {
|
||||
"must_not": {"exists": {"field": PlotFields.valid_plot}}
|
||||
}
|
||||
},
|
||||
]
|
||||
}
|
||||
}
|
||||
must = [plot_valid_condition]
|
||||
|
||||
if last_iterations_per_plot is None:
|
||||
must.append({"terms": {"task": tasks}})
|
||||
if metric_variants:
|
||||
must.append(get_metric_variants_condition(metric_variants))
|
||||
else:
|
||||
should = []
|
||||
for i, task_id in enumerate(tasks):
|
||||
last_iters = self.get_last_iterations_per_event_metric_variant(
|
||||
es_index, task_id, last_iterations_per_plot, event_type
|
||||
company_id=company_id,
|
||||
task_id=task_id,
|
||||
num_last_iterations=last_iterations_per_plot,
|
||||
event_type=event_type,
|
||||
metric_variants=metric_variants,
|
||||
)
|
||||
if not last_iters:
|
||||
continue
|
||||
@@ -462,11 +605,17 @@ class EventBLL(object):
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "get_task_plots"):
|
||||
es_res = self.es.search(
|
||||
index=es_index, body=es_req, ignore=404, scroll="1h",
|
||||
es_res = search_company_events(
|
||||
self.es,
|
||||
company_id=company_id,
|
||||
event_type=event_type,
|
||||
body=es_req,
|
||||
ignore=404,
|
||||
scroll="1h",
|
||||
)
|
||||
|
||||
events, total_events, next_scroll_id = self._get_events_from_es_res(es_res)
|
||||
self.uncompress_plots(events)
|
||||
return TaskEventsResult(
|
||||
events=events, next_scroll_id=next_scroll_id, total_events=total_events
|
||||
)
|
||||
@@ -485,33 +634,65 @@ class EventBLL(object):
|
||||
|
||||
return events, total_events, next_scroll_id
|
||||
|
||||
def get_plot_image_urls(
|
||||
self, company_id: str, task_id: str, scroll_id: Optional[str]
|
||||
) -> Tuple[Sequence[dict], Optional[str]]:
|
||||
if scroll_id == self.empty_scroll:
|
||||
return [], None
|
||||
|
||||
if scroll_id:
|
||||
es_res = self.es.scroll(scroll_id=scroll_id, scroll="10m")
|
||||
else:
|
||||
if check_empty_data(self.es, company_id, EventType.metrics_plot):
|
||||
return [], None
|
||||
|
||||
es_req = {
|
||||
"size": 1000,
|
||||
"_source": [PlotFields.source_urls],
|
||||
"query": {
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"task": task_id}},
|
||||
{"exists": {"field": PlotFields.source_urls}},
|
||||
]
|
||||
}
|
||||
},
|
||||
}
|
||||
es_res = search_company_events(
|
||||
self.es,
|
||||
company_id=company_id,
|
||||
event_type=EventType.metrics_plot,
|
||||
body=es_req,
|
||||
scroll="10m",
|
||||
)
|
||||
|
||||
events, _, next_scroll_id = self._get_events_from_es_res(es_res)
|
||||
return events, next_scroll_id
|
||||
|
||||
def get_task_events(
|
||||
self,
|
||||
company_id,
|
||||
task_id,
|
||||
event_type=None,
|
||||
company_id: str,
|
||||
task_id: str,
|
||||
event_type: EventType,
|
||||
metric=None,
|
||||
variant=None,
|
||||
last_iter_count=None,
|
||||
sort=None,
|
||||
size=500,
|
||||
scroll_id=None,
|
||||
):
|
||||
) -> TaskEventsResult:
|
||||
if scroll_id == self.empty_scroll:
|
||||
return [], scroll_id, 0
|
||||
return TaskEventsResult()
|
||||
|
||||
if scroll_id:
|
||||
with translate_errors_context(), TimingContext("es", "get_task_events"):
|
||||
es_res = self.es.scroll(scroll_id=scroll_id, scroll="1h")
|
||||
else:
|
||||
task_ids = [task_id] if isinstance(task_id, six.string_types) else task_id
|
||||
if event_type is None:
|
||||
event_type = "*"
|
||||
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
if not self.es.indices.exists(es_index):
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=event_type):
|
||||
return TaskEventsResult()
|
||||
|
||||
task_ids = [task_id] if isinstance(task_id, str) else task_id
|
||||
|
||||
must = []
|
||||
if metric:
|
||||
must.append({"term": {"metric": metric}})
|
||||
@@ -521,23 +702,24 @@ class EventBLL(object):
|
||||
if last_iter_count is None:
|
||||
must.append({"terms": {"task": task_ids}})
|
||||
else:
|
||||
should = []
|
||||
for i, task_id in enumerate(task_ids):
|
||||
last_iters = self.get_last_iters(
|
||||
es_index, task_id, event_type, last_iter_count
|
||||
)
|
||||
if not last_iters:
|
||||
continue
|
||||
should.append(
|
||||
{
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"task": task_id}},
|
||||
{"terms": {"iter": last_iters}},
|
||||
]
|
||||
}
|
||||
tasks_iters = self.get_last_iters(
|
||||
company_id=company_id,
|
||||
event_type=event_type,
|
||||
task_id=task_ids,
|
||||
iters=last_iter_count,
|
||||
)
|
||||
should = [
|
||||
{
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"task": task}},
|
||||
{"terms": {"iter": last_iters}},
|
||||
]
|
||||
}
|
||||
)
|
||||
}
|
||||
for task, last_iters in tasks_iters.items()
|
||||
if last_iters
|
||||
]
|
||||
if not should:
|
||||
return TaskEventsResult()
|
||||
must.append({"bool": {"should": should}})
|
||||
@@ -552,47 +734,59 @@ class EventBLL(object):
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "get_task_events"):
|
||||
es_res = self.es.search(
|
||||
index=es_index, body=es_req, ignore=404, scroll="1h",
|
||||
es_res = search_company_events(
|
||||
self.es,
|
||||
company_id=company_id,
|
||||
event_type=event_type,
|
||||
body=es_req,
|
||||
ignore=404,
|
||||
scroll="1h",
|
||||
)
|
||||
|
||||
events, total_events, next_scroll_id = self._get_events_from_es_res(es_res)
|
||||
if event_type in (EventType.metrics_plot, EventType.all):
|
||||
self.uncompress_plots(events)
|
||||
|
||||
return TaskEventsResult(
|
||||
events=events, next_scroll_id=next_scroll_id, total_events=total_events
|
||||
)
|
||||
|
||||
def get_metrics_and_variants(self, company_id, task_id, event_type):
|
||||
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
|
||||
if not self.es.indices.exists(es_index):
|
||||
def get_metrics_and_variants(
|
||||
self, company_id: str, task_id: str, event_type: EventType
|
||||
):
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=event_type):
|
||||
return {}
|
||||
|
||||
query = {"bool": {"must": [{"term": {"task": task_id}}]}}
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": EventMetrics.MAX_METRICS_COUNT,
|
||||
"size": EventSettings.max_metrics_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": EventMetrics.MAX_VARIANTS_COUNT,
|
||||
"size": EventSettings.max_variants_count,
|
||||
"order": {"_key": "asc"},
|
||||
}
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
"query": {"bool": {"must": [{"term": {"task": task_id}}]}},
|
||||
"query": query,
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "events_get_metrics_and_variants"
|
||||
):
|
||||
es_res = self.es.search(index=es_index, body=es_req)
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=event_type, body=es_req
|
||||
)
|
||||
|
||||
metrics = {}
|
||||
for metric_bucket in es_res["aggregations"]["metrics"].get("buckets"):
|
||||
@@ -603,34 +797,36 @@ class EventBLL(object):
|
||||
|
||||
return metrics
|
||||
|
||||
def get_task_latest_scalar_values(self, company_id, task_id):
|
||||
es_index = EventMetrics.get_index_name(company_id, "training_stats_scalar")
|
||||
|
||||
if not self.es.indices.exists(es_index):
|
||||
return {}
|
||||
def get_task_latest_scalar_values(
|
||||
self, company_id, task_id
|
||||
) -> Tuple[Sequence[dict], int]:
|
||||
event_type = EventType.metrics_scalar
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=event_type):
|
||||
return [], 0
|
||||
|
||||
query = {
|
||||
"bool": {
|
||||
"must": [
|
||||
{"query_string": {"query": "value:>0"}},
|
||||
{"term": {"task": task_id}},
|
||||
]
|
||||
}
|
||||
}
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": {
|
||||
"bool": {
|
||||
"must": [
|
||||
{"query_string": {"query": "value:>0"}},
|
||||
{"term": {"task": task_id}},
|
||||
]
|
||||
}
|
||||
},
|
||||
"query": query,
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": EventMetrics.MAX_METRICS_COUNT,
|
||||
"size": EventSettings.max_metrics_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": EventMetrics.MAX_VARIANTS_COUNT,
|
||||
"size": EventSettings.max_variants_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
@@ -661,7 +857,9 @@ class EventBLL(object):
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "events_get_metrics_and_variants"
|
||||
):
|
||||
es_res = self.es.search(index=es_index, body=es_req)
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=event_type, body=es_req
|
||||
)
|
||||
|
||||
metrics = []
|
||||
max_timestamp = 0
|
||||
@@ -688,9 +886,8 @@ class EventBLL(object):
|
||||
return metrics, max_timestamp
|
||||
|
||||
def get_vector_metrics_per_iter(self, company_id, task_id, metric, variant):
|
||||
|
||||
es_index = EventMetrics.get_index_name(company_id, "training_stats_vector")
|
||||
if not self.es.indices.exists(es_index):
|
||||
event_type = EventType.metrics_vector
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=event_type):
|
||||
return [], []
|
||||
|
||||
es_req = {
|
||||
@@ -708,7 +905,9 @@ class EventBLL(object):
|
||||
"sort": ["iter"],
|
||||
}
|
||||
with translate_errors_context(), TimingContext("es", "task_stats_vector"):
|
||||
es_res = self.es.search(index=es_index, body=es_req)
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=event_type, body=es_req
|
||||
)
|
||||
|
||||
vectors = []
|
||||
iterations = []
|
||||
@@ -718,32 +917,48 @@ class EventBLL(object):
|
||||
|
||||
return iterations, vectors
|
||||
|
||||
def get_last_iters(self, es_index, task_id, event_type, iters):
|
||||
if not self.es.indices.exists(es_index):
|
||||
return []
|
||||
def get_last_iters(
|
||||
self,
|
||||
company_id: str,
|
||||
event_type: EventType,
|
||||
task_id: Union[str, Sequence[str]],
|
||||
iters: int,
|
||||
) -> Mapping[str, Sequence]:
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=event_type):
|
||||
return {}
|
||||
|
||||
task_ids = [task_id] if isinstance(task_id, str) else task_id
|
||||
es_req: dict = {
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"iters": {
|
||||
"terms": {
|
||||
"field": "iter",
|
||||
"size": iters,
|
||||
"order": {"_key": "desc"},
|
||||
}
|
||||
"tasks": {
|
||||
"terms": {"field": "task"},
|
||||
"aggs": {
|
||||
"iters": {
|
||||
"terms": {
|
||||
"field": "iter",
|
||||
"size": iters,
|
||||
"order": {"_key": "desc"},
|
||||
}
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
"query": {"bool": {"must": [{"term": {"task": task_id}}]}},
|
||||
"query": {"bool": {"must": [{"terms": {"task": task_ids}}]}},
|
||||
}
|
||||
if event_type:
|
||||
es_req["query"]["bool"]["must"].append({"term": {"type": event_type}})
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "task_last_iter"):
|
||||
es_res = self.es.search(index=es_index, body=es_req)
|
||||
if "aggregations" not in es_res:
|
||||
return []
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=event_type, body=es_req,
|
||||
)
|
||||
|
||||
return [b["key"] for b in es_res["aggregations"]["iters"]["buckets"]]
|
||||
if "aggregations" not in es_res:
|
||||
return {}
|
||||
|
||||
return {
|
||||
tb["key"]: [ib["key"] for ib in tb["iters"]["buckets"]]
|
||||
for tb in es_res["aggregations"]["tasks"]["buckets"]
|
||||
}
|
||||
|
||||
def delete_task_events(self, company_id, task_id, allow_locked=False):
|
||||
with translate_errors_context():
|
||||
@@ -758,9 +973,33 @@ class EventBLL(object):
|
||||
extra_msg, company=company_id, id=task_id
|
||||
)
|
||||
|
||||
es_index = EventMetrics.get_index_name(company_id, "*")
|
||||
es_req = {"query": {"term": {"task": task_id}}}
|
||||
with translate_errors_context(), TimingContext("es", "delete_task_events"):
|
||||
es_res = self.es.delete_by_query(index=es_index, body=es_req, refresh=True)
|
||||
es_res = delete_company_events(
|
||||
es=self.es,
|
||||
company_id=company_id,
|
||||
event_type=EventType.all,
|
||||
body=es_req,
|
||||
refresh=True,
|
||||
)
|
||||
|
||||
return es_res.get("deleted", 0)
|
||||
|
||||
def delete_multi_task_events(self, company_id: str, task_ids: Sequence[str]):
|
||||
"""
|
||||
Delete mutliple task events. No check is done for tasks write access
|
||||
so it should be checked by the calling code
|
||||
"""
|
||||
es_req = {"query": {"terms": {"task": task_ids}}}
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "delete_multi_tasks_events"
|
||||
):
|
||||
es_res = delete_company_events(
|
||||
es=self.es,
|
||||
company_id=company_id,
|
||||
event_type=EventType.all,
|
||||
body=es_req,
|
||||
refresh=True,
|
||||
)
|
||||
|
||||
return es_res.get("deleted", 0)
|
||||
89
apiserver/bll/event/event_common.py
Normal file
89
apiserver/bll/event/event_common.py
Normal file
@@ -0,0 +1,89 @@
|
||||
from enum import Enum
|
||||
from typing import Union, Sequence, Mapping
|
||||
|
||||
from boltons.typeutils import classproperty
|
||||
from elasticsearch import Elasticsearch
|
||||
|
||||
from apiserver.config_repo import config
|
||||
|
||||
|
||||
class EventType(Enum):
|
||||
metrics_scalar = "training_stats_scalar"
|
||||
metrics_vector = "training_stats_vector"
|
||||
metrics_image = "training_debug_image"
|
||||
metrics_plot = "plot"
|
||||
task_log = "log"
|
||||
all = "*"
|
||||
|
||||
|
||||
MetricVariants = Mapping[str, Sequence[str]]
|
||||
|
||||
|
||||
class EventSettings:
|
||||
@classproperty
|
||||
def max_workers(self):
|
||||
return config.get("services.events.events_retrieval.max_metrics_concurrency", 4)
|
||||
|
||||
@classproperty
|
||||
def state_expiration_sec(self):
|
||||
return config.get(
|
||||
f"services.events.events_retrieval.state_expiration_sec", 3600
|
||||
)
|
||||
|
||||
@classproperty
|
||||
def max_metrics_count(self):
|
||||
return config.get("services.events.events_retrieval.max_metrics_count", 100)
|
||||
|
||||
@classproperty
|
||||
def max_variants_count(self):
|
||||
return config.get("services.events.events_retrieval.max_variants_count", 100)
|
||||
|
||||
|
||||
def get_index_name(company_id: str, event_type: str):
|
||||
event_type = event_type.lower().replace(" ", "_")
|
||||
return f"events-{event_type}-{company_id}"
|
||||
|
||||
|
||||
def check_empty_data(es: Elasticsearch, company_id: str, event_type: EventType) -> bool:
|
||||
es_index = get_index_name(company_id, event_type.value)
|
||||
if not es.indices.exists(es_index):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def search_company_events(
|
||||
es: Elasticsearch,
|
||||
company_id: Union[str, Sequence[str]],
|
||||
event_type: EventType,
|
||||
body: dict,
|
||||
**kwargs,
|
||||
) -> dict:
|
||||
es_index = get_index_name(company_id, event_type.value)
|
||||
return es.search(index=es_index, body=body, **kwargs)
|
||||
|
||||
|
||||
def delete_company_events(
|
||||
es: Elasticsearch, company_id: str, event_type: EventType, body: dict, **kwargs
|
||||
) -> dict:
|
||||
es_index = get_index_name(company_id, event_type.value)
|
||||
return es.delete_by_query(index=es_index, body=body, **kwargs)
|
||||
|
||||
|
||||
def get_metric_variants_condition(
|
||||
metric_variants: MetricVariants,
|
||||
) -> Sequence:
|
||||
conditions = [
|
||||
{
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"metric": metric}},
|
||||
{"terms": {"variant": variants}},
|
||||
]
|
||||
}
|
||||
}
|
||||
if variants
|
||||
else {"term": {"metric": metric}}
|
||||
for metric, variants in metric_variants.items()
|
||||
]
|
||||
|
||||
return {"bool": {"should": conditions}}
|
||||
@@ -1,7 +1,7 @@
|
||||
import itertools
|
||||
import math
|
||||
from collections import defaultdict
|
||||
from concurrent.futures.thread import ThreadPoolExecutor
|
||||
from enum import Enum
|
||||
from functools import partial
|
||||
from operator import itemgetter
|
||||
from typing import Sequence, Tuple
|
||||
@@ -9,79 +9,89 @@ from typing import Sequence, Tuple
|
||||
from elasticsearch import Elasticsearch
|
||||
from mongoengine import Q
|
||||
|
||||
from apierrors import errors
|
||||
from bll.event.scalar_key import ScalarKey, ScalarKeyEnum
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.task.task import Task
|
||||
from timing_context import TimingContext
|
||||
from tools import safe_get
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.bll.event.event_common import (
|
||||
EventType,
|
||||
EventSettings,
|
||||
search_company_events,
|
||||
check_empty_data,
|
||||
MetricVariants,
|
||||
get_metric_variants_condition,
|
||||
)
|
||||
from apiserver.bll.event.scalar_key import ScalarKey, ScalarKeyEnum
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.database.model.task.task import Task
|
||||
from apiserver.timing_context import TimingContext
|
||||
from apiserver.tools import safe_get
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class EventType(Enum):
|
||||
metrics_scalar = "training_stats_scalar"
|
||||
metrics_vector = "training_stats_vector"
|
||||
metrics_image = "training_debug_image"
|
||||
metrics_plot = "plot"
|
||||
task_log = "log"
|
||||
|
||||
|
||||
class EventMetrics:
|
||||
MAX_METRICS_COUNT = 100
|
||||
MAX_VARIANTS_COUNT = 100
|
||||
MAX_AGGS_ELEMENTS_COUNT = 50
|
||||
MAX_SAMPLE_BUCKETS = 6000
|
||||
|
||||
def __init__(self, es: Elasticsearch):
|
||||
self.es = es
|
||||
|
||||
@property
|
||||
def _max_concurrency(self):
|
||||
return config.get("services.events.max_metrics_concurrency", 4)
|
||||
|
||||
@staticmethod
|
||||
def get_index_name(company_id, event_type):
|
||||
event_type = event_type.lower().replace(" ", "_")
|
||||
return f"events-{event_type}-{company_id}"
|
||||
|
||||
def get_scalar_metrics_average_per_iter(
|
||||
self, company_id: str, task_id: str, samples: int, key: ScalarKeyEnum
|
||||
self,
|
||||
company_id: str,
|
||||
task_id: str,
|
||||
samples: int,
|
||||
key: ScalarKeyEnum,
|
||||
metric_variants: MetricVariants = None,
|
||||
) -> dict:
|
||||
"""
|
||||
Get scalar metric histogram per metric and variant
|
||||
The amount of points in each histogram should not exceed
|
||||
the requested samples
|
||||
"""
|
||||
es_index = self.get_index_name(company_id, "training_stats_scalar")
|
||||
if not self.es.indices.exists(es_index):
|
||||
event_type = EventType.metrics_scalar
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=event_type):
|
||||
return {}
|
||||
|
||||
return self._get_scalar_average_per_iter_core(
|
||||
task_id, es_index, samples, ScalarKey.resolve(key)
|
||||
task_id=task_id,
|
||||
company_id=company_id,
|
||||
event_type=event_type,
|
||||
samples=samples,
|
||||
key=ScalarKey.resolve(key),
|
||||
metric_variants=metric_variants,
|
||||
)
|
||||
|
||||
def _get_scalar_average_per_iter_core(
|
||||
self,
|
||||
task_id: str,
|
||||
es_index: str,
|
||||
company_id: str,
|
||||
event_type: EventType,
|
||||
samples: int,
|
||||
key: ScalarKey,
|
||||
run_parallel: bool = True,
|
||||
metric_variants: MetricVariants = None,
|
||||
) -> dict:
|
||||
intervals = self._get_task_metric_intervals(
|
||||
es_index=es_index, task_id=task_id, samples=samples, field=key.field
|
||||
company_id=company_id,
|
||||
event_type=event_type,
|
||||
task_id=task_id,
|
||||
samples=samples,
|
||||
field=key.field,
|
||||
metric_variants=metric_variants,
|
||||
)
|
||||
if not intervals:
|
||||
return {}
|
||||
interval_groups = self._group_task_metric_intervals(intervals)
|
||||
|
||||
get_scalar_average = partial(
|
||||
self._get_scalar_average, task_id=task_id, es_index=es_index, key=key
|
||||
self._get_scalar_average,
|
||||
task_id=task_id,
|
||||
company_id=company_id,
|
||||
event_type=event_type,
|
||||
key=key,
|
||||
)
|
||||
if run_parallel:
|
||||
with ThreadPoolExecutor(max_workers=self._max_concurrency) as pool:
|
||||
with ThreadPoolExecutor(max_workers=EventSettings.max_workers) as pool:
|
||||
metrics = itertools.chain.from_iterable(
|
||||
pool.map(get_scalar_average, interval_groups)
|
||||
)
|
||||
@@ -114,7 +124,7 @@ class EventMetrics:
|
||||
company=company_id,
|
||||
query=Q(id__in=task_ids),
|
||||
allow_public=allow_public,
|
||||
override_projection=("id", "name", "company"),
|
||||
override_projection=("id", "name", "company", "company_origin"),
|
||||
return_dicts=False,
|
||||
)
|
||||
if len(task_objs) < len(task_ids):
|
||||
@@ -122,24 +132,26 @@ class EventMetrics:
|
||||
raise errors.bad_request.InvalidTaskId(company=company_id, ids=invalid)
|
||||
task_name_by_id = {t.id: t.name for t in task_objs}
|
||||
|
||||
companies = {t.company for t in task_objs}
|
||||
companies = {t.get_index_company() for t in task_objs}
|
||||
if len(companies) > 1:
|
||||
raise errors.bad_request.InvalidTaskId(
|
||||
"only tasks from the same company are supported"
|
||||
)
|
||||
|
||||
es_index = self.get_index_name(next(iter(companies)), "training_stats_scalar")
|
||||
if not self.es.indices.exists(es_index):
|
||||
event_type = EventType.metrics_scalar
|
||||
company_id = next(iter(companies))
|
||||
if check_empty_data(self.es, company_id=company_id, event_type=event_type):
|
||||
return {}
|
||||
|
||||
get_scalar_average_per_iter = partial(
|
||||
self._get_scalar_average_per_iter_core,
|
||||
es_index=es_index,
|
||||
company_id=company_id,
|
||||
event_type=event_type,
|
||||
samples=samples,
|
||||
key=ScalarKey.resolve(key),
|
||||
run_parallel=False,
|
||||
)
|
||||
with ThreadPoolExecutor(max_workers=self._max_concurrency) as pool:
|
||||
with ThreadPoolExecutor(max_workers=EventSettings.max_workers) as pool:
|
||||
task_metrics = zip(
|
||||
task_ids, pool.map(get_scalar_average_per_iter, task_ids)
|
||||
)
|
||||
@@ -193,7 +205,13 @@ class EventMetrics:
|
||||
return metric_interval_groups
|
||||
|
||||
def _get_task_metric_intervals(
|
||||
self, es_index, task_id: str, samples: int, field: str = "iter"
|
||||
self,
|
||||
company_id: str,
|
||||
event_type: EventType,
|
||||
task_id: str,
|
||||
samples: int,
|
||||
field: str = "iter",
|
||||
metric_variants: MetricVariants = None,
|
||||
) -> Sequence[MetricInterval]:
|
||||
"""
|
||||
Calculate interval per task metric variant so that the resulting
|
||||
@@ -201,17 +219,27 @@ class EventMetrics:
|
||||
Return the list og metric variant intervals as the following tuple:
|
||||
(metric, variant, interval, samples)
|
||||
"""
|
||||
must = [{"term": {"task": task_id}}]
|
||||
if metric_variants:
|
||||
must.append(get_metric_variants_condition(metric_variants))
|
||||
query = {"bool": {"must": must}}
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": {"term": {"task": task_id}},
|
||||
"query": query,
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {"field": "metric", "size": self.MAX_METRICS_COUNT},
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": EventSettings.max_metrics_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": self.MAX_VARIANTS_COUNT,
|
||||
"size": EventSettings.max_variants_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"count": {"value_count": {"field": field}},
|
||||
@@ -225,7 +253,9 @@ class EventMetrics:
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "task_stats_get_interval"):
|
||||
es_res = self.es.search(index=es_index, body=es_req)
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=event_type, body=es_req,
|
||||
)
|
||||
|
||||
aggs_result = es_res.get("aggregations")
|
||||
if not aggs_result:
|
||||
@@ -252,11 +282,14 @@ class EventMetrics:
|
||||
|
||||
min_index = safe_get(data, "min_index/value", default=0)
|
||||
max_index = safe_get(data, "max_index/value", default=min_index)
|
||||
index_range = max_index - min_index + 1
|
||||
interval = max(1, math.ceil(float(index_range) / samples))
|
||||
max_samples = math.ceil(float(index_range) / interval)
|
||||
return (
|
||||
metric,
|
||||
variant,
|
||||
max(1, int(max_index - min_index + 1) // samples),
|
||||
samples,
|
||||
interval,
|
||||
max_samples,
|
||||
)
|
||||
|
||||
MetricData = Tuple[str, dict]
|
||||
@@ -265,7 +298,8 @@ class EventMetrics:
|
||||
self,
|
||||
metrics_interval: MetricIntervalGroup,
|
||||
task_id: str,
|
||||
es_index: str,
|
||||
company_id: str,
|
||||
event_type: EventType,
|
||||
key: ScalarKey,
|
||||
) -> Sequence[MetricData]:
|
||||
"""
|
||||
@@ -277,15 +311,15 @@ class EventMetrics:
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": self.MAX_METRICS_COUNT,
|
||||
"order": {"_key": "desc"},
|
||||
"size": EventSettings.max_metrics_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": self.MAX_VARIANTS_COUNT,
|
||||
"order": {"_key": "desc"},
|
||||
"size": EventSettings.max_variants_count,
|
||||
"order": {"_key": "asc"},
|
||||
},
|
||||
"aggs": aggregation,
|
||||
}
|
||||
@@ -293,7 +327,11 @@ class EventMetrics:
|
||||
}
|
||||
}
|
||||
aggs_result = self._query_aggregation_for_task_metrics(
|
||||
es_index, aggs=aggs, task_id=task_id, metrics=metrics
|
||||
company_id=company_id,
|
||||
event_type=event_type,
|
||||
aggs=aggs,
|
||||
task_id=task_id,
|
||||
metrics=metrics,
|
||||
)
|
||||
|
||||
if not aggs_result:
|
||||
@@ -324,7 +362,8 @@ class EventMetrics:
|
||||
|
||||
def _query_aggregation_for_task_metrics(
|
||||
self,
|
||||
es_index: str,
|
||||
company_id: str,
|
||||
event_type: EventType,
|
||||
aggs: dict,
|
||||
task_id: str,
|
||||
metrics: Sequence[Tuple[str, str]],
|
||||
@@ -355,7 +394,9 @@ class EventMetrics:
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "task_stats_scalar"):
|
||||
es_res = self.es.search(index=es_index, body=es_req)
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=event_type, body=es_req,
|
||||
)
|
||||
|
||||
return es_res.get("aggregations")
|
||||
|
||||
@@ -366,39 +407,41 @@ class EventMetrics:
|
||||
For the requested tasks return all the metrics that
|
||||
reported events of the requested types
|
||||
"""
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type.value)
|
||||
if not self.es.indices.exists(es_index):
|
||||
if check_empty_data(self.es, company_id, event_type):
|
||||
return {}
|
||||
|
||||
with ThreadPoolExecutor(self._max_concurrency) as pool:
|
||||
with ThreadPoolExecutor(EventSettings.max_workers) as pool:
|
||||
res = pool.map(
|
||||
partial(
|
||||
self._get_task_metrics, es_index=es_index, event_type=event_type,
|
||||
self._get_task_metrics,
|
||||
company_id=company_id,
|
||||
event_type=event_type,
|
||||
),
|
||||
task_ids,
|
||||
)
|
||||
return list(zip(task_ids, res))
|
||||
|
||||
def _get_task_metrics(self, task_id, es_index, event_type: EventType) -> Sequence:
|
||||
def _get_task_metrics(
|
||||
self, task_id: str, company_id: str, event_type: EventType
|
||||
) -> Sequence:
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": {
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"task": task_id}},
|
||||
{"term": {"type": event_type.value}},
|
||||
]
|
||||
}
|
||||
},
|
||||
"query": {"bool": {"must": [{"term": {"task": task_id}}]}},
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {"field": "metric", "size": self.MAX_METRICS_COUNT}
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": EventSettings.max_metrics_count,
|
||||
"order": {"_key": "asc"},
|
||||
}
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "_get_task_metrics"):
|
||||
es_res = self.es.search(index=es_index, body=es_req)
|
||||
es_res = search_company_events(
|
||||
self.es, company_id=company_id, event_type=event_type, body=es_req
|
||||
)
|
||||
|
||||
return [
|
||||
metric["key"]
|
||||
@@ -3,9 +3,13 @@ from typing import Optional, Tuple, Sequence
|
||||
import attr
|
||||
from elasticsearch import Elasticsearch
|
||||
|
||||
from bll.event.event_metrics import EventMetrics
|
||||
from database.errors import translate_errors_context
|
||||
from timing_context import TimingContext
|
||||
from apiserver.bll.event.event_common import (
|
||||
check_empty_data,
|
||||
search_company_events,
|
||||
EventType,
|
||||
)
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.timing_context import TimingContext
|
||||
|
||||
|
||||
@attr.s(auto_attribs=True)
|
||||
@@ -16,7 +20,7 @@ class TaskEventsResult:
|
||||
|
||||
|
||||
class LogEventsIterator:
|
||||
EVENT_TYPE = "log"
|
||||
EVENT_TYPE = EventType.task_log
|
||||
|
||||
def __init__(self, es: Elasticsearch):
|
||||
self.es = es
|
||||
@@ -29,13 +33,12 @@ class LogEventsIterator:
|
||||
navigate_earlier: bool = True,
|
||||
from_timestamp: Optional[int] = None,
|
||||
) -> TaskEventsResult:
|
||||
es_index = EventMetrics.get_index_name(company_id, self.EVENT_TYPE)
|
||||
if not self.es.indices.exists(es_index):
|
||||
if check_empty_data(self.es, company_id, self.EVENT_TYPE):
|
||||
return TaskEventsResult()
|
||||
|
||||
res = TaskEventsResult()
|
||||
res.events, res.total_events = self._get_events(
|
||||
es_index=es_index,
|
||||
company_id=company_id,
|
||||
task_id=task_id,
|
||||
batch_size=batch_size,
|
||||
navigate_earlier=navigate_earlier,
|
||||
@@ -45,7 +48,7 @@ class LogEventsIterator:
|
||||
|
||||
def _get_events(
|
||||
self,
|
||||
es_index,
|
||||
company_id: str,
|
||||
task_id: str,
|
||||
batch_size: int,
|
||||
navigate_earlier: bool,
|
||||
@@ -71,7 +74,12 @@ class LogEventsIterator:
|
||||
es_req["search_after"] = [from_timestamp]
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "get_task_events"):
|
||||
es_result = self.es.search(index=es_index, body=es_req)
|
||||
es_result = search_company_events(
|
||||
self.es,
|
||||
company_id=company_id,
|
||||
event_type=self.EVENT_TYPE,
|
||||
body=es_req,
|
||||
)
|
||||
hits = es_result["hits"]["hits"]
|
||||
hits_total = es_result["hits"]["total"]["value"]
|
||||
if not hits:
|
||||
@@ -92,22 +100,28 @@ class LogEventsIterator:
|
||||
}
|
||||
},
|
||||
}
|
||||
es_result = self.es.search(index=es_index, body=es_req)
|
||||
hits = es_result["hits"]["hits"]
|
||||
if not hits or len(hits) < 2:
|
||||
es_result = search_company_events(
|
||||
self.es,
|
||||
company_id=company_id,
|
||||
event_type=self.EVENT_TYPE,
|
||||
body=es_req,
|
||||
)
|
||||
last_second_hits = es_result["hits"]["hits"]
|
||||
if not last_second_hits or len(last_second_hits) < 2:
|
||||
# if only one element is returned for the last timestamp
|
||||
# then it is already present in the events
|
||||
return events, hits_total
|
||||
|
||||
last_events = [hit["_source"] for hit in es_result["hits"]["hits"]]
|
||||
already_present_ids = set(ev["_id"] for ev in events)
|
||||
already_present_ids = set(hit["_id"] for hit in hits)
|
||||
last_second_events = [
|
||||
hit["_source"]
|
||||
for hit in last_second_hits
|
||||
if hit["_id"] not in already_present_ids
|
||||
]
|
||||
|
||||
# return the list merged from original query results +
|
||||
# leftovers from the last timestamp
|
||||
return (
|
||||
[
|
||||
*events,
|
||||
*(ev for ev in last_events if ev["_id"] not in already_present_ids),
|
||||
],
|
||||
[*events, *last_second_events],
|
||||
hits_total,
|
||||
)
|
||||
@@ -4,9 +4,9 @@ Module for polymorphism over different types of X axes in scalar aggregations
|
||||
from abc import ABC, abstractmethod
|
||||
from enum import auto
|
||||
|
||||
from utilities.stringenum import StringEnum
|
||||
from bll.util import extract_properties_to_lists
|
||||
from config import config
|
||||
from apiserver.utilities import extract_properties_to_lists
|
||||
from apiserver.utilities.stringenum import StringEnum
|
||||
from apiserver.config_repo import config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
129
apiserver/bll/model/__init__.py
Normal file
129
apiserver/bll/model/__init__.py
Normal file
@@ -0,0 +1,129 @@
|
||||
from datetime import datetime
|
||||
from typing import Callable, Tuple
|
||||
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.apimodels.models import ModelTaskPublishResponse
|
||||
from apiserver.bll.task.utils import deleted_prefix
|
||||
from apiserver.database.model import EntityVisibility
|
||||
from apiserver.database.model.model import Model
|
||||
from apiserver.database.model.task.task import Task, TaskStatus
|
||||
|
||||
|
||||
class ModelBLL:
|
||||
@classmethod
|
||||
def get_company_model_by_id(
|
||||
cls, company_id: str, model_id: str, only_fields=None
|
||||
) -> Model:
|
||||
query = dict(company=company_id, id=model_id)
|
||||
qs = Model.objects(**query)
|
||||
if only_fields:
|
||||
qs = qs.only(*only_fields)
|
||||
model = qs.first()
|
||||
if not model:
|
||||
raise errors.bad_request.InvalidModelId(**query)
|
||||
return model
|
||||
|
||||
@classmethod
|
||||
def publish_model(
|
||||
cls,
|
||||
model_id: str,
|
||||
company_id: str,
|
||||
force_publish_task: bool = False,
|
||||
publish_task_func: Callable[[str, str, bool], dict] = None,
|
||||
) -> Tuple[int, ModelTaskPublishResponse]:
|
||||
model = cls.get_company_model_by_id(company_id=company_id, model_id=model_id)
|
||||
if model.ready:
|
||||
raise errors.bad_request.ModelIsReady(company=company_id, model=model_id)
|
||||
|
||||
published_task = None
|
||||
if model.task and publish_task_func:
|
||||
task = (
|
||||
Task.objects(id=model.task, company=company_id)
|
||||
.only("id", "status")
|
||||
.first()
|
||||
)
|
||||
if task and task.status != TaskStatus.published:
|
||||
task_publish_res = publish_task_func(
|
||||
model.task, company_id, force_publish_task
|
||||
)
|
||||
published_task = ModelTaskPublishResponse(
|
||||
id=model.task, data=task_publish_res
|
||||
)
|
||||
|
||||
updated = model.update(upsert=False, ready=True, last_update=datetime.utcnow())
|
||||
return updated, published_task
|
||||
|
||||
@classmethod
|
||||
def delete_model(
|
||||
cls, model_id: str, company_id: str, force: bool
|
||||
) -> Tuple[int, Model]:
|
||||
model = cls.get_company_model_by_id(
|
||||
company_id=company_id,
|
||||
model_id=model_id,
|
||||
only_fields=("id", "task", "project", "uri"),
|
||||
)
|
||||
deleted_model_id = f"{deleted_prefix}{model_id}"
|
||||
|
||||
using_tasks = Task.objects(models__input__model=model_id).only("id")
|
||||
if using_tasks:
|
||||
if not force:
|
||||
raise errors.bad_request.ModelInUse(
|
||||
"as execution model, use force=True to delete",
|
||||
num_tasks=len(using_tasks),
|
||||
)
|
||||
# update deleted model id in using tasks
|
||||
Task._get_collection().update_many(
|
||||
filter={"_id": {"$in": [t.id for t in using_tasks]}},
|
||||
update={"$set": {"models.input.$[elem].model": deleted_model_id}},
|
||||
array_filters=[{"elem.model": model_id}],
|
||||
upsert=False,
|
||||
)
|
||||
|
||||
if model.task:
|
||||
task = Task.objects(id=model.task).first()
|
||||
if task and task.status == TaskStatus.published:
|
||||
if not force:
|
||||
raise errors.bad_request.ModelCreatingTaskExists(
|
||||
"and published, use force=True to delete", task=model.task
|
||||
)
|
||||
if task.models.output and model_id in task.models.output:
|
||||
now = datetime.utcnow()
|
||||
Task._get_collection().update_one(
|
||||
filter={"_id": model.task, "models.output.model": model_id},
|
||||
update={
|
||||
"$set": {
|
||||
"models.output.$[elem].model": deleted_model_id,
|
||||
"output.error": f"model deleted on {now.isoformat()}",
|
||||
},
|
||||
"last_change": now,
|
||||
},
|
||||
array_filters=[{"elem.model": model_id}],
|
||||
upsert=False,
|
||||
)
|
||||
|
||||
del_count = Model.objects(id=model_id, company=company_id).delete()
|
||||
return del_count, model
|
||||
|
||||
@classmethod
|
||||
def archive_model(cls, model_id: str, company_id: str):
|
||||
cls.get_company_model_by_id(
|
||||
company_id=company_id, model_id=model_id, only_fields=("id",)
|
||||
)
|
||||
archived = Model.objects(company=company_id, id=model_id).update(
|
||||
add_to_set__system_tags=EntityVisibility.archived.value,
|
||||
last_update=datetime.utcnow(),
|
||||
)
|
||||
|
||||
return archived
|
||||
|
||||
@classmethod
|
||||
def unarchive_model(cls, model_id: str, company_id: str):
|
||||
cls.get_company_model_by_id(
|
||||
company_id=company_id, model_id=model_id, only_fields=("id",)
|
||||
)
|
||||
unarchived = Model.objects(company=company_id, id=model_id).update(
|
||||
pull__system_tags=EntityVisibility.archived.value,
|
||||
last_update=datetime.utcnow(),
|
||||
)
|
||||
|
||||
return unarchived
|
||||
63
apiserver/bll/organization/__init__.py
Normal file
63
apiserver/bll/organization/__init__.py
Normal file
@@ -0,0 +1,63 @@
|
||||
from collections import defaultdict
|
||||
from enum import Enum
|
||||
from typing import Sequence, Dict
|
||||
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.model.model import Model
|
||||
from apiserver.database.model.task.task import Task
|
||||
from apiserver.redis_manager import redman
|
||||
from .tags_cache import _TagsCache
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class Tags(Enum):
|
||||
Task = "task"
|
||||
Model = "model"
|
||||
|
||||
|
||||
class OrgBLL:
|
||||
def __init__(self, redis=None):
|
||||
self.redis = redis or redman.connection("apiserver")
|
||||
self._task_tags = _TagsCache(Task, self.redis)
|
||||
self._model_tags = _TagsCache(Model, self.redis)
|
||||
|
||||
def get_tags(
|
||||
self,
|
||||
company_id: str,
|
||||
entity: Tags,
|
||||
include_system: bool = False,
|
||||
filter_: Dict[str, Sequence[str]] = None,
|
||||
projects: Sequence[str] = None,
|
||||
) -> dict:
|
||||
tags_cache = self._get_tags_cache_for_entity(entity)
|
||||
if not projects:
|
||||
return tags_cache.get_tags(
|
||||
company_id, include_system=include_system, filter_=filter_
|
||||
)
|
||||
|
||||
ret = defaultdict(set)
|
||||
for project in projects:
|
||||
project_tags = tags_cache.get_tags(
|
||||
company_id,
|
||||
include_system=include_system,
|
||||
filter_=filter_,
|
||||
project=project,
|
||||
)
|
||||
for field, tags in project_tags.items():
|
||||
ret[field] |= tags
|
||||
|
||||
return ret
|
||||
|
||||
def update_tags(
|
||||
self, company_id: str, entity: Tags, project: str, tags=None, system_tags=None,
|
||||
):
|
||||
tags_cache = self._get_tags_cache_for_entity(entity)
|
||||
tags_cache.update_tags(company_id, project, tags, system_tags)
|
||||
|
||||
def reset_tags(self, company_id: str, entity: Tags, projects: Sequence[str]):
|
||||
tags_cache = self._get_tags_cache_for_entity(entity)
|
||||
tags_cache.reset_tags(company_id, projects=projects)
|
||||
|
||||
def _get_tags_cache_for_entity(self, entity: Tags) -> _TagsCache:
|
||||
return self._task_tags if entity == Tags.Task else self._model_tags
|
||||
@@ -1,17 +1,14 @@
|
||||
from collections import defaultdict
|
||||
from enum import Enum
|
||||
from itertools import chain
|
||||
from typing import Sequence, Union, Type, Dict
|
||||
|
||||
from mongoengine import Q
|
||||
from redis import Redis
|
||||
|
||||
from config import config
|
||||
from database.model.base import GetMixin
|
||||
from database.model.model import Model
|
||||
from database.model.task.task import Task
|
||||
from redis_manager import redman
|
||||
from utilities import json
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.bll.project import project_ids_with_children
|
||||
from apiserver.database.model.base import GetMixin
|
||||
from apiserver.database.model.model import Model
|
||||
from apiserver.database.model.task.task import Task
|
||||
|
||||
log = config.logger(__file__)
|
||||
_settings_prefix = "services.organization"
|
||||
@@ -20,6 +17,8 @@ _settings_prefix = "services.organization"
|
||||
class _TagsCache:
|
||||
_tags_field = "tags"
|
||||
_system_tags_field = "system_tags"
|
||||
_dummy_tag = "__dummy__"
|
||||
# prepend our list in redis with this tag since empty lists are auto deleted
|
||||
|
||||
def __init__(self, db_cls: Union[Type[Model], Type[Task]], redis: Redis):
|
||||
self.db_cls = db_cls
|
||||
@@ -31,24 +30,24 @@ class _TagsCache:
|
||||
|
||||
def _get_tags_from_db(
|
||||
self,
|
||||
company: str,
|
||||
company_id: str,
|
||||
field: str,
|
||||
project: str = None,
|
||||
filter_: Dict[str, Sequence[str]] = None,
|
||||
) -> set:
|
||||
query = Q(company=company)
|
||||
query = Q(company=company_id)
|
||||
if filter_:
|
||||
for name, vals in filter_.items():
|
||||
if vals:
|
||||
query &= GetMixin.get_list_field_query(name, vals)
|
||||
if project:
|
||||
query &= Q(project=project)
|
||||
query &= Q(project__in=project_ids_with_children([project]))
|
||||
|
||||
return self.db_cls.objects(query).distinct(field)
|
||||
|
||||
def _get_tags_cache_key(
|
||||
self,
|
||||
company: str,
|
||||
company_id: str,
|
||||
field: str,
|
||||
project: str = None,
|
||||
filter_: Dict[str, Sequence[str]] = None,
|
||||
@@ -64,12 +63,12 @@ class _TagsCache:
|
||||
filter_str = "_".join(
|
||||
["filter", *chain.from_iterable([f, *v] for f, v in filter_.items())]
|
||||
)
|
||||
key_parts = [company, project, self.db_cls.__name__, field, filter_str]
|
||||
key_parts = [field, company_id, project, self.db_cls.__name__, filter_str]
|
||||
return "_".join(filter(None, key_parts))
|
||||
|
||||
def get_tags(
|
||||
self,
|
||||
company: str,
|
||||
company_id: str,
|
||||
include_system: bool = False,
|
||||
filter_: Dict[str, Sequence[str]] = None,
|
||||
project: str = None,
|
||||
@@ -83,27 +82,29 @@ class _TagsCache:
|
||||
fields = [self._tags_field]
|
||||
if include_system:
|
||||
fields.append(self._system_tags_field)
|
||||
redis_keys = [
|
||||
self._get_tags_cache_key(company, field=f, project=project, filter_=filter_)
|
||||
for f in fields
|
||||
]
|
||||
cached = self.redis.mget(redis_keys)
|
||||
|
||||
ret = {}
|
||||
for field, tag_data, key in zip(fields, cached, redis_keys):
|
||||
if tag_data is not None:
|
||||
tags = json.loads(tag_data)
|
||||
for field in fields:
|
||||
redis_key = self._get_tags_cache_key(
|
||||
company_id, field=field, project=project, filter_=filter_
|
||||
)
|
||||
cached_tags = self.redis.lrange(redis_key, 0, -1)
|
||||
if cached_tags:
|
||||
tags = [c.decode() for c in cached_tags[1:]]
|
||||
else:
|
||||
tags = list(self._get_tags_from_db(company, field, project, filter_))
|
||||
self.redis.setex(
|
||||
key,
|
||||
time=self._tags_cache_expiration_seconds,
|
||||
value=json.dumps(tags),
|
||||
tags = list(
|
||||
self._get_tags_from_db(
|
||||
company_id, field=field, project=project, filter_=filter_
|
||||
)
|
||||
)
|
||||
self.redis.rpush(redis_key, self._dummy_tag, *tags)
|
||||
self.redis.expire(redis_key, self._tags_cache_expiration_seconds)
|
||||
|
||||
ret[field] = set(tags)
|
||||
|
||||
return ret
|
||||
|
||||
def update_tags(self, company: str, project: str, tags=None, system_tags=None):
|
||||
def update_tags(self, company_id: str, project: str, tags=None, system_tags=None):
|
||||
"""
|
||||
Updates tags. If reset is set then both tags and system_tags
|
||||
are recalculated. Otherwise only those that are not 'None'
|
||||
@@ -119,22 +120,22 @@ class _TagsCache:
|
||||
if not fields:
|
||||
return
|
||||
|
||||
self._delete_redis_keys(company, projects=[project], fields=fields)
|
||||
self._delete_redis_keys(company_id, projects=[project], fields=fields)
|
||||
|
||||
def reset_tags(self, company: str, projects: Sequence[str]):
|
||||
def reset_tags(self, company_id: str, projects: Sequence[str]):
|
||||
self._delete_redis_keys(
|
||||
company,
|
||||
company_id,
|
||||
projects=projects,
|
||||
fields=(self._tags_field, self._system_tags_field),
|
||||
)
|
||||
|
||||
def _delete_redis_keys(
|
||||
self, company: str, projects: [Sequence[str]], fields: Sequence[str]
|
||||
self, company_id: str, projects: [Sequence[str]], fields: Sequence[str]
|
||||
):
|
||||
redis_keys = list(
|
||||
chain.from_iterable(
|
||||
self.redis.keys(
|
||||
self._get_tags_cache_key(company, field=f, project=p) + "*"
|
||||
self._get_tags_cache_key(company_id, field=f, project=p) + "*"
|
||||
)
|
||||
for f in fields
|
||||
for p in set(projects) | {None}
|
||||
@@ -142,52 +143,3 @@ class _TagsCache:
|
||||
)
|
||||
if redis_keys:
|
||||
self.redis.delete(*redis_keys)
|
||||
|
||||
|
||||
class Tags(Enum):
|
||||
Task = "task"
|
||||
Model = "model"
|
||||
|
||||
|
||||
class OrgBLL:
|
||||
def __init__(self, redis=None):
|
||||
self.redis = redis or redman.connection("apiserver")
|
||||
self._task_tags = _TagsCache(Task, self.redis)
|
||||
self._model_tags = _TagsCache(Model, self.redis)
|
||||
|
||||
def get_tags(
|
||||
self,
|
||||
company: str,
|
||||
entity: Tags,
|
||||
include_system: bool = False,
|
||||
filter_: Dict[str, Sequence[str]] = None,
|
||||
projects: Sequence[str] = None,
|
||||
) -> dict:
|
||||
tags_cache = self._get_tags_cache_for_entity(entity)
|
||||
if not projects:
|
||||
return tags_cache.get_tags(
|
||||
company, include_system=include_system, filter_=filter_
|
||||
)
|
||||
|
||||
ret = defaultdict(set)
|
||||
for project in projects:
|
||||
project_tags = tags_cache.get_tags(
|
||||
company, include_system=include_system, filter_=filter_, project=project
|
||||
)
|
||||
for field, tags in project_tags.items():
|
||||
ret[field] |= tags
|
||||
|
||||
return ret
|
||||
|
||||
def update_tags(
|
||||
self, company: str, entity: Tags, project: str, tags=None, system_tags=None,
|
||||
):
|
||||
tags_cache = self._get_tags_cache_for_entity(entity)
|
||||
tags_cache.update_tags(company, project, tags, system_tags)
|
||||
|
||||
def reset_tags(self, company: str, entity: Tags, projects: Sequence[str]):
|
||||
tags_cache = self._get_tags_cache_for_entity(entity)
|
||||
tags_cache.reset_tags(company, projects=projects)
|
||||
|
||||
def _get_tags_cache_for_entity(self, entity: Tags) -> _TagsCache:
|
||||
return self._task_tags if entity == Tags.Task else self._model_tags
|
||||
2
apiserver/bll/project/__init__.py
Normal file
2
apiserver/bll/project/__init__.py
Normal file
@@ -0,0 +1,2 @@
|
||||
from .project_bll import ProjectBLL
|
||||
from .sub_projects import _ids_with_children as project_ids_with_children
|
||||
719
apiserver/bll/project/project_bll.py
Normal file
719
apiserver/bll/project/project_bll.py
Normal file
@@ -0,0 +1,719 @@
|
||||
import itertools
|
||||
from collections import defaultdict
|
||||
from datetime import datetime
|
||||
from functools import reduce
|
||||
from itertools import groupby
|
||||
from operator import itemgetter
|
||||
from typing import (
|
||||
Sequence,
|
||||
Optional,
|
||||
Type,
|
||||
Tuple,
|
||||
Dict,
|
||||
Set,
|
||||
TypeVar,
|
||||
Callable,
|
||||
Mapping,
|
||||
)
|
||||
|
||||
from mongoengine import Q, Document
|
||||
|
||||
from apiserver import database
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.model import EntityVisibility, AttributedDocument
|
||||
from apiserver.database.model.model import Model
|
||||
from apiserver.database.model.project import Project
|
||||
from apiserver.database.model.task.task import Task, TaskStatus, external_task_types
|
||||
from apiserver.database.utils import get_options, get_company_or_none_constraint
|
||||
from apiserver.timing_context import TimingContext
|
||||
from apiserver.utilities.dicts import nested_get
|
||||
from .sub_projects import (
|
||||
_reposition_project_with_children,
|
||||
_ensure_project,
|
||||
_validate_project_name,
|
||||
_update_subproject_names,
|
||||
_save_under_parent,
|
||||
_get_sub_projects,
|
||||
_ids_with_children,
|
||||
_ids_with_parents,
|
||||
_get_project_depth,
|
||||
)
|
||||
|
||||
log = config.logger(__file__)
|
||||
max_depth = config.get("services.projects.sub_projects.max_depth", 10)
|
||||
|
||||
|
||||
class ProjectBLL:
|
||||
@classmethod
|
||||
def merge_project(
|
||||
cls, company, source_id: str, destination_id: str
|
||||
) -> Tuple[int, int, Set[str]]:
|
||||
"""
|
||||
Move all the tasks and sub projects from the source project to the destination
|
||||
Remove the source project
|
||||
Return the amounts of moved entities and subprojects + set of all the affected project ids
|
||||
"""
|
||||
with TimingContext("mongo", "move_project"):
|
||||
if source_id == destination_id:
|
||||
raise errors.bad_request.ProjectSourceAndDestinationAreTheSame(
|
||||
parent=source_id
|
||||
)
|
||||
source = Project.get(company, source_id)
|
||||
destination = Project.get(company, destination_id)
|
||||
|
||||
children = _get_sub_projects(
|
||||
[source.id], _only=("id", "name", "parent", "path")
|
||||
)[source.id]
|
||||
cls.validate_projects_depth(
|
||||
projects=children,
|
||||
old_parent_depth=len(source.path) + 1,
|
||||
new_parent_depth=len(destination.path) + 1,
|
||||
)
|
||||
|
||||
moved_entities = 0
|
||||
for entity_type in (Task, Model):
|
||||
moved_entities += entity_type.objects(
|
||||
company=company,
|
||||
project=source_id,
|
||||
system_tags__nin=[EntityVisibility.archived.value],
|
||||
).update(upsert=False, project=destination_id)
|
||||
|
||||
moved_sub_projects = 0
|
||||
for child in Project.objects(company=company, parent=source_id):
|
||||
_reposition_project_with_children(
|
||||
project=child,
|
||||
children=[c for c in children if c.parent == child.id],
|
||||
parent=destination,
|
||||
)
|
||||
moved_sub_projects += 1
|
||||
|
||||
affected = {source.id, *(source.path or [])}
|
||||
source.delete()
|
||||
|
||||
if destination:
|
||||
destination.update(last_update=datetime.utcnow())
|
||||
affected.update({destination.id, *(destination.path or [])})
|
||||
|
||||
return moved_entities, moved_sub_projects, affected
|
||||
|
||||
@staticmethod
|
||||
def validate_projects_depth(
|
||||
projects: Sequence[Project], old_parent_depth: int, new_parent_depth: int
|
||||
):
|
||||
for current in projects:
|
||||
current_depth = len(current.path) + 1
|
||||
if current_depth - old_parent_depth + new_parent_depth > max_depth:
|
||||
raise errors.bad_request.ProjectPathExceedsMax(max_depth=max_depth)
|
||||
|
||||
@classmethod
|
||||
def move_project(
|
||||
cls, company: str, user: str, project_id: str, new_location: str
|
||||
) -> Tuple[int, Set[str]]:
|
||||
"""
|
||||
Move project with its sub projects from its current location to the target one.
|
||||
If the target location does not exist then it will be created. If it exists then
|
||||
it should be writable. The source location should be writable too.
|
||||
Return the number of moved projects + set of all the affected project ids
|
||||
"""
|
||||
with TimingContext("mongo", "move_project"):
|
||||
project = Project.get(company, project_id)
|
||||
old_parent_id = project.parent
|
||||
old_parent = (
|
||||
Project.get_for_writing(company=project.company, id=old_parent_id)
|
||||
if old_parent_id
|
||||
else None
|
||||
)
|
||||
|
||||
children = _get_sub_projects([project.id], _only=("id", "name", "path"))[
|
||||
project.id
|
||||
]
|
||||
cls.validate_projects_depth(
|
||||
projects=[project, *children],
|
||||
old_parent_depth=len(project.path),
|
||||
new_parent_depth=_get_project_depth(new_location),
|
||||
)
|
||||
|
||||
new_parent = _ensure_project(company=company, user=user, name=new_location)
|
||||
new_parent_id = new_parent.id if new_parent else None
|
||||
if old_parent_id == new_parent_id:
|
||||
raise errors.bad_request.ProjectSourceAndDestinationAreTheSame(
|
||||
location=new_parent.name if new_parent else ""
|
||||
)
|
||||
|
||||
moved = _reposition_project_with_children(
|
||||
project, children=children, parent=new_parent
|
||||
)
|
||||
|
||||
now = datetime.utcnow()
|
||||
affected = set()
|
||||
for p in filter(None, (old_parent, new_parent)):
|
||||
p.update(last_update=now)
|
||||
affected.update({p.id, *(p.path or [])})
|
||||
|
||||
return moved, affected
|
||||
|
||||
@classmethod
|
||||
def update(cls, company: str, project_id: str, **fields):
|
||||
with TimingContext("mongo", "projects_update"):
|
||||
project = Project.get_for_writing(company=company, id=project_id)
|
||||
if not project:
|
||||
raise errors.bad_request.InvalidProjectId(id=project_id)
|
||||
|
||||
new_name = fields.pop("name", None)
|
||||
if new_name:
|
||||
new_name, new_location = _validate_project_name(new_name)
|
||||
old_name, old_location = _validate_project_name(project.name)
|
||||
if new_location != old_location:
|
||||
raise errors.bad_request.CannotUpdateProjectLocation(name=new_name)
|
||||
fields["name"] = new_name
|
||||
|
||||
fields["last_update"] = datetime.utcnow()
|
||||
updated = project.update(upsert=False, **fields)
|
||||
|
||||
if new_name:
|
||||
old_name = project.name
|
||||
project.name = new_name
|
||||
children = _get_sub_projects(
|
||||
[project.id], _only=("id", "name", "path")
|
||||
)[project.id]
|
||||
_update_subproject_names(
|
||||
project=project, children=children, old_name=old_name
|
||||
)
|
||||
|
||||
return updated
|
||||
|
||||
@classmethod
|
||||
def create(
|
||||
cls,
|
||||
user: str,
|
||||
company: str,
|
||||
name: str,
|
||||
description: str = "",
|
||||
tags: Sequence[str] = None,
|
||||
system_tags: Sequence[str] = None,
|
||||
default_output_destination: str = None,
|
||||
) -> str:
|
||||
"""
|
||||
Create a new project.
|
||||
Returns project ID
|
||||
"""
|
||||
if _get_project_depth(name) > max_depth:
|
||||
raise errors.bad_request.ProjectPathExceedsMax(max_depth=max_depth)
|
||||
|
||||
name, location = _validate_project_name(name)
|
||||
now = datetime.utcnow()
|
||||
project = Project(
|
||||
id=database.utils.id(),
|
||||
user=user,
|
||||
company=company,
|
||||
name=name,
|
||||
description=description,
|
||||
tags=tags,
|
||||
system_tags=system_tags,
|
||||
default_output_destination=default_output_destination,
|
||||
created=now,
|
||||
last_update=now,
|
||||
)
|
||||
parent = _ensure_project(company=company, user=user, name=location)
|
||||
_save_under_parent(project=project, parent=parent)
|
||||
if parent:
|
||||
parent.update(last_update=now)
|
||||
|
||||
return project.id
|
||||
|
||||
@classmethod
|
||||
def find_or_create(
|
||||
cls,
|
||||
user: str,
|
||||
company: str,
|
||||
project_name: str,
|
||||
description: str,
|
||||
project_id: str = None,
|
||||
tags: Sequence[str] = None,
|
||||
system_tags: Sequence[str] = None,
|
||||
default_output_destination: str = None,
|
||||
) -> str:
|
||||
"""
|
||||
Find a project named `project_name` or create a new one.
|
||||
Returns project ID
|
||||
"""
|
||||
if not project_id and not project_name:
|
||||
raise ValueError("project id or name required")
|
||||
|
||||
if project_id:
|
||||
project = Project.objects(company=company, id=project_id).only("id").first()
|
||||
if not project:
|
||||
raise errors.bad_request.InvalidProjectId(id=project_id)
|
||||
return project_id
|
||||
|
||||
project_name, _ = _validate_project_name(project_name)
|
||||
project = Project.objects(company=company, name=project_name).only("id").first()
|
||||
if project:
|
||||
return project.id
|
||||
|
||||
return cls.create(
|
||||
user=user,
|
||||
company=company,
|
||||
name=project_name,
|
||||
description=description,
|
||||
tags=tags,
|
||||
system_tags=system_tags,
|
||||
default_output_destination=default_output_destination,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def move_under_project(
|
||||
cls,
|
||||
entity_cls: Type[Document],
|
||||
user: str,
|
||||
company: str,
|
||||
ids: Sequence[str],
|
||||
project: str = None,
|
||||
project_name: str = None,
|
||||
):
|
||||
"""
|
||||
Move a batch of entities to `project` or a project named `project_name` (create if does not exist)
|
||||
"""
|
||||
with TimingContext("mongo", "move_under_project"):
|
||||
project = cls.find_or_create(
|
||||
user=user,
|
||||
company=company,
|
||||
project_id=project,
|
||||
project_name=project_name,
|
||||
description="",
|
||||
)
|
||||
extra = (
|
||||
{"set__last_change": datetime.utcnow()}
|
||||
if hasattr(entity_cls, "last_change")
|
||||
else {}
|
||||
)
|
||||
entity_cls.objects(company=company, id__in=ids).update(
|
||||
set__project=project, **extra
|
||||
)
|
||||
|
||||
return project
|
||||
|
||||
archived_tasks_cond = {"$in": [EntityVisibility.archived.value, "$system_tags"]}
|
||||
|
||||
@classmethod
|
||||
def make_projects_get_all_pipelines(
|
||||
cls,
|
||||
company_id: str,
|
||||
project_ids: Sequence[str],
|
||||
specific_state: Optional[EntityVisibility] = None,
|
||||
) -> Tuple[Sequence, Sequence]:
|
||||
archived = EntityVisibility.archived.value
|
||||
|
||||
def ensure_valid_fields():
|
||||
"""
|
||||
Make sure system tags is always an array (required by subsequent $in in archived_tasks_cond
|
||||
"""
|
||||
return {
|
||||
"$addFields": {
|
||||
"system_tags": {
|
||||
"$cond": {
|
||||
"if": {"$ne": [{"$type": "$system_tags"}, "array"]},
|
||||
"then": [],
|
||||
"else": "$system_tags",
|
||||
}
|
||||
},
|
||||
"status": {"$ifNull": ["$status", "unknown"]},
|
||||
}
|
||||
}
|
||||
|
||||
status_count_pipeline = [
|
||||
# count tasks per project per status
|
||||
{
|
||||
"$match": {
|
||||
"company": {"$in": [None, "", company_id]},
|
||||
"project": {"$in": project_ids},
|
||||
}
|
||||
},
|
||||
ensure_valid_fields(),
|
||||
{
|
||||
"$group": {
|
||||
"_id": {
|
||||
"project": "$project",
|
||||
"status": "$status",
|
||||
archived: cls.archived_tasks_cond,
|
||||
},
|
||||
"count": {"$sum": 1},
|
||||
}
|
||||
},
|
||||
# for each project, create a list of (status, count, archived)
|
||||
{
|
||||
"$group": {
|
||||
"_id": "$_id.project",
|
||||
"counts": {
|
||||
"$push": {
|
||||
"status": "$_id.status",
|
||||
"count": "$count",
|
||||
archived: "$_id.%s" % archived,
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
]
|
||||
|
||||
def runtime_subquery(additional_cond):
|
||||
return {
|
||||
# the sum of
|
||||
"$sum": {
|
||||
# for each task
|
||||
"$cond": {
|
||||
# if completed and started and completed > started
|
||||
"if": {
|
||||
"$and": [
|
||||
"$started",
|
||||
"$completed",
|
||||
{"$gt": ["$completed", "$started"]},
|
||||
additional_cond,
|
||||
]
|
||||
},
|
||||
# then: floor((completed - started) / 1000)
|
||||
"then": {
|
||||
"$floor": {
|
||||
"$divide": [
|
||||
{"$subtract": ["$completed", "$started"]},
|
||||
1000.0,
|
||||
]
|
||||
}
|
||||
},
|
||||
"else": 0,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
group_step = {"_id": "$project"}
|
||||
|
||||
for state in EntityVisibility:
|
||||
if specific_state and state != specific_state:
|
||||
continue
|
||||
if state == EntityVisibility.active:
|
||||
group_step[state.value] = runtime_subquery(
|
||||
{"$not": cls.archived_tasks_cond}
|
||||
)
|
||||
elif state == EntityVisibility.archived:
|
||||
group_step[state.value] = runtime_subquery(cls.archived_tasks_cond)
|
||||
|
||||
runtime_pipeline = [
|
||||
# only count run time for these types of tasks
|
||||
{
|
||||
"$match": {
|
||||
"company": {"$in": [None, "", company_id]},
|
||||
"type": {"$in": ["training", "testing", "annotation"]},
|
||||
"project": {"$in": project_ids},
|
||||
}
|
||||
},
|
||||
ensure_valid_fields(),
|
||||
{
|
||||
# for each project
|
||||
"$group": group_step
|
||||
},
|
||||
]
|
||||
|
||||
return status_count_pipeline, runtime_pipeline
|
||||
|
||||
T = TypeVar("T")
|
||||
|
||||
@staticmethod
|
||||
def aggregate_project_data(
|
||||
func: Callable[[T, T], T],
|
||||
project_ids: Sequence[str],
|
||||
child_projects: Mapping[str, Sequence[Project]],
|
||||
data: Mapping[str, T],
|
||||
) -> Dict[str, T]:
|
||||
"""
|
||||
Given a list of project ids and data collected over these projects and their subprojects
|
||||
For each project aggregates the data from all of its subprojects
|
||||
"""
|
||||
aggregated = {}
|
||||
if not data:
|
||||
return aggregated
|
||||
for pid in project_ids:
|
||||
relevant_projects = {p.id for p in child_projects.get(pid, [])} | {pid}
|
||||
relevant_data = [data for p, data in data.items() if p in relevant_projects]
|
||||
if not relevant_data:
|
||||
continue
|
||||
aggregated[pid] = reduce(func, relevant_data)
|
||||
return aggregated
|
||||
|
||||
@classmethod
|
||||
def get_project_stats(
|
||||
cls,
|
||||
company: str,
|
||||
project_ids: Sequence[str],
|
||||
specific_state: Optional[EntityVisibility] = None,
|
||||
) -> Tuple[Dict[str, dict], Dict[str, dict]]:
|
||||
if not project_ids:
|
||||
return {}, {}
|
||||
|
||||
child_projects = _get_sub_projects(project_ids, _only=("id", "name"))
|
||||
project_ids_with_children = set(project_ids) | {
|
||||
c.id for c in itertools.chain.from_iterable(child_projects.values())
|
||||
}
|
||||
status_count_pipeline, runtime_pipeline = cls.make_projects_get_all_pipelines(
|
||||
company,
|
||||
project_ids=list(project_ids_with_children),
|
||||
specific_state=specific_state,
|
||||
)
|
||||
|
||||
default_counts = dict.fromkeys(get_options(TaskStatus), 0)
|
||||
|
||||
def set_default_count(entry):
|
||||
return dict(default_counts, **entry)
|
||||
|
||||
status_count = defaultdict(lambda: {})
|
||||
key = itemgetter(EntityVisibility.archived.value)
|
||||
for result in Task.aggregate(status_count_pipeline):
|
||||
for k, group in groupby(sorted(result["counts"], key=key), key):
|
||||
section = (
|
||||
EntityVisibility.archived if k else EntityVisibility.active
|
||||
).value
|
||||
status_count[result["_id"]][section] = set_default_count(
|
||||
{
|
||||
count_entry["status"]: count_entry["count"]
|
||||
for count_entry in group
|
||||
}
|
||||
)
|
||||
|
||||
def sum_status_count(
|
||||
a: Mapping[str, Mapping], b: Mapping[str, Mapping]
|
||||
) -> Dict[str, dict]:
|
||||
return {
|
||||
section: {
|
||||
status: nested_get(a, (section, status), 0)
|
||||
+ nested_get(b, (section, status), 0)
|
||||
for status in set(a.get(section, {})) | set(b.get(section, {}))
|
||||
}
|
||||
for section in set(a) | set(b)
|
||||
}
|
||||
|
||||
status_count = cls.aggregate_project_data(
|
||||
func=sum_status_count,
|
||||
project_ids=project_ids,
|
||||
child_projects=child_projects,
|
||||
data=status_count,
|
||||
)
|
||||
|
||||
runtime = {
|
||||
result["_id"]: {k: v for k, v in result.items() if k != "_id"}
|
||||
for result in Task.aggregate(runtime_pipeline)
|
||||
}
|
||||
|
||||
def sum_runtime(
|
||||
a: Mapping[str, Mapping], b: Mapping[str, Mapping]
|
||||
) -> Dict[str, dict]:
|
||||
return {
|
||||
section: a.get(section, 0) + b.get(section, 0)
|
||||
for section in set(a) | set(b)
|
||||
}
|
||||
|
||||
runtime = cls.aggregate_project_data(
|
||||
func=sum_runtime,
|
||||
project_ids=project_ids,
|
||||
child_projects=child_projects,
|
||||
data=runtime,
|
||||
)
|
||||
|
||||
def get_status_counts(project_id, section):
|
||||
return {
|
||||
"total_runtime": nested_get(runtime, (project_id, section), 0),
|
||||
"status_count": nested_get(
|
||||
status_count, (project_id, section), default_counts
|
||||
),
|
||||
}
|
||||
|
||||
report_for_states = [
|
||||
s for s in EntityVisibility if not specific_state or specific_state == s
|
||||
]
|
||||
|
||||
stats = {
|
||||
project: {
|
||||
task_state.value: get_status_counts(project, task_state.value)
|
||||
for task_state in report_for_states
|
||||
}
|
||||
for project in project_ids
|
||||
}
|
||||
|
||||
children = {
|
||||
project: sorted(
|
||||
[{"id": c.id, "name": c.name} for c in child_projects.get(project, [])],
|
||||
key=itemgetter("name"),
|
||||
)
|
||||
for project in project_ids
|
||||
}
|
||||
return stats, children
|
||||
|
||||
@classmethod
|
||||
def get_active_users(
|
||||
cls,
|
||||
company,
|
||||
project_ids: Sequence[str],
|
||||
user_ids: Optional[Sequence[str]] = None,
|
||||
) -> Set[str]:
|
||||
"""
|
||||
Get the set of user ids that created tasks/models in the given projects
|
||||
If project_ids is empty then all projects are examined
|
||||
If user_ids are passed then only subset of these users is returned
|
||||
"""
|
||||
with TimingContext("mongo", "active_users_in_projects"):
|
||||
query = Q(company=company)
|
||||
if user_ids:
|
||||
query &= Q(user__in=user_ids)
|
||||
|
||||
projects_query = query
|
||||
if project_ids:
|
||||
project_ids = _ids_with_children(project_ids)
|
||||
query &= Q(project__in=project_ids)
|
||||
projects_query &= Q(id__in=project_ids)
|
||||
|
||||
res = set(Project.objects(projects_query).distinct(field="user"))
|
||||
for cls_ in (Task, Model):
|
||||
res |= set(cls_.objects(query).distinct(field="user"))
|
||||
|
||||
return res
|
||||
|
||||
@classmethod
|
||||
def get_projects_with_active_user(
|
||||
cls,
|
||||
company: str,
|
||||
users: Sequence[str],
|
||||
project_ids: Optional[Sequence[str]] = None,
|
||||
allow_public: bool = True,
|
||||
) -> Sequence[str]:
|
||||
"""
|
||||
Get the projects ids where user created any tasks including all the parents of these projects
|
||||
If project ids are specified then filter the results by these project ids
|
||||
"""
|
||||
query = Q(user__in=users)
|
||||
|
||||
if allow_public:
|
||||
query &= get_company_or_none_constraint(company)
|
||||
else:
|
||||
query &= Q(company=company)
|
||||
|
||||
user_projects_query = query
|
||||
if project_ids:
|
||||
ids_with_children = _ids_with_children(project_ids)
|
||||
query &= Q(project__in=ids_with_children)
|
||||
user_projects_query &= Q(id__in=ids_with_children)
|
||||
|
||||
res = {p.id for p in Project.objects(user_projects_query).only("id")}
|
||||
for cls_ in (Task, Model):
|
||||
res |= set(cls_.objects(query).distinct(field="project"))
|
||||
|
||||
res = list(res)
|
||||
if not res:
|
||||
return res
|
||||
|
||||
ids_with_parents = _ids_with_parents(res)
|
||||
if project_ids:
|
||||
return [pid for pid in ids_with_parents if pid in project_ids]
|
||||
|
||||
return ids_with_parents
|
||||
|
||||
@classmethod
|
||||
def get_task_parents(
|
||||
cls,
|
||||
company_id: str,
|
||||
projects: Sequence[str],
|
||||
include_subprojects: bool,
|
||||
state: Optional[EntityVisibility] = None,
|
||||
) -> Sequence[dict]:
|
||||
"""
|
||||
Get list of unique parent tasks sorted by task name for the passed company projects
|
||||
If projects is None or empty then get parents for all the company tasks
|
||||
"""
|
||||
query = Q(company=company_id)
|
||||
if projects:
|
||||
if include_subprojects:
|
||||
projects = _ids_with_children(projects)
|
||||
query &= Q(project__in=projects)
|
||||
if state == EntityVisibility.archived:
|
||||
query &= Q(system_tags__in=[EntityVisibility.archived.value])
|
||||
elif state == EntityVisibility.active:
|
||||
query &= Q(system_tags__nin=[EntityVisibility.archived.value])
|
||||
|
||||
parent_ids = set(Task.objects(query).distinct("parent"))
|
||||
if not parent_ids:
|
||||
return []
|
||||
|
||||
parents = Task.get_many_with_join(
|
||||
company_id,
|
||||
query=Q(id__in=parent_ids),
|
||||
allow_public=True,
|
||||
override_projection=("id", "name", "project.name"),
|
||||
)
|
||||
return sorted(parents, key=itemgetter("name"))
|
||||
|
||||
@classmethod
|
||||
def get_task_types(cls, company, project_ids: Optional[Sequence]) -> set:
|
||||
"""
|
||||
Return the list of unique task types used by company and public tasks
|
||||
If project ids passed then only tasks from these projects are considered
|
||||
"""
|
||||
query = get_company_or_none_constraint(company)
|
||||
if project_ids:
|
||||
project_ids = _ids_with_children(project_ids)
|
||||
query &= Q(project__in=project_ids)
|
||||
res = Task.objects(query).distinct(field="type")
|
||||
return set(res).intersection(external_task_types)
|
||||
|
||||
@classmethod
|
||||
def get_model_frameworks(cls, company, project_ids: Optional[Sequence]) -> Sequence:
|
||||
"""
|
||||
Return the list of unique frameworks used by company and public models
|
||||
If project ids passed then only models from these projects are considered
|
||||
"""
|
||||
query = get_company_or_none_constraint(company)
|
||||
if project_ids:
|
||||
project_ids = _ids_with_children(project_ids)
|
||||
query &= Q(project__in=project_ids)
|
||||
return Model.objects(query).distinct(field="framework")
|
||||
|
||||
@classmethod
|
||||
def calc_own_contents(cls, company: str, project_ids: Sequence[str]) -> Dict[str, dict]:
|
||||
"""
|
||||
Returns the amount of task/models per requested project
|
||||
Use separate aggregation calls on Task/Model instead of lookup
|
||||
aggregation on projects in order not to hit memory limits on large tasks
|
||||
"""
|
||||
if not project_ids:
|
||||
return {}
|
||||
|
||||
pipeline = [
|
||||
{
|
||||
"$match": {
|
||||
"company": {"$in": [None, "", company]},
|
||||
"project": {"$in": project_ids},
|
||||
}
|
||||
},
|
||||
{
|
||||
"$project": {"project": 1}
|
||||
},
|
||||
{
|
||||
"$group": {
|
||||
"_id": "$project",
|
||||
"count": {"$sum": 1},
|
||||
}
|
||||
}
|
||||
]
|
||||
|
||||
def get_agrregate_res(cls_: Type[AttributedDocument]) -> dict:
|
||||
return {
|
||||
data["_id"]: data["count"]
|
||||
for data in cls_.aggregate(pipeline)
|
||||
}
|
||||
|
||||
with TimingContext("mongo", "get_security_groups"):
|
||||
tasks = get_agrregate_res(Task)
|
||||
models = get_agrregate_res(Model)
|
||||
return {
|
||||
pid: {
|
||||
"own_tasks": tasks.get(pid, 0),
|
||||
"own_models": models.get(pid, 0),
|
||||
}
|
||||
for pid in project_ids
|
||||
}
|
||||
176
apiserver/bll/project/project_cleanup.py
Normal file
176
apiserver/bll/project/project_cleanup.py
Normal file
@@ -0,0 +1,176 @@
|
||||
from typing import Tuple, Set, Sequence
|
||||
|
||||
import attr
|
||||
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.bll.event import EventBLL
|
||||
from apiserver.bll.task.task_cleanup import (
|
||||
collect_debug_image_urls,
|
||||
collect_plot_image_urls,
|
||||
TaskUrls,
|
||||
)
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.model import EntityVisibility
|
||||
from apiserver.database.model.model import Model
|
||||
from apiserver.database.model.project import Project
|
||||
from apiserver.database.model.task.task import Task, ArtifactModes
|
||||
from apiserver.timing_context import TimingContext
|
||||
from .sub_projects import _ids_with_children
|
||||
|
||||
log = config.logger(__file__)
|
||||
event_bll = EventBLL()
|
||||
|
||||
|
||||
@attr.s(auto_attribs=True)
|
||||
class DeleteProjectResult:
|
||||
deleted: int = 0
|
||||
disassociated_tasks: int = 0
|
||||
deleted_models: int = 0
|
||||
deleted_tasks: int = 0
|
||||
urls: TaskUrls = None
|
||||
|
||||
|
||||
def validate_project_delete(company: str, project_id: str):
|
||||
project = Project.get_for_writing(
|
||||
company=company, id=project_id, _only=("id", "path")
|
||||
)
|
||||
if not project:
|
||||
raise errors.bad_request.InvalidProjectId(id=project_id)
|
||||
|
||||
project_ids = _ids_with_children([project_id])
|
||||
ret = {}
|
||||
for cls in (Task, Model):
|
||||
ret[f"{cls.__name__.lower()}s"] = cls.objects(
|
||||
project__in=project_ids,
|
||||
).count()
|
||||
for cls in (Task, Model):
|
||||
ret[f"non_archived_{cls.__name__.lower()}s"] = cls.objects(
|
||||
project__in=project_ids,
|
||||
system_tags__nin=[EntityVisibility.archived.value],
|
||||
).count()
|
||||
|
||||
return ret
|
||||
|
||||
|
||||
def delete_project(
|
||||
company: str, project_id: str, force: bool, delete_contents: bool
|
||||
) -> Tuple[DeleteProjectResult, Set[str]]:
|
||||
project = Project.get_for_writing(
|
||||
company=company, id=project_id, _only=("id", "path")
|
||||
)
|
||||
if not project:
|
||||
raise errors.bad_request.InvalidProjectId(id=project_id)
|
||||
|
||||
project_ids = _ids_with_children([project_id])
|
||||
if not force:
|
||||
for cls, error in (
|
||||
(Task, errors.bad_request.ProjectHasTasks),
|
||||
(Model, errors.bad_request.ProjectHasModels),
|
||||
):
|
||||
non_archived = cls.objects(
|
||||
project__in=project_ids,
|
||||
system_tags__nin=[EntityVisibility.archived.value],
|
||||
).only("id")
|
||||
if non_archived:
|
||||
raise error("use force=true to delete", id=project_id)
|
||||
|
||||
if not delete_contents:
|
||||
with TimingContext("mongo", "update_children"):
|
||||
for cls in (Model, Task):
|
||||
updated_count = cls.objects(project__in=project_ids).update(
|
||||
project=None
|
||||
)
|
||||
res = DeleteProjectResult(disassociated_tasks=updated_count)
|
||||
else:
|
||||
deleted_models, model_urls = _delete_models(projects=project_ids)
|
||||
deleted_tasks, event_urls, artifact_urls = _delete_tasks(
|
||||
company=company, projects=project_ids
|
||||
)
|
||||
res = DeleteProjectResult(
|
||||
deleted_tasks=deleted_tasks,
|
||||
deleted_models=deleted_models,
|
||||
urls=TaskUrls(
|
||||
model_urls=list(model_urls),
|
||||
event_urls=list(event_urls),
|
||||
artifact_urls=list(artifact_urls),
|
||||
),
|
||||
)
|
||||
|
||||
affected = {*project_ids, *(project.path or [])}
|
||||
res.deleted = Project.objects(id__in=project_ids).delete()
|
||||
|
||||
return res, affected
|
||||
|
||||
|
||||
def _delete_tasks(company: str, projects: Sequence[str]) -> Tuple[int, Set, Set]:
|
||||
"""
|
||||
Delete only the task themselves and their non published version.
|
||||
Child models under the same project are deleted separately.
|
||||
Children tasks should be deleted in the same api call.
|
||||
If any child entities are left in another projects then updated their parent task to None
|
||||
"""
|
||||
tasks = Task.objects(project__in=projects).only("id", "execution__artifacts")
|
||||
if not tasks:
|
||||
return 0, set(), set()
|
||||
|
||||
task_ids = {t.id for t in tasks}
|
||||
with TimingContext("mongo", "delete_tasks_update_children"):
|
||||
Task.objects(parent__in=task_ids, project__nin=projects).update(parent=None)
|
||||
Model.objects(task__in=task_ids, project__nin=projects).update(task=None)
|
||||
|
||||
event_urls, artifact_urls = set(), set()
|
||||
for task in tasks:
|
||||
event_urls.update(collect_debug_image_urls(company, task.id))
|
||||
event_urls.update(collect_plot_image_urls(company, task.id))
|
||||
if task.execution and task.execution.artifacts:
|
||||
artifact_urls.update(
|
||||
{
|
||||
a.uri
|
||||
for a in task.execution.artifacts.values()
|
||||
if a.mode == ArtifactModes.output and a.uri
|
||||
}
|
||||
)
|
||||
|
||||
event_bll.delete_multi_task_events(company, list(task_ids))
|
||||
deleted = tasks.delete()
|
||||
return deleted, event_urls, artifact_urls
|
||||
|
||||
|
||||
def _delete_models(projects: Sequence[str]) -> Tuple[int, Set[str]]:
|
||||
"""
|
||||
Delete project models and update the tasks from other projects
|
||||
that reference them to reference None.
|
||||
"""
|
||||
with TimingContext("mongo", "delete_models"):
|
||||
models = Model.objects(project__in=projects).only("task", "id", "uri")
|
||||
if not models:
|
||||
return 0, set()
|
||||
|
||||
model_ids = list({m.id for m in models})
|
||||
|
||||
Task._get_collection().update_many(
|
||||
filter={
|
||||
"project": {"$nin": projects},
|
||||
"models.input.model": {"$in": model_ids},
|
||||
},
|
||||
update={"$set": {"models.input.$[elem].model": None}},
|
||||
array_filters=[{"elem.model": {"$in": model_ids}}],
|
||||
upsert=False,
|
||||
)
|
||||
|
||||
model_tasks = list({m.task for m in models if m.task})
|
||||
if model_tasks:
|
||||
Task._get_collection().update_many(
|
||||
filter={
|
||||
"_id": {"$in": model_tasks},
|
||||
"project": {"$nin": projects},
|
||||
"models.output.model": {"$in": model_ids},
|
||||
},
|
||||
update={"$set": {"models.output.$[elem].model": None}},
|
||||
array_filters=[{"elem.model": {"$in": model_ids}}],
|
||||
upsert=False,
|
||||
)
|
||||
|
||||
urls = {m.uri for m in models if m.uri}
|
||||
deleted = models.delete()
|
||||
return deleted, urls
|
||||
176
apiserver/bll/project/sub_projects.py
Normal file
176
apiserver/bll/project/sub_projects.py
Normal file
@@ -0,0 +1,176 @@
|
||||
import itertools
|
||||
from datetime import datetime
|
||||
from typing import Tuple, Optional, Sequence, Mapping
|
||||
|
||||
from apiserver import database
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.database.model.project import Project
|
||||
|
||||
name_separator = "/"
|
||||
|
||||
|
||||
def _get_project_depth(project_name: str) -> int:
|
||||
return len(list(filter(None, project_name.split(name_separator))))
|
||||
|
||||
|
||||
def _validate_project_name(project_name: str) -> Tuple[str, str]:
|
||||
"""
|
||||
Remove redundant '/' characters. Ensure that the project name is not empty
|
||||
Return the cleaned up project name and location
|
||||
"""
|
||||
name_parts = list(filter(None, project_name.split(name_separator)))
|
||||
if not name_parts:
|
||||
raise errors.bad_request.InvalidProjectName(name=project_name)
|
||||
|
||||
return name_separator.join(name_parts), name_separator.join(name_parts[:-1])
|
||||
|
||||
|
||||
def _ensure_project(company: str, user: str, name: str) -> Optional[Project]:
|
||||
"""
|
||||
Makes sure that the project with the given name exists
|
||||
If needed auto-create the project and all the missing projects in the path to it
|
||||
Return the project
|
||||
"""
|
||||
name = name.strip(name_separator)
|
||||
if not name:
|
||||
return None
|
||||
|
||||
project = _get_writable_project_from_name(company, name)
|
||||
if project:
|
||||
return project
|
||||
|
||||
now = datetime.utcnow()
|
||||
name, location = _validate_project_name(name)
|
||||
project = Project(
|
||||
id=database.utils.id(),
|
||||
user=user,
|
||||
company=company,
|
||||
created=now,
|
||||
last_update=now,
|
||||
name=name,
|
||||
description="",
|
||||
)
|
||||
parent = _ensure_project(company, user, location)
|
||||
_save_under_parent(project=project, parent=parent)
|
||||
if parent:
|
||||
parent.update(last_update=now)
|
||||
|
||||
return project
|
||||
|
||||
|
||||
def _save_under_parent(project: Project, parent: Optional[Project]):
|
||||
"""
|
||||
Save the project under the given parent project or top level (parent=None)
|
||||
Check that the project location matches the parent name
|
||||
"""
|
||||
location, _, _ = project.name.rpartition(name_separator)
|
||||
if not parent:
|
||||
if location:
|
||||
raise ValueError(
|
||||
f"Project location {location} does not match empty parent name"
|
||||
)
|
||||
project.parent = None
|
||||
project.path = []
|
||||
project.save()
|
||||
return
|
||||
|
||||
if location != parent.name:
|
||||
raise ValueError(
|
||||
f"Project location {location} does not match parent name {parent.name}"
|
||||
)
|
||||
project.parent = parent.id
|
||||
project.path = [*(parent.path or []), parent.id]
|
||||
project.save()
|
||||
|
||||
|
||||
def _get_writable_project_from_name(
|
||||
company,
|
||||
name,
|
||||
_only: Optional[Sequence[str]] = ("id", "name", "path", "company", "parent"),
|
||||
) -> Optional[Project]:
|
||||
"""
|
||||
Return a project from name. If the project not found then return None
|
||||
"""
|
||||
qs = Project.objects(company=company, name=name)
|
||||
if _only:
|
||||
qs = qs.only(*_only)
|
||||
return qs.first()
|
||||
|
||||
|
||||
def _get_sub_projects(
|
||||
project_ids: Sequence[str], _only: Sequence[str] = ("id", "path")
|
||||
) -> Mapping[str, Sequence[Project]]:
|
||||
"""
|
||||
Return the list of child projects of all the levels for the parent project ids
|
||||
"""
|
||||
qs = Project.objects(path__in=project_ids)
|
||||
if _only:
|
||||
_only = set(_only) | {"path"}
|
||||
qs = qs.only(*_only)
|
||||
subprojects = list(qs)
|
||||
|
||||
return {
|
||||
pid: [s for s in subprojects if pid in (s.path or [])] for pid in project_ids
|
||||
}
|
||||
|
||||
|
||||
def _ids_with_parents(project_ids: Sequence[str]) -> Sequence[str]:
|
||||
"""
|
||||
Return project ids with all the parent projects
|
||||
"""
|
||||
projects = Project.objects(id__in=project_ids).only("id", "path")
|
||||
parent_ids = set(itertools.chain.from_iterable(p.path for p in projects if p.path))
|
||||
return list({*(p.id for p in projects), *parent_ids})
|
||||
|
||||
|
||||
def _ids_with_children(project_ids: Sequence[str]) -> Sequence[str]:
|
||||
"""
|
||||
Return project ids with the ids of all the subprojects
|
||||
"""
|
||||
subprojects = Project.objects(path__in=project_ids).only("id")
|
||||
return list({*project_ids, *(child.id for child in subprojects)})
|
||||
|
||||
|
||||
def _update_subproject_names(
|
||||
project: Project,
|
||||
children: Sequence[Project],
|
||||
old_name: str,
|
||||
update_path: bool = False,
|
||||
old_path: Sequence[str] = None,
|
||||
) -> int:
|
||||
"""
|
||||
Update sub project names when the base project name changes
|
||||
Optionally update the paths
|
||||
"""
|
||||
updated = 0
|
||||
for child in children:
|
||||
child_suffix = name_separator.join(
|
||||
child.name.split(name_separator)[len(old_name.split(name_separator)) :]
|
||||
)
|
||||
updates = {"name": name_separator.join((project.name, child_suffix))}
|
||||
if update_path:
|
||||
updates["path"] = project.path + child.path[len(old_path) :]
|
||||
updated += child.update(upsert=False, **updates)
|
||||
|
||||
return updated
|
||||
|
||||
|
||||
def _reposition_project_with_children(
|
||||
project: Project, children: Sequence[Project], parent: Project
|
||||
) -> int:
|
||||
new_location = parent.name if parent else None
|
||||
old_name = project.name
|
||||
old_path = project.path
|
||||
project.name = name_separator.join(
|
||||
filter(None, (new_location, project.name.split(name_separator)[-1]))
|
||||
)
|
||||
_save_under_parent(project, parent=parent)
|
||||
|
||||
moved = 1 + _update_subproject_names(
|
||||
project=project,
|
||||
children=children,
|
||||
old_name=old_name,
|
||||
update_path=True,
|
||||
old_path=old_path,
|
||||
)
|
||||
return moved
|
||||
@@ -1,6 +1,6 @@
|
||||
from typing import Optional, Sequence, Iterable, Union
|
||||
|
||||
from config import config
|
||||
from apiserver.config_repo import config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
@@ -4,14 +4,14 @@ from typing import Callable, Sequence, Optional, Tuple
|
||||
|
||||
from elasticsearch import Elasticsearch
|
||||
|
||||
import database
|
||||
import es_factory
|
||||
from apierrors import errors
|
||||
from bll.queue.queue_metrics import QueueMetrics
|
||||
from bll.workers import WorkerBLL
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.queue import Queue, Entry
|
||||
from apiserver import database
|
||||
from apiserver.es_factory import es_factory
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.bll.queue.queue_metrics import QueueMetrics
|
||||
from apiserver.bll.workers import WorkerBLL
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.database.model.queue import Queue, Entry
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
@@ -32,6 +32,7 @@ class QueueBLL(object):
|
||||
name: str,
|
||||
tags: Optional[Sequence[str]] = None,
|
||||
system_tags: Optional[Sequence[str]] = None,
|
||||
metadata: Optional[Sequence[dict]] = None,
|
||||
) -> Queue:
|
||||
"""Creates a queue"""
|
||||
with translate_errors_context():
|
||||
@@ -43,6 +44,7 @@ class QueueBLL(object):
|
||||
name=name,
|
||||
tags=tags or [],
|
||||
system_tags=system_tags or [],
|
||||
metadata=metadata,
|
||||
last_update=now,
|
||||
)
|
||||
queue.save()
|
||||
@@ -5,13 +5,13 @@ from typing import Sequence
|
||||
import elasticsearch.helpers
|
||||
from elasticsearch import Elasticsearch
|
||||
|
||||
import es_factory
|
||||
from apierrors.errors import bad_request
|
||||
from bll.query import Builder as QueryBuilder
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.queue import Queue, Entry
|
||||
from timing_context import TimingContext
|
||||
from apiserver.es_factory import es_factory
|
||||
from apiserver.apierrors.errors import bad_request
|
||||
from apiserver.bll.query import Builder as QueryBuilder
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.database.model.queue import Queue, Entry
|
||||
from apiserver.timing_context import TimingContext
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
@@ -3,8 +3,8 @@ from typing import Optional, TypeVar, Generic, Type, Callable
|
||||
|
||||
from redis import StrictRedis
|
||||
|
||||
import database
|
||||
from timing_context import TimingContext
|
||||
from apiserver import database
|
||||
from apiserver.timing_context import TimingContext
|
||||
|
||||
T = TypeVar("T")
|
||||
|
||||
@@ -6,7 +6,7 @@ from time import sleep
|
||||
import attr
|
||||
import psutil
|
||||
|
||||
from utilities.threads_manager import ThreadsManager
|
||||
from apiserver.utilities.threads_manager import ThreadsManager
|
||||
|
||||
|
||||
class ResourceMonitor(Thread):
|
||||
@@ -11,18 +11,18 @@ import requests
|
||||
from requests.adapters import HTTPAdapter
|
||||
from requests.packages.urllib3.util.retry import Retry
|
||||
|
||||
from bll.query import Builder as QueryBuilder
|
||||
from bll.util import get_server_uuid
|
||||
from bll.workers import WorkerStats, WorkerBLL
|
||||
from config import config
|
||||
from config.info import get_deployment_type
|
||||
from database.model import Company, User
|
||||
from database.model.queue import Queue
|
||||
from database.model.task.task import Task
|
||||
from tools import safe_get
|
||||
from utilities.json import dumps
|
||||
from utilities.threads_manager import ThreadsManager
|
||||
from version import __version__ as current_version
|
||||
from apiserver.bll.query import Builder as QueryBuilder
|
||||
from apiserver.bll.util import get_server_uuid
|
||||
from apiserver.bll.workers import WorkerStats, WorkerBLL
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.config.info import get_deployment_type
|
||||
from apiserver.database.model import Company, User
|
||||
from apiserver.database.model.queue import Queue
|
||||
from apiserver.database.model.task.task import Task
|
||||
from apiserver.tools import safe_get
|
||||
from apiserver.utilities.json import dumps
|
||||
from apiserver.utilities.threads_manager import ThreadsManager
|
||||
from apiserver.version import __version__ as current_version
|
||||
from .resource_monitor import ResourceMonitor
|
||||
|
||||
log = config.logger(__file__)
|
||||
@@ -45,7 +45,7 @@ class StatisticsReporter:
|
||||
def start_reporter(cls):
|
||||
"""
|
||||
Periodically send statistics reports for companies who have opted in.
|
||||
Note: in trains we usually have only a single company
|
||||
Note: in clearml we usually have only a single company
|
||||
"""
|
||||
if not cls.supported:
|
||||
return
|
||||
@@ -3,5 +3,4 @@ from .utils import (
|
||||
ChangeStatusRequest,
|
||||
update_project_time,
|
||||
validate_status_change,
|
||||
split_by,
|
||||
)
|
||||
97
apiserver/bll/task/artifacts.py
Normal file
97
apiserver/bll/task/artifacts.py
Normal file
@@ -0,0 +1,97 @@
|
||||
from operator import itemgetter
|
||||
from typing import Sequence
|
||||
|
||||
from apiserver.apimodels.tasks import Artifact as ApiArtifact, ArtifactId
|
||||
from apiserver.bll.task.utils import get_task_for_update, update_task
|
||||
from apiserver.database.model.task.task import DEFAULT_ARTIFACT_MODE, Artifact
|
||||
from apiserver.database.utils import hash_field_name
|
||||
from apiserver.timing_context import TimingContext
|
||||
from apiserver.utilities.dicts import nested_get, nested_set
|
||||
from apiserver.utilities.parameter_key_escaper import mongoengine_safe
|
||||
|
||||
|
||||
def get_artifact_id(artifact: dict):
|
||||
"""
|
||||
Calculate id from 'key' and 'mode' fields
|
||||
Return hash on on the id so that it will not contain mongo illegal characters
|
||||
"""
|
||||
key_hash: str = hash_field_name(artifact["key"])
|
||||
mode: str = artifact.get("mode", DEFAULT_ARTIFACT_MODE)
|
||||
return f"{key_hash}_{mode}"
|
||||
|
||||
|
||||
def artifacts_prepare_for_save(fields: dict):
|
||||
artifacts_field = ("execution", "artifacts")
|
||||
artifacts = nested_get(fields, artifacts_field)
|
||||
if artifacts is None:
|
||||
return
|
||||
|
||||
nested_set(
|
||||
fields, artifacts_field, value={get_artifact_id(a): a for a in artifacts}
|
||||
)
|
||||
|
||||
|
||||
def artifacts_unprepare_from_saved(fields):
|
||||
artifacts_field = ("execution", "artifacts")
|
||||
artifacts = nested_get(fields, artifacts_field)
|
||||
if artifacts is None:
|
||||
return
|
||||
|
||||
nested_set(
|
||||
fields,
|
||||
artifacts_field,
|
||||
value=sorted(artifacts.values(), key=itemgetter("key")),
|
||||
)
|
||||
|
||||
|
||||
class Artifacts:
|
||||
@classmethod
|
||||
def add_or_update_artifacts(
|
||||
cls,
|
||||
company_id: str,
|
||||
task_id: str,
|
||||
artifacts: Sequence[ApiArtifact],
|
||||
force: bool,
|
||||
) -> int:
|
||||
with TimingContext("mongo", "update_artifacts"):
|
||||
task = get_task_for_update(
|
||||
company_id=company_id,
|
||||
task_id=task_id,
|
||||
force=force,
|
||||
)
|
||||
|
||||
artifacts = {
|
||||
get_artifact_id(a): Artifact(**a)
|
||||
for a in (api_artifact.to_struct() for api_artifact in artifacts)
|
||||
}
|
||||
|
||||
update_cmds = {
|
||||
f"set__execution__artifacts__{mongoengine_safe(name)}": value
|
||||
for name, value in artifacts.items()
|
||||
}
|
||||
return update_task(task, update_cmds=update_cmds)
|
||||
|
||||
@classmethod
|
||||
def delete_artifacts(
|
||||
cls,
|
||||
company_id: str,
|
||||
task_id: str,
|
||||
artifact_ids: Sequence[ArtifactId],
|
||||
force: bool,
|
||||
) -> int:
|
||||
with TimingContext("mongo", "delete_artifacts"):
|
||||
task = get_task_for_update(
|
||||
company_id=company_id,
|
||||
task_id=task_id,
|
||||
force=force,
|
||||
)
|
||||
|
||||
artifact_ids = [
|
||||
get_artifact_id(a)
|
||||
for a in (artifact_id.to_struct() for artifact_id in artifact_ids)
|
||||
]
|
||||
delete_cmds = {
|
||||
f"unset__execution__artifacts__{id_}": 1 for id_ in set(artifact_ids)
|
||||
}
|
||||
|
||||
return update_task(task, update_cmds=delete_cmds)
|
||||
247
apiserver/bll/task/hyperparams.py
Normal file
247
apiserver/bll/task/hyperparams.py
Normal file
@@ -0,0 +1,247 @@
|
||||
from itertools import chain
|
||||
from operator import attrgetter
|
||||
from typing import Sequence, Dict
|
||||
|
||||
from boltons import iterutils
|
||||
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.apimodels.tasks import (
|
||||
HyperParamKey,
|
||||
HyperParamItem,
|
||||
ReplaceHyperparams,
|
||||
Configuration,
|
||||
)
|
||||
from apiserver.bll.task import TaskBLL
|
||||
from apiserver.bll.task.utils import get_task_for_update, update_task
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.model.task.task import ParamsItem, Task, ConfigurationItem
|
||||
from apiserver.timing_context import TimingContext
|
||||
from apiserver.utilities.parameter_key_escaper import (
|
||||
ParameterKeyEscaper,
|
||||
mongoengine_safe,
|
||||
)
|
||||
|
||||
log = config.logger(__file__)
|
||||
task_bll = TaskBLL()
|
||||
|
||||
|
||||
class HyperParams:
|
||||
_properties_section = "properties"
|
||||
|
||||
@classmethod
|
||||
def get_params(cls, company_id: str, task_ids: Sequence[str]) -> Dict[str, dict]:
|
||||
only = ("id", "hyperparams")
|
||||
tasks = task_bll.assert_exists(
|
||||
company_id=company_id, task_ids=task_ids, only=only, allow_public=True,
|
||||
)
|
||||
|
||||
return {
|
||||
task.id: {"hyperparams": cls._get_params_list(items=task.hyperparams)}
|
||||
for task in tasks
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _get_params_list(
|
||||
cls, items: Dict[str, Dict[str, ParamsItem]]
|
||||
) -> Sequence[dict]:
|
||||
ret = list(chain.from_iterable(v.values() for v in items.values()))
|
||||
return [
|
||||
p.to_proper_dict() for p in sorted(ret, key=attrgetter("section", "name"))
|
||||
]
|
||||
|
||||
@classmethod
|
||||
def _normalize_params(cls, params: Sequence) -> bool:
|
||||
"""
|
||||
Lower case properties section and return True if it is the only section
|
||||
"""
|
||||
for p in params:
|
||||
if p.section.lower() == cls._properties_section:
|
||||
p.section = cls._properties_section
|
||||
|
||||
return all(p.section == cls._properties_section for p in params)
|
||||
|
||||
@classmethod
|
||||
def delete_params(
|
||||
cls,
|
||||
company_id: str,
|
||||
task_id: str,
|
||||
hyperparams: Sequence[HyperParamKey],
|
||||
force: bool,
|
||||
) -> int:
|
||||
with TimingContext("mongo", "delete_hyperparams"):
|
||||
properties_only = cls._normalize_params(hyperparams)
|
||||
task = get_task_for_update(
|
||||
company_id=company_id,
|
||||
task_id=task_id,
|
||||
allow_all_statuses=properties_only,
|
||||
force=force,
|
||||
)
|
||||
|
||||
with_param, without_param = iterutils.partition(
|
||||
hyperparams, key=lambda p: bool(p.name)
|
||||
)
|
||||
sections_to_delete = {p.section for p in without_param}
|
||||
delete_cmds = {
|
||||
f"unset__hyperparams__{ParameterKeyEscaper.escape(section)}": 1
|
||||
for section in sections_to_delete
|
||||
}
|
||||
|
||||
for item in with_param:
|
||||
section = ParameterKeyEscaper.escape(item.section)
|
||||
if item.section in sections_to_delete:
|
||||
raise errors.bad_request.FieldsConflict(
|
||||
"Cannot delete section field if the whole section was scheduled for deletion"
|
||||
)
|
||||
name = ParameterKeyEscaper.escape(item.name)
|
||||
delete_cmds[f"unset__hyperparams__{section}__{name}"] = 1
|
||||
|
||||
return update_task(
|
||||
task, update_cmds=delete_cmds, set_last_update=not properties_only
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def edit_params(
|
||||
cls,
|
||||
company_id: str,
|
||||
task_id: str,
|
||||
hyperparams: Sequence[HyperParamItem],
|
||||
replace_hyperparams: str,
|
||||
force: bool,
|
||||
) -> int:
|
||||
with TimingContext("mongo", "edit_hyperparams"):
|
||||
properties_only = cls._normalize_params(hyperparams)
|
||||
task = get_task_for_update(
|
||||
company_id=company_id,
|
||||
task_id=task_id,
|
||||
allow_all_statuses=properties_only,
|
||||
force=force,
|
||||
)
|
||||
|
||||
update_cmds = dict()
|
||||
hyperparams = cls._db_dicts_from_list(hyperparams)
|
||||
if replace_hyperparams == ReplaceHyperparams.all:
|
||||
update_cmds["set__hyperparams"] = hyperparams
|
||||
elif replace_hyperparams == ReplaceHyperparams.section:
|
||||
for section, value in hyperparams.items():
|
||||
update_cmds[
|
||||
f"set__hyperparams__{mongoengine_safe(section)}"
|
||||
] = value
|
||||
else:
|
||||
for section, section_params in hyperparams.items():
|
||||
for name, value in section_params.items():
|
||||
update_cmds[
|
||||
f"set__hyperparams__{section}__{mongoengine_safe(name)}"
|
||||
] = value
|
||||
|
||||
return update_task(
|
||||
task, update_cmds=update_cmds, set_last_update=not properties_only
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def _db_dicts_from_list(cls, items: Sequence[HyperParamItem]) -> Dict[str, dict]:
|
||||
sections = iterutils.bucketize(items, key=attrgetter("section"))
|
||||
return {
|
||||
ParameterKeyEscaper.escape(section): {
|
||||
ParameterKeyEscaper.escape(param.name): ParamsItem(**param.to_struct())
|
||||
for param in params
|
||||
}
|
||||
for section, params in sections.items()
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def get_configurations(
|
||||
cls, company_id: str, task_ids: Sequence[str], names: Sequence[str]
|
||||
) -> Dict[str, dict]:
|
||||
only = ["id"]
|
||||
if names:
|
||||
only.extend(
|
||||
f"configuration.{ParameterKeyEscaper.escape(name)}" for name in names
|
||||
)
|
||||
else:
|
||||
only.append("configuration")
|
||||
tasks = task_bll.assert_exists(
|
||||
company_id=company_id, task_ids=task_ids, only=only, allow_public=True,
|
||||
)
|
||||
|
||||
return {
|
||||
task.id: {
|
||||
"configuration": [
|
||||
c.to_proper_dict()
|
||||
for c in sorted(task.configuration.values(), key=attrgetter("name"))
|
||||
]
|
||||
}
|
||||
for task in tasks
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def get_configuration_names(
|
||||
cls, company_id: str, task_ids: Sequence[str], skip_empty: bool
|
||||
) -> Dict[str, list]:
|
||||
skip_empty_condition = {"$match": {"items.v.value": {"$nin": [None, ""]}}}
|
||||
pipeline = [
|
||||
{
|
||||
"$match": {
|
||||
"company": {"$in": [None, "", company_id]},
|
||||
"_id": {"$in": task_ids},
|
||||
}
|
||||
},
|
||||
{"$project": {"items": {"$objectToArray": "$configuration"}}},
|
||||
{"$unwind": "$items"},
|
||||
*([skip_empty_condition] if skip_empty else []),
|
||||
{"$group": {"_id": "$_id", "names": {"$addToSet": "$items.k"}}},
|
||||
]
|
||||
|
||||
with TimingContext("mongo", "get_configuration_names"):
|
||||
tasks = Task.aggregate(pipeline)
|
||||
|
||||
return {
|
||||
task["_id"]: {
|
||||
"names": sorted(
|
||||
ParameterKeyEscaper.unescape(name) for name in task["names"]
|
||||
)
|
||||
}
|
||||
for task in tasks
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def edit_configuration(
|
||||
cls,
|
||||
company_id: str,
|
||||
task_id: str,
|
||||
configuration: Sequence[Configuration],
|
||||
replace_configuration: bool,
|
||||
force: bool,
|
||||
) -> int:
|
||||
with TimingContext("mongo", "edit_configuration"):
|
||||
task = get_task_for_update(
|
||||
company_id=company_id, task_id=task_id, force=force
|
||||
)
|
||||
|
||||
update_cmds = dict()
|
||||
configuration = {
|
||||
ParameterKeyEscaper.escape(c.name): ConfigurationItem(**c.to_struct())
|
||||
for c in configuration
|
||||
}
|
||||
if replace_configuration:
|
||||
update_cmds["set__configuration"] = configuration
|
||||
else:
|
||||
for name, value in configuration.items():
|
||||
update_cmds[f"set__configuration__{mongoengine_safe(name)}"] = value
|
||||
|
||||
return update_task(task, update_cmds=update_cmds)
|
||||
|
||||
@classmethod
|
||||
def delete_configuration(
|
||||
cls, company_id: str, task_id: str, configuration: Sequence[str], force: bool
|
||||
) -> int:
|
||||
with TimingContext("mongo", "delete_configuration"):
|
||||
task = get_task_for_update(
|
||||
company_id=company_id, task_id=task_id, force=force
|
||||
)
|
||||
|
||||
delete_cmds = {
|
||||
f"unset__configuration__{ParameterKeyEscaper.escape(name)}": 1
|
||||
for name in set(configuration)
|
||||
}
|
||||
|
||||
return update_task(task, update_cmds=delete_cmds)
|
||||
@@ -1,11 +1,10 @@
|
||||
from datetime import timedelta, datetime
|
||||
from time import sleep
|
||||
|
||||
from apierrors import errors
|
||||
from bll.task import ChangeStatusRequest
|
||||
from config import config
|
||||
from database.model.task.task import TaskStatus, Task
|
||||
from utilities.threads_manager import ThreadsManager
|
||||
from apiserver.bll.task import update_project_time
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.model.task.task import TaskStatus, Task
|
||||
from apiserver.utilities.threads_manager import ThreadsManager
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
@@ -71,19 +70,29 @@ class NonResponsiveTasksWatchdog:
|
||||
return 0
|
||||
|
||||
err_count = 0
|
||||
project_ids = set()
|
||||
now = datetime.utcnow()
|
||||
for task in tasks:
|
||||
log.info(
|
||||
f"Stopping {task.id} ({task.name}), last updated at {task.last_update}"
|
||||
)
|
||||
# noinspection PyBroadException
|
||||
try:
|
||||
ChangeStatusRequest(
|
||||
task=task,
|
||||
new_status=TaskStatus.stopped,
|
||||
updated = Task.objects(id=task.id, status=task.status).update(
|
||||
status=TaskStatus.stopped,
|
||||
status_reason="Forced stop (non-responsive)",
|
||||
status_message="Forced stop (non-responsive)",
|
||||
force=True,
|
||||
).execute()
|
||||
except errors.bad_request.FailedChangingTaskStatus:
|
||||
err_count += 1
|
||||
status_changed=now,
|
||||
last_update=now,
|
||||
last_change=now,
|
||||
)
|
||||
if updated:
|
||||
project_ids.add(task.project)
|
||||
else:
|
||||
err_count += 1
|
||||
except Exception as ex:
|
||||
log.error("Failed setting status: %s", str(ex))
|
||||
|
||||
update_project_time(list(project_ids))
|
||||
|
||||
return len(tasks) - err_count
|
||||
@@ -1,12 +1,11 @@
|
||||
import itertools
|
||||
from typing import Sequence, Tuple
|
||||
from typing import Sequence, Tuple, Optional
|
||||
|
||||
import dpath
|
||||
|
||||
from apierrors import errors
|
||||
from database.model.task.task import Task
|
||||
from tools import safe_get
|
||||
from utilities.parameter_key_escaper import ParameterKeyEscaper
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.database.model.task.task import Task
|
||||
from apiserver.utilities.dicts import nested_get, nested_delete, nested_set
|
||||
from apiserver.utilities.parameter_key_escaper import ParameterKeyEscaper
|
||||
|
||||
|
||||
hyperparams_default_section = "Args"
|
||||
@@ -14,7 +13,7 @@ hyperparams_legacy_type = "legacy"
|
||||
tf_define_section = "TF_DEFINE"
|
||||
|
||||
|
||||
def split_param_name(full_name: str, default_section: str) -> Tuple[str, str]:
|
||||
def split_param_name(full_name: str, default_section: str) -> Tuple[Optional[str], str]:
|
||||
"""
|
||||
Return parameter section and name. The section is either TF_DEFINE or the default one
|
||||
"""
|
||||
@@ -62,7 +61,7 @@ def _remove_legacy_params(data: dict, with_sections: bool = False) -> int:
|
||||
return removed
|
||||
|
||||
|
||||
def _get_legacy_params(data: dict, with_sections: bool = False) -> Sequence[str]:
|
||||
def _get_legacy_params(data: dict, with_sections: bool = False) -> Sequence[dict]:
|
||||
"""
|
||||
Remove the legacy params from the data dict and return the number of removed params
|
||||
If the path not found then return 0
|
||||
@@ -71,8 +70,10 @@ def _get_legacy_params(data: dict, with_sections: bool = False) -> Sequence[str]
|
||||
return []
|
||||
|
||||
if with_sections:
|
||||
return itertools.chain.from_iterable(
|
||||
_get_legacy_params(section_data) for section_data in data.values()
|
||||
return list(
|
||||
itertools.chain.from_iterable(
|
||||
_get_legacy_params(section_data) for section_data in data.values()
|
||||
)
|
||||
)
|
||||
|
||||
return [
|
||||
@@ -86,15 +87,15 @@ def params_prepare_for_save(fields: dict, previous_task: Task = None):
|
||||
Escape all the section and param names for hyper params and configuration to make it mongo sage
|
||||
"""
|
||||
for old_params_field, new_params_field, default_section in (
|
||||
("execution/parameters", "hyperparams", hyperparams_default_section),
|
||||
("execution/model_desc", "configuration", None),
|
||||
(("execution", "parameters"), "hyperparams", hyperparams_default_section),
|
||||
(("execution", "model_desc"), "configuration", None),
|
||||
):
|
||||
legacy_params = safe_get(fields, old_params_field)
|
||||
legacy_params = nested_get(fields, old_params_field)
|
||||
if legacy_params is None:
|
||||
continue
|
||||
|
||||
if (
|
||||
not safe_get(fields, new_params_field)
|
||||
not fields.get(new_params_field)
|
||||
and previous_task
|
||||
and previous_task[new_params_field]
|
||||
):
|
||||
@@ -117,11 +118,11 @@ def params_prepare_for_save(fields: dict, previous_task: Task = None):
|
||||
new_param = dict(name=name, type=hyperparams_legacy_type, value=str(value))
|
||||
if section is not None:
|
||||
new_param["section"] = section
|
||||
dpath.new(fields, new_path, new_param)
|
||||
dpath.delete(fields, old_params_field)
|
||||
nested_set(fields, new_path, new_param)
|
||||
nested_delete(fields, old_params_field)
|
||||
|
||||
for param_field in ("hyperparams", "configuration"):
|
||||
params = safe_get(fields, param_field)
|
||||
params = fields.get(param_field)
|
||||
if params:
|
||||
escaped_params = {
|
||||
ParameterKeyEscaper.escape(key): {
|
||||
@@ -131,7 +132,7 @@ def params_prepare_for_save(fields: dict, previous_task: Task = None):
|
||||
else value
|
||||
for key, value in params.items()
|
||||
}
|
||||
dpath.set(fields, param_field, escaped_params)
|
||||
fields[param_field] = escaped_params
|
||||
|
||||
|
||||
def params_unprepare_from_saved(fields, copy_to_legacy=False):
|
||||
@@ -140,7 +141,7 @@ def params_unprepare_from_saved(fields, copy_to_legacy=False):
|
||||
If copy_to_legacy is set then copy hyperparams and configuration data to the legacy location for the old clients
|
||||
"""
|
||||
for param_field in ("hyperparams", "configuration"):
|
||||
params = safe_get(fields, param_field)
|
||||
params = fields.get(param_field)
|
||||
if params:
|
||||
unescaped_params = {
|
||||
ParameterKeyEscaper.unescape(key): {
|
||||
@@ -150,18 +151,18 @@ def params_unprepare_from_saved(fields, copy_to_legacy=False):
|
||||
else value
|
||||
for key, value in params.items()
|
||||
}
|
||||
dpath.set(fields, param_field, unescaped_params)
|
||||
fields[param_field] = unescaped_params
|
||||
|
||||
if copy_to_legacy:
|
||||
for new_params_field, old_params_field, use_sections in (
|
||||
(f"hyperparams", "execution/parameters", True),
|
||||
(f"configuration", "execution/model_desc", False),
|
||||
("hyperparams", ("execution", "parameters"), True),
|
||||
("configuration", ("execution", "model_desc"), False),
|
||||
):
|
||||
legacy_params = _get_legacy_params(
|
||||
safe_get(fields, new_params_field), with_sections=use_sections
|
||||
fields.get(new_params_field), with_sections=use_sections
|
||||
)
|
||||
if legacy_params:
|
||||
dpath.new(
|
||||
nested_set(
|
||||
fields,
|
||||
old_params_field,
|
||||
{_get_full_param_name(p): p["value"] for p in legacy_params},
|
||||
@@ -174,7 +175,7 @@ def _process_path(path: str):
|
||||
Need to unescape and apply a full mongo escaping
|
||||
"""
|
||||
parts = path.split(".")
|
||||
if len(parts) < 2 or len(parts) > 3:
|
||||
if len(parts) < 2 or len(parts) > 4:
|
||||
raise errors.bad_request.ValidationError("invalid task field", path=path)
|
||||
return ".".join(
|
||||
ParameterKeyEscaper.escape(ParameterKeyEscaper.unescape(p)) for p in parts
|
||||
@@ -184,7 +185,8 @@ def _process_path(path: str):
|
||||
def escape_paths(paths: Sequence[str]) -> Sequence[str]:
|
||||
for old_prefix, new_prefix in (
|
||||
("execution.parameters", f"hyperparams.{hyperparams_default_section}"),
|
||||
("execution.model_desc", f"configuration"),
|
||||
("execution.model_desc", "configuration"),
|
||||
("execution.docker_cmd", "container")
|
||||
):
|
||||
path: str
|
||||
paths = [path.replace(old_prefix, new_prefix) for path in paths]
|
||||
@@ -1,65 +1,63 @@
|
||||
import json
|
||||
from collections import OrderedDict
|
||||
from datetime import datetime
|
||||
from operator import attrgetter
|
||||
from random import random
|
||||
from time import sleep
|
||||
from typing import Collection, Sequence, Tuple, Any, Optional, List, Dict
|
||||
from datetime import datetime, timedelta
|
||||
from typing import Collection, Sequence, Tuple, Any, Optional, Dict
|
||||
|
||||
import dpath
|
||||
import pymongo.results
|
||||
import six
|
||||
from mongoengine import Q
|
||||
from redis import StrictRedis
|
||||
from six import string_types
|
||||
|
||||
import database.utils as dbutils
|
||||
import es_factory
|
||||
from apierrors import errors
|
||||
from apimodels.tasks import Artifact as ApiArtifact
|
||||
from bll.organization import OrgBLL, Tags
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.model import Model
|
||||
from database.model.project import Project
|
||||
from database.model.task.metrics import EventStats, MetricEventStats
|
||||
from database.model.task.output import Output
|
||||
from database.model.task.task import (
|
||||
import apiserver.database.utils as dbutils
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.apimodels.tasks import TaskInputModel
|
||||
from apiserver.bll.queue import QueueBLL
|
||||
from apiserver.bll.organization import OrgBLL, Tags
|
||||
from apiserver.bll.project import ProjectBLL, project_ids_with_children
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.database.model.model import Model
|
||||
from apiserver.database.model.project import Project
|
||||
from apiserver.database.model.task.metrics import EventStats, MetricEventStats
|
||||
from apiserver.database.model.task.output import Output
|
||||
from apiserver.database.model.task.task import (
|
||||
Task,
|
||||
TaskStatus,
|
||||
TaskStatusMessage,
|
||||
TaskSystemTags,
|
||||
ArtifactModes,
|
||||
Artifact,
|
||||
external_task_types,
|
||||
ModelItem,
|
||||
Models,
|
||||
DEFAULT_ARTIFACT_MODE,
|
||||
TaskModelNames,
|
||||
TaskModelTypes,
|
||||
)
|
||||
from database.utils import get_company_or_none_constraint, id as create_id
|
||||
from service_repo import APICall
|
||||
from timing_context import TimingContext
|
||||
from utilities.dicts import deep_merge
|
||||
from utilities.parameter_key_escaper import ParameterKeyEscaper
|
||||
from apiserver.database.model import EntityVisibility
|
||||
from apiserver.database.utils import get_company_or_none_constraint, id as create_id
|
||||
from apiserver.es_factory import es_factory
|
||||
from apiserver.redis_manager import redman
|
||||
from apiserver.service_repo import APICall
|
||||
from apiserver.services.utils import validate_tags, escape_dict_field, escape_dict
|
||||
from apiserver.timing_context import TimingContext
|
||||
from apiserver.utilities.parameter_key_escaper import ParameterKeyEscaper
|
||||
from .artifacts import artifacts_prepare_for_save
|
||||
from .param_utils import params_prepare_for_save
|
||||
from .utils import ChangeStatusRequest, validate_status_change
|
||||
from .utils import (
|
||||
ChangeStatusRequest,
|
||||
update_project_time,
|
||||
deleted_prefix,
|
||||
)
|
||||
|
||||
log = config.logger(__file__)
|
||||
org_bll = OrgBLL()
|
||||
queue_bll = QueueBLL()
|
||||
project_bll = ProjectBLL()
|
||||
|
||||
|
||||
class TaskBLL(object):
|
||||
def __init__(self, events_es=None):
|
||||
self.events_es = (
|
||||
events_es if events_es is not None else es_factory.connect("events")
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def get_types(cls, company, project_ids: Optional[Sequence]) -> set:
|
||||
"""
|
||||
Return the list of unique task types used by company and public tasks
|
||||
If project ids passed then only tasks from these projects are considered
|
||||
"""
|
||||
query = get_company_or_none_constraint(company)
|
||||
if project_ids:
|
||||
query &= Q(project__in=project_ids)
|
||||
res = Task.objects(query).distinct(field="type")
|
||||
return set(res).intersection(external_task_types)
|
||||
class TaskBLL:
|
||||
def __init__(self, events_es=None, redis=None):
|
||||
self.events_es = events_es or es_factory.connect("events")
|
||||
self.redis: StrictRedis = redis or redman.connection("apiserver")
|
||||
|
||||
@staticmethod
|
||||
def get_task_with_access(
|
||||
@@ -126,7 +124,9 @@ class TaskBLL(object):
|
||||
return_dicts=False,
|
||||
)
|
||||
if only:
|
||||
q = q.only(*only)
|
||||
# Make sure to reset fields filters (some fields are excluded by default) since this
|
||||
# is an internal call and specific fields were requested.
|
||||
q = q.all_fields().only(*only)
|
||||
|
||||
if q.count() != len(ids):
|
||||
raise errors.bad_request.InvalidTaskId(ids=task_ids)
|
||||
@@ -144,30 +144,32 @@ class TaskBLL(object):
|
||||
company=identity.company,
|
||||
created=now,
|
||||
last_update=now,
|
||||
last_change=now,
|
||||
**fields,
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def validate_execution_model(task, allow_only_public=False):
|
||||
if not task.execution or not task.execution.model:
|
||||
def validate_input_models(task, allow_only_public=False):
|
||||
if not task.models.input:
|
||||
return
|
||||
|
||||
company = None if allow_only_public else task.company
|
||||
model_id = task.execution.model
|
||||
model = Model.objects(
|
||||
Q(id=model_id) & get_company_or_none_constraint(company)
|
||||
).first()
|
||||
if not model:
|
||||
raise errors.bad_request.InvalidModelId(model=model_id)
|
||||
model_ids = set(m.model for m in task.models.input)
|
||||
models = Model.objects(
|
||||
Q(id__in=model_ids) & get_company_or_none_constraint(company)
|
||||
).only("id")
|
||||
missing = model_ids - {m.id for m in models}
|
||||
if missing:
|
||||
raise errors.bad_request.InvalidModelId(models=missing)
|
||||
|
||||
return model
|
||||
return
|
||||
|
||||
@classmethod
|
||||
def clone_task(
|
||||
cls,
|
||||
company_id,
|
||||
user_id,
|
||||
task_id,
|
||||
company_id: str,
|
||||
user_id: str,
|
||||
task_id: str,
|
||||
name: Optional[str] = None,
|
||||
comment: Optional[str] = None,
|
||||
parent: Optional[str] = None,
|
||||
@@ -176,12 +178,13 @@ class TaskBLL(object):
|
||||
system_tags: Optional[Sequence[str]] = None,
|
||||
hyperparams: Optional[dict] = None,
|
||||
configuration: Optional[dict] = None,
|
||||
container: Optional[dict] = None,
|
||||
execution_overrides: Optional[dict] = None,
|
||||
input_models: Optional[Sequence[TaskInputModel]] = None,
|
||||
validate_references: bool = False,
|
||||
) -> Task:
|
||||
task = cls.get_by_id(company_id=company_id, task_id=task_id, allow_public=True)
|
||||
execution_dict = task.execution.to_proper_dict() if task.execution else {}
|
||||
execution_model_overriden = False
|
||||
new_project_name: str = None,
|
||||
) -> Tuple[Task, dict]:
|
||||
validate_tags(tags, system_tags)
|
||||
params_dict = {
|
||||
field: value
|
||||
for field, value in (
|
||||
@@ -190,48 +193,110 @@ class TaskBLL(object):
|
||||
)
|
||||
if value is not None
|
||||
}
|
||||
|
||||
task = cls.get_by_id(company_id=company_id, task_id=task_id, allow_public=True)
|
||||
|
||||
now = datetime.utcnow()
|
||||
if input_models:
|
||||
input_models = [
|
||||
ModelItem(model=m.model, name=m.name, updated=now) for m in input_models
|
||||
]
|
||||
|
||||
execution_dict = task.execution.to_proper_dict() if task.execution else {}
|
||||
if execution_overrides:
|
||||
execution_model = execution_overrides.pop("model", None)
|
||||
if not input_models and execution_model:
|
||||
input_models = [
|
||||
ModelItem(
|
||||
model=execution_model,
|
||||
name=TaskModelNames[TaskModelTypes.input],
|
||||
updated=now,
|
||||
)
|
||||
]
|
||||
|
||||
docker_cmd = execution_overrides.pop("docker_cmd", None)
|
||||
if not container and docker_cmd:
|
||||
image, _, arguments = docker_cmd.partition(" ")
|
||||
container = {"image": image, "arguments": arguments}
|
||||
|
||||
artifacts_prepare_for_save({"execution": execution_overrides})
|
||||
|
||||
params_dict["execution"] = {}
|
||||
for legacy_param in ("parameters", "configuration"):
|
||||
legacy_value = execution_overrides.pop(legacy_param, None)
|
||||
if legacy_value is not None:
|
||||
params_dict["execution"] = legacy_value
|
||||
execution_dict = deep_merge(execution_dict, execution_overrides)
|
||||
execution_model_overriden = execution_overrides.get("model") is not None
|
||||
|
||||
escape_dict_field(execution_overrides, "model_labels")
|
||||
|
||||
execution_dict.update(execution_overrides)
|
||||
|
||||
params_prepare_for_save(params_dict, previous_task=task)
|
||||
|
||||
artifacts = execution_dict.get("artifacts")
|
||||
if artifacts:
|
||||
execution_dict["artifacts"] = [
|
||||
a for a in artifacts if a.get("mode") != ArtifactModes.output
|
||||
]
|
||||
now = datetime.utcnow()
|
||||
execution_dict["artifacts"] = {
|
||||
k: a
|
||||
for k, a in artifacts.items()
|
||||
if a.get("mode", DEFAULT_ARTIFACT_MODE) != ArtifactModes.output
|
||||
}
|
||||
execution_dict.pop("queue", None)
|
||||
|
||||
with translate_errors_context():
|
||||
new_project_data = None
|
||||
if not project and new_project_name:
|
||||
# Use a project with the provided name, or create a new project
|
||||
project = ProjectBLL.find_or_create(
|
||||
project_name=new_project_name,
|
||||
user=user_id,
|
||||
company=company_id,
|
||||
description="",
|
||||
)
|
||||
new_project_data = {"id": project, "name": new_project_name}
|
||||
|
||||
def clean_system_tags(input_tags: Sequence[str]) -> Sequence[str]:
|
||||
if not input_tags:
|
||||
return input_tags
|
||||
|
||||
return [
|
||||
tag
|
||||
for tag in input_tags
|
||||
if tag
|
||||
not in [TaskSystemTags.development, EntityVisibility.archived.value]
|
||||
]
|
||||
|
||||
with TimingContext("mongo", "clone task"):
|
||||
parent_task = (
|
||||
task.parent
|
||||
if task.parent and not task.parent.startswith(deleted_prefix)
|
||||
else None
|
||||
)
|
||||
new_task = Task(
|
||||
id=create_id(),
|
||||
user=user_id,
|
||||
company=company_id,
|
||||
created=now,
|
||||
last_update=now,
|
||||
last_change=now,
|
||||
name=name or task.name,
|
||||
comment=comment or task.comment,
|
||||
parent=parent or task.parent,
|
||||
parent=parent or parent_task,
|
||||
project=project or task.project,
|
||||
tags=tags or task.tags,
|
||||
system_tags=system_tags or [],
|
||||
system_tags=system_tags or clean_system_tags(task.system_tags),
|
||||
type=task.type,
|
||||
script=task.script,
|
||||
output=Output(destination=task.output.destination)
|
||||
if task.output
|
||||
else None,
|
||||
models=Models(input=input_models or task.models.input),
|
||||
container=escape_dict(container) or task.container,
|
||||
execution=execution_dict,
|
||||
configuration=params_dict.get("configuration") or task.configuration,
|
||||
hyperparams=params_dict.get("hyperparams") or task.hyperparams,
|
||||
)
|
||||
cls.validate(
|
||||
new_task,
|
||||
validate_model=validate_references or execution_model_overriden,
|
||||
validate_models=validate_references or input_models,
|
||||
validate_parent=validate_references or parent,
|
||||
validate_project=validate_references or project,
|
||||
)
|
||||
@@ -250,43 +315,55 @@ class TaskBLL(object):
|
||||
tags=updated_tags,
|
||||
system_tags=updated_system_tags,
|
||||
)
|
||||
update_project_time(new_task.project)
|
||||
|
||||
return new_task
|
||||
return new_task, new_project_data
|
||||
|
||||
@classmethod
|
||||
def validate(
|
||||
cls,
|
||||
task: Task,
|
||||
validate_model=True,
|
||||
validate_models=True,
|
||||
validate_parent=True,
|
||||
validate_project=True,
|
||||
):
|
||||
"""
|
||||
Validate task properties according to the flag
|
||||
Task project is always checked for being writable
|
||||
in order to disable the modification of public projects
|
||||
"""
|
||||
if (
|
||||
validate_parent
|
||||
and task.parent
|
||||
and not task.parent.startswith(deleted_prefix)
|
||||
and not Task.get(
|
||||
company=task.company, id=task.parent, _only=("id",), include_public=True
|
||||
)
|
||||
):
|
||||
raise errors.bad_request.InvalidTaskId("invalid parent", parent=task.parent)
|
||||
|
||||
if (
|
||||
validate_project
|
||||
and task.project
|
||||
and not Project.get_for_writing(company=task.company, id=task.project)
|
||||
):
|
||||
raise errors.bad_request.InvalidProjectId(id=task.project)
|
||||
if task.project:
|
||||
project = Project.get_for_writing(company=task.company, id=task.project)
|
||||
if validate_project and not project:
|
||||
raise errors.bad_request.InvalidProjectId(id=task.project)
|
||||
|
||||
if validate_model:
|
||||
cls.validate_execution_model(task)
|
||||
if validate_models:
|
||||
cls.validate_input_models(task)
|
||||
|
||||
@staticmethod
|
||||
def get_unique_metric_variants(company_id, project_ids=None):
|
||||
def get_unique_metric_variants(
|
||||
company_id, project_ids: Sequence[str], include_subprojects: bool
|
||||
):
|
||||
if project_ids:
|
||||
if include_subprojects:
|
||||
project_ids = project_ids_with_children(project_ids)
|
||||
project_constraint = {"project": {"$in": project_ids}}
|
||||
else:
|
||||
project_constraint = {}
|
||||
pipeline = [
|
||||
{
|
||||
"$match": dict(
|
||||
company=company_id,
|
||||
**({"project": {"$in": project_ids}} if project_ids else {}),
|
||||
company={"$in": [None, "", company_id]}, **project_constraint,
|
||||
)
|
||||
},
|
||||
{"$project": {"metrics": {"$objectToArray": "$last_metrics"}}},
|
||||
@@ -323,11 +400,31 @@ class TaskBLL(object):
|
||||
|
||||
@staticmethod
|
||||
def set_last_update(
|
||||
task_ids: Collection[str], company_id: str, last_update: datetime
|
||||
task_ids: Collection[str],
|
||||
company_id: str,
|
||||
last_update: datetime,
|
||||
**extra_updates,
|
||||
):
|
||||
return Task.objects(id__in=task_ids, company=company_id).update(
|
||||
upsert=False, last_update=last_update
|
||||
tasks = Task.objects(id__in=task_ids, company=company_id).only(
|
||||
"status", "started"
|
||||
)
|
||||
count = 0
|
||||
for task in tasks:
|
||||
updates = extra_updates
|
||||
if task.status == TaskStatus.in_progress and task.started:
|
||||
updates = {
|
||||
"active_duration": (
|
||||
datetime.utcnow() - task.started
|
||||
).total_seconds(),
|
||||
**extra_updates,
|
||||
}
|
||||
count += Task.objects(id=task.id, company=company_id).update(
|
||||
upsert=False,
|
||||
last_update=last_update,
|
||||
last_change=last_update,
|
||||
**updates,
|
||||
)
|
||||
return count
|
||||
|
||||
@staticmethod
|
||||
def update_statistics(
|
||||
@@ -390,264 +487,35 @@ class TaskBLL(object):
|
||||
}
|
||||
extra_updates["metric_stats"] = metric_stats
|
||||
|
||||
Task.objects(id=task_id, company=company_id).update(
|
||||
upsert=False, last_update=last_update, **extra_updates
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def model_set_ready(
|
||||
cls,
|
||||
model_id: str,
|
||||
company_id: str,
|
||||
publish_task: bool,
|
||||
force_publish_task: bool = False,
|
||||
) -> tuple:
|
||||
with translate_errors_context():
|
||||
query = dict(id=model_id, company=company_id)
|
||||
model = Model.objects(**query).first()
|
||||
if not model:
|
||||
raise errors.bad_request.InvalidModelId(**query)
|
||||
elif model.ready:
|
||||
raise errors.bad_request.ModelIsReady(**query)
|
||||
|
||||
published_task_data = {}
|
||||
if model.task and publish_task:
|
||||
task = (
|
||||
Task.objects(id=model.task, company=company_id)
|
||||
.only("id", "status")
|
||||
.first()
|
||||
)
|
||||
if task and task.status != TaskStatus.published:
|
||||
published_task_data["data"] = cls.publish_task(
|
||||
task_id=model.task,
|
||||
company_id=company_id,
|
||||
publish_model=False,
|
||||
force=force_publish_task,
|
||||
)
|
||||
published_task_data["id"] = model.task
|
||||
|
||||
updated = model.update(upsert=False, ready=True)
|
||||
return updated, published_task_data
|
||||
|
||||
@classmethod
|
||||
def publish_task(
|
||||
cls,
|
||||
task_id: str,
|
||||
company_id: str,
|
||||
publish_model: bool,
|
||||
force: bool,
|
||||
status_reason: str = "",
|
||||
status_message: str = "",
|
||||
) -> dict:
|
||||
task = cls.get_task_with_access(
|
||||
task_id, company_id=company_id, requires_write_access=True
|
||||
)
|
||||
if not force:
|
||||
validate_status_change(task.status, TaskStatus.published)
|
||||
|
||||
previous_task_status = task.status
|
||||
output = task.output or Output()
|
||||
publish_failed = False
|
||||
|
||||
try:
|
||||
# set state to publishing
|
||||
task.status = TaskStatus.publishing
|
||||
task.save()
|
||||
|
||||
# publish task models
|
||||
if task.output.model and publish_model:
|
||||
output_model = (
|
||||
Model.objects(id=task.output.model)
|
||||
.only("id", "task", "ready")
|
||||
.first()
|
||||
)
|
||||
if output_model and not output_model.ready:
|
||||
cls.model_set_ready(
|
||||
model_id=task.output.model,
|
||||
company_id=company_id,
|
||||
publish_task=False,
|
||||
)
|
||||
|
||||
# set task status to published, and update (or set) it's new output (view and models)
|
||||
return ChangeStatusRequest(
|
||||
task=task,
|
||||
new_status=TaskStatus.published,
|
||||
force=force,
|
||||
status_reason=status_reason,
|
||||
status_message=status_message,
|
||||
).execute(published=datetime.utcnow(), output=output)
|
||||
|
||||
except Exception as ex:
|
||||
publish_failed = True
|
||||
raise ex
|
||||
finally:
|
||||
if publish_failed:
|
||||
task.status = previous_task_status
|
||||
task.save()
|
||||
|
||||
@classmethod
|
||||
def stop_task(
|
||||
cls,
|
||||
task_id: str,
|
||||
company_id: str,
|
||||
user_name: str,
|
||||
status_reason: str,
|
||||
force: bool,
|
||||
) -> dict:
|
||||
"""
|
||||
Stop a running task. Requires task status 'in_progress' and
|
||||
execution_progress 'running', or force=True. Development task or
|
||||
task that has no associated worker is stopped immediately.
|
||||
For a non-development task with worker only the status message
|
||||
is set to 'stopping' to allow the worker to stop the task and report by itself
|
||||
:return: updated task fields
|
||||
"""
|
||||
|
||||
task = cls.get_task_with_access(
|
||||
task_id,
|
||||
return TaskBLL.set_last_update(
|
||||
task_ids=[task_id],
|
||||
company_id=company_id,
|
||||
only=(
|
||||
"status",
|
||||
"project",
|
||||
"tags",
|
||||
"system_tags",
|
||||
"last_worker",
|
||||
"last_update",
|
||||
),
|
||||
requires_write_access=True,
|
||||
last_update=last_update,
|
||||
**extra_updates,
|
||||
)
|
||||
|
||||
def is_run_by_worker(t: Task) -> bool:
|
||||
"""Checks if there is an active worker running the task"""
|
||||
update_timeout = config.get("apiserver.workers.task_update_timeout", 600)
|
||||
return (
|
||||
t.last_worker
|
||||
and t.last_update
|
||||
and (datetime.utcnow() - t.last_update).total_seconds() < update_timeout
|
||||
)
|
||||
|
||||
if TaskSystemTags.development in task.system_tags or not is_run_by_worker(task):
|
||||
new_status = TaskStatus.stopped
|
||||
status_message = f"Stopped by {user_name}"
|
||||
else:
|
||||
new_status = task.status
|
||||
status_message = TaskStatusMessage.stopping
|
||||
|
||||
return ChangeStatusRequest(
|
||||
task=task,
|
||||
new_status=new_status,
|
||||
status_reason=status_reason,
|
||||
status_message=status_message,
|
||||
force=force,
|
||||
).execute()
|
||||
|
||||
@classmethod
|
||||
def add_or_update_artifacts(
|
||||
cls, task_id: str, company_id: str, artifacts: List[ApiArtifact]
|
||||
) -> Tuple[List[str], List[str]]:
|
||||
key = attrgetter("key", "mode")
|
||||
|
||||
if not artifacts:
|
||||
return [], []
|
||||
|
||||
with translate_errors_context(), TimingContext("mongo", "update_artifacts"):
|
||||
artifacts: List[Artifact] = [
|
||||
Artifact(**artifact.to_struct()) for artifact in artifacts
|
||||
]
|
||||
|
||||
attempts = int(config.get("services.tasks.artifacts.update_attempts", 10))
|
||||
|
||||
for retry in range(attempts):
|
||||
task = cls.get_task_with_access(
|
||||
task_id, company_id=company_id, requires_write_access=True
|
||||
)
|
||||
|
||||
current = list(map(key, task.execution.artifacts))
|
||||
updated = [a for a in artifacts if key(a) in current]
|
||||
added = [a for a in artifacts if a not in updated]
|
||||
|
||||
filter = {"_id": task_id, "company": company_id}
|
||||
update = {}
|
||||
array_filters = None
|
||||
if current:
|
||||
filter["execution.artifacts"] = {
|
||||
"$size": len(current),
|
||||
"$all": [
|
||||
*(
|
||||
{"$elemMatch": {"key": key, "mode": mode}}
|
||||
for key, mode in current
|
||||
)
|
||||
],
|
||||
}
|
||||
else:
|
||||
filter["$or"] = [
|
||||
{"execution.artifacts": {"$exists": False}},
|
||||
{"execution.artifacts": {"$size": 0}},
|
||||
]
|
||||
|
||||
if added:
|
||||
update["$push"] = {
|
||||
"execution.artifacts": {"$each": [a.to_mongo() for a in added]}
|
||||
}
|
||||
if updated:
|
||||
update["$set"] = {
|
||||
f"execution.artifacts.$[artifact{index}]": artifact.to_mongo()
|
||||
for index, artifact in enumerate(updated)
|
||||
}
|
||||
array_filters = [
|
||||
{
|
||||
f"artifact{index}.key": artifact.key,
|
||||
f"artifact{index}.mode": artifact.mode,
|
||||
}
|
||||
for index, artifact in enumerate(updated)
|
||||
]
|
||||
|
||||
if not update:
|
||||
return [], []
|
||||
|
||||
result: pymongo.results.UpdateResult = Task._get_collection().update_one(
|
||||
filter=filter,
|
||||
update=update,
|
||||
array_filters=array_filters,
|
||||
upsert=False,
|
||||
)
|
||||
|
||||
if result.matched_count >= 1:
|
||||
break
|
||||
|
||||
wait_msec = random() * int(
|
||||
config.get("services.tasks.artifacts.update_retry_msec", 500)
|
||||
)
|
||||
|
||||
log.warning(
|
||||
f"Failed to update artifacts for task {task_id} (updated by another party),"
|
||||
f" retrying {retry+1}/{attempts} in {wait_msec}ms"
|
||||
)
|
||||
|
||||
sleep(wait_msec / 1000)
|
||||
else:
|
||||
raise errors.server_error.UpdateFailed(
|
||||
"task artifacts updated by another party"
|
||||
)
|
||||
|
||||
return [a.key for a in added], [a.key for a in updated]
|
||||
|
||||
@staticmethod
|
||||
def get_aggregated_project_parameters(
|
||||
company_id,
|
||||
project_ids: Sequence[str] = None,
|
||||
project_ids: Sequence[str],
|
||||
include_subprojects: bool,
|
||||
page: int = 0,
|
||||
page_size: int = 500,
|
||||
) -> Tuple[int, int, Sequence[dict]]:
|
||||
|
||||
if project_ids:
|
||||
if include_subprojects:
|
||||
project_ids = project_ids_with_children(project_ids)
|
||||
project_constraint = {"project": {"$in": project_ids}}
|
||||
else:
|
||||
project_constraint = {}
|
||||
page = max(0, page)
|
||||
page_size = max(1, page_size)
|
||||
pipeline = [
|
||||
{
|
||||
"$match": {
|
||||
"company": company_id,
|
||||
"company": {"$in": [None, "", company_id]},
|
||||
"hyperparams": {"$exists": True, "$gt": {}},
|
||||
**({"project": {"$in": project_ids}} if project_ids else {}),
|
||||
**project_constraint,
|
||||
}
|
||||
},
|
||||
{"$project": {"sections": {"$objectToArray": "$hyperparams"}}},
|
||||
@@ -661,6 +529,8 @@ class TaskBLL(object):
|
||||
{"$unwind": "$names"},
|
||||
{"$group": {"_id": {"section": "$section", "name": "$names.k"}}},
|
||||
{"$sort": OrderedDict({"_id.section": 1, "_id.name": 1})},
|
||||
{"$skip": page * page_size},
|
||||
{"$limit": page_size},
|
||||
{
|
||||
"$group": {
|
||||
"_id": 1,
|
||||
@@ -668,16 +538,9 @@ class TaskBLL(object):
|
||||
"results": {"$push": "$$ROOT"},
|
||||
}
|
||||
},
|
||||
{
|
||||
"$project": {
|
||||
"total": 1,
|
||||
"results": {"$slice": ["$results", page * page_size, page_size]},
|
||||
}
|
||||
},
|
||||
]
|
||||
|
||||
with translate_errors_context():
|
||||
result = next(Task.aggregate(pipeline), None)
|
||||
result = next(Task.aggregate(pipeline), None)
|
||||
|
||||
total = 0
|
||||
remaining = 0
|
||||
@@ -697,3 +560,148 @@ class TaskBLL(object):
|
||||
remaining = max(0, total - (len(results) + page * page_size))
|
||||
|
||||
return total, remaining, results
|
||||
|
||||
HyperParamValues = Tuple[int, Sequence[str]]
|
||||
|
||||
def _get_cached_hyperparam_values(
|
||||
self, key: str, last_update: datetime
|
||||
) -> Optional[HyperParamValues]:
|
||||
allowed_delta = timedelta(
|
||||
seconds=config.get(
|
||||
"services.tasks.hyperparam_values.cache_allowed_outdate_sec", 60
|
||||
)
|
||||
)
|
||||
try:
|
||||
cached = self.redis.get(key)
|
||||
if not cached:
|
||||
return
|
||||
|
||||
data = json.loads(cached)
|
||||
cached_last_update = datetime.fromtimestamp(data["last_update"])
|
||||
if (last_update - cached_last_update) < allowed_delta:
|
||||
return data["total"], data["values"]
|
||||
except Exception as ex:
|
||||
log.error(f"Error retrieving hyperparam cached values: {str(ex)}")
|
||||
|
||||
def get_hyperparam_distinct_values(
|
||||
self,
|
||||
company_id: str,
|
||||
project_ids: Sequence[str],
|
||||
section: str,
|
||||
name: str,
|
||||
include_subprojects: bool,
|
||||
allow_public: bool = True,
|
||||
) -> HyperParamValues:
|
||||
if allow_public:
|
||||
company_constraint = {"company": {"$in": [None, "", company_id]}}
|
||||
else:
|
||||
company_constraint = {"company": company_id}
|
||||
if project_ids:
|
||||
if include_subprojects:
|
||||
project_ids = project_ids_with_children(project_ids)
|
||||
project_constraint = {"project": {"$in": project_ids}}
|
||||
else:
|
||||
project_constraint = {}
|
||||
|
||||
key_path = f"hyperparams.{ParameterKeyEscaper.escape(section)}.{ParameterKeyEscaper.escape(name)}"
|
||||
last_updated_task = (
|
||||
Task.objects(
|
||||
**company_constraint,
|
||||
**project_constraint,
|
||||
**{f"{key_path.replace('.', '__')}__exists": True},
|
||||
)
|
||||
.only("last_update")
|
||||
.order_by("-last_update")
|
||||
.limit(1)
|
||||
.first()
|
||||
)
|
||||
if not last_updated_task:
|
||||
return 0, []
|
||||
|
||||
redis_key = f"hyperparam_values_{company_id}_{'_'.join(project_ids)}_{section}_{name}_{allow_public}"
|
||||
last_update = last_updated_task.last_update or datetime.utcnow()
|
||||
cached_res = self._get_cached_hyperparam_values(
|
||||
key=redis_key, last_update=last_update
|
||||
)
|
||||
if cached_res:
|
||||
return cached_res
|
||||
|
||||
max_values = config.get("services.tasks.hyperparam_values.max_count", 100)
|
||||
pipeline = [
|
||||
{
|
||||
"$match": {
|
||||
**company_constraint,
|
||||
**project_constraint,
|
||||
key_path: {"$exists": True},
|
||||
}
|
||||
},
|
||||
{"$project": {"value": f"${key_path}.value"}},
|
||||
{"$group": {"_id": "$value"}},
|
||||
{"$sort": {"_id": 1}},
|
||||
{"$limit": max_values},
|
||||
{
|
||||
"$group": {
|
||||
"_id": 1,
|
||||
"total": {"$sum": 1},
|
||||
"results": {"$push": "$$ROOT._id"},
|
||||
}
|
||||
},
|
||||
]
|
||||
|
||||
result = next(Task.aggregate(pipeline, collation=Task._numeric_locale), None)
|
||||
if not result:
|
||||
return 0, []
|
||||
|
||||
total = int(result.get("total", 0))
|
||||
values = result.get("results", [])
|
||||
|
||||
ttl = config.get("services.tasks.hyperparam_values.cache_ttl_sec", 86400)
|
||||
cached = dict(last_update=last_update.timestamp(), total=total, values=values)
|
||||
self.redis.setex(redis_key, ttl, json.dumps(cached))
|
||||
|
||||
return total, values
|
||||
|
||||
@classmethod
|
||||
def dequeue_and_change_status(
|
||||
cls, task: Task, company_id: str, status_message: str, status_reason: str,
|
||||
):
|
||||
cls.dequeue(task, company_id)
|
||||
|
||||
return ChangeStatusRequest(
|
||||
task=task,
|
||||
new_status=task.enqueue_status or TaskStatus.created,
|
||||
status_reason=status_reason,
|
||||
status_message=status_message,
|
||||
).execute(enqueue_status=None)
|
||||
|
||||
@classmethod
|
||||
def dequeue(cls, task: Task, company_id: str, silent_fail=False):
|
||||
"""
|
||||
Dequeue the task from the queue
|
||||
:param task: task to dequeue
|
||||
:param company_id: task's company ID.
|
||||
:param silent_fail: do not throw exceptions. APIError is still thrown
|
||||
:raise errors.bad_request.InvalidTaskId: if the task's status is not queued
|
||||
:raise errors.bad_request.MissingRequiredFields: if the task is not queued
|
||||
:raise APIError or errors.server_error.TransactionError: if internal call to queues.remove_task fails
|
||||
:return: the result of queues.remove_task call. None in case of silent failure
|
||||
"""
|
||||
if task.status not in (TaskStatus.queued,):
|
||||
if silent_fail:
|
||||
return
|
||||
raise errors.bad_request.InvalidTaskId(
|
||||
status=task.status, expected=TaskStatus.queued
|
||||
)
|
||||
|
||||
if not task.execution or not task.execution.queue:
|
||||
if silent_fail:
|
||||
return
|
||||
raise errors.bad_request.MissingRequiredFields(
|
||||
"task has no queue value", field="execution.queue"
|
||||
)
|
||||
|
||||
return {
|
||||
"removed": queue_bll.remove_task(
|
||||
company_id=company_id, queue_id=task.execution.queue, task_id=task.id
|
||||
)
|
||||
}
|
||||
278
apiserver/bll/task/task_cleanup.py
Normal file
278
apiserver/bll/task/task_cleanup.py
Normal file
@@ -0,0 +1,278 @@
|
||||
from itertools import chain
|
||||
from operator import attrgetter
|
||||
from typing import Sequence, Generic, Callable, Type, Iterable, TypeVar, List, Set
|
||||
|
||||
import attr
|
||||
from boltons.iterutils import partition
|
||||
from mongoengine import QuerySet, Document
|
||||
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.bll.event import EventBLL
|
||||
from apiserver.bll.event.event_bll import PlotFields
|
||||
from apiserver.bll.event.event_common import EventType
|
||||
from apiserver.bll.task.utils import deleted_prefix
|
||||
from apiserver.database.model.model import Model
|
||||
from apiserver.database.model.task.task import Task, TaskStatus, ArtifactModes
|
||||
from apiserver.timing_context import TimingContext
|
||||
|
||||
event_bll = EventBLL()
|
||||
T = TypeVar("T", bound=Document)
|
||||
|
||||
|
||||
class DocumentGroup(List[T]):
|
||||
"""
|
||||
Operate on a list of documents as if they were a query result
|
||||
"""
|
||||
|
||||
def __init__(self, document_type: Type[T], documents: Iterable[T]):
|
||||
super(DocumentGroup, self).__init__(documents)
|
||||
self.type = document_type
|
||||
|
||||
@property
|
||||
def ids(self) -> Set[str]:
|
||||
return {obj.id for obj in self}
|
||||
|
||||
def objects(self, *args, **kwargs) -> QuerySet:
|
||||
return self.type.objects(id__in=self.ids, *args, **kwargs)
|
||||
|
||||
|
||||
class TaskOutputs(Generic[T]):
|
||||
"""
|
||||
Split task outputs of the same type by the ready state
|
||||
"""
|
||||
|
||||
published: DocumentGroup[T]
|
||||
draft: DocumentGroup[T]
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
is_published: Callable[[T], bool],
|
||||
document_type: Type[T],
|
||||
children: Iterable[T],
|
||||
):
|
||||
"""
|
||||
:param is_published: predicate returning whether items is considered published
|
||||
:param document_type: type of output
|
||||
:param children: output documents
|
||||
"""
|
||||
self.published, self.draft = map(
|
||||
lambda x: DocumentGroup(document_type, x),
|
||||
partition(children, key=is_published),
|
||||
)
|
||||
|
||||
|
||||
@attr.s(auto_attribs=True)
|
||||
class TaskUrls:
|
||||
model_urls: Sequence[str]
|
||||
event_urls: Sequence[str]
|
||||
artifact_urls: Sequence[str]
|
||||
|
||||
def __add__(self, other: "TaskUrls"):
|
||||
if not other:
|
||||
return self
|
||||
|
||||
return TaskUrls(
|
||||
model_urls=list(set(self.model_urls) | set(other.model_urls)),
|
||||
event_urls=list(set(self.event_urls) | set(other.event_urls)),
|
||||
artifact_urls=list(set(self.artifact_urls) | set(other.artifact_urls)),
|
||||
)
|
||||
|
||||
|
||||
@attr.s(auto_attribs=True)
|
||||
class CleanupResult:
|
||||
"""
|
||||
Counts of objects modified in task cleanup operation
|
||||
"""
|
||||
|
||||
updated_children: int
|
||||
updated_models: int
|
||||
deleted_models: int
|
||||
urls: TaskUrls = None
|
||||
|
||||
def __add__(self, other: "CleanupResult"):
|
||||
if not other:
|
||||
return self
|
||||
|
||||
return CleanupResult(
|
||||
updated_children=self.updated_children + other.updated_children,
|
||||
updated_models=self.updated_models + other.updated_models,
|
||||
deleted_models=self.deleted_models + other.deleted_models,
|
||||
urls=self.urls + other.urls if self.urls else other.urls,
|
||||
)
|
||||
|
||||
|
||||
def collect_plot_image_urls(company: str, task: str) -> Set[str]:
|
||||
urls = set()
|
||||
next_scroll_id = None
|
||||
with TimingContext("es", "collect_plot_image_urls"):
|
||||
while True:
|
||||
events, next_scroll_id = event_bll.get_plot_image_urls(
|
||||
company_id=company, task_id=task, scroll_id=next_scroll_id
|
||||
)
|
||||
if not events:
|
||||
break
|
||||
for event in events:
|
||||
event_urls = event.get(PlotFields.source_urls)
|
||||
if event_urls:
|
||||
urls.update(set(event_urls))
|
||||
|
||||
return urls
|
||||
|
||||
|
||||
def collect_debug_image_urls(company: str, task: str) -> Set[str]:
|
||||
"""
|
||||
Return the set of unique image urls
|
||||
Uses DebugImagesIterator to make sure that we do not retrieve recycled urls
|
||||
"""
|
||||
metrics = event_bll.get_metrics_and_variants(
|
||||
company_id=company, task_id=task, event_type=EventType.metrics_image
|
||||
)
|
||||
if not metrics:
|
||||
return set()
|
||||
|
||||
task_metrics = {task: {m: [] for m in metrics}}
|
||||
scroll_id = None
|
||||
urls = set()
|
||||
while True:
|
||||
res = event_bll.debug_images_iterator.get_task_events(
|
||||
company_id=company,
|
||||
task_metrics=task_metrics,
|
||||
iter_count=10,
|
||||
state_id=scroll_id,
|
||||
)
|
||||
if not res.metric_events or not any(
|
||||
iterations for _, iterations in res.metric_events
|
||||
):
|
||||
break
|
||||
|
||||
scroll_id = res.next_scroll_id
|
||||
for task, iterations in res.metric_events:
|
||||
urls.update(ev.get("url") for it in iterations for ev in it["events"])
|
||||
|
||||
urls.discard({None})
|
||||
return urls
|
||||
|
||||
|
||||
def cleanup_task(
|
||||
task: Task,
|
||||
force: bool = False,
|
||||
update_children=True,
|
||||
return_file_urls=False,
|
||||
delete_output_models=True,
|
||||
) -> CleanupResult:
|
||||
"""
|
||||
Validate task deletion and delete/modify all its output.
|
||||
:param task: task object
|
||||
:param force: whether to delete task with published outputs
|
||||
:return: count of delete and modified items
|
||||
"""
|
||||
models = verify_task_children_and_ouptuts(task, force)
|
||||
|
||||
event_urls, artifact_urls, model_urls = set(), set(), set()
|
||||
if return_file_urls:
|
||||
event_urls = collect_debug_image_urls(task.company, task.id)
|
||||
event_urls.update(collect_plot_image_urls(task.company, task.id))
|
||||
if task.execution and task.execution.artifacts:
|
||||
artifact_urls = {
|
||||
a.uri
|
||||
for a in task.execution.artifacts.values()
|
||||
if a.mode == ArtifactModes.output and a.uri
|
||||
}
|
||||
model_urls = {m.uri for m in models.draft.objects().only("uri") if m.uri}
|
||||
|
||||
deleted_task_id = f"{deleted_prefix}{task.id}"
|
||||
if update_children:
|
||||
with TimingContext("mongo", "update_task_children"):
|
||||
updated_children = Task.objects(parent=task.id).update(
|
||||
parent=deleted_task_id
|
||||
)
|
||||
else:
|
||||
updated_children = 0
|
||||
|
||||
if models.draft and delete_output_models:
|
||||
with TimingContext("mongo", "delete_models"):
|
||||
deleted_models = models.draft.objects().delete()
|
||||
else:
|
||||
deleted_models = 0
|
||||
|
||||
if models.published and update_children:
|
||||
with TimingContext("mongo", "update_task_models"):
|
||||
updated_models = models.published.objects().update(task=deleted_task_id)
|
||||
else:
|
||||
updated_models = 0
|
||||
|
||||
event_bll.delete_task_events(task.company, task.id, allow_locked=force)
|
||||
|
||||
return CleanupResult(
|
||||
deleted_models=deleted_models,
|
||||
updated_children=updated_children,
|
||||
updated_models=updated_models,
|
||||
urls=TaskUrls(
|
||||
event_urls=list(event_urls),
|
||||
artifact_urls=list(artifact_urls),
|
||||
model_urls=list(model_urls),
|
||||
)
|
||||
if return_file_urls
|
||||
else None,
|
||||
)
|
||||
|
||||
|
||||
def verify_task_children_and_ouptuts(task: Task, force: bool) -> TaskOutputs[Model]:
|
||||
if not force:
|
||||
with TimingContext("mongo", "count_published_children"):
|
||||
published_children_count = Task.objects(
|
||||
parent=task.id, status=TaskStatus.published
|
||||
).count()
|
||||
if published_children_count:
|
||||
raise errors.bad_request.TaskCannotBeDeleted(
|
||||
"has children, use force=True",
|
||||
task=task.id,
|
||||
children=published_children_count,
|
||||
)
|
||||
|
||||
with TimingContext("mongo", "get_task_models"):
|
||||
models = TaskOutputs(
|
||||
attrgetter("ready"),
|
||||
Model,
|
||||
Model.objects(task=task.id).only("id", "task", "ready"),
|
||||
)
|
||||
if not force and models.published:
|
||||
raise errors.bad_request.TaskCannotBeDeleted(
|
||||
"has output models, use force=True",
|
||||
task=task.id,
|
||||
models=len(models.published),
|
||||
)
|
||||
|
||||
if task.models and task.models.output:
|
||||
with TimingContext("mongo", "get_task_output_model"):
|
||||
model_ids = [m.model for m in task.models.output]
|
||||
for output_model in Model.objects(id__in=model_ids):
|
||||
if output_model.ready:
|
||||
if not force:
|
||||
raise errors.bad_request.TaskCannotBeDeleted(
|
||||
"has output model, use force=True",
|
||||
task=task.id,
|
||||
model=output_model.id,
|
||||
)
|
||||
models.published.append(output_model)
|
||||
else:
|
||||
models.draft.append(output_model)
|
||||
|
||||
if models.draft:
|
||||
with TimingContext("mongo", "get_execution_models"):
|
||||
model_ids = models.draft.ids
|
||||
dependent_tasks = Task.objects(models__input__model__in=model_ids).only(
|
||||
"id", "models"
|
||||
)
|
||||
input_models = {
|
||||
m.model
|
||||
for m in chain.from_iterable(
|
||||
t.models.input for t in dependent_tasks if t.models
|
||||
)
|
||||
}
|
||||
if input_models:
|
||||
models.draft = DocumentGroup(
|
||||
Model, (m for m in models.draft if m.id not in input_models)
|
||||
)
|
||||
|
||||
return models
|
||||
397
apiserver/bll/task/task_operations.py
Normal file
397
apiserver/bll/task/task_operations.py
Normal file
@@ -0,0 +1,397 @@
|
||||
from datetime import datetime
|
||||
from typing import Callable, Any, Tuple, Union
|
||||
|
||||
from apiserver.apierrors import errors, APIError
|
||||
from apiserver.bll.queue import QueueBLL
|
||||
from apiserver.bll.task import (
|
||||
TaskBLL,
|
||||
validate_status_change,
|
||||
ChangeStatusRequest,
|
||||
update_project_time,
|
||||
)
|
||||
from apiserver.bll.task.task_cleanup import cleanup_task, CleanupResult
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.model import EntityVisibility
|
||||
from apiserver.database.model.model import Model
|
||||
from apiserver.database.model.task.output import Output
|
||||
from apiserver.database.model.task.task import (
|
||||
TaskStatus,
|
||||
Task,
|
||||
TaskSystemTags,
|
||||
TaskStatusMessage,
|
||||
ArtifactModes,
|
||||
Execution,
|
||||
DEFAULT_LAST_ITERATION,
|
||||
)
|
||||
from apiserver.utilities.dicts import nested_set
|
||||
|
||||
queue_bll = QueueBLL()
|
||||
|
||||
|
||||
def archive_task(
|
||||
task: Union[str, Task], company_id: str, status_message: str, status_reason: str,
|
||||
) -> int:
|
||||
"""
|
||||
Deque and archive task
|
||||
Return 1 if successful
|
||||
"""
|
||||
if isinstance(task, str):
|
||||
task = TaskBLL.get_task_with_access(
|
||||
task,
|
||||
company_id=company_id,
|
||||
only=(
|
||||
"id",
|
||||
"execution",
|
||||
"status",
|
||||
"project",
|
||||
"system_tags",
|
||||
"enqueue_status",
|
||||
),
|
||||
requires_write_access=True,
|
||||
)
|
||||
try:
|
||||
TaskBLL.dequeue_and_change_status(
|
||||
task, company_id, status_message, status_reason,
|
||||
)
|
||||
except APIError:
|
||||
# dequeue may fail if the task was not enqueued
|
||||
pass
|
||||
|
||||
return task.update(
|
||||
status_message=status_message,
|
||||
status_reason=status_reason,
|
||||
add_to_set__system_tags=EntityVisibility.archived.value,
|
||||
last_change=datetime.utcnow(),
|
||||
)
|
||||
|
||||
|
||||
def unarchive_task(
|
||||
task: str, company_id: str, status_message: str, status_reason: str,
|
||||
) -> int:
|
||||
"""
|
||||
Unarchive task. Return 1 if successful
|
||||
"""
|
||||
task = TaskBLL.get_task_with_access(
|
||||
task, company_id=company_id, only=("id",), requires_write_access=True,
|
||||
)
|
||||
return task.update(
|
||||
status_message=status_message,
|
||||
status_reason=status_reason,
|
||||
pull__system_tags=EntityVisibility.archived.value,
|
||||
last_change=datetime.utcnow(),
|
||||
)
|
||||
|
||||
|
||||
def dequeue_task(
|
||||
task_id: str,
|
||||
company_id: str,
|
||||
status_message: str,
|
||||
status_reason: str,
|
||||
) -> Tuple[int, dict]:
|
||||
query = dict(id=task_id, company=company_id)
|
||||
task = Task.get_for_writing(**query)
|
||||
if not task:
|
||||
raise errors.bad_request.InvalidTaskId(**query)
|
||||
|
||||
res = TaskBLL.dequeue_and_change_status(
|
||||
task,
|
||||
company_id,
|
||||
status_message=status_message,
|
||||
status_reason=status_reason,
|
||||
)
|
||||
return 1, res
|
||||
|
||||
|
||||
def enqueue_task(
|
||||
task_id: str,
|
||||
company_id: str,
|
||||
queue_id: str,
|
||||
status_message: str,
|
||||
status_reason: str,
|
||||
validate: bool = False,
|
||||
force: bool = False,
|
||||
) -> Tuple[int, dict]:
|
||||
if not queue_id:
|
||||
# try to get default queue
|
||||
queue_id = queue_bll.get_default(company_id).id
|
||||
|
||||
query = dict(id=task_id, company=company_id)
|
||||
task = Task.get_for_writing(**query)
|
||||
if not task:
|
||||
raise errors.bad_request.InvalidTaskId(**query)
|
||||
|
||||
if validate:
|
||||
TaskBLL.validate(task)
|
||||
|
||||
res = ChangeStatusRequest(
|
||||
task=task,
|
||||
new_status=TaskStatus.queued,
|
||||
status_reason=status_reason,
|
||||
status_message=status_message,
|
||||
allow_same_state_transition=False,
|
||||
force=force,
|
||||
).execute(enqueue_status=task.status)
|
||||
|
||||
try:
|
||||
queue_bll.add_task(company_id=company_id, queue_id=queue_id, task_id=task.id)
|
||||
except Exception:
|
||||
# failed enqueueing, revert to previous state
|
||||
ChangeStatusRequest(
|
||||
task=task,
|
||||
current_status_override=TaskStatus.queued,
|
||||
new_status=task.status,
|
||||
force=True,
|
||||
status_reason="failed enqueueing",
|
||||
).execute(enqueue_status=None)
|
||||
raise
|
||||
|
||||
# set the current queue ID in the task
|
||||
if task.execution:
|
||||
Task.objects(**query).update(execution__queue=queue_id, multi=False)
|
||||
else:
|
||||
Task.objects(**query).update(execution=Execution(queue=queue_id), multi=False)
|
||||
|
||||
nested_set(res, ("fields", "execution.queue"), queue_id)
|
||||
return 1, res
|
||||
|
||||
|
||||
def delete_task(
|
||||
task_id: str,
|
||||
company_id: str,
|
||||
move_to_trash: bool,
|
||||
force: bool,
|
||||
return_file_urls: bool,
|
||||
delete_output_models: bool,
|
||||
) -> Tuple[int, Task, CleanupResult]:
|
||||
task = TaskBLL.get_task_with_access(
|
||||
task_id, company_id=company_id, requires_write_access=True
|
||||
)
|
||||
|
||||
if (
|
||||
task.status != TaskStatus.created
|
||||
and EntityVisibility.archived.value not in task.system_tags
|
||||
and not force
|
||||
):
|
||||
raise errors.bad_request.TaskCannotBeDeleted(
|
||||
"due to status, use force=True",
|
||||
task=task.id,
|
||||
expected=TaskStatus.created,
|
||||
current=task.status,
|
||||
)
|
||||
|
||||
cleanup_res = cleanup_task(
|
||||
task,
|
||||
force=force,
|
||||
return_file_urls=return_file_urls,
|
||||
delete_output_models=delete_output_models,
|
||||
)
|
||||
|
||||
if move_to_trash:
|
||||
collection_name = task._get_collection_name()
|
||||
archived_collection = "{}__trash".format(collection_name)
|
||||
task.switch_collection(archived_collection)
|
||||
try:
|
||||
# A simple save() won't do due to mongoengine caching (nothing will be saved), so we have to force
|
||||
# an insert. However, if for some reason such an ID exists, let's make sure we'll keep going.
|
||||
task.save(force_insert=True)
|
||||
except Exception:
|
||||
pass
|
||||
task.switch_collection(collection_name)
|
||||
|
||||
task.delete()
|
||||
update_project_time(task.project)
|
||||
return 1, task, cleanup_res
|
||||
|
||||
|
||||
def reset_task(
|
||||
task_id: str,
|
||||
company_id: str,
|
||||
force: bool,
|
||||
return_file_urls: bool,
|
||||
delete_output_models: bool,
|
||||
clear_all: bool,
|
||||
) -> Tuple[dict, CleanupResult, dict]:
|
||||
task = TaskBLL.get_task_with_access(
|
||||
task_id, company_id=company_id, requires_write_access=True
|
||||
)
|
||||
|
||||
if not force and task.status == TaskStatus.published:
|
||||
raise errors.bad_request.InvalidTaskStatus(task_id=task.id, status=task.status)
|
||||
|
||||
dequeued = {}
|
||||
updates = {}
|
||||
|
||||
try:
|
||||
dequeued = TaskBLL.dequeue(task, company_id, silent_fail=True)
|
||||
except APIError:
|
||||
# dequeue may fail if the task was not enqueued
|
||||
pass
|
||||
|
||||
cleaned_up = cleanup_task(
|
||||
task,
|
||||
force=force,
|
||||
update_children=False,
|
||||
return_file_urls=return_file_urls,
|
||||
delete_output_models=delete_output_models,
|
||||
)
|
||||
|
||||
updates.update(
|
||||
set__last_iteration=DEFAULT_LAST_ITERATION,
|
||||
set__last_metrics={},
|
||||
set__metric_stats={},
|
||||
set__models__output=[],
|
||||
set__runtime={},
|
||||
unset__output__result=1,
|
||||
unset__output__error=1,
|
||||
unset__last_worker=1,
|
||||
unset__last_worker_report=1,
|
||||
)
|
||||
|
||||
if clear_all:
|
||||
updates.update(
|
||||
set__execution=Execution(), unset__script=1,
|
||||
)
|
||||
else:
|
||||
updates.update(unset__execution__queue=1)
|
||||
if task.execution and task.execution.artifacts:
|
||||
updates.update(
|
||||
set__execution__artifacts={
|
||||
key: artifact
|
||||
for key, artifact in task.execution.artifacts.items()
|
||||
if artifact.mode == ArtifactModes.input
|
||||
}
|
||||
)
|
||||
|
||||
res = ChangeStatusRequest(
|
||||
task=task,
|
||||
new_status=TaskStatus.created,
|
||||
force=force,
|
||||
status_reason="reset",
|
||||
status_message="reset",
|
||||
).execute(
|
||||
started=None,
|
||||
completed=None,
|
||||
published=None,
|
||||
active_duration=None,
|
||||
enqueue_status=None,
|
||||
**updates,
|
||||
)
|
||||
|
||||
return dequeued, cleaned_up, res
|
||||
|
||||
|
||||
def publish_task(
|
||||
task_id: str,
|
||||
company_id: str,
|
||||
force: bool,
|
||||
publish_model_func: Callable[[str, str], Any] = None,
|
||||
status_message: str = "",
|
||||
status_reason: str = "",
|
||||
) -> dict:
|
||||
task = TaskBLL.get_task_with_access(
|
||||
task_id, company_id=company_id, requires_write_access=True
|
||||
)
|
||||
if not force:
|
||||
validate_status_change(task.status, TaskStatus.published)
|
||||
|
||||
previous_task_status = task.status
|
||||
output = task.output or Output()
|
||||
publish_failed = False
|
||||
|
||||
try:
|
||||
# set state to publishing
|
||||
task.status = TaskStatus.publishing
|
||||
task.save()
|
||||
|
||||
# publish task models
|
||||
if task.models and task.models.output and publish_model_func:
|
||||
model_id = task.models.output[-1].model
|
||||
model = (
|
||||
Model.objects(id=model_id, company=company_id)
|
||||
.only("id", "ready")
|
||||
.first()
|
||||
)
|
||||
if model and not model.ready:
|
||||
publish_model_func(model.id, company_id)
|
||||
|
||||
# set task status to published, and update (or set) it's new output (view and models)
|
||||
return ChangeStatusRequest(
|
||||
task=task,
|
||||
new_status=TaskStatus.published,
|
||||
force=force,
|
||||
status_reason=status_reason,
|
||||
status_message=status_message,
|
||||
).execute(published=datetime.utcnow(), output=output)
|
||||
|
||||
except Exception as ex:
|
||||
publish_failed = True
|
||||
raise ex
|
||||
finally:
|
||||
if publish_failed:
|
||||
task.status = previous_task_status
|
||||
task.save()
|
||||
|
||||
|
||||
def stop_task(
|
||||
task_id: str, company_id: str, user_name: str, status_reason: str, force: bool,
|
||||
) -> dict:
|
||||
"""
|
||||
Stop a running task. Requires task status 'in_progress' and
|
||||
execution_progress 'running', or force=True. Development task or
|
||||
task that has no associated worker is stopped immediately.
|
||||
For a non-development task with worker only the status message
|
||||
is set to 'stopping' to allow the worker to stop the task and report by itself
|
||||
:return: updated task fields
|
||||
"""
|
||||
|
||||
task = TaskBLL.get_task_with_access(
|
||||
task_id,
|
||||
company_id=company_id,
|
||||
only=(
|
||||
"status",
|
||||
"project",
|
||||
"tags",
|
||||
"system_tags",
|
||||
"last_worker",
|
||||
"last_update",
|
||||
),
|
||||
requires_write_access=True,
|
||||
)
|
||||
|
||||
def is_run_by_worker(t: Task) -> bool:
|
||||
"""Checks if there is an active worker running the task"""
|
||||
update_timeout = config.get("apiserver.workers.task_update_timeout", 600)
|
||||
return (
|
||||
t.last_worker
|
||||
and t.last_update
|
||||
and (datetime.utcnow() - t.last_update).total_seconds() < update_timeout
|
||||
)
|
||||
|
||||
is_queued = task.status == TaskStatus.queued
|
||||
set_stopped = (
|
||||
is_queued
|
||||
or TaskSystemTags.development in task.system_tags
|
||||
or not is_run_by_worker(task)
|
||||
)
|
||||
|
||||
if set_stopped:
|
||||
if is_queued:
|
||||
try:
|
||||
TaskBLL.dequeue(task, company_id=company_id, silent_fail=True)
|
||||
except APIError:
|
||||
# dequeue may fail if the task was not enqueued
|
||||
pass
|
||||
|
||||
new_status = TaskStatus.stopped
|
||||
status_message = f"Stopped by {user_name}"
|
||||
else:
|
||||
new_status = task.status
|
||||
status_message = TaskStatusMessage.stopping
|
||||
|
||||
return ChangeStatusRequest(
|
||||
task=task,
|
||||
new_status=new_status,
|
||||
status_reason=status_reason,
|
||||
status_message=status_message,
|
||||
force=force,
|
||||
).execute()
|
||||
@@ -1,18 +1,19 @@
|
||||
from datetime import datetime
|
||||
from typing import TypeVar, Callable, Tuple, Sequence
|
||||
from typing import Sequence, Union
|
||||
|
||||
import attr
|
||||
import six
|
||||
|
||||
from apierrors import errors
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.project import Project
|
||||
from database.model.task.task import Task, TaskStatus, TaskSystemTags
|
||||
from database.utils import get_options
|
||||
from timing_context import TimingContext
|
||||
from utilities.attrs import typed_attrs
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.database.model.project import Project
|
||||
from apiserver.database.model.task.task import Task, TaskStatus, TaskSystemTags
|
||||
from apiserver.database.utils import get_options
|
||||
from apiserver.timing_context import TimingContext
|
||||
from apiserver.utilities.attrs import typed_attrs
|
||||
|
||||
valid_statuses = get_options(TaskStatus)
|
||||
deleted_prefix = "__DELETED__"
|
||||
|
||||
|
||||
@typed_attrs
|
||||
@@ -43,6 +44,7 @@ class ChangeStatusRequest(object):
|
||||
status_message=self.status_message,
|
||||
status_changed=now,
|
||||
last_update=now,
|
||||
last_change=now,
|
||||
)
|
||||
|
||||
if self.new_status == TaskStatus.queued:
|
||||
@@ -104,7 +106,7 @@ def validate_status_change(current_status, new_status):
|
||||
|
||||
state_machine = {
|
||||
TaskStatus.created: {TaskStatus.queued, TaskStatus.in_progress},
|
||||
TaskStatus.queued: {TaskStatus.created, TaskStatus.in_progress},
|
||||
TaskStatus.queued: {TaskStatus.created, TaskStatus.in_progress, TaskStatus.stopped},
|
||||
TaskStatus.in_progress: {
|
||||
TaskStatus.stopped,
|
||||
TaskStatus.failed,
|
||||
@@ -115,6 +117,7 @@ state_machine = {
|
||||
TaskStatus.closed,
|
||||
TaskStatus.created,
|
||||
TaskStatus.failed,
|
||||
TaskStatus.queued,
|
||||
TaskStatus.in_progress,
|
||||
TaskStatus.published,
|
||||
TaskStatus.publishing,
|
||||
@@ -152,22 +155,42 @@ def get_possible_status_changes(current_status):
|
||||
return possible
|
||||
|
||||
|
||||
def update_project_time(project_id):
|
||||
if project_id:
|
||||
Project.objects(id=project_id).update(last_update=datetime.utcnow())
|
||||
def update_project_time(project_ids: Union[str, Sequence[str]]):
|
||||
if not project_ids:
|
||||
return
|
||||
|
||||
if isinstance(project_ids, str):
|
||||
project_ids = [project_ids]
|
||||
|
||||
return Project.objects(id__in=project_ids).update(last_update=datetime.utcnow())
|
||||
|
||||
|
||||
T = TypeVar("T")
|
||||
|
||||
|
||||
def split_by(
|
||||
condition: Callable[[T], bool], items: Sequence[T]
|
||||
) -> Tuple[Sequence[T], Sequence[T]]:
|
||||
def get_task_for_update(
|
||||
company_id: str, task_id: str, allow_all_statuses: bool = False, force: bool = False
|
||||
) -> Task:
|
||||
"""
|
||||
split "items" to two lists by "condition"
|
||||
Loads only task id and return the task only if it is updatable (status == 'created')
|
||||
"""
|
||||
applied = zip(map(condition, items), items)
|
||||
return (
|
||||
[item for cond, item in applied if cond],
|
||||
[item for cond, item in applied if not cond],
|
||||
task = Task.get_for_writing(company=company_id, id=task_id, _only=("id", "status"))
|
||||
if not task:
|
||||
raise errors.bad_request.InvalidTaskId(id=task_id)
|
||||
|
||||
if allow_all_statuses:
|
||||
return task
|
||||
|
||||
allowed_statuses = (
|
||||
[TaskStatus.created, TaskStatus.in_progress] if force else [TaskStatus.created]
|
||||
)
|
||||
if task.status not in allowed_statuses:
|
||||
raise errors.bad_request.InvalidTaskStatus(
|
||||
expected=TaskStatus.created, status=task.status
|
||||
)
|
||||
return task
|
||||
|
||||
|
||||
def update_task(task: Task, update_cmds: dict, set_last_update: bool = True):
|
||||
now = datetime.utcnow()
|
||||
last_updates = dict(last_change=now)
|
||||
if set_last_update:
|
||||
last_updates.update(last_update=now)
|
||||
return task.update(**update_cmds, **last_updates)
|
||||
@@ -1,7 +1,7 @@
|
||||
from apierrors import errors
|
||||
from apimodels.users import CreateRequest
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.user import User
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.apimodels.users import CreateRequest
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.database.model.user import User
|
||||
|
||||
|
||||
class UserBLL:
|
||||
134
apiserver/bll/util.py
Normal file
134
apiserver/bll/util.py
Normal file
@@ -0,0 +1,134 @@
|
||||
import functools
|
||||
import itertools
|
||||
from concurrent.futures.thread import ThreadPoolExecutor
|
||||
from typing import (
|
||||
Optional,
|
||||
Callable,
|
||||
Dict,
|
||||
Any,
|
||||
Set,
|
||||
Iterable,
|
||||
Tuple,
|
||||
Sequence,
|
||||
TypeVar,
|
||||
)
|
||||
|
||||
from boltons import iterutils
|
||||
|
||||
from apiserver.apierrors import APIError
|
||||
from apiserver.database.model import AttributedDocument
|
||||
from apiserver.database.model.settings import Settings
|
||||
|
||||
|
||||
class SetFieldsResolver:
|
||||
"""
|
||||
The class receives set fields dictionary
|
||||
and for the set fields that require 'min' or 'max'
|
||||
operation replace them with a simple set in case the
|
||||
DB document does not have these fields set
|
||||
"""
|
||||
|
||||
SET_MODIFIERS = ("min", "max")
|
||||
|
||||
def __init__(self, set_fields: Dict[str, Any]):
|
||||
self.orig_fields = {}
|
||||
self.fields = {}
|
||||
self.add_fields(**set_fields)
|
||||
|
||||
def add_fields(self, **set_fields: Any):
|
||||
self.orig_fields.update(set_fields)
|
||||
self.fields.update(
|
||||
{
|
||||
f: fname
|
||||
for f, modifier, dunder, fname in (
|
||||
(f,) + f.partition("__") for f in set_fields.keys()
|
||||
)
|
||||
if dunder and modifier in self.SET_MODIFIERS
|
||||
}
|
||||
)
|
||||
|
||||
def _get_updated_name(self, doc: AttributedDocument, name: str) -> str:
|
||||
if name in self.fields and doc.get_field_value(self.fields[name]) is None:
|
||||
return self.fields[name]
|
||||
return name
|
||||
|
||||
def get_fields(self, doc: AttributedDocument):
|
||||
"""
|
||||
For the given document return the set fields instructions
|
||||
with min/max operations replaced with a single set in case
|
||||
the document does not have the field set
|
||||
"""
|
||||
return {
|
||||
self._get_updated_name(doc, name): value
|
||||
for name, value in self.orig_fields.items()
|
||||
}
|
||||
|
||||
def get_names(self) -> Set[str]:
|
||||
"""
|
||||
Returns the names of the fields that had min/max modifiers
|
||||
in the format suitable for projection (dot separated)
|
||||
"""
|
||||
return set(name.replace("__", ".") for name in self.fields.values())
|
||||
|
||||
|
||||
@functools.lru_cache()
|
||||
def get_server_uuid() -> Optional[str]:
|
||||
return Settings.get_by_key("server.uuid")
|
||||
|
||||
|
||||
def parallel_chunked_decorator(func: Callable = None, chunk_size: int = 100):
|
||||
"""
|
||||
Decorates a method for parallel chunked execution. The method should have
|
||||
one positional parameter (that is used for breaking into chunks)
|
||||
and arbitrary number of keyword params. The return value should be iterable
|
||||
The results are concatenated in the same order as the passed params
|
||||
"""
|
||||
if func is None:
|
||||
return functools.partial(parallel_chunked_decorator, chunk_size=chunk_size)
|
||||
|
||||
@functools.wraps(func)
|
||||
def wrapper(self, iterable: Iterable, **kwargs):
|
||||
assert iterutils.is_collection(
|
||||
iterable
|
||||
), "The positional parameter should be an iterable for breaking into chunks"
|
||||
|
||||
func_with_params = functools.partial(func, self, **kwargs)
|
||||
with ThreadPoolExecutor() as pool:
|
||||
return list(
|
||||
itertools.chain.from_iterable(
|
||||
filter(
|
||||
None,
|
||||
pool.map(
|
||||
func_with_params,
|
||||
iterutils.chunked_iter(iterable, chunk_size),
|
||||
),
|
||||
)
|
||||
),
|
||||
)
|
||||
|
||||
return wrapper
|
||||
|
||||
|
||||
T = TypeVar("T")
|
||||
|
||||
|
||||
def run_batch_operation(
|
||||
func: Callable[[str], T], ids: Sequence[str]
|
||||
) -> Tuple[Sequence[Tuple[str, T]], Sequence[dict]]:
|
||||
results = list()
|
||||
failures = list()
|
||||
for _id in ids:
|
||||
try:
|
||||
results.append((_id, func(_id)))
|
||||
except APIError as err:
|
||||
failures.append(
|
||||
{
|
||||
"id": _id,
|
||||
"error": {
|
||||
"codes": [err.code, err.subcode],
|
||||
"msg": err.msg,
|
||||
"data": err.error_data,
|
||||
},
|
||||
}
|
||||
)
|
||||
return results, failures
|
||||
@@ -5,10 +5,10 @@ from typing import Sequence, Set, Optional
|
||||
import attr
|
||||
import elasticsearch.helpers
|
||||
|
||||
import es_factory
|
||||
from apierrors import APIError
|
||||
from apierrors.errors import bad_request, server_error
|
||||
from apimodels.workers import (
|
||||
from apiserver.es_factory import es_factory
|
||||
from apiserver.apierrors import APIError
|
||||
from apiserver.apierrors.errors import bad_request, server_error
|
||||
from apiserver.apimodels.workers import (
|
||||
DEFAULT_TIMEOUT,
|
||||
IdNameEntry,
|
||||
WorkerEntry,
|
||||
@@ -17,16 +17,16 @@ from apimodels.workers import (
|
||||
QueueEntry,
|
||||
MachineStats,
|
||||
)
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.auth import User
|
||||
from database.model.company import Company
|
||||
from database.model.project import Project
|
||||
from database.model.queue import Queue
|
||||
from database.model.task.task import Task
|
||||
from redis_manager import redman
|
||||
from timing_context import TimingContext
|
||||
from tools import safe_get
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.database.model.auth import User
|
||||
from apiserver.database.model.company import Company
|
||||
from apiserver.database.model.project import Project
|
||||
from apiserver.database.model.queue import Queue
|
||||
from apiserver.database.model.task.task import Task
|
||||
from apiserver.redis_manager import redman
|
||||
from apiserver.timing_context import TimingContext
|
||||
from apiserver.tools import safe_get
|
||||
from .stats import WorkerStats
|
||||
|
||||
log = config.logger(__file__)
|
||||
@@ -164,6 +164,7 @@ class WorkerBLL:
|
||||
last_worker=report.worker,
|
||||
last_worker_report=now,
|
||||
last_update=now,
|
||||
last_change=now,
|
||||
)
|
||||
# modify(new=True, ...) returns the modified object
|
||||
task = Task.objects(**query).modify(new=True, **update)
|
||||
@@ -3,12 +3,12 @@ from typing import Optional, Sequence
|
||||
|
||||
from boltons.iterutils import bucketize
|
||||
|
||||
from apierrors.errors import bad_request
|
||||
from apimodels.workers import AggregationType, GetStatsRequest, StatItem
|
||||
from bll.query import Builder as QueryBuilder
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from timing_context import TimingContext
|
||||
from apiserver.apierrors.errors import bad_request
|
||||
from apiserver.apimodels.workers import AggregationType, GetStatsRequest, StatItem
|
||||
from apiserver.bll.query import Builder as QueryBuilder
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.errors import translate_errors_context
|
||||
from apiserver.timing_context import TimingContext
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
1
apiserver/config/__init__.py
Normal file
1
apiserver/config/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
from .basic import BasicConfig, ConfigurationError
|
||||
215
apiserver/config/basic.py
Normal file
215
apiserver/config/basic.py
Normal file
@@ -0,0 +1,215 @@
|
||||
import logging
|
||||
import logging.config
|
||||
import os
|
||||
import platform
|
||||
from functools import reduce
|
||||
from os import getenv
|
||||
from os.path import expandvars
|
||||
from pathlib import Path
|
||||
from typing import List, Any, TypeVar, Sequence
|
||||
|
||||
from boltons.iterutils import first
|
||||
from pyhocon import ConfigTree, ConfigFactory, ConfigValues
|
||||
from pyparsing import (
|
||||
ParseFatalException,
|
||||
ParseException,
|
||||
RecursiveGrammarException,
|
||||
ParseSyntaxException,
|
||||
)
|
||||
|
||||
from apiserver.utilities import json
|
||||
|
||||
EXTRA_CONFIG_PATHS = ("/opt/trains/config", "/opt/clearml/config")
|
||||
DEFAULT_PREFIXES = ("clearml", "trains")
|
||||
EXTRA_CONFIG_PATH_SEP = ":" if platform.system() != "Windows" else ";"
|
||||
|
||||
|
||||
class BasicConfig:
|
||||
NotSet = object()
|
||||
|
||||
extra_config_values_env_key_sep = "__"
|
||||
default_config_dir = "default"
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
folder: str = None,
|
||||
verbose: bool = True,
|
||||
prefix: Sequence[str] = DEFAULT_PREFIXES,
|
||||
):
|
||||
folder = (
|
||||
Path(folder)
|
||||
if folder
|
||||
else Path(__file__).with_name(self.default_config_dir)
|
||||
)
|
||||
if not folder.is_dir():
|
||||
raise ValueError("Invalid configuration folder")
|
||||
|
||||
self.verbose = verbose
|
||||
|
||||
self.extra_config_path_override_var = [
|
||||
f"{p.upper()}_CONFIG_DIR" for p in prefix
|
||||
]
|
||||
|
||||
self.prefix = prefix[0]
|
||||
self.extra_config_values_env_key_prefix = [
|
||||
f"{p.upper()}{self.extra_config_values_env_key_sep}"
|
||||
for p in reversed(prefix)
|
||||
]
|
||||
|
||||
self._paths = [folder, *self._get_paths()]
|
||||
self._config = self._reload()
|
||||
|
||||
def __getitem__(self, key):
|
||||
return self._config[key]
|
||||
|
||||
def get(self, key: str, default: Any = NotSet) -> Any:
|
||||
value = self._config.get(key, default)
|
||||
if value is self.NotSet:
|
||||
raise KeyError(
|
||||
f"Unable to find value for key '{key}' and default value was not provided."
|
||||
)
|
||||
return value
|
||||
|
||||
def to_dict(self) -> dict:
|
||||
return self._config.as_plain_ordered_dict()
|
||||
|
||||
def as_json(self) -> str:
|
||||
return json.dumps(self.to_dict(), indent=2)
|
||||
|
||||
def logger(self, name: str) -> logging.Logger:
|
||||
if Path(name).is_file():
|
||||
name = Path(name).stem
|
||||
path = ".".join((self.prefix, name))
|
||||
return logging.getLogger(path)
|
||||
|
||||
def _read_extra_env_config_values(self) -> ConfigTree:
|
||||
""" Loads extra configuration from environment-injected values """
|
||||
result = ConfigTree()
|
||||
|
||||
for prefix in self.extra_config_values_env_key_prefix:
|
||||
keys = sorted(k for k in os.environ if k.startswith(prefix))
|
||||
for key in keys:
|
||||
path = (
|
||||
key[len(prefix) :]
|
||||
.replace(self.extra_config_values_env_key_sep, ".")
|
||||
.lower()
|
||||
)
|
||||
result = self._merge_configs(
|
||||
result, ConfigFactory.parse_string(f"{path}: {os.environ[key]}")
|
||||
)
|
||||
|
||||
return result
|
||||
|
||||
def _get_paths(self) -> List[Path]:
|
||||
default_paths = EXTRA_CONFIG_PATH_SEP.join(EXTRA_CONFIG_PATHS)
|
||||
value = first(map(getenv, self.extra_config_path_override_var), default_paths)
|
||||
|
||||
paths = [
|
||||
Path(expandvars(v)).expanduser() for v in value.split(EXTRA_CONFIG_PATH_SEP)
|
||||
]
|
||||
|
||||
if value is not default_paths:
|
||||
invalid = [path for path in paths if not path.is_dir()]
|
||||
if invalid:
|
||||
print(
|
||||
f"WARNING: Invalid paths in {self.extra_config_path_override_var} env var: {' '.join(map(str, invalid))}"
|
||||
)
|
||||
|
||||
return [path for path in paths if path.is_dir()]
|
||||
|
||||
def reload(self):
|
||||
self._config = self._reload()
|
||||
|
||||
def _reload(self) -> ConfigTree:
|
||||
extra_config_values = self._read_extra_env_config_values()
|
||||
|
||||
configs = [self._read_recursive(path) for path in self._paths]
|
||||
|
||||
return reduce(
|
||||
lambda last, config: self._merge_configs(
|
||||
last, config, copy_trees=True
|
||||
),
|
||||
configs + [extra_config_values],
|
||||
ConfigTree(),
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def _merge_configs(cls, a, b, copy_trees=False, override_prefix="-"):
|
||||
"""Based on pyhocon.ConfigTree.merge_configs, with dict override support using a `-` key prefix"""
|
||||
for key, value in b.items():
|
||||
override = key.startswith(override_prefix)
|
||||
if override:
|
||||
key = key[len(override_prefix):]
|
||||
# if key is in both a and b and both values are dictionary then merge it otherwise override it
|
||||
if not override and key in a and isinstance(a[key], ConfigTree) and isinstance(b[key], ConfigTree):
|
||||
if copy_trees:
|
||||
a[key] = a[key].copy()
|
||||
cls._merge_configs(a[key], b[key], copy_trees=copy_trees)
|
||||
else:
|
||||
if isinstance(value, ConfigValues):
|
||||
value.parent = a
|
||||
value.key = key
|
||||
if key in a:
|
||||
value.overriden_value = a[key]
|
||||
a[key] = value
|
||||
if a.root:
|
||||
if b.root:
|
||||
a.history[key] = a.history.get(key, []) + b.history.get(key, [value])
|
||||
else:
|
||||
a.history[key] = a.history.get(key, []) + [value]
|
||||
|
||||
return a
|
||||
|
||||
def _read_recursive(self, conf_root) -> ConfigTree:
|
||||
conf = ConfigTree()
|
||||
|
||||
if not conf_root:
|
||||
return conf
|
||||
|
||||
if not conf_root.is_dir():
|
||||
if self.verbose:
|
||||
if not conf_root.exists():
|
||||
print(f"No config in {conf_root}")
|
||||
else:
|
||||
print(f"Not a directory: {conf_root}")
|
||||
return conf
|
||||
|
||||
if self.verbose:
|
||||
print(f"Loading config from {conf_root}")
|
||||
|
||||
for file in conf_root.rglob("*.conf"):
|
||||
key = ".".join(file.relative_to(conf_root).with_suffix("").parts)
|
||||
conf.put(key, self._read_single_file(file))
|
||||
|
||||
return conf
|
||||
|
||||
def _read_single_file(self, file_path):
|
||||
if self.verbose:
|
||||
print(f"Loading config from file {file_path}")
|
||||
|
||||
try:
|
||||
return ConfigFactory.parse_file(file_path)
|
||||
except ParseSyntaxException as ex:
|
||||
msg = f"Failed parsing {file_path} ({ex.__class__.__name__}): (at char {ex.loc}, line:{ex.lineno}, col:{ex.column})"
|
||||
raise ConfigurationError(msg, file_path=file_path) from ex
|
||||
except (ParseException, ParseFatalException, RecursiveGrammarException) as ex:
|
||||
msg = f"Failed parsing {file_path} ({ex.__class__.__name__}): {ex}"
|
||||
raise ConfigurationError(msg) from ex
|
||||
except Exception as ex:
|
||||
print(f"Failed loading {file_path}: {ex}")
|
||||
raise
|
||||
|
||||
def initialize_logging(self):
|
||||
logging_config = self.get("logging", None)
|
||||
if not logging_config:
|
||||
return
|
||||
logging.config.dictConfig(logging_config)
|
||||
|
||||
|
||||
class ConfigurationError(Exception):
|
||||
def __init__(self, msg, file_path=None, *args):
|
||||
super().__init__(msg, *args)
|
||||
self.file_path = file_path
|
||||
|
||||
|
||||
ConfigType = TypeVar("ConfigType", bound=BasicConfig)
|
||||
@@ -3,7 +3,7 @@
|
||||
debug: false # Debug mode
|
||||
pretty_json: false # prettify json response
|
||||
return_stack: true # return stack trace on error
|
||||
log_calls: true # Log API Calls
|
||||
return_stack_to_caller: true # top-level control on whether to return stack trace in an API response
|
||||
|
||||
# if 'return_stack' is true and error contains a status code, return stack trace only for these status codes
|
||||
# valid values are:
|
||||
@@ -69,7 +69,7 @@
|
||||
default_expiration_sec: 2592000
|
||||
|
||||
# cookie containing auth token, for requests arriving from a web-browser
|
||||
session_auth_cookie_name: "trains_token_basic"
|
||||
session_auth_cookie_name: "clearml_token_basic"
|
||||
|
||||
# cookie configuration for authorization cookies generated by auth.login
|
||||
cookies {
|
||||
@@ -80,8 +80,10 @@
|
||||
}
|
||||
|
||||
# # A list of fixed users
|
||||
# # Note: password may be bcrypt-hashed (generate using `python -c 'import bcrypt; print(bcrypt.hashpw("password", bcrypt.gensalt()))'`)
|
||||
# fixed_users {
|
||||
# enabled: true
|
||||
# pass_hashed: false
|
||||
# users: [
|
||||
# {
|
||||
# username: "john"
|
||||
@@ -116,9 +118,9 @@
|
||||
# Check for updates every 24 hours
|
||||
check_interval_sec: 86400
|
||||
|
||||
url: "https://updates.trains.allegro.ai/updates"
|
||||
url: "https://updates.clear.ml/updates"
|
||||
|
||||
component_name: "trains-server"
|
||||
component_name: "clearml-server"
|
||||
|
||||
# GET request timeout
|
||||
request_timeout_sec: 3.0
|
||||
@@ -128,7 +130,7 @@
|
||||
# Note: statistics are sent ONLY if the user has actively opted-in
|
||||
supported: true
|
||||
|
||||
url: "https://updates.trains.allegro.ai/stats"
|
||||
url: "https://updates.clear.ml/stats"
|
||||
|
||||
report_interval_hours: 24
|
||||
agent_relevant_threshold_days: 30
|
||||
@@ -1,6 +1,6 @@
|
||||
elastic {
|
||||
events {
|
||||
hosts: [{host: "127.0.0.1", port: 9211}]
|
||||
hosts: [{host: "127.0.0.1", port: 9200}]
|
||||
args {
|
||||
timeout: 60
|
||||
dead_timeout: 10
|
||||
@@ -11,7 +11,7 @@ elastic {
|
||||
}
|
||||
|
||||
workers {
|
||||
hosts: [{host:"127.0.0.1", port:9211}]
|
||||
hosts: [{host:"127.0.0.1", port:9200}]
|
||||
args {
|
||||
timeout: 60
|
||||
dead_timeout: 10
|
||||
@@ -16,7 +16,7 @@
|
||||
backupCount: 3
|
||||
maxBytes: 10240000,
|
||||
class: "logging.handlers.RotatingFileHandler",
|
||||
filename: "/var/log/trains/apiserver.log"
|
||||
filename: "/var/log/clearml/apiserver.log"
|
||||
}
|
||||
}
|
||||
root {
|
||||
@@ -28,6 +28,7 @@
|
||||
display_name: "Default User"
|
||||
user_key: "EGRTCO8JMSIGI6S39GTP43NFWXDQOW"
|
||||
user_secret: "x!XTov_G-#vspE*Y(h$Anm&DIc5Ou-F)jsl$PdOyj5wG1&E!Z8"
|
||||
revoke_in_fixed_mode: true
|
||||
}
|
||||
}
|
||||
}
|
||||
27
apiserver/config/default/services/events.conf
Normal file
27
apiserver/config/default/services/events.conf
Normal file
@@ -0,0 +1,27 @@
|
||||
es_index_prefix: "events"
|
||||
|
||||
ignore_iteration {
|
||||
metrics: [":monitor:machine", ":monitor:gpu"]
|
||||
}
|
||||
|
||||
|
||||
events_retrieval {
|
||||
state_expiration_sec: 3600
|
||||
|
||||
# max number of concurrent queries to ES when calculating events metrics
|
||||
# should not exceed the amount of concurrent connections set in the ES driver
|
||||
max_metrics_concurrency: 4
|
||||
|
||||
# the max amount of metrics to aggregate on
|
||||
max_metrics_count: 100
|
||||
|
||||
# the max amount of variants to aggregate on
|
||||
max_variants_count: 100
|
||||
}
|
||||
|
||||
# if set then plot str will be checked for the valid json on plot add
|
||||
# and the result of the check is written to the db
|
||||
validate_plot_str: false
|
||||
|
||||
# If not 0 then the plots equal or greater to the size will be stored compressed in the DB
|
||||
plot_compression_threshold: 100000
|
||||
18
apiserver/config/default/services/projects.conf
Normal file
18
apiserver/config/default/services/projects.conf
Normal file
@@ -0,0 +1,18 @@
|
||||
# Order of featured projects, by name or ID
|
||||
featured {
|
||||
order: [
|
||||
# {id: "<project-id>"}
|
||||
# OR
|
||||
# {name: "<project-name>"}
|
||||
# OR
|
||||
# {name_regex: "<python-regex>"}
|
||||
]
|
||||
|
||||
# default featured index for public projects not specified in the order
|
||||
public_default: 9999
|
||||
}
|
||||
|
||||
sub_projects {
|
||||
# the max sub project depth
|
||||
max_depth: 10
|
||||
}
|
||||
22
apiserver/config/default/services/tasks.conf
Normal file
22
apiserver/config/default/services/tasks.conf
Normal file
@@ -0,0 +1,22 @@
|
||||
non_responsive_tasks_watchdog {
|
||||
enabled: true
|
||||
|
||||
# In-progress tasks older than this value in seconds will be stopped by the watchdog
|
||||
threshold_sec: 7200
|
||||
|
||||
# Watchdog will sleep for this number of seconds after each cycle
|
||||
watch_interval_sec: 900
|
||||
}
|
||||
|
||||
multi_task_histogram_limit: 100
|
||||
|
||||
hyperparam_values {
|
||||
# maximal amount of distinct hyperparam values to retrieve
|
||||
max_count: 100
|
||||
|
||||
# max allowed outdate time for the cashed result
|
||||
cache_allowed_outdate_sec: 60
|
||||
|
||||
# cache ttl sec
|
||||
cache_ttl_sec: 86400
|
||||
}
|
||||
@@ -1,15 +1,19 @@
|
||||
from functools import lru_cache
|
||||
from os import getenv
|
||||
from pathlib import Path
|
||||
from version import __version__
|
||||
|
||||
from config import config
|
||||
from boltons.iterutils import first
|
||||
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.version import __version__
|
||||
|
||||
root = Path(__file__).parent.parent
|
||||
|
||||
|
||||
def _get(prop_name, env_suffix=None, default=""):
|
||||
value = getenv(f"TRAINS_SERVER_{env_suffix or prop_name}")
|
||||
suffix = env_suffix or prop_name
|
||||
keys = [f"{p}_SERVER_{suffix}" for p in ("CLEARML", "TRAINS")]
|
||||
value = first(map(getenv, keys))
|
||||
if value:
|
||||
return value
|
||||
|
||||
4
apiserver/config_repo.py
Normal file
4
apiserver/config_repo.py
Normal file
@@ -0,0 +1,4 @@
|
||||
from apiserver.config import BasicConfig
|
||||
|
||||
config = BasicConfig()
|
||||
config.initialize_logging()
|
||||
109
apiserver/database/__init__.py
Normal file
109
apiserver/database/__init__.py
Normal file
@@ -0,0 +1,109 @@
|
||||
from os import getenv
|
||||
|
||||
from boltons.iterutils import first
|
||||
from furl import furl
|
||||
from jsonmodels import models
|
||||
from jsonmodels.errors import ValidationError
|
||||
from jsonmodels.fields import StringField
|
||||
from mongoengine import register_connection
|
||||
from mongoengine.connection import get_connection, disconnect
|
||||
|
||||
from apiserver.config_repo import config
|
||||
from .defs import Database
|
||||
from .utils import get_items
|
||||
|
||||
log = config.logger("database")
|
||||
|
||||
strict = config.get("apiserver.mongo.strict", True)
|
||||
|
||||
OVERRIDE_HOST_ENV_KEY = (
|
||||
"CLEARML_MONGODB_SERVICE_HOST",
|
||||
"TRAINS_MONGODB_SERVICE_HOST",
|
||||
"MONGODB_SERVICE_HOST",
|
||||
"MONGODB_SERVICE_SERVICE_HOST",
|
||||
)
|
||||
OVERRIDE_PORT_ENV_KEY = (
|
||||
"CLEARML_MONGODB_SERVICE_PORT",
|
||||
"TRAINS_MONGODB_SERVICE_PORT",
|
||||
"MONGODB_SERVICE_PORT",
|
||||
)
|
||||
|
||||
|
||||
class DatabaseEntry(models.Base):
|
||||
host = StringField(required=True)
|
||||
alias = StringField()
|
||||
|
||||
|
||||
class DatabaseFactory:
|
||||
_entries = []
|
||||
|
||||
@classmethod
|
||||
def _create_db_entry(cls, alias: str, settings: dict) -> DatabaseEntry:
|
||||
return DatabaseEntry(alias=alias, **settings)
|
||||
|
||||
@classmethod
|
||||
def initialize(cls):
|
||||
db_entries = config.get("hosts.mongo", {})
|
||||
missing = []
|
||||
log.info("Initializing database connections")
|
||||
|
||||
override_hostname = first(map(getenv, OVERRIDE_HOST_ENV_KEY), None)
|
||||
if override_hostname:
|
||||
log.info(f"Using override mongodb host {override_hostname}")
|
||||
|
||||
override_port = first(map(getenv, OVERRIDE_PORT_ENV_KEY), None)
|
||||
if override_port:
|
||||
log.info(f"Using override mongodb port {override_port}")
|
||||
|
||||
for key, alias in get_items(Database).items():
|
||||
if key not in db_entries:
|
||||
missing.append(key)
|
||||
continue
|
||||
|
||||
entry = cls._create_db_entry(alias=alias, settings=db_entries.get(key))
|
||||
|
||||
if override_hostname:
|
||||
entry.host = furl(entry.host).set(host=override_hostname).url
|
||||
|
||||
if override_port:
|
||||
entry.host = furl(entry.host).set(port=override_port).url
|
||||
|
||||
try:
|
||||
entry.validate()
|
||||
log.info(
|
||||
"Registering connection to %(alias)s (%(host)s)" % entry.to_struct()
|
||||
)
|
||||
register_connection(**entry.to_struct())
|
||||
|
||||
cls._entries.append(entry)
|
||||
except ValidationError as ex:
|
||||
raise Exception("Invalid database entry `%s`: %s" % (key, ex.args[0]))
|
||||
if missing:
|
||||
raise ValueError(
|
||||
"Missing database configuration for %s" % ", ".join(missing)
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def get_entries(cls):
|
||||
return cls._entries
|
||||
|
||||
@classmethod
|
||||
def get_hosts(cls):
|
||||
return [entry.host for entry in cls.get_entries()]
|
||||
|
||||
@classmethod
|
||||
def get_aliases(cls):
|
||||
return [entry.alias for entry in cls.get_entries()]
|
||||
|
||||
@classmethod
|
||||
def reconnect(cls):
|
||||
for entry in cls.get_entries():
|
||||
# there is bug in the current implementation that prevents
|
||||
# reconnection from work so workaround this
|
||||
# get_connection(entry.alias, reconnect=True)
|
||||
disconnect(entry.alias)
|
||||
register_connection(**entry.to_struct())
|
||||
get_connection(entry.alias)
|
||||
|
||||
|
||||
db = DatabaseFactory()
|
||||
@@ -1,6 +1,7 @@
|
||||
import re
|
||||
from contextlib import contextmanager
|
||||
from functools import wraps
|
||||
from textwrap import shorten
|
||||
|
||||
import dpath
|
||||
from dpath.exceptions import InvalidKeyName
|
||||
@@ -17,7 +18,7 @@ from mongoengine.errors import (
|
||||
)
|
||||
from pymongo.errors import PyMongoError, NotMasterError
|
||||
|
||||
from apierrors import errors
|
||||
from apiserver.apierrors import errors
|
||||
|
||||
|
||||
class MakeGetAllQueryError(Exception):
|
||||
@@ -33,7 +34,7 @@ class ParseCallError(Exception):
|
||||
self.params = kwargs
|
||||
|
||||
|
||||
def throws_default_error(err_cls):
|
||||
def throws_default_error(err_cls, shorten_width: int = None):
|
||||
"""
|
||||
Used to make functions (Exception, str) -> Optional[str] searching for specialized error messages raise those
|
||||
messages in ``err_cls``. If the decorated function does not find a suitable error message,
|
||||
@@ -45,25 +46,49 @@ def throws_default_error(err_cls):
|
||||
@wraps(func)
|
||||
def wrapper(self, e, message, **kwargs):
|
||||
extra_info = func(self, e, message, **kwargs)
|
||||
raise err_cls(message, err=e, extra_info=extra_info)
|
||||
err = str(e)
|
||||
if shorten_width:
|
||||
err = shorten(err, shorten_width, placeholder="...")
|
||||
raise err_cls(message, err=err, extra_info=extra_info)
|
||||
|
||||
return wrapper
|
||||
|
||||
return decorator
|
||||
|
||||
|
||||
# noinspection RegExpRedundantEscape
|
||||
class ElasticErrorsHandler(object):
|
||||
@classmethod
|
||||
@throws_default_error(errors.server_error.DataError)
|
||||
def _bulk_meta_error(cls, error):
|
||||
try:
|
||||
_, err_type = next(dpath.search(error, "*/error/type", yielded=True))
|
||||
_, reason = next(dpath.search(error, "*/error/reason", yielded=True))
|
||||
if err_type == "cluster_block_exception":
|
||||
raise errors.server_error.LowDiskSpace(
|
||||
"metrics, logs and all indexed data is in read-only mode!",
|
||||
reason=re.sub(r"^index\s\[.*?\]\s", "", reason) if reason else ""
|
||||
)
|
||||
return
|
||||
except StopIteration:
|
||||
pass
|
||||
|
||||
@classmethod
|
||||
@throws_default_error(errors.server_error.DataError, shorten_width=200)
|
||||
def bulk_error(cls, e, _, **__):
|
||||
if not e.errors:
|
||||
return
|
||||
|
||||
# Currently we only handle the first error
|
||||
error = e.errors[0]
|
||||
|
||||
cls._bulk_meta_error(error)
|
||||
|
||||
# Else try returning a better error string
|
||||
for _, reason in dpath.search(e.errors[0], "*/error/reason", yielded=True):
|
||||
return reason
|
||||
|
||||
|
||||
# noinspection RegExpRedundantEscape
|
||||
class MongoEngineErrorsHandler(object):
|
||||
# NotUniqueError
|
||||
__not_unique_regex = re.compile(
|
||||
@@ -81,6 +106,7 @@ class MongoEngineErrorsHandler(object):
|
||||
def validation_error(cls, e: ValidationError, message, **_):
|
||||
# Thrown when a document is validated. Documents are validated by default on save and on update
|
||||
err_dict = e.errors or {e.field_name: e.message}
|
||||
err_dict = {key: str(value) for key, value in err_dict.items()}
|
||||
raise errors.bad_request.DataValidationError(message, **err_dict)
|
||||
|
||||
@classmethod
|
||||
@@ -14,7 +14,7 @@ from mongoengine import (
|
||||
DictField,
|
||||
DynamicField,
|
||||
)
|
||||
from mongoengine.fields import key_not_string, key_starts_with_dollar
|
||||
from mongoengine.fields import key_not_string, key_starts_with_dollar, EmailField
|
||||
|
||||
NoneType = type(None)
|
||||
|
||||
@@ -93,6 +93,24 @@ class CustomFloatField(FloatField):
|
||||
self.error("Float value must be greater than %s" % str(self.greater_than))
|
||||
|
||||
|
||||
class CanonicEmailField(EmailField):
|
||||
"""email field that is always lower cased"""
|
||||
def __set__(self, instance, value: str):
|
||||
if value is not None:
|
||||
try:
|
||||
value = value.lower()
|
||||
except AttributeError:
|
||||
pass
|
||||
super().__set__(instance, value)
|
||||
|
||||
def prepare_query_value(self, op, value):
|
||||
if not isinstance(op, six.string_types):
|
||||
return value
|
||||
if value is not None:
|
||||
value = value.lower()
|
||||
return super().prepare_query_value(op, value)
|
||||
|
||||
|
||||
class StrippedStringField(StringField):
|
||||
def __init__(
|
||||
self, regex=None, max_length=None, min_length=None, strip_chars=None, **kwargs
|
||||
@@ -158,6 +176,13 @@ class SafeMapField(MapField, DictValidationMixin):
|
||||
self.error("Empty keys are not allowed in a MapField")
|
||||
|
||||
|
||||
class NullableStringField(StringField):
|
||||
def validate(self, value):
|
||||
if value is None:
|
||||
return
|
||||
super(NullableStringField, self).validate(value)
|
||||
|
||||
|
||||
class SafeDictField(DictField, DictValidationMixin):
|
||||
def validate(self, value):
|
||||
self._safe_validate(value)
|
||||
@@ -2,10 +2,10 @@ from enum import Enum
|
||||
|
||||
from mongoengine import Document, StringField
|
||||
|
||||
from apierrors import errors
|
||||
from database.model.base import DbModelMixin, ABSTRACT_FLAG
|
||||
from database.model.company import Company
|
||||
from database.model.user import User
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.database.model.base import DbModelMixin, ABSTRACT_FLAG
|
||||
from apiserver.database.model.company import Company
|
||||
from apiserver.database.model.user import User
|
||||
|
||||
|
||||
class AttributedDocument(DbModelMixin, Document):
|
||||
@@ -6,10 +6,10 @@ from mongoengine import (
|
||||
DateTimeField,
|
||||
)
|
||||
|
||||
from database import Database, strict
|
||||
from database.model import DbModelMixin
|
||||
from database.model.base import AuthDocument
|
||||
from database.utils import get_options
|
||||
from apiserver.database import Database, strict
|
||||
from apiserver.database.model import DbModelMixin
|
||||
from apiserver.database.model.base import AuthDocument
|
||||
from apiserver.database.utils import get_options
|
||||
|
||||
|
||||
class Entities(object):
|
||||
@@ -72,5 +72,5 @@ class User(DbModelMixin, AuthDocument):
|
||||
credentials = EmbeddedDocumentListField(Credentials, default=list)
|
||||
""" Credentials generated for this user """
|
||||
|
||||
email = EmailField(unique=True, required=True)
|
||||
email = EmailField(unique=True, sparse=True)
|
||||
""" Email uniquely identifying the user """
|
||||
@@ -1,21 +1,21 @@
|
||||
import re
|
||||
from collections import namedtuple
|
||||
from functools import reduce
|
||||
from typing import Collection, Sequence, Union, Optional, Type, Tuple
|
||||
from typing import Collection, Sequence, Union, Optional, Type, Tuple, Mapping, Any
|
||||
|
||||
from boltons.iterutils import first, bucketize, partition
|
||||
from dateutil.parser import parse as parse_datetime
|
||||
from mongoengine import Q, Document, ListField, StringField
|
||||
from pymongo.command_cursor import CommandCursor
|
||||
|
||||
from apierrors import errors
|
||||
from apierrors.base import BaseError
|
||||
from config import config
|
||||
from database.errors import MakeGetAllQueryError
|
||||
from database.projection import project_dict, ProjectionHelper
|
||||
from database.props import PropsMixin
|
||||
from database.query import RegexQ, RegexWrapper
|
||||
from database.utils import (
|
||||
from apiserver.apierrors import errors
|
||||
from apiserver.apierrors.base import BaseError
|
||||
from apiserver.config_repo import config
|
||||
from apiserver.database.errors import MakeGetAllQueryError
|
||||
from apiserver.database.projection import project_dict, ProjectionHelper
|
||||
from apiserver.database.props import PropsMixin
|
||||
from apiserver.database.query import RegexQ, RegexWrapper
|
||||
from apiserver.database.utils import (
|
||||
get_company_or_none_constraint,
|
||||
get_fields_choices,
|
||||
field_does_not_exist,
|
||||
@@ -86,6 +86,7 @@ class GetMixin(PropsMixin):
|
||||
list_fields=("tags", "system_tags", "id"),
|
||||
datetime_fields=None,
|
||||
fields=None,
|
||||
range_fields=None,
|
||||
):
|
||||
"""
|
||||
:param pattern_fields: Fields for which a "string contains" condition should be generated
|
||||
@@ -97,6 +98,7 @@ class GetMixin(PropsMixin):
|
||||
self.fields = fields
|
||||
self.datetime_fields = datetime_fields
|
||||
self.list_fields = list_fields
|
||||
self.range_fields = range_fields
|
||||
self.pattern_fields = pattern_fields
|
||||
|
||||
class ListFieldBucketHelper:
|
||||
@@ -104,25 +106,34 @@ class GetMixin(PropsMixin):
|
||||
legacy_exclude_prefix = "-"
|
||||
|
||||
_default = "in"
|
||||
_ops = {"not": "nin"}
|
||||
_ops = {
|
||||
"not": ("nin", False),
|
||||
"all": ("all", True),
|
||||
"and": ("all", True),
|
||||
}
|
||||
_next = _default
|
||||
_sticky = False
|
||||
|
||||
def __init__(self, legacy=False):
|
||||
self._legacy = legacy
|
||||
|
||||
def key(self, v):
|
||||
def key(self, v) -> Optional[str]:
|
||||
if v is None:
|
||||
self._next = self._default
|
||||
return self._default
|
||||
elif self._legacy and v.startswith(self.legacy_exclude_prefix):
|
||||
self._next = self._default
|
||||
return self._ops["not"]
|
||||
return self._ops["not"][0]
|
||||
elif v.startswith(self.op_prefix):
|
||||
self._next = self._ops.get(v[len(self.op_prefix) :], self._default)
|
||||
self._next, self._sticky = self._ops.get(
|
||||
v[len(self.op_prefix) :], (self._default, self._sticky)
|
||||
)
|
||||
return None
|
||||
|
||||
next_ = self._next
|
||||
self._next = self._default
|
||||
if not self._sticky:
|
||||
self._next = self._default
|
||||
|
||||
return next_
|
||||
|
||||
def value_transform(self, v):
|
||||
@@ -175,6 +186,53 @@ class GetMixin(PropsMixin):
|
||||
parameters, parameters_options
|
||||
) & cls._prepare_perm_query(company, allow_public=allow_public)
|
||||
|
||||
@staticmethod
|
||||
def _pop_matching_params(
|
||||
patterns: Sequence[str], parameters: dict
|
||||
) -> Mapping[str, Any]:
|
||||
"""
|
||||
Pop the parameters that match the specified patterns and return
|
||||
the dictionary of matching parameters
|
||||
Pop None parameters since they are not the real queries
|
||||
"""
|
||||
if not patterns:
|
||||
return {}
|
||||
|
||||
fields = set()
|
||||
for pattern in patterns:
|
||||
if pattern.endswith("*"):
|
||||
prefix = pattern[:-1]
|
||||
fields.update(
|
||||
{field for field in parameters if field.startswith(prefix)}
|
||||
)
|
||||
elif pattern in parameters:
|
||||
fields.add(pattern)
|
||||
|
||||
pairs = ((field, parameters.pop(field, None)) for field in fields)
|
||||
return {k: v for k, v in pairs if v is not None}
|
||||
|
||||
@classmethod
|
||||
def _try_convert_to_numeric(cls, value: Union[str, Sequence[str]]):
|
||||
def convert_str(val: str) -> Union[float, str]:
|
||||
try:
|
||||
return float(val)
|
||||
except ValueError:
|
||||
return val
|
||||
|
||||
if isinstance(value, str):
|
||||
return convert_str(value)
|
||||
|
||||
if isinstance(value, (list, tuple)):
|
||||
return [convert_str(v) if isinstance(v, str) else v for v in value]
|
||||
|
||||
return value
|
||||
|
||||
@classmethod
|
||||
def _get_fixed_field_value(cls, field: str, value):
|
||||
if field.startswith("last_metrics."):
|
||||
return cls._try_convert_to_numeric(value)
|
||||
return value
|
||||
|
||||
@classmethod
|
||||
def _prepare_query_no_company(
|
||||
cls, parameters=None, parameters_options=QueryParameterOptions()
|
||||
@@ -197,22 +255,32 @@ class GetMixin(PropsMixin):
|
||||
dict_query = {}
|
||||
query = RegexQ()
|
||||
if parameters:
|
||||
parameters = parameters.copy()
|
||||
parameters = {
|
||||
k: cls._get_fixed_field_value(k, v) for k, v in parameters.items()
|
||||
}
|
||||
opts = parameters_options
|
||||
for field in opts.pattern_fields:
|
||||
pattern = parameters.pop(field, None)
|
||||
if pattern:
|
||||
dict_query[field] = RegexWrapper(pattern)
|
||||
|
||||
for field in tuple(opts.list_fields or ()):
|
||||
data = parameters.pop(field, None)
|
||||
if data:
|
||||
query &= cls.get_list_field_query(field, data)
|
||||
for field, data in cls._pop_matching_params(
|
||||
patterns=opts.list_fields, parameters=parameters
|
||||
).items():
|
||||
query &= cls.get_list_field_query(field, data)
|
||||
|
||||
for field in opts.fields or []:
|
||||
data = parameters.pop(field, None)
|
||||
if data is not None:
|
||||
dict_query[field] = data
|
||||
for field, data in cls._pop_matching_params(
|
||||
patterns=opts.range_fields, parameters=parameters
|
||||
).items():
|
||||
query &= cls.get_range_field_query(field, data)
|
||||
|
||||
for field, data in cls._pop_matching_params(
|
||||
patterns=opts.fields or [], parameters=parameters
|
||||
).items():
|
||||
if "._" in field or "_." in field:
|
||||
query &= Q(__raw__={field: data})
|
||||
else:
|
||||
dict_query[field.replace(".", "__")] = data
|
||||
|
||||
for field in opts.datetime_fields or []:
|
||||
data = parameters.pop(field, None)
|
||||
@@ -242,15 +310,53 @@ class GetMixin(PropsMixin):
|
||||
raise MakeGetAllQueryError("incorrect field format", field)
|
||||
if not data.fields:
|
||||
break
|
||||
regex = RegexWrapper(data.pattern, flags=re.IGNORECASE)
|
||||
sep_fields = [f.replace(".", "__") for f in data.fields]
|
||||
q = reduce(
|
||||
lambda a, x: func(a, RegexQ(**{x: regex})), sep_fields, RegexQ()
|
||||
)
|
||||
if any("._" in f for f in data.fields):
|
||||
q = reduce(
|
||||
lambda a, x: func(a, Q(__raw__={x: {"$regex": data.pattern, "$options": "i"}})),
|
||||
data.fields,
|
||||
Q()
|
||||
)
|
||||
else:
|
||||
regex = RegexWrapper(data.pattern, flags=re.IGNORECASE)
|
||||
sep_fields = [f.replace(".", "__") for f in data.fields]
|
||||
q = reduce(
|
||||
lambda a, x: func(a, RegexQ(**{x: regex})), sep_fields, RegexQ()
|
||||
)
|
||||
query = query & q
|
||||
|
||||
return query & RegexQ(**dict_query)
|
||||
|
||||
@classmethod
|
||||
def get_range_field_query(cls, field: str, data: Sequence[Optional[str]]) -> Q:
|
||||
"""
|
||||
Return a range query for the provided field. The data should contain min and max values
|
||||
Both intervals are included. For open range queries either min or max can be None
|
||||
In case the min value is None the records with missing or None value from db are included
|
||||
"""
|
||||
if not isinstance(data, (list, tuple)) or len(data) != 2:
|
||||
raise errors.bad_request.ValidationError(
|
||||
f"Min and max values should be specified for range field {field}"
|
||||
)
|
||||
|
||||
min_val, max_val = data
|
||||
if min_val is None and max_val is None:
|
||||
raise errors.bad_request.ValidationError(
|
||||
f"At least one of min or max values should be provided for field {field}"
|
||||
)
|
||||
|
||||
mongoengine_field = field.replace(".", "__")
|
||||
query = {}
|
||||
if min_val is not None:
|
||||
query[f"{mongoengine_field}__gte"] = min_val
|
||||
if max_val is not None:
|
||||
query[f"{mongoengine_field}__lte"] = max_val
|
||||
|
||||
q = Q(**query)
|
||||
if min_val is None:
|
||||
q |= Q(**{mongoengine_field: None})
|
||||
|
||||
return q
|
||||
|
||||
@classmethod
|
||||
def get_list_field_query(cls, field: str, data: Sequence[Optional[str]]) -> Q:
|
||||
"""
|
||||
@@ -260,9 +366,11 @@ class GetMixin(PropsMixin):
|
||||
|
||||
- Exclusion can be specified by a leading "-" for each value (API versions <2.8)
|
||||
or by a preceding "__$not" value (operator)
|
||||
- AND can be achieved using a preceding "__$all" or "__$and" value (operator)
|
||||
"""
|
||||
if not isinstance(data, (list, tuple)):
|
||||
raise MakeGetAllQueryError("expected list", field)
|
||||
data = [data]
|
||||
# raise MakeGetAllQueryError("expected list", field)
|
||||
|
||||
# TODO: backwards compatibility only for older API versions
|
||||
helper = cls.ListFieldBucketHelper(legacy=True)
|
||||
@@ -276,11 +384,7 @@ class GetMixin(PropsMixin):
|
||||
q = RegexQ()
|
||||
for action in filter(None, actions):
|
||||
q &= RegexQ(
|
||||
**{
|
||||
f"{mongoengine_field}__{action}": list(
|
||||
set(filter(None, actions[action]))
|
||||
)
|
||||
}
|
||||
**{f"{mongoengine_field}__{action}": list(set(actions[action]))}
|
||||
)
|
||||
|
||||
if not allow_empty:
|
||||
@@ -439,6 +543,12 @@ class GetMixin(PropsMixin):
|
||||
|
||||
return helper.project(results, projection_func)
|
||||
|
||||
@classmethod
|
||||
def _get_collation_override(cls, field: str) -> Optional[dict]:
|
||||
return first(
|
||||
v for k, v in cls._field_collation_overrides.items() if field.startswith(k)
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def get_many(
|
||||
cls,
|
||||
@@ -476,6 +586,13 @@ class GetMixin(PropsMixin):
|
||||
:param allow_public: If True, objects marked as public (no associated company) are also queried.
|
||||
:return: A list of objects matching the query.
|
||||
"""
|
||||
override_collation = None
|
||||
if query_dict:
|
||||
for field in query_dict:
|
||||
override_collation = cls._get_collation_override(field)
|
||||
if override_collation:
|
||||
break
|
||||
|
||||
if query_dict is not None:
|
||||
q = cls.prepare_query(
|
||||
parameters=query_dict,
|
||||
@@ -492,10 +609,14 @@ class GetMixin(PropsMixin):
|
||||
query=_query,
|
||||
parameters=parameters,
|
||||
override_projection=override_projection,
|
||||
override_collation=override_collation,
|
||||
)
|
||||
|
||||
return cls._get_many_no_company(
|
||||
query=_query, parameters=parameters, override_projection=override_projection
|
||||
query=_query,
|
||||
parameters=parameters,
|
||||
override_projection=override_projection,
|
||||
override_collation=override_collation,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@@ -519,6 +640,7 @@ class GetMixin(PropsMixin):
|
||||
query: Q,
|
||||
parameters=None,
|
||||
override_projection=None,
|
||||
override_collation=None,
|
||||
):
|
||||
"""
|
||||
Fetch all documents matching a provided query.
|
||||
@@ -538,12 +660,16 @@ class GetMixin(PropsMixin):
|
||||
parameters = parameters or {}
|
||||
search_text = parameters.get(cls._search_text_key)
|
||||
order_by = cls.validate_order_by(parameters=parameters, search_text=search_text)
|
||||
if order_by and not override_collation:
|
||||
override_collation = cls._get_collation_override(order_by[0])
|
||||
page, page_size = cls.validate_paging(parameters=parameters)
|
||||
include, exclude = cls.split_projection(
|
||||
cls.get_projection(parameters, override_projection)
|
||||
)
|
||||
|
||||
qs = cls.objects(query)
|
||||
if override_collation:
|
||||
qs = qs.collation(collation=override_collation)
|
||||
if search_text:
|
||||
qs = qs.search_text(search_text)
|
||||
if order_by:
|
||||
@@ -563,12 +689,41 @@ class GetMixin(PropsMixin):
|
||||
|
||||
return qs
|
||||
|
||||
@classmethod
|
||||
def _get_queries_for_order_field(
|
||||
cls, query: Q, order_field: str
|
||||
) -> Union[None, Tuple[Q, Q]]:
|
||||
"""
|
||||
In case the order_field is one of the cls fields and the sorting is ascending
|
||||
then return the tuple of 2 queries:
|
||||
1. original query with not empty constraint on the order_by field
|
||||
2. original query with empty constraint on the order_by field
|
||||
"""
|
||||
if not order_field or order_field.startswith("-") or "[" in order_field:
|
||||
return
|
||||
|
||||
mongo_field_name = order_field.replace(".", "__")
|
||||
mongo_field = first(
|
||||
v for k, v in cls.get_all_fields_with_instance() if k == mongo_field_name
|
||||
)
|
||||
|
||||
if isinstance(mongo_field, ListField):
|
||||
params = {"is_list": True}
|
||||
elif isinstance(mongo_field, StringField):
|
||||
params = {"empty_value": ""}
|
||||
else:
|
||||
params = {}
|
||||
non_empty = query & field_exists(mongo_field_name, **params)
|
||||
empty = query & field_does_not_exist(mongo_field_name, **params)
|
||||
return non_empty, empty
|
||||
|
||||
@classmethod
|
||||
def _get_many_override_none_ordering(
|
||||
cls: Union[Document, "GetMixin"],
|
||||
query: Q = None,
|
||||
parameters: dict = None,
|
||||
override_projection: Collection[str] = None,
|
||||
override_collation: dict = None,
|
||||
) -> Sequence[dict]:
|
||||
"""
|
||||
Fetch all documents matching a provided query. For the first order by field
|
||||
@@ -601,32 +756,17 @@ class GetMixin(PropsMixin):
|
||||
order_field = first(
|
||||
field for field in order_by if not field.startswith("$")
|
||||
)
|
||||
if (
|
||||
order_field
|
||||
and not order_field.startswith("-")
|
||||
and "[" not in order_field
|
||||
):
|
||||
params = {}
|
||||
mongo_field = order_field.replace(".", "__")
|
||||
if mongo_field in cls.get_field_names_for_type(of_type=ListField):
|
||||
params["is_list"] = True
|
||||
elif mongo_field in cls.get_field_names_for_type(of_type=StringField):
|
||||
params["empty_value"] = ""
|
||||
non_empty = query & field_exists(mongo_field, **params)
|
||||
empty = query & field_does_not_exist(mongo_field, **params)
|
||||
query_sets = [cls.objects(non_empty), cls.objects(empty)]
|
||||
|
||||
res = cls._get_queries_for_order_field(query, order_field)
|
||||
if res:
|
||||
query_sets = [cls.objects(q) for q in res]
|
||||
query_sets = [qs.order_by(*order_by) for qs in query_sets]
|
||||
if order_field:
|
||||
collation_override = first(
|
||||
v
|
||||
for k, v in cls._field_collation_overrides.items()
|
||||
if order_field.startswith(k)
|
||||
)
|
||||
if collation_override:
|
||||
query_sets = [
|
||||
qs.collation(collation=collation_override) for qs in query_sets
|
||||
]
|
||||
if order_field and not override_collation:
|
||||
override_collation = cls._get_collation_override(order_field)
|
||||
|
||||
if override_collation:
|
||||
query_sets = [
|
||||
qs.collation(collation=override_collation) for qs in query_sets
|
||||
]
|
||||
|
||||
if search_text:
|
||||
query_sets = [qs.search_text(search_text) for qs in query_sets]
|
||||
@@ -692,14 +832,24 @@ class GetMixin(PropsMixin):
|
||||
|
||||
|
||||
class UpdateMixin(object):
|
||||
__user_set_allowed_fields = None
|
||||
__locked_when_published_fields = None
|
||||
|
||||
@classmethod
|
||||
def user_set_allowed(cls):
|
||||
res = getattr(cls, "__user_set_allowed_fields", None)
|
||||
if res is None:
|
||||
res = cls.__user_set_allowed_fields = get_fields_choices(
|
||||
cls, "user_set_allowed"
|
||||
if cls.__user_set_allowed_fields is None:
|
||||
cls.__user_set_allowed_fields = dict(
|
||||
get_fields_choices(cls, "user_set_allowed")
|
||||
)
|
||||
return res
|
||||
return cls.__user_set_allowed_fields
|
||||
|
||||
@classmethod
|
||||
def locked_when_published(cls):
|
||||
if cls.__locked_when_published_fields is None:
|
||||
cls.__locked_when_published_fields = dict(
|
||||
get_fields_choices(cls, "locked_when_published")
|
||||
)
|
||||
return cls.__locked_when_published_fields
|
||||
|
||||
@classmethod
|
||||
def get_safe_update_dict(cls, fields):
|
||||
@@ -773,7 +923,7 @@ class DbModelMixin(GetMixin, ProperDictMixin, UpdateMixin):
|
||||
):
|
||||
if enabled:
|
||||
items = list(cls.objects(id__in=ids, company=company_id).only("id"))
|
||||
update = dict(set__company_origin=company_id, unset__company=1)
|
||||
update = dict(set__company_origin=company_id, set__company="")
|
||||
else:
|
||||
items = list(
|
||||
cls.objects(
|
||||
@@ -8,9 +8,9 @@ from mongoengine import (
|
||||
DateTimeField,
|
||||
)
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import StrippedStringField
|
||||
from database.model import DbModelMixin
|
||||
from apiserver.database import Database, strict
|
||||
from apiserver.database.fields import StrippedStringField
|
||||
from apiserver.database.model import DbModelMixin
|
||||
|
||||
|
||||
class ReportStatsOption(EmbeddedDocument):
|
||||
@@ -29,7 +29,7 @@ class Company(DbModelMixin, Document):
|
||||
meta = {"db_alias": Database.backend, "strict": strict}
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
name = StrippedStringField(unique=True, min_length=3)
|
||||
name = StrippedStringField(min_length=3)
|
||||
defaults = EmbeddedDocumentField(CompanyDefaults, default=CompanyDefaults)
|
||||
|
||||
@classmethod
|
||||
44
apiserver/database/model/metadata.py
Normal file
44
apiserver/database/model/metadata.py
Normal file
@@ -0,0 +1,44 @@
|
||||
from typing import Sequence, Type
|
||||
|
||||
from mongoengine import EmbeddedDocument, StringField, Document
|
||||
from pymongo import UpdateOne
|
||||
from pymongo.collection import Collection
|
||||
|
||||
from apiserver.database.model.base import ProperDictMixin
|
||||
|
||||
|
||||
class MetadataItem(EmbeddedDocument, ProperDictMixin):
|
||||
key = StringField(required=True)
|
||||
type = StringField(required=True)
|
||||
value = StringField(required=True)
|
||||
|
||||
|
||||
def metadata_add_or_update(cls: Type[Document], _id: str, items: Sequence[dict]) -> int:
|
||||
collection: Collection = cls._get_collection()
|
||||
res = collection.update_one(
|
||||
filter={"_id": _id},
|
||||
update={
|
||||
"$set": {f"metadata.$[elem{idx}]": item for idx, item in enumerate(items)}
|
||||
},
|
||||
array_filters=[
|
||||
{f"elem{idx}.key": item["key"]} for idx, item in enumerate(items)
|
||||
],
|
||||
upsert=False,
|
||||
)
|
||||
if len(items) == 1 and res.modified_count == 1:
|
||||
return res.modified_count
|
||||
|
||||
requests = [
|
||||
UpdateOne(
|
||||
filter={"_id": _id, "metadata.key": {"$ne": item["key"]}},
|
||||
update={"$push": {"metadata": item}},
|
||||
)
|
||||
for item in items
|
||||
]
|
||||
res = collection.bulk_write(requests)
|
||||
|
||||
return 1 if res.modified_count else 0
|
||||
|
||||
|
||||
def metadata_delete(cls: Type[Document], _id: str, keys: Sequence[str]) -> int:
|
||||
return cls.objects(id=_id).update_one(pull__metadata__key__in=keys)
|
||||
@@ -1,14 +1,27 @@
|
||||
from mongoengine import Document, StringField, DateTimeField, BooleanField
|
||||
from typing import Sequence
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import StrippedStringField, SafeDictField, SafeSortedListField
|
||||
from database.model import DbModelMixin
|
||||
from database.model.base import GetMixin
|
||||
from database.model.model_labels import ModelLabels
|
||||
from database.model.company import Company
|
||||
from database.model.project import Project
|
||||
from database.model.task.task import Task
|
||||
from database.model.user import User
|
||||
from mongoengine import (
|
||||
Document,
|
||||
StringField,
|
||||
DateTimeField,
|
||||
BooleanField,
|
||||
EmbeddedDocumentListField,
|
||||
)
|
||||
|
||||
from apiserver.database import Database, strict
|
||||
from apiserver.database.fields import (
|
||||
StrippedStringField,
|
||||
SafeDictField,
|
||||
SafeSortedListField,
|
||||
)
|
||||
from apiserver.database.model import DbModelMixin
|
||||
from apiserver.database.model.base import GetMixin
|
||||
from apiserver.database.model.metadata import MetadataItem
|
||||
from apiserver.database.model.model_labels import ModelLabels
|
||||
from apiserver.database.model.company import Company
|
||||
from apiserver.database.model.project import Project
|
||||
from apiserver.database.model.task.task import Task
|
||||
from apiserver.database.model.user import User
|
||||
|
||||
|
||||
class Model(DbModelMixin, Document):
|
||||
@@ -19,6 +32,9 @@ class Model(DbModelMixin, Document):
|
||||
"parent",
|
||||
"project",
|
||||
"task",
|
||||
"last_update",
|
||||
"metadata.key",
|
||||
"metadata.type",
|
||||
("company", "framework"),
|
||||
("company", "name"),
|
||||
("company", "user"),
|
||||
@@ -51,6 +67,7 @@ class Model(DbModelMixin, Document):
|
||||
"task",
|
||||
"parent",
|
||||
),
|
||||
datetime_fields=("last_update",),
|
||||
)
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
@@ -69,7 +86,11 @@ class Model(DbModelMixin, Document):
|
||||
design = SafeDictField()
|
||||
labels = ModelLabels()
|
||||
ready = BooleanField(required=True)
|
||||
last_update = DateTimeField()
|
||||
ui_cache = SafeDictField(
|
||||
default=dict, user_set_allowed=True, exclude_by_default=True
|
||||
)
|
||||
company_origin = StringField(exclude_by_default=True)
|
||||
metadata: Sequence[MetadataItem] = EmbeddedDocumentListField(
|
||||
MetadataItem, default=list, user_set_allowed=True
|
||||
)
|
||||
@@ -1,4 +1,4 @@
|
||||
from database.fields import NoneType, UnionField, SafeMapField
|
||||
from apiserver.database.fields import NoneType, UnionField, SafeMapField
|
||||
|
||||
|
||||
class ModelLabels(SafeMapField):
|
||||
@@ -1,22 +1,24 @@
|
||||
from mongoengine import StringField, DateTimeField, IntField
|
||||
from mongoengine import StringField, DateTimeField, IntField, ListField
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import StrippedStringField, SafeSortedListField
|
||||
from database.model import AttributedDocument
|
||||
from database.model.base import GetMixin
|
||||
from apiserver.database import Database, strict
|
||||
from apiserver.database.fields import StrippedStringField, SafeSortedListField
|
||||
from apiserver.database.model import AttributedDocument
|
||||
from apiserver.database.model.base import GetMixin
|
||||
|
||||
|
||||
class Project(AttributedDocument):
|
||||
|
||||
get_all_query_options = GetMixin.QueryParameterOptions(
|
||||
pattern_fields=("name", "description"),
|
||||
list_fields=("tags", "system_tags", "id"),
|
||||
list_fields=("tags", "system_tags", "id", "parent", "path"),
|
||||
)
|
||||
|
||||
meta = {
|
||||
"db_alias": Database.backend,
|
||||
"strict": strict,
|
||||
"indexes": [
|
||||
"parent",
|
||||
"path",
|
||||
("company", "name"),
|
||||
{
|
||||
"name": "%s.project.main_text_index" % Database.backend,
|
||||
@@ -34,7 +36,7 @@ class Project(AttributedDocument):
|
||||
min_length=3,
|
||||
sparse=True,
|
||||
)
|
||||
description = StringField(required=True)
|
||||
description = StringField()
|
||||
created = DateTimeField(required=True)
|
||||
tags = SafeSortedListField(StringField(required=True))
|
||||
system_tags = SafeSortedListField(StringField(required=True))
|
||||
@@ -44,3 +46,5 @@ class Project(AttributedDocument):
|
||||
logo_url = StringField()
|
||||
logo_blob = StringField(exclude_by_default=True)
|
||||
company_origin = StringField(exclude_by_default=True)
|
||||
parent = StringField(reference_field="Project")
|
||||
path = ListField(StringField(required=True), exclude_by_default=True)
|
||||
@@ -1,3 +1,5 @@
|
||||
from typing import Sequence
|
||||
|
||||
from mongoengine import (
|
||||
Document,
|
||||
EmbeddedDocument,
|
||||
@@ -6,12 +8,13 @@ from mongoengine import (
|
||||
EmbeddedDocumentListField,
|
||||
)
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import StrippedStringField, SafeSortedListField
|
||||
from database.model import DbModelMixin
|
||||
from database.model.base import ProperDictMixin, GetMixin
|
||||
from database.model.company import Company
|
||||
from database.model.task.task import Task
|
||||
from apiserver.database import Database, strict
|
||||
from apiserver.database.fields import StrippedStringField, SafeSortedListField
|
||||
from apiserver.database.model import DbModelMixin
|
||||
from apiserver.database.model.base import ProperDictMixin, GetMixin
|
||||
from apiserver.database.model.company import Company
|
||||
from apiserver.database.model.metadata import MetadataItem
|
||||
from apiserver.database.model.task.task import Task
|
||||
|
||||
|
||||
class Entry(EmbeddedDocument, ProperDictMixin):
|
||||
@@ -32,6 +35,7 @@ class Queue(DbModelMixin, Document):
|
||||
meta = {
|
||||
'db_alias': Database.backend,
|
||||
'strict': strict,
|
||||
"indexes": ["metadata.key", "metadata.type"],
|
||||
}
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
@@ -44,3 +48,6 @@ class Queue(DbModelMixin, Document):
|
||||
system_tags = SafeSortedListField(StringField(required=True), user_set_allowed=True)
|
||||
entries = EmbeddedDocumentListField(Entry, default=list)
|
||||
last_update = DateTimeField()
|
||||
metadata: Sequence[MetadataItem] = EmbeddedDocumentListField(
|
||||
MetadataItem, default=list, user_set_allowed=True
|
||||
)
|
||||
@@ -3,8 +3,8 @@ from typing import Any, Optional, Sequence, Tuple
|
||||
from mongoengine import Document, StringField, DynamicField, Q
|
||||
from mongoengine.errors import NotUniqueError
|
||||
|
||||
from database import Database, strict
|
||||
from database.model import DbModelMixin
|
||||
from apiserver.database import Database, strict
|
||||
from apiserver.database.model import DbModelMixin
|
||||
|
||||
|
||||
class SettingKeys:
|
||||
@@ -6,7 +6,7 @@ from mongoengine import (
|
||||
EmbeddedDocumentField,
|
||||
)
|
||||
|
||||
from database.fields import SafeMapField
|
||||
from apiserver.database.fields import SafeMapField
|
||||
|
||||
|
||||
class MetricEvent(EmbeddedDocument):
|
||||
@@ -1,7 +1,7 @@
|
||||
from mongoengine import EmbeddedDocument, StringField
|
||||
|
||||
from database.fields import StrippedStringField
|
||||
from database.utils import get_options
|
||||
from apiserver.database.fields import StrippedStringField
|
||||
from apiserver.database.utils import get_options
|
||||
|
||||
|
||||
class Result(object):
|
||||
@@ -11,6 +11,5 @@ class Result(object):
|
||||
|
||||
class Output(EmbeddedDocument):
|
||||
destination = StrippedStringField()
|
||||
model = StringField(reference_field='Model')
|
||||
error = StringField(user_set_allowed=True)
|
||||
result = StringField(choices=get_options(Result))
|
||||
@@ -1,3 +1,5 @@
|
||||
from typing import Dict, Sequence
|
||||
|
||||
from mongoengine import (
|
||||
StringField,
|
||||
EmbeddedDocumentField,
|
||||
@@ -8,20 +10,21 @@ from mongoengine import (
|
||||
LongField,
|
||||
)
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import (
|
||||
from apiserver.database import Database, strict
|
||||
from apiserver.database.fields import (
|
||||
StrippedStringField,
|
||||
SafeMapField,
|
||||
SafeDictField,
|
||||
UnionField,
|
||||
EmbeddedDocumentSortedListField,
|
||||
SafeSortedListField,
|
||||
EmbeddedDocumentListField,
|
||||
NullableStringField,
|
||||
)
|
||||
from database.model import AttributedDocument
|
||||
from database.model.base import ProperDictMixin, GetMixin
|
||||
from database.model.model_labels import ModelLabels
|
||||
from database.model.project import Project
|
||||
from database.utils import get_options
|
||||
from apiserver.database.model import AttributedDocument
|
||||
from apiserver.database.model.base import ProperDictMixin, GetMixin
|
||||
from apiserver.database.model.model_labels import ModelLabels
|
||||
from apiserver.database.model.project import Project
|
||||
from apiserver.database.utils import get_options
|
||||
from .metrics import MetricEvent, MetricEventStats
|
||||
from .output import Output
|
||||
|
||||
@@ -50,13 +53,13 @@ class TaskSystemTags(object):
|
||||
|
||||
|
||||
class Script(EmbeddedDocument, ProperDictMixin):
|
||||
binary = StringField(default="python")
|
||||
repository = StringField(default="")
|
||||
tag = StringField()
|
||||
branch = StringField()
|
||||
version_num = StringField()
|
||||
entry_point = StringField(default="")
|
||||
working_dir = StringField()
|
||||
binary = StringField(default="python", strip=True)
|
||||
repository = StringField(default="", strip=True)
|
||||
tag = StringField(strip=True)
|
||||
branch = StringField(strip=True)
|
||||
version_num = StringField(strip=True)
|
||||
entry_point = StringField(default="", strip=True)
|
||||
working_dir = StringField(strip=True)
|
||||
requirements = SafeDictField()
|
||||
diff = StringField()
|
||||
|
||||
@@ -72,10 +75,15 @@ class ArtifactModes:
|
||||
output = "output"
|
||||
|
||||
|
||||
DEFAULT_ARTIFACT_MODE = ArtifactModes.output
|
||||
|
||||
|
||||
class Artifact(EmbeddedDocument):
|
||||
key = StringField(required=True)
|
||||
type = StringField(required=True)
|
||||
mode = StringField(choices=get_options(ArtifactModes), default=ArtifactModes.output)
|
||||
mode = StringField(
|
||||
choices=get_options(ArtifactModes), default=DEFAULT_ARTIFACT_MODE
|
||||
)
|
||||
uri = StringField()
|
||||
hash = StringField()
|
||||
content_size = LongField()
|
||||
@@ -99,17 +107,37 @@ class ConfigurationItem(EmbeddedDocument, ProperDictMixin):
|
||||
description = StringField()
|
||||
|
||||
|
||||
class TaskModelTypes:
|
||||
input = "input"
|
||||
output = "output"
|
||||
|
||||
|
||||
TaskModelNames = {
|
||||
TaskModelTypes.input: "Input Model",
|
||||
TaskModelTypes.output: "Output Model",
|
||||
}
|
||||
|
||||
|
||||
class ModelItem(EmbeddedDocument, ProperDictMixin):
|
||||
name = StringField(required=True)
|
||||
model = StringField(required=True, reference_field="Model")
|
||||
updated = DateTimeField()
|
||||
|
||||
|
||||
class Models(EmbeddedDocument, ProperDictMixin):
|
||||
input: Sequence[ModelItem] = EmbeddedDocumentListField(ModelItem, default=list)
|
||||
output: Sequence[ModelItem] = EmbeddedDocumentListField(ModelItem, default=list)
|
||||
|
||||
|
||||
class Execution(EmbeddedDocument, ProperDictMixin):
|
||||
meta = {"strict": strict}
|
||||
test_split = IntField(default=0)
|
||||
parameters = SafeDictField(default=dict)
|
||||
model = StringField(reference_field="Model")
|
||||
model_desc = SafeMapField(StringField(default=""))
|
||||
model_labels = ModelLabels()
|
||||
framework = StringField()
|
||||
artifacts = EmbeddedDocumentSortedListField(Artifact)
|
||||
docker_cmd = StringField()
|
||||
queue = StringField()
|
||||
artifacts: Dict[str, Artifact] = SafeMapField(field=EmbeddedDocumentField(Artifact))
|
||||
queue = StringField(reference_field="Queue")
|
||||
""" Queue ID where task was queued """
|
||||
|
||||
|
||||
@@ -136,7 +164,6 @@ class Task(AttributedDocument):
|
||||
"execution.parameters.": _numeric_locale,
|
||||
"last_metrics.": _numeric_locale,
|
||||
"hyperparams.": _numeric_locale,
|
||||
"configuration.": _numeric_locale,
|
||||
}
|
||||
|
||||
meta = {
|
||||
@@ -146,21 +173,26 @@ class Task(AttributedDocument):
|
||||
"created",
|
||||
"started",
|
||||
"completed",
|
||||
"active_duration",
|
||||
"parent",
|
||||
"project",
|
||||
"models.input.model",
|
||||
("company", "name"),
|
||||
("company", "user"),
|
||||
("company", "status", "type"),
|
||||
("company", "system_tags", "last_update"),
|
||||
("company", "type", "system_tags", "status"),
|
||||
("company", "project", "type", "system_tags", "status"),
|
||||
("status", "last_update"), # for maintenance tasks
|
||||
{"fields": ["company", "project"], "collation": _numeric_locale},
|
||||
{
|
||||
"name": "%s.task.main_text_index" % Database.backend,
|
||||
"fields": [
|
||||
"$name",
|
||||
"$id",
|
||||
"$comment",
|
||||
"$execution.model",
|
||||
"$output.model",
|
||||
"$models.input.model",
|
||||
"$models.output.model",
|
||||
"$script.repository",
|
||||
"$script.entry_point",
|
||||
],
|
||||
@@ -169,8 +201,8 @@ class Task(AttributedDocument):
|
||||
"name": 10,
|
||||
"id": 10,
|
||||
"comment": 10,
|
||||
"execution.model": 2,
|
||||
"output.model": 2,
|
||||
"models.output.model": 2,
|
||||
"models.input.model": 2,
|
||||
"script.repository": 1,
|
||||
"script.entry_point": 1,
|
||||
},
|
||||
@@ -178,10 +210,20 @@ class Task(AttributedDocument):
|
||||
],
|
||||
}
|
||||
get_all_query_options = GetMixin.QueryParameterOptions(
|
||||
list_fields=("id", "user", "tags", "system_tags", "type", "status", "project"),
|
||||
datetime_fields=("status_changed",),
|
||||
list_fields=(
|
||||
"id",
|
||||
"user",
|
||||
"tags",
|
||||
"system_tags",
|
||||
"type",
|
||||
"status",
|
||||
"project",
|
||||
"parent",
|
||||
"hyperparams.*",
|
||||
),
|
||||
range_fields=("started", "active_duration", "last_metrics.*", "last_iteration"),
|
||||
datetime_fields=("status_changed", "last_update"),
|
||||
pattern_fields=("name", "comment"),
|
||||
fields=("parent",),
|
||||
)
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
@@ -192,14 +234,15 @@ class Task(AttributedDocument):
|
||||
type = StringField(required=True, choices=get_options(TaskType))
|
||||
status = StringField(default=TaskStatus.created, choices=get_options(TaskStatus))
|
||||
status_reason = StringField()
|
||||
status_message = StringField()
|
||||
status_message = StringField(user_set_allowed=True)
|
||||
status_changed = DateTimeField()
|
||||
comment = StringField(user_set_allowed=True)
|
||||
created = DateTimeField(required=True, user_set_allowed=True)
|
||||
started = DateTimeField()
|
||||
completed = DateTimeField()
|
||||
published = DateTimeField()
|
||||
parent = StringField()
|
||||
active_duration = IntField(default=None)
|
||||
parent = StringField(reference_field="Task")
|
||||
project = StringField(reference_field=Project, user_set_allowed=True)
|
||||
output: Output = EmbeddedDocumentField(Output, default=Output)
|
||||
execution: Execution = EmbeddedDocumentField(Execution, default=Execution)
|
||||
@@ -209,6 +252,7 @@ class Task(AttributedDocument):
|
||||
last_worker = StringField()
|
||||
last_worker_report = DateTimeField()
|
||||
last_update = DateTimeField()
|
||||
last_change = DateTimeField()
|
||||
last_iteration = IntField(default=DEFAULT_LAST_ITERATION)
|
||||
last_metrics = SafeMapField(field=SafeMapField(EmbeddedDocumentField(MetricEvent)))
|
||||
metric_stats = SafeMapField(field=EmbeddedDocumentField(MetricEventStats))
|
||||
@@ -217,3 +261,18 @@ class Task(AttributedDocument):
|
||||
hyperparams = SafeMapField(field=SafeMapField(EmbeddedDocumentField(ParamsItem)))
|
||||
configuration = SafeMapField(field=EmbeddedDocumentField(ConfigurationItem))
|
||||
runtime = SafeDictField(default=dict)
|
||||
models: Models = EmbeddedDocumentField(Models, default=Models)
|
||||
container = SafeMapField(field=NullableStringField())
|
||||
enqueue_status = StringField(
|
||||
choices=get_options(TaskStatus), exclude_by_default=True
|
||||
)
|
||||
|
||||
def get_index_company(self) -> str:
|
||||
"""
|
||||
Returns the company ID used for locating indices containing task data.
|
||||
In case the task has a valid company, this is the company ID.
|
||||
Otherwise, if the task has a company_origin, this is a task that has been made public and the
|
||||
origin company should be used.
|
||||
Otherwise, an empty company is used.
|
||||
"""
|
||||
return self.company or self.company_origin or ""
|
||||
@@ -1,9 +1,9 @@
|
||||
from mongoengine import Document, StringField, DynamicField
|
||||
|
||||
from database import Database, strict
|
||||
from database.model import DbModelMixin
|
||||
from database.model.base import GetMixin
|
||||
from database.model.company import Company
|
||||
from apiserver.database import Database, strict
|
||||
from apiserver.database.model import DbModelMixin
|
||||
from apiserver.database.model.base import GetMixin
|
||||
from apiserver.database.model.company import Company
|
||||
|
||||
|
||||
class User(DbModelMixin, Document):
|
||||
@@ -1,7 +1,7 @@
|
||||
from mongoengine import Document, DateTimeField, StringField
|
||||
|
||||
from database import Database, strict
|
||||
from database.model import DbModelMixin
|
||||
from apiserver.database import Database, strict
|
||||
from apiserver.database.model import DbModelMixin
|
||||
|
||||
|
||||
class Version(DbModelMixin, Document):
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user