17 KiB
| title |
|---|
| Task / Experiment |
ClearML Task lies at the heart of ClearML's experiment manager. A Task is an object that holds all the execution information: Code, Environment, Parameters, Artifacts and Results.
A Task is a single code execution session. To transform an existing script into a Task, one must call Task.init() which creates a Task object that automatically captures:
- Git information
- Python environment
- Parameters in the code
- Uncommitted code
- Outputs of the execution (e.g. console outputs, Tensorboard, logs etc.)
Previously executed Tasks can be accessed and utilized with code. It's possible to copy a Task multiple times and modify its:
- Arguments
- Environment (e.g. repo commit ID, Python package)
- Configurations (e.g. command line arguments, configuration file etc.).
In ClearML, Tasks are organized into projects, and Tasks can be identified either by a project name & task name combination or by a unique ID.
Projects and Sub Projects
In ClearML, Tasks are organized into projects. Projects are logical entities (similar to folders) that group tasks. Users can decide how to group tasks, but different models or objectives are usually grouped into different projects. Projects can be further divided into sub-projects (and sub-sub-projects, etc.) just like files and subdirectories on a computer, making experiment organization easier.
Task sections
A Task is comprised of multiple sections, linked together for traceability. After a Task has been initialized, it's possible to track, visualize, and, depending on its status, edit Task details, including:
Execution
The environment for executing the experiment.
Source code:
- Repository / Commit - Saves a reference to the git repository and specific commit ID of the current experiment.
- Script Path - Stores the entry point script for the experiment.
- Working Directory - The working directory for the current experiment. This is relative to the root git repository folder.
Uncommitted changes
Stores the uncommitted changes of the current experiment. If the experiment has no git repository, it will store the entire experiment script file here (ClearML only stores a single file, when using more than a single script for an experiment please use git 😄 )
Installed packages
Stores a list of all the packages that the experiment is using, including the specific version of the packages.
Only directly imported packages will appear here. This is done to make sure the important packages and versions used
by the experiment are captured.
The section itself is fully compatible with the Python requirements.txt standard, and is fully editable.
Base docker image
Specify the required docker image for remote execution of the code (see ClearML Agent).
A remote machine will execute the entire experiment inside the requested docker.
It's also possible to add parameters for the docker execution. For example:
nvcr.io/nvidia/pytorch:20.11-py3 --ipc=host
Output destination
Storage target to Automatically uploads all models / snapshots. This is applicable mostly when an experiment is executed by an agent, read more on Agents and Storage integration here.
Configuration
Configurations are a set of arguments / dictionaries / files used to define the experiment (read more here).
User properties
Editable key / value store, which enables adding information to an experiment after execution, making it easier to search / filter.
Hyperparameters
- Args - Command line arguments of the experiment process .
argparsevalues are automatically detected and logged here. - Environment - Specific Environment variables to be logged.
- General - The default section name for a general purpose dictionary of parameters that are logged. See the 'name'
parameter of
task_connect. - user_section - Custom section for logged python dictionaries & objects that are logged.
Configuration object:
- General - Default section for a dictionary or configuration file to store as plain test configuration. Modifiable when executed by an agent.
- user_section - Support for multiple configuration files (or dictionaries), name each configuration section. Modifiable when executed by an agent.
Artifacts
Artifacts are a way to store the outputs of an experiment, and later use those outputs as inputs in other processes.
See more information on Artifacts.
Models
- Input Model - Any model weights file loaded by the experiment will appear here.
- Output Model - Any stored weights file / model will be logged here. This is useful for searching and connecting output models to inference pipelines for production automation.
Results
Results recorded in the task. Supports text, graphs, plots, images audio and more including automatic reports by Tensorboard and Matplotlib. See logger.
Console
Stdout and stderr outputs will appear here automatically.
Scalars
Any time-series graphs appear here such as Tensorboard scalar, scalar reporting from code and machine performance (CPU / GPU / Net etc.).
Plots
Non-time-series plots appear here, such as Tensorboard Histograms \ Distribution and Matplotlib plots (with exception to imshow plots).
It's also possible to report plots directly to ClearML (e.g. scatter 2d / 3d tables, generic plotly objects etc).
Debug samples
Any media (image / audio / html) is saved here.
Media reported to Tensorboard is saved here as well as images shown with Matplotlib.plot.imshow.
It's also possible to manually report media / link an experiment produces with the Logger interface. See Logger.report_media.
Usage
Task Creation
Task.init() is the main method used to create Tasks in ClearML. It will create a Task, and populate it with:
- A link to the running git repository (including commit ID and local uncommitted changes)
- Python packages used (i.e. directly imported Python packages, and the versions available on the machine)
- Argparse arguments (default and specific to the current execution)
- Reports to Tensorboard & Matplotlib and model checkpoints.
from clearml import Task
task = Task.init(
project_name='example',
task_name='task template',
task_type=None,
tags=None,
reuse_last_task_id=True,
continue_last_task=False,
output_uri=None,
auto_connect_arg_parser=True,
auto_connect_frameworks=True,
auto_resource_monitoring=True,
auto_connect_streams=True,
)
Once a Task is created, the Task object can be accessed from anywhere in the code by calling Task.current_task().
If multiple Tasks need to be created in the same process (for example, for logging multiple manual runs),
make sure we close a Task, before initializing a new one. To close a task simply call task.close()
(see example here).
Projects can be divided into sub-projects, just like folders are broken into subfolders. For example:
Task.init(project_name='main_project/sub_project', task_name='test')
Nesting projects works on multiple levels. For example: project_name=main_project/sub_project/sub_sub_project
Task Reuse
Every Task.init call will create a new Task for the current execution.
In order to mitigate the clutter that a multitude of debugging Tasks might create, a Task will be reused if:
- The last time it was executed (on this machine) was under 72 hours ago (configurable, see
sdk.development.task_reuse_time_window_in_hoursin thesdk.developmentsection of the ClearML configuration reference) - The previous Task execution did not have any artifacts/models
It's possible to always create a new Task by passing reuse_last_task_id=False.
See full Task.init documentation here.
Empty Task Creation
A Task can also be created without the need to execute the code itself. Unlike the runtime detections, all the environment and configuration details needs to be provided explicitly.
For example:
task = Task.create(
project_name='example',
task_name='task template',
repo='https://github.com/allegroai/clearml.git',
branch='master',
script='examples/reporting/html_reporting.py',
working_directory='.',
docker=None,
)
See Task.create in the Python SDK reference.
Accessing Tasks
A Task can be identified by its project and name, and by a unique identifier (UUID string). The name and project of a Task can be changed after an experiment has been executed, but its ID can't be changed.
Programmatically, Task objects can be retrieved by querying the system based on either the Task ID or a project and name combination. If a project / name combination is used, and multiple Tasks have the exact same name, the function will return the last modified Task.
For example:
- Accessing a Task object with a Task ID:
a_task = Task.get_task(task_id='123456deadbeef')
- Accessing a Task with a project / name:
a_task = Task.get_task(project_name='examples', task_name='artifacts')
Once a Task object is obtained, it's possible to query the state of the Task, reported scalars, etc. The Task's outputs, such as artifacts and models, can also be retrieved.
Querying \ Searching Tasks
Searching and filtering Tasks can be done via the web UI, but also programmatically.
Input search parameters into the Task.get_tasks method, which returns a list of Task objects that match the search.
For example:
task_list = Task.get_tasks(
task_ids=None, # type Optional[Sequence[str]]
project_name=None, # Optional[str]
task_name=None, # Optional[str]
task_filter=None # Optional[Dict]
)
We can search for tasks by either their UUID or their project \ name combination
It's possible to also filter Tasks by passing filtering rules to task_filter.
For example:
task_filter={
# only Tasks with tag `included_tag` and without tag `excluded_tag`
'tags': ['included_tag', '-excluded_tag'],
# filter out archived Tasks
'system_tags': ['-archived'],
# only completed & published Tasks
'status': ['completed', 'published'],
# only training type Tasks
'type': ['training'],
# match text in Task comment or task name
'search_text': 'reg_exp_text'
}
Cloning & Executing Tasks
Once a Task object is created, it can be a copied (cloned). Task.clone returns a copy of the original Task (source_task).
By default, the cloned Task is added to the same project as the original, and it's called "Clone Of ORIGINAL_NAME", but
the name / project / comment of the cloned Task can be directly overridden.
cloned = Task.clone(
source_task=task, # type: Optional[Union[Task, str]]
# override default name
name='newly created task', # type: Optional[str]
comment=None, # type: Optional[str]
# insert cloned Task into a different project
project=None, # type: Optional[str]
)
A cloned Task starts in draft mode, so its Task configurations can be edited (see Task.set_parameters). Once a Task is modified, launch it by pushing it into an execution queue, then a ClearML Agent will pull it from the queue and execute the Task.
Task.enqueue(
task=task, # type: Union[Task, str]
queue_name='default', # type: Optional[str]
queue_id=None # type: Optional[str]
)
See enqueue example.
Advanced Remote Execution
A compelling workflow is:
- Running code on the development machine for a few iterations, or just setting up the environment.
- Moving the execution to a beefier remote machine for the actual training.
For example, to stop the current manual execution, and then re-run it on a remote machine, simply add the following function call to the code:
task.execute_remotely(
queue_name='default', # type: Optional[str]
clone=False, # type: bool
exit_process=True # type: bool
)
Once the function is called on the machine, it will stop the local process and enqueue the current Task into the default queue. From there, an agent will be able to pick it up and launch it.
Remote Function Execution
A specific function can also be launched on a remote machine with create_function_task.
For example:
def run_me_remotely(some_argument):
print(some_argument)
a_func_task = task.create_function_task(
func=run_me_remotely, # type: Callable
func_name='func_id_run_me_remotely', # type:Optional[str]
task_name='a func task', # type:Optional[str]
# everything below will be passed directly to our function as arguments
some_argument=123
)
Arguments passed to the function will be automatically logged under the Function section in the Hyperparameters tab.
Like any other arguments, they can be changed from the UI or programmatically.
:::note
Function Tasks must be created from within a regular Task, created by calling Task.init()
:::
Task Lifecycle
ClearML Tasks are created in one of the following methods:
- Manually running code that is instrumented with the ClearML SDK and invokes
Task.init(). - Cloning an existing task.
- Creating a task via CLI using clearml-task.
Logging Task Information
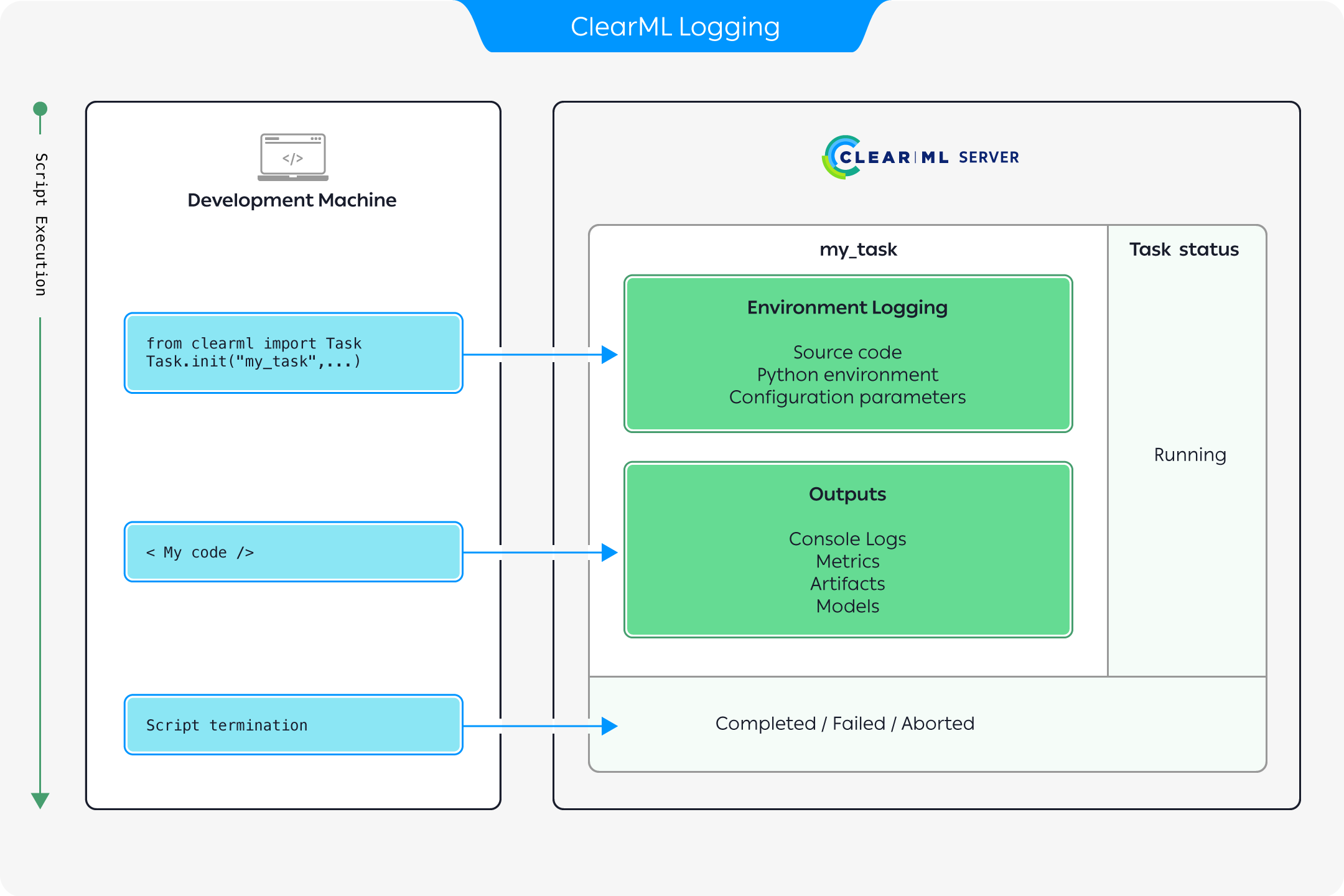
The above diagram describes how execution information is recorded when running code instrumented with ClearML:
- Once a ClearML Task is initialized, ClearML automatically logs the complete environment information
including:
- Source code
- Python environment
- Configuration parameters.
- As the execution progresses, any outputs produced are recorded including:
- Console logs
- Metrics and graphs
- Models and other artifacts
- Once the script terminates, the Task will change its status to either
Completed,Failed, orAborted.
All information logged can be viewed in the task details UI.
Cloning Tasks
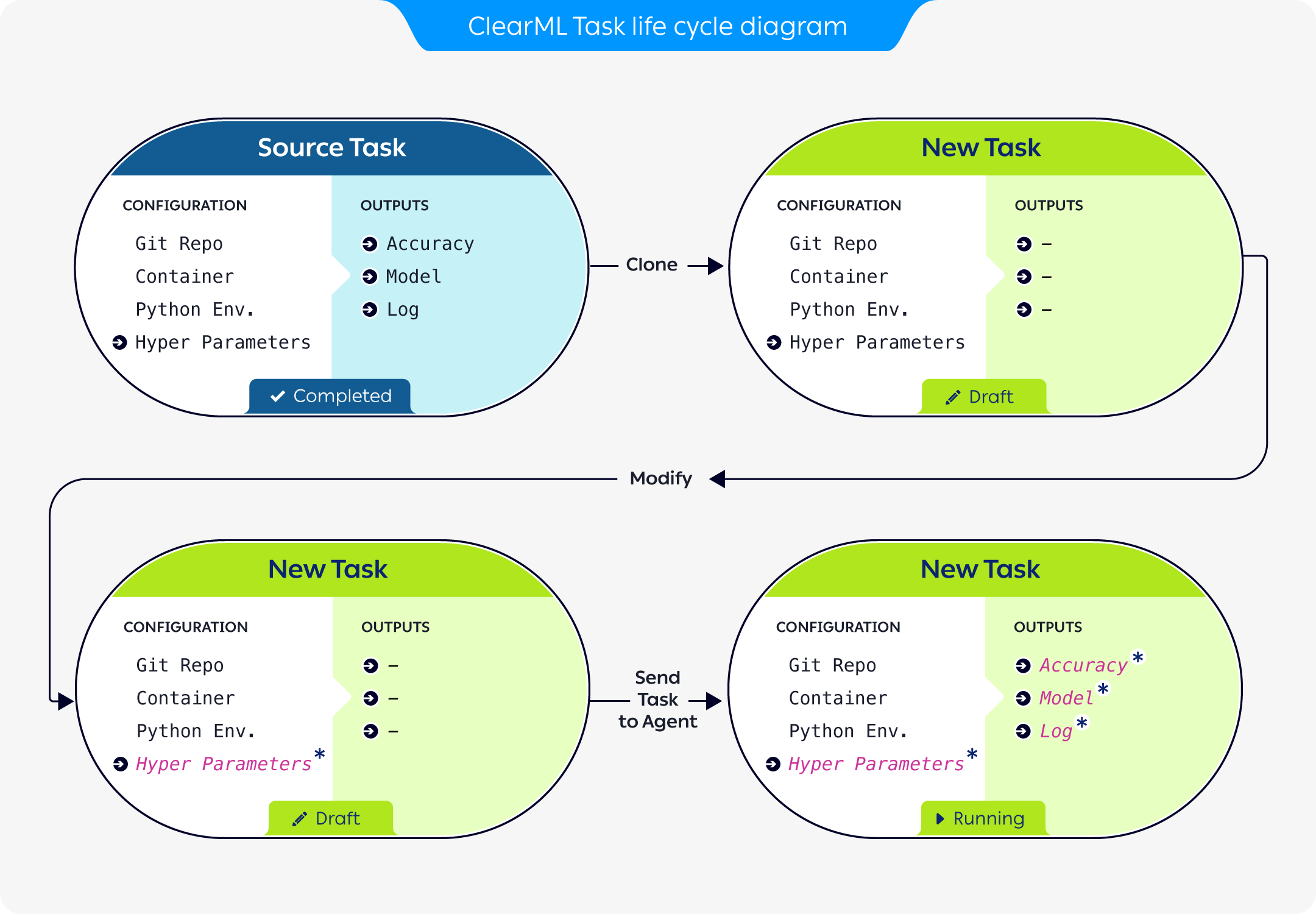
The above diagram demonstrates how a previously run task can be used as a baseline for experimentation:
- A previously run task is cloned, creating a new task, in draft mode.
The new task retains all of the source task's configuration. The original task's outputs are not carried over. - The new task's configuration is modified to reflect the desired parameters for the new execution.
- The new task is enqueued for execution.
- A
clearml-agentservicing the queue pulls the new task and executes it (where ClearML again logs all of the execution outputs).
Task states
The state of a Task represents its stage in the Task lifecycle. It indicates whether the Task is read-write (editable) or read-only. For each state, a state transition indicates which actions can be performed on an experiment, and the new state after performing an action.
The following table describes Task the states and state transitions.
| State | Description / Usage | State Transition |
|---|---|---|
| Draft | The experiment is editable. Only experiments in Draft mode are editable. The experiment is not running locally or remotely. | If the experiment is enqueued for a worker to fetch and execute, the state becomes Pending. |
| Pending | The experiment was enqueued and is waiting in a queue for a worker to fetch and execute it. | If the experiment is dequeued, the state becomes Draft. |
| Running | The experiment is running locally or remotely. | If the experiment is manually or programmatically terminated, the state becomes Aborted. |
| Completed | The experiment ran and terminated successfully. | If the experiment is reset or cloned, the state of the cloned experiment or newly cloned experiment becomes Draft. Resetting deletes the logs and output of a previous run. Cloning creates an exact, editable copy. |
| Failed | The experiment ran and terminated with an error. | The same as Completed. |
| Aborted | The experiment ran, and was manually or programmatically terminated. | The same as Completed. |
| Published | The experiment is read-only. Publish an experiment to prevent changes to its inputs and outputs. | A Published experiment cannot be reset. If it is cloned, the state of the newly cloned experiment becomes Draft. |
Task types
Tasks also have a type attribute, which denotes their purpose (Training / Testing / Data processing). This helps to further organize projects and ensure Tasks are easy to search and find. The default Task type is training. Available Task types are:
-
Experimentation
- training, testing, inference
-
Other workflows
- controller, optimizer
- monitor, service, application
- data_processing, qc
- custom