mirror of
https://github.com/open-webui/docs
synced 2025-06-16 11:28:36 +00:00
Update openai-edge-tts-integration.md
Updated screenshot to show configuration with broad compatibility, updated information about ffmpeg optionality, added link to Discord for support, and updated speed to its new default of 1.2
This commit is contained in:
parent
7126e3a9fa
commit
99e69d2d27
@ -24,7 +24,7 @@ Similar to [openedai-speech](https://github.com/matatonic/openedai-speech), [ope
|
||||
|
||||
- Docker installed on your system
|
||||
- Open WebUI running
|
||||
- ffmpeg installed (required for audio format conversion and playback speed adjustments)
|
||||
- ffmpeg (Optional - Only required if opting to not use `mp3` format)
|
||||
|
||||
## ⚡️ Quick start
|
||||
|
||||
@ -42,7 +42,7 @@ This will run the service at port 5050 with all the default configs
|
||||
- Set your TTS Settings to match the screenshot below
|
||||
- _Note: you can specify the TTS Voice here_
|
||||
|
||||
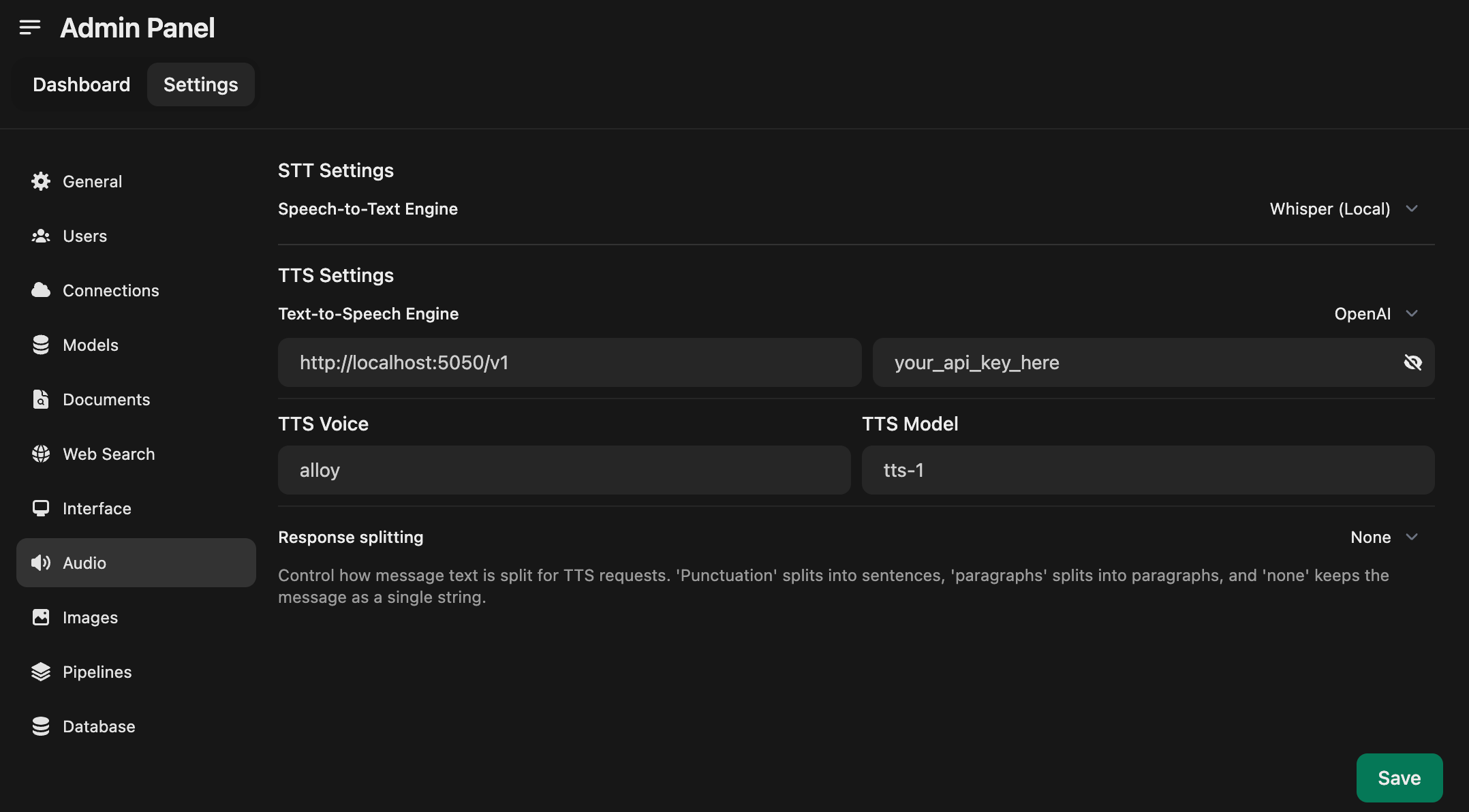
|
||||
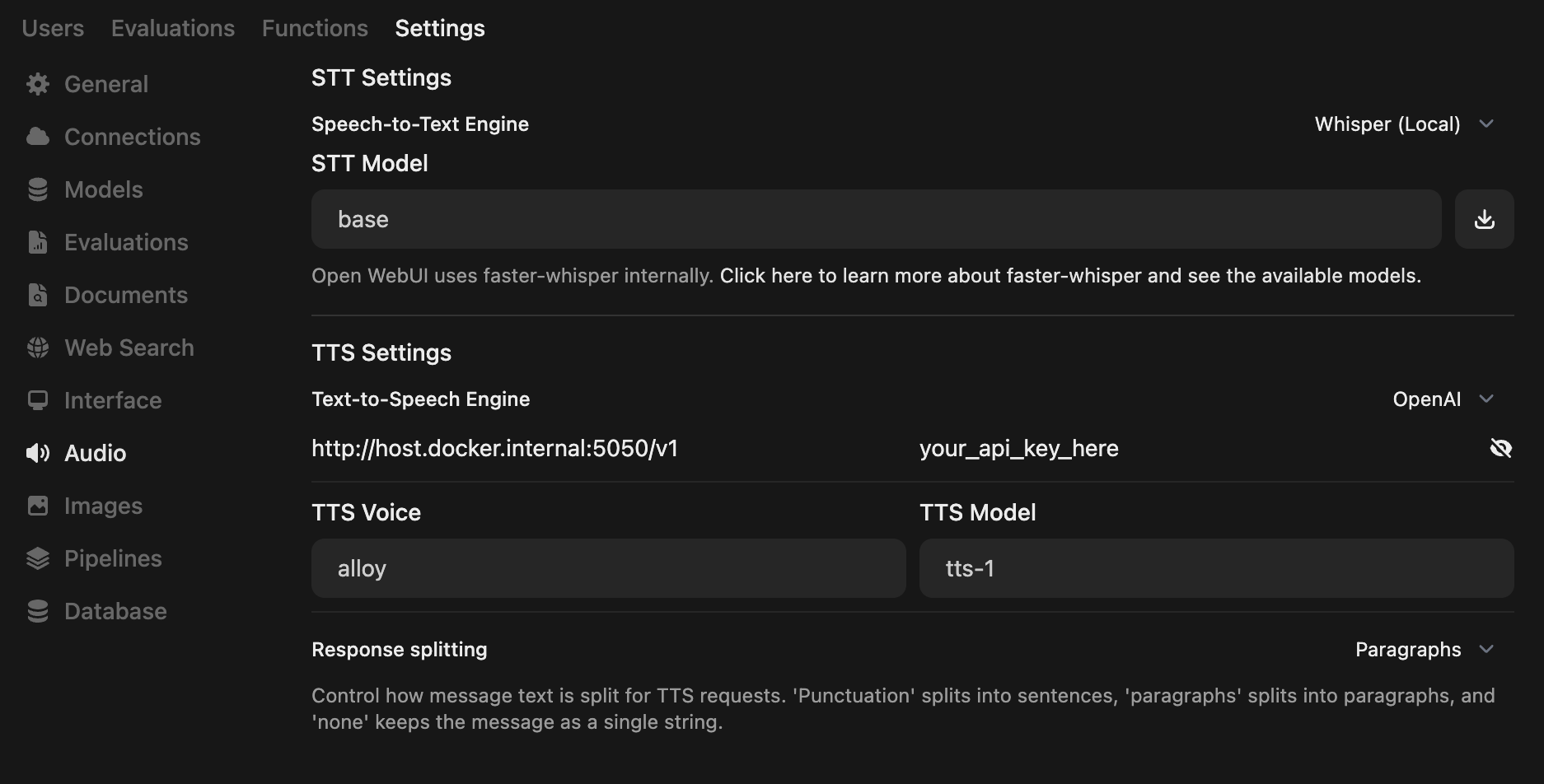
|
||||
|
||||
:::info
|
||||
The default API key is the string `your_api_key_here`. You do not have to change that value if you do not need the added security.
|
||||
@ -67,7 +67,7 @@ If you prefer to run this project directly with Python, follow these steps to se
|
||||
#### 1. Clone the Repository
|
||||
|
||||
```bash
|
||||
git clone https://github.com/your-username/openai-edge-tts.git
|
||||
git clone https://github.com/travisvn/openai-edge-tts.git
|
||||
cd openai-edge-tts
|
||||
```
|
||||
|
||||
@ -103,7 +103,7 @@ PORT=5050
|
||||
|
||||
DEFAULT_VOICE=en-US-AndrewNeural
|
||||
DEFAULT_RESPONSE_FORMAT=mp3
|
||||
DEFAULT_SPEED=1.0
|
||||
DEFAULT_SPEED=1.2
|
||||
|
||||
DEFAULT_LANGUAGE=en-US
|
||||
|
||||
@ -140,7 +140,7 @@ Generates audio from the input text. Available parameters:
|
||||
- **model** (string): Set to "tts-1" or "tts-1-hd" (default: `"tts-1"`).
|
||||
- **voice** (string): One of the OpenAI-compatible voices (alloy, echo, fable, onyx, nova, shimmer) or any valid `edge-tts` voice (default: `"en-US-AndrewNeural"`).
|
||||
- **response_format** (string): Audio format. Options: `mp3`, `opus`, `aac`, `flac`, `wav`, `pcm` (default: `mp3`).
|
||||
- **speed** (number): Playback speed (0.25 to 4.0). Default is `1.0`.
|
||||
- **speed** (number): Playback speed (0.25 to 4.0). Default is `1.2`.
|
||||
|
||||
:::tip
|
||||
You can browse available voices and listen to sample previews at [tts.travisvn.com](https://tts.travisvn.com)
|
||||
@ -205,7 +205,7 @@ docker run -d -p 5050:5050 \
|
||||
-e PORT=5050 \
|
||||
-e DEFAULT_VOICE=en-US-AndrewNeural \
|
||||
-e DEFAULT_RESPONSE_FORMAT=mp3 \
|
||||
-e DEFAULT_SPEED=1.0 \
|
||||
-e DEFAULT_SPEED=1.2 \
|
||||
-e DEFAULT_LANGUAGE=en-US \
|
||||
-e REQUIRE_API_KEY=True \
|
||||
travisvn/openai-edge-tts:latest
|
||||
@ -215,6 +215,8 @@ docker run -d -p 5050:5050 \
|
||||
|
||||
For more information on `openai-edge-tts`, you can visit the [GitHub repo](https://github.com/travisvn/openai-edge-tts)
|
||||
|
||||
For direct support, you can visit the [Voice AI & TTS Discord](https://discord.gg/GkFbBCBqJ6)
|
||||
|
||||
|
||||
## 🎙️ Voice Samples
|
||||
[Play voice samples and see all available Edge TTS voices](https://tts.travisvn.com/)
|
||||
|
||||
Loading…
Reference in New Issue
Block a user