15 KiB
| title |
|---|
| Fractional GPUs |
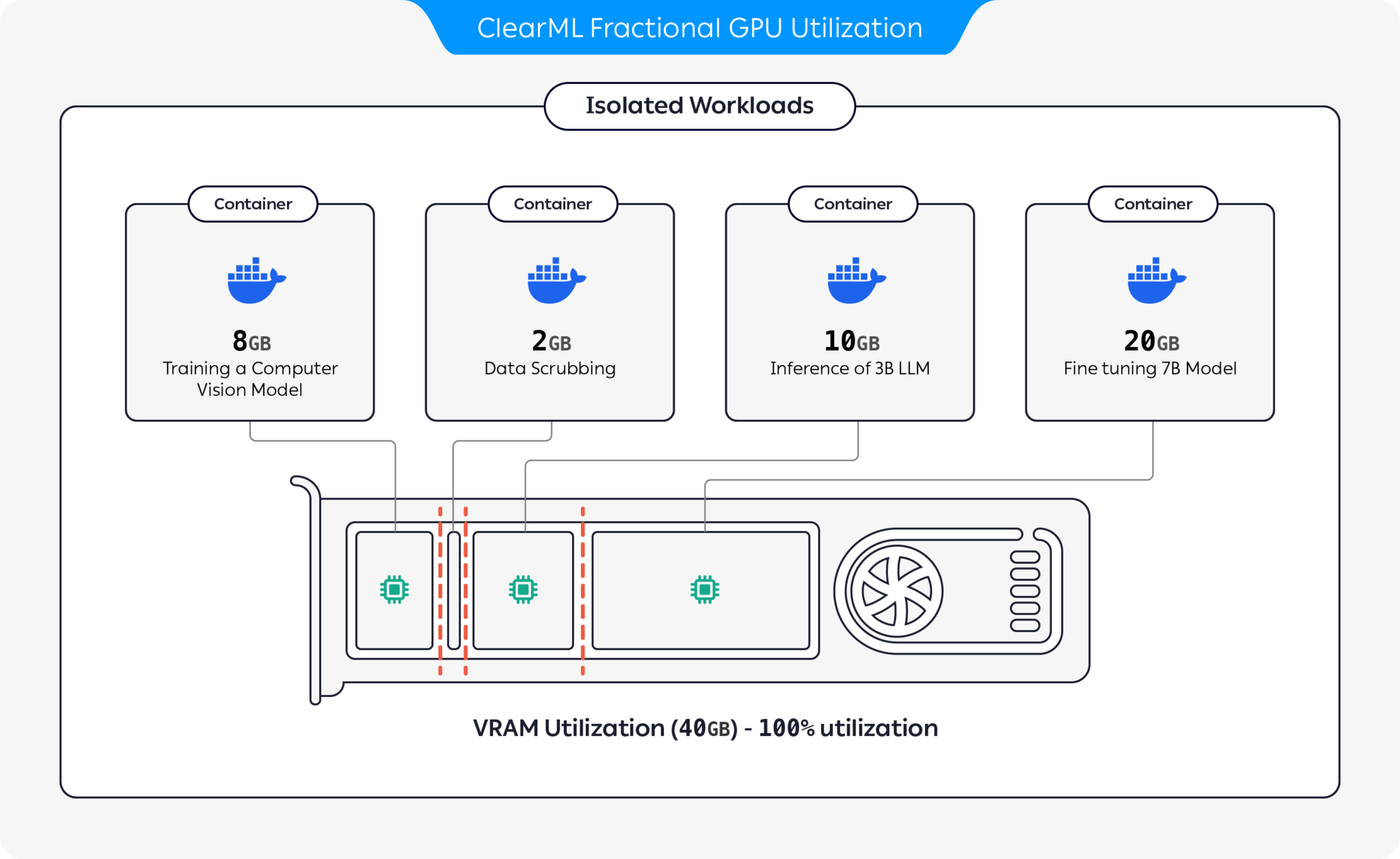
Some tasks that you send for execution need a minimal amount of compute and memory, but you end up allocating entire GPUs to them. In order to optimize your compute resource usage, you can partition GPUs into slices. You can have a GPU device run multiple isolated workloads on separate slices that will not impact each other, and will only use the fraction of GPU memory allocated to them.
ClearML provides several GPU slicing options to optimize compute resource utilization:
- Dynamic GPU Slicing: On-demand GPU slicing per task for both MIG and non-MIG devices (Available under the ClearML Enterprise plan):
- Container-based Memory Limits: Use pre-packaged containers with built-in memory limits to run multiple containers on the same GPU (Available as part of the ClearML open source offering)
- Kubernetes-based Static MIG Slicing: Set up Kubernetes support for NVIDIA MIG (Multi-Instance GPU) to define GPU fractions for specific workloads (Available as part of the ClearML open source offering)
Dynamic GPU Fractions
:::important Enterprise Feature Dynamic GPU slicing is available under the ClearML Enterprise plan. :::
ClearML dynamic GPU fractions provide on-the-fly, per task GPU slicing, without having to set up containers or pre-configure tasks with memory limits. Specify a GPU fraction for a queue in the agent invocation, and every task the agent pulls from the queue will run on a container with the specified limit. This way you can safely run multiple tasks simultaneously without worrying that one task will use all of the GPU's memory.
You can dynamically slice GPUs on bare metal or on Kubernetes, for both MIG-enabled and non-MIG devices.
Bare Metal Deployment
-
Install the required packages:
pip install clearml-agent clearml-agent-fractional-gpu -
Start the ClearML agent with dynamic GPU allocation. Use
--gpusto specify the active GPUs, and use the--queueflag to specify the queue name(s) and number (or fraction) of GPUs to allocate to them.clearml-agent daemon --dynamic-gpus --gpus 0, 1 --queue half_gpu=0.5 --docker
The agent can utilize 2 GPUs (GPUs 0 and 1). Every task enqueued to the half_gpu queue will be run by the agent and
only allocated 50% GPU memory (i.e. 4 tasks can run concurrently).
:::note You can allocate GPUs for a queue’s tasks by specifying either a fraction of a single GPU in increments as small as 0.125 (e.g. 0.125, 0.25, 0.50, etc.) or whole GPUs (e.g. 1, 2, 4, etc.). However, you cannot specify fractions greater than one GPU (e.g. 1.25). :::
You can set up multiple queues, each allocated a different number of GPUs per task. Note that the order that the queues are listed is their order of priority, so the agent will service tasks from the first listed queue before servicing subsequent queues:
clearml-agent daemon --dynamic-gpus --gpus 0-2 --queue dual_gpus=2 quarter_gpu=0.25 half_gpu=0.5 single_gpu=1 --docker
This agent will utilize 3 GPUs (GPUs 0, 1, and 2). The agent can spin multiple jobs from the different queues based on the number of GPUs configured to the queue.
Example Workflow
Let’s say that four tasks are enqueued, one task for each of the above queues (dual_gpus, quarter_gpu, half_gpu,
single_gpu). The agent will first pull the task from the dual_gpus queue since it is listed first, and will run it
using 2 GPUs. It will next run the tasks from quarter_gpu and half_gpu--both will run on the remaining available
GPU. This leaves the task in the single_gpu queue. Currently, 2.75 GPUs out of the 3 are in use so the task will only
be pulled and run when enough GPUs become available.
Kubernetes Deployment
ClearML supports fractional GPUs on Kubernetes through custom Enterprise Helm Charts for both MIG and non-MIG devices:
clearml-dynamic-mig-operatorfor MIG devicesclearml-fractional-gpu-injectorfor non-MIG devices
For either setup, you can set up in your Enterprise ClearML Agent Helm chart the resources requirements of tasks sent to each queue. When a task is enqueued in ClearML, it translates into a Kubernetes pod running on the designated device with the specified fractional resource as defined in the Agent Helm chart.
MIG-enabled GPUs
The ClearML Dynamic MIG Operator (CDMO) chart enables running AI workloads on K8s with optimized hardware utilization and workload performance by facilitating MIG GPU partitioning. Make sure you have a MIG capable GPU.
Prepare Cluster
-
Install the NVIDIA GPU Operator:
helm repo add nvidia https://helm.ngc.nvidia.com helm repo update helm install -n gpu-operator \ gpu-operator \ nvidia/gpu-operator \ --create-namespace \ --set migManager.enabled=false \ --set mig.strategy=mixed -
Enable MIG support:
-
Enable dynamic MIG support on your cluster by running following command on all nodes used for training (run for each GPU ID in your cluster):
nvidia-smi -i <gpu_id> -mig 1 -
Reboot node if required.
-
Add following label to all nodes that will be used for training:
kubectl label nodes <node-name> "cdmo.clear.ml/gpu-partitioning=mig"
-
Configure ClearML Queues
The ClearML Enterprise plan supports K8S servicing multiple ClearML queues, as well as providing a pod template for each queue for describing the resources for each pod to use.
In the values.yaml file, set the resource requirements of each ClearML queue. For example, the following configures
what resources to use for the default025 and the default050 queues:
agentk8sglue:
queues:
default025:
templateOverrides:
labels:
required-resources: "0.25"
resources:
limits:
nvidia.com/mig-1g.10gb: 1
default050:
templateOverrides:
labels:
required-resources: "0.50"
resources:
limits:
nvidia.com/mig-1g.10gb: 1
Non-MIG Devices
The Fractional GPU Injector chart enables running AI workloads on k8s in an optimized way, allowing you to use fractional GPUs on non-MIG devices.
Requirements
Install the Nvidia GPU Operator through the Helm chart. Make sure timeSlicing
is enabled.
For example:
devicePlugin:
config:
name: device-plugin-config
create: true
default: "any"
data:
any: |-
version: v1
flags:
migStrategy: none
sharing:
timeSlicing:
renameByDefault: false
failRequestsGreaterThanOne: false
resources:
- name: nvidia.com/gpu
replicas: 4
The number of replicas is the maximum number of slices on a GPU.
Configure ClearML Queues
In the values.yaml file, set the resource requirements of each ClearML queue. When a task is enqueued to the queue,
it translates into a Kubernetes pod running on the designated device with the specified resource slice. The queues must
be configured with specific labels and annotations. For example, the following configures the default0500 queue to use
50% of a GPU and the default0250 queue to use 25% of a GPU:
agentk8sglue:
queues:
default0500:
templateOverrides:
labels:
required-resources: "0.5"
clearml-injector/fraction: "0.500"
resources:
limits:
nvidia.com/gpu: 1
clear.ml/fraction-1: "0.5"
queueSettings:
maxPods: 10
default0250:
templateOverrides:
labels:
required-resources: "0.25"
clearml-injector/fraction: "0.250"
resources:
limits:
nvidia.com/gpu: 1
clear.ml/fraction-1: "0.25"
queueSettings:
maxPods: 10
If a pod has a label matching the pattern clearml-injector/fraction: "<gpu_fraction_value>", the injector will
configure that pod to utilize the specified fraction of the GPU:
labels:
clearml-injector/fraction: "<gpu_fraction_value>"
Where <gpu_fraction_value> must be set to one of the following values:
- "0.125"
- "0.250"
- "0.375"
- "0.500"
- "0.625"
- "0.750"
- "0.875"
Container-based Memory Limits
Use clearml-fractional-gpu's pre-packaged containers with
built-in hard memory limitations. Workloads running in these containers will only be able to use up to the container's
memory limit. Multiple isolated workloads can run on the same GPU without impacting each other.
Usage
Manual Execution
-
Choose the container with the appropriate memory limit. ClearML supports CUDA 11.x and CUDA 12.x with memory limits ranging from 2 GB to 12 GB (see clearml-fractional-gpu repository for full list).
-
Launch the container:
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bashThis example runs the ClearML Ubuntu 22 with CUDA 12.3 container on GPU 0, which is limited to use up to 8GB of its memory. :::note --pid=host is required to allow the driver to differentiate between the container's processes and other host processes when limiting memory usage :::
-
Run the following command inside the container to verify that the fractional gpu memory limit is working correctly:
nvidia-smiHere is the expected output for the previous, 8GB limited, example on an A100:
+---------------------------------------------------------------------------------------+ | NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A | | 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| +---------------------------------------------------------------------------------------+
Remote Execution
You can set a ClearML Agent to execute tasks in a fractional GPU container. Set an agent’s default container via its
command line. For example, all tasks pulled from the default queue by this agent will be executed in the Ubuntu 22
with CUDA 12.3 container, which is limited to use up to 8GB of its memory:
clearml-agent daemon --queue default --docker clearml/fractional-gpu:u22-cu12.3-8gb
The agent’s default container can be overridden via the UI:
-
Clone the task
-
Set the Docker in the cloned task's Execution tab > Container section

-
Enqueue the cloned task
The task will be executed in the container specified in the UI.
For more information, see Docker Mode.
Fractional GPU Containers on Kubernetes
Fractional GPU containers can be used to limit the memory consumption of your Kubernetes Job/Pod, and have multiple containers share GPU devices without interfering with each other.
For example, the following configures a K8s pod to run using the clearml/fractional-gpu:u22-cu12.3-8gb container,
which limits the pod to 8 GB of the GPU's memory:
apiVersion: v1
kind: Pod
metadata:
name: train-pod
labels:
app: trainme
spec:
hostPID: true
containers:
- name: train-container
image: clearml/fractional-gpu:u22-cu12.3-8gb
command: ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")']
:::note
hostPID: true is required to allow the driver to differentiate between the pod's processes and other host processes
when limiting memory usage.
:::
Custom Container
Build your own custom fractional GPU container by inheriting from one of ClearML's containers: In your Dockerfile, make
sure to include From <clearml_container_image> so the container will inherit from the relevant container.
See example custom Dockerfiles in the clearml-fractional-gpu repository.
Kubernetes Static MIG Fractions
Set up NVIDIA MIG (Multi-Instance GPU) support for Kubernetes to define GPU fraction profiles for specific workloads through your NVIDIA device plugin.
The standard way to configure a Kubernetes pod template to use specific MIG slices is for the template to specify the
requested GPU slices under Containers.resources.limits. For example, the
following configures a K8s pod to run a 3g.20gb MIG device:
# tf-benchmarks-mixed.yaml
apiVersion: v1
kind: Pod
metadata:
name: tf-benchmarks-mixed
spec:
restartPolicy: Never
Containers:
- name: tf-benchmarks-mixed
image: ""
command: []
args: []
resources:
limits:
nvidia.com/mig-3g.20gb: 1
nodeSelector: #optional
nvidia.com/gpu.product: A100-SXM4-40GB
The ClearML Agent Helm chart lets you specify a pod template for each queue which describes the resources that the pod will use. The ClearML Agent uses this configuration to generate the necessary Kubernetes pod template for executing tasks based on the queue through which they are scheduled.
When tasks are added to the relevant queue, the agent pulls the task and creates a pod to execute it, using the specified GPU slice.
For example, the following configures tasks from the default queue to use 1g.5gb MIG slices:
agentk8sglue:
queue: default
# …
basePodTemplate:
# …
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
nvidia.com/gpu.product: A100-SXM4-40GB-MIG-1g.5gb