mirror of
https://github.com/clearml/clearml-server
synced 2025-06-26 23:15:47 +00:00
Compare commits
81 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
2c3f0e4ba3 | ||
|
|
c48eb34d8d | ||
|
|
49515e06e1 | ||
|
|
4a1d97c02f | ||
|
|
6c6c1c3f41 | ||
|
|
0ad687008c | ||
|
|
fe3dbc92dc | ||
|
|
dc53970ff0 | ||
|
|
73592b991b | ||
|
|
47b981a993 | ||
|
|
b500bcab0b | ||
|
|
59e910db1a | ||
|
|
2ecb430f02 | ||
|
|
a08722e394 | ||
|
|
67c210d9d7 | ||
|
|
101ba540f4 | ||
|
|
82fc28d477 | ||
|
|
7b73f699d2 | ||
|
|
a7e5380f67 | ||
|
|
bcade31786 | ||
|
|
6b902f85f4 | ||
|
|
6d4c974045 | ||
|
|
2346c6f3f5 | ||
|
|
82e51b4d36 | ||
|
|
e63599254e | ||
|
|
8e7e234161 | ||
|
|
17d94b26c3 | ||
|
|
1e701becd3 | ||
|
|
18c8dd449d | ||
|
|
50031c4d6d | ||
|
|
6101dc4f11 | ||
|
|
5d17059cbe | ||
|
|
b93e843143 | ||
|
|
1a732ccd8e | ||
|
|
2ea25e498f | ||
|
|
1b1cdb34ad | ||
|
|
e171a8b523 | ||
|
|
539b76d362 | ||
|
|
64b5e1f1f0 | ||
|
|
6a1eb9cea0 | ||
|
|
24907b4eaa | ||
|
|
efc540b837 | ||
|
|
96ffc89c64 | ||
|
|
4f2564d33a | ||
|
|
70ae090cc0 | ||
|
|
4f01778961 | ||
|
|
596bdd06ec | ||
|
|
6c56d0fc33 | ||
|
|
5f0213d2de | ||
|
|
15eb00a931 | ||
|
|
becc4fb6a2 | ||
|
|
32476a216a | ||
|
|
a9ba1580dc | ||
|
|
cfcd0b22a0 | ||
|
|
780355250c | ||
|
|
fd65ad38bc | ||
|
|
e29973a0b2 | ||
|
|
c259d0883e | ||
|
|
9eab017a31 | ||
|
|
68c7f307a2 | ||
|
|
0aa5694b58 | ||
|
|
639d72c5d6 | ||
|
|
70708ecdcc | ||
|
|
dacdd5e965 | ||
|
|
c199976f70 | ||
|
|
c3e2bc5ad7 | ||
|
|
f0c900c174 | ||
|
|
1bdbc44720 | ||
|
|
c6e765bd07 | ||
|
|
c037ddd044 | ||
|
|
ffe4764f20 | ||
|
|
1681fd6bf4 | ||
|
|
e55ce5536a | ||
|
|
b714952ab1 | ||
|
|
07fd8b9f2f | ||
|
|
d24f633a8e | ||
|
|
bed714890d | ||
|
|
02671910b2 | ||
|
|
1a00f29415 | ||
|
|
b7614622fc | ||
|
|
bc2cbe9a91 |
2
.gitignore
vendored
2
.gitignore
vendored
@@ -4,6 +4,8 @@ static/build.json
|
||||
static/dashboard/node_modules
|
||||
static/webapp/node_modules
|
||||
static/webapp/.git
|
||||
scripts/
|
||||
generators/
|
||||
*.pyc
|
||||
__pycache__
|
||||
.ropeproject
|
||||
|
||||
2
LICENSE
2
LICENSE
@@ -1,7 +1,7 @@
|
||||
Server Side Public License
|
||||
VERSION 1, OCTOBER 16, 2018
|
||||
|
||||
Copyright © 2018 MongoDB, Inc.
|
||||
Copyright © 2019 allegro.ai, Inc.
|
||||
|
||||
Everyone is permitted to copy and distribute verbatim copies of this
|
||||
license document, but changing it is not allowed.
|
||||
|
||||
369
README.md
369
README.md
@@ -11,7 +11,7 @@
|
||||
|
||||
The **trains-server** is the backend service infrastructure for [TRAINS](https://github.com/allegroai/trains).
|
||||
It allows multiple users to collaborate and manage their experiments.
|
||||
By default, TRAINS is set up to work with the TRAINS demo server, which is open to anyone and resets periodically.
|
||||
By default, TRAINS is set up to work with the TRAINS demo server, which is open to anyone and resets periodically.
|
||||
In order to host your own server, you will need to install **trains-server** and point TRAINS to it.
|
||||
|
||||
**trains-server** contains the following components:
|
||||
@@ -22,287 +22,242 @@ In order to host your own server, you will need to install **trains-server** and
|
||||
* Querying experiments history, logs and results
|
||||
* Locally-hosted file server for storing images and models making them easily accessible using the Web-App
|
||||
|
||||
You can quickly setup your **trains-server** using a pre-built Docker image (see [Installation](#installation)).
|
||||
You can quickly setup your **trains-server** using:
|
||||
- [Docker Installation](#installation)
|
||||
- Pre-built Amazon [AWS image](#aws)
|
||||
- [Kubernetes Helm](https://github.com/allegroai/trains-server-helm#trains-server-for-kubernetes-clusters-using-helm)
|
||||
or manual [Kubernetes installation](https://github.com/allegroai/trains-server-k8s#trains-server-for-kubernetes-clusters)
|
||||
|
||||
When new releases are available, you can upgrade your pre-built Docker image (see [Upgrade](#upgrade)).
|
||||
|
||||
## System diagram
|
||||
## System design
|
||||
|
||||
|
||||
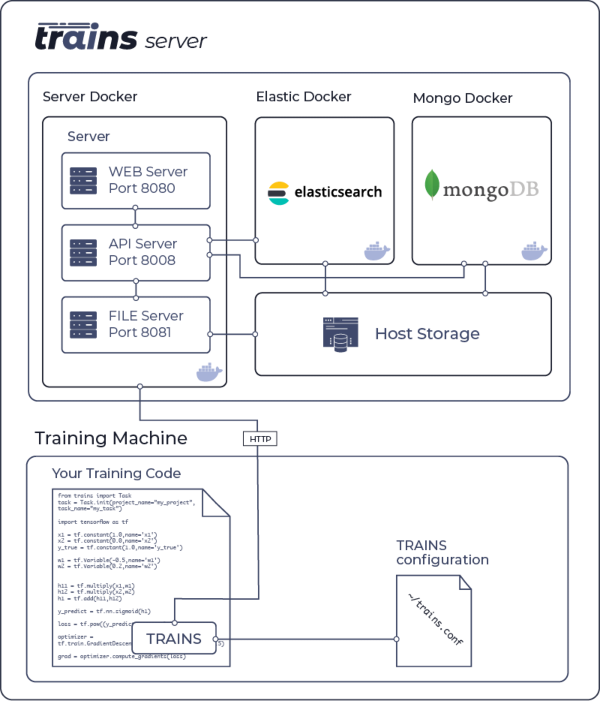
|
||||
|
||||
**trains-server** has two supported configurations:
|
||||
- Single IP (domain) with the following open ports
|
||||
- Web application on port 8080
|
||||
- API service on port 8008
|
||||
- File storage service on port 8081
|
||||
|
||||
## Install / Upgrade - AWS
|
||||
- Sub-Domain configuration with default http/s ports (80 or 443)
|
||||
- Web application on sub-domain: app.\*.\*
|
||||
- API service on sub-domain: api.\*.\*
|
||||
- File storage service on sub-domain: files.\*.\*
|
||||
|
||||
Use our pre-installed Amazon Machine Image for easy deployment in AWS.
|
||||
## Install / Upgrade - AWS <a name="aws"></a>
|
||||
|
||||
Details and instructions can be found [here](docs/install_aws.md).
|
||||
Use one of our pre-installed Amazon Machine Images for easy deployment in AWS.
|
||||
|
||||
## Installation - Docker
|
||||
For details and instructions, see [TRAINS-server: AWS pre-installed images](docs/install_aws.md).
|
||||
|
||||
This section contains the instructions to setup and launch a pre-built Docker image for the **trains-server**.
|
||||
This is the quickest way to get started with your own server.
|
||||
Alternatively, you can build the entire trains-server architecture using the code available in our repositories.
|
||||
## Docker Installation - Linux, macOS, and Windows <a name="installation"></a>
|
||||
|
||||
**Please Note**:
|
||||
* This Docker image was tested with Linux, only. For Windows users, we recommend running the server
|
||||
on a Linux virtual machine.
|
||||
Use our pre-built Docker image for easy deployment in Linux and macOS. <br>
|
||||
For [Windows](https://github.com/allegroai/trains-server/blob/master/docs/faq.md#docker_compose_win10), please see detailed docker-compose installation instructions on our [FAQ](https://github.com/allegroai/trains-server/blob/master/docs/faq.md#docker_compose_win10).<br>
|
||||
Latest docker images can be found [here](https://hub.docker.com/r/allegroai/trains).
|
||||
|
||||
* All command-line instructions below assume you're using `bash`.
|
||||
1. Setup Docker (docker-compose installation details: [Ubuntu](docs/faq.md#ubuntu) / [macOS](docs/faq.md#mac-osx))
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Make sure you are logged in as a user with sudo privileges.
|
||||
|
||||
### Setup
|
||||
|
||||
#### Step 1: Install Docker CE
|
||||
|
||||
In order to run the pre-packaged **trains-server**, install Docker.
|
||||
|
||||
* See [Supported platforms](https://docs.docker.com/install//#support) in the Docker documentation for instructions
|
||||
|
||||
* For example, to install in [Ubuntu](https://docs.docker.com/install/linux/docker-ce/ubuntu/) / Mint (x86_64/amd64):
|
||||
<details>
|
||||
<summary>Make sure ports 8080/8081/8008 are available for the TRAINS-server services:</summary>
|
||||
|
||||
For example, to see if port `8080` is in use:
|
||||
|
||||
```bash
|
||||
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
|
||||
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
|
||||
. /etc/os-release
|
||||
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $UBUNTU_CODENAME stable"
|
||||
sudo apt-get update
|
||||
sudo apt-get install -y docker-ce
|
||||
$ sudo lsof -Pn -i4 | grep :8080 | grep LISTEN
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
Increase vm.max_map_count for `ElasticSearch` docker
|
||||
|
||||
#### Step 2: Setup the Docker daemon
|
||||
- Linux
|
||||
```bash
|
||||
$ echo "vm.max_map_count=262144" > /tmp/99-trains.conf
|
||||
$ sudo mv /tmp/99-trains.conf /etc/sysctl.d/99-trains.conf
|
||||
$ sudo sysctl -w vm.max_map_count=262144
|
||||
$ sudo service docker restart
|
||||
```
|
||||
|
||||
- macOS
|
||||
```bash
|
||||
$ screen ~/Library/Containers/com.docker.docker/Data/vms/0/tty
|
||||
$ sysctl -w vm.max_map_count=262144
|
||||
```
|
||||
|
||||
To run the ElasticSearch Docker container, setup the Docker daemon by modifying the default
|
||||
values required by Elastic in your Docker configuration file (see [Notes for production use and defaults](https://www.elastic.co/guide/en/elasticsearch/reference/master/docker.html#_notes_for_production_use_and_defaults)). We provide instructions for the most common Docker configuration files.
|
||||
|
||||
Edit or create the Docker configuration file:
|
||||
|
||||
* If your system contains a `/etc/sysconfig/docker` Docker configuration file, edit it.
|
||||
|
||||
Add the options in quotes to the available arguments in the `OPTIONS` section:
|
||||
1. Create local directories for the databases and storage.
|
||||
|
||||
```bash
|
||||
OPTIONS="--default-ulimit nofile=1024:65536 --default-ulimit memlock=-1:-1"
|
||||
$ sudo mkdir -p /opt/trains/data/elastic
|
||||
$ sudo mkdir -p /opt/trains/data/mongo/db
|
||||
$ sudo mkdir -p /opt/trains/data/mongo/configdb
|
||||
$ sudo mkdir -p /opt/trains/data/redis
|
||||
$ sudo mkdir -p /opt/trains/logs
|
||||
$ sudo mkdir -p /opt/trains/data/fileserver
|
||||
$ sudo mkdir -p /opt/trains/config
|
||||
```
|
||||
|
||||
* Otherwise, edit `/etc/docker/daemon.json` (if it exists) or create it (if it does not exist).
|
||||
Set folder permissions
|
||||
|
||||
- Linux
|
||||
```bash
|
||||
$ sudo chown -R 1000:1000 /opt/trains
|
||||
```
|
||||
- macOS
|
||||
```bash
|
||||
$ sudo chown -R $(whoami):staff /opt/trains
|
||||
```
|
||||
|
||||
Add or modify the `defaults-ulimits` section as shown below. Be sure the `defaults-ulimits` section contains the `nofile` and `memlock` sub-sections and values shown.
|
||||
|
||||
**Note**: Your configuration file may contain other sections. If so, confirm that the sections are separated by commas (valid JSON format). For more information about Docker configuration files, see [Daemon configuration file](https://docs.docker.com/engine/reference/commandline/dockerd/#daemon-configuration-file) in the Docker documentation.
|
||||
|
||||
The **trains-server** required defaults values are:
|
||||
|
||||
```json
|
||||
{
|
||||
"default-ulimits": {
|
||||
"nofile": {
|
||||
"name": "nofile",
|
||||
"hard": 65536,
|
||||
"soft": 1024
|
||||
},
|
||||
"memlock":
|
||||
{
|
||||
"name": "memlock",
|
||||
"soft": -1,
|
||||
"hard": -1
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Step 3: Restart the Docker daemon
|
||||
|
||||
After modifying the configuration file, restart the Docker daemon:
|
||||
|
||||
```bash
|
||||
sudo service docker stop
|
||||
sudo service docker start
|
||||
```
|
||||
|
||||
#### Step 4: Set the Maximum Number of Memory Map Areas
|
||||
|
||||
The maximum number of memory map areas a process can use is defined
|
||||
using the `vm.max_map_count` kernel setting.
|
||||
|
||||
Elastic requires that `vm.max_map_count` is at least 262144 (see [Production mode](https://www.elastic.co/guide/en/elasticsearch/reference/master/docker.html#docker-cli-run-prod-mode)).
|
||||
|
||||
* For CentOS 7, Ubuntu 16.04, Mint 18.3, Ubuntu 18.04 and Mint 19 users, we tested the following commands to set
|
||||
`vm.max_map_count`:
|
||||
1. Download the `docker-compose.yml` file, either download [manually](https://raw.githubusercontent.com/allegroai/trains-server/master/docker-compose.yml) or execute:
|
||||
|
||||
```bash
|
||||
sudo echo "vm.max_map_count=262144" > /tmp/99-trains.conf
|
||||
sudo mv /tmp/99-trains.conf /etc/sysctl.d/99-trains.conf
|
||||
sudo sysctl -w vm.max_map_count=262144
|
||||
$ curl https://raw.githubusercontent.com/allegroai/trains-server/master/docker-compose.yml -o docker-compose.yml
|
||||
```
|
||||
|
||||
* For information about setting this parameter on other systems, see the [elastic](https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod-mode) documentation.
|
||||
1. Launch the Docker containers <a name="launch-docker"></a>
|
||||
|
||||
#### Step 5: Choose a Data Directory
|
||||
```bash
|
||||
$ docker-compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
Choose a directory on your system in which all data maintained by the **trains-server** is stored.
|
||||
Create this directory, and set its owner and group to `uid` 1000. The data stored in this directory will include the database, uploaded files and logs.
|
||||
1. Your server is now running on [http://localhost:8080](http://localhost:8080) and the following ports are available:
|
||||
|
||||
For example, if your data directory is `/opt/trains`, then use the following command:
|
||||
* Web server on port `8080`
|
||||
* API server on port `8008`
|
||||
* File server on port `8081`
|
||||
|
||||
```bash
|
||||
sudo mkdir -p /opt/trains/data/elastic && sudo chown -R 1000:1000 /opt/trains
|
||||
```
|
||||
**\* If something went wrong along the way, check our FAQ: [Docker Setup](docs/docker_setup.md#setup-docker), [Ubuntu Support](docs/faq.md#ubuntu), [macOS Support](docs/faq.md#mac-osx)**
|
||||
|
||||
### Configuration
|
||||
## Optional Configuration
|
||||
|
||||
The **trains-server** default configuration can be easily overridden using external configuration files. By default, the server will look for these files in `/opt/trains/config`.
|
||||
|
||||
If the configuration is changed while the server is running, the server should be restarted for changes to take effect.
|
||||
In order to apply the new configuration, you must restart the server (see [Restarting trains-server](#restart-server)).
|
||||
|
||||
<!---
|
||||
#### Fixed users mode (basic users management)
|
||||
### Adding Web Login Authentication
|
||||
|
||||
In this mode, the server authenticates users based on a pre-configured users list.
|
||||
By default anyone can login to the **trains-server** Web-App.
|
||||
You can configure the **trains-server** to allow only a specific set of users to access the system.
|
||||
|
||||
Enable this feature by placing an `apiserver.conf` file under `/opt/trains/config`, containing for example:
|
||||
Enable this feature by placing `apiserver.conf` file under `/opt/trains/config`.
|
||||
|
||||
fixed_users {
|
||||
enabled: true
|
||||
users: [
|
||||
{
|
||||
username: "jane"
|
||||
password: "123456"
|
||||
name: "Jane Doe"
|
||||
},
|
||||
{
|
||||
username: "john"
|
||||
password: "abcdef"
|
||||
name: "John Doe"
|
||||
}
|
||||
]
|
||||
}
|
||||
-->
|
||||
#### Non-responsive experiments watchdog
|
||||
Sample `apiserver.conf` configuration file can be found [here](https://github.com/allegroai/trains-server/blob/master/docs/apiserver.conf)
|
||||
|
||||
This watchdog monitors experiments that were not updated for a given period of time, and marks them as `stopped`. The watchdog is always active.
|
||||
To apply the changes, you must [restart the *trains-server*](#restart-server).
|
||||
|
||||
To change the watchdog's timeouts, place a `services.conf` file under `/opt/trains/config`, containing for example:
|
||||
### Configuring the Non-Responsive Experiments Watchdog
|
||||
|
||||
tasks {
|
||||
non_responsive_tasks_watchdog {
|
||||
# In-progress tasks that haven't been updated for at least 'value' seconds will be stopped by the watchdog
|
||||
threshold_sec: 7200
|
||||
|
||||
# Watchdog will sleep for this number of seconds after each cycle
|
||||
watch_interval_sec: 900
|
||||
The non-responsive experiment watchdog, monitors experiments that were not updated for a given period of time,
|
||||
and marks them as `aborted`. The watchdog is always active with a default of 7200 seconds (2 hours) of inactivity threshold.
|
||||
|
||||
To change the watchdog's timeouts, place a `services.conf` file under `/opt/trains/config`.
|
||||
|
||||
Sample watchdog `services.conf` configuration file can be found [here](https://github.com/allegroai/trains-server/blob/master/docs/services.conf)
|
||||
|
||||
To apply the changes, you must [restart the *trains-server*](#restart-server).
|
||||
|
||||
### Restarting trains-server <a name="restart-server"></a>
|
||||
|
||||
To restart the **trains-server**, you must first stop the containers, and then restart them.
|
||||
```bash
|
||||
$ docker-compose down
|
||||
$ docker-compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
|
||||
## Configuring **TRAINS** client
|
||||
|
||||
Once you have installed the **trains-server**, make sure to configure **TRAINS** [client](https://github.com/allegroai/trains)
|
||||
to use your locally installed server (and not the demo server).
|
||||
|
||||
- Run the `trains-init` command for an interactive setup
|
||||
|
||||
- Or manually edit `~/trains.conf` file, making sure the `api_server` value is configured correctly, for example:
|
||||
|
||||
api {
|
||||
# API server on port 8008
|
||||
api_server: "http://localhost:8008"
|
||||
|
||||
# web_server on port 8080
|
||||
web_server: "http://localhost:8080"
|
||||
|
||||
# file server on port 8081
|
||||
files_server: "http://localhost:8081"
|
||||
}
|
||||
}
|
||||
|
||||
### Launching Docker Containers
|
||||
* Notice that if you setup **trains-server** in a sub-domain configuration, there is no need to specify a port number,
|
||||
it will be inferred from the http/s scheme.
|
||||
|
||||
**Note**:
|
||||
* If your data directory is not `/opt/trains`, please find and replace `/opt/trains` in the following commands with your data directory path
|
||||
|
||||
* Make sure ports `8008`, `8080` and `8081` are not in use before starting the docker containers, as the containers will fail to initialize if these ports are already taken. If the following commands shows no output, the ports are available:
|
||||
```bash
|
||||
sudo netstat -tplna | egrep "8008|8080|8081"
|
||||
```
|
||||
|
||||
To launch the Docker containers, use the following commands:
|
||||
|
||||
```bash
|
||||
sudo docker run -d --restart="always" --name="trains-elastic" -e "ES_JAVA_OPTS=-Xms2g -Xmx2g" -e "bootstrap.memory_lock=true" -e "cluster.name=trains" -e "discovery.zen.minimum_master_nodes=1" -e "node.name=trains" -e "script.inline=true" -e "script.update=true" -e "thread_pool.bulk.queue_size=2000" -e "thread_pool.search.queue_size=10000" -e "xpack.security.enabled=false" -e "xpack.monitoring.enabled=false" -e "cluster.routing.allocation.node_initial_primaries_recoveries=500" -e "node.ingest=true" -e "http.compression_level=7" -e "reindex.remote.whitelist=*.*" -e "script.painless.regex.enabled=true" --network="host" -v /opt/trains/data/elastic:/usr/share/elasticsearch/data docker.elastic.co/elasticsearch/elasticsearch:5.6.16
|
||||
```
|
||||
|
||||
```bash
|
||||
sudo docker run -d --restart="always" --name="trains-mongo" -v /opt/trains/data/mongo/db:/data/db -v /opt/trains/data/mongo/configdb:/data/configdb --network="host" mongo:3.6.5
|
||||
```
|
||||
|
||||
```bash
|
||||
sudo docker run -d --restart="always" --name="trains-fileserver" --network="host" -v /opt/trains/logs:/var/log/trains -v /opt/trains/data/fileserver:/mnt/fileserver allegroai/trains:latest fileserver
|
||||
```
|
||||
|
||||
```bash
|
||||
sudo docker run -d --restart="always" --name="trains-apiserver" --network="host" -v /opt/trains/logs:/var/log/trains -v /opt/trains/config:/opt/trains/config allegroai/trains:latest apiserver
|
||||
```
|
||||
|
||||
```bash
|
||||
sudo docker run -d --restart="always" --name="trains-webserver" --network="host" -v /opt/trains/logs:/var/log/trains allegroai/trains:latest webserver
|
||||
```
|
||||
|
||||
After the **trains-server** Dockers are up, the following are available:
|
||||
|
||||
* API server on port `8008`
|
||||
* Web server on port `8080`
|
||||
* File server on port `8081`
|
||||
|
||||
### Configuring **trains**
|
||||
|
||||
Once you have installed the **trains-server**, make sure to configure **trains** to use your locally installed server (and not the demo server).
|
||||
|
||||
If you have already installed **trains**, run the `trains-init` command for an interactive setup or edit your `trains.conf` file and make sure the `api.host` value is configured as follows:
|
||||
|
||||
api {
|
||||
host: "http://localhost:8008"
|
||||
}
|
||||
|
||||
See [Installing and Configuring TRAINS](https://github.com/allegroai/trains#installing-and-configuring-trains) for more details.
|
||||
See [Installing and Configuring TRAINS](https://github.com/allegroai/trains#configuration) for more details.
|
||||
|
||||
## What next?
|
||||
|
||||
Now that the **trains-server** is installed, and TRAINS is configured to use it,
|
||||
you can [use](https://github.com/allegroai/trains#using-trains) TRAINS in your experiments and view them in the web server,
|
||||
Now that the **trains-server** is installed, and TRAINS is configured to use it,
|
||||
you can [use](https://github.com/allegroai/trains#using-trains) TRAINS in your experiments and view them in the web server,
|
||||
for example http://localhost:8080
|
||||
|
||||
## Upgrade
|
||||
## Upgrading <a name="upgrade"></a>
|
||||
|
||||
We are constantly updating, improving and adding to the **trains-server**.
|
||||
New releases will include new pre-built Docker images.
|
||||
When we release a new version and include a new pre-built Docker image for it, upgrade as follows:
|
||||
|
||||
1. Shut down and remove each of your Docker instances using the following commands:
|
||||
1. Shut down the docker containers
|
||||
```bash
|
||||
$ docker-compose down
|
||||
```
|
||||
|
||||
sudo docker stop <docker-name>
|
||||
sudo docker rm -v <docker-name>
|
||||
1. We highly recommend backing up your data directory before upgrading.
|
||||
|
||||
The Docker names are (see [Launching Docker Containers](#launching-docker-containers)):
|
||||
Assuming your data directory is `/opt/trains`, to archive all data into `~/trains_backup.tgz` execute:
|
||||
|
||||
* `trains-elastic`
|
||||
* `trains-mongo`
|
||||
* `trains-fileserver`
|
||||
* `trains-apiserver`
|
||||
* `trains-webserver`
|
||||
```bash
|
||||
$ sudo tar czvf ~/trains_backup.tgz /opt/trains/data
|
||||
```
|
||||
|
||||
2. Pull the new **trains-server** docker image using the following command:
|
||||
<details>
|
||||
<summary>Restore instructions:</summary>
|
||||
|
||||
sudo docker pull allegroai/trains:latest
|
||||
|
||||
If you wish to pull a different version, replace `latest` with the required version number, for example:
|
||||
To restore this example backup, execute:
|
||||
```bash
|
||||
$ sudo rm -R /opt/trains/data
|
||||
$ sudo tar -xzf ~/trains_backup.tgz -C /opt/trains/data
|
||||
```
|
||||
</details>
|
||||
|
||||
sudo docker pull allegroai/trains:0.10.0
|
||||
|
||||
3. We highly recommend backing up your data directory!. A simple way to do that is using `tar`:
|
||||
1. Download the latest `docker-compose.yml` file, either [manually](https://raw.githubusercontent.com/allegroai/trains-server/master/docker-compose.yml) or execute:
|
||||
|
||||
For example, if your data directory is `/opt/trains`, use the following command:
|
||||
```bash
|
||||
$ curl https://raw.githubusercontent.com/allegroai/trains-server/master/docker-compose.yml -o docker-compose.yml
|
||||
```
|
||||
|
||||
sudo tar czvf ~/trains_backup.tgz /opt/trains/data
|
||||
1. Spin up the docker containers, it will automatically pull the latest trains-server build
|
||||
```bash
|
||||
$ docker-compose -f docker-compose.yml pull
|
||||
$ docker-compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
This back ups all data to an archive in your home directory.
|
||||
**\* If something went wrong along the way, check our FAQ: [Docker Upgrade](docs/docker_setup.md#common-docker-upgrade-errors)**
|
||||
|
||||
To restore this example backup, use the following command:
|
||||
|
||||
sudo rm -R /opt/trains/data
|
||||
sudo tar -xzf ~/trains_backup.tgz -C /opt/trains/data
|
||||
## Community & Support
|
||||
|
||||
4. Launch the newly released Docker image (see [Launching Docker Containers](#launching-docker-containers)).
|
||||
If you have any questions, look to the TRAINS-server [FAQ](https://github.com/allegroai/trains-server/blob/master/docs/faq.md), or
|
||||
tag your questions on [stackoverflow](https://stackoverflow.com/questions/tagged/trains) with '**trains**' tag.
|
||||
|
||||
For feature requests or bug reports, please use [GitHub issues](https://github.com/allegroai/trains-server/issues).
|
||||
|
||||
Additionally, you can always find us at *trains@allegro.ai*
|
||||
|
||||
## License
|
||||
|
||||
[Server Side Public License v1.0](https://github.com/mongodb/mongo/blob/master/LICENSE-Community.txt)
|
||||
|
||||
**trains-server** relies on both [MongoDB](https://github.com/mongodb/mongo) and [ElasticSearch](https://github.com/elastic/elasticsearch).
|
||||
With the recent changes in both MongoDB's and ElasticSearch's OSS license, we feel it is our responsibility as a
|
||||
With the recent changes in both MongoDB's and ElasticSearch's OSS license, we feel it is our responsibility as a
|
||||
member of the community to support the projects we love and cherish.
|
||||
We believe the cause for the license change in both cases is more than just,
|
||||
We believe the cause for the license change in both cases is more than just,
|
||||
and chose [SSPL](https://www.mongodb.com/licensing/server-side-public-license) because it is the more general and flexible of the two licenses.
|
||||
|
||||
This is our way to say - we support you guys!
|
||||
|
||||
87
docker-compose-unified.yml
Normal file
87
docker-compose-unified.yml
Normal file
@@ -0,0 +1,87 @@
|
||||
version: "3.6"
|
||||
services:
|
||||
trainsserver:
|
||||
command:
|
||||
- -c
|
||||
- "echo \"#!/bin/bash\" > /opt/trains/all.sh && echo \"/opt/trains/wrapper.sh webserver&\" >> /opt/trains/all.sh && echo \"/opt/trains/wrapper.sh fileserver&\" >> /opt/trains/all.sh && echo \"/opt/trains/wrapper.sh apiserver\" >> /opt/trains/all.sh && cat /opt/trains/all.sh && chmod +x /opt/trains/all.sh && /opt/trains/all.sh"
|
||||
entrypoint: /bin/bash
|
||||
container_name: trains-server
|
||||
image: allegroai/trains:latest
|
||||
ports:
|
||||
- 8008:8008
|
||||
- 8080:80
|
||||
- 8081:8081
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/logs:/var/log/trains
|
||||
- /opt/trains/data/fileserver:/mnt/fileserver
|
||||
depends_on:
|
||||
- redis
|
||||
- mongo
|
||||
- elasticsearch
|
||||
environment:
|
||||
ELASTIC_SERVICE_HOST: elasticsearch
|
||||
MONGODB_SERVICE_HOST: mongo
|
||||
REDIS_SERVICE_HOST: redis
|
||||
networks:
|
||||
- backend
|
||||
elasticsearch:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-elastic
|
||||
environment:
|
||||
ES_JAVA_OPTS: -Xms2g -Xmx2g
|
||||
bootstrap.memory_lock: "true"
|
||||
cluster.name: trains
|
||||
cluster.routing.allocation.node_initial_primaries_recoveries: "500"
|
||||
discovery.zen.minimum_master_nodes: "1"
|
||||
http.compression_level: "7"
|
||||
node.ingest: "true"
|
||||
node.name: trains
|
||||
reindex.remote.whitelist: '*.*'
|
||||
script.inline: "true"
|
||||
script.painless.regex.enabled: "true"
|
||||
script.update: "true"
|
||||
thread_pool.bulk.queue_size: "2000"
|
||||
thread_pool.search.queue_size: "10000"
|
||||
xpack.monitoring.enabled: "false"
|
||||
xpack.security.enabled: "false"
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
nofile:
|
||||
soft: 65536
|
||||
hard: 65536
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.16
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/data/elastic:/usr/share/elasticsearch/data
|
||||
ports:
|
||||
- "9200:9200"
|
||||
mongo:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-mongo
|
||||
image: mongo:3.6.5
|
||||
restart: unless-stopped
|
||||
command: --setParameter internalQueryExecMaxBlockingSortBytes=196100200
|
||||
volumes:
|
||||
- /opt/trains/data/mongo/db:/data/db
|
||||
- /opt/trains/data/mongo/configdb:/data/configdb
|
||||
ports:
|
||||
- "27017:27017"
|
||||
redis:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-redis
|
||||
image: redis:5.0
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/data/redis:/data
|
||||
ports:
|
||||
- "6379:6379"
|
||||
|
||||
networks:
|
||||
backend:
|
||||
driver: bridge
|
||||
117
docker-compose-win10.yml
Normal file
117
docker-compose-win10.yml
Normal file
@@ -0,0 +1,117 @@
|
||||
version: "3.6"
|
||||
services:
|
||||
|
||||
apiserver:
|
||||
command:
|
||||
- apiserver
|
||||
container_name: trains-apiserver
|
||||
image: allegroai/trains:latest
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- c:/opt/trains/logs:/var/log/trains
|
||||
- c:/opt/trains/config:/opt/trains/config
|
||||
depends_on:
|
||||
- redis
|
||||
- mongo
|
||||
- elasticsearch
|
||||
- fileserver
|
||||
environment:
|
||||
ELASTIC_SERVICE_HOST: elasticsearch
|
||||
MONGODB_SERVICE_HOST: mongo
|
||||
REDIS_SERVICE_HOST: redis
|
||||
ports:
|
||||
- "8008:8008"
|
||||
networks:
|
||||
- backend
|
||||
|
||||
elasticsearch:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-elastic
|
||||
environment:
|
||||
ES_JAVA_OPTS: -Xms2g -Xmx2g
|
||||
bootstrap.memory_lock: "true"
|
||||
cluster.name: trains
|
||||
cluster.routing.allocation.node_initial_primaries_recoveries: "500"
|
||||
discovery.zen.minimum_master_nodes: "1"
|
||||
http.compression_level: "7"
|
||||
node.ingest: "true"
|
||||
node.name: trains
|
||||
reindex.remote.whitelist: '*.*'
|
||||
script.inline: "true"
|
||||
script.painless.regex.enabled: "true"
|
||||
script.update: "true"
|
||||
thread_pool.bulk.queue_size: "2000"
|
||||
thread_pool.search.queue_size: "10000"
|
||||
xpack.monitoring.enabled: "false"
|
||||
xpack.security.enabled: "false"
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
nofile:
|
||||
soft: 65536
|
||||
hard: 65536
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.16
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- c:/opt/trains/data/elastic:/usr/share/elasticsearch/data
|
||||
ports:
|
||||
- "9200:9200"
|
||||
|
||||
fileserver:
|
||||
networks:
|
||||
- backend
|
||||
command:
|
||||
- fileserver
|
||||
container_name: trains-fileserver
|
||||
image: allegroai/trains:latest
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- c:/opt/trains/logs:/var/log/trains
|
||||
- c:/opt/trains/data/fileserver:/mnt/fileserver
|
||||
ports:
|
||||
- "8081:8081"
|
||||
|
||||
mongo:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-mongo
|
||||
image: mongo:3.6.5
|
||||
restart: unless-stopped
|
||||
command: --setParameter internalQueryExecMaxBlockingSortBytes=196100200
|
||||
volumes:
|
||||
- mongodata:/data
|
||||
ports:
|
||||
- "27017:27017"
|
||||
|
||||
redis:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-redis
|
||||
image: redis:5.0
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- c:/opt/trains/data/redis:/data
|
||||
ports:
|
||||
- "6379:6379"
|
||||
|
||||
webserver:
|
||||
command:
|
||||
- webserver
|
||||
container_name: trains-webserver
|
||||
image: allegroai/trains:latest
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- c:/trains/logs:/var/log/trains
|
||||
depends_on:
|
||||
- apiserver
|
||||
ports:
|
||||
- "8080:80"
|
||||
|
||||
networks:
|
||||
backend:
|
||||
driver: bridge
|
||||
|
||||
volumes:
|
||||
mongodata:
|
||||
@@ -1,17 +1,32 @@
|
||||
version: "3.6"
|
||||
services:
|
||||
|
||||
apiserver:
|
||||
command:
|
||||
- apiserver
|
||||
container_name: trains-apiserver
|
||||
image: allegroai/trains:latest
|
||||
network_mode: host
|
||||
restart: always
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- type: bind
|
||||
source: /opt/trains/logs
|
||||
target: /var/log/trains
|
||||
- /opt/trains/logs:/var/log/trains
|
||||
- /opt/trains/config:/opt/trains/config
|
||||
depends_on:
|
||||
- redis
|
||||
- mongo
|
||||
- elasticsearch
|
||||
- fileserver
|
||||
environment:
|
||||
ELASTIC_SERVICE_HOST: elasticsearch
|
||||
MONGODB_SERVICE_HOST: mongo
|
||||
REDIS_SERVICE_HOST: redis
|
||||
ports:
|
||||
- "8008:8008"
|
||||
networks:
|
||||
- backend
|
||||
|
||||
elasticsearch:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-elastic
|
||||
environment:
|
||||
ES_JAVA_OPTS: -Xms2g -Xmx2g
|
||||
@@ -30,47 +45,71 @@ services:
|
||||
thread_pool.search.queue_size: "10000"
|
||||
xpack.monitoring.enabled: "false"
|
||||
xpack.security.enabled: "false"
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
nofile:
|
||||
soft: 65536
|
||||
hard: 65536
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.16
|
||||
network_mode: host
|
||||
restart: always
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- type: bind
|
||||
source: /opt/trains/data/elastic
|
||||
target: /usr/share/elasticsearch/data
|
||||
- /opt/trains/data/elastic:/usr/share/elasticsearch/data
|
||||
ports:
|
||||
- "9200:9200"
|
||||
|
||||
fileserver:
|
||||
networks:
|
||||
- backend
|
||||
command:
|
||||
- fileserver
|
||||
container_name: trains-fileserver
|
||||
image: allegroai/trains:latest
|
||||
network_mode: host
|
||||
restart: always
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- type: bind
|
||||
source: /opt/trains/logs
|
||||
target: /var/log/trains
|
||||
- type: bind
|
||||
source: /opt/trains/data/fileserver
|
||||
target: /mnt/fileserver
|
||||
- /opt/trains/logs:/var/log/trains
|
||||
- /opt/trains/data/fileserver:/mnt/fileserver
|
||||
ports:
|
||||
- "8081:8081"
|
||||
|
||||
mongo:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-mongo
|
||||
image: mongo:3.6.5
|
||||
network_mode: host
|
||||
restart: always
|
||||
restart: unless-stopped
|
||||
command: --setParameter internalQueryExecMaxBlockingSortBytes=196100200
|
||||
volumes:
|
||||
- type: bind
|
||||
source: /opt/trains/data/mongo/db
|
||||
target: /data/db
|
||||
- type: bind
|
||||
source: /opt/trains/data/mongo/configdb
|
||||
target: /data/configdb
|
||||
- /opt/trains/data/mongo/db:/data/db
|
||||
- /opt/trains/data/mongo/configdb:/data/configdb
|
||||
ports:
|
||||
- "27017:27017"
|
||||
|
||||
redis:
|
||||
networks:
|
||||
- backend
|
||||
container_name: trains-redis
|
||||
image: redis:5.0
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- /opt/trains/data/redis:/data
|
||||
ports:
|
||||
- "6379:6379"
|
||||
|
||||
webserver:
|
||||
command:
|
||||
- webserver
|
||||
container_name: trains-webserver
|
||||
image: allegroai/trains:latest
|
||||
network_mode: host
|
||||
restart: always
|
||||
restart: unless-stopped
|
||||
volumes:
|
||||
- type: bind
|
||||
source: /opt/trains/logs
|
||||
target: /var/log/trains
|
||||
- /opt/trains/logs:/var/log/trains
|
||||
depends_on:
|
||||
- apiserver
|
||||
ports:
|
||||
- "8080:80"
|
||||
|
||||
networks:
|
||||
backend:
|
||||
driver: bridge
|
||||
|
||||
19
docs/apiserver.conf
Normal file
19
docs/apiserver.conf
Normal file
@@ -0,0 +1,19 @@
|
||||
auth {
|
||||
# Fixed users login credetials
|
||||
# No other user will be able to login
|
||||
fixed_users {
|
||||
enabled: true
|
||||
users: [
|
||||
{
|
||||
username: "jane"
|
||||
password: "12345678"
|
||||
name: "Jane Doe"
|
||||
},
|
||||
{
|
||||
username: "john"
|
||||
password: "12345678"
|
||||
name: "John Doe"
|
||||
},
|
||||
]
|
||||
}
|
||||
}
|
||||
166
docs/docker_setup.md
Normal file
166
docs/docker_setup.md
Normal file
@@ -0,0 +1,166 @@
|
||||
# TRAINS-server: Using Docker Pre-Built Images
|
||||
|
||||
The pre-built Docker image for the **trains-server** is the quickest way to get started with your own **TRAINS** server.
|
||||
|
||||
You can also build the entire **trains-server** architecture using the code available in the [trains-server](https://github.com/allegroai/trains-server) repository.
|
||||
|
||||
**Note**: We tested this pre-built Docker image with Linux, only. For Windows users, we recommend installing the pre-built image on a Linux virtual machine.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You must be logged in as a user with sudo privileges
|
||||
* Use `bash` for all command-line instructions in this installation
|
||||
|
||||
## Setup Docker
|
||||
|
||||
### Step 1: Install Docker CE
|
||||
|
||||
You must first install Docker. For instructions about installing Docker, see [Supported platforms](https://docs.docker.com/install//#support) in the Docker documentation.
|
||||
|
||||
For example, to [install in Ubuntu](https://docs.docker.com/install/linux/docker-ce/ubuntu/) / Mint (x86_64/amd64):
|
||||
|
||||
```bash
|
||||
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
|
||||
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
|
||||
. /etc/os-release
|
||||
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $UBUNTU_CODENAME stable"
|
||||
sudo apt-get update
|
||||
sudo apt-get install -y docker-ce
|
||||
```
|
||||
|
||||
### Step 2: Set the Maximum Number of Memory Map Areas
|
||||
|
||||
Elastic requires that the `vm.max_map_count` kernel setting, which is the maximum number of memory map areas a process can use, is set to at least 262144.
|
||||
|
||||
For CentOS 7, Ubuntu 16.04, Mint 18.3, Ubuntu 18.04 and Mint 19.x, we tested the following commands to set `vm.max_map_count`:
|
||||
|
||||
```bash
|
||||
echo "vm.max_map_count=262144" > /tmp/99-trains.conf
|
||||
sudo mv /tmp/99-trains.conf /etc/sysctl.d/99-trains.conf
|
||||
sudo sysctl -w vm.max_map_count=262144
|
||||
```
|
||||
|
||||
For information about setting this parameter on other systems, see the [elastic](https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod-mode) documentation.
|
||||
|
||||
### Step 3: Restart the Docker daemon
|
||||
|
||||
Restart the Docker daemon.
|
||||
|
||||
```bash
|
||||
sudo service docker restart
|
||||
```
|
||||
|
||||
### Step 4: Choose a Data Directory
|
||||
|
||||
Choose a directory on your system in which all data maintained by the **trains-server** is stored.
|
||||
Create this directory, and set its owner and group to `uid` 1000. The data stored in this directory includes the database, uploaded files and logs.
|
||||
|
||||
For example, if your data directory is `/opt/trains`, then use the following command:
|
||||
|
||||
```bash
|
||||
sudo mkdir -p /opt/trains/data/elastic
|
||||
sudo mkdir -p /opt/trains/data/mongo/db
|
||||
sudo mkdir -p /opt/trains/data/mongo/configdb
|
||||
sudo mkdir -p /opt/trains/data/redis
|
||||
sudo mkdir -p /opt/trains/logs
|
||||
sudo mkdir -p /opt/trains/data/fileserver
|
||||
sudo mkdir -p /opt/trains/config
|
||||
|
||||
sudo chown -R 1000:1000 /opt/trains
|
||||
```
|
||||
|
||||
## TRAINS-server: Manually Launching Docker Containers <a name="launch"></a>
|
||||
|
||||
You can manually launch the Docker containers using the following commands.
|
||||
|
||||
If your data directory is not `/opt/trains`, then in the five `docker run` commands below, you must replace all occurrences of `/opt/trains` with your data directory path.
|
||||
|
||||
1. Launch the **trains-elastic** Docker container.
|
||||
|
||||
sudo docker run -d --restart="always" --name="trains-elastic" -e "bootstrap.memory_lock=true" --ulimit memlock=-1:-1 -e "ES_JAVA_OPTS=-Xms2g -Xmx2g" -e "bootstrap.memory_lock=true" -e "cluster.name=trains" -e "discovery.zen.minimum_master_nodes=1" -e "node.name=trains" -e "script.inline=true" -e "script.update=true" -e "thread_pool.bulk.queue_size=2000" -e "thread_pool.search.queue_size=10000" -e "xpack.security.enabled=false" -e "xpack.monitoring.enabled=false" -e "cluster.routing.allocation.node_initial_primaries_recoveries=500" -e "node.ingest=true" -e "http.compression_level=7" -e "reindex.remote.whitelist=*.*" -e "script.painless.regex.enabled=true" --network="host" -v /opt/trains/data/elastic:/usr/share/elasticsearch/data docker.elastic.co/elasticsearch/elasticsearch:5.6.16
|
||||
|
||||
1. Launch the **trains-mongo** Docker container.
|
||||
|
||||
sudo docker run -d --restart="always" --name="trains-mongo" -v /opt/trains/data/mongo/db:/data/db -v /opt/trains/data/mongo/configdb:/data/configdb --network="host" mongo:3.6.5
|
||||
|
||||
1. Launch the **trains-redis** Docker container.
|
||||
|
||||
sudo docker run -d --restart="always" --name="trains-redis" -v /opt/trains/data/redis:/data --network="host" redis:5.0
|
||||
|
||||
1. Launch the **trains-fileserver** Docker container.
|
||||
|
||||
sudo docker run -d --restart="always" --name="trains-fileserver" --network="host" -v /opt/trains/logs:/var/log/trains -v /opt/trains/data/fileserver:/mnt/fileserver allegroai/trains:latest fileserver
|
||||
|
||||
1. Launch the **trains-apiserver** Docker container.
|
||||
|
||||
sudo docker run -d --restart="always" --name="trains-apiserver" --network="host" -v /opt/trains/logs:/var/log/trains -v /opt/trains/config:/opt/trains/config allegroai/trains:latest apiserver
|
||||
|
||||
1. Launch the **trains-webserver** Docker container.
|
||||
|
||||
sudo docker run -d --restart="always" --name="trains-webserver" -p 8080:80 allegroai/trains:latest webserver
|
||||
|
||||
1. Your server is now running on [http://localhost:8080](http://localhost:8080) and the following ports are available:
|
||||
|
||||
* API server on port `8008`
|
||||
* Web server on port `8080`
|
||||
* File server on port `8081`
|
||||
|
||||
## Manually Upgrading TRAINS-server Containers <a name="upgrade"></a>
|
||||
|
||||
We are constantly updating, improving and adding to the **trains-server**.
|
||||
New releases will include new pre-built Docker images.
|
||||
When we release a new version and include a new pre-built Docker image for it, upgrade as follows:
|
||||
|
||||
1. Shut down and remove each of your Docker instances using the following commands:
|
||||
|
||||
```bash
|
||||
$ sudo docker stop <docker-name>
|
||||
$ sudo docker rm -v <docker-name>
|
||||
```
|
||||
|
||||
The Docker names are (see [Launching Docker Containers](#launch-docker)):
|
||||
|
||||
* `trains-elastic`
|
||||
* `trains-mongo`
|
||||
* `trains-redis`
|
||||
* `trains-fileserver`
|
||||
* `trains-apiserver`
|
||||
* `trains-webserver`
|
||||
|
||||
2. We highly recommend backing up your data directory!. A simple way to do that is using `tar`:
|
||||
|
||||
For example, if your data directory is `/opt/trains`, use the following command:
|
||||
|
||||
```bash
|
||||
$ sudo tar czvf ~/trains_backup.tgz /opt/trains/data
|
||||
```
|
||||
This backups all data to an archive in your home directory.
|
||||
|
||||
To restore this example backup, use the following command:
|
||||
```bash
|
||||
$ sudo rm -R /opt/trains/data
|
||||
$ sudo tar -xzf ~/trains_backup.tgz -C /opt/trains/data
|
||||
```
|
||||
|
||||
3. Pull the new **trains-server** docker image using the following command:
|
||||
|
||||
```bash
|
||||
$ sudo docker pull allegroai/trains:latest
|
||||
```
|
||||
|
||||
If you wish to pull a different version, replace `latest` with the required version number, for example:
|
||||
```bash
|
||||
$ sudo docker pull allegroai/trains:0.11.0
|
||||
```
|
||||
|
||||
4. Launch the newly released Docker image (see [Launching Docker Containers](#trains-server-manually-launching-docker-containers-)).
|
||||
|
||||
|
||||
#### Common Docker Upgrade Errors
|
||||
|
||||
* In case of a docker error: "... The container name "/trains-???" is already in use by ..."
|
||||
Try removing deprecated images with:
|
||||
```bash
|
||||
$ docker rm -f $(docker ps -a -q)
|
||||
```
|
||||
|
||||
224
docs/faq.md
Normal file
224
docs/faq.md
Normal file
@@ -0,0 +1,224 @@
|
||||
# TRAINS-server FAQ
|
||||
|
||||
* [Deploying trains-server on Kubernetes clusters](#kubernetes)
|
||||
|
||||
* [Creating a Helm Chart for trains-server Kubernetes deployment](#helm)
|
||||
|
||||
* [Running trains-server on Mac OS X](#mac-osx)
|
||||
|
||||
* [Running trains-server on Windows 10](#docker_compose_win10)
|
||||
|
||||
* [Installing trains-server on stand alone Linux Ubuntu systems ](#ubuntu)
|
||||
|
||||
* [Resolving port conflicts preventing fixed users mode authentication and login](#port-conflict)
|
||||
|
||||
* [Configuring trains-server for sub-domains and load balancers](#sub-domains)
|
||||
|
||||
|
||||
### Deploying trains-server on Kubernetes clusters <a name="kubernetes"></a>
|
||||
|
||||
**trains-server** supports Kubernetes. See [trains-server-k8s](https://github.com/allegroai/trains-server-k8s)
|
||||
which contains the YAML files describing the required services and detailed instructions for deploying
|
||||
**trains-server** to a Kubernetes clusters.
|
||||
|
||||
### Creating a Helm Chart for trains-server Kubernetes deployment <a name="helm"></a>
|
||||
|
||||
**trains-server** supports creating a Helm chart for Kubernetes deployment. See [trains-server-helm](https://github.com/allegroai/trains-server-helm)
|
||||
which you can use to create a Helm chart for **trains-server** and contains detailed instructions for deploying
|
||||
**trains-server** to a Kubernetes clusters using Helm.
|
||||
|
||||
### Running trains-server on Mac OS X <a name="mac-osx"></a>
|
||||
|
||||
To install and configure **trains-server** on Mac OS X, follow the steps below.
|
||||
|
||||
1. Install [docker for OS X](https://docs.docker.com/docker-for-mac/install/).
|
||||
|
||||
1. Configure [Docker](https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod-mode).
|
||||
|
||||
$ screen ~/Library/Containers/com.docker.docker/Data/vms/0/tty
|
||||
$ sysctl -w vm.max_map_count=262144
|
||||
|
||||
1. Create local directories for the databases and storage.
|
||||
|
||||
$ sudo mkdir -p /opt/trains/data/elastic
|
||||
$ sudo mkdir -p /opt/trains/data/mongo/db
|
||||
$ sudo mkdir -p /opt/trains/data/mongo/configdb
|
||||
$ sudo mkdir -p /opt/trains/data/redis
|
||||
$ sudo mkdir -p /opt/trains/logs
|
||||
$ sudo mkdir -p /opt/trains/config
|
||||
$ sudo mkdir -p /opt/trains/data/fileserver
|
||||
$ sudo chown -R $(whoami):staff /opt/trains
|
||||
|
||||
1. Open the Docker app, select **Preferences**, and then on the **File Sharing** tab, add `/opt/trains`.
|
||||
|
||||
1. Clone the [trains-server](https://github.com/allegroai/trains-server) repository and change directories to the new **trains-server** directory.
|
||||
|
||||
$ git clone https://github.com/allegroai/trains-server.git
|
||||
$ cd trains-server
|
||||
|
||||
1. Run `docker-compose` with the unified docker image.
|
||||
|
||||
$ docker-compose -f docker-compose-unified.yml up
|
||||
|
||||
Your server is now running on [http://localhost:8080](http://localhost:8080)
|
||||
|
||||
### Running trains-server on Windows 10 <a name="docker_compose_win10"></a>
|
||||
|
||||
You can run **trains-server** on Windows 10 using Docker Desktop for Windows (see the Docker [System Requirements](https://docs.docker.com/docker-for-windows/install/#system-requirements)).
|
||||
|
||||
To run **trains-server** on Windows 10, follow the steps below.
|
||||
|
||||
1. Install the Docker Desktop for Windows application by either:
|
||||
|
||||
* Following the [Install Docker Desktop on Windows](https://docs.docker.com/docker-for-windows/install/) instructions.
|
||||
* Running the Docker installation [wizard](https://hub.docker.com/?overlay=onboarding).
|
||||
|
||||
1. Increase the memory allocation in Docker Desktop to `4GB`.
|
||||
|
||||
1. In your Windows notification area (system tray), right click the Docker icon.
|
||||
|
||||
1. Click *Settings*, *Advanced*, and then set the memory to at least `4096`.
|
||||
|
||||
1. Click *Apply*.
|
||||
|
||||
1. Create local directories for data and logs. Open PowerShell and execute the following commands:
|
||||
|
||||
mkdir c:\opt\trains\logs
|
||||
mkdir c:\opt\trains\config
|
||||
mkdir c:\opt\trains\data
|
||||
mkdir c:\opt\trains\data\elastic
|
||||
mkdir c:\opt\trains\data\redis
|
||||
mkdir c:\opt\trains\data\fileserver
|
||||
|
||||
1. Save the **trains-server** docker-compose YAML file [docker-compose-win10.yml](https://raw.githubusercontent.com/allegroai/trains-server/master/docker-compose-win10.yml) as `c:\opt\trains\docker-compose.yml`.
|
||||
|
||||
1. Run `docker-compose`. In PowerShell, execute the following commands:
|
||||
|
||||
cd c:\opt\trains\
|
||||
docker-compose up
|
||||
|
||||
Your server is now running on [http://localhost:8080](http://localhost:8080)
|
||||
|
||||
### Installing trains-server on stand alone Linux Ubuntu systems <a name="ubuntu"></a>
|
||||
|
||||
To install **trains-server** on a stand alone Linux Ubuntu, follow the steps belows.
|
||||
|
||||
1. Install [docker for Ubuntu](https://docs.docker.com/install/linux/docker-ce/ubuntu/).
|
||||
|
||||
1. Install `docker-compose` using the following commands (for more detailed information, see the [Install Docker Compose](https://docs.docker.com/compose/install/) in the Docker documentation):
|
||||
|
||||
sudo curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
|
||||
sudo chmod +x /usr/local/bin/docker-compose
|
||||
|
||||
1. Remove the previous installation of **trains-server**.
|
||||
|
||||
**WARNING**: This clears all existing **TRAINS** databases.
|
||||
|
||||
$ sudo rm -R /opt/trains/
|
||||
|
||||
1. Create local directories for the databases and storage.
|
||||
|
||||
$ sudo mkdir -p /opt/trains/data/elastic
|
||||
$ sudo mkdir -p /opt/trains/data/mongo/db
|
||||
$ sudo mkdir -p /opt/trains/data/mongo/configdb
|
||||
$ sudo mkdir -p /opt/trains/logs
|
||||
$ sudo mkdir -p /opt/trains/config
|
||||
$ sudo mkdir -p /opt/trains/data/fileserver
|
||||
$ sudo chown -R 1000:1000 /opt/trains
|
||||
|
||||
1. Clone the [trains-server](https://github.com/allegroai/trains-server) repository and change directories to the new **trains-server** directory.
|
||||
|
||||
$ git clone https://github.com/allegroai/trains-server.git
|
||||
$ cd trains-server
|
||||
|
||||
1. Run `docker-compose`
|
||||
|
||||
$ /usr/local/bin/docker-compose -f docker-compose.yml up
|
||||
|
||||
Your server is now running on [http://localhost:8080](http://localhost:8080)
|
||||
|
||||
### Resolving port conflicts preventing fixed users mode authentication and login <a name="port-conflict"></a>
|
||||
|
||||
A port conflict may occur between the **trains-server** MongoDB and Elastic instances and other
|
||||
instances running on your system. **trains-server** uses the following default ports which may be in conflict with other instances:
|
||||
|
||||
* MongoDB port `27017`
|
||||
* Elastic port `9200`
|
||||
|
||||
You can check for port conflicts in the logs in `/opt/trains/log`.
|
||||
|
||||
If a port conflict occurs, first change the port in your **trains-server** `/opt/trains/server/config/default/hosts.conf` file to the new port and then
|
||||
run the `docker run` command with the `port` option specifying the new port to restart the **trains-server** instance.
|
||||
|
||||
For example, to resolve a MongoDB port conflict change port `27017` to `27018`:
|
||||
|
||||
1. Modify `/opt/trains/server/config/default/hosts.conf` changing the ports in the `mongo` section:
|
||||
|
||||
elastic {
|
||||
events {
|
||||
hosts: [{host: "127.0.0.1", port: 9200}]
|
||||
args {
|
||||
timeout: 60
|
||||
dead_timeout: 10
|
||||
max_retries: 5
|
||||
retry_on_timeout: true
|
||||
}
|
||||
index_version: "1"
|
||||
}
|
||||
}
|
||||
|
||||
mongo {
|
||||
backend {
|
||||
host: "mongodb://127.0.0.1:27018/backend"
|
||||
}
|
||||
auth {
|
||||
host: "mongodb://127.0.0.1:27018/auth"
|
||||
}
|
||||
}
|
||||
|
||||
2. Start the **trains-server** MongoDB container using `--port 27018`.
|
||||
|
||||
sudo docker run -d --restart="always" --name="trains-mongo" -v /opt/trains/data/mongo/db:/data/db -v /opt/trains/data/mongo/configdb:/data/configdb --network="host" mongo:3.6.5 mongod --port 27018
|
||||
|
||||
In a future version of **trains-server**, to start the API server, environment variables will be available to use instead of modifying the configuration file (instead of Step 1 above).
|
||||
The environment variables will be available to set different ports for both MongoDB and Elastic instances:
|
||||
|
||||
* `MONGODB_SERVICE_PORT` (e.g., `MONGODB_SERVICE_PORT=27018`)
|
||||
* `ELASTIC_SERVICE_POST` (e.g., `ELASTIC_SERVICE_POST=9201`)
|
||||
|
||||
### Configuring trains-server for sub-domains and load balancers <a name="sub-domains"></a>
|
||||
|
||||
You can configure **trains-server** for sub-domains and a load balancer.
|
||||
|
||||
For example, if your domain is `trains.mydomain.com` and your sub-domains are `app` and `api`, then do the following:
|
||||
|
||||
1. If you are not using the current **trains-server** version, [upgrade](https://github.com/allegroai/trains-server#upgrade) **trains-server**.
|
||||
|
||||
1. Add the following to `/opt/trains/config/apiserver.conf`:
|
||||
|
||||
auth {
|
||||
cookies {
|
||||
httponly: true
|
||||
secure: true
|
||||
domain: ".trains.mydomain.com"
|
||||
max_age: 99999999999
|
||||
}
|
||||
}
|
||||
|
||||
1. Use the following load balancer configuration:
|
||||
|
||||
* Listeners:
|
||||
* Optional: HTTP listener, that redirects all traffic to HTTPS.
|
||||
* HTTPS listener for `app.` forwarded to `AppTargetGroup`
|
||||
* HTTPS listener for `api.` forwarded to `ApiTargetGroup`
|
||||
* HTTPS listener for `files.` forwarded to `FilesTargetGroup`
|
||||
* Target groups:
|
||||
* `AppTargetGroup`: HTTP based target group, port `8080`
|
||||
* `ApiTargetGroup`: HTTP based target group, port `8008`
|
||||
* `FilesTargetGroup`: HTTP based target group, port `8081`
|
||||
* Security and routing:
|
||||
* Load balancer: make sure the load balancers are able to receive traffic from the relevant IP addresses (Security groups and Subnets definitions).
|
||||
* Instances: make sure the load balancers are able to access the instances, using the relevant ports (Security groups definitions).
|
||||
|
||||
1. Run the Docker containers with our updated `docker run` commands (see [Launching Docker Containers](#https://github.com/allegroai/trains-server#launching-docker-containers)).
|
||||
|
||||
@@ -21,10 +21,123 @@ The minimum recommended instance type is **t3a.large**
|
||||
|
||||
In order to upgrade **trains-server** on an existing EC2 instance based on one of these AMIs, SSH into the instance and follow the [upgrade instructions](../README.md#upgrade) for **trains-server**.
|
||||
|
||||
### Upgrading AMI's to v0.12
|
||||
**Including the automatically updated AMI**
|
||||
|
||||
Version 0.12 introduced an additional REDIS docker to the trains-server setup.
|
||||
|
||||
AMI upgrading instructions:
|
||||
|
||||
1. SSH to the EC2 machine running one of the `Latest Version AMI's`
|
||||
2. Execute the following bash commands
|
||||
```bash
|
||||
sudo bash
|
||||
echo "" >> /usr/bin/start_or_update_server.sh
|
||||
echo "sudo mkdir -p \${datadir}/redis" >> /usr/bin/start_or_update_server.sh
|
||||
echo "sudo docker stop trains-redis || true && sudo docker rm -v trains-redis || true" >> /usr/bin/start_or_update_server.sh
|
||||
echo "echo never | sudo tee -a /sys/kernel/mm/transparent_hugepage/enabled" >> /usr/bin/start_or_update_server.sh
|
||||
echo "sudo sysctl vm.overcommit_memory=1" >> /usr/bin/start_or_update_server.sh
|
||||
echo "sudo docker run -d --restart=always --name=trains-redis -v \${datadir}/redis:/data --network=host redis:5 redis-server" >> /usr/bin/start_or_update_server.sh
|
||||
```
|
||||
3. Reboot the EC2 machine
|
||||
|
||||
|
||||
## Released versions
|
||||
|
||||
The following sections provide a list containing AMI Image ID per region for each released **trains-server** version.
|
||||
|
||||
### Latest Version AMI <a name="autoupdate"></a>
|
||||
**For easier upgrades: The following AMI automatically update to the latest release every reboot**
|
||||
|
||||
* **eu-north-1** : ami-055909c1b9471451d
|
||||
* **ap-south-1** : ami-0476123cc77226faf
|
||||
* **eu-west-3** : ami-01df7d35ab63cca70
|
||||
* **eu-west-2** : ami-00e8004c11fd0228e
|
||||
* **eu-west-1** : ami-04293fbba6d3acad1
|
||||
* **ap-northeast-2** : ami-004331f9c5eb13e94
|
||||
* **ap-northeast-1** : ami-08cc80e2049b30e61
|
||||
* **sa-east-1** : ami-06d814a0b6ffa3153
|
||||
* **ca-central-1** : ami-069210ff757e9c1b7
|
||||
* **ap-southeast-1** : ami-0d12cc70d6e9c0f39
|
||||
* **ap-southeast-2** : ami-0b4615aa76c055267
|
||||
* **eu-central-1** : ami-06537f431e52e4763
|
||||
* **us-east-2** : ami-0c3cfbcb8e72ecfc5
|
||||
* **us-west-1** : ami-0d83de031b83b6880
|
||||
* **us-west-2** : ami-06968633c4f7187c4
|
||||
* **us-east-1** : ami-07ff2f5f7ef99e8f6
|
||||
|
||||
### v0.12.1
|
||||
* **eu-north-1** : ami-003118a8103286d84
|
||||
* **ap-south-1** : ami-02dfe86baa48e096f
|
||||
* **eu-west-3** : ami-0cc1f01267d2a780d
|
||||
* **eu-west-2** : ami-0e4c8332e5ce09585
|
||||
* **eu-west-1** : ami-03459a2f0b0a3b1ab
|
||||
* **ap-northeast-2** : ami-08f6c2aed3a53f24c
|
||||
* **ap-northeast-1** : ami-0b798eab95a7c5435
|
||||
* **sa-east-1** : ami-0d3ee166c09f0d1b2
|
||||
* **ca-central-1** : ami-00a758c56bd63acd5
|
||||
* **ap-southeast-1** : ami-0be64d4988cd03fbb
|
||||
* **ap-southeast-2** : ami-02087310d43a63f31
|
||||
* **eu-central-1** : ami-097bbefeac0c74225
|
||||
* **us-east-2** : ami-07eda256712b90f4d
|
||||
* **us-west-1** : ami-02ef2b55cbd01c7df
|
||||
* **us-west-2** : ami-037c6176ef4735360
|
||||
* **us-east-1** : ami-08715c20c0e3f1c15
|
||||
|
||||
### v0.12.0
|
||||
* **eu-north-1** : ami-03ff8ab48cd43e77e
|
||||
* **ap-south-1** : ami-079c1a41ff836487c
|
||||
* **eu-west-3** : ami-0121ef0398ae87ab0
|
||||
* **eu-west-2** : ami-09f0f97654d8c79de
|
||||
* **eu-west-1** : ami-0b7ba303f757bfcd9
|
||||
* **ap-northeast-2** : ami-053f416517b5f40a6
|
||||
* **ap-northeast-1** : ami-056dff06c698c2d9d
|
||||
* **sa-east-1** : ami-017ab655119258639
|
||||
* **ca-central-1** : ami-03bf5fa1d86ac97f6
|
||||
* **ap-southeast-1** : ami-0e667958002b0360c
|
||||
* **ap-southeast-2** : ami-091f1b69cb43b1933
|
||||
* **eu-central-1** : ami-068ec2f0e98c26541
|
||||
* **us-east-2** : ami-0524bbdc1b64ff83f
|
||||
* **us-west-1** : ami-0b4facd7534e393c9
|
||||
* **us-west-2** : ami-0018d5a7e58966848
|
||||
* **us-east-1** : ami-08f24178fc14a84d2
|
||||
|
||||
### v0.11.0
|
||||
* **eu-north-1** : ami-0cbe338f058018c97
|
||||
* **ap-south-1** : ami-06d72ff894f7a5e5d
|
||||
* **eu-west-3** : ami-00f2a45d67df2d2f3
|
||||
* **eu-west-2** : ami-0627ae688f4533237
|
||||
* **eu-west-1** : ami-00bf924ccb0354418
|
||||
* **ap-northeast-2** : ami-0800edf1d1dec1da8
|
||||
* **ap-northeast-1** : ami-07b2ed9709cdc4b15
|
||||
* **sa-east-1** : ami-0012c1648618b812c
|
||||
* **ca-central-1** : ami-02870b965d002fc8a
|
||||
* **ap-southeast-1** : ami-068ec23abf2473192
|
||||
* **ap-southeast-2** : ami-06664624728b5e01a
|
||||
* **eu-central-1** : ami-05f2a9304f237a6f0
|
||||
* **us-east-2** : ami-0ec242e6dca2b72b9
|
||||
* **us-west-1** : ami-050b6577acf246ceb
|
||||
* **us-west-2** : ami-0e384b6f78bf96ebe
|
||||
* **us-east-1** : ami-0a7b46f907d5d9c4a
|
||||
|
||||
### v0.10.1
|
||||
* **eu-north-1** : ami-09937ec4d18350c32
|
||||
* **ap-south-1** : ami-089d6ba7541ec4c7f
|
||||
* **eu-west-3** : ami-0accb1a94bdd5c5c1
|
||||
* **eu-west-2** : ami-0dd2c97bc678b8570
|
||||
* **eu-west-1** : ami-07a38865cbe7ca3cb
|
||||
* **ap-northeast-2** : ami-09aa0b7fe1cf3dd55
|
||||
* **ap-northeast-1** : ami-0905e7d1543e5ed36
|
||||
* **sa-east-1** : ami-08c0627daa67d7372
|
||||
* **ca-central-1** : ami-034add081712ff648
|
||||
* **ap-southeast-1** : ami-0c6caee3689b6e066
|
||||
* **ap-southeast-2** : ami-04994afd8dae5b417
|
||||
* **eu-central-1** : ami-06b10f8c30e1434f1
|
||||
* **us-east-2** : ami-0d3abe7a1fec535cc
|
||||
* **us-west-1** : ami-02bb610b70c55018b
|
||||
* **us-west-2** : ami-0d1cb8ba7de246ff0
|
||||
* **us-east-1** : ami-049ccba6abdb40cba
|
||||
|
||||
### v0.10.0
|
||||
* **eu-north-1** : ami-05ba33c763877e54e
|
||||
* **ap-south-1** : ami-0529eec569161cae5
|
||||
|
||||
9
docs/services.conf
Normal file
9
docs/services.conf
Normal file
@@ -0,0 +1,9 @@
|
||||
tasks {
|
||||
non_responsive_tasks_watchdog {
|
||||
# In-progress tasks that haven't been updated for at least 'value' seconds will be stopped by the watchdog
|
||||
threshold_sec: 7200
|
||||
|
||||
# Watchdog will sleep for this number of seconds after each cycle
|
||||
watch_interval_sec: 900
|
||||
}
|
||||
}
|
||||
@@ -1,7 +1,7 @@
|
||||
Server Side Public License
|
||||
VERSION 1, OCTOBER 16, 2018
|
||||
|
||||
Copyright © 2018 MongoDB, Inc.
|
||||
Copyright © 2019 allegro.ai, Inc.
|
||||
|
||||
Everyone is permitted to copy and distribute verbatim copies of this
|
||||
license document, but changing it is not allowed.
|
||||
|
||||
8
fileserver/config/default/fileserver.conf
Normal file
8
fileserver/config/default/fileserver.conf
Normal file
@@ -0,0 +1,8 @@
|
||||
download {
|
||||
# Add response headers requesting no caching for served files
|
||||
disable_browser_caching: false
|
||||
}
|
||||
|
||||
cors {
|
||||
origins: "*"
|
||||
}
|
||||
@@ -1,16 +1,18 @@
|
||||
""" A Simple file server for uploading and downloading files """
|
||||
import json
|
||||
import logging.config
|
||||
import os
|
||||
from argparse import ArgumentParser
|
||||
from pathlib import Path
|
||||
|
||||
from flask import Flask, request, send_from_directory, safe_join
|
||||
from pyhocon import ConfigFactory
|
||||
from flask_compress import Compress
|
||||
from flask_cors import CORS
|
||||
|
||||
logging.config.dictConfig(ConfigFactory.parse_file("logging.conf"))
|
||||
from config import config
|
||||
|
||||
app = Flask(__name__)
|
||||
CORS(app, **config.get("fileserver.cors"))
|
||||
Compress(app)
|
||||
|
||||
|
||||
@app.route("/", methods=["POST"])
|
||||
@@ -29,7 +31,15 @@ def upload():
|
||||
|
||||
@app.route("/<path:path>", methods=["GET"])
|
||||
def download(path):
|
||||
return send_from_directory(app.config["UPLOAD_FOLDER"], path)
|
||||
response = send_from_directory(app.config["UPLOAD_FOLDER"], path)
|
||||
if config.get("fileserver.download.disable_browser_caching", False):
|
||||
headers = response.headers
|
||||
headers["Pragma-directive"] = "no-cache"
|
||||
headers["Cache-directive"] = "no-cache"
|
||||
headers["Cache-control"] = "no-cache"
|
||||
headers["Pragma"] = "no-cache"
|
||||
headers["Expires"] = "0"
|
||||
return response
|
||||
|
||||
|
||||
def main():
|
||||
|
||||
@@ -1,2 +1,4 @@
|
||||
Flask
|
||||
Flask-Cors>=3.0.5
|
||||
Flask-Compress>=1.4.0
|
||||
pyhocon>=0.3.35
|
||||
18
migration/mongodb/0.12.1.py
Normal file
18
migration/mongodb/0.12.1.py
Normal file
@@ -0,0 +1,18 @@
|
||||
from pymongo.database import Database, Collection
|
||||
|
||||
from database.utils import partition_tags
|
||||
|
||||
|
||||
def migrate_backend(db: Database):
|
||||
for name in ("project", "task", "model"):
|
||||
collection: Collection = db[name]
|
||||
for doc in collection.find(projection=["tags", "system_tags"]):
|
||||
tags = doc.get("tags")
|
||||
if tags is not None:
|
||||
user_tags, system_tags = partition_tags(
|
||||
name, tags, doc.get("system_tags", [])
|
||||
)
|
||||
collection.update_one(
|
||||
{"_id": doc["_id"]},
|
||||
{"$set": {"system_tags": system_tags, "tags": user_tags}}
|
||||
)
|
||||
@@ -1,7 +1,7 @@
|
||||
Server Side Public License
|
||||
VERSION 1, OCTOBER 16, 2018
|
||||
|
||||
Copyright © 2018 MongoDB, Inc.
|
||||
Copyright © 2019 allegro.ai, Inc.
|
||||
|
||||
Everyone is permitted to copy and distribute verbatim copies of this
|
||||
license document, but changing it is not allowed.
|
||||
|
||||
@@ -48,7 +48,6 @@ _error_codes = {
|
||||
129: ('task_publish_in_progress', 'Task publish in progress'),
|
||||
130: ('task_not_found', 'task not found'),
|
||||
|
||||
|
||||
# Models
|
||||
200: ('model_error', 'general task error'),
|
||||
201: ('invalid_model_id', 'invalid model id'),
|
||||
@@ -70,9 +69,26 @@ _error_codes = {
|
||||
403: ('project_not_found', 'project not found'),
|
||||
405: ('project_has_models', 'project has associated models'),
|
||||
|
||||
# Queues
|
||||
701: ('invalid_queue_id', 'invalid queue id'),
|
||||
702: ('queue_not_empty', 'queue is not empty'),
|
||||
703: ('invalid_queue_or_task_not_queued', 'invalid queue id or task not in queue'),
|
||||
704: ('removed_during_reposition', 'task was removed by another party during reposition'),
|
||||
705: ('failed_adding_during_reposition', 'failed adding task back to queue during reposition'),
|
||||
706: ('task_already_queued', 'failed adding task to queue since task is already queued'),
|
||||
707: ('no_default_queue', 'no queue is tagged as the default queue for this company'),
|
||||
708: ('multiple_default_queues', 'more than one queue is tagged as the default queue for this company'),
|
||||
|
||||
# Database
|
||||
800: ('data_validation_error', 'data validation error'),
|
||||
801: ('expected_unique_data', 'value combination already exists'),
|
||||
|
||||
# Workers
|
||||
1001: ('invalid_worker_id', 'invalid worker id'),
|
||||
1002: ('worker_registration_failed', 'worker registration failed'),
|
||||
1003: ('worker_registered', 'worker is already registered'),
|
||||
1004: ('worker_not_registered', 'worker is not registered'),
|
||||
1005: ('worker_stats_not_found', 'worker stats not found'),
|
||||
},
|
||||
|
||||
(401, 'unauthorized'): {
|
||||
@@ -83,7 +99,8 @@ _error_codes = {
|
||||
21: ('bad_credentials', 'unauthorized (malformed credentials)'),
|
||||
22: ('invalid_credentials', 'unauthorized (invalid credentials)'),
|
||||
30: ('invalid_token', 'invalid token'),
|
||||
31: ('blocked_token', 'token is blocked')
|
||||
31: ('blocked_token', 'token is blocked'),
|
||||
40: ('invalid_fixed_user', 'fixed user ID was not found')
|
||||
},
|
||||
|
||||
(403, 'forbidden'): {
|
||||
|
||||
@@ -4,11 +4,10 @@ from enum import Enum
|
||||
from typing import Union, Type, Iterable
|
||||
|
||||
import jsonmodels.errors
|
||||
import jsonmodels.validators
|
||||
import six
|
||||
import validators
|
||||
from jsonmodels import fields
|
||||
from jsonmodels.fields import _LazyType
|
||||
from jsonmodels.fields import _LazyType, NotSet
|
||||
from jsonmodels.models import Base as ModelBase
|
||||
from jsonmodels.validators import Enum as EnumValidator
|
||||
from luqum.parser import parser, ParseError
|
||||
@@ -25,6 +24,12 @@ def make_default(field_cls, default_value):
|
||||
|
||||
|
||||
class ListField(fields.ListField):
|
||||
def __init__(self, items_types=None, *args, default=NotSet, **kwargs):
|
||||
if default is not NotSet and callable(default):
|
||||
default = default()
|
||||
|
||||
super(ListField, self).__init__(items_types, *args, default=default, **kwargs)
|
||||
|
||||
def _cast_value(self, value):
|
||||
try:
|
||||
return super(ListField, self)._cast_value(value)
|
||||
@@ -144,6 +149,46 @@ class EnumField(fields.StringField):
|
||||
return super().parse_value(value)
|
||||
|
||||
|
||||
class ActualEnumField(fields.StringField):
|
||||
@property
|
||||
def types(self):
|
||||
return (self.__enum,)
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
enum_class: Type[Enum],
|
||||
*args,
|
||||
validators=None,
|
||||
required=False,
|
||||
default=None,
|
||||
**kwargs
|
||||
):
|
||||
self.__enum = enum_class
|
||||
# noinspection PyTypeChecker
|
||||
choices = list(enum_class)
|
||||
validator_cls = EnumValidator if required else NullableEnumValidator
|
||||
validators = [*(validators or []), validator_cls(*choices)]
|
||||
super().__init__(
|
||||
default=default and self.parse_value(default),
|
||||
*args,
|
||||
required=required,
|
||||
validators=validators,
|
||||
**kwargs
|
||||
)
|
||||
|
||||
def parse_value(self, value):
|
||||
if value is None and not self.required:
|
||||
return self.get_default_value()
|
||||
try:
|
||||
# noinspection PyArgumentList
|
||||
return self.__enum(value)
|
||||
except ValueError:
|
||||
return value
|
||||
|
||||
def to_struct(self, value):
|
||||
return super().to_struct(value.value)
|
||||
|
||||
|
||||
class EmailField(fields.StringField):
|
||||
def validate(self, value):
|
||||
super().validate(value)
|
||||
@@ -160,3 +205,12 @@ class DomainField(fields.StringField):
|
||||
return
|
||||
if validators.domain(value) is not True:
|
||||
raise errors.bad_request.InvalidDomainName()
|
||||
|
||||
|
||||
class StringEnum(Enum):
|
||||
def __str__(self):
|
||||
return self.value
|
||||
|
||||
# noinspection PyMethodParameters
|
||||
def _generate_next_value_(name, start, count, last_values):
|
||||
return name
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
from jsonmodels.fields import IntField, StringField, BoolField, EmbeddedField
|
||||
from jsonmodels.fields import IntField, StringField, BoolField, EmbeddedField, DateTimeField
|
||||
from jsonmodels.models import Base
|
||||
from jsonmodels.validators import Max, Enum
|
||||
|
||||
@@ -79,6 +79,7 @@ class Credentials(Base):
|
||||
|
||||
class CredentialsResponse(Credentials):
|
||||
secret_key = StringField()
|
||||
last_used = DateTimeField(default=None)
|
||||
|
||||
|
||||
class CreateCredentialsResponse(Base):
|
||||
|
||||
20
server/apimodels/events.py
Normal file
20
server/apimodels/events.py
Normal file
@@ -0,0 +1,20 @@
|
||||
from typing import Sequence
|
||||
|
||||
from jsonmodels.fields import StringField
|
||||
from jsonmodels.models import Base
|
||||
|
||||
from apimodels import ListField, IntField, ActualEnumField
|
||||
from bll.event.scalar_key import ScalarKeyEnum
|
||||
|
||||
|
||||
class HistogramRequestBase(Base):
|
||||
samples: int = IntField(default=10000)
|
||||
key: ScalarKeyEnum = ActualEnumField(ScalarKeyEnum, default=ScalarKeyEnum.iter)
|
||||
|
||||
|
||||
class ScalarMetricsIterHistogramRequest(HistogramRequestBase):
|
||||
task: str = StringField(required=True)
|
||||
|
||||
|
||||
class MultiTaskScalarMetricsIterHistogramRequest(HistogramRequestBase):
|
||||
tasks: Sequence[str] = ListField(items_types=str)
|
||||
@@ -11,6 +11,7 @@ class CreateModelRequest(models.Base):
|
||||
uri = fields.StringField(required=True)
|
||||
labels = DictField(value_types=string_types+(int,), required=True)
|
||||
tags = ListField(items_types=string_types)
|
||||
system_tags = ListField(items_types=string_types)
|
||||
comment = fields.StringField()
|
||||
public = fields.BoolField(default=False)
|
||||
project = fields.StringField()
|
||||
|
||||
16
server/apimodels/projects.py
Normal file
16
server/apimodels/projects.py
Normal file
@@ -0,0 +1,16 @@
|
||||
from jsonmodels import models, fields
|
||||
|
||||
|
||||
class ProjectReq(models.Base):
|
||||
project = fields.StringField()
|
||||
|
||||
|
||||
class GetHyperParamReq(ProjectReq):
|
||||
page = fields.IntField(default=0)
|
||||
page_size = fields.IntField(default=500)
|
||||
|
||||
|
||||
class GetHyperParamResp(models.Base):
|
||||
parameters = fields.ListField(str)
|
||||
remaining = fields.IntField()
|
||||
total = fields.IntField()
|
||||
60
server/apimodels/queues.py
Normal file
60
server/apimodels/queues.py
Normal file
@@ -0,0 +1,60 @@
|
||||
from jsonmodels import validators
|
||||
from jsonmodels.fields import StringField, IntField, BoolField, FloatField
|
||||
from jsonmodels.models import Base
|
||||
|
||||
from apimodels import ListField
|
||||
|
||||
|
||||
class GetDefaultResp(Base):
|
||||
id = StringField(required=True)
|
||||
name = StringField(required=True)
|
||||
|
||||
|
||||
class CreateRequest(Base):
|
||||
name = StringField(required=True)
|
||||
tags = ListField(items_types=[str])
|
||||
system_tags = ListField(items_types=[str])
|
||||
|
||||
|
||||
class QueueRequest(Base):
|
||||
queue = StringField(required=True)
|
||||
|
||||
|
||||
class DeleteRequest(QueueRequest):
|
||||
force = BoolField(default=False)
|
||||
|
||||
|
||||
class UpdateRequest(QueueRequest):
|
||||
name = StringField()
|
||||
tags = ListField(items_types=[str])
|
||||
system_tags = ListField(items_types=[str])
|
||||
|
||||
|
||||
class TaskRequest(QueueRequest):
|
||||
task = StringField(required=True)
|
||||
|
||||
|
||||
class MoveTaskRequest(TaskRequest):
|
||||
count = IntField(default=1)
|
||||
|
||||
|
||||
class MoveTaskResponse(Base):
|
||||
position = IntField()
|
||||
|
||||
|
||||
class GetMetricsRequest(Base):
|
||||
queue_ids = ListField([str])
|
||||
from_date = FloatField(required=True, validators=validators.Min(0))
|
||||
to_date = FloatField(required=True, validators=validators.Min(0))
|
||||
interval = IntField(required=True, validators=validators.Min(1))
|
||||
|
||||
|
||||
class QueueMetrics(Base):
|
||||
queue = StringField()
|
||||
dates = ListField(int)
|
||||
avg_waiting_times = ListField([float, int])
|
||||
queue_lengths = ListField(int)
|
||||
|
||||
|
||||
class GetMetricsResponse(Base):
|
||||
queues = ListField(QueueMetrics)
|
||||
14
server/apimodels/server.py
Normal file
14
server/apimodels/server.py
Normal file
@@ -0,0 +1,14 @@
|
||||
from jsonmodels.fields import BoolField, DateTimeField, StringField
|
||||
from jsonmodels.models import Base
|
||||
|
||||
|
||||
class ReportStatsOptionRequest(Base):
|
||||
enabled = BoolField(default=None, nullable=True)
|
||||
|
||||
|
||||
class ReportStatsOptionResponse(Base):
|
||||
supported = BoolField(default=True)
|
||||
enabled = BoolField()
|
||||
enabled_time = DateTimeField(nullable=True)
|
||||
enabled_version = StringField(nullable=True)
|
||||
enabled_user = StringField(nullable=True)
|
||||
@@ -13,8 +13,17 @@ class StartedResponse(UpdateResponse):
|
||||
started = IntField()
|
||||
|
||||
|
||||
class EnqueueResponse(UpdateResponse):
|
||||
queued = IntField()
|
||||
|
||||
|
||||
class DequeueResponse(UpdateResponse):
|
||||
dequeued = IntField()
|
||||
|
||||
|
||||
class ResetResponse(UpdateResponse):
|
||||
deleted_indices = ListField(items_types=six.string_types)
|
||||
dequeued = DictField()
|
||||
frames = DictField()
|
||||
events = DictField()
|
||||
model_deleted = IntField()
|
||||
@@ -30,6 +39,10 @@ class UpdateRequest(TaskRequest):
|
||||
force = BoolField(default=False)
|
||||
|
||||
|
||||
class EnqueueRequest(UpdateRequest):
|
||||
queue = StringField()
|
||||
|
||||
|
||||
class DeleteRequest(UpdateRequest):
|
||||
move_to_trash = BoolField(default=True)
|
||||
|
||||
@@ -57,5 +70,5 @@ class CreateRequest(TaskData):
|
||||
type = StringField(required=True, validators=Enum(*get_options(TaskType)))
|
||||
|
||||
|
||||
class PingRequest(models.Base):
|
||||
task = StringField(required=True)
|
||||
class PingRequest(TaskRequest):
|
||||
pass
|
||||
|
||||
183
server/apimodels/workers.py
Normal file
183
server/apimodels/workers.py
Normal file
@@ -0,0 +1,183 @@
|
||||
import json
|
||||
from enum import Enum
|
||||
|
||||
import six
|
||||
from jsonmodels import validators
|
||||
from jsonmodels.fields import (
|
||||
StringField,
|
||||
EmbeddedField,
|
||||
DateTimeField,
|
||||
IntField,
|
||||
FloatField,
|
||||
BoolField,
|
||||
)
|
||||
from jsonmodels.models import Base
|
||||
|
||||
from apimodels import make_default, ListField, EnumField
|
||||
|
||||
DEFAULT_TIMEOUT = 10 * 60
|
||||
|
||||
|
||||
class WorkerRequest(Base):
|
||||
worker = StringField(required=True)
|
||||
|
||||
|
||||
class RegisterRequest(WorkerRequest):
|
||||
timeout = make_default(
|
||||
IntField, DEFAULT_TIMEOUT
|
||||
)() # registration timeout in seconds (default is 10min)
|
||||
queues = ListField(six.string_types) # list of queues this worker listens to
|
||||
|
||||
|
||||
class MachineStats(Base):
|
||||
cpu_usage = ListField(six.integer_types + (float,))
|
||||
cpu_temperature = ListField(six.integer_types + (float,))
|
||||
gpu_usage = ListField(six.integer_types + (float,))
|
||||
gpu_temperature = ListField(six.integer_types + (float,))
|
||||
gpu_memory_free = ListField(six.integer_types + (float,))
|
||||
gpu_memory_used = ListField(six.integer_types + (float,))
|
||||
memory_used = FloatField()
|
||||
memory_free = FloatField()
|
||||
network_tx = FloatField()
|
||||
network_rx = FloatField()
|
||||
disk_free_home = FloatField()
|
||||
disk_free_temp = FloatField()
|
||||
disk_read = FloatField()
|
||||
disk_write = FloatField()
|
||||
|
||||
|
||||
class StatusReportRequest(WorkerRequest):
|
||||
task = StringField() # task the worker is running on
|
||||
queue = StringField() # queue from which task was taken
|
||||
queues = ListField(
|
||||
str
|
||||
) # list of queues this worker listens to. if None, this will not update the worker's queues list.
|
||||
timestamp = IntField(required=True)
|
||||
machine_stats = EmbeddedField(MachineStats)
|
||||
|
||||
|
||||
class IdNameEntry(Base):
|
||||
id = StringField(required=True)
|
||||
name = StringField()
|
||||
|
||||
|
||||
class WorkerEntry(Base):
|
||||
key = StringField() # not required due to migration issues
|
||||
id = StringField(required=True)
|
||||
user = EmbeddedField(IdNameEntry)
|
||||
company = EmbeddedField(IdNameEntry)
|
||||
ip = StringField()
|
||||
task = EmbeddedField(IdNameEntry)
|
||||
queue = StringField() # queue from which current task was taken
|
||||
queues = ListField(str) # list of queues this worker listens to
|
||||
register_time = DateTimeField(required=True)
|
||||
register_timeout = IntField(required=True)
|
||||
last_activity_time = DateTimeField(required=True)
|
||||
last_report_time = DateTimeField()
|
||||
|
||||
def to_json(self):
|
||||
return json.dumps(self.to_struct())
|
||||
|
||||
@classmethod
|
||||
def from_json(cls, s):
|
||||
return cls(**json.loads(s))
|
||||
|
||||
|
||||
class CurrentTaskEntry(IdNameEntry):
|
||||
running_time = IntField()
|
||||
last_iteration = IntField()
|
||||
|
||||
|
||||
class QueueEntry(IdNameEntry):
|
||||
next_task = EmbeddedField(IdNameEntry)
|
||||
num_tasks = IntField()
|
||||
|
||||
|
||||
class WorkerResponseEntry(WorkerEntry):
|
||||
task = EmbeddedField(CurrentTaskEntry)
|
||||
queue = EmbeddedField(QueueEntry)
|
||||
queues = ListField(QueueEntry)
|
||||
|
||||
|
||||
class GetAllRequest(Base):
|
||||
last_seen = IntField(default=3600)
|
||||
|
||||
|
||||
class GetAllResponse(Base):
|
||||
workers = ListField(WorkerResponseEntry)
|
||||
|
||||
|
||||
class StatsBase(Base):
|
||||
worker_ids = ListField(str)
|
||||
|
||||
|
||||
class StatsReportBase(StatsBase):
|
||||
from_date = FloatField(required=True, validators=validators.Min(0))
|
||||
to_date = FloatField(required=True, validators=validators.Min(0))
|
||||
interval = IntField(required=True, validators=validators.Min(1))
|
||||
|
||||
|
||||
class AggregationType(Enum):
|
||||
avg = "avg"
|
||||
min = "min"
|
||||
max = "max"
|
||||
|
||||
|
||||
class StatItem(Base):
|
||||
key = StringField(required=True)
|
||||
aggregation = EnumField(AggregationType, default=AggregationType.avg)
|
||||
|
||||
|
||||
class GetStatsRequest(StatsReportBase):
|
||||
items = ListField(
|
||||
StatItem, required=True, validators=validators.Length(minimum_value=1)
|
||||
)
|
||||
split_by_variant = BoolField(default=False)
|
||||
|
||||
|
||||
class AggregationStats(Base):
|
||||
aggregation = EnumField(AggregationType)
|
||||
values = ListField(float)
|
||||
|
||||
|
||||
class MetricStats(Base):
|
||||
metric = StringField()
|
||||
variant = StringField()
|
||||
dates = ListField(int)
|
||||
stats = ListField(AggregationStats)
|
||||
|
||||
|
||||
class WorkerStatistics(Base):
|
||||
worker = StringField()
|
||||
metrics = ListField(MetricStats)
|
||||
|
||||
|
||||
class GetStatsResponse(Base):
|
||||
workers = ListField(WorkerStatistics)
|
||||
|
||||
|
||||
class GetMetricKeysRequest(StatsBase):
|
||||
pass
|
||||
|
||||
|
||||
class MetricCategory(Base):
|
||||
name = StringField()
|
||||
metric_keys = ListField(str)
|
||||
|
||||
|
||||
class GetMetricKeysResponse(Base):
|
||||
categories = ListField(MetricCategory)
|
||||
|
||||
|
||||
class GetActivityReportRequest(StatsReportBase):
|
||||
pass
|
||||
|
||||
|
||||
class ActivityReportSeries(Base):
|
||||
dates = ListField(int)
|
||||
counts = ListField(int)
|
||||
|
||||
|
||||
class GetActivityReportResponse(Base):
|
||||
total = EmbeddedField(ActivityReportSeries)
|
||||
active = EmbeddedField(ActivityReportSeries)
|
||||
@@ -1,24 +1,25 @@
|
||||
from collections import defaultdict
|
||||
from contextlib import closing
|
||||
from datetime import datetime
|
||||
from enum import Enum
|
||||
from operator import attrgetter
|
||||
from typing import Sequence
|
||||
|
||||
import attr
|
||||
import six
|
||||
from elasticsearch import helpers
|
||||
from enum import Enum
|
||||
|
||||
from mongoengine import Q
|
||||
from nested_dict import nested_dict
|
||||
|
||||
import database.utils as dbutils
|
||||
import es_factory
|
||||
from apierrors import errors
|
||||
from bll.event.event_metrics import EventMetrics
|
||||
from bll.task import TaskBLL
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.task.task import Task
|
||||
from database.model.task.metrics import MetricEvent
|
||||
from database.model.task.task import Task, TaskStatus
|
||||
from timing_context import TimingContext
|
||||
from utilities.dicts import flatten_nested_items
|
||||
|
||||
|
||||
class EventType(Enum):
|
||||
@@ -33,6 +34,9 @@ class EventType(Enum):
|
||||
EVENT_TYPES = set(map(attrgetter("value"), EventType))
|
||||
|
||||
|
||||
LOCKED_TASK_STATUSES = (TaskStatus.publishing, TaskStatus.published)
|
||||
|
||||
|
||||
@attr.s
|
||||
class TaskEventsResult(object):
|
||||
events = attr.ib(type=list, default=attr.Factory(list))
|
||||
@@ -44,9 +48,14 @@ class EventBLL(object):
|
||||
id_fields = ["task", "iter", "metric", "variant", "key"]
|
||||
|
||||
def __init__(self, events_es=None):
|
||||
self.es = events_es if events_es is not None else es_factory.connect("events")
|
||||
self.es = events_es or es_factory.connect("events")
|
||||
self._metrics = EventMetrics(self.es)
|
||||
|
||||
def add_events(self, company_id, events, worker):
|
||||
@property
|
||||
def metrics(self) -> EventMetrics:
|
||||
return self._metrics
|
||||
|
||||
def add_events(self, company_id, events, worker, allow_locked_tasks=False):
|
||||
actions = []
|
||||
task_ids = set()
|
||||
task_iteration = defaultdict(lambda: 0)
|
||||
@@ -94,7 +103,7 @@ class EventBLL(object):
|
||||
event["value"] = event["values"]
|
||||
del event["values"]
|
||||
|
||||
index_name = EventBLL.get_index_name(company_id, event_type)
|
||||
index_name = EventMetrics.get_index_name(company_id, event_type)
|
||||
es_action = {
|
||||
"_op_type": "index", # overwrite if exists with same ID
|
||||
"_index": index_name,
|
||||
@@ -127,11 +136,16 @@ class EventBLL(object):
|
||||
if task_ids:
|
||||
# verify task_ids
|
||||
with translate_errors_context(), TimingContext("mongo", "task_by_ids"):
|
||||
res = Task.objects(id__in=task_ids, company=company_id).only("id")
|
||||
extra_msg = None
|
||||
query = Q(id__in=task_ids, company=company_id)
|
||||
if not allow_locked_tasks:
|
||||
query &= Q(status__nin=LOCKED_TASK_STATUSES)
|
||||
extra_msg = "or task published"
|
||||
res = Task.objects(query).only("id")
|
||||
if len(res) < len(task_ids):
|
||||
invalid_task_ids = tuple(set(task_ids) - set(r.id for r in res))
|
||||
raise errors.bad_request.InvalidTaskId(
|
||||
company=company_id, ids=invalid_task_ids
|
||||
extra_msg, company=company_id, ids=invalid_task_ids
|
||||
)
|
||||
|
||||
errors_in_bulk = []
|
||||
@@ -154,13 +168,6 @@ class EventBLL(object):
|
||||
else:
|
||||
errors_in_bulk.append(info)
|
||||
|
||||
last_metrics = {
|
||||
t.id: t.to_proper_dict().get("last_metrics", {})
|
||||
for t in Task.objects(id__in=task_ids, company=company_id).only(
|
||||
"last_metrics"
|
||||
)
|
||||
}
|
||||
|
||||
remaining_tasks = set()
|
||||
now = datetime.utcnow()
|
||||
for task_id in task_ids:
|
||||
@@ -171,9 +178,8 @@ class EventBLL(object):
|
||||
company_id=company_id,
|
||||
task_id=task_id,
|
||||
now=now,
|
||||
iter=task_iteration.get(task_id),
|
||||
iter_max=task_iteration.get(task_id),
|
||||
last_events=task_last_events.get(task_id),
|
||||
last_metrics=last_metrics.get(task_id),
|
||||
)
|
||||
|
||||
if not updated:
|
||||
@@ -210,9 +216,7 @@ class EventBLL(object):
|
||||
if timestamp is None or timestamp < event["timestamp"]:
|
||||
last_events[metric_hash][variant_hash] = event
|
||||
|
||||
def _update_task(
|
||||
self, company_id, task_id, now, iter=None, last_events=None, last_metrics=None
|
||||
):
|
||||
def _update_task(self, company_id, task_id, now, iter_max=None, last_events=None):
|
||||
"""
|
||||
Update task information in DB with aggregated results after handling event(s) related to this task.
|
||||
|
||||
@@ -222,27 +226,17 @@ class EventBLL(object):
|
||||
"""
|
||||
fields = {}
|
||||
|
||||
if iter is not None:
|
||||
fields["last_iteration"] = iter
|
||||
if iter_max is not None:
|
||||
fields["last_iteration_max"] = iter_max
|
||||
|
||||
if last_events:
|
||||
|
||||
def get_metric_event(ev):
|
||||
me = MetricEvent.from_dict(**ev)
|
||||
if "timestamp" in ev:
|
||||
me.timestamp = datetime.utcfromtimestamp(ev["timestamp"] / 1000)
|
||||
return me
|
||||
|
||||
new_last_metrics = nested_dict(2, MetricEvent)
|
||||
new_last_metrics.update(last_metrics)
|
||||
|
||||
for metric_hash, variants in last_events.items():
|
||||
for variant_hash, event in variants.items():
|
||||
new_last_metrics[metric_hash][variant_hash] = get_metric_event(
|
||||
event
|
||||
)
|
||||
|
||||
fields["last_metrics"] = new_last_metrics.to_dict()
|
||||
fields["last_values"] = list(
|
||||
flatten_nested_items(
|
||||
last_events,
|
||||
nesting=2,
|
||||
include_leaves=["value", "metric", "variant"],
|
||||
)
|
||||
)
|
||||
|
||||
if not fields:
|
||||
return False
|
||||
@@ -270,7 +264,7 @@ class EventBLL(object):
|
||||
if event_type is None:
|
||||
event_type = "*"
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, event_type)
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
|
||||
if not self.es.indices.exists(es_index):
|
||||
return [], None, 0
|
||||
@@ -290,6 +284,125 @@ class EventBLL(object):
|
||||
|
||||
return events, next_scroll_id, total_events
|
||||
|
||||
def get_last_iterations_per_event_metric_variant(
|
||||
self, es_index: str, task_id: str, num_last_iterations: int, event_type: str
|
||||
):
|
||||
if not self.es.indices.exists(es_index):
|
||||
return []
|
||||
|
||||
es_req: dict = {
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {"field": "metric"},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {"field": "variant"},
|
||||
"aggs": {
|
||||
"iters": {
|
||||
"terms": {
|
||||
"field": "iter",
|
||||
"size": num_last_iterations,
|
||||
"order": {"_term": "desc"},
|
||||
}
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
"query": {"bool": {"must": [{"term": {"task": task_id}}]}},
|
||||
}
|
||||
if event_type:
|
||||
es_req["query"]["bool"]["must"].append({"term": {"type": event_type}})
|
||||
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "task_last_iter_metric_variant"
|
||||
):
|
||||
es_res = self.es.search(index=es_index, body=es_req, routing=task_id)
|
||||
if "aggregations" not in es_res:
|
||||
return []
|
||||
|
||||
return [
|
||||
(metric["key"], variant["key"], iter["key"])
|
||||
for metric in es_res["aggregations"]["metrics"]["buckets"]
|
||||
for variant in metric["variants"]["buckets"]
|
||||
for iter in variant["iters"]["buckets"]
|
||||
]
|
||||
|
||||
def get_task_plots(
|
||||
self,
|
||||
company_id: str,
|
||||
tasks: Sequence[str],
|
||||
last_iterations_per_plot: int = None,
|
||||
sort=None,
|
||||
size: int = 500,
|
||||
scroll_id: str = None,
|
||||
):
|
||||
if scroll_id:
|
||||
with translate_errors_context(), TimingContext("es", "get_task_events"):
|
||||
es_res = self.es.scroll(scroll_id=scroll_id, scroll="1h")
|
||||
else:
|
||||
event_type = "plot"
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
if not self.es.indices.exists(es_index):
|
||||
return TaskEventsResult()
|
||||
|
||||
query = {"bool": defaultdict(list)}
|
||||
|
||||
if last_iterations_per_plot is None:
|
||||
must = query["bool"]["must"]
|
||||
must.append({"terms": {"task": tasks}})
|
||||
else:
|
||||
should = query["bool"]["should"]
|
||||
for i, task_id in enumerate(tasks):
|
||||
last_iters = self.get_last_iterations_per_event_metric_variant(
|
||||
es_index, task_id, last_iterations_per_plot, event_type
|
||||
)
|
||||
if not last_iters:
|
||||
continue
|
||||
|
||||
for metric, variant, iter in last_iters:
|
||||
should.append(
|
||||
{
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"task": task_id}},
|
||||
{"term": {"metric": metric}},
|
||||
{"term": {"variant": variant}},
|
||||
{"term": {"iter": iter}},
|
||||
]
|
||||
}
|
||||
}
|
||||
)
|
||||
if not should:
|
||||
return TaskEventsResult()
|
||||
|
||||
if sort is None:
|
||||
sort = [{"timestamp": {"order": "asc"}}]
|
||||
|
||||
es_req = {"sort": sort, "size": min(size, 10000), "query": query}
|
||||
|
||||
routing = ",".join(tasks)
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "get_task_plots"):
|
||||
es_res = self.es.search(
|
||||
index=es_index,
|
||||
body=es_req,
|
||||
ignore=404,
|
||||
routing=routing,
|
||||
scroll="1h",
|
||||
)
|
||||
|
||||
events = [doc["_source"] for doc in es_res.get("hits", {}).get("hits", [])]
|
||||
# scroll id may be missing when queering a totally empty DB
|
||||
next_scroll_id = es_res.get("_scroll_id")
|
||||
total_events = es_res["hits"]["total"]
|
||||
|
||||
return TaskEventsResult(
|
||||
events=events, next_scroll_id=next_scroll_id, total_events=total_events
|
||||
)
|
||||
|
||||
def get_task_events(
|
||||
self,
|
||||
company_id,
|
||||
@@ -311,7 +424,7 @@ class EventBLL(object):
|
||||
if event_type is None:
|
||||
event_type = "*"
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, event_type)
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
if not self.es.indices.exists(es_index):
|
||||
return TaskEventsResult()
|
||||
|
||||
@@ -374,7 +487,7 @@ class EventBLL(object):
|
||||
|
||||
def get_metrics_and_variants(self, company_id, task_id, event_type):
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, event_type)
|
||||
es_index = EventMetrics.get_index_name(company_id, event_type)
|
||||
|
||||
if not self.es.indices.exists(es_index):
|
||||
return {}
|
||||
@@ -405,7 +518,7 @@ class EventBLL(object):
|
||||
return metrics
|
||||
|
||||
def get_task_latest_scalar_values(self, company_id, task_id):
|
||||
es_index = EventBLL.get_index_name(company_id, "training_stats_scalar")
|
||||
es_index = EventMetrics.get_index_name(company_id, "training_stats_scalar")
|
||||
|
||||
if not self.es.indices.exists(es_index):
|
||||
return {}
|
||||
@@ -488,147 +601,9 @@ class EventBLL(object):
|
||||
metrics.append(metric_summary)
|
||||
return metrics, max_timestamp
|
||||
|
||||
def compare_scalar_metrics_average_per_iter(
|
||||
self, company_id, task_ids, allow_public=True
|
||||
):
|
||||
assert isinstance(task_ids, list)
|
||||
|
||||
task_name_by_id = {}
|
||||
with translate_errors_context():
|
||||
task_objs = Task.get_many(
|
||||
company=company_id,
|
||||
query=Q(id__in=task_ids),
|
||||
allow_public=allow_public,
|
||||
override_projection=("id", "name"),
|
||||
return_dicts=False,
|
||||
)
|
||||
if len(task_objs) < len(task_ids):
|
||||
invalid = tuple(set(task_ids) - set(r.id for r in task_objs))
|
||||
raise errors.bad_request.InvalidTaskId(company=company_id, ids=invalid)
|
||||
|
||||
task_name_by_id = {t.id: t.name for t in task_objs}
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, "training_stats_scalar")
|
||||
if not self.es.indices.exists(es_index):
|
||||
return {}
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"_source": {"excludes": []},
|
||||
"query": {"terms": {"task": task_ids}},
|
||||
"aggs": {
|
||||
"iters": {
|
||||
"histogram": {"field": "iter", "interval": 1, "min_doc_count": 1},
|
||||
"aggs": {
|
||||
"metric_and_variant": {
|
||||
"terms": {
|
||||
"script": "doc['metric'].value +'/'+ doc['variant'].value",
|
||||
"size": 10000,
|
||||
},
|
||||
"aggs": {
|
||||
"tasks": {
|
||||
"terms": {"field": "task"},
|
||||
"aggs": {"avg_val": {"avg": {"field": "value"}}},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
with translate_errors_context(), TimingContext("es", "task_stats_comparison"):
|
||||
es_res = self.es.search(index=es_index, body=es_req)
|
||||
|
||||
if "aggregations" not in es_res:
|
||||
return
|
||||
|
||||
metrics = {}
|
||||
for iter_bucket in es_res["aggregations"]["iters"]["buckets"]:
|
||||
iteration = int(iter_bucket["key"])
|
||||
for metric_bucket in iter_bucket["metric_and_variant"]["buckets"]:
|
||||
metric_name = metric_bucket["key"]
|
||||
if metrics.get(metric_name) is None:
|
||||
metrics[metric_name] = {}
|
||||
|
||||
metric_data = metrics[metric_name]
|
||||
for task_bucket in metric_bucket["tasks"]["buckets"]:
|
||||
task_id = task_bucket["key"]
|
||||
value = task_bucket["avg_val"]["value"]
|
||||
if metric_data.get(task_id) is None:
|
||||
metric_data[task_id] = {
|
||||
"x": [],
|
||||
"y": [],
|
||||
"name": task_name_by_id[
|
||||
task_id
|
||||
], # todo: lookup task name from id
|
||||
}
|
||||
metric_data[task_id]["x"].append(iteration)
|
||||
metric_data[task_id]["y"].append(value)
|
||||
|
||||
return metrics
|
||||
|
||||
def get_scalar_metrics_average_per_iter(self, company_id, task_id):
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, "training_stats_scalar")
|
||||
if not self.es.indices.exists(es_index):
|
||||
return {}
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"_source": {"excludes": []},
|
||||
"query": {"term": {"task": task_id}},
|
||||
"aggs": {
|
||||
"iters": {
|
||||
"histogram": {"field": "iter", "interval": 1, "min_doc_count": 1},
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": 200,
|
||||
"order": {"_term": "desc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": 500,
|
||||
"order": {"_term": "desc"},
|
||||
},
|
||||
"aggs": {"avg_val": {"avg": {"field": "value"}}},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
"version": True,
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "task_stats_scalar"):
|
||||
es_res = self.es.search(index=es_index, body=es_req, routing=task_id)
|
||||
|
||||
metrics = {}
|
||||
if "aggregations" in es_res:
|
||||
for iter_bucket in es_res["aggregations"]["iters"]["buckets"]:
|
||||
iteration = int(iter_bucket["key"])
|
||||
for metric_bucket in iter_bucket["metrics"]["buckets"]:
|
||||
metric_name = metric_bucket["key"]
|
||||
if metrics.get(metric_name) is None:
|
||||
metrics[metric_name] = {}
|
||||
|
||||
metric_data = metrics[metric_name]
|
||||
for variant_bucket in metric_bucket["variants"]["buckets"]:
|
||||
variant = variant_bucket["key"]
|
||||
value = variant_bucket["avg_val"]["value"]
|
||||
if metric_data.get(variant) is None:
|
||||
metric_data[variant] = {"x": [], "y": [], "name": variant}
|
||||
metric_data[variant]["x"].append(iteration)
|
||||
metric_data[variant]["y"].append(value)
|
||||
return metrics
|
||||
|
||||
def get_vector_metrics_per_iter(self, company_id, task_id, metric, variant):
|
||||
|
||||
es_index = EventBLL.get_index_name(company_id, "training_stats_vector")
|
||||
es_index = EventMetrics.get_index_name(company_id, "training_stats_vector")
|
||||
if not self.es.indices.exists(es_index):
|
||||
return [], []
|
||||
|
||||
@@ -684,8 +659,20 @@ class EventBLL(object):
|
||||
|
||||
return [b["key"] for b in es_res["aggregations"]["iters"]["buckets"]]
|
||||
|
||||
def delete_task_events(self, company_id, task_id):
|
||||
es_index = EventBLL.get_index_name(company_id, "*")
|
||||
def delete_task_events(self, company_id, task_id, allow_locked=False):
|
||||
with translate_errors_context():
|
||||
extra_msg = None
|
||||
query = Q(id=task_id, company=company_id)
|
||||
if not allow_locked:
|
||||
query &= Q(status__nin=LOCKED_TASK_STATUSES)
|
||||
extra_msg = "or task published"
|
||||
res = Task.objects(query).only("id").first()
|
||||
if not res:
|
||||
raise errors.bad_request.InvalidTaskId(
|
||||
extra_msg, company=company_id, id=task_id
|
||||
)
|
||||
|
||||
es_index = EventMetrics.get_index_name(company_id, "*")
|
||||
es_req = {"query": {"term": {"task": task_id}}}
|
||||
with translate_errors_context(), TimingContext("es", "delete_task_events"):
|
||||
es_res = self.es.delete_by_query(
|
||||
@@ -693,8 +680,3 @@ class EventBLL(object):
|
||||
)
|
||||
|
||||
return es_res.get("deleted", 0)
|
||||
|
||||
@staticmethod
|
||||
def get_index_name(company_id, event_type):
|
||||
event_type = event_type.lower().replace(" ", "_")
|
||||
return "events-%s-%s" % (event_type, company_id)
|
||||
|
||||
398
server/bll/event/event_metrics.py
Normal file
398
server/bll/event/event_metrics.py
Normal file
@@ -0,0 +1,398 @@
|
||||
import itertools
|
||||
from collections import defaultdict
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
from functools import partial
|
||||
from operator import itemgetter
|
||||
|
||||
from elasticsearch import Elasticsearch
|
||||
from typing import Sequence, Tuple, Callable
|
||||
|
||||
from mongoengine import Q
|
||||
|
||||
from apierrors import errors
|
||||
from bll.event.scalar_key import ScalarKey, ScalarKeyEnum
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.task.task import Task
|
||||
from timing_context import TimingContext
|
||||
from utilities import safe_get
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class EventMetrics:
|
||||
MAX_TASKS_COUNT = 100
|
||||
MAX_METRICS_COUNT = 200
|
||||
MAX_VARIANTS_COUNT = 500
|
||||
|
||||
def __init__(self, es: Elasticsearch):
|
||||
self.es = es
|
||||
|
||||
@staticmethod
|
||||
def get_index_name(company_id, event_type):
|
||||
event_type = event_type.lower().replace(" ", "_")
|
||||
return f"events-{event_type}-{company_id}"
|
||||
|
||||
def get_scalar_metrics_average_per_iter(
|
||||
self, company_id: str, task_id: str, samples: int, key: ScalarKeyEnum
|
||||
) -> dict:
|
||||
"""
|
||||
Get scalar metric histogram per metric and variant
|
||||
The amount of points in each histogram should not exceed
|
||||
the requested samples
|
||||
"""
|
||||
|
||||
return self._run_get_scalar_metrics_as_parallel(
|
||||
company_id,
|
||||
task_ids=[task_id],
|
||||
samples=samples,
|
||||
key=ScalarKey.resolve(key),
|
||||
get_func=self._get_scalar_average,
|
||||
)
|
||||
|
||||
def compare_scalar_metrics_average_per_iter(
|
||||
self,
|
||||
company_id,
|
||||
task_ids: Sequence[str],
|
||||
samples,
|
||||
key: ScalarKeyEnum,
|
||||
allow_public=True,
|
||||
):
|
||||
"""
|
||||
Compare scalar metrics for different tasks per metric and variant
|
||||
The amount of points in each histogram should not exceed the requested samples
|
||||
"""
|
||||
task_name_by_id = {}
|
||||
with translate_errors_context():
|
||||
task_objs = Task.get_many(
|
||||
company=company_id,
|
||||
query=Q(id__in=task_ids),
|
||||
allow_public=allow_public,
|
||||
override_projection=("id", "name"),
|
||||
return_dicts=False,
|
||||
)
|
||||
if len(task_objs) < len(task_ids):
|
||||
invalid = tuple(set(task_ids) - set(r.id for r in task_objs))
|
||||
raise errors.bad_request.InvalidTaskId(company=company_id, ids=invalid)
|
||||
|
||||
task_name_by_id = {t.id: t.name for t in task_objs}
|
||||
|
||||
ret = self._run_get_scalar_metrics_as_parallel(
|
||||
company_id,
|
||||
task_ids=task_ids,
|
||||
samples=samples,
|
||||
key=ScalarKey.resolve(key),
|
||||
get_func=self._get_scalar_average_per_task,
|
||||
)
|
||||
|
||||
for metric_data in ret.values():
|
||||
for variant_data in metric_data.values():
|
||||
for task_id, task_data in variant_data.items():
|
||||
task_data["name"] = task_name_by_id[task_id]
|
||||
|
||||
return ret
|
||||
|
||||
TaskMetric = Tuple[str, str, str]
|
||||
|
||||
MetricInterval = Tuple[int, Sequence[TaskMetric]]
|
||||
MetricData = Tuple[str, dict]
|
||||
|
||||
def _run_get_scalar_metrics_as_parallel(
|
||||
self,
|
||||
company_id: str,
|
||||
task_ids: Sequence[str],
|
||||
samples: int,
|
||||
key: ScalarKey,
|
||||
get_func: Callable[
|
||||
[MetricInterval, Sequence[str], str, ScalarKey], Sequence[MetricData]
|
||||
],
|
||||
) -> dict:
|
||||
"""
|
||||
Group metrics per interval length and execute get_func for each group in parallel
|
||||
:param company_id: id of the company
|
||||
:params task_ids: ids of the tasks to collect data for
|
||||
:param samples: maximum number of samples per metric
|
||||
:param get_func: callable that given metric names for the same interval
|
||||
performs histogram aggregation for the metrics and return the aggregated data
|
||||
"""
|
||||
es_index = self.get_index_name(company_id, "training_stats_scalar")
|
||||
if not self.es.indices.exists(es_index):
|
||||
return {}
|
||||
|
||||
intervals = self._get_metric_intervals(
|
||||
es_index=es_index, task_ids=task_ids, samples=samples, field=key.field
|
||||
)
|
||||
|
||||
if not intervals:
|
||||
return {}
|
||||
|
||||
with ThreadPoolExecutor(len(intervals)) as pool:
|
||||
metrics = list(
|
||||
itertools.chain.from_iterable(
|
||||
pool.map(
|
||||
partial(
|
||||
get_func, task_ids=task_ids, es_index=es_index, key=key
|
||||
),
|
||||
intervals,
|
||||
)
|
||||
)
|
||||
)
|
||||
|
||||
ret = defaultdict(dict)
|
||||
for metric_key, metric_values in metrics:
|
||||
ret[metric_key].update(metric_values)
|
||||
return ret
|
||||
|
||||
def _get_metric_intervals(
|
||||
self, es_index, task_ids: Sequence[str], samples: int, field: str = "iter"
|
||||
) -> Sequence[MetricInterval]:
|
||||
"""
|
||||
Calculate interval per task metric variant so that the resulting
|
||||
amount of points does not exceed sample.
|
||||
Return metric variants grouped by interval value with 10% rounding
|
||||
For samples==0 return empty list
|
||||
"""
|
||||
default_intervals = [(1, [])]
|
||||
if not samples:
|
||||
return default_intervals
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": {"terms": {"task": task_ids}},
|
||||
"aggs": {
|
||||
"tasks": {
|
||||
"terms": {"field": "task", "size": self.MAX_TASKS_COUNT},
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": self.MAX_METRICS_COUNT,
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": self.MAX_VARIANTS_COUNT,
|
||||
},
|
||||
"aggs": {
|
||||
"count": {"value_count": {"field": field}},
|
||||
"min_index": {"min": {"field": field}},
|
||||
"max_index": {"max": {"field": field}},
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "task_stats_get_interval"):
|
||||
es_res = self.es.search(
|
||||
index=es_index, body=es_req, routing=",".join(task_ids)
|
||||
)
|
||||
|
||||
aggs_result = es_res.get("aggregations")
|
||||
if not aggs_result:
|
||||
return default_intervals
|
||||
|
||||
intervals = [
|
||||
(
|
||||
task["key"],
|
||||
metric["key"],
|
||||
variant["key"],
|
||||
self._calculate_metric_interval(variant, samples),
|
||||
)
|
||||
for task in aggs_result["tasks"]["buckets"]
|
||||
for metric in task["metrics"]["buckets"]
|
||||
for variant in metric["variants"]["buckets"]
|
||||
]
|
||||
|
||||
metric_intervals = []
|
||||
upper_border = 0
|
||||
interval_metrics = None
|
||||
for task, metric, variant, interval in sorted(intervals, key=itemgetter(3)):
|
||||
if not interval_metrics or interval > upper_border:
|
||||
interval_metrics = []
|
||||
metric_intervals.append((interval, interval_metrics))
|
||||
upper_border = interval + int(interval * 0.1)
|
||||
interval_metrics.append((task, metric, variant))
|
||||
|
||||
return metric_intervals
|
||||
|
||||
@staticmethod
|
||||
def _calculate_metric_interval(metric_variant: dict, samples: int) -> int:
|
||||
"""
|
||||
Calculate index interval per metric_variant variant so that the
|
||||
total amount of intervals does not exceeds the samples
|
||||
"""
|
||||
count = safe_get(metric_variant, "count/value")
|
||||
if not count or count < samples:
|
||||
return 1
|
||||
|
||||
min_index = safe_get(metric_variant, "min_index/value", default=0)
|
||||
max_index = safe_get(metric_variant, "max_index/value", default=min_index)
|
||||
return max(1, int(max_index - min_index + 1) // samples)
|
||||
|
||||
def _get_scalar_average(
|
||||
self,
|
||||
metrics_interval: MetricInterval,
|
||||
task_ids: Sequence[str],
|
||||
es_index: str,
|
||||
key: ScalarKey,
|
||||
) -> Sequence[MetricData]:
|
||||
"""
|
||||
Retrieve scalar histograms per several metric variants that share the same interval
|
||||
Note: the function works with a single task only
|
||||
"""
|
||||
|
||||
assert len(task_ids) == 1
|
||||
interval, task_metrics = metrics_interval
|
||||
aggregation = self._add_aggregation_average(key.get_aggregation(interval))
|
||||
aggs = {
|
||||
"metrics": {
|
||||
"terms": {
|
||||
"field": "metric",
|
||||
"size": self.MAX_METRICS_COUNT,
|
||||
"order": {"_term": "desc"},
|
||||
},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {
|
||||
"field": "variant",
|
||||
"size": self.MAX_VARIANTS_COUNT,
|
||||
"order": {"_term": "desc"},
|
||||
},
|
||||
"aggs": aggregation,
|
||||
}
|
||||
},
|
||||
}
|
||||
}
|
||||
aggs_result = self._query_aggregation_for_metrics_and_tasks(
|
||||
es_index, aggs=aggs, task_ids=task_ids, task_metrics=task_metrics
|
||||
)
|
||||
|
||||
if not aggs_result:
|
||||
return {}
|
||||
|
||||
metrics = [
|
||||
(
|
||||
metric["key"],
|
||||
{
|
||||
variant["key"]: {
|
||||
"name": variant["key"],
|
||||
**key.get_iterations_data(variant),
|
||||
}
|
||||
for variant in metric["variants"]["buckets"]
|
||||
},
|
||||
)
|
||||
for metric in aggs_result["metrics"]["buckets"]
|
||||
]
|
||||
return metrics
|
||||
|
||||
def _get_scalar_average_per_task(
|
||||
self,
|
||||
metrics_interval: MetricInterval,
|
||||
task_ids: Sequence[str],
|
||||
es_index: str,
|
||||
key: ScalarKey,
|
||||
) -> Sequence[MetricData]:
|
||||
"""
|
||||
Retrieve scalar histograms per several metric variants that share the same interval
|
||||
"""
|
||||
interval, task_metrics = metrics_interval
|
||||
|
||||
aggregation = self._add_aggregation_average(key.get_aggregation(interval))
|
||||
aggs = {
|
||||
"metrics": {
|
||||
"terms": {"field": "metric", "size": self.MAX_METRICS_COUNT},
|
||||
"aggs": {
|
||||
"variants": {
|
||||
"terms": {"field": "variant", "size": self.MAX_VARIANTS_COUNT},
|
||||
"aggs": {
|
||||
"tasks": {"terms": {"field": "task"}, "aggs": aggregation}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
aggs_result = self._query_aggregation_for_metrics_and_tasks(
|
||||
es_index, aggs=aggs, task_ids=task_ids, task_metrics=task_metrics
|
||||
)
|
||||
|
||||
if not aggs_result:
|
||||
return {}
|
||||
|
||||
metrics = [
|
||||
(
|
||||
metric["key"],
|
||||
{
|
||||
variant["key"]: {
|
||||
task["key"]: key.get_iterations_data(task)
|
||||
for task in variant["tasks"]["buckets"]
|
||||
}
|
||||
for variant in metric["variants"]["buckets"]
|
||||
},
|
||||
)
|
||||
for metric in aggs_result["metrics"]["buckets"]
|
||||
]
|
||||
return metrics
|
||||
|
||||
@staticmethod
|
||||
def _add_aggregation_average(aggregation):
|
||||
average_agg = {"avg_val": {"avg": {"field": "value"}}}
|
||||
return {
|
||||
key: {**value, "aggs": {**value.get("aggs", {}), **average_agg}}
|
||||
for key, value in aggregation.items()
|
||||
}
|
||||
|
||||
def _query_aggregation_for_metrics_and_tasks(
|
||||
self,
|
||||
es_index: str,
|
||||
aggs: dict,
|
||||
task_ids: Sequence[str],
|
||||
task_metrics: Sequence[TaskMetric],
|
||||
) -> dict:
|
||||
"""
|
||||
Return the result of elastic search query for the given aggregation filtered
|
||||
by the given task_ids and metrics
|
||||
"""
|
||||
if task_metrics:
|
||||
condition = {
|
||||
"should": [
|
||||
self._build_metric_terms(task, metric, variant)
|
||||
for task, metric, variant in task_metrics
|
||||
]
|
||||
}
|
||||
else:
|
||||
condition = {"must": [{"terms": {"task": task_ids}}]}
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"_source": {"excludes": []},
|
||||
"query": {"bool": condition},
|
||||
"aggs": aggs,
|
||||
"version": True,
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "task_stats_scalar"):
|
||||
es_res = self.es.search(
|
||||
index=es_index, body=es_req, routing=",".join(task_ids)
|
||||
)
|
||||
|
||||
return es_res.get("aggregations")
|
||||
|
||||
@staticmethod
|
||||
def _build_metric_terms(task: str, metric: str, variant: str) -> dict:
|
||||
"""
|
||||
Build query term for a metric + variant
|
||||
"""
|
||||
return {
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"task": task}},
|
||||
{"term": {"metric": metric}},
|
||||
{"term": {"variant": variant}},
|
||||
]
|
||||
}
|
||||
}
|
||||
161
server/bll/event/scalar_key.py
Normal file
161
server/bll/event/scalar_key.py
Normal file
@@ -0,0 +1,161 @@
|
||||
"""
|
||||
Module for polymorphism over different types of X axes in scalar aggregations
|
||||
"""
|
||||
from abc import ABC, abstractmethod
|
||||
from enum import auto
|
||||
|
||||
from apimodels import StringEnum
|
||||
from bll.util import extract_properties_to_lists
|
||||
from config import config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class ScalarKeyEnum(StringEnum):
|
||||
"""
|
||||
String enum representing X axes key
|
||||
"""
|
||||
|
||||
iter = auto()
|
||||
timestamp = auto()
|
||||
iso_time = auto()
|
||||
|
||||
|
||||
class ScalarKey(ABC):
|
||||
"""
|
||||
Abstract scalar key
|
||||
"""
|
||||
|
||||
_enum_to_key = {}
|
||||
bucket_key_key = "key"
|
||||
|
||||
@property
|
||||
@abstractmethod
|
||||
def enum_value(self) -> ScalarKeyEnum:
|
||||
"""
|
||||
Enum value accepted in API requests
|
||||
"""
|
||||
pass
|
||||
|
||||
@property
|
||||
@abstractmethod
|
||||
def name(self) -> str:
|
||||
"""
|
||||
Key name. Used as arbitrary internal key in elasticsearch queries
|
||||
"""
|
||||
pass
|
||||
|
||||
@property
|
||||
@abstractmethod
|
||||
def field(self) -> str:
|
||||
"""
|
||||
Event key to aggregate by
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_aggregation(self, interval: int) -> dict:
|
||||
"""
|
||||
Get aggregation for this type of key
|
||||
:param interval: elasticsearch aggregation interval
|
||||
"""
|
||||
pass
|
||||
|
||||
def __init_subclass__(cls, **kwargs):
|
||||
"""
|
||||
Save a mapping from enum values to key class
|
||||
"""
|
||||
if cls.enum_value not in ScalarKeyEnum:
|
||||
raise ValueError(f"{cls.enum_value!r} not in {ScalarKeyEnum.__name__}")
|
||||
if cls.enum_value in cls._enum_to_key:
|
||||
log.warning(
|
||||
f"'{cls.enum_value.value}' is already registered to {ScalarKey.__name__}"
|
||||
)
|
||||
cls._enum_to_key[cls.enum_value] = cls
|
||||
|
||||
@classmethod
|
||||
def resolve(cls, key: ScalarKeyEnum):
|
||||
"""
|
||||
Create a key instance from enum instance
|
||||
"""
|
||||
return cls._enum_to_key[key]()
|
||||
|
||||
def get_iterations_data(self, iter_buckets: dict) -> dict:
|
||||
"""
|
||||
Convert a list of bucket entries to `x`s array and `y`s array
|
||||
"""
|
||||
return extract_properties_to_lists(
|
||||
("x", "y"),
|
||||
iter_buckets[self.name]["buckets"],
|
||||
self._get_iterations_data_single,
|
||||
)
|
||||
|
||||
def _get_iterations_data_single(self, iter_data):
|
||||
"""
|
||||
Extract x value and y value from a single bucket item
|
||||
"""
|
||||
return int(iter_data[self.bucket_key_key]), iter_data["avg_val"]["value"]
|
||||
|
||||
|
||||
class TimestampKey(ScalarKey):
|
||||
"""
|
||||
Aggregate by timestamp in milliseconds since epoch
|
||||
"""
|
||||
|
||||
name = "timestamp"
|
||||
field = "timestamp"
|
||||
enum_value = ScalarKeyEnum.timestamp
|
||||
|
||||
def get_aggregation(self, interval: int) -> dict:
|
||||
return {
|
||||
self.name: {
|
||||
"date_histogram": {
|
||||
"field": "timestamp",
|
||||
"interval": interval,
|
||||
"min_doc_count": 1,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
class IterKey(ScalarKey):
|
||||
"""
|
||||
Aggregate by iteration number
|
||||
"""
|
||||
|
||||
name = "iters"
|
||||
field = "iter"
|
||||
enum_value = ScalarKeyEnum.iter
|
||||
|
||||
def get_aggregation(self, interval: int) -> dict:
|
||||
return {
|
||||
self.name: {
|
||||
"histogram": {"field": "iter", "interval": interval, "min_doc_count": 1}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
class ISOTimeKey(ScalarKey):
|
||||
"""
|
||||
Aggregate by time formatted as ISO strings
|
||||
"""
|
||||
|
||||
name = "iso_time"
|
||||
field = "timestamp"
|
||||
enum_value = ScalarKeyEnum.iso_time
|
||||
bucket_key_key = "key_as_string"
|
||||
|
||||
def get_aggregation(self, interval: int) -> dict:
|
||||
return {
|
||||
self.name: {
|
||||
"date_histogram": {
|
||||
"field": "timestamp",
|
||||
"interval": interval,
|
||||
"min_doc_count": 1,
|
||||
"format": "strict_date_time",
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
def _get_iterations_data_single(self, iter_data):
|
||||
return iter_data[self.bucket_key_key], iter_data["avg_val"]["value"]
|
||||
1
server/bll/query/__init__.py
Normal file
1
server/bll/query/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
from .builder import Builder
|
||||
36
server/bll/query/builder.py
Normal file
36
server/bll/query/builder.py
Normal file
@@ -0,0 +1,36 @@
|
||||
from typing import Optional, Sequence, Iterable, Union
|
||||
|
||||
from config import config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
RANGE_IGNORE_VALUE = -1
|
||||
|
||||
|
||||
class Builder:
|
||||
@staticmethod
|
||||
def dates_range(from_date: Union[int, float], to_date: Union[int, float]) -> dict:
|
||||
return {
|
||||
"range": {
|
||||
"timestamp": {
|
||||
"gte": int(from_date),
|
||||
"lte": int(to_date),
|
||||
"format": "epoch_second",
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@staticmethod
|
||||
def terms(field: str, values: Iterable[str]) -> dict:
|
||||
return {"terms": {field: list(values)}}
|
||||
|
||||
@staticmethod
|
||||
def normalize_range(
|
||||
range_: Sequence[Union[int, float]],
|
||||
ignore_value: Union[int, float] = RANGE_IGNORE_VALUE,
|
||||
) -> Optional[Sequence[Union[int, float]]]:
|
||||
if not range_ or set(range_) == {ignore_value}:
|
||||
return None
|
||||
if len(range_) < 2:
|
||||
return [range_[0]] * 2
|
||||
return range_
|
||||
1
server/bll/queue/__init__.py
Normal file
1
server/bll/queue/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
from .queue_bll import QueueBLL
|
||||
264
server/bll/queue/queue_bll.py
Normal file
264
server/bll/queue/queue_bll.py
Normal file
@@ -0,0 +1,264 @@
|
||||
from collections import defaultdict
|
||||
from datetime import datetime
|
||||
from typing import Callable, Sequence, Optional, Tuple
|
||||
|
||||
from elasticsearch import Elasticsearch
|
||||
|
||||
import database
|
||||
import es_factory
|
||||
from apierrors import errors
|
||||
from bll.queue.queue_metrics import QueueMetrics
|
||||
from bll.workers import WorkerBLL
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.queue import Queue, Entry
|
||||
|
||||
|
||||
class QueueBLL(object):
|
||||
def __init__(self, worker_bll: WorkerBLL = None, es: Elasticsearch = None):
|
||||
self.worker_bll = worker_bll or WorkerBLL()
|
||||
self.es = es or es_factory.connect("workers")
|
||||
self._metrics = QueueMetrics(self.es)
|
||||
|
||||
@property
|
||||
def metrics(self) -> QueueMetrics:
|
||||
return self._metrics
|
||||
|
||||
@staticmethod
|
||||
def create(
|
||||
company_id: str,
|
||||
name: str,
|
||||
tags: Optional[Sequence[str]] = None,
|
||||
system_tags: Optional[Sequence[str]] = None,
|
||||
) -> Queue:
|
||||
"""Creates a queue"""
|
||||
with translate_errors_context():
|
||||
now = datetime.utcnow()
|
||||
queue = Queue(
|
||||
id=database.utils.id(),
|
||||
company=company_id,
|
||||
created=now,
|
||||
name=name,
|
||||
tags=tags or [],
|
||||
system_tags=system_tags or [],
|
||||
last_update=now,
|
||||
)
|
||||
queue.save()
|
||||
return queue
|
||||
|
||||
def get_by_id(
|
||||
self, company_id: str, queue_id: str, only: Optional[Sequence[str]] = None
|
||||
) -> Queue:
|
||||
"""
|
||||
Get queue by id
|
||||
:raise errors.bad_request.InvalidQueueId: if the queue is not found
|
||||
"""
|
||||
with translate_errors_context():
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
qs = Queue.objects(**query)
|
||||
if only:
|
||||
qs = qs.only(*only)
|
||||
queue = qs.first()
|
||||
if not queue:
|
||||
raise errors.bad_request.InvalidQueueId(**query)
|
||||
|
||||
return queue
|
||||
|
||||
@classmethod
|
||||
def get_queue_with_task(cls, company_id: str, queue_id: str, task_id: str) -> Queue:
|
||||
with translate_errors_context():
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
queue = Queue.objects(entries__task=task_id, **query).first()
|
||||
if not queue:
|
||||
raise errors.bad_request.InvalidQueueOrTaskNotQueued(
|
||||
task=task_id, **query
|
||||
)
|
||||
|
||||
return queue
|
||||
|
||||
def get_default(self, company_id: str) -> Queue:
|
||||
"""
|
||||
Get the default queue
|
||||
:raise errors.bad_request.NoDefaultQueue: if the default queue not found
|
||||
:raise errors.bad_request.MultipleDefaultQueues: if more than one default queue is found
|
||||
"""
|
||||
with translate_errors_context():
|
||||
res = Queue.objects(company=company_id, system_tags="default").only(
|
||||
"id", "name"
|
||||
)
|
||||
if not res:
|
||||
raise errors.bad_request.NoDefaultQueue()
|
||||
if len(res) > 1:
|
||||
raise errors.bad_request.MultipleDefaultQueues(
|
||||
queues=tuple(r.id for r in res)
|
||||
)
|
||||
|
||||
return res.first()
|
||||
|
||||
def update(
|
||||
self, company_id: str, queue_id: str, **update_fields
|
||||
) -> Tuple[int, dict]:
|
||||
"""
|
||||
Partial update of the queue from update_fields
|
||||
:raise errors.bad_request.InvalidQueueId: if the queue is not found
|
||||
:return: number of updated objects and updated fields dictionary
|
||||
"""
|
||||
with translate_errors_context():
|
||||
# validate the queue exists
|
||||
self.get_by_id(company_id=company_id, queue_id=queue_id, only=("id",))
|
||||
return Queue.safe_update(company_id, queue_id, update_fields)
|
||||
|
||||
def delete(self, company_id: str, queue_id: str, force: bool) -> None:
|
||||
"""
|
||||
Delete the queue
|
||||
:raise errors.bad_request.InvalidQueueId: if the queue is not found
|
||||
:raise errors.bad_request.QueueNotEmpty: if the queue is not empty and 'force' not set
|
||||
"""
|
||||
with translate_errors_context():
|
||||
queue = self.get_by_id(company_id=company_id, queue_id=queue_id)
|
||||
if queue.entries and not force:
|
||||
raise errors.bad_request.QueueNotEmpty(
|
||||
"use force=true to delete", id=queue_id
|
||||
)
|
||||
queue.delete()
|
||||
|
||||
def get_all(self, company_id: str, query_dict: dict) -> Sequence[dict]:
|
||||
"""Get all the queues according to the query"""
|
||||
with translate_errors_context():
|
||||
return Queue.get_many(
|
||||
company=company_id, parameters=query_dict, query_dict=query_dict
|
||||
)
|
||||
|
||||
def get_queue_infos(self, company_id: str, query_dict: dict) -> Sequence[dict]:
|
||||
"""
|
||||
Get infos on all the company queues, including queue tasks and workers
|
||||
"""
|
||||
projection = Queue.get_extra_projection("entries.task.name")
|
||||
with translate_errors_context():
|
||||
res = Queue.get_many_with_join(
|
||||
company=company_id,
|
||||
query_dict=query_dict,
|
||||
override_projection=projection,
|
||||
)
|
||||
|
||||
queue_workers = defaultdict(list)
|
||||
for worker in self.worker_bll.get_all(company_id):
|
||||
for queue in worker.queues:
|
||||
queue_workers[queue].append(worker)
|
||||
|
||||
for item in res:
|
||||
item["workers"] = [
|
||||
{
|
||||
"name": w.id,
|
||||
"ip": w.ip,
|
||||
"task": w.task.to_struct() if w.task else None,
|
||||
}
|
||||
for w in queue_workers.get(item["id"], [])
|
||||
]
|
||||
|
||||
return res
|
||||
|
||||
def add_task(self, company_id: str, queue_id: str, task_id: str) -> dict:
|
||||
"""
|
||||
Add the task to the queue and return the queue update results
|
||||
:raise errors.bad_request.TaskAlreadyQueued: if the task is already in the queue
|
||||
:raise errors.bad_request.InvalidQueueOrTaskNotQueued: if the queue update operation failed
|
||||
"""
|
||||
with translate_errors_context():
|
||||
queue = self.get_by_id(company_id=company_id, queue_id=queue_id)
|
||||
if any(e.task == task_id for e in queue.entries):
|
||||
raise errors.bad_request.TaskAlreadyQueued(task=task_id)
|
||||
|
||||
self.metrics.log_queue_metrics_to_es(company_id=company_id, queues=[queue])
|
||||
|
||||
entry = Entry(added=datetime.utcnow(), task=task_id)
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
res = Queue.objects(entries__task__ne=task_id, **query).update_one(
|
||||
push__entries=entry, last_update=datetime.utcnow(), upsert=False
|
||||
)
|
||||
if not res:
|
||||
raise errors.bad_request.InvalidQueueOrTaskNotQueued(
|
||||
task=task_id, **query
|
||||
)
|
||||
|
||||
return res
|
||||
|
||||
def get_next_task(self, company_id: str, queue_id: str) -> Optional[Entry]:
|
||||
"""
|
||||
Atomically pop and return the first task from the queue (or None)
|
||||
:raise errors.bad_request.InvalidQueueId: if the queue does not exist
|
||||
"""
|
||||
with translate_errors_context():
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
queue = Queue.objects(**query).modify(
|
||||
pop__entries=-1, last_update=datetime.utcnow(), upsert=False
|
||||
)
|
||||
if not queue:
|
||||
raise errors.bad_request.InvalidQueueId(**query)
|
||||
|
||||
self.metrics.log_queue_metrics_to_es(company_id, queues=[queue])
|
||||
|
||||
if not queue.entries:
|
||||
return
|
||||
|
||||
return queue.entries[0]
|
||||
|
||||
def remove_task(self, company_id: str, queue_id: str, task_id: str) -> int:
|
||||
"""
|
||||
Removes the task from the queue and returns the number of removed items
|
||||
:raise errors.bad_request.InvalidQueueOrTaskNotQueued: if the task is not found in the queue
|
||||
"""
|
||||
with translate_errors_context():
|
||||
queue = self.get_queue_with_task(
|
||||
company_id=company_id, queue_id=queue_id, task_id=task_id
|
||||
)
|
||||
self.metrics.log_queue_metrics_to_es(company_id, queues=[queue])
|
||||
|
||||
entries_to_remove = [e for e in queue.entries if e.task == task_id]
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
res = Queue.objects(entries__task=task_id, **query).update_one(
|
||||
pull_all__entries=entries_to_remove, last_update=datetime.utcnow()
|
||||
)
|
||||
|
||||
return len(entries_to_remove) if res else 0
|
||||
|
||||
def reposition_task(
|
||||
self,
|
||||
company_id: str,
|
||||
queue_id: str,
|
||||
task_id: str,
|
||||
pos_func: Callable[[int], int],
|
||||
) -> int:
|
||||
"""
|
||||
Moves the task in the queue to the position calculated by pos_func
|
||||
Returns the updated task position in the queue
|
||||
"""
|
||||
with translate_errors_context():
|
||||
queue = self.get_queue_with_task(
|
||||
company_id=company_id, queue_id=queue_id, task_id=task_id
|
||||
)
|
||||
|
||||
position = next(i for i, e in enumerate(queue.entries) if e.task == task_id)
|
||||
new_position = pos_func(position)
|
||||
|
||||
if new_position != position:
|
||||
entry = queue.entries[position]
|
||||
query = dict(id=queue_id, company=company_id)
|
||||
updated = Queue.objects(entries__task=task_id, **query).update_one(
|
||||
pull__entries=entry, last_update=datetime.utcnow()
|
||||
)
|
||||
if not updated:
|
||||
raise errors.bad_request.RemovedDuringReposition(
|
||||
task=task_id, **query
|
||||
)
|
||||
inst = {"$push": {"entries": {"$each": [entry.to_proper_dict()]}}}
|
||||
if new_position >= 0:
|
||||
inst["$push"]["entries"]["$position"] = new_position
|
||||
res = Queue.objects(entries__task__ne=task_id, **query).update_one(
|
||||
__raw__=inst
|
||||
)
|
||||
if not res:
|
||||
raise errors.bad_request.FailedAddingDuringReposition(
|
||||
task=task_id, **query
|
||||
)
|
||||
|
||||
return new_position
|
||||
265
server/bll/queue/queue_metrics.py
Normal file
265
server/bll/queue/queue_metrics.py
Normal file
@@ -0,0 +1,265 @@
|
||||
from collections import defaultdict
|
||||
from datetime import datetime
|
||||
from typing import Sequence
|
||||
|
||||
import elasticsearch.helpers
|
||||
from elasticsearch import Elasticsearch
|
||||
|
||||
import es_factory
|
||||
from apierrors.errors import bad_request
|
||||
from bll.query import Builder as QueryBuilder
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.queue import Queue, Entry
|
||||
from timing_context import TimingContext
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class QueueMetrics:
|
||||
class EsKeys:
|
||||
DOC_TYPE = "metrics"
|
||||
WAITING_TIME_FIELD = "average_waiting_time"
|
||||
QUEUE_LENGTH_FIELD = "queue_length"
|
||||
TIMESTAMP_FIELD = "timestamp"
|
||||
QUEUE_FIELD = "queue"
|
||||
|
||||
def __init__(self, es: Elasticsearch):
|
||||
self.es = es
|
||||
|
||||
@staticmethod
|
||||
def _queue_metrics_prefix_for_company(company_id: str) -> str:
|
||||
"""Returns the es index prefix for the company"""
|
||||
return f"queue_metrics_{company_id}_"
|
||||
|
||||
@staticmethod
|
||||
def _get_es_index_suffix():
|
||||
"""Get the index name suffix for storing current month data"""
|
||||
return datetime.utcnow().strftime("%Y-%m")
|
||||
|
||||
@staticmethod
|
||||
def _calc_avg_waiting_time(entries: Sequence[Entry]) -> float:
|
||||
"""
|
||||
Calculate avg waiting time for the given tasks.
|
||||
Return 0 if the list is empty
|
||||
"""
|
||||
if not entries:
|
||||
return 0
|
||||
|
||||
now = datetime.utcnow()
|
||||
total_waiting_in_secs = sum((now - e.added).total_seconds() for e in entries)
|
||||
return total_waiting_in_secs / len(entries)
|
||||
|
||||
def log_queue_metrics_to_es(self, company_id: str, queues: Sequence[Queue]) -> bool:
|
||||
"""
|
||||
Calculate and write queue statistics (avg waiting time and queue length) to Elastic
|
||||
:return: True if the write to es was successful, false otherwise
|
||||
"""
|
||||
es_index = (
|
||||
self._queue_metrics_prefix_for_company(company_id)
|
||||
+ self._get_es_index_suffix()
|
||||
)
|
||||
|
||||
timestamp = es_factory.get_timestamp_millis()
|
||||
|
||||
def make_doc(queue: Queue) -> dict:
|
||||
entries = [e for e in queue.entries if e.added]
|
||||
return dict(
|
||||
_index=es_index,
|
||||
_type=self.EsKeys.DOC_TYPE,
|
||||
_source={
|
||||
self.EsKeys.TIMESTAMP_FIELD: timestamp,
|
||||
self.EsKeys.QUEUE_FIELD: queue.id,
|
||||
self.EsKeys.WAITING_TIME_FIELD: self._calc_avg_waiting_time(
|
||||
entries
|
||||
),
|
||||
self.EsKeys.QUEUE_LENGTH_FIELD: len(entries),
|
||||
},
|
||||
)
|
||||
|
||||
actions = list(map(make_doc, queues))
|
||||
|
||||
es_res = elasticsearch.helpers.bulk(self.es, actions)
|
||||
added, errors = es_res[:2]
|
||||
return (added == len(actions)) and not errors
|
||||
|
||||
def _log_current_metrics(self, company_id: str, queue_ids=Sequence[str]):
|
||||
query = dict(company=company_id)
|
||||
if queue_ids:
|
||||
query["id__in"] = list(queue_ids)
|
||||
queues = Queue.objects(**query)
|
||||
self.log_queue_metrics_to_es(company_id, queues=list(queues))
|
||||
|
||||
def _search_company_metrics(self, company_id: str, es_req: dict) -> dict:
|
||||
return self.es.search(
|
||||
index=f"{self._queue_metrics_prefix_for_company(company_id)}*",
|
||||
doc_type=self.EsKeys.DOC_TYPE,
|
||||
body=es_req,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def _get_dates_agg(cls, interval) -> dict:
|
||||
"""
|
||||
Aggregation for building date histogram with internal grouping per queue.
|
||||
We are grouping by queue inside date histogram and not vice versa so that
|
||||
it will be easy to average between queue metrics inside each date bucket.
|
||||
Ignore empty buckets.
|
||||
"""
|
||||
return {
|
||||
"dates": {
|
||||
"date_histogram": {
|
||||
"field": cls.EsKeys.TIMESTAMP_FIELD,
|
||||
"interval": f"{interval}s",
|
||||
"min_doc_count": 1,
|
||||
},
|
||||
"aggs": {
|
||||
"queues": {
|
||||
"terms": {"field": cls.EsKeys.QUEUE_FIELD},
|
||||
"aggs": cls._get_top_waiting_agg(),
|
||||
}
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _get_top_waiting_agg(cls) -> dict:
|
||||
"""
|
||||
Aggregation for getting max waiting time and the corresponding queue length
|
||||
inside each date->queue bucket
|
||||
"""
|
||||
return {
|
||||
"top_avg_waiting": {
|
||||
"top_hits": {
|
||||
"sort": [
|
||||
{cls.EsKeys.WAITING_TIME_FIELD: {"order": "desc"}},
|
||||
{cls.EsKeys.QUEUE_LENGTH_FIELD: {"order": "desc"}},
|
||||
],
|
||||
"_source": {
|
||||
"includes": [
|
||||
cls.EsKeys.WAITING_TIME_FIELD,
|
||||
cls.EsKeys.QUEUE_LENGTH_FIELD,
|
||||
]
|
||||
},
|
||||
"size": 1,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
def get_queue_metrics(
|
||||
self,
|
||||
company_id: str,
|
||||
from_date: float,
|
||||
to_date: float,
|
||||
interval: int,
|
||||
queue_ids: Sequence[str],
|
||||
) -> dict:
|
||||
"""
|
||||
Get the company queue metrics in the specified time range.
|
||||
Returned as date histograms of average values per queue and metric type.
|
||||
The from_date is extended by 'metrics_before_from_date' seconds from
|
||||
queues.conf due to possibly small amount of points. The default extension is 3600s
|
||||
In case no queue ids are specified the avg across all the
|
||||
company queues is calculated for each metric
|
||||
"""
|
||||
# self._log_current_metrics(company, queue_ids=queue_ids)
|
||||
|
||||
if from_date >= to_date:
|
||||
raise bad_request.FieldsValueError("from_date must be less than to_date")
|
||||
|
||||
seconds_before = config.get("services.queues.metrics_before_from_date", 3600)
|
||||
must_terms = [QueryBuilder.dates_range(from_date - seconds_before, to_date)]
|
||||
if queue_ids:
|
||||
must_terms.append(QueryBuilder.terms("queue", queue_ids))
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": {"bool": {"must": must_terms}},
|
||||
"aggs": self._get_dates_agg(interval),
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "get_queue_metrics"):
|
||||
res = self._search_company_metrics(company_id, es_req)
|
||||
|
||||
if "aggregations" not in res:
|
||||
return {}
|
||||
|
||||
date_metrics = [
|
||||
dict(
|
||||
timestamp=d["key"],
|
||||
queue_metrics=self._extract_queue_metrics(d["queues"]["buckets"]),
|
||||
)
|
||||
for d in res["aggregations"]["dates"]["buckets"]
|
||||
if d["doc_count"] > 0
|
||||
]
|
||||
if queue_ids:
|
||||
return self._datetime_histogram_per_queue(date_metrics)
|
||||
|
||||
return self._average_datetime_histogram(date_metrics)
|
||||
|
||||
@classmethod
|
||||
def _datetime_histogram_per_queue(cls, date_metrics: Sequence[dict]) -> dict:
|
||||
"""
|
||||
Build datetime histogram per queue from datetime histogram where every
|
||||
bucket contains all the queues metrics
|
||||
"""
|
||||
queues_data = defaultdict(list)
|
||||
for date_data in date_metrics:
|
||||
timestamp = date_data["timestamp"]
|
||||
for queue, metrics in date_data["queue_metrics"].items():
|
||||
queues_data[queue].append({"date": timestamp, **metrics})
|
||||
|
||||
return queues_data
|
||||
|
||||
@classmethod
|
||||
def _average_datetime_histogram(cls, date_metrics: Sequence[dict]) -> dict:
|
||||
"""
|
||||
Calculate weighted averages and total count for each bucket of date_metrics histogram.
|
||||
If for any queue the data is missing then take it from the previous bucket
|
||||
The result is returned as a dictionary with one key 'total'
|
||||
"""
|
||||
queues_total = []
|
||||
last_values = {}
|
||||
for date_data in date_metrics:
|
||||
date_metrics = date_data["queue_metrics"]
|
||||
queue_metrics = {
|
||||
**date_metrics,
|
||||
**{k: v for k, v in last_values.items() if k not in date_metrics},
|
||||
}
|
||||
|
||||
total_length = sum(m["queue_length"] for m in queue_metrics.values())
|
||||
if total_length:
|
||||
total_average = sum(
|
||||
m["avg_waiting_time"] * m["queue_length"] / total_length
|
||||
for m in queue_metrics.values()
|
||||
)
|
||||
else:
|
||||
total_average = 0
|
||||
|
||||
queues_total.append(
|
||||
dict(
|
||||
date=date_data["timestamp"],
|
||||
avg_waiting_time=total_average,
|
||||
queue_length=total_length,
|
||||
)
|
||||
)
|
||||
|
||||
for k, v in date_metrics.items():
|
||||
last_values[k] = v
|
||||
|
||||
return dict(total=queues_total)
|
||||
|
||||
@classmethod
|
||||
def _extract_queue_metrics(cls, queue_buckets: Sequence[dict]) -> dict:
|
||||
"""
|
||||
Extract ES data for single date and queue bucket
|
||||
"""
|
||||
queue_metrics = dict()
|
||||
for queue_data in queue_buckets:
|
||||
if not queue_data["doc_count"]:
|
||||
continue
|
||||
res = queue_data["top_avg_waiting"]["hits"]["hits"][0]["_source"]
|
||||
queue_metrics[queue_data["key"]] = {
|
||||
"queue_length": res[cls.EsKeys.QUEUE_LENGTH_FIELD],
|
||||
"avg_waiting_time": res[cls.EsKeys.WAITING_TIME_FIELD],
|
||||
}
|
||||
return queue_metrics
|
||||
87
server/bll/statistics/resource_monitor.py
Normal file
87
server/bll/statistics/resource_monitor.py
Normal file
@@ -0,0 +1,87 @@
|
||||
from datetime import datetime
|
||||
import operator
|
||||
from threading import Thread, Lock
|
||||
from time import sleep
|
||||
|
||||
import attr
|
||||
import psutil
|
||||
|
||||
|
||||
class ResourceMonitor(Thread):
|
||||
@attr.s(auto_attribs=True)
|
||||
class Sample:
|
||||
cpu_usage: float = 0.0
|
||||
mem_used_gb: float = 0
|
||||
mem_free_gb: float = 0
|
||||
|
||||
@classmethod
|
||||
def _apply(cls, op, *samples):
|
||||
return cls(
|
||||
**{
|
||||
field: op(*(getattr(sample, field) for sample in samples))
|
||||
for field in attr.fields_dict(cls)
|
||||
}
|
||||
)
|
||||
|
||||
def min(self, sample):
|
||||
return self._apply(min, self, sample)
|
||||
|
||||
def max(self, sample):
|
||||
return self._apply(max, self, sample)
|
||||
|
||||
def avg(self, sample, count):
|
||||
res = self._apply(lambda x: x * count, self)
|
||||
res = self._apply(operator.add, res, sample)
|
||||
res = self._apply(lambda x: x / (count + 1), res)
|
||||
return res
|
||||
|
||||
def __init__(self, sample_interval_sec=5):
|
||||
super(ResourceMonitor, self).__init__(daemon=True)
|
||||
self.sample_interval_sec = sample_interval_sec
|
||||
self._lock = Lock()
|
||||
self._clear()
|
||||
|
||||
def _clear(self):
|
||||
sample = self._get_sample()
|
||||
self._avg = sample
|
||||
self._min = sample
|
||||
self._max = sample
|
||||
self._clear_time = datetime.utcnow()
|
||||
self._count = 1
|
||||
|
||||
@classmethod
|
||||
def _get_sample(cls) -> Sample:
|
||||
return cls.Sample(
|
||||
cpu_usage=psutil.cpu_percent(),
|
||||
mem_used_gb=psutil.virtual_memory().used / (1024 ** 3),
|
||||
mem_free_gb=psutil.virtual_memory().free / (1024 ** 3),
|
||||
)
|
||||
|
||||
def run(self):
|
||||
while True:
|
||||
sample = self._get_sample()
|
||||
|
||||
with self._lock:
|
||||
self._min = self._min.min(sample)
|
||||
self._max = self._max.max(sample)
|
||||
self._avg = self._avg.avg(sample, self._count)
|
||||
self._count += 1
|
||||
|
||||
sleep(self.sample_interval_sec)
|
||||
|
||||
def get_stats(self) -> dict:
|
||||
""" Returns current resource statistics and clears internal resource statistics """
|
||||
with self._lock:
|
||||
min_ = attr.asdict(self._min)
|
||||
max_ = attr.asdict(self._max)
|
||||
avg = attr.asdict(self._avg)
|
||||
res = {
|
||||
"interval_sec": (datetime.utcnow() - self._clear_time).total_seconds(),
|
||||
"num_cores": psutil.cpu_count(),
|
||||
**{
|
||||
k: {"min": v, "max": max_[k], "avg": avg[k]}
|
||||
for k, v in min_.items()
|
||||
}
|
||||
}
|
||||
self._clear()
|
||||
return res
|
||||
306
server/bll/statistics/stats_reporter.py
Normal file
306
server/bll/statistics/stats_reporter.py
Normal file
@@ -0,0 +1,306 @@
|
||||
import logging
|
||||
import queue
|
||||
import random
|
||||
import time
|
||||
from datetime import timedelta, datetime
|
||||
from time import sleep
|
||||
from typing import Sequence, Optional
|
||||
|
||||
import dpath
|
||||
import requests
|
||||
from requests.adapters import HTTPAdapter
|
||||
from requests.packages.urllib3.util.retry import Retry
|
||||
|
||||
from bll.query import Builder as QueryBuilder
|
||||
from bll.util import get_server_uuid
|
||||
from bll.workers import WorkerStats, WorkerBLL
|
||||
from config import config
|
||||
from config.info import get_deployment_type
|
||||
from database.model import Company, User
|
||||
from database.model.queue import Queue
|
||||
from database.model.task.task import Task
|
||||
from utilities import safe_get
|
||||
from utilities.json import dumps
|
||||
from utilities.threads_manager import ThreadsManager
|
||||
from version import __version__ as current_version
|
||||
from .resource_monitor import ResourceMonitor
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
worker_bll = WorkerBLL()
|
||||
|
||||
|
||||
class StatisticsReporter:
|
||||
threads = ThreadsManager("Statistics", resource_monitor=ResourceMonitor)
|
||||
send_queue = queue.Queue()
|
||||
supported = config.get("apiserver.statistics.supported", True)
|
||||
|
||||
@classmethod
|
||||
def start(cls):
|
||||
cls.start_sender()
|
||||
cls.start_reporter()
|
||||
|
||||
@classmethod
|
||||
@threads.register("reporter", daemon=True)
|
||||
def start_reporter(cls):
|
||||
"""
|
||||
Periodically send statistics reports for companies who have opted in.
|
||||
Note: in trains we usually have only a single company
|
||||
"""
|
||||
if not cls.supported:
|
||||
return
|
||||
|
||||
report_interval = timedelta(
|
||||
hours=config.get("apiserver.statistics.report_interval_hours", 24)
|
||||
)
|
||||
|
||||
while True:
|
||||
|
||||
sleep(report_interval.total_seconds())
|
||||
|
||||
try:
|
||||
for company in Company.objects(
|
||||
defaults__stats_option__enabled=True
|
||||
).only("id"):
|
||||
stats = cls.get_statistics(company.id)
|
||||
cls.send_queue.put(stats)
|
||||
|
||||
except Exception as ex:
|
||||
log.exception(f"Failed collecting stats: {str(ex)}")
|
||||
|
||||
@classmethod
|
||||
@threads.register("sender", daemon=True)
|
||||
def start_sender(cls):
|
||||
if not cls.supported:
|
||||
return
|
||||
|
||||
url = config.get("apiserver.statistics.url")
|
||||
|
||||
retries = config.get("apiserver.statistics.max_retries", 5)
|
||||
max_backoff = config.get("apiserver.statistics.max_backoff_sec", 5)
|
||||
session = requests.Session()
|
||||
adapter = HTTPAdapter(max_retries=Retry(retries))
|
||||
session.mount("http://", adapter)
|
||||
session.mount("https://", adapter)
|
||||
session.headers["Content-type"] = "application/json"
|
||||
|
||||
WarningFilter.attach()
|
||||
|
||||
while True:
|
||||
try:
|
||||
report = cls.send_queue.get()
|
||||
|
||||
# Set a random backoff factor each time we send a report
|
||||
adapter.max_retries.backoff_factor = random.random() * max_backoff
|
||||
|
||||
session.post(url, data=dumps(report))
|
||||
|
||||
except Exception as ex:
|
||||
pass
|
||||
|
||||
@classmethod
|
||||
def get_statistics(cls, company_id: str) -> dict:
|
||||
"""
|
||||
Returns a statistics report per company
|
||||
"""
|
||||
return {
|
||||
"time": datetime.utcnow(),
|
||||
"company_id": company_id,
|
||||
"server": {
|
||||
"version": current_version,
|
||||
"deployment": get_deployment_type(),
|
||||
"uuid": get_server_uuid(),
|
||||
"queues": {"count": Queue.objects(company=company_id).count()},
|
||||
"users": {"count": User.objects(company=company_id).count()},
|
||||
"resources": cls.threads.resource_monitor.get_stats(),
|
||||
"experiments": next(
|
||||
iter(cls._get_experiments_stats(company_id).values()), {}
|
||||
),
|
||||
},
|
||||
"agents": cls._get_agents_statistics(company_id),
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _get_agents_statistics(cls, company_id: str) -> Sequence[dict]:
|
||||
result = cls._get_resource_stats_per_agent(company_id, key="resources")
|
||||
dpath.merge(
|
||||
result, cls._get_experiments_stats_per_agent(company_id, key="experiments")
|
||||
)
|
||||
return [{"uuid": agent_id, **data} for agent_id, data in result.items()]
|
||||
|
||||
@classmethod
|
||||
def _get_resource_stats_per_agent(cls, company_id: str, key: str) -> dict:
|
||||
agent_resource_threshold_sec = timedelta(
|
||||
hours=config.get("apiserver.statistics.report_interval_hours", 24)
|
||||
).total_seconds()
|
||||
to_timestamp = int(time.time())
|
||||
from_timestamp = to_timestamp - int(agent_resource_threshold_sec)
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": QueryBuilder.dates_range(from_timestamp, to_timestamp),
|
||||
"aggs": {
|
||||
"workers": {
|
||||
"terms": {"field": "worker"},
|
||||
"aggs": {
|
||||
"categories": {
|
||||
"terms": {"field": "category"},
|
||||
"aggs": {"count": {"cardinality": {"field": "variant"}}},
|
||||
},
|
||||
"metrics": {
|
||||
"terms": {"field": "metric"},
|
||||
"aggs": {
|
||||
"min": {"min": {"field": "value"}},
|
||||
"max": {"max": {"field": "value"}},
|
||||
"avg": {"avg": {"field": "value"}},
|
||||
},
|
||||
},
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
res = cls._run_worker_stats_query(company_id, es_req)
|
||||
|
||||
def _get_cardinality_fields(categories: Sequence[dict]) -> dict:
|
||||
names = {"cpu": "num_cores"}
|
||||
return {
|
||||
names[c["key"]]: safe_get(c, "count/value")
|
||||
for c in categories
|
||||
if c["key"] in names
|
||||
}
|
||||
|
||||
def _get_metric_fields(metrics: Sequence[dict]) -> dict:
|
||||
names = {
|
||||
"cpu_usage": "cpu_usage",
|
||||
"memory_used": "mem_used_gb",
|
||||
"memory_free": "mem_free_gb",
|
||||
}
|
||||
return {
|
||||
names[m["key"]]: {
|
||||
"min": safe_get(m, "min/value"),
|
||||
"max": safe_get(m, "max/value"),
|
||||
"avg": safe_get(m, "avg/value"),
|
||||
}
|
||||
for m in metrics
|
||||
if m["key"] in names
|
||||
}
|
||||
|
||||
buckets = safe_get(res, "aggregations/workers/buckets", default=[])
|
||||
return {
|
||||
b["key"]: {
|
||||
key: {
|
||||
"interval_sec": agent_resource_threshold_sec,
|
||||
**_get_cardinality_fields(safe_get(b, "categories/buckets", [])),
|
||||
**_get_metric_fields(safe_get(b, "metrics/buckets", [])),
|
||||
}
|
||||
}
|
||||
for b in buckets
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _get_experiments_stats_per_agent(cls, company_id: str, key: str) -> dict:
|
||||
agent_relevant_threshold = timedelta(
|
||||
days=config.get("apiserver.statistics.agent_relevant_threshold_days", 30)
|
||||
)
|
||||
to_timestamp = int(time.time())
|
||||
from_timestamp = to_timestamp - int(agent_relevant_threshold.total_seconds())
|
||||
workers = cls._get_active_workers(company_id, from_timestamp, to_timestamp)
|
||||
if not workers:
|
||||
return {}
|
||||
|
||||
stats = cls._get_experiments_stats(company_id, list(workers.keys()))
|
||||
return {
|
||||
worker_id: {key: {**workers[worker_id], **stat}}
|
||||
for worker_id, stat in stats.items()
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _get_active_workers(
|
||||
cls, company_id, from_timestamp: int, to_timestamp: int
|
||||
) -> dict:
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"query": QueryBuilder.dates_range(from_timestamp, to_timestamp),
|
||||
"aggs": {
|
||||
"workers": {
|
||||
"terms": {"field": "worker"},
|
||||
"aggs": {"last_activity_time": {"max": {"field": "timestamp"}}},
|
||||
}
|
||||
},
|
||||
}
|
||||
res = cls._run_worker_stats_query(company_id, es_req)
|
||||
buckets = safe_get(res, "aggregations/workers/buckets", default=[])
|
||||
return {
|
||||
b["key"]: {"last_activity_time": b["last_activity_time"]["value"]}
|
||||
for b in buckets
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _run_worker_stats_query(cls, company_id, es_req) -> dict:
|
||||
return worker_bll.es_client.search(
|
||||
index=f"{WorkerStats.worker_stats_prefix_for_company(company_id)}*",
|
||||
doc_type="stat",
|
||||
body=es_req,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def _get_experiments_stats(
|
||||
cls, company_id, workers: Optional[Sequence] = None
|
||||
) -> dict:
|
||||
pipeline = [
|
||||
{
|
||||
"$match": {
|
||||
"company": company_id,
|
||||
"started": {"$exists": True, "$ne": None},
|
||||
"last_update": {"$exists": True, "$ne": None},
|
||||
"status": {"$nin": ["created", "queued"]},
|
||||
**({"last_worker": {"$in": workers}} if workers else {}),
|
||||
}
|
||||
},
|
||||
{
|
||||
"$group": {
|
||||
"_id": "$last_worker" if workers else None,
|
||||
"count": {"$sum": 1},
|
||||
"avg_run_time_sec": {
|
||||
"$avg": {
|
||||
"$divide": [
|
||||
{"$subtract": ["$last_update", "$started"]},
|
||||
1000,
|
||||
]
|
||||
}
|
||||
},
|
||||
"avg_iterations": {"$avg": "$last_iteration"},
|
||||
}
|
||||
},
|
||||
{
|
||||
"$project": {
|
||||
"count": 1,
|
||||
"avg_run_time_sec": {"$trunc": "$avg_run_time_sec"},
|
||||
"avg_iterations": {"$trunc": "$avg_iterations"},
|
||||
}
|
||||
},
|
||||
]
|
||||
return {
|
||||
group["_id"]: {k: v for k, v in group.items() if k != "_id"}
|
||||
for group in Task.aggregate(*pipeline)
|
||||
}
|
||||
|
||||
|
||||
class WarningFilter(logging.Filter):
|
||||
@classmethod
|
||||
def attach(cls):
|
||||
from urllib3.connectionpool import (
|
||||
ConnectionPool,
|
||||
) # required to make sure the logger is created
|
||||
|
||||
assert ConnectionPool # make sure import is not optimized out
|
||||
|
||||
logging.getLogger("urllib3.connectionpool").addFilter(cls())
|
||||
|
||||
def filter(self, record):
|
||||
if (
|
||||
record.levelno == logging.WARNING
|
||||
and len(record.args) > 2
|
||||
and record.args[2] == "/stats"
|
||||
):
|
||||
return False
|
||||
return True
|
||||
@@ -2,8 +2,7 @@ import re
|
||||
from collections import OrderedDict
|
||||
from datetime import datetime, timedelta
|
||||
from time import sleep
|
||||
from typing import Mapping, Collection
|
||||
from urllib.parse import urlparse
|
||||
from typing import Collection, Sequence, Tuple, Any
|
||||
|
||||
import six
|
||||
from mongoengine import Q
|
||||
@@ -13,12 +12,15 @@ import es_factory
|
||||
from apierrors import errors
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.fields import OutputDestinationField
|
||||
from database.model.model import Model
|
||||
from database.model.project import Project
|
||||
from database.model.task.metrics import MetricEvent
|
||||
from database.model.task.output import Output
|
||||
from database.model.task.task import Task, TaskStatus, TaskStatusMessage, TaskTags
|
||||
from database.model.task.task import (
|
||||
Task,
|
||||
TaskStatus,
|
||||
TaskStatusMessage,
|
||||
TaskSystemTags,
|
||||
)
|
||||
from database.utils import get_company_or_none_constraint, id as create_id
|
||||
from service_repo import APICall
|
||||
from timing_context import TimingContext
|
||||
@@ -27,7 +29,7 @@ from .utils import ChangeStatusRequest, validate_status_change
|
||||
|
||||
|
||||
class TaskBLL(object):
|
||||
threads = ThreadsManager()
|
||||
threads = ThreadsManager("TaskBLL")
|
||||
|
||||
def __init__(self, events_es=None):
|
||||
self.events_es = (
|
||||
@@ -143,7 +145,7 @@ class TaskBLL(object):
|
||||
return model
|
||||
|
||||
@classmethod
|
||||
def validate(cls, task: Task, force=False):
|
||||
def validate(cls, task: Task):
|
||||
assert isinstance(task, Task)
|
||||
|
||||
if task.parent and not Task.get(
|
||||
@@ -154,24 +156,12 @@ class TaskBLL(object):
|
||||
if task.project:
|
||||
Project.get_for_writing(company=task.company, id=task.project)
|
||||
|
||||
model = cls.validate_execution_model(task)
|
||||
if model and not force and not model.ready:
|
||||
raise errors.bad_request.ModelNotReady(
|
||||
"can't be used in a task", model=model.id
|
||||
)
|
||||
cls.validate_execution_model(task)
|
||||
|
||||
if task.execution:
|
||||
if task.execution.parameters:
|
||||
cls._validate_execution_parameters(task.execution.parameters)
|
||||
|
||||
if task.output and task.output.destination:
|
||||
parsed_url = urlparse(task.output.destination)
|
||||
if parsed_url.scheme not in OutputDestinationField.schemes:
|
||||
raise errors.bad_request.FieldsValueError(
|
||||
"unsupported scheme for output destination",
|
||||
dest=task.output.destination,
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def _validate_execution_parameters(parameters):
|
||||
invalid_keys = [k for k in parameters if re.search(r"\s", k)]
|
||||
@@ -218,7 +208,7 @@ class TaskBLL(object):
|
||||
]
|
||||
|
||||
with translate_errors_context():
|
||||
result = Task.objects.aggregate(*pipeline)
|
||||
result = Task.aggregate(*pipeline)
|
||||
return [r["metrics"][0] for r in result]
|
||||
|
||||
@staticmethod
|
||||
@@ -236,7 +226,7 @@ class TaskBLL(object):
|
||||
last_update: datetime = None,
|
||||
last_iteration: int = None,
|
||||
last_iteration_max: int = None,
|
||||
last_metrics: Mapping[str, Mapping[str, MetricEvent]] = None,
|
||||
last_values: Sequence[Tuple[Tuple[str, ...], Any]] = None,
|
||||
**extra_updates,
|
||||
):
|
||||
"""
|
||||
@@ -248,7 +238,7 @@ class TaskBLL(object):
|
||||
task's last iteration value.
|
||||
:param last_iteration_max: Last reported iteration. Use this to conditionally set a value only
|
||||
if the current task's last iteration value is smaller than the provided value.
|
||||
:param last_metrics: Last reported metrics summary.
|
||||
:param last_values: Last reported metrics summary (value, metric, variant).
|
||||
:param extra_updates: Extra task updates to include in this update call.
|
||||
:return:
|
||||
"""
|
||||
@@ -259,10 +249,18 @@ class TaskBLL(object):
|
||||
elif last_iteration_max is not None:
|
||||
extra_updates.update(max__last_iteration=last_iteration_max)
|
||||
|
||||
if last_metrics is not None:
|
||||
extra_updates.update(last_metrics=last_metrics)
|
||||
if last_values is not None:
|
||||
|
||||
return Task.objects(id=task_id, company=company_id).update(
|
||||
def op_path(op, *path):
|
||||
return "__".join((op, "last_metrics") + path)
|
||||
|
||||
for path, value in last_values:
|
||||
extra_updates[op_path("set", *path)] = value
|
||||
if path[-1] == "value":
|
||||
extra_updates[op_path("min", *path[:-1], "min_value")] = value
|
||||
extra_updates[op_path("max", *path[:-1], "max_value")] = value
|
||||
|
||||
Task.objects(id=task_id, company=company_id).update(
|
||||
upsert=False, last_update=last_update, **extra_updates
|
||||
)
|
||||
|
||||
@@ -378,11 +376,27 @@ class TaskBLL(object):
|
||||
task = TaskBLL.get_task_with_access(
|
||||
task_id,
|
||||
company_id=company_id,
|
||||
only=("status", "project", "tags", "last_update"),
|
||||
only=(
|
||||
"status",
|
||||
"project",
|
||||
"tags",
|
||||
"system_tags",
|
||||
"last_worker",
|
||||
"last_update",
|
||||
),
|
||||
requires_write_access=True,
|
||||
)
|
||||
|
||||
if TaskTags.development in task.tags:
|
||||
def is_run_by_worker(t: Task) -> bool:
|
||||
"""Checks if there is an active worker running the task"""
|
||||
update_timeout = config.get("apiserver.workers.task_update_timeout", 600)
|
||||
return (
|
||||
t.last_worker
|
||||
and t.last_update
|
||||
and (datetime.utcnow() - t.last_update).total_seconds() < update_timeout
|
||||
)
|
||||
|
||||
if TaskSystemTags.development in task.system_tags or not is_run_by_worker(task):
|
||||
new_status = TaskStatus.stopped
|
||||
status_message = f"Stopped by {user_name}"
|
||||
else:
|
||||
@@ -448,3 +462,58 @@ class TaskBLL(object):
|
||||
|
||||
except Exception as ex:
|
||||
log.exception(f"Failed stopping tasks: {str(ex)}")
|
||||
|
||||
@staticmethod
|
||||
def get_aggregated_project_execution_parameters(
|
||||
company_id,
|
||||
project_ids: Sequence[str] = None,
|
||||
page: int = 0,
|
||||
page_size: int = 500,
|
||||
) -> Tuple[int, int, Sequence[str]]:
|
||||
|
||||
page = max(0, page)
|
||||
page_size = max(1, page_size)
|
||||
|
||||
pipeline = [
|
||||
{
|
||||
"$match": {
|
||||
"company": company_id,
|
||||
"execution.parameters": {"$exists": True, "$gt": {}},
|
||||
**({"project": {"$in": project_ids}} if project_ids else {}),
|
||||
}
|
||||
},
|
||||
{"$project": {"parameters": {"$objectToArray": "$execution.parameters"}}},
|
||||
{"$unwind": "$parameters"},
|
||||
{"$group": {"_id": "$parameters.k"}},
|
||||
{"$sort": {"_id": 1}},
|
||||
{
|
||||
"$group": {
|
||||
"_id": 1,
|
||||
"total": {"$sum": 1},
|
||||
"results": {"$push": "$$ROOT"},
|
||||
}
|
||||
},
|
||||
{
|
||||
"$project": {
|
||||
"total": 1,
|
||||
"results": {"$slice": ["$results", page * page_size, page_size]},
|
||||
}
|
||||
},
|
||||
]
|
||||
|
||||
with translate_errors_context():
|
||||
result = next(
|
||||
Task.aggregate(*pipeline),
|
||||
None,
|
||||
)
|
||||
|
||||
total = 0
|
||||
remaining = 0
|
||||
results = []
|
||||
|
||||
if result:
|
||||
total = int(result.get("total", -1))
|
||||
results = [r["_id"] for r in result.get("results", [])]
|
||||
remaining = max(0, total - (len(results) + page * page_size))
|
||||
|
||||
return total, remaining, results
|
||||
|
||||
@@ -7,7 +7,7 @@ import six
|
||||
from apierrors import errors
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.project import Project
|
||||
from database.model.task.task import Task, TaskStatus
|
||||
from database.model.task.task import Task, TaskStatus, TaskSystemTags
|
||||
from database.utils import get_options
|
||||
from timing_context import TimingContext
|
||||
from utilities.attrs import typed_attrs
|
||||
@@ -25,9 +25,10 @@ class ChangeStatusRequest(object):
|
||||
status_message = attr.ib(type=six.string_types, default="")
|
||||
force = attr.ib(type=bool, default=False)
|
||||
allow_same_state_transition = attr.ib(type=bool, default=True)
|
||||
current_status_override = attr.ib(default=None)
|
||||
|
||||
def execute(self, **kwargs):
|
||||
current_status = self.task.status
|
||||
current_status = self.current_status_override or self.task.status
|
||||
project_id = self.task.project
|
||||
|
||||
# Verify new status is allowed from current status (will throw exception if not valid)
|
||||
@@ -44,6 +45,9 @@ class ChangeStatusRequest(object):
|
||||
last_update=now,
|
||||
)
|
||||
|
||||
if self.new_status == TaskStatus.queued:
|
||||
fields["pull__system_tags"] = TaskSystemTags.development
|
||||
|
||||
def safe_mongoengine_key(key):
|
||||
return f"__{key}" if key in control else key
|
||||
|
||||
@@ -66,6 +70,10 @@ class ChangeStatusRequest(object):
|
||||
)
|
||||
|
||||
update_project_time(project_id)
|
||||
|
||||
# make sure that _raw_ queries are not returned back to the client
|
||||
fields.pop("__raw__", None)
|
||||
|
||||
return dict(updated=updated, fields=fields)
|
||||
|
||||
def validate_transition(self, current_status):
|
||||
@@ -95,7 +103,8 @@ def validate_status_change(current_status, new_status):
|
||||
|
||||
|
||||
state_machine = {
|
||||
TaskStatus.created: {TaskStatus.in_progress},
|
||||
TaskStatus.created: {TaskStatus.queued, TaskStatus.in_progress},
|
||||
TaskStatus.queued: {TaskStatus.created, TaskStatus.in_progress},
|
||||
TaskStatus.in_progress: {
|
||||
TaskStatus.stopped,
|
||||
TaskStatus.failed,
|
||||
@@ -125,7 +134,7 @@ state_machine = {
|
||||
TaskStatus.published,
|
||||
TaskStatus.in_progress,
|
||||
TaskStatus.created,
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
@@ -135,9 +144,11 @@ def get_possible_status_changes(current_status):
|
||||
:return possible states from current state
|
||||
"""
|
||||
possible = state_machine.get(current_status)
|
||||
assert (
|
||||
possible is not None
|
||||
), f"Current status {current_status} not supported by state machine"
|
||||
if possible is None:
|
||||
raise errors.server_error.InternalError(
|
||||
f"Current status {current_status} not supported by state machine"
|
||||
)
|
||||
|
||||
return possible
|
||||
|
||||
|
||||
|
||||
73
server/bll/util.py
Normal file
73
server/bll/util.py
Normal file
@@ -0,0 +1,73 @@
|
||||
import functools
|
||||
from operator import itemgetter
|
||||
from typing import Sequence, Optional, Callable, Tuple, Dict, Any, Set
|
||||
|
||||
from database.model import AttributedDocument
|
||||
from database.model.settings import Settings
|
||||
|
||||
|
||||
def extract_properties_to_lists(
|
||||
key_names: Sequence[str],
|
||||
data: Sequence[dict],
|
||||
extract_func: Optional[Callable[[dict], Tuple]] = None,
|
||||
) -> dict:
|
||||
"""
|
||||
Given a list of dictionaries and names of dictionary keys
|
||||
builds a dictionary with the requested keys and values lists
|
||||
:param key_names: names of the keys in the resulting dictionary
|
||||
:param data: sequence of dictionaries to extract values from
|
||||
:param extract_func: the optional callable that extracts properties
|
||||
from a dictionary and put them in a tuple in the order corresponding to
|
||||
key_names. If not specified then properties are extracted according to key_names
|
||||
"""
|
||||
value_sequences = zip(*map(extract_func or itemgetter(*key_names), data))
|
||||
return dict(zip(key_names, map(list, value_sequences)))
|
||||
|
||||
|
||||
class SetFieldsResolver:
|
||||
"""
|
||||
The class receives set fields dictionary
|
||||
and for the set fields that require 'min' or 'max'
|
||||
operation replace them with a simple set in case the
|
||||
DB document does not have these fields set
|
||||
"""
|
||||
|
||||
SET_MODIFIERS = ("min", "max")
|
||||
|
||||
def __init__(self, set_fields: Dict[str, Any]):
|
||||
self.orig_fields = set_fields
|
||||
self.fields = {
|
||||
f: fname
|
||||
for f, modifier, dunder, fname in (
|
||||
(f,) + f.partition("__") for f in set_fields.keys()
|
||||
)
|
||||
if dunder and modifier in self.SET_MODIFIERS
|
||||
}
|
||||
|
||||
def _get_updated_name(self, doc: AttributedDocument, name: str) -> str:
|
||||
if name in self.fields and doc.get_field_value(self.fields[name]) is None:
|
||||
return self.fields[name]
|
||||
return name
|
||||
|
||||
def get_fields(self, doc: AttributedDocument):
|
||||
"""
|
||||
For the given document return the set fields instructions
|
||||
with min/max operations replaced with a single set in case
|
||||
the document does not have the field set
|
||||
"""
|
||||
return {
|
||||
self._get_updated_name(doc, name): value
|
||||
for name, value in self.orig_fields.items()
|
||||
}
|
||||
|
||||
def get_names(self) -> Set[str]:
|
||||
"""
|
||||
Returns the names of the fields that had min/max modifiers
|
||||
in the format suitable for projection (dot separated)
|
||||
"""
|
||||
return set(name.replace("__", ".") for name in self.fields.values())
|
||||
|
||||
|
||||
@functools.lru_cache()
|
||||
def get_server_uuid() -> Optional[str]:
|
||||
return Settings.get_by_key("server.uuid")
|
||||
422
server/bll/workers/__init__.py
Normal file
422
server/bll/workers/__init__.py
Normal file
@@ -0,0 +1,422 @@
|
||||
import itertools
|
||||
from datetime import datetime, timedelta
|
||||
from typing import Sequence, Set, Optional
|
||||
|
||||
import attr
|
||||
import elasticsearch.helpers
|
||||
|
||||
import es_factory
|
||||
from apierrors import APIError
|
||||
from apierrors.errors import bad_request, server_error
|
||||
from apimodels.workers import (
|
||||
DEFAULT_TIMEOUT,
|
||||
IdNameEntry,
|
||||
WorkerEntry,
|
||||
StatusReportRequest,
|
||||
WorkerResponseEntry,
|
||||
QueueEntry,
|
||||
MachineStats,
|
||||
)
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.auth import User
|
||||
from database.model.company import Company
|
||||
from database.model.queue import Queue
|
||||
from database.model.task.task import Task
|
||||
from redis_manager import redman
|
||||
from timing_context import TimingContext
|
||||
from tools import safe_get
|
||||
from .stats import WorkerStats
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class WorkerBLL:
|
||||
def __init__(self, es=None, redis=None):
|
||||
self.es_client = es if es is not None else es_factory.connect("workers")
|
||||
self.redis = redis if redis is not None else redman.connection("workers")
|
||||
self._stats = WorkerStats(self.es_client)
|
||||
|
||||
@property
|
||||
def stats(self) -> WorkerStats:
|
||||
return self._stats
|
||||
|
||||
def register_worker(
|
||||
self,
|
||||
company_id: str,
|
||||
user_id: str,
|
||||
worker: str,
|
||||
ip: str = "",
|
||||
queues: Sequence[str] = None,
|
||||
timeout: int = 0,
|
||||
) -> WorkerEntry:
|
||||
"""
|
||||
Register a worker
|
||||
:param company_id: worker's company ID
|
||||
:param user_id: user ID under which this worker is running
|
||||
:param worker: worker ID
|
||||
:param ip: the real ip of the worker
|
||||
:param queues: queues reported as being monitored by the worker
|
||||
:param timeout: registration expiration timeout in seconds
|
||||
:raise bad_request.InvalidUserId: in case the calling user or company does not exist
|
||||
:return: worker entry instance
|
||||
"""
|
||||
key = WorkerBLL._get_worker_key(company_id, user_id, worker)
|
||||
|
||||
timeout = timeout or DEFAULT_TIMEOUT
|
||||
queues = queues or []
|
||||
|
||||
with translate_errors_context():
|
||||
query = dict(id=user_id, company=company_id)
|
||||
user = User.objects(**query).only("id", "name").first()
|
||||
if not user:
|
||||
raise bad_request.InvalidUserId(**query)
|
||||
company = Company.objects(id=company_id).only("id", "name").first()
|
||||
if not company:
|
||||
raise server_error.InternalError("invalid company", company=company_id)
|
||||
|
||||
queue_objs = Queue.objects(company=company_id, id__in=queues).only("id")
|
||||
if len(queue_objs) < len(queues):
|
||||
invalid = set(queues).difference(q.id for q in queue_objs)
|
||||
raise bad_request.InvalidQueueId(ids=invalid)
|
||||
|
||||
now = datetime.utcnow()
|
||||
entry = WorkerEntry(
|
||||
key=key,
|
||||
id=worker,
|
||||
user=user.to_proper_dict(),
|
||||
company=company.to_proper_dict(),
|
||||
ip=ip,
|
||||
queues=queues,
|
||||
register_time=now,
|
||||
register_timeout=timeout,
|
||||
last_activity_time=now,
|
||||
)
|
||||
|
||||
self.redis.setex(key, timedelta(seconds=timeout), entry.to_json())
|
||||
|
||||
return entry
|
||||
|
||||
def unregister_worker(self, company_id: str, user_id: str, worker: str) -> None:
|
||||
"""
|
||||
Unregister a worker
|
||||
:param company_id: worker's company ID
|
||||
:param user_id: user ID under which this worker is running
|
||||
:param worker: worker ID
|
||||
:raise bad_request.WorkerNotRegistered: the worker was not previously registered
|
||||
"""
|
||||
with TimingContext("redis", "workers_unregister"):
|
||||
res = self.redis.delete(
|
||||
company_id, self._get_worker_key(company_id, user_id, worker)
|
||||
)
|
||||
if not res:
|
||||
raise bad_request.WorkerNotRegistered(worker=worker)
|
||||
|
||||
def status_report(
|
||||
self, company_id: str, user_id: str, ip: str, report: StatusReportRequest
|
||||
) -> None:
|
||||
"""
|
||||
Write worker status report
|
||||
:param company_id: worker's company ID
|
||||
:param user_id: user_id ID under which this worker is running
|
||||
:raise bad_request.InvalidTaskId: the reported task was not found
|
||||
:return: worker entry instance
|
||||
"""
|
||||
entry = self._get_worker(company_id, user_id, report.worker)
|
||||
|
||||
try:
|
||||
entry.ip = ip
|
||||
now = datetime.utcnow()
|
||||
entry.last_activity_time = now
|
||||
|
||||
if report.machine_stats:
|
||||
self._log_stats_to_es(
|
||||
company_id=company_id,
|
||||
company_name=entry.company.name,
|
||||
worker=report.worker,
|
||||
timestamp=report.timestamp,
|
||||
task=report.task,
|
||||
machine_stats=report.machine_stats,
|
||||
)
|
||||
|
||||
entry.queue = report.queue
|
||||
|
||||
if report.queues:
|
||||
entry.queues = report.queues
|
||||
|
||||
if not report.task:
|
||||
entry.task = None
|
||||
else:
|
||||
with translate_errors_context():
|
||||
query = dict(id=report.task, company=company_id)
|
||||
update = dict(
|
||||
last_worker=report.worker,
|
||||
last_worker_report=now,
|
||||
last_update=now,
|
||||
)
|
||||
# modify(new=True, ...) returns the modified object
|
||||
task = Task.objects(**query).modify(new=True, **update)
|
||||
if not task:
|
||||
raise bad_request.InvalidTaskId(**query)
|
||||
entry.task = IdNameEntry(id=task.id, name=task.name)
|
||||
|
||||
entry.last_report_time = now
|
||||
except APIError:
|
||||
raise
|
||||
except Exception as e:
|
||||
msg = "Failed processing worker status report"
|
||||
log.exception(msg)
|
||||
raise server_error.DataError(msg, err=e.args[0])
|
||||
finally:
|
||||
self._save_worker(entry)
|
||||
|
||||
def get_all(
|
||||
self, company_id: str, last_seen: Optional[int] = None
|
||||
) -> Sequence[WorkerEntry]:
|
||||
"""
|
||||
Get all the company workers that were active during the last_seen period
|
||||
:param company_id: worker's company id
|
||||
:param last_seen: period in seconds to check. Min value is 1 second
|
||||
:return:
|
||||
"""
|
||||
try:
|
||||
workers = self._get(company_id)
|
||||
except Exception as e:
|
||||
raise server_error.DataError("failed loading worker entries", err=e.args[0])
|
||||
|
||||
if last_seen:
|
||||
ref_time = datetime.utcnow() - timedelta(seconds=max(1, last_seen))
|
||||
workers = [
|
||||
w
|
||||
for w in workers
|
||||
if w.last_activity_time.replace(tzinfo=None) >= ref_time
|
||||
]
|
||||
|
||||
return workers
|
||||
|
||||
def get_all_with_projection(
|
||||
self, company_id: str, last_seen: int
|
||||
) -> Sequence[WorkerResponseEntry]:
|
||||
|
||||
helpers = list(
|
||||
map(
|
||||
WorkerConversionHelper.from_worker_entry,
|
||||
self.get_all(company_id=company_id, last_seen=last_seen),
|
||||
)
|
||||
)
|
||||
|
||||
task_ids = set(filter(None, (helper.task_id for helper in helpers)))
|
||||
all_queues = set(
|
||||
itertools.chain.from_iterable(helper.queue_ids for helper in helpers)
|
||||
)
|
||||
|
||||
queues_info = {}
|
||||
if all_queues:
|
||||
projection = [
|
||||
{"$match": {"_id": {"$in": list(all_queues)}}},
|
||||
{
|
||||
"$project": {
|
||||
"name": 1,
|
||||
"next_entry": {"$arrayElemAt": ["$entries", 0]},
|
||||
"num_entries": {"$size": "$entries"},
|
||||
}
|
||||
},
|
||||
]
|
||||
queues_info = {
|
||||
res["_id"]: res for res in Queue.objects.aggregate(*projection)
|
||||
}
|
||||
task_ids = task_ids.union(
|
||||
filter(
|
||||
None,
|
||||
(
|
||||
safe_get(info, "next_entry/task")
|
||||
for info in queues_info.values()
|
||||
),
|
||||
)
|
||||
)
|
||||
|
||||
tasks_info = {}
|
||||
if task_ids:
|
||||
tasks_info = {
|
||||
task.id: task
|
||||
for task in Task.objects(id__in=task_ids).only(
|
||||
"name", "started", "last_iteration"
|
||||
)
|
||||
}
|
||||
|
||||
def update_queue_entries(*entries):
|
||||
for entry in entries:
|
||||
if not entry:
|
||||
continue
|
||||
info = queues_info.get(entry.id, None)
|
||||
if not info:
|
||||
continue
|
||||
entry.name = info.get("name", None)
|
||||
entry.num_tasks = info.get("num_entries", 0)
|
||||
task_id = safe_get(info, "next_entry/task")
|
||||
if task_id:
|
||||
task = tasks_info.get(task_id, None)
|
||||
entry.next_task = IdNameEntry(
|
||||
id=task_id, name=task.name if task else None
|
||||
)
|
||||
|
||||
for helper in helpers:
|
||||
worker = helper.worker
|
||||
if helper.task_id:
|
||||
task = tasks_info.get(helper.task_id, None)
|
||||
if task:
|
||||
worker.task.running_time = (
|
||||
int((datetime.utcnow() - task.started).total_seconds() * 1000)
|
||||
if task.started
|
||||
else 0
|
||||
)
|
||||
worker.task.last_iteration = task.last_iteration
|
||||
|
||||
update_queue_entries(worker.queue)
|
||||
if worker.queues:
|
||||
update_queue_entries(*worker.queues)
|
||||
|
||||
return [helper.worker for helper in helpers]
|
||||
|
||||
@staticmethod
|
||||
def _get_worker_key(company: str, user: str, worker_id: str) -> str:
|
||||
"""Build redis key from company, user and worker_id"""
|
||||
return f"worker_{company}_{user}_{worker_id}"
|
||||
|
||||
def _get_worker(self, company_id: str, user_id: str, worker: str) -> WorkerEntry:
|
||||
"""
|
||||
Get a worker entry for the provided worker ID. The entry is loaded from Redis
|
||||
if it exists (i.e. worker has already been registered), otherwise the worker
|
||||
is registered and its entry stored into Redis).
|
||||
:param company_id: worker's company ID
|
||||
:param user_id: user ID under which this worker is running
|
||||
:param worker: worker ID
|
||||
:raise bad_request.InvalidWorkerId: in case the worker id was not found
|
||||
:return: worker entry instance
|
||||
"""
|
||||
key = self._get_worker_key(company_id, user_id, worker)
|
||||
|
||||
with TimingContext("redis", "get_worker"):
|
||||
data = self.redis.get(key)
|
||||
|
||||
if data:
|
||||
try:
|
||||
entry = WorkerEntry.from_json(data)
|
||||
if not entry.key:
|
||||
entry.key = key
|
||||
self._save_worker(entry)
|
||||
return entry
|
||||
except Exception as e:
|
||||
msg = "Failed parsing worker entry"
|
||||
log.exception(msg)
|
||||
raise server_error.DataError(msg, err=e.args[0])
|
||||
|
||||
# Failed loading worker from Redis
|
||||
if config.get("apiserver.workers.auto_register", False):
|
||||
try:
|
||||
return self.register_worker(company_id, user_id, worker)
|
||||
except Exception:
|
||||
log.error(
|
||||
"Failed auto registration of {} for company {}".format(
|
||||
worker, company_id
|
||||
)
|
||||
)
|
||||
|
||||
raise bad_request.InvalidWorkerId(worker=worker)
|
||||
|
||||
def _save_worker(self, entry: WorkerEntry) -> None:
|
||||
"""Save worker entry in Redis"""
|
||||
try:
|
||||
self.redis.setex(
|
||||
entry.key, timedelta(seconds=entry.register_timeout), entry.to_json()
|
||||
)
|
||||
except Exception:
|
||||
msg = "Failed saving worker entry"
|
||||
log.exception(msg)
|
||||
|
||||
def _get(
|
||||
self, company: str, user: str = "*", worker_id: str = "*"
|
||||
) -> Sequence[WorkerEntry]:
|
||||
"""Get worker entries matching the company and user, worker patterns"""
|
||||
match = self._get_worker_key(company, user, worker_id)
|
||||
with TimingContext("redis", "workers_get_all"):
|
||||
res = self.redis.scan_iter(match)
|
||||
return [WorkerEntry.from_json(self.redis.get(r)) for r in res]
|
||||
|
||||
@staticmethod
|
||||
def _get_es_index_suffix():
|
||||
"""Get the index name suffix for storing current month data"""
|
||||
return datetime.utcnow().strftime("%Y-%m")
|
||||
|
||||
def _log_stats_to_es(
|
||||
self,
|
||||
company_id: str,
|
||||
company_name: str,
|
||||
worker: str,
|
||||
timestamp: int,
|
||||
task: str,
|
||||
machine_stats: MachineStats,
|
||||
) -> bool:
|
||||
"""
|
||||
Actually writing the worker statistics to Elastic
|
||||
:return: True if successful, False otherwise
|
||||
"""
|
||||
es_index = (
|
||||
f"{self._stats.worker_stats_prefix_for_company(company_id)}"
|
||||
f"{self._get_es_index_suffix()}"
|
||||
)
|
||||
|
||||
def make_doc(category, metric, variant, value) -> dict:
|
||||
return dict(
|
||||
_index=es_index,
|
||||
_type="stat",
|
||||
_source=dict(
|
||||
timestamp=timestamp,
|
||||
worker=worker,
|
||||
company=company_name,
|
||||
task=task,
|
||||
category=category,
|
||||
metric=metric,
|
||||
variant=variant,
|
||||
value=float(value),
|
||||
),
|
||||
)
|
||||
|
||||
actions = []
|
||||
for field, value in machine_stats.to_struct().items():
|
||||
if not value:
|
||||
continue
|
||||
category = field.partition("_")[0]
|
||||
metric = field
|
||||
if not isinstance(value, (list, tuple)):
|
||||
actions.append(make_doc(category, metric, "total", value))
|
||||
else:
|
||||
actions.extend(
|
||||
make_doc(category, metric, str(i), val)
|
||||
for i, val in enumerate(value)
|
||||
)
|
||||
|
||||
es_res = elasticsearch.helpers.bulk(self.es_client, actions)
|
||||
added, errors = es_res[:2]
|
||||
return (added == len(actions)) and not errors
|
||||
|
||||
|
||||
@attr.s(auto_attribs=True)
|
||||
class WorkerConversionHelper:
|
||||
worker: WorkerResponseEntry
|
||||
task_id: str
|
||||
queue_ids: Set[str]
|
||||
|
||||
@classmethod
|
||||
def from_worker_entry(cls, worker: WorkerEntry):
|
||||
data = worker.to_struct()
|
||||
queue = data.pop("queue", None) or None
|
||||
queue_ids = set(data.pop("queues", []))
|
||||
queues = [QueueEntry(id=id) for id in queue_ids]
|
||||
if queue:
|
||||
queue = next((q for q in queues if q.id == queue), None)
|
||||
return cls(
|
||||
worker=WorkerResponseEntry(queues=queues, queue=queue, **data),
|
||||
task_id=worker.task.id if worker.task else None,
|
||||
queue_ids=queue_ids,
|
||||
)
|
||||
244
server/bll/workers/stats.py
Normal file
244
server/bll/workers/stats.py
Normal file
@@ -0,0 +1,244 @@
|
||||
from operator import attrgetter
|
||||
from typing import Optional, Sequence
|
||||
|
||||
from boltons.iterutils import bucketize
|
||||
|
||||
from apierrors.errors import bad_request
|
||||
from apimodels.workers import AggregationType, GetStatsRequest, StatItem
|
||||
from bll.query import Builder as QueryBuilder
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from timing_context import TimingContext
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class WorkerStats:
|
||||
def __init__(self, es):
|
||||
self.es = es
|
||||
|
||||
@staticmethod
|
||||
def worker_stats_prefix_for_company(company_id: str) -> str:
|
||||
"""Returns the es index prefix for the company"""
|
||||
return f"worker_stats_{company_id}_"
|
||||
|
||||
def _search_company_stats(self, company_id: str, es_req: dict) -> dict:
|
||||
return self.es.search(
|
||||
index=f"{self.worker_stats_prefix_for_company(company_id)}*",
|
||||
doc_type="stat",
|
||||
body=es_req,
|
||||
)
|
||||
|
||||
def get_worker_stats_keys(
|
||||
self, company_id: str, worker_ids: Optional[Sequence[str]]
|
||||
) -> dict:
|
||||
"""
|
||||
Get dictionary of metric types grouped by categories
|
||||
:param company_id: company id
|
||||
:param worker_ids: optional list of workers to get metric types from.
|
||||
If not specified them metrics for all the company workers returned
|
||||
:return:
|
||||
"""
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"categories": {
|
||||
"terms": {"field": "category"},
|
||||
"aggs": {"metrics": {"terms": {"field": "metric"}}},
|
||||
}
|
||||
},
|
||||
}
|
||||
if worker_ids:
|
||||
es_req["query"] = QueryBuilder.terms("worker", worker_ids)
|
||||
|
||||
res = self._search_company_stats(company_id, es_req)
|
||||
|
||||
if not res["hits"]["total"]:
|
||||
raise bad_request.WorkerStatsNotFound(
|
||||
f"No statistic metrics found for the company {company_id} and workers {worker_ids}"
|
||||
)
|
||||
|
||||
return {
|
||||
category["key"]: [
|
||||
metric["key"] for metric in category["metrics"]["buckets"]
|
||||
]
|
||||
for category in res["aggregations"]["categories"]["buckets"]
|
||||
}
|
||||
|
||||
def get_worker_stats(self, company_id: str, request: GetStatsRequest) -> dict:
|
||||
"""
|
||||
Get statistics for company workers metrics in the specified time range
|
||||
Returned as date histograms for different aggregation types
|
||||
grouped by worker, metric type (and optionally metric variant)
|
||||
Buckets with no metrics are not returned
|
||||
Note: all the statistics are retrieved as one ES query
|
||||
"""
|
||||
if request.from_date >= request.to_date:
|
||||
raise bad_request.FieldsValueError("from_date must be less than to_date")
|
||||
|
||||
def get_dates_agg() -> dict:
|
||||
es_to_agg_types = (
|
||||
("avg", AggregationType.avg.value),
|
||||
("min", AggregationType.min.value),
|
||||
("max", AggregationType.max.value),
|
||||
)
|
||||
|
||||
return {
|
||||
"dates": {
|
||||
"date_histogram": {
|
||||
"field": "timestamp",
|
||||
"interval": f"{request.interval}s",
|
||||
"min_doc_count": 1,
|
||||
},
|
||||
"aggs": {
|
||||
agg_type: {es_agg: {"field": "value"}}
|
||||
for es_agg, agg_type in es_to_agg_types
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
def get_variants_agg() -> dict:
|
||||
return {
|
||||
"variants": {"terms": {"field": "variant"}, "aggs": get_dates_agg()}
|
||||
}
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"workers": {
|
||||
"terms": {"field": "worker"},
|
||||
"aggs": {
|
||||
"metrics": {
|
||||
"terms": {"field": "metric"},
|
||||
"aggs": get_variants_agg()
|
||||
if request.split_by_variant
|
||||
else get_dates_agg(),
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
query_terms = [
|
||||
QueryBuilder.dates_range(request.from_date, request.to_date),
|
||||
QueryBuilder.terms("metric", {item.key for item in request.items}),
|
||||
]
|
||||
if request.worker_ids:
|
||||
query_terms.append(QueryBuilder.terms("worker", request.worker_ids))
|
||||
es_req["query"] = {"bool": {"must": query_terms}}
|
||||
|
||||
with translate_errors_context(), TimingContext("es", "get_worker_stats"):
|
||||
data = self._search_company_stats(company_id, es_req)
|
||||
|
||||
return self._extract_results(data, request.items, request.split_by_variant)
|
||||
|
||||
@staticmethod
|
||||
def _extract_results(
|
||||
data: dict, request_items: Sequence[StatItem], split_by_variant: bool
|
||||
) -> dict:
|
||||
"""
|
||||
Clean results returned from elastic search (remove "aggregations", "buckets" etc.),
|
||||
leave only aggregation types requested by the user and return a clean dictionary
|
||||
and return a "clean" dictionary of
|
||||
:param data: aggregation data retrieved from ES
|
||||
:param request_items: aggs types requested by the user
|
||||
:param split_by_variant: if False then aggregate by metric type, otherwise metric type + variant
|
||||
"""
|
||||
if "aggregations" not in data:
|
||||
return {}
|
||||
|
||||
items_by_key = bucketize(request_items, key=attrgetter("key"))
|
||||
aggs_per_metric = {
|
||||
key: [item.aggregation for item in items]
|
||||
for key, items in items_by_key.items()
|
||||
}
|
||||
|
||||
def extract_date_stats(date: dict, metric_key) -> dict:
|
||||
return {
|
||||
"date": date["key"],
|
||||
"count": date["doc_count"],
|
||||
**{agg: date[agg]["value"] for agg in aggs_per_metric[metric_key]},
|
||||
}
|
||||
|
||||
def extract_metric_results(
|
||||
metric_or_variant: dict, metric_key: str
|
||||
) -> Sequence[dict]:
|
||||
return [
|
||||
extract_date_stats(date, metric_key)
|
||||
for date in metric_or_variant["dates"]["buckets"]
|
||||
if date["doc_count"]
|
||||
]
|
||||
|
||||
def extract_variant_results(metric: dict) -> dict:
|
||||
metric_key = metric["key"]
|
||||
return {
|
||||
variant["key"]: extract_metric_results(variant, metric_key)
|
||||
for variant in metric["variants"]["buckets"]
|
||||
}
|
||||
|
||||
def extract_worker_results(worker: dict) -> dict:
|
||||
return {
|
||||
metric["key"]: extract_variant_results(metric)
|
||||
if split_by_variant
|
||||
else extract_metric_results(metric, metric["key"])
|
||||
for metric in worker["metrics"]["buckets"]
|
||||
}
|
||||
|
||||
return {
|
||||
worker["key"]: extract_worker_results(worker)
|
||||
for worker in data["aggregations"]["workers"]["buckets"]
|
||||
}
|
||||
|
||||
def get_activity_report(
|
||||
self,
|
||||
company_id: str,
|
||||
from_date: float,
|
||||
to_date: float,
|
||||
interval: int,
|
||||
active_only: bool,
|
||||
) -> Sequence[dict]:
|
||||
"""
|
||||
Get statistics for company workers metrics in the specified time range
|
||||
Returned as date histograms for different aggregation types
|
||||
grouped by worker, metric type (and optionally metric variant)
|
||||
Note: all the statistics are retrieved using one ES query
|
||||
"""
|
||||
if from_date >= to_date:
|
||||
raise bad_request.FieldsValueError("from_date must be less than to_date")
|
||||
|
||||
must = [QueryBuilder.dates_range(from_date, to_date)]
|
||||
if active_only:
|
||||
must.append({"exists": {"field": "task"}})
|
||||
|
||||
es_req = {
|
||||
"size": 0,
|
||||
"aggs": {
|
||||
"dates": {
|
||||
"date_histogram": {
|
||||
"field": "timestamp",
|
||||
"interval": f"{interval}s",
|
||||
},
|
||||
"aggs": {"workers_count": {"cardinality": {"field": "worker"}}},
|
||||
}
|
||||
},
|
||||
"query": {"bool": {"must": must}},
|
||||
}
|
||||
|
||||
with translate_errors_context(), TimingContext(
|
||||
"es", "get_worker_activity_report"
|
||||
):
|
||||
data = self._search_company_stats(company_id, es_req)
|
||||
|
||||
if "aggregations" not in data:
|
||||
return {}
|
||||
|
||||
ret = [
|
||||
dict(date=date["key"], count=date["workers_count"]["value"])
|
||||
for date in data["aggregations"]["dates"]["buckets"]
|
||||
]
|
||||
|
||||
if ret and ret[-1]["date"] > (to_date - 0.9 * interval):
|
||||
# remove last interval if it's incomplete. Allow 10% tolerance
|
||||
ret.pop()
|
||||
|
||||
return ret
|
||||
@@ -1,4 +1,5 @@
|
||||
import logging
|
||||
import os
|
||||
from functools import reduce
|
||||
from os import getenv
|
||||
from os.path import expandvars
|
||||
@@ -16,6 +17,9 @@ DEFAULT_EXTRA_CONFIG_PATH = "/opt/trains/config"
|
||||
EXTRA_CONFIG_PATH_ENV_KEY = "TRAINS_CONFIG_DIR"
|
||||
EXTRA_CONFIG_PATH_SEP = ":"
|
||||
|
||||
EXTRA_CONFIG_VALUES_ENV_KEY_SEP = "__"
|
||||
EXTRA_CONFIG_VALUES_ENV_KEY_PREFIX = f"TRAINS{EXTRA_CONFIG_VALUES_ENV_KEY_SEP}"
|
||||
|
||||
|
||||
class BasicConfig:
|
||||
NotSet = object()
|
||||
@@ -46,6 +50,20 @@ class BasicConfig:
|
||||
path = ".".join((self.prefix, Path(name).stem))
|
||||
return logging.getLogger(path)
|
||||
|
||||
def _read_extra_env_config_values(self):
|
||||
""" Loads extra configuration from environment-injected values """
|
||||
result = ConfigTree()
|
||||
prefix = EXTRA_CONFIG_VALUES_ENV_KEY_PREFIX
|
||||
|
||||
keys = sorted(k for k in os.environ if k.startswith(prefix))
|
||||
for key in keys:
|
||||
path = key[len(prefix) :].replace(EXTRA_CONFIG_VALUES_ENV_KEY_SEP, ".")
|
||||
result = ConfigTree.merge_configs(
|
||||
result, ConfigFactory.parse_string(f"{path}: {os.environ[key]}")
|
||||
)
|
||||
|
||||
return result
|
||||
|
||||
def _read_env_paths(self, key):
|
||||
value = getenv(EXTRA_CONFIG_PATH_ENV_KEY, DEFAULT_EXTRA_CONFIG_PATH)
|
||||
if value is None:
|
||||
@@ -64,12 +82,17 @@ class BasicConfig:
|
||||
|
||||
def _load(self, verbose=True):
|
||||
extra_config_paths = self._read_env_paths(EXTRA_CONFIG_PATH_ENV_KEY) or []
|
||||
extra_config_values = self._read_extra_env_config_values()
|
||||
configs = [
|
||||
self._read_recursive(path, verbose=verbose)
|
||||
for path in [self.folder] + extra_config_paths
|
||||
]
|
||||
|
||||
self._config = reduce(
|
||||
lambda config, path: ConfigTree.merge_configs(
|
||||
config, self._read_recursive(path, verbose=verbose), copy_trees=True
|
||||
lambda last, config: ConfigTree.merge_configs(
|
||||
last, config, copy_trees=True
|
||||
),
|
||||
[self.folder] + extra_config_paths,
|
||||
configs + [extra_config_values],
|
||||
ConfigTree(),
|
||||
)
|
||||
|
||||
|
||||
@@ -21,12 +21,19 @@
|
||||
version {
|
||||
required: false
|
||||
default: 1.0
|
||||
# if set then calls to endpoints with the version
|
||||
# greater that the current max version will be rejected
|
||||
check_max_version: false
|
||||
}
|
||||
|
||||
mongo {
|
||||
# controls whether FieldDoesNotExist exception will be raised for any extra attribute existing in stored data
|
||||
# but not declared in a data model
|
||||
strict: false
|
||||
|
||||
aggregate {
|
||||
allow_disk_use: true
|
||||
}
|
||||
}
|
||||
|
||||
auth {
|
||||
@@ -66,7 +73,46 @@
|
||||
|
||||
cors {
|
||||
origins: "*"
|
||||
|
||||
# Not supported when origins is "*"
|
||||
supports_credentials: true
|
||||
}
|
||||
|
||||
default_company: "d1bd92a3b039400cbafc60a7a5b1e52b"
|
||||
|
||||
workers {
|
||||
# Auto-register unknown workers on status reports and other calls
|
||||
auto_register: true
|
||||
# Timeout in seconds on task status update. If exceeded
|
||||
# then task can be stopped without communicating to the worker
|
||||
task_update_timeout: 600
|
||||
}
|
||||
|
||||
check_for_updates {
|
||||
enabled: true
|
||||
|
||||
# Check for updates every 24 hours
|
||||
check_interval_sec: 86400
|
||||
|
||||
url: "https://updates.trains.allegro.ai/updates"
|
||||
|
||||
component_name: "trains-server"
|
||||
|
||||
# GET request timeout
|
||||
request_timeout_sec: 3.0
|
||||
}
|
||||
|
||||
statistics {
|
||||
# Note: statistics are sent ONLY if the user has actively opted-in
|
||||
supported: true
|
||||
|
||||
url: "https://updates.trains.allegro.ai/stats"
|
||||
|
||||
report_interval_hours: 24
|
||||
agent_relevant_threshold_days: 30
|
||||
|
||||
max_retries: 5
|
||||
max_backoff_sec: 5
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@@ -9,6 +9,17 @@ elastic {
|
||||
}
|
||||
index_version: "1"
|
||||
}
|
||||
|
||||
workers {
|
||||
hosts: [{host:"127.0.0.1", port:9200}]
|
||||
args {
|
||||
timeout: 60
|
||||
dead_timeout: 10
|
||||
max_retries: 5
|
||||
retry_on_timeout: true
|
||||
}
|
||||
index_version: "1"
|
||||
}
|
||||
}
|
||||
|
||||
mongo {
|
||||
@@ -19,3 +30,11 @@ mongo {
|
||||
host: "mongodb://127.0.0.1:27017/auth"
|
||||
}
|
||||
}
|
||||
|
||||
redis {
|
||||
workers {
|
||||
host: "127.0.0.1"
|
||||
port: 6379
|
||||
db: 4
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
from functools import lru_cache
|
||||
from pathlib import Path
|
||||
from os import getenv
|
||||
|
||||
root = Path(__file__).parent.parent
|
||||
|
||||
@@ -18,3 +19,25 @@ def get_version():
|
||||
return (root / "VERSION").read_text().strip()
|
||||
except FileNotFoundError:
|
||||
return ""
|
||||
|
||||
|
||||
@lru_cache()
|
||||
def get_commit_number():
|
||||
try:
|
||||
return (root / "COMMIT").read_text().strip()
|
||||
except FileNotFoundError:
|
||||
return ""
|
||||
|
||||
|
||||
@lru_cache()
|
||||
def get_deployment_type() -> str:
|
||||
value = getenv("TRAINS_SERVER_DEPLOYMENT_TYPE")
|
||||
if value:
|
||||
return value
|
||||
|
||||
try:
|
||||
value = (root / "DEPLOY").read_text().strip()
|
||||
except FileNotFoundError:
|
||||
pass
|
||||
|
||||
return value or "manual"
|
||||
|
||||
@@ -1,3 +1,7 @@
|
||||
from os import getenv
|
||||
|
||||
from boltons.iterutils import first
|
||||
from furl import furl
|
||||
from jsonmodels import models
|
||||
from jsonmodels.errors import ValidationError
|
||||
from jsonmodels.fields import StringField
|
||||
@@ -8,9 +12,16 @@ from config import config
|
||||
from .defs import Database
|
||||
from .utils import get_items
|
||||
|
||||
log = config.logger(__file__)
|
||||
log = config.logger("database")
|
||||
|
||||
strict = config.get('apiserver.mongo.strict', True)
|
||||
strict = config.get("apiserver.mongo.strict", True)
|
||||
|
||||
OVERRIDE_HOST_ENV_KEY = (
|
||||
"TRAINS_MONGODB_SERVICE_HOST",
|
||||
"MONGODB_SERVICE_HOST",
|
||||
"MONGODB_SERVICE_SERVICE_HOST",
|
||||
)
|
||||
OVERRIDE_PORT_ENV_KEY = ("TRAINS_MONGODB_SERVICE_PORT", "MONGODB_SERVICE_PORT")
|
||||
|
||||
_entries = []
|
||||
|
||||
@@ -21,28 +32,47 @@ class DatabaseEntry(models.Base):
|
||||
|
||||
@property
|
||||
def health_alias(self):
|
||||
return '__health__' + self.alias
|
||||
return "__health__" + self.alias
|
||||
|
||||
|
||||
def initialize():
|
||||
db_entries = config.get('hosts.mongo', {})
|
||||
db_entries = config.get("hosts.mongo", {})
|
||||
missing = []
|
||||
log.info('Initializing database connections')
|
||||
log.info("Initializing database connections")
|
||||
|
||||
override_hostname = first(map(getenv, OVERRIDE_HOST_ENV_KEY), None)
|
||||
if override_hostname:
|
||||
log.info(f"Using override mongodb host {override_hostname}")
|
||||
|
||||
override_port = first(map(getenv, OVERRIDE_PORT_ENV_KEY), None)
|
||||
if override_port:
|
||||
log.info(f"Using override mongodb port {override_port}")
|
||||
|
||||
for key, alias in get_items(Database).items():
|
||||
if key not in db_entries:
|
||||
missing.append(key)
|
||||
continue
|
||||
|
||||
entry = DatabaseEntry(alias=alias, **db_entries.get(key))
|
||||
|
||||
if override_hostname:
|
||||
entry.host = furl(entry.host).set(host=override_hostname).url
|
||||
|
||||
if override_port:
|
||||
entry.host = furl(entry.host).set(port=override_port).url
|
||||
|
||||
try:
|
||||
entry.validate()
|
||||
log.info('Registering connection to %(alias)s (%(host)s)' % entry.to_struct())
|
||||
log.info(
|
||||
"Registering connection to %(alias)s (%(host)s)" % entry.to_struct()
|
||||
)
|
||||
register_connection(alias=alias, host=entry.host)
|
||||
|
||||
_entries.append(entry)
|
||||
except ValidationError as ex:
|
||||
raise Exception('Invalid database entry `%s`: %s' % (key, ex.args[0]))
|
||||
raise Exception("Invalid database entry `%s`: %s" % (key, ex.args[0]))
|
||||
if missing:
|
||||
raise ValueError('Missing database configuration for %s' % ', '.join(missing))
|
||||
raise ValueError("Missing database configuration for %s" % ", ".join(missing))
|
||||
|
||||
|
||||
def get_entries():
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
import re
|
||||
from operator import itemgetter
|
||||
from sys import maxsize
|
||||
from typing import Type, Tuple
|
||||
|
||||
import six
|
||||
from mongoengine import (
|
||||
@@ -11,6 +12,7 @@ from mongoengine import (
|
||||
SortedListField,
|
||||
MapField,
|
||||
DictField,
|
||||
DynamicField,
|
||||
)
|
||||
|
||||
|
||||
@@ -88,104 +90,6 @@ class CustomFloatField(FloatField):
|
||||
self.error("Float value must be greater than %s" % str(self.greater_than))
|
||||
|
||||
|
||||
# TODO: bucket name should be at most 63 characters....
|
||||
aws_s3_bucket_only_regex = (
|
||||
r"^s3://"
|
||||
r"(?:(?:\w[A-Z0-9\-]+\w)\.)*(?:\w[A-Z0-9\-]+\w)" # bucket name
|
||||
)
|
||||
|
||||
aws_s3_url_with_bucket_regex = (
|
||||
r"^s3://"
|
||||
r"(?:(?:\w[A-Z0-9\-]+\w)\.)*(?:\w[A-Z0-9\-]+\w)" # bucket name
|
||||
r"(?:(?:[A-Z0-9](?:[A-Z0-9-]{0,61}[A-Z0-9])?\.)+(?:[A-Z]{2,6}\.?|[A-Z0-9-]{2,}(?<!-)\.?))" # domain...
|
||||
)
|
||||
|
||||
non_aws_s3_regex = (
|
||||
r"^s3://"
|
||||
r"(?:(?:[A-Z0-9](?:[A-Z0-9-]{0,61}[A-Z0-9])?\.)+(?:[A-Z]{2,6}\.?|[A-Z0-9-]{2,}(?<!-)\.?)|" # domain...
|
||||
r"localhost|" # localhost...
|
||||
r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}|" # ...or ipv4
|
||||
r"\[?[A-F0-9]*:[A-F0-9:]+\]?)" # ...or ipv6
|
||||
r"(?::\d+)?" # optional port
|
||||
r"(?:/(?:(?:\w[A-Z0-9\-]+\w)\.)*(?:\w[A-Z0-9\-]+\w))" # bucket name
|
||||
)
|
||||
|
||||
google_gs_bucket_only_regex = (
|
||||
r"^gs://"
|
||||
r"(?:(?:\w[A-Z0-9\-_]+\w)\.)*(?:\w[A-Z0-9\-_]+\w)" # bucket name
|
||||
)
|
||||
|
||||
file_regex = r"^file://"
|
||||
|
||||
generic_url_regex = (
|
||||
r"^%s://" # scheme placeholder
|
||||
r"(?:(?:[A-Z0-9](?:[A-Z0-9-]{0,61}[A-Z0-9])?\.)+(?:[A-Z]{2,6}\.?|[A-Z0-9-]{2,}(?<!-)\.?)|" # domain...
|
||||
r"localhost|" # localhost...
|
||||
r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}|" # ...or ipv4
|
||||
r"\[?[A-F0-9]*:[A-F0-9:]+\]?)" # ...or ipv6
|
||||
r"(?::\d+)?" # optional port
|
||||
)
|
||||
|
||||
path_suffix = r"(?:/?|[/?]\S+)$"
|
||||
file_path_suffix = r"(?:/\S*[^/]+)$"
|
||||
|
||||
|
||||
class _RegexURLField(StringField):
|
||||
_regex = []
|
||||
|
||||
def __init__(self, regex, **kwargs):
|
||||
super(_RegexURLField, self).__init__(**kwargs)
|
||||
regex = regex if isinstance(regex, (tuple, list)) else [regex]
|
||||
self._regex = [
|
||||
re.compile(e, re.IGNORECASE) if isinstance(e, six.string_types) else e
|
||||
for e in regex
|
||||
]
|
||||
|
||||
def validate(self, value):
|
||||
# Check first if the scheme is valid
|
||||
if not any(regex for regex in self._regex if regex.match(value)):
|
||||
self.error("Invalid URL: {}".format(value))
|
||||
return
|
||||
|
||||
|
||||
class OutputDestinationField(_RegexURLField):
|
||||
""" A field representing task output URL """
|
||||
|
||||
schemes = ["s3", "gs", "file"]
|
||||
_expressions = (
|
||||
aws_s3_bucket_only_regex + path_suffix,
|
||||
aws_s3_url_with_bucket_regex + path_suffix,
|
||||
non_aws_s3_regex + path_suffix,
|
||||
google_gs_bucket_only_regex + path_suffix,
|
||||
file_regex + path_suffix,
|
||||
)
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
super(OutputDestinationField, self).__init__(self._expressions, **kwargs)
|
||||
|
||||
|
||||
class SupportedURLField(_RegexURLField):
|
||||
""" A field representing a model URL """
|
||||
|
||||
schemes = ["s3", "gs", "file", "http", "https"]
|
||||
|
||||
_expressions = tuple(
|
||||
pattern + file_path_suffix
|
||||
for pattern in (
|
||||
aws_s3_bucket_only_regex,
|
||||
aws_s3_url_with_bucket_regex,
|
||||
non_aws_s3_regex,
|
||||
google_gs_bucket_only_regex,
|
||||
file_regex,
|
||||
(generic_url_regex % "http"),
|
||||
(generic_url_regex % "https"),
|
||||
)
|
||||
)
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
super(SupportedURLField, self).__init__(self._expressions, **kwargs)
|
||||
|
||||
|
||||
class StrippedStringField(StringField):
|
||||
def __init__(
|
||||
self, regex=None, max_length=None, min_length=None, strip_chars=None, **kwargs
|
||||
@@ -235,3 +139,42 @@ class SafeDictField(DictField):
|
||||
|
||||
if contains_empty_key(value):
|
||||
self.error("Empty keys are not allowed in a DictField")
|
||||
|
||||
|
||||
class SafeSortedListField(SortedListField):
|
||||
"""
|
||||
SortedListField that does not raise an error in case items are not comparable
|
||||
(in which case they will be sorted by their string representation)
|
||||
"""
|
||||
def to_mongo(self, *args, **kwargs):
|
||||
try:
|
||||
return super(SafeSortedListField, self).to_mongo(*args, **kwargs)
|
||||
except TypeError:
|
||||
return self._safe_to_mongo(*args, **kwargs)
|
||||
|
||||
def _safe_to_mongo(self, value, use_db_field=True, fields=None):
|
||||
value = super(SortedListField, self).to_mongo(value, use_db_field, fields)
|
||||
if self._ordering is not None:
|
||||
def key(v): return str(itemgetter(self._ordering)(v))
|
||||
else:
|
||||
key = str
|
||||
return sorted(value, key=key, reverse=self._order_reverse)
|
||||
|
||||
|
||||
class UnionField(DynamicField):
|
||||
def __init__(self, types, *args, **kwargs):
|
||||
super(UnionField, self).__init__(*args, **kwargs)
|
||||
self.types: Tuple[Type] = tuple(types)
|
||||
|
||||
def validate(self, value, clean=True):
|
||||
if not isinstance(value, self.types):
|
||||
type_names = [t.__name__ for t in self.types]
|
||||
expected = " or ".join(
|
||||
filter(
|
||||
None,
|
||||
(", ".join(type_names[:-1]), type_names[-1]))
|
||||
)
|
||||
self.error(
|
||||
f"Expected {expected}, got {type(value).__name__}: {value}"
|
||||
)
|
||||
super(UnionField, self).validate(value, clean)
|
||||
|
||||
@@ -1,3 +1,5 @@
|
||||
from enum import Enum
|
||||
|
||||
from mongoengine import Document, StringField
|
||||
|
||||
from apierrors import errors
|
||||
@@ -54,3 +56,7 @@ def validate_id(cls, company, **kwargs):
|
||||
**{name: obj_id for obj_id in missing for name in id_to_name[obj_id]}
|
||||
)
|
||||
|
||||
|
||||
class EntityVisibility(Enum):
|
||||
active = "active"
|
||||
archived = "archived"
|
||||
|
||||
@@ -45,6 +45,7 @@ class Role(object):
|
||||
class Credentials(EmbeddedDocument):
|
||||
key = StringField(required=True)
|
||||
secret = StringField(required=True)
|
||||
last_used = DateTimeField()
|
||||
|
||||
|
||||
class User(DbModelMixin, AuthDocument):
|
||||
|
||||
@@ -1,11 +1,12 @@
|
||||
import re
|
||||
from collections import namedtuple
|
||||
from functools import reduce
|
||||
from typing import Collection
|
||||
from typing import Collection, Sequence, Union
|
||||
|
||||
from boltons.iterutils import first
|
||||
from dateutil.parser import parse as parse_datetime
|
||||
from mongoengine import Q, Document
|
||||
from six import string_types
|
||||
from mongoengine import Q, Document, ListField, StringField
|
||||
from pymongo.command_cursor import CommandCursor
|
||||
|
||||
from apierrors import errors
|
||||
from config import config
|
||||
@@ -13,7 +14,12 @@ from database.errors import MakeGetAllQueryError
|
||||
from database.projection import project_dict, ProjectionHelper
|
||||
from database.props import PropsMixin
|
||||
from database.query import RegexQ, RegexWrapper
|
||||
from database.utils import get_company_or_none_constraint, get_fields_with_attr
|
||||
from database.utils import (
|
||||
get_company_or_none_constraint,
|
||||
get_fields_choices,
|
||||
field_does_not_exist,
|
||||
field_exists,
|
||||
)
|
||||
|
||||
log = config.logger("dbmodel")
|
||||
|
||||
@@ -56,6 +62,7 @@ class GetMixin(PropsMixin):
|
||||
_text_score = "$text_score"
|
||||
|
||||
_ordering_key = "order_by"
|
||||
_search_text_key = "search_text"
|
||||
|
||||
_multi_field_param_sep = "__"
|
||||
_multi_field_param_prefix = {
|
||||
@@ -68,7 +75,7 @@ class GetMixin(PropsMixin):
|
||||
def __init__(
|
||||
self,
|
||||
pattern_fields=("name",),
|
||||
list_fields=("tags", "id"),
|
||||
list_fields=("tags", "system_tags", "id"),
|
||||
datetime_fields=None,
|
||||
fields=None,
|
||||
):
|
||||
@@ -215,6 +222,24 @@ class GetMixin(PropsMixin):
|
||||
return get_company_or_none_constraint(company)
|
||||
return Q(company=company)
|
||||
|
||||
@classmethod
|
||||
def validate_order_by(cls, parameters, search_text) -> Sequence:
|
||||
"""
|
||||
Validate and extract order_by params as a list
|
||||
"""
|
||||
order_by = parameters.get(cls._ordering_key)
|
||||
if not order_by:
|
||||
return []
|
||||
|
||||
order_by = order_by if isinstance(order_by, list) else [order_by]
|
||||
order_by = [cls._text_score if x == "@text_score" else x for x in order_by]
|
||||
if not search_text and cls._text_score in order_by:
|
||||
raise errors.bad_request.FieldsValueError(
|
||||
"text score cannot be used in order_by when search text is not used"
|
||||
)
|
||||
|
||||
return order_by
|
||||
|
||||
@classmethod
|
||||
def validate_paging(
|
||||
cls, parameters=None, default_page=None, default_page_size=None
|
||||
@@ -332,8 +357,9 @@ class GetMixin(PropsMixin):
|
||||
`@text_score` keyword. A text index must be defined on the document type, otherwise an error will
|
||||
be raised.
|
||||
:param return_dicts: Return a list of dictionaries. If True, a list of dicts is returned (if projection was
|
||||
requested, each contains only the requested projection).
|
||||
If False, a QuerySet object is returned (lazy evaluated)
|
||||
requested, each contains only the requested projection). If False, a QuerySet object is returned
|
||||
(lazy evaluated). If return_dicts is requested then the entities with the None value in order_by field
|
||||
are returned last in the ordering.
|
||||
:param company: Company ID (required)
|
||||
:param parameters: Parameters dict from which paging ordering and searching parameters are extracted.
|
||||
:param query_dict: If provided, passed to prepare_query() along with all of the relevant arguments to produce
|
||||
@@ -356,17 +382,19 @@ class GetMixin(PropsMixin):
|
||||
q = cls._prepare_perm_query(company, allow_public=allow_public)
|
||||
_query = (q & query) if query else q
|
||||
|
||||
if return_dicts:
|
||||
return cls._get_many_override_none_ordering(
|
||||
query=_query,
|
||||
parameters=parameters,
|
||||
override_projection=override_projection,
|
||||
)
|
||||
|
||||
return cls._get_many_no_company(
|
||||
query=_query,
|
||||
parameters=parameters,
|
||||
override_projection=override_projection,
|
||||
return_dicts=return_dicts,
|
||||
query=_query, parameters=parameters, override_projection=override_projection
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def _get_many_no_company(
|
||||
cls, query, parameters=None, override_projection=None, return_dicts=True
|
||||
):
|
||||
def _get_many_no_company(cls, query, parameters=None, override_projection=None):
|
||||
"""
|
||||
Fetch all documents matching a provided query.
|
||||
This is a company-less version for internal uses. We assume the caller has either added any necessary
|
||||
@@ -375,44 +403,25 @@ class GetMixin(PropsMixin):
|
||||
NOTE: BE VERY CAREFUL WITH THIS CALL, as it allows returning data across companies.
|
||||
|
||||
:param query: Query object (mongoengine.Q)
|
||||
:param return_dicts: Return a list of dictionaries. If True, a list of dicts is returned (if projection was
|
||||
requested, each contains only the requested projection).
|
||||
If False, a QuerySet object is returned (lazy evaluated)
|
||||
:param parameters: Parameters dict from which paging ordering and searching parameters are extracted.
|
||||
:param override_projection: A list of projection fields overriding any projection specified in the `param_dict`
|
||||
argument
|
||||
"""
|
||||
parameters = parameters or {}
|
||||
|
||||
if not query:
|
||||
raise ValueError("query or call_data must be provided")
|
||||
|
||||
parameters = parameters or {}
|
||||
search_text = parameters.get(cls._search_text_key)
|
||||
order_by = cls.validate_order_by(parameters=parameters, search_text=search_text)
|
||||
page, page_size = cls.validate_paging(parameters=parameters)
|
||||
|
||||
order_by = parameters.get(cls._ordering_key)
|
||||
if order_by:
|
||||
order_by = order_by if isinstance(order_by, list) else [order_by]
|
||||
order_by = [cls._text_score if x == "@text_score" else x for x in order_by]
|
||||
|
||||
search_text = parameters.get("search_text")
|
||||
|
||||
only = cls.get_projection(parameters, override_projection)
|
||||
|
||||
if not search_text and order_by and cls._text_score in order_by:
|
||||
raise errors.bad_request.FieldsValueError(
|
||||
"text score cannot be used in order_by when search text is not used"
|
||||
)
|
||||
|
||||
qs = cls.objects(query)
|
||||
if search_text:
|
||||
qs = qs.search_text(search_text)
|
||||
if order_by:
|
||||
# add ordering
|
||||
qs = (
|
||||
qs.order_by(order_by)
|
||||
if isinstance(order_by, string_types)
|
||||
else qs.order_by(*order_by)
|
||||
)
|
||||
qs = qs.order_by(*order_by)
|
||||
if only:
|
||||
# add projection
|
||||
qs = qs.only(*only)
|
||||
@@ -424,10 +433,91 @@ class GetMixin(PropsMixin):
|
||||
# add paging
|
||||
qs = qs.skip(page * page_size).limit(page_size)
|
||||
|
||||
if return_dicts:
|
||||
return [obj.to_proper_dict(only=only) for obj in qs]
|
||||
return qs
|
||||
|
||||
@classmethod
|
||||
def _get_many_override_none_ordering(
|
||||
cls: Union[Document, "GetMixin"],
|
||||
query: Q = None,
|
||||
parameters: dict = None,
|
||||
override_projection: Collection[str] = None,
|
||||
) -> Sequence[dict]:
|
||||
"""
|
||||
Fetch all documents matching a provided query. For the first order by field
|
||||
the None values are sorted in the end regardless of the sorting order.
|
||||
This is a company-less version for internal uses. We assume the caller has either added any necessary
|
||||
constraints to the query or that no constraints are required.
|
||||
|
||||
NOTE: BE VERY CAREFUL WITH THIS CALL, as it allows returning data across companies.
|
||||
|
||||
:param query: Query object (mongoengine.Q)
|
||||
:param parameters: Parameters dict from which paging ordering and searching parameters are extracted.
|
||||
:param override_projection: A list of projection fields overriding any projection specified in the `param_dict`
|
||||
argument
|
||||
"""
|
||||
if not query:
|
||||
raise ValueError("query or call_data must be provided")
|
||||
|
||||
parameters = parameters or {}
|
||||
search_text = parameters.get(cls._search_text_key)
|
||||
order_by = cls.validate_order_by(parameters=parameters, search_text=search_text)
|
||||
page, page_size = cls.validate_paging(parameters=parameters)
|
||||
only = cls.get_projection(parameters, override_projection)
|
||||
|
||||
query_sets = [cls.objects(query)]
|
||||
if order_by:
|
||||
order_field = first(
|
||||
field for field in order_by if not field.startswith("$")
|
||||
)
|
||||
if (
|
||||
order_field
|
||||
and not order_field.startswith("-")
|
||||
and "[" not in order_field
|
||||
):
|
||||
params = {}
|
||||
mongo_field = order_field.replace(".", "__")
|
||||
if mongo_field in cls.get_field_names_for_type(of_type=ListField):
|
||||
params["is_list"] = True
|
||||
elif mongo_field in cls.get_field_names_for_type(of_type=StringField):
|
||||
params["empty_value"] = ""
|
||||
non_empty = query & field_exists(mongo_field, **params)
|
||||
empty = query & field_does_not_exist(mongo_field, **params)
|
||||
query_sets = [cls.objects(non_empty), cls.objects(empty)]
|
||||
|
||||
query_sets = [qs.order_by(*order_by) for qs in query_sets]
|
||||
|
||||
if search_text:
|
||||
query_sets = [qs.search_text(search_text) for qs in query_sets]
|
||||
|
||||
if only:
|
||||
# add projection
|
||||
query_sets = [qs.only(*only) for qs in query_sets]
|
||||
else:
|
||||
exclude = set(cls.get_exclude_fields())
|
||||
if exclude:
|
||||
query_sets = [qs.exclude(*exclude) for qs in query_sets]
|
||||
|
||||
if page is None or not page_size:
|
||||
return [obj.to_proper_dict(only=only) for qs in query_sets for obj in qs]
|
||||
|
||||
# add paging
|
||||
ret = []
|
||||
start = page * page_size
|
||||
for qs in query_sets:
|
||||
qs_size = qs.count()
|
||||
if qs_size < start:
|
||||
start -= qs_size
|
||||
continue
|
||||
ret.extend(
|
||||
obj.to_proper_dict(only=only) for obj in qs.skip(start).limit(page_size)
|
||||
)
|
||||
if len(ret) >= page_size:
|
||||
break
|
||||
start = 0
|
||||
page_size -= len(ret)
|
||||
|
||||
return ret
|
||||
|
||||
@classmethod
|
||||
def get_for_writing(
|
||||
cls, *args, _only: Collection[str] = None, **kwargs
|
||||
@@ -464,8 +554,8 @@ class UpdateMixin(object):
|
||||
def user_set_allowed(cls):
|
||||
res = getattr(cls, "__user_set_allowed_fields", None)
|
||||
if res is None:
|
||||
res = cls.__user_set_allowed_fields = dict(
|
||||
get_fields_with_attr(cls, "user_set_allowed")
|
||||
res = cls.__user_set_allowed_fields = get_fields_choices(
|
||||
cls, "user_set_allowed"
|
||||
)
|
||||
return res
|
||||
|
||||
@@ -503,7 +593,24 @@ class UpdateMixin(object):
|
||||
class DbModelMixin(GetMixin, ProperDictMixin, UpdateMixin):
|
||||
""" Provide convenience methods for a subclass of mongoengine.Document """
|
||||
|
||||
pass
|
||||
@classmethod
|
||||
def aggregate(
|
||||
cls: Document, *pipeline: dict, allow_disk_use=None, **kwargs
|
||||
) -> CommandCursor:
|
||||
"""
|
||||
Aggregate objects of this document class according to the provided pipeline.
|
||||
:param pipeline: a list of dictionaries describing the pipeline stages
|
||||
:param allow_disk_use: if True, allow the server to use disk space if aggregation query cannot fit in memory.
|
||||
If None, default behavior will be used (see apiserver.conf/mongo/aggregate/allow_disk_use)
|
||||
:param kwargs: additional keyword arguments passed to mongoengine
|
||||
:return:
|
||||
"""
|
||||
kwargs.update(
|
||||
allowDiskUse=allow_disk_use
|
||||
if allow_disk_use is not None
|
||||
else config.get("apiserver.mongo.aggregate.allow_disk_use", True)
|
||||
)
|
||||
return cls.objects.aggregate(*pipeline, **kwargs)
|
||||
|
||||
|
||||
def validate_id(cls, company, **kwargs):
|
||||
|
||||
@@ -1,23 +1,36 @@
|
||||
from mongoengine import Document, EmbeddedDocument, EmbeddedDocumentField, StringField, Q
|
||||
from mongoengine import (
|
||||
Document,
|
||||
EmbeddedDocument,
|
||||
EmbeddedDocumentField,
|
||||
StringField,
|
||||
Q,
|
||||
BooleanField,
|
||||
DateTimeField,
|
||||
)
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import StrippedStringField
|
||||
from database.model import DbModelMixin
|
||||
|
||||
|
||||
class ReportStatsOption(EmbeddedDocument):
|
||||
enabled = BooleanField(default=False) # opt-in for statistics reporting
|
||||
enabled_version = StringField() # server version when enabled
|
||||
enabled_time = DateTimeField() # time when enabled
|
||||
enabled_user = StringField() # ID of user who enabled
|
||||
|
||||
|
||||
class CompanyDefaults(EmbeddedDocument):
|
||||
cluster = StringField()
|
||||
stats_option = EmbeddedDocumentField(ReportStatsOption, default=ReportStatsOption)
|
||||
|
||||
|
||||
class Company(DbModelMixin, Document):
|
||||
meta = {
|
||||
'db_alias': Database.backend,
|
||||
'strict': strict,
|
||||
}
|
||||
meta = {"db_alias": Database.backend, "strict": strict}
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
name = StrippedStringField(unique=True, min_length=3)
|
||||
defaults = EmbeddedDocumentField(CompanyDefaults)
|
||||
defaults = EmbeddedDocumentField(CompanyDefaults, default=CompanyDefaults)
|
||||
|
||||
@classmethod
|
||||
def _prepare_perm_query(cls, company, allow_public=False):
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
from mongoengine import Document, StringField, DateTimeField, ListField, BooleanField
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import SupportedURLField, StrippedStringField, SafeDictField
|
||||
from database.fields import StrippedStringField, SafeDictField
|
||||
from database.model import DbModelMixin
|
||||
from database.model.model_labels import ModelLabels
|
||||
from database.model.company import Company
|
||||
@@ -48,7 +48,8 @@ class Model(DbModelMixin, Document):
|
||||
task = StringField(reference_field=Task)
|
||||
comment = StringField(user_set_allowed=True)
|
||||
tags = ListField(StringField(required=True), user_set_allowed=True)
|
||||
uri = SupportedURLField(default='', user_set_allowed=True)
|
||||
system_tags = ListField(StringField(required=True), user_set_allowed=True)
|
||||
uri = StrippedStringField(default='', user_set_allowed=True)
|
||||
framework = StringField()
|
||||
design = SafeDictField()
|
||||
labels = ModelLabels()
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
from mongoengine import StringField, DateTimeField, ListField
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import OutputDestinationField, StrippedStringField
|
||||
from database.fields import StrippedStringField
|
||||
from database.model import AttributedDocument
|
||||
from database.model.base import GetMixin
|
||||
|
||||
@@ -9,7 +9,8 @@ from database.model.base import GetMixin
|
||||
class Project(AttributedDocument):
|
||||
|
||||
get_all_query_options = GetMixin.QueryParameterOptions(
|
||||
pattern_fields=("name", "description"), list_fields=("tags", "id")
|
||||
pattern_fields=("name", "description"),
|
||||
list_fields=("tags", "system_tags", "id"),
|
||||
)
|
||||
|
||||
meta = {
|
||||
@@ -34,6 +35,7 @@ class Project(AttributedDocument):
|
||||
)
|
||||
description = StringField(required=True)
|
||||
created = DateTimeField(required=True)
|
||||
tags = ListField(StringField(required=True), default=list)
|
||||
default_output_destination = OutputDestinationField()
|
||||
tags = ListField(StringField(required=True))
|
||||
system_tags = ListField(StringField(required=True))
|
||||
default_output_destination = StrippedStringField()
|
||||
last_update = DateTimeField()
|
||||
|
||||
47
server/database/model/queue.py
Normal file
47
server/database/model/queue.py
Normal file
@@ -0,0 +1,47 @@
|
||||
from mongoengine import (
|
||||
Document,
|
||||
EmbeddedDocument,
|
||||
StringField,
|
||||
DateTimeField,
|
||||
EmbeddedDocumentListField,
|
||||
ListField,
|
||||
)
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import StrippedStringField
|
||||
from database.model import DbModelMixin
|
||||
from database.model.base import ProperDictMixin, GetMixin
|
||||
from database.model.company import Company
|
||||
from database.model.task.task import Task
|
||||
|
||||
|
||||
class Entry(EmbeddedDocument, ProperDictMixin):
|
||||
""" Entry representing a task waiting in the queue """
|
||||
task = StringField(required=True, reference_field=Task)
|
||||
''' Task ID '''
|
||||
added = DateTimeField(required=True)
|
||||
''' Added to the queue '''
|
||||
|
||||
|
||||
class Queue(DbModelMixin, Document):
|
||||
|
||||
get_all_query_options = GetMixin.QueryParameterOptions(
|
||||
pattern_fields=("name",),
|
||||
list_fields=("tags", "system_tags", "id"),
|
||||
)
|
||||
|
||||
meta = {
|
||||
'db_alias': Database.backend,
|
||||
'strict': strict,
|
||||
}
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
name = StrippedStringField(
|
||||
required=True, unique_with="company", min_length=3, user_set_allowed=True
|
||||
)
|
||||
company = StringField(required=True, reference_field=Company)
|
||||
created = DateTimeField(required=True)
|
||||
tags = ListField(StringField(required=True), default=list, user_set_allowed=True)
|
||||
system_tags = ListField(StringField(required=True), user_set_allowed=True)
|
||||
entries = EmbeddedDocumentListField(Entry, default=list)
|
||||
last_update = DateTimeField()
|
||||
57
server/database/model/settings.py
Normal file
57
server/database/model/settings.py
Normal file
@@ -0,0 +1,57 @@
|
||||
from typing import Any, Optional, Sequence, Tuple
|
||||
|
||||
from mongoengine import Document, StringField, DynamicField, Q
|
||||
from mongoengine.errors import NotUniqueError
|
||||
|
||||
from database import Database, strict
|
||||
from database.model import DbModelMixin
|
||||
|
||||
|
||||
class Settings(DbModelMixin, Document):
|
||||
meta = {
|
||||
"db_alias": Database.backend,
|
||||
"strict": strict,
|
||||
}
|
||||
|
||||
key = StringField(primary_key=True)
|
||||
value = DynamicField()
|
||||
|
||||
@classmethod
|
||||
def get_by_key(cls, key: str, default: Optional[Any] = None, sep: str = ".") -> Any:
|
||||
key = key.strip(sep)
|
||||
res = Settings.objects(key=key).first()
|
||||
if not res:
|
||||
return default
|
||||
return res.value
|
||||
|
||||
@classmethod
|
||||
def get_by_prefix(
|
||||
cls, key_prefix: str, default: Optional[Any] = None, sep: str = "."
|
||||
) -> Sequence[Tuple[str, Any]]:
|
||||
key_prefix = key_prefix.strip(sep)
|
||||
query = Q(key=key_prefix) | Q(key__startswith=key_prefix + sep)
|
||||
res = Settings.objects(query)
|
||||
if not res:
|
||||
return default
|
||||
return [(x.key, x.value) for x in res]
|
||||
|
||||
@classmethod
|
||||
def set_or_add_value(cls, key: str, value: Any, sep: str = ".") -> bool:
|
||||
""" Sets a new value or adds a new key/value setting (if key does not exist) """
|
||||
key = key.strip(sep)
|
||||
res = Settings.objects(key=key).update(key=key, value=value, upsert=True)
|
||||
# if Settings.objects(key=key).only("key"):
|
||||
#
|
||||
# else:
|
||||
# res = Settings(key=key, value=value).save()
|
||||
return bool(res)
|
||||
|
||||
@classmethod
|
||||
def add_value(cls, key: str, value: Any, sep: str = ".") -> bool:
|
||||
""" Adds a new key/value settings. Fails if key already exists. """
|
||||
key = key.strip(sep)
|
||||
try:
|
||||
res = Settings(key=key, value=value).save(force_insert=True)
|
||||
return bool(res)
|
||||
except NotUniqueError:
|
||||
return False
|
||||
@@ -1,14 +1,14 @@
|
||||
from mongoengine import EmbeddedDocument, StringField, DateTimeField, LongField, DynamicField
|
||||
from mongoengine import EmbeddedDocument, StringField, DynamicField
|
||||
|
||||
|
||||
class MetricEvent(EmbeddedDocument):
|
||||
metric = StringField(required=True, )
|
||||
variant = StringField(required=True)
|
||||
type = StringField(required=True)
|
||||
timestamp = DateTimeField(default=0, required=True)
|
||||
iter = LongField()
|
||||
value = DynamicField(required=True)
|
||||
meta = {
|
||||
# For backwards compatibility reasons
|
||||
'strict': False,
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, **kwargs):
|
||||
return cls(**{k: v for k, v in kwargs.items() if k in cls._fields})
|
||||
metric = StringField(required=True)
|
||||
variant = StringField(required=True)
|
||||
value = DynamicField(required=True)
|
||||
min_value = DynamicField() # for backwards compatibility reasons
|
||||
max_value = DynamicField() # for backwards compatibility reasons
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
from mongoengine import EmbeddedDocument, StringField
|
||||
from database.utils import get_options
|
||||
|
||||
from database.fields import OutputDestinationField
|
||||
from database.fields import StrippedStringField
|
||||
from database.utils import get_options
|
||||
|
||||
|
||||
class Result(object):
|
||||
@@ -10,7 +10,7 @@ class Result(object):
|
||||
|
||||
|
||||
class Output(EmbeddedDocument):
|
||||
destination = OutputDestinationField()
|
||||
destination = StrippedStringField()
|
||||
model = StringField(reference_field='Model')
|
||||
error = StringField(user_set_allowed=True)
|
||||
result = StringField(choices=get_options(Result))
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
from enum import Enum
|
||||
|
||||
from mongoengine import (
|
||||
StringField,
|
||||
EmbeddedDocumentField,
|
||||
@@ -7,10 +5,18 @@ from mongoengine import (
|
||||
DateTimeField,
|
||||
IntField,
|
||||
ListField,
|
||||
LongField,
|
||||
)
|
||||
|
||||
from database import Database, strict
|
||||
from database.fields import StrippedStringField, SafeMapField, SafeDictField
|
||||
from database.fields import (
|
||||
StrippedStringField,
|
||||
SafeMapField,
|
||||
SafeDictField,
|
||||
UnionField,
|
||||
EmbeddedDocumentSortedListField,
|
||||
SafeSortedListField,
|
||||
)
|
||||
from database.model import AttributedDocument
|
||||
from database.model.model_labels import ModelLabels
|
||||
from database.model.project import Project
|
||||
@@ -22,27 +28,28 @@ DEFAULT_LAST_ITERATION = 0
|
||||
|
||||
|
||||
class TaskStatus(object):
|
||||
created = 'created'
|
||||
in_progress = 'in_progress'
|
||||
stopped = 'stopped'
|
||||
publishing = 'publishing'
|
||||
published = 'published'
|
||||
closed = 'closed'
|
||||
failed = 'failed'
|
||||
completed = 'completed'
|
||||
unknown = 'unknown'
|
||||
created = "created"
|
||||
queued = "queued"
|
||||
in_progress = "in_progress"
|
||||
stopped = "stopped"
|
||||
publishing = "publishing"
|
||||
published = "published"
|
||||
closed = "closed"
|
||||
failed = "failed"
|
||||
completed = "completed"
|
||||
unknown = "unknown"
|
||||
|
||||
|
||||
class TaskStatusMessage(object):
|
||||
stopping = 'stopping'
|
||||
stopping = "stopping"
|
||||
|
||||
|
||||
class TaskTags(object):
|
||||
development = 'development'
|
||||
class TaskSystemTags(object):
|
||||
development = "development"
|
||||
|
||||
|
||||
class Script(EmbeddedDocument):
|
||||
binary = StringField(default='python')
|
||||
binary = StringField(default="python")
|
||||
repository = StringField(required=True)
|
||||
tag = StringField()
|
||||
branch = StringField()
|
||||
@@ -53,51 +60,70 @@ class Script(EmbeddedDocument):
|
||||
diff = StringField()
|
||||
|
||||
|
||||
class ArtifactTypeData(EmbeddedDocument):
|
||||
preview = StringField()
|
||||
content_type = StringField()
|
||||
data_hash = StringField()
|
||||
|
||||
|
||||
class Artifact(EmbeddedDocument):
|
||||
key = StringField(required=True)
|
||||
type = StringField(required=True)
|
||||
mode = StringField(choices=("input", "output"), default="output")
|
||||
uri = StringField()
|
||||
hash = StringField()
|
||||
content_size = LongField()
|
||||
timestamp = LongField()
|
||||
type_data = EmbeddedDocumentField(ArtifactTypeData)
|
||||
display_data = SafeSortedListField(ListField(UnionField((int, float, str))))
|
||||
|
||||
|
||||
class Execution(EmbeddedDocument):
|
||||
test_split = IntField(default=0)
|
||||
parameters = SafeDictField(default=dict)
|
||||
model = StringField(reference_field='Model')
|
||||
model_desc = SafeMapField(StringField(default=''))
|
||||
model = StringField(reference_field="Model")
|
||||
model_desc = SafeMapField(StringField(default=""))
|
||||
model_labels = ModelLabels()
|
||||
framework = StringField()
|
||||
|
||||
artifacts = EmbeddedDocumentSortedListField(Artifact)
|
||||
docker_cmd = StringField()
|
||||
queue = StringField()
|
||||
''' Queue ID where task was queued '''
|
||||
""" Queue ID where task was queued """
|
||||
|
||||
|
||||
class TaskType(object):
|
||||
training = 'training'
|
||||
testing = 'testing'
|
||||
training = "training"
|
||||
testing = "testing"
|
||||
|
||||
|
||||
class Task(AttributedDocument):
|
||||
meta = {
|
||||
'db_alias': Database.backend,
|
||||
'strict': strict,
|
||||
'indexes': [
|
||||
'created',
|
||||
'started',
|
||||
'completed',
|
||||
"db_alias": Database.backend,
|
||||
"strict": strict,
|
||||
"indexes": [
|
||||
"created",
|
||||
"started",
|
||||
"completed",
|
||||
{
|
||||
'name': '%s.task.main_text_index' % Database.backend,
|
||||
'fields': [
|
||||
'$name',
|
||||
'$id',
|
||||
'$comment',
|
||||
'$execution.model',
|
||||
'$output.model',
|
||||
'$script.repository',
|
||||
'$script.entry_point',
|
||||
"name": "%s.task.main_text_index" % Database.backend,
|
||||
"fields": [
|
||||
"$name",
|
||||
"$id",
|
||||
"$comment",
|
||||
"$execution.model",
|
||||
"$output.model",
|
||||
"$script.repository",
|
||||
"$script.entry_point",
|
||||
],
|
||||
'default_language': 'english',
|
||||
'weights': {
|
||||
'name': 10,
|
||||
'id': 10,
|
||||
'comment': 10,
|
||||
'execution.model': 2,
|
||||
'output.model': 2,
|
||||
'script.repository': 1,
|
||||
'script.entry_point': 1,
|
||||
"default_language": "english",
|
||||
"weights": {
|
||||
"name": 10,
|
||||
"id": 10,
|
||||
"comment": 10,
|
||||
"execution.model": 2,
|
||||
"output.model": 2,
|
||||
"script.repository": 1,
|
||||
"script.entry_point": 1,
|
||||
},
|
||||
},
|
||||
],
|
||||
@@ -123,12 +149,10 @@ class Task(AttributedDocument):
|
||||
output = EmbeddedDocumentField(Output, default=Output)
|
||||
execution: Execution = EmbeddedDocumentField(Execution, default=Execution)
|
||||
tags = ListField(StringField(required=True), user_set_allowed=True)
|
||||
system_tags = ListField(StringField(required=True), user_set_allowed=True)
|
||||
script = EmbeddedDocumentField(Script)
|
||||
last_worker = StringField()
|
||||
last_worker_report = DateTimeField()
|
||||
last_update = DateTimeField()
|
||||
last_iteration = IntField(default=DEFAULT_LAST_ITERATION)
|
||||
last_metrics = SafeMapField(field=SafeMapField(EmbeddedDocumentField(MetricEvent)))
|
||||
|
||||
|
||||
class TaskVisibility(Enum):
|
||||
active = 'active'
|
||||
archived = 'archived'
|
||||
|
||||
18
server/database/model/version.py
Normal file
18
server/database/model/version.py
Normal file
@@ -0,0 +1,18 @@
|
||||
from mongoengine import Document, DateTimeField, StringField
|
||||
|
||||
from database import Database, strict
|
||||
from database.model import DbModelMixin
|
||||
|
||||
|
||||
class Version(DbModelMixin, Document):
|
||||
meta = {
|
||||
"collection": "versions", # custom collection name ('version' is not a proper collection name...)
|
||||
"db_alias": Database.backend, # although we'll use this model for all databases, a default must be defined
|
||||
"strict": strict,
|
||||
"indexes": [("-created", "-num")],
|
||||
}
|
||||
|
||||
id = StringField(primary_key=True)
|
||||
num = StringField(required=True)
|
||||
created = DateTimeField(required=True)
|
||||
desc = StringField()
|
||||
@@ -1,13 +1,17 @@
|
||||
import threading
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
from itertools import groupby, chain
|
||||
from typing import Sequence, Dict, Callable, Tuple, Any, Type
|
||||
|
||||
import dpath
|
||||
import dpath.path
|
||||
|
||||
from apierrors import errors
|
||||
from database.props import PropsMixin
|
||||
|
||||
SEP = "."
|
||||
|
||||
def project_dict(data, projection, separator='.'):
|
||||
|
||||
def project_dict(data, projection, separator=SEP):
|
||||
"""
|
||||
Project partial data from a dictionary into a new dictionary
|
||||
:param data: Input dictionary
|
||||
@@ -30,19 +34,27 @@ def project_dict(data, projection, separator='.'):
|
||||
if path_part not in dst:
|
||||
dst[path_part] = [{} for _ in range(len(src_part))]
|
||||
elif not isinstance(dst[path_part], (list, tuple)):
|
||||
raise TypeError('Incompatible destination type %s for %s (list expected)'
|
||||
% (type(dst), separator.join(path_parts[:depth + 1])))
|
||||
raise TypeError(
|
||||
"Incompatible destination type %s for %s (list expected)"
|
||||
% (type(dst), separator.join(path_parts[: depth + 1]))
|
||||
)
|
||||
elif not len(dst[path_part]) == len(src_part):
|
||||
raise ValueError('Destination list length differs from source length for %s'
|
||||
% separator.join(path_parts[:depth + 1]))
|
||||
raise ValueError(
|
||||
"Destination list length differs from source length for %s"
|
||||
% separator.join(path_parts[: depth + 1])
|
||||
)
|
||||
|
||||
dst[path_part] = [copy_path(path_parts[depth + 1:], s, d)
|
||||
for s, d in zip(src_part, dst[path_part])]
|
||||
dst[path_part] = [
|
||||
copy_path(path_parts[depth + 1:], s, d)
|
||||
for s, d in zip(src_part, dst[path_part])
|
||||
]
|
||||
|
||||
return destination
|
||||
else:
|
||||
raise TypeError('Unsupported projection type %s for %s'
|
||||
% (type(src), separator.join(path_parts[:depth + 1])))
|
||||
raise TypeError(
|
||||
"Unsupported projection type %s for %s"
|
||||
% (type(src), separator.join(path_parts[: depth + 1]))
|
||||
)
|
||||
|
||||
last_part = path_parts[-1]
|
||||
dst[last_part] = src[last_part]
|
||||
@@ -53,12 +65,35 @@ def project_dict(data, projection, separator='.'):
|
||||
|
||||
for projection_path in sorted(projection):
|
||||
copy_path(
|
||||
path_parts=projection_path.split(separator),
|
||||
source=data,
|
||||
destination=result)
|
||||
path_parts=projection_path.split(separator), source=data, destination=result
|
||||
)
|
||||
return result
|
||||
|
||||
|
||||
class _ReferenceProxy(dict):
|
||||
def __init__(self, id):
|
||||
super(_ReferenceProxy, self).__init__(**({"id": id} if id else {}))
|
||||
|
||||
|
||||
class _ProxyManager:
|
||||
lock = threading.Lock()
|
||||
|
||||
def __init__(self):
|
||||
self._proxies: Dict[str, _ReferenceProxy] = {}
|
||||
|
||||
def add(self, id):
|
||||
with self.lock:
|
||||
proxy = self._proxies.get(id)
|
||||
if proxy is None:
|
||||
proxy = self._proxies[id] = _ReferenceProxy(id)
|
||||
return proxy
|
||||
|
||||
def update(self, result):
|
||||
proxy = self._proxies.get(result.get("id"))
|
||||
if proxy is not None:
|
||||
proxy.update(result)
|
||||
|
||||
|
||||
class ProjectionHelper(object):
|
||||
pool = ThreadPoolExecutor()
|
||||
|
||||
@@ -72,6 +107,11 @@ class ProjectionHelper(object):
|
||||
self._doc_cls = doc_cls
|
||||
self._doc_projection = None
|
||||
self._ref_projection = None
|
||||
self._proxy_manager = _ProxyManager()
|
||||
|
||||
# Cached dpath paths for each of the result documents
|
||||
self._cached_results_paths: Dict[int, Sequence[Tuple[Any, Type]]] = {}
|
||||
|
||||
self._parse_projection(projection)
|
||||
|
||||
def _collect_projection_fields(self, doc_cls, projection):
|
||||
@@ -81,8 +121,12 @@ class ProjectionHelper(object):
|
||||
:param projection: List of projection fields
|
||||
:return: A tuple of document projection and reference fields information
|
||||
"""
|
||||
doc_projection = set() # Projection fields for this class (used in the main query)
|
||||
ref_projection_info = [] # Projection information for reference fields (used in join queries)
|
||||
doc_projection = (
|
||||
set()
|
||||
) # Projection fields for this class (used in the main query)
|
||||
ref_projection_info = (
|
||||
[]
|
||||
) # Projection information for reference fields (used in join queries)
|
||||
for field in projection:
|
||||
for ref_field, ref_field_cls in doc_cls.get_reference_fields().items():
|
||||
if not field.startswith(ref_field):
|
||||
@@ -93,7 +137,7 @@ class ProjectionHelper(object):
|
||||
# use '<reference field name>.*')
|
||||
continue
|
||||
subfield = field[len(ref_field):]
|
||||
if not subfield.startswith('.'):
|
||||
if not subfield.startswith(SEP):
|
||||
# Starts with something that looks like a reference field, but isn't
|
||||
continue
|
||||
|
||||
@@ -103,10 +147,12 @@ class ProjectionHelper(object):
|
||||
# Not a reference field, just add to the top-level projection
|
||||
# We strip any trailing '*' since it means nothing for simple fields and for embedded documents
|
||||
orig_field = field
|
||||
if field.endswith('.*'):
|
||||
if field.endswith(".*"):
|
||||
field = field[:-2]
|
||||
if not field:
|
||||
raise errors.bad_request.InvalidFields(field=orig_field, object=doc_cls.__name__)
|
||||
raise errors.bad_request.InvalidFields(
|
||||
field=orig_field, object=doc_cls.__name__
|
||||
)
|
||||
doc_projection.add(field)
|
||||
return doc_projection, ref_projection_info
|
||||
|
||||
@@ -124,12 +170,14 @@ class ProjectionHelper(object):
|
||||
if not projection:
|
||||
return [], {}
|
||||
|
||||
doc_projection, ref_projection_info = self._collect_projection_fields(doc_cls, projection)
|
||||
doc_projection, ref_projection_info = self._collect_projection_fields(
|
||||
doc_cls, projection
|
||||
)
|
||||
|
||||
def normalize_cls_projection(cls_, fields):
|
||||
""" Normalize projection for this class and group (expand *, for once) """
|
||||
if '*' in fields:
|
||||
return list(fields.difference('*').union(cls_.get_fields()))
|
||||
if "*" in fields:
|
||||
return list(fields.difference("*").union(cls_.get_fields()))
|
||||
return list(fields)
|
||||
|
||||
def compute_ref_cls_projection(cls_, group):
|
||||
@@ -143,12 +191,16 @@ class ProjectionHelper(object):
|
||||
# Aggregate by reference field. We'll leave out '*' from the projected items since
|
||||
ref_projection = {
|
||||
ref_field: dict(cls=ref_cls, only=compute_ref_cls_projection(ref_cls, g))
|
||||
for (ref_field, ref_cls), g in groupby(sorted(ref_projection_info, key=sort_key), sort_key)
|
||||
for (ref_field, ref_cls), g in groupby(
|
||||
sorted(ref_projection_info, key=sort_key), sort_key
|
||||
)
|
||||
}
|
||||
|
||||
# Make sure this doesn't contain any reference field we'll join anyway
|
||||
# (i.e. in case only_fields=[project, project.name])
|
||||
doc_projection = normalize_cls_projection(doc_cls, doc_projection.difference(ref_projection).union({'id'}))
|
||||
doc_projection = normalize_cls_projection(
|
||||
doc_cls, doc_projection.difference(ref_projection).union({"id"})
|
||||
)
|
||||
|
||||
# Make sure that in case one or more field is a subfield of another field, we only use the the top-level field.
|
||||
# This is done since in such a case, MongoDB will only use the most restrictive field (most nested field) and
|
||||
@@ -158,13 +210,20 @@ class ProjectionHelper(object):
|
||||
doc_projection = [
|
||||
field
|
||||
for field in doc_projection
|
||||
if not any(field.startswith(f"{other_field}.") for other_field in projection_set - {field})
|
||||
if not any(
|
||||
field.startswith(f"{other_field}.")
|
||||
for other_field in projection_set - {field}
|
||||
)
|
||||
]
|
||||
|
||||
# Make sure we didn't get any invalid projection fields for this class
|
||||
invalid_fields = [f for f in doc_projection if f.split('.')[0] not in doc_cls.get_fields()]
|
||||
invalid_fields = [
|
||||
f for f in doc_projection if f.split(SEP)[0] not in doc_cls.get_fields()
|
||||
]
|
||||
if invalid_fields:
|
||||
raise errors.bad_request.InvalidFields(fields=invalid_fields, object=doc_cls.__name__)
|
||||
raise errors.bad_request.InvalidFields(
|
||||
fields=invalid_fields, object=doc_cls.__name__
|
||||
)
|
||||
|
||||
if ref_projection:
|
||||
# Join mode - use both normal projection fields and top-level reference fields
|
||||
@@ -178,11 +237,44 @@ class ProjectionHelper(object):
|
||||
self._doc_projection = doc_projection
|
||||
self._ref_projection = ref_projection
|
||||
|
||||
@staticmethod
|
||||
def _search(doc_cls, obj, path, only_values=True):
|
||||
""" Call dpath.search with yielded=True, collect result values """
|
||||
def _search(
|
||||
self,
|
||||
doc_cls: PropsMixin,
|
||||
obj: dict,
|
||||
path: str,
|
||||
factory: Callable[[str], dict] = None,
|
||||
) -> Sequence[str]:
|
||||
"""
|
||||
Search for a path in the given object, return the list of values found for the
|
||||
given path (multiple values may exist if the path is a glob expression)
|
||||
:param doc_cls: The document class represented by the object
|
||||
:param obj: Data object
|
||||
:param path: Path to a leaf in the data object ("." separated, may contain "*")
|
||||
(in case the path contains "*", there may be multiple values)
|
||||
:param factory: If provided, replace each value found with an instance provided by the factory.
|
||||
"""
|
||||
norm_path = doc_cls.get_dpath_translated_path(path)
|
||||
return [v if only_values else (k, v) for k, v in dpath.search(obj, norm_path, separator='.', yielded=True)]
|
||||
globlist = norm_path.strip(SEP).split(SEP)
|
||||
|
||||
obj_paths = self._cached_results_paths.get(id(obj))
|
||||
if obj_paths is None:
|
||||
obj_paths = self._cached_results_paths[id(obj)] = list(
|
||||
dpath.path.paths(obj, dirs=True, skip=True)
|
||||
)
|
||||
|
||||
paths = [p for p in obj_paths if dpath.path.match(p, globlist)]
|
||||
|
||||
def search_and_replace(p: Sequence[Tuple[str, Type]]) -> Any:
|
||||
parent = None
|
||||
target = obj
|
||||
for part in p:
|
||||
parent = target
|
||||
target = target[part[0]]
|
||||
if parent and factory:
|
||||
parent[p[-1][0]] = factory(target)
|
||||
return target
|
||||
|
||||
return [search_and_replace(p) for p in paths]
|
||||
|
||||
def project(self, results, projection_func):
|
||||
"""
|
||||
@@ -197,28 +289,50 @@ class ProjectionHelper(object):
|
||||
|
||||
if ref_projection:
|
||||
# Join mode - get results for each reference fields projection required (this is the join step)
|
||||
# Note: this is a recursive step, so we support nested reference fields
|
||||
# Note: this is a recursive step, so nested reference fields are supported
|
||||
|
||||
def do_projection(item):
|
||||
ref_field_name, data = item
|
||||
res = {}
|
||||
ids = list(filter(None, set(chain.from_iterable(self._search(cls, res, ref_field_name)
|
||||
for res in results))))
|
||||
if ids:
|
||||
doc_type = data['cls']
|
||||
doc_only = list(filter(None, data['only']))
|
||||
doc_only = list({'id'} | set(doc_only)) if doc_only else None
|
||||
res = {r['id']: r for r in projection_func(doc_type=doc_type, projection=doc_only, ids=ids)}
|
||||
data['res'] = res
|
||||
def collect_ids(ref_field_name):
|
||||
"""
|
||||
Collect unique IDs for the given reference path from all result documents.
|
||||
All collected IDs are replaced in the result dictionaries with a reference proxy generated by the
|
||||
proxies manager to allow rapid update later on when projection results are obtained.
|
||||
"""
|
||||
all_ids = (
|
||||
self._search(
|
||||
cls, res, ref_field_name, factory=self._proxy_manager.add
|
||||
)
|
||||
for res in results
|
||||
)
|
||||
return list(filter(None, set(chain.from_iterable(all_ids))))
|
||||
|
||||
items = list(ref_projection.items())
|
||||
if len(ref_projection) == 1:
|
||||
do_projection(items[0])
|
||||
else:
|
||||
for _ in self.pool.map(do_projection, items):
|
||||
# From ThreadPoolExecutor.map() documentation: If a call raises an exception then that exception
|
||||
# will be raised when its value is retrieved from the map() iterator
|
||||
pass
|
||||
items = [
|
||||
tup
|
||||
for tup in (
|
||||
(*item, collect_ids(item[0])) for item in ref_projection.items()
|
||||
)
|
||||
if tup[2]
|
||||
]
|
||||
|
||||
if items:
|
||||
def do_projection(item):
|
||||
ref_field_name, data, ids = item
|
||||
|
||||
doc_type = data["cls"]
|
||||
doc_only = list(filter(None, data["only"]))
|
||||
doc_only = list({"id"} | set(doc_only)) if doc_only else None
|
||||
|
||||
for res in projection_func(
|
||||
doc_type=doc_type, projection=doc_only, ids=ids
|
||||
):
|
||||
self._proxy_manager.update(res)
|
||||
|
||||
if len(ref_projection) == 1:
|
||||
do_projection(items[0])
|
||||
else:
|
||||
for _ in self.pool.map(do_projection, items):
|
||||
# From ThreadPoolExecutor.map() documentation: If a call raises an exception then that exception
|
||||
# will be raised when its value is retrieved from the map() iterator
|
||||
pass
|
||||
|
||||
def do_expand_reference_ids(result, skip_fields=None):
|
||||
ref_fields = cls.get_reference_fields()
|
||||
@@ -226,44 +340,18 @@ class ProjectionHelper(object):
|
||||
ref_fields = set(ref_fields) - set(skip_fields)
|
||||
self._expand_reference_fields(cls, result, ref_fields)
|
||||
|
||||
def merge_projection_result(result):
|
||||
for ref_field_name, data in ref_projection.items():
|
||||
res = data.get('res')
|
||||
if not res:
|
||||
self._expand_reference_fields(cls, result, [ref_field_name])
|
||||
continue
|
||||
ref_ids = self._search(cls, result, ref_field_name, only_values=False)
|
||||
if not ref_ids:
|
||||
continue
|
||||
for path, value in ref_ids:
|
||||
obj = res.get(value) or {'id': value}
|
||||
dpath.new(result, path, obj, separator='.')
|
||||
|
||||
# any reference field not projected should be expanded
|
||||
do_expand_reference_ids(result, skip_fields=list(ref_projection))
|
||||
|
||||
update_func = merge_projection_result if ref_projection else \
|
||||
do_expand_reference_ids if self._should_expand_reference_ids else None
|
||||
|
||||
if update_func:
|
||||
# any reference field not projected should be expanded
|
||||
if self._should_expand_reference_ids:
|
||||
for result in results:
|
||||
update_func(result)
|
||||
do_expand_reference_ids(
|
||||
result, skip_fields=list(ref_projection) if ref_projection else None
|
||||
)
|
||||
|
||||
return results
|
||||
|
||||
@classmethod
|
||||
def _expand_reference_fields(cls, doc_cls, result, fields):
|
||||
def _expand_reference_fields(self, doc_cls, result, fields):
|
||||
for ref_field_name in fields:
|
||||
ref_ids = cls._search(doc_cls, result, ref_field_name, only_values=False)
|
||||
if not ref_ids:
|
||||
continue
|
||||
for path, value in ref_ids:
|
||||
dpath.set(
|
||||
result,
|
||||
path,
|
||||
{'id': value} if value else {},
|
||||
separator='.')
|
||||
self._search(doc_cls, result, ref_field_name, factory=_ReferenceProxy)
|
||||
|
||||
@classmethod
|
||||
def expand_reference_ids(cls, doc_cls, result):
|
||||
cls._expand_reference_fields(doc_cls, result, doc_cls.get_reference_fields())
|
||||
def expand_reference_ids(self, doc_cls, result):
|
||||
self._expand_reference_fields(doc_cls, result, doc_cls.get_reference_fields())
|
||||
|
||||
@@ -1,17 +1,19 @@
|
||||
from collections import OrderedDict
|
||||
from collections import OrderedDict, defaultdict
|
||||
from itertools import chain
|
||||
from operator import attrgetter
|
||||
from threading import Lock
|
||||
from typing import Sequence
|
||||
|
||||
import six
|
||||
from mongoengine import EmbeddedDocumentField, EmbeddedDocumentListField
|
||||
from mongoengine.base import get_document
|
||||
from mongoengine.base import get_document, BaseField
|
||||
|
||||
from database.fields import (
|
||||
LengthRangeEmbeddedDocumentListField,
|
||||
UniqueEmbeddedDocumentListField,
|
||||
EmbeddedDocumentSortedListField,
|
||||
)
|
||||
from database.utils import get_fields, get_fields_and_attr
|
||||
from database.utils import get_fields, get_fields_attr
|
||||
|
||||
|
||||
class PropsMixin(object):
|
||||
@@ -19,6 +21,7 @@ class PropsMixin(object):
|
||||
__cached_reference_fields = None
|
||||
__cached_exclude_fields = None
|
||||
__cached_fields_with_instance = None
|
||||
__cached_field_names_per_type = None
|
||||
|
||||
__cached_dpath_computed_fields_lock = Lock()
|
||||
__cached_dpath_computed_fields = None
|
||||
@@ -29,6 +32,39 @@ class PropsMixin(object):
|
||||
cls.__cached_fields = get_fields(cls)
|
||||
return cls.__cached_fields
|
||||
|
||||
@classmethod
|
||||
def get_field_names_for_type(cls, of_type=BaseField):
|
||||
"""
|
||||
Return field names per type including subfields
|
||||
The fields of derived types are also returned
|
||||
"""
|
||||
assert issubclass(of_type, BaseField)
|
||||
if cls.__cached_field_names_per_type is None:
|
||||
fields = defaultdict(list)
|
||||
for name, field in get_fields(cls, return_instance=True, subfields=True):
|
||||
fields[type(field)].append(name)
|
||||
for type_ in fields:
|
||||
fields[type_].extend(
|
||||
chain.from_iterable(
|
||||
fields[other_type]
|
||||
for other_type in fields
|
||||
if other_type != type_ and issubclass(other_type, type_)
|
||||
)
|
||||
)
|
||||
cls.__cached_field_names_per_type = fields
|
||||
|
||||
if of_type not in cls.__cached_field_names_per_type:
|
||||
names = list(
|
||||
chain.from_iterable(
|
||||
field_names
|
||||
for type_, field_names in cls.__cached_field_names_per_type.items()
|
||||
if issubclass(type_, of_type)
|
||||
)
|
||||
)
|
||||
cls.__cached_field_names_per_type[of_type] = names
|
||||
|
||||
return cls.__cached_field_names_per_type[of_type]
|
||||
|
||||
@classmethod
|
||||
def get_fields_with_instance(cls, doc_cls):
|
||||
if cls.__cached_fields_with_instance is None:
|
||||
@@ -42,7 +78,7 @@ class PropsMixin(object):
|
||||
@staticmethod
|
||||
def _get_fields_with_attr(cls_, attr):
|
||||
""" Get all fields with the specified attribute (supports nested fields) """
|
||||
res = get_fields_and_attr(cls_, attr=attr)
|
||||
res = get_fields_attr(cls_, attr=attr)
|
||||
|
||||
def resolve_doc(v):
|
||||
if not isinstance(v, six.string_types):
|
||||
@@ -122,6 +158,14 @@ class PropsMixin(object):
|
||||
cls.__cached_reference_fields = OrderedDict(sorted(fields.items()))
|
||||
return cls.__cached_reference_fields
|
||||
|
||||
@classmethod
|
||||
def get_extra_projection(cls, fields: Sequence) -> tuple:
|
||||
if isinstance(fields, str):
|
||||
fields = [fields]
|
||||
return tuple(
|
||||
set(fields).union(cls.get_fields()).difference(cls.get_exclude_fields())
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def get_exclude_fields(cls):
|
||||
if cls.__cached_exclude_fields is None:
|
||||
@@ -140,3 +184,18 @@ class PropsMixin(object):
|
||||
result = separator.join(translated)
|
||||
cls.__cached_dpath_computed_fields[path] = result
|
||||
return cls.__cached_dpath_computed_fields[path]
|
||||
|
||||
def get_field_value(self, field_path: str, default=None):
|
||||
"""
|
||||
Return the document field_path value by the field_path name.
|
||||
The path may contain '.'. If on any level the path is
|
||||
not found then the default value is returned
|
||||
"""
|
||||
path_elements = field_path.split(".")
|
||||
current = self
|
||||
for name in path_elements:
|
||||
current = getattr(current, name, default)
|
||||
if current == default:
|
||||
break
|
||||
|
||||
return current
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
import hashlib
|
||||
from inspect import ismethod, getmembers
|
||||
from typing import Sequence, Tuple, Set, Optional, Callable, Any
|
||||
from uuid import uuid4
|
||||
|
||||
from mongoengine import EmbeddedDocumentField, ListField, Document, Q
|
||||
@@ -8,61 +9,65 @@ from mongoengine.base import BaseField
|
||||
from .errors import translate_errors_context, ParseCallError
|
||||
|
||||
|
||||
def get_fields(cls, of_type=BaseField, return_instance=False):
|
||||
def get_fields(cls, of_type=BaseField, return_instance=False, subfields=False):
|
||||
return _get_fields(
|
||||
cls,
|
||||
of_type=of_type,
|
||||
subfields=subfields,
|
||||
selector=lambda k, v: (k, v) if return_instance else k,
|
||||
)
|
||||
|
||||
|
||||
def get_fields_attr(cls, attr):
|
||||
""" get field names from a class containing mongoengine fields """
|
||||
res = []
|
||||
for cls_ in reversed(cls.mro()):
|
||||
res.extend([k if not return_instance else (k, v)
|
||||
for k, v in vars(cls_).items()
|
||||
if isinstance(v, of_type)])
|
||||
return res
|
||||
return dict(
|
||||
_get_fields(cls, with_attr=attr, selector=lambda k, v: (k, getattr(v, attr)))
|
||||
)
|
||||
|
||||
|
||||
def get_fields_and_attr(cls, attr):
|
||||
""" get field names from a class containing mongoengine fields """
|
||||
res = {}
|
||||
for cls_ in reversed(cls.mro()):
|
||||
res.update({k: getattr(v, attr)
|
||||
for k, v in vars(cls_).items()
|
||||
if isinstance(v, BaseField) and hasattr(v, attr)})
|
||||
return res
|
||||
def get_fields_choices(cls, attr):
|
||||
def get_choices(field_name: str, field: BaseField) -> Tuple:
|
||||
if isinstance(field, ListField):
|
||||
return field_name, field.field.choices
|
||||
return field_name, field.choices
|
||||
|
||||
return dict(_get_fields(cls, with_attr=attr, subfields=True, selector=get_choices))
|
||||
|
||||
|
||||
def _get_field_choices(name, field):
|
||||
field_t = type(field)
|
||||
if issubclass(field_t, EmbeddedDocumentField):
|
||||
obj = field.document_type_obj
|
||||
n, choices = _get_field_choices(field.name, obj.field)
|
||||
return '%s__%s' % (name, n), choices
|
||||
elif issubclass(type(field), ListField):
|
||||
return name, field.field.choices
|
||||
return name, field.choices
|
||||
|
||||
|
||||
def get_fields_with_attr(cls, attr, default=False):
|
||||
def _get_fields(
|
||||
cls,
|
||||
with_attr=None,
|
||||
of_type=BaseField,
|
||||
subfields=False,
|
||||
selector: Optional[Callable[[str, BaseField], Any]] = None,
|
||||
path: Tuple[str, ...] = (),
|
||||
):
|
||||
fields = []
|
||||
for field_name, field in cls._fields.items():
|
||||
if not getattr(field, attr, default):
|
||||
continue
|
||||
field_t = type(field)
|
||||
if issubclass(field_t, EmbeddedDocumentField):
|
||||
fields.extend((('%s__%s' % (field_name, name), choices)
|
||||
for name, choices in get_fields_with_attr(field.document_type, attr, default)))
|
||||
elif issubclass(type(field), ListField):
|
||||
fields.append((field_name, field.field.choices))
|
||||
else:
|
||||
fields.append((field_name, field.choices))
|
||||
field_path = path + (field_name,)
|
||||
if isinstance(field, of_type) and (not with_attr or hasattr(field, with_attr)):
|
||||
full_name = "__".join(field_path)
|
||||
fields.append(selector(full_name, field) if selector else full_name)
|
||||
|
||||
if subfields and isinstance(field, EmbeddedDocumentField):
|
||||
fields.extend(
|
||||
_get_fields(
|
||||
field.document_type,
|
||||
with_attr=with_attr,
|
||||
of_type=of_type,
|
||||
subfields=subfields,
|
||||
selector=selector,
|
||||
path=field_path,
|
||||
)
|
||||
)
|
||||
|
||||
return fields
|
||||
|
||||
|
||||
def get_items(cls):
|
||||
""" get key/value items from an enum-like class (members represent enumeration key/value) """
|
||||
|
||||
res = {
|
||||
k: v
|
||||
for k, v in getmembers(cls)
|
||||
if not (k.startswith("_") or ismethod(v))
|
||||
}
|
||||
res = {k: v for k, v in getmembers(cls) if not (k.startswith("_") or ismethod(v))}
|
||||
return res
|
||||
|
||||
|
||||
@@ -81,7 +86,7 @@ def parse_from_call(call_data, fields, cls_fields, discard_none_values=True):
|
||||
fields = {k: None for k in fields}
|
||||
fields = {k: v for k, v in fields.items() if k in cls_fields}
|
||||
res = {}
|
||||
with translate_errors_context('parsing call data'):
|
||||
with translate_errors_context("parsing call data"):
|
||||
for field, desc in fields.items():
|
||||
value = call_data.get(field)
|
||||
if value is None:
|
||||
@@ -93,20 +98,34 @@ def parse_from_call(call_data, fields, cls_fields, discard_none_values=True):
|
||||
if callable(desc):
|
||||
desc(value)
|
||||
else:
|
||||
if issubclass(desc, (list, tuple, dict)) and not isinstance(value, desc):
|
||||
raise ParseCallError('expecting %s' % desc.__name__, field=field)
|
||||
if issubclass(desc, Document) and not desc.objects(id=value).only('id'):
|
||||
raise ParseCallError('expecting %s id' % desc.__name__, id=value, field=field)
|
||||
if issubclass(desc, (list, tuple, dict)) and not isinstance(
|
||||
value, desc
|
||||
):
|
||||
raise ParseCallError(
|
||||
"expecting %s" % desc.__name__, field=field
|
||||
)
|
||||
if issubclass(desc, Document) and not desc.objects(id=value).only(
|
||||
"id"
|
||||
):
|
||||
raise ParseCallError(
|
||||
"expecting %s id" % desc.__name__, id=value, field=field
|
||||
)
|
||||
res[field] = value
|
||||
return res
|
||||
|
||||
|
||||
def init_cls_from_base(cls, instance):
|
||||
return cls(**{k: v for k, v in instance.to_mongo(use_db_field=False).to_dict().items() if k[0] != '_'})
|
||||
return cls(
|
||||
**{
|
||||
k: v
|
||||
for k, v in instance.to_mongo(use_db_field=False).to_dict().items()
|
||||
if k[0] != "_"
|
||||
}
|
||||
)
|
||||
|
||||
|
||||
def get_company_or_none_constraint(company=None):
|
||||
return Q(company__in=(company, None, '')) | Q(company__exists=False)
|
||||
return Q(company__in=(company, None, "")) | Q(company__exists=False)
|
||||
|
||||
|
||||
def field_does_not_exist(field: str, empty_value=None, is_list=False) -> Q:
|
||||
@@ -118,23 +137,43 @@ def field_does_not_exist(field: str, empty_value=None, is_list=False) -> Q:
|
||||
the length of the array will be used (len==0 means empty)
|
||||
:return:
|
||||
"""
|
||||
query = (Q(**{f"{field}__exists": False}) |
|
||||
Q(**{f"{field}__in": {empty_value, None}}))
|
||||
query = Q(**{f"{field}__exists": False}) | Q(
|
||||
**{f"{field}__in": {empty_value, None}}
|
||||
)
|
||||
if is_list:
|
||||
query |= Q(**{f"{field}__size": 0})
|
||||
return query
|
||||
|
||||
|
||||
def field_exists(field: str, empty_value=None, is_list=False) -> Q:
|
||||
"""
|
||||
Creates a query object used for finding a field that exists and is not None or empty.
|
||||
:param field: Field name
|
||||
:param empty_value: The empty value to test for (None means no specific empty value will be used)
|
||||
:param is_list: Is this a list (array) field. In this case, instead of testing for an empty value,
|
||||
the length of the array will be used (len==0 means empty)
|
||||
:return:
|
||||
"""
|
||||
query = Q(**{f"{field}__exists": True}) & Q(
|
||||
**{f"{field}__nin": {empty_value, None}}
|
||||
)
|
||||
if is_list:
|
||||
query &= Q(**{f"{field}__not__size": 0})
|
||||
return query
|
||||
|
||||
|
||||
def get_subkey(d, key_path, default=None):
|
||||
""" Get a key from a nested dictionary. kay_path is a '.' separated string of keys used to traverse
|
||||
the nested dictionary.
|
||||
"""
|
||||
keys = key_path.split('.')
|
||||
keys = key_path.split(".")
|
||||
for i, key in enumerate(keys):
|
||||
if not isinstance(d, dict):
|
||||
raise KeyError('Expecting a dict (%s)' % ('.'.join(keys[:i]) if i else 'bad input'))
|
||||
raise KeyError(
|
||||
"Expecting a dict (%s)" % (".".join(keys[:i]) if i else "bad input")
|
||||
)
|
||||
d = d.get(key)
|
||||
if key is None:
|
||||
if d is None:
|
||||
return default
|
||||
return d
|
||||
|
||||
@@ -158,3 +197,42 @@ def merge_dicts(*dicts):
|
||||
def filter_fields(cls, fields):
|
||||
"""From the fields dictionary return only the fields that match cls fields"""
|
||||
return {key: fields[key] for key in fields if key in get_fields(cls)}
|
||||
|
||||
|
||||
def _names_set(*names: str) -> Set[str]:
|
||||
"""
|
||||
Given a list of names return set with names and '-names'
|
||||
"""
|
||||
return set(names) | set(f"-{name}" for name in names)
|
||||
|
||||
|
||||
system_tag_names = {
|
||||
"model": _names_set("active", "archived"),
|
||||
"project": _names_set("archived", "public", "default"),
|
||||
"task": _names_set("active", "archived", "development"),
|
||||
"queue": _names_set("default"),
|
||||
}
|
||||
|
||||
system_tag_prefixes = {"task": _names_set("annotat")}
|
||||
|
||||
|
||||
def partition_tags(
|
||||
entity: str, tags: Sequence[str], system_tags: Optional[Sequence[str]] = ()
|
||||
) -> Tuple[Sequence[str], Sequence[str]]:
|
||||
"""
|
||||
Partition the given tags sequence into system and user-defined tags
|
||||
:param entity: The name of the entity that defines the list of the system tags
|
||||
:param tags: The tags to partition
|
||||
:param system_tags: Optional. If passed then these tags are considered system together
|
||||
with those defined for the entity.
|
||||
:return: a tuple where the first element is the sequence of user-defined tags and
|
||||
the second element is the sequence of system tags
|
||||
"""
|
||||
tags = set(tags)
|
||||
system_tags = set(system_tags)
|
||||
system_tags |= tags & system_tag_names[entity]
|
||||
|
||||
prefixes = system_tag_prefixes.get(entity, [])
|
||||
system_tags |= {t for t in tags for p in prefixes if t.lower().startswith(p)}
|
||||
|
||||
return list(tags - system_tags), list(system_tags)
|
||||
|
||||
27
server/elastic/mappings/queue_metrics.json
Normal file
27
server/elastic/mappings/queue_metrics.json
Normal file
@@ -0,0 +1,27 @@
|
||||
{
|
||||
"template": "queue_metrics_*",
|
||||
"settings": {
|
||||
"number_of_shards": 1
|
||||
},
|
||||
"mappings": {
|
||||
"metrics": {
|
||||
"_source": {
|
||||
"enabled": true
|
||||
},
|
||||
"properties": {
|
||||
"timestamp": {
|
||||
"type": "date"
|
||||
},
|
||||
"queue": {
|
||||
"type": "keyword"
|
||||
},
|
||||
"average_waiting_time": {
|
||||
"type": "float"
|
||||
},
|
||||
"queue_length": {
|
||||
"type": "integer"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
23
server/elastic/mappings/worker_stats.json
Normal file
23
server/elastic/mappings/worker_stats.json
Normal file
@@ -0,0 +1,23 @@
|
||||
{
|
||||
"template": "worker_stats_*",
|
||||
"settings": {
|
||||
"number_of_shards": 1
|
||||
},
|
||||
"mappings": {
|
||||
"stat": {
|
||||
"_source": {
|
||||
"enabled": true
|
||||
},
|
||||
"properties": {
|
||||
"timestamp": { "type": "date" },
|
||||
"worker": { "type": "keyword" },
|
||||
"category": { "type": "keyword" },
|
||||
"metric": { "type": "keyword" },
|
||||
"variant": { "type": "keyword" },
|
||||
"value": { "type": "float" },
|
||||
"unit": { "type": "keyword" },
|
||||
"task": { "type": "keyword" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -1,11 +1,28 @@
|
||||
from datetime import datetime
|
||||
from os import getenv
|
||||
|
||||
from boltons.iterutils import first
|
||||
from elasticsearch import Elasticsearch, Transport
|
||||
|
||||
from config import config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
OVERRIDE_HOST_ENV_KEY = (
|
||||
"TRAINS_ELASTIC_SERVICE_HOST",
|
||||
"ELASTIC_SERVICE_HOST",
|
||||
"ELASTIC_SERVICE_SERVICE_HOST",
|
||||
)
|
||||
OVERRIDE_PORT_ENV_KEY = ("TRAINS_ELASTIC_SERVICE_PORT", "ELASTIC_SERVICE_PORT")
|
||||
|
||||
OVERRIDE_HOST = first(filter(None, map(getenv, OVERRIDE_HOST_ENV_KEY)))
|
||||
if OVERRIDE_HOST:
|
||||
log.info(f"Using override elastic host {OVERRIDE_HOST}")
|
||||
|
||||
OVERRIDE_PORT = first(filter(None, map(getenv, OVERRIDE_PORT_ENV_KEY)))
|
||||
if OVERRIDE_PORT:
|
||||
log.info(f"Using override elastic port {OVERRIDE_PORT}")
|
||||
|
||||
_instances = {}
|
||||
|
||||
|
||||
@@ -13,6 +30,7 @@ class MissingClusterConfiguration(Exception):
|
||||
"""
|
||||
Exception when cluster configuration is not found in config files
|
||||
"""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
@@ -20,6 +38,7 @@ class InvalidClusterConfiguration(Exception):
|
||||
"""
|
||||
Exception when cluster configuration does not contain required properties
|
||||
"""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
@@ -33,28 +52,41 @@ def connect(cluster_name):
|
||||
:raises InvalidClusterConfiguration: in case cluster config section misses needed properties
|
||||
"""
|
||||
if cluster_name not in _instances:
|
||||
cluster_config = _get_cluster_config(cluster_name)
|
||||
hosts = cluster_config.get('hosts', None)
|
||||
cluster_config = get_cluster_config(cluster_name)
|
||||
hosts = cluster_config.get("hosts", None)
|
||||
if not hosts:
|
||||
raise InvalidClusterConfiguration(cluster_name)
|
||||
args = cluster_config.get('args', {})
|
||||
_instances[cluster_name] = Elasticsearch(hosts=hosts, transport_class=Transport, **args)
|
||||
|
||||
args = cluster_config.get("args", {})
|
||||
_instances[cluster_name] = Elasticsearch(
|
||||
hosts=hosts, transport_class=Transport, **args
|
||||
)
|
||||
|
||||
return _instances[cluster_name]
|
||||
|
||||
|
||||
def _get_cluster_config(cluster_name):
|
||||
def get_cluster_config(cluster_name):
|
||||
"""
|
||||
Returns cluster config for the specified cluster path
|
||||
:param cluster_name: Dot separated cluster path in the configuration file
|
||||
:return: config section for the cluster
|
||||
:raises MissingClusterConfiguration: in case no config section is found for the cluster
|
||||
"""
|
||||
cluster_key = '.'.join(('hosts.elastic', cluster_name))
|
||||
cluster_key = ".".join(("hosts.elastic", cluster_name))
|
||||
cluster_config = config.get(cluster_key, None)
|
||||
if not cluster_config:
|
||||
raise MissingClusterConfiguration(cluster_name)
|
||||
|
||||
def set_host_prop(key, value):
|
||||
for host in cluster_config.get("hosts", []):
|
||||
host[key] = value
|
||||
|
||||
if OVERRIDE_HOST:
|
||||
set_host_prop("host", OVERRIDE_HOST)
|
||||
|
||||
if OVERRIDE_PORT:
|
||||
set_host_prop("port", OVERRIDE_PORT)
|
||||
|
||||
return cluster_config
|
||||
|
||||
|
||||
|
||||
@@ -1,17 +1,32 @@
|
||||
import importlib.util
|
||||
from datetime import datetime
|
||||
from pathlib import Path
|
||||
from uuid import uuid4
|
||||
|
||||
import attr
|
||||
from furl import furl
|
||||
from mongoengine.connection import get_db
|
||||
from semantic_version import Version
|
||||
|
||||
from database.model.user import User
|
||||
from database.model.auth import User as AuthUser, Credentials
|
||||
import database.utils
|
||||
from bll.queue import QueueBLL
|
||||
from config import config
|
||||
from database import Database
|
||||
from database.model.auth import Role
|
||||
from database.model.auth import User as AuthUser, Credentials
|
||||
from database.model.company import Company
|
||||
from database.model.queue import Queue
|
||||
from database.model.settings import Settings
|
||||
from database.model.user import User
|
||||
from database.model.version import Version as DatabaseVersion
|
||||
from elastic.apply_mappings import apply_mappings_to_host
|
||||
from es_factory import get_cluster_config
|
||||
from service_repo.auth.fixed_user import FixedUser
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
migration_dir = (Path(__file__) / "../../migration/mongodb").resolve()
|
||||
|
||||
|
||||
class MissingElasticConfiguration(Exception):
|
||||
"""
|
||||
@@ -22,10 +37,9 @@ class MissingElasticConfiguration(Exception):
|
||||
|
||||
|
||||
def init_es_data():
|
||||
hosts_key = "hosts.elastic.events.hosts"
|
||||
hosts_config = config.get(hosts_key, None)
|
||||
hosts_config = get_cluster_config("events").get("hosts")
|
||||
if not hosts_config:
|
||||
raise MissingElasticConfiguration(hosts_key)
|
||||
raise MissingElasticConfiguration("for cluster 'events'")
|
||||
|
||||
for conf in hosts_config:
|
||||
host = furl(scheme="http", host=conf["host"], port=conf["port"]).url
|
||||
@@ -47,6 +61,18 @@ def _ensure_company():
|
||||
return company_id
|
||||
|
||||
|
||||
def _ensure_default_queue(company):
|
||||
"""
|
||||
If no queue is present for the company then
|
||||
create a new one and mark it as a default
|
||||
"""
|
||||
queue = Queue.objects(company=company).only("id").first()
|
||||
if queue:
|
||||
return
|
||||
|
||||
QueueBLL.create(company, name="default", system_tags=["default"])
|
||||
|
||||
|
||||
def _ensure_auth_user(user_data, company_id):
|
||||
ensure_credentials = {"key", "secret"}.issubset(user_data.keys())
|
||||
if ensure_credentials:
|
||||
@@ -85,10 +111,7 @@ def _ensure_user(user: FixedUser, company_id: str):
|
||||
data["email"] = f"{user.user_id}@example.com"
|
||||
data["role"] = Role.user
|
||||
|
||||
_ensure_auth_user(
|
||||
user_data=data,
|
||||
company_id=company_id,
|
||||
)
|
||||
_ensure_auth_user(user_data=data, company_id=company_id)
|
||||
|
||||
given_name, _, family_name = user.name.partition(" ")
|
||||
|
||||
@@ -101,12 +124,82 @@ def _ensure_user(user: FixedUser, company_id: str):
|
||||
).save()
|
||||
|
||||
|
||||
def _apply_migrations():
|
||||
if not migration_dir.is_dir():
|
||||
raise ValueError(f"Invalid migration dir {migration_dir}")
|
||||
|
||||
try:
|
||||
previous_versions = sorted(
|
||||
(Version(ver.num) for ver in DatabaseVersion.objects().only("num")),
|
||||
reverse=True,
|
||||
)
|
||||
except ValueError as ex:
|
||||
raise ValueError(f"Invalid database version number encountered: {ex}")
|
||||
|
||||
last_version = previous_versions[0] if previous_versions else Version("0.0.0")
|
||||
|
||||
try:
|
||||
new_scripts = {
|
||||
ver: path
|
||||
for ver, path in ((Version(f.stem), f) for f in migration_dir.glob("*.py"))
|
||||
if ver > last_version
|
||||
}
|
||||
except ValueError as ex:
|
||||
raise ValueError(f"Failed parsing migration version from file: {ex}")
|
||||
|
||||
dbs = {Database.auth: "migrate_auth", Database.backend: "migrate_backend"}
|
||||
|
||||
migration_log = log.getChild("mongodb_migration")
|
||||
|
||||
for script_version in sorted(new_scripts.keys()):
|
||||
script = new_scripts[script_version]
|
||||
spec = importlib.util.spec_from_file_location(script.stem, str(script))
|
||||
module = importlib.util.module_from_spec(spec)
|
||||
spec.loader.exec_module(module)
|
||||
|
||||
for alias, func_name in dbs.items():
|
||||
func = getattr(module, func_name, None)
|
||||
if not func:
|
||||
continue
|
||||
try:
|
||||
migration_log.info(f"Applying {script.stem}/{func_name}()")
|
||||
func(get_db(alias))
|
||||
except Exception:
|
||||
migration_log.exception(f"Failed applying {script}:{func_name}()")
|
||||
raise ValueError("Migration failed, aborting. Please restore backup.")
|
||||
|
||||
DatabaseVersion(
|
||||
id=database.utils.id(),
|
||||
num=script.stem,
|
||||
created=datetime.utcnow(),
|
||||
desc="Applied on server startup",
|
||||
).save()
|
||||
|
||||
|
||||
def _ensure_uuid():
|
||||
Settings.add_value("server.uuid", str(uuid4()))
|
||||
|
||||
|
||||
def init_mongo_data():
|
||||
try:
|
||||
_apply_migrations()
|
||||
|
||||
_ensure_uuid()
|
||||
|
||||
company_id = _ensure_company()
|
||||
_ensure_default_queue(company_id)
|
||||
|
||||
users = [
|
||||
{"name": "apiserver", "role": Role.system, "email": "apiserver@example.com"},
|
||||
{"name": "webserver", "role": Role.system, "email": "webserver@example.com"},
|
||||
{
|
||||
"name": "apiserver",
|
||||
"role": Role.system,
|
||||
"email": "apiserver@example.com",
|
||||
},
|
||||
{
|
||||
"name": "webserver",
|
||||
"role": Role.system,
|
||||
"email": "webserver@example.com",
|
||||
},
|
||||
{"name": "tests", "role": Role.user, "email": "tests@example.com"},
|
||||
]
|
||||
|
||||
@@ -117,7 +210,11 @@ def init_mongo_data():
|
||||
_ensure_auth_user(user, company_id)
|
||||
|
||||
if FixedUser.enabled():
|
||||
log.info("Fixed users mode is enabled")
|
||||
for user in FixedUser.from_config():
|
||||
_ensure_user(user, company_id)
|
||||
try:
|
||||
_ensure_user(user, company_id)
|
||||
except Exception as ex:
|
||||
log.error(f"Failed creating fixed user {user['name']}: {ex}")
|
||||
except Exception as ex:
|
||||
pass
|
||||
log.exception("Failed initializing mongodb")
|
||||
|
||||
195
server/redis_manager.py
Normal file
195
server/redis_manager.py
Normal file
@@ -0,0 +1,195 @@
|
||||
import threading
|
||||
from os import getenv
|
||||
from time import sleep
|
||||
|
||||
from boltons.iterutils import first
|
||||
from redis import StrictRedis
|
||||
from redis.sentinel import Sentinel, SentinelConnectionPool
|
||||
|
||||
from apierrors.errors.server_error import ConfigError, GeneralError
|
||||
from config import config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
OVERRIDE_HOST_ENV_KEY = ("TRAINS_REDIS_SERVICE_HOST", "REDIS_SERVICE_HOST")
|
||||
OVERRIDE_PORT_ENV_KEY = ("TRAINS_REDIS_SERVICE_PORT", "REDIS_SERVICE_PORT")
|
||||
|
||||
OVERRIDE_HOST = first(filter(None, map(getenv, OVERRIDE_HOST_ENV_KEY)))
|
||||
if OVERRIDE_HOST:
|
||||
log.info(f"Using override redis host {OVERRIDE_HOST}")
|
||||
|
||||
OVERRIDE_PORT = first(filter(None, map(getenv, OVERRIDE_PORT_ENV_KEY)))
|
||||
if OVERRIDE_PORT:
|
||||
log.info(f"Using override redis port {OVERRIDE_PORT}")
|
||||
|
||||
|
||||
class MyPubSubWorkerThread(threading.Thread):
|
||||
def __init__(self, sentinel, on_new_master, msg_sleep_time, daemon=True):
|
||||
super(MyPubSubWorkerThread, self).__init__()
|
||||
self.daemon = daemon
|
||||
self.sentinel = sentinel
|
||||
self.on_new_master = on_new_master
|
||||
self.sentinel_host = sentinel.connection_pool.connection_kwargs["host"]
|
||||
self.msg_sleep_time = msg_sleep_time
|
||||
self._running = False
|
||||
self.pubsub = None
|
||||
|
||||
def subscribe(self):
|
||||
if self.pubsub:
|
||||
try:
|
||||
self.pubsub.unsubscribe()
|
||||
self.pubsub.punsubscribe()
|
||||
except Exception:
|
||||
pass
|
||||
finally:
|
||||
self.pubsub = None
|
||||
|
||||
subscriptions = {"+switch-master": self.on_new_master}
|
||||
|
||||
while not self.pubsub or not self.pubsub.subscribed:
|
||||
try:
|
||||
self.pubsub = self.sentinel.pubsub()
|
||||
self.pubsub.subscribe(**subscriptions)
|
||||
except Exception as ex:
|
||||
log.warn(
|
||||
f"Error while subscribing to sentinel at {self.sentinel_host} ({ex.args[0]}) Sleeping and retrying"
|
||||
)
|
||||
sleep(3)
|
||||
log.info(f"Subscribed to sentinel {self.sentinel_host}")
|
||||
|
||||
def run(self):
|
||||
if self._running:
|
||||
return
|
||||
self._running = True
|
||||
|
||||
self.subscribe()
|
||||
|
||||
while self.pubsub.subscribed:
|
||||
try:
|
||||
self.pubsub.get_message(
|
||||
ignore_subscribe_messages=True, timeout=self.msg_sleep_time
|
||||
)
|
||||
except Exception as ex:
|
||||
log.warn(
|
||||
f"Error while getting message from sentinel {self.sentinel_host} ({ex.args[0]}) Resubscribing"
|
||||
)
|
||||
self.subscribe()
|
||||
|
||||
self.pubsub.close()
|
||||
self._running = False
|
||||
|
||||
def stop(self):
|
||||
# stopping simply unsubscribes from all channels and patterns.
|
||||
# the unsubscribe responses that are generated will short circuit
|
||||
# the loop in run(), calling pubsub.close() to clean up the connection
|
||||
self.pubsub.unsubscribe()
|
||||
self.pubsub.punsubscribe()
|
||||
|
||||
|
||||
# todo,future - multi master clusters?
|
||||
class RedisCluster(object):
|
||||
def __init__(self, sentinel_hosts, service_name, **connection_kwargs):
|
||||
self.service_name = service_name
|
||||
self.sentinel = Sentinel(sentinel_hosts, **connection_kwargs)
|
||||
self.master = None
|
||||
self.master_host_port = None
|
||||
self.reconfigure()
|
||||
self.sentinel_threads = {}
|
||||
self.listen()
|
||||
|
||||
def reconfigure(self):
|
||||
try:
|
||||
self.master_host_port = self.sentinel.discover_master(self.service_name)
|
||||
self.master = self.sentinel.master_for(self.service_name)
|
||||
log.info(f"Reconfigured master to {self.master_host_port}")
|
||||
except Exception as ex:
|
||||
log.error(f"Error while reconfiguring. {ex.args[0]}")
|
||||
|
||||
def listen(self):
|
||||
def on_new_master(workerThread):
|
||||
self.reconfigure()
|
||||
|
||||
for sentinel in self.sentinel.sentinels:
|
||||
sentinel_host = sentinel.connection_pool.connection_kwargs["host"]
|
||||
self.sentinel_threads[sentinel_host] = MyPubSubWorkerThread(
|
||||
sentinel, on_new_master, msg_sleep_time=0.001, daemon=True
|
||||
)
|
||||
self.sentinel_threads[sentinel_host].start()
|
||||
|
||||
|
||||
class RedisManager(object):
|
||||
def __init__(self, redis_config_dict):
|
||||
self.aliases = {}
|
||||
for alias, alias_config in redis_config_dict.items():
|
||||
|
||||
alias_config = alias_config.as_plain_ordered_dict()
|
||||
|
||||
is_cluster = alias_config.get("cluster", False)
|
||||
|
||||
host = OVERRIDE_HOST or alias_config.get("host", None)
|
||||
if host:
|
||||
alias_config["host"] = host
|
||||
|
||||
port = OVERRIDE_PORT or alias_config.get("port", None)
|
||||
if port:
|
||||
alias_config["port"] = port
|
||||
|
||||
db = alias_config.get("db", 0)
|
||||
|
||||
sentinels = alias_config.get("sentinels", None)
|
||||
service_name = alias_config.get("service_name", None)
|
||||
|
||||
if not is_cluster and sentinels:
|
||||
raise ConfigError(
|
||||
"Redis configuration is invalid. mixed regular and cluster mode",
|
||||
alias=alias,
|
||||
)
|
||||
if is_cluster and (not sentinels or not service_name):
|
||||
raise ConfigError(
|
||||
"Redis configuration is invalid. missing sentinels or service_name",
|
||||
alias=alias,
|
||||
)
|
||||
if not is_cluster and (not port or not host):
|
||||
raise ConfigError(
|
||||
"Redis configuration is invalid. missing port or host", alias=alias
|
||||
)
|
||||
|
||||
if is_cluster:
|
||||
# todo support all redis connection args via sentinel's connection_kwargs
|
||||
del alias_config["sentinels"]
|
||||
del alias_config["cluster"]
|
||||
del alias_config["service_name"]
|
||||
self.aliases[alias] = RedisCluster(
|
||||
sentinels, service_name, **alias_config
|
||||
)
|
||||
else:
|
||||
self.aliases[alias] = StrictRedis(**alias_config)
|
||||
|
||||
def connection(self, alias):
|
||||
obj = self.aliases.get(alias)
|
||||
if not obj:
|
||||
raise GeneralError(f"Invalid Redis alias {alias}")
|
||||
if isinstance(obj, RedisCluster):
|
||||
obj.master.get("health")
|
||||
return obj.master
|
||||
else:
|
||||
obj.get("health")
|
||||
return obj
|
||||
|
||||
def host(self, alias):
|
||||
r = self.connection(alias)
|
||||
pool = r.connection_pool
|
||||
if isinstance(pool, SentinelConnectionPool):
|
||||
connections = pool.connection_kwargs[
|
||||
"connection_pool"
|
||||
]._available_connections
|
||||
else:
|
||||
connections = pool._available_connections
|
||||
|
||||
if len(connections) > 0:
|
||||
return connections[0].host
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
redman = RedisManager(config.get("hosts.redis"))
|
||||
@@ -26,3 +26,6 @@ fastjsonschema>=2.8
|
||||
boltons>=19.1.0
|
||||
semantic_version>=2.6.0,<3
|
||||
furl>=2.0.0
|
||||
redis>=2.10.5
|
||||
humanfriendly==4.18
|
||||
psutil>=5.6.5
|
||||
|
||||
@@ -15,6 +15,11 @@ _definitions {
|
||||
type: string
|
||||
description: ""
|
||||
}
|
||||
last_used {
|
||||
type: string
|
||||
description: ""
|
||||
format: "date-time"
|
||||
}
|
||||
}
|
||||
}
|
||||
role {
|
||||
@@ -52,6 +57,22 @@ login {
|
||||
}
|
||||
}
|
||||
|
||||
logout {
|
||||
internal: false
|
||||
allow_roles = [ "*" ]
|
||||
"2.2" {
|
||||
description: """Removes the authentication cookie from the current session"""
|
||||
request {
|
||||
type: object
|
||||
additionalProperties: false
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
additionalProperties: false
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
get_token_for_user {
|
||||
"2.1" {
|
||||
description: """Get a token for the specified user. Intended for internal use."""
|
||||
@@ -255,33 +276,6 @@ revoke_credentials {
|
||||
}
|
||||
}
|
||||
|
||||
delete_user {
|
||||
allow_roles = [ "system", "root", "admin" ]
|
||||
internal: false
|
||||
"2.1" {
|
||||
description: """Delete a new user manually. Only supported in on-premises deployments. This only removes the user's auth entry so that any references to the deleted user's ID will still have valid user information"""
|
||||
request {
|
||||
type: object
|
||||
required: [ user ]
|
||||
properties {
|
||||
user {
|
||||
type: string
|
||||
description: User ID
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
deleted {
|
||||
description: "True if user was successfully deleted, False otherwise"
|
||||
type: boolean
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
edit_user {
|
||||
internal: false
|
||||
allow_roles: ["system", "root", "admin"]
|
||||
|
||||
@@ -149,6 +149,14 @@
|
||||
}
|
||||
}
|
||||
}
|
||||
scalar_key_enum {
|
||||
type: string
|
||||
enum: [
|
||||
iter
|
||||
timestamp
|
||||
iso_time
|
||||
]
|
||||
}
|
||||
log_level_enum {
|
||||
type: string
|
||||
enum: [
|
||||
@@ -216,7 +224,7 @@
|
||||
}
|
||||
add_batch {
|
||||
"2.1" {
|
||||
description: "Adds a batch of events in a single call."
|
||||
description: "Adds a batch of events in a single call (json-lines format, stream-friendly)"
|
||||
batch_request: {
|
||||
action: add
|
||||
version: 1.5
|
||||
@@ -243,6 +251,11 @@
|
||||
type: string
|
||||
description: "Task ID"
|
||||
}
|
||||
allow_locked {
|
||||
type: boolean
|
||||
description: "Allow deleting events even if the task is locked"
|
||||
default: false
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
@@ -444,6 +457,10 @@
|
||||
type: integer
|
||||
description: "Number of events to return each time"
|
||||
}
|
||||
event_type {
|
||||
type: string
|
||||
description: "Return only events of this type"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
@@ -682,6 +699,19 @@
|
||||
type: string
|
||||
description: "Task ID"
|
||||
}
|
||||
samples {
|
||||
description: "The amount of histogram points to return (0 to return all the points). Optional, the default value is 10000."
|
||||
type: integer
|
||||
}
|
||||
key {
|
||||
description: """
|
||||
Histogram x axis to use:
|
||||
iter - iteration number
|
||||
iso_time - event time as ISO formatted string
|
||||
timestamp - event timestamp as milliseconds since epoch
|
||||
"""
|
||||
"$ref": "#/definitions/scalar_key_enum"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
@@ -715,7 +745,19 @@
|
||||
description: "List of task Task IDs"
|
||||
}
|
||||
}
|
||||
|
||||
samples {
|
||||
description: "The amount of histogram points to return (0 to return all the points). Optional, the default value is 10000."
|
||||
type: integer
|
||||
}
|
||||
key {
|
||||
description: """
|
||||
Histogram x axis to use:
|
||||
iter - iteration number
|
||||
iso_time - event time as ISO formatted string
|
||||
timestamp - event timestamp as milliseconds since epoch
|
||||
"""
|
||||
"$ref": "#/definitions/scalar_key_enum"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
|
||||
@@ -57,9 +57,14 @@
|
||||
}
|
||||
tags {
|
||||
type: array
|
||||
description: "Tags"
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
framework {
|
||||
description: "Framework on which the model is based. Should be identical to the framework of the task which created the model"
|
||||
type: string
|
||||
@@ -159,7 +164,12 @@
|
||||
type: boolean
|
||||
}
|
||||
tags {
|
||||
description: "Tags list used to filter results. Prepend '-' to tag name to indicate exclusion"
|
||||
description: "User-defined tags list used to filter results. Prepend '-' to tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list used to filter results. Prepend '-' to system tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -263,10 +273,15 @@
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
override_model_id {
|
||||
description: "Override model ID. If provided, this model is updated in the task."
|
||||
type: string
|
||||
@@ -325,10 +340,15 @@
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
framework {
|
||||
description: "Framework on which the model is based. Case insensitive. Should be identical to the framework of the task which created the model."
|
||||
type: string
|
||||
@@ -344,7 +364,7 @@
|
||||
additionalProperties { type: integer }
|
||||
}
|
||||
ready {
|
||||
description: "Indication if the model is final and can be used by other tasks Default is false."
|
||||
description: "Indication if the model is final and can be used by other tasks. Default is false."
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
@@ -408,10 +428,15 @@
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
framework {
|
||||
description: "Framework on which the model is based. Case insensitive. Should be identical to the framework of the task which created the model."
|
||||
type: string
|
||||
@@ -485,10 +510,15 @@
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
ready {
|
||||
description: "Indication if the model is final and can be used by other tasks Default is false."
|
||||
type: boolean
|
||||
|
||||
@@ -1,462 +1,523 @@
|
||||
{
|
||||
_description: "Provides support for defining Projects containing Tasks, Models and Dataset Versions."
|
||||
_definitions {
|
||||
multi_field_pattern_data {
|
||||
_description: "Provides support for defining Projects containing Tasks, Models and Dataset Versions."
|
||||
_definitions {
|
||||
multi_field_pattern_data {
|
||||
type: object
|
||||
properties {
|
||||
pattern {
|
||||
description: "Pattern string (regex)"
|
||||
type: string
|
||||
}
|
||||
fields {
|
||||
description: "List of field names"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
project {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
user {
|
||||
description: "Associated user id"
|
||||
type: string
|
||||
}
|
||||
company {
|
||||
description: "Company id"
|
||||
type: string
|
||||
}
|
||||
created {
|
||||
description: "Creation time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
tags {
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
last_update {
|
||||
description: """Last project update time. Reflects the last time the project metadata was changed or a task in this project has changed status"""
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
}
|
||||
}
|
||||
stats_status_count {
|
||||
type: object
|
||||
properties {
|
||||
total_runtime {
|
||||
description: "Total run time of all tasks in project (in seconds)"
|
||||
type: integer
|
||||
}
|
||||
status_count {
|
||||
description: "Status counts"
|
||||
type: object
|
||||
properties {
|
||||
created {
|
||||
description: "Number of 'created' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
queued {
|
||||
description: "Number of 'queued' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
in_progress {
|
||||
description: "Number of 'in_progress' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
stopped {
|
||||
description: "Number of 'stopped' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
published {
|
||||
description: "Number of 'published' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
closed {
|
||||
description: "Number of 'closed' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
failed {
|
||||
description: "Number of 'failed' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
unknown {
|
||||
description: "Number of 'unknown' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
stats {
|
||||
type: object
|
||||
properties {
|
||||
active {
|
||||
description: "Stats for active tasks"
|
||||
"$ref": "#/definitions/stats_status_count"
|
||||
}
|
||||
archived {
|
||||
description: "Stats for archived tasks"
|
||||
"$ref": "#/definitions/stats_status_count"
|
||||
}
|
||||
}
|
||||
}
|
||||
projects_get_all_response_single {
|
||||
// copy-paste from project definition
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
user {
|
||||
description: "Associated user id"
|
||||
type: string
|
||||
}
|
||||
company {
|
||||
description: "Company id"
|
||||
type: string
|
||||
}
|
||||
created {
|
||||
description: "Creation time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
tags {
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
// extra properties
|
||||
stats: {
|
||||
description: "Additional project stats"
|
||||
"$ref": "#/definitions/stats"
|
||||
}
|
||||
}
|
||||
}
|
||||
metric_variant_result {
|
||||
type: object
|
||||
properties {
|
||||
metric {
|
||||
description: "Metric name"
|
||||
type: string
|
||||
}
|
||||
metric_hash {
|
||||
description: """Metric name hash. Used instead of the metric name when categorizing
|
||||
last metrics events in task objects."""
|
||||
type: string
|
||||
}
|
||||
variant {
|
||||
description: "Variant name"
|
||||
type: string
|
||||
}
|
||||
variant_hash {
|
||||
description: """Variant name hash. Used instead of the variant name when categorizing
|
||||
last metrics events in task objects."""
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
create {
|
||||
"2.1" {
|
||||
description: "Create a new project"
|
||||
request {
|
||||
type: object
|
||||
required :[
|
||||
name
|
||||
description
|
||||
]
|
||||
properties {
|
||||
pattern {
|
||||
description: "Pattern string (regex)"
|
||||
name {
|
||||
description: "Project name Unique within the company."
|
||||
type: string
|
||||
}
|
||||
fields {
|
||||
description: "List of field names"
|
||||
description {
|
||||
description: "Project description. "
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
project_tags_enum {
|
||||
type: string
|
||||
enum: [ archived, public, default ]
|
||||
}
|
||||
project {
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
user {
|
||||
description: "Associated user id"
|
||||
type: string
|
||||
}
|
||||
company {
|
||||
description: "Company id"
|
||||
type: string
|
||||
}
|
||||
created {
|
||||
description: "Creation time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
tags {
|
||||
description: "Tags"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/project_tags_enum" }
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
last_update {
|
||||
description: """Last project update time. Reflects the last time the project metadata was changed or a task in this project has changed status"""
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
}
|
||||
}
|
||||
stats_status_count {
|
||||
type: object
|
||||
properties {
|
||||
total_runtime {
|
||||
description: "Total run time of all tasks in project (in seconds)"
|
||||
type: integer
|
||||
}
|
||||
status_count {
|
||||
description: "Status counts"
|
||||
type: object
|
||||
properties {
|
||||
created {
|
||||
description: "Number of 'created' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
queued {
|
||||
description: "Number of 'queued' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
in_progress {
|
||||
description: "Number of 'in_progress' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
stopped {
|
||||
description: "Number of 'stopped' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
published {
|
||||
description: "Number of 'published' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
closed {
|
||||
description: "Number of 'closed' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
failed {
|
||||
description: "Number of 'failed' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
unknown {
|
||||
description: "Number of 'unknown' tasks in project"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
stats {
|
||||
type: object
|
||||
properties {
|
||||
active {
|
||||
description: "Stats for active tasks"
|
||||
"$ref": "#/definitions/stats_status_count"
|
||||
}
|
||||
archived {
|
||||
description: "Stats for archived tasks"
|
||||
"$ref": "#/definitions/stats_status_count"
|
||||
}
|
||||
}
|
||||
}
|
||||
projects_get_all_response_single {
|
||||
// copy-paste from project definition
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
user {
|
||||
description: "Associated user id"
|
||||
type: string
|
||||
}
|
||||
company {
|
||||
description: "Company id"
|
||||
type: string
|
||||
}
|
||||
created {
|
||||
description: "Creation time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
tags {
|
||||
description: "Tags"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/project_tags_enum" }
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
// extra properties
|
||||
stats: {
|
||||
description: "Additional project stats"
|
||||
"$ref": "#/definitions/stats"
|
||||
}
|
||||
}
|
||||
}
|
||||
metric_variant_result {
|
||||
type: object
|
||||
properties {
|
||||
metric {
|
||||
description: "Metric name"
|
||||
type: string
|
||||
}
|
||||
metric_hash {
|
||||
description: """Metric name hash. Used instead of the metric name when categorizing
|
||||
last metrics events in task objects."""
|
||||
type: string
|
||||
}
|
||||
variant {
|
||||
description: "Variant name"
|
||||
type: string
|
||||
}
|
||||
variant_hash {
|
||||
description: """Variant name hash. Used instead of the variant name when categorizing
|
||||
last metrics events in task objects."""
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
create {
|
||||
"2.1" {
|
||||
description: "Create a new project"
|
||||
request {
|
||||
type: object
|
||||
required :[
|
||||
name
|
||||
description
|
||||
]
|
||||
properties {
|
||||
name {
|
||||
description: "Project name Unique within the company."
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description. "
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/project_tags_enum" }
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_by_id {
|
||||
"2.1" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
project {
|
||||
description: "Project info"
|
||||
"$ref": "#/definitions/project"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_all {
|
||||
"2.1" {
|
||||
description: "Get all the company's projects and all public projects"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "List of IDs to filter by"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
name {
|
||||
description: "Get only projects whose name matches this pattern (python regular expression syntax)"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Get only projects whose description matches this pattern (python regular expression syntax)"
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list used to filter results. Prepend '-' to tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
order_by {
|
||||
description: "List of field names to order by. When search_text is used, '@text_score' can be used as a field representing the text score of returned documents. Use '-' prefix to specify descending order. Optional, recommended when using page"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
page {
|
||||
description: "Page number, returns a specific page out of the resulting list of dataviews"
|
||||
type: integer
|
||||
minimum: 0
|
||||
}
|
||||
page_size {
|
||||
description: "Page size, specifies the number of results returned in each page (last page may contain fewer results)"
|
||||
type: integer
|
||||
minimum: 1
|
||||
}
|
||||
search_text {
|
||||
description: "Free text search query"
|
||||
type: string
|
||||
}
|
||||
only_fields {
|
||||
description: "List of document's field names (nesting is supported using '.', e.g. execution.model_labels). If provided, this list defines the query's projection (only these fields will be returned for each result entry)"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
_all_ {
|
||||
description: "Multi-field pattern condition (all fields match pattern)"
|
||||
"$ref": "#/definitions/multi_field_pattern_data"
|
||||
}
|
||||
_any_ {
|
||||
description: "Multi-field pattern condition (any field matches pattern)"
|
||||
"$ref": "#/definitions/multi_field_pattern_data"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
projects {
|
||||
description: "Projects list"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/projects_get_all_response_single" }
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_all_ex {
|
||||
internal: true
|
||||
"2.1": ${get_all."2.1"} {
|
||||
request {
|
||||
properties {
|
||||
include_stats {
|
||||
description: "If true, include project statistic in response."
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
stats_for_state {
|
||||
description: "Report stats include only statistics for tasks in the specified state. If Null is provided, stats for all task states will be returned."
|
||||
type: string
|
||||
enum: [ active, archived ]
|
||||
default: active
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
update {
|
||||
"2.1" {
|
||||
description: "Update project information"
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name. Unique within the company."
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description. "
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
updated {
|
||||
description: "Number of projects updated (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
fields {
|
||||
description: "Updated fields names and values"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
delete {
|
||||
"2.1" {
|
||||
description: "Deletes a project"
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
force {
|
||||
description: """If not true, fails if project has tasks.
|
||||
If true, and project has tasks, they will be unassigned"""
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
deleted {
|
||||
description: "Number of projects deleted (0 or 1)"
|
||||
type: integer
|
||||
}
|
||||
disassociated_tasks {
|
||||
description: "Number of tasks disassociated from the deleted project"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_unique_metric_variants {
|
||||
"2.1" {
|
||||
description: """Get all metric/variant pairs reported for tasks in a specific project.
|
||||
If no project is specified, metrics/variant paris reported for all tasks will be returned.
|
||||
If the project does not exist, an empty list will be returned."""
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
project {
|
||||
description: "Project ID"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
metrics {
|
||||
description: "A list of metric variants reported for tasks in this project"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/metric_variant_result" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_by_id {
|
||||
"2.1" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
project {
|
||||
description: "Project info"
|
||||
"$ref": "#/definitions/project"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_all {
|
||||
"2.1" {
|
||||
description: "Get all the company's projects and all public projects"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "List of IDs to filter by"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
name {
|
||||
description: "Get only projects whose name matches this pattern (python regular expression syntax)"
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Get only projects whose description matches this pattern (python regular expression syntax)"
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "User-defined tags list used to filter results. Prepend '-' to tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list used to filter results. Prepend '-' to system tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
order_by {
|
||||
description: "List of field names to order by. When search_text is used, '@text_score' can be used as a field representing the text score of returned documents. Use '-' prefix to specify descending order. Optional, recommended when using page"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
page {
|
||||
description: "Page number, returns a specific page out of the resulting list of dataviews"
|
||||
type: integer
|
||||
minimum: 0
|
||||
}
|
||||
page_size {
|
||||
description: "Page size, specifies the number of results returned in each page (last page may contain fewer results)"
|
||||
type: integer
|
||||
minimum: 1
|
||||
}
|
||||
search_text {
|
||||
description: "Free text search query"
|
||||
type: string
|
||||
}
|
||||
only_fields {
|
||||
description: "List of document's field names (nesting is supported using '.', e.g. execution.model_labels). If provided, this list defines the query's projection (only these fields will be returned for each result entry)"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
_all_ {
|
||||
description: "Multi-field pattern condition (all fields match pattern)"
|
||||
"$ref": "#/definitions/multi_field_pattern_data"
|
||||
}
|
||||
_any_ {
|
||||
description: "Multi-field pattern condition (any field matches pattern)"
|
||||
"$ref": "#/definitions/multi_field_pattern_data"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
projects {
|
||||
description: "Projects list"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/projects_get_all_response_single" }
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_all_ex {
|
||||
internal: true
|
||||
"2.1": ${get_all."2.1"} {
|
||||
request {
|
||||
properties {
|
||||
include_stats {
|
||||
description: "If true, include project statistic in response."
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
stats_for_state {
|
||||
description: "Report stats include only statistics for tasks in the specified state. If Null is provided, stats for all task states will be returned."
|
||||
type: string
|
||||
enum: [ active, archived ]
|
||||
default: active
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
update {
|
||||
"2.1" {
|
||||
description: "Update project information"
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Project name. Unique within the company."
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description. "
|
||||
type: string
|
||||
}
|
||||
description {
|
||||
description: "Project description"
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
type: array
|
||||
description: "User-defined tags"
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
type: array
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
items {type: string}
|
||||
}
|
||||
default_output_destination {
|
||||
description: "The default output destination URL for new tasks under this project"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
updated {
|
||||
description: "Number of projects updated (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
fields {
|
||||
description: "Updated fields names and values"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
delete {
|
||||
"2.1" {
|
||||
description: "Deletes a project"
|
||||
request {
|
||||
type: object
|
||||
required: [ project ]
|
||||
properties {
|
||||
project {
|
||||
description: "Project id"
|
||||
type: string
|
||||
}
|
||||
force {
|
||||
description: """If not true, fails if project has tasks.
|
||||
If true, and project has tasks, they will be unassigned"""
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
deleted {
|
||||
description: "Number of projects deleted (0 or 1)"
|
||||
type: integer
|
||||
}
|
||||
disassociated_tasks {
|
||||
description: "Number of tasks disassociated from the deleted project"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_unique_metric_variants {
|
||||
"2.1" {
|
||||
description: """Get all metric/variant pairs reported for tasks in a specific project.
|
||||
If no project is specified, metrics/variant paris reported for all tasks will be returned.
|
||||
If the project does not exist, an empty list will be returned."""
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
project {
|
||||
description: "Project ID"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
metrics {
|
||||
description: "A list of metric variants reported for tasks in this project"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/metric_variant_result" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_hyper_parameters {
|
||||
"2.2" {
|
||||
description: """Get a list of all hyper parameter names used in tasks within the given project."""
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
project {
|
||||
description: "Project ID"
|
||||
type: string
|
||||
}
|
||||
page {
|
||||
description: "Page number"
|
||||
default: 0
|
||||
type: integer
|
||||
}
|
||||
page_size {
|
||||
description: "Page size"
|
||||
default: 500
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
parameters {
|
||||
description: "A list of hyper parameter names"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
remaining {
|
||||
description: "Remaining results"
|
||||
type: integer
|
||||
}
|
||||
total {
|
||||
description: "Total number of results"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
568
server/schema/services/queues.conf
Normal file
568
server/schema/services/queues.conf
Normal file
@@ -0,0 +1,568 @@
|
||||
{
|
||||
_description: "Provides a management API for queues of tasks waiting to be executed by workers deployed anywhere (see Workers Service)."
|
||||
_definitions {
|
||||
queue_metrics {
|
||||
type: object
|
||||
properties: {
|
||||
queue: {
|
||||
type: string
|
||||
description: "ID of the queue"
|
||||
}
|
||||
dates {
|
||||
type: array
|
||||
description: "List of timestamps (in seconds from epoch) in the acceding order. The timestamps are separated by the requested interval. Timestamps where no queue status change was recorded are omitted."
|
||||
items { type: integer }
|
||||
}
|
||||
avg_waiting_times {
|
||||
type: array
|
||||
description: "List of average waiting times for tasks in the queue. The points correspond to the timestamps in the dates list. If more than one value exists for the given interval then the maximum value is taken."
|
||||
items { type: number }
|
||||
}
|
||||
queue_lengths {
|
||||
type: array
|
||||
description: "List of tasks counts in the queue. The points correspond to the timestamps in the dates list. If more than one value exists for the given interval then the count that corresponds to the maximum average value is taken."
|
||||
items { type: integer }
|
||||
}
|
||||
}
|
||||
}
|
||||
entry {
|
||||
type: object
|
||||
properties: {
|
||||
task {
|
||||
description: "Queued task ID"
|
||||
type: string
|
||||
}
|
||||
added {
|
||||
description: "Time this entry was added to the queue"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
}
|
||||
}
|
||||
queue {
|
||||
type: object
|
||||
properties: {
|
||||
id {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Queue name"
|
||||
type: string
|
||||
}
|
||||
user {
|
||||
description: "Associated user id"
|
||||
type: string
|
||||
}
|
||||
company {
|
||||
description: "Company id"
|
||||
type: string
|
||||
}
|
||||
created {
|
||||
description: "Queue creation time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
tags {
|
||||
description: "User-defined tags"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
entries {
|
||||
description: "List of ordered queue entries"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/entry" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
get_by_id {
|
||||
"2.4" {
|
||||
description: "Gets queue information"
|
||||
request {
|
||||
type: object
|
||||
required: [ queue ]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue ID"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue info"
|
||||
"$ref": "#/definitions/queue"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
// typescript generation hack
|
||||
get_all_ex {
|
||||
internal: true
|
||||
"2.4": ${get_all."2.4"}
|
||||
}
|
||||
get_all {
|
||||
"2.4" {
|
||||
description: "Get all queues"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
name {
|
||||
description: "Get only queues whose name matches this pattern (python regular expression syntax)"
|
||||
type: string
|
||||
}
|
||||
id {
|
||||
description: "List of Queue IDs used to filter results"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
tags {
|
||||
description: "User-defined tags list used to filter results. Prepend '-' to tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list used to filter results. Prepend '-' to system tag name to indicate exclusion"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
page {
|
||||
description: "Page number, returns a specific page out of the result list of results."
|
||||
type: integer
|
||||
minimum: 0
|
||||
}
|
||||
page_size {
|
||||
description: "Page size, specifies the number of results returned in each page (last page may contain fewer results)"
|
||||
type: integer
|
||||
minimum: 1
|
||||
}
|
||||
order_by {
|
||||
description: "List of field names to order by. When search_text is used, '@text_score' can be used as a field representing the text score of returned documents. Use '-' prefix to specify descending order. Optional, recommended when using page"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
search_text {
|
||||
description: "Free text search query"
|
||||
type: string
|
||||
}
|
||||
only_fields {
|
||||
description: "List of document field names (nesting is supported using '.', e.g. execution.model_labels). If provided, this list defines the query's projection (only these fields will be returned for each result entry)"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
queues {
|
||||
description: "Queues list"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/queue"}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_default {
|
||||
"2.4" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
properties {}
|
||||
additionalProperties: false
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Queue name"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
create {
|
||||
"2.4" {
|
||||
description: "Create a new queue"
|
||||
request {
|
||||
type: object
|
||||
required: [ name ]
|
||||
properties {
|
||||
name {
|
||||
description: "Queue name Unique within the company."
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "New queue ID"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
update {
|
||||
"2.4" {
|
||||
description: "Update queue information"
|
||||
request {
|
||||
type: object
|
||||
required: [ queue ]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Queue name Unique within the company."
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
updated {
|
||||
description: "Number of queues updated (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
fields {
|
||||
description: "Updated fields names and values"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
delete {
|
||||
"2.4" {
|
||||
description: "Deletes a queue. If the queue is not empty and force is not set to true, queue will not be deleted."
|
||||
request {
|
||||
type: object
|
||||
required: [ queue ]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
force {
|
||||
description: "Force delete of non-empty queue. Defaults to false"
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
deleted {
|
||||
description: "Number of queues deleted (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
add_task {
|
||||
"2.4" {
|
||||
description: "Adds a task entry to the queue."
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
added {
|
||||
description: "Number of tasks added (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_next_task {
|
||||
"2.4" {
|
||||
description: "Gets the next task from the top of the queue (FIFO). The task entry is removed from the queue."
|
||||
request {
|
||||
type: object
|
||||
required: [ queue ]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
entry {
|
||||
description: "Entry information"
|
||||
"$ref": "#/definitions/entry"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
remove_task {
|
||||
"2.4" {
|
||||
description: "Removes a task entry from the queue."
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
removed {
|
||||
description: "Number of tasks removed (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
move_task_forward: {
|
||||
"2.4" {
|
||||
description: "Moves a task entry one step forward towards the top of the queue."
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
count {
|
||||
description: "Number of positions in the queue to move the task forward relative to the current position. Optional, the default value is 1."
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
position {
|
||||
description: "The new position of the task entry in the queue (index, -1 represents bottom of queue)"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
move_task_backward: {
|
||||
"2.4" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
count {
|
||||
description: "Number of positions in the queue to move the task forward relative to the current position. Optional, the default value is 1."
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
position {
|
||||
description: "The new position of the task entry in the queue (index, -1 represents bottom of queue)"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
move_task_to_front: {
|
||||
"2.4" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
position {
|
||||
description: "The new position of the task entry in the queue (index, -1 represents bottom of queue)"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
move_task_to_back: {
|
||||
"2.4" {
|
||||
description: ""
|
||||
request {
|
||||
type: object
|
||||
required: [
|
||||
queue
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id"
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "Task id"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
position {
|
||||
description: "The new position of the task entry in the queue (index, -1 represents bottom of queue)"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_queue_metrics : {
|
||||
"2.4" {
|
||||
description: "Returns metrics of the company queues. The metrics are avaraged in the specified interval."
|
||||
request {
|
||||
type: object
|
||||
required: [from_date, to_date, interval]
|
||||
properties: {
|
||||
from_date {
|
||||
description: "Starting time (in seconds from epoch) for collecting metrics"
|
||||
type: number
|
||||
}
|
||||
to_date {
|
||||
description: "Ending time (in seconds from epoch) for collecting metrics"
|
||||
type: number
|
||||
}
|
||||
interval {
|
||||
description: "Time interval in seconds for a single metrics point. The minimal value is 1"
|
||||
type: integer
|
||||
}
|
||||
queue_ids {
|
||||
description: "List of queue ids to collect metrics for. If not provided or empty then all then average metrics across all the company queues will be returned."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties: {
|
||||
queues {
|
||||
type: array
|
||||
description: "List of the requested queues with their metrics. If no queue ids were requested then 'all' queue is returned with the metrics averaged accross all the company queues."
|
||||
items { "$ref": "#/definitions/queue_metrics" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
123
server/schema/services/server.conf
Normal file
123
server/schema/services/server.conf
Normal file
@@ -0,0 +1,123 @@
|
||||
_description: "server utilities"
|
||||
_default {
|
||||
internal: true
|
||||
allow_roles: ["root", "system"]
|
||||
}
|
||||
get_stats {
|
||||
"2.1" {
|
||||
description: "Get the server collected statistics."
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
interval {
|
||||
description: "The period for statistics collection in seconds."
|
||||
type: long
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties: {
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
config {
|
||||
"2.1" {
|
||||
description: "Get server configuration. Secure section is not returned."
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
path {
|
||||
description: "Path of config value. Defaults to root"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
info {
|
||||
authorize = false
|
||||
allow_roles = [ "*" ]
|
||||
"2.1" {
|
||||
description: "Get server information, including version and build number"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
version {
|
||||
description: "Version string"
|
||||
type: string
|
||||
}
|
||||
build {
|
||||
description: "Build number"
|
||||
type: string
|
||||
}
|
||||
commit {
|
||||
description: "VCS commit number"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
endpoints {
|
||||
"2.1" {
|
||||
description: "Show available endpoints"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
report_stats_option {
|
||||
"2.4" {
|
||||
description: "Get or set the report statistics option per-company"
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
enabled {
|
||||
description: "If provided, sets the report statistics option (true/false)"
|
||||
type: boolean
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
enabled {
|
||||
description: "Returns the current report stats option value"
|
||||
type: boolean
|
||||
}
|
||||
enabled_time {
|
||||
description: "If enabled, returns the time at which option was enabled"
|
||||
type: string
|
||||
format: date-time
|
||||
}
|
||||
enabled_version {
|
||||
description: "If enabled, returns the server version at the time option was enabled"
|
||||
type: string
|
||||
}
|
||||
enabled_user {
|
||||
description: "If enabled, returns Id of the user who enabled the option"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -120,9 +120,83 @@ _definitions {
|
||||
frame_per_roi
|
||||
]
|
||||
}
|
||||
artifact_type_data {
|
||||
type: object
|
||||
properties {
|
||||
preview {
|
||||
description: "Description or textual data"
|
||||
type: string
|
||||
}
|
||||
content_type {
|
||||
description: "System defined raw data content type"
|
||||
type: string
|
||||
}
|
||||
data_hash {
|
||||
description: "Hash of raw data, without any headers or descriptive parts"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
artifact {
|
||||
type: object
|
||||
required: [key, type]
|
||||
properties {
|
||||
key {
|
||||
description: "Entry key"
|
||||
type: string
|
||||
}
|
||||
type {
|
||||
description: "System defined type"
|
||||
type: string
|
||||
}
|
||||
mode {
|
||||
description: "System defined input/output indication"
|
||||
type: string
|
||||
enum: [
|
||||
input
|
||||
output
|
||||
]
|
||||
default: output
|
||||
}
|
||||
uri {
|
||||
description: "Raw data location"
|
||||
type: string
|
||||
}
|
||||
content_size {
|
||||
description: "Raw data length in bytes"
|
||||
type: integer
|
||||
}
|
||||
hash {
|
||||
description: "Hash of entire raw data"
|
||||
type: string
|
||||
}
|
||||
timestamp {
|
||||
description: "Epoch time when artifact was created"
|
||||
type: integer
|
||||
}
|
||||
type_data {
|
||||
description: "Additional fields defined by the system"
|
||||
"$ref": "#/definitions/artifact_type_data"
|
||||
}
|
||||
display_data {
|
||||
description: "User-defined list of key/value pairs, sorted"
|
||||
type: array
|
||||
items {
|
||||
type: array
|
||||
items {
|
||||
type: string # can also be a number... TODO: upgrade the generator
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
execution {
|
||||
type: object
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue ID where task was queued."
|
||||
type: string
|
||||
}
|
||||
parameters {
|
||||
description: "Json object containing the Task parameters"
|
||||
type: object
|
||||
@@ -149,12 +223,22 @@ _definitions {
|
||||
description: """Framework related to the task. Case insensitive. Mandatory for Training tasks. """
|
||||
type: string
|
||||
}
|
||||
docker_cmd {
|
||||
description: "Command for running docker script for the execution of the task"
|
||||
type: string
|
||||
}
|
||||
artifacts {
|
||||
description: "Task artifacts"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/artifact" }
|
||||
}
|
||||
}
|
||||
}
|
||||
task_status_enum {
|
||||
type: string
|
||||
enum: [
|
||||
created
|
||||
queued
|
||||
in_progress
|
||||
stopped
|
||||
published
|
||||
@@ -183,21 +267,16 @@ _definitions {
|
||||
description: "Variant name"
|
||||
type: string
|
||||
}
|
||||
type {
|
||||
description: "Event type"
|
||||
type: string
|
||||
}
|
||||
timestamp {
|
||||
description: "Event report time (UTC)"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
iter {
|
||||
description: "Iteration number"
|
||||
type: integer
|
||||
}
|
||||
value {
|
||||
description: "Value"
|
||||
description: "Last value reported"
|
||||
type: number
|
||||
}
|
||||
min_value {
|
||||
description: "Minimum value reported"
|
||||
type: number
|
||||
}
|
||||
max_value {
|
||||
description: "Maximum value reported"
|
||||
type: number
|
||||
}
|
||||
}
|
||||
@@ -278,7 +357,12 @@ _definitions {
|
||||
"$ref": "#/definitions/script"
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -300,6 +384,15 @@ _definitions {
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
last_worker {
|
||||
description: "ID of last worker that handled the task"
|
||||
type: string
|
||||
}
|
||||
last_worker_report {
|
||||
description: "Last time a worker reported while working on this task"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
last_update {
|
||||
description: "Last time this task was created, updated, changed or events for this task were reported"
|
||||
type: string
|
||||
@@ -392,7 +485,12 @@ get_all {
|
||||
items { type: string }
|
||||
}
|
||||
tags {
|
||||
description: "List of task tags. Use '-' prefix to exclude tags"
|
||||
description: "List of task user-defined tags. Use '-' prefix to exclude tags"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "List of task system tags. Use '-' prefix to exclude system tags"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -467,7 +565,12 @@ create {
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -527,7 +630,12 @@ validate {
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -585,7 +693,12 @@ update {
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -667,7 +780,12 @@ edit {
|
||||
type: string
|
||||
}
|
||||
tags {
|
||||
description: "Tags list"
|
||||
description: "User-defined tags list"
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
system_tags {
|
||||
description: "System tags list. This field is reserved for system use, please don't use it."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
@@ -738,6 +856,11 @@ reset {
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
dequeued {
|
||||
description: "Response from queues.remove_task"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
frames {
|
||||
description: "Response from frames.rollback"
|
||||
type: object
|
||||
@@ -1014,7 +1137,85 @@ publish {
|
||||
}
|
||||
}
|
||||
}
|
||||
enqueue {
|
||||
"1.5" {
|
||||
description: """Adds a task into a queue.
|
||||
|
||||
Fails if task state is not 'created'.
|
||||
|
||||
Fails if the following parameters in the task were not filled:
|
||||
|
||||
* execution.script.repository
|
||||
|
||||
* execution.script.entrypoint
|
||||
"""
|
||||
request = {
|
||||
type: object
|
||||
required: [
|
||||
task
|
||||
]
|
||||
properties {
|
||||
queue {
|
||||
description: "Queue id. If not provided, task is added to the default queue."
|
||||
type: string
|
||||
}
|
||||
}
|
||||
|
||||
} ${_references.status_change_request}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
queued {
|
||||
description: "Number of tasks queued (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
updated {
|
||||
description: "Number of tasks updated (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
fields {
|
||||
description: "Updated fields names and values"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
dequeue {
|
||||
"1.5" {
|
||||
description: """Remove a task from its queue.
|
||||
Fails if task status is not queued."""
|
||||
request = {
|
||||
type: object
|
||||
required: [
|
||||
task
|
||||
]
|
||||
} ${_references.status_change_request}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
dequeued {
|
||||
description: "Number of tasks dequeued (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
updated {
|
||||
description: "Number of tasks updated (0 or 1)"
|
||||
type: integer
|
||||
enum: [ 0, 1 ]
|
||||
}
|
||||
fields {
|
||||
description: "Updated fields names and values"
|
||||
type: object
|
||||
additionalProperties: true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
set_requirements {
|
||||
"2.1" {
|
||||
description: """Set the script requirements for a task"""
|
||||
@@ -1062,7 +1263,7 @@ completed {
|
||||
task
|
||||
]
|
||||
properties.force = ${_references.force_arg} {
|
||||
description: "If not true, call fails if the task status is not created/in_progress/published"
|
||||
description: "If not true, call fails if the task status is not in_progress/stopped"
|
||||
}
|
||||
} ${_references.status_change_request}
|
||||
response {
|
||||
|
||||
483
server/schema/services/workers.conf
Normal file
483
server/schema/services/workers.conf
Normal file
@@ -0,0 +1,483 @@
|
||||
{
|
||||
_description: "Provides an API for worker machines, allowing workers to report status and get tasks for execution"
|
||||
_definitions {
|
||||
metrics_category {
|
||||
type: object
|
||||
properties {
|
||||
name {
|
||||
type: string
|
||||
description: "Name of the metrics category."
|
||||
}
|
||||
metric_keys {
|
||||
type: array
|
||||
items { type: string }
|
||||
description: "The names of the metrics in the category."
|
||||
}
|
||||
}
|
||||
}
|
||||
aggregation_type {
|
||||
type: string
|
||||
enum: [ avg, min, max ]
|
||||
description: "Metric aggregation type"
|
||||
}
|
||||
stat_item {
|
||||
type: object
|
||||
properties {
|
||||
key {
|
||||
type: string
|
||||
description: "Name of a metric"
|
||||
}
|
||||
category {
|
||||
"$ref": "#/definitions/aggregation_type"
|
||||
}
|
||||
}
|
||||
}
|
||||
aggregation_stats {
|
||||
type: object
|
||||
properties {
|
||||
aggregation {
|
||||
"$ref": "#/definitions/aggregation_type"
|
||||
}
|
||||
values {
|
||||
type: array
|
||||
description: "List of values corresponding to the dates in metric statistics"
|
||||
items { type: number }
|
||||
}
|
||||
}
|
||||
}
|
||||
metric_stats {
|
||||
type: object
|
||||
properties {
|
||||
metric {
|
||||
type: string
|
||||
description: "Name of the metric ("cpu_usage", "memory_used" etc.)"
|
||||
}
|
||||
variant {
|
||||
type: string
|
||||
description: "Name of the metric component. Set only if 'split_by_variant' was set in the request"
|
||||
}
|
||||
dates {
|
||||
type: array
|
||||
description: "List of timestamps (in seconds from epoch) in the acceding order. The timestamps are separated by the requested interval. Timestamps where no workers activity was recorded are omitted."
|
||||
items { type: integer }
|
||||
}
|
||||
stats {
|
||||
type: array
|
||||
description: "Statistics data by type"
|
||||
items { "$ref": "#/definitions/aggregation_stats" }
|
||||
}
|
||||
}
|
||||
}
|
||||
worker_stats {
|
||||
type: object
|
||||
properties {
|
||||
worker {
|
||||
type: string
|
||||
description: "ID of the worker"
|
||||
}
|
||||
metrics {
|
||||
type: array
|
||||
description: "List of the metrics statistics for the worker"
|
||||
items { "$ref": "#/definitions/metric_stats" }
|
||||
}
|
||||
}
|
||||
}
|
||||
activity_series {
|
||||
type: object
|
||||
properties {
|
||||
dates {
|
||||
type: array
|
||||
description: "List of timestamps (in seconds from epoch) in the acceding order. The timestamps are separated by the requested interval."
|
||||
items {type: integer}
|
||||
}
|
||||
counts {
|
||||
type: array
|
||||
description: "List of worker counts corresponding to the timestamps in the dates list. None values are returned for the dates with no workers."
|
||||
items {type: integer}
|
||||
}
|
||||
}
|
||||
}
|
||||
worker {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Worker ID"
|
||||
type: string
|
||||
}
|
||||
user {
|
||||
description: "Associated user (under whose credentials are used by the worker daemon)"
|
||||
"$ref": "#/definitions/id_name_entry"
|
||||
}
|
||||
company {
|
||||
description: "Associated company"
|
||||
"$ref": "#/definitions/id_name_entry"
|
||||
}
|
||||
ip {
|
||||
description: "IP of the worker"
|
||||
type: string
|
||||
}
|
||||
register_time {
|
||||
description: "Registration time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
last_activity_time {
|
||||
description: "Last activity time (even if an error occurred)"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
last_report_time {
|
||||
description: "Last successful report time"
|
||||
type: string
|
||||
format: "date-time"
|
||||
}
|
||||
task {
|
||||
description: "Task currently being run by the worker"
|
||||
"$ref": "#/definitions/current_task_entry"
|
||||
}
|
||||
queue {
|
||||
description: "Queue from which running task was taken"
|
||||
"$ref": "#/definitions/queue_entry"
|
||||
}
|
||||
queues {
|
||||
description: "List of queues on which the worker is listening"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/queue_entry" }
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
id_name_entry {
|
||||
type: object
|
||||
properties {
|
||||
id {
|
||||
description: "Worker ID"
|
||||
type: string
|
||||
}
|
||||
name {
|
||||
description: "Worker name"
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
current_task_entry = ${_definitions.id_name_entry} {
|
||||
properties {
|
||||
running_time {
|
||||
description: "Task running time"
|
||||
type: integer
|
||||
}
|
||||
last_iteration {
|
||||
description: "Last task iteration"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
queue_entry = ${_definitions.id_name_entry} {
|
||||
properties {
|
||||
next_task {
|
||||
description: "Next task in the queue"
|
||||
"$ref": "#/definitions/id_name_entry"
|
||||
}
|
||||
num_tasks {
|
||||
description: "Number of task entries in the queue"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
machine_stats {
|
||||
type: object
|
||||
properties {
|
||||
cpu_usage {
|
||||
description: "Average CPU usage per core"
|
||||
type: array
|
||||
items { type: number }
|
||||
}
|
||||
gpu_usage {
|
||||
description: "Average GPU usage per GPU card"
|
||||
type: array
|
||||
items { type: number }
|
||||
}
|
||||
memory_used {
|
||||
description: "Used memory MBs"
|
||||
type: integer
|
||||
}
|
||||
memory_free {
|
||||
description: "Free memory MBs"
|
||||
type: integer
|
||||
}
|
||||
gpu_memory_free {
|
||||
description: "GPU free memory MBs"
|
||||
type: array
|
||||
items { type: integer }
|
||||
}
|
||||
gpu_memory_used {
|
||||
description: "GPU used memory MBs"
|
||||
type: array
|
||||
items { type: integer }
|
||||
}
|
||||
network_tx {
|
||||
description: "Mbytes per second"
|
||||
type: integer
|
||||
}
|
||||
network_rx {
|
||||
description: "Mbytes per second"
|
||||
type: integer
|
||||
}
|
||||
disk_free_home {
|
||||
description: "Mbytes free space of /home drive"
|
||||
type: integer
|
||||
}
|
||||
disk_free_temp {
|
||||
description: "Mbytes free space of /tmp drive"
|
||||
type: integer
|
||||
}
|
||||
disk_read {
|
||||
description: "Mbytes read per second"
|
||||
type: integer
|
||||
}
|
||||
disk_write {
|
||||
description: "Mbytes write per second"
|
||||
type: integer
|
||||
}
|
||||
cpu_temperature {
|
||||
description: "CPU temperature"
|
||||
type: array
|
||||
items { type: number }
|
||||
}
|
||||
gpu_temperature {
|
||||
description: "GPU temperature"
|
||||
type: array
|
||||
items { type: number }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_all {
|
||||
"2.4" {
|
||||
description: "Returns information on all registered workers."
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
last_seen {
|
||||
description: """Filter out workers not active for more than last_seen seconds.
|
||||
A value or 0 or 'none' will disable the filter."""
|
||||
type: integer
|
||||
default: 3600
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
workers {
|
||||
type: array
|
||||
items { "$ref": "#/definitions/worker" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
register {
|
||||
"2.4" {
|
||||
description: "Register a worker in the system. Called by the Worker Daemon."
|
||||
request {
|
||||
required: [ worker ]
|
||||
type: object
|
||||
properties {
|
||||
worker {
|
||||
description: "Worker id. Must be unique in company."
|
||||
type: string
|
||||
}
|
||||
timeout {
|
||||
description: "Registration timeout in seconds. If timeout seconds have passed since the worker's last call to register or status_report, the worker is automatically removed from the list of registered workers."
|
||||
type: integer
|
||||
default: 600
|
||||
}
|
||||
queues {
|
||||
description: "List of queue IDs on which the worker is listening."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {}
|
||||
}
|
||||
}
|
||||
}
|
||||
unregister {
|
||||
"2.4" {
|
||||
description: "Unregister a worker in the system. Called by the Worker Daemon."
|
||||
request {
|
||||
required: [ worker ]
|
||||
type: object
|
||||
properties {
|
||||
worker {
|
||||
description: "Worker id. Must be unique in company."
|
||||
type: string
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {}
|
||||
}
|
||||
}
|
||||
}
|
||||
status_report {
|
||||
"2.4" {
|
||||
description: "Called periodically by the worker daemon to report machine status"
|
||||
request {
|
||||
required: [
|
||||
worker
|
||||
timestamp
|
||||
]
|
||||
type: object
|
||||
properties {
|
||||
worker {
|
||||
description: "Worker id."
|
||||
type: string
|
||||
}
|
||||
task {
|
||||
description: "ID of a task currently being run by the worker. If no task is sent, the worker's task field will be cleared."
|
||||
type: string
|
||||
}
|
||||
queue {
|
||||
description: "ID of the queue from which task was received. If no queue is sent, the worker's queue field will be cleared."
|
||||
type: string
|
||||
}
|
||||
queues {
|
||||
description: "List of queue IDs on which the worker is listening. If null, the worker's queues list will not be updated."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
timestamp {
|
||||
description: "UNIX time in seconds since epoch."
|
||||
type: integer
|
||||
}
|
||||
machine_stats {
|
||||
description: "The machine statistics."
|
||||
"$ref": "#/definitions/machine_stats"
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_metric_keys {
|
||||
"2.4" {
|
||||
description: "Returns worker statistics metric keys grouped by categories."
|
||||
request {
|
||||
type: object
|
||||
properties {
|
||||
worker_ids {
|
||||
description: "List of worker ids to collect metrics for. If not provided or empty then all the company workers metrics are analyzed."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
categories {
|
||||
type: array
|
||||
description: "List of unique metric categories found in the statistics of the requested workers."
|
||||
items { "$ref": "#/definitions/metrics_category" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_stats {
|
||||
"2.4" {
|
||||
description: "Returns statistics for the selected workers and time range aggregated by date intervals."
|
||||
request {
|
||||
type: object
|
||||
required: [ from_date, to_date, interval, items ]
|
||||
properties {
|
||||
worker_ids {
|
||||
description: "List of worker ids to collect metrics for. If not provided or empty then all the company workers metrics are analyzed."
|
||||
type: array
|
||||
items { type: string }
|
||||
}
|
||||
from_date {
|
||||
description: "Starting time (in seconds from epoch) for collecting statistics"
|
||||
type: number
|
||||
}
|
||||
to_date {
|
||||
description: "Ending time (in seconds from epoch) for collecting statistics"
|
||||
type: number
|
||||
}
|
||||
interval {
|
||||
description: "Time interval in seconds for a single statistics point. The minimal value is 1"
|
||||
type: integer
|
||||
}
|
||||
items {
|
||||
description: "List of metric keys and requested statistics"
|
||||
type: array
|
||||
items { "$ref": "#/definitions/stat_item" }
|
||||
}
|
||||
split_by_variant {
|
||||
description: "If true then break statistics by hardware sub types"
|
||||
type: boolean
|
||||
default: false
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
workers {
|
||||
type: array
|
||||
description: "List of the requested workers with their statistics"
|
||||
items { "$ref": "#/definitions/worker_stats" }
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
get_activity_report {
|
||||
"2.4" {
|
||||
description: "Returns count of active company workers in the selected time range."
|
||||
request {
|
||||
type: object
|
||||
required: [ from_date, to_date, interval ]
|
||||
properties {
|
||||
from_date {
|
||||
description: "Starting time (in seconds from epoch) for collecting statistics"
|
||||
type: number
|
||||
}
|
||||
to_date {
|
||||
description: "Ending time (in seconds from epoch) for collecting statistics"
|
||||
type: number
|
||||
}
|
||||
interval {
|
||||
description: "Time interval in seconds for a single statistics point. The minimal value is 1"
|
||||
type: integer
|
||||
}
|
||||
}
|
||||
}
|
||||
response {
|
||||
type: object
|
||||
properties {
|
||||
total {
|
||||
description: "Activity series that include all the workers that sent reports in the given time interval."
|
||||
"$ref": "#/definitions/activity_series"
|
||||
}
|
||||
active {
|
||||
description: "Activity series that include only workers that worked on a task in the given time interval."
|
||||
"$ref": "#/definitions/activity_series"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -7,16 +7,18 @@ from werkzeug.exceptions import BadRequest
|
||||
|
||||
import database
|
||||
from apierrors.base import BaseError
|
||||
from bll.statistics.stats_reporter import StatisticsReporter
|
||||
from config import config
|
||||
from init_data import init_es_data, init_mongo_data
|
||||
from service_repo import ServiceRepo, APICall
|
||||
from service_repo.auth import AuthType
|
||||
from service_repo.errors import PathParsingError
|
||||
from timing_context import TimingContext
|
||||
from updates import check_updates_thread
|
||||
from utilities import json
|
||||
from init_data import init_es_data, init_mongo_data
|
||||
|
||||
app = Flask(__name__, static_url_path="/static")
|
||||
CORS(app, supports_credentials=True, **config.get("apiserver.cors"))
|
||||
CORS(app, **config.get("apiserver.cors"))
|
||||
Compress(app)
|
||||
|
||||
log = config.logger(__file__)
|
||||
@@ -35,6 +37,10 @@ ServiceRepo.load("services")
|
||||
log.info(f"Exposed Services: {' '.join(ServiceRepo.endpoint_names())}")
|
||||
|
||||
|
||||
check_updates_thread.start()
|
||||
StatisticsReporter.start()
|
||||
|
||||
|
||||
@app.before_first_request
|
||||
def before_app_first_request():
|
||||
pass
|
||||
@@ -52,7 +58,9 @@ def before_request():
|
||||
content, content_type = ServiceRepo.handle_call(call)
|
||||
headers = {}
|
||||
if call.result.filename:
|
||||
headers["Content-Disposition"] = f"attachment; filename={call.result.filename}"
|
||||
headers[
|
||||
"Content-Disposition"
|
||||
] = f"attachment; filename={call.result.filename}"
|
||||
|
||||
if call.result.headers:
|
||||
headers.update(call.result.headers)
|
||||
@@ -63,7 +71,12 @@ def before_request():
|
||||
|
||||
if call.result.cookies:
|
||||
for key, value in call.result.cookies.items():
|
||||
response.set_cookie(key, value, **config.get("apiserver.auth.cookies"))
|
||||
if value is None:
|
||||
response.set_cookie(key, "", expires=0)
|
||||
else:
|
||||
response.set_cookie(
|
||||
key, value, **config.get("apiserver.auth.cookies")
|
||||
)
|
||||
|
||||
return response
|
||||
except Exception as ex:
|
||||
@@ -104,7 +117,6 @@ def update_call_data(call, req):
|
||||
form[key] = True
|
||||
elif form[key].lower() == "false":
|
||||
form[key] = False
|
||||
# NOTE: dict() form data to make sure we won't pass along a MultiDict or some other nasty crap
|
||||
call.data = json_body or form or {}
|
||||
|
||||
|
||||
|
||||
@@ -7,8 +7,7 @@ from jsonmodels import models
|
||||
from six import string_types
|
||||
|
||||
import database
|
||||
import timing_context
|
||||
from timing_context import TimingContext
|
||||
from timing_context import TimingContext, TimingStats
|
||||
from utilities import json
|
||||
from .auth import Identity
|
||||
from .auth import Payload as AuthPayload
|
||||
@@ -104,7 +103,7 @@ class DataContainer(object):
|
||||
if self._batched_data:
|
||||
try:
|
||||
data_model = [cls(**item) for item in self._batched_data]
|
||||
except TypeError as ex:
|
||||
except (ValueError, TypeError) as ex:
|
||||
raise CallParsingError(str(ex))
|
||||
|
||||
for m in data_model:
|
||||
@@ -112,7 +111,7 @@ class DataContainer(object):
|
||||
else:
|
||||
try:
|
||||
data_model = cls(**self.data)
|
||||
except TypeError as ex:
|
||||
except (ValueError, TypeError) as ex:
|
||||
raise CallParsingError(str(ex))
|
||||
|
||||
if not self.schema_validator.enabled:
|
||||
@@ -182,8 +181,6 @@ class APICallResult(DataContainer):
|
||||
traceback=self._traceback,
|
||||
extra=self._extra,
|
||||
)
|
||||
if self.log_data:
|
||||
res["data"] = self.data
|
||||
return res
|
||||
|
||||
def copy_from(self, result):
|
||||
@@ -258,6 +255,7 @@ class MissingIdentity(Exception):
|
||||
class APICall(DataContainer):
|
||||
HEADER_AUTHORIZATION = "Authorization"
|
||||
HEADER_REAL_IP = "X-Real-IP"
|
||||
HEADER_FORWARDED_FOR = "X-Forwarded-For"
|
||||
""" Standard headers """
|
||||
|
||||
_transaction_headers = ("X-Trains-Trx",)
|
||||
@@ -308,8 +306,6 @@ class APICall(DataContainer):
|
||||
):
|
||||
super(APICall, self).__init__(data=data, batched_data=batched_data)
|
||||
|
||||
timing_context.clear()
|
||||
|
||||
self._id = database.utils.id()
|
||||
self._files = files # currently dic of key to flask's FileStorage)
|
||||
self._start_ts = time.time()
|
||||
@@ -387,8 +383,13 @@ class APICall(DataContainer):
|
||||
|
||||
@property
|
||||
def real_ip(self):
|
||||
real_ip = self.get_header(self.HEADER_REAL_IP)
|
||||
return real_ip or self._remote_addr or "untrackable"
|
||||
""" Obtain visitor's IP address """
|
||||
return (
|
||||
self.get_header(self.HEADER_FORWARDED_FOR)
|
||||
or self.get_header(self.HEADER_REAL_IP)
|
||||
or self._remote_addr
|
||||
or "untrackable"
|
||||
)
|
||||
|
||||
@property
|
||||
def failed(self):
|
||||
@@ -510,7 +511,7 @@ class APICall(DataContainer):
|
||||
def mark_end(self):
|
||||
self._end_ts = time.time()
|
||||
self._duration = int((self._end_ts - self._start_ts) * 1000)
|
||||
self.stats = timing_context.stats()
|
||||
self.stats = TimingStats.aggregate()
|
||||
|
||||
def get_response(self):
|
||||
def make_version_number(version):
|
||||
|
||||
@@ -1,19 +1,19 @@
|
||||
import base64
|
||||
from datetime import datetime
|
||||
|
||||
import jwt
|
||||
from mongoengine import Q
|
||||
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.company import Company
|
||||
from database.utils import get_options
|
||||
from database.model.auth import User, Entities, Credentials
|
||||
from apierrors import errors
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.auth import User, Entities, Credentials
|
||||
from database.model.company import Company
|
||||
from database.utils import get_options
|
||||
from timing_context import TimingContext
|
||||
|
||||
from .payload import Payload, Token, Basic, AuthType
|
||||
from .identity import Identity
|
||||
from .fixed_user import FixedUser
|
||||
|
||||
from .identity import Identity
|
||||
from .payload import Payload, Token, Basic, AuthType
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
@@ -38,12 +38,16 @@ def authorize_token(jwt_token, *_, **__):
|
||||
return Token.from_encoded_token(jwt_token)
|
||||
|
||||
except jwt.exceptions.InvalidKeyError as ex:
|
||||
raise errors.unauthorized.InvalidToken('jwt invalid key error', reason=ex.args[0])
|
||||
raise errors.unauthorized.InvalidToken(
|
||||
"jwt invalid key error", reason=ex.args[0]
|
||||
)
|
||||
except jwt.InvalidTokenError as ex:
|
||||
raise errors.unauthorized.InvalidToken('invalid jwt token', reason=ex.args[0])
|
||||
raise errors.unauthorized.InvalidToken("invalid jwt token", reason=ex.args[0])
|
||||
except ValueError as ex:
|
||||
log.exception('Failed while processing token: %s' % ex.args[0])
|
||||
raise errors.unauthorized.InvalidToken('failed processing token', reason=ex.args[0])
|
||||
log.exception("Failed while processing token: %s" % ex.args[0])
|
||||
raise errors.unauthorized.InvalidToken(
|
||||
"failed processing token", reason=ex.args[0]
|
||||
)
|
||||
|
||||
|
||||
def authorize_credentials(auth_data, service, action, call_data_items):
|
||||
@@ -58,6 +62,8 @@ def authorize_credentials(auth_data, service, action, call_data_items):
|
||||
|
||||
query = Q(credentials__match=Credentials(key=access_key, secret=secret_key))
|
||||
|
||||
fixed_user = None
|
||||
|
||||
if FixedUser.enabled():
|
||||
fixed_user = FixedUser.get_by_username(access_key)
|
||||
if fixed_user:
|
||||
@@ -67,9 +73,14 @@ def authorize_credentials(auth_data, service, action, call_data_items):
|
||||
|
||||
with TimingContext("mongo", "user_by_cred"), translate_errors_context('authorizing request'):
|
||||
user = User.objects(query).first()
|
||||
if not user:
|
||||
raise errors.unauthorized.InvalidCredentials('failed to locate provided credentials')
|
||||
|
||||
if not user:
|
||||
raise errors.unauthorized.InvalidCredentials('failed to locate provided credentials')
|
||||
if not fixed_user:
|
||||
# In case these are proper credentials, update last used time
|
||||
User.objects(id=user.id, credentials__key=access_key).update(
|
||||
**{"set__credentials__$__last_used": datetime.utcnow()}
|
||||
)
|
||||
|
||||
with TimingContext("mongo", "company_by_id"):
|
||||
company = Company.objects(id=user.company).only('id', 'name').first()
|
||||
@@ -85,13 +96,13 @@ def authorize_credentials(auth_data, service, action, call_data_items):
|
||||
return basic
|
||||
|
||||
|
||||
def authorize_impersonation(user, identity, service, action, call_data_items):
|
||||
def authorize_impersonation(user, identity, service, action, call):
|
||||
""" Returns a new basic object (auth payload)"""
|
||||
if not user:
|
||||
raise ValueError('missing user')
|
||||
raise ValueError("missing user")
|
||||
|
||||
company = Company.objects(id=user.company).only('id', 'name').first()
|
||||
company = Company.objects(id=user.company).only("id", "name").first()
|
||||
if not company:
|
||||
raise errors.unauthorized.InvalidCredentials('invalid user company')
|
||||
raise errors.unauthorized.InvalidCredentials("invalid user company")
|
||||
|
||||
return Payload(auth_type=None, identity=identity)
|
||||
|
||||
@@ -19,7 +19,7 @@ class FixedUser:
|
||||
self.user_id = hashlib.md5(f"{self.username}:{self.password}".encode()).hexdigest()
|
||||
|
||||
@classmethod
|
||||
def enabled(self):
|
||||
def enabled(cls):
|
||||
return config.get("apiserver.auth.fixed_users.enabled", False)
|
||||
|
||||
@classmethod
|
||||
|
||||
@@ -30,6 +30,8 @@ def get_secret_key(length=50):
|
||||
Create a random secret key.
|
||||
|
||||
Taken from the Django project.
|
||||
NOTE: asterisk is not supported due to issues with environment variables containing
|
||||
asterisks (in case the secret key is stored in an environment variable)
|
||||
"""
|
||||
chars = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*(-_=+)'
|
||||
chars = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&(-_=+)'
|
||||
return get_random_string(length, chars)
|
||||
|
||||
@@ -76,7 +76,7 @@ class Endpoint(object):
|
||||
Provided endpoints and their schemas on a best-effort basis.
|
||||
"""
|
||||
d = {
|
||||
"min_version": self.min_version,
|
||||
"min_version": str(self.min_version),
|
||||
"required_fields": self.required_fields,
|
||||
"request_data_model": None,
|
||||
"response_data_model": None,
|
||||
|
||||
@@ -12,7 +12,7 @@ from config import config
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
@attr.s(auto_attribs=True, auto_exc=True)
|
||||
@attr.s(auto_attribs=True, cmp=False)
|
||||
class FastValidationError(Exception):
|
||||
error: fastjsonschema.JsonSchemaException
|
||||
data: dict
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
import re
|
||||
from importlib import import_module
|
||||
from itertools import chain
|
||||
from typing import cast, Iterable, List, MutableMapping
|
||||
from pathlib import Path
|
||||
from typing import cast, Iterable, List, MutableMapping, Optional, Tuple
|
||||
|
||||
import jsonmodels.models
|
||||
from pathlib import Path
|
||||
|
||||
import timing_context
|
||||
from apierrors import APIError
|
||||
@@ -30,7 +30,11 @@ class ServiceRepo(object):
|
||||
_version_required = config.get("apiserver.version.required")
|
||||
""" If version is required, parsing will fail for endpoint paths that do not contain a valid version """
|
||||
|
||||
_max_version = PartialVersion("2.1")
|
||||
_check_max_version = config.get("apiserver.version.check_max_version")
|
||||
"""If the check is set, parsing will fail for endpoint request with the version that is grater than the current
|
||||
maximum """
|
||||
|
||||
_max_version = PartialVersion("2.4")
|
||||
""" Maximum version number (the highest min_version value across all endpoints) """
|
||||
|
||||
_endpoint_exp = (
|
||||
@@ -133,7 +137,7 @@ class ServiceRepo(object):
|
||||
return cls._max_version
|
||||
|
||||
@classmethod
|
||||
def _get_endpoint(cls, name, version):
|
||||
def _get_endpoint(cls, name, version) -> Optional[Endpoint]:
|
||||
versions = cls._endpoints.get(name)
|
||||
if not versions:
|
||||
return None
|
||||
@@ -144,7 +148,7 @@ class ServiceRepo(object):
|
||||
return None
|
||||
|
||||
@classmethod
|
||||
def _resolve_endpoint_from_call(cls, call):
|
||||
def _resolve_endpoint_from_call(cls, call: APICall) -> Optional[Endpoint]:
|
||||
assert isinstance(call, APICall)
|
||||
endpoint = cls._get_endpoint(
|
||||
call.endpoint_name, call.requested_endpoint_version
|
||||
@@ -167,7 +171,7 @@ class ServiceRepo(object):
|
||||
return endpoint
|
||||
|
||||
@classmethod
|
||||
def parse_endpoint_path(cls, path):
|
||||
def parse_endpoint_path(cls, path: str) -> Tuple[PartialVersion, str]:
|
||||
""" Parse endpoint version, service and action from request path. """
|
||||
m = cls._endpoint_exp.match(path)
|
||||
if not m:
|
||||
@@ -182,14 +186,14 @@ class ServiceRepo(object):
|
||||
version = PartialVersion(version)
|
||||
except ValueError as e:
|
||||
raise RequestPathHasInvalidVersion(version=version, reason=e)
|
||||
if version > cls._max_version:
|
||||
if cls._check_max_version and version > cls._max_version:
|
||||
raise InvalidVersionError(
|
||||
f"Invalid API version (max. supported version is {cls._max_version})"
|
||||
)
|
||||
return version, endpoint_name
|
||||
|
||||
@classmethod
|
||||
def _should_return_stack(cls, code, subcode):
|
||||
def _should_return_stack(cls, code: int, subcode: int) -> bool:
|
||||
if not cls._return_stack or code not in cls._return_stack_on_code:
|
||||
return False
|
||||
if subcode is None:
|
||||
@@ -202,7 +206,7 @@ class ServiceRepo(object):
|
||||
return subcode in subcode_list
|
||||
|
||||
@classmethod
|
||||
def _validate_call(cls, call):
|
||||
def _validate_call(cls, call: APICall) -> Optional[Endpoint]:
|
||||
endpoint = cls._resolve_endpoint_from_call(call)
|
||||
if call.failed:
|
||||
return
|
||||
@@ -210,11 +214,13 @@ class ServiceRepo(object):
|
||||
return endpoint
|
||||
|
||||
@classmethod
|
||||
def validate_call(cls, call):
|
||||
def validate_call(cls, call: APICall):
|
||||
cls._validate_call(call)
|
||||
|
||||
@classmethod
|
||||
def _get_company(cls, call, endpoint=None, ignore_error=False):
|
||||
def _get_company(
|
||||
cls, call: APICall, endpoint: Endpoint = None, ignore_error: bool = False
|
||||
) -> Optional[str]:
|
||||
authorize = endpoint and endpoint.authorize
|
||||
if ignore_error or not authorize:
|
||||
try:
|
||||
@@ -224,7 +230,7 @@ class ServiceRepo(object):
|
||||
return call.identity.company
|
||||
|
||||
@classmethod
|
||||
def handle_call(cls, call):
|
||||
def handle_call(cls, call: APICall):
|
||||
try:
|
||||
assert isinstance(call, APICall)
|
||||
|
||||
|
||||
@@ -150,7 +150,7 @@ def validate_impersonation(endpoint, call):
|
||||
),
|
||||
service=service,
|
||||
action=action,
|
||||
call_data_items=call.batched_data,
|
||||
call=call,
|
||||
)
|
||||
else:
|
||||
return False
|
||||
|
||||
@@ -31,10 +31,8 @@ log = config.logger(__file__)
|
||||
request_data_model=GetTokenRequest,
|
||||
response_data_model=GetTokenResponse,
|
||||
)
|
||||
def login(call):
|
||||
def login(call: APICall, *_, **__):
|
||||
""" Generates a token based on the authenticated user (intended for use with credentials) """
|
||||
assert isinstance(call, APICall)
|
||||
|
||||
call.result.data_model = AuthBLL.get_token_for_user(
|
||||
user_id=call.identity.user,
|
||||
company_id=call.identity.company,
|
||||
@@ -47,6 +45,11 @@ def login(call):
|
||||
] = call.result.data_model.token
|
||||
|
||||
|
||||
@endpoint("auth.logout", min_version="2.2")
|
||||
def logout(call: APICall, *_, **__):
|
||||
call.result.cookies[config.get("apiserver.auth.session_auth_cookie_name")] = None
|
||||
|
||||
|
||||
@endpoint(
|
||||
"auth.get_token_for_user",
|
||||
request_data_model=GetTokenForUserRequest,
|
||||
@@ -140,7 +143,8 @@ def get_credentials(call):
|
||||
# we return ONLY the key IDs, never the secrets (want a secret? create new credentials)
|
||||
call.result.data_model = GetCredentialsResponse(
|
||||
credentials=[
|
||||
CredentialsResponse(access_key=c.key) for c in user.credentials
|
||||
CredentialsResponse(access_key=c.key, last_used=c.last_used)
|
||||
for c in user.credentials
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
@@ -5,7 +5,12 @@ from operator import itemgetter
|
||||
import six
|
||||
|
||||
from apierrors import errors
|
||||
from apimodels.events import (
|
||||
MultiTaskScalarMetricsIterHistogramRequest,
|
||||
ScalarMetricsIterHistogramRequest,
|
||||
)
|
||||
from bll.event import EventBLL
|
||||
from bll.event.event_metrics import EventMetrics
|
||||
from bll.task import TaskBLL
|
||||
from service_repo import APICall, endpoint
|
||||
from utilities import json
|
||||
@@ -15,28 +20,24 @@ event_bll = EventBLL()
|
||||
|
||||
|
||||
@endpoint("events.add")
|
||||
def add(call, company_id, req_model):
|
||||
assert isinstance(call, APICall)
|
||||
added, batch_errors = event_bll.add_events(company_id, [call.data.copy()], call.worker)
|
||||
call.result.data = dict(
|
||||
added=added,
|
||||
errors=len(batch_errors)
|
||||
def add(call: APICall, company_id, req_model):
|
||||
data = call.data.copy()
|
||||
allow_locked = data.pop("allow_locked", False)
|
||||
added, batch_errors = event_bll.add_events(
|
||||
company_id, [data], call.worker, allow_locked_tasks=allow_locked
|
||||
)
|
||||
call.result.data = dict(added=added, errors=len(batch_errors))
|
||||
call.kpis["events"] = 1
|
||||
|
||||
|
||||
@endpoint("events.add_batch")
|
||||
def add_batch(call, company_id, req_model):
|
||||
assert isinstance(call, APICall)
|
||||
def add_batch(call: APICall, company_id, req_model):
|
||||
events = call.batched_data
|
||||
if events is None or len(events) == 0:
|
||||
raise errors.bad_request.BatchContainsNoItems()
|
||||
|
||||
added, batch_errors = event_bll.add_events(company_id, events, call.worker)
|
||||
call.result.data = dict(
|
||||
added=added,
|
||||
errors=len(batch_errors)
|
||||
)
|
||||
call.result.data = dict(added=added, errors=len(batch_errors))
|
||||
call.kpis["events"] = len(events)
|
||||
|
||||
|
||||
@@ -48,16 +49,16 @@ def get_task_log(call, company_id, req_model):
|
||||
scroll_id = call.data.get("scroll_id")
|
||||
batch_size = int(call.data.get("batch_size") or 500)
|
||||
events, scroll_id, total_events = event_bll.scroll_task_events(
|
||||
company_id, task_id, order,
|
||||
company_id,
|
||||
task_id,
|
||||
order,
|
||||
event_type="log",
|
||||
batch_size=batch_size,
|
||||
scroll_id=scroll_id)
|
||||
call.result.data = dict(
|
||||
events=events,
|
||||
returned=len(events),
|
||||
total=total_events,
|
||||
scroll_id=scroll_id,
|
||||
)
|
||||
call.result.data = dict(
|
||||
events=events, returned=len(events), total=total_events, scroll_id=scroll_id
|
||||
)
|
||||
|
||||
|
||||
@endpoint("events.get_task_log", min_version="1.7", required_fields=["task"])
|
||||
@@ -70,7 +71,7 @@ def get_task_log_v1_7(call, company_id, req_model):
|
||||
scroll_id = call.data.get("scroll_id")
|
||||
batch_size = int(call.data.get("batch_size") or 500)
|
||||
|
||||
scroll_order = 'asc' if (from_ == 'head') else 'desc'
|
||||
scroll_order = "asc" if (from_ == "head") else "desc"
|
||||
|
||||
events, scroll_id, total_events = event_bll.scroll_task_events(
|
||||
company_id=company_id,
|
||||
@@ -78,54 +79,57 @@ def get_task_log_v1_7(call, company_id, req_model):
|
||||
order=scroll_order,
|
||||
event_type="log",
|
||||
batch_size=batch_size,
|
||||
scroll_id=scroll_id
|
||||
scroll_id=scroll_id,
|
||||
)
|
||||
|
||||
if scroll_order != order:
|
||||
events = events[::-1]
|
||||
|
||||
call.result.data = dict(
|
||||
events=events,
|
||||
returned=len(events),
|
||||
total=total_events,
|
||||
scroll_id=scroll_id,
|
||||
events=events, returned=len(events), total=total_events, scroll_id=scroll_id
|
||||
)
|
||||
|
||||
|
||||
@endpoint('events.download_task_log', required_fields=['task'])
|
||||
@endpoint("events.download_task_log", required_fields=["task"])
|
||||
def download_task_log(call, company_id, req_model):
|
||||
task_id = call.data['task']
|
||||
task_id = call.data["task"]
|
||||
task_bll.assert_exists(company_id, task_id, allow_public=True)
|
||||
|
||||
line_type = call.data.get('line_type', 'json').lower()
|
||||
line_format = str(call.data.get('line_format', '{asctime} {worker} {level} {msg}'))
|
||||
line_type = call.data.get("line_type", "json").lower()
|
||||
line_format = str(call.data.get("line_format", "{asctime} {worker} {level} {msg}"))
|
||||
|
||||
is_json = (line_type == 'json')
|
||||
is_json = line_type == "json"
|
||||
if not is_json:
|
||||
if not line_format:
|
||||
raise errors.bad_request.MissingRequiredFields('line_format is required for plain text lines')
|
||||
raise errors.bad_request.MissingRequiredFields(
|
||||
"line_format is required for plain text lines"
|
||||
)
|
||||
|
||||
# validate line format placeholders
|
||||
valid_task_log_fields = {'asctime', 'timestamp', 'level', 'worker', 'msg'}
|
||||
valid_task_log_fields = {"asctime", "timestamp", "level", "worker", "msg"}
|
||||
|
||||
invalid_placeholders = set()
|
||||
while True:
|
||||
try:
|
||||
line_format.format(**dict.fromkeys(valid_task_log_fields | invalid_placeholders))
|
||||
line_format.format(
|
||||
**dict.fromkeys(valid_task_log_fields | invalid_placeholders)
|
||||
)
|
||||
break
|
||||
except KeyError as e:
|
||||
invalid_placeholders.add(e.args[0])
|
||||
except Exception as e:
|
||||
raise errors.bad_request.FieldsValueError('invalid line format', error=e.args[0])
|
||||
raise errors.bad_request.FieldsValueError(
|
||||
"invalid line format", error=e.args[0]
|
||||
)
|
||||
|
||||
if invalid_placeholders:
|
||||
raise errors.bad_request.FieldsValueError(
|
||||
'undefined placeholders in line format',
|
||||
placeholders=invalid_placeholders
|
||||
"undefined placeholders in line format",
|
||||
placeholders=invalid_placeholders,
|
||||
)
|
||||
|
||||
# make sure line_format has a trailing newline
|
||||
line_format = line_format.rstrip('\n') + '\n'
|
||||
line_format = line_format.rstrip("\n") + "\n"
|
||||
|
||||
def generate():
|
||||
scroll_id = None
|
||||
@@ -137,30 +141,30 @@ def download_task_log(call, company_id, req_model):
|
||||
order="asc",
|
||||
event_type="log",
|
||||
batch_size=batch_size,
|
||||
scroll_id=scroll_id
|
||||
scroll_id=scroll_id,
|
||||
)
|
||||
if not log_events:
|
||||
break
|
||||
for ev in log_events:
|
||||
ev['asctime'] = ev.pop('@timestamp')
|
||||
ev["asctime"] = ev.pop("@timestamp")
|
||||
if is_json:
|
||||
ev.pop('type')
|
||||
ev.pop('task')
|
||||
yield json.dumps(ev) + '\n'
|
||||
ev.pop("type")
|
||||
ev.pop("task")
|
||||
yield json.dumps(ev) + "\n"
|
||||
else:
|
||||
try:
|
||||
yield line_format.format(**ev)
|
||||
except KeyError as ex:
|
||||
raise errors.bad_request.FieldsValueError(
|
||||
'undefined placeholders in line format',
|
||||
placeholders=[str(ex)]
|
||||
"undefined placeholders in line format",
|
||||
placeholders=[str(ex)],
|
||||
)
|
||||
|
||||
if len(log_events) < batch_size:
|
||||
break
|
||||
|
||||
call.result.filename = 'task_%s.log' % task_id
|
||||
call.result.content_type = 'text/plain'
|
||||
call.result.filename = "task_%s.log" % task_id
|
||||
call.result.content_type = "text/plain"
|
||||
call.result.raw_data = generate()
|
||||
|
||||
|
||||
@@ -169,7 +173,9 @@ def get_vector_metrics_and_variants(call, company_id, req_model):
|
||||
task_id = call.data["task"]
|
||||
task_bll.assert_exists(company_id, task_id, allow_public=True)
|
||||
call.result.data = dict(
|
||||
metrics=event_bll.get_metrics_and_variants(company_id, task_id, "training_stats_vector")
|
||||
metrics=event_bll.get_metrics_and_variants(
|
||||
company_id, task_id, "training_stats_vector"
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@@ -178,39 +184,46 @@ def get_scalar_metrics_and_variants(call, company_id, req_model):
|
||||
task_id = call.data["task"]
|
||||
task_bll.assert_exists(company_id, task_id, allow_public=True)
|
||||
call.result.data = dict(
|
||||
metrics=event_bll.get_metrics_and_variants(company_id, task_id, "training_stats_scalar")
|
||||
metrics=event_bll.get_metrics_and_variants(
|
||||
company_id, task_id, "training_stats_scalar"
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
# todo: !!! currently returning 10,000 records. should decide on a better way to control it
|
||||
@endpoint("events.vector_metrics_iter_histogram", required_fields=["task", "metric", "variant"])
|
||||
@endpoint(
|
||||
"events.vector_metrics_iter_histogram",
|
||||
required_fields=["task", "metric", "variant"],
|
||||
)
|
||||
def vector_metrics_iter_histogram(call, company_id, req_model):
|
||||
task_id = call.data["task"]
|
||||
task_bll.assert_exists(company_id, task_id, allow_public=True)
|
||||
metric = call.data["metric"]
|
||||
variant = call.data["variant"]
|
||||
iterations, vectors = event_bll.get_vector_metrics_per_iter(company_id, task_id, metric, variant)
|
||||
iterations, vectors = event_bll.get_vector_metrics_per_iter(
|
||||
company_id, task_id, metric, variant
|
||||
)
|
||||
call.result.data = dict(
|
||||
metric=metric,
|
||||
variant=variant,
|
||||
vectors=vectors,
|
||||
iterations=iterations
|
||||
metric=metric, variant=variant, vectors=vectors, iterations=iterations
|
||||
)
|
||||
|
||||
|
||||
@endpoint("events.get_task_events", required_fields=["task"])
|
||||
def get_task_events(call, company_id, req_model):
|
||||
def get_task_events(call, company_id, _):
|
||||
task_id = call.data["task"]
|
||||
batch_size = call.data.get("batch_size")
|
||||
event_type = call.data.get("event_type")
|
||||
scroll_id = call.data.get("scroll_id")
|
||||
order = call.data.get("order") or "asc"
|
||||
|
||||
task_bll.assert_exists(company_id, task_id, allow_public=True)
|
||||
result = event_bll.get_task_events(
|
||||
company_id, task_id,
|
||||
company_id,
|
||||
task_id,
|
||||
sort=[{"timestamp": {"order": order}}],
|
||||
event_type=event_type,
|
||||
scroll_id=scroll_id
|
||||
scroll_id=scroll_id,
|
||||
size=batch_size,
|
||||
)
|
||||
|
||||
call.result.data = dict(
|
||||
@@ -229,11 +242,12 @@ def get_scalar_metric_data(call, company_id, req_model):
|
||||
|
||||
task_bll.assert_exists(company_id, task_id, allow_public=True)
|
||||
result = event_bll.get_task_events(
|
||||
company_id, task_id,
|
||||
company_id,
|
||||
task_id,
|
||||
event_type="training_stats_scalar",
|
||||
sort=[{"iter": {"order": "desc"}}],
|
||||
metric=metric,
|
||||
scroll_id=scroll_id
|
||||
scroll_id=scroll_id,
|
||||
)
|
||||
|
||||
call.result.data = dict(
|
||||
@@ -248,35 +262,54 @@ def get_scalar_metric_data(call, company_id, req_model):
|
||||
def get_task_latest_scalar_values(call, company_id, req_model):
|
||||
task_id = call.data["task"]
|
||||
task = task_bll.assert_exists(company_id, task_id, allow_public=True)
|
||||
metrics, last_timestamp = event_bll.get_task_latest_scalar_values(company_id, task_id)
|
||||
es_index = EventBLL.get_index_name(company_id, "*")
|
||||
metrics, last_timestamp = event_bll.get_task_latest_scalar_values(
|
||||
company_id, task_id
|
||||
)
|
||||
es_index = EventMetrics.get_index_name(company_id, "*")
|
||||
last_iters = event_bll.get_last_iters(es_index, task_id, None, 1)
|
||||
call.result.data = dict(
|
||||
metrics=metrics,
|
||||
last_iter=last_iters[0] if last_iters else 0,
|
||||
name=task.name,
|
||||
status=task.status,
|
||||
last_timestamp=last_timestamp
|
||||
last_timestamp=last_timestamp,
|
||||
)
|
||||
|
||||
|
||||
# todo: should not repeat iter (x-axis) for each metric/variant, JS client should get raw data and fill gaps if needed
|
||||
@endpoint("events.scalar_metrics_iter_histogram", required_fields=["task"])
|
||||
def scalar_metrics_iter_histogram(call, company_id, req_model):
|
||||
task_id = call.data["task"]
|
||||
task_bll.assert_exists(call.identity.company, task_id, allow_public=True)
|
||||
metrics = event_bll.get_scalar_metrics_average_per_iter(company_id, task_id)
|
||||
@endpoint(
|
||||
"events.scalar_metrics_iter_histogram",
|
||||
request_data_model=ScalarMetricsIterHistogramRequest,
|
||||
)
|
||||
def scalar_metrics_iter_histogram(
|
||||
call, company_id, req_model: ScalarMetricsIterHistogramRequest
|
||||
):
|
||||
task_bll.assert_exists(call.identity.company, req_model.task, allow_public=True)
|
||||
metrics = event_bll.metrics.get_scalar_metrics_average_per_iter(
|
||||
company_id, task_id=req_model.task, samples=req_model.samples, key=req_model.key
|
||||
)
|
||||
call.result.data = metrics
|
||||
|
||||
|
||||
@endpoint("events.multi_task_scalar_metrics_iter_histogram", required_fields=["tasks"])
|
||||
def multi_task_scalar_metrics_iter_histogram(call, company_id, req_model):
|
||||
task_ids = call.data["tasks"]
|
||||
@endpoint(
|
||||
"events.multi_task_scalar_metrics_iter_histogram",
|
||||
request_data_model=MultiTaskScalarMetricsIterHistogramRequest,
|
||||
)
|
||||
def multi_task_scalar_metrics_iter_histogram(
|
||||
call, company_id, req_model: MultiTaskScalarMetricsIterHistogramRequest
|
||||
):
|
||||
task_ids = req_model.tasks
|
||||
if isinstance(task_ids, six.string_types):
|
||||
task_ids = [s.strip() for s in task_ids.split(",")]
|
||||
# Note, bll already validates task ids as it needs their names
|
||||
call.result.data = dict(
|
||||
metrics=event_bll.compare_scalar_metrics_average_per_iter(company_id, task_ids, allow_public=True)
|
||||
metrics=event_bll.metrics.compare_scalar_metrics_average_per_iter(
|
||||
company_id,
|
||||
task_ids=task_ids,
|
||||
samples=req_model.samples,
|
||||
allow_public=True,
|
||||
key=req_model.key,
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@@ -287,21 +320,27 @@ def get_multi_task_plots_v1_7(call, company_id, req_model):
|
||||
scroll_id = call.data.get("scroll_id")
|
||||
|
||||
tasks = task_bll.assert_exists(
|
||||
company_id=call.identity.company, only=('id', 'name'), task_ids=task_ids, allow_public=True
|
||||
company_id=call.identity.company,
|
||||
only=("id", "name"),
|
||||
task_ids=task_ids,
|
||||
allow_public=True,
|
||||
)
|
||||
|
||||
# Get last 10K events by iteration and group them by unique metric+variant, returning top events for combination
|
||||
result = event_bll.get_task_events(
|
||||
company_id, task_ids,
|
||||
company_id,
|
||||
task_ids,
|
||||
event_type="plot",
|
||||
sort=[{"iter": {"order": "desc"}}],
|
||||
size=10000,
|
||||
scroll_id=scroll_id
|
||||
scroll_id=scroll_id,
|
||||
)
|
||||
|
||||
tasks = {t.id: t.name for t in tasks}
|
||||
|
||||
return_events = _get_top_iter_unique_events_per_task(result.events, max_iters=iters, tasks=tasks)
|
||||
return_events = _get_top_iter_unique_events_per_task(
|
||||
result.events, max_iters=iters, tasks=tasks
|
||||
)
|
||||
|
||||
call.result.data = dict(
|
||||
plots=return_events,
|
||||
@@ -318,20 +357,26 @@ def get_multi_task_plots(call, company_id, req_model):
|
||||
scroll_id = call.data.get("scroll_id")
|
||||
|
||||
tasks = task_bll.assert_exists(
|
||||
company_id=call.identity.company, only=('id', 'name'), task_ids=task_ids, allow_public=True
|
||||
company_id=call.identity.company,
|
||||
only=("id", "name"),
|
||||
task_ids=task_ids,
|
||||
allow_public=True,
|
||||
)
|
||||
|
||||
result = event_bll.get_task_events(
|
||||
company_id, task_ids,
|
||||
company_id,
|
||||
task_ids,
|
||||
event_type="plot",
|
||||
sort=[{"iter": {"order": "desc"}}],
|
||||
last_iter_count=iters,
|
||||
scroll_id=scroll_id
|
||||
scroll_id=scroll_id,
|
||||
)
|
||||
|
||||
tasks = {t.id: t.name for t in tasks}
|
||||
|
||||
return_events = _get_top_iter_unique_events_per_task(result.events, max_iters=iters, tasks=tasks)
|
||||
return_events = _get_top_iter_unique_events_per_task(
|
||||
result.events, max_iters=iters, tasks=tasks
|
||||
)
|
||||
|
||||
call.result.data = dict(
|
||||
plots=return_events,
|
||||
@@ -349,7 +394,7 @@ def get_task_plots_v1_7(call, company_id, req_model):
|
||||
|
||||
task_bll.assert_exists(call.identity.company, task_id, allow_public=True)
|
||||
# events, next_scroll_id, total_events = event_bll.get_task_events(
|
||||
# company_id, task_id,
|
||||
# company, task_id,
|
||||
# event_type="plot",
|
||||
# sort=[{"iter": {"order": "desc"}}],
|
||||
# last_iter_count=iters,
|
||||
@@ -357,11 +402,12 @@ def get_task_plots_v1_7(call, company_id, req_model):
|
||||
|
||||
# get last 10K events by iteration and group them by unique metric+variant, returning top events for combination
|
||||
result = event_bll.get_task_events(
|
||||
company_id, task_id,
|
||||
company_id,
|
||||
task_id,
|
||||
event_type="plot",
|
||||
sort=[{"iter": {"order": "desc"}}],
|
||||
size=10000,
|
||||
scroll_id=scroll_id
|
||||
scroll_id=scroll_id,
|
||||
)
|
||||
|
||||
return_events = _get_top_iter_unique_events(result.events, max_iters=iters)
|
||||
@@ -381,12 +427,12 @@ def get_task_plots(call, company_id, req_model):
|
||||
scroll_id = call.data.get("scroll_id")
|
||||
|
||||
task_bll.assert_exists(call.identity.company, task_id, allow_public=True)
|
||||
result = event_bll.get_task_events(
|
||||
company_id, task_id,
|
||||
event_type="plot",
|
||||
result = event_bll.get_task_plots(
|
||||
company_id,
|
||||
tasks=[task_id],
|
||||
sort=[{"iter": {"order": "desc"}}],
|
||||
last_iter_count=iters,
|
||||
scroll_id=scroll_id
|
||||
last_iterations_per_plot=iters,
|
||||
scroll_id=scroll_id,
|
||||
)
|
||||
|
||||
return_events = result.events
|
||||
@@ -407,7 +453,7 @@ def get_debug_images_v1_7(call, company_id, req_model):
|
||||
|
||||
task_bll.assert_exists(call.identity.company, task_id, allow_public=True)
|
||||
# events, next_scroll_id, total_events = event_bll.get_task_events(
|
||||
# company_id, task_id,
|
||||
# company, task_id,
|
||||
# event_type="training_debug_image",
|
||||
# sort=[{"iter": {"order": "desc"}}],
|
||||
# last_iter_count=iters,
|
||||
@@ -415,11 +461,12 @@ def get_debug_images_v1_7(call, company_id, req_model):
|
||||
|
||||
# get last 10K events by iteration and group them by unique metric+variant, returning top events for combination
|
||||
result = event_bll.get_task_events(
|
||||
company_id, task_id,
|
||||
company_id,
|
||||
task_id,
|
||||
event_type="training_debug_image",
|
||||
sort=[{"iter": {"order": "desc"}}],
|
||||
size=10000,
|
||||
scroll_id=scroll_id
|
||||
scroll_id=scroll_id,
|
||||
)
|
||||
|
||||
return_events = _get_top_iter_unique_events(result.events, max_iters=iters)
|
||||
@@ -441,11 +488,12 @@ def get_debug_images(call, company_id, req_model):
|
||||
|
||||
task_bll.assert_exists(call.identity.company, task_id, allow_public=True)
|
||||
result = event_bll.get_task_events(
|
||||
company_id, task_id,
|
||||
company_id,
|
||||
task_id,
|
||||
event_type="training_debug_image",
|
||||
sort=[{"iter": {"order": "desc"}}],
|
||||
last_iter_count=iters,
|
||||
scroll_id=scroll_id
|
||||
scroll_id=scroll_id,
|
||||
)
|
||||
|
||||
return_events = result.events
|
||||
@@ -462,36 +510,39 @@ def get_debug_images(call, company_id, req_model):
|
||||
@endpoint("events.delete_for_task", required_fields=["task"])
|
||||
def delete_for_task(call, company_id, req_model):
|
||||
task_id = call.data["task"]
|
||||
allow_locked = call.data.get("allow_locked", False)
|
||||
|
||||
task_bll.assert_exists(company_id, task_id)
|
||||
call.result.data = dict(
|
||||
deleted=event_bll.delete_task_events(company_id, task_id)
|
||||
deleted=event_bll.delete_task_events(
|
||||
company_id, task_id, allow_locked=allow_locked
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
def _get_top_iter_unique_events_per_task(events, max_iters, tasks):
|
||||
key = itemgetter('metric', 'variant', 'task', 'iter')
|
||||
key = itemgetter("metric", "variant", "task", "iter")
|
||||
|
||||
unique_events = itertools.chain.from_iterable(
|
||||
itertools.islice(group, max_iters)
|
||||
for _, group in itertools.groupby(sorted(events, key=key, reverse=True), key=key))
|
||||
for _, group in itertools.groupby(
|
||||
sorted(events, key=key, reverse=True), key=key
|
||||
)
|
||||
)
|
||||
|
||||
def collect(evs, fields):
|
||||
if not fields:
|
||||
evs = list(evs)
|
||||
return {
|
||||
'name': tasks.get(evs[0].get('task')),
|
||||
'plots': evs
|
||||
}
|
||||
return {"name": tasks.get(evs[0].get("task")), "plots": evs}
|
||||
return {
|
||||
str(k): collect(group, fields[1:])
|
||||
for k, group in itertools.groupby(evs, key=itemgetter(fields[0]))
|
||||
}
|
||||
|
||||
collect_fields = ('metric', 'variant', 'task', 'iter')
|
||||
collect_fields = ("metric", "variant", "task", "iter")
|
||||
return collect(
|
||||
sorted(unique_events, key=itemgetter(*collect_fields), reverse=True),
|
||||
collect_fields
|
||||
collect_fields,
|
||||
)
|
||||
|
||||
|
||||
@@ -502,6 +553,8 @@ def _get_top_iter_unique_events(events, max_iters):
|
||||
evs = top_unique_events[key]
|
||||
if len(evs) < max_iters:
|
||||
evs.append(e)
|
||||
unique_events = list(itertools.chain.from_iterable(list(top_unique_events.values())))
|
||||
unique_events = list(
|
||||
itertools.chain.from_iterable(list(top_unique_events.values()))
|
||||
)
|
||||
unique_events.sort(key=lambda e: e["iter"], reverse=True)
|
||||
return unique_events
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
from datetime import datetime
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from mongoengine import Q, EmbeddedDocument
|
||||
|
||||
@@ -16,7 +15,6 @@ from apimodels.models import (
|
||||
from bll.task import TaskBLL
|
||||
from config import config
|
||||
from database.errors import translate_errors_context
|
||||
from database.fields import SupportedURLField
|
||||
from database.model import validate_id
|
||||
from database.model.model import Model
|
||||
from database.model.project import Project
|
||||
@@ -27,13 +25,23 @@ from database.utils import (
|
||||
filter_fields,
|
||||
)
|
||||
from service_repo import APICall, endpoint
|
||||
from services.utils import conform_tag_fields, conform_output_tags
|
||||
from timing_context import TimingContext
|
||||
|
||||
log = config.logger(__file__)
|
||||
get_all_query_options = Model.QueryParameterOptions(
|
||||
pattern_fields=("name", "comment"),
|
||||
fields=("ready",),
|
||||
list_fields=("tags", "framework", "uri", "id", "project", "task", "parent"),
|
||||
list_fields=(
|
||||
"tags",
|
||||
"system_tags",
|
||||
"framework",
|
||||
"uri",
|
||||
"id",
|
||||
"project",
|
||||
"task",
|
||||
"parent",
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
@@ -43,20 +51,20 @@ def get_by_id(call):
|
||||
model_id = call.data["model"]
|
||||
|
||||
with translate_errors_context():
|
||||
res = Model.get_many(
|
||||
models = Model.get_many(
|
||||
company=call.identity.company,
|
||||
query_dict=call.data,
|
||||
query=Q(id=model_id),
|
||||
allow_public=True,
|
||||
)
|
||||
if not res:
|
||||
if not models:
|
||||
raise errors.bad_request.InvalidModelId(
|
||||
"no such public or company model",
|
||||
id=model_id,
|
||||
company=call.identity.company,
|
||||
)
|
||||
|
||||
call.result.data = {"model": res[0]}
|
||||
conform_output_tags(call, models[0])
|
||||
call.result.data = {"model": models[0]}
|
||||
|
||||
|
||||
@endpoint("models.get_by_task_id", required_fields=["task"])
|
||||
@@ -66,31 +74,32 @@ def get_by_task_id(call):
|
||||
|
||||
with translate_errors_context():
|
||||
query = dict(id=task_id, company=call.identity.company)
|
||||
res = Task.get(_only=["output"], **query)
|
||||
if not res:
|
||||
task = Task.get(_only=["output"], **query)
|
||||
if not task:
|
||||
raise errors.bad_request.InvalidTaskId(**query)
|
||||
if not res.output:
|
||||
if not task.output:
|
||||
raise errors.bad_request.MissingTaskFields(field="output")
|
||||
if not res.output.model:
|
||||
if not task.output.model:
|
||||
raise errors.bad_request.MissingTaskFields(field="output.model")
|
||||
|
||||
model_id = res.output.model
|
||||
res = Model.objects(
|
||||
model_id = task.output.model
|
||||
model = Model.objects(
|
||||
Q(id=model_id) & get_company_or_none_constraint(call.identity.company)
|
||||
).first()
|
||||
if not res:
|
||||
if not model:
|
||||
raise errors.bad_request.InvalidModelId(
|
||||
"no such public or company model",
|
||||
id=model_id,
|
||||
company=call.identity.company,
|
||||
)
|
||||
call.result.data = {"model": res.to_proper_dict()}
|
||||
model_dict = model.to_proper_dict()
|
||||
conform_output_tags(call, model_dict)
|
||||
call.result.data = {"model": model_dict}
|
||||
|
||||
|
||||
@endpoint("models.get_all_ex", required_fields=[])
|
||||
def get_all_ex(call):
|
||||
assert isinstance(call, APICall)
|
||||
|
||||
def get_all_ex(call: APICall):
|
||||
conform_tag_fields(call, call.data)
|
||||
with translate_errors_context():
|
||||
with TimingContext("mongo", "models_get_all_ex"):
|
||||
models = Model.get_many_with_join(
|
||||
@@ -99,14 +108,13 @@ def get_all_ex(call):
|
||||
allow_public=True,
|
||||
query_options=get_all_query_options,
|
||||
)
|
||||
|
||||
conform_output_tags(call, models)
|
||||
call.result.data = {"models": models}
|
||||
|
||||
|
||||
@endpoint("models.get_all", required_fields=[])
|
||||
def get_all(call):
|
||||
assert isinstance(call, APICall)
|
||||
|
||||
def get_all(call: APICall):
|
||||
conform_tag_fields(call, call.data)
|
||||
with translate_errors_context():
|
||||
with TimingContext("mongo", "models_get_all"):
|
||||
models = Model.get_many(
|
||||
@@ -116,13 +124,14 @@ def get_all(call):
|
||||
allow_public=True,
|
||||
query_options=get_all_query_options,
|
||||
)
|
||||
|
||||
conform_output_tags(call, models)
|
||||
call.result.data = {"models": models}
|
||||
|
||||
|
||||
create_fields = {
|
||||
"name": None,
|
||||
"tags": list,
|
||||
"system_tags": list,
|
||||
"task": Task,
|
||||
"comment": None,
|
||||
"uri": None,
|
||||
@@ -134,22 +143,10 @@ create_fields = {
|
||||
"ready": None,
|
||||
}
|
||||
|
||||
schemes = list(SupportedURLField.schemes)
|
||||
|
||||
|
||||
def _validate_uri(uri):
|
||||
parsed_uri = urlparse(uri)
|
||||
if parsed_uri.scheme not in schemes:
|
||||
raise errors.bad_request.InvalidModelUri("unsupported scheme", uri=uri)
|
||||
elif not parsed_uri.path:
|
||||
raise errors.bad_request.InvalidModelUri("missing path", uri=uri)
|
||||
|
||||
|
||||
def parse_model_fields(call, valid_fields):
|
||||
fields = parse_from_call(call.data, valid_fields, Model.get_fields())
|
||||
tags = fields.get("tags")
|
||||
if tags:
|
||||
fields["tags"] = list(set(tags))
|
||||
conform_tag_fields(call, fields)
|
||||
return fields
|
||||
|
||||
|
||||
@@ -251,15 +248,14 @@ def create(call, company, req_model):
|
||||
if project:
|
||||
validate_id(Project, company=company, project=project)
|
||||
|
||||
uri = req_model.uri
|
||||
if uri:
|
||||
_validate_uri(uri)
|
||||
task = req_model.task
|
||||
req_data = req_model.to_struct()
|
||||
if task:
|
||||
validate_task(call, req_data)
|
||||
|
||||
fields = filter_fields(Model, req_data)
|
||||
conform_tag_fields(call, fields)
|
||||
|
||||
# create and save model
|
||||
model = Model(
|
||||
id=database.utils.id(),
|
||||
@@ -276,12 +272,31 @@ def create(call, company, req_model):
|
||||
def prepare_update_fields(call, fields):
|
||||
fields = fields.copy()
|
||||
if "uri" in fields:
|
||||
_validate_uri(fields["uri"])
|
||||
|
||||
# clear UI cache if URI is provided (model updated)
|
||||
fields["ui_cache"] = fields.pop("ui_cache", {})
|
||||
if "task" in fields:
|
||||
validate_task(call, fields)
|
||||
|
||||
if "labels" in fields:
|
||||
labels = fields["labels"]
|
||||
|
||||
def find_other_types(iterable, type_):
|
||||
res = [x for x in iterable if not isinstance(x, type_)]
|
||||
try:
|
||||
return set(res)
|
||||
except TypeError:
|
||||
# Un-hashable, probably
|
||||
return res
|
||||
|
||||
invalid_keys = find_other_types(labels.keys(), str)
|
||||
if invalid_keys:
|
||||
raise errors.bad_request.ValidationError("labels keys must be strings", keys=invalid_keys)
|
||||
|
||||
invalid_values = find_other_types(labels.values(), int)
|
||||
if invalid_values:
|
||||
raise errors.bad_request.ValidationError("labels values must be integers", values=invalid_values)
|
||||
|
||||
conform_tag_fields(call, fields)
|
||||
return fields
|
||||
|
||||
|
||||
@@ -290,8 +305,7 @@ def validate_task(call, fields):
|
||||
|
||||
|
||||
@endpoint("models.edit", required_fields=["model"], response_data_model=UpdateResponse)
|
||||
def edit(call):
|
||||
assert isinstance(call, APICall)
|
||||
def edit(call: APICall):
|
||||
identity = call.identity
|
||||
model_id = call.data["model"]
|
||||
|
||||
@@ -327,13 +341,13 @@ def edit(call):
|
||||
|
||||
if fields:
|
||||
updated = model.update(upsert=False, **fields)
|
||||
conform_output_tags(call, fields)
|
||||
call.result.data_model = UpdateResponse(updated=updated, fields=fields)
|
||||
else:
|
||||
call.result.data_model = UpdateResponse(updated=0)
|
||||
|
||||
|
||||
def _update_model(call, model_id=None):
|
||||
assert isinstance(call, APICall)
|
||||
def _update_model(call: APICall, model_id=None):
|
||||
identity = call.identity
|
||||
model_id = model_id or call.data["model"]
|
||||
|
||||
@@ -358,6 +372,7 @@ def _update_model(call, model_id=None):
|
||||
updated_count, updated_fields = Model.safe_update(
|
||||
call.identity.company, model.id, data
|
||||
)
|
||||
conform_output_tags(call, updated_fields)
|
||||
return UpdateResponse(updated=updated_count, fields=updated_fields)
|
||||
|
||||
|
||||
|
||||
@@ -9,27 +9,32 @@ from mongoengine import Q
|
||||
import database
|
||||
from apierrors import errors
|
||||
from apimodels.base import UpdateResponse
|
||||
from apimodels.projects import GetHyperParamReq, GetHyperParamResp, ProjectReq
|
||||
from bll.task import TaskBLL
|
||||
from database.errors import translate_errors_context
|
||||
from database.model import EntityVisibility
|
||||
from database.model.model import Model
|
||||
from database.model.project import Project
|
||||
from database.model.task.task import Task, TaskStatus, TaskVisibility
|
||||
from database.model.task.task import Task, TaskStatus
|
||||
from database.utils import parse_from_call, get_options, get_company_or_none_constraint
|
||||
from service_repo import APICall, endpoint
|
||||
from services.utils import conform_tag_fields, conform_output_tags
|
||||
from timing_context import TimingContext
|
||||
|
||||
task_bll = TaskBLL()
|
||||
archived_tasks_cond = {"$in": [TaskVisibility.archived.value, "$tags"]}
|
||||
archived_tasks_cond = {"$in": [EntityVisibility.archived.value, "$system_tags"]}
|
||||
|
||||
create_fields = {
|
||||
"name": None,
|
||||
"description": None,
|
||||
"tags": list,
|
||||
"system_tags": list,
|
||||
"default_output_destination": None,
|
||||
}
|
||||
|
||||
get_all_query_options = Project.QueryParameterOptions(
|
||||
pattern_fields=("name", "description"), list_fields=("tags", "id")
|
||||
pattern_fields=("name", "description"),
|
||||
list_fields=("tags", "system_tags", "id"),
|
||||
)
|
||||
|
||||
|
||||
@@ -43,32 +48,39 @@ def get_by_id(call):
|
||||
query = Q(id=project_id) & get_company_or_none_constraint(
|
||||
call.identity.company
|
||||
)
|
||||
res = Project.objects(query).first()
|
||||
if not res:
|
||||
project = Project.objects(query).first()
|
||||
if not project:
|
||||
raise errors.bad_request.InvalidProjectId(id=project_id)
|
||||
|
||||
res = res.to_proper_dict()
|
||||
project_dict = project.to_proper_dict()
|
||||
conform_output_tags(call, project_dict)
|
||||
|
||||
call.result.data = {"project": res}
|
||||
call.result.data = {"project": project_dict}
|
||||
|
||||
|
||||
def make_projects_get_all_pipelines(project_ids, specific_state=None):
|
||||
archived = TaskVisibility.archived.value
|
||||
status_count_pipeline = [
|
||||
# count tasks per project per status
|
||||
{"$match": {"project": {"$in": project_ids}}},
|
||||
# make sure tags is always an array (required by subsequent $in in archived_tasks_cond)
|
||||
{
|
||||
archived = EntityVisibility.archived.value
|
||||
|
||||
def ensure_system_tags():
|
||||
"""
|
||||
Make sure system tags is always an array (required by subsequent $in in archived_tasks_cond
|
||||
"""
|
||||
return {
|
||||
"$addFields": {
|
||||
"tags": {
|
||||
"system_tags": {
|
||||
"$cond": {
|
||||
"if": {"$ne": [{"$type": "$tags"}, "array"]},
|
||||
"if": {"$ne": [{"$type": "$system_tags"}, "array"]},
|
||||
"then": [],
|
||||
"else": "$tags",
|
||||
"else": "$system_tags",
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
}
|
||||
|
||||
status_count_pipeline = [
|
||||
# count tasks per project per status
|
||||
{"$match": {"project": {"$in": project_ids}}},
|
||||
ensure_system_tags(),
|
||||
{
|
||||
"$group": {
|
||||
"_id": {
|
||||
@@ -125,12 +137,12 @@ def make_projects_get_all_pipelines(project_ids, specific_state=None):
|
||||
|
||||
group_step = {"_id": "$project"}
|
||||
|
||||
for state in TaskVisibility:
|
||||
for state in EntityVisibility:
|
||||
if specific_state and state != specific_state:
|
||||
continue
|
||||
if state == TaskVisibility.active:
|
||||
if state == EntityVisibility.active:
|
||||
group_step[state.value] = runtime_subquery({"$not": archived_tasks_cond})
|
||||
elif state == TaskVisibility.archived:
|
||||
elif state == EntityVisibility.archived:
|
||||
group_step[state.value] = runtime_subquery(archived_tasks_cond)
|
||||
|
||||
runtime_pipeline = [
|
||||
@@ -141,6 +153,7 @@ def make_projects_get_all_pipelines(project_ids, specific_state=None):
|
||||
"project": {"$in": project_ids},
|
||||
}
|
||||
},
|
||||
ensure_system_tags(),
|
||||
{
|
||||
# for each project
|
||||
"$group": group_step
|
||||
@@ -151,32 +164,33 @@ def make_projects_get_all_pipelines(project_ids, specific_state=None):
|
||||
|
||||
|
||||
@endpoint("projects.get_all_ex")
|
||||
def get_all_ex(call):
|
||||
assert isinstance(call, APICall)
|
||||
def get_all_ex(call: APICall):
|
||||
include_stats = call.data.get("include_stats")
|
||||
stats_for_state = call.data.get("stats_for_state", TaskVisibility.active.value)
|
||||
stats_for_state = call.data.get("stats_for_state", EntityVisibility.active.value)
|
||||
|
||||
if stats_for_state:
|
||||
try:
|
||||
specific_state = TaskVisibility(stats_for_state)
|
||||
specific_state = EntityVisibility(stats_for_state)
|
||||
except ValueError:
|
||||
raise errors.bad_request.FieldsValueError(stats_for_state=stats_for_state)
|
||||
else:
|
||||
specific_state = None
|
||||
|
||||
conform_tag_fields(call, call.data)
|
||||
with translate_errors_context(), TimingContext("mongo", "projects_get_all"):
|
||||
res = Project.get_many_with_join(
|
||||
projects = Project.get_many_with_join(
|
||||
company=call.identity.company,
|
||||
query_dict=call.data,
|
||||
query_options=get_all_query_options,
|
||||
allow_public=True,
|
||||
)
|
||||
conform_output_tags(call, projects)
|
||||
|
||||
if not include_stats:
|
||||
call.result.data = {"projects": res}
|
||||
call.result.data = {"projects": projects}
|
||||
return
|
||||
|
||||
ids = [project["id"] for project in res]
|
||||
ids = [project["id"] for project in projects]
|
||||
status_count_pipeline, runtime_pipeline = make_projects_get_all_pipelines(
|
||||
ids, specific_state=specific_state
|
||||
)
|
||||
@@ -187,11 +201,11 @@ def get_all_ex(call):
|
||||
return dict(default_counts, **entry)
|
||||
|
||||
status_count = defaultdict(lambda: {})
|
||||
key = itemgetter(TaskVisibility.archived.value)
|
||||
for result in Task.objects.aggregate(*status_count_pipeline):
|
||||
key = itemgetter(EntityVisibility.archived.value)
|
||||
for result in Task.aggregate(*status_count_pipeline):
|
||||
for k, group in groupby(sorted(result["counts"], key=key), key):
|
||||
section = (
|
||||
TaskVisibility.archived if k else TaskVisibility.active
|
||||
EntityVisibility.archived if k else EntityVisibility.active
|
||||
).value
|
||||
status_count[result["_id"]][section] = set_default_count(
|
||||
{
|
||||
@@ -202,7 +216,7 @@ def get_all_ex(call):
|
||||
|
||||
runtime = {
|
||||
result["_id"]: {k: v for k, v in result.items() if k != "_id"}
|
||||
for result in Task.objects.aggregate(*runtime_pipeline)
|
||||
for result in Task.aggregate(*runtime_pipeline)
|
||||
}
|
||||
|
||||
def safe_get(obj, path, default=None):
|
||||
@@ -219,32 +233,32 @@ def get_all_ex(call):
|
||||
}
|
||||
|
||||
report_for_states = [
|
||||
s for s in TaskVisibility if not specific_state or specific_state == s
|
||||
s for s in EntityVisibility if not specific_state or specific_state == s
|
||||
]
|
||||
|
||||
for project in res:
|
||||
for project in projects:
|
||||
project["stats"] = {
|
||||
task_state.value: get_status_counts(project["id"], task_state.value)
|
||||
for task_state in report_for_states
|
||||
}
|
||||
|
||||
call.result.data = {"projects": res}
|
||||
call.result.data = {"projects": projects}
|
||||
|
||||
|
||||
@endpoint("projects.get_all")
|
||||
def get_all(call):
|
||||
assert isinstance(call, APICall)
|
||||
|
||||
def get_all(call: APICall):
|
||||
conform_tag_fields(call, call.data)
|
||||
with translate_errors_context(), TimingContext("mongo", "projects_get_all"):
|
||||
res = Project.get_many(
|
||||
projects = Project.get_many(
|
||||
company=call.identity.company,
|
||||
query_dict=call.data,
|
||||
query_options=get_all_query_options,
|
||||
parameters=call.data,
|
||||
allow_public=True,
|
||||
)
|
||||
conform_output_tags(call, projects)
|
||||
|
||||
call.result.data = {"projects": res}
|
||||
call.result.data = {"projects": projects}
|
||||
|
||||
|
||||
@endpoint("projects.create", required_fields=["name", "description"])
|
||||
@@ -254,6 +268,7 @@ def create(call):
|
||||
|
||||
with translate_errors_context():
|
||||
fields = parse_from_call(call.data, create_fields, Project.get_fields())
|
||||
conform_tag_fields(call, fields)
|
||||
now = datetime.utcnow()
|
||||
project = Project(
|
||||
id=database.utils.id(),
|
||||
@@ -271,7 +286,7 @@ def create(call):
|
||||
@endpoint(
|
||||
"projects.update", required_fields=["project"], response_data_model=UpdateResponse
|
||||
)
|
||||
def update(call):
|
||||
def update(call: APICall):
|
||||
"""
|
||||
update
|
||||
|
||||
@@ -280,7 +295,6 @@ def update(call):
|
||||
:return: updated - `int` - number of projects updated
|
||||
fields - `[string]` - updated fields
|
||||
"""
|
||||
assert isinstance(call, APICall)
|
||||
project_id = call.data["project"]
|
||||
|
||||
with translate_errors_context():
|
||||
@@ -291,9 +305,11 @@ def update(call):
|
||||
fields = parse_from_call(
|
||||
call.data, create_fields, Project.get_fields(), discard_none_values=False
|
||||
)
|
||||
conform_tag_fields(call, fields)
|
||||
fields["last_update"] = datetime.utcnow()
|
||||
with TimingContext("mongo", "projects_update"):
|
||||
updated = project.update(upsert=False, **fields)
|
||||
conform_output_tags(call, fields)
|
||||
call.result.data_model = UpdateResponse(updated=updated, fields=fields)
|
||||
|
||||
|
||||
@@ -317,7 +333,7 @@ def delete(call):
|
||||
(Model, errors.bad_request.ProjectHasModels),
|
||||
):
|
||||
res = cls.objects(
|
||||
project=project_id, tags__nin=[TaskVisibility.archived.value]
|
||||
project=project_id, system_tags__nin=[EntityVisibility.archived.value]
|
||||
).only("id")
|
||||
if res and not force:
|
||||
raise error("use force=true to delete", id=project_id)
|
||||
@@ -329,12 +345,33 @@ def delete(call):
|
||||
call.result.data = {"deleted": 1, "disassociated_tasks": updated_count}
|
||||
|
||||
|
||||
@endpoint("projects.get_unique_metric_variants")
|
||||
def get_unique_metric_variants(call, company_id, req_model):
|
||||
project_id = call.data.get("project")
|
||||
@endpoint("projects.get_unique_metric_variants", request_data_model=ProjectReq)
|
||||
def get_unique_metric_variants(call: APICall, company_id: str, request: ProjectReq):
|
||||
|
||||
metrics = task_bll.get_unique_metric_variants(
|
||||
company_id, [project_id] if project_id else None
|
||||
company_id, [request.project] if request.project else None
|
||||
)
|
||||
|
||||
call.result.data = {"metrics": metrics}
|
||||
|
||||
|
||||
@endpoint(
|
||||
"projects.get_hyper_parameters",
|
||||
min_version="2.2",
|
||||
request_data_model=GetHyperParamReq,
|
||||
response_data_model=GetHyperParamResp,
|
||||
)
|
||||
def get_hyper_parameters(call: APICall, company_id: str, request: GetHyperParamReq):
|
||||
|
||||
total, remaining, parameters = TaskBLL.get_aggregated_project_execution_parameters(
|
||||
company_id,
|
||||
project_ids=[request.project] if request.project else None,
|
||||
page=request.page,
|
||||
page_size=request.page_size,
|
||||
)
|
||||
|
||||
call.result.data = {
|
||||
"total": total,
|
||||
"remaining": remaining,
|
||||
"parameters": parameters,
|
||||
}
|
||||
|
||||
218
server/services/queues.py
Normal file
218
server/services/queues.py
Normal file
@@ -0,0 +1,218 @@
|
||||
from apimodels.base import UpdateResponse
|
||||
from apimodels.queues import (
|
||||
GetDefaultResp,
|
||||
CreateRequest,
|
||||
DeleteRequest,
|
||||
UpdateRequest,
|
||||
MoveTaskRequest,
|
||||
MoveTaskResponse,
|
||||
TaskRequest,
|
||||
QueueRequest,
|
||||
GetMetricsRequest,
|
||||
GetMetricsResponse,
|
||||
QueueMetrics,
|
||||
)
|
||||
from bll.queue import QueueBLL
|
||||
from bll.util import extract_properties_to_lists
|
||||
from bll.workers import WorkerBLL
|
||||
from service_repo import APICall, endpoint
|
||||
from services.utils import conform_tag_fields, conform_output_tags, conform_tags
|
||||
|
||||
worker_bll = WorkerBLL()
|
||||
queue_bll = QueueBLL(worker_bll)
|
||||
|
||||
|
||||
@endpoint("queues.get_by_id", min_version="2.4", request_data_model=QueueRequest)
|
||||
def get_by_id(call: APICall, company_id, req_model: QueueRequest):
|
||||
queue = queue_bll.get_by_id(company_id, req_model.queue)
|
||||
queue_dict = queue.to_proper_dict()
|
||||
conform_output_tags(call, queue_dict)
|
||||
call.result.data = {"queue": queue_dict}
|
||||
|
||||
|
||||
@endpoint("queues.get_default", min_version="2.4", response_data_model=GetDefaultResp)
|
||||
def get_by_id(call: APICall):
|
||||
queue = queue_bll.get_default(call.identity.company)
|
||||
call.result.data_model = GetDefaultResp(id=queue.id, name=queue.name)
|
||||
|
||||
|
||||
@endpoint("queues.get_all_ex", min_version="2.4")
|
||||
def get_all_ex(call: APICall):
|
||||
conform_tag_fields(call, call.data)
|
||||
queues = queue_bll.get_queue_infos(
|
||||
company_id=call.identity.company, query_dict=call.data
|
||||
)
|
||||
conform_output_tags(call, queues)
|
||||
|
||||
call.result.data = {"queues": queues}
|
||||
|
||||
|
||||
@endpoint("queues.get_all", min_version="2.4")
|
||||
def get_all(call: APICall):
|
||||
conform_tag_fields(call, call.data)
|
||||
queues = queue_bll.get_all(company_id=call.identity.company, query_dict=call.data)
|
||||
conform_output_tags(call, queues)
|
||||
|
||||
call.result.data = {"queues": queues}
|
||||
|
||||
|
||||
@endpoint("queues.create", min_version="2.4", request_data_model=CreateRequest)
|
||||
def create(call: APICall, company_id, request: CreateRequest):
|
||||
tags, system_tags = conform_tags(call, request.tags, request.system_tags)
|
||||
queue = queue_bll.create(
|
||||
company_id=company_id, name=request.name, tags=tags, system_tags=system_tags
|
||||
)
|
||||
call.result.data = {"id": queue.id}
|
||||
|
||||
|
||||
@endpoint(
|
||||
"queues.update",
|
||||
min_version="2.4",
|
||||
request_data_model=UpdateRequest,
|
||||
response_data_model=UpdateResponse,
|
||||
)
|
||||
def update(call: APICall, company_id, req_model: UpdateRequest):
|
||||
data = call.data_model_for_partial_update
|
||||
conform_tag_fields(call, data)
|
||||
updated, fields = queue_bll.update(
|
||||
company_id=company_id, queue_id=req_model.queue, **data
|
||||
)
|
||||
conform_output_tags(call, fields)
|
||||
call.result.data_model = UpdateResponse(updated=updated, fields=fields)
|
||||
|
||||
|
||||
@endpoint("queues.delete", min_version="2.4", request_data_model=DeleteRequest)
|
||||
def delete(call: APICall, company_id, req_model: DeleteRequest):
|
||||
queue_bll.delete(
|
||||
company_id=company_id, queue_id=req_model.queue, force=req_model.force
|
||||
)
|
||||
call.result.data = {"deleted": 1}
|
||||
|
||||
|
||||
@endpoint("queues.add_task", min_version="2.4", request_data_model=TaskRequest)
|
||||
def add_task(call: APICall, company_id, req_model: TaskRequest):
|
||||
call.result.data = {
|
||||
"added": queue_bll.add_task(
|
||||
company_id=company_id, queue_id=req_model.queue, task_id=req_model.task
|
||||
)
|
||||
}
|
||||
|
||||
|
||||
@endpoint("queues.get_next_task", min_version="2.4", request_data_model=QueueRequest)
|
||||
def get_next_task(call: APICall, company_id, req_model: QueueRequest):
|
||||
task = queue_bll.get_next_task(company_id=company_id, queue_id=req_model.queue)
|
||||
if task:
|
||||
call.result.data = {"entry": task.to_proper_dict()}
|
||||
|
||||
|
||||
@endpoint("queues.remove_task", min_version="2.4", request_data_model=TaskRequest)
|
||||
def remove_task(call: APICall, company_id, req_model: TaskRequest):
|
||||
call.result.data = {
|
||||
"removed": queue_bll.remove_task(
|
||||
company_id=company_id, queue_id=req_model.queue, task_id=req_model.task
|
||||
)
|
||||
}
|
||||
|
||||
|
||||
@endpoint(
|
||||
"queues.move_task_forward",
|
||||
min_version="2.4",
|
||||
request_data_model=MoveTaskRequest,
|
||||
response_data_model=MoveTaskResponse,
|
||||
)
|
||||
def move_task_forward(call: APICall, company_id, req_model: MoveTaskRequest):
|
||||
call.result.data_model = MoveTaskResponse(
|
||||
position=queue_bll.reposition_task(
|
||||
company_id=company_id,
|
||||
queue_id=req_model.queue,
|
||||
task_id=req_model.task,
|
||||
pos_func=lambda p: max(0, p - req_model.count),
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@endpoint(
|
||||
"queues.move_task_backward",
|
||||
min_version="2.4",
|
||||
request_data_model=MoveTaskRequest,
|
||||
response_data_model=MoveTaskResponse,
|
||||
)
|
||||
def move_task_backward(call: APICall, company_id, req_model: MoveTaskRequest):
|
||||
call.result.data_model = MoveTaskResponse(
|
||||
position=queue_bll.reposition_task(
|
||||
company_id=company_id,
|
||||
queue_id=req_model.queue,
|
||||
task_id=req_model.task,
|
||||
pos_func=lambda p: max(0, p + req_model.count),
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@endpoint(
|
||||
"queues.move_task_to_front",
|
||||
min_version="2.4",
|
||||
request_data_model=TaskRequest,
|
||||
response_data_model=MoveTaskResponse,
|
||||
)
|
||||
def move_task_to_front(call: APICall, company_id, req_model: TaskRequest):
|
||||
call.result.data_model = MoveTaskResponse(
|
||||
position=queue_bll.reposition_task(
|
||||
company_id=company_id,
|
||||
queue_id=req_model.queue,
|
||||
task_id=req_model.task,
|
||||
pos_func=lambda p: 0,
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@endpoint(
|
||||
"queues.move_task_to_back",
|
||||
min_version="2.4",
|
||||
request_data_model=TaskRequest,
|
||||
response_data_model=MoveTaskResponse,
|
||||
)
|
||||
def move_task_to_back(call: APICall, company_id, req_model: TaskRequest):
|
||||
call.result.data_model = MoveTaskResponse(
|
||||
position=queue_bll.reposition_task(
|
||||
company_id=company_id,
|
||||
queue_id=req_model.queue,
|
||||
task_id=req_model.task,
|
||||
pos_func=lambda p: -1,
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@endpoint(
|
||||
"queues.get_queue_metrics",
|
||||
min_version="2.4",
|
||||
request_data_model=GetMetricsRequest,
|
||||
response_data_model=GetMetricsResponse,
|
||||
)
|
||||
def get_queue_metrics(
|
||||
call: APICall, company_id, req_model: GetMetricsRequest
|
||||
) -> GetMetricsResponse:
|
||||
ret = queue_bll.metrics.get_queue_metrics(
|
||||
company_id=company_id,
|
||||
from_date=req_model.from_date,
|
||||
to_date=req_model.to_date,
|
||||
interval=req_model.interval,
|
||||
queue_ids=req_model.queue_ids,
|
||||
)
|
||||
|
||||
queue_dicts = {
|
||||
queue: extract_properties_to_lists(
|
||||
["date", "avg_waiting_time", "queue_length"], data
|
||||
)
|
||||
for queue, data in ret.items()
|
||||
}
|
||||
return GetMetricsResponse(
|
||||
queues=[
|
||||
QueueMetrics(
|
||||
queue=queue,
|
||||
dates=data["date"],
|
||||
avg_waiting_times=data["avg_waiting_time"],
|
||||
queue_lengths=data["queue_length"],
|
||||
) if data else QueueMetrics(queue=queue)
|
||||
for queue, data in queue_dicts.items()
|
||||
]
|
||||
)
|
||||
93
server/services/server/__init__.py
Normal file
93
server/services/server/__init__.py
Normal file
@@ -0,0 +1,93 @@
|
||||
from datetime import datetime
|
||||
|
||||
from pyhocon.config_tree import NoneValue
|
||||
|
||||
from apierrors import errors
|
||||
from apimodels.server import ReportStatsOptionRequest, ReportStatsOptionResponse
|
||||
from bll.statistics.stats_reporter import StatisticsReporter
|
||||
from config import config
|
||||
from config.info import get_version, get_build_number, get_commit_number
|
||||
from database.errors import translate_errors_context
|
||||
from database.model import Company
|
||||
from database.model.company import ReportStatsOption
|
||||
from service_repo import ServiceRepo, APICall, endpoint
|
||||
from version import __version__ as current_version
|
||||
|
||||
|
||||
@endpoint("server.get_stats")
|
||||
def get_stats(call: APICall):
|
||||
call.result.data = StatisticsReporter.get_statistics(
|
||||
company_id=call.identity.company
|
||||
)
|
||||
|
||||
|
||||
@endpoint("server.config")
|
||||
def get_config(call: APICall):
|
||||
path = call.data.get("path")
|
||||
if path:
|
||||
c = dict(config.get(path))
|
||||
else:
|
||||
c = config.to_dict()
|
||||
|
||||
def remove_none_value(x):
|
||||
"""
|
||||
Pyhocon bug in Python 3: leaves dummy "NoneValue"s in tree,
|
||||
see: https://github.com/chimpler/pyhocon/issues/111
|
||||
"""
|
||||
if isinstance(x, dict):
|
||||
return {key: remove_none_value(value) for key, value in x.items()}
|
||||
if isinstance(x, list):
|
||||
return list(map(remove_none_value, x))
|
||||
if isinstance(x, NoneValue):
|
||||
return None
|
||||
return x
|
||||
|
||||
c.pop("secure", None)
|
||||
|
||||
call.result.data = remove_none_value(c)
|
||||
|
||||
|
||||
@endpoint("server.endpoints")
|
||||
def get_endpoints(call: APICall):
|
||||
call.result.data = ServiceRepo.endpoints_summary()
|
||||
|
||||
|
||||
@endpoint("server.info")
|
||||
def info(call: APICall):
|
||||
call.result.data = {
|
||||
"version": get_version(),
|
||||
"build": get_build_number(),
|
||||
"commit": get_commit_number(),
|
||||
}
|
||||
|
||||
|
||||
@endpoint(
|
||||
"server.report_stats_option",
|
||||
request_data_model=ReportStatsOptionRequest,
|
||||
response_data_model=ReportStatsOptionResponse,
|
||||
)
|
||||
def report_stats(call: APICall, company: str, request: ReportStatsOptionRequest):
|
||||
if not StatisticsReporter.supported:
|
||||
result = ReportStatsOptionResponse(supported=False)
|
||||
else:
|
||||
enabled = request.enabled
|
||||
with translate_errors_context():
|
||||
query = Company.objects(id=company)
|
||||
if enabled is None:
|
||||
stats_option = query.first().defaults.stats_option
|
||||
else:
|
||||
stats_option = ReportStatsOption(
|
||||
enabled=enabled,
|
||||
enabled_time=datetime.utcnow(),
|
||||
enabled_version=current_version,
|
||||
enabled_user=call.identity.user,
|
||||
)
|
||||
updated = query.update(defaults__stats_option=stats_option)
|
||||
if not updated:
|
||||
raise errors.server_error.InternalError(
|
||||
f"Failed setting report_stats to {enabled}"
|
||||
)
|
||||
|
||||
result = ReportStatsOptionResponse(**stats_option.to_mongo())
|
||||
|
||||
call.result.data_model = result
|
||||
@@ -11,7 +11,7 @@ from mongoengine import EmbeddedDocument, Q
|
||||
from mongoengine.queryset.transform import COMPARISON_OPERATORS
|
||||
from pymongo import UpdateOne
|
||||
|
||||
from apierrors import errors
|
||||
from apierrors import errors, APIError
|
||||
from apimodels.base import UpdateResponse
|
||||
from apimodels.tasks import (
|
||||
StartedResponse,
|
||||
@@ -24,22 +24,34 @@ from apimodels.tasks import (
|
||||
TaskRequest,
|
||||
DeleteRequest,
|
||||
PingRequest,
|
||||
EnqueueRequest,
|
||||
EnqueueResponse,
|
||||
DequeueResponse,
|
||||
)
|
||||
from bll.event import EventBLL
|
||||
from bll.queue import QueueBLL
|
||||
from bll.task import TaskBLL, ChangeStatusRequest, update_project_time, split_by
|
||||
from bll.util import SetFieldsResolver
|
||||
from database.errors import translate_errors_context
|
||||
from database.model.model import Model
|
||||
from database.model.task.output import Output
|
||||
from database.model.task.task import Task, TaskStatus, Script, DEFAULT_LAST_ITERATION
|
||||
from database.model.task.task import (
|
||||
Task,
|
||||
TaskStatus,
|
||||
Script,
|
||||
DEFAULT_LAST_ITERATION,
|
||||
Execution,
|
||||
)
|
||||
from database.utils import get_fields, parse_from_call
|
||||
from service_repo import APICall, endpoint
|
||||
from services.utils import conform_tag_fields, conform_output_tags
|
||||
from timing_context import TimingContext
|
||||
from utilities import safe_get
|
||||
|
||||
task_fields = set(Task.get_fields())
|
||||
task_script_fields = set(get_fields(Script))
|
||||
get_all_query_options = Task.QueryParameterOptions(
|
||||
list_fields=("id", "user", "tags", "type", "status", "project"),
|
||||
list_fields=("id", "user", "tags", "system_tags", "type", "status", "project"),
|
||||
datetime_fields=("status_changed",),
|
||||
pattern_fields=("name", "comment"),
|
||||
fields=("parent",),
|
||||
@@ -47,20 +59,23 @@ get_all_query_options = Task.QueryParameterOptions(
|
||||
|
||||
task_bll = TaskBLL()
|
||||
event_bll = EventBLL()
|
||||
queue_bll = QueueBLL()
|
||||
|
||||
|
||||
TaskBLL.start_non_responsive_tasks_watchdog()
|
||||
|
||||
|
||||
def set_task_status_from_call(
|
||||
request: UpdateRequest, company_id, new_status=None, **kwargs
|
||||
request: UpdateRequest, company_id, new_status=None, **set_fields
|
||||
) -> dict:
|
||||
fields_resolver = SetFieldsResolver(set_fields)
|
||||
task = TaskBLL.get_task_with_access(
|
||||
request.task,
|
||||
company_id=company_id,
|
||||
only=("status", "project"),
|
||||
only=tuple({"status", "project"} | fields_resolver.get_names()),
|
||||
requires_write_access=True,
|
||||
)
|
||||
|
||||
status_reason = request.status_reason
|
||||
status_message = request.status_message
|
||||
force = request.force
|
||||
@@ -70,7 +85,7 @@ def set_task_status_from_call(
|
||||
status_reason=status_reason,
|
||||
status_message=status_message,
|
||||
force=force,
|
||||
).execute(**kwargs)
|
||||
).execute(**fields_resolver.get_fields(task))
|
||||
|
||||
|
||||
@endpoint("tasks.get_by_id", request_data_model=TaskRequest)
|
||||
@@ -79,11 +94,13 @@ def get_by_id(call: APICall, company_id, req_model: TaskRequest):
|
||||
req_model.task, company_id=company_id, allow_public=True
|
||||
)
|
||||
task_dict = task.to_proper_dict()
|
||||
conform_output_tags(call, task_dict)
|
||||
call.result.data = {"task": task_dict}
|
||||
|
||||
|
||||
@endpoint("tasks.get_all_ex", required_fields=[])
|
||||
def get_all_ex(call: APICall):
|
||||
conform_tag_fields(call, call.data)
|
||||
with translate_errors_context():
|
||||
with TimingContext("mongo", "task_get_all_ex"):
|
||||
tasks = Task.get_many_with_join(
|
||||
@@ -92,12 +109,13 @@ def get_all_ex(call: APICall):
|
||||
query_options=get_all_query_options,
|
||||
allow_public=True, # required in case projection is requested for public dataset/versions
|
||||
)
|
||||
|
||||
conform_output_tags(call, tasks)
|
||||
call.result.data = {"tasks": tasks}
|
||||
|
||||
|
||||
@endpoint("tasks.get_all", required_fields=[])
|
||||
def get_all(call: APICall):
|
||||
conform_tag_fields(call, call.data)
|
||||
with translate_errors_context():
|
||||
with TimingContext("mongo", "task_get_all"):
|
||||
tasks = Task.get_many(
|
||||
@@ -107,6 +125,7 @@ def get_all(call: APICall):
|
||||
query_options=get_all_query_options,
|
||||
allow_public=True, # required in case projection is requested for public dataset/versions
|
||||
)
|
||||
conform_output_tags(call, tasks)
|
||||
call.result.data = {"tasks": tasks}
|
||||
|
||||
|
||||
@@ -160,7 +179,7 @@ def started(call: APICall, company_id, req_model: UpdateRequest):
|
||||
req_model,
|
||||
company_id,
|
||||
new_status=TaskStatus.in_progress,
|
||||
started=datetime.utcnow(),
|
||||
min__started=datetime.utcnow(), # don't override a previous, smaller "started" field value
|
||||
)
|
||||
)
|
||||
res.started = res.updated
|
||||
@@ -188,6 +207,7 @@ def close(call: APICall, company_id, req_model: UpdateRequest):
|
||||
create_fields = {
|
||||
"name": None,
|
||||
"tags": list,
|
||||
"system_tags": list,
|
||||
"type": None,
|
||||
"error": None,
|
||||
"comment": None,
|
||||
@@ -219,10 +239,7 @@ def prepare_create_fields(
|
||||
output = Output(destination=output_dest)
|
||||
fields["output"] = output
|
||||
|
||||
# Make sure there are no duplicate tags
|
||||
tags = fields.get("tags")
|
||||
if tags:
|
||||
fields["tags"] = list(set(tags))
|
||||
conform_tag_fields(call, fields)
|
||||
|
||||
# Strip all script fields (remove leading and trailing whitespace chars) to avoid unusable names and paths
|
||||
for field in task_script_fields:
|
||||
@@ -251,7 +268,7 @@ def _validate_and_get_task_from_call(call: APICall, **kwargs):
|
||||
task = task_bll.create(call, fields)
|
||||
|
||||
with TimingContext("code", "validate"):
|
||||
task_bll.validate(task, force=call.data.get("force", False))
|
||||
task_bll.validate(task)
|
||||
|
||||
return task
|
||||
|
||||
@@ -272,16 +289,14 @@ def create(call: APICall, company_id, req_model: CreateRequest):
|
||||
call.result.data = {"id": task.id}
|
||||
|
||||
|
||||
def prepare_update_fields(task, call_data):
|
||||
def prepare_update_fields(call: APICall, task, call_data):
|
||||
valid_fields = deepcopy(task.__class__.user_set_allowed())
|
||||
update_fields = {k: v for k, v in create_fields.items() if k in valid_fields}
|
||||
update_fields["output__error"] = None
|
||||
t_fields = task_fields
|
||||
t_fields.add("output__error")
|
||||
fields = parse_from_call(call_data, update_fields, t_fields)
|
||||
tags = fields.get("tags")
|
||||
if tags:
|
||||
fields["tags"] = list(set(tags))
|
||||
conform_tag_fields(call, fields)
|
||||
return fields, valid_fields
|
||||
|
||||
|
||||
@@ -296,7 +311,7 @@ def update(call: APICall, company_id, req_model: UpdateRequest):
|
||||
if not task:
|
||||
raise errors.bad_request.InvalidTaskId(id=task_id)
|
||||
|
||||
partial_update_dict, valid_fields = prepare_update_fields(task, call.data)
|
||||
partial_update_dict, valid_fields = prepare_update_fields(call, task, call.data)
|
||||
|
||||
if not partial_update_dict:
|
||||
return UpdateResponse(updated=0)
|
||||
@@ -309,7 +324,7 @@ def update(call: APICall, company_id, req_model: UpdateRequest):
|
||||
)
|
||||
|
||||
update_project_time(updated_fields.get("project"))
|
||||
|
||||
conform_output_tags(call, updated_fields)
|
||||
return UpdateResponse(updated=updated_count, fields=updated_fields)
|
||||
|
||||
|
||||
@@ -364,7 +379,7 @@ def update_batch(call: APICall):
|
||||
|
||||
bulk_ops = []
|
||||
for id, data in items.items():
|
||||
fields, valid_fields = prepare_update_fields(tasks[id], data)
|
||||
fields, valid_fields = prepare_update_fields(call, tasks[id], data)
|
||||
partial_update_dict = Task.get_safe_update_dict(fields)
|
||||
if not partial_update_dict:
|
||||
continue
|
||||
@@ -421,7 +436,7 @@ def edit(call: APICall, company_id, req_model: UpdateRequest):
|
||||
d.update(value)
|
||||
fields[key] = d
|
||||
|
||||
task_bll.validate(task_bll.create(call, fields), force=force)
|
||||
task_bll.validate(task_bll.create(call, fields))
|
||||
|
||||
# make sure field names do not end in mongoengine comparison operators
|
||||
fixed_fields = {
|
||||
@@ -434,11 +449,131 @@ def edit(call: APICall, company_id, req_model: UpdateRequest):
|
||||
fixed_fields.update(last_update=now)
|
||||
updated = task.update(upsert=False, **fixed_fields)
|
||||
update_project_time(fields.get("project"))
|
||||
conform_output_tags(call, fields)
|
||||
call.result.data_model = UpdateResponse(updated=updated, fields=fields)
|
||||
else:
|
||||
call.result.data_model = UpdateResponse(updated=0)
|
||||
|
||||
|
||||
@endpoint(
|
||||
"tasks.enqueue",
|
||||
request_data_model=EnqueueRequest,
|
||||
response_data_model=EnqueueResponse,
|
||||
)
|
||||
def enqueue(call: APICall, company_id, req_model: EnqueueRequest):
|
||||
task_id = req_model.task
|
||||
queue_id = req_model.queue
|
||||
status_message = req_model.status_message
|
||||
status_reason = req_model.status_reason
|
||||
|
||||
if not queue_id:
|
||||
# try to get default queue
|
||||
queue_id = queue_bll.get_default(company_id).id
|
||||
|
||||
with translate_errors_context():
|
||||
query = dict(id=task_id, company=company_id)
|
||||
task = Task.get_for_writing(
|
||||
_only=("type", "script", "execution", "status", "project", "id"), **query
|
||||
)
|
||||
if not task:
|
||||
raise errors.bad_request.InvalidTaskId(**query)
|
||||
|
||||
res = EnqueueResponse(
|
||||
**ChangeStatusRequest(
|
||||
task=task,
|
||||
new_status=TaskStatus.queued,
|
||||
status_reason=status_reason,
|
||||
status_message=status_message,
|
||||
allow_same_state_transition=False,
|
||||
).execute()
|
||||
)
|
||||
|
||||
try:
|
||||
queue_bll.add_task(
|
||||
company_id=company_id, queue_id=queue_id, task_id=task.id
|
||||
)
|
||||
except Exception:
|
||||
# failed enqueueing, revert to previous state
|
||||
ChangeStatusRequest(
|
||||
task=task,
|
||||
current_status_override=TaskStatus.queued,
|
||||
new_status=task.status,
|
||||
force=True,
|
||||
status_reason="failed enqueueing",
|
||||
).execute()
|
||||
raise
|
||||
|
||||
# set the current queue ID in the task
|
||||
if task.execution:
|
||||
Task.objects(**query).update(execution__queue=queue_id, multi=False)
|
||||
else:
|
||||
Task.objects(**query).update(
|
||||
execution=Execution(queue=queue_id), multi=False
|
||||
)
|
||||
|
||||
res.queued = 1
|
||||
res.fields.update(**{"execution.queue": queue_id})
|
||||
|
||||
call.result.data_model = res
|
||||
|
||||
|
||||
@endpoint(
|
||||
"tasks.dequeue",
|
||||
request_data_model=UpdateRequest,
|
||||
response_data_model=DequeueResponse,
|
||||
)
|
||||
def dequeue(call: APICall, company_id, req_model: UpdateRequest):
|
||||
task = TaskBLL.get_task_with_access(
|
||||
req_model.task,
|
||||
company_id=company_id,
|
||||
only=("id", "execution", "status", "project"),
|
||||
requires_write_access=True,
|
||||
)
|
||||
if task.status not in (TaskStatus.queued,):
|
||||
raise errors.bad_request.InvalidTaskId(
|
||||
status=task.status, expected=TaskStatus.queued
|
||||
)
|
||||
|
||||
_dequeue(task, company_id)
|
||||
|
||||
status_message = req_model.status_message
|
||||
status_reason = req_model.status_reason
|
||||
res = DequeueResponse(
|
||||
**ChangeStatusRequest(
|
||||
task=task,
|
||||
new_status=TaskStatus.created,
|
||||
status_reason=status_reason,
|
||||
status_message=status_message,
|
||||
).execute(unset__execution__queue=1)
|
||||
)
|
||||
res.dequeued = 1
|
||||
|
||||
call.result.data_model = res
|
||||
|
||||
|
||||
def _dequeue(task: Task, company_id: str, silent_fail=False):
|
||||
"""
|
||||
Dequeue the task from the queue
|
||||
:param task: task to dequeue
|
||||
:param silent_fail: do not throw exceptions. APIError is still thrown
|
||||
:raise errors.bad_request.MissingRequiredFields: if the task is not queued
|
||||
:raise APIError or errors.server_error.TransactionError: if internal call to queues.remove_task fails
|
||||
:return: the result of queues.remove_task call. None in case of silent failure
|
||||
"""
|
||||
if not task.execution or not task.execution.queue:
|
||||
if silent_fail:
|
||||
return
|
||||
raise errors.bad_request.MissingRequiredFields(
|
||||
"task has no queue value", field="execution.queue"
|
||||
)
|
||||
|
||||
return {
|
||||
"removed": queue_bll.remove_task(
|
||||
company_id=company_id, queue_id=task.execution.queue, task_id=task.id
|
||||
)
|
||||
}
|
||||
|
||||
|
||||
@endpoint(
|
||||
"tasks.reset", request_data_model=UpdateRequest, response_data_model=ResetResponse
|
||||
)
|
||||
@@ -455,6 +590,16 @@ def reset(call: APICall, company_id, req_model: UpdateRequest):
|
||||
api_results = {}
|
||||
updates = {}
|
||||
|
||||
try:
|
||||
dequeued = _dequeue(task, company_id, silent_fail=True)
|
||||
except APIError:
|
||||
# dequeue may fail if the task was not enqueued
|
||||
pass
|
||||
else:
|
||||
if dequeued:
|
||||
api_results.update(dequeued=dequeued)
|
||||
updates.update(unset__execution__queue=1)
|
||||
|
||||
cleaned_up = cleanup_task(task, force)
|
||||
api_results.update(attr.asdict(cleaned_up))
|
||||
|
||||
@@ -463,6 +608,7 @@ def reset(call: APICall, company_id, req_model: UpdateRequest):
|
||||
set__last_metrics={},
|
||||
unset__output__result=1,
|
||||
unset__output__model=1,
|
||||
__raw__={"$pull": {"execution.artifacts": {"mode": {"$ne": "input"}}}},
|
||||
)
|
||||
|
||||
res = ResetResponse(
|
||||
@@ -670,7 +816,10 @@ def publish(call: APICall, company_id, req_model: PublishRequest):
|
||||
|
||||
|
||||
@endpoint(
|
||||
"tasks.completed", min_version="2.2", request_data_model=UpdateRequest, response_data_model=UpdateResponse
|
||||
"tasks.completed",
|
||||
min_version="2.2",
|
||||
request_data_model=UpdateRequest,
|
||||
response_data_model=UpdateResponse,
|
||||
)
|
||||
def completed(call: APICall, company_id, request: PublishRequest):
|
||||
call.result.data_model = UpdateResponse(
|
||||
@@ -688,4 +837,3 @@ def ping(_, company_id, request: PingRequest):
|
||||
TaskBLL.set_last_update(
|
||||
task_ids=[request.task], company_id=company_id, last_update=datetime.utcnow()
|
||||
)
|
||||
|
||||
|
||||
63
server/services/utils.py
Normal file
63
server/services/utils.py
Normal file
@@ -0,0 +1,63 @@
|
||||
from typing import Union, Sequence, Tuple
|
||||
|
||||
from database.utils import partition_tags
|
||||
from service_repo import APICall
|
||||
from service_repo.base import PartialVersion
|
||||
|
||||
|
||||
def conform_output_tags(call: APICall, documents: Union[dict, Sequence[dict]]):
|
||||
"""
|
||||
For old clients both tags and system tags are returned in 'tags' field
|
||||
"""
|
||||
if call.requested_endpoint_version >= PartialVersion("2.3"):
|
||||
return
|
||||
if isinstance(documents, dict):
|
||||
documents = [documents]
|
||||
for doc in documents:
|
||||
system_tags = doc.get("system_tags")
|
||||
if system_tags:
|
||||
doc["tags"] = list(set(doc.get("tags", [])) | set(system_tags))
|
||||
|
||||
|
||||
def conform_tag_fields(call: APICall, document: dict):
|
||||
"""
|
||||
Upgrade old client tags in place
|
||||
"""
|
||||
if "tags" in document:
|
||||
tags, system_tags = conform_tags(
|
||||
call, document["tags"], document.get("system_tags")
|
||||
)
|
||||
if tags != document.get("tags"):
|
||||
document["tags"] = tags
|
||||
if system_tags != document.get("system_tags"):
|
||||
document["system_tags"] = system_tags
|
||||
|
||||
|
||||
def conform_tags(
|
||||
call: APICall, tags: Sequence, system_tags: Sequence
|
||||
) -> Tuple[Sequence, Sequence]:
|
||||
"""
|
||||
Make sure that 'tags' from the old SDK clients
|
||||
are correctly split into 'tags' and 'system_tags'
|
||||
Make sure that there are no duplicate tags
|
||||
"""
|
||||
if call.requested_endpoint_version < PartialVersion("2.3"):
|
||||
tags, system_tags = _upgrade_tags(call, tags, system_tags)
|
||||
return _get_unique_values(tags), _get_unique_values(system_tags)
|
||||
|
||||
|
||||
def _upgrade_tags(call: APICall, tags: Sequence, system_tags: Sequence):
|
||||
if tags is not None and not system_tags:
|
||||
service_name = call.endpoint_name.partition(".")[0]
|
||||
entity = service_name[:-1] if service_name.endswith("s") else service_name
|
||||
return partition_tags(entity, tags)
|
||||
|
||||
return tags, system_tags
|
||||
|
||||
|
||||
def _get_unique_values(values: Sequence) -> Sequence:
|
||||
"""Get unique values from the given sequence"""
|
||||
if not values:
|
||||
return values
|
||||
|
||||
return list(set(values))
|
||||
202
server/services/workers.py
Normal file
202
server/services/workers.py
Normal file
@@ -0,0 +1,202 @@
|
||||
import itertools
|
||||
from operator import attrgetter
|
||||
from typing import Optional, Sequence, Union
|
||||
|
||||
from boltons.iterutils import bucketize
|
||||
|
||||
from apierrors.errors import bad_request
|
||||
from apimodels.workers import (
|
||||
WorkerRequest,
|
||||
StatusReportRequest,
|
||||
GetAllRequest,
|
||||
GetAllResponse,
|
||||
RegisterRequest,
|
||||
GetStatsRequest,
|
||||
MetricCategory,
|
||||
GetMetricKeysRequest,
|
||||
GetMetricKeysResponse,
|
||||
GetStatsResponse,
|
||||
WorkerStatistics,
|
||||
MetricStats,
|
||||
AggregationStats,
|
||||
GetActivityReportRequest,
|
||||
GetActivityReportResponse,
|
||||
ActivityReportSeries,
|
||||
)
|
||||
from bll.util import extract_properties_to_lists
|
||||
from bll.workers import WorkerBLL
|
||||
from config import config
|
||||
from service_repo import APICall, endpoint
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
worker_bll = WorkerBLL()
|
||||
|
||||
|
||||
@endpoint(
|
||||
"workers.get_all",
|
||||
min_version="2.4",
|
||||
request_data_model=GetAllRequest,
|
||||
response_data_model=GetAllResponse,
|
||||
)
|
||||
def get_all(call: APICall, company_id: str, request: GetAllRequest):
|
||||
call.result.data_model = GetAllResponse(
|
||||
workers=worker_bll.get_all_with_projection(company_id, request.last_seen)
|
||||
)
|
||||
|
||||
|
||||
@endpoint("workers.register", min_version="2.4", request_data_model=RegisterRequest)
|
||||
def register(call: APICall, company_id, req_model: RegisterRequest):
|
||||
worker = req_model.worker
|
||||
timeout = req_model.timeout
|
||||
queues = req_model.queues
|
||||
|
||||
if not timeout or timeout <= 0:
|
||||
raise bad_request.WorkerRegistrationFailed(
|
||||
"invalid timeout", timeout=timeout, worker=worker
|
||||
)
|
||||
|
||||
worker_bll.register_worker(
|
||||
company_id=company_id,
|
||||
user_id=call.identity.user,
|
||||
worker=worker,
|
||||
ip=call.real_ip,
|
||||
queues=queues,
|
||||
timeout=timeout,
|
||||
)
|
||||
|
||||
|
||||
@endpoint("workers.unregister", min_version="2.4", request_data_model=WorkerRequest)
|
||||
def unregister(call: APICall, company_id, req_model: WorkerRequest):
|
||||
worker_bll.unregister_worker(company_id, call.identity.user, req_model.worker)
|
||||
|
||||
|
||||
@endpoint("workers.status_report", min_version="2.4", request_data_model=StatusReportRequest)
|
||||
def status_report(call: APICall, company_id, request: StatusReportRequest):
|
||||
worker_bll.status_report(
|
||||
company_id=company_id,
|
||||
user_id=call.identity.user,
|
||||
ip=call.real_ip,
|
||||
report=request,
|
||||
)
|
||||
|
||||
|
||||
@endpoint(
|
||||
"workers.get_metric_keys",
|
||||
min_version="2.4",
|
||||
request_data_model=GetMetricKeysRequest,
|
||||
response_data_model=GetMetricKeysResponse,
|
||||
validate_schema=True,
|
||||
)
|
||||
def get_metric_keys(
|
||||
call: APICall, company_id, req_model: GetMetricKeysRequest
|
||||
) -> GetMetricKeysResponse:
|
||||
ret = worker_bll.stats.get_worker_stats_keys(
|
||||
company_id, worker_ids=req_model.worker_ids
|
||||
)
|
||||
return GetMetricKeysResponse(
|
||||
categories=[MetricCategory(name=k, metric_keys=v) for k, v in ret.items()]
|
||||
)
|
||||
|
||||
|
||||
@endpoint(
|
||||
"workers.get_activity_report",
|
||||
min_version="2.4",
|
||||
request_data_model=GetActivityReportRequest,
|
||||
response_data_model=GetActivityReportResponse,
|
||||
validate_schema=True,
|
||||
)
|
||||
def get_activity_report(
|
||||
call: APICall, company_id, req_model: GetActivityReportRequest
|
||||
) -> GetActivityReportResponse:
|
||||
def get_activity_series(active_only: bool = False) -> ActivityReportSeries:
|
||||
ret = worker_bll.stats.get_activity_report(
|
||||
company_id=company_id,
|
||||
from_date=req_model.from_date,
|
||||
to_date=req_model.to_date,
|
||||
interval=req_model.interval,
|
||||
active_only=active_only,
|
||||
)
|
||||
if not ret:
|
||||
return ActivityReportSeries(dates=[], counts=[])
|
||||
count_by_date = extract_properties_to_lists(["date", "count"], ret)
|
||||
return ActivityReportSeries(
|
||||
dates=count_by_date["date"], counts=count_by_date["count"]
|
||||
)
|
||||
|
||||
return GetActivityReportResponse(
|
||||
total=get_activity_series(), active=get_activity_series(active_only=True)
|
||||
)
|
||||
|
||||
|
||||
@endpoint(
|
||||
"workers.get_stats",
|
||||
min_version="2.4",
|
||||
request_data_model=GetStatsRequest,
|
||||
response_data_model=GetStatsResponse,
|
||||
validate_schema=True,
|
||||
)
|
||||
def get_stats(call: APICall, company_id, request: GetStatsRequest):
|
||||
ret = worker_bll.stats.get_worker_stats(company_id, request)
|
||||
|
||||
def _get_variant_metric_stats(
|
||||
metric: str,
|
||||
agg_names: Sequence[str],
|
||||
stats: Sequence[dict],
|
||||
variant: Optional[str] = None,
|
||||
) -> MetricStats:
|
||||
stat_by_name = extract_properties_to_lists(agg_names, stats)
|
||||
return MetricStats(
|
||||
metric=metric,
|
||||
variant=variant,
|
||||
dates=stat_by_name["date"],
|
||||
stats=[
|
||||
AggregationStats(aggregation=name, values=aggs)
|
||||
for name, aggs in stat_by_name.items()
|
||||
if name != "date"
|
||||
],
|
||||
)
|
||||
|
||||
def _get_metric_stats(
|
||||
metric: str, stats: Union[dict, Sequence[dict]], agg_types: Sequence[str]
|
||||
) -> Sequence[MetricStats]:
|
||||
"""
|
||||
Return statistics for a certain metric or a list of statistic for
|
||||
metric variants if break_by_variant was requested
|
||||
"""
|
||||
agg_names = ["date"] + list(set(agg_types))
|
||||
if not isinstance(stats, dict):
|
||||
# no variants were requested
|
||||
return [_get_variant_metric_stats(metric, agg_names, stats)]
|
||||
|
||||
return [
|
||||
_get_variant_metric_stats(metric, agg_names, variant_stats, variant)
|
||||
for variant, variant_stats in stats.items()
|
||||
]
|
||||
|
||||
def _get_worker_metrics(stats: dict) -> Sequence[MetricStats]:
|
||||
"""
|
||||
Convert the worker statistics data from the internal format of lists of structs
|
||||
to a more "compact" format for json transfer (arrays of dates and arrays of values)
|
||||
"""
|
||||
# removed metrics that were requested but for some reason
|
||||
# do not exist in stats data
|
||||
metrics = [metric for metric in request.items if metric.key in stats]
|
||||
|
||||
aggs_by_metric = bucketize(
|
||||
metrics, key=attrgetter("key"), value_transform=attrgetter("aggregation")
|
||||
)
|
||||
|
||||
return list(
|
||||
itertools.chain.from_iterable(
|
||||
_get_metric_stats(metric, metric_stats, aggs_by_metric[metric])
|
||||
for metric, metric_stats in stats.items()
|
||||
)
|
||||
)
|
||||
|
||||
return GetStatsResponse(
|
||||
workers=[
|
||||
WorkerStatistics(worker=worker, metrics=_get_worker_metrics(stats))
|
||||
for worker, stats in ret.items()
|
||||
]
|
||||
)
|
||||
@@ -1,6 +1,8 @@
|
||||
import abc
|
||||
import sys
|
||||
from datetime import datetime, timezone
|
||||
from functools import partial
|
||||
from typing import Iterable
|
||||
from unittest import TestCase
|
||||
|
||||
from tests.api_client import APIClient
|
||||
@@ -88,6 +90,19 @@ class TestService(TestCase, TestServiceInterface):
|
||||
log.exception(ex)
|
||||
self._deferred = []
|
||||
|
||||
def assertEqualNoOrder(self, first: Iterable, second: Iterable):
|
||||
"""Compares 2 sequences regardless of their items order"""
|
||||
self.assertEqual(set(first), set(second))
|
||||
|
||||
|
||||
def header(info, title="=" * 20):
|
||||
print(title, info, title, file=sys.stderr)
|
||||
|
||||
|
||||
def utc_now_tz_aware() -> datetime:
|
||||
"""
|
||||
Returns utc now with the utc time zone.
|
||||
Suitable for subsequent usage with functions that
|
||||
make use of tz info like 'timestamp'
|
||||
"""
|
||||
return datetime.now(timezone.utc)
|
||||
|
||||
@@ -1,159 +0,0 @@
|
||||
"""
|
||||
Comprehensive test of all(?) use cases of datasets and frames
|
||||
"""
|
||||
import json
|
||||
import unittest
|
||||
|
||||
import es_factory
|
||||
from tests.api_client import APIClient
|
||||
from config import config
|
||||
|
||||
log = config.logger(__file__)
|
||||
|
||||
|
||||
class TestDatasetsService(unittest.TestCase):
|
||||
|
||||
def setUp(self):
|
||||
self.api = APIClient(base_url="http://localhost:5100/v1.0")
|
||||
self.created_tasks = []
|
||||
|
||||
self.task = dict(
|
||||
name="test task events",
|
||||
type="training",
|
||||
)
|
||||
res, self.task_id = self.api.send('tasks.create', self.task, extract="id")
|
||||
assert (res.meta.result_code == 200)
|
||||
self.created_tasks.append(self.task_id)
|
||||
|
||||
def tearDown(self):
|
||||
log.info("Cleanup...")
|
||||
for task_id in self.created_tasks:
|
||||
try:
|
||||
self.api.send('tasks.delete', dict(task=task_id, force=True))
|
||||
except Exception as ex:
|
||||
log.exception(ex)
|
||||
|
||||
def create_task_event(self, type, iteration):
|
||||
return {
|
||||
"worker": "test",
|
||||
"type": type,
|
||||
"task": self.task_id,
|
||||
"iter": iteration,
|
||||
"timestamp": es_factory.get_timestamp_millis()
|
||||
}
|
||||
|
||||
def copy_and_update(self, src_obj, new_data):
|
||||
obj = src_obj.copy()
|
||||
obj.update(new_data)
|
||||
return obj
|
||||
|
||||
def test_task_logs(self):
|
||||
events = []
|
||||
for iter in range(10):
|
||||
log_event = self.create_task_event("log", iteration=iter)
|
||||
events.append(self.copy_and_update(log_event, {
|
||||
"msg": "This is a log message from test task iter " + str(iter)
|
||||
}))
|
||||
# sleep so timestamp is not the same
|
||||
import time
|
||||
time.sleep(0.01)
|
||||
self.send_batch(events)
|
||||
|
||||
data = self.api.events.get_task_log(task=self.task_id)
|
||||
assert len(data["events"]) == 10
|
||||
|
||||
self.api.tasks.reset(task=self.task_id)
|
||||
data = self.api.events.get_task_log(task=self.task_id)
|
||||
assert len(data["events"]) == 0
|
||||
|
||||
def test_task_plots(self):
|
||||
event = self.create_task_event("plot", 0)
|
||||
event["metric"] = "roc"
|
||||
event.update({
|
||||
"plot_str": json.dumps({
|
||||
"data": [
|
||||
{
|
||||
"x": [0, 1, 2, 3, 4, 5, 6, 7, 8],
|
||||
"y": [0, 1, 2, 3, 4, 5, 6, 7, 8],
|
||||
"text": ["Th=0.1", "Th=0.2", "Th=0.3", "Th=0.4", "Th=0.5", "Th=0.6", "Th=0.7", "Th=0.8"],
|
||||
"name": 'class1'
|
||||
},
|
||||
{
|
||||
"x": [0, 1, 2, 3, 4, 5, 6, 7, 8],
|
||||
"y": [2.0, 3.0, 5.0, 8.2, 6.4, 7.5, 9.2, 8.1, 10.0],
|
||||
"text": ["Th=0.1", "Th=0.2", "Th=0.3", "Th=0.4", "Th=0.5", "Th=0.6", "Th=0.7", "Th=0.8"],
|
||||
"name": 'class2',
|
||||
}
|
||||
],
|
||||
"layout": {
|
||||
"title": "ROC for iter 0",
|
||||
"xaxis": {
|
||||
"title": 'my x axis'
|
||||
},
|
||||
"yaxis": {
|
||||
"title": 'my y axis'
|
||||
}
|
||||
}
|
||||
})
|
||||
})
|
||||
self.send(event)
|
||||
|
||||
event = self.create_task_event("plot", 100)
|
||||
event["metric"] = "confusion"
|
||||
event.update({
|
||||
"plot_str": json.dumps({
|
||||
"data": [
|
||||
{
|
||||
"y": [
|
||||
"lying",
|
||||
"sitting",
|
||||
"standing",
|
||||
"people",
|
||||
"backgroun"
|
||||
],
|
||||
"x": [
|
||||
"lying",
|
||||
"sitting",
|
||||
"standing",
|
||||
"people",
|
||||
"backgroun"
|
||||
],
|
||||
"z": [
|
||||
[758, 163, 0, 0, 23],
|
||||
[63, 858, 3, 0, 0],
|
||||
[0, 50, 188, 21, 35],
|
||||
[0, 22, 8, 40, 4, ],
|
||||
[12, 91, 26, 29, 368]
|
||||
],
|
||||
"type": "heatmap"
|
||||
}
|
||||
],
|
||||
"layout": {
|
||||
"title": "Confusion Matrix for iter 100",
|
||||
"xaxis": {
|
||||
"title": "Predicted value"
|
||||
},
|
||||
"yaxis": {
|
||||
"title": "Real value"
|
||||
}
|
||||
}
|
||||
})
|
||||
})
|
||||
self.send(event)
|
||||
|
||||
data = self.api.events.get_task_plots(task=self.task_id)
|
||||
assert len(data["plots"]) == 2
|
||||
|
||||
self.api.tasks.reset(task=self.task_id)
|
||||
data = self.api.events.get_task_plots(task=self.task_id)
|
||||
assert len(data["plots"]) == 0
|
||||
|
||||
def send_batch(self, events):
|
||||
self.api.send_batch('events.add_batch', events)
|
||||
|
||||
def send(self, event):
|
||||
self.api.send('events.add', event)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
unittest.main()
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user