8.8 KiB
| title |
|---|
| Model Deployment |
:::important Enterprise Feature The Model Deployment App is available under the ClearML Enterprise plan. :::
The Model Deployment application enables users to quickly deploy LLM models as networking services over a secure endpoint. This application supports various model configurations and customizations to optimize performance and resource usage. The Model Deployment application serves your model on a machine of your choice. Once an app instance is running, it serves your model through a secure, publicly accessible network endpoint. The app monitors endpoint activity and shuts down if the model remains inactive for a specified maximum idle time.
:::info Task Traffic Router The Model Deployment app relies on the ClearML Traffic Router which implements a secure, authenticated network channel to the model :::
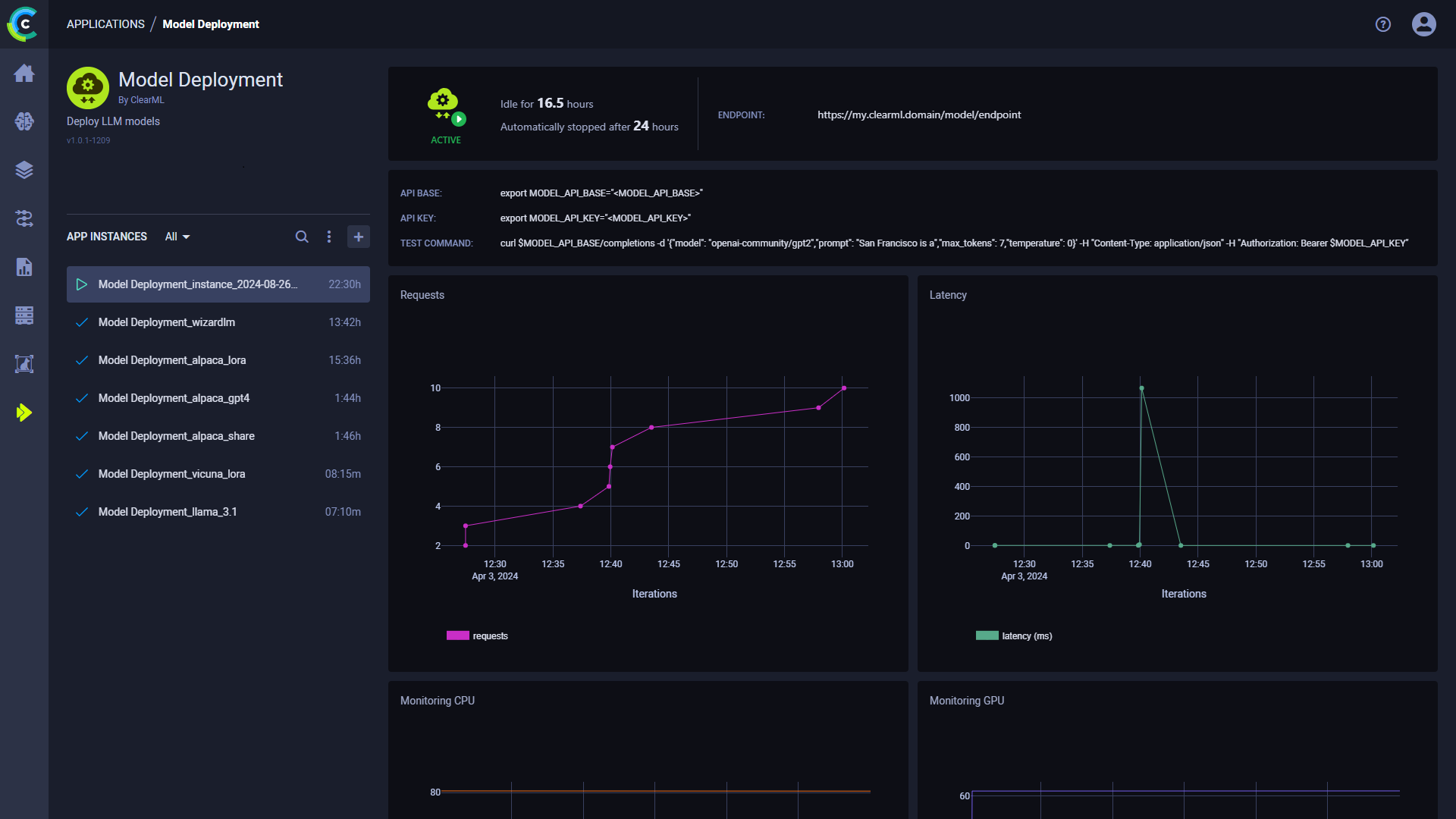
Once you start a Model Deployment instance, you can view the following information in its dashboard:
- Status indicator
 - App instance is running and is actively in use
- App instance is running and is actively in use - App instance is setting up
- App instance is setting up - App instance is idle
- App instance is idle - App instance is stopped
- App instance is stopped
- Idle time - Time elapsed since last activity
- Endpoint - The publicly accessible URL of the model endpoint
- API base - The base URL for the model endpoint
- API key - The authentication key for the model endpoint
- Test Command - An example command line to test the deployed model
- Requests - Number of requests over time
- Latency - Request response time (ms) over time
- Endpoint resource monitoring metrics over time
- CPU usage
- Network throughput
- Disk performance
- Memory performance
- GPU utilization
- GPU memory usage
- GPU temperature
- Console log - The console log shows the app instance's console output: setup progress, status changes, error messages, etc.
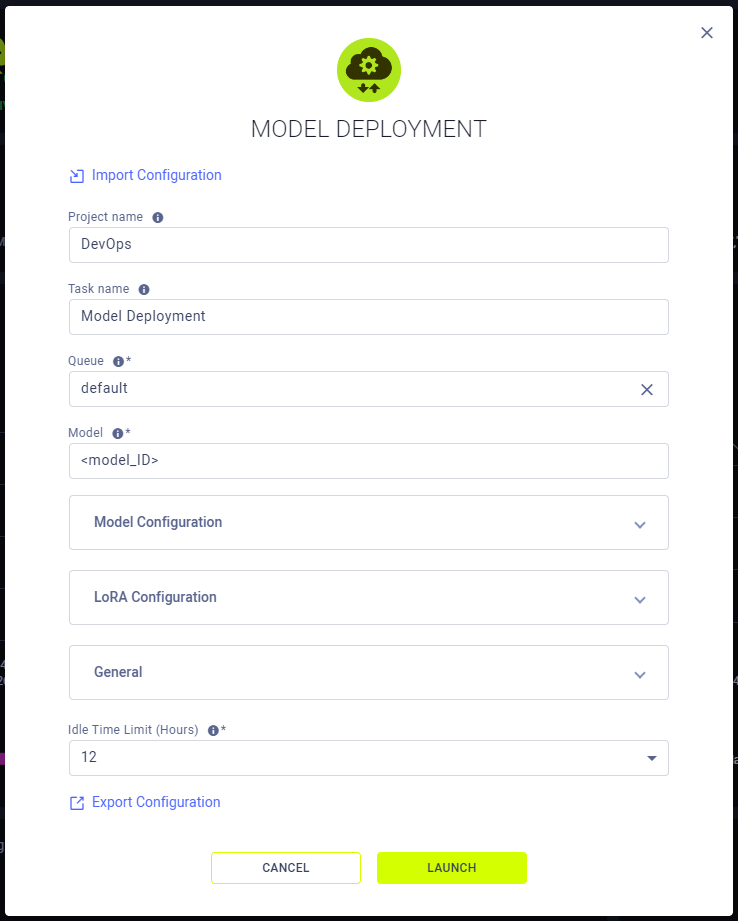
Model Deployment Instance Configuration
When configuring a new Model Deployment instance, you can fill in the required parameters or reuse the configuration of a previously launched instance.
Launch an app instance with the configuration of a previously launched instance using one of the following options:
- Cloning a previously launched app instance will open the instance launch form with the original instance's configuration prefilled.
- Importing an app configuration file. You can export the configuration of a previously launched instance as a JSON file when viewing its configuration.
The prefilled configuration form can be edited before launching the new app instance.
To configure a new app instance, click Launch New ![]() to open the app's configuration form.
to open the app's configuration form.
Configuration Options
- Import Configuration - Import an app instance configuration file. This will fill the instance launch form with the values from the file, which can be modified before launching the app instance
- Project name - ClearML Project Name
- Task name - Name of ClearML Task for your Model Deployment app instance
- Queue - The ClearML Queue to which the Model Deployment app instance task will be enqueued (make sure an agent is assigned to that queue)
- Model - A ClearML Model ID or a HuggingFace model name (e.g.
openai-community/gpt2) - Model Configuration
- Trust Remote Code - Select to set Hugging Face
trust_remote_codetotrue. - Revision - The specific Hugging Face version of the model (i.e. weights) you want to use. You
can use a specific commit ID or a branch like
refs/pr/2. - Code Revision - The specific revision to use for the model code on HuggingFace Hub. It can be a branch name, a tag name, or a commit ID. If unspecified, will use the default version.
- Max Model Length - Model context length. If unspecified, will be automatically derived from the model
- Tokenizer - A ClearML Model ID or a Hugging Face tokenizer
- Tokenizer Revision - The specific tokenizer Hugging Face version to use. It can be a branch name, a tag name, or a commit ID. If unspecified, will use the default version.
- Tokenizer Mode - Select the tokenizer mode:
auto- Uses the fast tokenizer if availableslow- Uses the slow tokenizer.
- Trust Remote Code - Select to set Hugging Face
- LoRA Configuration
- Enable LoRA - If checked, enable handling of LoRA adapters.
- LoRA Modules - LoRA module configurations in the format
name=path. Multiple modules can be specified. - Max LoRAs - Max number of LoRAs in a single batch.
- Max LoRA Rank
- LoRA Extra Vocabulary Size - Maximum size of extra vocabulary that can be present in a LoRA adapter (added to the base model vocabulary).
- LoRA Dtype - Select the data type for LoRA. Select one of the following:
auto- If selected, will default to base model data type.float16bfloat16float32
- Max CPU LoRAs - Maximum number of LoRAs to store in CPU memory. Must be greater or equal to the
Max Number of Sequencesfield in the General section below. Defaults toMax Number of Sequences.
- General
- Disable Log Stats - Disable logging statistics
- Enforce Eager - Always use eager-mode PyTorch. If False, a hybrid of eager mode and CUDA graph will be used for maximal performance and flexibility.
- Disable Custom All Reduce - See vllm ParallelConfig
- Disable Logging Requests
- Fixed API Access Key - Key to use for authenticating API access. Set a fixed API key if you've set up the server to be accessible without authentication. Setting an API key ensures that only authorized users can access the endpoint.
- HuggingFace Token - Token for accessing HuggingFace models that require authentication
- Load Format - Select the model weights format to load:
auto- Load the weights in the safetensors format and fall back to the pytorch bin format if safetensors format is not available.pt- Load the weights in the pytorch bin format.safetensors- Load the weights in the safetensors format.npcache- Load the weights in pytorch format and store a numpy cache to speed up the loading.dummyInitialize the weights with random values. Mainly used for profiling.
- Dtype - Select the data type for model weights and activations:
auto- if selected, will use FP16 precision for FP32 and FP16 models, and BF16 precision for BF16 models.halffloat16bfloat16floatfloat32
- KV Cache Type - Select data type for kv cache storage:
auto- If selected, will use the model data type. Note FP8 is not supported when cuda version is lower than 11.8.fp8_e5m2
- Pipeline Parallel Size - Number of pipeline stages
- Tensor Parallel Size - Number of tensor parallel replicas
- Max Parallel Loading Workers - Load model sequentially in multiple batches, to avoid RAM OOM when using tensor parallel and large models
- Token Block Size
- Random Seed
- Swap Space - CPU swap space size (GiB) per GPU
- GPU Memory Utilization - The fraction of GPU memory to be used for the model executor, which can range from 0 to 1
- Max Number of Batched Tokens - Maximum number of batched tokens per iteration
- Max Number of Sequences - Maximum number of sequences per iteration
- Max Number of Paddings - Maximum number of paddings in a batch
- Quantization - Method used to quantize the weights. If None, we first check the
quantization_configattribute in the model config file. If that is None, we assume the model weights are not quantized and usedtypeto determine the data type of the weights. - Max Context Length to Capture - Maximum context length covered by CUDA graphs. When a sequence has context length larger than this, we fall back to eager mode.
- Max Log Length - Max number of prompt characters or prompt ID numbers being printed in log. Default: unlimited
- Idle Time Limit (Hours) - Maximum idle time after which the app instance will shut down
- Export Configuration - Export the app instance configuration as a JSON file, which you can later import to create a new instance with the same configuration