4.1 KiB
| title |
|---|
| Pipelines |
Users can automate Tasks to run consecutively or according to some logic by putting the tasks into a pipeline. Tasks in a pipeline can leverage other tasks' work products such as artifacts and parameters.
Pipelines are controlled by a Controller Task that holds the logic of the pipeline execution steps.
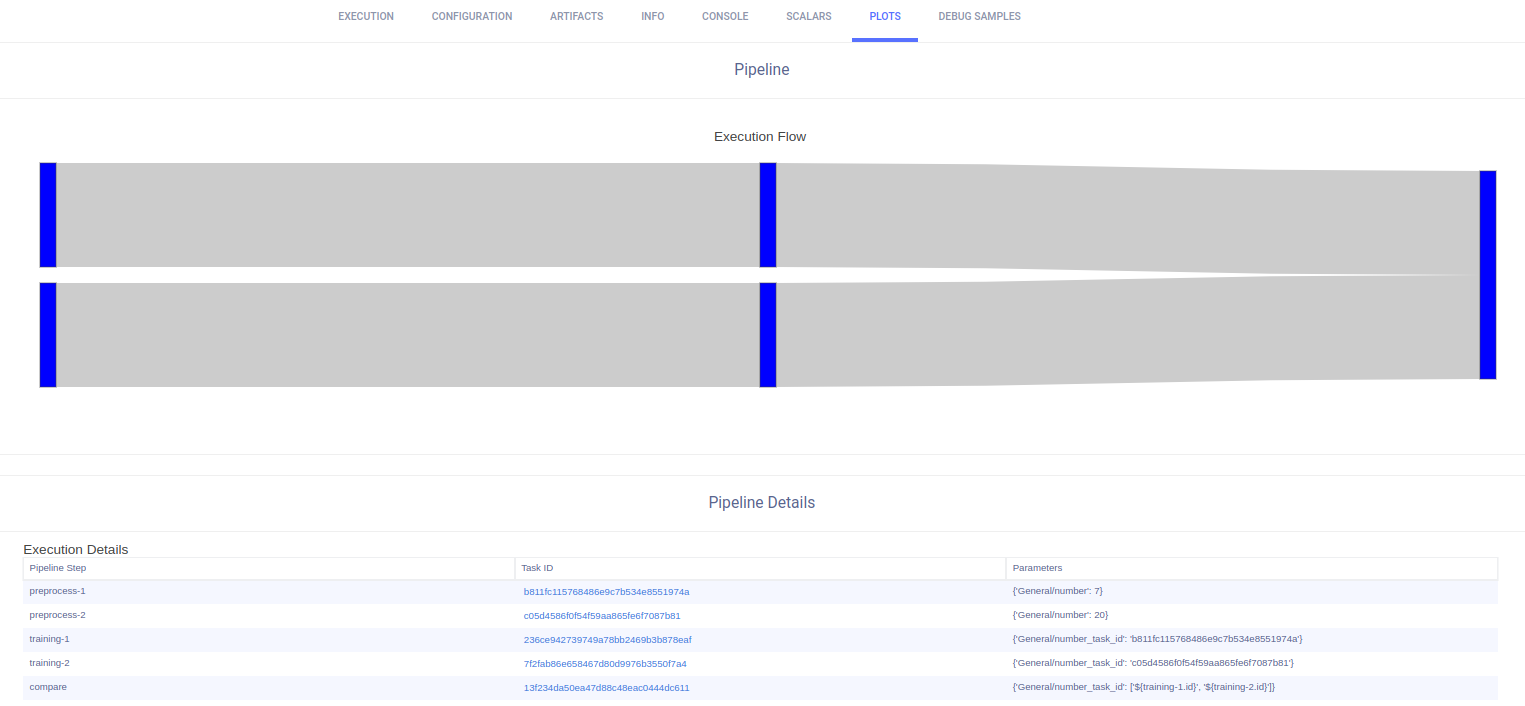
How do pipelines work?
Before running a pipeline, we need to configure a Controller Task, in which the pipeline is defined. Pipelines are made up of steps. Each step consists of a task that already exists in the ClearML Server and is used as a template. The user decides the controlling logic of the step interactions, whether it be simple (DAG) or more complex.
Once the pipeline is running, it starts sequentially launching the steps configured in the Controller. In each step, the template task is cloned, and the cloned task is sent for execution. Depending on the specifications laid out in the Controller Task, a step's parameters can be overridden, and / or a step can use a previous step's work products.
Callbacks can be utilized to control pipeline execution flow. A callback can be defined to be called before and / or after the execution of every task in a pipeline. Additionally, there is an option to create customized, step-specific callbacks.
Simple DAG pipelines
For a simple, DAG based logic, use the off-the-shelf PipelineController class to define the DAG (see an example
here). Once the PipelineController object is populated and configured,
we can start the pipeline, which will begin executing the steps in succession, then it waits until the pipeline is completed.
The pipeline control logic is processed in a background thread.
:::note We recommend enqueuing Pipeline Controller Tasks into a services queue :::
Callback functions can be specified to be called in the steps of a PipelineController object.
There is an option to define a callback to be called before and / or after every step in the pipeline,
using the step_task_created_callback or the step_task_completed_callback parameters of the start
method. Alternatively, step-specific callback functions can be specified with the pre_execute_callback and / or
post_execute_callback parameters of the add_step
method.
Advanced pipelines
Since a pipeline Controller Task is itself a ClearML Task, it can be used as a pipeline step and can be used to create more complicated workflows, such as pipelines running other pipelines, or a pipeline running multiple tasks concurrently.
For example, it could be useful to have one pipeline for data preparation, which triggers a second pipeline that trains networks.
It could also be useful to run a pipeline that runs tasks concurrently, training multiple networks with different hyperparameter values simultaneously. See the Tabular training pipeline example of a pipeline with concurrent steps.
Custom pipelines
In cases where a DAG is insufficient (for example, when needing to launch one pipeline, then, if performance is inadequate, rerun pipeline again), users can apply custom logic, using generic methods to enqueue tasks, implemented in python code. The custom logic of the pipeline sits in the Controller Task's script.
Custom pipelines usually involve cloning template tasks, modifying their parameters, and manually enqueuing them to queues (for execution by agents). It's possible to create custom logic that controls inputs (e.g. overriding hyperparameters and artifacts) and acts upon task outputs.
See an example of a custom pipeline here.