mirror of
https://github.com/open-webui/docs
synced 2025-06-16 11:28:36 +00:00
Markdownlit corrections in formatting
Markdownlit corrections in formatting
This commit is contained in:
@@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 1000
|
||||
sidebar_position: 1600
|
||||
title: "🤝 Contributing"
|
||||
---
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 600
|
||||
sidebar_position: 1200
|
||||
title: "📋 FAQ"
|
||||
---
|
||||
|
||||
|
||||
@@ -37,9 +37,9 @@ Environment Variable Description
|
||||
---------------------------------
|
||||
|
||||
* `WEBUI_BANNERS`:
|
||||
+ Type: list of dict
|
||||
+ Default: `[]`
|
||||
+ Description: List of banners to show to users.
|
||||
* Type: list of dict
|
||||
* Default: `[]`
|
||||
* Description: List of banners to show to users.
|
||||
|
||||
Banner Options
|
||||
----------------
|
||||
|
||||
@@ -59,9 +59,9 @@ Suppose a user wants to set their own system prompt for their account. They can
|
||||
:::tip **Bonus Tips**
|
||||
**This tip applies for both administrators and user accounts. To achieve maximum flexibility with your system prompts, we recommend considering the following setup:**
|
||||
|
||||
* Assign your primary System Prompt (**i.e., to give an LLM a defining character**) you want to use in your **General** settings **System Prompt** field. This sets it on a per-account level and allows it to work as the system prompt across all your LLMs without requiring adjustments within a model from the **Workspace** section.
|
||||
- Assign your primary System Prompt (**i.e., to give an LLM a defining character**) you want to use in your **General** settings **System Prompt** field. This sets it on a per-account level and allows it to work as the system prompt across all your LLMs without requiring adjustments within a model from the **Workspace** section.
|
||||
|
||||
* For your secondary System Prompt (**i.e, to give an LLM a task to perform**), choose whether to place it in the **System Prompt** field within the **Chat Controls** sidebar (on a per-chat basis) or the **Models** section of the **Workspace** section (on a per-model basis) for Admins, allowing you to set them directly. This allows your account-level system prompt to work in conjunction with either the per-chat level system prompt provided by **Chat Controls**, or the per-model level system prompt provided by **Models**.
|
||||
- For your secondary System Prompt (**i.e, to give an LLM a task to perform**), choose whether to place it in the **System Prompt** field within the **Chat Controls** sidebar (on a per-chat basis) or the **Models** section of the **Workspace** section (on a per-model basis) for Admins, allowing you to set them directly. This allows your account-level system prompt to work in conjunction with either the per-chat level system prompt provided by **Chat Controls**, or the per-model level system prompt provided by **Models**.
|
||||
|
||||
* As an administrator, you should assign your LLM parameters on a per-model basis using **Models** section for optimal flexibility. For both of these secondary System Prompts, ensure to set them in a manner that maximizes flexibility and minimizes required adjustments across different per-account or per-chat instances. It is essential for both your Admin account as well as all User accounts to understand the priority order by which system prompts within **Chat Controls** and the **Models** section will be applied to the **LLM**.
|
||||
- As an administrator, you should assign your LLM parameters on a per-model basis using **Models** section for optimal flexibility. For both of these secondary System Prompts, ensure to set them in a manner that maximizes flexibility and minimizes required adjustments across different per-account or per-chat instances. It is essential for both your Admin account as well as all User accounts to understand the priority order by which system prompts within **Chat Controls** and the **Models** section will be applied to the **LLM**.
|
||||
:::
|
||||
|
||||
@@ -24,7 +24,7 @@ If you are managing multiple projects, you can create separate folders for each
|
||||
|
||||
Tags provide an additional layer of organization by allowing you to label conversations with keywords or phrases.
|
||||
|
||||
- **Adding Tags to Conversations**: Tags can be applied to conversations based on their content or purpose. Tags are flexible and can be added or removed as needed.
|
||||
- **Adding Tags to Conversations**: Tags can be applied to conversations based on their content or purpose. Tags are flexible and can be added or removed as needed.
|
||||

|
||||
- **Using Tags for Searching**: Tags make it easy to locate specific conversations by using the search feature. You can filter conversations by tags to quickly find those related to specific topics.
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
sidebar_position: 4
|
||||
title: "📝 Evaluation"
|
||||
---
|
||||
|
||||
|
||||
@@ -15,10 +15,13 @@ Open WebUI supports image generation through the **AUTOMATIC1111** [API](https:/
|
||||
|
||||
1. Ensure that you have [AUTOMATIC1111](https://github.com/AUTOMATIC1111/stable-diffusion-webui) installed.
|
||||
2. Launch AUTOMATIC1111 with additional flags to enable API access:
|
||||
|
||||
```
|
||||
./webui.sh --api --listen
|
||||
```
|
||||
|
||||
3. For Docker installation of WebUI with the environment variables preset, use the following command:
|
||||
|
||||
```
|
||||
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -e AUTOMATIC1111_BASE_URL=http://host.docker.internal:7860/ -e ENABLE_IMAGE_GENERATION=True -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
|
||||
```
|
||||
@@ -28,9 +31,11 @@ Open WebUI supports image generation through the **AUTOMATIC1111** [API](https:/
|
||||
1. In Open WebUI, navigate to the **Admin Panel** > **Settings** > **Images** menu.
|
||||
2. Set the `Image Generation Engine` field to `Default (Automatic1111)`.
|
||||
3. In the API URL field, enter the address where AUTOMATIC1111's API is accessible:
|
||||
|
||||
```
|
||||
http://<your_automatic1111_address>:7860/
|
||||
```
|
||||
|
||||
If you're running a Docker installation of Open WebUI and AUTOMATIC1111 on the same host, use `http://host.docker.internal:7860/` as your address.
|
||||
|
||||
## ComfyUI
|
||||
@@ -41,34 +46,46 @@ ComfyUI provides an alternative interface for managing and interacting with imag
|
||||
|
||||
1. Download and extract the ComfyUI software package from [GitHub](https://github.com/comfyanonymous/ComfyUI) to your desired directory.
|
||||
2. To start ComfyUI, run the following command:
|
||||
|
||||
```
|
||||
python main.py
|
||||
```
|
||||
|
||||
For systems with low VRAM, launch ComfyUI with additional flags to reduce memory usage:
|
||||
|
||||
```
|
||||
python main.py --lowvram
|
||||
```
|
||||
|
||||
3. For Docker installation of WebUI with the environment variables preset, use the following command:
|
||||
|
||||
```
|
||||
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -e COMFYUI_BASE_URL=http://host.docker.internal:7860/ -e ENABLE_IMAGE_GENERATION=True -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
|
||||
```
|
||||
|
||||
### Setting Up Open WebUI with ComfyUI
|
||||
|
||||
#### Setting Up FLUX.1 Models:
|
||||
#### Setting Up FLUX.1 Models
|
||||
|
||||
1. **Model Checkpoints**:
|
||||
* Download either the `FLUX.1-schnell` or `FLUX.1-dev` model from the [black-forest-labs HuggingFace page](https://huggingface.co/black-forest-labs).
|
||||
* Place the model checkpoint(s) in both the `models/checkpoints` and `models/unet` directories of ComfyUI. Alternatively, you can create a symbolic link between `models/checkpoints` and `models/unet` to ensure both directories contain the same model checkpoints.
|
||||
|
||||
* Download either the `FLUX.1-schnell` or `FLUX.1-dev` model from the [black-forest-labs HuggingFace page](https://huggingface.co/black-forest-labs).
|
||||
* Place the model checkpoint(s) in both the `models/checkpoints` and `models/unet` directories of ComfyUI. Alternatively, you can create a symbolic link between `models/checkpoints` and `models/unet` to ensure both directories contain the same model checkpoints.
|
||||
|
||||
2. **VAE Model**:
|
||||
* Download `ae.safetensors` VAE from [here](https://huggingface.co/black-forest-labs/FLUX.1-schnell/blob/main/ae.safetensors).
|
||||
* Place it in the `models/vae` ComfyUI directory.
|
||||
|
||||
* Download `ae.safetensors` VAE from [here](https://huggingface.co/black-forest-labs/FLUX.1-schnell/blob/main/ae.safetensors).
|
||||
* Place it in the `models/vae` ComfyUI directory.
|
||||
|
||||
3. **CLIP Model**:
|
||||
* Download `clip_l.safetensors` from [here](https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main).
|
||||
* Place it in the `models/clip` ComfyUI directory.
|
||||
|
||||
* Download `clip_l.safetensors` from [here](https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main).
|
||||
* Place it in the `models/clip` ComfyUI directory.
|
||||
|
||||
4. **T5XXL Model**:
|
||||
* Download either the `t5xxl_fp16.safetensors` or `t5xxl_fp8_e4m3fn.safetensors` model from [here](https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main).
|
||||
* Place it in the `models/clip` ComfyUI directory.
|
||||
|
||||
* Download either the `t5xxl_fp16.safetensors` or `t5xxl_fp8_e4m3fn.safetensors` model from [here](https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main).
|
||||
* Place it in the `models/clip` ComfyUI directory.
|
||||
|
||||
To integrate ComfyUI into Open WebUI, follow these steps:
|
||||
|
||||
@@ -77,8 +94,8 @@ To integrate ComfyUI into Open WebUI, follow these steps:
|
||||
1. Navigate to the **Admin Panel** in Open WebUI.
|
||||
2. Click on **Settings** and then select the **Images** tab.
|
||||
3. In the `Image Generation Engine` field, choose `ComfyUI`.
|
||||
4. In the **API URL** field, enter the address where ComfyUI's API is accessible, following this format: `http://<your_comfyui_address>:8188/`.
|
||||
- Set the environment variable `COMFYUI_BASE_URL` to this address to ensure it persists within the WebUI.
|
||||
4. In the **API URL** field, enter the address where ComfyUI's API is accessible, following this format: `http://<your_comfyui_address>:8188/`.
|
||||
* Set the environment variable `COMFYUI_BASE_URL` to this address to ensure it persists within the WebUI.
|
||||
|
||||
#### Step 2: Verify the Connection and Enable Image Generation
|
||||
|
||||
@@ -93,6 +110,7 @@ To integrate ComfyUI into Open WebUI, follow these steps:
|
||||
3. Return to Open WebUI and click the **Click here to upload a workflow.json file** button.
|
||||
4. Select the `workflow_api.json` file to import the exported workflow from ComfyUI into Open WebUI.
|
||||
5. After importing the workflow, you must map the `ComfyUI Workflow Nodes` according to the imported workflow node IDs.
|
||||
|
||||
:::info
|
||||
You may need to adjust an `Input Key` or two within Open WebUI's `ComfyUI Workflow Nodes` section to match a node within your workflow.
|
||||
For example, `seed` may need to be renamed to `noise_seed` to match a node ID within your imported workflow.
|
||||
@@ -100,16 +118,18 @@ For example, `seed` may need to be renamed to `noise_seed` to match a node ID wi
|
||||
:::tip
|
||||
Some workflows, such as ones that use any of the Flux models, may utilize multiple nodes IDs that is necessary to fill in for their node entry fields within Open WebUI. If a node entry field requires multiple IDs, the node IDs should be comma separated (e.g. `1` or `1, 2`).
|
||||
:::
|
||||
|
||||
6. Click `Save` to apply the settings and enjoy image generation with ComfyUI integrated into Open WebUI!
|
||||
|
||||
After completing these steps, your ComfyUI setup should be integrated with Open WebUI, and you can use the Flux.1 models for image generation.
|
||||
|
||||
### Configuring with SwarmUI
|
||||
|
||||
SwarmUI utilizes ComfyUI as its backend. In order to get Open WebUI to work with SwarmUI you will have to append `ComfyBackendDirect` to the `ComfyUI Base URL`. Additionally, you will want to setup SwarmUI with LAN access. After aforementioned adjustments, setting up SwarmUI to work with Open WebUI will be the same as [Step one: Configure Open WebUI Settings](https://github.com/open-webui/docs/edit/main/docs/features/images.md#step-1-configure-open-webui-settings) as outlined above.
|
||||
SwarmUI utilizes ComfyUI as its backend. In order to get Open WebUI to work with SwarmUI you will have to append `ComfyBackendDirect` to the `ComfyUI Base URL`. Additionally, you will want to setup SwarmUI with LAN access. After aforementioned adjustments, setting up SwarmUI to work with Open WebUI will be the same as [Step one: Configure Open WebUI Settings](https://github.com/open-webui/docs/edit/main/docs/features/images.md#step-1-configure-open-webui-settings) as outlined above.
|
||||

|
||||
|
||||
#### SwarmUI API URL
|
||||
|
||||
The address you will input as the ComfyUI Base URL will look like: `http://<your_swarmui_address>:7801/ComfyBackendDirect`
|
||||
|
||||
## OpenAI DALL·E
|
||||
@@ -126,8 +146,8 @@ Open WebUI also supports image generation through the **OpenAI DALL·E APIs**. T
|
||||
2. Set the `Image Generation Engine` field to `Open AI (Dall-E)`.
|
||||
3. Enter your OpenAI API key.
|
||||
4. Choose the DALL·E model you wish to use. Note that image size options will depend on the selected model:
|
||||
- **DALL·E 2**: Supports `256x256`, `512x512`, or `1024x1024` images.
|
||||
- **DALL·E 3**: Supports `1024x1024`, `1792x1024`, or `1024x1792` images.
|
||||
* **DALL·E 2**: Supports `256x256`, `512x512`, or `1024x1024` images.
|
||||
* **DALL·E 3**: Supports `1024x1024`, `1792x1024`, or `1024x1792` images.
|
||||
|
||||
### Azure OpenAI
|
||||
|
||||
@@ -142,9 +162,7 @@ Using Azure OpenAI Dall-E directly is unsupported, but you can [set up a LiteLLM
|
||||
3. After the image has finished generating, it will be returned automatically in chat.
|
||||
|
||||
:::tip
|
||||
|
||||
You can also edit the LLM's response and enter your image generation prompt as the message
|
||||
to send off for image generation instead of using the actual response provided by the
|
||||
LLM.
|
||||
|
||||
:::
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
sidebar_position: 400
|
||||
title: "⭐ Features"
|
||||
---
|
||||
|
||||
|
||||
@@ -36,14 +36,14 @@ Environment Variable Descriptions
|
||||
---------------------------------
|
||||
|
||||
* `JWT_EXPIRES_IN`:
|
||||
+ Type: int
|
||||
+ Default: -1
|
||||
+ Description: Sets the JWT expiration time in seconds. A value of -1 disables expiration.
|
||||
* Type: int
|
||||
* Default: -1
|
||||
* Description: Sets the JWT expiration time in seconds. A value of -1 disables expiration.
|
||||
* `WEBUI_SECRET_KEY`:
|
||||
+ Type: str
|
||||
+ Default: t0p-s3cr3t
|
||||
+ Docker Default: Randomly generated on first start
|
||||
+ Description: Overrides the randomly generated string used for JSON Web Token.
|
||||
* Type: str
|
||||
* Default: t0p-s3cr3t
|
||||
* Docker Default: Randomly generated on first start
|
||||
* Description: Overrides the randomly generated string used for JSON Web Token.
|
||||
|
||||
Valid Time Units
|
||||
-----------------
|
||||
|
||||
@@ -8,6 +8,7 @@ In this tutorial, we will demonstrate how to configure multiple OpenAI (or compa
|
||||
## Docker Run
|
||||
|
||||
Here's an example `docker run` command similar to what you might use for Open WebUI:
|
||||
|
||||
```bash
|
||||
docker run -d -p 3000:8080 \
|
||||
-v open-webui:/app/backend/data \
|
||||
@@ -17,6 +18,7 @@ docker run -d -p 3000:8080 \
|
||||
--restart always \
|
||||
ghcr.io/open-webui/open-webui:main
|
||||
```
|
||||
|
||||
This command sets the following environment variables:
|
||||
|
||||
* `OPENAI_API_BASE_URLS`: A list of API base URLs separated by semicolons (;). In this example, we use OpenAI and Mistral.
|
||||
@@ -27,6 +29,7 @@ You can adapt this command to your own needs, and add even more endpoint/key pai
|
||||
## Docker Compose
|
||||
|
||||
Alternatively, you can use a `docker-compose.yaml` file to define and run the Open WebUI container. Here's an abridged version of what that might look like:
|
||||
|
||||
```yaml
|
||||
services:
|
||||
open-webui:
|
||||
@@ -34,7 +37,9 @@ services:
|
||||
- 'OPENAI_API_BASE_URLS=${OPENAI_API_BASE_URLS}'
|
||||
- 'OPENAI_API_KEYS=${OPENAI_API_KEYS}'
|
||||
```
|
||||
|
||||
You can edit the `${VARIABLES}` directly, or optionally define the values of these variables in an `.env` file, which should be placed in the same directory as the `docker-compose.yaml` file:
|
||||
|
||||
```ini
|
||||
OPENAI_API_BASE_URLS="https://api.openai.com/v1;https://api.mistral.ai/v1"
|
||||
OPENAI_API_KEYS="<OPENAI_API_KEY_1>;<OPENAI_API_KEY_2>"
|
||||
|
||||
4
docs/features/playground(beta)/chat.md
Normal file
4
docs/features/playground(beta)/chat.md
Normal file
@@ -0,0 +1,4 @@
|
||||
---
|
||||
sidebar_position: 0
|
||||
title: "💬 Chat"
|
||||
---
|
||||
4
docs/features/playground(beta)/completions.md
Normal file
4
docs/features/playground(beta)/completions.md
Normal file
@@ -0,0 +1,4 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
title: "✅ Completions"
|
||||
---
|
||||
8
docs/features/playground(beta)/index.mdx
Normal file
8
docs/features/playground(beta)/index.mdx
Normal file
@@ -0,0 +1,8 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
title: "🛝 Playground (Beta)"
|
||||
---
|
||||
|
||||
import { TopBanners } from "@site/src/components/TopBanners";
|
||||
|
||||
<TopBanners />
|
||||
@@ -3,10 +3,9 @@ sidebar_position: 6
|
||||
title: "Actions"
|
||||
---
|
||||
|
||||
# Actions
|
||||
Action functions allow you to write custom buttons to the message toolbar for end users to interact
|
||||
with. This feature enables more interactive messaging, enabling users to grant permission before a
|
||||
task is performed, generate visualizations of structured data, download an audio snippet of chats,
|
||||
Action functions allow you to write custom buttons to the message toolbar for end users to interact
|
||||
with. This feature enables more interactive messaging, enabling users to grant permission before a
|
||||
task is performed, generate visualizations of structured data, download an audio snippet of chats,
|
||||
and many other use cases.
|
||||
|
||||
A scaffold of Action code can be found [in the community section](https://openwebui.com/f/hub/custom_action/).
|
||||
|
||||
@@ -3,8 +3,6 @@ sidebar_position: 4
|
||||
title: "Retrieval Augmented Generation (RAG)"
|
||||
---
|
||||
|
||||
# Retrieval Augmented Generation (RAG)
|
||||
|
||||
Retrieval Augmented Generation (RAG) is a a cutting-edge technology that enhances the conversational capabilities of chatbots by incorporating context from diverse sources. It works by retrieving relevant information from a wide range of sources such as local and remote documents, web content, and even multimedia sources like YouTube videos. The retrieved text is then combined with a predefined RAG template and prefixed to the user's prompt, providing a more informed and contextually relevant response.
|
||||
|
||||
One of the key advantages of RAG is its ability to access and integrate information from a variety of sources, making it an ideal solution for complex conversational scenarios. For instance, when a user asks a question related to a specific document or web page, RAG can retrieve and incorporate the relevant information from that source into the chat response. RAG can also retrieve and incorporate information from multimedia sources like YouTube videos. By analyzing the transcripts or captions of these videos, RAG can extract relevant information and incorporate it into the chat response.
|
||||
|
||||
@@ -24,7 +24,7 @@ The following table lists the available URL parameters, their function, and exam
|
||||
|
||||
- **Description**: The `models` and `model` parameters allow you to specify which [language models](/features/workspace/models.md) should be used for a particular chat session.
|
||||
- **How to Set**: You can use either `models` for multiple models or `model` for a single model.
|
||||
- **Example**:
|
||||
- **Example**:
|
||||
- `/?models=model1,model2` – This initializes the chat with `model1` and `model2`.
|
||||
- `/?model=model1` – This sets `model1` as the sole model for the chat.
|
||||
|
||||
@@ -80,15 +80,15 @@ Suppose a user wants to initiate a quick chat session without saving the history
|
||||
## Using Multiple Parameters Together
|
||||
|
||||
These URL parameters can be combined to create highly customized chat sessions. For example:
|
||||
|
||||
```bash
|
||||
/chat?models=model1,model2&youtube=VIDEO_ID&web-search=true&tools=tool1,tool2&call=true&q=Hello%20there&temporary-chat=true
|
||||
```
|
||||
|
||||
This URL will:
|
||||
|
||||
- Initialize the chat with `model1` and `model2`.
|
||||
- Enable YouTube transcription, web search, and specified tools.
|
||||
- Display a call overlay.
|
||||
- Set an initial prompt of "Hello there."
|
||||
- Mark the chat as temporary, avoiding any history saving.
|
||||
|
||||
|
||||
|
||||
4
docs/features/usergroups/assign-user.md
Normal file
4
docs/features/usergroups/assign-user.md
Normal file
@@ -0,0 +1,4 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
title: "👨👧👦 Assign Users to Usergroup"
|
||||
---
|
||||
4
docs/features/usergroups/index.mdx
Normal file
4
docs/features/usergroups/index.mdx
Normal file
@@ -0,0 +1,4 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
title: "👨👧👦 User Groups"
|
||||
---
|
||||
4
docs/features/usergroups/providing-access.md
Normal file
4
docs/features/usergroups/providing-access.md
Normal file
@@ -0,0 +1,4 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
title: "👨👧👦 Provide User Group Access"
|
||||
---
|
||||
4
docs/features/usergroups/usergroup-perms.md
Normal file
4
docs/features/usergroups/usergroup-perms.md
Normal file
@@ -0,0 +1,4 @@
|
||||
---
|
||||
sidebar_position: 0
|
||||
title: "👨👧👦 User Group Permissions"
|
||||
---
|
||||
@@ -3,8 +3,6 @@ sidebar_position: 8
|
||||
title: "Model Whitelisting"
|
||||
---
|
||||
|
||||
# Model Whitelisting
|
||||
|
||||
Open WebUI allows you to filter specific models for use in your instance. This feature is especially useful for administrators who want to control which models are available to users. Filtering can be done through the WebUI or by adding environment variables to the backend.
|
||||
|
||||
## Filtering via WebUI
|
||||
|
||||
@@ -1,10 +1,8 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
sidebar_position: 1
|
||||
title: "🧠 Knowledge"
|
||||
---
|
||||
|
||||
# 🧠 Knowledge
|
||||
|
||||
Knowledge part of Open WebUI is like a memory bank that makes your interactions even more powerful and context-aware. Let's break down what "Knowledge" really means in Open WebUI, how it works, and why it’s incredibly helpful for enhancing your experience.
|
||||
|
||||
## TL;DR
|
||||
@@ -24,15 +22,17 @@ The **Knowledge section** is a storage area within Open WebUI where you can save
|
||||
Imagine you're working on a long-term project and want the system to remember certain parameters, settings, or even key notes about the project without having to remind it every time. Or perhaps, you want it to remember specific personal preferences for chats and responses. The Knowledge section is where you can store this kind of **persistent information** so that Open WebUI can reference it in future conversations, creating a more **coherent, personalized experience**.
|
||||
|
||||
Some examples of what you might store in Knowledge:
|
||||
|
||||
- Important project parameters or specific data points you’ll frequently reference.
|
||||
- Custom commands, workflows, or settings you want to apply.
|
||||
- Personal preferences, guidelines, or rules that Open WebUI can follow in every chat.
|
||||
|
||||
### How to Use Knowledge in Chats
|
||||
|
||||
Accessing stored Knowledge in your chats is easy! By simply referencing what’s saved(using '#' before the name), Open WebUI can pull in data or follow specific guidelines that you’ve set up in the Knowledge section.
|
||||
Accessing stored Knowledge in your chats is easy! By simply referencing what’s saved(using '#' before the name), Open WebUI can pull in data or follow specific guidelines that you’ve set up in the Knowledge section.
|
||||
|
||||
For example:
|
||||
|
||||
- When discussing a project, Open WebUI can automatically recall your specified project details.
|
||||
- It can apply custom preferences to responses, like formality levels or preferred phrasing.
|
||||
|
||||
@@ -52,5 +52,4 @@ Admins can add knowledge to the workspace, which users can access and use; howev
|
||||
- **Use Knowledge to keep the system aware** of important details, ensuring a personalized chat experience.
|
||||
- You can **directly reference Knowledge in chats** to bring in stored data whenever you need it using '#' + name of the knowlege.
|
||||
|
||||
|
||||
🌟 Remember, there’s always more to discover, so dive in and make Open WebUI truly your own!
|
||||
|
||||
@@ -1,11 +1,8 @@
|
||||
---
|
||||
sidebar_position: 16
|
||||
title: "Models"
|
||||
sidebar_position: 0
|
||||
title: "🤖 Models"
|
||||
---
|
||||
|
||||
**Models**
|
||||
=======================
|
||||
|
||||
The `Models` section of the `Workspace` within Open WebUI is a powerful tool that allows you to create and manage custom models tailored to specific purposes. This section serves as a central hub for all your modelfiles, providing a range of features to edit, clone, share, export, and hide your models.
|
||||
|
||||
### Modelfile Management
|
||||
@@ -39,7 +36,7 @@ The `Models` section also includes features for importing and exporting models:
|
||||
* **Import Models**: Use this button to import models from a .json file or other sources.
|
||||
* **Export Models**: Use this button to export all your modelfiles in a single .json file.
|
||||
|
||||
To download models, navigate to the **Ollama Settings** in the Connections tab.
|
||||
To download models, navigate to the **Ollama Settings** in the Connections tab.
|
||||
Alternatively, you can also download models directly by typing a command like `ollama run hf.co/[model creator]/[model name]` in the model selection dropdown.
|
||||
This action will create a button labeled "Pull [Model Name]" for downloading.
|
||||
|
||||
@@ -47,12 +44,12 @@ This action will create a button labeled "Pull [Model Name]" for downloading.
|
||||
|
||||
**Example**: Switching between **Mistral**, **LLaVA**, and **GPT-3.5** in a Multi-Stage Task
|
||||
|
||||
- **Scenario**: A multi-stage conversation involves different task types, such as starting with a simple FAQ, interpreting an image, and then generating a creative response.
|
||||
- **Reason for Switching**: The user can leverage each model's specific strengths for each stage:
|
||||
- **Mistral** for general questions to reduce computation time and costs.
|
||||
- **LLaVA** for visual tasks to gain insights from image-based data.
|
||||
- **GPT-3.5** for generating more sophisticated and nuanced language output.
|
||||
- **Process**: The user switches between models, depending on the task type, to maximize efficiency and response quality.
|
||||
* **Scenario**: A multi-stage conversation involves different task types, such as starting with a simple FAQ, interpreting an image, and then generating a creative response.
|
||||
* **Reason for Switching**: The user can leverage each model's specific strengths for each stage:
|
||||
* **Mistral** for general questions to reduce computation time and costs.
|
||||
* **LLaVA** for visual tasks to gain insights from image-based data.
|
||||
* **GPT-3.5** for generating more sophisticated and nuanced language output.
|
||||
* **Process**: The user switches between models, depending on the task type, to maximize efficiency and response quality.
|
||||
|
||||
**How To**:
|
||||
1. **Select the Model**: Within the chat interface, select the desired models from the model switcher dropdown. You can select up to two models simultaneously, and both responses will be generated. You can then navigate between them by using the back and forth arrows.
|
||||
|
||||
4
docs/features/workspace/prompts.md
Normal file
4
docs/features/workspace/prompts.md
Normal file
@@ -0,0 +1,4 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
title: "📚 Prompts"
|
||||
---
|
||||
4
docs/features/workspace/tools.md
Normal file
4
docs/features/workspace/tools.md
Normal file
@@ -0,0 +1,4 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
title: "🛠️ Tools"
|
||||
---
|
||||
@@ -6,22 +6,27 @@ title: "🔗 API Endpoints"
|
||||
This guide provides essential information on how to interact with the API endpoints effectively to achieve seamless integration and automation using our models. Please note that this is an experimental setup and may undergo future updates for enhancement.
|
||||
|
||||
## Authentication
|
||||
|
||||
To ensure secure access to the API, authentication is required 🛡️. You can authenticate your API requests using the Bearer Token mechanism. Obtain your API key from **Settings > Account** in the Open WebUI, or alternatively, use a JWT (JSON Web Token) for authentication.
|
||||
|
||||
## Notable API Endpoints
|
||||
|
||||
### 📜 Retrieve All Models
|
||||
|
||||
- **Endpoint**: `GET /api/models`
|
||||
- **Description**: Fetches all models created or added via Open WebUI.
|
||||
- **Example**:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer YOUR_API_KEY" http://localhost:3000/api/models
|
||||
```
|
||||
|
||||
### 💬 Chat Completions
|
||||
|
||||
- **Endpoint**: `POST /api/chat/completions`
|
||||
- **Description**: Serves as an OpenAI API compatible chat completion endpoint for models on Open WebUI including Ollama models, OpenAI models, and Open WebUI Function models.
|
||||
- **Example**:
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:3000/api/chat/completions \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
@@ -47,11 +52,14 @@ To utilize external data in RAG responses, you first need to upload the files. T
|
||||
|
||||
- **Endpoint**: `POST /api/v1/files/`
|
||||
- **Curl Example**:
|
||||
|
||||
```bash
|
||||
curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Accept: application/json" \
|
||||
-F "file=@/path/to/your/file" http://localhost:3000/api/v1/files/
|
||||
```
|
||||
|
||||
- **Python Example**:
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
@@ -72,13 +80,16 @@ After uploading, you can group files into a knowledge collection or reference th
|
||||
|
||||
- **Endpoint**: `POST /api/v1/knowledge/{id}/file/add`
|
||||
- **Curl Example**:
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:3000/api/v1/knowledge/{knowledge_id}/file/add \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{"file_id": "your-file-id-here"}'
|
||||
```
|
||||
|
||||
- **Python Example**:
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
@@ -103,6 +114,7 @@ This method is beneficial when you want to focus the chat model's response on th
|
||||
|
||||
- **Endpoint**: `POST /api/chat/completions`
|
||||
- **Curl Example**:
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:3000/api/chat/completions \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
@@ -119,6 +131,7 @@ This method is beneficial when you want to focus the chat model's response on th
|
||||
```
|
||||
|
||||
- **Python Example**:
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
@@ -143,6 +156,7 @@ Leverage a knowledge collection to enhance the response when the inquiry may ben
|
||||
|
||||
- **Endpoint**: `POST /api/chat/completions`
|
||||
- **Curl Example**:
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:3000/api/chat/completions \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
@@ -159,6 +173,7 @@ Leverage a knowledge collection to enhance the response when the inquiry may ben
|
||||
```
|
||||
|
||||
- **Python Example**:
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
@@ -180,7 +195,9 @@ Leverage a knowledge collection to enhance the response when the inquiry may ben
|
||||
These methods enable effective utilization of external knowledge via uploaded files and curated knowledge collections, enhancing chat applications' capabilities using the Open WebUI API. Whether using files individually or within collections, you can customize the integration based on your specific needs.
|
||||
|
||||
## Advantages of Using Open WebUI as a Unified LLM Provider
|
||||
|
||||
Open WebUI offers a myriad of benefits, making it an essential tool for developers and businesses alike:
|
||||
|
||||
- **Unified Interface**: Simplify your interactions with different LLMs through a single, integrated platform.
|
||||
- **Ease of Implementation**: Quick start integration with comprehensive documentation and community support.
|
||||
|
||||
@@ -204,4 +221,4 @@ Access detailed API documentation for different services provided by Open WebUI:
|
||||
|
||||
Each documentation portal offers interactive examples, schema descriptions, and testing capabilities to enhance your understanding and ease of use.
|
||||
|
||||
By following these guidelines, you can swiftly integrate and begin utilizing the Open WebUI API. Should you encounter any issues or have questions, feel free to reach out through our Discord Community or consult the FAQs. Happy coding! 🌟
|
||||
By following these guidelines, you can swiftly integrate and begin utilizing the Open WebUI API. Should you encounter any issues or have questions, feel free to reach out through our Discord Community or consult the FAQs. Happy coding! 🌟
|
||||
|
||||
@@ -28,6 +28,7 @@ Welcome to the **Open WebUI Development Setup Guide!** Whether you're a novice o
|
||||
### 🐧 Local Development Setup
|
||||
|
||||
1. **Clone the Repository**:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/open-webui/open-webui.git
|
||||
cd open-webui
|
||||
@@ -35,37 +36,51 @@ Welcome to the **Open WebUI Development Setup Guide!** Whether you're a novice o
|
||||
|
||||
2. **Frontend Setup**:
|
||||
- Create a `.env` file:
|
||||
|
||||
```bash
|
||||
cp -RPp .env.example .env
|
||||
```
|
||||
|
||||
- Install dependencies:
|
||||
|
||||
```bash
|
||||
npm install
|
||||
```
|
||||
|
||||
- Start the frontend server:
|
||||
|
||||
```bash
|
||||
npm run dev
|
||||
```
|
||||
|
||||
🌐 Available at: [http://localhost:5173](http://localhost:5173).
|
||||
|
||||
3. **Backend Setup**:
|
||||
- Navigate to the backend:
|
||||
|
||||
```bash
|
||||
cd backend
|
||||
```
|
||||
|
||||
- Use **Conda** for environment setup:
|
||||
|
||||
```bash
|
||||
conda create --name open-webui python=3.11
|
||||
conda activate open-webui
|
||||
```
|
||||
|
||||
- Install dependencies:
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt -U
|
||||
```
|
||||
|
||||
- Start the backend:
|
||||
|
||||
```bash
|
||||
sh dev.sh
|
||||
```
|
||||
|
||||
📄 API docs available at: [http://localhost:8080/docs](http://localhost:8080/docs).
|
||||
|
||||
</TabItem>
|
||||
@@ -75,6 +90,7 @@ Welcome to the **Open WebUI Development Setup Guide!** Whether you're a novice o
|
||||
### 🐳 Docker-Based Development Setup
|
||||
|
||||
1. **Create the Docker Compose File**:
|
||||
|
||||
```yaml
|
||||
name: open-webui-dev
|
||||
|
||||
@@ -115,11 +131,13 @@ Welcome to the **Open WebUI Development Setup Guide!** Whether you're a novice o
|
||||
```
|
||||
|
||||
2. **Start the Development Containers**:
|
||||
|
||||
```bash
|
||||
docker compose -f compose-dev.yaml up --watch
|
||||
```
|
||||
|
||||
3. **Stop the Containers**:
|
||||
|
||||
```bash
|
||||
docker compose -f compose-dev.yaml down
|
||||
```
|
||||
@@ -132,22 +150,27 @@ Welcome to the **Open WebUI Development Setup Guide!** Whether you're a novice o
|
||||
If you prefer using **Conda** for isolation:
|
||||
|
||||
1. **Create and Activate the Environment**:
|
||||
|
||||
```bash
|
||||
conda create --name open-webui-dev python=3.11
|
||||
conda activate open-webui-dev
|
||||
```
|
||||
|
||||
2. **Install Dependencies**:
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
3. **Run the Servers**:
|
||||
- Frontend:
|
||||
|
||||
```bash
|
||||
npm run dev
|
||||
```
|
||||
|
||||
- Backend:
|
||||
|
||||
```bash
|
||||
sh dev.sh
|
||||
```
|
||||
@@ -163,6 +186,7 @@ If you prefer using **Conda** for isolation:
|
||||
If you encounter memory-related errors during the build, increase the **Node.js heap size**:
|
||||
|
||||
1. **Modify Dockerfile**:
|
||||
|
||||
```dockerfile
|
||||
ENV NODE_OPTIONS=--max-old-space-size=4096
|
||||
```
|
||||
@@ -189,11 +213,13 @@ If you encounter memory-related errors during the build, increase the **Node.js
|
||||
|
||||
1. **Commit Changes Regularly** to track progress.
|
||||
2. **Sync with the Main Branch** to avoid conflicts:
|
||||
|
||||
```bash
|
||||
git pull origin main
|
||||
```
|
||||
|
||||
3. **Run Tests Before Pushing**:
|
||||
|
||||
```bash
|
||||
npm run test
|
||||
```
|
||||
|
||||
@@ -6,8 +6,8 @@ title: "🌍 Environment Variable Configuration"
|
||||
|
||||
## Overview
|
||||
|
||||
Open WebUI provides a range of environment variables that allow you to customize and configure
|
||||
various aspects of the application. This page serves as a comprehensive reference for all available
|
||||
Open WebUI provides a range of environment variables that allow you to customize and configure
|
||||
various aspects of the application. This page serves as a comprehensive reference for all available
|
||||
environment variables, including their types, default values, and descriptions.
|
||||
|
||||
:::info
|
||||
@@ -16,9 +16,9 @@ Last updated: v0.3.20
|
||||
|
||||
## App/Backend
|
||||
|
||||
The following environment variables are used by `backend/config.py` to provide Open WebUI startup
|
||||
configuration. Please note that some variables may have different default values depending on
|
||||
whether you're running Open WebUI directly or via Docker. For more information on logging
|
||||
The following environment variables are used by `backend/config.py` to provide Open WebUI startup
|
||||
configuration. Please note that some variables may have different default values depending on
|
||||
whether you're running Open WebUI directly or via Docker. For more information on logging
|
||||
environment variables, see our [logging documentation](./logging#appbackend).
|
||||
|
||||
### General
|
||||
@@ -41,9 +41,9 @@ environment variables, see our [logging documentation](./logging#appbackend).
|
||||
- Description: This setting enables or disables authentication.
|
||||
|
||||
:::danger
|
||||
If set to `False`, authentication will be disabled for your Open WebUI instance. However, it's
|
||||
important to note that turning off authentication is only possible for fresh installations without
|
||||
any existing users. If there are already users registered, you cannot disable authentication
|
||||
If set to `False`, authentication will be disabled for your Open WebUI instance. However, it's
|
||||
important to note that turning off authentication is only possible for fresh installations without
|
||||
any existing users. If there are already users registered, you cannot disable authentication
|
||||
directly. Ensure that no users are present in the database, if you intend to turn off `WEBUI_AUTH`.
|
||||
:::
|
||||
|
||||
@@ -67,7 +67,7 @@ directly. Ensure that no users are present in the database, if you intend to tur
|
||||
|
||||
:::info
|
||||
This is the maximum amount of time the client will wait for a response before timing out.
|
||||
If set to an empty string (' '), the timeout will be set to `None`, effectively disabling the timeout and
|
||||
If set to an empty string (' '), the timeout will be set to `None`, effectively disabling the timeout and
|
||||
allowing the client to wait indefinitely.
|
||||
:::
|
||||
|
||||
@@ -107,7 +107,7 @@ allowing the client to wait indefinitely.
|
||||
- Description: Toggles email, password, sign in and "or" (only when `ENABLE_OAUTH_SIGNUP` is set to True) elements.
|
||||
|
||||
:::danger
|
||||
This should **only** ever be set to `False` when [ENABLE_OAUTH_SIGNUP](https://docs.openwebui.com/getting-started/env-configuration#enable_oauth_signup)
|
||||
This should **only** ever be set to `False` when [ENABLE_OAUTH_SIGNUP](https://docs.openwebui.com/getting-started/env-configuration#enable_oauth_signup)
|
||||
is also being used and set to `True`. Failure to do so will result in the inability to login.
|
||||
:::
|
||||
|
||||
@@ -215,7 +215,7 @@ is also being used and set to `True`. Failure to do so will result in the inabil
|
||||
#### `WEBUI_AUTH_TRUSTED_NAME_HEADER`
|
||||
|
||||
- Type: `str`
|
||||
- Description: Defines the trusted request header for the username of anyone registering with the
|
||||
- Description: Defines the trusted request header for the username of anyone registering with the
|
||||
`WEBUI_AUTH_TRUSTED_EMAIL_HEADER` header. See [SSO docs](/features/sso).
|
||||
|
||||
#### `WEBUI_SECRET_KEY`
|
||||
@@ -235,7 +235,7 @@ is also being used and set to `True`. Failure to do so will result in the inabil
|
||||
|
||||
- Type: `bool`
|
||||
- Default: `False`
|
||||
- Description: Builds the Docker image with NVIDIA CUDA support. Enables GPU acceleration
|
||||
- Description: Builds the Docker image with NVIDIA CUDA support. Enables GPU acceleration
|
||||
for local Whisper and embeddings.
|
||||
|
||||
#### `DATABASE_URL`
|
||||
@@ -253,7 +253,7 @@ Documentation on URL scheme available [here](https://docs.sqlalchemy.org/en/20/c
|
||||
|
||||
- Type: `int`
|
||||
- Default: `0`
|
||||
- Description: Specifies the size of the database pool. A value of `0` disables pooling.
|
||||
- Description: Specifies the size of the database pool. A value of `0` disables pooling.
|
||||
|
||||
#### `DATABASE_POOL_MAX_OVERFLOW`
|
||||
|
||||
@@ -334,11 +334,11 @@ If installed via Python, you must instead pass `--port` as a command line argume
|
||||
|
||||
- Type: `str` (enum: `lax`, `strict`, `none`)
|
||||
- Options:
|
||||
- `lax` - Sets the `SameSite` attribute to lax, allowing session cookies to be sent with
|
||||
- `lax` - Sets the `SameSite` attribute to lax, allowing session cookies to be sent with
|
||||
requests initiated by third-party websites.
|
||||
- `strict` - Sets the `SameSite` attribute to strict, blocking session cookies from being sent
|
||||
- `strict` - Sets the `SameSite` attribute to strict, blocking session cookies from being sent
|
||||
with requests initiated by third-party websites.
|
||||
- `none` - Sets the `SameSite` attribute to none, allowing session cookies to be sent with
|
||||
- `none` - Sets the `SameSite` attribute to none, allowing session cookies to be sent with
|
||||
requests initiated by third-party websites, but only over HTTPS.
|
||||
- Default: `lax`
|
||||
- Description: Sets the `SameSite` attribute for session cookies.
|
||||
@@ -358,7 +358,7 @@ requests initiated by third-party websites, but only over HTTPS.
|
||||
#### `AIOHTTP_CLIENT_TIMEOUT`
|
||||
|
||||
- Type: `int`
|
||||
- Description: Sets the timeout in seconds for internal aiohttp connections. This impacts things
|
||||
- Description: Sets the timeout in seconds for internal aiohttp connections. This impacts things
|
||||
such as connections to Ollama and OpenAI endpoints.
|
||||
|
||||
### `AIOHTTP_CLIENT_TIMEOUT_OPENAI_MODEL_LIST`
|
||||
@@ -392,7 +392,7 @@ such as connections to Ollama and OpenAI endpoints.
|
||||
#### `OLLAMA_BASE_URLS`
|
||||
|
||||
- Type: `str`
|
||||
- Description: Configures load-balanced Ollama backend hosts, separated by `;`. See
|
||||
- Description: Configures load-balanced Ollama backend hosts, separated by `;`. See
|
||||
[`OLLAMA_BASE_URL`](#ollama_base_url). Takes precedence over[`OLLAMA_BASE_URL`](#ollama_base_url).
|
||||
|
||||
#### `USE_OLLAMA_DOCKER`
|
||||
@@ -442,13 +442,13 @@ such as connections to Ollama and OpenAI endpoints.
|
||||
#### `TASK_MODEL`
|
||||
|
||||
- Type: `str`
|
||||
- Description: The default model to use for tasks such as title and web search query generation
|
||||
- Description: The default model to use for tasks such as title and web search query generation
|
||||
when using Ollama models.
|
||||
|
||||
#### `TASK_MODEL_EXTERNAL`
|
||||
|
||||
- Type: `str`
|
||||
- Description: The default model to use for tasks such as title and web search query generation
|
||||
- Description: The default model to use for tasks such as title and web search query generation
|
||||
when using OpenAI-compatible endpoints.
|
||||
|
||||
#### `TITLE_GENERATION_PROMPT_TEMPLATE`
|
||||
@@ -568,7 +568,7 @@ Available Tools: {{TOOLS}}\nReturn an empty string if no tools match the query.
|
||||
|
||||
- Type: `bool`
|
||||
- Default: `False`
|
||||
- Description: Enables the use of ensemble search with `BM25` + `ChromaDB`, with reranking using
|
||||
- Description: Enables the use of ensemble search with `BM25` + `ChromaDB`, with reranking using
|
||||
`sentence_transformers` models.
|
||||
|
||||
#### `ENABLE_RAG_WEB_LOADER_SSL_VERIFICATION`
|
||||
@@ -653,7 +653,7 @@ You are given a user query, some textual context and rules, all inside xml tags.
|
||||
|
||||
- Type: `bool`
|
||||
- Default: `False`
|
||||
- Description: Determines whether or not to allow custom models defined on the Hub in their own
|
||||
- Description: Determines whether or not to allow custom models defined on the Hub in their own
|
||||
modeling files for reranking.
|
||||
|
||||
#### `RAG_OPENAI_API_BASE_URL`
|
||||
@@ -678,7 +678,7 @@ modeling files for reranking.
|
||||
|
||||
- Type: `bool`
|
||||
- Default: `False`
|
||||
- Description: Enables local web fetching for RAG. Enabling this allows Server Side Request
|
||||
- Description: Enables local web fetching for RAG. Enabling this allows Server Side Request
|
||||
Forgery attacks against local network resources.
|
||||
|
||||
#### `YOUTUBE_LOADER_LANGUAGE`
|
||||
@@ -758,7 +758,7 @@ Forgery attacks against local network resources.
|
||||
#### `SEARXNG_QUERY_URL`
|
||||
|
||||
- Type: `str`
|
||||
- Description: The [SearXNG search API](https://docs.searxng.org/dev/search_api.html) URL supporting JSON output. `<query>` is replaced with
|
||||
- Description: The [SearXNG search API](https://docs.searxng.org/dev/search_api.html) URL supporting JSON output. `<query>` is replaced with
|
||||
the search query. Example: `http://searxng.local/search?q=<query>`
|
||||
|
||||
#### `GOOGLE_PSE_API_KEY`
|
||||
@@ -960,7 +960,6 @@ the search query. Example: `http://searxng.local/search?q=<query>`
|
||||
- Default: `${OPENAI_API_BASE_URL}`
|
||||
- Description: Sets the OpenAI-compatible base URL to use for DALL-E image generation.
|
||||
|
||||
|
||||
#### `IMAGES_OPENAI_API_KEY`
|
||||
|
||||
- Type: `str`
|
||||
@@ -996,8 +995,8 @@ the search query. Example: `http://searxng.local/search?q=<query>`
|
||||
|
||||
- Type: `bool`
|
||||
- Default: `False`
|
||||
- Description: If enabled, merges OAuth accounts with existing accounts using the same email
|
||||
address. This is considered unsafe as providers may not verify email addresses and can lead to
|
||||
- Description: If enabled, merges OAuth accounts with existing accounts using the same email
|
||||
address. This is considered unsafe as providers may not verify email addresses and can lead to
|
||||
account takeovers.
|
||||
|
||||
#### `OAUTH_USERNAME_CLAIM`
|
||||
|
||||
@@ -24,4 +24,4 @@ The choice of HTTPS encryption solution is up to the user and should align with
|
||||
|
||||
For detailed instructions and community-submitted tutorials on actual HTTPS encryption deployments, please refer to the [Deployment Tutorials](../../tutorials/deployment/).
|
||||
|
||||
This documentation provides a starting point for understanding the options available for enabling HTTPS encryption in your environment.
|
||||
This documentation provides a starting point for understanding the options available for enabling HTTPS encryption in your environment.
|
||||
|
||||
@@ -6,6 +6,7 @@ title: "📜 Open WebUI Logging"
|
||||
## Browser Client Logging ##
|
||||
|
||||
Client logging generally occurs via [JavaScript](https://developer.mozilla.org/en-US/docs/Web/API/console/log_static) `console.log()` and can be accessed using the built-in browser-specific developer tools:
|
||||
|
||||
* Blink
|
||||
* [Chrome/Chromium](https://developer.chrome.com/docs/devtools/)
|
||||
* [Edge](https://learn.microsoft.com/en-us/microsoft-edge/devtools-guide-chromium/overview)
|
||||
@@ -34,11 +35,12 @@ The following [logging levels](https://docs.python.org/3/howto/logging.html#logg
|
||||
### Global ###
|
||||
|
||||
The default global log level of `INFO` can be overridden with the `GLOBAL_LOG_LEVEL` environment variable. When set, this executes a [basicConfig](https://docs.python.org/3/library/logging.html#logging.basicConfig) statement with the `force` argument set to *True* within `config.py`. This results in reconfiguration of all attached loggers:
|
||||
> _If this keyword argument is specified as true, any existing handlers attached to the root logger are removed and closed, before carrying out the configuration as specified by the other arguments._
|
||||
> *If this keyword argument is specified as true, any existing handlers attached to the root logger are removed and closed, before carrying out the configuration as specified by the other arguments.*
|
||||
|
||||
The stream uses standard output (`sys.stdout`). In addition to all Open-WebUI `log()` statements, this also affects any imported Python modules that use the Python Logging module `basicConfig` mechanism including [urllib](https://docs.python.org/3/library/urllib.html).
|
||||
|
||||
For example, to set `DEBUG` logging level as a Docker parameter use:
|
||||
|
||||
```
|
||||
--env GLOBAL_LOG_LEVEL="DEBUG"
|
||||
```
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
sidebar_position: 200
|
||||
title: "🚀 Getting Started"
|
||||
---
|
||||
|
||||
@@ -10,18 +10,21 @@ Welcome to the **Open WebUI Documentation Hub!** Below is a list of essential gu
|
||||
---
|
||||
|
||||
## ⏱️ Quick Start
|
||||
|
||||
Get up and running quickly with our [Quick Start Guide](./quick-start).
|
||||
|
||||
---
|
||||
|
||||
## 📚 Using OpenWebUI
|
||||
|
||||
Learn the basics and explore key concepts in our [Using OpenWebUI Guide](./using-openwebui).
|
||||
|
||||
---
|
||||
|
||||
## 🛠️ Advanced Topics
|
||||
|
||||
Take a deeper dive into configurations and development tips in our [Advanced Topics Guide](./advanced-topics).
|
||||
|
||||
---
|
||||
|
||||
Happy exploring! 🎉 If you have questions, join our [community](https://discord.gg/5rJgQTnV4s) or raise an issue on [GitHub](https://github.com/open-webui/open-webui).
|
||||
Happy exploring! 🎉 If you have questions, join our [community](https://discord.gg/5rJgQTnV4s) or raise an issue on [GitHub](https://github.com/open-webui/open-webui).
|
||||
|
||||
@@ -51,4 +51,4 @@ deploy:
|
||||
capabilities: [gpu]
|
||||
```
|
||||
|
||||
This setup ensures that your application can leverage GPU resources when available.
|
||||
This setup ensures that your application can leverage GPU resources when available.
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
This installation method requires knowledge on Docker Swarms, as it utilizes a stack file to deploy 3 seperate containers as services in a Docker Swarm.
|
||||
|
||||
It includes isolated containers of ChromaDB, Ollama, and OpenWebUI.
|
||||
It includes isolated containers of ChromaDB, Ollama, and OpenWebUI.
|
||||
Additionally, there are pre-filled [Environment Variables](../advanced-topics/env-configuration) to further illustrate the setup.
|
||||
|
||||
Choose the appropriate command based on your hardware setup:
|
||||
@@ -21,7 +21,7 @@ Choose the appropriate command based on your hardware setup:
|
||||
|
||||
- **With GPU Support**:
|
||||
|
||||
#### Docker-stack.yaml
|
||||
#### Docker-stack.yaml
|
||||
```yaml
|
||||
version: '3.9'
|
||||
|
||||
@@ -105,17 +105,18 @@ Choose the appropriate command based on your hardware setup:
|
||||
- ./data/ollama:/root/.ollama
|
||||
|
||||
```
|
||||
- **Additional Requirements**:
|
||||
|
||||
- **Additional Requirements**:
|
||||
|
||||
1. Ensure CUDA is Enabled, follow your OS and GPU instructions for that.
|
||||
2. Enable Docker GPU support, see [Nvidia Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html " on Nvidia's site.")
|
||||
3. Follow the [Guide here on configuring Docker Swarm to with with your GPU](https://gist.github.com/tomlankhorst/33da3c4b9edbde5c83fc1244f010815c#configuring-docker-to-work-with-your-gpus)
|
||||
- Ensure _GPU Resource_ is enabled in `/etc/nvidia-container-runtime/config.toml` and enable GPU resource advertising by uncommenting the `swarm-resource = "DOCKER_RESOURCE_GPU"`. The docker daemon must be restarted after updating these files on each node.
|
||||
|
||||
2. Enable Docker GPU support, see [Nvidia Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html " on Nvidia's site.")
|
||||
3. Follow the [Guide here on configuring Docker Swarm to with with your GPU](https://gist.github.com/tomlankhorst/33da3c4b9edbde5c83fc1244f010815c#configuring-docker-to-work-with-your-gpus)
|
||||
- Ensure _GPU Resource_ is enabled in `/etc/nvidia-container-runtime/config.toml` and enable GPU resource advertising by uncommenting the `swarm-resource = "DOCKER_RESOURCE_GPU"`. The docker daemon must be restarted after updating these files on each node.
|
||||
|
||||
- **With CPU Support**:
|
||||
|
||||
Modify the Ollama Service within `docker-stack.yaml` and remove the lines for `generic_resources:`
|
||||
|
||||
```yaml
|
||||
ollama:
|
||||
image: ollama/ollama:latest
|
||||
|
||||
@@ -3,24 +3,33 @@
|
||||
To update your local Docker installation to the latest version, you can either use **Watchtower** or manually update the container.
|
||||
|
||||
### Option 1: Using Watchtower
|
||||
|
||||
With [Watchtower](https://containrrr.dev/watchtower/), you can automate the update process:
|
||||
|
||||
```bash
|
||||
docker run --rm --volume /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower --run-once open-webui
|
||||
```
|
||||
|
||||
_(Replace `open-webui` with your container's name if it's different.)_
|
||||
|
||||
### Option 2: Manual Update
|
||||
|
||||
1. Stop and remove the current container:
|
||||
|
||||
```bash
|
||||
docker rm -f open-webui
|
||||
```
|
||||
|
||||
2. Pull the latest version:
|
||||
|
||||
```bash
|
||||
docker pull ghcr.io/open-webui/open-webui:main
|
||||
```
|
||||
|
||||
3. Start the container again:
|
||||
|
||||
```bash
|
||||
docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main
|
||||
```
|
||||
|
||||
Both methods will get your Docker instance updated and running with the latest build.
|
||||
Both methods will get your Docker instance updated and running with the latest build.
|
||||
|
||||
@@ -19,10 +19,12 @@ docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open-webui ghc
|
||||
```
|
||||
|
||||
### Important Flags
|
||||
|
||||
- **Volume Mapping (`-v open-webui:/app/backend/data`)**: Ensures persistent storage of your data. This prevents data loss between container restarts.
|
||||
- **Port Mapping (`-p 3000:8080`)**: Exposes the WebUI on port 3000 of your local machine.
|
||||
|
||||
### Using GPU Support
|
||||
|
||||
For Nvidia GPU support, add `--gpus all` to the `docker run` command:
|
||||
|
||||
```bash
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
|
||||
|
||||
# Kustomize Setup for Kubernetes
|
||||
|
||||
Kustomize allows you to customize Kubernetes YAML configurations.
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
|
||||
|
||||
# Install with Conda
|
||||
|
||||
1. **Create a Conda Environment:**
|
||||
|
||||
@@ -8,4 +8,4 @@ pip install -U open-webui
|
||||
|
||||
The `-U` (or `--upgrade`) flag ensures that `pip` upgrades the package to the latest available version.
|
||||
|
||||
That's it! Your **Open-WebUI** package is now updated and ready to use.
|
||||
That's it! Your **Open-WebUI** package is now updated and ready to use.
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 1400
|
||||
sidebar_position: 2000
|
||||
title: "🎯 Our Mission"
|
||||
---
|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@ title: "FAQ"
|
||||
---
|
||||
|
||||
# FAQ
|
||||
|
||||
**What's the difference between Functions and Pipelines?**
|
||||
|
||||
The main difference between Functions and Pipelines are that Functions are executed directly on the Open WebUI server, while Pipelines are executed on a separate server. Functions are not capable of downloading new packages in Open WebUI, meaning that you are only able to import libraries into Functions that are packaged into Open WebUI. Pipelines, on the other hand, are more extensible, enabling you to install any Python dependencies your filter or pipe could need. Pipelines also execute on a separate server, potentially reducing the load on your Open WebUI instance.
|
||||
|
||||
The main difference between Functions and Pipelines are that Functions are executed directly on the Open WebUI server, while Pipelines are executed on a separate server. Functions are not capable of downloading new packages in Open WebUI, meaning that you are only able to import libraries into Functions that are packaged into Open WebUI. Pipelines, on the other hand, are more extensible, enabling you to install any Python dependencies your filter or pipe could need. Pipelines also execute on a separate server, potentially reducing the load on your Open WebUI instance.
|
||||
|
||||
@@ -4,6 +4,7 @@ title: "Filters"
|
||||
---
|
||||
|
||||
# Filters
|
||||
|
||||
Filters are used to perform actions against incoming user messages and outgoing assistant (LLM) messages. Potential actions that can be taken in a filter include sending messages to monitoring platforms (such as Langfuse or DataDog), modifying message contents, blocking toxic messages, translating messages to another language, or rate limiting messages from certain users. A list of examples is maintained in the [Pipelines repo](https://github.com/open-webui/pipelines/tree/main/examples/filters). Filters can be executed as a Function or on a Pipelines server. The general workflow can be seen in the image below.
|
||||
|
||||
<p align="center">
|
||||
@@ -12,4 +13,4 @@ Filters are used to perform actions against incoming user messages and outgoing
|
||||
</a>
|
||||
</p>
|
||||
|
||||
When a filter pipeline is enabled on a model or pipe, the incoming message from the user (or "inlet") is passed to the filter for processing. The filter performs the desired action against the message before requesting the chat completion from the LLM model. Finally, the filter performs post-processing on the outgoing LLM message (or "outlet") before it is sent to the user.
|
||||
When a filter pipeline is enabled on a model or pipe, the incoming message from the user (or "inlet") is passed to the filter for processing. The filter performs the desired action against the message before requesting the chat completion from the LLM model. Finally, the filter performs post-processing on the outgoing LLM message (or "outlet") before it is sent to the user.
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
sidebar_position: 1000
|
||||
title: "⚡ Pipelines"
|
||||
---
|
||||
|
||||
|
||||
@@ -5,18 +5,21 @@ title: "Tutorials"
|
||||
|
||||
# Tutorials
|
||||
|
||||
## Tutorials Welcome!
|
||||
## Tutorials Welcome
|
||||
|
||||
Are you a content creator with a blog post or YouTube video about your pipeline setup? Get in touch
|
||||
Are you a content creator with a blog post or YouTube video about your pipeline setup? Get in touch
|
||||
with us, as we'd love to feature it here!
|
||||
|
||||
## Featured Tutorials
|
||||
|
||||
[Monitoring Open WebUI with Filters](https://medium.com/@0xthresh/monitor-open-webui-with-datadog-llm-observability-620ef3a598c6) (Medium article by @0xthresh)
|
||||
- A detailed guide to monitoring the Open WebUI using DataDog LLM observability.
|
||||
|
||||
- A detailed guide to monitoring the Open WebUI using DataDog LLM observability.
|
||||
|
||||
[Building Customized Text-To-SQL Pipelines](https://www.youtube.com/watch?v=y7frgUWrcT4&t=14s) (YouTube video by Jordan Nanos)
|
||||
- Learn how to develop tailored text-to-sql pipelines, unlocking the power of data analysis and extraction.
|
||||
|
||||
- Learn how to develop tailored text-to-sql pipelines, unlocking the power of data analysis and extraction.
|
||||
|
||||
[Demo and Code Review for Text-To-SQL with Open-WebUI](https://www.youtube.com/watch?v=iLVyEgxGbg4) (YouTube video by Jordan Nanos)
|
||||
- A hands-on demonstration and code review on utilizing text-to-sql tools powered by the Open WebUI.
|
||||
|
||||
- A hands-on demonstration and code review on utilizing text-to-sql tools powered by the Open WebUI.
|
||||
|
||||
@@ -4,10 +4,13 @@ title: "Valves"
|
||||
---
|
||||
|
||||
# Valves
|
||||
Valves are input variables that are set per pipeline. Valves are set as a subclass of the `Pipeline` class, and initialized as part of the `__init__` method of the `Pipeline` class.
|
||||
|
||||
Valves are input variables that are set per pipeline. Valves are set as a subclass of the `Pipeline` class, and initialized as part of the `__init__` method of the `Pipeline` class.
|
||||
|
||||
When adding valves to your pipeline, include a way to ensure that valves can be reconfigured by admins in the web UI. There are a few options for this:
|
||||
|
||||
- Use `os.getenv()` to set an environment variable to use for the pipeline, and a default value to use if the environment variable isn't set. An example can be seen below:
|
||||
|
||||
```
|
||||
self.valves = self.Valves(
|
||||
**{
|
||||
@@ -17,7 +20,9 @@ self.valves = self.Valves(
|
||||
}
|
||||
)
|
||||
```
|
||||
- Set the valve to the `Optional` type, which will allow the pipeline to load even if no value is set for the valve.
|
||||
|
||||
- Set the valve to the `Optional` type, which will allow the pipeline to load even if no value is set for the valve.
|
||||
|
||||
```
|
||||
class Pipeline:
|
||||
class Valves(BaseModel):
|
||||
@@ -26,4 +31,4 @@ class Pipeline:
|
||||
```
|
||||
|
||||
If you don't leave a way for valves to be updated in the web UI, you'll see the following error in the Pipelines server log after trying to add a pipeline to the web UI:
|
||||
`WARNING:root:No Pipeline class found in <pipeline name>`
|
||||
`WARNING:root:No Pipeline class found in <pipeline name>`
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 800
|
||||
sidebar_position: 1400
|
||||
title: "🛣️ Roadmap"
|
||||
---
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 1100
|
||||
sidebar_position: 1800
|
||||
title: "🌐 Sponsorships"
|
||||
---
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 1500
|
||||
sidebar_position: 2200
|
||||
title: "👥 Our Team"
|
||||
---
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 300
|
||||
sidebar_position: 600
|
||||
title: "🛠️ Troubleshooting"
|
||||
---
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"label": "📝 Tutorials",
|
||||
"position": 500,
|
||||
"position": 800,
|
||||
"link": {
|
||||
"type": "generated-index"
|
||||
}
|
||||
|
||||
@@ -7,7 +7,6 @@ title: "Hosting UI and Models separately"
|
||||
This tutorial is a community contribution and is not supported by the OpenWebUI team. It serves only as a demonstration on how to customize OpenWebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
:::
|
||||
|
||||
|
||||
# Hosting UI and Models separately
|
||||
|
||||
:::note
|
||||
@@ -139,7 +138,7 @@ When your computer restarts, the Ollama server will now be listening on the IP:P
|
||||
|
||||
# Ollama Model Configuration
|
||||
|
||||
## For the Ollama model configuration, use the following Apache VirtualHost setup:
|
||||
## For the Ollama model configuration, use the following Apache VirtualHost setup
|
||||
|
||||
Navigate to the apache sites-available directory:
|
||||
|
||||
|
||||
@@ -7,7 +7,6 @@ title: "Browser Search Engine"
|
||||
This tutorial is a community contribution and is not supported by the OpenWebUI team. It serves only as a demonstration on how to customize OpenWebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
:::
|
||||
|
||||
|
||||
# Browser Search Engine Integration
|
||||
|
||||
Open WebUI allows you to integrate directly into your web browser. This tutorial will guide you through the process of setting up Open WebUI as a custom search engine, enabling you to execute queries easily from your browser's address bar.
|
||||
@@ -48,7 +47,7 @@ WEBUI_URL=https://<your-open-webui-url>
|
||||
|
||||
### Step 2: Add Open WebUI as a Custom Search Engine
|
||||
|
||||
### For Chrome:
|
||||
### For Chrome
|
||||
|
||||
1. Open Chrome and navigate to **Settings**.
|
||||
2. Select **Search engine** from the sidebar, then click on **Manage search engines**.
|
||||
@@ -56,19 +55,22 @@ WEBUI_URL=https://<your-open-webui-url>
|
||||
4. Fill in the details as follows:
|
||||
- **Search engine**: Open WebUI Search
|
||||
- **Keyword**: webui (or any keyword you prefer)
|
||||
- **URL with %s in place of query**:
|
||||
- **URL with %s in place of query**:
|
||||
|
||||
```
|
||||
https://<your-open-webui-url>/?q=%s
|
||||
```
|
||||
|
||||
5. Click **Add** to save the configuration.
|
||||
|
||||
### For Firefox:
|
||||
### For Firefox
|
||||
|
||||
1. Go to Open WebUI in Firefox.
|
||||
2. Expand the address bar by clicking on it.
|
||||
3. Click the plus icon that is enclosed in a green circle at the bottom of the expanded address bar. This adds Open WebUI's search to the search engines in your preferences.
|
||||
|
||||
Alternatively:
|
||||
|
||||
1. Go to Open WebUI in Firefox.
|
||||
2. Right-click on the address bar.
|
||||
3. Select "Add Open WebUI" (or similar) from the context menu.
|
||||
@@ -100,4 +102,3 @@ If you encounter any issues, check the following:
|
||||
- Ensure the `WEBUI_URL` is correctly configured and points to a valid Open WebUI instance.
|
||||
- Double-check that the search engine URL format is correctly entered in your browser settings.
|
||||
- Confirm your internet connection is active and that the Open WebUI service is running smoothly.
|
||||
|
||||
|
||||
@@ -7,8 +7,6 @@ title: "Continue.dev VSCode Extension with Open WebUI"
|
||||
This tutorial is a community contribution and is not supported by the OpenWebUI team. It serves only as a demonstration on how to customize OpenWebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
:::
|
||||
|
||||
|
||||
|
||||
# Integrating Continue.dev VSCode Extension with Open WebUI
|
||||
|
||||
### Download Extension
|
||||
@@ -21,7 +19,6 @@ Open this. Down at the bottom right you should see a settings icon (looks like a
|
||||
|
||||
Once you click on the settings icon a `config.json` should open up in the editor.
|
||||
|
||||
|
||||
Here you'll be able to configure continue to use Open WebUI.
|
||||
|
||||
---
|
||||
@@ -35,15 +32,16 @@ We can still setup Continue to use the openai provider which will allow us to us
|
||||
---
|
||||
|
||||
## Config
|
||||
|
||||
In `config.json` all you will need to do is add/change the following options.
|
||||
|
||||
### Change provider to openai
|
||||
|
||||
```json
|
||||
"provider": "openai"
|
||||
```
|
||||
|
||||
|
||||
### Add or update apiBase.
|
||||
### Add or update apiBase
|
||||
|
||||
Set this to your Open Web UI domain + /ollama/v1 on the end.
|
||||
|
||||
@@ -51,7 +49,7 @@ Set this to your Open Web UI domain + /ollama/v1 on the end.
|
||||
"apiBase": "http://localhost:3000/ollama/v1" #If you followed Getting Started Docker
|
||||
```
|
||||
|
||||
### Add apiKey
|
||||
### Add apiKey
|
||||
|
||||
```json
|
||||
"apiKey": "sk-79970662256d425eb274fc4563d4525b" # Replace with your API key
|
||||
@@ -61,7 +59,6 @@ You can find and generate your api key from Open WebUI -> Settings -> Account ->
|
||||
|
||||
You'll want to copy the "API Key" (this starts with sk-)
|
||||
|
||||
|
||||
## Example Config
|
||||
|
||||
Here is a base example of config.json using Open WebUI via an openai provider. Using Granite Code as the model.
|
||||
@@ -97,8 +94,7 @@ Make sure you pull the model into your ollama instance/s beforehand.
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Save your `config.json` and thats it!
|
||||
Save your `config.json` and thats it!
|
||||
|
||||
You should now see your model in the Continue tab model selection.
|
||||
|
||||
|
||||
@@ -7,7 +7,6 @@ title: Setting up with custom CA store
|
||||
This tutorial is a community contribution and is not supported by the OpenWebUI team. It serves only as a demonstration on how to customize OpenWebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
:::
|
||||
|
||||
|
||||
If you get an `[SSL: CERTIFICATE_VERIFY_FAILED]` error when trying to run OI, most likely the issue is that you are on a network which intercepts HTTPS traffic (e.g. a corporate network).
|
||||
|
||||
To fix this, you will need to add the new cert into OI's truststore.
|
||||
@@ -17,7 +16,7 @@ To fix this, you will need to add the new cert into OI's truststore.
|
||||
1. Mount the certificiate store from your host machine into the container by passing `--volume=/etc/ssl/certs/ca-certificiate.crt:/etc/ssl/certs/ca-certificiates.crt:ro` as a command-line option to `docker run`
|
||||
2. Force python to use the system truststore by setting `REQUESTS_CA_BUNDLE=/etc/ssl/certs/ca-certificates.crt` (see https://docs.docker.com/reference/cli/docker/container/run/#env)
|
||||
|
||||
If the environment variable `REQUESTS_CA_BUNDLE` does not work try to set `SSL_CERT_FILE` (as per the [httpx documentation](https://www.python-httpx.org/environment_variables/#ssl_cert_file)) instead with the same value.
|
||||
If the environment variable `REQUESTS_CA_BUNDLE` does not work try to set `SSL_CERT_FILE` (as per the [httpx documentation](https://www.python-httpx.org/environment_variables/#ssl_cert_file)) instead with the same value.
|
||||
|
||||
Example `compose.yaml` from [@KizzyCode](https://github.com/open-webui/open-webui/issues/1398#issuecomment-2258463210):
|
||||
|
||||
@@ -45,13 +44,17 @@ The `ro` flag mounts the CA store as read-only and prevents accidental changes t
|
||||
|
||||
You can also add the certificates in the build process by modifying the `Dockerfile`. This is useful if you want to make changes to the UI, for instance.
|
||||
Since the build happens in [multiple stages](https://docs.docker.com/build/building/multi-stage/), you have to add the cert into both
|
||||
1. Frontend (`build` stage):
|
||||
|
||||
1. Frontend (`build` stage):
|
||||
|
||||
```dockerfile
|
||||
COPY package.json package-lock.json <YourRootCert>.crt ./
|
||||
ENV NODE_EXTRA_CA_CERTS=/app/<YourRootCert>.crt
|
||||
RUN npm ci
|
||||
```
|
||||
|
||||
2. Backend (`base` stage):
|
||||
|
||||
```dockerfile
|
||||
COPY <CorporateSSL.crt> /usr/local/share/ca-certificates/
|
||||
RUN update-ca-certificates
|
||||
|
||||
@@ -7,7 +7,6 @@ title: Installing Docker
|
||||
This tutorial is a community contribution and is not supported by the OpenWebUI team. It serves only as a demonstration on how to customize OpenWebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
:::
|
||||
|
||||
|
||||
# Installing Docker
|
||||
|
||||
## For Windows and Mac Users
|
||||
@@ -23,6 +22,7 @@ This tutorial is a community contribution and is not supported by the OpenWebUI
|
||||
1. **Open your terminal.**
|
||||
|
||||
2. **Set up Docker’s apt repository:**
|
||||
|
||||
```bash
|
||||
sudo apt-get update
|
||||
sudo apt-get install ca-certificates curl
|
||||
@@ -40,12 +40,14 @@ If using an **Ubuntu derivative** (e.g., Linux Mint), use `UBUNTU_CODENAME` inst
|
||||
:::
|
||||
|
||||
3. **Install Docker Engine:**
|
||||
|
||||
```bash
|
||||
sudo apt-get update
|
||||
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
|
||||
```
|
||||
|
||||
4. **Verify Docker Installation:**
|
||||
|
||||
```bash
|
||||
sudo docker run hello-world
|
||||
```
|
||||
|
||||
@@ -11,6 +11,7 @@ This tutorial is a community contribution and is not supported by the OpenWebUI
|
||||
Ensuring secure communication between your users and the Open WebUI is paramount. HTTPS (HyperText Transfer Protocol Secure) encrypts the data transmitted, protecting it from eavesdroppers and tampering. By configuring Nginx as a reverse proxy, you can seamlessly add HTTPS to your Open WebUI deployment, enhancing both security and trustworthiness.
|
||||
|
||||
This guide provides two methods to set up HTTPS:
|
||||
|
||||
- **Self-Signed Certificates**: Ideal for development and internal use.
|
||||
- **Let's Encrypt**: Perfect for production environments requiring trusted SSL certificates.
|
||||
|
||||
@@ -41,4 +42,3 @@ After setting up HTTPS, access Open WebUI securely at:
|
||||
Ensure that your DNS records are correctly configured if you're using a domain name. For production environments, it's recommended to use Let's Encrypt for trusted SSL certificates.
|
||||
|
||||
---
|
||||
|
||||
|
||||
@@ -7,7 +7,6 @@ title: "Local LLM Setup with IPEX-LLM on Intel GPU"
|
||||
This tutorial is a community contribution and is not supported by the OpenWebUI team. It serves only as a demonstration on how to customize OpenWebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
:::
|
||||
|
||||
|
||||
:::note
|
||||
This guide is verified with Open WebUI setup through [Manual Installation](/getting-started/index.md).
|
||||
:::
|
||||
@@ -39,5 +38,5 @@ If the connection is successful, you will see a message stating `Service Connect
|
||||
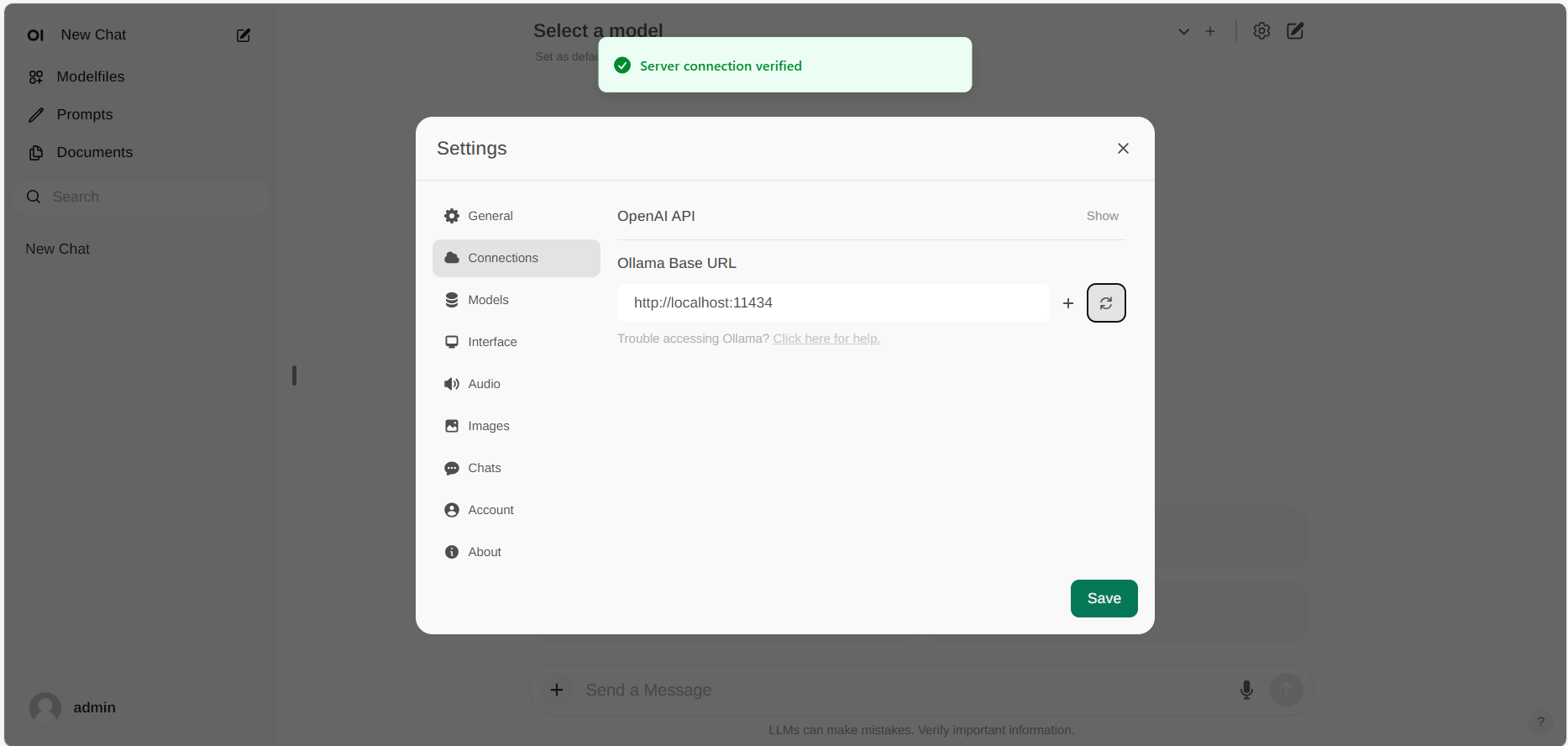
|
||||
|
||||
:::tip
|
||||
If you want to use an Ollama server hosted at a different URL, simply update the **Ollama Base URL** to the new URL and press the **Refresh** button to re-confirm the connection to Ollama.
|
||||
:::
|
||||
If you want to use an Ollama server hosted at a different URL, simply update the **Ollama Base URL** to the new URL and press the **Refresh** button to re-confirm the connection to Ollama.
|
||||
:::
|
||||
|
||||
@@ -13,7 +13,7 @@ title: "Monitoring and debugging with Langfuse"
|
||||
- Replay sessions to debug issues
|
||||
- [Evaluations](https://langfuse.com/docs/scores/overview)
|
||||
|
||||
## How to integrate Langfuse with OpenWebUI:
|
||||
## How to integrate Langfuse with OpenWebUI
|
||||
|
||||
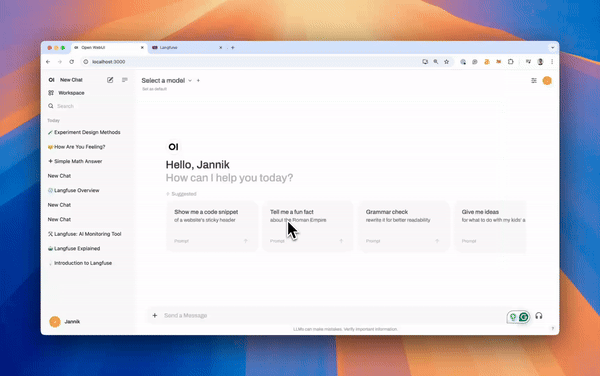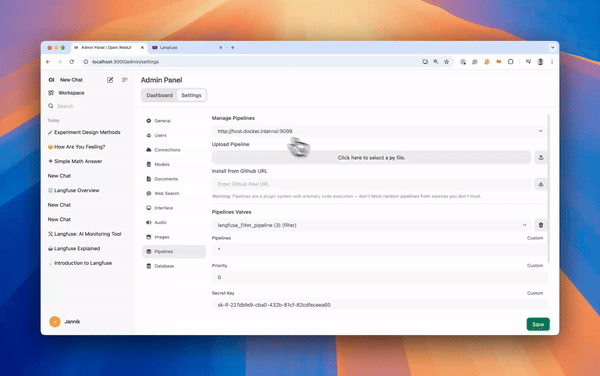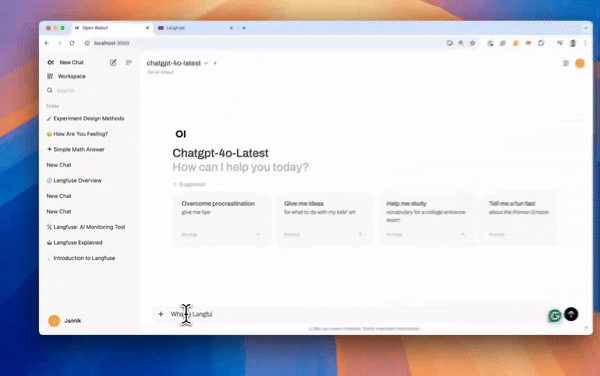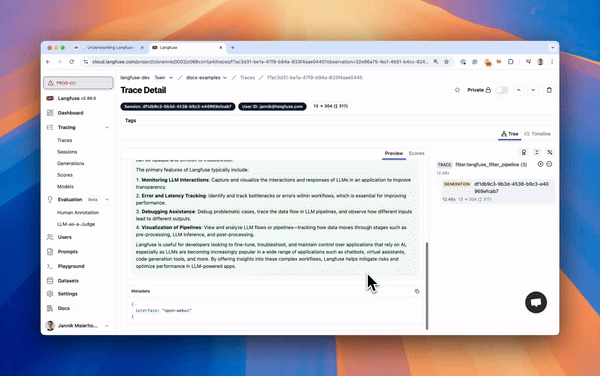
|
||||
_Langfuse integration steps_
|
||||
@@ -57,7 +57,7 @@ Now, add your Langfuse API keys below. If you haven't signed up to Langfuse yet,
|
||||
|
||||
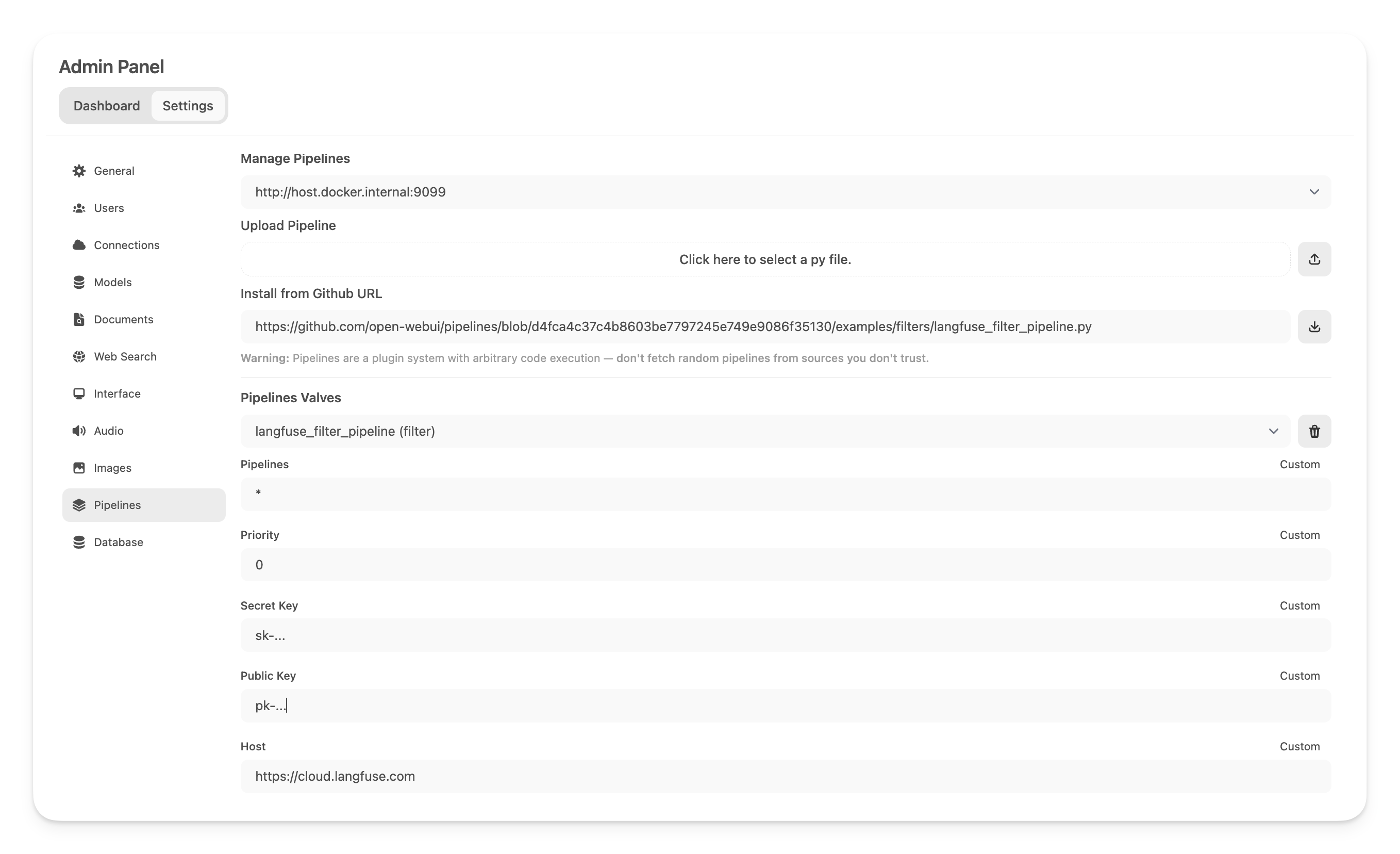
|
||||
|
||||
_**Note:** Capture usage (token counts) for OpenAi models while streaming is enabled, you have to navigate to the model settings in OpenWebUI and check the "Usage" [box](https://github.com/open-webui/open-webui/discussions/5770#discussioncomment-10778586) below *Capabilities*._
|
||||
_**Note:** Capture usage (token counts) for OpenAi models while streaming is enabled, you have to navigate to the model settings in OpenWebUI and check the "Usage" [box](https://github.com/open-webui/open-webui/discussions/5770#discussioncomment-10778586) below _Capabilities_._
|
||||
|
||||
### Step 5: See your traces in Langfuse
|
||||
|
||||
|
||||
@@ -7,16 +7,15 @@ title: "Edge TTS"
|
||||
This tutorial is a community contribution and is not supported by the OpenWebUI team. It serves only as a demonstration on how to customize OpenWebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
:::
|
||||
|
||||
|
||||
# Integrating `openai-edge-tts` 🗣️ with Open WebUI
|
||||
|
||||
## What is `openai-edge-tts`, and how is it different from `openedai-speech`?
|
||||
|
||||
Similar to [openedai-speech](https://github.com/matatonic/openedai-speech), [openai-edge-tts](https://github.com/travisvn/openai-edge-tts) is a text-to-speech API endpoint that mimics the OpenAI API endpoint, allowing for a direct substitute in scenarios where the OpenAI Speech endpoint is callable and the server endpoint URL can be configured.
|
||||
|
||||
`openedai-speech` is a more comprehensive option that allows for entirely offline generation of speech with many modalities to choose from.
|
||||
`openedai-speech` is a more comprehensive option that allows for entirely offline generation of speech with many modalities to choose from.
|
||||
|
||||
`openai-edge-tts` is a simpler option that uses a Python package called `edge-tts` to generate the audio.
|
||||
`openai-edge-tts` is a simpler option that uses a Python package called `edge-tts` to generate the audio.
|
||||
|
||||
`edge-tts` ([repo](https://github.com/rany2/edge-tts)) leverages the Edge browser's free "Read Aloud" feature to emulate a request to Microsoft / Azure in order to receive very high quality text-to-speech for free.
|
||||
|
||||
@@ -54,7 +53,7 @@ See the [Usage](#usage) section for request examples.
|
||||
|
||||
# Please ⭐️ star the repo on GitHub if you find [OpenAI Edge TTS](https://github.com/travisvn/openai-edge-tts) useful
|
||||
|
||||
:::tip
|
||||
:::tip
|
||||
You can define the environment variables directly in the `docker run` command. See [Quick Config for Docker](#-quick-config-for-docker) below.
|
||||
:::
|
||||
|
||||
@@ -123,7 +122,6 @@ The server will start running at `http://localhost:5050`.
|
||||
#### 6. Test the API
|
||||
|
||||
You can now interact with the API at `http://localhost:5050/v1/audio/speech` and other available endpoints. See the [Usage](#usage) section for request examples.
|
||||
|
||||
|
||||
#### Usage
|
||||
|
||||
@@ -217,6 +215,6 @@ For more information on `openai-edge-tts`, you can visit the [GitHub repo](https
|
||||
|
||||
For direct support, you can visit the [Voice AI & TTS Discord](https://discord.gg/GkFbBCBqJ6)
|
||||
|
||||
|
||||
## 🎙️ Voice Samples
|
||||
|
||||
[Play voice samples and see all available Edge TTS voices](https://tts.travisvn.com/)
|
||||
|
||||
@@ -7,7 +7,6 @@ title: "TTS - OpenedAI-Speech using Docker"
|
||||
This tutorial is a community contribution and is not supported by the OpenWebUI team. It serves only as a demonstration on how to customize OpenWebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
:::
|
||||
|
||||
|
||||
**Integrating `openedai-speech` into Open WebUI using Docker**
|
||||
==============================================================
|
||||
|
||||
@@ -48,6 +47,7 @@ This will download the `openedai-speech` repository to your local machine, which
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
In the `openedai-speech` repository folder, create a new file named `speech.env` with the following contents:
|
||||
|
||||
```yaml
|
||||
TTS_HOME=voices
|
||||
HF_HOME=voices
|
||||
@@ -74,14 +74,19 @@ You can use any of the following Docker Compose files:
|
||||
Before running the Docker Compose file, you need to build the Docker image:
|
||||
|
||||
* **Nvidia GPU (CUDA support)**:
|
||||
|
||||
```bash
|
||||
docker build -t ghcr.io/matatonic/openedai-speech .
|
||||
```
|
||||
|
||||
* **AMD GPU (ROCm support)**:
|
||||
|
||||
```bash
|
||||
docker build -f Dockerfile --build-arg USE_ROCM=1 -t ghcr.io/matatonic/openedai-speech-rocm .
|
||||
```
|
||||
|
||||
* **CPU only, No GPU (Piper only)**:
|
||||
|
||||
```bash
|
||||
docker build -f Dockerfile.min -t ghcr.io/matatonic/openedai-speech-min .
|
||||
```
|
||||
@@ -90,21 +95,29 @@ docker build -f Dockerfile.min -t ghcr.io/matatonic/openedai-speech-min .
|
||||
----------------------------------------------------------
|
||||
|
||||
* **Nvidia GPU (CUDA support)**: Run the following command to start the `openedai-speech` service in detached mode:
|
||||
|
||||
```bash
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
* **AMD GPU (ROCm support)**: Run the following command to start the `openedai-speech` service in detached mode:
|
||||
|
||||
```bash
|
||||
docker compose -f docker-compose.rocm.yml up -d
|
||||
```
|
||||
|
||||
* **ARM64 (Apple M-series, Raspberry Pi)**: XTTS only has CPU support here and will be very slow. You can use the Nvidia image for XTTS with CPU (slow), or use the Piper only image (recommended):
|
||||
|
||||
```bash
|
||||
docker compose -f docker-compose.min.yml up -d
|
||||
```
|
||||
|
||||
* **CPU only, No GPU (Piper only)**: For a minimal docker image with only Piper support (< 1GB vs. 8GB):
|
||||
|
||||
```bash
|
||||
docker compose -f docker-compose.min.yml up -d
|
||||
```
|
||||
|
||||
This will start the `openedai-speech` service in detached mode.
|
||||
|
||||
**Option 2: Using Docker Run Commands**
|
||||
@@ -113,17 +126,23 @@ This will start the `openedai-speech` service in detached mode.
|
||||
You can also use the following Docker run commands to start the `openedai-speech` service in detached mode:
|
||||
|
||||
* **Nvidia GPU (CUDA)**: Run the following command to build and start the `openedai-speech` service:
|
||||
|
||||
```bash
|
||||
docker build -t ghcr.io/matatonic/openedai-speech .
|
||||
docker run -d --gpus=all -p 8000:8000 -v voices:/app/voices -v config:/app/config --name openedai-speech ghcr.io/matatonic/openedai-speech
|
||||
```
|
||||
|
||||
* **ROCm (AMD GPU)**: Run the following command to build and start the `openedai-speech` service:
|
||||
|
||||
> To enable ROCm support, uncomment the `#USE_ROCM=1` line in the `speech.env` file.
|
||||
|
||||
```bash
|
||||
docker build -f Dockerfile --build-arg USE_ROCM=1 -t ghcr.io/matatonic/openedai-speech-rocm .
|
||||
docker run -d --privileged --init --name openedai-speech -p 8000:8000 -v voices:/app/voices -v config:/app/config ghcr.io/matatonic/openedai-speech-rocm
|
||||
```
|
||||
|
||||
* **CPU only, No GPU (Piper only)**: Run the following command to build and start the `openedai-speech` service:
|
||||
|
||||
```bash
|
||||
docker build -f Dockerfile.min -t ghcr.io/matatonic/openedai-speech-min .
|
||||
docker run -d -p 8000:8000 -v voices:/app/voices -v config:/app/config --name openedai-speech ghcr.io/matatonic/openedai-speech-min
|
||||
|
||||
@@ -74,4 +74,4 @@ Access Open WebUI via HTTPS at:
|
||||
|
||||
[https://your_domain_or_IP](https://your_domain_or_IP)
|
||||
|
||||
---
|
||||
---
|
||||
|
||||
@@ -29,7 +29,6 @@ We appreciate your interest in contributing tutorials to the Open WebUI document
|
||||
- Under **Source**, select the branch you want to deploy (e.g., `main`) and the folder (e.g.,`/docs`).
|
||||
- Click **Save** to enable GitHub Pages.
|
||||
|
||||
|
||||
4. **Configure GitHub Environment Variables**
|
||||
|
||||
- In your forked repository, go to **Settings** > **Secrets and variables** > **Actions** > **Variables**.
|
||||
@@ -42,7 +41,9 @@ We appreciate your interest in contributing tutorials to the Open WebUI document
|
||||
If you need to adjust deployment settings to fit your custom setup, here’s what to do:
|
||||
|
||||
a. **Update `.github/workflows/gh-pages.yml`**
|
||||
- Add environment variables for `BASE_URL` and `SITE_URL` to the build step if necessary:
|
||||
|
||||
- Add environment variables for `BASE_URL` and `SITE_URL` to the build step if necessary:
|
||||
|
||||
```yaml
|
||||
- name: Build
|
||||
env:
|
||||
@@ -52,7 +53,9 @@ a. **Update `.github/workflows/gh-pages.yml`**
|
||||
```
|
||||
|
||||
b. **Modify `docusaurus.config.ts` to Use Environment Variables**
|
||||
- Update `docusaurus.config.ts` to use these environment variables, with default values for local or direct deployment:
|
||||
|
||||
- Update `docusaurus.config.ts` to use these environment variables, with default values for local or direct deployment:
|
||||
|
||||
```typescript
|
||||
const config: Config = {
|
||||
title: "Open WebUI",
|
||||
@@ -63,7 +66,8 @@ b. **Modify `docusaurus.config.ts` to Use Environment Variables**
|
||||
...
|
||||
};
|
||||
```
|
||||
- This setup ensures consistent deployment behavior for forks and custom setups.
|
||||
|
||||
- This setup ensures consistent deployment behavior for forks and custom setups.
|
||||
|
||||
5. **Run the `gh-pages` GitHub Workflow**
|
||||
|
||||
@@ -91,6 +95,7 @@ b. **Modify `docusaurus.config.ts` to Use Environment Variables**
|
||||
## Important
|
||||
|
||||
Community-contributed tutorials must include the the following:
|
||||
|
||||
```
|
||||
:::warning
|
||||
This tutorial is a community contribution and is not supported by the OpenWebUI team. It serves only as a demonstration on how to customize OpenWebUI for your specific use case. Want to contribute? Check out the contributing tutorial.
|
||||
@@ -110,4 +115,4 @@ npm run build # Build the site for production
|
||||
This will help you catch any issues before deploying
|
||||
:::
|
||||
|
||||
---
|
||||
---
|
||||
|
||||
@@ -20,6 +20,7 @@ In this tutorial, you will learn how to use **Retrieval-Augmented Generation (RA
|
||||
Retrieval-Augmented Generation (RAG) combines **LLMs** with **retrieved knowledge** from external sources. The system retrieves relevant data from uploaded documents or knowledge bases, enhancing the quality and accuracy of responses.
|
||||
|
||||
This tutorial demonstrates how to:
|
||||
|
||||
- Upload the latest OpenWebUI Documentation as a knowledge base.
|
||||
- Connect it to a custom model.
|
||||
- Query the knowledge base for enhanced assistance.
|
||||
@@ -102,4 +103,3 @@ Follow these steps to set up RAG with **OpenWebUI Documentation**:
|
||||
---
|
||||
|
||||
With this setup, you can effectively use the **OpenWebUI Documentation** to assist users by retrieving relevant information for their queries. Enjoy building and querying your custom knowledge-enhanced models!
|
||||
|
||||
|
||||
@@ -18,6 +18,7 @@ Set the following environment variables (or the respective UI settings for an ex
|
||||
Much of the memory consumption is due to loaded ML models. Even if you are using an external language model (OpenAI or unbundled ollama), many models may be loaded for additional purposes.
|
||||
|
||||
As of v0.3.10 this includes:
|
||||
|
||||
* Speech-to-text (whisper by default)
|
||||
* RAG embedding engine (defaults to local SentenceTransformers model)
|
||||
* Image generation engine (disabled by default)
|
||||
|
||||
Reference in New Issue
Block a user