---
title: ClearML Serving
---
`clearml-serving` is a command line utility for model deployment and orchestration.
It enables model deployment including serving and preprocessing code to a Kubernetes cluster or custom container based
solution.
## Features
* Easy to deploy and configure
* Support Machine Learning Models (Scikit Learn, XGBoost, LightGBM)
* Support Deep Learning Models (TensorFlow, PyTorch, ONNX)
* Customizable RestAPI for serving (i.e. allow per model pre/post-processing for easy integration)
* Flexible
* On-line model deployment
* On-line endpoint model/version deployment (i.e. no need to take the service down)
* Per model standalone preprocessing and postprocessing Python code
* Scalable
* Multi model per container
* Multi models per serving service
* Multi-service support (fully separated multiple serving service running independently)
* Multi cluster support
* Out-of-the-box node autoscaling based on load/usage
* Efficient
* Multi-container resource utilization
* Support for CPU and GPU nodes
* Auto-batching for DL models
* [Automatic deployment](clearml_serving_tutorial.md#automatic-model-deployment)
* Automatic model upgrades with canary support
* Programmable API for model deployment
* [Canary A/B deployment](clearml_serving_tutorial.md#canary-endpoint-setup) - online Canary updates
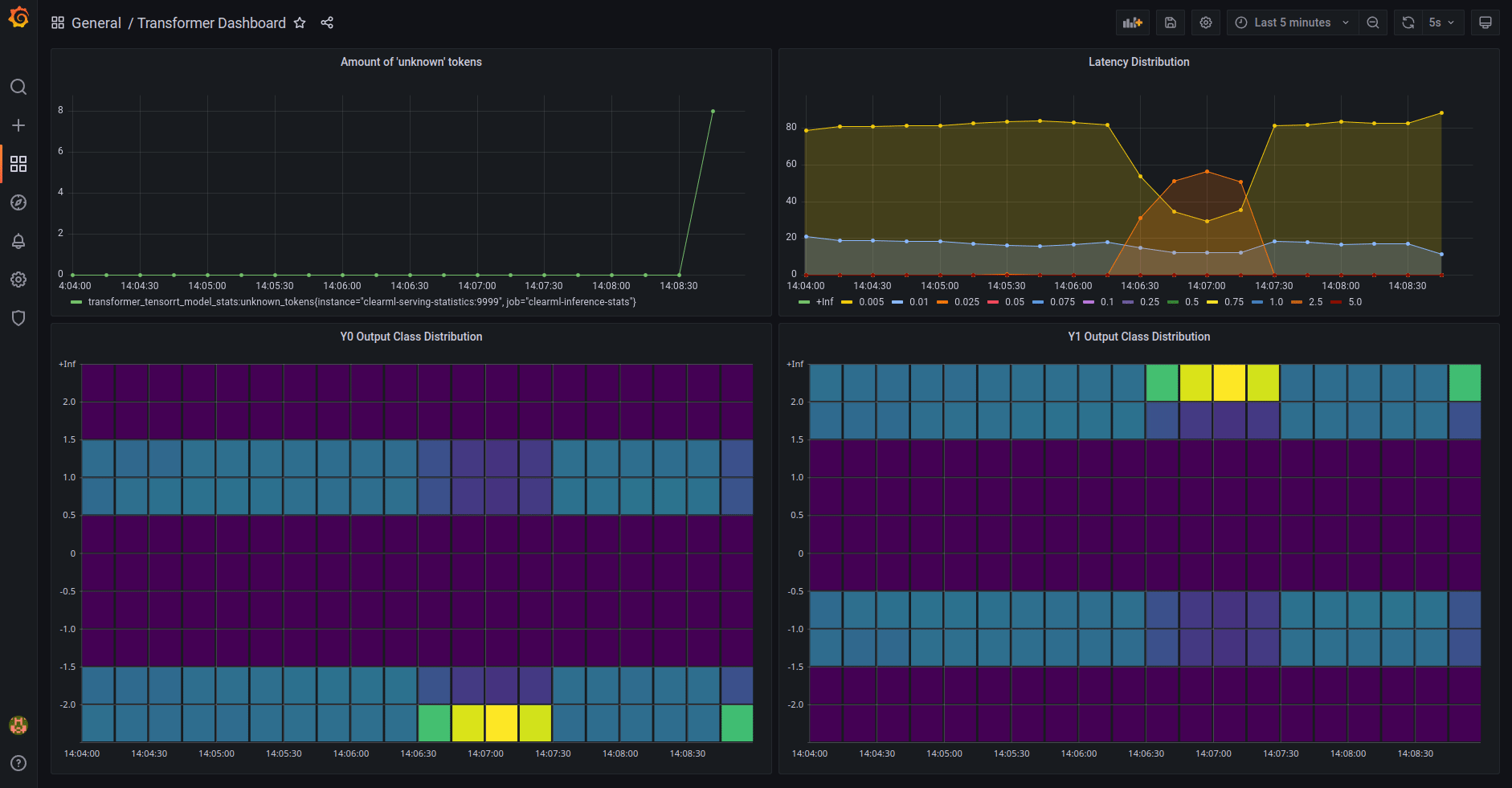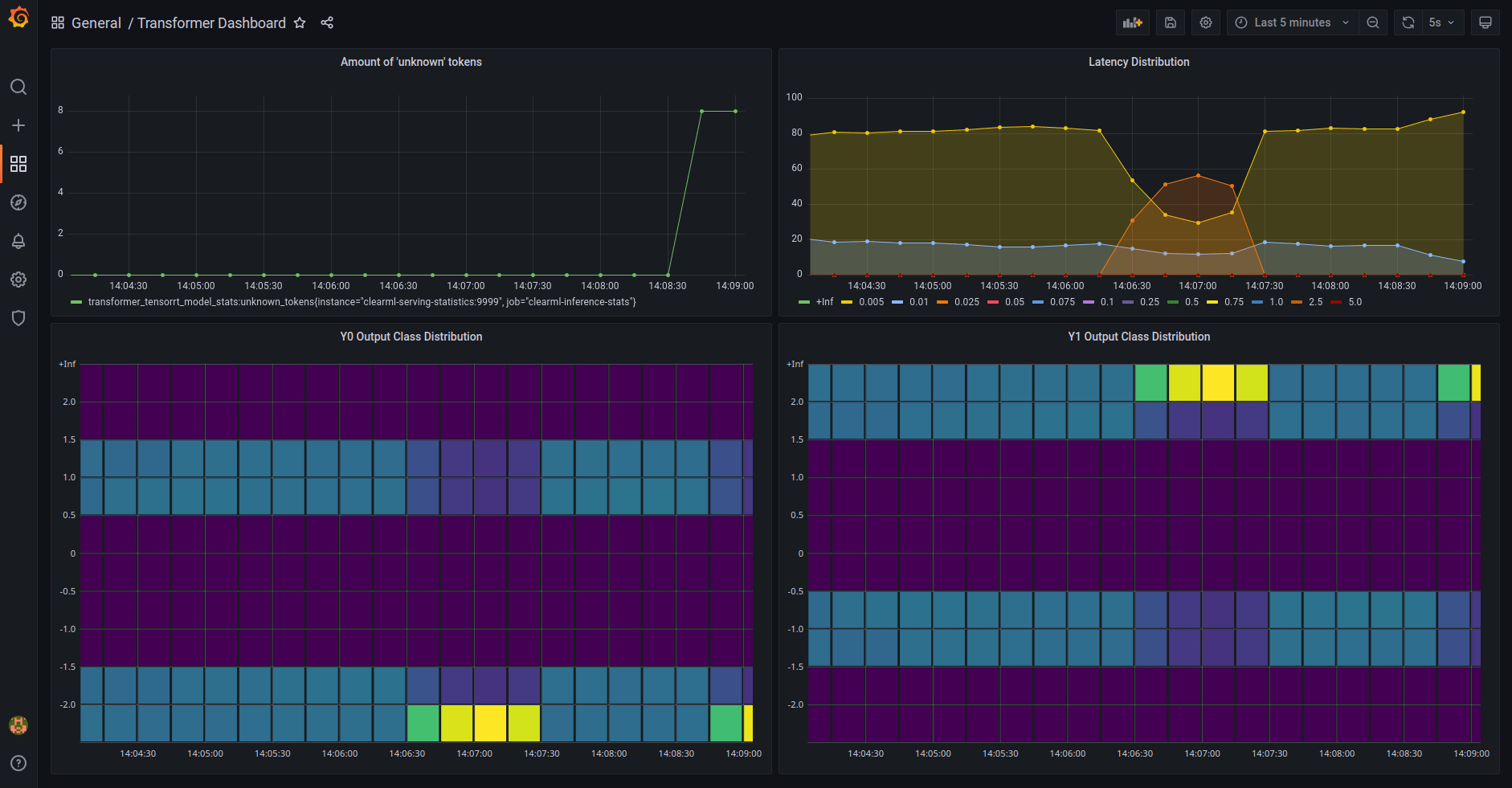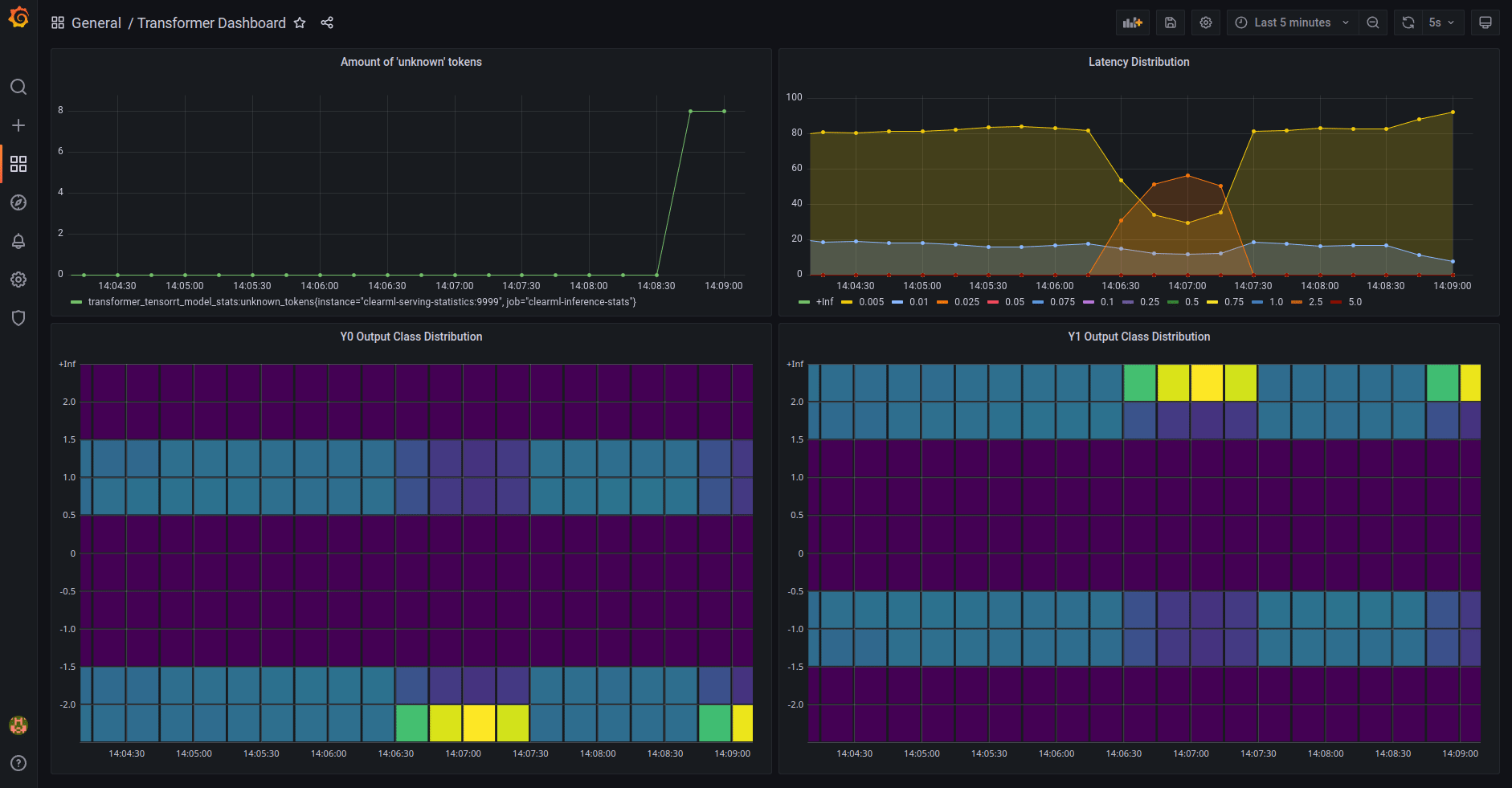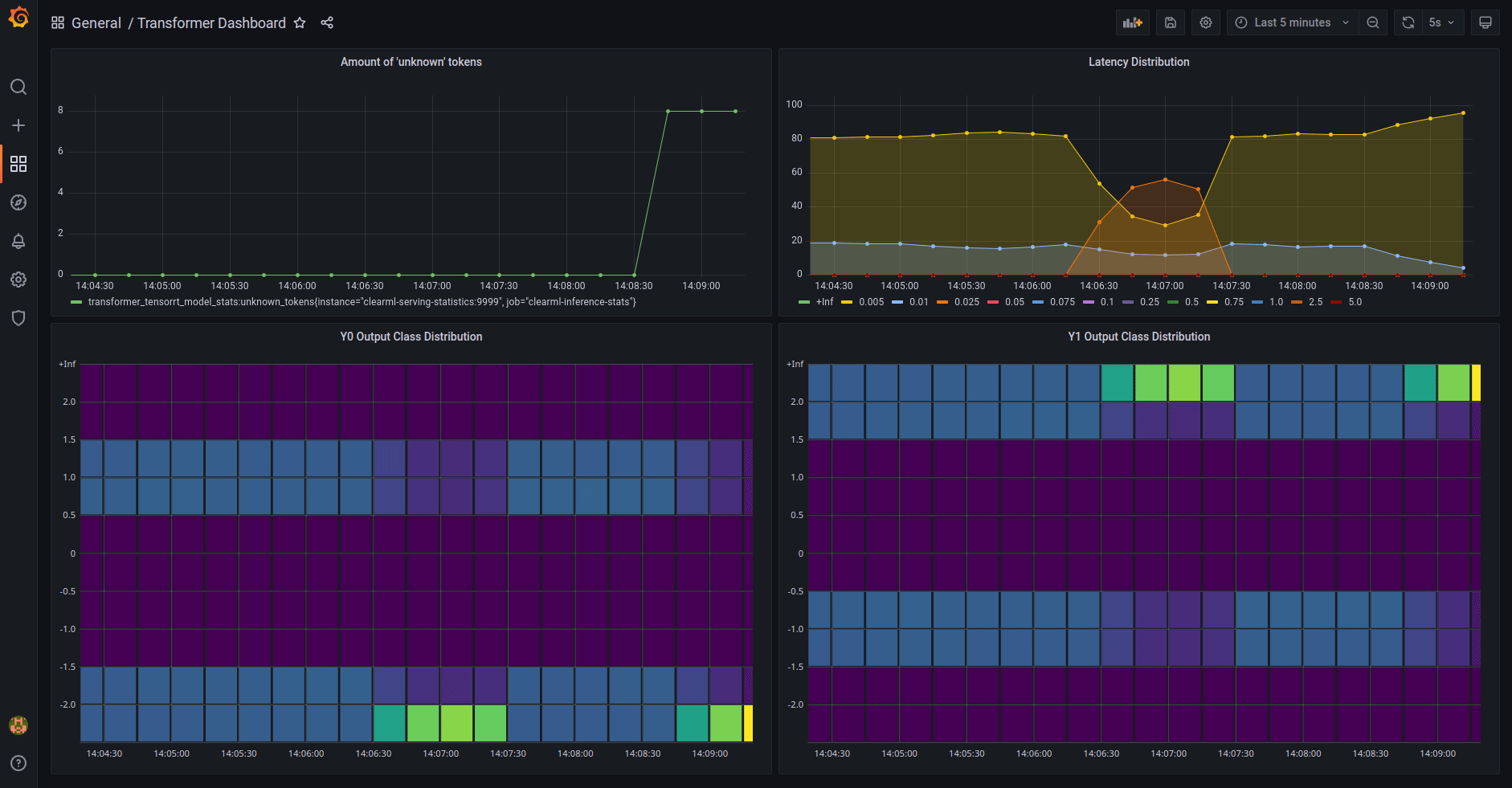
* [Model Monitoring](clearml_serving_tutorial.md#model-monitoring-and-performance-metrics)
* Usage Metric reporting
* Metric Dashboard
* Model performance metric
* Model performance Dashboard
## Components

* **CLI** - Secure configuration interface for on-line model upgrade/deployment on running Serving Services
* **Serving Service Task** - Control plane object storing configuration on all the endpoints. Supports multiple separate
instances, deployed on multiple clusters.
* **Inference Services** - Inference containers, performing model serving pre/post-processing. Also supports CPU model
inferencing.
* **Serving Engine Services** - Inference engine containers (e.g. Nvidia Triton, TorchServe etc.) used by the Inference
Services for heavier model inference.
* **Statistics Service** - Single instance per Serving Service collecting and broadcasting model serving and performance
statistics
* **Time-series DB** - Statistics collection service used by the Statistics Service, e.g. Prometheus
* **Dashboards** - Customizable dashboard solution on top of the collected statistics, e.g. Grafana
## Next Steps
See ClearML Serving setup instructions [here](clearml_serving_setup.md). For further details, see the ClearML Serving
[Tutorial](clearml_serving_tutorial.md).