11 KiB
| title |
|---|
| Dataset Management Using CIFAR10 |
In this tutorial, we are going use a CIFAR example, manage the CIFAR dataset with clearml-data, and then replace our
current dataset read method with one that interfaces with clearml-data.
Creating the Dataset
Downloading the Data
Before we can register the CIFAR dataset with clearml-data we need to obtain a local copy of it.
Execute this python script to download the data
from clearml import StorageManager
# We're using the StorageManager to download the data for us!
# It's a neat little utility that helps us download
# files we need and cache them :)
manager = StorageManager()
dataset_path = manager.get_local_copy(remote_url="https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz")
# make sure to copy the printed value
print("COPY THIS DATASET PATH: {}".format(dataset_path))
Expected reponse:
COPY THIS DATASET PATH: /home/erez/.clearml/cache/storage_manager/global/f2751d3a22ccb78db0e07874912b5c43.cifar-10-python_artifacts_archive_None
The script prints the path to the downloaded data. It'll be needed later one
Creating the Dataset
To create the dataset, in a CLI, execute:
clearml-data create --project cifar --name cifar_dataset
Expected response:
clearml-data - Dataset Management & Versioning CLI
Creating a new dataset:
New dataset created id=*********
Where ********* is the dataset ID.
Adding Files
Add the files we just downloaded to the dataset:
clearml-data add --files <dataset_path>
where dataset_path is the path that was printed earlier, which denotes the location of the downloaded dataset.
:::note There's no need to specify a dataset_id as clearml-data session stores it. :::
Finalizing the Dataset
Run the close command to upload the files (it'll be uploaded to file server by default):
clearml-data close
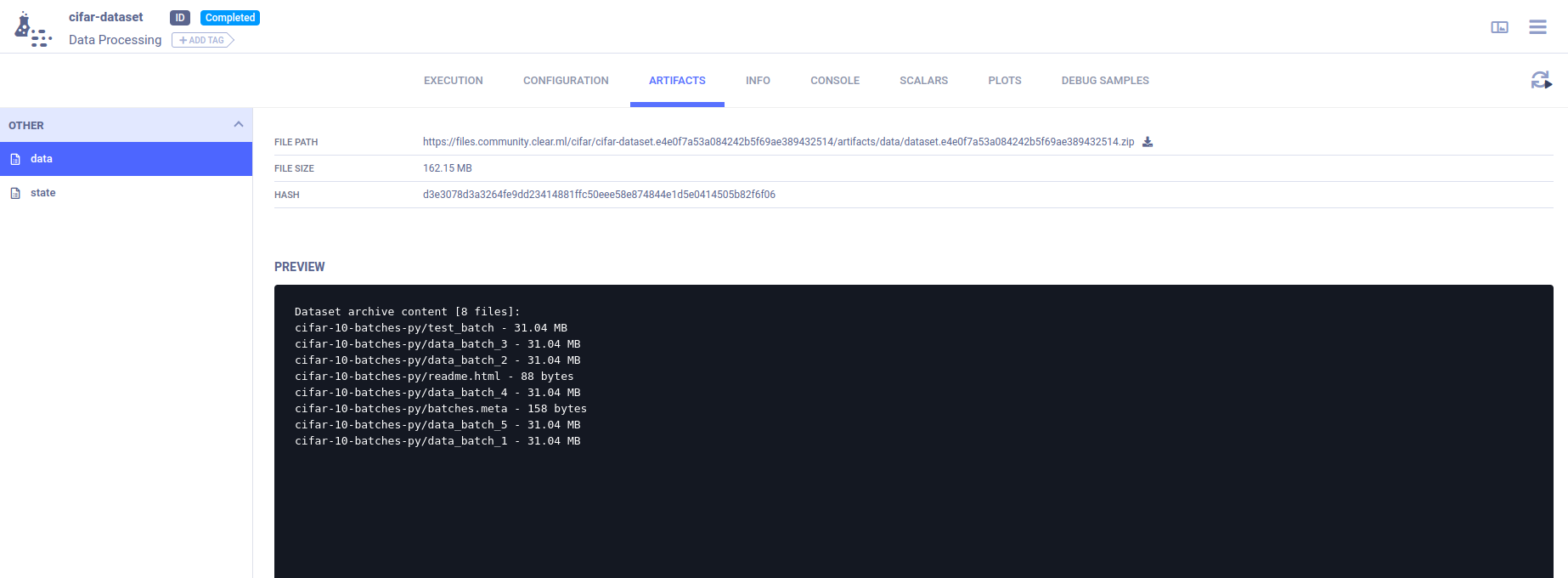
Using the Dataset
Now that we have a new dataset registered, we can consume it.
We take this script as a base to train on the CIFAR dataset.
We replace the file load part with ClearML's Dataset object. The Dataset's get_local_copy() method will return a path
to the cached, downloaded dataset.
Then we provide the path to Pytorch's dataset object.
dataset_id = "ee1c35f60f384e65bc800f42f0aca5ec"
from clearml import Dataset
dataset_path = Dataset.get(dataset_id=dataset_id).get_local_copy()
trainset = datasets.CIFAR10(root=dataset_path,
train=True,
download=False,
transform=transform)
Full example code using dataset:
#These are the obligatory imports
from pathlib import Path
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from ignite.contrib.handlers import TensorboardLogger
from ignite.engine import Events, create_supervised_trainer, create_supervised_evaluator
from ignite.handlers import global_step_from_engine
from ignite.metrics import Accuracy, Loss, Recall
from ignite.utils import setup_logger
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
from clearml import Task, StorageManager
# Connecting ClearML with the current process,
# from here on everything is logged automatically
task = Task.init(project_name='Image Example', task_name='image classification CIFAR10')
params = {'number_of_epochs': 20, 'batch_size': 64, 'dropout': 0.25, 'base_lr': 0.001, 'momentum': 0.9, 'loss_report': 100}
params = task.connect(params) # enabling configuration override by clearml/
print(params) # printing actual configuration (after override in remote mode)
# This is our original data retrieval code. it uses storage manager to just download and cache our dataset.
'''
manager = StorageManager()
dataset_path = Path(manager.get_local_copy(remote_url="https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz"))
'''
# Let's now modify it to utilize for the new dataset API, you'll need to copy the created dataset id
# to the next variable
dataset_id = "ee1c35f60f384e65bc800f42f0aca5ec"
# The below gets the dataset and stores in the cache. If you want to download the dataset regardless if it's in the
# cache, use the Dataset.get(dataset_id).get_mutable_local_copy(path to download)
from clearml import Dataset
dataset_path = Dataset.get(dataset_id=dataset_id).get_local_copy()
# Dataset and Dataloader initializations
transform = transforms.Compose([transforms.ToTensor()])
trainset = datasets.CIFAR10(root=dataset_path,
train=True,
download=False,
transform=transform)
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=params.get('batch_size', 4),
shuffle=True,
num_workers=10)
testset = datasets.CIFAR10(root=dataset_path,
train=False,
download=False,
transform=transform)
testloader = torch.utils.data.DataLoader(testset,
batch_size=params.get('batch_size', 4),
shuffle=False,
num_workers=10)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
tb_logger = TensorboardLogger(log_dir="cifar-output")
# Helper function to store predictions and scores using matplotlib
def predictions_gt_images_handler(engine, logger, *args, **kwargs):
x, _ = engine.state.batch
y_pred, y = engine.state.output
num_x = num_y = 4
le = num_x * num_y
fig = plt.figure(figsize=(20, 20))
trans = transforms.ToPILImage()
for idx in range(le):
preds = torch.argmax(F.softmax(y_pred[idx],dim=0))
probs = torch.max(F.softmax(y_pred[idx],dim=0))
ax = fig.add_subplot(num_x, num_y, idx + 1, xticks=[], yticks=[])
ax.imshow(trans(x[idx]))
ax.set_title("{0} {1:.1f}% (label: {2})".format(
classes[preds],
probs * 100,
classes[y[idx]]),
color=("green" if preds == y[idx] else "red")
)
logger.writer.add_figure('predictions vs actuals', figure=fig, global_step=engine.state.epoch)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 6 * 6, 120)
self.fc2 = nn.Linear(120, 84)
self.dorpout = nn.Dropout(p=params.get('dropout', 0.25))
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 6 * 6)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(self.dorpout(x))
return x
# Training
def run(epochs, lr, momentum, log_interval):
device = "cuda" if torch.cuda.is_available() else "cpu"
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=lr, momentum=momentum)
trainer = create_supervised_trainer(net, optimizer, criterion, device=device)
trainer.logger = setup_logger("trainer")
val_metrics = {"accuracy": Accuracy(),"loss": Loss(criterion), "recall": Recall()}
evaluator = create_supervised_evaluator(net, metrics=val_metrics, device=device)
evaluator.logger = setup_logger("evaluator")
# Attach handler to plot trainer's loss every 100 iterations
tb_logger.attach_output_handler(
trainer,
event_name=Events.ITERATION_COMPLETED(every=params.get('loss_report')),
tag="training",
output_transform=lambda loss: {"loss": loss},
)
# Attach handler to dump evaluator's metrics every epoch completed
for tag, evaluator in [("training", trainer), ("validation", evaluator)]:
tb_logger.attach_output_handler(
evaluator,
event_name=Events.EPOCH_COMPLETED,
tag=tag,
metric_names="all",
global_step_transform=global_step_from_engine(trainer),
)
# Attach function to build debug images and report every epoch end
tb_logger.attach(
evaluator,
log_handler=predictions_gt_images_handler,
event_name=Events.EPOCH_COMPLETED(once=1),
);
desc = "ITERATION - loss: {:.2f}"
pbar = tqdm(initial=0, leave=False, total=len(trainloader), desc=desc.format(0))
@trainer.on(Events.ITERATION_COMPLETED(every=log_interval))
def log_training_loss(engine):
pbar.desc = desc.format(engine.state.output)
pbar.update(log_interval)
@trainer.on(Events.EPOCH_COMPLETED)
def log_training_results(engine):
pbar.refresh()
evaluator.run(trainloader)
metrics = evaluator.state.metrics
avg_accuracy = metrics["accuracy"]
avg_nll = metrics["loss"]
tqdm.write(
"Training Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f}".format(
engine.state.epoch, avg_accuracy, avg_nll
)
)
@trainer.on(Events.EPOCH_COMPLETED)
def log_validation_results(engine):
evaluator.run(testloader)
metrics = evaluator.state.metrics
avg_accuracy = metrics["accuracy"]
avg_nll = metrics["loss"]
tqdm.write(
"Validation Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f}".format(
engine.state.epoch, avg_accuracy, avg_nll
)
)
pbar.n = pbar.last_print_n = 0
@trainer.on(Events.EPOCH_COMPLETED | Events.COMPLETED)
def log_time():
tqdm.write(
"{} took {} seconds".format(trainer.last_event_name.name, trainer.state.times[trainer.last_event_name.name])
)
trainer.run(trainloader, max_epochs=epochs)
pbar.close()
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
print('Finished Training')
print('Task ID number is: {}'.format(task.id))
run(params.get('number_of_epochs'), params.get('base_lr'), params.get('momentum'), 10)
That's it! All you need to do now is run the full script.