 +
+## ClearML Experiment Manager
+
+**Adding only 2 lines to your code gets you the following**
+
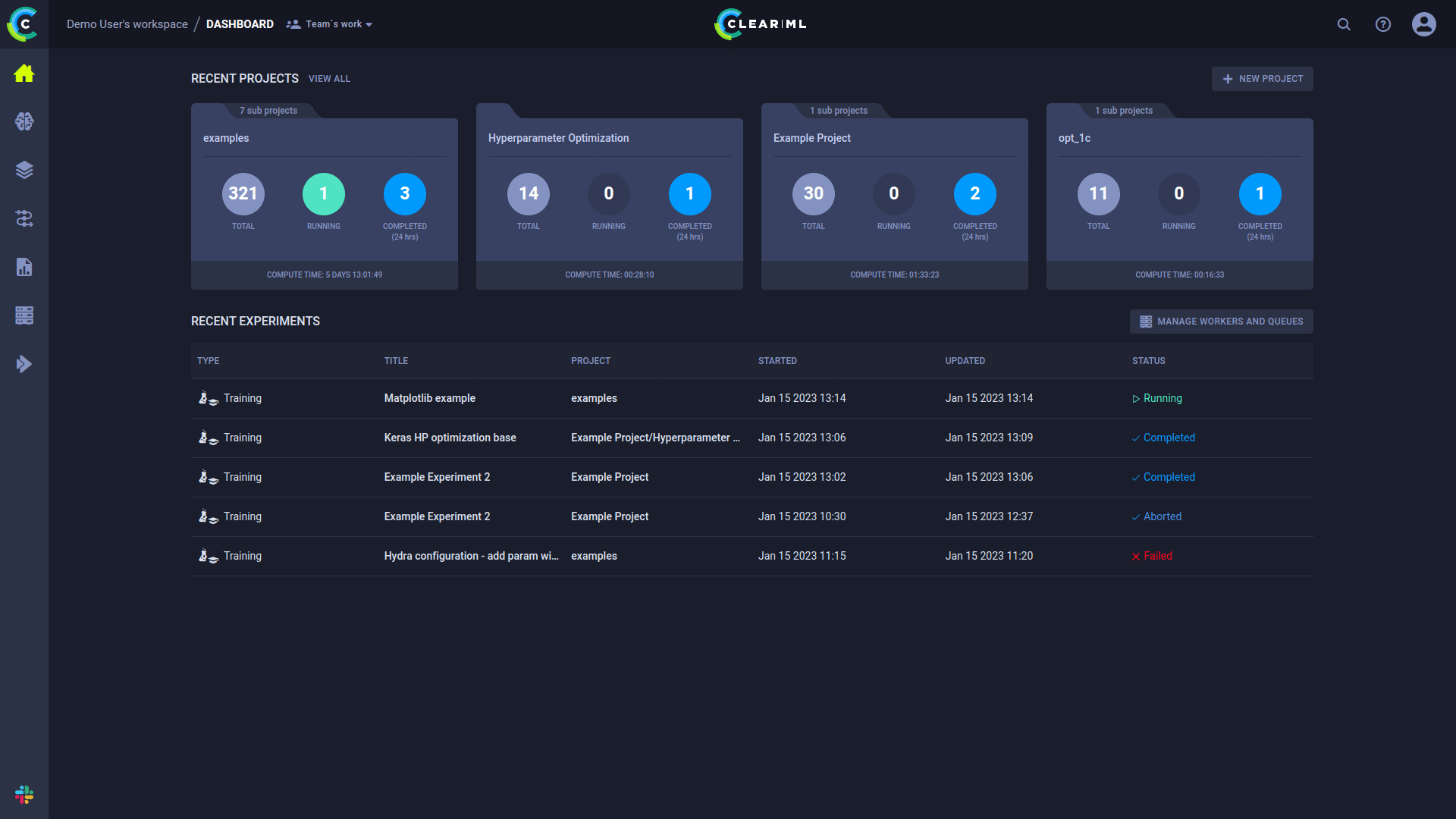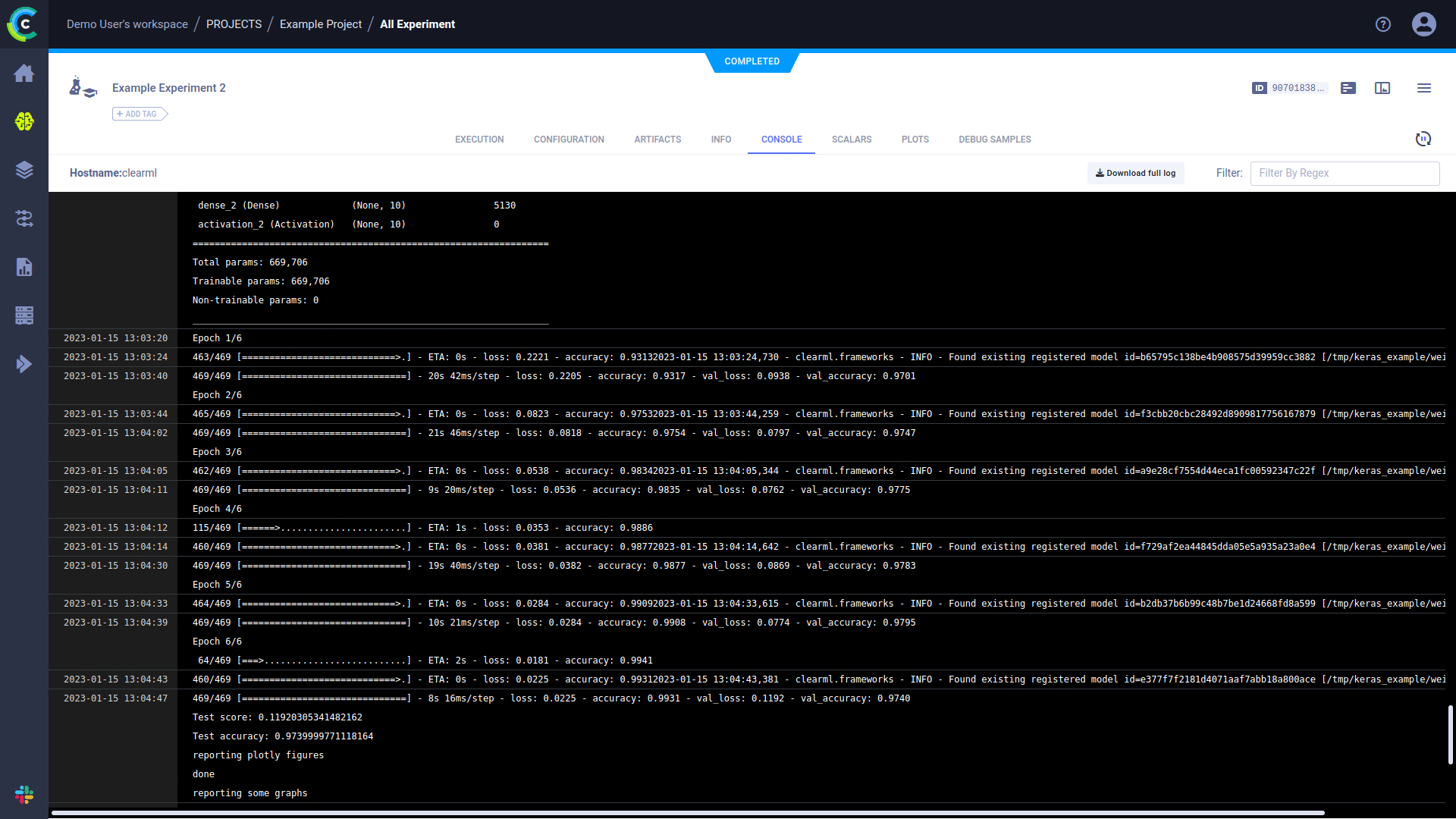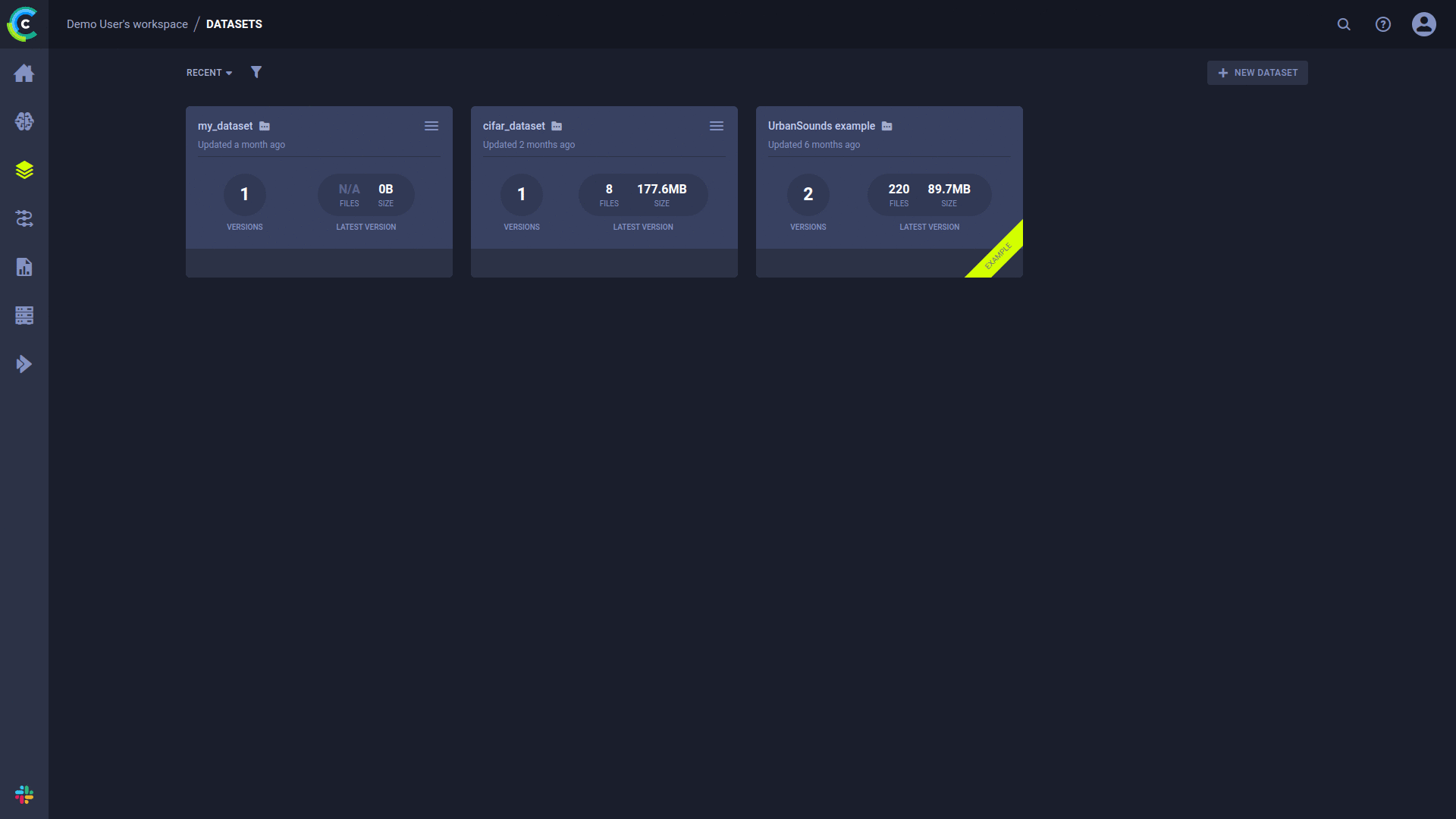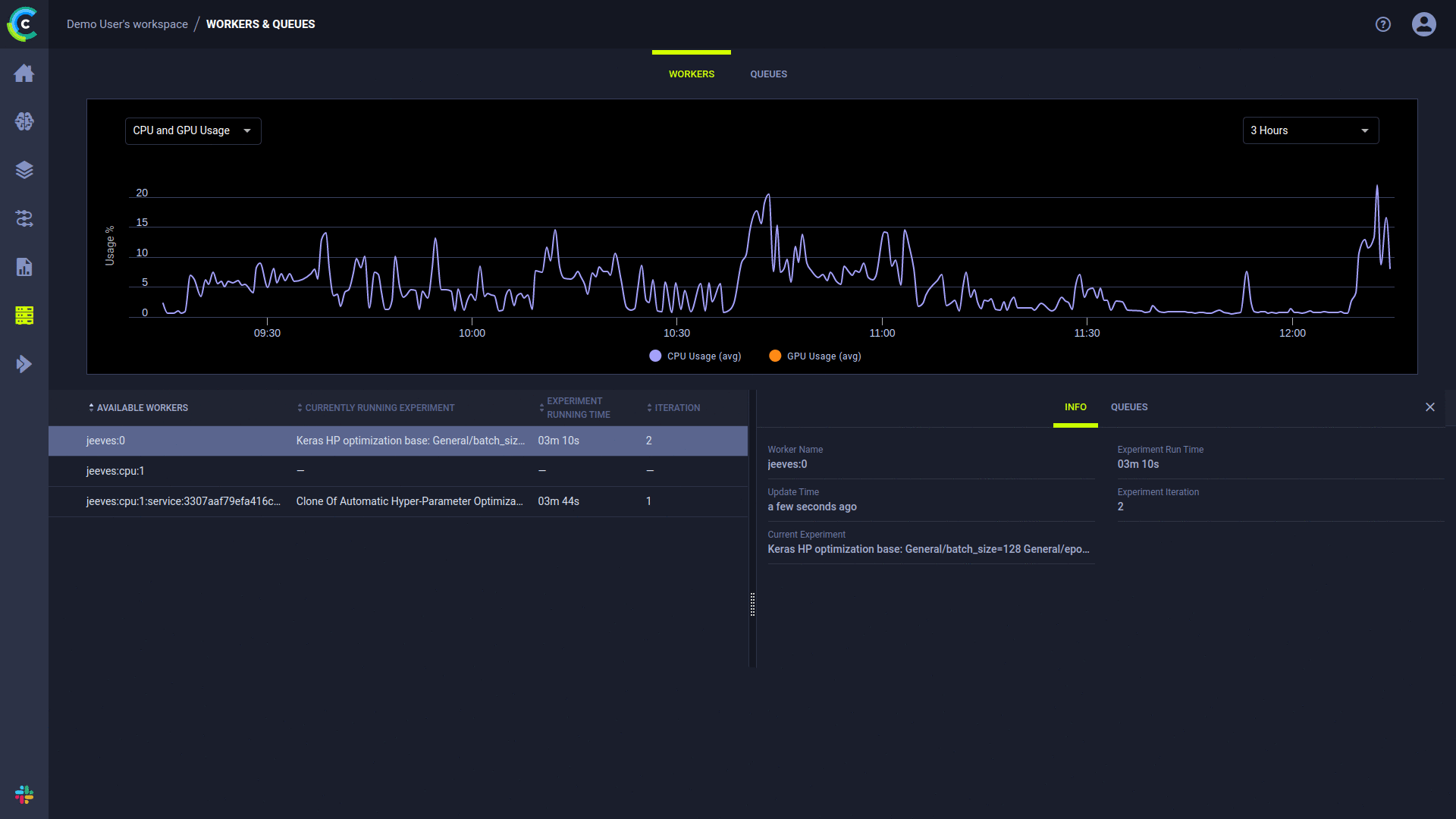
+* Complete experiment setup log
+ * Full source control info including non-committed local changes
+ * Execution environment (including specific packages & versions)
+ * Hyper-parameters
+ * ArgParser for command line parameters with currently used values
+ * Explicit parameters dictionary
+ * Tensorflow Defines (absl-py)
+ * Hydra configuration and overrides
+ * Initial model weights file
+* Full experiment output automatic capture
+ * stdout and stderr
+ * Resource Monitoring (CPU/GPU utilization, temperature, IO, network, etc.)
+ * Model snapshots (With optional automatic upload to central storage: Shared folder, S3, GS, Azure, Http)
+ * Artifacts log & store (Shared folder, S3, GS, Azure, Http)
+ * Tensorboard/TensorboardX scalars, metrics, histograms, **images, audio and video samples**
+ * [Matplotlib & Seaborn](https://github.com/allegroai/trains/tree/master/examples/frameworks/matplotlib)
+ * [ClearML Explicit Logging](https://allegro.ai/clearml/docs/examples/reporting/) interface for complete flexibility.
+* Extensive platform support and integrations
+ * Supported ML/DL frameworks: [PyTorch](https://github.com/allegroai/trains/tree/master/examples/frameworks/pytorch)(incl' ignite/lightning), [Tensorflow](https://github.com/allegroai/trains/tree/master/examples/frameworks/tensorflow), [Keras](https://github.com/allegroai/trains/tree/master/examples/frameworks/keras), [AutoKeras](https://github.com/allegroai/trains/tree/master/examples/frameworks/autokeras), [XGBoost](https://github.com/allegroai/trains/tree/master/examples/frameworks/xgboost) and [Scikit-Learn](https://github.com/allegroai/trains/tree/master/examples/frameworks/scikit-learn)
+ * Seamless integration (including version control) with **Jupyter Notebook**
+ and [*PyCharm* remote debugging](https://github.com/allegroai/trains-pycharm-plugin)
+
+#### [Start using ClearML](https://allegro.ai/clearml/docs/getting_started/getting_started/)
+
+```bash
+pip install clearml
+```
+
+Add two lines to your code:
+```python
+from clearml import Task
+task = Task(project_name='examples', task_name='hello world')
+```
+
+You are done, everything your process outputs is now automagically logged into ClearML.
+
+
+## ClearML Experiment Manager
+
+**Adding only 2 lines to your code gets you the following**
+
+* Complete experiment setup log
+ * Full source control info including non-committed local changes
+ * Execution environment (including specific packages & versions)
+ * Hyper-parameters
+ * ArgParser for command line parameters with currently used values
+ * Explicit parameters dictionary
+ * Tensorflow Defines (absl-py)
+ * Hydra configuration and overrides
+ * Initial model weights file
+* Full experiment output automatic capture
+ * stdout and stderr
+ * Resource Monitoring (CPU/GPU utilization, temperature, IO, network, etc.)
+ * Model snapshots (With optional automatic upload to central storage: Shared folder, S3, GS, Azure, Http)
+ * Artifacts log & store (Shared folder, S3, GS, Azure, Http)
+ * Tensorboard/TensorboardX scalars, metrics, histograms, **images, audio and video samples**
+ * [Matplotlib & Seaborn](https://github.com/allegroai/trains/tree/master/examples/frameworks/matplotlib)
+ * [ClearML Explicit Logging](https://allegro.ai/clearml/docs/examples/reporting/) interface for complete flexibility.
+* Extensive platform support and integrations
+ * Supported ML/DL frameworks: [PyTorch](https://github.com/allegroai/trains/tree/master/examples/frameworks/pytorch)(incl' ignite/lightning), [Tensorflow](https://github.com/allegroai/trains/tree/master/examples/frameworks/tensorflow), [Keras](https://github.com/allegroai/trains/tree/master/examples/frameworks/keras), [AutoKeras](https://github.com/allegroai/trains/tree/master/examples/frameworks/autokeras), [XGBoost](https://github.com/allegroai/trains/tree/master/examples/frameworks/xgboost) and [Scikit-Learn](https://github.com/allegroai/trains/tree/master/examples/frameworks/scikit-learn)
+ * Seamless integration (including version control) with **Jupyter Notebook**
+ and [*PyCharm* remote debugging](https://github.com/allegroai/trains-pycharm-plugin)
+
+#### [Start using ClearML](https://allegro.ai/clearml/docs/getting_started/getting_started/)
+
+```bash
+pip install clearml
+```
+
+Add two lines to your code:
+```python
+from clearml import Task
+task = Task(project_name='examples', task_name='hello world')
+```
+
+You are done, everything your process outputs is now automagically logged into ClearML.
+ +
+## Additional Modules
+
+- [clearml-session](https://github.com/allegroai/clearml-session) - **Launch remote JupyterLab / VSCode-server inside any docker, on Cloud/On-Prem machines**
+- [clearml-task](https://github.com/allegroai/clearml/doc/clearml-task.md) - Run any codebase on remote machines with full remote logging of Tensorboard, Matplotlib & Console outputs
+- [clearml-data](https://github.com/allegroai/clearml/doc/clearml-data.md) - **CLI for managing and versioning your datasets, including creating / uploading / downloading of data from S3/GS/Azure/NAS**
+- [AWS Auto-Scaler](examples/services/aws-autoscaler/aws_autoscaler.py) - Automatically spin EC2 instances based on your workloads with preconfigured budget! No need for K8s!
+- [Hyper-Parameter Optimization](examples/services/hyper-parameter-optimization/hyper_parameter_optimizer.py) - Optimize any code with black-box approach and state of the art Bayesian optimization algorithms
+- [Automation Pipeline](examples/pipeline/pipeline_controller.py) - Build pipelines based on existing experiments / jobs, supports building pipelines of pipelines!
+- [Slack Integration](examples/services/monitoring/slack_alerts.py) - Report experiments progress / failure directly to Slack (fully customizable!)
+
+## Why ClearML?
+
+ClearML is our solution to a problem we share with countless other researchers and developers in the machine
learning/deep learning universe: Training production-grade deep learning models is a glorious but messy process.
-Trains tracks and controls the process by associating code version control, research projects,
+ClearML tracks and controls the process by associating code version control, research projects,
performance metrics, and model provenance.
-We designed Trains specifically to require effortless integration so that teams can preserve their existing methods
-and practices. Use it on a daily basis to boost collaboration and visibility, or use it to automatically collect
-your experimentation logs, outputs, and data to one centralized server.
+We designed ClearML specifically to require effortless integration so that teams can preserve their existing methods
+and practices.
-**We have a demo server up and running at [https://demoapp.trains.allegro.ai](https://demoapp.trains.allegro.ai).**
-
-### :steam_locomotive: [Getting Started Tutorial](https://allegro.ai/blog/setting-up-allegro-ai-platform/) :rocket:
-
-**You can try out Trains and [test your code](#integrate-trains), with no additional setup.**
-
-
-
-## Trains Automatically Logs Everything
-**With only two lines of code, this is what you are getting:**
-
-* Git repository, branch, commit id, entry point and local git diff
-* Python environment (including specific packages & versions)
-* stdout and stderr
-* Resource Monitoring (CPU/GPU utilization, temperature, IO, network, etc.)
-* Hyper-parameters
- * ArgParser for command line parameters with currently used values
- * Explicit parameters dictionary
- * Tensorflow Defines (absl-py)
-* Initial model weights file
-* Model snapshots (With optional automatic upload to central storage: Shared folder, S3, GS, Azure, Http)
-* Artifacts log & store (Shared folder, S3, GS, Azure, Http)
-* Tensorboard/TensorboardX scalars, metrics, histograms, **images, audio and video**
-* [Matplotlib & Seaborn](https://github.com/allegroai/trains/tree/master/examples/frameworks/matplotlib)
-* Supported frameworks: [PyTorch](https://github.com/allegroai/trains/tree/master/examples/frameworks/pytorch), [Tensorflow](https://github.com/allegroai/trains/tree/master/examples/frameworks/tensorflow), [Keras](https://github.com/allegroai/trains/tree/master/examples/frameworks/keras), [AutoKeras](https://github.com/allegroai/trains/tree/master/examples/frameworks/autokeras), [XGBoost](https://github.com/allegroai/trains/tree/master/examples/frameworks/xgboost) and [Scikit-Learn](https://github.com/allegroai/trains/tree/master/examples/frameworks/scikit-learn) (MxNet is coming soon)
-* Seamless integration (including version control) with **Jupyter Notebook**
- and [*PyCharm* remote debugging](https://github.com/allegroai/trains-pycharm-plugin)
-
-**Additionally, log data explicitly using [Trains Explicit Logging](https://allegro.ai/docs/examples/reporting/).**
-
-## Using Trains
-
-Trains is a two part solution:
-
-1. Trains [python package](https://pypi.org/project/trains/) auto-magically connects with your code
-
- **Trains requires only two lines of code for full integration.**
-
- To connect your code with Trains:
-
- - Install Trains
-
- pip install trains
-
+
+## Additional Modules
+
+- [clearml-session](https://github.com/allegroai/clearml-session) - **Launch remote JupyterLab / VSCode-server inside any docker, on Cloud/On-Prem machines**
+- [clearml-task](https://github.com/allegroai/clearml/doc/clearml-task.md) - Run any codebase on remote machines with full remote logging of Tensorboard, Matplotlib & Console outputs
+- [clearml-data](https://github.com/allegroai/clearml/doc/clearml-data.md) - **CLI for managing and versioning your datasets, including creating / uploading / downloading of data from S3/GS/Azure/NAS**
+- [AWS Auto-Scaler](examples/services/aws-autoscaler/aws_autoscaler.py) - Automatically spin EC2 instances based on your workloads with preconfigured budget! No need for K8s!
+- [Hyper-Parameter Optimization](examples/services/hyper-parameter-optimization/hyper_parameter_optimizer.py) - Optimize any code with black-box approach and state of the art Bayesian optimization algorithms
+- [Automation Pipeline](examples/pipeline/pipeline_controller.py) - Build pipelines based on existing experiments / jobs, supports building pipelines of pipelines!
+- [Slack Integration](examples/services/monitoring/slack_alerts.py) - Report experiments progress / failure directly to Slack (fully customizable!)
+
+## Why ClearML?
+
+ClearML is our solution to a problem we share with countless other researchers and developers in the machine
learning/deep learning universe: Training production-grade deep learning models is a glorious but messy process.
-Trains tracks and controls the process by associating code version control, research projects,
+ClearML tracks and controls the process by associating code version control, research projects,
performance metrics, and model provenance.
-We designed Trains specifically to require effortless integration so that teams can preserve their existing methods
-and practices. Use it on a daily basis to boost collaboration and visibility, or use it to automatically collect
-your experimentation logs, outputs, and data to one centralized server.
+We designed ClearML specifically to require effortless integration so that teams can preserve their existing methods
+and practices.
-**We have a demo server up and running at [https://demoapp.trains.allegro.ai](https://demoapp.trains.allegro.ai).**
-
-### :steam_locomotive: [Getting Started Tutorial](https://allegro.ai/blog/setting-up-allegro-ai-platform/) :rocket:
-
-**You can try out Trains and [test your code](#integrate-trains), with no additional setup.**
-
-
-
-## Trains Automatically Logs Everything
-**With only two lines of code, this is what you are getting:**
-
-* Git repository, branch, commit id, entry point and local git diff
-* Python environment (including specific packages & versions)
-* stdout and stderr
-* Resource Monitoring (CPU/GPU utilization, temperature, IO, network, etc.)
-* Hyper-parameters
- * ArgParser for command line parameters with currently used values
- * Explicit parameters dictionary
- * Tensorflow Defines (absl-py)
-* Initial model weights file
-* Model snapshots (With optional automatic upload to central storage: Shared folder, S3, GS, Azure, Http)
-* Artifacts log & store (Shared folder, S3, GS, Azure, Http)
-* Tensorboard/TensorboardX scalars, metrics, histograms, **images, audio and video**
-* [Matplotlib & Seaborn](https://github.com/allegroai/trains/tree/master/examples/frameworks/matplotlib)
-* Supported frameworks: [PyTorch](https://github.com/allegroai/trains/tree/master/examples/frameworks/pytorch), [Tensorflow](https://github.com/allegroai/trains/tree/master/examples/frameworks/tensorflow), [Keras](https://github.com/allegroai/trains/tree/master/examples/frameworks/keras), [AutoKeras](https://github.com/allegroai/trains/tree/master/examples/frameworks/autokeras), [XGBoost](https://github.com/allegroai/trains/tree/master/examples/frameworks/xgboost) and [Scikit-Learn](https://github.com/allegroai/trains/tree/master/examples/frameworks/scikit-learn) (MxNet is coming soon)
-* Seamless integration (including version control) with **Jupyter Notebook**
- and [*PyCharm* remote debugging](https://github.com/allegroai/trains-pycharm-plugin)
-
-**Additionally, log data explicitly using [Trains Explicit Logging](https://allegro.ai/docs/examples/reporting/).**
-
-## Using Trains
-
-Trains is a two part solution:
-
-1. Trains [python package](https://pypi.org/project/trains/) auto-magically connects with your code
-
- **Trains requires only two lines of code for full integration.**
-
- To connect your code with Trains:
-
- - Install Trains
-
- pip install trains
-  -
-
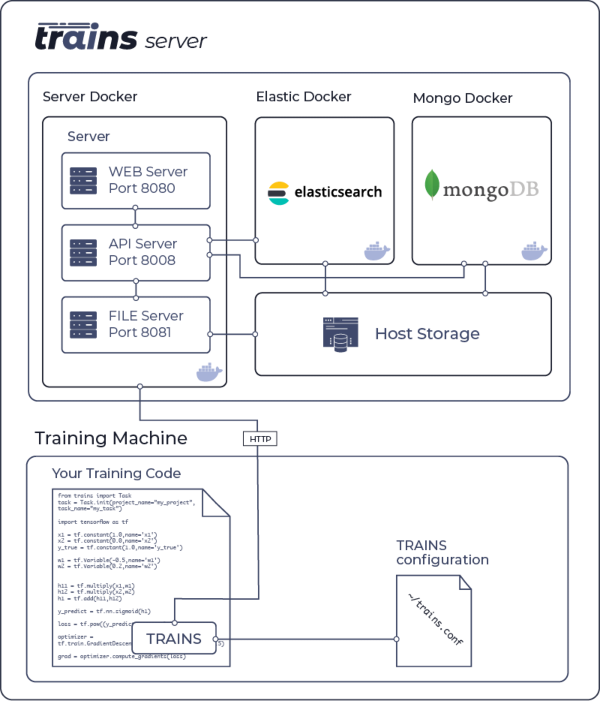
-## Configuring Your Own Trains server
-
-1. Install and run *trains-server* (see [Installing the Trains Server](https://github.com/allegroai/trains-server))
-
-2. Run the initial configuration wizard for your Trains installation and follow the instructions to setup Trains package
-(http://**_trains-server-ip_**:__port__ and user credentials)
-
- trains-init
-
-After installing and configuring, you can access your configuration file at `~/trains.conf`
-
-Sample configuration file available [here](https://github.com/allegroai/trains/blob/master/docs/trains.conf).
+ - Use it on a daily basis to boost collaboration and visibility in your team
+ - Create a remote job from any experiment with a click of a button
+ - Automate processes and create pipelines to collect your experimentation logs, outputs, and data
+ - Store all you data on any object-storage solution, with the simplest interface possible
+ - Make you data transparent by cataloging it all on the ClearML platform
+We believe ClearML is ground-breaking. We wish to establish new standards of true seamless integration between
+experiment management,ML-Ops and data management.
## Who We Are
-Trains is supported by the same team behind *allegro.ai*,
+ClearML is supported by the team behind *allegro.ai*,
where we build deep learning pipelines and infrastructure for enterprise companies.
-We built Trains to track and control the glorious but messy process of training production-grade deep learning models.
-We are committed to vigorously supporting and expanding the capabilities of Trains.
+We built ClearML to track and control the glorious but messy process of training production-grade deep learning models.
+We are committed to vigorously supporting and expanding the capabilities of ClearML.
-## Why Are We Releasing Trains?
-
-We believe Trains is ground-breaking. We wish to establish new standards of experiment management in
-deep-learning and ML. Only the greater community can help us do that.
-
-We promise to always be backwardly compatible. If you start working with Trains today,
-even though this project is currently in the beta stage, your logs and data will always upgrade with you.
+We promise to always be backwardly compatible, making sure all your logs, data and pipelines
+will always upgrade with you.
## License
@@ -145,19 +136,19 @@ Apache License, Version 2.0 (see the [LICENSE](https://www.apache.org/licenses/L
## Documentation, Community & Support
-More information in the [official documentation](https://allegro.ai/docs) and [on YouTube](https://www.youtube.com/c/AllegroAI).
+More information in the [official documentation](https://allegro.ai//clearml/docs) and [on YouTube](https://www.youtube.com/c/AllegroAI).
-For examples and use cases, check the [examples folder](https://github.com/allegroai/trains/tree/master/examples) and [corresponding documentation](https://allegro.ai/docs/examples/examples_overview/).
+For examples and use cases, check the [examples folder](https://github.com/allegroai/trains/tree/master/examples) and [corresponding documentation](https://allegro.ai/clearml/docs/examples/examples_overview/).
If you have any questions: post on our [Slack Channel](https://join.slack.com/t/allegroai-trains/shared_invite/enQtOTQyMTI1MzQxMzE4LTY5NTUxOTY1NmQ1MzQ5MjRhMGRhZmM4ODE5NTNjMTg2NTBlZGQzZGVkMWU3ZDg1MGE1MjQxNDEzMWU2NmVjZmY), or tag your questions on [stackoverflow](https://stackoverflow.com/questions/tagged/trains) with '**trains**' tag.
For feature requests or bug reports, please use [GitHub issues](https://github.com/allegroai/trains/issues).
-Additionally, you can always find us at *trains@allegro.ai*
+Additionally, you can always find us at *clearml@allegro.ai*
## Contributing
-See the Trains [Guidelines for Contributing](https://github.com/allegroai/trains/blob/master/docs/contributing.md).
+See the ClearML [Guidelines for Contributing](https://github.com/allegroai/trains/blob/master/docs/contributing.md).
_May the force (and the goddess of learning rates) be with you!_
diff --git a/clearml/__init__.py b/clearml/__init__.py
index c05221e3..0ad97be4 100644
--- a/clearml/__init__.py
+++ b/clearml/__init__.py
@@ -1,4 +1,4 @@
-""" TRAINS open SDK """
+""" ClearML open SDK """
from .version import __version__
from .task import Task
@@ -6,5 +6,7 @@ from .model import InputModel, OutputModel, Model
from .logger import Logger
from .storage import StorageManager
from .errors import UsageError
+from .datasets import Dataset
-__all__ = ["__version__", "Task", "InputModel", "OutputModel", "Model", "Logger", "StorageManager", "UsageError"]
+__all__ = ["__version__", "Task", "InputModel", "OutputModel", "Model", "Logger",
+ "StorageManager", "UsageError", "Dataset"]
diff --git a/clearml/automation/__init__.py b/clearml/automation/__init__.py
index d2ac6d46..71b68351 100644
--- a/clearml/automation/__init__.py
+++ b/clearml/automation/__init__.py
@@ -1,6 +1,7 @@
from .parameters import UniformParameterRange, DiscreteParameterRange, UniformIntegerParameterRange, ParameterSet
from .optimization import GridSearch, RandomSearch, HyperParameterOptimizer, Objective
from .job import TrainsJob
+from .controller import PipelineController
__all__ = ["UniformParameterRange", "DiscreteParameterRange", "UniformIntegerParameterRange", "ParameterSet",
- "GridSearch", "RandomSearch", "HyperParameterOptimizer", "Objective", "TrainsJob"]
+ "GridSearch", "RandomSearch", "HyperParameterOptimizer", "Objective", "TrainsJob", "PipelineController"]
diff --git a/clearml/automation/auto_scaler.py b/clearml/automation/auto_scaler.py
index b35d0d64..66b51d4a 100644
--- a/clearml/automation/auto_scaler.py
+++ b/clearml/automation/auto_scaler.py
@@ -102,15 +102,15 @@ class AutoScaler(object):
def spin_up_worker(self, resource, worker_id_prefix, queue_name):
"""
- Creates a new worker for trains (cloud-specific implementation).
+ Creates a new worker for clearml (cloud-specific implementation).
First, create an instance in the cloud and install some required packages.
- Then, define trains-agent environment variables and run trains-agent for the specified queue.
+ Then, define clearml-agent environment variables and run clearml-agent for the specified queue.
NOTE: - Will wait until instance is running
- This implementation assumes the instance image already has docker installed
:param str resource: resource name, as defined in self.resource_configurations and self.queues.
:param str worker_id_prefix: worker name prefix
- :param str queue_name: trains queue to listen to
+ :param str queue_name: clearml queue to listen to
"""
pass
@@ -137,17 +137,17 @@ class AutoScaler(object):
minutes would be removed.
"""
- # Worker's id in trains would be composed from prefix, name, instance_type and cloud_id separated by ';'
+ # Worker's id in clearml would be composed from prefix, name, instance_type and cloud_id separated by ';'
workers_pattern = re.compile(
r"^(?P
-
-
-## Configuring Your Own Trains server
-
-1. Install and run *trains-server* (see [Installing the Trains Server](https://github.com/allegroai/trains-server))
-
-2. Run the initial configuration wizard for your Trains installation and follow the instructions to setup Trains package
-(http://**_trains-server-ip_**:__port__ and user credentials)
-
- trains-init
-
-After installing and configuring, you can access your configuration file at `~/trains.conf`
-
-Sample configuration file available [here](https://github.com/allegroai/trains/blob/master/docs/trains.conf).
+ - Use it on a daily basis to boost collaboration and visibility in your team
+ - Create a remote job from any experiment with a click of a button
+ - Automate processes and create pipelines to collect your experimentation logs, outputs, and data
+ - Store all you data on any object-storage solution, with the simplest interface possible
+ - Make you data transparent by cataloging it all on the ClearML platform
+We believe ClearML is ground-breaking. We wish to establish new standards of true seamless integration between
+experiment management,ML-Ops and data management.
## Who We Are
-Trains is supported by the same team behind *allegro.ai*,
+ClearML is supported by the team behind *allegro.ai*,
where we build deep learning pipelines and infrastructure for enterprise companies.
-We built Trains to track and control the glorious but messy process of training production-grade deep learning models.
-We are committed to vigorously supporting and expanding the capabilities of Trains.
+We built ClearML to track and control the glorious but messy process of training production-grade deep learning models.
+We are committed to vigorously supporting and expanding the capabilities of ClearML.
-## Why Are We Releasing Trains?
-
-We believe Trains is ground-breaking. We wish to establish new standards of experiment management in
-deep-learning and ML. Only the greater community can help us do that.
-
-We promise to always be backwardly compatible. If you start working with Trains today,
-even though this project is currently in the beta stage, your logs and data will always upgrade with you.
+We promise to always be backwardly compatible, making sure all your logs, data and pipelines
+will always upgrade with you.
## License
@@ -145,19 +136,19 @@ Apache License, Version 2.0 (see the [LICENSE](https://www.apache.org/licenses/L
## Documentation, Community & Support
-More information in the [official documentation](https://allegro.ai/docs) and [on YouTube](https://www.youtube.com/c/AllegroAI).
+More information in the [official documentation](https://allegro.ai//clearml/docs) and [on YouTube](https://www.youtube.com/c/AllegroAI).
-For examples and use cases, check the [examples folder](https://github.com/allegroai/trains/tree/master/examples) and [corresponding documentation](https://allegro.ai/docs/examples/examples_overview/).
+For examples and use cases, check the [examples folder](https://github.com/allegroai/trains/tree/master/examples) and [corresponding documentation](https://allegro.ai/clearml/docs/examples/examples_overview/).
If you have any questions: post on our [Slack Channel](https://join.slack.com/t/allegroai-trains/shared_invite/enQtOTQyMTI1MzQxMzE4LTY5NTUxOTY1NmQ1MzQ5MjRhMGRhZmM4ODE5NTNjMTg2NTBlZGQzZGVkMWU3ZDg1MGE1MjQxNDEzMWU2NmVjZmY), or tag your questions on [stackoverflow](https://stackoverflow.com/questions/tagged/trains) with '**trains**' tag.
For feature requests or bug reports, please use [GitHub issues](https://github.com/allegroai/trains/issues).
-Additionally, you can always find us at *trains@allegro.ai*
+Additionally, you can always find us at *clearml@allegro.ai*
## Contributing
-See the Trains [Guidelines for Contributing](https://github.com/allegroai/trains/blob/master/docs/contributing.md).
+See the ClearML [Guidelines for Contributing](https://github.com/allegroai/trains/blob/master/docs/contributing.md).
_May the force (and the goddess of learning rates) be with you!_
diff --git a/clearml/__init__.py b/clearml/__init__.py
index c05221e3..0ad97be4 100644
--- a/clearml/__init__.py
+++ b/clearml/__init__.py
@@ -1,4 +1,4 @@
-""" TRAINS open SDK """
+""" ClearML open SDK """
from .version import __version__
from .task import Task
@@ -6,5 +6,7 @@ from .model import InputModel, OutputModel, Model
from .logger import Logger
from .storage import StorageManager
from .errors import UsageError
+from .datasets import Dataset
-__all__ = ["__version__", "Task", "InputModel", "OutputModel", "Model", "Logger", "StorageManager", "UsageError"]
+__all__ = ["__version__", "Task", "InputModel", "OutputModel", "Model", "Logger",
+ "StorageManager", "UsageError", "Dataset"]
diff --git a/clearml/automation/__init__.py b/clearml/automation/__init__.py
index d2ac6d46..71b68351 100644
--- a/clearml/automation/__init__.py
+++ b/clearml/automation/__init__.py
@@ -1,6 +1,7 @@
from .parameters import UniformParameterRange, DiscreteParameterRange, UniformIntegerParameterRange, ParameterSet
from .optimization import GridSearch, RandomSearch, HyperParameterOptimizer, Objective
from .job import TrainsJob
+from .controller import PipelineController
__all__ = ["UniformParameterRange", "DiscreteParameterRange", "UniformIntegerParameterRange", "ParameterSet",
- "GridSearch", "RandomSearch", "HyperParameterOptimizer", "Objective", "TrainsJob"]
+ "GridSearch", "RandomSearch", "HyperParameterOptimizer", "Objective", "TrainsJob", "PipelineController"]
diff --git a/clearml/automation/auto_scaler.py b/clearml/automation/auto_scaler.py
index b35d0d64..66b51d4a 100644
--- a/clearml/automation/auto_scaler.py
+++ b/clearml/automation/auto_scaler.py
@@ -102,15 +102,15 @@ class AutoScaler(object):
def spin_up_worker(self, resource, worker_id_prefix, queue_name):
"""
- Creates a new worker for trains (cloud-specific implementation).
+ Creates a new worker for clearml (cloud-specific implementation).
First, create an instance in the cloud and install some required packages.
- Then, define trains-agent environment variables and run trains-agent for the specified queue.
+ Then, define clearml-agent environment variables and run clearml-agent for the specified queue.
NOTE: - Will wait until instance is running
- This implementation assumes the instance image already has docker installed
:param str resource: resource name, as defined in self.resource_configurations and self.queues.
:param str worker_id_prefix: worker name prefix
- :param str queue_name: trains queue to listen to
+ :param str queue_name: clearml queue to listen to
"""
pass
@@ -137,17 +137,17 @@ class AutoScaler(object):
minutes would be removed.
"""
- # Worker's id in trains would be composed from prefix, name, instance_type and cloud_id separated by ';'
+ # Worker's id in clearml would be composed from prefix, name, instance_type and cloud_id separated by ';'
workers_pattern = re.compile(
r"^(?P