mirror of
https://github.com/open-webui/docs
synced 2025-06-16 11:28:36 +00:00
Merge pull request #248 from travisvn/patch-1
Create openai-edge-tts-integration.md
This commit is contained in:
commit
f2c6b3f6b9
187
docs/tutorials/integrations/openai-edge-tts-integration.md
Normal file
187
docs/tutorials/integrations/openai-edge-tts-integration.md
Normal file
@ -0,0 +1,187 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 18
|
||||||
|
title: "Edge TTS"
|
||||||
|
---
|
||||||
|
|
||||||
|
# Integrating `openai-edge-tts` with Open WebUI
|
||||||
|
|
||||||
|
## What is `openai-edge-tts`, and how is it different from `openedai-speech`?
|
||||||
|
|
||||||
|
Similar to [openedai-speech](https://github.com/matatonic/openedai-speech), [openai-edge-tts](https://github.com/travisvn/openai-edge-tts) is a text-to-speech API endpoint that mimics the OpenAI API endpoint, allowing for a direct substitute in scenarios where the OpenAI Speech endpoint is callable and the server endpoint URL can be configured.
|
||||||
|
|
||||||
|
`openedai-speech` is a more comprehensive option that allows for entirely offline generation of speech with many modalities to choose from.
|
||||||
|
|
||||||
|
`openai-edge-tts` is a simpler option that uses a Python package called `edge-tts` to generate the audio.
|
||||||
|
|
||||||
|
`edge-tts` leverages the Edge browser's free "Read Aloud" feature to emulate a request to Microsoft / Azure in order to receive very high quality text-to-speech for free.
|
||||||
|
|
||||||
|
## Requirements
|
||||||
|
|
||||||
|
- Docker installed on your system
|
||||||
|
- Open WebUI running
|
||||||
|
- ffmpeg installed (required for audio format conversion and playback speed adjustments)
|
||||||
|
|
||||||
|
## Quick start
|
||||||
|
|
||||||
|
The simplest way to get started without having to configure anything is to run the command below
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker run -d -p 5050:5050 travisvn/openai-edge-tts:latest
|
||||||
|
```
|
||||||
|
|
||||||
|
This will run the service at port 5050 with all the default configs
|
||||||
|
|
||||||
|
## Setting up Open WebUI to use `openai-edge-tts`
|
||||||
|
|
||||||
|
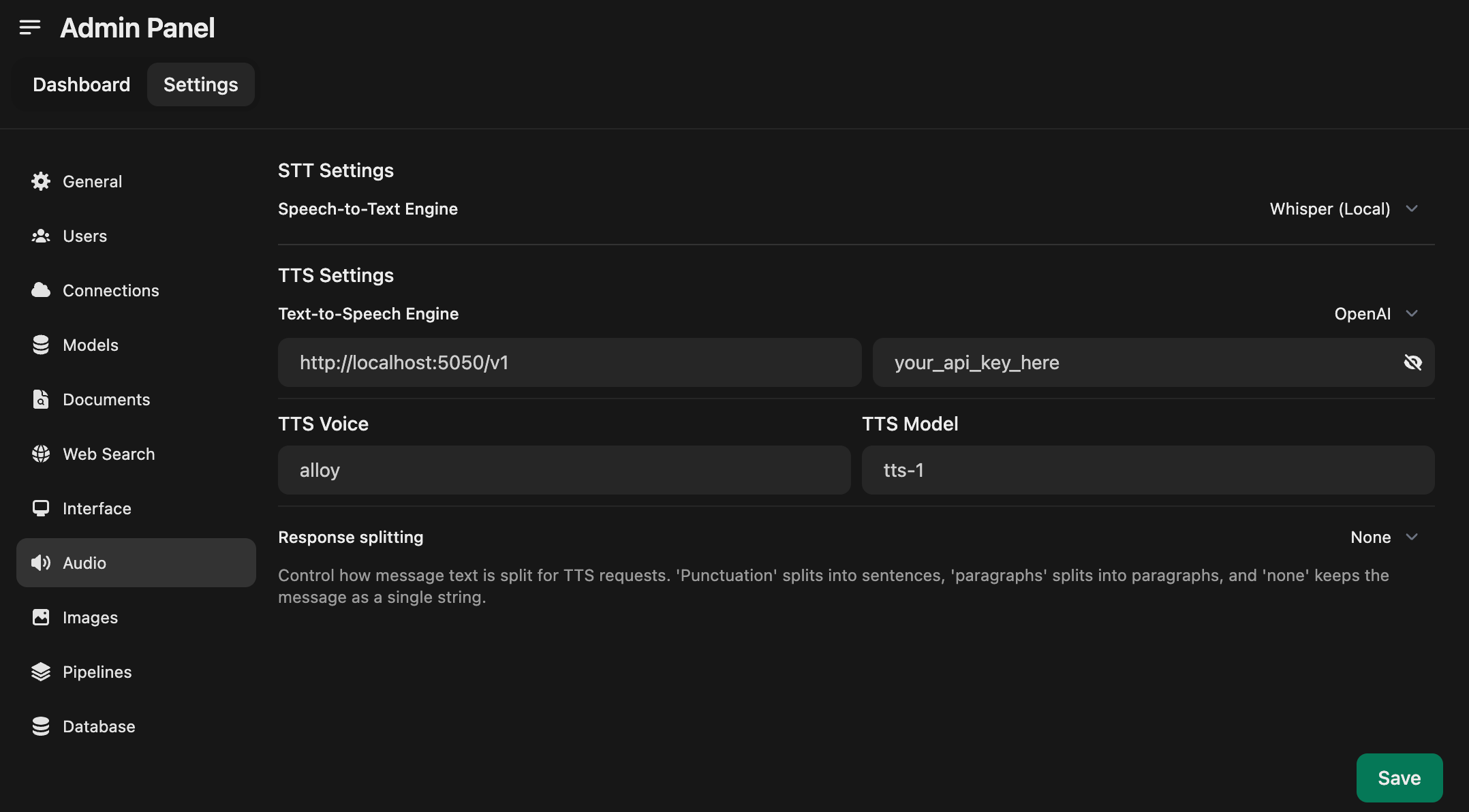
- Open the Admin Panel and go to Settings -> Audio
|
||||||
|
- Set your TTS Settings to match the screenshot below
|
||||||
|
- _Note: you can specify the TTS Voice here_
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
:::info
|
||||||
|
The default API key is the string `your_api_key_here`. You do not have to change that value if you do not need the added security.
|
||||||
|
:::
|
||||||
|
|
||||||
|
**And that's it! You can end here**
|
||||||
|
|
||||||
|
See the [Usage](#usage) section for request examples.
|
||||||
|
|
||||||
|
## Alternative Options
|
||||||
|
|
||||||
|
### Running with Python
|
||||||
|
|
||||||
|
If you prefer to run this project directly with Python, follow these steps to set up a virtual environment, install dependencies, and start the server.
|
||||||
|
|
||||||
|
#### 1. Clone the Repository
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/your-username/openai-edge-tts.git
|
||||||
|
cd openai-edge-tts
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 2. Set Up a Virtual Environment
|
||||||
|
|
||||||
|
Create and activate a virtual environment to isolate dependencies:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# For macOS/Linux
|
||||||
|
python3 -m venv venv
|
||||||
|
source venv/bin/activate
|
||||||
|
|
||||||
|
# For Windows
|
||||||
|
python -m venv venv
|
||||||
|
venv\Scripts\activate
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 3. Install Dependencies
|
||||||
|
|
||||||
|
Use `pip` to install the required packages listed in `requirements.txt`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install -r requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 4. Configure Environment Variables
|
||||||
|
|
||||||
|
Create a `.env` file in the root directory and set the following variables:
|
||||||
|
|
||||||
|
```plaintext
|
||||||
|
API_KEY=your_api_key_here
|
||||||
|
PORT=5050
|
||||||
|
|
||||||
|
DEFAULT_VOICE=en-US-AndrewNeural
|
||||||
|
DEFAULT_RESPONSE_FORMAT=mp3
|
||||||
|
DEFAULT_SPEED=1.0
|
||||||
|
|
||||||
|
DEFAULT_LANGUAGE=en-US
|
||||||
|
|
||||||
|
REQUIRE_API_KEY=True
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 5. Run the Server
|
||||||
|
|
||||||
|
Once configured, start the server with:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python app/server.py
|
||||||
|
```
|
||||||
|
|
||||||
|
The server will start running at `http://localhost:5050`.
|
||||||
|
|
||||||
|
#### 6. Test the API
|
||||||
|
|
||||||
|
You can now interact with the API at `http://localhost:5050/v1/audio/speech` and other available endpoints. See the [Usage](#usage) section for request examples.
|
||||||
|
|
||||||
|
|
||||||
|
#### Usage
|
||||||
|
|
||||||
|
##### Endpoint: `/v1/audio/speech`
|
||||||
|
|
||||||
|
Generates audio from the input text. Available parameters:
|
||||||
|
|
||||||
|
**Required Parameter:**
|
||||||
|
|
||||||
|
- **input** (string): The text to be converted to audio (up to 4096 characters).
|
||||||
|
|
||||||
|
**Optional Parameters:**
|
||||||
|
|
||||||
|
- **model** (string): Set to "tts-1" or "tts-1-hd" (default: `"tts-1"`).
|
||||||
|
- **voice** (string): One of the OpenAI-compatible voices (alloy, echo, fable, onyx, nova, shimmer) or any valid `edge-tts` voice (default: `"en-US-AndrewNeural"`).
|
||||||
|
- **response_format** (string): Audio format. Options: `mp3`, `opus`, `aac`, `flac`, `wav`, `pcm` (default: `mp3`).
|
||||||
|
- **speed** (number): Playback speed (0.25 to 4.0). Default is `1.0`.
|
||||||
|
|
||||||
|
Example request with `curl` and saving the output to an mp3 file:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST http://localhost:5050/v1/audio/speech \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-H "Authorization: Bearer your_api_key_here" \
|
||||||
|
-d '{
|
||||||
|
"input": "Hello, I am your AI assistant! Just let me know how I can help bring your ideas to life.",
|
||||||
|
"voice": "echo",
|
||||||
|
"response_format": "mp3",
|
||||||
|
"speed": 1.0
|
||||||
|
}' \
|
||||||
|
--output speech.mp3
|
||||||
|
```
|
||||||
|
|
||||||
|
Or, to be in line with the OpenAI API endpoint parameters:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST http://localhost:5050/v1/audio/speech \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-H "Authorization: Bearer your_api_key_here" \
|
||||||
|
-d '{
|
||||||
|
"model": "tts-1",
|
||||||
|
"input": "Hello, I am your AI assistant! Just let me know how I can help bring your ideas to life.",
|
||||||
|
"voice": "alloy"
|
||||||
|
}' \
|
||||||
|
--output speech.mp3
|
||||||
|
```
|
||||||
|
|
||||||
|
And an example of a language other than English:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST http://localhost:5050/v1/audio/speech \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-H "Authorization: Bearer your_api_key_here" \
|
||||||
|
-d '{
|
||||||
|
"model": "tts-1",
|
||||||
|
"input": "じゃあ、行く。電車の時間、調べておくよ。",
|
||||||
|
"voice": "ja-JP-KeitaNeural"
|
||||||
|
}' \
|
||||||
|
--output speech.mp3
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Additional Endpoints
|
||||||
|
|
||||||
|
- **GET /v1/models**: Lists available TTS models.
|
||||||
|
- **GET /v1/voices**: Lists `edge-tts` voices for a given language / locale.
|
||||||
|
- **GET /v1/voices/all**: Lists all `edge-tts` voices, with language support information.
|
||||||
|
|
||||||
|
|
||||||
|
## Additional Resources
|
||||||
|
|
||||||
|
For more information on `openai-edge-tts`, you can visit the [GitHub repo](https://github.com/travisvn/openai-edge-tts)
|
||||||
|
|
||||||
Loading…
Reference in New Issue
Block a user