| data | ||
| logs | ||
| prompts | ||
| scripts | ||
| tasks | ||
| .gitignore | ||
| fake.png | ||
| LICENSE | ||
| models.py | ||
| readme.md | ||
| requirements.txt | ||
| run.py | ||
| teaser.png | ||
{kind=link}
{kind=link}
Official Repo of Tree of Thoughts (ToT)
![]()
Note: https://github.com/kyegomez/tree-of-thoughts is NOT the correct implementation to replicate paper results. In fact, people have reported that his code cannot properly run, and is probably automatically generated by ChatGPT, and kyegomez has done so for other popular ML methods, while intentionally refusing to link to official implementations for his own interests (see https://github.com/kyegomez/tree-of-thoughts/issues/54, https://github.com/kyegomez/tree-of-thoughts/issues/55, https://github.com/kyegomez/tree-of-thoughts/issues/56). Unfortunately, Google/Github searches go to kyegomez's malicious repo by default as it has more stars. Please DE-STAR his repo and STAR this to help other people avoid being misled, thanks!
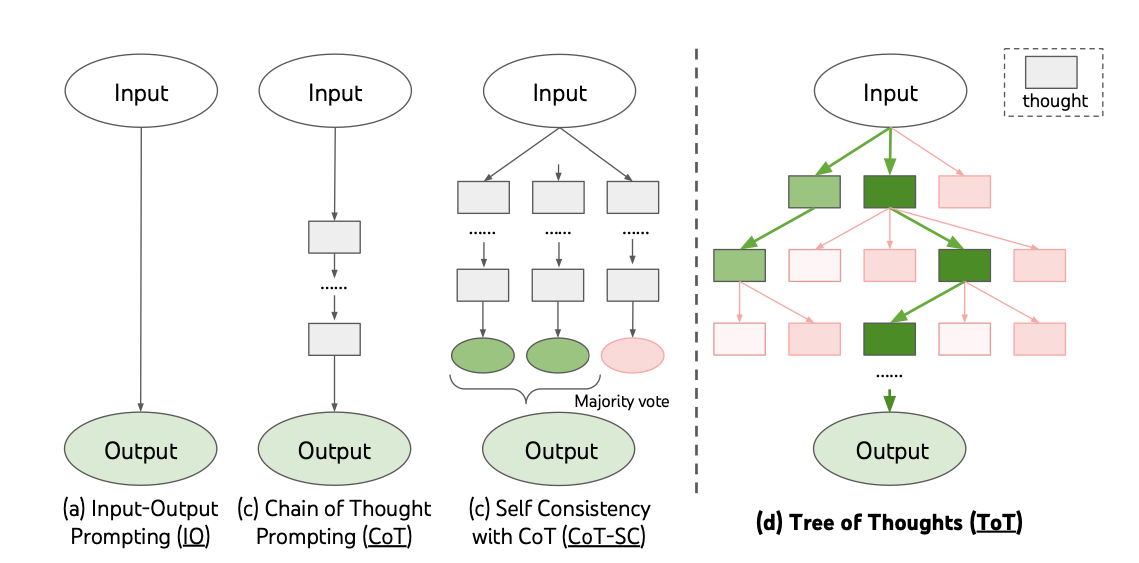
Official implementation for paper Tree of Thoughts: Deliberate Problem Solving with Large Language Models with code, prompts, model outputs. Also check its tweet thread in 1min.
Please cite the paper and star this repo if you use ToT and find it interesting/useful. Thanks!
@misc{yao2023tree,
title={{Tree of Thoughts}: Deliberate Problem Solving with Large Language Models},
author={Shunyu Yao and Dian Yu and Jeffrey Zhao and Izhak Shafran and Thomas L. Griffiths and Yuan Cao and Karthik Narasimhan},
year={2023},
eprint={2305.10601},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Setup
You need to first have an OpenAI API key and store it in the environment variable OPENAI_API_KEY (see here). If you use custom base url, set it by environment variable OPENAI_API_BASE (e.g. https://api.openai.com/v1).
Package requirement: pip install openai backoff sympy numpy
Experiments
Run experiments via sh scripts/{game24, text, crosswords}/{standard_sampling, cot_sampling, bfs}.sh, except in crosswords we use a DFS algorithm for ToT, which can be run via scripts/crosswords/search_crosswords-dfs.ipynb.
The very simple run.py implements the ToT + BFS algorithm, as well as the naive IO/CoT sampling. Some key arguments:
--naive_run: if True, run naive IO/CoT sampling instead of ToT + BFS.--prompt_sample(choices=[standard,cot]): sampling prompt--method_generate(choices=[sample,propose]): thought generator, whether to sample independent thoughts (used in Creative Writing) or propose sequential thoughts (used in Game of 24)--method_evaluate(choices=[value,vote]): state evaluator, whether to use the value states independently (used in Game of 24) or vote on states together (used in Creative Writing)--n_generate_sample: number of times to prompt for thought generation--n_evaluate_sample: number of times to prompt for state evaluation--n_select_sample: number of states to keep from each step (i.e.bin the paper's ToT + BFS algorithm)
Trajectories
logs/ contains all the trajectories from the paper's experiments, except for logs/game24/gpt-4_0.7_propose1_value3_greedy5_start900_end1000.json which was reproduced after the paper (as the original experiment was done in a notebook) and achieved a 69% score instead of the original 74% score due to randomness in GPT decoding. We hope to aggregate multiple runs in the future to account for sampling randomness and update the paper, but this shouldn't affect the main conclusions of the paper.
Questions
Feel free to contact shunyuyao.cs@gmail.com or open an issue if you have any questions.